PERBANDINGAN METODE K-NEAREST NEIGHBOR (KNN) dan METODE NEAREST CLUSTER CLASSIFIER (NCC) DALAM PENGKLASIFIKASIAN
KUALITAS BATIK TULIS
Nesi Syafitri1
ABSTRACT
Various problem that are related to classification object can be solve easier with using classification techniques. For example in the medical field, classification application can be applied to classify diseases level of patient so that easier for a doctor to give right therapy solution And in industries field and trading of batik, classification application needed to assignment of batik tulis quality.
To solve such classification problem, several methods have been applied.
In soft computing field, there are many classification technique has been improved. So, classification process can be done relatively faster with using precise classification algorithm.
In this research two classification methods for classify quality of batik tulis, k-nearest neighbor and nearest cluster classifier are compared. K-nearest neighbor is a method that based on probabilistic approach and nearest cluster classifier is a method that based on similarity. Focus of this research is a accuration ratio or succes ratio that result it. The result of this research showed that classification in quality of batik tulis with k-nearest neighbor method is better than nearest cluster classifier method in rate of accuration ratio or succes ratio.
Keywords : Classification, k-nearest neighbor, nearest cluster classifier, probabilistic approach, similarity, accuration ratio.
INTISARI
Berbagai kasus yang berkaitan dengan pengelompokkan objek dapat diselesaikan lebih mudah dengan menerapkan teknik-teknik klasifikasi. Sebagai contoh pada bidang medis, aplikasi klasifikasi dapat digunakan untuk klasifikasi tingkat penyakit yang diderita oleh seorang pasien sehingga memudahkan dokter dalam memberikan solusi terapi yang tepat. Dan di dunia industri dan perdagangan batik, aplikasi klasifikasi juga dibutuhkan untuk menentukan kualitas batik.
Untuk memecahkan masalah klasifikasi, berbagai macam metode telah diterapkan. Dibidang soft computing, mulai banyak dikembangkan juga teknik- teknik klasifikasi. Sehingga proses klasifikasi dapat dilakukan dalam waktu yang relatif lebih cepat dengan menggunakan algoritma klasifikasi yang tepat.
Dalam penelitian ini dibandingkan dua metode klasifikasi yaitu k-nearest neighbor dan nearest cluster classifier untuk proses klasifikasi kualitas batik tulis.
Metode k-nearest neighbor adalah metode yang berdasarkan pada pendekatan
1 Dosen STMIK Indonesia Padang
probabilistik sedangkan nearest cluster classifier berdasarkan pada kemiripan.
Fokus penelitian ini adalah pada tingkat akurasi atau succes ratio yang dihasilkan oleh masing-masing metode. Dari hasil penelitian menunjukkan bahwa klasifikasi kualitas batik tulis dengan metode k-nearest neighbor menunjukkan tingkat akurasi atau succes ratio yang lebih baik dibandingkan dengan metode nearest cluster classifier.
Kata Kunci : Klasifikasi, k-nearest neighbor, nearest cluster classifier, pendekatan probabilitas, similarity, tingkat akurasi.
PENDAHULUAN
Klasifikasi merupakan suatu metode untuk mengelompokkan sebuah objek ke dalam kelompok atau kelas tertentu. Berbagai kasus
yang berkaitan dengan
pengelompokkan objek dapat diselesaikan lebih mudah dengan menerapkan teknik-teknik klasifikasi.
Sebagai contoh pada bidang kesehatan, aplikasi klasifikasi dapat digunakan untuk mengetahui tingkat penyakit yang diderita oleh seorang pasien sehingga memudahkan dokter dalam memberikan solusi terapi yang tepat. Pada bidang ekonomi, aplikasi klasifikasi juga dapat digunakan oleh sebuah bank yang ingin mengetahui apakah customer yang mengajukan kredit termasuk dalam kategori customer yang menguntungkan atau tidak.
Sementara itu dalam dunia industri dan perdagangan batik di Indonesia, prinsip-prinsip klasifikasi juga dibutuhkan, seperti dalam menentukan kualitas sebuah batik.
Kualitas suatu batik tidak dapat langsung ditentukan begitu saja secara visual. Untuk dapat mengetahui kualitas dari suatu batik yang dihasilkan maka perlu dilakukan serangkaian pengujian terlebih dahulu. Hasil pengujian inilah yang kemudian akan diklasifikasikan atau dikelompokkan sehingga akhirnya ditemukan kualitas dari suatu batik tersebut.
