MARKOV MODEL
Anak Agung Ngurah Bagus Maha Praja Dinata¹, Suyanto², Agung Toto Wibowo³
¹Teknik Informatika, Fakultas Teknik Informatika, Universitas Telkom
Abstrak
Memodelkan sinyal model untuk pengenalan suara adalah suatu tugas yang menantang. Pemodelan tersebut akan menuntut kita sejumlah besar informasi tentang masalah yang akan dimodelkan. Sistem pengenalan suara pada umumnya mengasumsikan bahwa sinyal suara adalah realisasi dari beberapa pesan, yang terkodekan dalam satu atau lebih sekuen simbol simbol. Simbol-simbol ini disebut dengan fitur suara (sekuen vector suara yang teramati). Dalam
pengenalan suara berbasis HMM, biasanya diasumsikan bahwa sekuen vektor suara yang teramati tersebut akan diberkoresponden dengan setiap kata, yang dipresentasikan oleh suatu model suara yang disebut Markov Model.
Dalam tugas akhir ini, fitur-fitur suara akan dianalisa menggunakan MFCC (Mel Frequency Cepstral Coefficient), dan digunakan algoritma Viterbi untuk mencapai jalur rangkaian terbaik dari sekuen simbol-simbol, yang berkorespondensi dengan suatu kata, yang dikembalikan sebagai hasil pengenalan.
Kata Kunci : fitur, MFCC, HMM, Algoritma Viterbi
Abstract
Modeling signal model for speech recognition is challenging task. It gives us great deal of
information about problem being modeled. Speech recognition systems generally assume that the speech signal is a realization of some mesage encoded as a sequence of one or more symbols. These symbols called speech features (sequence of observed speech vectors). In HMM based speech recognition, it is assumed that the sequence of observed speech vectors corresponding to each word, represented by a speech model called Markov Model.
In this final project, speech feature analysed with MFCC (Mel Freuency Cepstral Coefiecient), and Viterbi Algorithm is used to find the best path of symbols sequence corresponding to a word and return is as recognition result.
15 BAB I
PENDAHULUAN
1. Latar belakang masalah
Salah satu perkembangan teknologi terbesar saat ini adalah mencoba
membuat sistem komputer, yang dalam hal ini mesin, untuk dapat mengenali
perintah yang diucapkan user dan kemudian memberikan respon yang sesuai
perintah tersebut. Teknologi ini disebut speech recognition system. Dengan
menerapkan teknologi ini, seseorang tidak perlu menekan tombol mouse atau
mengetik di keyboard jika menginginkan komputer melakukan sesuatu, tetapi
cukup memberikan perintah suara dan komputer akan menjalankannya.
Speech recognition system adalah proses pengubahan suatu sinyal suara
akustik yang diterima oleh alat input microphone, menjadi serangkaian data
masukan untuk dikenali oleh mesin (contohnya: byte, binary code, dll), untuk
kemudian diterjemahkan dan dilaksanakan aksi yang sesuai seperti dengan yang
telah ditentukan. Sistem pengenalan suara (speech recognition system) bukanlah
teknologi baru, dan telah dikembangkan lebih dari empat dekade.
Pada awal tahun 1970-an diperkenalkan suatu metode statistik yang disebut
dengan Hidden Markov Model. Penerapan metode ini dalam teknologi speech baru
diimplementasikan dan menjadi pupoler beberapa tahun ini. Hidden Markov Model
memberikan struktur matematis yang sangat kaya dan karenanya dapat digunakan
untuk membentuk dasar-dasar teori untuk berbagai aplikasi [UCHAT6,05].
