131
ANALISIS REGRESI DENGAN METODE KOMPONEN UTAMA DALAM MENGATASI MASALAH MULTIKOLINEARITAS
Pendi
INTISARI
Multikolinearitas adalah suatu kondisi dimana terjadinya korelasi antara variabel bebas. Salah satu permasalahan yang perlu mendapat perhatian khusus dalam pengunaan analisis regresi linier berganda adalah kemungkinan adanya multikolinearitas dalam variabel bebas. Analisis regresi linier berganda tidak mungkin dapat dilakukan jika terdapat multikolinearitas yang sempurna antara variabel bebas yang terdapat dalam model regresi. Tujuan dari penelitian ini adalah mengatasi masalah multikolinearitas pada data penelitian dengan menggunakan metode komponen utama. Data penelitian yang digunakan adalah data angka kematian bayi yang diperoleh dari profil Kesehatan Provinsi Kalimantan Barat pada tahun 2018 berjumlah 14 data Kabupaten/Kota. Pada data tersebut terdapat dua variabel bebas yang mengalami masalah multikolinearitas, yaitu pelayanan kesehatan bayi (X4) dan pemberian Vitamin A usia 6-11 bulan (X5). Sehingga masalah tersebut akan diatasi menggunakan metode komponen utama. Berdasarkan analisis yang telah dilakukan, diperoleh satu komponen utama (K1) yang terbentuk dengan nilai eigen lebih besar dari satu yaitu 3,778 dengan total variansi komulatif yang dijelaskan sebesar 75,566%.
Kata Kunci: Multikolinearitas, Metode Komponen Utama, Angka Kematian Bayi
PENDAHULUAN
Analisis regresi adalah salah satu teknik statistik yang paling populer yang biasa digunakan untuk tujuan peramalan atau pendugaan tentang nilai variabel dependen (Y). Analisis regresi terbagi menjadi dua bagian yaitu analisis regresi linier sederhana dan analisis regresi linier berganda. Analisis regresi linier sederhana adalah analisis yang menduga satu variabel dependen (Y) oleh satu variabel bebas (X) saja. Sedangkan analisis regresi linier berganda adalah regresi dengan dua atau lebih variabel bebas (X), sehingga merupakan perluasan dari analisis regresi linier sederhana. Analisis regresi linier berganda yang mempunyai banyak variabel bebas sering timbul masalah karena terjadinya hubungan antara dua atau lebih variabel bebas. Variabel bebas yang saling berkorelasi disebut multikolinearitas [1]. Untuk mengatasi masalah multikolinearitas diperlukan suatu metode yaitu analisis komponen utama Principal Component Analysis (PCA). PCA merupakan suatu teknik statistik untuk mengubah dari sebagian besar variabel asli yang digunakan dan saling berkorelasi satu dengan yang lainnya, menjadi satu set variabel baru yang lebih kecil dan saling bebas (tidak berkorelasi lagi) [2].
Tujuan PCA adalah untuk menyederhanakan variabel yang diamati dengan cara menyusutkan (mereduksi) dimensinya. Penghitungan dengan metode PCA memerlukan suatu model analisis regresi yaitu Principal Component Regression (PCR). PCR merupakan salah satu metode yang telah dikembangkan untuk mengatasi masalah multikolinearitas. Analisis PCR merupakan analisis regresi dari variabel dependen terhadap komponen utama yang tidak saling berkorelasi, dimana setiap komponen utama merupakan kombinasi linier dari semua variabel bebas [3].
Data yang digunakan adalah data sekunder yang diperoleh dari profil Kesehatan Provinsi Kalimantan Barat pada tahun 2018. Variabel penelitian yang digunkan berupa variabel dependen (Y) yakni angka kematian bayi dan variabel bebas (X) meliputi variabel jumlah kelahiran bayi (X1), berat badan lahir rendah (X2), pemberian ASI eksklusif usia 0-6 bulan (X3), pelayanan kesehatan bayi (X4) dan pemberian vitamin A usia 6-11 bulan (X5) di 14 Kabupaten/Kota Provinsi Kalimantan Barat [4].
