1 Penerapan Data Mining Untuk Memprediksi Pengiriman Barang
Menggunakan Algoritma K-Nearest Neighbor
Winda Sri Utami1 , Yoga Religia2 , Sifa Fauziah3
Teknik Informatika, Fakultas Teknik, Universitas Pelita Bangsa Korespondensi email : [email protected]
Abstrak
Ketepatan waktu pengiriman barang sangat penting dalam perusahaan, untuk itu perlu diperhatikan hal apa saja yang dapat berpengaruh terhadap hal tersebut.
Banyak faktor yang mempengaruhi keterlambatan pengiriman barang antara lain proses produksi yang terhambat akibat kerusakan mesin produksi, human error dan keterlambatan pengiriman bahan baku dari supplier.
Teknik data mining memungkinkan untuk melakukan prediksi pengiriman barang dengan metode klasifikasi.
Dalam penelitian ini algoritma K- Nearest Neighbor dipilih untuk memprediksi pengiriman barang.
Tujuan dari penelitian ini adalah untuk
mengetahui tingkat akurasi prediksi pengiriman barang menggunakan algoritma K-Nearest Neighbor.
Penelitian ini dilakukan pengujian sebanyak 5 kali untuk mendapatkan hasil yang optimal yaitu dengan membagi data ke dalam 5 cluster antara lain k=3, k=5, k=7, k=9 dan k=11.
Setelah dilakukan pengujian, diperoleh performa yang paling bagus dengan tingkat akurasi sebesar 98,64% dengan cluster data k=3, dan nilai AUC tertinggi adalah 0,989 dengan cluster data k=9.
Kata kunci : Data Mining, Klasifikasi, K-Nearest Neighbor
1. Pendahuluan
PT Yamaha Music Manufacturing Asia merupakan perusahaan elektronik dan pro audio dimana didalam aktifitas produksinya menggunakan bahan baku (raw material) yang kemudian diproses menjadi barang setengah jadi (WIP) dan selanjutnya WIP di proses menjadi barang jadi (finish good). Salah satu section tersebut adalah Electrical Part Section, dimana produk yang dihasilkan
dari bagian ini merupakan produk setengah jadi berjenis elektrik yaitu PCB (Printed Circuit Board). PCB ini memiliki berbagai jenis model dengan fungsinya masing-masing. Perusahaan yang baik tentu memiliki perencanaan dalam jangka panjang agar perusahaan tersebut bisa terus eksis didunia bahkan menjadi lebih maju. Didalam era perkembangan teknologi yang sangat
2 pesat ini, perusahaan sangat dituntut
untuk selalu berinovasi dan mengikuti perkembangan zaman.
Banyaknya jenis barang yang di produksi mengakibatkan perencanaan produksi tidak stabil. Akibatnya terjadi keterlambatan produksi pada jenis barang tertentu yang mengakibatkan pemborosan, baik pemborosan dalam bentuk waktu maupun biaya. Kondisi keterlambatan produksi bisa saja terjadi akibat adanya komunikasi yang tidak lancar, jadwal produksi yang tidak akurat, maupun kendala yang lain seperti kesalahan manusia itu sendiri (human error) dan kerusakan pada mesin (machine error). Keterlambatan pengiriman bahan baku oleh supplier juga sering kali menjadi masalah yang tidak bisa dihindari oleh perusahaan.
Meramalkan perencanaan produksi dimasa mendatang berarti menentukan perkiraan besarnya volume produksi, penyusunan rencana sesuai kapasitas mesin produksi, sumber daya manusia, dan material atau bahan baku yang dibutuhkan, sehingga perusahaan bisa memperkirakan biaya yang akan dikeluarkan di masa yang akan datang.
Di era yang sangat modern ini telah berkembang teknologi yang sangat beragam, diantaranya adalah data mining. Teknik peramalan menggunakan data mining adalah bukan sesuatu yang baru. Data mining merupakan serangkaian proses untuk menggali nilai tambah berupa pengetahuan yang selama ini tidak diketahui secara manual [1].