Hidden Markov Model merupakan model statistik dimana sistem yang
dimodelkan diasumsikan sebagai Markov proses dengan parameter yang tidak
diketahui, dan bertujuan untuk menentukan parameter-parameter tersembunyi
(hidden) tersebut berdasarkan parameter-parameter yang dapat diketahui
[RAB2,01]. Pada speech recognition engine, sinyal suara input akan mengalami
front-end processing. Hasil dari front-end processing/frequency analysis berupa
segmen-segmen suara (phonemes) dan fitur-fitur yang kemudian akan dikirimkan
ke decoder untuk dilakukan pengenalan pola terhadap model yang dibentuk dengan
HMM (pattern reconitiori) dengan berdasar pada acoustic model, language model,
dan lexicon. Proses recognition sendiri dilakukan dengan memaksimalkan nilai
probabilitas P(O|λ) dari suatu sekuen pengamatan signal suara O = O1,O2,..Or
terhadap model yang diberikan A=(A,B,π), dimana A adalah matrik probabilitas
transisi (aij) = P(qt=j \ qt-i=i)> B adalah set parameter untuk menentukan probabilitas
bj(0t) = P(ot \ qt =j), dan π adalah initial state distribution (πi) = P(qi = i). Sekuen
state dengan P(O\A) terbaik akan dikembalikan sebagai satu pola kata yang dikenali
dan dinyatakan dalam text untuk kemudian diproses di level aplikasi untuk
dilakukan respon [RAB2,05].
Fokus pembahasan dan pengerjaan akan dilakukan pada speech processing
dan aplikasinya, yang melibatkan proses statistical modeling untuk pengenalan
sinyal suara. Dalam penerapannya, dilakukan dengan memanfaatkan
komponen-komponen serta toolkit yang dapat diperoleh secara gratis dari internet seperti Java
SAPI sebagai antarmuka ataupun template-template dataset model yang diperlukan
untuk keseluruhan proses. Analisis yang membedakan dengan referensi-referensi
yang ada, yaitu parameter-parameter uji seperti word error rate (WER),
penggunaan memori akan diukur secara langsung pada percobaan tanpa perlu
perekaman suara terlebih dulu, serta dilakukan penelitian terhadap frekuensi sample
suara manusia yang paling cocok terhadap sistem pengenalan suara dengan model
HMM.
2. Perumusan masalah
Implementasi rumusan Tugas Akhir ini berangkat dari konsep dasar bahwa
suara dapat diambil karakteristik-karakteristik khususnya dan dinyatakan dalam
serangkaian objek pengamatan, untuk kemudian dikenali dengan mencoba menilai
kemiripan polanya dengan model HMM yang ada. Diharapkan dengan Hidden
Markov Model ini, sistem pengenalan suara akan memiliki performansi yang baik
dalam hal akurasi dan kecepatan respon. Permasalahan yang timbul dari latar
17 1. Bagaimana memanfaatkan Hidden Markov Model pada suatu
speech recognition system.
2. Membuat aplikasi speech personal asisten pada komputer dengan
memanfaatkan speech engine yang telah dibuat untuk menangani proses
command and control Windows pada isolated word recognition.
3. Bagaimana mengukur tingkat akurasi berdasar jumlah kebenaran respon
yang diberikan aplikasi pada input sejumlah user, serta performansi dalam
kaitannya dengan waktu respon dan penggunaan memori.
3. Tujuan
Beberapa tujuan yang ingin dicapai dari pengerjaan tugas akhir ini nantinya
dapat dijelaskan sebagai berikut:
a) Menerapkan suatu sistem pengenalan suara dengan berbasiskan Hidden Markov
Model. Suatu sistem pengenalan suara terdiri dari modul-modul yang
mendefinisikan dan melakukan pemrosesan recognition berdasarkan input yang
diterima dan model yang ada.
b) Menerapkan speech engine yang telah dibuat ke dalam suatu aplikasi Speech
Computer Personal Assistant, yang mampu menjalankan sejumlah aksi pada
sistem operasi Windows dengan perintah yang diberikan melalui ucapan.
c) Melakukan pengukuran akurasi terhadap hasil pengerjaan dengan menghitung
word error rate, performansi dalam kaitannya dengan waktu respon dan
penggunaan sumber daya memori, serta efektifltas implementasi dalam hal
frekuensi sample suara manusia yang terbaik untuk digunakan.
4. Batasan masalah
Adapun batasan-batasan masalah yang diberikan pada Tugas akhir ini adalah :
− Input suara yang dikenali adalah pengucapan dalam bahasa Inggris serta menggunakan template dataset yang telah tersedia.