Tahapan yang dilakukan dalam PCA adalah menginput data penelitian dan menghitung gambaran
umum data penelitian yang diringkas dalam statistik deskriptif. Selanjutnya melakukan pendugaan koefisien menggunakan metode kuadrat terkecil kemudian menganalisis masalah multikolinearitas dan menghitung korelasi masing-masing variabel bebas. Setelah diketahui data terjadi masalah multikolinearitas, dilanjutkan dengan menggunakan PCA. Langkah pertama yang dilakukan ialah melakukan pengecekan kecukupan data yang digunakan dalam analisis PCA. Selanjutnya menentukan kriteria pembentukkan komponen utama dengan menstandarisasikan semua variabel bebas (X) kedalam bentuk variabel baku (Z). Setelah mendapatkan komponen utama, selanjutnya meregresikan komponen utama kedalam variabel dependen (Y) untuk mendapatkan model regresi komponen utama.
Sedangkan jika diketahui data tidak mengalami masalah multikolinearitas maka dilakukan dengan mengganti data penelitian dan melakukan analisis kembali hingga data mengalami masalah multikolinearitas.
UJI MULTIKOLINEARITAS
Uji multikolinearitas bertujuan untuk mengetahui adanya korelasi yang tinggi antar variabel prediktor pada model regresi. Besaran (quantity) yang dapat digunakan untuk mendeteksi adanya multikolinearitas adalah faktor inflasi ragam (Variance Inflation Factor/VIF). VIF digunakan sebagai kriteria untuk mendeteksi multikolinier pada regresi linier yang melibatkan lebih dari dua variabel bebas. Nilai VIF lebih besar dari 10 mengindikasikan adanya masalah multikolinearitas yang serius.
Nilai VIF dapat dihitung dengan rumus sebagai berikut [5]:
1
21 R
jVIF
dengan Rj2 adalah koefisien determinasi antara Xj dengan variabel bebas lainnya dimana j = 1, 2,..,k.
UJI KORELASI
Korelasi memiliki arti sebagai suatu hubungan timbal balik atau sebab akibat anatara dua buah kejadian. Salah satu perhitungan koefisien korelasi adalah metode pearson yang digunakan untuk melihat hubungan diantara variabel. Nilai korelasi pearson antara x dan y dapat dihitung dengan rumus sebagai berikut[6]:
2 2 2 2y y
n x x
n
y x xy
r
xyn
Korelasi dilambangkan dengan nilai r, dengan ketentuan 1 r 1. Apabila r = 1 artinya negatif sempurna; r = 0 tidak ada korelasi; dan r = 1 artinya korelasi sangat kuat. Untuk mengetahui korelasi antara dua variabel, hipotesis yang digunakan adalah sebagai berikut:
0
0
:
H
(tidak terdapat korelasi) H1:
0 (terdapat korelasi)Dengan statistik ujinya adalah sebagai berikut:
1
22 r n t
hitungr
dan akan ditolak H0 jika nilai thitung > t/2;n2 atau nilai p-value <
KRITERIA PEMBENTUKAN PCA
Ada tiga kriteria dalam pemilihan komponen utama yang digunakan yaitu dengan melihat nilai eigen yang lebih besar dari satu, melihat sudut pada scree plot yang menunjukkan perubahan nilai eigen yang besar, dan proporsi variansi komulatif mencapai 70% sampai dengan 80% [5].
