BAB 2
LANDASAN TEORI
2.1 Definisi Kamus
Kamus adalah sejenis buku rujukan yang menerangkan makna kata-kata. Kamus berfungsi untuk membantu seseorang mengenal perkataan baru. Selain menerangkan maksud kata kamus juga mungkin mempunyai pedoman sebutan, asal usul (etimologi) sesuatu perkataan dan juga contoh penggunaan bagi sesuatu perkataan. Untuk memperjelas kadang kala terdapat juga ilustrasi didalam kamus (Susanto,2014).
2.2 Definisi Algoritma
Algoritma adalah langkah detail yang ditunjukkan untuk komputer guna menyelesaikan suatu masalah. Proses semacam algoritma sebenarnya dapat dijumpai dalam kehidupan sehari hari. Untuk lebih mudah memahami arti dari algoritma, dapat diilustrasikan seperti membaca resep makanan.
Jika membaca resep makanan pasti akan melihat prosedur untuk membuat masakan. Prosedur dalam resep itu sebenarnya menyatakan seperti algoritma. Dengan mengikuti langkah-langkah yang diberikan maka dapat membuat masakan tersebut. Dalam pengertian sekarang,algoritma mempunyai kesamaan tidak hanya dengan resep tetapi juga dengan proses,metode dan prosedur (Kadir, A. & Heriyanto. 2005).
2.2.1 Algoritma String Matching (pencocokan kata)
(string matching) merupakan bagian penting dari sebuah proses pencarian string(string searching) dalam sebuah dokumen. Hasil dari sebuah sebuah pencarian string dalam
dokumen tergantung dari teknik dan cara pencocokan string yang digunakan (Buulolo, E. 2013).
Menurut Singla, N. & Garg, D. (2012) ada dua teknik utama dalam algoritma string matching yaitu exact matching dimana hasil pencocokannya mengandung string
yang sama persis dengan string yang di-input, contohnya pada algoritma Needleman Wunsch, algoritma Smith Waterman, algoritma Knuth-Morris-Pratt, algoritma
Boyer-Moore-Horspool dan approximate matching dimana hasil pencocokannya mengandung
string yang tidak harus persis dengan string yang di-input, contohnya pada algoritma
Fuzzy String Searching, algoritma Rabin Karp, algoritma Brute Force.
Prinsip kerja algoritma string matching adalah sebagai berikut:
1. Memindai teks dengan bantuan sebuah window yang ukurannya sama dengan panjang pattern.
2. Menempatkan window pada awal teks.
3. Membandingkan karakter pada window dengan karakter dari pattern. Setelah pencocokan (baik hasilnya cocok atau tidak cocok), dilakukan shift ke kanan pada window. Prosedur ini dilakukan berulang-ulang sampai window berada pada akhir teks. Mekanisme ini disebut mekanisme sliding-window (Effendi, D., et al. 2013).
Algoritma string matching mempunyai tiga komponen utama, yaitu:
1. Pattern, yaitu deretan karakter yang akan dicocokkan dengan teks, dinyatakan dengan x[0..m-1], panjang pattern dinyatakan dengan m.
2. Teks, yaitu tempat pencocokan pattern dilakukan, dinyatakan dengan y[0..n-1], panjang teks dinyatakan dengan n.
3. Alfabet, yang berisi semua simbol yang digunakan oleh bahasa pada teks dan pattern, dinyatakan dengan Σ dengan ukuran dinyatakan dengan ASIZE (Effendi, D., et al. 2013).
2.2.1.1 Algoritma Knuth Morris Pratt
bersamaan pada tahun 1977. Algoritma Knuth Morris Pratt melakukan perbandingan karakter teks dan karakter pada pola dari kiri ke kanan. Ide dari algoritma ini adalah bagaimana memanfaatkan karakter-karakter pola yang sudah diketahui ada di dalam teks sampai terjadinya ketidakcocokkan untuk melakukan pergeseran (Ervana, A. & Pertiwi, A. 2012).
Secara sistematis, langkah-langkah yang dilakukan algoritma Knuth Morris Pratt pada saat mencocokkan string :
1. Algoritma Knuth Morris Pratt mulai mencocokkan pattern pada awal teks.
2. Dari kiri ke kanan, algoritma ini akan mencocokkan karakter per karakter pattern dengan karakter di teks yang bersesuaian, sampai salah satu kondisi berikut dipenuhi :
a) Karakter di pattern dan di teks yang dibandingkan tidak cocok (mismatch). b) Semua karakter di pattern cocok.Kemudian algoritma akan memberitahukan
penemuan di posisi ini.
