PERBANDINGAN METODE KUANTISASI VEKTOR DAN MODEL
MARKOV TERSEMBUNYI PADA PENGENALAN PEMBICARA
BERBAHASA INDONESIA
TESIS
Karya tulis sebagai salah satu syarat untuk memperoleh gelar Magister dari
Institut Teknologi Bandung
Oleh
DEVI HANDAYA NIM : 23214029
(Program Studi Magister Teknik Elektro)
INSTITUT TEKNOLOGI BANDUNG
Juni 2016
i
ABSTRAK
PERBANDINGAN METODE KUANTISASI VEKTOR DAN
MODEL MARKOV TERSEMBUNYI PADA PENGENALAN
PEMBICARA BERBAHASA INDONESIA
Oleh
Devi Handaya
NIM: 23214029
(Program Studi Magister Teknik Elektro)
Tesis ini menyajikan perbandingan dua buah metode pengklasifikasi berdasarkan tingkat akurasi dalam mengenali pembicara berbahasa Indonesia. Metode pertama adalah Kuantisasi Vektor (KV) yang merupakan sebuah metode pengenalan pembicara berbasis jarak distorsi dan metode kedua adalah Model Markov Tersembunyi (MMT) berbasis nilai peluang dari data yang terobservasi. Perbandingan dilakukan untuk pengucapan sebuah kata, kalimat sederhana, dan kalimat lengkap. Berdasarkan eksperimen, dapat disimpulkan bahwa umumnya metode MMT menghasilkan akurasi yang lebih baik dari pada metode KV terutama untuk data dengan pengucapan kalimat sederhana.
Kata kunci: Kuantisasi Vektor (KV), Model Markov Tersembunyi (MMT), Pengenalan Pembicara Berbahasa Indonesia
ii
ABSTRACT
COMPARISON OF THE INDONESIAN SPEAKER
RECOGNITION USING VECTOR QUANTIZATION AND
HIDDEN MARKOV MODEL
By
Devi Handaya
NIM: 23214029
(Electrical Engineering Master Program )
This thesis presents a comparison of two classifier methods based on the level of accuracy in recognizing the Indonesian speaker. The first method is Vector Quantization (VQ), which is a speaker recognition method based on distortion distance and the second method is Hidden Markov Model (HMM) based on the probability value of the data is observed. Comparisons are made in the pronunciation of a word, simple sentences, and complete sentences. Based on the experiments, it can be concluded that in general HMM method yields better accuracy than VQ method especially for data with the pronunciation of simple sentences.
Keywords: Vector Quantization (VQ), Hidden Markov Model (HMM), Indonesian Speaker Recognition
iii
PEDOMAN PENGGUNAAN TESIS
Tesis S2 yang tidak dipublikasikan terdaftar dan tersedia di Perpustakaan Institut Teknologi Bandung, dan terbuka untuk umum dengan ketentuan bahwa hak cipta ada pada pengarang dengan mengikuti aturan HaKI yang berlaku di Institut Teknologi Bandung. Referensi kepustakaan diperkenankan dicatat, tetapi pengutipan atau peringkasan hanya dapat dilakukan seizin pengarang dan harus disertai dengan kaidah ilmiah untuk menyebutkan sumbernya.
Sitasi hasil penelitian Tesis ini dapat ditulis dalam bahasa Indonesia sebagai berikut:
Handaya, D. (2016): Perbandingan Metode Kuantisasi Vektor dan Model Markov
Tersembunyi Pada Pengenalan Pembicara Berbahasa Indonesia , Tesis Program
Magister, Institut Teknologi Bandung.
dan dalam bahasa Inggris sebagai berikut:
Handaya, D. (2016): Comparison of the Indonesian speaker recognition using vector quantization and hidden markov model, Master’s Program Thesis, Institut Teknologi Bandung.
Memperbanyak atau menerbitkan sebagian atau seluruh tesis haruslah seizin Dekan Sekolah Pascasarjana, Institut Teknologi Bandung.
iv
KATA PENGANTAR
Dengan menyebut nama Allah yang Maha Pemurah lagi Maha Penyayang, puji syukur diucapkan ke hadirat-Nya, akhirnya penulis dapat menyusun dan menyelesaikan tesis yang berjudul “Perbandingan Metode Kuantisasi Vektor dan Model Markov Tersembunyi Pada Pengenalan Pembicara Berbahasa Indonesia". Tesis ini disusun guna memenuhi persyaratan untuk menyelesaikan jenjang magister dari Program Studi Magister Teknik Elektro, Institut Teknologi Bandung.
Penulis juga mengucapkan terima kasih atas kerjasama dan dukungan dari berbagai pihak baik secara psikis maupun disiplin ilmu kepada:
Bapak Prof. Dr. Carmadi Machbub, selaku pembimbing pertama yang telah memberikan bimbingan, arahan dan motivasi dalam menyelesaikan tesis ini. Bapak Dr. Egi Muhammad Idris Hidayat, selaku pembimbing kedua yang telah
memberikan bimbingan, arahan dan motivasi dalam menyelesaikan tesis ini. Bapak Dr. Iyas Munawar, selaku dosen wali yang telah memberikan bimbingan,
arahan dan motivasi dalam menyelesaikan perkuliahan.
Bapak Iwan, Resti Fauziah, bapak Hanif F dan kang Wisnu yang selalu menyertai penulis selama mengerjakan penelitian dan bekerjasama dalam menyelesaikan tesis ini.
Rekan – rekan Kendali dan Sistem Cerdas 2014 yang selalu memberikan semangat, kejutan, dan diskusi–diskusinya selama menyelesaikan perkuliahan. Kedua orang tua yang saya cintai, Bapak dan Ibu terima kasih dukungan dan
do’anya, sehingga penulis dapat menyelesaikan tesis ini.
Relawan yang bersedia menyumbangkan suaranya sebagai objek penelitian dalam penelitian tesis ini.
Dan pihak – pihak yang juga telah banyak memberikan bantuan kepada penulis yang tidak dapat penulis sebutkan satu per satu.
v
Penulis menyadari bahwa tesis ini masih jauh dari sempurna, banyak kelemahan baik dalam penyajian maupun penulisannya. Oleh karena itu penulis mengharapkan kritik dan saran yang membangun guna penyempurnaan penelitian dan penulisan selanjutnya. Akhir kata penulis berharap semoga penulisan tesis ini dapat bermanfaat bagi kita semua.
Bandung, Juni 2016
vi
DAFTAR ISI
ABSTRAK ... i
ABSTRACT ... ii
PEDOMAN PENGGUNAAN TESIS... iii
KATA PENGANTAR ... iv
DAFTAR ISI ... vi
DAFTAR LAMPIRAN ... vii
DAFTAR GAMBAR ... viii
DAFTAR TABEL ... x
Bab I Pendahuluan ... 1
I.1 Latar Belakang ... 1
I.2 Tujuan ... 2
I.3 Batasan Masalah ... 3
I.4 Metode Penelitian ... 3
I.5 Sistematika Penulisan ... 4
Bab II Tinjauan Pustaka ... 6
II.1 Pengenalan Suara ... 6
II.2 Ekstraksi Fitur: Mel – Frequency Cepstral Coefficients ... 8
II.3 Kuantisasi Vektor (KV) ... 13
II.4 Model Markov Tersembunyi (MMT) ... 15
II.5 Bahasa Indonesia ... 19
Bab III Perancangan Sistem dan Eksperimen ... 21
III.1 Perancangan Awal Sistem dan Eksperimen Pengenalan Pembicara 22 III.2 Perancangan Sistem dan Eksperimen Ekstraksi Fitur ... 23
III.3 Perancangan Sistem dan Eksperimen Pengklasifikasi ... 25
Bab IV Pengujian dan Pembahasan ... 32
IV.1 Pengujian Sistem ... 32
IV.2 Pembahasan ... 40
Bab V Kesimpulan dan Saran ... 44
V.1 Kesimpulan ... 44
V.2 Saran ... 44
vii
DAFTAR LAMPIRAN
Lampiran A Data Hasil Pengujian Pengenalan Pembicara dengan Metode
Kuantisasi Vektor ...L1 A.1 Pengujian Kata ...L1 A.2 Pengujian Kalimat Sederhana ...L3 A.3 Pengujian Kalimat Lengkap ...L5 Lampiran B Data Hasil Pengujian Pengenalan Pembicara dengan Metode Model
Markov Tersembunyi ...L7 B.1 Pengujian Kata ...L7 B.2 Pengujian Kalimat Sederhana ...L9 B.3 Pengujian Kalimat Lengkap ...L11
viii
DAFTAR GAMBAR
Gambar II.1 Sistem produksi suara manusia... 6
Gambar II.2 Sistem pendengaran dalam teling manusia ... 7
Gambar II.3 Diagram blok proses MFCC ... 8
Gambar II.4 Proses frame blocking ... 9
Gambar II.5 Mel – frequency wrapping ... 12
Gambar II.6 Konsep diagram dalam formasi buku kode kuantisasi vektor ... 14
Gambar II.7 Model markov tersembunyi tipe ergodik... 15
Gambar II.8 Model markov tersembunyi tipe kiri ke kanan ... 15
Gambar II.9 Alur proses algoritma maju ... 16
Gambar II.10 Alur proses algoritma mundur ... 17
Gambar III.1 Diagram blok utama dalam sistem pengenalan pembicara ... 22
Gambar III.2 Mel filter bank ... 24
Gambar III.3 Proses pengenalan pembicara dengan metode kuantisasi vektor .... 25
Gambar III.4 Diagram alir pelatihan algoritma Linde, Buzo, dan Gray ... 26
Gambar III.5 Proses pengenalan pembicara menggunakan metode model markov tersembunyi ... 27
Gambar III.6 Diagram alir pelatihan dengan metode model markov tersembunyi ... 27
Gambar III.7 Diagram alir algoritma Baum Welch ... 29
Gambar III.8 Diagram alir pengujian dengan metode model markov tersembunyi ... 30
Gambar IV.1 Digram blok perbandingan pengujian pengenalan pembicara ... 32
Gambar IV.2 Penggambaran sinyal suara dalam pengucapan kata “saya” yang digunakan sebagai data latih ... 33
Gambar IV.3 Penggambaran sinyal suara dalam pengucapan kata “saya” yang digunakan sebagai data uji ... 34
Gambar IV.4 Penggambaran sinyal suara dalam pengucapan kalimat “saya sedang belajar” yang digunakan sebagai data uji ... 34
ix
Gambar IV.5 Penggambaran sinyal suara dalam pengucapan kalimat “saya berangkat menggunakan bus ke kampus” yang digunakan sebagai data uji ... 35 Gambar IV.6 Pengujian kata dalam kuantisasi vektor dan model markov
tersembunyi ... 40 Gambar IV.7 Pengujian kalimat sederhana dalam kuantisasi vektor dan model
markov tersembunyi... 41 Gambar IV.8 Pengujian kalimat lengkap dalam kuantisasi vektor dan model
x
DAFTAR TABEL
Tabel III.1 Waktu pengambilan data untuk data latih dan data uji ... 23 Tabel IV.1 Data hasil pengenalan pembicara dalam pengujian kata dengan metode kuantisasi vektor ... 36 Tabel IV.2 Data hasil pengenalan pembicara dalam pengujian kalimat sederhana
dengan metode kuantisasi vektor ... 36 Tabel IV.3 Data hasil pengenalan pembicara dalam pengujian kalimat lengkap
dengan metode kuantisasi vektor ... 37 Tabel IV.4 Data hasil pengenalan pembicara dalam pengujian kata dengan metode HMM ... 38 Tabel IV.5 Data hasil pengenalan pembicara dalam pengujian kalimat sederhana
dengan metode HMM... 39 Tabel IV.6 Data hasil pengenalan pembicara dalam pengujian kalimat lengkap
dengan metode HMM... 39 Tabel IV.7 Perbandingan hasil rekapitulasi akurasi ... 42
1
Bab I Pendahuluan
I.1 Latar Belakang
Suara merupakan salah satu komponen penunjang yang digunakan manusia dalam berkomunikasi. Seperti halnya gambar atau citra, suara manusia juga memiliki keunikannya masing–masing walaupun terkadang ada yang dapat menirukan suara orang lain, tetapi dasarnya tidak akan identik dengan pemilik suara aslinya. Hal yang unik dari suara manusia berupa amplitudo suara, nada bicara, bahkan setiap wilayah memiliki logatnya masing–masing dan sebagainya. Dengan adanya keunikan tersebut, maka setiap suara manusia dapat dibedakan. Manusia dapat mengenali pemilik suara orang lain dengan frekuensi kebiasaan mendengar suara tersebut, sehingga lama – kelamaan akan hafal.
