Umboro Lasminto & Listya Hery Mularto
Jurusan Teknik Sipil, Fakultas Teknik Sipil dan Perencanaan Institut Teknologi Sepuluh Nopember Surabaya
ABSTRAK
Makalah ini berisi hasil penelitian yang dilakukan untuk membangun model prediksi level muka air di stasiun pengamatan Bojonegoro. Model dibangun dengan menggunakan teknik Model Tree Machine Learning. Model Tree menghasilkan beberapa fungsi linier yang transparan dan lebih diterima oleh pengambil keputusan. Pembangunan model didahului dengan pemilihan atribut input dengan menghitung korelasi antara variabel output dengan masing-masing variabel input.
Model Tree dapat menghasilkan fungsi-fungsi linier dengan jumlah sangat
banyak, oleh sebab itu untuk memperkecil jumlah persamaan dapat dilakukan dengan memotong jumlah cabang dari model dengan menggunakan pruning
factor. Angka pruning factor semakin besar maka jumlah cabang yang dipotong
menjadi banyak dan fungsi linier yang dihasilkan oleh model lebih sedikit. Pemotongan jumlah cabang pada model membawa dampak menurunnya performa dari model.
Model prediksi yang dibangun dengan Model Tree pada penelitian ini memiliki performa cukup baik untuk memprediksi level muka air harian rata-rata di Stasiun Bojonegoro dengan input data dari stasiun Babat, Cepu, Karangnongko dan Napel. Model ini berguna untuk melengkapi data level muka air di stasiun Bojonegoro yang kosong dan sebagai awal dari pembangunan model peramalan banjir Bengawan Solo di stasiun Bojonegoro.
Kata kunci: Prediksi, level muka air, Model Tree, Pruning Factor
1. PENDAHULUAN
Sungai Bengawan Solo merupakan sungai terpanjang di Pulau Jawa dengan panjang sungai kurang lebih 600 km. Daerah aliran sungai (DAS) bengawan Solo dibagi menjadi Sub DAS Bengawan Solo hulu dengan luas 6.072 km2, Sub DAS Kali Madiun dengan luas 3.755 km2 dan Sub DAS Bengawan Solo Hilir seluas 6273 km2. Aliran air dari Sub DAS Bengawan Solo Hulu dan Sub DAS Kali Madiun bertemu di Ngawi dan kemudian mengalir ke hilir. Aliran air Sungai Bengawan Solo hilir selain berasal dari Sub DAS Bengawan Solo Hulu dan Sub DAS Kali Madiun juga berasal dari Sub-Sub DAS dari anak-anak sungai di sepanjang Sungai bagian hilir. Pada sungai Bengawan Solo Hilir terdapat beberapa stasiun pengamatan muka air sungai yaitu Napel, Karangnongko, Cepu, Bojonegoro, Babat dan stasiun-stasiun
lainnya. Kelima stasiun pengamatan yang disebut diatas memiliki data rekaman pengamatan level muka air lebih lengkap dari stasiun-stasiun yang lain. Namun dalam rekaman serial data beberapa tahun di Stasiun Bojonegoro masih terdapat data-data yang kosong akibat tidak tercatatnya level muka air karena peralatan rusak maupun sebab lain.
Tujuan dari penelitian ini adalah mem-bangun model prediksi level permukaan air rata-rata harian sungai Bengawan Solo di stasiun pengamatan Bojonegoro untuk memperkirakan level muka air berdasarkan dari data atau informasi level muka air di stasiun yang lain baik di hulu maupun dihilirnya.
