PEMODELAN PERSENTASE KEMISKINAN DI JAWA TIMUR DENGAN PENDEKATAN REGRESI NONPARAMETRIK ADITIF BERDASARKAN
ESTIMATOR PENALIZED SPLINE
SKRIPSI
CHETRIN WIDYOWATI
PROGRAM STUDI S-1 STATISTIKA DEPARTEMEN MATEMATIKA FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS AIRLANGGA SURABAYA
PEMODELAN PERSENTASE KEMISKINAN DI JAWA TIMUR DENGAN PENDEKATAN REGRESI NONPARAMETRIK ADITIF BERDASARKAN
ESTIMATOR PENALIZED SPLINE
SKRIPSI
CHETRIN WIDYOWATI
PROGRAM STUDI S-1 STATISTIKA DEPARTEMEN MATEMATIKA FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS AIRLANGGA SURABAYA
PEDOMAN PENGGUNAAN SKRIPSI
Skripsi ini tidak dipublikasikan, namun tersedia di perpustakaan dalam lingkungan Universitas Airlangga, diperkenankan untuk dipakai sebagai referensi kepustakaan, tetapi pengutipan harus seijin penulis dan harus menyebutkan sumbernya sesuai kebiasaan ilmiah. Dokumen skripsi ini merupakan hak milik Universitas Airlangga.
KATA PENGANTAR
Puji syukur kehadirat Allah SWT yang telah melimpahkan karunia-Nya sehingga penulis dapat menyelesaikan skripsi yang berjudul “Pemodelan Persentase Kemiskinan di Jawa Timur dengan Pendekatan Regresi Nonparametrik Aditif Berdasarkan Estimator Penalized Spline”. Adapun
maksud dari penyusunan skripsi ini adalah sebagai salah satu syarat untuk menyelesaikan tugas akhir.
Pada kesempatan ini, penulis menyampaikan ucapan terima kasih yang sebesar-besarnya kepada:
1. Kedua orang tua: Bapak Djoko Wahyudi dan Ibu Isti Gunawati, adik tersayang M. Danu Haryoyudanto yang telah menjadi penyemangat dan memberi dukungan serta selalu mendoakan penulis agar dilancarkan dalam proses pengerjaan proposal dan penyelesaian skripsi.
2. Badrus Zaman, S.Kom., M.Cs selaku Kepala Departemen Matematika Fakultas Sains dan Teknologi Universitas Airlangga dan Drs. Eko Tjahjono, M.Si, selaku Koordinator Program Studi S1 Statistika, Fakultas Sains dan Teknologi Universitas Airlangga.
3. Drs. Suliyanto, M.Si selaku dosen pembimbing I dan Drs. Sediono, M.Si selaku dosen pembimbing II yang senantiasa memberikan pengarahan dan bimbingan dari awal hingga terselesaikannya proposal dan skripsi.
5. Seluruh dosen statistika dan teman-teman statistika angkatan 2012 yang telah memberi semangat dan memberi dukungan.dalam proses belajar di program studi statistika di Universitas Airlangga.
6. Tentor skripsi penulis Trisna Irnanti yang telah memberi inspirasi dan pencerahan dalam penyusunan skripsi ini.
7. Sahabat terkasih Tsamrotul Masruroh, Darwati, dan Nur Azmi C.K. yang selalu mengiringi perjalanan penulis dengan setia mulai awal hingga akhir dalam menempuh pendidikan di statistika di Universitas Airlangga.
8. Serta pihak – pihak yang telah banyak membantu dalam pengerjaan skripsi ini yang tidak dapat penulis sebutkan satu persatu.
Penulis menyadari bahwa penyusunan skripsi ini jauh dari kesempurnaan. Karena itu, kritik dan saran dari semua pihak sangat penulis harapkan. Semoga skripsi ini bisa bermanfaat bagi pembaca pada umumnya dan penulis pada khususnya.
Surabaya, Juni 2016 Penulis,
Chetrin Widyowati, 2016. Pemodelan Persentase Kemiskinan di Jawa Timur dengan Pendekatan Regresi Nonparametrik Aditif Berdasarkan Estimator
Penalized Spline. Skripsi dibawah bimbingan Drs. Suliyanto, M.Si dan Drs. H.
Sediono, M.Si Program Studi S-1 Statistika, Departemen Matematika, Fakultas Sains dan Teknologi, Universitas Airlangga, Surabaya.
ABSTRAK
Kemiskinan merupakan persoalan mendasar dan menjadi perhatian serius oleh berbagai Negara di seluruh dunia. Negara Indonesia yang merupakan negara berkembang memiliki fokus untuk menurunkan kemiskinan salah satunya Provinsi Jawa Timur. Persentase penduduk miskin merupakan alat ukur untuk mengukur kemiskinan suatu wilayah. Penelitian ini menggunakan 6 faktor yang diduga mempengaruhi penduduk miskin di Jawa Timur yang meliputi angka melek huruf, tingkat pengangguran terbuka, laju pertumbuhan ekonomi, perkerja di sektor pertanian, rata-rata lama sekolah dan angka partisipasi sekolah. Metode yang digunakan untuk memodelkan persentase penduduk miskin adalah regresi nonparametrik penalized spline. Metode ini digunakan karena dapat mengontrol sifat smooth suatu kurva, sehingga kurva terhindar dari sifat rigid dan over-fitting. Metode penalized spline terbaik yang dihasilkan dari penelitian ini adalah model penalized spline dengan satu titik knot optimal. Penerapan model regresi nonparametrik aditif berdasarkan estimator penalized spline pada persentase penduduk miskin di Jawa Timur mempunyai MSE sebesar 7,371886 dan R-square 72,09%.
Chetrin Widyowati, 2016. Percentage Modeling of Poverty in Jawa Timur using Additive Nonparametric Regression based on Estimator Penalized Spline. Supervised by Drs. Suliyanto, M.Si and Drs. H. Sediono, M.Si. S-1 Statistic Study Program, Mathematic Department, Faculty of Sains and Technology, Airlangga University, Surabaya
ABSTRACT
Poverty is one of the basic problem and always been a major issue around the globe. Indonesia, one of the developing country in the world, have the goal to decrease the number of poverty especially in the province of Jawa Timur. One of the tools to measure poverty in an area is using the poverty percentage of that area population. This research use 6 factors that contribute to poverty in Jawa Timur which is, illiteracy, open unemployment, economic growth, agriculture worker, average education level, number of school participant. To model the percentage of impoverish people, this research are using regression nonparametric penalized spline. This method were used because this method can control the smoothness of the curve, so it prevent the models to have a rigid and overfitting structure. The best model penalized spline in this research is model penalized spline with one spot knot optimal. The result of application this model is that this model are suitable to make the model for the percentage of poverty in Jawa Timur with MSE of 7,371886 and R-square 72,09%.
DAFTAR ISI
Halaman
HALAMAN JUDUL ... i
LEMBAR PERNYATAAN ... ii
LEMBAR PENGESAHAN ... iii
PEDOMAN PENGGUNAAN SKRIPSI ... iv
SURAT PERNYATAAN TENTANG ORISINALITAS ... v
KATA PENGANTAR ... vi
ABSTRAK ... viii
ABSTRACT ... ix
DAFTAR ISI ... x
DAFTAR GAMBAR ... xiii
DAFTAR TABEL ... xv
DAFTAR LAMPIRAN ... xvi
BAB I PENDAHULUAN ... 1
1.1 Latar Belakang ... 1
1.2 Rumusan Masalah ... 5
1.3 Tujuan ... 6
1.4 Manfaat ... 6
1.5 Batasan Masalah ... 7
BAB II TINJAUAN PUSTAKA ... 8
2.2 Faktor-Faktor yang MempengaruhiKemiskinan ... 16
2.3 Matriks ... 20
2.4 Regresi Nonparametrik ... 21
2.5 Estimator Penalized Spline Multiprediktor ... 22
2.6 Pemilihan Parameter Penghalus (𝜆) Optimal ... 27
2.7 Pemilihan Jumlah Knot (𝑘) Optimal ... 27
2.8 Algoritma Back-Fitting ... 29
2.9 OSS-R ... 30
BAB III METODE PENELITIAN ... 34
3.1 Data dan Sumber Data ... 34
3.2 Variabel Penelitian ... 34
3.3 Langkah Analisis Data ... 35
BAB IV HASIL DAN PEMBAHASAN ... 43
4.1 Deskripsi Variabel Terikat Persentase Penduduk Miskin Kota atau Kabupaten di Jawa Timur ... 43
4.2 Estimasi Model Hubungan Persentase Penduduk Miskin pada Masing-Masing Variabel ... 50
4.3 Menginterpretasi Hasil Pemodelan Regresi Nonparametrik Aditif Persentase Penduduk Miskin di Jawa Timur ... 56
BAB V PENUTUP ... 67
5.1 Kesimpulan ... 67
DAFTAR GAMBAR
Nomor Judul Gambar Halaman
4.1
Diagram Batang Penduduk Miskin Tiap Kabupaten/Kota di Jawa Timur Tahun 2013
Scatter Plot 𝑌dengan 𝑋1
Miskin Berdasarkan Angka Melek Huruf
51
4.9 Plot antara 𝑌 dan 𝒇̂𝟐(𝑿𝟐) pada Data Persentase Penduduk
Miskin Berdasarkan Tingkat Pengangguran Terbuka
52
4.10 Plot antara 𝑌 dan 𝒇̂𝟑(𝑿𝟑) pada Data Persentase Penduduk
Miskin Berdasarkan Pekerja di Sektor Pertanian
53
4.11 Plot antara 𝑌 dan 𝒇̂𝟒(𝑿𝟒) pada Data Persentase Penduduk Miskin Berdasarkan Tingkat Pengangguran Terbuka
54
4.12 Plot antara 𝑌 dan 𝒇̂𝟓(𝑿𝟓) pada Data Persentase Penduduk Miskin Berdasarkan Tingkat Pengangguran Terbuka
55
4.14
Penduduk Miskin Hasil Estimasi
Plot antara Persentase Penduduk Miskin Jawa Timur dan Persentase Penduduk Miskin Nasional
DAFTAR TABEL
Nomor Judul Tabel Halaman
3.1 Variabel-Variabel Penelitian 34
4.1 Karakteristik Persentase Penduduk Miskin Kota/Kabupaten Provinsi Jawa Timur
43
4.2 Nilai KorelasiData Persentase Penduduk Miskin di Jawa Timur
49
DAFTAR LAMPIRAN
Nomor Judul Lampiran
1 Data Persentase Penduduk Miskin Kota/Kabupaten Provinsi Jawa Timur
2
3
4
5
6
7
8
Statistik Deskriptif Variabel Terkait Persentase Penduduk Miskin Kota/Kabupaten Jawa Timur
Diagram Batang Angka Melek Huruf (AMH) Tiap Kabupaten/Kota di Jawa Timur Tahun 2013
Diagram Batang Tingkat Pengangguran Terbuka (TPT) Tiap Kabupaten/Kota di Jawa Timur Tahun 2013
Diagram Batang Pekerja di Sektor Pertanian Tiap Kabupaten/Kota di Jawa Timur Tahun 2013
Diagram Batang Laju Pertumbuhan Ekonomi (LPE) Tiap Kabupaten/Kota di Jawa Timur Tahun 2013
Diagram Batang Rata-Rata Lama Sekolah (RLS) Tiap Kabupaten/Kota di Jawa Timur Tahun 2013
Diagram Batang Angka Partisipasi Sekolah (APS) Tiap Kabupaten/Kota di Jawa Timur Tahun 2013
9 Nilai Korelasi antara Persentase Penduduk Miskin dengan Masing-Masing Variabel Prediktor
11 Output Parameter Smoothing Optimum Masing-Masing Prediktor 12 Program Estimasi Model Regresi Nonparametrik Satu Prediktor 13 Output Estimasi Model Regresi Nonparametrik Satu Prediktor 14 Plot 𝑌 dan 𝒇̂ Masing-Masing Prediktor
15 Program Estimasi Model Regresi Nonparametrik Aditif 16
17
Output Estimasi Model Regresi Nonparametrik Aditif Plot 𝑌 dan 𝒇̂∗ Masing-Masing Prediktor
18 19
BAB I PENDAHULUAN
1.1Latar Belakang
Kemiskinan merupakan persoalan mendasar dan menjadi perhatian serius dari pemerintah. Jumlah penduduk yang banyak dengan sebagian besar penduduknya memiliki tingkat pendidikan yang rendah akan memicu adanya kesenjangan sosial dan terjadi kemiskinan. Masalah kemiskinan bukan hanya merupakan masalah nasional, melainkan sudah menjadi masalah global. Pada September 2000, Perserikatan Bangsa-Bangsa (PBB) telah mendeklarasikan sebuah kebijakan yaitu MDGs (Millenium Development Goals), dengan sasaran pertama dari MDGs tersebut adalah memberantas kemiskinan dan kelaparan ekstrem (United Nations, 2007).
