1 PENDAHULUAN
Latar Belakang
Salah satu persoalan lingkungan yang muncul hampir setiap tahun di Indonesia terutama pasca tahun 2000 adalah kebakaran hutan, termasuk di wilayah provinsi Riau. Kebakaran hutan dan lahan merupakan salah satu bentuk bencana yang makin sering terjadi, dan dampak yang ditimbulkan sangat merugikan bila dilihat dari aspek fisik-kimia, biologi, sosial ekonomi maupun aspek ekologi. Dampak tersebut tidak hanya dialami oleh masyarakat di provinsi Riau saja, tetapi juga oleh masyarakat di provinsi sekitar Riau. Selain dekat dengan wilayah lain di Indonesia, provinsi Riau juga dekat dengan wilayah dari negara lain, yaitu Singapura. Sehingga apabila terjadi kebakaran hutan di wilayah provinsi Riau, asap yang ditimbulkan tidak hanya dirasakan oleh penduduk Indonesia saja, tetapi juga dapat dirasakan oleh penduduk Singapura. Apabila peristiwa ini mendapat pencegahan atau penanggulangan yang baik akan mengurangi kuantitas dampak yang ditimbulkan. Salah satunya dengan deteksi hotspot.
Persebaran hotspot merupakan informasi yang dapat digunakan untuk pencegahan dan analisis terjadinya kebakaran hutan dan lahan. Data persebaran hotspot dapat digunakan untuk deteksi dini kebakaran hutan. Data ini dapat diperoleh dengan pencitraan jarak jauh menggunakan satelit. Apabila lokasi hotspot dapat diketahui maka dapat diambil langkah dini untuk menanggulangi kebakaran hutan.
Data persebaran hotspot berukuran besar dapat dianalisis menggunakan teknik spatial data mining. Salah satu teknik dalam spatial data mining adalah spatial decision tree. Spatial decision tree akan membangun sebuah decision tree dari data spasial yang dapat digunakan untuk membentuk aturan-aturan klasifikasi. Salah satu metode pembentukan spatial decision tree adalah dengan menghitung hubungan spasial antarobjek. Kemudian hubungan spasial tersebut diperlakukan seperti atribut biasa. Sehingga algoritma pembentukan decision tree konvensional dapat diterapkan untuk membangun spatial decision tree. Tujuan
Penelitian ini bertujuan membentuk sebuah model klasifikasi yang dapat digunakan untuk memprediksi jumlah hotspot di suatu wilayah dengan mempertimbangkan hubungan antara jumlah hotspot di wilayah tersebut dan data spasial (HPH, HTI, TGHK, land system). Selain
itu, penelitian ini juga bertujuan melihat karakteristik suatu wilayah tempat terjadinya hotspot.
Ruang Lingkup
Ruang lingkup penelitian ini adalah membentuk spatial decision tree untuk data persebaran hotspot di wilayah provinsi Riau pada tahun 2005. Data yang digunakan adalah data provinsi Riau yang meliputi data persebaran hotspot pada tahun 2005, data land system, data sebaran Hak Pengusahaan Hutan (HPH), data sebaran Hutan Tanaman Industri (HTI), dan data Tata Guna Hutan Kesepakatan (TGHK).
Manfaat Penelitian
Penelitian ini diharapkan dapat membentuk model klasifikasi dari persebaran hotspot untuk wilayah provinsi Riau. Selain itu, pengguna juga dapat mengetahui karakteristik suatu wilayah tempat terjadinya hotspot, sehingga dapat dilakukan penanggulangan yang tepat dan sesuai dengan karakteristik wilayah tersebut.
TINJAUAN PUSTAKA Data Spasial dan Operasi Spasial
Data spasial menjelaskan tentang lokasi dari feature geografis dan atributnya (informasi tentang sebuah feature biasanya disimpan sebagai koordinat dan topologi). Model dari data spasial dibedakan menjadi dua kategori, yaitu field dan objek. Dalam sistem informasi geografis, model fungsional disebut model field. Jika data spasial dimodelkan sebagai sebuah koleksi dari polygon, maka data tersebut disebut model objek. Model field biasanya digunakan untuk memodelkan data spasial yang cenderung kontinyu seperti elevasi, temperatur, dan variasi tanah. Sedangkan model objek lebih digunakan untuk memodelkan jaringan jalan dan bidang tanah yang merupakan properti pajak (Shekhar & Chawla 2003).