2. TINJAUAN PUSTAKA
Banyak aplikasi model input-output dalam praktek digunakan untuk memprediksi data
numerik yang bersifat kontinyu yang dihubungkan dengan studi kasus tertentu. Ada beberapa teknik pembelajaran yang melakukan prediksi nilai numerik seperti regresi standar, Neural Network, dan
Regression Tree. Regresi standar bukan cara
yang baik untuk merepresentasikan sebuah fungsi karena regresi standar memaksakan hubungan linier pada data. Neural network lebih kuat dalam merepresentasikan namun model tidak menyatakan sesuatu tentang struktur fungsi yang direpresentasikannya. Regression Tree melakukan pendekatan sebuah fungsi dengan sebuah konstanta. Teknik lain yang dikembangkan untuk mengurangi kelemahan yang ada pada
Regression Tree adalah Model Tree (MT). Model Tree menggunakan ide yaitu membagi
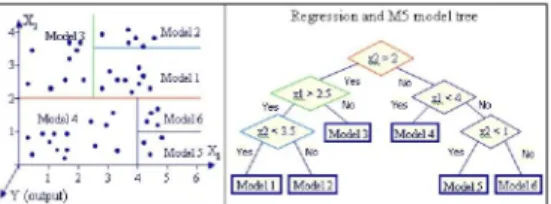
parameter ruang menjadi sub-sub parameter ruang dan membuat setiap sub parameter ruang tersebut satu model regresi linier seperti terlihat pada Gambar 1. Sehingga model yang dihasilkan terlihat seperti sebuah model modular atau seperti sebuah Committee Machine dengan model linier dispesialisasikan ke subset ruang input tertentu. Menggunakan konsep sebuah pohon, setiap daun dari model mohon tersebut berisi satu Linier Model (LM). Pendekatan Model Tree didasarkan pada prinsip teori informasi yang memungkinkan untuk memisahkan parameter ruang multi dimensi dan secara otomatis membangun model berdasarkan kriteria kualitas.
Gambar 1. konsep dari Regression dan M5 Model Tree
Pemisahan di model tree mengikuti ide dari decision tree, namun perbedaannya model tree memiliki fungsi regresi linier pada daun-daun modelnya sedangkan decision tree pada daun-daun modelnya terdiri dari class label. Perhitungan yang diperlukan pada model tree meningkat secara cepat dengan bertambahnya dimensi. Model tree melakukan pembelajaran lebih efisien dan dapat menyelesaikan masalah dengan dimensi sangat banyak. Kelebihan utamanya adalah model tree lebih kecil dari decision
tree, keputusannya jelas dan fungsi regresinya tidak melibatkan banyak variabel.
Algoritma yang dikenal sebagai M5 di-gunakan untuk membangun model tree (Quinlan, 1992). Tujuannya adalah mem-bangun sebuah model yang menghubungkan sebuah nilai target dari kasus training pada input atributnya. Kualitas dari model akan diukur dengan akurasi dimana akan memprediksi nilai target.
Kriteria pemisahan dalam algoritma M5 Model Tree didasarkan pada perlakuan standar deviasi dari nilai class yang men-jangkau sebuah node sebagai sebuah ukuran error pada node itu, dan menghitung pengurangan yang diharapkan pada error ini sebagai hasil evaluasi pada setiap atribut pada node tersebut. Persamaan untuk menghitung standard deviation reduction (SDR) adalah:
…………..(1) Dimana T menggambarkan set data yang menjangkau node; Ti merepresentasikan
subset dari data yang memiliki hasil ke-i dari set potensial dan sd merepresentasikan standar deviasi.
Setelah mengevaluasi semua kemungkinan pemisahan, M5 memisahkan dan memilih satu yang maksimum dalam mereduksi error yang diharapkan. Pemisahan di M5 berhenti manakala nilai class dari semua data kejadian yang menjangkau sebuah node hanya mengalami sedikit perubahan atau hanya sedikit data kejadian yang tertinggal. Pemisahan tersebut terkadang menghasilkan jumlah linier model berlebihan sehingga harus di pangkas, sebagai contoh meng-gantikan suatu sub-pohon dengan suatu daun. Di langkah akhir, suatu proses mem-perlancar dilakukan sebagai kompensasi pada diskontinyuitas yang tajam yang akan terjadi diantara model-model linier yang bersebelahan pada daun dari model yang dipangkas, terutama untuk model yang dibangun dari data yang jumlahnya sedikit. Dalam memperlancar, persamaan linier yang bersebelahan diperbaharui sedemikian sehingga output hasil prediksi untuk vektor input yang bertetangga bersesuaian pada persamaan yang berbeda menjadi dekat nilainya. Proses yang lebih detail dapat
ditemui dalam Quinlan (1992) dan dijelaskan pula oleh Witten & Frank (2000).
3. METODOLOGI
Untuk membangun model prediksi level muka air di Stasiun Bojonegoro (BN), tersedia data hasil pengamatan level muka air di stasiun pengamat muka air lain yaitu : stasiun Napel (NP), stasiun Karangnongko (KN), stasiun Cepu (CP), dan stasiun Babat (BB). Sebelum menggunakan data dari stasiun-stasiun diatas sebagai input model maka perlu diketahui hubungan antara data stasiun tersebut dengan menghitung cross correlation untuk mengetahui seberapa besar korelasinya.
