29
BAB III
METODOLOGI PENELITIAN
3.1. Objek Penelitian
Objek penelitian pada penelitian ini adalah untuk melakukan analisis sentimen masyarakat terhadap pelaksanaan pendidikan di Indonesia selama masa pandemi COVID-19. Dengan adanya COVID-19 di Indonesia, maka pemerintah mengeluarkan peraturan tentang sosial distancing atau pembatasan interaksi sosial secara mendadak.
Sektor pendidikan menjadi salah satu sektor yang terkena dampak adanya COVID-19, sehingga pemerintah meliburkan dan merubah proses belajar dan mengajar dilakukan dari rumah[3].
Penelitian ini akan memanfaatkan media sosial Twitter sebagai sumber data dan akan dilakukan analisis untuk mendapatkan sentimen masyarakat terhadap pelaksanaan pendidikan di Indonesia selama masa pandemi COVID-19. Pengambilan data dilakukan dengan kata kunci “pembelajaran online”, berdasarkan dengan Surat Edaran Nomor 15 Tahun 2020 yang diterbitkan oleh Kementerian Pendidikan dan Kebudayaan atau yang biasa disebut dengan “Kemendikbud”, yaitu tentang penyelenggaraan Belajar Dari Rumah dalam masa darurat penyebaran COVID-19. Dalam surat edaran tersebut, disebutkan bahwa tujuan pelaksanaan Belajar Dari Rumah adalah untuk memastikan hak para peserta didik terpenuhi selama masa darurat COVID-19[34].
Penelitian ini akan berfokus kepada hasil analisis sentimen masyarakat terhadap pelaksanaan pendidikan di Indonesia selama masa pandemi COVID-19, apakah hasil
30 sentimen mengarah kepada hal yang positif atau negatif, serta penelitian ini dapat dijadikan sumber informasi agar pelaksanaan proses pendidikan selama masa pandemi COVID-19 dapat dipertahankan serta dikembangkan melalui hasil sentimen masyarakat. Algoritma Naïve Bayes, K-Nearest Neighbor dan Support Vector Machine akan digunakan untuk melakukan analisis sentimen pada penelitian kali ini.
3.2. Teknik Pengumpulan Data
Pengumpulan data dilakukan dengan menggunakan Python yang memiliki fitur untuk melakukan pengambilan data pada media sosial Twitter atau biasa disebut dengan data scraping yang dapat melakukan pengambilan data historical tweets tanpa menggunakan API Twitter. Fitur pada Python yang digunakan pada pengumpulan data adalah twint yang merupakan sebuah package yang telah disediakan dan dapat digunakan dalam melakukan pengambilan data dari media sosial Twitter yang bersifat gratis dan dapat digunakan tanpa harus mendaftar pada media sosial Twitter. Data yang terkumpul pada penelitian ini yaitu berjumlah sebanyak 15085 data dengan kata kunci
“pembelajaranonline” dan disimpan dalam format csv.
3.3. Alur Penelitian
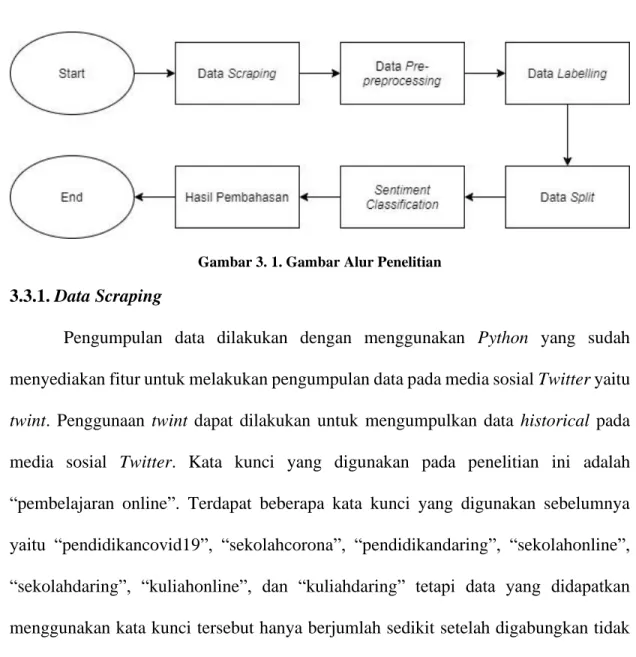
Penelitian ini terdiri dari beberapa tahapan yaitu Data Scraping, Data Pre- Processing, Data Labeling, Data Sampling, Sentiment Classification, Hasil Pembahasan. Penelitian ini menggunakan referensi dari penelitian sebelumnya yang dilakukan oleh Muhammad Rangga Aziz Nasution, Mardhiya Hayaty yang melakukan perbandingan akurasi dan waktu proses algoritma K-NN dan SVM dalam analisis
31 sentimen twitter[8]. Penelitian yang dilakukan sebelumnya memiliki tahapan pengumpulan data, pre-processing, pembobotan, pelatihan dan pengujian, evaluasi model, dan validasi model. Alur pada penelitian ini dapat dilihat pada gambar 3.1 dibawah ini.