Operasi spasial pada data model field merupakan hubungan dan interaksi antarfield yang berbeda, yang dinyatakan dengan operasi field. Dalam operasi field, subset sebuah field dipetakan kepada field lainnya. Contoh dari operasi field adalah union (+) dan composition (o).
f+g :x →f(x)+ g(x) f o g :x →f g(x)
Pada data model objek, hubungan antarobjek ditentukan oleh posisi objek tersebut dalam
2 ruang (Shekhar & Chawla 2003). Topologi
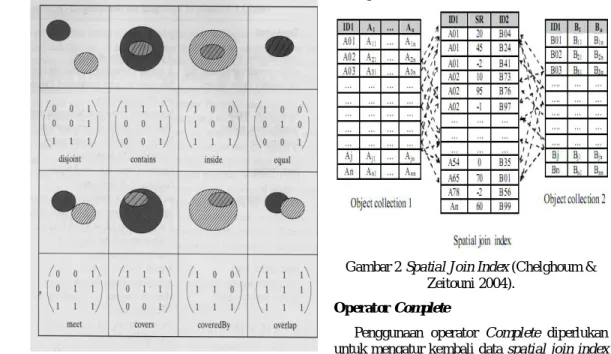
merupakan informasi tentang hubungan antaratribut spasial (Demer 2003). Hubungan topological biner di antara dua objek, A dan B dalam ruang R 2 ditentukan berdasarkan perpotongan (intersection) antara interior A (Ao), batas (boundary) A (∂A) dan eksterior A (A-) dengan interior B (Bo), batas (boundary) B (∂B) dan eksterior B (B-). Matriks nine intersection dibentuk oleh keenam bagian objek tersebut yang mendefinisikan hubungan topological.
Sembilan hubungan yang dapat ditunjukkan dengan menggunakan matriks nine intersection adalah disjoint, meet, overlap, equal, contains, inside, covers, dan covered by, seperti terlihat pada Gambar 1. Sebagai contoh, hubungan disjoint dapat dijelaskan dalam model matriks nine intersection, yaitu dengan matriks boolean berikut
Nilai 0 menunjukkan bahwa interior (A) tidak memiliki titik bersama dengan interior (B) ataupun dengan batas (B). Begitu juga dengan interior (B) dengan batas (A) dan batas (A) dengan batas (B) (Shekhar & Chawla 2003).
Gambar 1 Hubungan Topological Biner (Shekhar & Chawla 2003).
Hubungan Spasial
Salah satu perhatian utama dalam spatial data mining adalah mempertimbangkan hubungan spasial di antara objek. Dalam klasifikasi spasial nilai atribut dari objek-objek tetangga mungkin ikut menentukan sebuah objek digolongkan sebagai kelas tertentu, sehingga nilai atribut objek tetangga harus diperhitungkan (Zeitouni & Chelghoum 2001).
Hubungan spasial merupakan suatu hubungan atau asosiasi dari properti lingkungan geografis. Tetapi tidak seperti model data relational, hubungan spasial bersifat tersembunyi. Untuk menghitungnya diperlukan banyak operasi spatial join (Chelgoum et al 2002).