Selanjutnya untuk menentukan variabel (attribute) input dari model dilakukan perhitungan korelasi dari masing-masing calon variabel terhadap target prediksi yaitu level muka air di stasiun Bojonegoro. Simulasi model dilakukan dengan 6 skenario. Masing skenario ini dibedakan dengan nilai Pruning Factor yang berbeda. Tujaannya adalah mendapatkan model yang sederhana tetapi masih memiliki performa yang baik. Pruning factor dari model adalah 0.5, 1, 2, 3, 4 dan 5.
Setiap attribute model terdiri dari 4973 hari data level muka air masing-masing stasiun. Dari 4973 data tersebut 90% digunakan untuk proses training (kalibrasi) dan 10 % digunakan untuk Cross-Validation. Selain iut dilakukan test split dengan menggunakan data sebesar 66 %.
Performa setiap model dievaluasi berdasarkan nilai Coeffisien Correlation
(CC), Mean Absolut Error (MAE), Root Mean Square Error (RMSE), Relative Absolut Error (RAE), Root Relative Square Error (RRSE)
dan Jumlah Linear Model (LM).
4. ANALISA DAN HASIL
Hasil perhitungan korelasi masing-masing stasiun terhadap stasiun Bojonegoro ditampilkan pada Tabel 1. dibawah ini.
TABEL 1
KORELASI DARI MASING-MASING STASIUN PENGAMAT MUKA AIR
Atribute NP KN CP BB
KN 0.85
CP 0.93 0.85
BB 0.79 0.82 0.80 BN 0.86 0.83 0.88 0.85
Dari hasil analisa cross-correlation pada tabel di atas terlihat bahwa korelasi terbesar antara stasiun pengamatan Napel dan Babat yaitu 0.79. Sedangkan korelasi terbesar diperoleh antara data stasiun Cepu dan Stasiun Napel.
Secara keseluruhan korelasi data level muka air dari setiap stasiun pengamatan cukup besar sehingga data dari masing-masing stasiun pengamat memiliki hubungan yang cukup kuat dan dapat digunakan sebagai paramater dari model.
Hasil Korelasi dari attribute output dengan masing-masing attribute input disajikan pada Gambar 2.
Gambar 2. Korelasi antara attribute input terhadap attribute output
Hasil korelasi attribute output daTa stasiun Bojonegoro (BNt) dengan attribute input data stasiun Napel sehari sebelumnya (NPt-1) adalah 0,89, sedangkan korelasi dengan
attribute input data stasiun Napel pada hari
yang sama (NPt) adalah 0.86. Korelasi data di stasiun Napel sehari sebelumnya lebih besar dari hasil korelasi data stasiun Napel pada waktu yang sama dengan Stasiun Bojonegoro. Demikian juga hasil perhitungan korelasi data di stasiun yang lain yaitu stasiun Karangnongko sehari sebelum (KNt-1) lebih besar dari Karangnongko hari yang sama (KNt), data di stasiun Cepu sehari sebelumnya (CPt-1) lebih besar dari data di stasiun Cepu pada waktu yang sama (CPt). Sedangkan korelasi data di stasiun Babat sehari sebelumnya (BBt-1) lebih kecil dari data di stasiun Babat pada hari yang sama. Hal ini disebabkan oleh posisi stasiun Babat berada di hilir stasiun Bojonegoro. Namun karena nilai koefisien korelasi Stasiun Babat cukup besar yaitu 0.84, maka data stasiun Babat juga dapat digunakan sebagai attribute input.
Selengkapnya attribute input untuk model prediksi level muka air di stasiun Bojonegoro disajikan pada Tabel 2.
TABEL 2
ATTRIBUTE MODEL PREDIKSI
Input Output Napel (NPt-1) Bojonegoro (BNt) Napel (NPt) Karangnongko (KNt-1) Karangnongko (KNt) Cepu (CPt-1) Cepu (CPt) Babat (BBt-1) Babat (BBt)
Simulasi model dilakukan dengan menggunakan software WEKA 3-2 yang dikembangkan oleh Waikato University. Hasil simulasi keenam model dengan perbedaan angka pruning factor ditampilkan dalam Gambar 3 s/d Gambar 8.
Pada Gambar 3. Menunjukkan bahwa dengan meningkatnya Pruning Factor menyebabkan menurunnya korelasi antara attribute input dan attribute output.
