HARAPAN BANGSA
CENTER FOR DATA SCIENCE
D r. Ir. Samuel Tarigan, MBA
2018
EXPLORATORY
CONCEPT REVIEW
β
False negative (Type II error)α
False positive (Type I error)1-
α
1-
β
(POWER) No difference REALITY Difference ST A TISTIC AL DEC ISION Di fferen ce No diff erenc eHarapan Bangsa Center for Data Science ©
CONCEPT REVIEW: POWER DITENTUKAN OLEH
1. EFFECT SIZE, 2. ALPHA, 3. SAMPLE SIZE
CONCEPT REVIEW: POWER DITENTUKAN OLEH
1. EFFECT SIZE, 2. ALPHA, 3. SAMPLE SIZE
Harapan Bangsa Center for Data Science ©
TUJUAN PEMBELAJARAN
1. Mampu membedakan teknik Factor Analysis (FA) dari teknik multivariate lainnya
2. Mampu membedakan Confirmatory dan Exploratory FA
3. Mampu menjelaskan 7 langkah dalam melakukan FA
4. Mampu membedakan FA jenis R dan Q
5. Mampu menjelaskan perbedaan Principal Component Analysis dari FA
6. Mampu menentukan jumlah faktor yang akan diekstrak
7. Mampu menjelaskan konsep rotasi faktor
8. Mampu memberikan label (nama) untuk sebuah faktor
9. Mampu menjelaskan penggunaan tambahan lainnya dari FA
10.Mampu menjelaskan keterbatasan teknik FA
FACTOR ANALYSIS
Definisi dan Konsep Factor Analysis
Langkah-Langkah Factor Analysis
Harapan Bangsa Center for Data Science © 77
INTERDEPENDENCE METHOD
IS THE STRUCTURE OF RELATIONSHIP AMONG: How are the attributes measured? Multidimensional Scaling Correspondence AnalysisVariables Cases/Respondents Objects
Metric Non Metric Cluster
Analysis Factor
FACTOR ANALYSIS ADALAH METODE UNTUK
MENEMUKAN POLA DALAM SEJUMLAH BESAR VARIABEL
Factor Analysis adalah metode interdependence untuk menemukan pola dan
hubungan (relationships) dalam sejumlah besar variabel, serta untuk menentukan apakah informasi tersebut dapat dipadatkan atau disarikan (summarized) dalam data set dari sejumlah faktor (factors) atau komponen (components) yang lebih sederhana.
Secara spesifik tujuan Factor Analysis adalah :
Menemukan underlying structure (faktor) dari sejumlah variable; DAN/ATAU
Mengurangi jumlah data (data reduction), yakni dengan menentukan nilai empiris untuk setiap dimensi yang akan menggantikan nilai asalnya
Harapan Bangsa Center for Data Science ©
TUJUAN FA: MENEMUKAN STRUKTUR DATA,
DAN/ATAU MENGURANGI JUMLAH DATA
9 x1 x2 x3 x4 x5 x6 x7 x8 x9 x1 x2 x3 x4 x5 x6 x7 x8 x9 F1 F2 F3 F1 F2 F3 Data awal Identifikasi underlying structure (mendefinisikan beberapa faktor yang cukup dapat mewakili data awal)
Mengurangi jumlah data (mengidentifikasikan variabel-variabel perwakilan atau menciptakan variabel baru dengan jumlah yang lebih sedikit)
ILUSTRASI FA: DIMENSION REDUCTION
X1
X2 Ketika data 2 dimensi (Xberkorelasi tinggi diubah menjadi 1 dimensi 1dan X2) yang
saja (X1), hanya sedikit information loss.
X1
X1 X2
Ketika data 2 dimensi (X1 dan X2) yang berkorelasi rendah diubah menjadi 1 dimensi saja (X1), terjadi banyak information loss.
Harapan Bangsa Center for Data Science ©
ILUSTRASI FA: DIMENSION REDUCTION
11
Ketika data 3 dimensi (X1, X2 dan X3) yang
berkorelasi tinggi diubah menjadi 2 dimensi (F1dan F2) kemudian direduksi kembali menjadi F1, hanya terjadi sedikit information loss.
X1 X2 X3 F2 F1 F3 F1 F2 F1
PCA MENCARI SUMBU TERBAIK, YAITU SUMBU YANG
MEMBERIKAN
VARIANCE TERBESAR (PROYEKSI TERDEKAT)
X1 X2
Kecocokan sumbu (fit) dapat diukur dari jumlah
kuadrat (sum of square) dari proyeksi masing-masing titik (variance)
b c a2=b2+c2 a X1 X2
Best fit tercapai saat variance terbesar (atau
jarak titik ke proyeksi paling dekat)
Harapan Bangsa Center for Data Science ©
1
2 2
1
PCA MENCARI SUMBU TERBAIK, YAITU SUMBU YANG
MEMBERIKAN
VARIANCE TERBESAR (PROYEKSI TERDEKAT)
13
Eigenvalue adalah jumlah
kuadrat dari jarak antara seluruh titik-titik proyeksi ke pusat elips
= d2
Data memiliki sebaran sebesar eigen value 1 (1) di sumbu eigenvector 1. Sumbu 1memiliki eigenvalue
terbesar dari elips ini.
Data memiliki sebaran sebesar eigen value 2 (2) di sumbu eigenvector 2. Sumbu 2memiliki eigenvalue
terbesar kedua dari elips ini. Demikian seterusnya.
Baik 1 dan 2merupakan kombinasi linier dari X1 dan X2.