Pulau Jawa dengan total 15,3 juta orang atau 10,92% dari total penduduk Jawa. Serta dalam bulan Maret 2011 - Maret 2012 Provinsi Jawa Timur dinobatkan sebagai provinsi yang memiliki jumlah penduduk miskin terbanyak kedua se-Indonesia oleh BPS. Provinsi Jawa Timur yang merupakan provinsi dengan jumlah penduduk terbesar setelah Provinsi Jawa Barat memiliki ketimpangan terhadap jumlah penduduk miskin. Ketimpangan tersebut terjadi baik di pedesaan maupun di perkotaan, terutama dengan penduduk berstrata ekonomi rendah serta memiliki pendidikan yang rendah (Wulandari, 2014).
berpengaruh signifikan terhadap kemiskinan adalah laju pertumbuhan ekonomi, persentase buta huruf, tingkat pengangguran terbuka, dan tingkat pendidikan SMP.
Penelitian mengenai kemiskinan tersebut mengindikasikan bahwa banyak sekali faktor yang mempengaruhi kemiskinan di suatu wilayah. Sehingga perlu dilakukan identifikasi faktor-faktor yang paling berpengaruh terhadap kemiskinan, agar dapat dipergunakan sebagai perencanaan pembangunan sehingga pembangunan lebih terarah pada pengentasan kemiskinan (Ayu dan Otok, 2014).
tersegmen inilah yang memberikan fleksibilitas lebih daripada polinomial biasa sehingga memungkinkan untuk menyesuaikan diri secara efektif terhadap karakteristik lokal dari fungsi atau data. Penalized Spline memiliki banyak kesamaan dengan smoothing spline hanya saja tipe penalty yang digunakan Penalized Spline lebih umum daripada penalty yang digunakan smoothing spline (Ruppert, 2002).
Estimator penalized spline dapat diperoleh dengan meminimumkan fungsi Penalized Least Square (PLS). Pada umumnya untuk mengestimasi kurva regresi nonparametrik dengan pendekatan spline dapat dilakukan dengan memilih parameter penghalus 𝜆 yang optimal atau memilih titik knot optimal (Budiantara, 2005). Titik knot pada penalized spline telah ditentukan, yaitu pada sampel kuantil dari nilai unique variabel prediktor {𝑥𝑖} yang ditetapkan, sehingga untuk mengestimasi kurva regresi nonparametrik penulis menggunakan penalized spline dan dapat dilakukan dengan pemilihan jumlah knot optimal dan parameter penghalus optimal (Ruppert, et.al, 2003).
Pemilihan jumlah knot digunakan algoritma back-fitting yang merupakan suatu algoritma umum yang cocok untuk setiap model regresi aditif (Hastie dan Tibbshirani, 1990), sedangkan untuk menentukan parameter penghalus optimal digunakan kriteria Generalized Cross Validation (GCV) minimum (Ruppert, et.al, 2003).
penduduk miskin di Provinsi Jawa Timur sebagai variabel respon sedangkan variabel prediktor berupa angka melek huruf, tingkat pengangguran terbuka, laju pertumbuhan ekonomi, pekerja di sektor pertanian, rata-rata lama sekolah dan angka partisipasi sekolah, hal ini mengacu pada penelitian-penelitian sebelumnya. Dalam pemodelan tersebut dibahas bagaimana mengestimasi model regresi aditif nonparametrik berdasarkan estimator Penalized Spline, membuat algoritma dan program pada software R untuk mengestimasi model regresi nonparametrik aditif, dan menerapkan program yang telah dibuat untuk memodelkan kemiskinan di Jawa Timur.
1.2Rumusan Masalah
Berdasarkan latar belakang yang telah dikemukakan, rumusan masalah yang akan dibahas pada penelitian ini adalah sebagai berikut.
1. Bagaimana mendeskripsikan variabel prediktor yang terkait dengan persentase kemiskinan di Jawa Timur?
2. Bagaimana memodelkan persentase kemiskinan di Jawa Timur dengan pendekatan regresi nonparametrik aditif berdasarkan estimator penalized spline?
1.3Tujuan
Berdasarkan permasalahan yang telah dirumuskan di atas, maka tujuan dari penelitian ini adalah sebagai berikut.
1. Mengetahui deskriptif variabel prediktor yang terkait dengan persentase kemiskinan di Jawa Timur.
2. Memperoleh model persentase kemiskinan di Jawa Timur dengan pendekatan regresi nonparametrik aditif berdasarkan estimator penalized spline.
3. Menganalisa dan menginterpretasi hasil pemodelan persentase kemiskinan di Jawa Timur dengan pendekatan regresi nonparametrik aditif berdasarkan estimator penalized spline?
1.4Manfaat
Manfaat yang ingin diperoleh dari penelitian ini adalah sebagai berikut. 1. Membuka wawasan keilmuan kepada penulis khususnya dan kepada
masyarakat pada umumnya tentang penggunaan regresi nonparametrik aditif dengan pendekatan Penalized Spline.
2. Memberikan pemahaman tentang model regresi nonparametrik dengan pendekatan penalized spline khususnya terhadap data kemiskinan di Jawa Timur.
1.5Batasan Masalah
BAB II
TINJAUAN PUSTAKA
Pada bab ini akan diuraikan beberapa tinjauan pustaka yang digunakan untuk mendukung penulisan skripsi ini.
2.1Kemiskinan
Persentase penduduk miskin adalah salah satu indikator kemiskinan yang memberikan makna persentase penduduk yang berada di bawah garis kemiskinan (BPS, 2014). BPS mengeluarkan dua jenis data kemiskinan, yaitu data kemiskinan makro dan data kemiskinan mikro.
suatu wilayah, maka data mikro mampu menyediakan informasi mengenai penduduk miskin sampai dengan nama dan alamat penduduk miskin tersebut (BPS, 2012).
Kemiskinan dapat dilihat dari dua sisi yaitu kemiskinan absolut dan kemiskinan relatif. Kemiskinan absolut dan kemiskinan relatif adalah konsep kemiskinan yang mengacu pada kepemilikan materi dikaitkan dengan standar kelayakan hidup seseoramg atau keluarga. Kedua istilah itu menunjuk pada perbedaan sosial (social distinction) yang ada dalam masyarakat di distribusi pendapatan. Perbedaannya adalah bahwa pada kemiskinan absolut ukurannya sudah terlebih dahulu ditentukan dengan angka-angka nyata (garis kemiskinan) dan indikator atau kriteria yang digunakan, sementara pada kemiskinan relatif kategori kemiskinan ditentukan berdasarkan perbandingan relatif tingkat kesejahteraan antar penduduk (Hendra, 2011).
2.1.1 Kemiskinan Absolut
kebutuhan dasarnya. Tingkat pendapatan minimum merupakan pembatas antara keadaaan miskin dengan tidak miskin.
Garis kemiskinan di Indonesia secara luas digunakan pertama kali dikenalkan oleh Sajogyo pada tahun 1964 yang diukur berdasarkan konsumsi setara beras per tahun. Menurut Sajogyo terdapat tiga ukuran garis kemiskinan yaitu miskin, sangat miskin, dan melarat yang diukur berdasarkan konsumsi kapita per tahun setara beras sebanyak 480 kg, 360 kg dan 270 kg untuk daerah perkotaan dan 320 kg, 240 kg dan 180 kg untuk daerah pedesaan (Rahmawati, 2014).