− Tipe aplikasi speech recognition adalah speaker independent (tidak
memperhatikan /tergantung pada pembicara tertentu)
− Implementasi hanya pada sistem command and control windows dengan
isolated word (kata perintah yang telah ditentukan dan dibatasi untuk dikenali).
− Perintah yang diterima sistem pengenalan suara untuk menjalankan aksi di Windows hanya terbatas pada beberapa kata perintah berikut: start, open note,
open word, open excel, press enter, press escape, press up, press down, press
left, press right, dan close application.
5. Metodologi penyelesaian masalah
Metodologi penelitian yang dilakukan dalam penyusunan Tugas Akhir ini meliputi:
1. Studi literatur
Studi literatur dilakukan untuk memahami teori dasar mengenai struktur Java
SAPI, Hidden Markov Model, Viterbi algorithm, optimasi fungsi P(O|λ), serta
teori-teori dasar lain tentang teknologi speech recognition itu sediri.
2. Analisis Perancangan Perangkat Lunak
Dilakukan proses analisis requirement dari sistem yang akan dibangun sehingga
didapat gambaran mengenai sistem yang akan dibuat.
3. Implementasi Desain Sistem
Melakukan implementasi terhadap hasil desain sistem yang telah dilakukan
dengan menggunakan bantuan NetBeans IDE 6.7 sebagai program pembangun.
Implementasi dimulai dengan pemrosesan terhadap input sinyal suara.
Selanjutnya pembuatan speech engine dengan menerapkan HMM sebagai dasar
metode modelnya dan menghasilkan output text dari input yang berupa sinyal
suara digital yang telah diolah sebelumnya. Output dari engine akan dijadikan
input untuk aplikasi speech dan melakukan suatu respon terhadap input tersebut.
4. Analisa Data dan Pelaporan
Menganalisis hasil implementasi aplikasi sehingga didapat data-data mengenai
performansi dan akurasi dari metode yang diimplementasikan, serta
19 6. Jadwal kegiatan
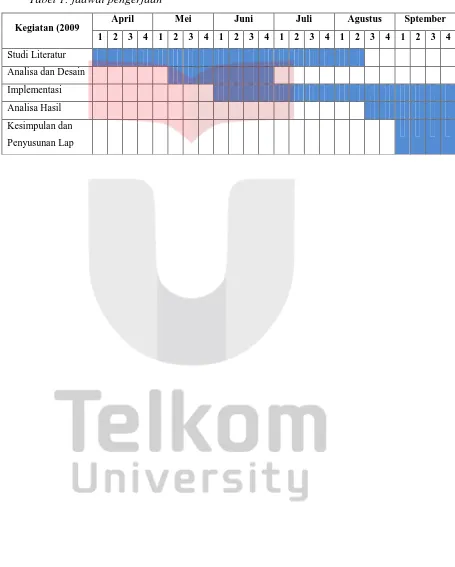
Tabel 1: jadwal pengerjaan
Kegiatan (2009 April Mei Juni Juli Agustus Sptember 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4
Studi Literatur
Analisa dan Desain
Implementasi
Analisa Hasil
Kesimpulan dan
Penyusunan Lap
Powered by TCPDF (www.tcpdf.org)
BAB I
PENDAHULUAN
1. Latar belakang masalah
Salah satu perkembangan teknologi terbesar saat ini adalah mencoba
membuat sistem komputer, yang dalam hal ini mesin, untuk dapat mengenali
perintah yang diucapkan user dan kemudian memberikan respon yang sesuai
perintah tersebut. Teknologi ini disebut speech recognition system. Dengan
menerapkan teknologi ini, seseorang tidak perlu menekan tombol mouse atau
mengetik di keyboard jika menginginkan komputer melakukan sesuatu, tetapi
cukup memberikan perintah suara dan komputer akan menjalankannya.
Speech recognition system adalah proses pengubahan suatu sinyal suara
akustik yang diterima oleh alat input microphone, menjadi serangkaian data
masukan untuk dikenali oleh mesin (contohnya: byte, binary code, dll), untuk
kemudian diterjemahkan dan dilaksanakan aksi yang sesuai seperti dengan yang
telah ditentukan. Sistem pengenalan suara (speech recognition system) bukanlah
teknologi baru, dan telah dikembangkan lebih dari empat dekade.
