Landasan Teori
2.1Teori – teori Dasar / Umum
2.1.1 Pengertian Data Mining
Menurut (Han, Kamber, & Pei, 2011)menjelaskan bahwa “Data Mining merupakan pemilihan atau “menggali” pengetahuan dari jumlah data yang banyak.” Hal ini diperkuat oleh teori dari (Han, Kamber, & Pei, 2011) yang mengatakan data mining adalah proses menemukan pola yang menarik dan pengetahuan dari data yang berjumlah besar dan juga teori dari (Segall, 2008) yang menjelaskan “Data Mining disebut penemuan pengetahuan atau menemukan pola yang tersembunyi dalam data. Jadi bisa disimpulkan kalau Data Mining adalah suatu proses untuk menemukan knowledge (pengetahuan) yang tersembunyi melalui pola – pola menarik dari data yang berjumlah besar.
2.1.2 Teknik Data Mining
Banyak fungsi data mining yang dapat digunakan. Dalam kasus tertentu fungsi data mining dapat digabungkan untuk menjawab masalah yang dihadapi (MacLennan, 2009). Berikut adalah fungsi data mining secara umum:
1. Classification
Fungsi dari Classification adalah untuk mengklasifikasikan suatu target class ke dalam kategori yang dipilih. Menurut (Purba), Classification untuk membangun model (fungsi) yang menguraikan dan membedakan kelas atau konsep untuk peramalan kedepan. Misal, mengklasifkasikan negara berdasarkan iklim atau mengklasifikasikan mobil berdasarkan konsumsi bahan bakarnya. Jadi Classification adalah teknik yang mengklasifikasikan target class untuk dijadikan pendukung kesimpulan peramalan kedepannya.
Gambar 2.1 Proses klasifikasi menggunakan Decision Tree Sumber: (MacLennan, 2009)
2.Clustering
Fungsi dari clustering adalah untuk mencari pengelompokan atribut ke dalam segmentasi-segmentasi berdasarkan similaritas.
Gambar 2.2 Mengelompokanpendapatan kedalam tiga kategori umur Sumber: (MacLennan, 2009)
3. Association
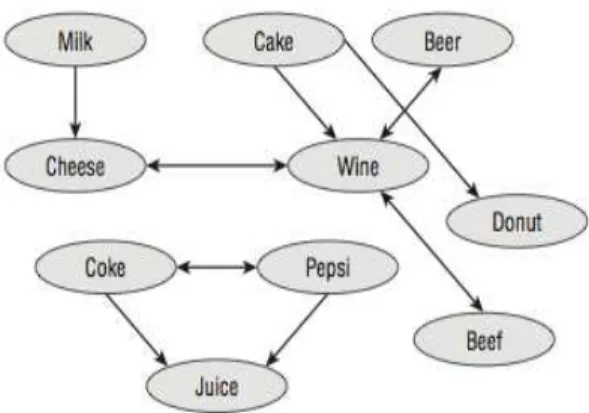
Fungsi dari association adalah untuk mencari keterkaitan antara atribut atau item set, berdasarkan jumlah item yang muncul dan ruleassociation yang ada.
Gambar 2.3 Keterkaitan mencari pola pembelian antara satu prodak dengan prodak lainnya
Sumber: (MacLennan, 2009)
4. Regression
Fungsi dari regression hampir miripdengan klasifikasi.Fungsi dari regression adalah bertujuanuntuk mencari prediksi dari suatu pola yang ada.
5. Forecasting
Fungsi dari forecasting adalah untuk peramalan waktu yang akan datang berdasarkantrend yang telah terjadi di waktu sebelumnya.
Gambar 2.4 Peramalan pada kemungkinan kejadian/ fenomena akan terjadi di waktu yang akan datang
Sumber: (MacLennan, 2009)
6. Sequence Analysis
Fungsi dari sequenceanalysis adalah untuk mencari pola urutan dari rangkaian kejadian.
Gambar 2.5 Menyusun pola kejadian/ fenomena yang ada berdasarkan urutan terjadinya
Sumber: (MacLennan, 2009)
7. Deviation Analysis
Fungsi dari devation analysis adalah untuk mencari kejadian langka yang sangat berbeda dari keadaan normal (kejadian abnormal).
2.1.3 Naïve Bayes
Naïve Bayes merupakan pengklasifikasian dengan metode probabilitas dan statistik yang dikemukakan oleh ilmuwan Inggris Thomas Bayes, yaitu memprediksi peluang di masa depan berdasarkan pengalaman di masa sebelumnya sehingga dikenal sebagai Teorema Bayes. Menurut(Santoso, 2007), klasifikasi Bayesian adalah klasifikasi statistik yang bisa memprediksi probabilitas sebuah class. Menurut (Olson & Dursun, 2008) yang menjelaskan Naïve bayes untuk setiap kelas keputusan, menghitung probabilitas dengan syarat bahwa kelas keputusan adalah benar, mengingat vektor informasi obyek.
Klasifikasi Bayesian ini dihitung berdasarkan Teorema Bayes berikut ini :
Sumber: (Han, Kamber, & Pei, 2011)
Berdasarkan rumus di atas kejadian H merepresentasikan sebuah kelas dan X merepresentasikan sebuah atribut. P(H) disebut prior probability H, contoh dalam kasus ini adalah probabilitas kelas yang mendeklarasikan normal. P(X) merupakan prior probability X, contoh untuk probabilitas sebuah atribut protocol_type. P(H|X) adalah posterior probability yang merefleksikan probabilitas munculnya kelas normal terhadap data atribut protocol_type.
P(X|H) menunjukkan kemungkinan munculnya prediktor X (protocol_type) pada kelas normal. Dan begitu juga seterusnya untuk proses menghitung probabilitas ke-empat kelas lainnya.