Umumnya teknologi pengenalan identitas dari keunikan ini yang biasa dikenal dengan teknologi biometrik dengan membandingkan kecocokan antara data biometrik seseorang yang berada di basis data. Beberapa jenis teknologi tersebut digunakan dalam pengenalan suara (voice recognition), pengenalan wajah (face recognition), pengenalan iris mata (iris recognition), pengenalan sidik jari, dan pengenalan tulisan tangan (handwriting recognition).
Teknologi pengolahan sinyal suara saat ini telah dikembangkan dalam mengenali sinyal suara tersebut. Pengolahan sinyal suara tidak kalah pentingnya dibandingkan dengan pengolaha citra. Hal ini dikarenakan pengolahan citra atau gambar hanya terbatas jika terdapat kontak langsung dengan objek, sehingga pengembangnya perlu memikirkan cara untuk menembus batasan – batasan tersebut seperti objek yang tidak tampak karena terhalangi oleh gedung atau tembok, sedangkan pengolahan sinyal suara dapat diamati saat amplitudo suaranya besar, sehingga mencakup jarak pengamat.
Pengenalan pembicara (speaker recognition) yang merupakan bagian dari pengenalan suara adalah proses yang dilakukan mesin cerdas dalam mengenali pembicara berdasarkan informasi keunikan pribadi dari sinyal suaranya (Irino T ,
2
dkk., 2002) . Pengenalan pembicara telah digunakan dalam melakukan verifikasi identitas pembicara dan mengendalikan sistem seperti penekanan nomor telepon (voice dialing), absensi, kemanan benda rahasia, dan pengendali jarak jauh dengan komputer (Abdallah S, dkk., 2012) .
Penelitian dalam pengolahan sinyal suara menjadi bahan perbincangan praktisi sistem kecerdasan buatan (Artificial Inteligence). Dengan munculnya beberapa metode yang digunakan dalam melakukan pengenalan pembicara seperti yang dilakukan oleh Yuan Yujin, dkk. (2010) dalam mengekstraksi suara menggunakan Mel Frequency Cepstral Coefficient (MFCC) yang memiliki rata-rata pengenalan pembicara sebesar 89,2% dan Linear Prediction Cepstrum Coefficient (LPCC) yang memiliki rata-rata pengenalan pembicara sebesar 87,63%, sehingga MFCC dapat lebih baik dalam mengekstraksi suara. Kemudian beberapa penelitian yang menggunakan Model Markov Tersembunyi (MMT) dan Kuantisasi Vektor (KV) sebagai pengklasifikasi dalam penelitian yang dilakukan Ivan K. T. dan Danie Kurniawan (2011) menggunakan MMT dapat mencapai tingkat keberhasilan 76,52% , penelitian menggunakan KV dengan akurasi 95% yang dilakukan oleh Danko Komlen (2011), kemudian dengan tingkat akurasi 82% menggunakan MFCC - KV lebih baik dibandingkan menggunakan LPCC – KV (Jorge Martinez, 2012), dan begitu pula disampaikan penelitian Shahzadi Farah dan Azra Shamim (2013) bahwa MFCC – KV lebih baik dibandingkan dengan menggunakan Linear Predictive Coding (LPC) - KV. Dengan demikian penelitian ini akan membuktikan kehandalan dua buah metode yang banyak digunakan oleh peneliti sebelumnya dengan pengujian untuk pembicara yang menggunakan bahasa Indonesia untuk metode Kuantisasi Vektor (KV) dan Model Markov Tersembunyi (MMT). Analisis perbandingan ini belum pernah dilakukan untuk pembicara yang menggunakan bahasa Indonesia, sehingga pengujian dilakukan kepada pembicara yang menggunakan bahasa Indonesia.
I.2 Tujuan
Tujuan penelitian yang dilakukan adalah sebagai berikut.
3
2. Mengamati pengaruh sistem pengenalan suara manusia berbahasa Indonesia terhadap pengujian kata dan kalimat dari data latih kata
3. Membandingkan sistem pengenalan suara manusia berbahasa Indonesia melalui metode Kuantisasi Vektor (KV) dan Model Markov Tersembunyi (MMT)
I.3 Batasan Masalah
Untuk menyederhanakan masalah dan efisiensi waktu serta biaya, dalam penelitian ini terdapat pembatasan masalah sebagai berikut.
1. Perangkat yang digunakan berupa mikrofon analog 16 Bit dengan frekuensi sampling 22050 Hz, laptop dengan prosesor core i3 dan RAM 2GB
2. Perancangan pemrograman simulasi pengenalan suara menggunakan Matlab R2013b
3. Sampel suara yang direkam berupa kata “saya” sebagai data latih dan data uji dengan durasi 2 detik, kalimat “saya sedang belajar” sebagai data uji dengan durasi 3 detik, dan kalimat “Saya berangkat menggunakan bus ke kampus” yang kemudian disimpan dalam format .wav
4. Pengambilan data dilakukan secara luar jaringan (offline) agar mendapatkan beberapa data pengukuran seperti jarak euclidean, parameter pemodelan, dan nilai parameter evaluasi
I.4 Metode Penelitian
Dalam menyelesaikan penelitian tesis ini diperlukan langkah – langkah sebagai berikut:
1. Studi literatur
Mempelajari dan menganalisis berbagai sumber informasi seperti buku – buku dan literatur referensi yang serupa dengan penelitian yang akan dilakukan 2. Analisis desain
Berdasarkan hasil studi literatur akan dibuat analisis desain dalam menyelesaikan proses perbandingan algoritma untuk setiap metode
3. Pembuatan sistem
Hasil perancangan diimplementasikan dengan menggunakan Matlab sebagai pemrosesan sistem pengenalan suara
4 4. Pengujian dan evaluasi
Berdasarkan aplikasi yang telah dibuat kemudian dilakukan uji coba sistem dan mengevaluasi sistem sesuai dengan tujuan penelitian
5. Pengambilan data
Setelah pengujian dan didapatkan hasil yang sesuai dengan tujuan penelitian kemudian dilakukan pengambilan data
6. Penulisan laporan
Penulisan laporan hasil pengujian dan pengambilan data dibukukan dalam laporan penelitian
I.5 Sistematika Penulisan
Dalam penulisan laporan tesis ini terdiri dari lima bab dengan masing–masing bab menguraikan beberapa hal yang terkait dengan perancangan yang dilakukan.
Bab I Pendahuluan. Bab ini mengemukakan latar belakang, tujuan, batasan
masalah, metode penelitian, dan sistematika penulisan.
Bab II Tinjauan Pustaka. Bab ini menjelaskan teori dasar mengenai pengenalan
pembicara (speaker recognition), mel-frequency cepstral coefficient, kuantisasi vektor, model markov tersembunyi, dan bahasa Indonesia.
Bab III Perancangan Sistem dan Eksperimen. Bab ini membahas perancangan
awal sistem dan eksperimen pengenalan pembicara, perancangan sistem dan eksperimen yakni ekstraksi fitur, dan perancangan sistem dan ekesperimen untuk pengklasifikasi, serta perangkat lunak pengenalan pembicara.
Bab IV Pengujian dan Pembahasan. Bab ini membahas pengujian sistem
pengenalan pembicara yang menghasilkan data yang dibutuhkan sebagai analisis pembahasan perbandingan metode.
5
Bab V Penutup. Bab ini mengemukakan bagian penutup dari pelaporan penelitian
yang meliputi kesimpulan dan saran agar dapat dikembangkan dengan metode lainnya untuk sistem kerja yang sama.
Dalam bab selanjutnya akan disampaikan teori-teori dasar hasil dari peninjauan beberapa literatur yang digunakan. Literatur tersebut dapat berupa buku-buku, makalah penelitian yang telah dipublikasikan, dan sebagainya yang dijadikan sebagai referensi dalam melakukan penelitian ini.
6
Bab II Tinjauan Pustaka
II.1 Pengenalan Suara II.1.1 Suara Manusia
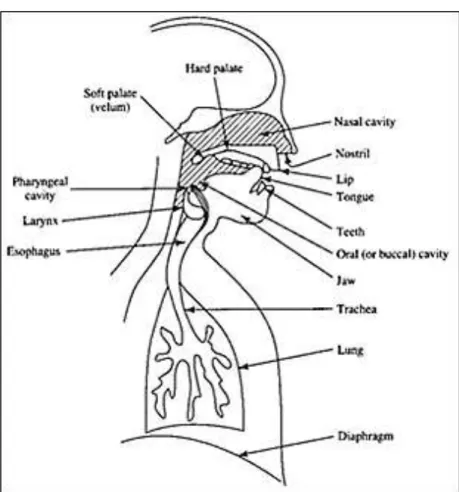
Suara manusia merupakan operasi penyaringan sinyal akustik saat bekerjanya laring dan paru sebagai sumber perangsang dan hidung sebagai filter. Fitur utama dari suara manusia yaitu nada dan pola suara yang berasal dari pita suara saat bergetar, sehingga membentuk frekuensi nada. Ketika udara melalui laring, udara bergetar dengan frekuensi nada. Kemudian udara yang mengalir melalui supralaring akan mulai bergaung dengan frekuensi tertentu yang ditentukan berdasarkan panjang dan diameter rongga saluran supralaring yang biasa disebut sebagai resonansi (Elminir, 2012).