BPS menghitung jumlah dan persentase penduduk miskin (head count index) yaitu penduduk yang hidup dibawah garis kemiskinan berdasarkan data hasil Survei Sosial Ekonomi Nasional (Susenas). Garis kemiskinan yang merupakan dasar penghitungan jumlah penduduk miskin dihitung dengan menggunakan pendekatan kebutuhan dasar (basic needs approach) yaitu besarnya rupiah yang dibutuhkan untuk memenuhi kebutuhan dasar minimum makanan dan non makanan atau lebih dikenal dengan garis kemiskinan makanan dan non makanan.
makanan terpilih hasil Susenas modul konsumsi. Sedangkan garis kemiskinan non makanan adalah nilai rupiah dari 27 sub kelompok pengeluaran yang terdiri atas 51 jenis komoditi dasar non makanan di perkotaan dan 47 jenis komoditi di pedesaan.
Dapat disimpulkan secara umum bahwa kemiskinan absolut adalah kondisi kemiskinan yang terburuk yang diukur dari tingkat kemampuan suatu keluarga dalam membiayai kebutuhan yang paling minimal untuk dapat hidup sesuai dengan taraf hidup kemanusiaan yang paling rendah.
2.1.2 Kemiskinan Relatif
Kemiskinan relatif pada dasarnya menunjuk pada perbedaan relatif tingkat kesejahteraan antar kelompok masyarakat. Mereka yang berada dilapis terbawah dalam persentil derajat kemiskinan suatu masyarakat di golongkan sebagai penduduk miskin. Dalam kategori ini, dapat saja mereka yang digolongkan sebagai miskin sebenarnya sudah dapat mencukupi hak dasarnya, namun tingkat keterpenuhannya berada di lapisan terbawah.
Dalam hal mengidentifikasi dan menentukan sasaran penduduk miskin, maka garis kemiskinan relatif cukup untuk digunakan dan perlu disesuaikan terhadap tingkat pembangunan negara secara keseluruhan. Garis kemiskinan relatif tidak dapat dipakai untuk membandingkan tingkat kemiskinan antar negara dan waktu karena tidak mencerminkan tingkat kesejahteraan yang sama.
World Bank mengelompokkan penduduk ke dalam tiga kelompok sesuai dengan besarnya pendapatan: 40 persen penduduk dengan pendapatan rendah, 40 persen penduduk dengan pendapatan menengah dan 20 persen penduduk dengan pendapatan tinggi. Ketimpangan pendapatan diukur dengan menghitung persentase jumlah pendapatan penduduk dari kelompok yang berpendapatan 40 persen terendah dibandingkan total pendapatan seluruh penduduk.
Kategori ketimpangan ditentukan dengan menggunakan kriteria seperti berikut:
Jika proporsi jumlah pendapatan dari penduduk yang masuk kategori 40 persen terendah terhadap total pendapatan seluruh penduduk kurang dari 12 persen dikategorikan ketimpangan pendapatan tinggi.
Jika proporsi jumlah pendapatan dari penduduk yang masuk kategori 40 persen terendah terhadap total pendapatan seluruh penduduk antara 12-17 persen dikategorikan ketimpangan pendapatan sedang.
2.1.3 Ukuran Kemiskinan
Untuk mengetahui jumlah penduduk miskin, sebaran dan kondisi kemiskinan diperlukan pengukuran kemiskinan yang tepat sehingga upaya untuk mengurangi kemiskinan melalui berbagai kebijakan dan program pengurangan kemiskinan akan efektif. Pengukuran kemiskinan yang dapat dipercaya menjadi instrumen yang tangguh bagi pengambil kebijakan dalam memfokuskan perhatian pada kondisi hidup orang miskin. Pengukuran kemiskinan yang baik akan memungkinkan dalam melakukan evaluasi dampak dari pelaksanaan proyek, membandingkan kemiskinan antar waktu dan menentukan target penduduk miskin dengan tujuan untuk menguranginya (World Bank, Introduction to Poverty Analysis, 2005).
Metode penghitungan penduduk miskin yang dilakukan BPS sejak pertama kali hingga saat ini menggunakan pendekatan yang sama yaitu pendekatan kebutuhan dasar (basic need approach). Dengan pendekatan ini, kemiskinan didefinisikan sebagai ketidakmampuan dalam memenuhi kebutuhan dasar. Dengan kata lain, kemiskinan dipandang sebagai ketidakmampuan dari sisi ekonomi untuk memenuhi kebutuhan makanan maupun non makanan yang bersifat mendasar. Berdasarkan pendekatan ini indikator yang digunakan adalah Head Countu Index (HCI) yaitu jumlah dan persentase penduduk miskin yang berada di bawah garis kemiskinan (poverty line).
Selain head count index (P0) terdapat juga indikator lain yang digunakan
index) atau P2 yang dirumuskan oleh Foster-Greer-Thorbecke (Tambunan, 2001). Metode penghitungan ini merupakan dasar penghitungan persentase penduduk miskin untuk seluruh kabupaten/kota.
Rumus yang digunakan adalah:
𝑃𝑎 = 𝑁 ∑ (1 𝑍 − 𝑌𝑍 )𝑖 𝑎 𝑞
𝑖=1
dengan 𝑍 adalah garis kemiskinan, 𝑌𝑖 adalah rata-rata pengeluaran per kapita
penduduk yang berada dibawah garis kemiskinan, 𝑞 adalah banyak penduduk yang berada dibawah garis kemiskinan, 𝑁 adalah jumlah penduduk, dan 𝛼 = 0, 1, 2
𝛼 = 0 ; poverty head count index (P0)
𝛼 = 1 ; poverty gap index (P1)
𝛼 = 2 ; poverty distributionally sensitive index (P2)
Head count index (P0) merupakan jumlah persentase penduduk yang berada dibawah garis kemiskinan. Semakin kecil angka ini menunjukkan semakin berkurangnya jumlah penduduk yang berada dibawah garis kemiskinan. Demikian juga sebaliknya, bila angka P0 besar maka menunjukkan tingginya jumlah persentase penduduk yang berada dibawah garis kemiskinan.
kemiskinan. Semakin tinggi angka ini maka semakin besar kesenjangan pengeluaran penduduk miskin terhadap garis kemiskinan atau dengan kata lain semakin tinggi nilai indeks menunjukkan kehidupan ekonomi penduduk semakin terpuruk.
Distributionally Sensitive Index (P2) memberikan gambaran mengenai penyebaran pengeluaran diantara penduduk miskin. Angka ini memperlihatkan sensitivitas distribusi pendapatan antar kelompok miskin. Semakin kecil angka ini menunjukkan distribusi pendapatan diantara penduduk miskin semakin merata.
Masalah kemiskinan merupakan salah satu persoalan yang mendasar yang menjadi pusat perhatian pemerintah di negara manapun. Salah satu aspek penting untuk mendukung Strategi Penangggulangan Kemiskinan adalah tersedianya data kemiskinan yang akurat dan tepat sasaran. Pengukuran kemiskinan yang dapat dipercaya dapat menjadi instrumen tangguh bagi pengambil kebijakan dalam memfokuskan perhatian pada kondisi hidup orang miskin. Data kemiskinan yang pbaik dapat digunakan untuk mengevaluasi kebijakan pemerintah terhadap kemiskinan, membandingkan kemiskinan antar waktu dan daerah, serta menentukan target penduduk miskin dengan tujuan untuk memperbaiki kondisi mereka (BPS, 2013).
2.2Faktor-Faktor yang Mempengaruhi Kemiskinan
Berbagai penelitian telah banyak dilakukan untuk mengetahui penyebab dan faktor-faktor yang terkait dengan kemiskinan diantaranya:
2.2.1 Angka Melek Huruf
Angka melek huruf dapat mencerminkan potensi perkembangan intelektual sekaligus kontribusi terhadap pembangunan daerah. Angka melek huruf di dapat dengan membagi jumlah penduduk usia 15 tahun ke atas yang dapat membaca dan menulis dengan jumlah penduduk usia 15 tahun ke atas kemudian hasilnya dikalikan dengan seratus (BPS, 2012). Melek huruf yang dimaksudkan disini adalah melek huruf latin, atau huruf arab, atau haruf lainnya (BPS, 2013).
Menurut penelitian Hadliroh (2014) faktor yang paling mempengaruhi kemiskinan di Provinsi Jawa Timur Tahun 2000-2013 adalah pendidikan. Hubungan antara kemiskinan dan pendidikan sangat penting, karena pendidikan (menurunnya persentase buta huruf) sangat mempengaruhi kemiskinan. Orang yang berpendidikan lebih baik akan mempunyai peluang yang lebih kecil menjadi miskin. Menurut Surwati (2005) keterkaitan kemiskinan dan pendidikan sangat besar karena pendidikan memberikan kemampuan untuk berkembang lewat penguasaan ilmu dan keterampilan (BPS, 2011).
2.2.2 Tingkat Pengangguran
diwujudkan. Turunnya tingkat kesejahteraan masyarakat karena menganggur akan meningkatkan peluang masyarakat dalam kemiskinan. Selain pertumbuhan ekonomi, kinerja pembangunan dapat diketahui dari seberapa efektif pembangunan tersebut dapat menyerap angkatan kerja yang tersedia sehingga mengurangi pengangguran dan selanjutnya akan menurunkan tingkat kemiskinan.
Dibandingkan dengan tingkat pengangguran terbuka (TPT) nasional, TPT Provinsi Jawa Timur termasuk rendah. Persentase penduduk miskin di Provinsi Jawa Timur cenderung menurun selama periode 2006-2013. Namun demikian secara nasional tingkat kemiskinan di Provinsi Jawa Timur masih tergolong cukup tinggi (BPS, 2014).
Islam (2003) melakukan penelitian di 23 negara berkembang dan menyimpulkan bahwa kemiskinan dapat berkurang seiring dengan peningkatan pendidikan (menurunnya persentase buta huruf) dan peningkatan persentase tenaga kerja di sektor industri.
2.2.3 Pekerja di Sektor Pertanian
2.2.4 Laju Pertumbuhan Ekonomi
Bank Dunia dalam Laporan Monitoring Global tahun 2005 menjelaskan bahwa pertumbuhan ekonomi berperan penting dalam upaya menurunkan kemiskinan dan mencapai tujuan pembangunan global. Dapat dikatakan bahwa pengurangan penduduk miskin tidak mungkin dilakukan apabila ekonomi tidak berkembang. Pertumbuhan ekonomi adalah syarat utama dalam mengatasi persoalan kemiskinan (World Bank, 2005). Pertumbuhan ekonomi yang terjadi dapat mendorong pengurangan kemiskinan secara lebih cepat (BPS, 2014).