Spatial Join Index
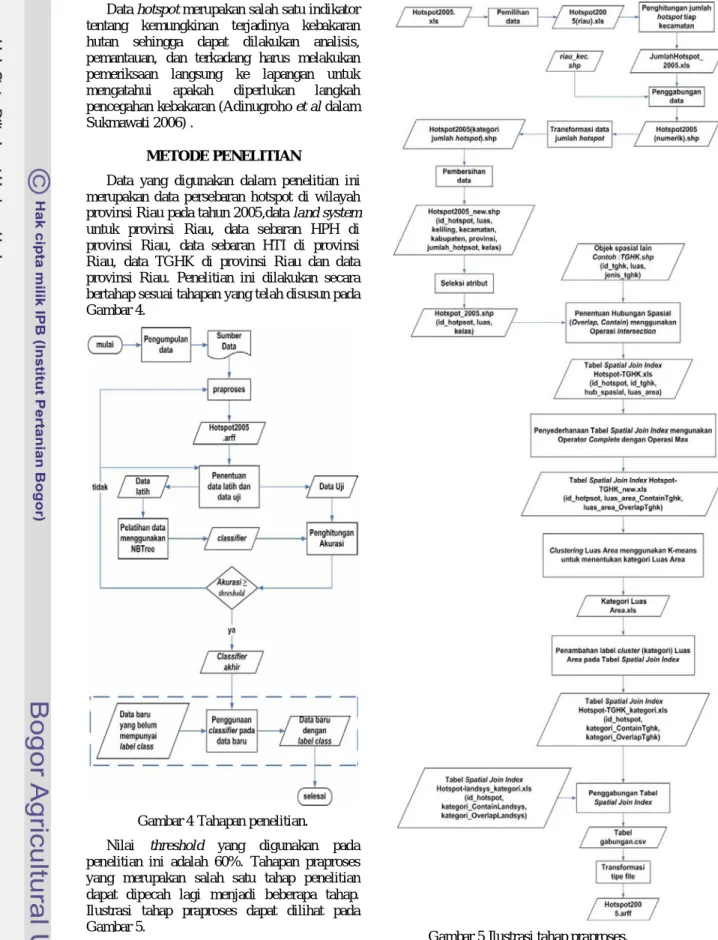
Join index merupakan sebuah teknik yang digunakan untuk mempercepat penggabungan dalam kerangka basis data relasional. Perluasan dari join index untuk digunakan pada data spasial dengan menambahkan atribut ketiga yang menunjukkan hubungan spasial diantara dua objek adalah spatial join index (Chelghoum & Zeitouni 2004).
Spatial join index merupakan sebuah tabel tambahan yang menjadi acuan dalam mempertemukan objek dari layer thematic R dengan S dan menyimpan nilai hubungan spasial keduanya, seperti terlihat pada Gambar 2 (Chelghoum et al 2002).
Gambar 2 Spatial Join Index (Chelghoum & Zeitouni 2004).
Operator Complete
Penggunaan operator Complete diperlukan untuk mengatur kembali data spatial join index ke dalam sebuah tabel yang unik tanpa adanya duplikasi data objek. Prinsip dari operator
3 Complete adalah membangkitkan untuk setiap
nilai atribut tabel yang terhubung dengan atribut dari tabel hasil. Pada tabel yang dihasilkan, berbagai metode data mining konvensional dapat diaplikasikan (Chelghoum & Zeitouni 2004).
Definisi dari operator Complete dapat dilihat di bawah ini (Chelghoum & Zeitouni 2004) Misalkan terdapat tiga tabel, yaitu R (ID1, A1,…, An), V (ID2, B1, …, Bm) dan I (ID1, ID2, W). Atribut kunci untuk setiap tabel ditandai dengan atribut yang digaris bawahi. Atribut Bi (i=1, …, m) adalah atribut kualitatif dan b ij (j = 1 , …Ki) adalan nilai beda untuk atribut tersebut.
Misalkan F = {F1, F2,…, Fm} adalah kumpulan fungsi agregat.
COMPLETE (R, V, I, F) adalah sebuah tabel T yang mengikuti skema ini:
T (ID1, A1,… An, W_b11, …, W_b1K1, …, W_bm1, …, W_b mKm) dimana:
ID1 adalah atribut kunci,
t = (id1, a1, a2, …, an, W_b11, …, W_b1K1, …, W_bm1, W_bm2, …, W_bmKm) Œ T,
- (id1, a1, a2, …, an ) = s (ID1 = Id1 )(R), - W_bij = Fi (s (ID1 = Id1) (I) • s (Bi =
bij) (V); W) if s (ID1 = Id1) (I) jika ID1 tidak kosong, selainnya diisi dengan NULL.
Contoh penggunaan dari operator COMPLETE terdapat pada Gambar 3.
