Teknik Informatika / Universitas Surabaya
Halaman C-47
BENCHMARKING ALGORITMA PEMILIHAN ATRIBUT PADA
KLASIFIKASI DATA MINING
Intan Yuniar Purbasari1, Budi Nugroho2 1,2
Jurusan Teknik Informatika, Fakultas Teknologi Industri, UPN “Veteran” Jatim Jl. Rungkut Madya, Surabaya
email : [email protected], [email protected], [email protected]
Abstract: In data mining, the process of information retrieval success is influenced by several factors. One key
factor is the quality of the data. If the data has too much noise, or a lot of data is redundant and irrelevant, the training process of information discovery will be troublesome. Attribute selection technique is one technique for selecting data attributes to identify and eliminate irrelevant and redundant information. This study compared the performance of six attribute selection algorithms available in Weka to classify 25 datasets, using two classification algorithms: Naïve Bayes and C4.5. From the test results, it obtained Wrapper technique which has the best performance on both types of classification algorithms, which provides improved correct datasets classification on 13 and 8, respectively.
Keywords: benchmarking, attribute selection algorithms, data mining, classification
1.
PENDAHULUAN
Di dalam data mining, kesuksesan proses penemuan informasi dipengaruhi oleh beberapa faktor. Salah satu faktor kuncinya adalah kualitas data. Jika data memiliki terlalu banyak noise, atau banyak data yang redundant dan tidak relevan, proses pelatihan penemuan informasi akan mengalami kesulitan.
Teknik pemilihan atribut adalah salah satu teknik untuk menseleksi atribut data dengan mengidentifikasi dan menghilangkan informasi yang tidak relevan dan redundan. Dengan mengurangi dimensi data, ruang hipotesis akan mengecil dan algoritma lea rning akan berjalan lebih cepat. Dengan demikian, pemilihan teknik seleksi atribut yang tepat akan mempercepat proses pembelajaran pada klasifikasi data pada data mining. Banyak algoritma pemilihan atribut yang menggunakan pendekatan permasalahan searching dimana setiap subset dari solusi permasalahan merupakan kelompok atribut yang terpilih [1]. Ukuran ruang hipotesis yang eksponensial menjadikan diperlukannya pencarian heuristik untuk seluruh dataset. Dalam prosesnya, setelah sejumlah atribut terpilih menjadi kandidat, diperlukan evaluator tingkat utilitas atribut untuk menilai kelayakan terpilihnya kandidat atribut tersebut. Ini menyebabkan terbentuknya permutasi yang sangat besar sehingga proses penilaian atribut ini akan memakan waktu yang cukup lama. Hal inilah yang menyebabkan tidak banyaknya studi yang dilakukan tentang benchmarking algoritma pemilihan atribut pada dataset nontrivial.
Beberapa studi yang telah dilakukan antara lain di [1], [2], dan [3]. Di [2], dataset yang digunakan adalah dataset artifisial yang berukuran kecil dan beberapa algoritma pemilihan atribut dinilai kekurangan dan kelebihannya terhadap noise, perbedaan tipe atribut, dataset multiclass, dan kompleksitas waktu komputasi. Pada [3], percobaan dilakukan pada 25 dataset UCI1 yang sering digunakan pada proses klasifikasi dan mengujicobanya dengan menggunakan algoritma klasifikasi Naïve-Bayes dan C45.
Penelitian ini membandingkan kinerja enam algoritma seleksi atribut dalam meningkatkan kesuksesan hasil klasifikasi dengan menggunakan algoritma klasifikasi Naïve-Bayes dan C4.5. Penelitian ini banyak mengacu pada tahapan-tahapan yang dilakukan di [3], dalam hal dataset yang digunakan, algoritma pemilihan atribut, dan algoritma klasifikasi yang digunakan dengan penambahan 10 dataset baru untuk memberikan referensi yang lebih lengkap tentang performa setiap algoritma pemilihan atribut yang ada terhadap dataset yang lebih banyak.
2.
MODEL, ANALISIS, DESAIN, DAN IMPLEMENTASI
Penelitian ini menggunakan softwa re tool untuk data mining Weka2 versi 3.6.6, yang merupakan softwa re gratis yang memiliki fitur lengkap untuk machine learning dan data mining.
Teknik Informatika / Universitas Surabaya
Halaman C-48
2.1.
Dataset
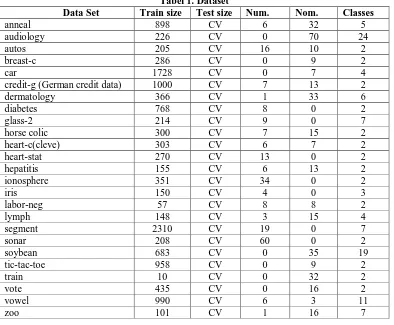
Penelitian sebelumnya menggunakan dataset UCI1, namun dataset tersedia dalam beberapa versi dan dalam format C4.5 (dengan ekstensi .data dan .names). Karena Weka paling baik bekerja pada dataset berekstensi .arff, beberapa dataset mengalami kesulitan ketika di-load ke dalam Weka, walaupun telah menggunakan converter yang disediakan. Oleh karena itu, dataset yang sama dengan ekstensi .arff telah diperoleh dari [4] sebanyak 25 dataset seperti pada tabel 1.
2.2.
Tahap pra-pemrosesan
Tiga dari enam teknik pemilihan atribut pada tabel 1 hanya beroperasi pada atribut yang bertipe diskrit. Oleh karena itu, agar teknik tersebut dapat dioperasikan pada atribut bertipe numerik, perlu dilakukan tahap diskretisasi sebagai tahap pra-pemrosesan. Penelitian ini menggunakan teknik supervised discretization yang digagas oleh Fayyad dan Irani [5] yang telah tersedia di dalam Weka pada class
weka.filters.supervised.attribute.Discretize sebagai teknik diskretisasi default.
Tabel 1. Dataset
Data Set Train size Test size Num. Nom. Classes
anneal 898 CV 6 32 5
audiology 226 CV 0 70 24
autos 205 CV 16 10 2
breast-c 286 CV 0 9 2
car 1728 CV 0 7 4
credit-g (German credit data) 1000 CV 7 13 2
dermatology 366 CV 1 33 6
diabetes 768 CV 8 0 2
glass-2 214 CV 9 0 7
horse colic 300 CV 7 15 2
heart-c(cleve) 303 CV 6 7 2
heart-stat 270 CV 13 0 2
hepatitis 155 CV 6 13 2
ionosphere 351 CV 34 0 2
iris 150 CV 4 0 3
labor-neg 57 CV 8 8 2
lymph 148 CV 3 15 4
segment 2310 CV 19 0 7
sonar 208 CV 60 0 2
soybean 683 CV 0 35 19
tic-tac-toe 958 CV 0 9 2
train 10 CV 0 32 2
vote 435 CV 0 16 2
vowel 990 CV 6 3 11
zoo 101 CV 1 16 7
2.3.
Teknik Seleksi Atribut
Menurut [3], ada dua kategori utama pada teknik seleksi atribut: filter dan wrapper. Teknik filter menggunakan karakteristik umum dari data untuk mengevaluasi atribut dan beroperasi secara independen terhadap sembarang algoritma pembelajaran. Teknik wrapper mengevaluasi atribut dengan menggunakan estimasi akurasi dari algoritma pembelajaran target.
Jenis kategori yang lain membagi teknik seleksi atribut menjadi kategori teknik yang mengevaluasi atribut secara individual dan kategori yang mengevaluasi subset atribut sekaligus.
Teknik Informatika / Universitas Surabaya
Halaman C-49
LinearFor wardSelection merupakan modifikasi dari BestFirst dengan penambahan sejumlah k atribut ke dalam penilaian. Metode RankSearch melakukan perangkingan atribut dengan menggunakan evaluator atribut/subset.2.3.1
Teknik Information Gain (IG)
Teknik ini merangking atribut dengan menghitung entropi dari sebuah kelas C sebelum dan setelah mengamati sebuah atribut A. Nilai penurunan entropi disebut information gain. Persamaan (1) dan (2) menghitung entropi kelas sebelum dan sesudah pengamatan terhadap atribut A. Setiap atribut diberikan sebuah skor berdasarkan information gain-nya. Rumus perhitungan information gain terdapat pada persamaan (3).
(1)
(2)
(3)
Teknik ini mengharuskan data numerik didiskritkan terlebih dahulu. Pada Weka, fungsi ini tersedia dalam class
weka.attributeSelection.InfoGainAttributeEval dan dipasangkan dengan metode pencarian
Ranker.
2.3.2
Relief (RLF)
Relief adalah metode perangkingan atribut berbasis instance yang secara acak mengambil sampel sebuah instance data dan mencari nearest neighbor pada class yang sama dan berlawanan. Pada awalnya, metode ini digunakan pada permasalahan klasifikasi 2 class. Nilai atribut dari nearest neighbor dibandingkan dengan sampel instance data dan digunakan untuk menghasilkan skor untuk setiap atribut. Proses ini diulangi untuk m instance, dimana nilai m dapat ditentukan oleh user.
Versi pengembangan dari Relief adalah ReliefF dan dapat digunakan untuk menangani noise dan dataset dengan banyak cla ss. Noise data dihaluskan dengan merata-rata kontribusi dari k nea rest neighbors dari class yang sama dan berlawanan dari setiap sampel instance. Pada Weka, teknik ini tersedia dalam class
weka.attributeSelection.ReliefFAttributeEval dan dipasangkan dengan metode pencarian
Ranker. Gambar 1 merupakan algoritma dari ReliefF.
Gambar 1. Algoritma ReliefF
2.3.3
Principal Component (PC)
Analisis Principal Component menggunakan perhitungan statistik untuk mengurangi dimensionalitas data dengan menghasilkan eigenvector dari atribut. Eigenvector tersebut lalu dirangking berdasarkan jumlah variasi dalam data asli yang mereka wakili. Hanya sedikit dari beberapa atribut pertama yang berkontribusi terhadap variasi data yang akan diambil.
Pada Weka, teknik ini terdapat dalam class
weka.attributeSelection.PrincipalComponents dan dipasangkan dengan metode pencarian
Teknik Informatika / Universitas Surabaya
Halaman C-50
2.3.4
Correlation-Based Feature Selection (CFS)
Teknik ini termasuk ke dalam kategori seleksi fitur yang mengevaluasi subset dari atribut. Teknik ini mempertimbangkan kegunaan atribut individual untuk memprediksi class dan juga level inter-korelasi di antara mereka. Sebuah fungsi heuristik (4) memberikan skor tinggi kepada subset yang berisi atribut-atribut yang berkorelasi tinggi dengan class-nya dan memiliki inter-korelasi rendah dengan satu sama lain.
(4)
CFS mengharuskan atribut numerik didiskritkan terlebih dahulu sebelum menggunakan symmetrical uncertainty untuk mengestimasi derajat asosiasi antara dua fitur diskrit. Pada Weka, teknik ini tersedia dalam class weka.attributeSelection.CfsSubsetEval dan dipasangkan dengan metode pencarian Forwa rdSelection.
2.3.5
Consistency-Based Subset Evaluation (CNS)
Teknik ini menggunakan konsistensi class sebagai metrik evaluasi (5) yang mencari kombinasi atribut yang nilainya membagi data ke dalam subset yang berisi class mayoritas tunggal yang kuat.
(5)
Teknik ini juga mengharuskan atribut numerik didiskritkan terlebih dahulu sebelum diproses. Dalam Weka, fitur ini tersedia dalam class weka.attributeSelection.ConsistencySubsetEval dan
dipasangkan dengan metode pencarian Forwa rdSelection.
2.3.6
Wrapper Subset Evaluation (WRP)
Pada implementasi teknik ini di Weka, dilakukan 5-fold cross validation untuk estimasi akurasi. Cross validation diulangi selama standar deviasi yang didapat lebih besar dari 1% dari rata-rata akurasi atau hingga lima repetisi telah dilakukan. Pada Weka, teknik ini tersedia di class
weka.attributeSelection.WrapperSubsetEval dan dipasangkan dengan metode pencarian
Forwa rdSelection.
2.4.
Reduksi Dimensionalitas
Sebelum dataset diberikan kepada algoritma learning, setiap selektor atribut mengurangi dimensionalitas berdasarkan ranking atribut. Karena metode 10-fold cross validation digunakan, setiap training set dari pemisahan set train-test digunakan untuk mengestimasi kelayakan dari n rangking atribut tertinggi untuk dipilih sebagai subset atribut terbaik. Nilai n didapat dengan menggunakan forward selection hill climbing search untuk mencari subset atribut terbaik.
2.5.
Algoritma Klasifikasi C4.5 dan Naïve-Bayes
Mengikuti teknik yang diterapkan pada [3], digunakan 2 jenis algoritma klasifikasi, yakni C4.5 dan Naïve-Bayes. Alasan digunakan 2 jenis ini adalah karena keduanya menggunakan pendekatan yang berbeda dan memiliki waktu running yang relatif cepat, serta keduanya telah tersedia di dalam Weka.
Algoritma Naïve-Bayes menghitung probabilitas nilai atribut secara independen di dalam setiap class dari training instance. Ketika sebuah training insta nce datang, probabilitas posterior dari setiap class dihitung menggunakan nilai atribut dari instance tersebut dan instance akan dimasukkan ke dalam class yang memiliki probabilitas tertinggi.
Sementara itu, algoritma C4.5 secara rekursif mempartisi training data berdasarkan tes yang dilakukan pada nilai atribut untuk memisahkan class. Tes atribut ini dipilih satu-persatu dengan pendekatan greedy dan bergantung pada hasil yang didapat dari tes sebelumnya.
2.6.
Metodologi
Naïve-Teknik Informatika / Universitas Surabaya
Halaman C-51
Bayes dan C4.5. Dataset ini bervariasi dari segi ukuran, mulai puluhan hingga ribuan, yang masing-masingnya memiliki kurang dari 100 atribut.Untuk membandingkan hasil klasifikasi, digunakan mode Weka Experimenter pada Weka. Persentase kebenaran klasifikasi dirata-rata dari 10 kali 10-fold cross validation dan untuk setiap tekniknya, dibandingkan antara hasil sebelum dan sesudah dilakukan pemilihan atribut. Weka memiliki class
weka.classifiers.meta.AttributeSelectedClassifier yang memungkinkan untuk
menerapkan teknik pemilihan atribut dan mengurangi dimensi data sebelum dilewatkan pada sebuah algoritma classifier. Setting parameter yang akan digunakan pada penelitian ini adalah setting default dari Weka.
3.
HASIL DAN PEMBAHASAN
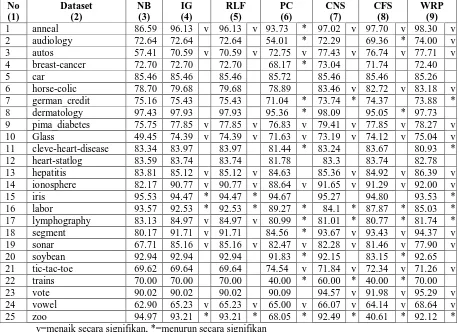
Seperti yang telah dijelaskan pada subbab metodologi, penerapan teknik pemilihan atribut dan hasil klasifikasi dilakukan dalam mode Weka Experimenter. Untuk keduapuluhlima dataset, persentase kebenaran klasifikasi dari masing-masing algoritma learning dirata-rata dari 10 kali 10-fold cross validation. Tabel 2 menunjukkan hasil benchmark dari 6 algoritma terhadap 25 dataset dengan menggunakan algoritma klasifikasi Naïve-Bayes dan Tabel 4 menunjukkan hasil benchmark dengan menggunakan algoritma klasifikasi C4.5.
Tabel 2. Hasil untuk Seleksi Atribut dengan Naïve Bayes
No
Teknik Informatika / Universitas Surabaya
Halaman C-52
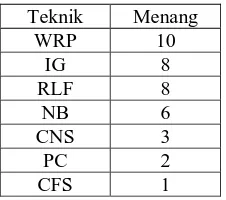
dataset.Tabel 3 menggambarkan ranking dari seluruh teknik seleksi atribut terhadap keakuratan kebenaran klasifikasi dengan algoritma Naïve Bayes pada 25 dataset. Beberapa teknik seleksi atribut memiliki kebenaran klasifikasi yang sama dan tertinggi di antara yang lain, sehingga teknik-teknik seleksi tersebut dihitung bersama-sama sebagai pemenang. Dari tabel 3, terlihat bahwa Wrapper tetap yang paling unggul dibandingkan metode lainnya dengan 10 kemenangan, sedangkan CFS secara mengejutkan berada pada posisi terakhir dengan hanya menang di 1 dataset saja (dataset 12) bersama-sama dengan IG dan RLF.
Tabel 3. Ranking Teknik Seleksi Atribut pada algoritma Naïve Bayes
Teknik Menang
Tabel 4. Hasil untuk Seleksi Atribut dengan C4.5
No
Teknik Informatika / Universitas Surabaya
Halaman C-53
dengan memberikan kenaikan kebenaran klasifikasi pada 8 dataset dan penurunan pada 5 dataset. CNS menjadi yang terbaik kedua dengan memberikan kenaikan pada 8 dataset dan penurunan pada 9 dataset, sedangkan CFS berada sedikit di bawah CNS dengan kenaikan pada 8 dataset dan penurunan pada 10 dataset. Dua teknik memiliki posisi yang sama, yakni IG dan RLF, yang sama-sama memiliki kenaikan pada 6 dataset dan penurunan pada 2 dataset. Di posisi terbawah adalah PC dengan kenaikan pada 7 dataset dan penurunan pada 15 dataset.Walaupun IG dan RLF sama-sama memiliki nilai kenaikan dataset yang lebih rendah dibandingkan Wrapper, namun keduanya memiliki selisih naik-turun yang terbesar (yakni 4) dibandingkan dengan Wrapper yang sebesar 3.
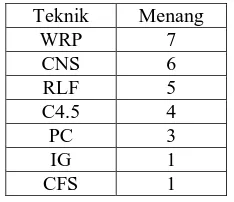
Tabel 5 menggambarkan ranking dari seluruh teknik seleksi atribut terhadap keakuratan kebenaran klasifikasi dengan algoritma C4.5 pada 25 dataset. Beberapa teknik seleksi atribut memiliki kebenaran klasifikasi yang sama dan tertinggi di antara yang lain, sehingga teknik-teknik seleksi tersebut dihitung bersama-sama sebagai pemenang.
Tabel 5. Ranking Teknik Seleksi Atribut pada algoritma C4.5
Teknik Menang
WRP 7
CNS 6
RLF 5
C4.5 4
PC 3
IG 1
CFS 1
Dari tabel 5, dapat dilihat bahwa Wrapper masih lebih unggul dari teknik lainnya dengan menang pada 7 dataset, sedangkan CFS kembali menempati posisi terakhir dengan unggul hanya pada 1 dataset saja (dataset 7).
Hasil ini sedikit berbeda dengan [3] dimana yang menjadi pemenang adalah RLF. Hal ini dimungkinkan karena adanya perbedaan pada jumlah dataset yang dijadikan ujicoba. Setiap dataset memiliki karakteristik tersendiri yang dapat mempengaruhi baik tidaknya kinerja teknik seleksi atribut yang diterapkan. Kemungkinan penyebab lain adalah penggunaan metode pencarian yang berbeda. Pada penelitian ini, untuk IG, RLF, dan PC digunakan metode pencarian Ranker, karena metode tersebut adalah satu-satunya metode pencarian pada Weka yang dapat dipasangkan dengan ketiganya. Sedangkan untuk CFS, CNS, dan WRP digunakan metode pencarian Linear Forwa rd Selection sesuai dengan metode yang digunakan pada [3] dan merupakan pendekatan greedy sederhana yang secara sekuensial menambahkan sebuah atribut yang memiliki nilai tertinggi ketika dikombinasikan dengan sejumlah atribut lain yang sudah terpilih.
Sebagai perbandingan pula dari segi running time, percobaan pertama dengan 25 dataset, 6 algoritma seleksi atribut dan menggunakan algoritma klasifikasi Naïve Bayes, dibutuhkan waktu 2 jam dan 37 menit. Sedangkan percobaan kedua dengan jumlah dataset dan algoritma seleksi atribut yang sama dan menggunakan algoritma klasifikasi C4.5, dibutuhkan waktu 4 jam dan 56 menit. Proses dengan algoritma C4.5 membutuhkan waktu lebih lama karena algoritma tersebut membangun model tree terlebih dahulu dari dataset yang ada, baru kemudian melakukan proses klasifikasi. Semakin banyak jumlah atribut dari sebuah dataset, semakin lama proses menghasilkan model tree-nya. Lingkungan ujicoba penelitian ini menggunakan prosesor Intel 1.8GHz dengan memori 4GB.
4.
KESIMPULAN
Penelitian ini telah melakukan studi perbandingan terhadap kinerja 6 teknik seleksi atribut pada 25 dataset. Berdasarkan hasil ujicoba yang telah dilakukan, diperoleh kesimpulan bahwa teknik seleksi atribut Wrapper adalah yang terbaik dari 5 teknik lainnya, sekaligus merupakan teknik yang membutuhkan waktu paling lama, baik dengan algoritma klasifikasi Naïve Bayes maupun C4.5.
Teknik Informatika / Universitas Surabaya
Halaman C-54
5.
SARAN
Proses ujicoba yang cukup memakan waktu merupakan salah satu kendala yang menyebabkan kurang menyeluruhnya pembandingan faktor-faktor lainnya untuk dilakukan, selain ketepatan hasil klasifikasi, seperti sensitivitas masing-masing teknik terhadap missing data serta noise, juga jumlah tree yang dihasilkan oleh tiap teknik pada penggunaan algoritma klasifikasi C4.5. Untuk selanjutnya, peneliti akan memasukkan faktor-faktor tersebut sebagai kinerja yang diukur pada penelitian berikutnya.
6.
Daftar Pustaka
[1] A. Blum and P. Langley, “Selection of Relevant Features andExamples in Machine Learning,” Artificial Intelligence, vol. 97, nos. 1-2, pp. 245-271, 1997.
[2] M. Dash and H. Liu, “Feature Selection for Classification,” Intelligent Data Analysis, vol. 1, no. 3, 1997. [3] Hall and Holmes, “Benchmarking Attribute Selection Techniques for Discrete Class Data Mining”, IEEE
Transactions on Knowledge and Data Engineering, Vol. 15, No. 6, IEEE Computer Society, 2003.
[4] Repository of Software Environment for the Advancement of Scholarly Research (SEASR). [Online]. Available: http://repository.seasr.org/Datasets/UCI/arff/.
[5] U.M. Fayyad and K.B. Irani, Multiinterval Discretisation of Continuous-Valued Attributes, Proc. 13th Int’l Joint Conf. Artificial Intelligence, pp. 1022-1027, 1993.
, E., Brohee, S. & van Helden, J., "Regulatory Sequence Analysis Tools (RSAT) Nucleic Acids Res.,” 2008.
Available: http://rsat.ulb.ac.be/.
Acids Res.," 2008. Available: http://rsat.ulb.ac.be/.