3. Algoritma kemudian menggeser pattern berdasarkan tabel shift, lalu mengulangi langkah 2 sampai pattern berada di ujung teks (Ervana, A. & Pertiwi, A. 2012).
Cara kerja Algoritma Knuth Morris Pratt yang digunakan untuk melakukan jumlah pergeseran adalah sebagai berikut :
Tabel 2.1 Hasil Perhitungan kmpNext[i] dan shift[i]
Langkah-langkah untuk
menghitung nilai kmpNext[i] dan shift[i] adalah sebagai berikut :
1. Untuk mendapatkan hasil pergeseran, mula-mula isi kmpNext[i] dengan nilai awal -1
i 0 1 2 3 4
x [i] A B A B
kmpNext[i] -1 0 -1 0 2 Shift[i] 1 1 3 3 2
i 0 1 2 3 4
x [i] A B A B
2. Membandingkan karakter dari kiri ke kanan
Bandingkan karakter A dan B jika tidak sama beri nilai 0 Bandingkan karakter A dan A jika sama beri nilai -1 Bandingkan karakter B dan B jika sama beri nilai 0 Bandingkan karakter A dan - jika tidak sama beri nilai 2
(untuk karakter yang sama lihat nilai kmpNext[i] untuk mengisi tabel kmpNext[i], sedangkan untuk karakter yang tidak sama lihat nilai i untuk
mengisi tabel kmpNext[i])
3. Pengisian kolom Shift dilakukan dengan memakai rumus i - kmpNext[i] i - kmpNext[i] = 0 – (-1) = 1
i - kmpNext[i] = 1 – (0) = 1 i - kmpNext[i] = 2 – (-1) = 3 i - kmpNext[i] = 3 – (0) = 3 i - kmpNext[i] = 4 – (2) = 2
Setelah mendapatkan hasil pergeseran yang diperoleh dari Tabel 2.1 maka pencocokan kata dapat dilakukan dengan langkah-langkah berikut :
i 0 1 2 3 4
x [i] A B A B
kmpNext[i] -1 0 -1 0 2 Shift[i]
i 0 1 2 3 4
x [i] A B A B
kmpNext[i] -1 0 -1 0 2 Shift[i] 1 1 3 3 2
Index 0 1 2 3 4 5 6 7 8 9
Text B A C B A B A B A B
Keterangan : Text menjelaskan tentang teks yang telah disimpan dalam database dan Pattern menjelaskan tentang pola atau inputan kata yang ingin dicari atau dicocokkan
kedalam teks. Langkah 1 :
Index 0 1 2 3 4 5 6 7 8 9
Text B A C B A B A B A B
Index 0 1 2 3 Pattern A B A B
Keterangan : Terlihat karakter B dan A tidak cocok. Nilai Shift [0] yang berkarakter A bernilai 1 seperti terlihat pada Tabel 2.1 maka terjadi pergeseran sebanyak 1 kali. Langkah 2 :
Index 0 1 2 3 4 5 6 7 8 9
Text B A C B A B A B A B
Index 0 1 2 3
Pattern A B A B
Keterangan : Terlihat karakter C dan B tidak cocok. Nilai Shift [1] yang berkarakter B bernilai 1 seperti terlihat pada Tabel 2.1 maka terjadi pergeseran sebanyak 1 kali. Langkah 3 :
Index 0 1 2 3 4 5 6 7 8 9
Text B A C B A B A B A B
Index 0 1 2 3
Pattern A B A B
Langkah 4 :
Index 0 1 2 3 4 5 6 7 8 9
Text B A C B A B A B A B
Index 0 1 2 3
Pattern A B A B
Keterangan : Terlihat karakter B dan A tidak cocok. Nilai Shift [0] yang berkarakter A bernilai 1 seperti terlihat pada Tabel 2.1 maka terjadi pergeseran sebanyak 1 kali. Langkah 5 :
Index 0 1 2 3 4 5 6 7 8 9
Text B A C B A B A B A B
Index 0 1 2 3
Pattern A B A B
Keterangan : Terlihat semua karakter telah cocok. Tetapi karakter masih bisa bergeser dan kemungkinan ada kecocokan karakter maka harus shift dengan nilai Shift[4]. Nilai Shift[4] pada Tabel 2.1 adalah bernilai 2. Maka lakukan pergeseran sebanyak 2 kali. Langkah 6 :
Index 0 1 2 3 4 5 6 7 8 9
Text B A C B A B A B A B
Index 0 1 2 3
Pattern A B A B
Keterangan : Terlihat semua karakter telah cocok dan window berada pada akhir teks maka tidak ada lagi pergeseran.