Gambar II.1 Sistem produksi suara manusia
7
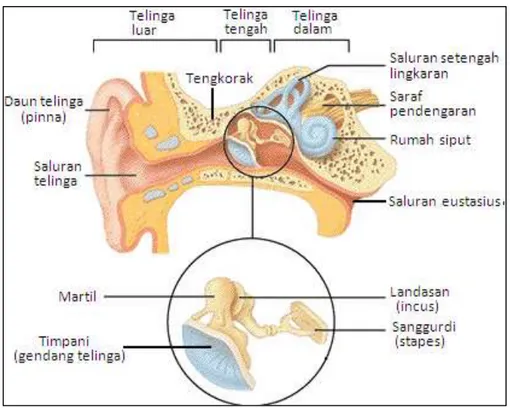
Telinga merupakan organ tubuh yang digunakan manusia dalam sistem pendengaran. Melakukan pembuatan sistem pendengaran manusia menjadi tantangan para peneliti untuk dapat melakukan pengolahan sifat – sifat suara yang ada dalam suara manusia dengan berbagai jenis kebisingan lingkungan. Model pengembangan komputasi dibuat dengan meniru sifat psikoakustik dari telinga bagian dalam berdasarkan fitur sistem penyaringan mekanis dan getaran.
Gambar II.2 Sistem pendengaran dalam telinga manusia
(http://fiskadiana.blogspot.co.id/2015/04/alat-indera-indera-pendengaran.html)
II.1.2 Pengenalan Pembicara (Speaker Recognition)
Konsep pengenalan suara umumnya dapat dikategorikan dua bagian, yaitu pengenalan pembicaraan (speech recognition) dan pengenalan pembicara (speaker recognition). Pengenalan pembicaraan berkaitan dengan proses mengenali pembicaraan berdasarkan sinyal suara yang diucapakan seperti aplikasi suara ke teks (Speech-to-Text) atau teks ke suara (Text-to-Speech), sedangkan pengenalan pembicara merupakan sistem yang digunakan secara otomatis dalam mengenali pemilik atau individu yang sedang berbicara melalui sinyal suaranya. Proses tersebut dilakukan oleh “mesin cerdas” berdasarkan informasi keunikan pribadi dari sinyal suaranya (Irino T , dkk., 2002).
8
Pengenalan pembicara sendiri sebenarnya dapat dibagi menjadi dua, yaitu verifikasi pembicara (speaker verification) merupakan proses verifikasi seorang pembicara yang sebelumnya identitas pembicara telah diketahui. Proses dilakukan dengan membandingkan one to one (1:1), dengan kata lain fitur suara yang masuk saat itu dibandingkan langsung dengan fitur suara seseorang tertentu, sedangkan identifikasi pembicara (speaker identification) merupakan proses mendapatkan identitas dari seorang pembicara dengan melakukan perbandingan fitur suara yang dimasukan dengan semua fitur suara dari tiap – tiap pembicara yang telah disimpan dalam basis data. Proses ini dilakukan dengan membandingkan one to many (1:N) (Darma Putra dan Adi Resmawan, 2011). Dalam penelitian ini ditekankan terhadap sistem pengenalan pembicara khususnya identifikasi pembicara karena suara yang dimasukan akan dibandingkan dengan beberapa suara yang telah disimpan sebelumnya di basis data. Hasil perhitungan perbandingan yang paling mendekati kecocokannya dianggap sebagai pemilik suara dari individu tertentu.
II.2 Ekstraksi Fitur: Mel – Frequency Cepstral Coefficients
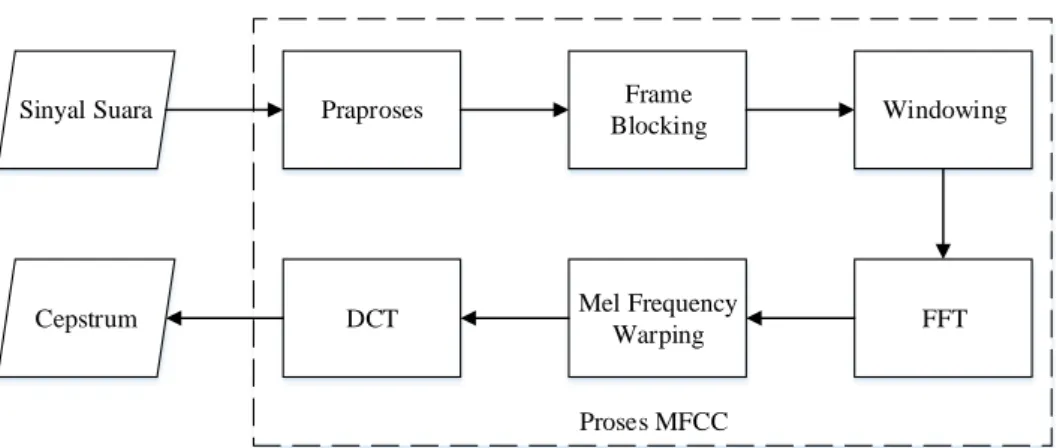
Setiap sinyal suara atau ucapan memiliki cirinya masing–masing yang menjadikannya unik dimiliki setiap individu, sehingga dapat digunakan dalam mengenali pembicara. Untuk dapat dikenali, tentunya sinyal suara tersebut perlu dicari ciri–cirinya dengan metode komputasi yang dapat mengekstraksi ciri suara seseorang. Salah satu metode yang banyak digunakan dalam mengekstrasi ciri suara yaitu metode Mel – Frequency Cepstral Coefficients (MFCC). Diagram blok proses MFCC digambarkan sebagai berikut.
Proses MFCC Sinyal Suara Praproses Frame
Blocking Windowing
FFT Mel Frequency
Warping
Cepstrum DCT
9
Di awal proses MFCC, dilakukan proses normalisasi terhadap sinyal suara yang lemah dan dilakukan penyaringan (filtering) menggunakan tapis lolos rendah (lowpass filter) agar derau spektrum tinggi yang tidak diperlukan tidak perlu diolah. Tahap–tahap yang dilalui dalam proses MFCC dijelaskan sebagai berikut.
II.2.1 Frame Blocking dan Windowing
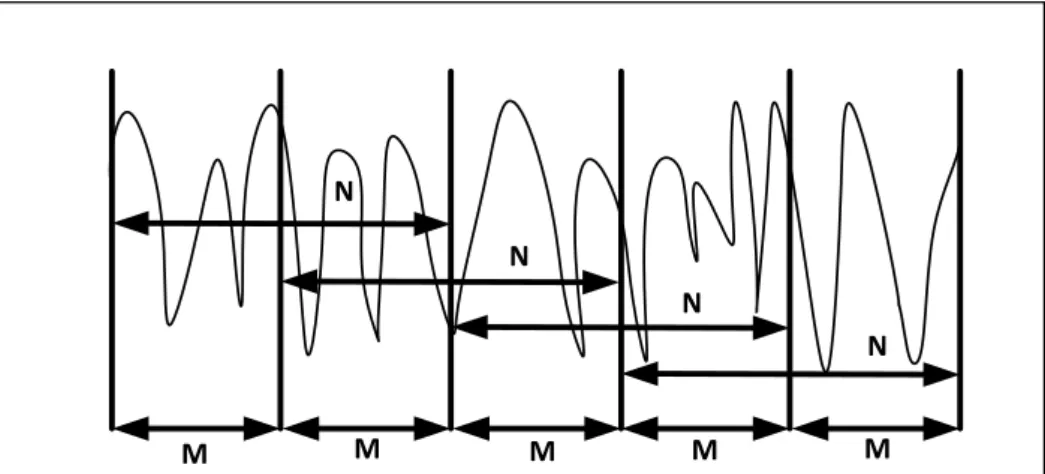
Sinyal suara merupakan sinyal yang tidak stasioner atau sifatnya berubah – ubah terhadap, sehingga tidak dapat dilakukan ekstraksi ciri secara langsung. Oleh karena itu, sinyal dikelompokkan menjadi beberapa blok dan proses diskontinyu diminimalkan di bagian awal dan akhir sinyal. Parameter proses windowing yaitu lebar jendela, jarak antar jendela, dan bentuk jendela yang kemudian menghasilkan ukuran bingkai (M) dan perpindahan bingkai (N). Prosesnya dapat dilihat seperti gambar berikut. M M M M M N N N N
Gambar II.4 Proses frame blocking
Persamaan yang digunakan dalam proses windowing dalam penelitian ini menggunakan hamming window dengan persamaan berikut.
𝑤[𝑛] = 0,54 − 0,46 𝑐𝑜𝑠(2𝜋𝑛
𝑁𝑥−1) (II.1)
dengan:
𝑤[𝑛] = windowing ke-n
𝑁𝑥 = jumlah data dari sinyal / jumlah sampel dalam tiap bingkai n = waktu diskrit ke-n dengan nilai fungsi jendela untuk waktu ke–n,
Hasil perhitungan persamaan (II.1) selanjutnya dimasukan ke persamaan berikut.
10 dengan:
𝑦[𝑛] = sinyal setelah windowing 𝑠[𝑛] = sinyal asli
II.2.2 Fast Fourier Transform (FFT)
Setiap sinyal yang berada dalam ranah waktu untuk dapat diproses MFCC tentunya harus ditransformasikan terlebih dahulu ke dalam ranah frekuensi dengan menggunakan Fast Fourier Transform. Dasarnya, sinyal yang masuk untuk diproses adalah sinyal diskrit, sehingga proses transformasinya menggunakan persamaan Discrete Fourier Transform (DFT) berikut.