2.2.5 Rata-Rata Lama Sekolah
Rata-rata lama sekolah menggambarkan jumlah tahun yang digunakan oleh penduduk usia 15 tahun ke atas dalam menjalani pendidikan formal. Perhitungan rata-rata lama sekolah menggunakan dua batasan yang dipakai sesuai kesepakatan beberapa negara. Rata-rata lama sekolah memiliki batas maksimumnya 15 tahun dan batas minimumnya 0 tahun. Hubungan antara kemiskinan dan pendidikan sangat penting, karena pendidikan sangat berperan dalam mempengaruhi angka kemiskinan. Orang yang berpendidikan lebih baik dan memiliki pendidikan yang lebih tinggi akan mempunyai peluang yang rendah menjadi miskin (BPS, 2014).
pendidikan lebih tinggi, diukur dengan lamanya waktu untuk sekolah akan memiliki pekerjaan dan upah yang lebih baik dibanding dengan orang yang pendidikannya rendah.
2.2.6 Angka Partisipasi Sekolah
Angka partisipasi sekolah adalah proporsi dari semua anak yang masih sekolah pada suatu kelompok tertentu terhadap penduduk dengan kelompok tertentu. APS merupakan indikator penting dalam pendidikan yang menunjukkan persentase penduduk usia 7-12 tahun yang masih terlibat dalam sistem persekolahan. Adakalanya penduduk usia 7-12 tahun belum sama sekali menikmati pendidikan, tetapi ada sebagian kecil dari kelompok mereka yang sudah menyelesaikan jenjang pendidikan setingkat sekolah dasar (BPS, 2014).
2.3Matriks
Matriks adalah susunan bilangan atau fungsi yang diletakkan atas baris dan kolom serta diapit oleh dua kurung siku. Bilangan atau fungsi tersebut disebut entri atau elemen matriks. Matriks dilambangkan dengan huruf besar, sedangkan elemen matriks dilambangkan dengan huruf kecil, mempunyai 𝑛 baris dan 𝑝
kolom. Secara umum sebuah matriks dapat ditulis dengan bentuk:
𝑨(𝑛 × 𝑝) = [
𝑎11 𝑎12 𝑎21 𝑎22
⋮
𝑎𝑛1 𝑎𝑛2⋮
… 𝑎1𝑝 … 𝑎2𝑝
… ⋮ 𝑎𝑛𝑝
]
(Rencher dan Schaalje, 2008) Beberapa sifat-sifat matriks adalah sebagai berikut:
1. Tranpose dari matriks 𝑨 didefinisikan sebagai 𝑨𝑻, maka (𝑨𝒀)𝑻 = 𝒀𝑻𝑨𝑻
2. Invers dari matriks 𝑨 didefinisikan sebagai 𝑨−𝟏, maka (𝑨𝒀)−𝟏 = 𝒀−𝟏𝑨−𝟏
3. Jika 𝑨 adalah matriks nonsingular, maka 𝑨𝑻 adalah nonsingular, dan
(𝑨𝑻)−𝟏= (𝑨−𝟏)𝑻
Definisi Trace
Jika 𝑨 matriks berukuran 𝑛 × 𝑛 maka trace dari 𝑨 dilambangkan dengan berukuran 𝑡𝑟(𝑨) adalah
𝑡𝑟(𝑨 ) = ∑𝑛𝑖=1𝑎𝑖𝑖 (2.1)
2.4Regresi Nonparametrik
Regresi nonparametrik merupakan suatu metode statistika yang digunakan untuk mengetahui hubungan antara variabel respon dan prediktor, jika bentuk hubungan antara variabel respon dan prediktor tidak diketahui atau tidak didapatkan informasi sebelumnya. Misalkan 𝑦 adalah variabel respon dan 𝑥
adalah variabel prediktor untuk 𝑛 pengamatan, maka hubungan antara variabel-variabel tersebut dapat dinyatakan sebagai
𝑦𝑖 = 𝑓(𝑥𝑖) + 𝜀𝑖, 𝑖 = 1,2, … , 𝑛 (2.2)
dengan 𝜀𝑖 adalah error random yang diasumsikan independen dengan
mean nol dan masing-masing variannya 𝜎2 dan 𝑓(𝑥𝑖) merupakan fungsi regresi
yang tidak diketahui bentuknya. Fungsi regresi 𝑓 diasumsikan mulus (smooth) sehingga lebih menjamin fleksibilitas dalam mengestimasi fungsi regresinya.
(Eubank, 1999) Model aditif mempunyai variabel respon 𝑦 yang bergantung pada penjumlahan beberapa fungsi dari variabel prediktor 𝑥, maka model aditifnya berbentuk:
𝑦𝑖 = ∑𝑑𝑗=1𝑓𝑗(𝑥𝑗𝑖) + 𝜀𝑖 (2.3)
dengan 𝜀𝑖 adalah error random yang diasumsikan berdistribusi identik dan
independen dengan mean nol dan variansi 𝜎2.
2.5Estimator Penalized Spline Multiprediktor
yang tidak diketahui bentuknya akan diestimasi dengan menggunakan pendekatan estimator penalized spline.
Dalam estimator penalized spline, bentuk estimasi fungsi regresi 𝑓𝑗 diperoleh dengan suatu pendekatan
𝑓𝑗 (𝑥𝑗𝑖) = ∑𝑝ℎ=0𝑗+𝑘𝑗𝛽𝑗ℎ𝜙ℎ(𝑥𝑗𝑖) ; 𝑖 = 1, … , 𝑛 𝑗 = 1, … , 𝑑
Didefinisikan matriks 𝑿𝒋 adalah
Fungsi penalized spline untuk 𝑛 pengamatan dapat dituliskan dalam bentuk matriks sebagai berikut:
Fungsi kriteria pendugaan yang menggabungkan kedua ukuran tersebut dinamakan PLS (Penalized Least Square). Nilai 𝜷𝒋 pada persamaan (2.7) diperoleh dengan meminimumkan fungsi PLS dari variabel prediktor 𝑥𝑗 sebagai
berikut:
dengan 𝜆𝑗 adalah suatu parameter penghalus prediktor 𝑥𝑗. Untuk meminimumkan
1
Diketahui matriks 𝑫𝒋 adalah suatu matriks diagonal sebagai berikut:
𝑫𝒋= [… … …𝟎 ⋮ 𝟎
𝟎 ⋮ 𝐈] (2.11)
I adalah matriks identitas untuk
𝛽(𝒑𝒋+𝟏)(𝒑𝒋+𝟏), 𝛽(𝒑𝒋+𝟐)(𝒑𝒋+𝟐), 𝛽(𝒑𝒋+𝟑)(𝒑𝒋+𝟑), … , 𝛽(𝒑𝒋+𝒌𝒋+𝟏)(𝒑𝒋+𝒌𝒋+𝟏)
Subtitusikan persamaan (2.14) pada persamaan (2.7) sehingga diperoleh fungsi penalized spline dari variabel prediktor 𝑥𝑗 adalah
𝒇̂𝒋(𝑿𝒋) = 𝑿𝒋(𝑿𝒋𝑻𝑿𝒋+ 𝑛𝜆𝑗𝑫𝒋)−𝟏𝑿𝒋𝑻𝒀 (2.15)
Estimasi fungsi penalized spline dari variabel prediktor 𝑥𝑗 pada persamaan (2.15) dapat dinyatakan sebagai:
𝒇̂𝒋(𝑿𝒋) = 𝑯(𝜆𝑗)𝒀 (2.16)
dengan
𝑯(𝜆𝑗) = 𝑿𝒋(𝑿𝒋𝑻𝑿𝒋+ 𝑛𝜆𝑗𝑫𝒋)−𝟏𝑿𝒋𝑻 (2.17)
Selanjutnya dalam regresi nonparametrik multiprediktor yang dilakukan adalah menentukan fungsi penghalus dari masing-masing prediktor dengan meminimumkan fungsi sebagai berikut :
𝑆 =𝑛1∑ (𝑦𝑖𝑖=1𝑛 − ∑𝑑𝑗=1𝑓𝑗(𝑥𝑗𝑖))2+ ∑ (𝜆𝑗∑ 𝛽𝑗(𝑝2 𝑗+ℎ) 𝑘𝑗
ℎ=1 )
𝑑
𝑗=1 (2.18)
Untuk meminimumkan fungsi pada persamaan (2.18) dapat dilakukan dengan langkah mengubah komponen least square dalam bentuk matriks :
1
Matriks yang diperoleh dengan menggabungkan persamaan (2.12) dan (2.19)
𝑄 =𝑛 (𝒀1 𝑻𝒀 − 2 ∑(𝜷
Kemudian menurunkan fungsi 𝑄 terhadap 𝜷𝒋 untuk mendapatkan 𝜷̃𝒋 𝜕𝑄𝑗
Berdasarkan persamaan (2.16) maka persamaan (2.21) dapat dituliskan sebagai :
𝒇̂𝒋(𝑿𝒋) = 𝑯(𝜆𝑗)(𝒀 − ∑𝒉≠𝒋𝑿𝒉𝜷𝒉) (2.22)
Fungsi 𝒇̂𝒋 pada persamaan (2.22) kemudian digunakan untuk melakukan iterasi
hingga didapatkan jumlah kuadrat residual yang konvergen.
2.6Pemilihan Parameter Penghalus (𝜆) Optimal
Parameter 𝜆 merupakan pengontrol keseimbangan antara kemulusan fungsi dan kesesuaian fungsi terhadap data. Jika 𝜆 besar maka estimasi fungsi yang diperoleh akan semakin mulus, sedangkan jika 𝜆 kecil maka estimasi fungsi yang diperoleh akan semakin besar atau fungsi-fungsi menjadi semakin fluktuatif. Oleh karena itu, dalam memilih nilai 𝜆 diharapkan nilainya optimal. Pemilihan 𝜆
optimal sangat penting, agar estimator yang diperoleh juga optimal.