Dengan banyaknya jenis produk yang dihasilkan maka dibutuhkan peramalan pengiriman barang setengah jadi menggunakan data mining dengan metode K Nearest Neighbor (K-NN). K- NN adalah algoritma supervised leaning yang artinya, algoritma ini
menggunakan data yang telah ada dan outputnya telah diketahui [2]. Algoritma K-Nearest Neighbor merupakan metode klasifikasi yang mengelompokkan data baru berdasarkan jarak data baru tersebut kebeberapa data/tetangga terdekat [3]. Metode K-NN ini merupakan metode yang mudah diimplementasikan, untuk itu metode K- NN seharusnya bisa menghasilkan informasi dengan tingkat akurasi yang tinggi. Kelebihan menggunakan metode K-Nearest Neighbor ini diperkirakan dapat memberikan hasil akurasi yang cukup bagus sehingga menghasilkan informasi yang berguna untuk perusahaan.
2. Tinjauan Pustaka
Algoritma K-Nearest Neighbor ini pernah digunakan sebagai penelitian ilmiah yang berjudul “Penerapan Algoritma K-Nearest Neighbor untuk Memprediksi Kelulusan Mahasiswa”.
Data yang digunakan dalam penelitian ini adalah data dengan atribut nilai dari semester 1 sampai semester 6, dengan label “Tepat Waktu” dan “Terlambat”.
Dimana didalam penelitian ini, peneliti mengklasterkan data k=1, k=2, k=3, k=4, k=5 dan diperoleh hasil dengan cluster data k=5 dengan accuracy sebesar 85,5%. Adapun peneliti juga menghitung nilai AUC dan diperoleh hasil accuracy sebesar 0.888 [4].
2.1. Pengiriman Barang dalam proses Secara umum, pengiriman merupakan suatu kegiatan mendistribusikan barang dari satu subjek ke subjek lain. Subjek atau pelaku dalam pengiriman barang antara lain adalah produsen dan konsumen.
Manfaat pengiriman barang adalah untuk memindahkan barang sebagai aktifitas jual beli dalam pelaksanaan
3 kegiatan ekonomi. Pelaksanaan
pengiriman barang merupakan suatu kegiatan dasar dalam pengawasan untuk mencapai tujuan tertentu sehingaa kegiatan pengiriman barang menciptakan sebuah arus saluran pemasaran.
Dua hal yang sangat berperan dalam aktifitas pengiriman barang adalah produsen dan konsumen.
Produsen berperan sebagai subjek bagaimana suatu produk dapat dikirimkan secara merata sesuai sasaran, sedangkan konsumen merupakan suatu subjek yang ingin mendapatkan dan menerima produk yang sudah ditawarkan dan dapat menerima produk dengan mudah.
2.2 Data Mining
Secara sederhana data mining merupakan penemuan informasi baru dengan mencari pola atau aturan tertentu dari sejumlah data yang sangat besar (Davies, 2004). Data mining didefinisikan sebagai proses untuk menemukan hubungan, pola tertentu dan tren baru yang bermakna dengan cara menyaring data yang sangat besar, yang tersimpan dalam suatu penyimpanan, menggunakan teknik pengenalan pola seperti teknik statistik dan matematika.
Data mining bukanlah...bidang yang sama sekali baru. Salah satu kesulitan untuk bisa mendefinisikan data mining ialah kenyataan bahwa data mining biasanya mewarisi banyak aspek dan teknik dari bidang-bidang ilmu yang sudah mapan terlebih dahulu.
2.3. Algoritma K-Nearest Neighbor K-Nearest Neighbor atau yang sering disingkat dengan KNN adalah salah satu algoritma yang digunakan untuk melakukan klasifikasi terhadap objek berdasarkan dari data
pembelajaran (data training) yang jaraknya paling dekat dengan objek tersebut [2]. Tujuan dari algoritma KNN adalah objek baru berdasarkan atribut dan sampel-sampel dari data training.
rumus yang paling sering digunakan dalam penghitungan KNN adalah Euclidean Distance, rumus tersebut yaitu :
𝑑𝑖𝑠𝑡(𝑥, 𝑦) = √∑(𝑥𝑖 − 𝑦𝑖)2
𝑛
𝑖=1
Gambar 1 Rumus Euclidean Distance 2.4. Cross Validation
Cross validation adalah teknik validasi dengan membagi data secara acak kedalam k bagian dan akan dilakukan proses klasifikasi [5]. Dengan menggunakan cross validation percobaan yang akan dilakukan adalah sebanyak k. data yang digunakan untuk pembentukan model disebut dengan data latih atau data training sedangkan data yang akan dipakai sebagai validasi disebut sebagai data uji (data testing) [11]. data training akan digunakan pada percobaan ini untuk mencari error rate secara keseluruhan.