2.2.1.2 Algoritma Boyer Moore
Algoritma Boyer Moore adalah salah satu algoritma untuk mencari suatu string di dalam teks, dibuat oleh R.M Boyer dan J.S Moore. Algoritma Boyer Moore melakukan perbandingan dimulai dari kanan ke kiri, tetapi pergeseran window tetap dari kiri ke kanan. Jika terjadi ketidakcocokan, maka akan dicek nilai pergeseran yang dilakukan dengan melihat ke tabel bad character shitf dan good suffix shift. Nilai terbesar yang didapat diantara kedua tabel tersebut akan diambil dan pergeseran akan dilakukan sesuai dengan nilai tersebut.
Algoritma Boyer-Moore menggunakan dua buah tabel untuk mengolah informasi saat terjadi kegagalan pencocokan pattern. Tabel pertama disebut bad character shitf juga sering disebut occurrence heuristic (OH). Tabel kedua disebut
dengan istilah good suffix shift juga disebut match heuristic (MH) (Charras, C. & Lecroq, T. 2004).
Secara sistematis, langkah-langkah yang dilakukan Algoritma Boyer Moore pada saat mencocokkan string :
1. Algoritma Boyer-Moore mulai mencocokkan pattern pada awal teks.
2. Dari kanan ke kiri, algorima ini akan mencocokan karakter per karakter pattern dengan karakter di teks yang bersesuaian, sampai salah satu kondisi berikut dipenuhi:
a) Karakter di pattern dan di teks yang dibandingkan tidak cocok (mismatch). b) Semua karakter di pattern cocok kemudian algoritma akan memberitahukan
penemuan diposisi ini.
3. Algoritma kemudian menggeser pattern dengan memaksimalkan nilai penggeseran good suffix dan penggeseran bad-character, lalu mengulangi langkah 2 sampai pattern
berada di ujung teks (Susanto,2014).
Cara kerja Algoritma Boyer Moore yang digunakan untuk melakukan jumlah pergeseran adalah sebagai berikut :
2.2.1.2.1 Suffix
Tabel 2.2 Hasil Perhitungan Suffix
Langkah-langkah untuk menghitung nilai Suffix adalah sebagai berikut :
1. Isi kolom Suffix paling kanan dengan nilai m. m adalah panjang karakter pattern
2. Membandingkan karakter dari kanan ke kiri
Bandingkan karakter B dan A jika tidak cocok maka beri nilai 0 Bandingkan karakter B dan B jika cocok maka jangan beri nilai Bandingkan karakter B dan A jika tidak cocok maka beri nilai 0
3. Pengisian kolom yang tidak bernilai dilakukan dengan memakai rumus i – i – s . s adalah nilai berapa kali pergeseran karakter yang cocok. i – i – s = 1 – (1 – 2) = 2
2.2.1.2.2 Good-Suffix Shift (Match Heuristic)
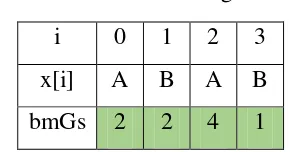
Tabel Match Heuristic sering disebut juga Good-Suffix Shift (bmGs), dimana pergeserannya dilakukan berdasarkan posisi ketidakcocokkan karakter yang terjadi. Maksudnya untuk menghitung tabel bmGs perlu diketahui pada posisi keberapa terjadi ketidakcocokkan. Posisi ketidakcocokkan itulah yang akan menentukan besar pergeseran (Argakusumah, K.W. & Hansun, S. 2014).
i 0 1 2 3 x[i] A B A B Suffix 0 2 0 4
i 0 1 2 3 x[i] A B A B
Suffix 4
i 0 1 2 3 x[i] A B A B Suffix 0 0 4
Tabel 2.3 Hasil Perhitungan bmGs
Langkah-langkah untuk menghitung nilai bmGs adalah sebagai berikut : 1. Isi bmGs sesuai dengan panjang karakter yaitu 4.