𝑋𝑘=∑ 𝑥𝑟𝑒 −𝑗2𝜋𝑘𝑟 𝑁𝑓 𝑁𝑓−1 𝑟=0 (II.3) dengan:
𝑋𝑘= sinyal dalam ranah frekuensi 𝑁𝑓 = jumlah sinyal sampling 𝑟 = sinyal periodik sampling 𝑘 = indeks ranah frekuensi
Persamaan (II.3) dapat ditulis kembali menjadi, 𝑋𝑘=∑𝑁𝑓−1𝑥𝑟𝑤𝑟𝑘
𝑟=0 , 𝑑𝑒𝑛𝑔𝑎𝑛 𝑤 = 𝑒
−𝑗2𝜋
𝑁𝑓 (II.4)
Misalkan bahwa 𝑁𝑓 dapat dibagi dua, maka persamaan (II.4) menjadi 𝑟 genap dan
𝑟 ganjil, sehingga persamaan menjadi berikut. 𝑋𝑘 = ∑ 𝑥2𝑟𝑤2𝑟𝑘 𝑁𝑓 2−1 𝑟=0 + ∑ 𝑥(2𝑟+1)𝑤(2𝑟+1)𝑘 𝑁𝑓 2−1 𝑟=0 = ∑ 𝑥2𝑟𝑤2𝑟𝑛 𝑁 2−1 𝑟=0 + 𝑤𝑛∑ 𝑥(2𝑟+1)𝑤2𝑟𝑛 𝑁 2−1 𝑟=0 (II.5)
Suku pertama persamaan (II.5) yaitu 𝑟 genap {𝑥0, 𝑥2, …, 𝑥Nf−2} 𝐸𝑘 = ∑ 𝑥2𝑟𝑤2𝑟𝑛
𝑁𝑓 2−1
𝑟=0 (II.6)
Suku kedua persamaan (II.5) yaitu 𝑟 ganjil {𝑥1, 𝑥3, …, 𝑥Nf−1} 𝑂𝑘= ∑ 𝑥(2𝑟+1)𝑤2𝑟𝑛
𝑁𝑓 2−1
𝑟=0 (II.7)
Kemudian DFT dalam deret 𝑁𝑓 dapat dinyatakan dengan persamaan berikut.
11
Karena DFT dalam deret 𝑁2𝑓, maka hubungan periodiknya menjadi, 𝐸𝑘 = 𝐸
𝑘+𝑁𝑓2 (II.9)
dan 𝑂𝑘 = 𝑂
𝑘+𝑁𝑓2 (II.10)
Dengan demikian, untuk dapat mencari spektrum tertentu hanya perlu melakukan sebanyak dua kali (𝑁𝑓
2 ) 2
atau 𝑁𝑓 2
2 perkalian (Indah Susilawati, 2009). Sesuai dengan
namanya yaitu fast atau cepat dalam FFT lebih cepat dibandingkan dengan DFT misalkan terdapat 𝑛 buah data, dengan DFT memerlukan perhitungan 𝑛2 kali perhitungan. Dalam
FFT perhitungan memerlukan (𝑛
2+ 1)𝑛 + 𝑛
2 kali. Misalkan jika 𝑛 = 100, maka dengan
DFT perlu 1002 = 10.000 kali perhitungan, sedangkan dengan FFT cukup dilakukan (100
2 + 1)100 + 100
2 = (51𝑥100) + 50 = 5150 kali perhitungan.
II.2.3 Mel Frequency Warping
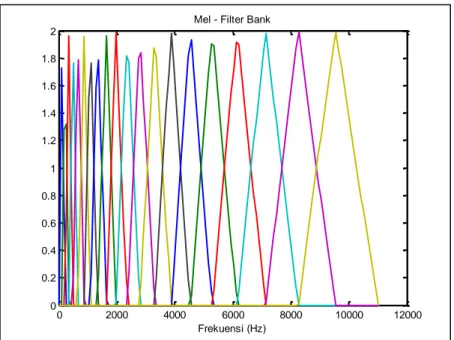
Proses warping spectrum sinyal dengan menggunakan mel – filter bank segitiga. Proses ini dilakukan untuk melinierkan ekstraksi ciri agar memperoleh vektor fitur yang mewakili amplitude terkompresi secara logaritmik. Untuk mengubah frekuensi suara menjadi frekuensi mel menggunakan skala mel yang dimaksudkan karena pendengaran manusia tidak berskala linier, sehingga tinggi subjektif di tiap nada dapat terukur dengan skala mel (Zilvan, 2011). Persamaan dalam membentuk skala mel adalah sebagai berikut.
𝑚𝑒𝑙 (𝑓) = 2595 ∗ 𝑙𝑜𝑞10(1 + 𝑓
700) (II.11)
dengan:
𝑓 = frekuensi (Hz)
12
Gambar II.5 Mel – frequency wrapping
Seperti yang disebutkan sebelumnya bahwa mel – filter bank berbentuk segitiga. Dengan frekuensi (Hz) diwakili oleh sumbu X dan power (dB) sinyal suara diwakili oleh sumbu Y.
II.2.4 Discrete Cosine Transform (DCT)
Bagian ini, merupakan proses terakhir agar diperoleh vektor ciri yang diinginkan. Discrete Cosine Transform merupakan transformasi Fourier yang dikenakan untuk fungsi sinyal diskrit dengan hanya mengambil bagian cosinus saja dari eksponensial kompleks. Persamaan yang diberikan adalah sebagai berikut.
𝐹(𝑘) = ∑𝑁𝑟=0𝑓−1𝑓(𝑛). 𝑐𝑜𝑠(2𝜋𝑟𝑘
𝑁 ) (II.12)
dengan:
𝐹(𝑘) = fungsi sinyal diskrit cosinus 𝑓(𝑛)= fungsi sinyal diskrit
Jika dalam DFT dihasilkan variabel kompleks yang terdiri dari bagian riil dan imajiner, maka hasil DCT hanya berupa bagian riil tanpa imajiner. Hal ini banyak membantu karena dapat mengurangi perhitungan. Dalam DCT nilai besaran adalah hasil dari DCT itu sendiri dan tanpa memperhatikan fasanya.
0 2000 4000 6000 8000 10000 12000 0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2
Mel - Filter Bank
13
II.3 Kuantisasi Vektor (KV)
Kuantisasi vektor adalah sebuah proses dalam memetakan vektor dari ruang vektor yang besar menjadi bentuk terbatas dalam ruang tersebut (Yegnanarayana B, dkk., 2001) . Kuantisasi vektor yang digunakan dalam penelitian ini adalah metode
Linde, Buzo, dan Gray (LBG). Dasarnya kuantisasi vektor ini berawal dari algoritma Lloyd (K-means algorithm atau Lloyd algorithm), yang kemudian dikembangkan menjadi algoritma LBG (Linde Y, dkk., 1980) . Algoritma Lloyd membagi satu set vektor training menjadi 𝐿 sel . Secara sederhana dipaparkan oleh I. Elfitri (2002), algoritmanya dapat dijelaskan sebagai berikut.
Inisialisasi
Atur untuk 𝑚 = 0 (iterasi ke-𝑚). Tentukan satu set vektor kode 𝑦𝑖(0), 1 ≤ 𝑖 ≤ 𝐿. (buku kode awal).
Klasifikasi
Buat satu set vektor latih ke dalam 𝐿 sel dengan aturan nearest neighbor : 𝑥 ∈ 𝐶𝑖(𝑚𝑣𝑞), jika 𝑑[𝑥, 𝑦𝑖(𝑚𝑚𝑣𝑞)] ≤ 𝑑[𝑥, 𝑦𝑗(𝑚𝑣𝑞)], untuk semua 𝑗 ≠ 𝑖 (II.13) dengan:
𝑑 = distance
𝐶𝑖(𝑚𝑣𝑞) = indeks centroid
Perbaharui vektor kode
Ubah 𝑚𝑣𝑞 menjadi 𝑚𝑣𝑞+ 1. Hitung kembali vektor kode yang baru di tiap sel
dengan prinsip centroid.
𝑦𝑖(𝑚𝑣𝑞) = 𝑐𝑒𝑛𝑡𝑟𝑜𝑖𝑑[𝐶𝑖(𝑚𝑣𝑞)], 1 ≤ 𝑖 ≤ 𝐿 (II.14)
Tes terminasi iterasi
Jika terdapat penurunan distorsi D(𝑚𝑣𝑞) dalam iterasi ke-m relatif terhadap D’
= D(𝑚𝑣𝑞-1) lebih kecil dari nilai ambang tertentu, maka iterasi dihentikan. Jika tidak, maka kembali lagi ke langkah dua
Agar tiap-tiap iterasi dapat menghasilkan sebuah buku kode yang optimal, maka harus dipenuhi dengan dua keadaan yaitu aturan nearest neighbor dan centroid. Nearest neighbor melakukan klasifikasi berdasarkan kedekatan lokasi suatu data dengan data lain (Eko Prasetyo, 2012). Algoritma LBG merupakan penyempurnaan algoritma Lloyd dengan menambahkan proses pembagian (splitting) agar memperoleh buku kode awal. Centroid dari semua vektor masukan dibagi menjadi
14
dua vektor kode. Kemudian dalam satu set vektor training akan dibagi dua dengan aturan nearest neighbor. Centroid dari kedua kluster tersebut kemudian diiterasi dengan algoritma Lloyd, sehingga diperoleh dua vektor kode dalam 1 bit quantizer. Proses tersebut kembali diiterasi, sehingga didapatkan vektor quantizer yang diinginkan (I. Elfitri, 2008) .
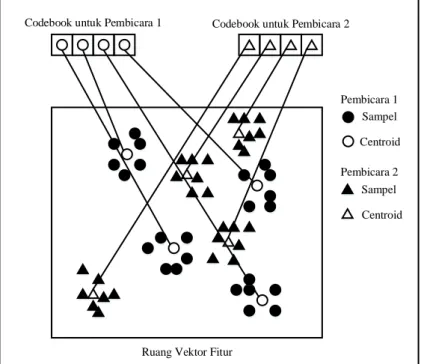
Masukan fitur vektor dibandingkan dengan seluruh kode buku. Kode buku dengan nilai jarak rata–rata paling dekat yang dipilih. Rumus untuk menghitung besarnya jarak euclidean didefinisikan berikut.
𝑦 = √∑𝑛𝑒𝑖=1𝑖 (𝑝𝑒𝑖− 𝑞𝑒𝑖)2 (II.15)
dengan:
𝑦 = jarak euclidean
𝑒𝑖 = jumlah euclidean indeks 𝑛𝑖 = jumlah semua euclidean
Dengan p dan q merupakan nilai centroid dari kode buku (G. Nijhawan dan MK. Soni, 2014) yang diilustrasikan seperti dalam gambar berikut.