Pada awal tahun 1970-an diperkenalkan suatu metode statistik yang disebut
dengan Hidden Markov Model. Penerapan metode ini dalam teknologi speech baru
diimplementasikan dan menjadi pupoler beberapa tahun ini. Hidden Markov Model
memberikan struktur matematis yang sangat kaya dan karenanya dapat digunakan
untuk membentuk dasar-dasar teori untuk berbagai aplikasi [UCHAT6,05].
Hidden Markov Model merupakan model statistik dimana sistem yang
dimodelkan diasumsikan sebagai Markov proses dengan parameter yang tidak
diketahui, dan bertujuan untuk menentukan parameter-parameter tersembunyi
(hidden) tersebut berdasarkan parameter-parameter yang dapat diketahui
[RAB2,01]. Pada speech recognition engine, sinyal suara input akan mengalami
front-end processing. Hasil dari front-end processing/frequency analysis berupa
segmen-segmen suara (phonemes) dan fitur-fitur yang kemudian akan dikirimkan
16 HMM (pattern reconitiori) dengan berdasar pada acoustic model, language model,
dan lexicon. Proses recognition sendiri dilakukan dengan memaksimalkan nilai
probabilitas P(O|λ) dari suatu sekuen pengamatan signal suara O = O1,O2,..Or
terhadap model yang diberikan A=(A,B,π), dimana A adalah matrik probabilitas
transisi (aij) = P(qt=j \ qt-i=i)> B adalah set parameter untuk menentukan probabilitas
bj(0t) = P(ot \ qt =j), dan π adalah initial state distribution (πi) = P(qi = i). Sekuen
state dengan P(O\A) terbaik akan dikembalikan sebagai satu pola kata yang dikenali
dan dinyatakan dalam text untuk kemudian diproses di level aplikasi untuk
dilakukan respon [RAB2,05].
Fokus pembahasan dan pengerjaan akan dilakukan pada speech processing
dan aplikasinya, yang melibatkan proses statistical modeling untuk pengenalan
sinyal suara. Dalam penerapannya, dilakukan dengan memanfaatkan
komponen-komponen serta toolkit yang dapat diperoleh secara gratis dari internet seperti Java
SAPI sebagai antarmuka ataupun template-template dataset model yang diperlukan
untuk keseluruhan proses. Analisis yang membedakan dengan referensi-referensi
yang ada, yaitu parameter-parameter uji seperti word error rate (WER),
penggunaan memori akan diukur secara langsung pada percobaan tanpa perlu
perekaman suara terlebih dulu, serta dilakukan penelitian terhadap frekuensi sample
suara manusia yang paling cocok terhadap sistem pengenalan suara dengan model
HMM.
2. Perumusan masalah
Implementasi rumusan Tugas Akhir ini berangkat dari konsep dasar bahwa
suara dapat diambil karakteristik-karakteristik khususnya dan dinyatakan dalam
serangkaian objek pengamatan, untuk kemudian dikenali dengan mencoba menilai
kemiripan polanya dengan model HMM yang ada. Diharapkan dengan Hidden
Markov Model ini, sistem pengenalan suara akan memiliki performansi yang baik
dalam hal akurasi dan kecepatan respon. Permasalahan yang timbul dari latar
belakang pembuatan Tugas Akhir ini diantaranya sebagai berikut:
1. Bagaimana memanfaatkan Hidden Markov Model pada suatu
speech recognition system.
2. Membuat aplikasi speech personal asisten pada komputer dengan
memanfaatkan speech engine yang telah dibuat untuk menangani proses
command and control Windows pada isolated word recognition.
3. Bagaimana mengukur tingkat akurasi berdasar jumlah kebenaran respon
yang diberikan aplikasi pada input sejumlah user, serta performansi dalam
kaitannya dengan waktu respon dan penggunaan memori.