2. Lakukan pengecekan dari kanan, lakukan pengecekan hingga i = 0 i = 3, jika i + 1 = 4 dan ternyata Suffix bernilai 4 maka tandai kolom
i = 2, jika i + 1 = 3 dan ternyata Suffix bernilai 0 maka jangan beri tanda pada kolom
i = 1, jika i + 1 = 2 dan ternyata Suffix bernilai 2 maka tandai kolom
i = 0, jika i + 1 = 1 dan ternyata Suffix bernilai 0 jangan beri tanda pada kolom
3. Masukkan rumus m – 1 – i pada nilai yang telah diberi ceklis
m – 1 – i = 4 – 1 – 3 = 0. Karena hasilnya 0 maka tidak melakukan perhitungan m – 1 – i = 4 – 1 – 1 = 2. Karena hasilnya 2 maka perhitungan indeks dari 0 sampai 1
4. Ubahlah nilai indeks 0 dan 1 dengan rumus m- 1 – i m- 1 – i = 4 – 1 – 1 = 2
i 0 1 2 3 x[i] A B A B bmGs 2 2 4 1
i 0 1 2 3 x[i] A B A B Suffix 0 2 0 4 bmGs 4 4 4 4
i 0 1 2 3 x[i] A B A B Suffix 0 2 0 4 bmGs 4 4 4 4
5. Lakukan pengecekan sampai m – 2 = 4 – 2 = 2, artinya menghitung indeks dari 0 sampai 2
6. Masukkan rumus m – 1 – suffix untuk mengisi kolom bmGs i = 0
4 – 1 – 0 = 3, 3 adalah nilai i yang akan diisi pada kolom bmGs m – 1 – i = 4 – 1 – 0 = 3
i = 1
4 – 1 – 2 = 1, 1 adalah nilai i yang akan diisi pada kolom bmGs m – 1 – i = 4 – 1 – 1 = 2
i = 2
4 – 1 – 0 = 3, adalah nilai i yang akan diisi pada kolom bmGs m – 1 – i = 4 – 1 – 2 = 1
2.2.1.2.3 Bad-Character Shift (Occurance Heuristic)
Tabel Occurrence Heuristic sering disebut juga Bad-Character Shift (bmBc), dimana pergeserannya dilakukan berdasarkan karakter apa yang menyebabkan tidak cocok dan seberapa jauh karakter tersebut dari karakter paling akhir (Argakusumah, K.W. & Hansun, S. 2014).
i 0 1 2 3 x[i] A B A B Suffix 0 2 0 4 bmGs 2 2 4 3
i 0 1 2 3 x[i] A B A B Suffix 0 2 0 4 bmGs 2 2 4 3
Tabel 2.4 Hasil Perhitungan bmBc
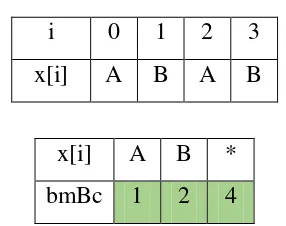
Langkah-langkah untuk menghitung nilai bmBc adalah sebagai berikut : 1. Isi * dengan panjang karakter yaitu 4
x[i] A B *
bmBc 4
2. Pengisian tabel dimulai dari 0 sampai m - 2 yaitu 4 – 2 = 2
3. Isi tabel bmBc dengan rumus m – 1 – i i = 0
m – 1 – i = 4 – 1 – 0 = 3, i = 0 menunjukkan karakter A maka isi tabel bmBc dengan nilai 3
i = 1
m – 1 – i = 4 – 1 – 1 = 2, i = 1 menunjukkan karakter B maka isi tabel bmBc dengan nilai 2
i 0 1 2 3 x[i] A B A B
x[i] A B * bmBc 1 2 4
i 0 1 2 3 x[i] A B A B
i 0 1 2 3 x[i] A B A B
x[i] A B *
bmBc 3 4
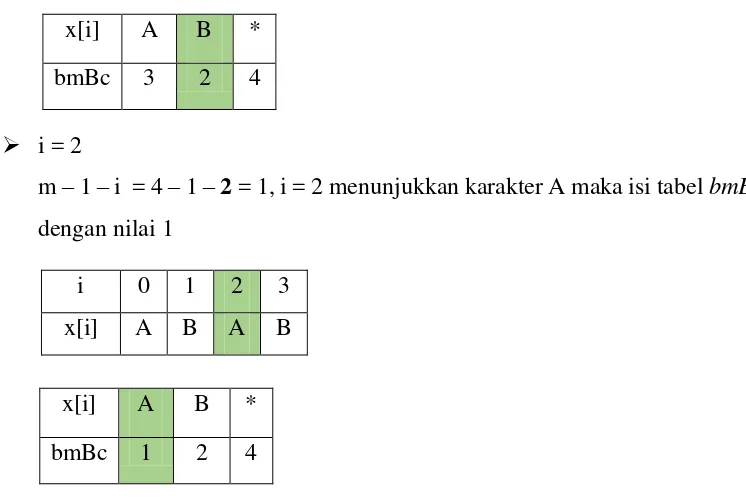
i = 2
m – 1 – i = 4 – 1 – 2 = 1, i = 2 menunjukkan karakter A maka isi tabel bmBc dengan nilai 1
Setelah mendapatkan hasil pergeseran yang diperoleh dari Tabel 2.3 dan Tabel 2.4 maka pencocokan kata dapat dilakukan dengan langkah-langkah berikut :
Tabel 2.5 Pergeseran karakter untuk bmBc