2.5. Confusion Matrix
Confusion Matrix adalah suatu metode yang digunakan untuk melakukan perhitungan nilai akurasi pada data mining berdasarkan ringkasan tabel dari jumlah prediksi yang benar dan salah yang dibuat oleh classifier.
Confusion matrix memberikan keputusan yang diperoleh dalam data training dan data testing [5]. Confusion matrix digunakan untuk mencari nilai accuracy, precision, recall, dan F1- score. Ada 4 istilah yang dihasilkan pada proses klasifikasi menggunakan
4 confusion matrix yaitu true positive
(TP), true negative (TN), false positive (FP) dan false Negative (FN). True positive berarti data positif yang terdeteksi benar, dan false negative merupakan data positif yang terdeteksi data negatif, sebaliknya false negative merupakan data negatif yang terdeteksi sebagai data positif.
2.6. Rapidminer
Rapid miner adalah sebuah tools yang digunakan untuk kebutuhan machine learning, data mining, text mining, dan predictive analytics [14].
Rapid miner merupakan software untuk pengolahan data. Rapid miner bekerja dengan prinsip dan algoritma data mining untuk mengekstraksi pola-pola dari dataset yang sangat besar dengan memadukan metode statistik, kecerdasan buatan dan database.
Rapid miner merupakan salah satu software yang sangat familiar dalam bidang data mining. Fitur-fitur yang dimiliki oleh rapid miner tergolong sangat memudahkan penggunanya dengan memanfaatkan operator- operator yang terdapat dalam software tersebut. Operator dalam rapid miner berfungsi untuk memodifikasi data, data yang dihasilkan oleh software ini pun sangat jelas dengan tampilan visual dan grafik. Operator yang dimiliki oleh rapid miner antara lain data access, blending, cleansing, scoring, validation, dll.
3. Metode Penelitian 3.1. Data yang digunakan
Data yang digunakan dalam penelitian ini adalah data pengiriman barang setengah jadi (WIP) selama bulan maret 2021 yang berasal dari aplikasi Cossy Kaizen Report pada PT.
Yamaha Music Manufacturing Asia.
Data tersebut memiliki jumlah data sebanyak 8.035 dengan 8 atribut dan 1 label dengan type data Boolean.
Data pengiriman barang merupakan riwayat dokumen yang di input dari aktifitas mengalirkan barang dari proses satu ke proses selanjutnya atau dari section satu ke section yang lain. Hal tersebut bertujuan sebagai bukti transaksi dan untuk mengetahui sejauh mana aktifitas produksi berjalan. Setiap atribut dan label yang digunakan dalam penelitian ini akan dijelaskan pada tabel dibawah ini :
Tabel 1 Konten dari Data Pengiriman Barang
Konten Penjelasan Ket Slip
number
Kode transaksi setiap slip
ID
Start date Tanggal mulai produksi yang ditetapkan
Atribut
Finish date
Tanggal selesai produksi yang ditetapkan
Atribut
Delivery date
Tanggal
pengiriman barang
Atribut
Slip quantity
Jumlah barang yang harus selesai di produksi setiap slip
Atribut
Delivery quantity
Jumlah barang actual yang dikirim
Atribut
Process Urutan proses produksi
Atribut
Part Name
Nama barang yang di produksi
Atribut
Status Status pengiriman barang
(Terlambat, Tepat)
Label
5 3.2. Model Penelitian
Penelitian ini dilakukan dengan menggunakan teknik data mining dengan metode klasifikasi, dimana data yang digunakan merupakan data pengiriman barang setengah jadi. Data pengiriman barang sudah siap dipakai apabila sudah melewati seleksi data dan pemrosesan, sehingga data tidak memiliki missing value dan terdapat data yang double. Data tersebut kemudian akan dibagi menjadi data training dan data testing dengan menggunakan cross validation sebagai teknik validasi.
Teknik ini akan membagi k secara acak.