3. Tujuan
Beberapa tujuan yang ingin dicapai dari pengerjaan tugas akhir ini nantinya
dapat dijelaskan sebagai berikut:
a) Menerapkan suatu sistem pengenalan suara dengan berbasiskan Hidden Markov
Model. Suatu sistem pengenalan suara terdiri dari modul-modul yang
mendefinisikan dan melakukan pemrosesan recognition berdasarkan input yang
diterima dan model yang ada.
b) Menerapkan speech engine yang telah dibuat ke dalam suatu aplikasi Speech
Computer Personal Assistant, yang mampu menjalankan sejumlah aksi pada
sistem operasi Windows dengan perintah yang diberikan melalui ucapan.
c) Melakukan pengukuran akurasi terhadap hasil pengerjaan dengan menghitung
word error rate, performansi dalam kaitannya dengan waktu respon dan
penggunaan sumber daya memori, serta efektifltas implementasi dalam hal
frekuensi sample suara manusia yang terbaik untuk digunakan.
4. Batasan masalah
Adapun batasan-batasan masalah yang diberikan pada Tugas akhir ini adalah :
− Input suara yang dikenali adalah pengucapan dalam bahasa Inggris serta menggunakan template dataset yang telah tersedia.
− Tipe aplikasi speech recognition adalah speaker independent (tidak
18
− Implementasi hanya pada sistem command and control windows dengan
isolated word (kata perintah yang telah ditentukan dan dibatasi untuk dikenali).
− Perintah yang diterima sistem pengenalan suara untuk menjalankan aksi di Windows hanya terbatas pada beberapa kata perintah berikut: start, open note,
open word, open excel, press enter, press escape, press up, press down, press
left, press right, dan close application.
5. Metodologi penyelesaian masalah
Metodologi penelitian yang dilakukan dalam penyusunan Tugas Akhir ini meliputi:
1. Studi literatur
Studi literatur dilakukan untuk memahami teori dasar mengenai struktur Java
SAPI, Hidden Markov Model, Viterbi algorithm, optimasi fungsi P(O|λ), serta
teori-teori dasar lain tentang teknologi speech recognition itu sediri.
2. Analisis Perancangan Perangkat Lunak
Dilakukan proses analisis requirement dari sistem yang akan dibangun sehingga
didapat gambaran mengenai sistem yang akan dibuat.
3. Implementasi Desain Sistem
Melakukan implementasi terhadap hasil desain sistem yang telah dilakukan
dengan menggunakan bantuan NetBeans IDE 6.7 sebagai program pembangun.
Implementasi dimulai dengan pemrosesan terhadap input sinyal suara.
Selanjutnya pembuatan speech engine dengan menerapkan HMM sebagai dasar
metode modelnya dan menghasilkan output text dari input yang berupa sinyal
suara digital yang telah diolah sebelumnya. Output dari engine akan dijadikan
input untuk aplikasi speech dan melakukan suatu respon terhadap input tersebut.
4. Analisa Data dan Pelaporan
Menganalisis hasil implementasi aplikasi sehingga didapat data-data mengenai
performansi dan akurasi dari metode yang diimplementasikan, serta
mendokumentasikannya dalam bentuk laporan Tugas Akhir.
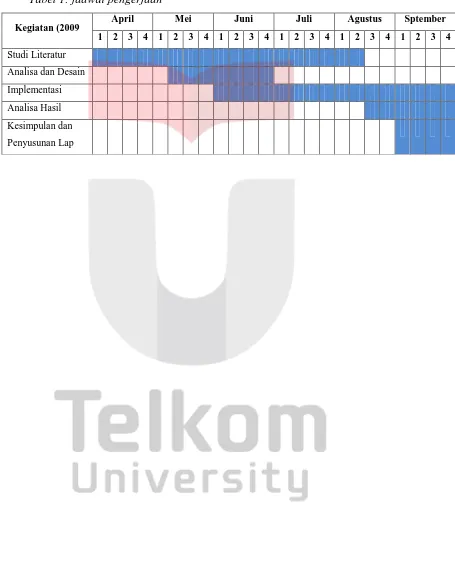
6. Jadwal kegiatan
Tabel 1: jadwal pengerjaan
Kegiatan (2009 April Mei Juni Juli Agustus Sptember 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4
Studi Literatur
Analisa dan Desain
Implementasi
Analisa Hasil
Kesimpulan dan