Codebook untuk Pembicara 1
Pembicara 1 Sampel Centroid
Sampel Centroid
Ruang Vektor Fitur
Codebook untuk Pembicara 2
Pembicara 2
15
II.4 Model Markov Tersembunyi (MMT)
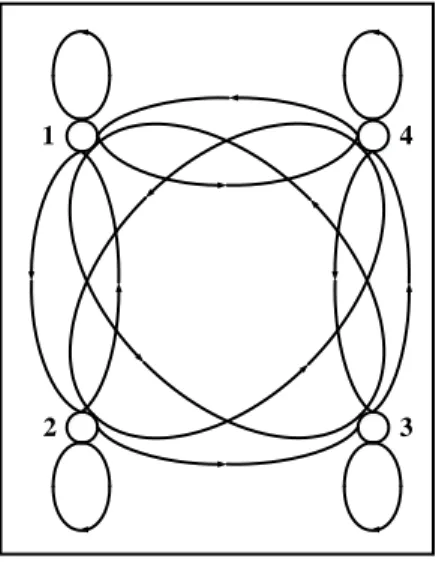
Model Markov Tersembunyi (MMT) merupakan model dari rantai Markov yang statusnya tidak dapat diamati secara langsung (tersembunyi), tetapi hanya dapat diobservasi melalui suatu himpunan pengamatan variabel lain. Model markov tersembunyi memiliki tipe model ergodik dan kiri ke kanan (left to right). Model ergodik merupakan tipe model markov tersembunyi yang setiap statusnya terhubung, sedangkan model kiri ke kanan merupakan tipe model markov tersembunyi yang urutan statusnya terhubung dengan dirinya dan terhubung dari kiri ke kanan. Jenis kiri ke kanan untuk model yang sifatnya berubah dari waktu ke waktu dan tidak dapat kembali ke status sebelumnya seperti pembicaraan (speech) (Rabiner, 1989).
1
2 3
4
Gambar II.7 Model markov tersembunyi tipe ergodik
1 2 3 4
Gambar II.8 Model markov tersembunyi tipe kiri ke kanan Dasarnya model markov tersembunyi terdiri dari tiga hal.
II.4.1 Evaluasi
Evaluasi merupakan proses penghitungan peluang dari urutan nilai observasi yang diberikan oleh model markov tersembunyi. Dalam tahap ini, diasumsikan parameter model telah ditemukan, sehingga evaluasi atau pencarian nilai peluang dapat
16
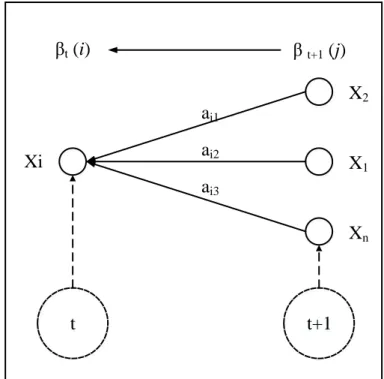
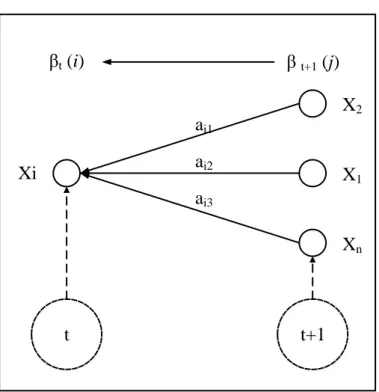
dilakukan. Tahap evaluasi menggunakan algoritma maju dan mundur, berikut penjelasannya. Algoritma maju t t+1 X1 Xn X2 βt (i) β t+1 (j) Xi ai1 ai2 ai3
Gambar II.9 Alur proses algoritma maju Jika variabel maju 𝛼𝑡(𝑖), disaat t dan status i, maka persamaannya.
𝛼𝑡(𝑖) = 𝑃(𝑂1, 𝑂2, … , 𝑂𝑇, 𝑞𝑡 = 𝑖|𝜆) (II.16)
dengan:
𝑂 = indeks matrik terobservasi
Penyelesain dengan n keadaan dan observasi sampai T secara iterasi.
Inisialisasi
𝛼𝑡(𝑖) = 𝜋𝑖𝑏𝑖(𝑂1), 1 ≤ 𝑖 ≤ 𝑛 (II.17)
dengan:
𝜋 = matrik status awal
𝑏𝑖(𝑂1) = matriks pertama yang terobservasi
Induksi
𝛼𝑡+1(𝑗) = [∑𝑛𝑖=1𝑖 𝛼𝑡(𝑖)𝑎𝑖𝑗]𝑏𝑗(𝑂𝑡+1) (II.18)
dengan:
𝑛𝑖 = jumlah status 𝑎𝑖𝑗 = matrik transisi
17 Terminasi 𝑃(𝑂|𝜆) = ∑𝑛𝑖 𝛼𝑡(𝑖) 𝑖=1 (II.19) Algoritma mundur t t+1 X1 Xn X2 βt (i) β t+1 (j) Xi ai1 ai2 ai3
Gambar II.10 Alur proses algoritma mundur
Keadaan mengalir ke belakang dari observasi terakhir saat t. Persamaan peluang algoritma mundur 𝛽𝑡(𝑖) sebagai berikut:
𝛽𝑡(𝑖) = 𝑃(𝑂𝑡+1, 𝑂𝑡+2, … , 𝑂𝑇, 𝑞𝑡= 𝑖|𝜆) (II.20)
dan dianalogikan dengan prosedur algoritma maju 𝛽𝑡(𝑖) dengan langkah:
Inisialisasi
𝛽𝑡(𝑖) = 1 1 ≤ 𝑖 ≤ 𝑛 (II.21)
Induksi
𝛼𝑡+1(𝑗) = ∑ 𝑎𝑖𝑗𝑏𝑗(𝑂𝑡+1)𝛽𝑡+1(𝑗), 𝑡 = 𝑇 − 1, 𝑇 − 2, … , 1 , 1 ≤ 𝑖 ≤ 𝑛 (II.22)
II.4.2 Pengkodean (Decoding)
Pengkodean dilakukan untuk mencari status yang terbaik dari urutan observasi model markov tersembunyi dengan algoritma Viterbi. Dalam tahap ini juga sama seperti tahap evaluasi, yaitu parameter model diasumsikan sudah ditemukan, sehingga pencarian status terbaik dapat ditentukan. Langkah–langkah tahap pengodean sebagai berikut.
18 Inisialisasi 𝛿𝑡(𝑖) = 𝜋𝑖𝑏𝑖(𝑂1), 1 ≤ 𝑖 ≤ 𝑛 (II.23) Rekursi 𝛿𝑡(𝑗) =1≤𝑖≤𝑛𝑚𝑎𝑥 [𝛿𝑡−1(𝑖)𝑎𝑖𝑗]𝑏𝑗(𝑂𝑡) , 1 ≤ 𝑗 ≤ 𝑛 (II.24) Terminasi 𝑃 = 𝑚𝑎𝑥 1≤𝑖≤𝑛[𝛿𝑡(𝑖)] (II.25) dengan: 𝑃 = peluang
II.4.3 Parameter Estimasi
Algoritma Baum – Welch melakukan pelatihan untuk memperoleh parameter model markov tersembunyi.
Parameter A
Parameter A ditunjukkan dengan kumpulan status transisi yang membentuk matrik tertentu yaitu 𝐴 = {𝑎𝑖𝑗}, untuk 1 ≤ 𝑖, 𝑗 ≤ 𝑛. Bentuk 𝑎𝑖𝑗 = 𝑃[𝑞𝑡+1= 𝑋𝑗 |𝑞𝑡 = 𝑋𝑖] merupakan peluang ketika status j untuk waktu t+1 jika dalam waktu t berada di status i
dengan:
𝑎𝑖𝑗 = peluang transisi dari status i ke status j
𝑃 = peluang
𝑞𝑡+1 = kondisi setelah 𝑞𝑡 𝑞𝑡 = kondisi saat t 𝑋𝑗 = status ke j
𝑋𝑖 = status ke i
𝑛 = banyaknya status tersembunyi dalam model Parameter B
Parameter B ditunjukkan bahwa 𝐵 = {𝑏𝑗(𝑘)}, untuk 1 ≤ 𝑗 ≤ 𝑛, 1 ≤ 𝑘 ≤ 𝑚 yang merupakan 𝑏𝑗(𝑘) = 𝑃[𝑦𝑘 terhadap 𝑡 |𝑞𝑡 = 𝑋𝑗], 0 ≤ 𝑏𝑗(𝑘) dan ∑𝑚 𝑏𝑗(𝑘) = 1
𝑘=1 .
dengan:
𝑏𝑗(𝑘) = peluang distribusi matriks observasi
19
𝑚 = banyaknya simbol observasi yang berbeda setiap status
Kerapatan kontinyu (continuos density) MMT sering dikarakterisasi oleh fungsi kerapatan (density function) atau campuran fungsi kepadatan tertentu di setiap status yang telah dijelaskan oleh L. R. Rabiner (1989), hal tersebut senada pula seperti yang diungkapkan oleh Mikael Nilsson (2005). Dengan asumsi penggunaan Gaussian Mixture, kepadatan emisi status 𝑗 didefinisikan sebagai:
𝑏𝑗(𝑜𝑡) = ∑𝐾𝑘=1𝑤𝑗𝑘𝒩(𝑂; 𝜇𝑗𝑘; ∑𝑗𝑘),𝑗 = 1,2, … , 𝑁 (II.26)
dengan:
𝐾 = number of mixture 𝑤𝑗𝑘 = mixing coefficient
Untuk 𝑘𝑡ℎ Gaussian, status j dengan batasan stokastik dengan persamaan berikut.
∑𝐾𝑘=1𝑤𝑗𝑘 = 1𝑗 = 1,2, … , 𝑁 (II.27)
dengan:
𝒩 = Gaussian density function dengan mean 𝜇𝑗𝑘𝜖𝑅𝑑 dan matriks kovarian
∑𝑗𝑘𝜖𝑅𝑑𝑥𝑑 untuk 𝑘𝑡ℎ campuran.
Matriks inisial di status i
Diperlukan inisialisasi matriks awal status yang ditunjukkan oleh 𝜋 = {𝜋𝑖} , dengan 𝜋𝑖 = 𝑃[𝑞1 𝑋𝑖], 0 ≤ 𝜋𝑖 dan ∑𝑛𝑖=1𝜋𝑖 = 1, sehingga model markov tersembunyi
dapat dilambangkan dengan 𝜆 = (𝐴, 𝐵, 𝜋).
II.5 Bahasa Indonesia
Dalam komunikasi lisan dan tulisan membutuhkan kemampuan berbahasa yang memadai, sehingga menghasilkan sebuah komunikasi sesuai dengan Ejaan Yang Disempurnakan (EYD). Indonesia memiliki berbagai keragaman budaya dan bahasa, sehingga dalam tata bahasa Indonesia terdapat interferensi yang unik. Seperti yang disampaikan Jendra (1991) bahwa interferensi dalam tata bahasa dapat meliputi bidang tata bunyi (fonologi), tata bentukan kata (morfologi), tata kalimat (sintaksis), dan kosakata (leksikon). Berbagai interferensi tentunya akan memengaruhi berbagai bentuk pengucapan untuk pembicara yang menggunakan bahasa Indonesia. Pengaruh tersebut juga akan memengaruhi bentuk dari vektor ciri yang dimiliki para pembicara berbahasa Indonesia.
