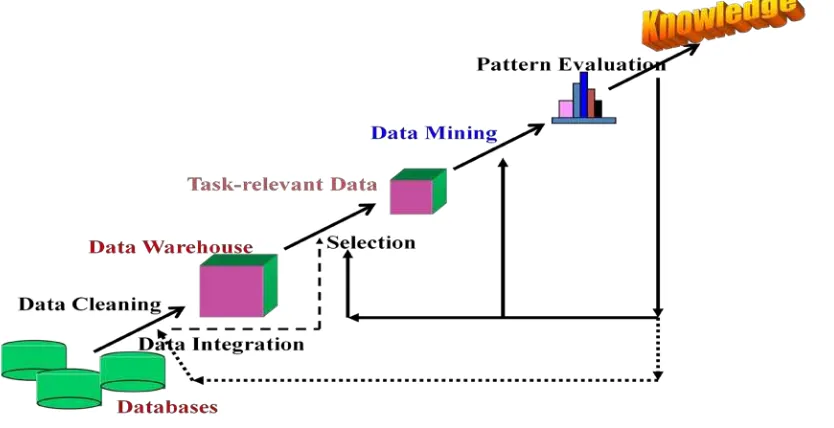
BAB II TINJAUAN PUSTAKA 2.1. Penambangan Data (Data Mining) Penambangan data (Data Mining) adalah serangkaian proses untuk menggali nilai tambah dari sekumpulan data berupa pengetahuan yang selama ini tersembunyi dibalik data atau tidak diketahui secara m
Teks penuh
Gambar
Dokumen terkait
tidak hanya dipengaruhi oleh metode atau media saja juga dipengaruhi oleh banyak faktor yang bisa datang dari dalam siswa (internal) ataupun dalam diri siswa (eksternal).
Hubungan antara Amerika Serikat dengan Arab Saudi peneliti lihat dengan konsep interdependensi. Dalam konsep ini, kedua negara merupakan entitas yang memerlukan
Berdasarkan dua kajian tersebut, pengkajian di buat keatas usahawan bumiputera IKS secara umum, manakala kajian ini lebih menjurus dan memberi fokus kepada faktor
Aplikasi ini sudah mampu melakukan proses klasifikasi data abstrak tugas akhir untuk menentukan kelasnya dengan baik.Akan tetapi proses klasifikasi semakin akurat
Obyek wisata yang berupa bangunan wisata dapat “dijual” untuk menunjang pembentukan dan sustainability city branding kota Cirebon. Untuk dapat “dijual”, bangunan wisata
Interpretan atau makna pesan moral pada webtoon Lucunya Hidup Ini yaitu berupa kritikan sosial dan pesan moral yang disesuaikan dengan nilai-nilai moral yang terdapat
Pada Undang-undang kesehatan no.36 tahun 2009 indikasi aborsi selain gawat darurat janin dan ibu juga diatur tentang aborsi pada korban akibat perkosaan yang
Berdasarkan rumusan masalah di atas, maka tujuan dalam penelitian ini adalah “Untuk Mengetahui Perbedaan Minat Belajar PKn yang diajarkan menggunakan Model