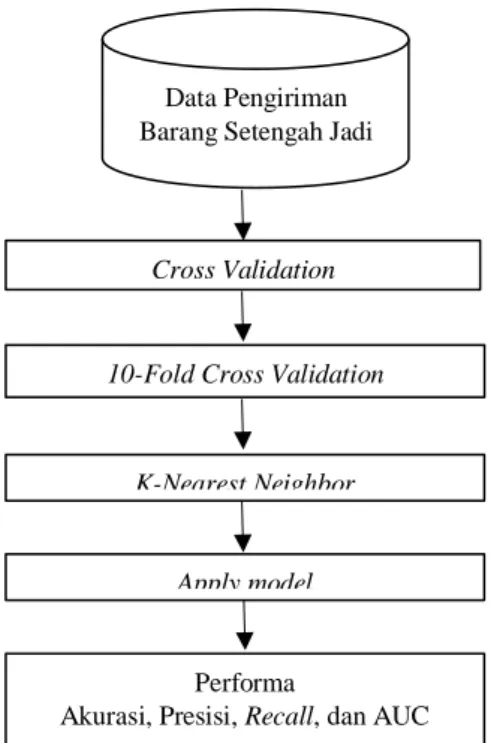
Pada cross validation pelatihan dan pengujian dilakukan sebanyak k, k yang dipilih untuk penelitian ini adalah 10 (10-fold cross validation), kemudian hasil dari proses ini akan dilakukan apply model untuk menghasilkan nilai akurasi, presisi, recall dan AUC (Area Under Curve). Untuk lebih jelasnya model penelitian digambarkan seperti alur berikut ini :
Gambar 2 Model Penelitian
Berdasarkan gambar 3.1 dapat diketahui bahwa penelitian prediksi pengiriman barang tersebut menggunakan algoritma K-Nearest Neighbor dengan setting nilai k sebanyak 10, menggunakan teknik cross validation. Dari setiap clustering data yang ditentukan menghasilkan masing-masing nilai akurasi, presisi, recall, dan AUC.
4. Hasil dan Pembahasan
Data yang digunakan pada penelitian ini merupakan data sekunder yang didapatkan dari aplikasi Cossy Kaizen Report PT. Yamaha Music Manufacturing Asia dan kemudian diklasifikasikan menggunakan Algoritma K-NN. Model penelitian ini akan dilakukan pengujian menggunakan tools Rapidminer 9.8 dan menghasilkan nilai akurasi, presisi, recall, AUC.
4.1. Hasil Penelitian
Pada penelitian Prediksi Pengiriman Barang menggunakan Algoritma K-NN ini, pengujian model akan dilakukan sebanyak 5 kali menggunakan teknik cross validation.
pengujian dilakukan dengan menggunakan tools rapidminer dimana operator yang dipakai adalah cross validation, k-NN, apply model dan performance. Dari hasil pengujian model ini akan didapatkan hasil akurasi,presisi, recall dan AUC.
Tabel 2. Confusion Matrix dengan K=3
Berdasarkan Tabel 2 Jumlah True Positive (TP) adalah 1.066 record diklasifikasikan sebagai “Terlambat”
Data Pengiriman Barang Setengah Jadi
K-Nearest Neighbor Cross Validation
10-Fold Cross Validation
Performa Akurasi, Presisi, Recall, dan AUC
Apply model
6 terpilih dan False Negative (FN)
sebanyak 23 record diklasifikasikan sebagai “Terlambat” terpilih tetapi
“Tepat” terpilih. Selanjutnya 6.860 record untuk True Negative (TN) diklasifikasikan sebagai “Tepat”
terpilih, dan 86 record False Positive diklasifikasikan sebagai “Tepat” terpilih tetapi ternyata “Terlambat”.
Tabel 3 Hasil Akurasi, Presisi, Recall Nilai
k
Akurasi Presisi Recall k = 3 98,64 % 98,76 % 99,67 % k = 5 98.37 % 98,33 % 99,80 % k = 7 98,15 % 98,02 % 99,85 % k = 9 97,96 % 97,77 % 99,90 % k = 11 97,64 % 97,48 % 99,83 % Dari Tabel 3 menunjukkan bahwa tingkat akurasi tertinggi adalah 98,64%
dengan kondisi k=3, sedangkan nilai presisi tertinggi adalah 98,76% dengan kondisi k=3, dan nilai recall tertinggi adalah 99,90% dengan kondisi k=9, sehingga kesimpulannya adalah semakin banyak nilai k maka tingkat akurasi dan presisi akan semakin rendah.
Setelah mendapatkan nilai akurasi, presisi, dan recall selanjutnya akan dilakukan perbandingan klasifikasi menggunakan kurva ROC hasil dari confusion matrix. Kurva ROC (Receiver Operating Characteristic) adalah suatu alternatif lain untuk mengevaluasi akurasi dari klasifikasi secara visual [5].
Berikut ini adalah nilai AUC (Area Under Curve) yang dihasilkan dari evaluasi ROC curve berdasarkan clustering data :
Tabel 4. Hasil Nilai AUC Nilai k AUC Kesimpulan
k = 3 0,957 Excellent Classification
k = 5 0,964 Excellent Classification k = 7 0,970 Excellent
Classification k = 9 0,989 Excellent
Classification k = 11 0,986 Excellent
Classification Berdasarkan Tabel 4 dapat diketahui bahwa semua cluster masuk ke dalam kategori excellent classification karena memiliki nilai AUC diatas 0,90. Nilai AUC diperoleh dari hubungan nilai false positive dan true positive dengan nilai maksimal 1 dan nilai minimal 0.
Representasi hasil nilai AUC pada penelitian ini digambarkan dengan grafik dibawah ini :
Gambar 3 Grafik AUC dengan k=3 4.2. Analisa Hasil Pengujian
Berdasarkan pengujian yang telah dilakukan dalam penelitian Prediksi Pengiriman Barang menggunakan Algoritma K-Nearest Neighbor ini, dapat diketahui bahwa tingkat akurasi dapat dipengaruhi oleh jumlah clustering data, Semakin banyak jumlah clustering data maka nilai akurasi akan semakin rendah, dan sebaliknya semakin sedikit jumlah clustering data maka semakin tinggi nilai akurasinya.
Selain nilai akurasi, jumlah clustering data ternyata juga
AUC: 0.957 +/- 0.021 (micro average: 0.957) ROC ROC (Thresholds)
7 mempengaruhi nilai presisi pada
pengujian yang telah dilakukan dalam penelitian ini. Berdasarkan hasil pengujian yang diperoleh, dapat diketahui bahwa Semakin banyak jumlah clustering data maka nilai presisi akan semakin rendah, sebaliknya semakin sedikit jumlah clustering data maka semakin tinggi nilai presisinya.
Jumlah clustering data merupakan salah satu hal yang sangat berpengaruh dalam klasifikasi data. Banyaknya jumlah klasifikasi menghasilkan klasifikasi data seperti True Positive (TN), False Positive (FP), False Negative (FN) dan True Negative (TN) yang beragam dan memiliki pola tertentu. Salah satu yang mempengaruhi nilai recall atau ketepatan data adalah jumlah record data yang diklasifikasikan sebagai True Negatives (TN), semakin banyak record sebagai True Negative maka semakin tinggi tingkat recall yang dihasilkan.
Sedangkan dilihat dari ROC curve dari pengujian model yang dilakukan, semua cluster memiliki nilai AUC (Area Under Curve) diatas 0.900 sehingga model klasifikasi yang dibangun termasuk ke dalam kategori Excellent Classification. Nilai AUC (Area Under Curve) tertinggi yaitu 0,989 dengan nilai k=9, sedangkan nilai AUC terendah yaitu 0,957 dengan nilai k=3. Dari hasil pengujian model diatas dapat disimpulkan bahwa penelitian ini layak untuk menyelesaikan kasus lain dengan permasalahan dan data yang sama.
5. Kesimpulan
Dalam penelitian Prediksi Pengiriman Barang ini pengujian model dilakukan dengan menggunakan Algoritma K-Nearest Neighbor (KNN).
Pengujian model dilakukan dengan menggunakan Teknik 10-Fold Cross
Validation dan Evaluasi ROC (Receiver Operating Characteristic) Curve dengan tools RapidMiner 9.8. Dari hasil penelitian didapatkan hasil bahwa semakin banyak jumlah clustering data maka semakin rendah nilai akurasinya, sedangkan semakin sedikit jumlah clustering data maka semakin tinggi nilai akurasinya.
Hasil pengujian menunjukkan bahwa nilai akurasi tertinggi adalah 98,64% dengan cluster data k = 3, sedangkan nilai akurasi terendah adalah 97,64% dengan cluster data k=11. Hasil pengujian model juga menghasilkan nilai presisi tertinggi dengan cluster data k=3 yaitu sebesar 98,76% dan nilai presisi terkecil yaitu 97,48 % dengan k=11. Ketepatan data atau recall tertinggi yaitu 99,83% dengan cluster data k=9. Dari semua clustering data nilai AUC yang dihasilkan diatas 0.90 sehingga dapat dikategorikan sebagai Excellent Classification.
Untuk penelitian selanjutnya, perlu menggabungkan beberapa metode lain (Random Forest) untuk mendapatkan hasil yang lebih optimal. Random forest merupakan ensemble learning method untuk melakukan regresi, klasifikasi, dan tugas lain untuk menghasilkan pohon keputusan (decision tree) dan menyediakan output dari pohon individu yang mendasarinya.
Daftar Rujukan
[1] Y. Religia and Amali, "Perbandingan Optimasi Feature Selection pada Naive Bayes untuk Klasifikasi Kepuasan Airline Passanger," Jurnal Resti, vol. IX NO. 3, 2019.
[2] N. Usnah, "Penerapan Data Mining untuk Prediksi Penjualan Produk Furniture Terlaris Menggunakan
8 Metode K-Nearest Neighbor," p. 69,
2019.
[3] W. Zarman, A. Darmawan and S.
Lorena Br Ginting, "Teknik Data Mining Untuk Memprediksi Masa Studi Mahasiswa Menggunakan Algoritma K-Nearest Neigbor,"
Jurnal Teknik Komputer Unikom, vol.
3, p. 29, 2014.
[4] Sukamto, Y. Andriyani and R. Aulia,
"Prediksi Kelompok UKT Mahasiswa Menggunakan Algoritma K-Nearest Neighbor," JUITA, vol. 8, p. 130, 2020.
[5] A. Rahman, "Model Algoritma K- Nearest Neighbor (K-NN) Untuk Prediksi Kelulusan Mahasiswa," p.
90, 2019.
[6] O. Dewi Lestari and T. Christy,
"Analisis Perbandingan Pengiriman Barang Menggunakan Metode Vogel's Approximation Method (VAM) Dan Modified Distribution (MODI)," JURTEKSI (Jurnal Teknologi dan Sistem Informasi, vol.
V, no. 1, pp. 51-58, 2018.
[7] D. Jollyta, W. Ramadhan and M.
Zarlis, Konsep Data Mining dan Penerapan, Yogyakarta: Deepublish, 2020.
[8] R. T. Handayanto and H. , Data Mining dan Machine Learning Menggunakan Matlab dan Python, Bandung, 2020.
[9] D. Putri Asih, "Implementasi Data Mining Dalam Melihat Prediksi Cuaca Menggunakan Algoritma C4.5," 2020.
[10] P. B, F. M. T. and W. S. H., "Prediksi Jumlah Keubutuhan Pemakaian Air Menggunakan Metode Smothing," J.
Pengemb. ekno. Inf. dan Ilmu
komputer Univ Brawijaya, vol. 2, pp.
4679-4686, 2018.
[11] I. Ayu Made Spartini, K. Gede Sukarsa and I. G. Ayu Made Srinadi,
"Analisis Diskiriminan pada Klasifikasi Desa di Kabupaten Tabanan Menggunakan Metode K- Fold Cross Validation," E- Matematika, vol. 6 (2), pp. 106-115, 2017.
[12] M. De Rooij, "Cross-Validation : A Methode Every Psychologist Should Know," Tutorial, pp. 250-251, 2019.
[13] Haryati, A. Sudarsono and E. Suryana,
"Implementasi Data Mining Untuk Memprediksi Masa Studi Mahasiswa Menggunakan Algoritma C4.5," J.
Media Infotama, vol. 11 , pp. 130-138, 2015.
[14] D. Noviyanti, "Implementasi Algoritma Naive Bayes pada Data Set Hipatitis Menggunakan Rapid Miner," Paradigma, vol. XXI, no. 1, pp. 49-53, 2019.