20 Interferensi fonologi
Menurut Harimurti Kridalaksana (1985), fonologi yaitu bidang linguistik yang mengkaji bunyi – bunyi bahasa menurut fungsinya. Interferensi fonologi seperti penghilangan, penambahan, dan perubahan sebuah huruf dalam satu kata yang seharusnya. Sebagai contoh dalam penyebutan kata “meliat” yang seharusnya kata “melihat” dengan pengurangan huruf /h/. Perubahan dapat saja terjadi seperti penghilangan fonem baik di awal, tengah, maupun akhir.
Interferensi morfologi
Morfologi merupakan cabang ilmu linguistik yang menyelidiki tentang seluk beluk pembentukan kata (awalan, akhiran, sisipan) (M. Ramlan, 2001). Interferensi morfologi seperti penggantian imbuhan yang seharusnya digunakan. Seperti kata “ketabrak”, bentuk kata tersebut berasal dari kata dasar bahasa Indonesia yang ditambah dengan afiks bahasa daerah tertentu. Hal ini sebenarnya tidar diperlukan karena dalam bahasa Indonesia sudah ada padanannya sendiri berupa afiks ter-, sehingga menjadi “tertabrak”.
Interferensi sintaksis
Sintaksis yang membahas struktur internal kalimat berupa frasa, klausa, dan kalimat. Interferensi sintaksis seperti penyimpangan struktur kalimat di dalam diri penutur terjadi kontak antara bahasa Indonesia dan bahasa lainnya yang telah dikuasai (Suwito, 1988). Seperti dicontohkan dalam kalimat “Mobilnya ayahnya Joko yang paling bagus sendiri di desa itu”, seharusnya dalam bahasa Indonesia yang benar menjadi “ Mobil ayah Joko yang paling bagus di desa itu”.
Interferensi leksikon
Leksikon merupakan kajian perbendaharaan kata, sehingga jika tercampur dalam setiap pengucapan akan berbicara dalam beberapa bahasa dalam satu kalimat. Hal ini seperti yang biasa diucapkan oleh penutur tertentu karena terbiasa berbahasa daerah, sehingga dalam berbicara bahasa Indonesia masih terdapat suara khasnya atau dengan kata lain biasa disebut logat.
Dalam bab berikutnya dijelaskan mengenai perancang yang dilakukan dalam mencapai rencana pembuatan sistem pengenalan pembicara. Kemudian cara-cara
21
eksperimen yang digunakan dalam tahap pelatihan dan pengujian berupa diagram blok dan diagram alir algoritma.
22
III.1 Perancangan Awal Sistem dan Eksperimen Pengenalan Pembicara
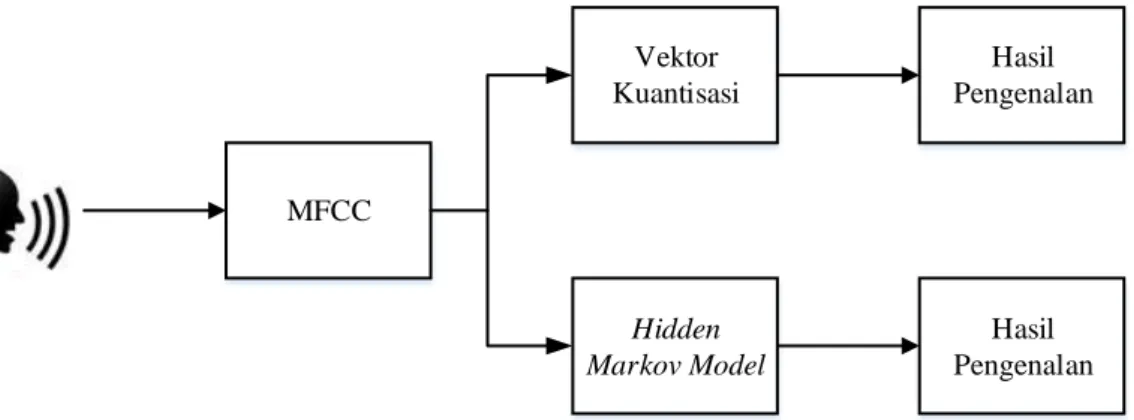
Sistem pengenalan pembicara dirancang dengan menggunakan mel – frequency cepstral coefficient sebagai ekstraksi fiturnya, sehingga didapatkan vektor ciri yang kemudian akan didistribusikan sebagai masukan untuk pengklasifikasi. Kuantisasi vektor dan model markov tersembunyi sebagai pengklasifikasi akan melakukan tugasnya untuk menentukan pemilik suara dari suara yang diujikan. Gambaran umum dari sistem diberikan oleh diagram berikut.
MFCC Vektor Kuantisasi Hidden Markov Model Hasil Pengenalan Hasil Pengenalan
Gambar III.1 Diagram blok utama dalam sistem pengenalan pembicara Dalam penelitian ini dikenal data latih dan data uji. Berikut penjelasan dari kedua jenis data tersebut.
Data latih
Data latih merupakan kumpulan data suara responden yang akan dilatih untuk kemudian disimpan sebagai basis data kepemilikan identitas suara individu responden.
Data uji
Data uji merupakan kumpulan data suara responden yang akan dimasukan dalam tahap pengujian untuk kemudian dibandingkan dengan basis data dari data latih dan ditentukan kepemilikan identitas suara individu responden tersebut.
Jumlah reponden yang direkam sebanyak empat pembicara. Untuk data latih, dilakukan perekaman secara langsung dengan menggunakan Matlab. Berikut teknik yang digunakan dalam pengambilan data latih.
Setiap pembicara dilakukan perekaman untuk data latih sebanyak lima kali Rekaman data latih berupa pengucapan kata “saya”.
23
Hasil perekaman dilakukan pelatihan dan disimpan sebagai basis data di Matlab.
Saat pengambilan data uji, dilakukan dalam tiga tipe tingkat kesulitan, yaitu: Pengujian kata
Saat pengujian kata ini dilakukan masing–masing responden sebanyak sepuluh kali perekaman dalam pengucapan kata “saya”. Perekaman pengujian kata dilakukan dengan durasi 2 detik.
Pengujian kalimat sederhana
Saat pengujian kalimat sederhana, dilakukan masing–masing responden sebanyak sepuluh kali perekaman dalam pengucapan kalimat “saya sedang belajar”. Perekaman pengujian kalimat sederhana dilakukan dengan durasi 3 detik.
Pengujian kalimat lengkap
Saat pengujian kalimat lengkap yang berarti memiliki kelengkapan berupa subjek, predikat, objek, dan keterangan, dilakukan masing–masing responden sebanyak sepuluh kali perekaman dalam pengucapan kalimat “saya berangkat menggunakan bus ke kampus”. Perekaman pengujian kalimat lengkap dilakukan dengan durasi 7 detik.
Ketiga bentuk pengambilan data pengujian diambil dengan perbedaan rentang waktu satu minggu dengan rincian berikut.
Tabel III.1 Waktu pengambilan data untuk data latih dan data uji
Minggu ke- Pengambilan Data
1 Data latih : Pengucapan kata Data uji : Pengucapan kata
2 Data uji : Pengucapan kalimat sederhana 3 Data uji : Pengucapan kalimat lengkap
III.2 Perancangan Sistem dan Eksperimen Ekstraksi Fitur
Sistem ekstraksi fitur dalam penelitian ini menggunakan mel – frequency cepstral coefficient dengan tahap sebagai berikut.
24
Suara yang telah direkam, kemudian dibuat menjadi 256 sampel tiap bingkainya dan jarak antar bingkai 100. Setelah itu, dilakukan windowing dengan hamming window untuk kemudian hasilnya dikalikan dengan sinyal aslinya, sehingga didapat fungsi sinyal yang baru.
Fast Fourier Transform (FFT)
Sinyal yang akan diproses dalam filter bank di tahap selanjutnya tentu harus ditransformasikan terlebih dahulu menuju ranah frekuensi dengan transformasi Fourier. Sinyal suara ini sudah berupa sinyal diskrit, sehingga proses transformasinya menggunakan transformasi Fourier diskrit atau DFT. Dasarnya, FFT merupakan DFT yang dikembangkan agar proses komputasinya lebih singkat. Hasil keluaran dari proses ini berupa sinyal diskrit dalam ranah frekuensi.
Mel Frequency Warping
Tahap mel frequency warping merupakan tahap inti dari ekstraksi fitur. Jumlah warping yang digunakan sebanyak 20 buah filterbank untuk kemudian terbentuk cepstrum. Bentuk dari 20 segitiga filterbank yang digunakan oleh salah satu pengujian kata seperti gambar berikut.
Gambar III.2 Mel filter bank
Discrete Cosine Transform (DCT)
0 2000 4000 6000 8000 10000 12000 0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2
Mel - Filter Bank
25
Sinyal – sinyal yang telah dilakukan penyaringan akan berupa variabel kompleks. Untuk dapat membantu mengurangi perhitungan, maka DCT akan mengambil bagian cosinusnya dari eksponensial kompleks. Hasil yang didapat berupa bagian riil yang merupakan nilai besarannya.
III.3 Perancangan Sistem dan Eksperimen Pengklasifikasi
III.3.1 Tahap Pelatihan dan Pengujian dengan Metode Kuantisasi Vektor
Dalam proses pengenalan pembicara menggunakan metode kuantisasi vektor, secara umum prosesnya dapat dilihat oleh gambar di bawah ini.
Data Latih Data Uji Ekstraksi Ciri Ekstraksi Ciri Pelatihan Penentuan Centroid Evaluasi Jarak Euclidean Jarak
Terpendek Hasil Prediksi
Gambar III.3 Proses pengenalan pembicara dengan metode kuantisasi vektor Tahap pelatihan yang dibangun metode kuantisasi vektor menggunakan algoritma LBG yang merupakan pengembangan algoritma Llyod. Pengembangan tersebut berada di bagian masukan awal vektor dengan membagi dua vektor kode menggunakan aturan nearest neighbour. Kemudian masing–masing dikluster dan diiterasi dengan algoritma Lloyd sampai didapatkan vektor quantizer yang diinginkan. Metode kuantisasi vektor yang dilakukan sesuai dengan diagram alir dalam Gambar III.4 berikut.
26
Tentukan Centroid
Bagi tiap Centroid (D=0) mvq= 2*mvq Buat Kluster Vektor Tentukan Centroid Hitung Distorsi (D) ((D - D) / D) < e mvq< M Mulai Selesai Ya Tidak Ya Tidak A A D = D
Gambar III.4 Diagram alir pelatihan algoritma Linde, Buzo, dan Gray (LBG) (Adaptasi dari Lawrence Rabiner dan Biing-Hwang Juang, 1993)
Dalam tahap pengujian, tiap–tiap kode buku akan dihitung jarak euclidean-nya menggunakan persamaan (II.15) dan jarak yang paling dekat dipilih sebagai kesamaan vektor ciri antara data uji dan data latih.