Salah satu metode untuk mendapatkan 𝜆 optimal adalah dengan menggunakan metode Generalized Cross Validation (GCV) yang didefinisikan sebagai berikut:
𝐺𝐶𝑉(λ) = 𝑀𝑆𝐸(𝜆)
(𝑛1𝑡𝑟[𝐼−𝐻(𝜆)])2 (2.23)
dengan
𝑀𝑆𝐸(𝜆) = 𝑛−1∑ (𝑦𝑖 − 𝑓̂ 𝜆𝑖)2 𝑛
𝑖=1 (2.24)
(Eubank, 1988)
2.7Pemilihan Jumlah Knot (𝑘) Optimal
Jumlah knot merupakan banyaknya titik knot atau banyaknya titik dimana terjadi perubahan perilaku fungsi pada interval yang berlainan. Dalam penalized spline, knot terletak pada sampel kuantil dari nilai unique (tunggal) variabel independen {𝑥𝑖}𝑖=1𝑛 . Dengan kata lain, titik knot pada penalized spline terletak
pada nilai-nilai tunggal variabel independen {𝑥𝑖}𝑖=1𝑛 yang membagi segugus
jumlah knot sangat berpengaruh dalam menentukan titik knot pada penalized spline.
Algoritma yang digunakan penulis untuk memilih jumlah knot (𝑘) optimal adalah algoritma Full-Seacrh. Dalam algoritma Full-Seacrh, jumlah knot yang akan dihitung tidak dipilih, melainkan dihitung semua yaitu 1,2,3,4,5,… untuk
𝑘 < (𝑛𝑢𝑛𝑖𝑞− 𝑝 − 1), dengan 𝑛𝑢𝑛𝑖𝑞adalah banyaknya nilai unique dari variabel
independen {𝑥𝑖}𝑖=1𝑛 , sehingga jumlah knot (𝑘) kurang dari jumlah pengamatan.
Langkah-langkah dalam Algoritma Full-Search adalah sebagai berikut:
1. Membandingkan nilai GCV(𝜆) untuk 𝑘 = 1 dan 𝑘 = 2 untuk masing-masing parameter penghalus (𝜆) yang meminimumkan nilai GCV
a. Apabila nilai GCV(𝜆) pada 𝑘 = 2 lebih besar 0.98 kali dari pada nilai GCV(𝜆) pada 𝑘 = 1 (𝐺𝐶𝑉(𝜆; 𝑘 = 2) > 0.98 ∗ 𝐺𝐶𝑉(𝜆; 𝑘 = 1)) maka algoritma akan berhenti, dengan memilih jumlah knot (𝑘) antara 𝑘 = 1
dan 𝑘 = 2 yang memiliki nilai GCV(𝜆) paling kecil.
b. Apabila nilai GCV(𝜆) pada 𝑘 = 2 sama atau lebih kecil 0.98 kali dari pada nilai GCV(𝜆) pada 𝑘 = 1(𝐺𝐶𝑉(𝜆; 𝑘 = 2) ≤ 0.98 ∗ 𝐺𝐶𝑉(𝜆; 𝑘 = 1)) maka algoritma akan dilanjutkan dengan membandingkan nilai GCV(𝜆) untuk 𝑘 = 2 dan 𝑘 = 3.
2. Membandingkan nilai GCV(𝜆) untuk 𝑘 = 2 dan 𝑘 = 3 untuk masing-masing parameter penghalus (𝜆) yang meminimumkan nilai GCV
algoritma akan berhenti, dengan memilih jumlah knot (𝑘) antara 𝑘 = 2
dan 𝑘 = 3 yang memiliki nilai GCV(𝜆) paling kecil.
b. Apabila nilai GCV(𝜆) pada 𝑘 = 3 sama atau lebih kecil 0.98 kali dari pada nilai GCV(𝜆) pada 𝑘 = 2(𝐺𝐶𝑉(𝜆; 𝑘 = 3) ≤ 0.98 ∗ 𝐺𝐶𝑉(𝜆; 𝑘 = 2)) maka algoritma akan dilanjutkan dengan membandingkan nilai GCV(𝜆) untuk 𝑘 = 3 dan 𝑘 = 4.
3. Membandingkan nilai GCV(𝜆) untuk 𝑘 = 3 dan 𝑘 = 4 untuk masing-masing parameter penghalus (𝜆) yang meminimumkan nilai GCV, dapat dilakukan dengan cara yang sama seperti di atas, dan seterusnya.
(Ruppert, 2002) 2.8Algoritma Back-Fitting
Algoritma back-fitting merupakan algoritma umum yang cocok untuk setiap model regresi aditif. Langkah-langkah pada algoritma back-fitting yaitu
1. Mendefinisikan nilai awal 𝑓10, 𝑓20, … , 𝑓𝑑0 pada saat 𝑚 = 0, yang diperoleh
dari estimasi 𝑓 pada masing-masing prediktor. 2. Iterasi :
Untuk 𝑗 = 1 sampai 𝑑 maka: a. Menghitung residual parsial
𝑹𝒋(𝒎+𝟏) = 𝒀 − ∑ℎ=1𝑗−1𝒇𝒉(𝒎)(𝑋ℎ) − ∑𝑑ℎ=𝑗+1𝒇𝒉(𝒎)(𝑋ℎ) (2.25)
b. Menghitung fungsi-fungsi dalam model penghalusan
𝒇𝒋(𝒎+𝟏)(𝑿𝒋) = 𝑯(𝜆)𝑗𝑹𝒋(𝒎+𝟏) (2.26)
𝑅𝑆𝑆𝑚+1= 1
𝑛(𝒀 − ∑𝑑𝑗=1𝒇𝒋(𝒎+𝟏)(𝑿𝒋)) 𝑻
(𝒀 − ∑𝑑𝑗=1𝒇𝒋(𝒎+𝟏)(𝑿𝒋))
(2.27)
3. Iterasi berhenti jika nilai RSS sudah konvergen.
(Hastie dan Tibshirani, 1990)
2.9 OSS- R
R adalah salah satu paket analisis data open source yang dapat diperoleh secara cuma-cuma di situs http://www.r-project.org/. atau http://cran.r-project.org/. R merupakan paket pemrograman yang termasuk keluarga S (bahasa S). Paket program R ini sudah dilengkapi dengan banyak kemampuan internal untuk menganalisis data dan menampilkan grafik sehingga R bisa dikategorikan sebagai paket pengolahan data (paket statistika). Beberapa kemampuan yang menonjol dari R yang menjadi alasan banyak statistisi memilihnya sebagai paket aplikasi antara lain sebagai berikut (Tirta, 2008):
1. R memiliki koleksi program analisis data, yang disebut library atau pustaka yang sangat luas seperti statistika deskriptif, regresi, pemodelan statistika (baik linear maupun nonlinear), anova dan multivariat.
2. Variasi penampilan grafiknya sangat banyak dan berkualitas tinggi, baik penampilan di layar monitor maupun dalam bentuk cetak di atas kertas. 3. Kemampuan pemrograman (bahasa S) dapat dikembangkan secara
fleksibel untuk kepentingan khusus yang lebih lanjut.
di kemudian hari maka R dapat mengambilnya tanpa harus melakukan perhitungan ulang dari awal.
Beberapa perintah internal yang digunakan dalam R adalah sebagai berikut: a. function( )
merupakan perintah untuk menunjukkan fungsi yang akan digunakan dalam program.
Bentuknya: function(...) b. length( )
merupakan perintah untuk menunjukkan banyaknya data. Bentuknya: length(...)
c. rep(a,b)
merupakan perintah untuk membentuk sebuah vektor yang anggotanya a sebanyak b.
Bentuknya: rep(...,...) d. matrix(a,b,c)
merupakan perintah untuk membentuk sebuah matriks yang anggotanya a dengan jumlah baris sebanyak b dan jumlah kolom sebanyak c.
Bentuknya: matrix(...,...,...) e. cat( )
merupakan perintah untuk menuliskan argumentasi dalam bentuk karakter dan kemudian mencetak hasil atau file yang telah ditetapkan. Bentuknya: cat(“...”)
merupakan perintah untuk mengulang satu blok pernyataan berulang kali sesuai dengan kondisi yang telah ditentukan.
Bentuknya: for(kondisi){pernyataan} g. sum( )
merupakan perintah untuk menjumlahkan semua bilangan anggota dari suatu vektor.
Bentuknya: sum(...) h. win.graph( )
merupakan perintah awal dalam membuat gambar. Bentuknya: win.graph( )
i. plot( )
merupakan perintah untuk membuat plot atau grafik. Bentuknya: plot(x, y, ...)
j. if-else
merupakan perintah untuk menjalankan pernyataan pertama jika kondisi benar dan pernyataan kedua akan dieksekusi jika kondisi bernilai salah. Bentuknya: if(kondisi)
pernyataan pertama else pernyataan kedua k. while
{ pernyataan }
l. repeat
merupakan perintah untuk mengulangi eksekusi pernyataan secara terus menerus, sehingga diperlukan pernyataan lain untuk menghentikan perulangan eksekusi.
Bentuknya: repeat
BAB III
METODE PENELITIAN
3.1Data dan Sumber Data
Penelitian ini menggunakan data sekunder tahun 2013 yang diperoleh dari publikasi BPS Provinsi Jawa Timur berdasarkan hasil survei sosial ekonomi nasional (SUSENAS) dengan unit observasi adalah seluruh Kabupaten/Kota yaitu sebanyak 38 Kabupaten/Kota di Provinsi Jawa Timur.
3.2Variabel Penelitian
Berdasarkan pada latar belakang dan tujuan penelitian, terdapat satu variabel respon dan lima variabel prediktor yang digunakan. Variabel-variabel tersebut dapat diuraikan dalam Tabel 3.1
Tabel 3.1 Variabel-Variabel Penelitian
Variabel Keterangan Variabel Tipe Data
Respon
Y Persentase Penduduk Miskin Kontinu Prediktor
𝑋1 AMH = Angka Melek Huruf Kontinu
𝑋2 TPT = Tingkat Pengangguran Terbuka Kontinu
𝑋3 Pekerja di sektor pertanian Kontinu
𝑋4 LPE = Laju Pertumbuhan Ekonomi Kontinu
𝑋5 RLS = Rata-rata Lama Sekolah Kontinu
3.3Langkah Analisis Data
Untuk menjawab tujuan penelitian akan dilakukan langkah analisis data adalah sebagai berikut:
1. Mendeskripsikan masing-masing variabel prediktor yang terkait dengan kemiskinan di Jawa Timur dilakukan dengan langkah-langkah sebagai berikut:
a. Membuat statistika deskriptif dari masing-masing variabel prediktor untuk mengetahui karakteristik masing-masing kabupaten/kota di Jawa Timur meliputi nilai maksimum, nilai maksimum, rata-rata, dan variansi dari masing-masing variabel prediktor untuk mengetahui karakteristik kota/kabupaten di Jawa Timur.
b. Membuat scatter plot antara variabel respon (𝑌) dengan masing-masing variabel prediktor.