X1 X2 d 11/2 21/2
PCA MENCARI SUMBU TERBAIK, YAITU SUMBU YANG
MEMBERIKAN
VARIANCE TERBESAR (PROYEKSI TERDEKAT)
EIGENVALUE DECOMPOSITION OF COVARIANCE MATRIX
OR PCA
SINGULAR VALUE DECOMPOSITION (SVD)
S = V D V
TS = matriks covariance V = eigenvector
D = eigenvalue
Pilih eigenvector terbesar sebanyak k factor
X = U
Ʃ
V
TX = matriks data awal (NxD) U = (N x k)
Ʃ = Singular value (diagonal matrix) k x k VT = k x D
0 0
skala
sebaran arah vektor Posisi data di
Data awal
Harapan Bangsa Center for Data Science ©
DEFINISI FACTOR ANALYSIS
Factor Analysis adalah metode
interdependence
yang bertujuan untuk
menemukan
underlying structure
dari sejumlah variabel.
FA menggabungkan highly correlated variables menjadi beberapa
kelompok yang disebut faktor atau komponen.
Sebagai teknik interdependence, FA tidak memiliki variabel
independent/dependent variables, seluruh variable dianalisis secara
sekaligus (bersamaan).
Harapan Bangsa Center for Data Science ©
CORRELATION MATRIX
(CONTOH STORE IMAGE ELEMENTS)
16 V V1 1 VV22 VV3 3 VV44 VV5 5 VV66 VV7 7 VV88 VV9 9 V V11 PPrricicee LLeevevell 1.00 V V22 SSttororee PPererssoonnnneell .427 1.00 V V33 RReettuurrnn PPooliliccyy .302 .771 1.00 V V44 PPrrododuucct t AAvvaaililaabbiilliitty y .470 .497 .427 1.00 V V55 PPrrododuucct t QQuuaalliitty y .765 .406 .307 .472 1.00 V V66 AAssssororttmemenntt DDeeppthth .281 .445 .423 .713 .325 1.00 V V77 AAssssororttmemenntt WWiiddtthh .354 .490 .471 .719 .378 .724 1.00 V V88 IInn--SStotorre e SSeerrviviccee .242 .719 .733 .428 .240 .311 .435 1.00 V V99 SSttororee AtAtmmosospphheerre e .372 .737 .774 .479 .326 .429 .466 .710 1.00
Harapan Bangsa Center for Data Science ©
CORRELATION MATRIX
(CONTOH STORE IMAGE ELEMENTS)
17 V V33 VV88 VV99 VV22 VV66 VV77 VV44 VV11 VV55 V V33 RReettuurrnnPPoolliiccyy 1.00 V V88 IInn--ssttoorreeSSeerrvviiccee .733 1.00 V V99 SSttoorreeAAttmmoosspphheerree .774 .710 1.00 V V22 SSttoorreePPeerrssoonnnneell .741 .719 .787 1.00 V V66 AAssssoorrttmmeennttDDeepptthh .423 .311 .429 .445 1.00 V V77 AAssssoorrttmmeennttWWiiddtthh .471 .435 .468 .490 .724 1.00 V V44 PPrroodduuccttAAvvaaiillaabbiilliittyy .427 .428 .479 .497 .713 .719 1.00 V V11 PPrriicceeLLeevveell .302 .242 .372 .427 .281 .354 .470 1. 00 V V55 PPrroodduuccttQQuuaalliittyy .307 .240 .326 .406 .325 .378 .472 .765 1.00
Daerah berwarna menggambarkan variabel-variabel yang sangat
mungkin akan digabungkan oleh Factor Analysis.
CONTOH PENERAPAN FACTOR ANALYSIS
DI RESTORAN CEPAT SAJI
Waktu tunggu Kebersihan Keramahan Kualitas rasa Suhu makanan Kesegaran Kualitas Pelayanan Kualitas Makanan VARIABEL FAKTOR
Harapan Bangsa Center for Data Science ©
FACTOR ANALYSIS
Definisi dan Konsep Factor Analysis
Langkah-Langkah Factor Analysis
Ilustrasi Pengolahan Data Factor Analysis
7 LANGKAH FACTOR ANALYSIS
Stage 1: Tujuan Factor Analysis
Stage 2: Rancangan Factor Analysis
Stage 3: Asumsi Factor Analysis
Stage 4: Menentukan Faktor dan Menilai Overall Fit
Stage 5: Interpretasi dari Faktor
Stage 6: Validasi
21
STAGE 1: TUJUAN FACTOR ANALYSIS
Pertanyaan 1. Apakah tujuan FA Exploratory atau Confirmatory?
Penelitian Exploratory FA (EFA) artinya peneliti tidak punya dugaan (teori) mengenai berapa jumlah faktor yang ada dan bagaimana pengelompokan variabel ke dalam faktor tersebut. Sedangkan metode confirmatory (CFA), peneliti ingin menguji apakah jumlah faktor dan pengelompokan variabelnya sesuai dengan teori yang ada.
Bila penelitian akan bersifat confirmatory maka gunakan Structural Equation Modeling (SEM)
Harapan Bangsa Center for Data Science ©
STAGE 1: TUJUAN FACTOR ANALYSIS
Pertanyaan 2. Apakah Unit of Analysis adalah pengelompokan variabel
(R-analysis) atau pengelompokan respondent atau cases (Q-analysis)?
23 x1 x2 x3 x4 x5 x6 x7 x8 x9
F1R-analysisF2 F3 Q-Factor Analysis
x1 x2 x3 x4 x5 x6 x7 x8 x9
Group 1
Group 2
Pengelompokan respondent (cases) yang serupa. Q-Factor Analysis tidak sering digunakan karena kesulitan komputasi saat jumlah respondent banyak. Kebanyakan peneliti menggunakan cluster analysis.