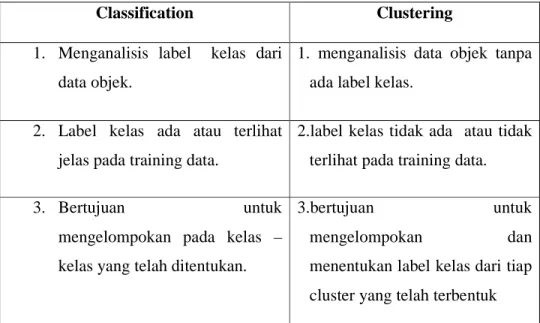
2.1.4 Classification vs Clustering
Dari tugas – tugas data mining yang telah di jelaskan, perbandingan antara Classification dan Clustering menurut (Han & Kamber, Data Mining : Concept and Techniques Second Edition, 2006) lebih spesifik digambarkan sebagai berikut :
Tabel 2.1 Perbandingan Metode Classification dan Clustering
Classification Clustering
1. Menganalisis label kelas dari data objek.
1. menganalisis data objek tanpa ada label kelas.
2. Label kelas ada atau terlihat jelas pada training data.
2.label kelas tidak ada atau tidak terlihat pada training data.
3. Bertujuan untuk
mengelompokan pada kelas – kelas yang telah ditentukan.
3.bertujuan untuk
mengelompokan dan
menentukan label kelas dari tiap cluster yang telah terbentuk
4. Proses Klasifikasi berdasarkan pada menemukan sebuah model
atau fungsi yang
menggambarkan dan
membedakan data kelas atau konsep, dengan tujuan untuk dapat menggunakan model untuk memprediksi objek kelas yang kelas labelnya belum diketahui. Model tersebut berdasarkan pada analisis dari training data (data objek yang kelas labelnya telah diketahui.)
4. Proses Clustering berdasarkan pada prinsip: objek yang ada di dalam satu cluster memiliki kemiripan yang tinggi dari pada yang lainnya, tetapi sangat berbeda dengan objek yang ada pada cluster lainnya.
Jadi berdasarkan perbandingan antara teknik data mining di atas, maka ditentukan teknik data mining yang digunakan, yaitu classification. Karena adanya penggunaan label kelas pada data yang digunakan yaitu antara jantung dan tidak jantung sehingga bisa membantu analisa pada data pasien baru yang kelas labelnya belum diketahui.
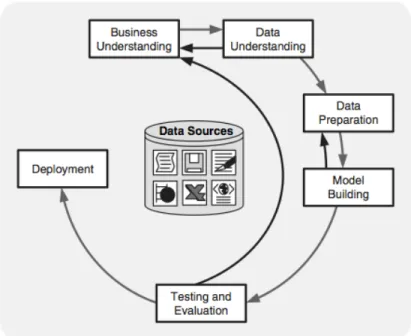
2.1.5 CRISP DM
Penelitian ini melakukan proses data mining dengan memanfaatkan metodologi CRISP-DM. Metodologi initerdiridarienam tahapprosessiklus. Metodologi ini membuat data mining yang besar dapat dilakukan dengan lebih cepat, lebih ekonomis, dan mudah untuk diatur. Bahkan, datamining yang berukuran kecil pun dapat memperoleh keuntungan dari CRISP-DM (Olson & Dursun, 2008). Berikut adalah enam tahap yang disebut sebagai siklus:
1. Business understanding
Business understanding meliputi penentuan tujuan bisnis, menilai situasi saat ini, menetapkan tujuan data mining, dan mengembangkan rencana proyek.
2. Data understanding
Setelah tujuan bisnis dan rencana proyek ditetapkan, Data understanding mempertimbangkan persyaratan data. Langkah inidapat mencakup
pengumpulan data awal, deskripsi data, eksplorasi data, dan verifikasi data yang berkualitas.
3. Data preparation
Setelah sumber data telah tersedia untuk diidentifikasi. Data tersebut perlu untuk dipilih, dibersihkan, dibangun ke dalam model yang diinginkan, dan diformat. Pembersihan data dan transformasi data dalam penyusunan pemodelan data perlu terjadi ditahap ini.
Gambar 2.6 Greedy (heuristic) methods for attribute subset selection.
Sumber: (Han, Kamber, & Pei, Data Mining Concepts and Techniques 3rd Edition, 2011)
Terdapat beberapa teknik dalam mengolah data seperti Data Transformation, Data Reduction dan Data Cleaning, diantaranya :
• Generalization
Mengubah data atribut low level menjadi atribut high level, contoh: atribut numerical menjadi ordinal.
• Attribute construction
Penambahan atribut baru untuk kepentingan proses mining.
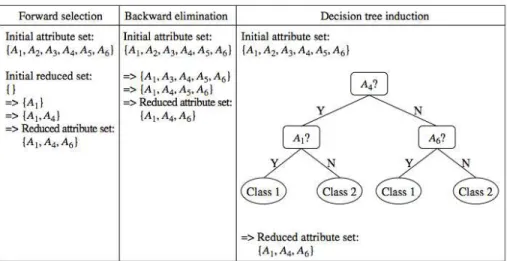
• Attribute subset selection
Attribute subset selection dilakukan untuk pemilihan atribut yang menjadi atribut predictor. Ada 4 (empat) metode yang dapat digunakan dalam melakukan attribute subset selection, yaitu :
a. Stepwise forward selection
Proses metode ini adalah untuk mencari atribut terbaik dari seluruh data set dan di masukkan ke dalam data set baru berdasarkan atribut terbaik yang telah dipilih.
b. Stepwise backward elimination
Proses metode ini adalah untuk mencari atribut yang tidak berkaitan dengan data mining yang dicari, lalu langsung menghapusnya dari data set.
c. Combination of forward selection and backward elimination Proses metode ini adalah penggabungan dari metode stepwise forward selection dan stepwise backward elimination.
d. Decision tree induction
Proses metode ini menggunakan algoritma decision tree, seperti algoritma ID3, C4.5, dan cart dalam mencari atribut yang terbaik.