27
III.3.2 Tahap Pelatihan dan Pengujian dengan Metode Model Markov Tersembunyi
Dalam penelitian ini menggunakan model markov tersembunyi model kiri ke kanan, karena menurut L. R. Rabiner (1989) untuk proses pengenalan suara yang sifatnya tersembunyi lebih baik dirancang menggunakan model kiri ke kanan dari pada model ergodik dan menggunakan tipe Continuous Hidden Markov Model (CHMM). Status yang digunakan dalam metode model markov tersembunyi ini berjumlah 6 (Dimasatria, 2016). Secara umum, diagram blok dari proses pengenalan pembicara menggunakan metode model markov tersembunyi dalam Gambar III.5. Data Latih Data Uji Ekstraksi Ciri Ekstraksi Ciri Pelatihan / Pemodelan HMM Evaluasi Probabilitas
Terbesar Hasil Prediksi
Gambar III.5 Proses pengenalan pembicara menggunakan metode model markov tersembunyi
Tahap pelatihan dengan metode model markov tersembunyi
Tahap pelatihan dilakukan untuk menentukan parameter estimasi, sehingga terbentuk model markov tersembunyi berupa 𝜆 = (𝐴, 𝐵, 𝜋). Dalam penelitian ini menggunakan CHMM, sehingga untuk parameter B terdiri dari mean dan kovarian. Berikut diagram alir pelatihan dengan metode model markov tersembunyi.
Mulai
Ekstraksi Ciri : MFCC
Pemodelan HMM – Algoritma Baum Welch
Muat Basis Data Sinyal Suara Latih
Selesai
28
Data latih yang berada di basis data, kemudian diproses ekstraksi ciri. Keluaran dari ekstraksi ciri merupakan vektor yang terobservasi yang kemudian dijadikan sebagai masukan oleh proses pelatihan dengan algoritma Baum Welch Masukan diproses dengan algoritma maju dan mundur untuk mendapatkan nilai parameter A. Dalam parameter B, diwakili oleh mean dan kovarian dengan masukan dari vektor yang terobservasi juga. Begitu pula untuk matrik awal atau parameter 𝜋, sehingga didapat model untuk model markov tersembunyi. Berikut diagram alir dari algoritma Baum Welch dalam Gambar III.7.
29 Mulai Inisialisasi Parameter HMM Latih Parameter HMM Selesai Simpan Parameter HMM Sesuaikan Model HMM
Hitung Nilai Log dari tiap Model
Nilai Maksimum Log
Model HMM A A Masukkan Urutan Data Data yang Terobservasi
Pilih State dan Tipe Model
HMM
30
Tahap pengujian dengan metode model markov tersembunyi
Pengujian dilakukan untuk mengetahui seberapa besar nilai peluang data suara uji terhadap kecocokannya dengan data latih. Jika dalam tahap pelatihan, inisialisasi matriks transisi dan matriks emisi diisi dengan acak, sedangkan untuk tahap pengujian, inisialisasi matriks transisi dan matriks emisi berasal dari data proses pelatihan.
Di awal proses pengujian tetap dilakukan ekstraksi ciri, kemudian keluarannya dijadikan vektor ciri. Proses pengujian atau evaluasi ini menggunakan algoritma maju karena yang ingin dicari hanya nilai peluang dari data uji di setiap basis data hasil pelatihan. Nilai peluang yang paling tinggi, menentukan kecocokan antara data uji terhadap basis data latih. Nilai peluang yang didapat merupakan hasil penyekalaan (scaling) dikarenakan rentang datanya terlalu jauh (Nilsson, 2005). Berikut maju yang digunakan dalam tahap pengujian dengan metode model markov tersembunyi.
Mulai
Selesai Muat Basis Data Sinyal Suara Uji
Ekstraksi Ciri : MFCC
Evaluasi HMM – Algoritma Maju
Pembicara Dikenali
31
Dalam bab selanjutnya dijelaskan mengenai pengujian sistem pengenalan pembicara baik diujikan menggunakan metode kuantisasi vektor maupun metode model markov tersembunyi. Setelah dilakukan pengujian akan dipaparkan data hasil pengujiannya berupa pembahasan dari hasil pengujian kata, kalimat sederhana, dan kalimat lengkap.
32
Bab IV Pengujian dan Pembahasan
IV.1 Pengujian Sistem
Pengujian dilaksanakan dengan membandingkan hasil eksperimen dari sistem pengenalan pembicara dengan menggunakan metode kuantisasi vektor dan model markov tersembunyi. Hasil eksperimen berupa nilai akurasi dari masing–masing pembicara yang dihitung dengan persamaan Speaker Identification Rate (SIR), didefinisikan berikut.
%𝑆𝐼𝑅 =𝐽𝑢𝑚𝑙𝑎ℎ𝑑𝑎𝑡𝑎𝑡𝑒𝑟𝑖𝑑𝑒𝑛𝑡𝑖𝑓𝑖𝑘𝑎𝑠𝑖
𝐽𝑢𝑚𝑙𝑎ℎ𝑡𝑜𝑡𝑎𝑙𝑑𝑎𝑡𝑎 (IV.1)
Diagram blok pengujian perbandingan hasil eksperimen pengenalan pembicara ini diberikan dalam gambar berikut.
MFCC Kuantisasi Vektor Model Markov Tersembunyi Hasil Pengenalan Hasil Pengenalan Hitung Persentase Pengenalan Hitung Persentase Pengenalan Bandingkan Hasil Akurasi Pengujian Kata Uji Kata Uji Kalimat
Sederhana Uji Kalimat Lengkap Hasil Pengenalan Hasil Pengenalan Hasil Pengenalan Uji Kata Uji Kalimat
Sederhana Uji Kalimat Lengkap Hasil Pengenalan Hitung Persentase Pengenalan Hitung Persentase Pengenalan Hitung Persentase Pengenalan Hitung Persentase Pengenalan Bandingkan Hasil Akurasi Pengujian Kalimat Sederhana Bandingkan Hasil Akurasi Pengujian Kalimat Lengkap
33 Berikut penjelasan dari diagram blok di atas.
Suara diekstraksi cirinya menggunakan mel – frequency cepstral coefficient Hasil ekstraksi ciri, kemudian dilakukan pengujian dengan metode kuantisasi
vektor dan model markov tersembunyi
Masing–masing metode, akan dihasilkan berupa hasil pengenalan yang diujikan dalam tiga tingkat kesulitan yang telah dibahas sebelumnya yaitu pengujian kata, kalimat sederhana, dan kalimat lengkap
Berdasarkan pengujian selama sepuluh kali, maka hasil pengenalan akan dibentuk dalam persentase keakuratan sistem metode tersebut
Membandingkan tingkat akurasi dari masing–masing metode terhadap tingkat kesulitannya
IV.1.1 Pengujian Sistem Perekaman Suara
Suara yang menjadi objek langsung direkam dan diolah di Matlab, untuk itu perlu ditinjau keadaan suaranya baik melalui penggambaran sinyal suara maupun mendengarkan hasil rekaman. Berikut akan disampaikan hasil pengujian berupa beberapa contoh penggambaran sinyal suara dari salah satu responden.
sa ya
Gambar IV.2 Penggambaran sinyal suara dalam pengucapan kata “saya” yang digunakan sebagai data latih
34
sa ya
Gambar IV.3 Penggambaran sinyal suara dalam pengucapan kata “saya” yang digunakan sebagai data uji
saya sedang belajar
Gambar IV.4 Penggambaran sinyal suara dalam pengucapan kalimat “saya sedang belajar” yang digunakan sebagai data uji
35 saya berangkat menggunakan bis ke kampus
Gambar IV.5 Penggambaran sinyal suara dalam pengucapan kalimat “saya berangkat menggunakan bus ke kampus” yang digunakan sebagai data uji Berdasarkan pengujian dengan memunculkan grafik suara dan diputar rekamannya, maka perekaman suara telah sesuai dengan kata dan kalimat pengucapan yang diinginkan.
IV.1.2 Hasil Pengujian Sistem Pengenalan Pembicara dengan Metode Kuantisasi Vektor
Hasil Pengujian Kata
Pengujian dilakukan dengan memasukan data suara ke dalam sistem. Pengujian dilakukan selama sepuluh kali pengucapan kata “saya”. Sistem akan menghitung jarak dari masing–masing euclidean antara seluruh data latih dengan data uji yang dimasukkan. Kemudian ditentukan jarak terdekat merupakan hasil pengenalan pembicara. Data hasil penghitungan jarak dalam pengujian pengucapan kata “saya” terlampir. Berdasarkan hasil penghitungan jarak, didapat hasil pengenalan pembicara dengan metode kuantisasi vektor dalam Tabel IV.1.
36
Tabel IV.1 Data hasil pengenalan pembicara dalam pengujian kata dengan metode kuantisasi vektor No. Pembicara A B C D 1 √ x X √ 2 √ x √ √ 3 √ x √ √ 4 x x √ √ 5 √ x √ √ 6 x √ X √ 7 √ √ √ √ 8 x x √ √ 9 x x √ √ 10 √ x √ X Akurasi 60% 20% 80% 90%
Hasil Pengujian Kalimat Sederhana
Dalam pengujian kalimat sederhana, dengan dilakukan pemasukan data suara ke dalam sistem selama sepuluh kali pengucapan kalimat “saya sedang belajar”. Sistem juga akan menghitung jarak euclidean antara seluruh data latih dengan data uji yang dimasukkan. Data hasil penghitungan jarak untuk pengujian pengucapan kalimat “saya sedang belajar” pun terlampir. Setelah melihat data hasil penghitungan jarak didapat hasil pengenalan pembicara dengan metode kuantisasi vektor dalam tabel berikut.
Tabel IV.2 Data hasil pengenalan pembicara dalam pengujian kalimat sederhana dengan metode kuantisasi vektor
No. Pembicara A B C D 1 x x √ X 2 x x √ √ 3 x x √ √ 4 x x √ √ 5 x x √ √ 6 x x √ √ 7 x x √ √ 8 x x √ √ 9 x x √ √ 10 x x √ √ Akurasi 0% 0% 100% 90%
37 Hasil Pengujian Kalimat Lengkap
Dalam pengujian kalimat lengkap, yang merupakan pengujian dengan tingkat tersulit karena diujikan terhadap data latih yang hanya berupa kata. Pengujian ini dilakukan dengan memasukan data suara pengucapan kalimat “saya berangkat menggunakan bus ke kampus” selama sepuluh kali. Penghitungan dilakukan dalam jarak euclidean antara seluruh data latih dengan data uji yang dimasukkan. Data hasil penghitungan jarak dalam pengujian pengucapan kalimat “saya berangkat menggunakan bus ke kampus” pun terlampir. Setelah melihat data hasil penghitungan jarak, maka didapat hasil pengenalan pembicara dengan metode kuantisasi vektor dalam tabel berikut.