PRINCIPAL COMPONENT REGRESSION (PCR)
PCR merupakan analisis regresi variabel dependen terhadap komponen-komponen utama yang tidak saling berkorelasi, regresi komponen utama dapat dinyatakan sebagai berikut [3]:
Y = w0 + w1K1 + w2K2 + ... + wmKm (1) K1, K2,...,Km merupakan komponen utama yang dilibatkan dalam analisis regresi komponen utama, dimana besaran m lebih kecil dari pada banyaknya variabel bebas yaitu sejumlah p, w0 merupakan konstanta, w1, w2, ...,wm merupakan parameter regresi dan Y merupakan variabel dependen.
Komponen utama merupakan kombinasi linier dari varuabel baku (Z) yaitu:
K1 = a11Z1 + a21Z2 + ... + ap1Zp
K1 = a12Z1 + a22Z2 + ... + ap2Zp
Km = a1mZ1 + a2mZ2 + ... + apmZp (2) dengan persamaan regresi dugaan komponen utama adalah sebagai berikut:
Y = b0 + b1Z1 + b2Z2 + ... + bpZP (3) dengan Y merupakan variabel dependen, b0 merupakan konstanta, b1, b2, ..., bp merupakan parameter regresi dan Z1, Z2,..., Zp merupakan variabel baku.
UJI ASUMSI PCA
Uji KMO digunakan menguji kecukupan data yang digunakan dalam analisis komponen utama.
Hipotesis untuk uji kecukupan sampel secara keseluruhan menggunakan Kaiser Mayer Olkin (KMO) sebagai berikut [5]:
H0: ukuran data cukup untuk dianalisis komponen utama H1: ukuran data tidak cukup untuk dianalisis komponen utama Statistik uji:
p
j
p
j p
k jk p
k jk p
j p
k jk
a r
r KMO
1 1 1
2 1
2
1 1
2
untuk j = 1,2,3,..., p dan k = 1,2,3,..., p. Tolak H0 jika nilai KMO < 0,5.
Sedangkan hipotesis uji kecukupan data untuk masing-masing variabel menggunakan Measure Sampling of Adequacy (MSA) sebagai beriku:
H0: variabel memadai untuk dianalisis lebih lanjut H1: variabel tidak memadai untuk dianalisis lebih lanjut Statistik uji:
p k
p
k jk
jk p k jk
j
r a
r MSA
1 1
2 2
1 2
dengan rjk merupakan koefisien korelasi antara variabel j dan k, ajk merupakan koefisien korelasi parsial antara variabel j dan k. Tolak H0 jika nilai MSA < 0,5.
UJI SIGNIFIKANSI MODEL REGRESI
Uji signifikansi PCA ada dua tahap yaitu uji signifikansi model regresi dan uji signifikan regresi secara individual [7] :
a. Uji signifikansi model regresi
Uji signifikansi model regresi bertujuan untuk menguji apakah ada hubungan linier antara variabel dependent (Y) dengan variabel bebas (X) secara bersama-sama. Hipotesis uji F adalah:
1. Hipotesis
H0 :
1=
2= ...=
mH1 : terdapat
j
0 dengan j = 1,2,...,m.2. Statistik uji
MSE MSR m
n JKS
k
F
hitungJKR
) 1 (
3. Kriteria Uji
H0 ditolak jika F hitung >F(,k,nm1) atau p-value <
b. Uji koefisien regresi secara individuUji koefisien regresi secara individu digunakan untuk menguji ada tidaknya pengaruh yang signifikan antara masing-masing variabel dependen (Y) terhadap model regresi linier sebagai berikut:
1. Hipotesis H0 :
j= 0
H1 :
j 0 2. Statistik ujiˆ) (
ˆ
se thitung 3. Kriteria ujiTolak H0 jika nilai t hitung >t(/2;nm1) atau p-value <
PEMBAHASAN