• Missing Value
Nilai null yang terdapat dalam data set dapat mengganggu pembuatan mining yang dilakukan. Ada 6 (enam) metode yang dapat digunakan dalam mengolah nilai null yang terdapat dalam data, yaitu :
a. Ignore the tuple: tidak menggunakan tuple yang memiliki nilai null.
b. Fill in the missing value manually: mengisi sendiri nilai null yang terdapat dalam data.
c. Use global constant to fill in the missing value: mengganti nilai null dengan label constant, seperti “Unknown”.
d. Use the attribute mean to fill in the missing value: mengganti nilai null dengan rata-rata yang dimiliki atribut.
e. Use the attribute mean for all samples belonging to the same class the given tuple: mengganti nilai null dengan nilai rata-rata yang dimilik atribut berdasarkan target kelas yang dicari.
f. Use the most probable value to fill in the missing value: mengganti nilai null dengan nilai yang paling mungkin muncul berdasarkan atribut target kelas yang dicari.
4. Modeling
Tujuan dari pemodelan data mining adalah untuk mencari hasil dari berbagai situasi yang ada. Alat perangkat lunak untuk data mining seperti visualisasi (men-split data dan membangun hubungan) dan analisis kluster (untuk mengidentifikasikan variabel berjalan dengan baik secara bersamaan) dapat berguna untuk analisis awal model yang akan digunakan. Pembagian data ke dalam set pelatihan dan pengujian juga diperlukan untuk pemodelan.
5. Evaluation
Hasil model harus dievaluasi sesuai tujuan bisnis pada tahap pertama (pemahaman bisnis). Evaluasi dilakukan dari hasil visualisasi dan perhitungan statistik pengujian berdasarkan pemodelan yang dibuat. Pada akhir dari tahap ini, keputusan penggunaan hasil data mining telah ditentukan.
6. Deployment
Pembuatan dari model bukanlah akhir dari proyek data mining. Meskipun tujuan dari pemodelan adalah untuk meningkatkan pengetahuan dari data, pengetahuan data tersebut perlu dibangun dengan terorganisasi dan dibuat pada satu bentuk yang dapat digunakan oleh pengguna.
Gambar 2.7 CRISP-DM process Sumber: (Olson & Dursun, 2008)
2.1.6 Kelebihan dan Keterbatasan Data Mining
Kelebihan dari menggunakan data mining di berbagai aplikasi seperti Perbankan, Manufacturing dan Produksi, Pemasaran, Kesehatan, dll adalah sebagai berikut(Vikram &
Upadhayaya, 2011) :
1. Perbankan: Data mining mendukung sektor perbankan dalam proses pencarian pola yang sebelumnya belum diketahui dari database yang besar; otomatisasi proses penemuan informasi yang prediktif. Data mining membantu memperkirakan tingkat pinjaman yang buruk dan pelanggaran dalam penggunaan kartu kredit, memprediksi penggunaan kartu kredit oleh nasabah baru dan memprediksi nasabah mana yang memiliki respon cepat terhadap penawaran pinjaman yang ditawarkan.
2. Manufacturing dan Produksi: Data mining membantu memprediksi kegagalan mesin dan menemukan faktor kunci yang mengontrol optimisasi dari kapasitas manufacturing.
3. Marketing: Data mining memfasilitasi pemasaran sektor klasifikasi pelanggan demografis yang dapat digunakan untuk memprediksi dimana pelanggan akan
menanggapi mailing atau membeli produk tertentu dan hal ini sangat membantu dalam pertumbuhan bisnis.
4. Kesehatan: Data mining mendukung banyak di sektor kesehatan. Mendukung sektor kesehatan oleh berhubungan demografi pasien dengan penyakit kritis, mengembangkan wawasan yang lebih baik pada gejala dan penyebab mereka dan belajar bagaimana untuk memberikan perawatan yang tepat.
5. Asuransi: Data mining membantu sektor asuransi dalam memprediksi klaim palsu dan cakupan medis yang biaya, faktor penting yang mempengaruhi cakupan medis mengklasifikasikan dan memprediksi pelanggan pola Pelanggan yang akan membeli kebijakan baru.
6. Hukum: Penegakan hukum dibantu oleh data mining oleh pemantauan pola perilaku penjahat. Melacak pola kejahatan, lokasi dan perilaku kriminal, mengidentifikasi berbagai atribut untuk data pertambangan, membantu dalam memecahkan kasus- kasus kriminal.
7. Pemerintahan dan Pertahanan: Data mining membantu untuk memperkirakan biaya bergerak peralatan militer dan memprediksi konsumsi sumber daya. Selain itu membantu dalam pengujian strategi untuk keterlibatan militer yang potensial dan meningkatkan keamanan dalam negeri dengan pertambangan data dari berbagai sumber.
8. Broker dan Bursa Efek: Data mining membantu memprediksi perubahan harga obligasi dan peramalan kisaran fluktuasi saham yang menentukan kapan harus membeli atau menjual saham.
9. Hardware dan Software Komputer: Memprediksi kegagalan disk dan potensi pelanggaran keamanan dapat dilakukan dengan data mining.
10. Penerbangan: Mendukung dalam memeriksa kelayakan menambahkan rute untuk meningkatkan laba usaha dan untuk mengurangi kehilangan dengan menangkap data di mana penumpang terbang dan tujuan akhir dari penumpang.