STAGE 1: TUJUAN FACTOR ANALYSIS
Q-Factor Analysis berbasis correlations
respondent A dan C ada dalam satu group, B dan D di kelompok lainnya
Cluster Analysis berbasis distance
respondent A dan B dalam satu group, sedangkan C dan D di kelompok lainnya.
Harapan Bangsa Center for Data Science ©
STAGE 1: TUJUAN FACTOR ANALYSIS
Pertanyaan 3. Apakah tujuan FA cukup sampai data summarization
(menemukan faktor) atau termasuk dengan data reduction?
Apabila hanya sampai dengan data summarization maka FA akan berhenti sampai lengkah ke enam. Namun apabila tujuan FA sampai dengan data reduction, maka FA akan dilakukan sampai langkah ke 7, di mana langkah terakhir adalah menentukan (menghitung) data untuk masing-masing faktor yang akan menggantikan nilai variabel sebelumnya.
Ada tiga jenis data pengganti tersebut: surrogate, summated scale, atau
factor score.
STAGE 1: TUJUAN FACTOR ANALYSIS
Pertanyaan 4. Apakah FA akan dilanjutkan dengan analisis lainnya?
Underlying structure membantu peneliti mengenali variabel-variabel yang mirip (berkorelasi tinggi). Dalam stepwise regression contohnya, peneliti akan tahu variabel-variabel mana yang tidak akan secara signifikan menambah predictive power.
Data reduction akan mengurangi high intercorrelations antar variabel, yang tidak diinginkan dalam beberapa analisis multivariate.
Harapan Bangsa Center for Data Science ©
STAGE 1: TUJUAN FACTOR ANALYSIS
Pertanyaan 3. Apakah tujuan FA cukup sampai data summarization
(menemukan faktor) atau termasuk dengan data reduction?
Apabila hanya sampai dengan data reduction maka FA akan berhenti sampai lengkah ke enam. Namun apabila tujuan FA sampai dengan data reduction, maka FA akan dilakukan sampai langkah ke 7, di mana langkah terakhir adalah menentukan (menghitung) data untuk masing-masing faktor yang akan menggantikan variabel sebelumnya.
STAGE 2: RANCANGAN FACTOR ANALYSIS
Dalam membuat desain (rancangan) FA, terdapat tiga keputusan utama:
1. Perhitungan input data – akan berbeda untuk R vs. Q analysis 2. Jumlah variabel, pengukuran variabel, dan jenis variabel
Harapan Bangsa Center for Data Science ©
STAGE 2: RANCANGAN FACTOR ANALYSIS
FA umumnya dilakukan untuk variabel metrik, meskipun ada metode khusus yang bisa digunakan untuk “dummy variables”. Sejumlah kecil dummy
variables bisa dimasukkan ke dalam metric variables.
Bila study dirancang untuk menemukan struktur faktor, maka upayakan untuk memiliki setidaknya 5 variabel untuk setiap faktor yang diajukan.
Ukuran sample :
• Jumlah observasi harus lebih banyak dari jumlah variabel.
• Jumlah absolut minimum sampel adalah 50 observasi.
• Maksimalkan jumlah observasi per variabel, minimum 5 dan lebih baik setidaknya 10 observasi per variabel.
29
STAGE 3: ASUMSI FACTOR ANALYSIS
ISSUE KONSEPTUAL
Underlying structure harus memang secara konseptual ada dalam variabel-variabel yang akan dianalisis (variabel-variabel-variabel-variabelnya harus relevan)
Sampel harus homogen. Hindari variabel di mana sampel akan memberi respon berbeda (misalnya antara responden pria dan wanita).
ISSUE STATISTICAL ISSUES
Normalitas, homoscedasticity, linearitas akan mengurangi korelasi
yang tampak.
Uji statistik yang dibutuhkan hanyalah uji normalitas.
Multicollinearity
Harapan Bangsa Center for Data Science ©
STAGE 3: ASUMSI FACTOR ANALYSIS
MULTICOLLINEARITY
Diukur dengan MSA (Measure of Sampling Adequacy). MSA diukur dengan Kaiser-Meyer-Olkin (KMO) statistic. KMO akan memprediksi apakah data akan menghasilkan faktor, berdasarkan korelasi dan korelasi parsial yang ada.
Terdapat KMO keseluruhan dan KMO per variabel. KMO memliki rentang 0-1. KMO keseluruhan harus lebih besar daripada 0.50.
Bila KMO keseluruhan belum mencapai 0.50, buang variabel dengan KMO terkecil sampai KMO individual dan keseluruhan mencapai di atas 0.50
STAGE 3: ASUMSI FACTOR ANALYSIS
Sebelum melakukan FA, harus terdapat fondasi konseptual (teoretikal) yang kuat untuk menopang asumsi bahwa terdapat struktur di balik
variabel-variabel yang ada.
Bartlett’s test of sphericity (sig < 0.05) menunjukkan bahwa terdapat korelasi yang cukup di antara variabel-variabel yang ada agar langkah-langkah FA selanjutnya dapat dilaksanakan. Statistik ini menguji adanya
non-zero correlations dalam data, bukan pola korelasinya.
MSA individual dan keseluruhan harus mencapai di atas 0.50. Variabel dengan MSA<0.5 harus dibuang, mulai dengan MSA yang terkecil.
Harapan Bangsa Center for Data Science ©
STAGE 4: MENENTUKAN (MENGEKSTRAK)
FAKTOR DAN MENILAI OVERALL FIT
33
KEPUTUSAN EKSTRAKSI
Metode ekstraksi yang mana yang akan digunakan?
• Principal Component Anlaysis
• Common Factor Analysis
Metode rotasi yang mana yang akan digunakan?
• Rotasi Orthogonal
• Rotasi Oblique
STAGE 4: MENENTUKAN (MENGEKSTRAK)
FAKTOR DAN MENILAI OVERALL FIT
METODE EKSTRAKSI MENENTUKAN JENIS VARIANCE YANG AKAN DIGUNAKAN DALAM FACTOR MATRIX
RULE OF THUMB 2
DIAGONAL VALUE JENIS VARIANCE
Unity (1)
Communality
Total Variance
Specific and Error
Variance extracted Variance not used
Harapan Bangsa Center for Data Science ©
STAGE 4: MENENTUKAN (MENGEKSTRAK)
FAKTOR DAN MENILAI OVERALL FIT
35
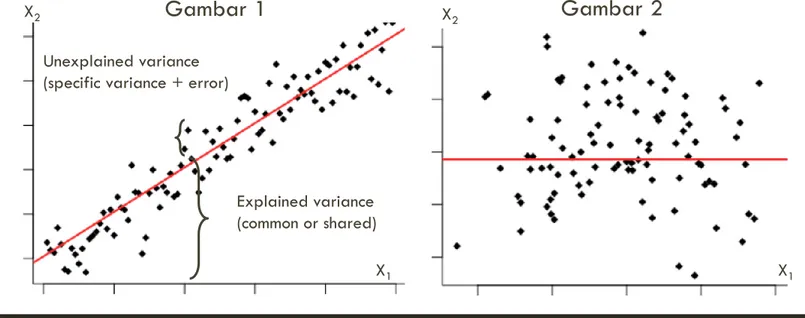
SHARED VARIANCE DAN COMMUNALITY
Dalam Gambar 1, X1 berbagi lebih banyak variance (share more variance, higher
communality) dengan X2 daripada di Gambar 2. Dengan kata lain, di Gambar1,
variance X1 dapat menjelaskan lebih banyak variance X2 demikian juga sebaliknya (kedunya berbagi variance), daripada di Gambar 2.
Gambar 1 Gambar 2
Unexplained variance (specific variance + error)
Explained variance (common or shared) X2 X1 X2 X1
STAGE 4: MENENTUKAN (MENGEKSTRAK)
FAKTOR DAN MENILAI OVERALL FIT
SHARED VARIANCE DAN COMMUNALITY
SHARED VARIANCE
Ketika sebuah variabel berkorelasi dengan variabel lainnya, variabel tersebut dikatakan berbagi variance dengan variabel lainnya tersebut. Jumlah shared variance tersebut adalah kuadrat dari korelasinya. Contoh
ketika: korelasi dua variabel adalah 0.5, maka dikatkaan kedua variabel tersebut berbagi 25% variance (0.52).
COMMUNALITY
Adalah jumlah total shared variance yang dimiliki sebuah variabel tertentu terhadap seluruh variabel-variabel lainnya yang terdapat dalam sebuah faktor.
Harapan Bangsa Center for Data Science ©
STAGE 4: MENENTUKAN (MENGEKSTRAK)
FAKTOR DAN MENILAI OVERALL FIT
37
JENIS-JENIS VARIANCERULE OF THUMB 2
Common Variance adalah variance yang di-share antara satu variabel dengan variabel lainnya (lihat penjelasan shared variance dan
communality).
Specific atau Unique Variance adalah variance yang hanya dimiliki oleh satu variabel tertentu saja (tidak di-share)
Error Variance adalah variance yang dihasilkan karena kesalahan atau ketidakhandalan proses pengumpulan data, kesalahan pengukuran, atau komponen random dalam variabel tersebut. Variance ini juga tidak dapat dijelaskan oleh korelasi dengan variabel-variabel lainnya.
STAGE 4: MENENTUKAN (MENGEKSTRAK)
FAKTOR DAN MENILAI OVERALL FIT
PEMILIHAN METODE: PCA atau COMMON FA?
Dalam analisis FA, PCA menggunakan Total Variance sehingga tidak ada information loss, data berbicara apa adanya.
Sedangkan, FA menggunakan Common Variance sehingga terdapat information loss, namun variance yang digunakan hanya yang dapat dijelaskan oleh variabel-variabel lainnya, sehingga hasilnya seharusnya lebih relevan.
Namun dalam praktek, keduanya sering memberikan hasil yang sama (terutama bila jumlah variabel di atas 30).
Harapan Bangsa Center for Data Science ©
STAGE 4: MENENTUKAN (MENGEKSTRAK)
FAKTOR DAN MENILAI OVERALL FIT
39
PEMILIHAN METODE: PCA atau COMMON FA?
KRITERIA PCA Common FA
Lebih tepat Lebih tepat
Tujuan FA
Pengetahuan sebelumnya tentang variance dalam variabel-variabel yang dianalisis
Data reduction Underlying structure
Specific & error variance relative kecil terhadap
total variance
Proporsi masing-masing jenis variance tidak
V V33 VV88 VV99 VV22 VV66 VV77 VV44 VV11 VV55 V V33 RReetuturrnn PPoolliiccy y 1.00 V V88 IInn--sstotorree SSeerrvviicce e .733 1.00 V V99 SSttoorree AAttmmoossphpheerere .774 .710 1.00 V V22 SSttoorree PPeerrssoonnnneell .741 .719 .787 1.00 V V66 AAssssororttmmeentnt DDeeppthth .423 .311 .429 .445 1.00 V V77 AAssssororttmmeentnt WWiiddtth h .471 .435 .468 .490 .724 1.00 V V44 PPrroodduuctct AvAvaaiillababiilliittyy .427 .428 .479 .497 .713 .719 1.00 V V11 PPrriiccee LLeevveell .302 .242 .372 .427 .281 .354 .470 1. 00 V V55 PPrroodduuctct QQuualaliittyy .307 .240 .326 .406 .325 .378 .472 .765 1.00
Dalam Common Factor Analysis ganti unity (angka 1) di kolom diagonal
dengan Communality (disebut pula reduced variance)
Diagonal value: unity atau communality
STAGE 4: MENENTUKAN (MENGEKSTRAK)
FAKTOR DAN MENILAI OVERALL FIT
Harapan Bangsa Center for Data Science ©
STAGE 4: MENENTUKAN (MENGEKSTRAK)
FAKTOR DAN MENILAI OVERALL FIT
MENENTUKAN JUMLAH FAKTOR
Terdapat empat cara menentukan jumlah faktor yang akan dihasilkan FA:
A Priori Criterion, peneliti sudah memiliki dugaan kuat tentang jumlah faktor yang seharusnya ada dalam data.
Latent Root Criterion, disebut pula kriteria eigen value.
Percentage of Variance, seberapa banyak variance yang dapat dijelaskan oleh sejumlah faktor
Scree Test Criterion, menggunakan diagram scree dan memilih jumlah faktor sebelum titik infleksi (inflection point).
Eigenvalue Plot untuk Scree Test Criterion
STAGE 4: MENENTUKAN (MENGEKSTRAK)
FAKTOR DAN MENILAI OVERALL FIT
Harapan Bangsa Center for Data Science ©
STAGE 4: MENENTUKAN (MENGEKSTRAK)
FAKTOR DAN MENILAI OVERALL FIT
43
Meskipun PCA dan Common FA sering menghasilkan hasil yang mirip (khususnya bila jumlah variabel 30 atau lebih, atau communalities di atas 0.60 untuk
kebanyak variabel), namun PCA lebih cocok untuk tujuan data reduction
sedangkan FA untuk menemukan underlying structure (aplikasi berbasis teori). Jumlah faktor ditentukan berdasarkan beberapa pertimbangan:
• Gunakan beberapa stopping criteria
• Faktor dengan eigenvalue di atas 1.0
• Jumlah faktor yang sudah ditentukan sebelumnya (dari riset sebelumnya)
• Persentase explained variance yang cukup (umumnya di atas 60%)
• Faktor sebelum inflection point dalam Scree test.
• Pertimbangkan juga beberapa solusi alternatif (plus/minus satu faktor) untuk mendapat struktur terbaik.
STAGE 4: MENENTUKAN (MENGEKSTRAK)
FAKTOR DAN MENILAI OVERALL FIT
MELAKUKAN EKSTRAKSI FAKTOR
Langkah-langkah melakukan ekstraksi faktor: Lakukan estimasi Factor Matrix
Lakukan Rotasi Faktor
Lakukan Interpretasi Faktor
Respesifikasi model bila diperlukan, misalnya dengan cara:
• menghapus variabel
• melakukan rotasi yang berbeda
• menggunakan jumlah faktor yagn berbeda
Harapan Bangsa Center for Data Science ©
STAGE 4: MENENTUKAN (MENGEKSTRAK)
FAKTOR DAN MENILAI OVERALL FIT
HASIL EKSTRAKSI FAKTOR
FACTOR MATRIX dan FACTOR LOADINGS
45
STAGE 4: MENENTUKAN (MENGEKSTRAK)
FAKTOR DAN MENILAI OVERALL FIT
ROTASI FAKTOR
Rotasi faktor adalah upaya mengubah sumbu-sumbu acuan faktor-faktor di sekitar titik origin ke posisi lain untuk memudahkan pengelompokan variabel ke dalam faktor.
Karena unrotated factor solutions mengekstrak faktor berdasarkan seberapa banyak variance yang dijelaskannya, maka faktor pertama akan menjelaskan variance sebesar mungkin, sehingga variance yang dijelaskan di tahap
berikutnya oleh faktor lainnya akan semakin kecil.
Dengan rotasi, variance akan diredistribusikan dari faktor awal ke faktor-faktor berikutnya sehingga akan muncul pola faktor-faktor yang lebih sederhana dan memiliki makna teoretikal yang lebih baik.
Harapan Bangsa Center for Data Science ©
STAGE 4: MENENTUKAN (MENGEKSTRAK)
FAKTOR DAN MENILAI OVERALL FIT
ROTASI FAKTOR
47
Terdapat dua jenis rotasi faktor:
Orthogonal : sumbu-sumbu tetap dipertahankan pada sudut 90 derajat, artinya semua faktor tidak berkorelasi alias independen.
Oblique : sumbu-sumbu tidak harus dipertahankan pada sudut 90 derajat, sehingga terdapat korelasi antar faktor.
STAGE 4: MENENTUKAN (MENGEKSTRAK)
FAKTOR DAN MENILAI OVERALL FIT
ORTHOGONAL FACTOR ROTATION
Unrotated Factor II Unrotated Factor I Rotated Factor I Rotated Factor II -1.0 -.50 0 +.50 +1.0 -.50 +1.0 +.50 V1 V2 V3 V4 V5
Harapan Bangsa Center for Data Science ©
STAGE 4: MENENTUKAN (MENGEKSTRAK)
FAKTOR DAN MENILAI OVERALL FIT
OBLIQUE FACTOR ROTATION
49 Unrotated Factor II Unrotated Factor I Oblique Rotation: Factor I Orthogonal Rotation: Factor II
-1.0 -.50 0 +.50 +1.0 -.50 -1.0 +1.0 +.50 V1 V2 V3 V4 V5 Orthogonal Rotation: Factor I
STAGE 4: MENENTUKAN (MENGEKSTRAK)
FAKTOR DAN MENILAI OVERALL FIT
METODE ROTASI ORTHOGONAL
Terdapat tiga jenis rotasi faktor orthogonal:
Quartimax: simplify row, memastikan bahwa setiap variabel (baris) tertentu memiliki loading tinggi hanya di satu faktor saja.
Varimax: simplify column, memastikan dalam faktor (kolom) tertentu hanya variabel-variabel tertentu saja
memiliki loading tinggi. Metode ini adalah yang paling banyak
digunakan.
Harapan Bangsa Center for Data Science ©
STAGE 4: MENENTUKAN (MENGEKSTRAK)
FAKTOR DAN MENILAI OVERALL FIT
51
Metode rotasi orthogonal adalah metode yang paling banyak digunakan. Metode ini cocok digunakan bila tujuan riset adalah mengurangi data (data
reduction) agar memiliki lebih sedikit variabel yang tidak saling terkorelasi, untuk kepentingan analisis multivariat lainnya.
Metode rotasi oblique lebih tepat digunakan dalam riset yang bertujuan untuk menghasilkan beberapa faktor (constructs) yang memiliki makna teoretis. Di dunia nyata, hanya sedikit sekali faktor yang tidak berkorelasi satu dengan yang
lainnya.
STAGE 4: MENENTUKAN (MENGEKSTRAK)
FAKTOR DAN MENILAI OVERALL FIT
TINGKAT LOADING YANG SIGNIFIKAN
Untuk menentukan berapa batas loading yang signifikan peneliti perlu mempertimbangkan
Customary criteria (kebiasaan). Umumnya practical significance ada pada tingkat 0.3-0.4 minimum, sekitar 0.5 untuk signifikansi yang lebih besar, dan >0.7 menunjukkan struktur yang terdefinisi dengan jelas.
Sample Size dan Jumlah Variabel. Bila jumlah sampel atau jumlah variabel semakin banyak maka tingkat loading sebagai batas signifikansi menjadi lebih kecil.
Jumlah Faktor: Loading yang lebih besar diperlukan bila terdapat lebih banyak jumlah faktor dalam factor solution, khususnya dalam mengevaluasi loading pada faktor-faktor lanjutan (bukan awal).
Harapan Bangsa Center for Data Science ©
STAGE 4: MENENTUKAN (MENGEKSTRAK)
FAKTOR DAN MENILAI OVERALL FIT
53
PANDUAN SAMPLE SIZE DAN TINGKAT LOADING YANG SIGNIFIKAN PADA TINGKAT POWER 80%
Factor Loading Sample Size Needed for Significance* .30 350 .35 250 .40 200 .45 150 .50 120 .55 100 .60 85 .65 70 .70 60 .75 50
*Significance is based on a .05 significance level (a), a power level of 80 percent, and standard errors assumed to be
STAGE 4: MENENTUKAN (MENGEKSTRAK)
FAKTOR DAN MENILAI OVERALL FIT
Minimum loading yang dapat diterima adalah 0.3-0.4, namun untuk memiliki signifikansi praktis, sebuah variabel perlu memiliki loading di atas 0.5.
Untuk menjadi signifikan:
• Loading lebih rendah diperlukan bila jumlah sampel atau jumlah variabelnya lebih banyak.
• Loading lebih tinggi diperlukan bila jumlah faktor lebih banyak, khususnya di later factors.
Uji statistik untuk signifikansi loading factors biasanya bersifat sangat konservatif, sehingga digunakan hanya sebagai langkah awal untuk memasukkan sebuah variabel untuk pertimbangan selanjutnya.
Harapan Bangsa Center for Data Science ©
STAGE 5: INTERPRETASI FAKTOR
55
Langkah-langkah dalam stage ini:
1. Pelajari loading dalam factor matrix. Untuk metode rotasi oblique maka akan dihasilkan dua matrix: factor pattern dan factor structure. Kebanyak peneliti menggunakan factor pattern.
2. Identifikasi loading tertinggi yang dimiliki setiap variabel terhadap semua faktor (antar faktor).
3. Periksa communalities dari variabel-variabel dalam satu faktor
STAGE 5: INTERPRETASI FAKTOR
Struktur optimal terjadi saat setiap variabel hanya memiliki loading tinggi di satu faktor saja.
Variabel yang memiliki cross-load (loading tinggi pada dua atau lebih faktor) biasanya dibuang.
Variabel harus memiliki communality di atas 0.50 untuk dipertahankan dalam analisis.
Respesifikasi FA dapat dilakukan dengan cara:
• Membuang variabel
• Mengubah metode rotasi, dan/atau
• Menambah atua mengurangi jumlah faktor RULE OF THUMB 6
Harapan Bangsa Center for Data Science ©
STAGE 6: VALIDASI FA
57
Validasi FA dapat dilakukan dengan cara:
Confirmatory perspective – mengggunakan CFA di SEM
Menilai kestabilan Factor Structure. Stabilitas struktur faktor biasanya tergantung kepada rasio case to variable. Bila jumlah sample memungkinkan, maka pecah sampel menjadi dua kelompok dan bandingkan factor matrix-nya.
STAGE 7: PENGGUNAAN TAMBAHAN FA
Pada tahap opsional ini, FA dilanjutkan dengan penentuan nilai pengganti untuk menggantikan nilai variabel dengan salah satu cara berikut:
Memilih Surrogate Variable. Dalam metode ini, nilai pengganti biasnaya
memakai nilai dari variabel dengan nilai loading tertinggi dalam sebuah faktor Menciptakan Summated Scale. Dengan cara ini, nilai pengganti biasanya
menggunakan rata-rata nilai dari seluruh variabel dalam setiap faktor
Menghitung Factor Score. Nilai pengganti dihitung dengan memperhitungkan factor loading.
Harapan Bangsa Center for Data Science ©
STAGE 7: PENGGUNAAN TAMBAHAN FA
59
Summated scale hanya akan memiliki kualitas sebaik item-item yang digunakan dalam konstruk tersebut. Summated scale tidak bisa digunakan tanpa justifikasi teoretis. Pastikan content/face validity.
Jangan menggunakan summated scale tanpa menilai unidimensionality dari variabel-variabelnya menggunakan EFA/CFA.
Bila sebuah scale dipandang unidimensional, maka reliability-nya diukur dengan Cronbach’s alpha. Nilainya harus > 0.70 (bisa 0.60 dalam studi exploratory). Nilai ambang akan meningkat seiring dengan penambahan item di atas 10. Setelah memastikan reliability, maka validitas scale harus diukur dari aspek:
• Convergent validity: scale berkorelasi dengan scale sejenis
• Discriminant validity: scale cukup berbeda dari scale lain yang berhubungan
• Nomological validity: scale dapat memprediksi seperti dugaan teoretis. RULE OF THUMB 7: SUMMATED SCALE
STAGE 7: PENGGUNAAN TAMBAHAN FA
Single Surrogate Variable. Keuntungan: mudah dilakukan dan diinterpretasikan
Kekurangan: tidak mencerminkan semua facet dari sebuah faktor, serta rentan terhadap kesalahan pengukuran.
Factor Scores. Keuntungan: mewakili semua variabel dalam faktor, merupakan metode terbaik untuk data reduction, serta bersifat orthogonal (menghilangkan masalah multikolinearitas). Kekurangan: hasilnya sulit diinterpretasikan karena semua variabel berkontribusi, serta sulit direplikasi antar studi.
Summated Scale. Keuntungan: kompromi antara surrogate dan factor score, mengurangi measurement error, mewakili semua variabel dalam faktor dan semua facet dalam sebuah konsep, serta mudah direplikasi antar studi.
Kekurangan: hanya memasukkan variabel dengan loading tinggi, belum tentu orthogonal, membutuhkan analisis mendalam menyangkut reliabilitas dan
validitasnya.
Harapan Bangsa Center for Data Science ©
CHECK PEMAHAMAN FA
61 1. Apakah kegunaan utama dari FA?
2. Apakah perbedaan PCA dan Common FA?
3. Apakah rotasi faktor diperlukan?
4. Bagaimana cara menentukan jumlah faktor yang akan diekstrak?
5. Apakah yang disebut dengan factor loading yang signifikan?
6. Bagaimana cara memberikan nama kepada sebuah faktor?
7. Apakah sebaiknya kita menggunakan factor scores atau summated scale dalam analisis lanjutan?
FACTOR ANALYSIS
Definisi dan Konsep Factor Analysis
Langkah-Langkah Factor Analysis
Harapan Bangsa Center for Data Science ©
ILLUSTRASI PENGOLAHAN DATA
FACTOR ANALYSIS
63
Variable Description Variable Type
Data Warehouse Classification Variables
X1 Customer Type nonmetric
X2 Industry Type nonmetric
X3 Firm Size nonmetric
X4 Region nonmetric
X5 Distribution System nonmetric
Performance Perceptions Variables
X6 Product Quality metric
X7 E-Commerce Activities/Website metric
X8 Technical Support metric
X9 Complaint Resolution metric
X10 Advertising metric
X11 Product Line metric
X12 Salesforce Image metric
X13 Competitive Pricing metric
X14 Warranty & Claims metric
X15 New Products metric
X16 Ordering & Billing metric
X17 Price Flexibility metric
X18 Delivery Speed metric
Outcome/Relationship Measures
X19 Satisfaction metric
X20 Likelihood of Recommendation metric
X21 Likelihood of Future Purchase metric
X22 Current Purchase/Usage Level metric
ILLUSTRASI PENGOLAHAN DATA
FACTOR ANALYSIS
Stage 1: Tujuan Factor Analysis
Stage 2: Rancangan Factor Analysis
Stage 3: Asumsi Factor Analysis
Stage 4: Menentukan Faktor dan Menilai Overall Fit
Stage 5: Interpretasi dari Faktor
Stage 6: Validasi
Harapan Bangsa Center for Data Science ©
ILLUSTRASI PENGOLAHAN DATA FA
STAGE 1: TUJUAN FACTOR ANALYSIS
65
Tujuan dalam contoh ini:
Memahami apakah berbagai variabel persepsi dapat
dikelompokkan.
ILLUSTRASI PENGOLAHAN DATA FA
STAGE 2: RANCANGAN FACTOR ANALYSIS
Untuk memahami struktur variabel persepsi dibutuhkan
R-type
factor
anlaysis dan correlation matrix antar variabel, bukan antar responden.
Seluruh variabel bersifat
metric
dan berasal dari persepsi yang
homogen
Harapan Bangsa Center for Data Science ©
ILLUSTRASI PENGOLAHAN DATA FA
STAGE 3: ASUMSI FACTOR ANALYSIS
67
29 dari 78 correlations (37%) signifikan pada p 0.01 cukup untuk proses selanjutnya
Bartlett significant terdapat nonzero correlations (tetapi tidak menilai pola antar variabel-nya) MSA menilai pola antar variables. Overall MSA > 0.5 range yang dapat diterima
ILLUSTRASI PENGOLAHAN DATA FA
STAGE 3: ASUMSI FACTOR ANALYSIS
X15 dibuang (MSA terendah), lalu MSA di-run kembali. Setelah itu, X17 dibuang karena tenyata MSA-nya masih rendah. Perhatikan bahwa X15 memiliki jumlah significant correlations yang paling sedikit sementara X17 memiliki jumlah significant correlations terbanyak.
Harapan Bangsa Center for Data Science ©
ILLUSTRASI PENGOLAHAN DATA FA
STAGE 3: ASUMSI FACTOR ANALYSIS
ILLUSTRASI PENGOLAHAN DATA FA
STAGE 4: MENENTUKAN FAKTOR DAN OVERALL FIT
Berdasarkan eigenvalue criteria 4 faktor (eigenvalue >1)
Berdasarkan scree (elbow) criteria mungkin 5 faktor, but faktor ke 5 memiliki eigenvalue rendah (0.61). Bila eigenvalue-nya dekat angka 1, faktor ini mungkin akan dipertahankan.
Harapan Bangsa Center for Data Science ©
ILLUSTRASI PENGOLAHAN DATA FA
STAGE 5: INTERPRETASI FAKTOR
71
Step 1: Memeriksa Loadings pada Unrotated Factor Matrix
Sum of squares of
loadings
Dalam PCA setiap variabel memiliki eigenvalue 1 Total trace = 11
Communality (kolom ke 5) memberikan summary statistics tentang seberapa baik setiap variabel dijelaskan oleh keempat komponen (faktor).
ILLUSTRASI PENGOLAHAN DATA FA
STAGE 5: INTERPRETASI FAKTOR
Step 2: Mengidentifikasi significant loadings pada Unrotated Factor Matrix Step 3: Memeriksa communalities variable pada Unrotated Factor Matrix
High loadings (>0.4 for sample size of 100 menurut table referensi tersebar di
Semua communalities cukup tinggi >0.5 (berdasarkan practical consideration)
Harapan Bangsa Center for Data Science ©
ILLUSTRASI PENGOLAHAN DATA FA
STAGE 5: INTERPRETASI FAKTOR
73
Menerapkan Varimax Rotation terhadap 11 variabel (full set)
Buang variabel
ILLUSTRASI PENGOLAHAN DATA FA
STAGE 5: INTERPRETASI FAKTOR
Menerapkan Varimax Rotation terhadap 10 variabel (reduced set)
Harapan Bangsa Center for Data Science ©
ILLUSTRASI PENGOLAHAN DATA FA
STAGE 5: INTERPRETASI FAKTOR
75
Menerapkan Varimax Rotation terhadap 10 variabel (reduced set)
Step 4 : Respesifikasi Factor Model bila diperlukan Step 5 : Beri nama faktor
Factor 1 Postsale Customer Service (X9, X18, X16) Factor 2 Marketing (X12,X7,X10) Factor 3 Technical Support (X8, X14) Factor 4 Product value (X6, X13 note opposite signs)
ILLUSTRASI PENGOLAHAN DATA FA
STAGE 5: INTERPRETASI FAKTOR
Harapan Bangsa Center for Data Science ©
ILLUSTRASI PENGOLAHAN DATA FA
STAGE 5: INTERPRETASI FAKTOR
77
ILLUSTRASI PENGOLAHAN DATA FA
STAGE 6: VALIDASI FACTOR ANALYSIS
Harapan Bangsa Center for Data Science ©
ILLUSTRASI PENGOLAHAN DATA FA
STAGE 7: LANJUTAN FACTOR ANALYSIS
79
KEY FINDINGS
1. Summated scales yang dihasilkan RELIABLE
(berdasarkan Cronbach’s Alpha):
• Scale 1 0.9
• Scale 2 0.78
• Scale 3 0.8
• Scale 4 0.57
2. Pola Surrogate, Factor Scores, and Summated Scales
KONSISTEN
X12and X6,
Factor 2 and Factor 4, Scale 2 and Scale 4
Semuanya memiliki rata-rata
(means) yang berbeda secara signifikan antar kelompok
customer, i.e. USA/North America and Outsude USA/North America (X4).
ILLUSTRASI PENGOLAHAN DATA FA
Harapan Bangsa Center for Data Science ©
ILLUSTRASI PENGOLAHAN DATA FA
STAGE 4&5: COMMON FACTOR ANALYSIS
ILLUSTRASI PENGOLAHAN DATA FA
Harapan Bangsa Center for Data Science ©
ILLUSTRASI PENGOLAHAN DATA FA
MANAGERIAL OVERVIEW
83
Baik component (PCA) dan common factor analyses (CFA) memberikan kepada peneliti beberapa insights terkait struktur variabel dan beberapa opsi untuk data reduction.
• Customer HBAT melakukan evaluasi terhadap kinerja perusahaan (persepsi) menggunakan empat dimensi yang berbeda. Dimensi-dimensi tersebut meliputi berbagai aspek (elemen) yang luas dalam pengalaman customer. Perencana pengembangan bisnis di HBAT sekarang dapat menggunakan empat area dalam perencanaan, dan tidak harus menggunakan 13 variabel yang ada. • Peneliti sekarang memiliki sebuah metode untuk menggabungkan
variabel-variabel di dalam setiap faktor menjadi nilai tunggal (single score) yang dapat menggantikan nilai variabel awal menjadi empat composite variables.
STAGE 1: TUJUAN FACTOR ANALYSIS
Pertanyaan 2. Apakah Unit of Analysis adalah pengelompokan variabel
(R-analysis) atau pengelompokan respondent atau cases (Q-analysis)
x1 x2 x3 x4 x5 x6 x7 x8 x9 x1 x2 x3 x4 x5 x6 x7 x8 x9 F1 F2 F3 F1 F2 F3 R-analysis