Pengujian kualitas suatu batik dilakukan di Balai Besar Kerajinan dan Batik Indonesia yang berada di kota Yogyakarta. Parameter yang digunakan dalam menguji kualitas batik ini berdasarkan pada ketentuan standar penilaian yang sudah ditetapkan oleh Badan Standarisasi Nasional (BSN).
Hingga saat ini, penilaian dan penentukan kualitas dari sebuah batik sangat dipengaruhi oleh pengalaman dan kemampuan pegawai yang bekerja di Balai Besar
Kerajinan dan Batik Indonesia.
Semakin berpengalaman pegawai tersebut dalam menilai kualitas suatu batik, maka semakin cepat proses penentuan kualitas batik yang diuji tersebut. Sebaliknya apabila pegawai tersebut masih belum berpengalaman, maka proses pengklasifikasian kualitas batik tersebut menjadi lebih lambat.
Dengan demikian keterlibatan individu tersebut dapat dikatakan masih sangat dominan dan proses klasifikasi yang dilakukan juga masih bersifat manual. Kenyataannya, jika proses klasifikasi dilakukan secara manual maka hal ini akan menjadi
sebuah pekerjaan yang
membutuhkan banyak waktu.
Dalam memecahkan masalah klasifikasi, para ahli telah mengembangkan berbagai metode klasifikasi. Dibidang soft computing, mulai banyak dikembangkan juga teknik-teknik klasifikasi sehingga proses klasifikasi dapat dilakukan dalam waktu yang relatif lebih cepat dengan menggunakan algoritma klasifikasi yang tepat.
Namun di sisi lain, tidak semua metode klasifikasi yang ada dapat diterapkan pada semua kasus. Oleh karena itu untuk menemukan metode yang sesuai dan baik dalam klasifikasi kualitas batik khususnya pada batik tulis, maka pada penelitian ini akan dibahas perbandingan dua metode klasifikasi yaitu k-nearest neighbor (KNN) dan nearest cluster classifier (NCC).
Kedua metode ini akan dicoba dalam pengklasifikasian kualitas batik tulis. Metode yang memberikan tingkat akurasi atau succes ratio yang lebih baik, dapat dipilih sebagai prototype dalam membangun sebuah sistem klasifikasi kualitas batik tulis pada Balai Besar Kerajinan dan Batik Indonesia nantinya.
PEMBAHASAN
Dalam proses klasifikasi kualitas batik tulis ini akan digunakan dua metode klasifikasi yaitu metode k-nearest neighbor (KNN) dan metode nearest cluster classifier (NCC). Metode KNN merupakan metode klasifikasi berdasarkan probabilistik, sedangkan metode NCC merupakan metode klasifikasi berdasarkan kemiripan. Penggunaan dua metode tersebut bertujuan untuk melihat perbandingan tingkat akurasi (ketepatan) kedua model tersebut dalam mengklasifikasikan objek.
Metode klasifikasi terbagi atas supervised classification dan unsupervised classification. Metode KNN dan NCC termasuk ke dalam supervised classification. Untuk membangun sistem klasifikasi yang bersifat supervised classification, sebelumnya sistem harus memiliki memori atau pengetahuan menyangkut objek yang akan diklasifikasikan. Representasi memori atau pengetahuan ini dapat dibangun melalui proses learning.
Dua tahapan yang harus dilalui dalam proses learning adalah tahapan pelatihan (training) dan tahapan pengenalan (testing). Pada fase pelatihan, sebagian data yang telah diketahui kelas datanya diumpankan untuk membentuk model prediksi. Selanjutnya pada fase pengenalan, fitur-fitur pada objek baru atau yang disebut sebagai data testing diujikan dengan model prediksi yang terbentuk.
Pengujian yang dimaksud adalah untuk mencari tingkat akurasi model dalam melakukan klasifikasi.
Selanjutnya setelah model prediksi yang diperoleh dianggap telah sesuai maka proses klasifikasi objek baru dapat dilakukan. Metode yang digunakan untuk mengukur kemiripan tersebut adalah dengan metode jarak euclidean distance dan metode classifier yang dipilih adalah
metode k-nearest neighbor dan nearest cluster classifier.
Klasifikasi dengan Metode K- Nearest Neightbor (KNN)
K-Nearest Neighbor (KNN) merupakan algoritma supervised learning dimana output dari suatu data baru diklasifikasikan berdasarkan kelompok mayoritas dari k buah tetangga terdekat.