Disamping kelebihan ada juga keterbatasan data mining yang juga dijelaskan sebagai berikut:
1. Masalah Privasi
Salah satu kelemahan adalah masalah privasi pribadi. Dalam beberapa tahun terakhir, dengan boom internet, kekhawatiran tentang privasi telah meningkat sangat. Karena keprihatinan privasi ini, individu seperti pengguna internet, karyawan, pelanggan
sangat takut bahwa tidak diketahui orang mungkin memiliki akses ke informasi pribadi mereka dan kemudian menggunakan informasi dalam cara yang tidak etis dan ini dapat menyebabkan kerusakan pada mereka. Meskipun, beberapa hukum dilindungi pengguna untuk menjual atau memperdagangkan informasi pribadi antara organisasi berbeda, menjual informasi pribadi terjadi
2. Masalah Keamanan
Kelemahan terbesar yang lain adalah masalah keamanan yang selalu menjadi perhatian utama dalam teknologi informasi. Perusahaan memiliki banyak informasi tentang karyawan dan pelanggan termasuk nomor jaminan sosial, tanggal lahir, gaji dll, dan juga tersedia di online. Tapi, mereka tidak memiliki cukup sistem keamanan di tempat untuk melindungi informasi ini. Mereka telah banyak kasus di mana hacker mengakses dan mencuri data pribadi pelanggan.
3. Penyalahgunaan informasi / Informasi Tidak Akurat
Tren memperoleh dari data mining yang dimaksudkan untuk digunakan untuk beberapa tujuan etis atau bisnis. Namun dapat disalahgunakan untuk tujuan lain tidak etis. Bisnis yang tidak etis atau individu mungkin menggunakan informasi untuk mengambil keuntungan dari orang-orang rentan atau untuk melakukan diskriminasi terhadap sekelompok orang tertentu. Selain itu, data pertambangan teknik bukanlah persen persen akurat. Dengan demikian kesalahan yang mungkin terjadi yang dapat memiliki konsekuensi serius.
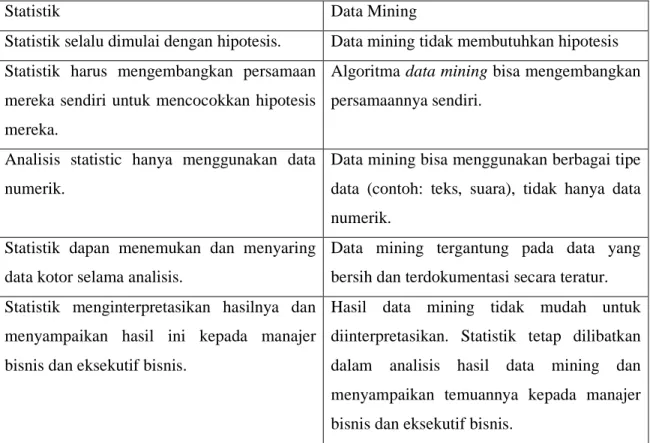
2.1.7 Data Mining vs Statistik
Menurut (Moss & Atre, 2003), data mining dan statistik sama - sama mempunyai kekuatan dan kelemahan.
Tabel 2.2 PerbandinganData Mining Dan Statistika
Statistik Data Mining
Statistik selalu dimulai dengan hipotesis. Data mining tidak membutuhkan hipotesis Statistik harus mengembangkan persamaan
mereka sendiri untuk mencocokkan hipotesis mereka.
Algoritma data mining bisa mengembangkan persamaannya sendiri.
Analisis statistic hanya menggunakan data numerik.
Data mining bisa menggunakan berbagai tipe data (contoh: teks, suara), tidak hanya data numerik.
Statistik dapan menemukan dan menyaring data kotor selama analisis.
Data mining tergantung pada data yang bersih dan terdokumentasi secara teratur.
Statistik menginterpretasikan hasilnya dan menyampaikan hasil ini kepada manajer bisnis dan eksekutif bisnis.
Hasil data mining tidak mudah untuk diinterpretasikan. Statistik tetap dilibatkan dalam analisis hasil data mining dan menyampaikan temuannya kepada manajer bisnis dan eksekutif bisnis.
Jadi berdasarkan perbandingan diatas maka digunakan Data Mining dengan pertimbangan analisis data yang mengandung teks di dalamnya.
2.1.8 Data Mining vs DSS
Menurut (Sehgal, Sehgal, Sehgal, & Chauhan, 2012), DSS (Decision Support System) menyediakan pelayanan manajemen, operasi dan level perencanaan dari suatu organisasi dan membantu dalam pengambilan keputusan. Sedangkan Data Mining mempunyai peran vital untuk mengekstrak informasi penting untuk membantu dalam pengambilan keputusan dari DSS.
Jadi bisa disimpulkan bahwa data mining dan DSS berkaitan oleh karena data mining merupakan proses analisis yang bisa terlibat dalam DSS yang berfungsi menghasilkan knowledge baru untuk mendukung pengambilan keputusan.
2.1.9 Classfier accuracy Measurables
Classifier Accuracy Measures menurut (Han & Kamber, Data Mining : Concept and Techniques Second Edition, 2006) adalah metode klasifikasi yang dilakukan berdasarkan tingkat akurasi model dalam melakukan prediksi. Hal ini dilakukan karena keakuratan dalam mengolah data merupakan salah satu hal yang penting.
Metode yang digunakan untuk menguji tingkat akurasi model klasifikasi ini adalah metode holdout. Dalam metode ini, data asli dipartisi menjadi dua himpunan yang saling terpisah yang dinamakan training set dan test set. Model klasifikasi kemudian dibangun berdasarkan training set dan hasilnya kemudian dievaluasi dengan menggunakan testing set.
Akurasi dari masing-masing metode klasifikasi dapat diestimasi berdasarkan akurasi yang diperoleh dari test set. Proporsi antara training set dan test set tidak mengikat tetapi agar variansi dalam model tidak terlalu besar maka dapat ditentukan bahwa proporsi training set lebih besar daripada test set-nya. Biasanya 2/3 dari data dijadikan training set dan 1/3 lagi dijadikan testing set.
Ukuran dari tingkat akurasi sebuah classifier dapat ditentukan dengan menggunakan perhitungan-perhitungan Classifier Accuracy Measurables, yaitu sebagai berikut:
Sensivity =
Specificity =
Precision =
Accuracy = sensivity + specifity
Sumber:(Han, Kamber, & Pei, 2011)
t_pos adalah jumlah true positive yaitu jumlah data yang berhasil di prediksi oleh classifier dengan benar (misalkan jumlah data kelas “yes” dari sampel yang secara benar dapat di prediksi sebagaimana mestinya oleh model klasifikasi), pos adalah jumlah sampel data positives (“yes”), t_neg adalah jumlah true negativesyaitu adalah kebalikan dari true positive (misalkan jumlah data kelas “no” dari sampel yang benar dapat diprediksi sebagaimana mestinya oleh model klasifikasi), neg adalah jumlah total sampel negatives (“no” ), dan f_pos adalah false positives yaitu jumlah data yang salah di prediksi oleh classifier (“no” diprediksi sebagai “yes”).
Sensivity adalah ukuran tingkatan derajat classifier dapat mengenal positives samples (“yes”) berdasarkan jumlah true positives yang dapat diprediksi secara benar jika yang diberikan adalah sampel positives.
Specificity adalah ukuran tingkatan derajat classifier dapat mengenal negatives samples (“no”) berdasarkan true negatives yang dapat diprediksi secara benar jika yang diberikan adalah sampel negatives.
Precision adalah besarnya presentase classifier dalam menebak dengan tepat kelas true positives (“yes”) dengan melihat perbandingan true positive yang dapat diprediksi dengan penjumlahan true positive dan false positive.
Accuracy adalah derajat ukuran yang merupakan fungsi dari Sensivity dan Specificity model klasifikasi dalam melakukan prediksi.
2.1.10 Confusion Matrix
Menurut (Han, Kamber, & Pei, 2011)Confusion matrix adalah alat yang berguna untuk menganalisis seberapa baik classifier mengenali tuple dari kelas yang berbeda. TP dan TN memberikan informasi ketika classifier benar, sedangkan FP dan FN memberitahu ketika classifier salah.
Sumber:(Han, Kamber, & Pei, 2011)
Ukuran tingkat kesalahan klasifikasi juga dapat dihitung dengan mencari Error Rate:
Sumber:(Han, Kamber, & Pei, 2011)
2.1.11 Laplacian Correction
Laplacian Correction (atau Laplace Estimator) adalah suatu cara untuk menangani nilai probabilitas 0 (nol). Dari sekian banyak data di training set, pada setiap perhitungan datanya ditambah 1 (satu) dan tidak akan membuat perbedaan yang berarti pada estimasi probabilitas sehingga bisa menghindari kasus nilai probabilitas 0 (nol).
Sebagai contoh, asumsikan ada class buy=yes di suatu training set, memiliki 1000 (seribu ) sampel, ada 0 (nol) sampel dengan income=low, 990 sampel dengan income=medium, dan 10 sampel dengan income=high. Probabilitas dari kejadian ini tanpa Laplacian Correction adalah 0, 0.990 (dari 990/1000), dan 0.010 (dari 10/1000).
Menggunakan Laplacian Correction dari tiga sampel diatas, diasumsikan ada 1 sampel lagi untuk masing – masing nilai income. Dengan cara ini, didapatkanlah probabilitas sebagai berikut (dibulatkan menjadi 3 angka dibelakang koma):
Sumber:(Han, Kamber, & Pei, 2011)
Probabilitas yang “dibenarkan” hasilnya tidak berbeda jauh dengan hasil probabilitas sebelumnya sehingga nilai probabilitas 0 (nol) dapat dihindari (Leung, 2007).
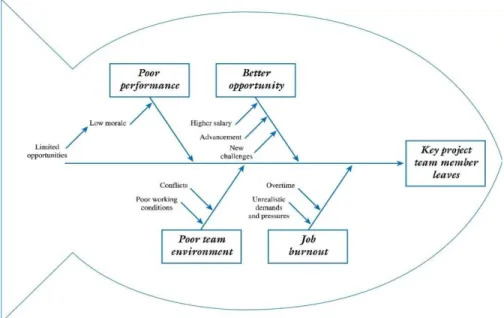
2.1.12 Fishbone Diagram
Diagram sebab akibat “Cause-and-effect” diagram atau dikenal sebagai “fishbone”
atau diagram ishikawa adalah diagram yang mengklasifikasikan berbagai macam penyebab pada efek operasi kedalam sebuah desain, ditunjukan dengan sebuah panah yang menghubungkan antara sebab dan akibat (Kai Yang, Ph.D &Basem S.El-Haik, Ph.D, Design For Six Sigma, 2003).
2.1.12.1 Manfaat Fishbone Diagram
Fishbone diagram digunakan untuk menstrukturkan masalah yang bersifat kompleks dengan membangun hubungan sebab akibat pada analisisnya. Berikut adalah rincian manfaatnya :
• Mengidentifikasi kemungkinan akar penyebab, alasan dasar, bagi sebuah dampak yang spesifik
• Menyortir dan mengaitkan beberapa interaksi antara faktor yang mempengaruhi sebuah proses atau akibat
• Menganalisis permasalahan yang ada sehingga tindakan yang benar dapat diambil
Gambar 2.8 Fishbone Diagram
Sumber :Copyright 2012 John Wiley & Sons, Inc.
Project Management Slide
2.1.12.2 Mengembangkan Fishbone Diagram
1. Mengidentifikasi dan mendefinisikan secara jelas hasil atau efek yang dianalisis
Memutuskan akibat yang akan diperiksa, akibat dinyatakan secara khusus sebagai karakteristik atau masalah hasil dari kerja, perencanaan objektif dan sejenisnya. Akibat bisa positif (sebuah objektif) atau negative (sebuah masalah), tergantung pada isu yang dibahas.
2. Menggunakan bagan yang diposisikan dengan membuat tulang dan membuat kotak akibat di bagian ujung kanan
3. Mengidentifikasi penyebab utama yang berkontribusi pada akibat yang dipelajari
Membangun penyebab utama atau katogori atau penyebab utama lainnya yang didaftarkan. Bebarapa kategori utamanya antara lain;
metode, material, mesin, orang, kebijakan, prosedur, dan lingkungan.
4. Mengidentifikasi faktor dari setiap penyebab utama sebagai subfaktor
5. Mengidentifikasi secara detail level sebab akibat dengan menggunakan pertanyaan yang mengacu pada ketergantungan antara sebab dan akibat.
2.1.13 PHP
Menurut (Prasetyo, 2004), PHP merupakan bahasascripting server-side, dimana pemrosesan datanya dilakukan pada sisi server. Sederhananya, serverlah yang akan menerjemahkan skrip program, barukemudian hasilnya akan dikirim kepada client yang melakukan permintaan.
2.1.13.1 Keunggulan PHP
Seluruh aplikasi berbasis web dapat dibuat dengan PHP. Namunkekuatan yang paling utama PHP adalah pada konektivitasnya dengan sistem database di dalam web.
Kelebihan-kelebihan dari PHP diantaranya adalah :
a. PHP mudah dibuat dan dijalankan, maksudnya PHP dapat berjalan dalam Web Server dan dalam Sistem Operasi yang berbeda pula.
b. PHP adalah software open-source yang gratis dan bebas didistribusikan kembali di bawah lisensi GPL (GNU Public License). User dapat mendownload kode-kode PHP tanpa harus mengeluarkan uang atau khawatir dituntut oleh pihak pencipta PHP.
c. PHP bisa dioperasikan pada platform Linux ataupun Windows.
d. PHP sangat efisien, karena PHP hanya memerlukan resource system yang sangat sedikit dibanding dengan bahasa pemograman lain.
e. Ada banyak Web Server yang mendukung PHP, seperti Apache, PWS, IIS, dan lain- lain.
f. PHP juga didukung oleh banyak database, seperti MySQL, PostgreSQL, Interbase, SQL, dan lain-lain.
g. Bahasa pemograman PHP sintaknya sederhana, singkat dan mudah untuk dipahami.
h. HTML-embedded, artinya PHP adalah bahasa yang dapat ditulis dengan menempelkan pada sintak-sintak HTML.
2.1.14 MySQL
Menurut (Prasetyo, 2004), MySQL merupakan salah satudatabase server yang berkembang di lingkungan open source dan didistribusikansecara free (gratis) dibawah lisensi GPL.
MySQL merupakan RDBMS (Relational Database Management System) server. RDBMS adalah program yang memungkinkan pengguna databaseuntuk membuat, mengelola, dan menggunakan data pada suatu model relational.Dengan demikian, tabel-tabel yang ada pada database memiliki relasi antara satutabel dengan tabel lainnya.
2.1.14.1 Keunggulan MySQL
Beberapa keunggulan dari MySQL yaitu : a. Cepat, handal dan Mudah dalam penggunaannya
MySQL lebih cepat tiga sampai empat kali dari pada database serverkomersial yang beredar saat ini, mudah diatur dan tidak memerlukan seseorang yang ahli untuk mengatur administrasi pemasangan MySQL.
b. Didukung oleh berbagai bahasa
Database server MySQL dapat memberikan pesan error dalam berbagaibahasa seperti Belanda, Portugis, Spanyol, Inggris, Perancis, Jerman,dan Italia.
c. Mampu membuat tabel berukuran sangat besar
Ukuran maksimal dari setiap tabel yang dapat dibuat dengan MySQLadalah 4 GB sampai dengan ukuran file yang dapat ditangani oleh sistem operasi yang dipakai.
d. Lebih Murah
MySQL bersifat open source dan didistribusikan dengan gratis tanpa biaya untuk UNIX platform, OS/2 dan Windows platform.
e. Melekatnya integrasi PHP dengan MySQL
Keterikatan antara PHP dengan MySQL yang sama-sama software open source sangat kuat, sehingga koneksi yang terjadi lebih cepat jika dibandingkan dengan menggunakan database server lainnya. Modul MySQL di PHP telah dibuat built-in sehingga tidak memerlukan konfigurasi tambahan pada file konfigurasi php ini.
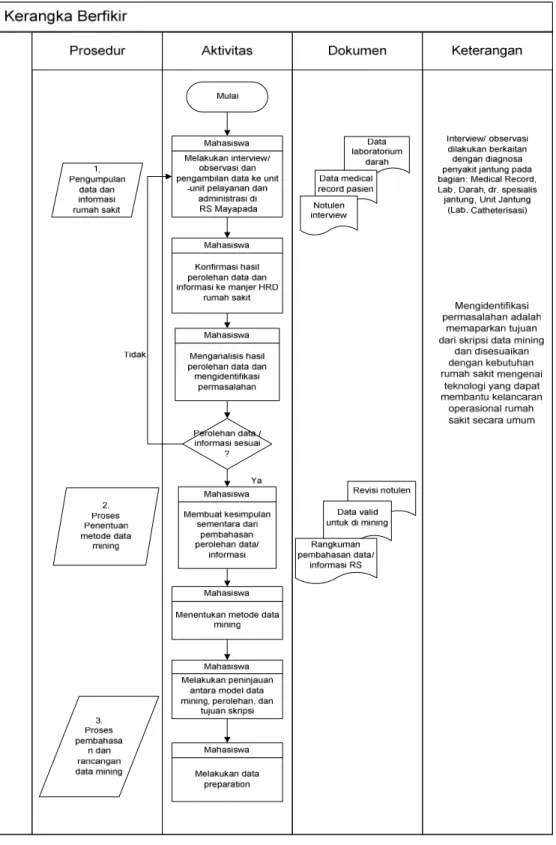
2.1.15 Kerangka Berpikir
Tabel 2.3 Kerangka Berpikir Penelitian
2.2 Teori-teori Khusus yang Berhubungan dengan Topik yang Dibahas
2.2.1 Definisi, Jenis dan Karakteristik penyakit jantung
Menurut (Rosiawati, 2010), jantung adalah organ berupa otot, berbentuk kerucut, berongga dan denganbasisnya di atas dan puncaknya di bawah. Apex – nya (puncak ) miring ke sebelahkiri. Berat jantung kira – kira 300 gram. Jantung berada di dalam torak, antara kedua paru – paru di belakang sternum, dan lebih menghadap ke kiri dari pada ke kanan.
Ukuran jantung kira – kira sebesar kepalan tangan. Jantung terbagi oleh sebuahseptum, (sekat) menjadi dua belahan, yaitu kiri dan kanan. Sesudah lahir tidak adahubungan satu dengan yang lain antara kedua belahan ini. Setiap belahan kemudiandibagi lagi dalam dua ruang, yang atas disebut atrium dan yang bawah disebutventrikel. Maka di kiri terdapat 1 atrium dan 1 ventrikel, dan di kanan juga ada 1atrium 1 ventrikel.
Penyakit jantung terbagi menjadi 10 (sepuluh) bagian, diantaranya adalah sebagai berikut (Rosiawati, 2010):
1. Gagal Jantung Kronik
Kondisi patofisiologi (kelainan fungsi jantung), dimana terdapat kegagalan jantung memompa darah yang sesuai dengan kebutuhan jaringan.
2. Gagal Jantung Akut
Serangan cepat ( rapid onset ) dari gejala – gejala atau tanda – tanda ( symptom and signs) akibat fungsi jantung yang abnormal.
3. Jantung Katup
Penyakit jantung yang disebabkan karena kelainan katup jantung 4. Jantung Perikarditis
Inflamansi pericardius, kantung membrane yang membungkus jantung / peradangan perikard ( selaput jantung).
5. Jantung Koroner
Penyakit jantung akibat gangguan / kelainan pada pembuluh darah koroner 6. Jantung Hipertensi
Penyakit jantung yang disebabkan karena hipertensi.
7. Jantung Kardiomiopati
Suatu kelompok penyakit yang langsung mengenai otot jantung atau miokaditu sendiri.
8. Penyakit Jantung Kongenital/ bawaan
Merupakan kelainan struktur atau fungsi dari sistem kardiovaskuler yang ditemukan pada saat lahir walaupun dapat ditemukan di kemudian hari.
9. Penyakit Jantung Paru
Pembesaran jantung kanan yang disebabkan oleh penyakit paru kronis dan tidak berhubungan dengan kelainan jantung kiri.
10. Penyakit Jantung Teroid
Penyakit Jantung teroid disebabkan oleh kelebihan atau kekurangan hormon teroid.
2.2.2 Pemeriksaan medis
Medical check up (MCU) dengan pemeriksaan fisik adalah hal yang sama. Menurut (Medical Check Up: RS Mitra Keluarga Bekasi), MCU merupakan suatu proses yang dilakukan oleh seorang dokter dalam melakukan pemeriksaan tubuh pasien untuk mencari adanya kejanggalan atau gejala dari suatu penyakit. Lebih lanjut lagi, dikemukakan juga tujuan dari MCU, yaitu:
1. Mendeteksi secara dini adanya suatu penyakit dalam tubuh seseorang 2. Mengatasi secepat mungkin gangguan kesehatan yang telah ditemukan 3. Mencegah penyakit yang telah dideteksi secara dini tidak berlanjut
Prosedur yang dilakukan oleh seorang dokter dalam melakukan pemeriksaan medical check up mulai dengan tanya jawab atau dikenal dengan istilah anamnesa. Kemudian dilanjutkan dengan pemeriksaan tambahan berupa laboratorium (baik pemeriksaan darah, urine, dll), rontgen dada, EKG/Treadmill Test(Medical Check Up: RS Mitra Keluarga Bekasi). Dalam MCU pemeriksaan yang dilakukan menyeluruh dan pemeriksaan tambahan dilakukan tanpa melihat kondisi pasien.
2.2.3 Lab kimia darah
Kebanyakan laporan laboratorium memperlihatkan tes kimia darah. Tes ini mengukur berbagai zat kimia dalam darah kita untuk melihat apakah tubuh manusia berfungsi dengan baik. Setiap laboratorium mempunyai nilai rujukan untuk hasil tes. Biasanya laporan laboratorium mencantumkan nilai rujukannya dan menandai hasil tes yang berada di luar nilai rujukan (Mentor Healthcare). Pemeriksaan kimia darah yang terdapat di laboratorium
menurut (Bio Medika) meliputi uji fungsi hati, otot jantung, ginjal, lemak darah, gula darah, fungsi pankreas, elektrolit yang digunakan untuk membantu menegakkan diagnosis dokter.
Berikutnya, di bawah ini akan dijabarkan beberapa laboratorium klinik yang berkaitan dengan diagnosis penyakit jantung, yaitu laboratorium fungsi ginjal, laboratorium diabetes, laboratorium lemak dan laboratorium fungsi jantung. Keempat tes laboratorium ini diambil berdasarkan penyakit penyebab penyakit jantung yang sudah dijelaskan diatas.
2.2.3.1 Laboratorium Fungsi Ginjal
Menurut (Bio Medika), uji fungsi ginjal terutama adalah pemeriksaan ureum dan kreatinin. Ureum adalah produk akhir dari metabolisme protein di dalam tubuh yang diproduksi oleh hati dan dikeluarkan lewat urin. Pada gangguan ekskresi ginjal, pengeluaran ureum ke dalam urin terhambat sehingga kadar ureum akan meningkat di dalam darah. Kreatinin merupakan zat yang dihasilkan oleh otot dan dikeluarkan dari tubuh melalui urin. Oleh karena itu kadar kreatinin dalam serum dipengaruhi oleh besar otot, jenis kelamin dan fungsi ginjal. Di Laboratorium Klinik Utama Bio Medika pemeriksaan kadar kreatinin dilaporkan dalam mg/dl dan estimated GFR (eGFR) yaitu nilai yang dipakai untuk mengetahui perkiraan laju filtrasi glomerulus yang dapat memperkirakan beratnya kelainan fungsi ginjal.
Beratnya kelainan ginjal diketahui dengan mengukur uji bersihan kreatinin (creatinine clearance test/CCT). Creatinine clearance test/CCT memerlukan urin kumpulan 24 jam, sehingga bila pengumpulan urin tidak berlangsung dengan baik hasil pengukuran akan mempengaruhi nilai CCT. Akhir-akhir ini, penilaian fungsi ginjal dilakukan dengan pemeriksaan cystatin-C dalam darah yang tidak dipengaruhi oleh kesalahan dalam pengumpulan urin. Cystatin adalah zat dengan berat molekul rendah, dihasilkan oleh semua sel berinti di dalam tubuh yang tidak dipengaruhi oleh proses radang atau kerusakan jaringan. Zat tersebut akan dikeluarkan melalui ginjal. Oleh karena itu kadar Cystatin dipakai sebagai indikator yang sensitif untuk mengetahui kemunduran fungsi ginjal.
2.2.3.2 Laboratorium Diabetes
Menurut (Mayo Clinic), pengecekan darah yang dilakukan untuk mengetahui pasien terkena diabetes atau tidak, ada 4 (empat) tes darah yang dilakukan, yaitu :
• Tes Glycated hemoglobin (A1C)
Tes darah ini menunjukkan tingkat rata-rata gula darah Anda selama dua sampai tiga bulan. Mengukur persentase gula darah yang melekat pada hemoglobin, protein pengangkut oksigen dalam sel darah merah. Semakin tinggi tingkat gula darah, maka akan tinggi juga hemoglobin seseorang dengan memiliki kandungan gula didalamnya.
A1C tingkat 6,5 persen atau lebih tinggi pada dua terpisah tes menunjukkan bahwa seseorang memiliki diabetes.
• Tes Random Blood Sugar
Sampel darah akan diambil pada waktu acak. Terlepas dari Kapan Anda terakhir makan, gula darah acak tingkat 200 miligram per deciliter (mg/dL) — 11.1 millimoles per liter (mmol/L) atau lebih mengisyaratkan terkenanya diabetes.
• Tes Fasting Blood Sugar
Sampel darah akan diambil setelah semalam berlalu. Tingkat gula darah puasa antara 100 dan 125 mg/dL (5,6 dan 6.9 mmol/L) dianggap prediabetes. Jika pada 126 mg/dL (7 mmol/L) atau yang lebih tinggi di dua tes terpisah, maka seseorang akan dapat didiagnosis dengan diabetes.
• Tes Oral glucose tolerance
Sampel darah akan diambil setelah Anda puasa untuk setidaknya delapan jam atau semalam. Kemudian Anda akan diminta minum gula, dan tingkat gula darah Anda akan diukur lagi setelah dua jam. Gula darah tingkat kurang dari 140 mg/dL (7.8 mmol/L) normal. Tingkat gula darah dari 140 untuk 199 mg/dL (7,8 sampai 11 mmol/L) dianggap prediabetes. Ini kadang-kadang disebut sebagai gangguan toleransi glukosa.
2.2.3.3 Laboratorium Lemak
Menurut (Bio Medika), pemeriksaan lemak darah meliputi pemeriksaan kadar kolesterol total, trigliserida, HDL dan LDL kolesterol. Pemeriksaan tersebut terutama dilakukan pada pasien yang memiliki kelainan pada pembuluh darah seperti pasien
dengan kelainan pembuluh darah otak, penyumbatan pembuluh darah jantung, pasien dengan diabetes melitus (DM) dan hipertensi serta pasien dengan keluarga yang menunjukkan peningkatan kadar lemak darah. Untuk pemeriksaan lemak darah ini, sebaiknya berpuasa selama 12 - 14 jam. Bila pada pemeriksaan kimia darah, serum yang diperoleh sangat keruh karena peningkatan kadar trigliserida sebaiknya pemeriksaan diulang setelah berpuasa > 14 jam untuk mengurangi kekeruhan yang ada.
Untuk pemeriksaan kolesterol total, kolesterol HDL dan kolesterol LDL tidak perlu berpuasa. Selain itu dikenal pemeriksaan lipoprotein (a) bila meningkat dapat merupakan faktor risiko terjadinya penyakit jantung koroner.
2.2.3.4 Laboratorium Fungsi Jantung
Menurut (Bio Medika), Uji fungsi jantung dapat dipakai pemeriksaan creatine kinase (CK), isoenzim creatine kinase yaitu CKMB, N-terminal pro brain natriuretic peptide (NT pro-BNP) dan Troponin-T. Kerusakan dari otot jantung dapat diketahui dengan memeriksa aktifitas CKMB, NT pro-BNP, Troponin-T dan hsCRP.
Pemeriksaan LDH tidak spesifik untuk kelainan otot jantung, karena hasil yang meningkat dapat dijumpai pada beberapa kerusakan jaringan tubuh seperti hati, pankreas, keganasan terutama dengan metastasis, anemia hemolitik dan leukemia.