2. Memodelkan kemiskinan di Jawa Timur menggunakan regresi nonparametrik aditif berdasarkan estimator penalized spline, terdapat tiga tahapan yaitu: Tahap 1
Algoritma program untuk menentukan nilai estimasi dari 𝒇𝒋(𝑿𝒋) untuk
masing-masing prediktor berdasarkan estimator penalized spline adalah:
1. Menentukan orde polinomial, jumlah knot, dan parameter penghalus optimal dengan kriteria GCV, dengan langkah-langkah sebagai berikut:
a. Menginputkan data variabel respon (𝑌) dan variabel prediktor (𝑥𝑗),
b. Menentukan orde polinomial (𝑝𝑗), jumlah knot (𝑘𝑗), batas bawah 𝜆𝑗, batas
atas 𝜆𝑗, dan nilai parameter penghalus (𝜆𝑗).
c. Menentukan titik knot dengan langkah-langkah sebagai berikut:
1) Mendefinisikan prediktor baru yang berisi nilai unique dari prediktor 𝑥𝑗, kemudian diurutkan dari nilai terkecil sampai
terbesar.
2) Menentukan sampel kuantil dari prediktor baru sebagai titik knot, berdasarkan jumlah knot (𝑘𝑗) dengan membagi prediktor baru
sebanyak 𝑘𝑗 + 1 bagian.
d. Mendefinisikan 𝑿𝒋 berdasarkan persamaan (2.6).
e. Mendefinisikan matriks 𝑫𝒋 berdasarkan persamaan (2.11). f. Menghitung nilai 𝜷̂𝒋 berdasarkan persamaan (2.14).
g. Menghitung nilai 𝒇̂𝒋(𝑿𝒋) berdasarkan persamaan (2.15).
h. Menghitung matriks 𝑯(𝜆𝑗) berdasarkan persamaan (2.17). i. Menghitung nilai MSE berdasarkan persamaan (2.24). j. Menghitung nilai GCV berdasarkan persamaan (2.23).
k. Ulangi langkah b sampai dengan didapatkan nilai GCV minimum. Orde polinomial, jumlah knot, dan parameter penghalus yang bersesuaian dengan nilai GCV minimum adalah yang optimal.
2. Mendefinisikan matriks 𝑿𝒋 dengan memasukkan titik knot dan orde polinomial
3. Menghitung nilai 𝜷̂𝒋 dengan memasukkan nilai parameter penghalus optimal
berdasarkan persamaan (2.14).
4. Menghitung 𝒇̂𝒋(𝑿𝒋) berdasarkan persamaan (2.15).
Tahap 2
Menggunakan algoritma back fitting untuk mengestimasi fungsi regresi nonparametrik multiprediktor berdasarkan estimator penalized spline sebagai berikut :
1. Menginputkan data variabel respon (𝑌) dan variabel prediktor (𝑋𝑗), dengan
𝑗 = 1,2,3,4,5.
2. Menentukan fungsi awal 𝒇̂𝒋(𝑿𝒋) pada saat 𝑚 = 0 untuk masing-masing
prediktor dari Tahap 1.
3. Iterasi untuk 𝑗 = 1,2,3,4,5 maka akan dihitung : a. Menentukan residual parsial persamaan (2.25)
b. Menentukan fungsi-fungsi dalam model dengan penghalusan berdasarkan persamaan (2.26)
c. Mencari nilai jumlah kuadrat residual berdasarkan persamaan (2.27) dan melakukan iterasi hingga diperoleh nilai RSS yang konvergen, yaitu
Tahap 3
Menganalisa dan menginterpretasikan hasil dari pemodelan dengan langkah-langkah sebagai berikut:
1. Melihat kesesuaian model hasil estimasi dengan cara membuat plot nilai persentase kemiskinan riil dan nilai kemiskinan dugaan, selanjutnya melihat fleksibilitas model dalam mengikuti pola persebaran nilai persentase kemiskinan riil berdasarkan visualisasi plot yang diperoleh.
2. Mendeskripsikan persebaran nilai persentase kemiskinan kota/kabupaten di Provinsi Jawa Timur berdasarkan nilai persentase kemiskinan dugaan. 3. Mengelompokkan nilai estimasi variabel prediktor berdasarkan persebaran
titik knot.
4. Menjelaskan makna nilai estimasi variabel prediktor yang berkaitan terhadap perubahan nilai pada variabel respon dengan asumsi variabel lainnya kostan.
1. Diagram alir untuk mendapatkan parameter penghalus optimum
Memperoleh parameter smoothing untuk masing-masing variabel prediktor dengan metode full search berdasarkan kriteria GCV
Mendefinisikan 𝑘 = 1 dan menghitung nilai GCV(𝜆) pada 𝑘 = 1
Membandingkan nilai GCV(𝜆) pada 𝑘 dengan nilai GCV(𝜆) pada 𝑘 + 1
Menentukan nilai dari 𝑘 = 𝑘 + 1 dan menghitung nilai GCV(𝜆) pada 𝑘 = 𝑘 + 1
Nilai GCV(𝜆) pada 𝑘 lebih besar daripada nilai GCV(𝜆)
pada 𝑘 + 1 Nilai GCV(𝜆) pada 𝑘 lebih
kecil atau sama dengan nilai GCV(𝜆) pada 𝑘 + 1
Nilai 𝑘 optimum untuk jumlah orde ke- 𝑝 adalah 𝑘
2. Diagram alir untuk mendaparkan estimasi model regesi nonparametrik aditif berdasarkan estimator penalized spline
Input data 𝑦𝑖, 𝑥𝑗𝑖
Menentukan orde polonomial(𝑝𝑗), jumlah knot (𝑘𝑗), dan parameter penghalus
(𝜆𝑗)
Menentukan titik knot dengan mendefinisikan prediktor baru sebagai nilau unique dari variabel prediktor 𝑥𝑗
Menentukan sampel kuantil dengan membagi prediktor baru sebanyak 𝑘𝑗+ 1 bagian
Mendefinisikan 𝑿𝑗 berdasarkan persamaan (2.6)
A
Mendefinisikan 𝑫𝑗 berdasarkan persamaan (2.11)
Menghitung nilai 𝜷̂𝑗 berdasarkan persaam (2.14)
Menghitung nilai 𝒇̂𝑗(𝑿𝑗) berdasarkan persamaan (2.15)
Menghitung matriks 𝑯(𝜆𝑗) berdasarkan persamaan (2.17)
Menghitung nilai MSE berdasarkan persamaan (2.24)
A
Mendefinisikan 𝑿𝑗 berdasarkan persamaan (2.6) dengan orde polinomial,dan jumlah knot optimal
Menghitung nilai 𝜷̂𝑗 berdasarkan persamaan (2.14)
Menghitung nilai 𝒇̂𝑗(𝑿𝑗) berdasarkan persamaan (2.15)
Mendapat fungsi dugaan regresi nonparametrik aditif berdasarkan estimator penalized spline dengan metode back fitting
Fungsi 𝒇̂𝑗(𝑿𝑗) yang diperoleh dengan memasukkan orde
polinomial dan jumlah knot optimal untuk m=0
Melakukan iterasi untuk semua variabel prediktor D
Menentukan residu parsial
𝑹𝒋(𝒎+𝟏) = 𝒀 − ℎ=1𝑗−1𝒇𝒉(𝒎)(𝑋ℎ) − 𝑑ℎ=𝑗+1𝒇(𝒎)𝒉 (𝑋ℎ)
Menghitung funngsi-fungsi dalam model dengan smoothing
𝒇𝒋(𝒎+𝟏)(𝑿𝒋) = 𝑯(𝜆)𝑗𝑹𝒋(𝒎+𝟏)
C
|𝑅𝑆𝑆(𝑚+1)− 𝑅𝑆𝑆(𝑚)| < 𝜀
model regresi nonparametrik aditif adalah 𝒇̂𝑗(𝑿𝑗)
D
C
Menentukan nilai jumlah kuadrat residual
𝑅𝑆𝑆(𝑚+1)= 1
𝑛 𝒀 − 𝒇̂𝑗
(𝑚+1)
(𝑿𝑗) 𝑑
𝑗=1
𝑇
𝒀 − 𝑑𝑗=1𝒇̂𝑗(𝑚+1)(𝑿𝑗)
E
BAB IV PEMBAHASAN
4.1Deskripsi Variabel Terikat Persentase Penduduk Miskin Kota/Kabupaten di Jawa Timur
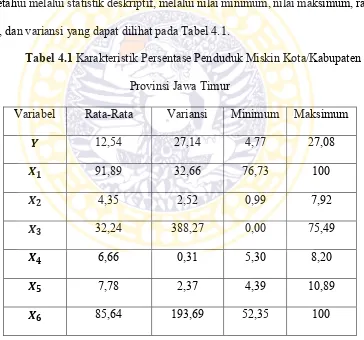
Karakteristik persentase penduduk miskin kota/kabupaten di Provinsi Jawa Timur beserta faktor yang mempengaruhi persentase penduduk miskin dapat diketahui melalui statistik deskriptif, melalui nilai minimum, nilai maksimum, rata-rata, dan variansi yang dapat dilihat pada Tabel 4.1.
Tabel 4.1 Karakteristik Persentase Penduduk Miskin Kota/Kabupaten Provinsi Jawa Timur
Variabel Rata-Rata Variansi Minimum Maksimum
𝒀 12,54 27,14 4,77 27,08
𝑿𝟏 91,89 32,66 76,73 100
𝑿𝟐 4,35 2,52 0,99 7,92
𝑿𝟑 32,24 388,27 0,00 75,49
𝑿𝟒 6,66 0,31 5,30 8,20
𝑿𝟓 7,78 2,37 4,39 10,89
𝑿𝟔 85,64 193,69 52,35 100
tersebar di 38 kabupaten/kota di Jawa Timur adalah 12,54% dari total persentase penduduk miskin di masing-masing kabupaten/kota. Persentase tertinggi penduduk miskin di Provinsi Jawa Timur adalah sebesar 27,08% dan terendah sebesar 4,77%. Nilai variansi yang berfluktuasi tinggi mengindikasikan bahwa terdapat kesenjangan ekonomi antar kota/kabupaten di Jawa Timur yang ditandai dengan adanya Kota Batu yang memiliki persentase penduduk miskin terendah 4,77% dan Kabupaten Sampang yang memiliki persentase penduduk miskin terbesar 27,08% di Jawa Timur, sehingga dalam menetapkan suatu kebijakan atau upaya dalam penanganan penduduk miskin, pemerintah harus menetapkan kebijakan yang disesuaikan dengan porsi kebutuhan masing-masing kota/kabupaten.