Gambar 3 Penggunaan Operator COMPLETE (Chelghoum & Zeitouni 2004). Tujuan utama penggunaan operator Complete adalah untuk menghilangkan duplikasi yang terjadi pada atribut ID1 di Tabel I, yang merupakan objek dari Accident R. Sehingga diperoleh satu tabel baru yang berisi semua nilai ID1 dengan kombinasi antara nilai atribut ID2 dan nilai atribut distance.
Spatial Decision Tree
Klasifikasi atau pengenalan kelas memberikan deskripsi logis yang menghasilkan pembagian yang terbaik dari kumpulan data yang diambil berdasarkan satu atau beberapa atribut. Aturan klasifikasi merupakan sebuah decision tree dimana setiap node mengandung sebuah kriteria dari sebuah atribut. Leaf node mengandung objek yang seharusnya termasuk ke suatu kelas.
Decision tree adalah sebuah struktur tree dimana setiap internal node menunjukkan sebuah kriteria dalam sebuah atribut, setiap brach menunjukkan sebuah hasil dari kriteria tersebut, dan sebuah leaf node menunjukkan label kelas (Han & Kamber 2006). Spatial decision tree merupakan perluasan dari sebuah decision tree dilihat dari dimensi spasial yang dimilikinya (Zeitouni & Chelghoum 2001). Algoritme NBTree
Salah satu algoritme pembentukan decision tree adalah algoritme NBTree. Algoritme NBTree merupakan algoritme hasil penggabungan teknik decision tree classifier dengan naïve-bayes classifier. Algoritme ini akan membangun decision tree dengan node yang mengandung univariate split seperti decision tree biasa, tetapi pada node leaf terkandung naïve-bayes classifier (Kohavi 1996).
Algoritme NBTree (Kohavi 1996)
Input : himpunan T yang terdiri dari instance dengan label
Output : sebuah pohon keputusan dengan pengkategori Naïve-bayes pada daun
1. Hitung utility untuk setiap atribut , . Untuk atribut kontinyu, dibuat sebuah threshold.
2. Misalkan adalah atribut
dengan nilai utility tertinggi.
3. Jika tidak lebih tinggi dibanding nilai utility yang dimiliki node yang sekarang, buat model Naïve-Bayes untuk node yang sekarang dan kembali ke langkah 1. 4. Bagi T menurut pengujian di . Jika
adalah kontinyu, sebuah pembagian menggunakan threshold dibuat untuk semua nilai yang mungkin.
5. Untuk setiap child, panggil algoritme secara rekursif untuk membagi T yang sesuai dengan pengujian dari child. Dengan memberikan sekumpulan instance ke suatu node, algoritme NBTree akan
4 melakukan evaluasi utility of split untuk setiap
atribut. Jika utility terbesar dari semua atribut lebih tinggi dibanding utility yang dimiliki node yang sekarang, maka akan dilakukan pembagian instance-instance yang ada berdasarkan atribut tersebut (William et all 2006).
Utility of node dihitung dengan melakukan diskretisasi pada data yang ada dan menghitung estimasi akurasi 5-fold cross validation dari penggunaan naïve-bayes di node tersebut. Sedangkan utility of split adalah jumlah bobot dari utility of node, dimana bobot yang diberikan ke sebuah node sebanding dengan jumlah instance yang diturunkan node tersebut. Pembagian ditetapkan signifikan jika reduksi relatif terhadap kesalahan lebih bagus dari 5% dan setidaknya terdapat 30 instance di node tersebut. Hal ini untuk menghindari terjadinya pembagian dengan nilai yang kecil (Kohavi 1996).
Naive Bayes Classifier
Untuk mengklasifikasikan sebuah record, model Naive Bayes melakukan penghitungan posterior probability untuk setiap kelas Y (Tan et al 2005).
P(Y|X)= P(Y)Πi=1
d P(X i|Y)
P(X)
Peluang bersyarat P( = | = ) diperkirakan dengan membagi jumlah instance di kelas yang memiliki atribut dengan jumlah instance di kelas .