Gambar 4. Menunjukkan bahwa peningkatan
Pruning Factor menyebabkan harga Mean Absolut Error meningkat. Harga MAE
terendah 0.4 meter dan tertinggi 0.5 meter.
Gambar 3. Coefisien Correlation
Gambar 4. Mean Absolut Error
Gambar 5. Menunjukkan bahwa peningkatan
Pruning Factor menyebabkan harga Root Mean Square Error meningkat. Model 1
memiliki RMSE 0.60 dan meningkat sampai model 6 memiliki RMSE 0.75.
Gambar 6 dan Gambar 7. menunjukkan bahwa peningkatan Pruning Factor
menyebabkan prosentase dari Relative
Absolut Error dan Root Relative Square
Error meningkat sejalan dengan
meningkatnya MAE dan RMSE.
Gambar 5. Root Mean Square Error
Gambar 7. Root Relative Square Error Sedangkan Gambar 8. menunjukkan bahwa peningkatan Pruning Factor menyebabkan terjadinya penurunan yang cukup tajam pada jumlah Linear Model (LM) dari jumlah LM 317 menjadi jumlah LM tinggal 2.
Gambar 8. Jumlah Linier model
Performa masing-masing model dari hasil kalibrasi (training), cross-validation dan test
split dari masing-masing model disajikan
pada Tabel 3.
TABEL 3
PERFORMA MASING-MASING MODEL
N o Test P F LM Performa Model CC MAE (m) RM-SE (m) RAE (%) RRSE (%) 1 Training 0.5 317 0.95 0.40 0.60 23.28 29.8 4 Validasi 0.94 0.48 0.71 27.55 35.2 7 Split 0.93 0.48 0.73 27.22 35.6 2 2 Training 1 172 0.95 0.43 0.63 24.53 31.2 8 Validasi 0.94 0.48 0.71 27.61 35.1 2 Split 0.94 0.48 0.72 27.00 35.3 5 3 Training 2 86 0.94 0.45 0.67 25.97 33.0 3 Validasi 0.93 0.50 0.73 28.64 36.1 5 Split 0.93 0.48 0.74 27.32 35.8 8 4 Training 3 52 0.94 0.47 0.69 26.83 33.9 2 Validasi 0.93 0.51 0.74 29.31 36.4 4 Split 0.93 0.49 0.73 27.60 35.8 1 5 Training 4 34 0.94 0.47 0.70 27.25 34.6 0 Validasi 0.93 0.52 0.75 29.70 36.8 9 Split 0.93 0.49 0.73 27.84 35.8 2 6 Training 5 2 0.93 0.52 0.75 29.91 36.8 8 Validasi 0.93 0.52 0.75 30.06 37.0 8 Split 0.93 0.49 0.73 27.83 35.8 2
Berdasarkan nilai performa tabel di atas maka bila diinginkan model dengan nilai
error paling kecil maka dapat dipilih model
pertama. Namun perlu diingat bahwa model pertama terdiri dari 317 fungsi linier yang tentukan jumlah ini cukup banyak. Sedangkan bila diinginkan model paling sederhana maka dapat digunakan model prediksi ke enam dengan hanya 2 fungsi linier. Model ini memiliki akurasi paling rendah dari model-model yan lain. Pertimbangan yang lain adalah dapat memilih model dengan jumlah linear model tidak terlalu banyak tetapi akurasi yang dihasilkan masih cukup baik.
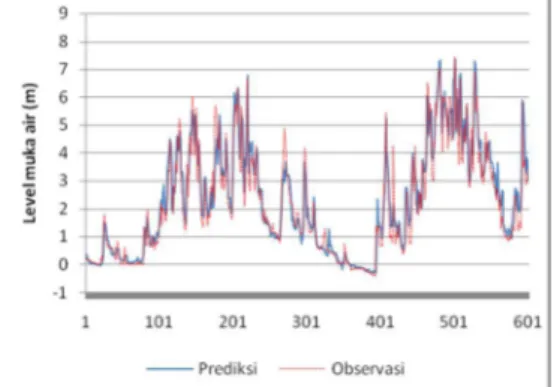
Untuk mendapatkan gambaran tentang perbandingan level muka air hasil prediksi dan level muka air hasil pengamatan di lapangan maka performa dari model 1 ditampilkan secara visual pada Gambar 9.