Karakteristik variabel 𝑋1 yaitu persentase Angka Melek Huruf (AMH) yang memiliki rata-rata 91,89 dengan variansi 32,66. Rata-rata AMH sebesar 91,89 menunjukkan bahwa AMH di kota/kabupaten di Jawa Timur sudah tinggi ditandai dengan 91,89% dari total penduduk usia 15 tahun ke atas sudah mampu membaca dan menulis, dengan adanya Kabupaten Situbondo yang memiliki persentase AMH terendah 78,46% dan Kota Madiun memiliki persentase AMH tertinggi 100% (Lampiran 3).
terdapat TPT sebesar 79 penduduk di Kota Kediri (Lampiran 4), sehingga dapat dinyatakan bahwa TPT di 38 kabupaten/kota di Provinsi Jawa Timur adalah berada pada kisaran 10 sampai 79 penduduk dari tiap 1000 penduduk.
Karakteristik variabel 𝑋3 yaitu pekerja di sektor pertanian memiliki rata-rata sebesar 32,24% artinya bila terdapat 1000 penduduk maka terdapat 322 penduduk yang bekerja di sektor pertanian pada tahun 2013 dengan keragaman sebesar 388,27. Nilai minimum sebesar 0% di Kota Malang artinya tidak ada pekerja di sektor pertanian pada tahun 2013 di Kota Malang dari tiap 1000 penduduk dan tertinggi sebesar 75,49% di Kabupaten Pacitan artinya sebesar 754 dari tiap 1000 penduduk (Lampiran 5).
Karakteristik variabel 𝑋4 yaitu Laju Pertumbuhan Ekonomi (LPE) memiliki rata-rata sebesar 6,66% yang berarti bahwa terdapat proses kenaikan kapasitas produksi suatu perekonomian yang diwujudkan dalam kenaikan pendapatan nasional rata-rata pada 38 kabupaten/kota di Provinsi Jawa Timur pada tahun 2013 dengan keragaman sebesar 0,31. Nilai minimum sebesar 5,30% di Kabupaten Bojonegoro artinya terdapat proses kenaikan kapasitas produksi suatu perekonomian yang diwujudkan dalam kenaikan pendapatan nasional sebesar 5,30% dan tertinggi sebesar 8,20% di Kota Batu (Lampiran 6), sehingga dapat dinyatakan bahwa laju pertumbuhan ekonomi penduduk di 38 kabupaten/kota di Provinsi Jawa Timur adalah berada pada kisaran 5,30% sampai dengan 8,20%.
penduduk usia 15 tahun ke atas yang didata hanya menempuh pendidikan formal selama 7,78 tahun atau setara dengan Sekolah Menengah Pertama (SMP). Nilai terendah RLS 4,39 di Kab. Sampang dan tertinggi 10,89 di Kota Malang (Lampiran 7), berdasarkan RLS tertinggi dapat diketahui bahwa pendidikan formal tertinggi yang mampu diperoleh penduduk di Provinsi Jawa TImur adalah jenjang pendidikan setara dengan Sekolah Menengah Atas (SMA).
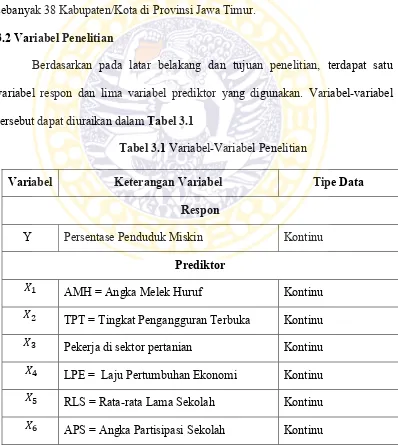
Karakteristik penduduk miskin disajikan dalam bentuk diagram batang pada Gambar 4.1 sebagai berikut.
Gambar 4.1 Diagram Batang Penduduk Miskin Tiap Kabupaten/Kota di Jawa Timur Tahun 2013
Berdasarkan Gambar 4.1 terlihat bahwa persentase penduduk miskin terendah dari kabupaten/kota di Provinsi Jawa Timur adalah Kota Batu yakni sebesar 4,77% dan penduduk miskin tertinggi adalah Kabupaten Sampang sebesar 27,08%.
Penentuan model hubungan antara persentase penduduk miskin dengan masing-masing variabel prediktor dilakukan dengan tiga tahapan, yaitu membuat scatter plot antara variabel respon dengan masing-masing variabel prediktor, menentukan parameter smoothing optimal dengan menggunakan algoritma full search berdasarkan kriteria GCV dan memodelkan persentase penduduk miskin dengan masing-masing variabel prediktor menggunakan parameter smoothing optimum.
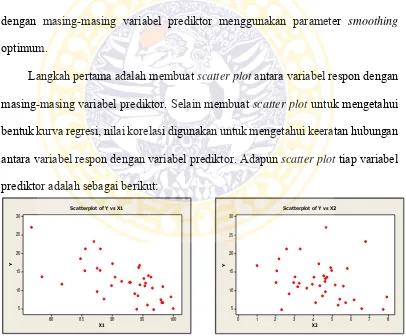
Langkah pertama adalah membuat scatter plot antara variabel respon dengan masing-masing variabel prediktor. Selain membuat scatter plot untuk mengetahui bentuk kurva regresi, nilai korelasi digunakan untuk mengetahui keeratan hubungan antara variabel respon dengan variabel prediktor. Adapun scatter plot tiap variabel prediktor adalah sebagai berikut:
Scatterplot of Y vs X1
8
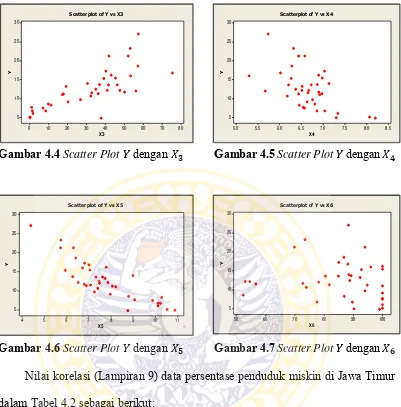
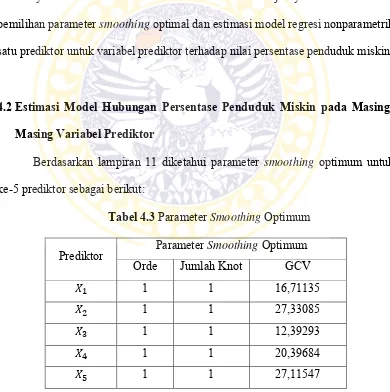
Gambar 4.4 Scatter Plot 𝑌dengan 𝑋3 Gambar 4.5 Scatter Plot 𝑌dengan 𝑋4
Gambar 4.6 Scatter Plot 𝑌dengan 𝑋5 Gambar 4.7 Scatter Plot 𝑌dengan 𝑋6 Nilai korelasi (Lampiran 9) data persentase penduduk miskin di Jawa Timur dalam Tabel 4.2 sebagai berikut:
Tabel 4.2 Nilai KorelasiData Persentase Penduduk Miskin di Jawa Timur Variabel Nilai Korelasi Pola Persebaran Data
AMH -0.658 Acak Tidak Beraturan
TPT -0.268 Acak Tidak Beraturan
Pekerja di Sektor Pertanian 0.761 Acak Tidak Beraturan
LPE -0.555 Acak Tidak Beraturan
RLS -0.851 Linier
APS -0.123 Acak Tidak Beraturan
80
Scatterplot of Y vs X3
8.5
Scatterplot of Y vs X4
11
Scatterplot of Y vs X5
100
Berdasarkan Gambar 4.2, Gambar 4.3, Gambar 4.4, Gambar 4.5, Gambar 4.6, dan Gambar 4.7, diketahui bahwa dari 6 variabel yang diasumsikan persentase penduduk miskin di Jawa Timur, variabel Rata-Rata Lama Sekolah (RLS) linier dan hanya terdapat 5 variabel prediktor yang sesuai dengan metode regresi nonparametrik, yaitu Angka Melek Huruf (AMH), Tingkat Pengangguran Terbuka (TPT), pekerja di sektor pertanian, Laju Pertumbuhan Ekonomi (LPE), dan Angka Partisipasi Sekolah (APS) yang dipilih karena memiliki kurva regresi yang bentuknya tidak diketahui atau acak tidak beraturan. Selanjutnya adalah melakukan pemilihan parameter smoothing optimal dan estimasi model regresi nonparametrik satu prediktor untuk variabel prediktor terhadap nilai persentase penduduk miskin.