Gambar 3. 1. Gambar Alur Penelitian
3.3.1. Data Scraping
Pengumpulan data dilakukan dengan menggunakan Python yang sudah menyediakan fitur untuk melakukan pengumpulan data pada media sosial Twitter yaitu twint. Penggunaan twint dapat dilakukan untuk mengumpulkan data historical pada media sosial Twitter. Kata kunci yang digunakan pada penelitian ini adalah
“pembelajaran online”. Terdapat beberapa kata kunci yang digunakan sebelumnya yaitu “pendidikancovid19”, “sekolahcorona”, “pendidikandaring”, “sekolahonline”,
“sekolahdaring”, “kuliahonline”, dan “kuliahdaring” tetapi data yang didapatkan menggunakan kata kunci tersebut hanya berjumlah sedikit setelah digabungkan tidak mencapai 500 jumlah data. Dengan itu penelitian ini menggunakan kata kunci
“pembelajaran online” yang terdapat pada website Pusdatin Kemendikbud (Pusat Data
32 dan Teknologi Informasi Kementerian Pendidikan dan Kebudayaan) tentang
“Pembelajaran Online di Tengah Pandemi Covid-19, Tantangan yang Mendewasakan”
3.3.2. Data Pre-Processing
Tahapan Pre-Processing merupakan langkah pertama yang dilakukan pada melakukan Text Mining untuk melakukan perubahan terhadap agar sesuai dengan yang diingkan. Tahapan ini dilakukan dengan menggunakan R Studio sebagai tools.
Terdapat beberapa langkah untuk melakukan Pre-Processing:
1. Transform Cases = mengubah semua tulisan menjadi huruf kecil agar tidak ada tulisan dengan huruf besar.
2. Tokenize = pemecahan text menjadi beberapa komponen kecil berdasarkan kata pada tweet.
3. Remove URL = menghilangkan alamat website yang terdapat pada text tweet, karena alamat URL adalah text yang tidak efektif dan tidak memiliki arti untuk analisa.
4. Remove Duplicates = data yang didapat tentunya memiliki beberapa data yang sama, sehingga akan dilakukan penghapusan terhadap data yang sama atau adanya duplikat.
5. Remove Punctuation = menghapus simbol, atau karakter yang bukan merupakan alphabet.
6. Remove Emoticon = menghilangkan emoticon yang terdapat pada data.
33 7. Filter Stopwords = membuat teks atau dokumen agar sesuai dengan kata – kata
dasar dengan aturan bahasa Indonesia.
3.3.3. Data Labeling
Setelah melakukan tahap pembersihan data, Langkah selanjutnya adalah untuk memberikan label pada setiap data. Data labelling dilakukan untuk memberikan label positif dan negatif dari setiap data yang sudah melalui tahapan Pre-Processing. Pada penelitian ini, proses pelabelan data dilakukan dengan menggunakan aplikasi Rapid Miner dengan operator yang telah disediakan oleh aplikasi Rapid Miner yaitu operator Extract Sentiment. Pemberian label pada data akan dilakukan menggunakan sentiwordnet yang merupakan sebuah basis data yang diciptakan untuk melakukan klasifikasi sentimen pada saat melakukan opinion mining dengan memanfaatkan aplikasi RapidMiner. Pemberian label menggunakan sentiwordnet dapat menghasilkan klasifikasi sentimen dalam bentuk angka berupa skor yang nantinya akan menjadi indikasi untuk pemberian label positif, negatif, maupun juga netral. Pada penelitian yang dilakukan oleh Sherly Christina dan Deddy Ronaldo dengan judul penelitian “A SURVEY OF SENTIMENT ANALYSIS USING SENTIWORDNET ON BAHASA INDONESIA” menyebutkan bahwa kinerja sentiwordnet untuk mendukung hasil analisis sentimen menunjukkan bahwa melakukan data labelling dengan sentiwordnet dapat berkontribusi untuk meningkatkan hasil akurasi yang dilakukan[35]. Contohnya adalah dengan sebuah logika “jika angka skor lebih besar dari pada 0, maka klasifikasi
34 bersifat positif, jika angka skor lebih kecil dari pada 0 maka klasifikasi bersifat negatif, dan jika angka skor sama dengan 0 maka hasil klasifikasi bersifat netral”[35].