Data yang digunakan adalah data sekunder yang diperoleh dari profil Kesehatan Provinsi Kalimantan Barat pada tahun 2018. Data penelitian yang digunakan adalah berjumlah 14 data Kabupaten/Kota di Provinsi Kalimantan Barat. Variabel penelitian yang digunkan berupa variabel dependen (Y) yakni angka kematian bayi dan variabel bebas (X) meliputi variabel jumlah kelahiran bayi (X1), berat badan lahir rendah (X2), pemberian ASI eksklusif usia 0-6 bulan (X3), pelayanan kesehatan bayi (X4) dan pemberian vitamin A usia 6-11 bulan (X5). Pengerjaan awal yang dilakukan adalah menghitung gambaran umum data penelitian yang diringkas dalam statistik deskriptif dengan menggunakan SPSS 20 pada tabel 1 sebagai berikut:
Tabel 1 Statistik Deskriptif Variabel Bebas dan Variabel Dependen
Variabel Minimum Maksimum Rata-Rata Standar Deviasi
Y 21 92 45,5714 21,16134
X1 1441 10791 5476,5 2663,02938
X2 19 493 200,5 150,86864
X3 410 6009 2317,2143 1722,61417
X4 1528 9606 5460,7143 2685,39581
X5 2431 11215 6452,1429 3082,39604
Tabel 1 merupakan tabel statistik deskriptif variabel bebas dan variabel dependen, dimana pada hasil rata-rata dilakukan pembulatan, selanjutnya memperoleh persamaan regresi menggunakan metode kuadrat terkecil dan menentukan parameter kuadrat terkecil mana yang signifikan terhadap variabel dependen. Persamaan regresi yang diperoleh menggunakan metode kuadrat terkecil yaitu:
5 4
3 2
1
0 , 062 0 , 001 0 , 010 0 , 011
004 , 0 121 ,
ˆ 21 X X X X X
Y
Model persamaan tersebut menjelaskan bahwa setiap angka kematian bayi akan bertambah sebesar 0,004 untuk setiap kenaikan jumlah kelahiran bayi (X1) sebesar satu satuan dengan sayarat variabel bebas lainnya tetap. Setiap kenaikan berat badan lahir rendah (X2) sebesar satu satuan akan menambah angka kematian bayi sebesar 0,062 dengan syarat variabel bebas lainnya tetap. Setiap kenaikan pemberian ASI eksklusif usia 0-6 bulan sebesar satu satuan akan menaikan angka kematian bayi sebesar 0,001 (X3) dengan syarat variabel bebas lainnya tetap. Angka kematian bayi akan bertambah sebesar 0,010 setiap kenaikan pelayanan kesehatan bayi (X4) sebesar satu satuan dengan syarat variabel bebas lainnya tetap. Setiap penurunan pemberian vitamin A sebesar satu satuan akan menaikan angka kematian sebesar 0,011 (X5) dengan syarat variabel bebas lainnya tetap. Selanjutnya melakukan uji signifikansi parameter kuadrat terkecil, diketahui bahwa variabel X1, X2, X3, X4 dan X5
berpengaruh secara signifikan terhadap Y. Selanjutnya melakukan uji multikolinearitas dilakukan dengan melihat nilai VIF > 10, berdasarkan output SPSS 20 diperoleh nilai VIF sebagai berikut:
Tabel 2 Hasil Uji Multikolinearitas
Variabel Nilai VIF
X1 3,413
X2 2,210
X3 3,328
X4 19,479
X5 20,913