Tujuan dari algoritma ini adalah mengelompokkan data baru berdasarkan atribut dan data training [1].
Algoritma metode KNN sangatlah sederhana, bekerja berdasarkan pada jarak terpendek dari objek query ke training sample untuk menentukan sejumlah k- neighbor pointnya. Setelah mengumpulkan k-neighbor point, kemudian diambil mayoritas dari k- neighbor point untuk dijadikan prediksi dari objek query. Untuk mendapatkan nilai k yang optimal dapat digunakan optimasi parameter, misalnya dengan menggunakan k-fold cross validation.
Pada KNN, classifier tidak menggunakan model apapun untuk dicocokkan dan hanya berdasarkan pada memori. Proses training tidak dilakukan pada metode ini, tapi langsung proses testing. Sebuah objek query diberikan kemudian akan dihitung jaraknya dengan masing-masing training sample dan kemudian diambil sejumlah k neighbor point yang paling dekat dengan objek query. Klasifikasi menggunakan voting terbanyak di antara klasifikasi dari k neighbor point terdekat.
K-Fold Cross Validation
Cross validation digunakan dalam rangka menemukan parameter terbaik dari satu model.
Ini dilakukan dengan cara menguji besarnya error pada data testing.
Dalam cross validation, data dibagi
ke dalam k sampel dengan ukuran yang sama. Dari k subset data yang digunakan akan dipakai k-1 sampel sebagai data training dan 1 sampel sisanya untuk data testing.
Selanjutnya dilakukan proses training dan testing kemudian dihitung rata-rata error (error mean).
Setiap running akan ditemukan error untuk data testing, model yang memberikan rata-rata error terkecil dipilih menjadi metode terbaik.
Persamaan yang dapat digunakan untuk menghitung rata- rata dan standar deviasi error dapat dinyatakan sebagai berikut [2]:
a. Mean :
ni
n Ui m
1
1
(2.1)
b. Variansi :
n
i
m n Ui
v
1
)
21 (
1
(2.2) c. Standar deviasi :
v
(2.3)Klasifikasi dengan Metode Nearest Cluster Classifier (NCC)
Algoritma NCC merupakan algoritma untuk mengklasifikasikan suatu objek berdasarkan jarak terdekatnya dengan suatu pusat cluster. Metode ini juga disebut dengan minimum euclidean distance classifier [3]. Pada metode NCC proses learning dilakukan untuk menemukan model prediksi yang tepat. Pada awal fase pelatihan (training), semua data training dipartisi ke dalam beberapa cluster yang telah ditentukan dan kemudian dicari pusat cluster dari masing- masing cluster yang terbentuk.
Untuk membentuk cluster dan menemukan pusat cluster dari data training, dihitung dengan menggunakan salah satu metode clustering yaitu metode Fuzzy C-
Means (F-CM). Setelah cluster terbentuk dan pusat cluster diketahui, selanjutnya akan ditentukan tingkat probabilitas dari setiap kelas terhadap suatu cluster, dengan persamaan yaitu:
n(K) n(JK)
P (JK)
Dimana:
P(JK) = Probabilitas suatu kelas j terhadap cluster k
n(JK) = Banyaknya anggota kelas j yang masuk pada cluster k
n(K) = Ruang sampel yang menunjukkan banyaknya anggota dari cluster k.
Selanjutnya pada proses pengenalan (testing), akan dihitung jarak antara data testing dengan setiap pusat cluster yang diperoleh.
Jarak dihitung dengan
menggunakan euclidean metric pada persamaan 2.5:
Euclidean metric :
N
i
i i
Eucl x y x y
D
1
)
2,
(
(2.5)Menemukan Pusat Cluster dengan metode Fuzzy C-Means
Untuk menemukan pusat cluster dan anggota-anggota cluster dengan menggunakan metode Fuzzy C-Means (FCM), proses diawali dengan menentukan jumlah cluster yang akan dibentuk, batasan error terkecil, fungsi objektif awal, dan maksimum iterasi yang akan dilakukan.
Pada iterasi pertama, pusat cluster yang menandai lokasi rata- rata untuk setiap cluster dan juga derajat keanggotaan setiap data training pada masing-masing cluster ditentukan secara random / acak.