3.3.4. Data Split
Sampling merupakan pengambilan sebanyak n objek dari sebuah populasi yang berukuran n. Populasi merupakan sebuah objek penelitian, yang dapat berupa benda sebagai pengukuran. Sedangkan sample(n) merupakan sebagian dari jumlah populasi.
Sampling probabilitas atau biasa dikenal dengan random sampling, adalah memilih atau mengambil beberapa unit sampel yang ditentukan besarnya peluang satuan sampel untuk terpilih kedalam sampel. Teknik simple random sampling adalah memilih secara acak sampel yang akan dipilih. Peluang terpilihnya harus diketahui jumlah rasio yang akan menentukan data yang akan ditentukan menjadi data train dan juga data test[36].
Pada penelitian sebelumnya dengan judul “ANALISIS SENTIMEN TERHADAP KINERJA PELAYANAN PUBLIK DI KOTA SURABAYA BERDASARKAN KLASIFIKASI KOMENTAR DI MEDIA SOSIAL DENGAN MENGGUNAKAN ALGORITMA NAÏVE BAYES” pembagian data atau data split sebesar 70% data train dan 30% data test yang berhasil melakukan klasifikasi sentimen dengan menggunakan twitter sebagai sumber data[37].
3.4.4. Sentiment Classification
Proses sentiment classification dilakukan untuk membandingkan metode sentimen yaitu Naïve Bayes, K-Nearest Neighbor, dan Support Vector Machine pada pelaksanaan pendidikan selama masa pandemi COVID-19 yang terjadi di Indonesia.
35 Tahapan ini dilakukan untuk mengetahui metode yang tepat untuk melakukan analisis sentimen masyarakat pada pendidikan di Indonesia selama masa pandemi COVID-19.
Perbandingan metode akan dilakukan untuk melakukan analisa sentimen terhadap data yang telah dikumpulkan melalui aplikasi RapidMiner. Proses sentiment classification dilakukan dengan menggunakan operator cross validation yang telah disediakan oleh RapidMiner. Cross Validation merupakan sebuah metode pada text mining yang memiliki tujuan untuk memperoleh hasil akurasi yang lebih baik. Cross Validation biasa juga disebut dengan k-fold cross validation, yaitu melakukan proses pada data sebanyak k kali dengan menggunakan parameter yang sama menurut Santosa dan Umam[38]. Cross Validation juga merupakan sebuah teknik validasi dari model Split Validation yang melakukan validasi dengan mengukur training error pada data test yang di uji. Pada penelitian yang telah dilakukan oleh beberapa ahli data mining, model pengujian dengan Cross Validation biasanya menerapkan 10-Cross Validation yang sudah merupakan suatu standar dan mampu melakukan validasi yang lebih praktis dan efisien serta akan meningkatkan nilai performanya. Penggunaan k-fold cross validation dapat dilakukan pada aplikasi RapidMiner[38].
Operator cross validation pada RapidMiner menggunakan Number of folds yang digunakan untuk memberikan nilai k pada cross validation sedangkan sampling type digunakan untuk membagi teknik sampling pada dataset. Konsep k-fold cross validation adalah tidak hanya membuat sampel pada data uji, tetapi membagi dataset menjadi bagian berbeda dengan ukuran sama. Subset data latih akan dilatih dan
36 divalidasi dengan subset validasi atau data uji untuk menghasilkan nilai akurasi sebenarnya yang dihasilkan oleh metode klasifikasi.
3.3.5. Hasil Penelitian
Setelah proses klasifikasi sentimen dengan menggunakan metode Naïve bayes, K-Nearest Neighbor, dan Support Vector Machine hasil yang didapat akan dilakukan evaluasi untuk mengetahui seberapa besar akurasi yang dihasilkan masing – masing metode tersebut. Proses evaluasi akan dilakukan dengan melakukan uji pada Confusion Matrix dengan parameter accuracy, precision, dan recall[24]:
Tabel 3. 1. Tabel Confusion Matrix
Parameter Rumus
Accuracy (A+D) / (A+B+C+D)
Precision A / (C+A)
Recall A / (A+D)
Tabel 3.1 merupakan tabel confusion matrix yang dapat dilakukan untuk menentukan nilai akurasi, presisi, dan recall. Akurasi dapat diartikan sebagai nilai prediksi yang mendekati hasil nilai aktual atau nilai yang sebenarnya, sedangkan presisi, merupakan nilai yang menunjukan kesamaan atau ketepatan proses klasifikasi, dan recall dapat diartikan sebagai nilai yang menunjukkan banyaknya suatu dokumen atau teks yang diprediksi positif dan benar yang dibandingkan dengan keseluruhan dokumen atau teks saat melakukan klasifikasi menurut Theopilus Bayu Sasongko[39].