Dari Tabel 2 diperoleh bahwa variabel X4 dan X5 yaitu pelayanan kesehatan bayi dan pemberian vitamin A usia 6-11 bulan memiliki nilai VIF >10 sehingga data yang digunakan mengalami masalah multikolinearitas. Selanjutnya akan di cek nilai masing-masing variabel karena variabel yang saling berkorelasi yang akan di atasi dengan metode PCA. Hasil output SPSS 20 dapat dilihat pada Tabel 3 sebagai berikut:
Tabel 3 Uji Korelasi
Dari tabel 3 dapat disimpulkan bahwa X1 dan X2, X1 dan X3, X1 dan X4, X1 dan X5, X2 dan X3, X2
dan X4, X2 dan X5, X3 dan X4, X3 dan X5, X4 dan X5 adalah variabel-variabel yang saling berkorelasi dimana nilai p-value < 0,05. Selanjutnya yaitu mengatasi masalah multikolinearitas dengan metode Principal Component Analisis (PCA). Langkah pertama yang dilakukan adalah melakukan standarisasi semua variabel bebas (X) kedalam bentuk variabel baku (Z), selanjutnya menguji asumsi komponen utama yaitu dengan melakukan uji KMO dan MSA. Uji KMO digunakan untuk menguji kecukupan data yang digunakan dalam PCA. Berikut adalah hasil uji KMO berdasarkan output SPSS 20 adalah sebagai berikut:
Tabel 4 Uji KMO
Keterangan Nilai
Kaiser-Meyer-Olkin Measure of Sampling Adequacy (KMO) 0,783
Dari Tabel 4 diperoleh bahwa nilai KMO = 0,783 > 0,5 sehingga dapat disimpulkan bahwa ukuran data cukup untuk dianalisis komponen utama. Selanjutnya melakukan hipotesis uji kecukupan data masing-masing variabel dengan menggunakan uji MSA. Uji MSA dilakukan untuk memastikan bahwa
X1 X2 X3 X4 X5
X1 1
X2 korelasi 0,630 p-value 0,016
X3 korelasi 0,770 0,730 p-value 0,001 0,003
X4 korelasi 0,732 0,508 0,638 p-value 0,003 0,064 0,014
X5 korelasi 0,753 0,531 0,652 0,974
p-value 0,002 0,051 0,12 0,000 1
variabel memadai untuk dianalisis lebih lanjut atau tidak. Berikut ini hasil olahan uji MSA sebagai yang diperoleh dari output SPSS 20 adalah sebagai berikut:
Tabel 5 Uji MSA
Variabel Nilai MSA
Z1 0,9
Z2 0,848
Z3 0,821
Z4 0,706
Z5 0,705
Berdasarkan Tabel 5 terlihat bahwa nilai MSA > 0,5. Kriteria keputusan terima H0 Sehingga dapat disimpulkan bahwa variabel jumlah kelahiran bayi (Z1), berat badan lahir rendah (Z2), pemberian ASI eksklusif usia 0-6 bulan (Z3), pelayanan kesehatan bayi (Z4) dan pemberian vitamin A usia 6-11 bulan (Z5) memadai untuk dianalisis lebih lanjut. Selanjutnya menentukan jumlah komponen utama yang terbentuk dengan memilih nilai eigen yang lebih besar dari satu dan total variansi yang dihasilkan pada tabel 6 hasil output SPSS 20 sebagai berikut:
Tabel 6 Nilai Eigen dan Total Variansi
Komponen Nilai Eigen
Total Variansi (%) Komulatif (%)
1 3,778 75,566 75,566
2 0,699 13,976 89,541
3 0,298 5,967 95,509
4 0,199 3,982 99,491
5 0,025 0,509 100
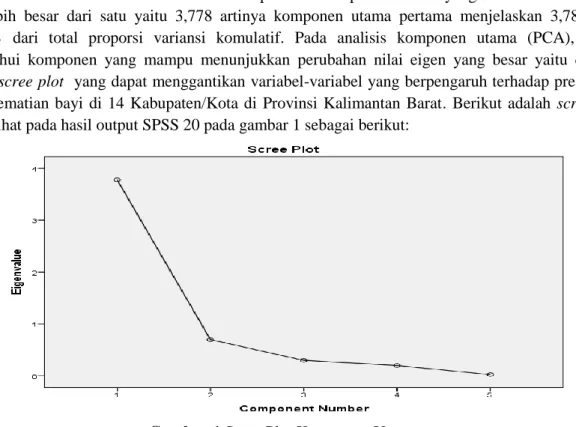