Derajat keanggotaan setiap data pada masing-masing cluster dijadikan sebagai elemen-elemen matrik partisi. Pada awalnya, pusat
cluster yang terbentuk masih belum akurat. Pusat cluster dan derajat keanggotaan setiap titik data akan diperbaiki secara berulang-ulang sampai ditemukan pusat cluster yang tepat. Perulangan akan terus dilakukan selama selisih fungsi objektif masih lebih besar dari batas error terkecil yang telah ditetapkan atau banyak iterasi masih kecil dari maksimum iterasinya. Selisih fungsi objektif diperoleh dari pengurangan fungsi objektif terakhir dengan fungsi objektif sebelumnya. Setelah data menuju lokasi cluster yang tepat maka proses pun berhenti.
Output yang diperoleh adalah deretan pusat cluster dan derajat keanggotaan untuk setiap data.
Berikut ini algoritma proses clustering dengan metode FCM:
1. Diawal proses cluster tentukan jumlah cluster, maksimum iterasi, error terkecil, fungsi objektif awal, iterasi awal.
2. Bangkitkan bilangan random ik, i
= 1,2,...,n; k=1,2,...,c; sebagai elemen-elemen matrik partisi awal U. Hitung jumlah setiap kolom (atribut):
k c
k ij
ij 1μ
Q
dengan j = 1,2,...,m.
Hitung:
ij k ik
Q
newi
μ
3. Hitung pusat cluster ke-k : Vkj, dengan k= 1,2,...,c; dan j = 1,2,...,m
n
i
w ik n
i
ij w ik kj
X V
1 1
) (
)
* ) ((
4. Hitung fungsi obyektif pada iterasi ke-t, Pt:
) ) (μ
* ] ) V X ( ([
P 2 i
1 1 1
t w
k kj
n i
c k
m
j ij
5. Hitung perubahan matriks partisi:
c
1 k
m 1 j
1 w1 2] ) V (X [ m
1 j
1 w1 2] ) V (X [ μik
ij kj ij kj
Dengan i = 1,2,...,n; dan k = 1,2,...,c
6. Cek kondisi:
a. Jika ( | Pt – ( Pt-1)| ) atau ( t > MaxIter ) maka proses berhenti;
b. Jika tidak t = t +1, maka ulangi langkah ke-4
Pengujian Tingkat Akurasi
Pengujian tingkat akurasi yang dimaksud adalah untuk menemukan persentase ketepatan dalam proses pengklasifikasian terhadap data testing yang diuji.
Tingkat akurasi dihitung dengan menggunakan rumus:
% 100 tp *
match ac
Dimana:
ac = tingkat akurasi ( %)
match = Jumlah klasifikasi yang benar
tp = Jumlah data testing
Pengujian Sistem Pembentuk Kelas
Pengujian sistem pembentuk kelas dilakukan untuk mengetahui seberapa besar keberhasilan sistem ini pada masing-masing metode.
Pengujian sistem pembentuk kelas, dengan menggunakan data training dan data testing. Tiap-tiap data training akan diuji dengan setiap data testing. Perlakuan sampel pada sistem pembentuk kelas yang digunakan pada fase training dan
fase testing untuk kelompok uji batik tulis adalah seperti yang terlihat
pada Tabel 1:
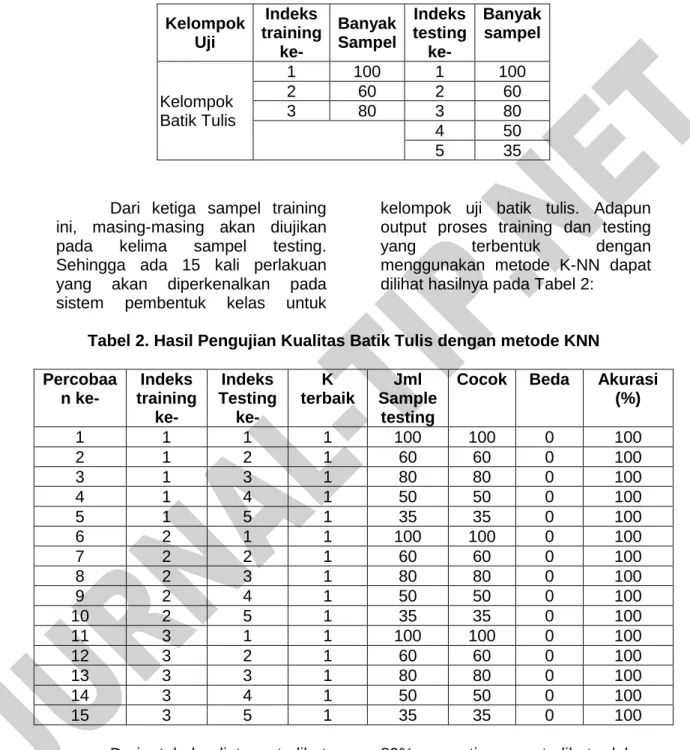
Tabel 1. Sampel pada Kelompok Uji Batik Tulis
Kelompok Uji
Indeks training
ke-
Banyak Sampel
Indeks testing
ke-
Banyak sampel
Kelompok Batik Tulis
1 100 1 100
2 60 2 60
3 80 3 80
4 50
5 35
Dari ketiga sampel training ini, masing-masing akan diujikan pada kelima sampel testing.