Algoritme K-Means
Algoritme K-Means merupakan salah satu algoritme pembentukan cluster dengan jenis cluster prototype-based. Cluster yang dihasilkan oleh teknik prototype-based merupakan himpunan objek, sehingga sebuah objek di dalam cluster lebih dekat dengan pusat cluster tersebut dibanding dengan pusat cluster lain. Pusat cluster pada K-Means merupakan sebuah centroid yang biasanya nilai rata-rata dari titik yang ada di dalam cluster. Langkah pertama dari algoritme K-Means adalah memilih k centroid awal, dimana k merupakan jumlah cluster yang diinginkan pengguna. Kemudian, setiap titik dimasukkan ke dalam cluster dengan jarak ke centorid yang terdekat. Langkah selanjutnya nilai centroid dari setiap cluster diperbarui berdasarkan titik yang terdapat dalam cluster. Langkah-langkah tersebut dilakukan berulang sampai nilai centroid tidak berubah (Tan et al 2005). Algoritme K-Means (Tan et al 2005 )
1. Tentukan k buah objek sebagai pusat cluster awal;
2. ulangi
3. tandai masing - masing untuk sebuah cluster, dimana objek tersebut lebih mirip didasarkan pada nilai rataan objek tersebut dalam sebuah cluster;
4. hitung nilai pusat cluster untuk masing masing cluster;
5. sampai tidak ada perubahan.
Algoritme K-Means mengambil parameter masukan k, dan membagi sebuah himpunan objek ke dalam k cluster, sehingga menghasilkan similaritas intracluster tinggi tetapi similaritas intercluster rendah (Han & Kamber 2006).
Confusion Matrix
Confusion matrix merupakan sebuah tabel yang berisi jumlah banyaknya test record yang diprediksi secara benar dan tidak benar oleh model klasifikasi. Bentuk dari confussion matrix terlihat pada Tabel 1. Setiap entri pada fij
pada tabel ini menyatakan banyaknya record dari kelas i yang diprediksi ke dalam kelas j. Tabel 1 Confussion Matrix (Tan et al 2005)
Kelas yang diprediksi Kelas = 1 Kelas = 0 Kelas
aktual
Kelas = 1 f11 f11
Kelas = 2 f01 f00
Informasi dari confusion matrix diperlukan untuk menentukan kinerja suatu model klasifikasi. Informasi ini dapat diringkas ke dalam suatu nilai seperti akurasi (Tan et al 2005).
akurasi=banyaknya prediksi yang benar total banyaknya prediksi = f11+ f00
f11+ f10+ f01+ f00
Hotspot (titik panas)
Hotspot (titik panas) merupakan suatu istilah untuk titik yang memiliki suhu lebih tinggi dibanding dengan nilai ambang yang ditentukan data digital satelit. Data digital yang digunakan berasal dari satelit NOAA-AVHRR (National Oceanic Atmospheric Administration, Advanced Very High Resolution Radiometer). Nilai ambang batas yang digunakan dalam menentukan suatu titik panas yaitu 315 K (42o C) untuk tangkapan sinyal siang hari dan 310 K (37oC) untuk tangkapan sinyal pada malam hari (Dephut dalam Yonatan 2006).
5 Data hotspot merupakan salah satu indikator
tentang kemungkinan terjadinya kebakaran hutan sehingga dapat dilakukan analisis, pemantauan, dan terkadang harus melakukan pemeriksaan langsung ke lapangan untuk mengatahui apakah diperlukan langkah pencegahan kebakaran (Adinugroho et al dalam Sukmawati 2006) .
METODE PENELITIAN
Data yang digunakan dalam penelitian ini merupakan data persebaran hotspot di wilayah provinsi Riau pada tahun 2005,data land system untuk provinsi Riau, data sebaran HPH di provinsi Riau, data sebaran HTI di provinsi Riau, data TGHK di provinsi Riau dan data provinsi Riau. Penelitian ini dilakukan secara bertahap sesuai tahapan yang telah disusun pada Gambar 4.
Gambar 4 Tahapan penelitian.
Nilai threshold yang digunakan pada penelitian ini adalah 60%. Tahapan praproses yang merupakan salah satu tahap penelitian dapat dipecah lagi menjadi beberapa tahap. Ilustrasi tahap praproses dapat dilihat pada Gambar 5.