Berdasarkan tabel 6 diketahui bahwa terdapat satu komponen utama yang memiliki nilai eigen yang lebih besar dari satu yaitu 3,778 artinya komponen utama pertama menjelaskan 3,788 atau 75,566% dari total proporsi variansi komulatif. Pada analisis komponen utama (PCA), untuk mengetahui komponen yang mampu menunjukkan perubahan nilai eigen yang besar yaitu dengan melihat scree plot yang dapat menggantikan variabel-variabel yang berpengaruh terhadap presentase angka kematian bayi di 14 Kabupaten/Kota di Provinsi Kalimantan Barat. Berikut adalah scree plot yang dilihat pada hasil output SPSS 20 pada gambar 1 sebagai berikut:
Gambar 1 Scree Plot Komponen Utama
Berdasarkan gambar 1 dapat dilihat bahwa terjadi penurunan pada nilai eigen kesatu artinya terdapat satu komponen utama yang dipilih untuk mengantikan variabel-variabel yang berpengaruh terhadap
jumlah kematian bayi di 14 Kabupaten/Kota di Provinsi Kalimantan Barat. Langkah selanjutnya yaitu mencari nilai skor komponen koefisien matriks yang terbentuk untuk membentuk persamaan PCR.
Skor komponen koefisien matriks digunakan untuk menentukan banyaknya variabel yang akan terbentuk untuk menggantikan variabel X1, X2, X3, X4 dan X5 dengan variabel baru. Berikut adalah skor komponen koefisien matriks yang diperoleh dari output SPSS 20 sebagai berikut:
Tabel 7 Nilai skor komponen koefisien matriks
Variabel Komponen
1
Z1 0,237
Z2 0,204
Z3 0,230
Z4 0,237
Z5 0,240
Berdasarkan tabel 7 diperoleh persamaan regresi komponen utama yang terbentuk adalah:
K1 = 0,237Z1 + 0,204Z2 + 0,230Z3 + 0,237Z4 + 0,240Z5
Selanjutnya menentukan variabel baru untuk menggantikan variabel X1, X2, X3, X4 dan X5 dengan cara menstandarisasikan semua variabel X1, X2, X3, X4 dan X5 kedalam bentuk variabel baku (Z). Berikut adalah tabel variabel baru komponen utama yang terbentuk dari hasil output SPSS 20 hasil standarisasi variabel bebas (X) pada tabel 8 sebagai berikut:
Tabel 8 Variabel baru komponen utama Faktor 1
2,09734 -0,61886 0,68383 -0,51388 0,05771 1,10470 0,75333 -0,59177 -1,92724 -0,81210 -1,46153 0,51299 0,69023 -0,97477
Berdasarkan tabel 8 diperoleh bahwa satu komponen adalah jumlah yang paling optimal untuk mereduksi kelima variabel bebas (X). Selanjutnya melakukan pembentukan model regresi komponen utama dilakukan dengan meregresikan variabel dependen (Y) kedalam variabel baru komponen utama yang terbentuk. Selanjutnya menguji signifikansi parameter yang dilakukan menggunakan dua pengujian yaitu uji F dan uji koefisien regresi secara individu. Berikut adalah hasil output SPSS 20 uji F pada tabel 9 sebagai berikut:
Tabel 9 Uji F Sumber
Variansi
Derajat Bebas
Jumlah Kuadrat
Rata-rata Kuadrat
Fhitung P-value
Regresi 1 2223,105 2223,105 7,414 0,019
Error 12 3598,323 299,860
Total 13 5821,429
Berdasarkan tabel 9 diperoleh Fhitung = 7,414 lebih besar dari Ftabel = 4,75 atau p-value sebesar 0,019 lebih kecil dari alpha = 0,05 sehingga dapat disimpulkan setidaknya ada satu parameter yang
signifikan terhadap model. Berikutnya melakukan uji koefisien regresi secara individu dengan hipotesis dan hasil pengujian output SPSS 20 pada tabel 10 sebagai berikut:
Tabel 10 Uji Signifikansi
Variabel Koefisien titung P-value
Y 45,571 9,847 0,000
K1 13,077 2,723 0,019
Berdasarkan tabel 10 diperoleh nilai titung = 9,847 lebih besar dari t(0025;12) = 2.17 atau p-value lebih kecil dari alpha = 0,05 artinya tidak terjadi pengaruh signifikan terhadap model persamaan regresi, sehingga diperoleh model persamaan regresi menggunakan metode PCR sebagai berikut:
077 1
, 13 571 ,
ˆ 45 K
Y
PENUTUP
Berdasarkan analisis yang dilakukan, maka dapat disimpulkan bahwa:
1. Multikolinearitas yang terjadi pada variabel X4 dan X5 dapat teratasi dengan metode komponen utama. Data angka kematian bayi yang memiliki lima variabel bebas telah direduksi menjadi satu komponen utama dengan nilai eigen lebih besar dari satu yaitu 3,778 dengan total variansi komulatif yang dijelaskan sebesar 75,566%.
2. Penerapan metode komponen utama dengan satu variabel dependen dan lima variabel bebas pada data angka kematian bayi di 14 Kabupaten/Kota Provinsi Kalimantan Barat tahun 2018 diperoleh model regresi komponen utama yaitu:
077 1
, 13 571 ,
ˆ 45 K
Y
3. Berdasarkan model, faktor yang mempengeruhi angka kematian bayi yaitu variabel X1 adalah jumlah kelahiran bayi, kemudian variabel X2 adalah jumlah Berat Badan Lahir Rendah (BBLR), kemudian variabel X3 adalah Pemberian ASI Eksklusif usia 0-6 bulan, kemudian variabel X4
adalah pelayanan kesehatan bayi dan variabel X5 adalah pemberian Vitamin A usia 6-11 bulan.
DAFTAR PUSTAKA
[1] Kusnandar D. Metode Statistik dan Aplikasinya dengan Minitab dan Excel, Yogyakarta: Madyan Press. 2003.
[2] Delsen M S N V, Wattimena A Z, Saputri S D. Penggunaan Metode Analisis Komponen Utama Untuk Mereduksi Faktor-Faktor Inflasi Di Kota Ambon. Barekeng Jurnal Ilmu Matematika dan Terapan, 2017; 11(2)109-118.
[3] Supriyadi E, Mariani S, Sugiman. Perbandingan Metode Partial Least Square (PLS) dan Principal Component Regression (PCR) Untuk Mengatasi Multikolinearitas Pada Model Regresi Linear Berganda. UNNES Journal of Mathematices. 2017; 6(2)117-128.
[4] Profil Kesehatan Kalimantan Barat Tahun 2018.pdf [Internet]. 2020 [cited 2020 jun 23].
Avaliablefrom:https://datacloud.kalbarprov.go.id/index.php/s/jb3roCn4ipkdTnc?path=%2FProvin si#pdfviewer
[5] Sari N, Yasin H, Prahutama A. Geographically Weighted Regression Principal Component Analysis (GWRPCA) Pada Pemodelan Pendapatan Asli Daerah Di Jawa Tengah. Jurnal Gaussian.
2016; 5(4)717-726.
[6] Bain L. J, Engelhardt M. Introduction To Probability and Mathematical Statistics. second edition.
Duxbury-Press, California. 1992.
[7] Siburian J N J O, Rahmawati R, Hoyyi A. Regresi Komponen Utama Robust S-Estimator Untuk Analisis Pengaruh Jumlah Pengangguran Di Jawa Tengah. Jurnal Gaussian. 2019; 8(4)439-450.
PENDI : Jurusan Matematika FMIPA UNTAN, Pontianak.
pendichow@student.untan.ac.id