Sehingga ada 15 kali perlakuan yang akan diperkenalkan pada sistem pembentuk kelas untuk
kelompok uji batik tulis. Adapun output proses training dan testing
yang terbentuk dengan
menggunakan metode K-NN dapat dilihat hasilnya pada Tabel 2:
Tabel 2. Hasil Pengujian Kualitas Batik Tulis dengan metode KNN Percobaa
n ke-
Indeks training
ke-
Indeks Testing
ke-
K terbaik
Jml Sample
testing
Cocok Beda Akurasi (%)
1 1 1 1 100 100 0 100
2 1 2 1 60 60 0 100
3 1 3 1 80 80 0 100
4 1 4 1 50 50 0 100
5 1 5 1 35 35 0 100
6 2 1 1 100 100 0 100
7 2 2 1 60 60 0 100
8 2 3 1 80 80 0 100
9 2 4 1 50 50 0 100
10 2 5 1 35 35 0 100
11 3 1 1 100 100 0 100
12 3 2 1 60 60 0 100
13 3 3 1 80 80 0 100
14 3 4 1 50 50 0 100
15 3 5 1 35 35 0 100
Dari tabel diatas terlihat dengan menggunakan metode KNN, tingkat akurasi yang diperoleh 100%.
Artinya, semua data testing yang diujikan dapat diklasifikasikan dengan benar. Sedangkan dengan metode NCC tingkat akurasi yang diperoleh rata-rata hanya sebesar
89% seperti yang terlihat dalam Tabel 3. Dengan metode NCC, ternyata tidak semua data dapat diklasifikasikan secara tepat, walaupun data testing yang digunakan sama persis dengan data trainingnya.
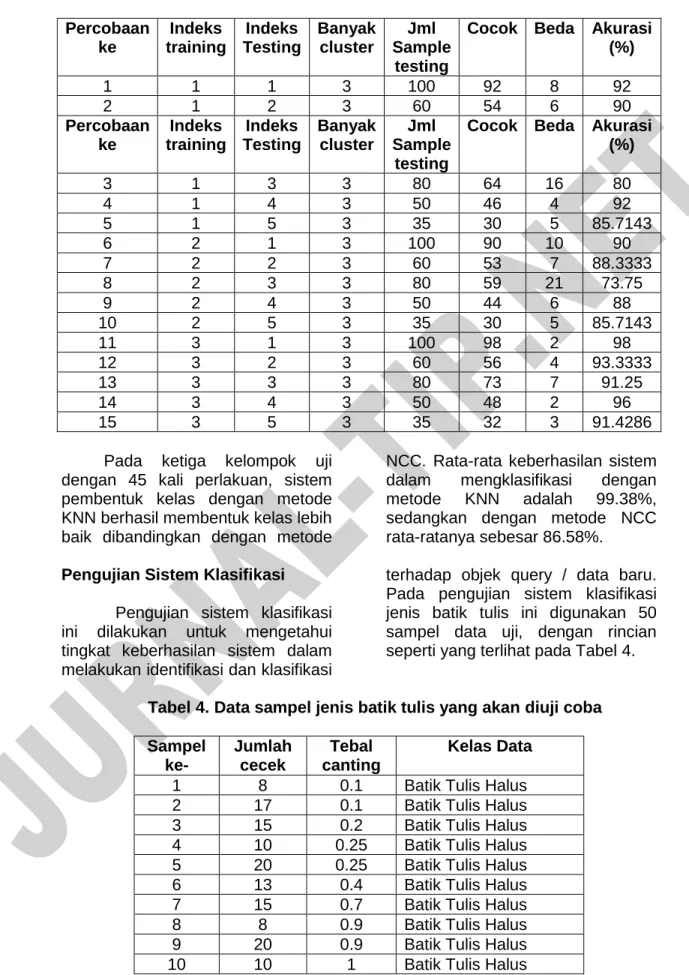