Tabel IV.3 Data hasil pengenalan pembicara dalam pengujian kalimat lengkap dengan metode kuantisasi vektor
No. Pembicara A B C D 1 x x √ x 2 x x √ x 3 x x √ √ 4 √ x √ √ 5 √ x √ √ 6 √ x √ √ 7 √ x x √ 8 √ x √ √ 9 √ x √ √ 10 √ x √ √ Akurasi 70% 0% 90% 80%
IV.1.3 Hasil Pengujian Sistem Pengenalan Pembicara dengan Metode Model Markov Tersembunyi
Hasil Pengujian Kata
Pengujian dilakukan dengan memasukan pengucapan kata “saya” sebanyak sepuluh kali. Kemudian sistem melakukan penghitungan evaluasi dengan menghasilkan nilai peluang. Nilai peluang yang tertinggi menunjukkan tingkat kemiripan data suara yang diujikan terhadap basis data yang merupakan hasil pelatihan data latih. Data hasil penghitungan nilai peluang dalam pengujian ini ditampilkan dalam lampiran.
38
Berdasarkan penghitungan nilai peluang didapat hasil pengenalan pembicara dengan metode model markov tersembunyi sebagai berikut.
Tabel IV.4 Data hasil pengenalan pembicara dalam pengujian kata dengan metode model markov tersembunyi
No. Pembicara A B C D 1 √ √ x √ 2 √ √ √ √ 3 √ √ √ √ 4 √ √ √ √ 5 √ √ x √ 6 √ √ √ √ 7 √ √ √ √ 8 √ x √ √ 9 √ √ √ √ 10 √ √ √ x Akurasi 100% 90% 80% 90%
Hasil Pengujian Kalimat Sederhana
Dalam pengujian dengan tingkat kesulitan berupa kalimat sederhana dengan pengucapan “saya sedang belajar” sebanyak sepuluh kali. Perhitungan evaluasi dilakukan dengan menghasilkan nilai peluang. Nilai peluang yang tertinggi merupakan kemiripan data suara yang diujikan terhadap basis data dari data latih. Hasil penghitungan ditunjukkan dalam lampiran. Berdasarkan penghitungan nilai peluang didapat hasil pengenalan pembicara dalam pengujian kalimat sederhana dengan metode model markov tersembunyi yang diperlihatkan dalam Tabel IV.5 berikut.
39
Tabel IV.5 Data hasil pengenalan pembicara dalam pengujian kalimat sederhana dengan metode model markov tersembunyi
No. Pembicara A B C D 1 √ x √ √ 2 √ x x √ 3 √ √ √ √ 4 √ x x √ 5 √ √ √ √ 6 √ √ √ √ 7 √ √ √ √ 8 √ √ √ √ 9 √ √ √ √ 10 √ √ √ √ Akurasi 100% 70% 80% 100%
Hasil Pengujian Kalimat Lengkap
Pengujian kalimat lengkap dilakukan dengan pengucapan kalimat “saya berangkat menggunakan bus ke kampus” sebanyak sepuluh kali. Evaluasi dilakukan dengan proses penghitungan menjadi peluang. Nilai peluang tersebut yang dijadikan acuan dalam pengenalan pembicara. Hasil penghitungan evaluasi terlampir. Berdasarkan penghitungan nilai peluang didapat hasil pengenalan pembicara dalam pengujian kalimat lengkap dengan metode model markov tersembunyi sebagai berikut.
Tabel IV.6 Data hasil pengenalan pembicara dalam pengujian kalimat sederhana dengan metode model markov tersembunyi
No. Pembicara A B C D 1 √ x x x 2 √ √ x √ 3 √ √ x √ 4 √ √ x √ 5 √ x x √ 6 √ √ x √ 7 √ √ x √ 8 √ √ x √ 9 √ x x √ 10 √ √ x √ Akurasi 100% 70% 0% 90%
40
IV.2 Pembahasan
Pengujian sistem pengenalan pembicara baik menggunakan metode kuantisasi vektor maupun metode model markov tersembunyi telah dilaksanakan, sehingga menghasilkan data akurasi. Berdasarkan seluruh data yang terhimpun akan ditampilkan grafik yang membandingkan kedua metode tersebut seiring dengan tingkat kesulitan pengenalan yang semakin kompleks.
IV.2.1 Perbandingan Pengujian Kata
Berikut ini merupakan grafik dari hasil pengujian kata “saya”.
Gambar IV.6 Pengujian kata dalam kuantisasi vektor dan model markov tersembunyi
Grafik di atas merepresentasikan berdasarkan pengambilan sepuluh kali pengucapan kata “saya” yang dibandingkan terhadap basis data latih dengan pengucapan kata “saya” sebanyak lima kali, maka pembicara A dan B memiliki hasil yang lebih baik dengan diuji menggunakan model markov tersembunyi, sedangkan pembicara C dan D memiliki hasil yang sama dengan masing–masing hasil akurasi sebesar 80% dan 90%. Hasil pengujian menggunakan metode kuantisasi vektor pembicara B memiliki hasil yang paling tidak baik, hal tersebut dikarenakan adanya perbedaan akurasi yang cukup jauh yaitu sebesar 70%.
60% 20% 80% 90% 100% 90% 80% 90% 0% 20% 40% 60% 80% 100% A B C D
Pengujian Kata dalam Kuantisasi Vektor dan Model Markov Tersembunyi
41
IV.2.2 Perbandingan Pengujian Kalimat Sederhana
Berikut grafik dari hasil pengujian kalimat “saya sedang belajar”.
Gambar IV.7 Pengujian kalimat sederhana dalam kuantisasi vektor dan model markov tersembunyi
Berdasarkan pengucapan sepuluh kali untuk kalimat sederhana secara berulang yang dibandingkan terhadap lima kali pengucapan kata “saya” sebagai data latihnya, grafik di atas merepresentasikan pembicara A dan B memiliki hasil yang jauh lebih baik dengan pengujian menggunakan model markov tersembunyi. Pengujian dengan metode kuantisasi vektor pembicara A dan B tidak dapat dikenali sama sekali atau dengan kata lain memiliki akurasi 0%. Kemudian pembicara C, metode kuantisasi vektor dapat mengungguli 20% di atas model markov tersembunyi dan pembicara D, metode model markov tersembunyi masih tetap unggul dibandingkan dengan metode kuantisasi vektor. Dengan demikian, pengujian kalimat sederhana, metode model markov tersembunyi yang umumnya dianggap lebih unggul dibandingkan metode kuantisasi vektor.
0% 0% 100% 90% 100% 70% 80% 100% 0% 20% 40% 60% 80% 100% A B C D
Pengujian Kalimat Sederhana dalam Kuantisasi Vektor dan Model Markov Tersembunyi
42
IV.2.3 Perbandingan Pengujian Kalimat Lengkap
Berikut grafik dari hasil pengujian kalimat “saya berangkat menggunakan bus ke kampus”.
Gambar IV.8 Pengujian kalimat lengkap dalam kuantisasi vektor dan model markov tersembunyi
Pengujian dalam grafik di atas merupakan pengujian sepuluh kali pengucapan kalimat lengkap secara berulang yang dibandingkan terhadap lima kata sebagai data latihnya. Pembicara A dan D memiliki perbedaan akurasi yang tidak besar yaitu masing–masing sebesar 30% dan 10%. Terjadi kegagalan dalam mengenali dua pembicara dengan akurasi 0%, yaitu dalam metode kuantisasi vektor tidak dapat mengenali pembicara B, begitu juga metode model markov tersembunyi tidak dapat mengenali pembicara C. Kedua metode memiliki akurasi yang hampir sama.
IV.2.4 Rekapitulasi Pembahasan dari Seluruh Hasil Pengujian
Seluruh hasil pengujian kemudian dihitung rata–rata hasil akurasinya, sehingga didapakan nilai akurasi masing–masing metode berdasarkan pengujian dengan tingkat kesulitannya dalam tabel berikut.
Tabel IV.7 Perbandingan hasil rekapitulasi akurasi
Metode Pengujian
Kata Kalimat Sederhana Kalimat Lengkap
Kuantisasi Vektor 63% 48% 60%
Model Markov Tersembunyi 90% 88% 65%
70% 0% 90% 80% 100% 70% 0% 90% 0% 20% 40% 60% 80% 100% A B C D
Pengujian Kalimat Lengkap dalam Kuantisasi Vektor dan Model Markov Tersembunyi
43
Dalam pengujian pengucapan kata, model markov tersembunyi dapat mudah mengenali pembicara dengan akurasi 90%, sedangkan metode kuantisasi vektor hanya mampu mengenali sebesar 63%. Kemudian berdasarkan pengujian pengucapan kalimat sederhana, performa metode model markov tersembunyi masih mengungguli sebesar 88% dibandingkan kuantisasi vektor yang turun cukup jauh sebesar 48%. Walaupun metoda model markov tersembunyi turun 2% dari pengujian pengucapan kata, tetapi perbedaannya tidak sejauh metode kuantisasi vektor. Dalam pengujian pengucapan kalimat lengkap, metode model markov tersembunyi tetap masih unggul walaupun akurasinya hanya 65% dibandingkan dengan kuantisasi vektor yang tidak begitu jauh sebesar 60%.
Jika diperhatikan berdasarkan masing–masing pembicara, pembicara B banyak memiliki kegagalan dalam proses pengenalan pembicara dengan perbedaan akurasi yang cukup jauh bahkan sampai pernah tidak dapat dikenali. Walaupun pembicara A dan C juga pernah sampai tidak dikenali, tetapi dalam pengujian lain, memiliki akurasi yang cukup baik.
Beberapa permasalahan tersebut dapat terjadi karena kondisi kesehatan responden di saat pengambilan suara. Perbedaan waktu dengan selang selama satu minggu tersebut dapat memengaruhi kualitas suara. Kemudian keterbatasan kualitas peralatan yang digunakan. Kekurangan dalam kuantisasi vektor dapat saja diatasi dengan memperbanyak jumlah vektor dalam buku kode dan frekuensi sampling seperti yang dilakukan dalam penelitian Ali Zulfikar, dkk.(2009).
Berdasarkan hasil dan analisa didapatkan bahwa metode model markov tersembunyi dapat digunakan sebagai pengenalan pembicara berbahasa Indonesia lebih baik dibandingkan metode kuantisasi vektor, pengujian dilakukan baik menggunakan kata, kalimat sederhana maupun kalimat lengkap dengan hanya menggunakan data latih berupa pengucapan sebuah kata.
Bab selanjutnya merupakan bab terakhir yang menjelaskan kesimpulan dari hasil penelitian. Selain itu terdapat saran yang dapat dilakukan oleh peneliti selanjutnya.