0 1 2 3 4 5 6 7 8 9
B A C B A B A B A B
Tabel 2.6 Pergeseran posisi untuk bmGs
Langkah 1 :
Index 0 1 2 3 4 5 6 7 8 9 bmBc B A C B A B A B A B
Index 0 1 2 3 bmGs A B A B
Keterangan : Terlihat karakter C dan A tidak cocok maka dibandingkan nilai bmBc dan bmGs. Nilai bmBc C bernilai 4 seperti terlihat pada Tabel 2.4,lalu mengambil nilai bmBc masukkan rumus 4 - (m + 1 + i ) = 4 – (4 + 1 + 2 ) = -3. Sedangkan nilai bmGs A bernilai 4 seperti terlihat pada Tabel 2.3 Maka bmBc bernilai -3 dan bmGs
x[i] A B *
bmBc 3 2 4
i 0 1 2 3 x[i] A B A B
x[i] A B * bmBc 1 2 4
bernilai 4. Bandingkanlah maka hasil maksimum yang diperoleh untuk mengambil pergeseran yaitu 4 kali pergeseran.
Langkah 2 :
Index 0 1 2 3 4 5 6 7 8 9 bmBc B A C B A B A B A B
Index 0 1 2 3
bmGs A B A B
Keterangan : Terlihat semua karakter cocok. Jika semua karakter telah cocok maka harus shift dengan nilai bmGs [0]. Nilai bmGs [0] pada Tabel 2.3 adalah bernilai 2. Maka lakukan pergeseran sebanyak 2 kali tanpa membandingkan nilai bmGs dan bmBc.
Langkah 3 :
Index 0 1 2 3 4 5 6 7 8 9 bmBc B A C B A B A B A B
Index 0 1 2 3
bmGs A B A B
Keterangan : Terlihat semua karakter telah cocok dan window berada pada akhir teks maka tidak ada lagi pergeseran.
2.3 Definisi Kompleksitas Algoritma
Kebenaran suatu algoritma harus diuji dengan jumlah masukan tertentu untuk melihat kinerja algoritma berupa waktu yang diperlukan untuk menjalankan algoritmanya dan ruang memori yang diperlukan untuk struktur datanya. Algoritma yang bagus adalah algoritma yang mangkus (efisien). Kemangkusan algoritma diukur dari jumlah waktu dan ruang memori yang dibutuhkan untuk menjalankan algoritma tersebut.
kemangkusan algoritma dengan kompleksitasnya. Besaran yang dipakai untuk menerangkan model penilaian waktu atau ruang algoritma adalah dengan menggunakan kompleksitas algoritma.
Ada dua macam kompleksitas algoritma, yaitu kompleksitas waktu dan kompleksitas ruang. Kompleksitas waktu dari algoritma adalah mengukur jumlah perhitungan (komputasi) yang dikerjakan oleh komputer ketika menyelesaikan suatu masalah dengan menggunakan algoritma. Ukuran yang dimaksud mengacu ke jumlah langkah-langkah perhitungan dan waktu tempuh pemrosesan. Kompleksitas waktu merupakan hal penting untuk mengukur efisiensi suatu algoritma.
Kompleksitas waktu dari suatu algoritma yang terukur sebagai suatu fungsi ukuran masalah. Kompleksitas waktu dari algoritma berisi ekspresi bilangan dan jumlah langkah yang dibutuhkan sebagai fungsi dari ukuran permasalahan. Kompleksitas ruang berkaitan dengan sistem memori yang dibutuhkan dalam eksekusi program.