Gambar 9. Perbadingan level muka air prediksi dan observasi di stsiun Bojonegoro. 5. KESIMPULAN
1. Secara keseluruhan dari model 1 sampai model 6 memiliki performa cukup baik dengan nilai RMSE 0.7 meter (31 % dari
level rata-rata dan 7.8 % dari level maksimum)
2. Peningkatan RMSE dari model 1 ke model 6 tidak terlalu besar yaitu hanya 0.15 meter dibanding dengan penurunan jumlah Linier Model sebanyak 315. 6. SARAN
1. Untuk mendapatkan model dengan performa baik diperlukan pemilihan attribute dan data yang memiliki korelasi atau hubungan dengan atribut dan data yang akan diprediksi.
2. Metode penelitian ini dapat digunakan untuk memprediksi level muka air di lokasi stasiun yang lain.
7. DAFTAR PUSTAKA
1. Dulal, K. N. (2002) Application of Data
Driven Techniques in Hydrological
Modelling, M.Sc. Thesis, HH 434, IHE,
Delft, The Netherlands.
2. Frank, E., Wang, Y., Inglis, S., Holmes, G., and Witten, I.H., (1997) Using Model Trees for Classification, Machine Learning Juornal. Vol. 32, No. 1, pages
63-76.
3. Garner, S.R. (1995) WEKA : The Waikato Enviroment for Kowledge Analysis, Proc
new Zealand Computer Science
Research Students Confrence, University
of Waikato, Hamilton, New Zealand, Pages 57-64.
4. Lasminto U (2004), Aplikasi Artificial
Network untuk Peramalan Banjir kali Surabaya, Seminar Nasional Universitas
Pembangunan Nasional Surabaya. 5. Lasminto U. (2004), Model Peramalan
Banjir di Kali Surabaya, Seminar
Nasional Penanganan Banjir Dies Natalis ke 44 ITS Surabaya
6. Lasminto U. (2004), Peramalan Elevasi
Permukaan Air untuk keperluan
Pelayaran di Muara sungai Musi,
Seminar Nasional Pertemuaan Ilmiah Tahunan XXI Himpunan Ahli Teknik Hidraulik Indonesia, Bali.
7. Lasminto U. (2004), Aplikasi Model Non
Linier M5 Model Tree untuk peramalan debit Banjir Kali Surabaya, Seminar
Nasional Penanganan Banjir Dies Natalis ke 44 ITS Surabaya, 2004
8. Lasminto, U. (2004), Flood Modelling
and Forecasting in the Surabaya River,
M.Sc. Thesis, HH 479, IHE, Delft, The Netherlands.
9. Lasminto U. (2005), Flood Forecasting
at Gunungsari Dam for Surabaya Drainage Warning System, International
Seminar On Early Warning Sistem of Disaster, Surabaya.
10. Lasminto, U. (2007), Model Peramalan
permukaan air sungai 24 jam kedepan di Muara Sungai Musi, Seminar Nasional
Pasca Sarjana VII ITS
11. Shrestha, I., 2003, Conceptual and Data
Driven Hydrological Modelling of
Bagmati River Basin, Nepal, M.Sc.
Thesis, HH 451, IHE, Delft, The Netherlands
12. Siek, M.B., (2003) Flexibility and
Optimality in Model Trees Learning with Application to Water-related Problem,
M.Sc. Thesis, HH 472, IHE, Delft, The Netherlands.
13. Sikonja, M.R. and Kononenko, I. (1998) Pruning Regression Trees with MDDL. ECAI 98, 13th European Conference in Artificial Intelligence.
14. Solomatine, D. P. and Dulal, K. N. (2002) Model Tree as an Alternative to Neural Network in Rainfall Runoff Modelling, Hydrological Sciences Journal, Vol. 48, No. 3, Pages 399-411.
15. Solomatine, D. P. (2001) Data Driven Modelling: Machine learning, Data Mining and Knowledge Discovery, IHE lecture notes, HH482/02/1
16. Waikato ML Group (1996) Tutorial-Weka
the Waikato for Knowledge Analysis,
Departement of Computer Science, University of Waikato, November, Pages 110.
17. Waikato ML Group (1997) User
Manual-Weka the Waikato for Knowledge Analysis. Departement of Computer
Science, University of Waikato, June, Pages 260.
18. Wang, Y. and Witten, I.H. (1997) Introduction of Model Trees for Predicting Continuous Classes.
Proceeding of the Poster Papers of the
European Conference on machine
Learning, University of Economics,
Faculty of Informatic and Statistic, Prague, Czech Republic, Pages 128-137