Tabel 3. Hasil Pengujian Kualitas Batik Tulis dengan metode NCC Percobaan
ke
Indeks training
Indeks Testing
Banyak cluster
Jml Sample
testing
Cocok Beda Akurasi (%)
1 1 1 3 100 92 8 92
2 1 2 3 60 54 6 90
Percobaan ke
Indeks training
Indeks Testing
Banyak cluster
Jml Sample
testing
Cocok Beda Akurasi (%)
3 1 3 3 80 64 16 80
4 1 4 3 50 46 4 92
5 1 5 3 35 30 5 85.7143
6 2 1 3 100 90 10 90
7 2 2 3 60 53 7 88.3333
8 2 3 3 80 59 21 73.75
9 2 4 3 50 44 6 88
10 2 5 3 35 30 5 85.7143
11 3 1 3 100 98 2 98
12 3 2 3 60 56 4 93.3333
13 3 3 3 80 73 7 91.25
14 3 4 3 50 48 2 96
15 3 5 3 35 32 3 91.4286
Pada ketiga kelompok uji dengan 45 kali perlakuan, sistem pembentuk kelas dengan metode KNN berhasil membentuk kelas lebih baik dibandingkan dengan metode
NCC. Rata-rata keberhasilan sistem dalam mengklasifikasi dengan metode KNN adalah 99.38%, sedangkan dengan metode NCC rata-ratanya sebesar 86.58%.
Pengujian Sistem Klasifikasi Pengujian sistem klasifikasi ini dilakukan untuk mengetahui tingkat keberhasilan sistem dalam melakukan identifikasi dan klasifikasi
terhadap objek query / data baru.
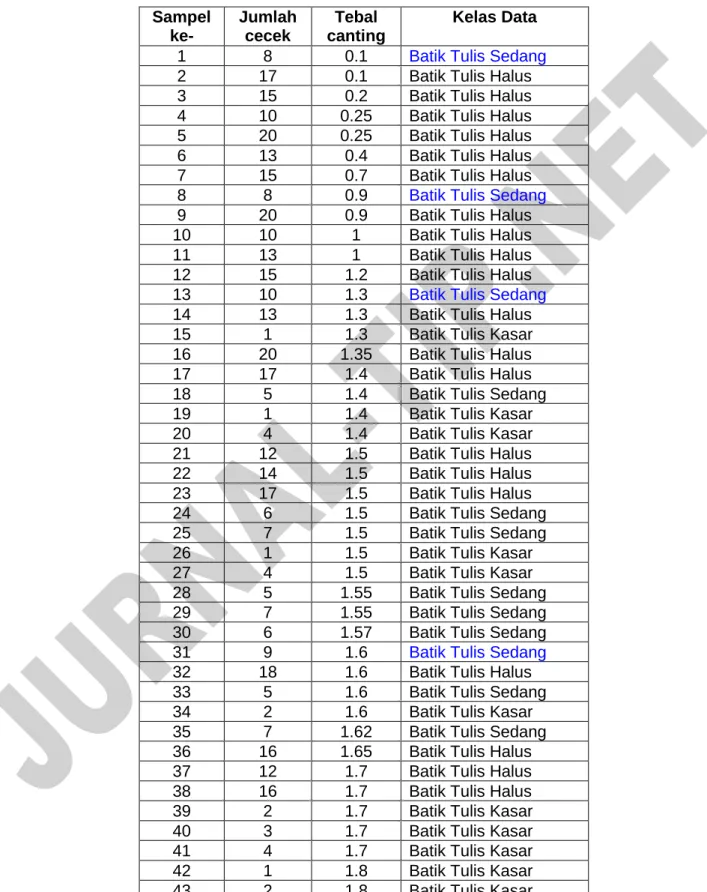
Pada pengujian sistem klasifikasi jenis batik tulis ini digunakan 50 sampel data uji, dengan rincian seperti yang terlihat pada Tabel 4.
Tabel 4. Data sampel jenis batik tulis yang akan diuji coba Sampel
ke-
Jumlah cecek
Tebal canting
Kelas Data
1 8 0.1 Batik Tulis Halus
2 17 0.1 Batik Tulis Halus
3 15 0.2 Batik Tulis Halus
4 10 0.25 Batik Tulis Halus
5 20 0.25 Batik Tulis Halus
6 13 0.4 Batik Tulis Halus
7 15 0.7 Batik Tulis Halus
8 8 0.9 Batik Tulis Halus
9 20 0.9 Batik Tulis Halus
10 10 1 Batik Tulis Halus
11 13 1 Batik Tulis Halus
12 15 1.2 Batik Tulis Halus
13 10 1.3 Batik Tulis Halus
14 13 1.3 Batik Tulis Halus
15 1 1.3 Batik Tulis Kasar
16 20 1.35 Batik Tulis Halus
17 17 1.4 Batik Tulis Halus
Sampel ke-
Jumlah cecek
Tebal canting
Hasil Klasifikasi Sistem
18 5 1.4 Batik Tulis Sedang
19 1 1.4 Batik Tulis Kasar
20 4 1.4 Batik Tulis Kasar
21 12 1.5 Batik Tulis Halus
22 14 1.5 Batik Tulis Halus
23 17 1.5 Batik Tulis Halus
24 6 1.5 Batik Tulis Sedang
25 7 1.5 Batik Tulis Sedang
26 1 1.5 Batik Tulis Kasar
27 4 1.5 Batik Tulis Kasar
28 5 1.55 Batik Tulis Sedang
29 7 1.55 Batik Tulis Sedang
30 6 1.57 Batik Tulis Sedang
31 9 1.6 Batik Tulis Halus
32 18 1.6 Batik Tulis Halus
33 5 1.6 Batik Tulis Sedang
34 2 1.6 Batik Tulis Kasar
35 7 1.62 Batik Tulis Sedang
36 16 1.65 Batik Tulis Halus
37 12 1.7 Batik Tulis Halus
38 16 1.7 Batik Tulis Halus
39 2 1.7 Batik Tulis Kasar
40 3 1.7 Batik Tulis Kasar
41 4 1.7 Batik Tulis Kasar
42 1 1.8 Batik Tulis Kasar
43 2 1.8 Batik Tulis Kasar
44 3 1.8 Batik Tulis Kasar
45 4 1.8 Batik Tulis Kasar
46 2 1.85 Batik Tulis Kasar
47 3 1.85 Batik Tulis Kasar
48 1 2 Batik Tulis Kasar
49 2 2 Batik Tulis Kasar
50 3 2 Batik Tulis Kasar
Dari 50 sampel data uji yang diujikan pada sistem klasifikasi kualitas batik tulis dengan metode KNN, semua sampel dapat diklasifikasikan dengan baik dan benar pada masing-masing pengujian. Sedangkan dengan metode NCC, dari 50 sampel data uji
yang diujikan ternyata tidak semua data dapat diklasifikasikan dengan benar. Pada pengujian ini diperoleh sampel ke-1, 8, 13 dan 31 diklasifikasikan pada kelompok yang berbeda, hal ini seperti yang terlihat pada Tabel 5. Dari pengujian ini tingkat akurasi yang diperoleh
dengan menggunakan metode NCC adalah sebesar 92%
.
Tabel 5. Hasil Klasifikasi yang salah dengan metode KNN
Sampel ke-
Jumlah cecek
Tebal canting
Kelas Data
1 8 0.1 Batik Tulis Sedang
2 17 0.1 Batik Tulis Halus
3 15 0.2 Batik Tulis Halus
4 10 0.25 Batik Tulis Halus
5 20 0.25 Batik Tulis Halus
6 13 0.4 Batik Tulis Halus
7 15 0.7 Batik Tulis Halus
8 8 0.9 Batik Tulis Sedang
9 20 0.9 Batik Tulis Halus
10 10 1 Batik Tulis Halus
11 13 1 Batik Tulis Halus
12 15 1.2 Batik Tulis Halus
13 10 1.3 Batik Tulis Sedang
14 13 1.3 Batik Tulis Halus
15 1 1.3 Batik Tulis Kasar
16 20 1.35 Batik Tulis Halus
17 17 1.4 Batik Tulis Halus
18 5 1.4 Batik Tulis Sedang
19 1 1.4 Batik Tulis Kasar
20 4 1.4 Batik Tulis Kasar
21 12 1.5 Batik Tulis Halus
22 14 1.5 Batik Tulis Halus
23 17 1.5 Batik Tulis Halus
24 6 1.5 Batik Tulis Sedang
25 7 1.5 Batik Tulis Sedang
26 1 1.5 Batik Tulis Kasar
27 4 1.5 Batik Tulis Kasar
28 5 1.55 Batik Tulis Sedang
29 7 1.55 Batik Tulis Sedang
30 6 1.57 Batik Tulis Sedang
31 9 1.6 Batik Tulis Sedang
32 18 1.6 Batik Tulis Halus
33 5 1.6 Batik Tulis Sedang
34 2 1.6 Batik Tulis Kasar
35 7 1.62 Batik Tulis Sedang
36 16 1.65 Batik Tulis Halus
37 12 1.7 Batik Tulis Halus
38 16 1.7 Batik Tulis Halus
39 2 1.7 Batik Tulis Kasar
40 3 1.7 Batik Tulis Kasar
41 4 1.7 Batik Tulis Kasar
42 1 1.8 Batik Tulis Kasar
43 2 1.8 Batik Tulis Kasar
44 3 1.8 Batik Tulis Kasar Sampel
ke-
Jumlah cecek
Tebal canting
Kelas Data
45 4 1.8 Batik Tulis Kasar
46 2 1.85 Batik Tulis Kasar
47 3 1.85 Batik Tulis Kasar
48 1 2 Batik Tulis Kasar
49 2 2 Batik Tulis Kasar
50 3 2 Batik Tulis Kasar
Pada ketiga kelompok uji dengan 9 kali percobaan diatas, sistem klasifikasi dengan metode KNN berhasil mengklasifikasikan sampel lebih baik dibandingkan dengan metode NCC. Rata-rata keberhasilan sistem dalam mengklasifikasi dengan metode KNN adalah 99.11%, sedangkan dengan metode NCC rata-rata keberhasilan sistem dalam mengklasifikasikan adalah sebesar 86.44%.
KESIMPULAN
Berdasarkan pengujian yang dilakukan, implementasi metode KNN pada sistem pembentuk kelas dan sistem klasifikasi memberikan hasil yang lebih baik dibandingkan dengan menggunakan metode NCC.
Pada sistem pembentuk kelas menggunakan metode KNN, semua data testing dapat dikembalikan dengan benar, baik untuk data testing yang sama persis dengan data trainingnya maupun data testing yang berbeda dengan data testingnya. Tingkat akurasi yang diperoleh dari 45 kali pengujian rata- rata mencapai 99.38% .
Sedangkan pada sistem pembentuk kelas menggunakan metode NCC, baik untuk data testing yang sama persis dengan data training maupun data testing yang berbeda dengan data training tingkat akurasi yang diperoleh hanya mencapai 87% untuk 45 kali pengujian yang telah dilakukan.
Semakin banyak jumlah data training yang diperkenalkan pada sistem, maka kemampuan sistem mengenali data testing semakin baik. Hal ini dibuktikan pada pengujian dengan kelompok uji kain mori, dimana jumlah data training yang diujikan mulai dari 350, 440 hingga 770 data. Rata-rata tingkat akurasi hampir sama yaitu 99.98%
dengan menggunakan metode KNN dan 99.97% dengan menggunakan metode NCC.
Untuk sistem klasifikasi pada ketiga kelompok uji dengan menggunakan metode KNN, sistem berhasil mengklasifikasikan 50 sampel dengan benar dibandingkan dengan menggunakan metode NCC.
Rata-rata keberhasilan sistem klasifikasi dengan menggunakan metode KNN adalah 99.11%
sedangkan dengan metode NCC keberhasilannya hanya mencapai 86.44%.
Dalam penelitian ini mungkin masih ditemukan beberapa kekurangan, dan masih dapat dikembangkan lagi dengan metode lainnya. Salah satunya penggunaan metode distance metric yang lain untuk mengukur kemiripan atau kedekatan antara vektor fitur dapat dicoba pada penelitian berikutnya.
Selain itu juga pada metode NCC, untuk menemukan pusat cluster dapat dipergunakan metode clustering lainnya.
DAFTAR PUSTAKA
[1] Teknomo, K. K-Nearest Neighbors Tutorial, Tersedia di situs:
http://people.revoledu.com/kar di/ tutorial/KNN .2006. [25 Juni 2008]
[2]. Kusumadewi, S. Aplikasi
Logika Fuzzy untuk
Pendukung Keputusan, Graha Ilmu, Yogyakarta. 2002.
[3]. Schowengert, R.A., Multispectral Classification, Arizona. 2003.