Untuk mengukur kebutuhan waktu sebuah algoritma yaitu dengan mengeksekusi langsung algoritma tersebut pada sebuah komputer, lalu dihitung berapa lama durasi waktu yang dibutuhkan untuk menyelesaikan sebuah persoalan dengan n yang berbeda-beda. Kemudian dibandingkan hasil komputasi algoritma tersebut dengan notasi kompleksitas waktunya untuk mengetahui efisiensi algoritmanya (Nugraha, D.W. 2012).
Kompleksitas algoritma diukur berdasarkan kinerjanya dengan menghitung waktu eksekusi suatu algoritma. Menurut Cormen et al. (2009) waktu eksekusi algoritma dapat diklasifikasikan menjadi tiga kelompok besar, yaitu best-case (kasus terbaik), average-case (kasus rata-rata) dan worst-case (kasus terjelek).
Pada pemrograman yang dimaksud dengan kasus terbaik, kasus terjelek dan kasus rata-rata suatu algoritma adalah besar kecilnya atau banyak sedikitnya sumber-sumber yang digunakan oleh suatu algoritma. Makin sedikit makin baik, makin banyak makin jelek (Subandijo. 2011).
2.4 Definisi Android
Android adalah sebuah sistem operasi untuk perangkat mobile berbasis linux yang mencangkup sistem operasi, middleware dan aplikasi. Android menyediakan platform yang terbuka bagi para pengembang untuk menciptakan aplikasi-aplikasi
Awalnya, Google Inc. membeli Android Inc., pendatang baru yang membuat peranti lunak untuk ponsel. Kemudian untuk mengembangkan Android, dibentuklah Open Handset Alliance, konsorsium dari 34 perusahaan peranti keras, peranti lunak, dan telekomunikasi, termasuk Google, HTC, Intel, Motorola, Qualcomm, T-Mobile, dan Nvidia (Buulolo, E. 2013).
2.5 Penelitian yang relevan
Berikut ini beberapa penelitian yang terkait dengan Algoritma Knuth Morris Pratt dan Algoritma Boyer Moore :
1. Adli Abdillah Nababan (2015) dalam skripsi yang berjudul Implementasi Algoritma Brute Force dan Algoritma Knuth Morris Pratt (KMP) dalam
pencarian word suggestion Menyatakan bahwa algoritma Knuth Morris Pratt menyimpan sebuah informasi yang digunakan untuk melakukan jumlah pergeseran,sehingga algoritma ini melakukan pergeseran yang lebih baik. Dengan menggunakan Algoritma Knuth Morris Pratt pencarian dapat mempersingkat waktu (Nababan, A.A. 2015).
2. Mego Suntoro (2015) dalam skripsi yang berjudul Implementasi algoritma pecocokan string Boyer-moore dalam pembuatan contact manager Pada
platform android Menyatakan bahwa Algoritma Boyer Moore pergeseran Bad
Character paling baik digunakan dari pada pergeseran Good Suffix (Suntoro, M.
2015).
3. Ryan Dhika Priyatna (2015) dalam skripsi yang berjudul Implementasi Algoritma Levenshtein Distance dan Knuth Morris Pratt dalam fitur word
completion pada search engine Menyatakan bahwa penerapan algoritma Knuth
Morris Pratt dapat digunakan dengan baik karena dapat menemukan kata
dengan karakter per karakter sampai karakter dinyatakan cocok (Priyatna, R.D. 2015).
4. Teuku Ighfar Hajar (2015) dalam skripsi yang berjudul Implementasi Algoritma Levenshtein Distance dan Boyer Moore untuk fitur Autocomplete dan
Autocorrect pada aplikasi katalog perpustakaan daerah Aceh Timur
karena sifatnya efisien maka banyak dikembangkan algoritma string matching dengan bertumpu pada konsep algoritma Boyer Moore (Hajar, T.I. 2015). 5. Yohanes Silitonga (2015) dalam skripsi yang berjudul Implementasi Pembuatan
Kamus Bahasa Batak Toba-Indonesia-Inggris menggunakan Algoritma
Boyer-Moore pada Platform Android Menyatakan bahwa proses pencocokan String
![Tabel 2.1 Hasil Perhitungan kmpNext[i] dan shift[i]](https://thumb-ap.123doks.com/thumbv2/123dok/2047836.1195648/3.595.218.431.489.576/tabel-hasil-perhitungan-kmpnext-i-dan-shift-i.webp)