4.2Estimasi Model Hubungan Persentase Penduduk Miskin pada Masing-Masing Variabel Prediktor
Berdasarkan lampiran 11 diketahui parameter smoothing optimum untuk ke-5 prediktor sebagai berikut:
Tabel 4.3 Parameter Smoothing Optimum
Prediktor Parameter Smoothing Optimum Orde Jumlah Knot GCV
𝑋1 1 1 16,71135
𝑋2 1 1 27,33085
𝑋3 1 1 12,39293
𝑋4 1 1 20,39684
a. Estimasi model antara persentase penduduk miskin dan Angka Melek Huruf
Berdasarkan Tabel 4.3 diperoleh informasi bahwa nilai GCV minimum sebesar 16,71135 terdapat pada orde (𝑝1) =1, jumlah knot (𝑘1) =1 dan lambda
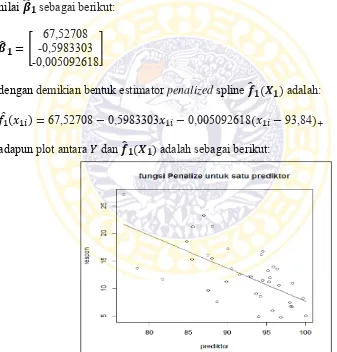
(𝜆1)=100 dengan titik knot [1]=93,84 (Lampiran 13). Kemudian dihitung nilai estimasi 𝒇̂𝟏(𝑿𝟏) dengan program software R (Lampiran 12), sehingga diperoleh nilai 𝜷̂𝟏 sebagai berikut:
𝜷̂𝟏 = [
67,52708 -0,5983303 -0,005092618]
dengan demikian bentuk estimator penalized spline 𝒇̂𝟏(𝑿𝟏) adalah:
𝑓̂1(𝑥1𝑖) =67,52708−0,5983303𝑥1𝑖−0,005092618(𝑥1𝑖−93,84)+ adapun plot antara 𝑌 dan 𝒇̂𝟏(𝑿𝟏) adalah sebagai berikut:
Gambar 4.8 Plot antara 𝑌 dan 𝒇̂𝟏(𝑿𝟏) pada Data Persentase Penduduk Miskin berdasarkan Angka Melek Huruf
Keterangan : • data observasi (𝑥1𝑖, 𝑦𝑖)
b. Estimasi model antara persentase penduduk miskin dengan Tingkat Pengangguran Terbuka
Berdasarkan Tabel 4.3 diperoleh informasi bahwa nilai GCV minimum sebesar 27,33085 terdapat pada orde (𝑝2) = 1, jumlah knot (𝑘2) = 1 dan lambda
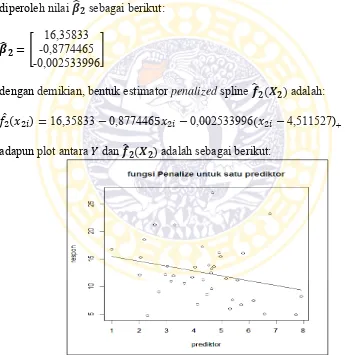
(𝜆2) = 100 dengan titik knot [1] = 4,511527 (Lampiran 13). Kemudian dihitung nilai estimasi 𝒇̂𝟐(𝑿𝟐) dengan program software R (Lampiran 12), sehingga diperoleh nilai 𝜷̂𝟐 sebagai berikut:
𝜷̂𝟐 = [
16,35833 -0,8774465 -0,002533996]
dengan demikian, bentuk estimator penalized spline 𝒇̂𝟐(𝑿𝟐) adalah:
𝑓̂2(𝑥2𝑖) =16,35833−0,8774465𝑥2𝑖−0,002533996(𝑥2𝑖−4,511527)+ adapun plot antara 𝑌 dan 𝒇̂𝟐(𝑿𝟐) adalah sebagai berikut:
Gambar 4.9 Plot antara 𝑌 dan 𝒇̂𝟐(𝑿𝟐) pada Data Persentase Penduduk Miskin berdasarkan Tingkat Pengangguran Terbuka
Keterangan : • data observasi (𝑥2𝑖, 𝑦𝑖)
c. Estimasi model antara persentase penduduk miskin dengan pekerja di sektor pertanian
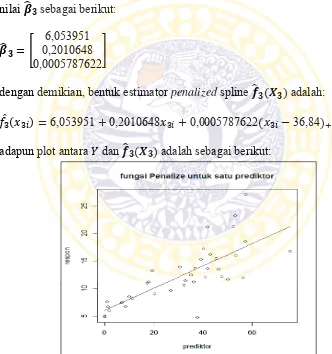
Berdasarkan Tabel 4.3 diperoleh informasi bahwa nilai GCV minimum sebesar 12,39293 terdapat pada orde (𝑝3)= 1, jumlah knot (𝑘3) = 1 dan lambda
(𝜆3) = 1000 dengan titik knot [1] = 36,84 (Lampiran 13). Kemudian dihitung nilai estimasi 𝒇̂𝟑(𝑿𝟑) dengan program software R (Lampiran 12), sehingga diperoleh nilai 𝜷̂𝟑 sebagai berikut:
𝜷̂𝟑 = [
6,053951 0,2010648 0,0005787622]
dengan demikian, bentuk estimator penalized spline 𝒇̂𝟑(𝑿𝟑) adalah:
𝑓̂3(𝑥3𝑖) =6,053951+0,2010648𝑥3𝑖+0,0005787622(𝑥3𝑖−36,84)+ adapun plot antara 𝑌 dan 𝒇̂𝟑(𝑿𝟑) adalah sebagai berikut:
Gambar 4.10 Plot antara 𝑌 dan 𝒇̂𝟑(𝑿𝟑) pada Data Persentase Penduduk Miskin berdasarkan Pekerja di Sektor Pertanian
Keterangan : • data observasi (𝑥3𝑖, 𝑦𝑖)
d. Estimasi model antara persentase penduduk miskin dengan Laju Pertumbuhan Ekonomi
Berdasarkan Tabel 4.3 diperoleh informasi bahwa nilai GCV minimum sebesar 20,39684 terdapat pada orde (𝑝4) = 1, jumlah knot (𝑘4) = 1 dan lambda
(𝜆4) = 100 dengan titik knot [1] = 6,64 (Lampiran 13). Kemudian dihitung nilai estimasi 𝒇̂𝟒(𝑿𝟒) dengan program software R (Lampiran 12), sehingga diperoleh nilai 𝜷̂𝟒 sebagai berikut:
𝜷̂𝟒 = [
47,12564 -5,190772 -0,008126266]
dengan demikian, bentuk estimator penalized spline 𝒇̂𝟒(𝑿𝟒) adalah:
𝑓̂4(𝑥4𝑖) =47,12564−5,190772𝑥4𝑖−0,008126266(𝑥4𝑖−6,64)+ adapun plot antara 𝑌 dan 𝒇̂𝟒(𝑿𝟒) adalah sebagai berikut:
Gambar 4.11 Plot antara 𝑌 dan 𝒇̂𝟒(𝑿𝟒) pada Data Persentase Penduduk Miskin berdasarkan Laju Pertumbuhan Ekonomi
Keterangan : • data observasi (𝑥4𝑖, 𝑦𝑖)
e. Estimasi model antara persentase penduduk miskin dengan Angka Partisipasi Sekolah
Berdasarkan Tabel 4.3 diperoleh informasi bahwa nilai GCV minimum sebesar 27,11547 terdapat pada orde (𝑝5) = 1, jumlah knot (𝑘5) = 1 dan lambda
(𝜆5) = 3,6 dengan titik knot [1] = 86,895 (Lampiran 13). Kemudian dihitung nilai estimasi 𝒇̂𝟓(𝑿𝟓) dengan program software R (Lampiran 12), sehingga diperoleh nilai 𝜷̂𝟓 sebagai berikut:
𝜷̂𝟓 = [
8,85902 0,06304346
-0,3750014]
dengan demikian, bentuk estimator penalized spline 𝒇̂𝟓(𝑿𝟓) adalah:
𝑓̂5(𝑥5𝑖) =8.85902+0,06304346𝑥5𝑖−0,3750014(𝑥4𝑖−86,895)+ adapun plot antara 𝑌 dan 𝒇̂𝟓(𝑿𝟓) adalah sebagai berikut:
Gambar 4.12 Plot antara 𝑌 dan 𝒇̂𝟓(𝑿𝟓) pada Data Persentase Penduduk Miskin berdasarkan Angka Partisipasi Sekolah
Keterangan : • data observasi (𝑥5𝑖, 𝑦𝑖)
4.3 Menginterpretasi Hasil Pemodelan Regresi Nonparametrik Aditif Persentase Penduduk Miskin di Jawa Timur
Setelah mendapatkan fungsi penalized untuk masing-masing prediktor, selanjutnya adalah melakukan iterasi dengan menggunakan algoritma back fitting untuk mendapatkan koefisien regresi (𝛽𝑗∗) yang menghasilkan jumlah kuadrat residual yang konvergen dengan menggunakan program (Lampiran 15). Berdasarkan hasil estimasi (Lampiran 16) dapat dibuat plot antara nilai persentase penduduk miskin observasi dengan nilai persentase penduduk miskin hasil estimasi model regresi nonparametrik aditif berdasarkan estimator penalized spline untuk mengetahui tingkat fleksibelitas model hasil estimasi model dalam mengikuti pola data persentase penduduk miskin observasi. Adapun pola antara nilai persentase penduduk miskin observasi dengan nilai persentase penduduk miskin hasil estimasi adalah sebagai berikut:
Gambar 4.13 Plot antara Persentase Penduduk Miskin dengan Persentase Penduduk Miskin Hasil Estimasi
0 5 10 15 20 25 30
1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35 37
Berdasarkan Gambar 4.13 Diketahui bahwa nilai hasil estimasi model regresi nonparametrik aditif berdasarkan estimator penalized spline merupakan model yang sesuai untuk persentase penduduk miskin di Jawa Timur dengan fleksibilitas yang baik, hal tersebut ditunjukkan dengan plot estimasi yang mampu mengikuti persebaran data persentase penduduk miskin observasi. Selanjutnya diperoleh nilai MSE = 7,371886 dan 𝑅2 = 72,09%, dengan hasil estimasi model regresi nonparametrik aditif dengan sebagai berikut:
𝛽̂1∗𝑇 = ( −10,408405; −0,296156;0,002505)
𝛽̂2∗𝑇 = (10,306818;0,513456; −0,001535)
𝛽̂3∗𝑇 = (7,460649;0,157577; −0,000235)
𝛽̂4∗𝑇 = (22,927252; −1,555319; −0,119036)
𝛽̂5∗𝑇 = (11,064386;0,018063; −0,015637)
sehingga diperoleh 𝑌̂ = ∑5𝑗=1𝑓̂𝑗(𝑋𝑗) dengan bentuk estimator penalized spline masing-masing 𝑓̂𝑗(𝑋𝑗) adalah:
a. 𝑓̂1(𝑋1) = −10,408405−0,296156𝑋1+0,002505(𝑋1−93,84)+ (4.1)
atau dapat ditulis:
𝑓̂1(𝑋1) = {−10,643474−10,408405−0,293651−0,296156𝑋 𝑋1 ; 𝑋1 <93,84 1 ; 𝑋1 ≥93,84 b. 𝑓̂2(𝑋2) =10,306818+0,513456𝑋2−0,001535(𝑋2−4,511527)+
(4.2) atau dapat ditulis: