KAJIAN BEBERAPA METODE PENDUGAAN
NILAI RESIKO OPERASIONAL
TRY SUTRISNA
DEP ARTEMEN STATISTIKA
FAKULTAS MATEMATIKA DAN ILMU PENG ETAHUAN ALAM INSTITUT PERTANIAN BOGOR
Dengan ini saya menyatakan bahwa skripsi berjudul Kajian Beberapa Metode Pendugaan Nilai Resiko Operasional adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, April 2014
Try Sutrisna
TRY SUTRISNA. Kajian Beberapa Metode Pendugaan Nilai Resiko Operasional. Dibimbing oleh I MADE SUMERTAJAYA dan BAGUS SARTONO.
Pengukuran nilai kerugian akibat resiko operasional merupakan hal yang sangat penting dalam melakukan manajemen resiko operasional, sehingga pengukurannya harus dilakukan seakurat mungkin. Karakteristiknya yang berbeda dengan jenis resiko lainnya mengakibatkan resiko operasional harus ditangani dengan metode- metode yang khusus, hal ini mengakibatkan banyak muncul metode- metode alternatif dalam menduga nilai kerugian resiko operasional. Kajian simulasi dilakukan pada empat metode pendugaan sebaran dalam menduga
Value at Risk (VaR) yaitu penduga kepekatan kernel, transformasi penduga
kepekatan kernel dengan sebaran normal (TKN), transformasi penduga kepekatan kernel dengan sebaran Champernowne termodifikasi (TKCM), dan generalized
pareto distribution (GPD). Hasil simulasi memperlihatkan bahwa GPD
memberikan hasil yang paling baik dalam menduga VaR dibandingkan metode lainnya. Penduga kepekatan kernel dan TKCM juga memberikan hasil yang baik meskipun tidak sebaik GPD. Sedangkan TKN memberikan hasil yang buruk di mana dugaan yang dihasilkan cenderung underestimate pada kuantil-kuantil akhir. Dalam penerapannya pada data aktual, GPD mampu menjelaskan sebaran kerugian dengan baik. Laju dugaan VaR(100q) yang dihasilkan GPD meningkat seiring dengan meningkatnya kuantil. Faktor F (Incapacity benefits) merupakan faktor yang memiliki dampak finansial terbesar dan paling beragam, sedangkan Faktor C (Non-dependent deduction) merupakan faktor yang memiliki dampak finansial terkecil. Hasil back testing memperlihatkan bahwa GPD mampu dengan baik menduga VaR(100q) untuk keseluruhan faktor pada data aktual.
TRY SUTRISNA. Study of Several Estimation Method of Operational Value at Risk. Supervised by I MADE SUMERTAJAYA and BAGUS SARTONO.
Measurement of risk value caused by operational risk is an important procedure for doing a good operational risk management, because of that the measurement should done as precise as possible. The characteristic that differ from other type of risk made operational risk should handled carefully with several special methods, in result there are many alternative method proposed for the measurement. Simulation study done for four Value at Risk (VaR) estimation methods, there are kernel density estimator, transformation kernel density estimator with normal distribution (TKN), transformation kernel density estimator with modified Champernowne distribution (TKCM), and generalized pareto distribution (GPD). The result of simulation study identify that GPD gave the best result from all other methods in estimating VaR. Kernel density estimator and TKCM also gave good result although no t as good as GPD. In other hand TKN gave the worst result, where the estimated value tend to underestimate on last quantiles. The application of GPD in actual data study showed that GPD can explain operational risk loss data distribution very well. The estimation of VaR(100q) resulted by GPD raise drastically as the quantil raise. Factor of Incapacity benefit have the highest financial impact of all factors, meanwhile Factor of Non-dependent deduction have the least. The result of back testing showed that GPD estimates VaR(100q) of all factors very well.
KAJIAN BEBERAPA METODE PENDUGAAN
NILAI RESIKO OPERASIONAL
Skripsi
sebagai salah satu syarat untuk memperoleh gelar
Sarjana Statistika
pada
Departemen Statistika
DEP ARTEMEN STATISTIKA
FAKULTAS MATEMATIKA DAN ILMU PENG ETAHUAN ALAM INSTITUT PERTANIAN BOGOR
Disetujui oleh
Diketahui oleh
Dr Anang Kurnia, MSi Ketua Departemen
Tanggal Lulus:
Dr Ir I Made Sumertajaya, MS i Pembimbing I
Dr Bagus Sartono, MSi Pembimbing II
Puji dan syukur penulis panjatkan kepada Tuhan Yang Maha Esa atas segala karunia-Nya sehingga karya ilmiah ini berhasil diselesaikan. Tema yang dipilih dalam penelitian ini adalah pengukuran nilai resiko, dengan judul Kajian Beberapa Metode Pendugaan Nilai Resiko Operasional.
Terima kasih penulis ucapkan kepada Bapak Dr Ir I Made Sumertajaya, MS i dan Bapak Dr Bagus Sartono, MSi selaku pembimbing. Di samping itu, penghargaan penulis sampaikan kepada seluruh dosen dan staff pengajar Departemen Statistika atas ilmu yang diajarkan kepada penulis. Ungkapan terima kasih juga disampaikan kepada ibu, ayah, serta seluruh keluarga, atas doa dan dukungannya.
Semoga karya ilmiah ini bermanfaat.
Bogor, April 2014
DAFTAR TABEL vi DAFTAR GAMBAR vi DAFTAR LAMPIRAN vi PENDAHULUAN 1 Latar Belakang 1 Tujuan 2 METODOLOGI 2 Data 4 Metode Penelitian 5
HASIL DAN PEMBAHASAN 6
Ekplorasi Data 6
Penerapan Beberapa Metode Pendugaan Sebaran dalam menduga VaR pada Data Simulasi yang Bersifat Ekor Gemuk 7 Penerapan Metode Terbaik dalam Menduga VaR pada Data Welfare
Reform 10
SIMPULAN DAN SARAN 15
Simpulan 15
Saran 15
DAFTAR PUSTAKA 16
1 Sebaran yang digunakan dalam simulasi 4 2 Faktor-faktor kerugian pada data Welfare Reform 5 3 Hasil eksplorasi data pada masing- masing faktor data Welfare Reform 7 4 Hasil simulasi dengan populasi menyebar Eksponensial(2) dan n = 500 9
5 Hasil pemodelan data dengan sebaran GPD 10
6 Hasil pendugaan VaR(100q) 10
7 Banyak pelanggaran terhadap dugaan VaR(100q) 13
8 Nilai-p hasil back testing terhadap dugaan VaR(100q) 14
DAFTAR GAMBAR
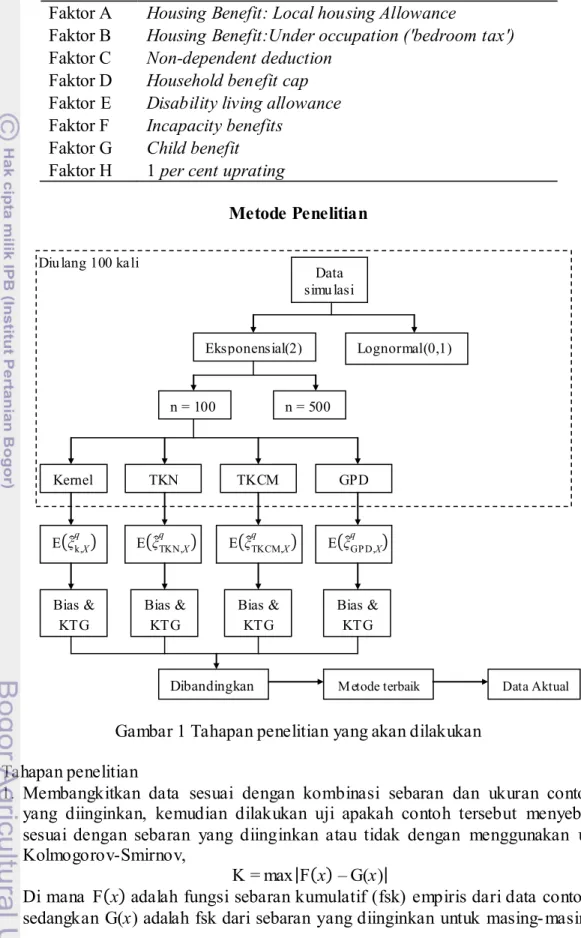
1 Tahapan penelitian yang akan dilakukan 5
2 Teladan transformasi penduga kepekatan kernel 8 3 Scatter plot hasil simulasi dengan populasi yang menyebar
Eksponensial(2) dan n = 500 9
4 Plot kuantil-kuantil hasil simulasi dengan populasi yang menyebar
Eksponensial(2) dan n = 500 9
5 Plot fungsi kebalikan sebaran kumulatif empirik (garis patah-patah) dan
GPD (garis tegas) 13
DAFTAR LAMPIRAN
1 Visualisasi data simulasi 17
2 Visualisasi data Welfare Reform 17
3 Hasil simulasi populasi menyebar Eksponensial(2) dan n = 100 18 4 Hasil simulasi populasi menyebar Lognormal(0,1) dan n = 100 18 5 Hasil simulasi populasi menyebar Lognormal(0,1) dan n = 500 19 6 Plot sebaran hasil pemodelan data dengan sebaran GPD 20
PENDAHULUAN
Latar Belakang
Dalam industri keuangan dikenal tiga jenis resiko yaitu resiko pasar, resiko kredit, dan resiko operasional. Ketiga resiko tersebut selalu diperhatikan karena memiliki dampak yang besar terhadap kondisi keuangan dari suatu industri keuangan. Resiko operasional merupakan resiko yang menarik untuk diamati karena memiliki karakteristik yang berbeda dengan resiko lainnya. Secara sederhana resiko operasional merupakan potensi kerugian yang ditimbulkan dari suatu kejadian acak yang disebabkan oleh kegiatan operasional suatu industri keuangan, misalnya kesalahan transaksi teller, kerusakan ATM, kebakaran gedung dan lainnya. Resiko operasional juga dialami oleh industri non-keuangan, salah satunya industri pertanian.
Pengukuran nilai kerugian akibat resiko operasional merupakan hal yang sangat penting dalam melakukan manajemen resiko operasional karena berkaitan dengan pemenuhan kecukupan modal untuk menutupi kerugian tersebut (Muslich 2007). Apabila nilai resiko diukur terlampau kecil maka kerugian-kerugian besar menjadi tidak bisa tertutupi, sedangkan jika nilai resiko diukur terlampau besar maka akan mengakibatkan modal yang seharusnya diinvestasikan ke sektor lain menjadi tersimpan secara percuma. Pendekatan yang umum digunakan dalam mengukur resiko operasional adalah Advance Measurement Approach (AMA) yang didasarkan pada Loss Distribution Approach (LDA) di mana data kerugian per periode waktu tertentu dimodelkan fungsi kepekatan peluang (fkp) atau sebarannya (Alexander 2003), kemudian dari sebaran tersebut dicari Value at Risk (VaR)- nya. VaR merupakan nilai kerugian maksimum potensial yang diakibatkan oleh suatu resiko operasional dalam periode tertentu dan pada tingkat kepercayaan tertentu, sehingga VaR tidak lain mengukur nilai kuantil dari sebaran kerugian (Lewis 2004).
Kerugian akibat resiko operasional umumnya bernilai kecil dengan frekuensi sering dan bernilai besar dengan frekuensi jarang. Meskipun kerugian yang bernilai besar jarang terjadi, dampaknya sangat signifikan terhadap industri keuangan. Karena karakternya tersebut, sebaran kerugian resiko operasional umumnya tidak simetri dan cenderung memiliki skewness ‘kemencengan’ positif (sebaran menjulur ke kanan). Selain itu, menurut Alexander (2003) sebaran tersebut juga cenderung bersifat fat tail ‘ekor gemuk’, ditandai dengan nilai kurtosisnya yang tinggi (leptokurtis), semakin tinggi semakin bersifat ekor gemuk. Dan pastinya sebaran kerugian resiko operasional selalu bernilai 0 pada
< 0 (kerugian selalu bernilai positif).
Metode yang umum digunakan dalam mengukur VaR adalah Extreme Value
Theory (EVT). Pendekatan EVT bersifat parametrik dan hanya memodelkan ekor
(nilai ekstrim) dari sebaran kerugian atau dengan kata lain hanya memodelkan kerugian yang bernilai besar (ekstrim) saja. Penggunaan EVT memiliki kendala dalam menentukan threshold ‘nilai ambang’ di mana suatu kerugian dikatakan ekstrim atau tidak. Terdapat banyak metode dalam menentukan nilai ambang (Coles 2001), hal ini mengakibatkan penentuan nilai ambang menjadi suatu hal yang sangat sulit.
Suatu alternatif dalam memodelkan sebaran kerugian resiko operasional adalah dengan menggunakan metode non-parametrik, yaitu dengan penduga kepekatan kernel. Penduga kepekatan kernel menghasilkan sebaran yang sangat fleksibel. Meskipun demikian, penduga kepekatan kernel pun memiliki beberapa kendala, diantaranya dalam penentuan fungsi kernel dan penentuan lebar jendela. Guna mengatasi masalah ini maka dilakukan transformasi kernel. Wand dan Jones (1995) menyatakan bahwa transformasi kernel meningkatkan akurasi penduga kepekatan kernel. Haryanto (2012) mengkaji sebaran normal sebagai dasar transformasi kernel, tapi kajian tersebut fokus pada resiko pasar dan bukan pada resiko operasional. Sedangkan Buch-Larsen et al. (2005) menggunakan sebaran Champernowne termodifikasi dalam mengukur kerugian resiko operasional, dan memperlihatkan bahwa sebaran tersebut sangat baik diterapkan pada data yang bersifat ekor gemuk.
Tujuan Tujuan dari penelitian ini adalah:
1. Mengkaji beberapa metode pendugaan sebaran dalam menduga VaR pada data simulasi yang bersifat ekor gemuk.
2. Mengkaji metode terbaik hasil dari Tujuan 1 dalam menduga VaR pada data kerugian operasional aktual.
METODOLOGI
Pada penelitian ini terdapat dua hal yang akan dilakukan, yaitu: (1) mengkaji beberapa metode pendugaan sebaran dalam menduga VaR dan membandingkan performa nilai dugaan yang dihasilkan masing- masing metode tersebut dan (2) menerapkan metode terbaik hasil dari tahap sebelumnya terhadap data aktual. Sehingga pada penelitian ini diperlukan dua jenis data yaitu data simulasi dan data aktual. Penjelasan mengenai data yang akan digunakan pada penelitian ini dipaparkan pada Subbab Data.
Metode yang akan dikaji pada penelitian ini terdiri dari empat metode pendugaan sebaran yang umum diterapkan dalam menduga VaR beserta metode-metode alternatifnya. Keempat metode-metode tersebut antara lain penduga kepekatan kernel, transformasi penduga kepekatan kernel dengan sebaran normal (TKN), transformasi penduga kepekatan kernel dengan sebaran Champernowne termodifikasi (TKCM), dan salah satu sebaran EVT yaitu Generalized Pareto
Ditribution (GPD). Kajian keempat metode tersebut dilakukan pada data simulasi
di mana sebaran data simulasi tersebut mendekati sebaran kerugian resiko operasional pada umumnya. Dari kajian tersebut akan dievaluas i nilai bias dan dugaan kuadrat tengah galat (KTG)-nya, metode yang memberikan nilai bias mutlak dan dugaan KTG paling kecil akan dipilih sebagai metode terbaik. Metode terbaik yang didapat dari kajian simulasi akan diterapkan pada data ak tual. Berikut dipaparkan proses pendugaan sebaran kerugian resiko operasional pada masing- masing metode.
a. Fungsi kepekatan kernel fk,X x = 1 nh K x – Xi h n i = 1 untuk x ≥ 0, di mana K t = 3 4 1 – t
2 , t < 1 (fungsi kernel Epanechnikov) dan lebar
jendela h = 1.59 (n)– 1/3 (kriteria Sheater-Jones) di mana adalah simpangan baku data contoh, sedangkan n adalah ukuran contoh. Fungsi kernel Epanechnikov dipilih karena fungsi ini merupakan fungsi kernel paling efisien (Wand dan Jones 1995).
b. Fungsi transformasi kepekatan kernel dengan sebaran normal 1. Melakukan pemodelan terhadap sebaran normal
sX x| , = 1 2 exp – 1 2 x – 2 x R
di mana > 0. Pemodelan dilakukan dengan menggunakan Penduga Kemungkinan Maksimum (PKM), sehingga didapat (rataan contoh) dan (simpangan baku contoh).
2. Melakukan transformasi pada masing- masing amatan dengan menggunakan fungsi sebaran kumulatif (fsk) normal
SX xi| , = yi(xi) = 1 2 exp – 1 2 x – 2 dx xi -∞ xi R
sehingga didapat yi yang merupakan transformasi dari xi (amatan ke-i dari data contoh). Nilai yi akan berada pada selang [0, 1].
3. Melakukan pendugaan kepekatan kernel pada amatan yi, dengan koreksi batas pada selang [0, 1], sehingga didapat fY(y) yang merupakan sebaran dari data yang ditransformasi.
fY y = 1 nky K y – Yi h n i= 1 dengan ky = K(u) du min(1,(1 – y)/h) max( – 1, – y/h)
di mana K t dan h ditentukan seperti pada fungsi kepekatan kernel. 4. Melakukan transformasi balik dengan menggunakan fungsi
fkn,X x = fY(SX x| , ) sX x| ,
sehingga didapat fkn,X x yang merupakan sebaran dari data contoh dengan
menggunakan transformasi penduga kepekatan kernel dengan sebaran normal.
c. Fungsi transformasi kepekatan kernel dengan sebaran Champernowne termodifikasi
1. Melakukan pemodelan terhadap sebaran Champernowne termodifikasi
tX x| ,M,c = x + c
– 1 M + c – c
x + c + M + c – 2c 2 x R+
di mana > 0, M > 0, dan c ≥ 0. Pemodelan dilakukan dengan menggunakan PKM, sehingga didapat dan c, sedangkan M diduga oleh median contoh. 2. Melakukan transformasi pada masing- masing amatan dengan menggunakan
fsk Champernowne termodifikasi
TX xi| ,M,c = zi(xi) = xi + c – c xi + c + M + c – 2c
xi R+
sehingga didapat zi yang merupakan transformasi dari xi (amatan ke-i dari data contoh). Nilai zi akan berada pada selang [0, 1].
3. Melakukan pendugaan kepekatan kernel pada amatan zi, dengan koreksi batas pada selang [0, 1], sehingga didapat fZ(z) yang merupakan sebaran dari data yang ditransformasi.
fZ z = 1 nkz K z– Zi h n i = 1 dengan kz = K(u) du min(1,(1 – z)/h) max( – 1, – z/h)
di mana K t dan h ditentukan seperti pada fungsi kepekatan kernel. 4. Melakukan transformasi balik dengan menggunakan fungsi
fkc,X x = fZ(TX x| ,M,c ) tX x| ,M,c
sehingga didapat fkc,X x yang merupakan sebaran dari data contoh dengan
menggunakan transformasi penduga kepekatan kernel dengan sebaran Champernowne termodifikasi.
d. Fungsi Generalized Pareto Distribution (Coles 2001)
a. Menentukan nilai ambang yang akan digunakan yaitu kuantil 0.9, sehingga didapat n × (1 – 0.9) amatan paling besar.
b. Melakukan pemodelan terhadap sebaran GPD
fGPD,X x k , , = 1 1 + k(x – )
– 1 – 1k
Parameter GPD diduga dengan menggunakan PKM, sehingga didapat k dan , sedangkan besarnya sama dengan nilai ambang.
Data Data dibagi menjadi dua kategori:
1. Data simulasi yang dibangkitkan mengikuti dua sebaran yang tercantum pada Tabel 1, sebaran tersebut dipilih karena secara umum resiko operasional mengikuti sebaran tersebut (Cruz 2002). Sebaran tersebut juga cenderung memiliki kemencengan yang positif yang berarti bahwa sebaran tersebut menjulur ke kanan. Selain itu, menurut Vose (2008) sebaran Ekponensial dan Lognormal bersifat leptokurtis ditandai dengan nilai kurtosisnya yang besar (jika dibandingkan dengan sebaran normal yang kurtosisnya bernilai 3). Kedua sebaran tersebut juga bernilai 0 pada saat x < 0.
Tabel 1 Sebaran yang digunakan dalam simulasi
Sebaran fX x pada x ≥ 0 Kemencengan Kurtosis
Eksponensial(2) fX x = 2e – 2x 2 9
Lognormal(0,1) fX x = 1
y 2 exp
ln(y)2
2 5 50
2. Data aktual, data Welfare Reform Inggris Raya oleh Christina Beatty. Data menggambarkan kerugian finansial per individu usia produktif per tahun yang dikaji berdasarkan delapan faktor kerugian (dapat dilihat pada Tabel 2) dan diukur dalam pound sterling. Data memiliki 379 amatan setiap faktornya. Makna ‘faktor’ dalam kajian ini adalah suatu kerugian operasional, bukan ‘faktor’ dalam arti peubah bebas.
Tabel 2 Faktor- faktor kerugian pada data Welfare Reform
Faktor Kerugian finansial per individu usia produktif per tahun (diukur dalam pound sterling) yang diakibatkan oleh Faktor A Housing Benefit: Local housing Allowance
Faktor B Housing Benefit:Under occupation ('bedroom tax')
Faktor C Non-dependent deduction
Faktor D Household benefit cap
Faktor E Disability living allowance
Faktor F Incapacity benefits
Faktor G Child benefit
Faktor H 1 per cent uprating
Metode Penelitian
Gambar 1 Tahapan penelitian yang akan dilakukan
Tahapan penelitian
1. Membangkitkan data sesuai dengan kombinasi sebaran dan ukuran contoh yang diinginkan, kemudian dilakukan uji apakah contoh tersebut menyebar sesuai dengan sebaran yang diinginkan atau tidak dengan menggunakan uji Kolmogorov-Smirnov,
K = max F x – G(x)
Di mana F x adalah fungsi sebaran kumulatif (fsk) empiris dari data contoh, sedangkan G(x) adalah fsk dari sebaran yang diinginkan untuk masing- masing
Diu lang 100 ka li Data simu lasi Eksponensial(2) Lognormal(0,1) n = 100 n = 500 Kernel TKN TKCM GPD E k,Xq E TKN,Xq E TKCM,Xq E GP D,Xq
Dibandingkan M etode terbaik Data Aktual
Bias & KTG Bias & KTG Bias & KTG Bias & KTG
nilai amatan. Hipotesis nol adalah contoh menyebar sesuai dengan sebaran yang diinginkan, dan hipotesis nol tidak ditolak jika nilai-p (diambil dari tabel Kolmogorov-Smirnov) lebih dari 0.05. Langkah ini dilakukan hingga didapat kesimpulan hipotesis nol tidak ditolak.
2. Dari keempat sebaran fk,X x , fkn,X x , fkc,X x , dan fGPD,X x masing- masing
ditentukan fsk-nya, dan dari masing- masing fsk ditentukan fungsi kebalikan sebaran kumulatif (fksk)-nya. Di mana fksk adalah k,Xq = Fk,X
– 1 (q),
kn,X
q
= Fkn,X – 1 (q), kc,Xq = F – 1kc,X(q), dan GPD,Xq = FGPD,X – 1 q – 0.9 10 yang tidak
lain merupakan fungsi kuantil. Masing- masing fksk dicari nilainya pada kuantil 0.90, 0.91, …, 0.99.
3. Mengulangi langkah 1 dan 2 sebanyak 100 ulangan.
4. Mencari nilai harapan untuk masing metode pendugaan pada masing-masing kuantil dari seluruh hasil ulangan, dan didapat E k,Xq , E kn,Xq , E kc,Xq , dan E GPD,Xq .
5. Mencari nilai bias untuk masing metode pendugaan pada masing-masing kuantil, biasq,metode - j = E j,Xq – q, di mana q merupakan nilai kuantil populasi pada kuantil q. Dan mencari nilai dugaan kuadrat tengah galat (KTG) masing- masing metode pendugaan pada masing- masing kuantil,
KTGq,metode - j = metode - j,X,ulangan - i
q
– q 2
100
i=1
100 .
6. Mengulangi tahapan 1-5 untuk kombinasi simulasi lainnya.
7. Mengevaluasi nilai bias dan nilai dugaan KTG yang dihasilkan masing- masing metode pada masing- masing kombinasi simulasi. Dari hasil evaluasi tersebut diambil metode terbaik.
8. Metode terbaik selanjutnya diterapkan dalam menduga VaR pada data Welfare
Reform untuk masing- masing faktor. Guna keperluan evaluasi hasil pendugaan
maka data akan dibagi menjadi dua bagian yaitu data pelatihan yang digunakan untuk keperluan pendugaan VaR dan data validasi yang digunakan untuk keperluan evaluasi dengan menggunakan back testing. Proporsi data pelatihan dan data validasi yang digunakan adalah 50:50, setengah bagian data adalah data pelatihan dan setengah bagian lainnya adalah data validasi. Data tersebut dibagi secara acak.
Perangkat lunak yang digunakan dalam penelitian ini adalah MATLAB® R2009b, dan Microsoft Office.
HASIL DAN PEMBAHASAN
Eksplorasi Data
Data yang digunakan dalam penelitian ini terdiri dari dua kategori. Kategori pertama yaitu data simulasi secara visual ditampilkan pada Lampiran 1, dapat dilihat bahwa contoh histogram cenderung menjulur ke kanan begitu juga dengan sebarannya yang terlihat bersifat ekor gemuk pada ekor kanan. Kategori kedua
yaitu data Welfare Reform, masing- masing faktor ditampilkan secara visual pada Lampiran 2, dapat dilihat bahwa secara umum histogram cenderung menjulur ke kanan yang terlihat bersifat ekor gemuk pada ekor kanan. Pengecualian pada Faktor G dan Faktor H, pada faktor tersebut histogram cenderung mendekati simetri dan normal.
Pada umumnya sebaran kerugian resiko operasional tidak mengikuti sebaran Normal dan cenderung memiliki karakteristik tersendiri seperti yang dijelaskan pada Bab Pendahuluan. Sifatnya yang tidak mengikuti sebaran Normal tersebut mengakibatkan hasil analisis tidak akan memberikan hasil yang baik apabila analisis dilakukan dengan mengasumsikan data menyebar Normal seperti analisis-analisis statistika pada umumnya. Setelah diuji dengan menggunakan uji kenormalan Kolmogorov-Smirnov, dapat dilihat pada Tabel 3 bahwa seluruh faktor tidak menyebar normal. Data kategori pertama dan kedua memiliki persamaan sifat yaitu sama-sama menjulur pada salah satu sisi dan sebarannya sama-sama cenderung bersifat ekor gemuk.
Tabel 3 Hasil eksplorasi data pada masing- masing faktor data Welfare Reform Faktor Kemencengan Kurtosis Nilai-pa Keterangana
A 5.879 59.609 < 0.010 Tidak menyebar normal B 1.110 3.748 < 0.010 Tidak menyebar normal
C 0.382 2.604 0.017 Tidak menyebar normal
D 4.575 29.282 < 0.010 Tidak menyebar normal E 0.704 3.149 < 0.010 Tidak menyebar normal F 0.872 3.414 < 0.010 Tidak menyebar normal G 0.413 3.560 < 0.010 Tidak menyebar normal H 0.296 2.629 < 0.010 Tidak menyebar normal a
Berdasarkan hasil uji kenormalan Kolmogorov-Smirnov
Penerapan Beberapa Metode Pendugaan Sebaran dalam Menduga VaR pada Data Simulasi yang Bersifat Ekor Gemuk
Simulasi dilakukan guna melihat sifat bias dari masing- masing metode pendugaan. Dari keseluruhan metode, transformasi penduga kepekatan kernel merupakan yang paling rumit. Transformasi penduga kepekatan kernel merupakan gabungan dari metode non-parametrik dan metode parametrik dengan menggabungkan kelebihan masing- masing metode, sehingga sebagian menyebutnya sebagai metode semi-parametrik.
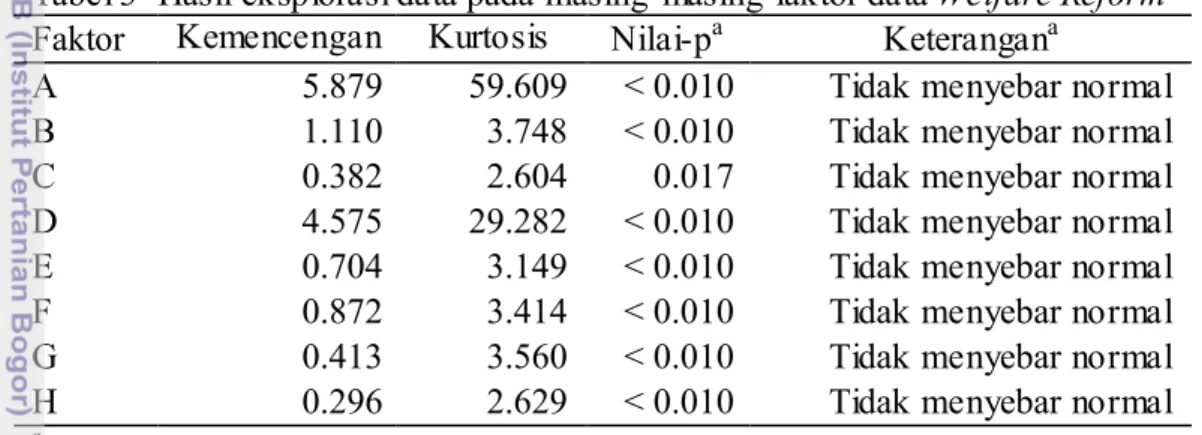
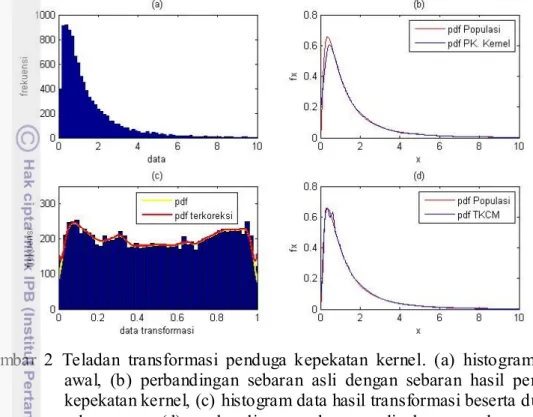
Secara garis besar transformasi penduga kepekatan kernel dilakukan seperti pada Gambar 2. Data ditransformasi sehingga nilainya berkisar antara 0 sampai 1 dan data menyebar mendekati sebaran Seragam(0,1), transformasi dilakukan dengan menggunakan fungsi sebaran kumulatif dari sebaran tertentu. Setelah data ditransformasi, dilakukan penduga kepekatan kernel biasa pada data tersebut kemudian dilakukan transformasi balik. Meskipun fungsi kernel dan kriteria lebar jendela yang digunakan sama dengan penduga kepekatan kernel bia sa, sebaran hasil transformasi penduga kepekatan kernel lebih mendekati sebaran sebenarnya dibandingkan dengan sebaran hasil penduga kepekatan kernel biasa. Transformasi
penduga kepekatan kernel dilakukan apabila sebaran peluang data contoh relatif sulit diduga (Wand dan Jones 1995).
Gambar 2 Teladan transformasi penduga kepekatan kernel. (a) histogram data awal, (b) perbandingan sebaran asli dengan sebaran hasil penduga kepekatan kernel, (c) histogram data hasil transformasi beserta dugaan sebarannya, (d) perbandingan sebaran asli dengan sebaran hasil transformasi penduga kepekatan kernel.
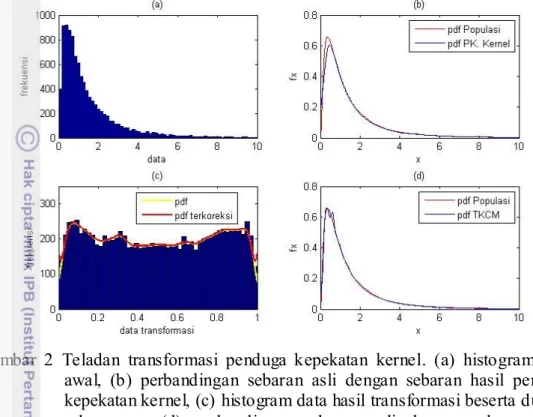
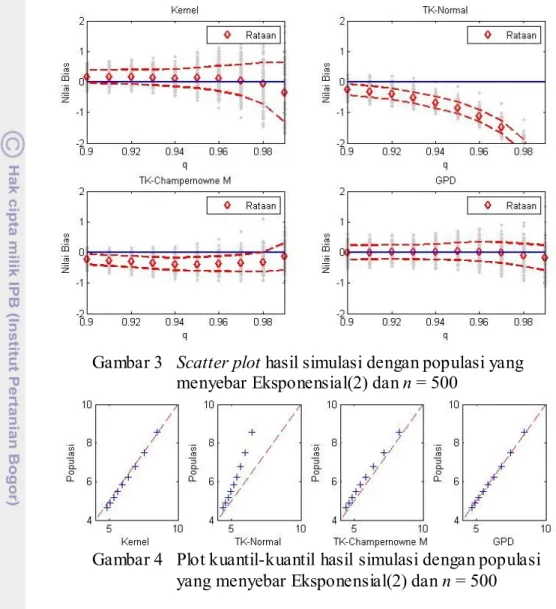
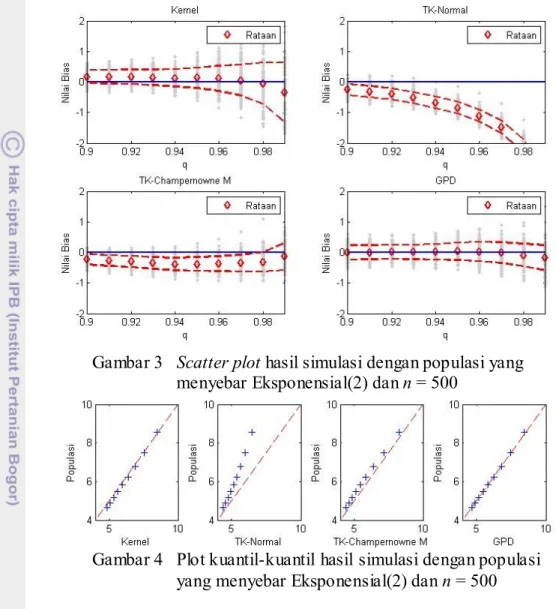
Pada keseluruhan simulasi, generalized pareto distribution (GPD) secara konsisten memberikan hasil yang paling baik untuk keseluruhan kuantil yang diteliti. Transformasi penduga kepekatan kernel dengan sebaran Champernowne termodifikasi (TKCM) dan penduga kepekatan kernel juga memberikan hasil yang baik, meskipun tidak sebaik GPD. Transformasi penduga kepekatan kernel dengan sebaran normal (TKN) memberikan hasil yang relatif buruk untuk keseluruhan simulasi, semakin tinggi kuantil yang ingin diduga nilainya semakin tinggi pula kecenderungan underestimate-nya. Hal ini memperlihatkan bahwa sebaran normal memang kurang cocok diterapkan dalam transformasi penduga kepekatan kernel jika terdapat kecenderungan ekor gemuk pada sebaran data. Plot kuantil-kuantil yang dihasilkan masing- masing simulasi pun memperlihatkan bahwa GPD lebih mendekati kuantil empirik dari data sesungguhnya dibandingkan dengan metode lainnya. Pada Tabel 4 diperlihatkan hasil numerik dari salah satu hasil simulasi, secara umum GPD memberikan hasil yang terbaik. Pada kuantil 0.99 terlihat bahwa TKCM memberikan hasil yang paling baik, meskipun demikian nilai dugaan yang dihasilkan GPD tidak jauh berbeda dengan nilai dugaan yang dihasilkan TKCM. Secara umum seluruh simulasi memperlihatkan pola yang sama seperti yang ditampilkan pada Gambar 3, Gambar 4, dan Tabel 4.
Masing- masing metode pendugaan memperlihatkan pola yang relatif sama untuk keseluruhan simulasi yaitu semakin tinggi nilai kuantil yang ingin diduga semakin menyebar juga nilai-nilai dugaannya. Dan dengan bertambahnya ukuran
contoh akan mengakibatkan nilai- nilai dugaannya menjadi lebih terpusat, nilai bias mutlak dan nilai dugaan kuadrat tengah galat (KTG)- nya menjadi lebih kecil.
Gambar 3 Scatter plot hasil simulasi dengan populasi yang menyebar Eksponensial(2) dan n = 500
Gambar 4 Plot kuantil-kuantil hasil simulasi dengan populasi yang menyebar Eksponensial(2) dan n = 500
Tabel 4 Hasil simulasi dengan populasi menyebar Eksponensial(2) dan n = 500
q Bias Dugaan KTG Kernel TKN TKCM GPD Kernel TKN TKCM GPD 0.90 0.17970 -0.24935 -0.22872 0.00000 0.07796 0.09567 0.08103 0.05744 0.91 0.16622 -0.31813 -0.26938 0.00135 0.07727 0.13552 0.10358 0.05270 0.92 0.16825 -0.39324 -0.29735 0.01676 0.08209 0.18890 0.12229 0.05246 0.93 0.15000 -0.51733 -0.34308 0.01343 0.08449 0.30183 0.15519 0.05641 0.94 0.13045 -0.67250 -0.37868 0.01474 0.09558 0.48725 0.18563 0.06534 0.95 0.13564 -0.84635 -0.37580 0.03904 0.12644 0.75289 0.19005 0.08040 0.96 0.11158 -1.10865 -0.37398 0.02884 0.18018 1.26811 0.19798 0.09769 0.97 0.05847 -1.48310 -0.34941 -0.00543 0.25725 2.24156 0.19398 0.11703 0.98 -0.04043 -2.09650 -0.30663 -0.08727 0.44787 4.44142 0.19255 0.14244 0.99 -0.34557 -3.24791 -0.12661 -0.17664 1.07286 10.60279 0.21218 0.19873
Penerapan Metode Terbaik dalam Menduga VaR pada Data Welfare Reform
Generalized Pareto Distribution (GPD) diterapkan dalam menduga sebaran
pada data kerugian operasional aktual yang bersifat ekor gemuk, dan dari sebaran tersebut diduga VaR- nya. Pada eksplorasi data didapat bahwa keseluruhan faktor tidak menyebar normal, sehingga pemodelan biasa terhadap sebaran normal tidak akan memberikan hasil yang baik. GPD diharapkan mampu memberikan hasil yang baik. Tabel 5 menampilkan hasil pendugaan parameter GPD. Penentuan nilai ambang yang digunakan dalam pemodelan GPD menggunakan kriteria yang umum digunakan yaitu kuantil 0.9 dari data
Tabel 5 Hasil pemodelan data dengan sebaran GPD
Faktor Parameter GPD Hasil uji Kolmogorov-Smirnov (nilai-p)b
Faktor A 60.49 0.47 19.96 0.96 Faktor B 19.26 -0.54 6.05 0.50 Faktor C 11.20 -0.24 1.58 0.85 Faktor D 8.36 0.05 11.66 0.44 Faktor E 53.62 -0.20 8.74 0.86 Faktor F 171.91 -0.13 30.47 0.92 Faktor G 84.33 -0.27 7.06 0.81 Faktor H 112.32 -0.09 13.15 0.54 b
Hipotesis nol adalah amatan-amatan ekstrim contoh menyebar GPD A. Interpretasi hasil pe modelan data dengan sebaran GPD
Dalam sebaran GPD parameter k atau parameter bentuk memberikan gambaran dari ‘bentuk’ sebaran GPD, apabila nilainya positif maka sebaran cenderung curam, semakin besar nilai k maka akan semakin curam sebarannya. Jika nilai k = 0 maka sebaran GPD akan identik dengan bentuk sebaran Eksponensial. Suatu hal yang menarik adalah ketika nilai k bernilai negatif maka sebaran tidak bernilai nol pada selang tertentu saja yaitu pada selang [ , – /k], tidak seperti ketika 0 di mana sebaran tidak bernilai nol pada selang [ , ∞]. Parameter atau parameter skala memberikan gambaran seberapa mampatnya sebaran, semakin besar nilai maka semakin mampat sebarannya (karakteristiknya sama seperti pada sebaran normal). Sedangkan parameter atau parameter nilai ambang seperti yang telah dijelaskan merupakan nilai pemisah antara amatan yang dimodelkan dan amatan yang tidak dimodelkan.
Hasil uji Kolmogorov-Smirnov pada Tabel 5 menunjukkan bahwa GPD mampu dengan baik menjelaskan sebaran ekor dari masing- masing faktor. Meskipun GPD memberikan hasil uji Kolmogorov-Smirnov yang baik, GPD hanya menjelaskan sebaran ekor dari data dan dalam proses pemodelan hanya menggunakan 10% informasi dari data (19 amatan dari 190 amatan). Uji Kolmogorov-Smirnov yang dilakukan adalah antara GPD dengan amatan ekstrim, bukan dengan keseluruhan amatan. Hasil pemodelan data dengan sebaran GPD dapat dilihat pada Lampiran 6. Sebaran data seluruh faktor (kecuali Faktor A dan Faktor D) hasil pemodelan dengan sebaran GPD memiliki nilai negatif, hal ini berarti bahwa peluang nilai kerugian di atas nilai – / untuk faktor tersebut
bernilai nol atau dengan kata lain GPD secara eksplisit memberikan nilai kerugian maksimum yang akan tercapai. Dalam manajemen resiko operasional dapat dilakukan perlindungan 100% dengan menggunakan dugaan VaR(100) atas faktor- faktor tersebut. Sedangkan pada Faktor A dan Faktor D tidak dapat dilakukan perlindungan 100% karena dugaan VaR(100) pada faktor- faktor tersebut bernilai tak hingga.
Pada Lampiran 6 dan Tabel 6 dapat dilihat juga dampak nilai hasil pemodelan data dengan sebaran GPD. Pada Faktor C yang nilai -nya bernilai kecil, dugaan-dugaan VaR yang dihasilkan cenderung terletak pada selang yang pendek (antara 11 dan 14) tidak seperti pada Faktor D yang memiliki yang besar di mana dugaan-dugaan VaR yang dihasilkan cenderung terletak pada selang yang panjang (antara 8 dan 38). Secara umum semakin besar maka selang dugaan-dugaan VaR yang dihasilkan semakin panjang.
B. Strategi penanganan dampak finansial resiko operasional
Dugaan VaR yang dihasilkan GPD pada data pelatihan untuk kuantil 0.90 hingga kuantil 0.99 ditampilkan pada Tabel 6. Dugaan VaR ditampilkan untuk keseluruhan kuantil. Pada aplikasinya dalam dunia industri keuangan, VaR yang sering digunakan adalah VaR(95) dan VaR(99) karena berkaitan dengan regulasi yang diterapkan pada industri keuangan. Regulasi tersebut diatur pada Basel I dan Basel II. Pada Basel I digunakan VaR(95) sedangkan pada Basel II ditingkatkan menjadi VaR(99), hal ini menunjukkan bahwa dampak dari resiko menjadi sesuatu yang semakin tidak boleh dihindari. Pada penelitian ini karena data yang digunakan merupakan data pemerintahan dan bukan merupakan data industri keuangan sehingga penentuan VaR(100q) mana yang digunakan tidak terpaut oleh regulasi melainkan ditentukan oleh pembuat kebijakan.
Tabel 6 Hasil pendugaan VaR(100q) (diukur dalam pound sterling)
q Faktor Faktor A Faktor B Faktor C Faktor D Faktor E Faktor F Faktor G Faktor H 0.90 64.84 19.22 11.21 8.29 53.34 169.20 84.53 111.15 0.91 67.28 19.79 11.39 9.47 54.56 172.16 85.18 112.39 0.92 70.22 20.40 11.58 10.82 55.87 175.43 85.89 113.79 0.93 73.81 21.05 11.78 12.37 57.29 179.07 86.67 115.38 0.94 78.35 21.74 11.99 14.18 58.86 183.21 87.56 117.22 0.95 84.32 22.50 12.23 16.36 60.61 188.00 88.58 119.41 0.96 92.61 23.35 12.50 19.10 62.61 193.72 89.79 122.10 0.97 105.16 24.32 12.81 22.72 64.98 200.86 91.28 125.59 0.98 127.13 25.48 13.18 28.03 67.96 210.50 93.28 130.57 0.99 180.33 27.01 13.69 37.65 72.19 225.92 96.40 139.20
VaR mengukur nilai kerugian maksimum potensial dalam periode tertentu
dan pada tingkat kepercayaan tertentu. VaR(95) dapat diartikan bahwa 95% kerugian-kerugian finansial yang akan terjadi tidak akan melebihi nilai tersebut. Sebagai teladan misalkan VaR(95) pada Faktor A dapat dilihat dalam Tabel 6 pada kolom faktor A dan pada q = 0.95. VaR(95) pada Faktor A bernilai 76.84 pound sterling, hal ini dapat diartikan bahwa untuk tahun berikutnya dari 100 amatan nilai kerugian finansial pada Faktor A, 95 amatan di antaranya diduga
tidak akan melebihi 76.84 pound sterling sedangkan 5 amatan lainnya diduga melebihi 76.84 pound sterling. Kerugian finansial pada Faktor F, Faktor A, dan Faktor H merupakan yang terbesar, hal ini berarti bahwa faktor- faktor tersebut merupakan faktor yang harus mendapat perhatian lebih besar dari pembuat kebijakan. Sedangkan pada Faktor C, kerugian finansial yang diakibatkannya merupakan yang terkecil dibandingkan seluruh faktor. Salah satu strategi penanganan resiko yang dapat dilakukan adalah dengan strategi finansial, yaitu melakukan pencadangan dana yang cukup guna menutupi kerugian tersebut pada tahun selanjutnya. Pembuat kebijakan sebaiknya mencadangkan dana sebesar yang ditampilkan pada Tabel 6 per individunya sesuai kuantil yang ingin digunakan. Tentunya semakin tinggi kuantil yang digunakan akan mengakibatkan alokasi dana yang semakin tinggi pula, akan tetapi hal ini juga mengakibatkan semakin tinggi juga jaminan bahwa kerugian finansial menjadi lebih tertutupi.
Apabila pembuat kebijakan bertujuan untuk menutupi seluruh kerugian potensial pada masing- masing faktor maka pembuat kebijakan tersebut perlu mencadangkan dana sebesar ukuran populasi negara × VaRFaktor - i untuk Faktor- i. Jika ingin melihat VaR gabungan dari keseluruhan faktor secara bersamaan (sehingga didapat nilai VaR tunggal) dengan mempertimbangkan korelasi nyata antar faktor maka perlu dilakukan kajian lebih lanjut di mana data Welfare Reform dikaji dengan pendekatan analisis peubah ganda.
C. Evaluasi hasil pe modelan data dengan sebaran GPD
Pada Tabel 6 terlihat bahwa semakin tinggi kuantil maka laju dugaan
VaR(100q)- nya pun semakin meningkat, misalnya pada Faktor A di mana VaR(91) dan VaR(90) selisihnya hanya 2.44 pound sterling sedangkan VaR(99)
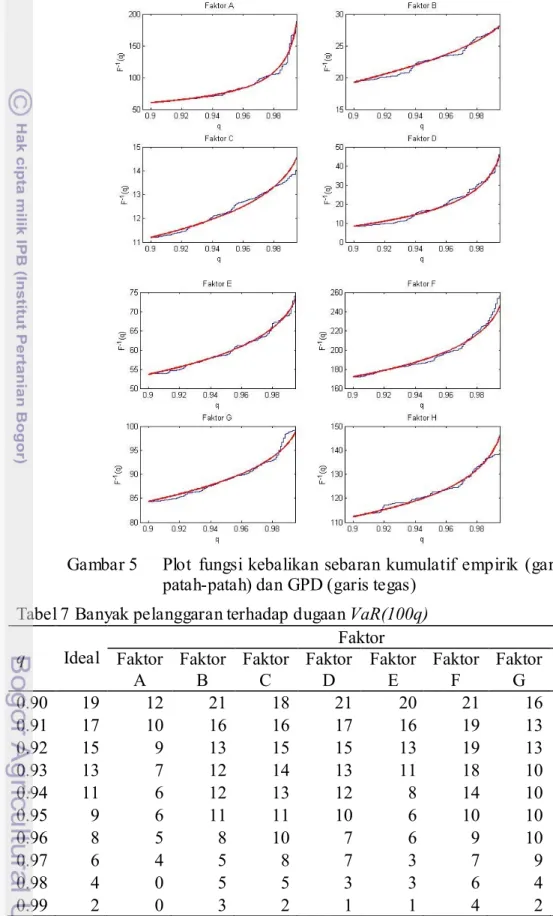
dan VaR(98) selisihnya mencapai 53.20 poundsterling. Peningkatan yang sangat drastis pada dugaan VaR(100q) ini diharapkan, karena hal tersebut menandakan bahwa sebaran memiliki ekor yang panjang dan juga gemuk (dapat dilihat pada Lampiran 6). Karakteristik ini juga diperlihatkan pada Gambar 5. Semakin tinggi kuantil maka dugaan VaR(100q)- nya pun akan semakin meningkat secara drastis. Gambar 5 juga memperlihatkan bahwa dugaan VaR(100q) tidak jauh berbeda dengan nilai kuantil empirik dari masing- masing faktor (dapat dilihat juga pada plot kuatil-kuantil pada Lampiran 7). Plot sebaran yang dihasilkan GPD pada Lampiran 6 memperlihatkan bahwa GPD mampu dengan baik menjelaskan sebaran dari data (histogram dan sebarannya berhimpit).
VaR(100q) tidak lain merupakan nilai kuantil pada kuantil q. Hasil analisis
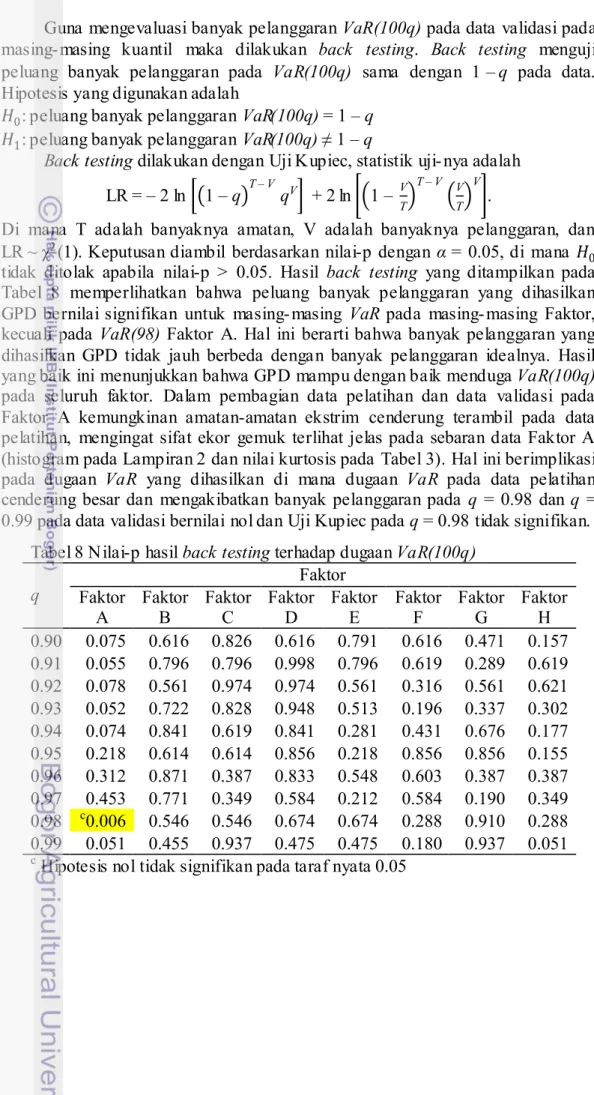
pada data validasi ditampilkan pada Tabel 7, pada tabel tersebut ditampilkan nilai amatan yang melebihi VaR hasil pemodelan pada data pelatihan. Secara sederhana, banyaknya amatan yang nilainya berada di bawah VaR(100q) diharapkan sebanyak 189× , artinya sebanyak q bagian dari data nilainya berada di bawah VaR(100q) sesuai dengan definisi VaR. Sedangkan 189× 1 – q amatan lainnya diharapkan berada di atas nilai VaR(100q). Amatan yang nilainya melebihi VaR(100q) didefinisikan sebagai pelanggaran, dan besarnya pelanggaran didefinisikan sebagai banyaknya amatan yang melebihi VaR(100q). Besarnya pelanggaran untuk masing- masing VaR(100q) dicantumkan pada kolom Ideal pada Tabel 7. Sebagai teladan misalkan pada Faktor A dan kuantil q = 0.95, banyaknya pelanggaran adalah 6 hal ini berarti bahwa terdapat 6 amatan pada Faktor A yang melebihi nilai VaR(95) sedangkan banyaknya amatan yang
diharapkan melebihi VaR(95) adalah sebesar 9 (terdapat pada Kolom Ideal). Secara umum pada keseluruhan kuantil banyaknya pelanggaran yang dihasilkan cenderung beragam, meskipun demikian banyaknya pelanggaran tetap berada pada kisaran nilai idealnya.
Gambar 5 Plot fungsi kebalikan sebaran kumulatif empirik (garis patah-patah) dan GPD (garis tegas)
Tabel 7 Banyak pelanggaran terhadap dugaan VaR(100q)
q Ideal Faktor Faktor A Faktor B Faktor C Faktor D Faktor E Faktor F Faktor G Faktor H 0.90 19 12 21 18 21 20 21 16 25 0.91 17 10 16 16 17 16 19 13 19 0.92 15 9 13 15 15 13 19 13 17 0.93 13 7 12 14 13 11 18 10 17 0.94 11 6 12 13 12 8 14 10 16 0.95 9 6 11 11 10 6 10 10 14 0.96 8 5 8 10 7 6 9 10 10 0.97 6 4 5 8 7 3 7 9 8 0.98 4 0 5 5 3 3 6 4 6 0.99 2 0 3 2 1 1 4 2 0
Guna mengevaluasi banyak pelanggaran VaR(100q) pada data validasi pada masing- masing kuantil maka dilakukan back testing. Back testing menguji peluang banyak pelanggaran pada VaR(100q) sama dengan 1 – q pada data. Hipotesis yang digunakan adalah
0: peluang banyak pelanggaran VaR(100q) = 1 – q 1: peluang banyak pelanggaran VaR(100q) ≠ 1 – q
Back testing dilakukan dengan Uji Kupiec, statistik uji- nya adalah
LR = – 2 ln 1 – q T – V qV + 2 ln 1 – V T T– V V T V .
Di mana T adalah banyaknya amatan, V adalah banyaknya pelanggaran, dan LR ~ 2(1). Keputusan diambil berdasarkan nilai-p dengan = 0.05, di mana
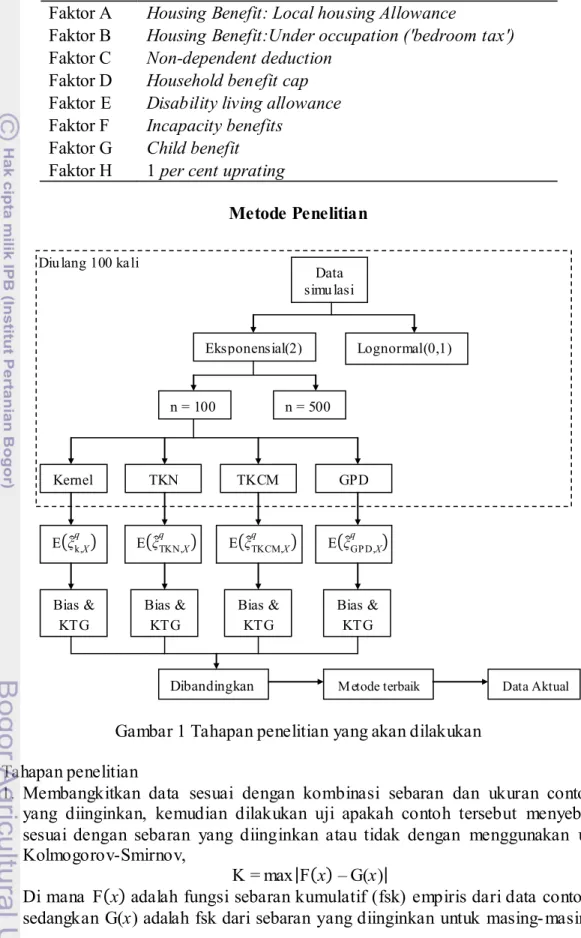
0 tidak ditolak apabila nilai-p > 0.05. Hasil back testing yang ditampilkan pada Tabel 8 memperlihatkan bahwa peluang banyak pelanggaran yang dihasilkan GPD bernilai signifikan untuk masing- masing VaR pada masing- masing Faktor, kecuali pada VaR(98) Faktor A. Hal ini berarti bahwa banyak pelanggaran yang dihasilkan GPD tidak jauh berbeda denga n banyak pelanggaran idealnya. Hasil yang baik ini menunjukkan bahwa GPD mampu dengan baik menduga VaR(100q) pada seluruh faktor. Dalam pembagian data pelatihan dan data validasi pada Faktor A kemungkinan amatan-amatan ekstrim cenderung terambil pada data pelatihan, mengingat sifat ekor gemuk terlihat jelas pada sebaran data Faktor A (histogram pada Lampiran 2 dan nilai kurtosis pada Tabel 3). Hal ini berimplikasi pada dugaan VaR yang dihasilkan di mana dugaan VaR pada data pelatihan cenderung besar dan mengakibatkan banyak pelanggaran pada q = 0.98 dan q = 0.99 pada data validasi bernilai nol dan Uji Kupiec pada q = 0.98 tidak signifikan.
Tabel 8 Nilai-p hasil back testing terhadap dugaan VaR(100q)
q Faktor Faktor A Faktor B Faktor C Faktor D Faktor E Faktor F Faktor G Faktor H 0.90 0.075 0.616 0.826 0.616 0.791 0.616 0.471 0.157 0.91 0.055 0.796 0.796 0.998 0.796 0.619 0.289 0.619 0.92 0.078 0.561 0.974 0.974 0.561 0.316 0.561 0.621 0.93 0.052 0.722 0.828 0.948 0.513 0.196 0.337 0.302 0.94 0.074 0.841 0.619 0.841 0.281 0.431 0.676 0.177 0.95 0.218 0.614 0.614 0.856 0.218 0.856 0.856 0.155 0.96 0.312 0.871 0.387 0.833 0.548 0.603 0.387 0.387 0.97 0.453 0.771 0.349 0.584 0.212 0.584 0.190 0.349 0.98 c0.006 0.546 0.546 0.674 0.674 0.288 0.910 0.288 0.99 0.051 0.455 0.937 0.475 0.475 0.180 0.937 0.051 c
SIMPULAN DAN SARAN
Simpulan
Pada data simulasi, generalized pareto distribution (GPD) secara konsisten memberikan hasil yang paling baik. Transformasi penduga kepekatan kernel dengan sebaran Champernowne termodifikasi (TKCM) dan penduga kepekatan kernel juga memberikan hasil yang baik, meskipun tidak sebaik GPD, transformasi penduga kepekatan kernel dengan sebaran normal (TKN) memberikan hasil yang relatif buruk untuk keseluruhan simulasi, membuktikan bahwa sebaran normal tidak cocok digunakan sebagai dasar transformasi pada data kerugian resiko operasional. Semakin tinggi kuantil yang ingin diduga nilainya semakin menyebar juga dugaan-dugaan nilainya, dan semakin besar ukuran contoh akan mengakibatkan dugaan-dugaan nilainya menjadi lebih terpusat, nilai bias mutlak dan nilai dugaan kuadrat tengah galat- nya menjadi lebih kecil. Pada data aktual, GPD memberikan laju dugaan VaR(100q) yang meningkat seiring meningkatnya kuantil. Faktor F (Incapacity benefits) merupakan faktor yang memiliki dampak finansial terbesar dan dugaan VaR yang dihasilkan pun terletak pada selang yang sangat panjang (antara 170 sampai 235), sedangkan Faktor C (Non-dependent deduction) merupakan faktor yang memiliki dampak finansial terkecil. Hasil back testing pada data validasi memperlihatkan bahwa GPD mampu dengan baik menduga VaR(100q) untuk masing- masing faktor.
Saran
Dalam kajian ini penduga kepekatan kernel dan transformasi penduga kepekatan kernel tidak mampu memberikan performa yang lebih baik dibandingkan generalized pareto distribution. Perlu dilakukan kajian lebih lanjut dan lebih dalam lagi mengenai fungsi kernel dan kriteria lebar jendela yang sekiranya akan memengaruhi performa nilai dugaan yang dihasilkan oleh penduga kepekatan kernel dan transformasi penduga kepekatan kernel. Kriteria evaluasi
VaR tidak hanya dilihat pada back testing saja, akan tetapi juga dapat dilihat dari
selang dugaan VaR. Kajian lebih lanjut disarankan menggunakan metode pendugaan selang guna memperluas kriteria evaluasi. Pada kajian ini masing-masing kerugian operasional pada data aktual dianalisis secara terpisah (analisis dilakukan per kerugian operasional, bukan secara keseluruhan) dan meniadakan korelasi yang mungkin terjadi antar kerugian operasional. Pada kajian sela njutnya disarankan untuk memperluas kajian dengan memasukkan unsur hubungan antar kerugian operasional dalam analisis.
DAFTAR PUSTAKA
Alexander C. 2003. Operational Risk: Regulation, Analysis, and Management. London (UK): Financial Times Prentice Hall.
Buch-Larsen T, Nielsen JP, Guillén M, Bolancé. 2005. Kernel density estimator for heavy tailed distribution using the Champernowne transformation.
Statistics. 39(6): 503-518. Doi: 10.1080/02331880500439782.
Coles S. 2001. An Introduction to Statistical Modeling of Extreme Values. London (GB): Springer.
Cruz MG. 2002. Modeling, Measuring, and Hedging Operational Risk. New York (US): John Wiley & Sons.
Haryanto B. 2012. Pendugaan Nilai Resiko dengan Sebaran Transformasi-Kernel dan Sebaran Nilai Ekstrim [tesis]. Bogor (ID): Institut Pertanian Bogor. Lewis NDC. 2004. Operational Risk – with Excel and VBA – Applied Statistical
Methods for Risk Management. Canada: John Wiley & Sons.
Muslich M. 2007. Manajemen Resiko Operasional: Teori & Praktik . Jakarta (ID): Bumi Aksara.
Vose D. 2008. Risk Analysis: A Quantitative Guide 3rd Edition. England (UK): John Wiley & Sons.
LAMPIRAN
Lampiran 1 Visualisasi data simulasi
Lampiran 3 Hasil simulasi populasi menyebar Eksponensial(2) dan n = 100
Lampiran 6 Plot sebaran hasil pemodelan data dengan sebaran GPD
RIWAYAT HIDUP
Penulis dilahirkan di Tangerang pada tanggal 28 Agustus 1991 dari Bapak Santosa dan Ibu Ratmi. Penulis adalah putra bungsu dari tiga bersaudara. Tahun 2009 penulis lulus dari SMA Negeri 1 Bogor dan pada tahun yang sama penulis lulus seleksi masuk Institut Pertanian Bogor (IPB) melalui jalur Undangan Seleksi Masuk IPB dan diterima di Departemen Statistika, Fakultas Matematika dan Ilmu Pengetahuan Alam.
Selama mengikuti perkuliahan, penulis menjadi asisten responsi Mata Kuliah Perancangan Percobaan pada tahun ajaran 2011/2012, asisten responsi Mata Kuliah Metode Statistika pada tahun ajaran 2012/2013. Penulis juga aktif dalam Unit Kegiatan Mahasiswa Tarung Derajat IPB sebagai ketua divisi hubungan eksternal (tahun 2010-2011) dan sebagai anggota (tahun 2009-2014). Selain itu penulis juga aktif dalam Himpunan Keprofesian Gamma Sigma Beta sebagai Badan Pengawas (tahun 2011-2013). Pada bulan Juli- Agustus 2013 penulis melaksanakan kegiatan Praktik Lapang di Direktorat Administrasi dan Pendidikan IPB.
PENDAHULUAN
Latar Belakang
Dalam industri keuangan dikenal tiga jenis resiko yaitu resiko pasar, resiko kredit, dan resiko operasional. Ketiga resiko tersebut selalu diperhatikan karena memiliki dampak yang besar terhadap kondisi keuangan dari suatu industri keuangan. Resiko operasional merupakan resiko yang menarik untuk diamati karena memiliki karakteristik yang berbeda dengan resiko lainnya. Secara sederhana resiko operasional merupakan potensi kerugian yang ditimbulkan dari suatu kejadian acak yang disebabkan oleh kegiatan operasional suatu industri keuangan, misalnya kesalahan transaksi teller, kerusakan ATM, kebakaran gedung dan lainnya. Resiko operasional juga dialami oleh industri non-keuangan, salah satunya industri pertanian.
Pengukuran nilai kerugian akibat resiko operasional merupakan hal yang sangat penting dalam melakukan manajemen resiko operasional karena berkaitan dengan pemenuhan kecukupan modal untuk menutupi kerugian tersebut (Muslich 2007). Apabila nilai resiko diukur terlampau kecil maka kerugian-kerugian besar menjadi tidak bisa tertutupi, sedangkan jika nilai resiko diukur terlampau besar maka akan mengakibatkan modal yang seharusnya diinvestasikan ke sektor lain menjadi tersimpan secara percuma. Pendekatan yang umum digunakan dalam mengukur resiko operasional adalah Advance Measurement Approach (AMA) yang didasarkan pada Loss Distribution Approach (LDA) di mana data kerugian per periode waktu tertentu dimodelkan fungsi kepekatan peluang (fkp) atau sebarannya (Alexander 2003), kemudian dari sebaran tersebut dicari Value at Risk (VaR)- nya. VaR merupakan nilai kerugian maksimum potensial yang diakibatkan oleh suatu resiko operasional dalam periode tertentu dan pada tingkat kepercayaan tertentu, sehingga VaR tidak lain mengukur nilai kuantil dari sebaran kerugian (Lewis 2004).
Kerugian akibat resiko operasional umumnya bernilai kecil dengan frekuensi sering dan bernilai besar dengan frekuensi jarang. Meskipun kerugian yang bernilai besar jarang terjadi, dampaknya sangat signifikan terhadap industri keuangan. Karena karakternya tersebut, sebaran kerugian resiko operasional umumnya tidak simetri dan cenderung memiliki skewness ‘kemencengan’ positif (sebaran menjulur ke kanan). Selain itu, menurut Alexander (2003) sebaran tersebut juga cenderung bersifat fat tail ‘ekor gemuk’, ditandai dengan nilai kurtosisnya yang tinggi (leptokurtis), semakin tinggi semakin bersifat ekor gemuk. Dan pastinya sebaran kerugian resiko operasional selalu bernilai 0 pada
< 0 (kerugian selalu bernilai positif).
Metode yang umum digunakan dalam mengukur VaR adalah Extreme Value
Theory (EVT). Pendekatan EVT bersifat parametrik dan hanya memodelkan ekor
(nilai ekstrim) dari sebaran kerugian atau dengan kata lain hanya memodelkan kerugian yang bernilai besar (ekstrim) saja. Penggunaan EVT memiliki kendala dalam menentukan threshold ‘nilai ambang’ di mana suatu kerugian dikatakan ekstrim atau tidak. Terdapat banyak metode dalam menentukan nilai ambang (Coles 2001), hal ini mengakibatkan penentuan nilai ambang menjadi suatu hal yang sangat sulit.
Suatu alternatif dalam memodelkan sebaran kerugian resiko operasional adalah dengan menggunakan metode non-parametrik, yaitu dengan penduga kepekatan kernel. Penduga kepekatan kernel menghasilkan sebaran yang sangat fleksibel. Meskipun demikian, penduga kepekatan kernel pun memiliki beberapa kendala, diantaranya dalam penentuan fungsi kernel dan penentuan lebar jendela. Guna mengatasi masalah ini maka dilakukan transformasi kernel. Wand dan Jones (1995) menyatakan bahwa transformasi kernel meningkatkan akurasi penduga kepekatan kernel. Haryanto (2012) mengkaji sebaran normal sebagai dasar transformasi kernel, tapi kajian tersebut fokus pada resiko pasar dan bukan pada resiko operasional. Sedangkan Buch-Larsen et al. (2005) menggunakan sebaran Champernowne termodifikasi dalam mengukur kerugian resiko operasional, dan memperlihatkan bahwa sebaran tersebut sangat baik diterapkan pada data yang bersifat ekor gemuk.
Tujuan Tujuan dari penelitian ini adalah:
1. Mengkaji beberapa metode pendugaan sebaran dalam menduga VaR pada data simulasi yang bersifat ekor gemuk.
2. Mengkaji metode terbaik hasil dari Tujuan 1 dalam menduga VaR pada data kerugian operasional aktual.
METODOLOGI
Pada penelitian ini terdapat dua hal yang akan dilakukan, yaitu: (1) mengkaji beberapa metode pendugaan sebaran dalam menduga VaR dan membandingkan performa nilai dugaan yang dihasilkan masing- masing metode tersebut dan (2) menerapkan metode terbaik hasil dari tahap sebelumnya terhadap data aktual. Sehingga pada penelitian ini diperlukan dua jenis data yaitu data simulasi dan data aktual. Penjelasan mengenai data yang akan digunakan pada penelitian ini dipaparkan pada Subbab Data.
Metode yang akan dikaji pada penelitian ini terdiri dari empat metode pendugaan sebaran yang umum diterapkan dalam menduga VaR beserta metode-metode alternatifnya. Keempat metode-metode tersebut antara lain penduga kepekatan kernel, transformasi penduga kepekatan kernel dengan sebaran normal (TKN), transformasi penduga kepekatan kernel dengan sebaran Champernowne termodifikasi (TKCM), dan salah satu sebaran EVT yaitu Generalized Pareto
Ditribution (GPD). Kajian keempat metode tersebut dilakukan pada data simulasi
di mana sebaran data simulasi tersebut mendekati sebaran kerugian resiko operasional pada umumnya. Dari kajian tersebut akan dievaluas i nilai bias dan dugaan kuadrat tengah galat (KTG)-nya, metode yang memberikan nilai bias mutlak dan dugaan KTG paling kecil akan dipilih sebagai metode terbaik. Metode terbaik yang didapat dari kajian simulasi akan diterapkan pada data ak tual. Berikut dipaparkan proses pendugaan sebaran kerugian resiko operasional pada masing- masing metode.
a. Fungsi kepekatan kernel fk,X x = 1 nh K x – Xi h n i = 1 untuk x ≥ 0, di mana K t = 3 4 1 – t
2 , t < 1 (fungsi kernel Epanechnikov) dan lebar
jendela h = 1.59 (n)– 1/3 (kriteria Sheater-Jones) di mana adalah simpangan baku data contoh, sedangkan n adalah ukuran contoh. Fungsi kernel Epanechnikov dipilih karena fungsi ini merupakan fungsi kernel paling efisien (Wand dan Jones 1995).
b. Fungsi transformasi kepekatan kernel dengan sebaran normal 1. Melakukan pemodelan terhadap sebaran normal
sX x| , = 1 2 exp – 1 2 x – 2 x R
di mana > 0. Pemodelan dilakukan dengan menggunakan Penduga Kemungkinan Maksimum (PKM), sehingga didapat (rataan contoh) dan (simpangan baku contoh).
2. Melakukan transformasi pada masing- masing amatan dengan menggunakan fungsi sebaran kumulatif (fsk) normal
SX xi| , = yi(xi) = 1 2 exp – 1 2 x – 2 dx xi -∞ xi R
sehingga didapat yi yang merupakan transformasi dari xi (amatan ke-i dari data contoh). Nilai yi akan berada pada selang [0, 1].
3. Melakukan pendugaan kepekatan kernel pada amatan yi, dengan koreksi batas pada selang [0, 1], sehingga didapat fY(y) yang merupakan sebaran dari data yang ditransformasi.
fY y = 1 nky K y – Yi h n i= 1 dengan ky = K(u) du min(1,(1 – y)/h) max( – 1, – y/h)
di mana K t dan h ditentukan seperti pada fungsi kepekatan kernel. 4. Melakukan transformasi balik dengan menggunakan fungsi
fkn,X x = fY(SX x| , ) sX x| ,
sehingga didapat fkn,X x yang merupakan sebaran dari data contoh dengan
menggunakan transformasi penduga kepekatan kernel dengan sebaran normal.
c. Fungsi transformasi kepekatan kernel dengan sebaran Champernowne termodifikasi
1. Melakukan pemodelan terhadap sebaran Champernowne termodifikasi
tX x| ,M,c = x + c
– 1 M + c – c
x + c + M + c – 2c 2 x R+
di mana > 0, M > 0, dan c ≥ 0. Pemodelan dilakukan dengan menggunakan PKM, sehingga didapat dan c, sedangkan M diduga oleh median contoh. 2. Melakukan transformasi pada masing- masing amatan dengan menggunakan
fsk Champernowne termodifikasi
TX xi| ,M,c = zi(xi) = xi + c – c xi + c + M + c – 2c
xi R+
sehingga didapat zi yang merupakan transformasi dari xi (amatan ke-i dari data contoh). Nilai zi akan berada pada selang [0, 1].
3. Melakukan pendugaan kepekatan kernel pada amatan zi, dengan koreksi batas pada selang [0, 1], sehingga didapat fZ(z) yang merupakan sebaran dari data yang ditransformasi.
fZ z = 1 nkz K z– Zi h n i = 1 dengan kz = K(u) du min(1,(1 – z)/h) max( – 1, – z/h)
di mana K t dan h ditentukan seperti pada fungsi kepekatan kernel. 4. Melakukan transformasi balik dengan menggunakan fungsi
fkc,X x = fZ(TX x| ,M,c ) tX x| ,M,c
sehingga didapat fkc,X x yang merupakan sebaran dari data contoh dengan
menggunakan transformasi penduga kepekatan kernel dengan sebaran Champernowne termodifikasi.
d. Fungsi Generalized Pareto Distribution (Coles 2001)
a. Menentukan nilai ambang yang akan digunakan yaitu kuantil 0.9, sehingga didapat n × (1 – 0.9) amatan paling besar.
b. Melakukan pemodelan terhadap sebaran GPD
fGPD,X x k , , = 1 1 + k(x – )
– 1 – 1k
Parameter GPD diduga dengan menggunakan PKM, sehingga didapat k dan , sedangkan besarnya sama dengan nilai ambang.
Data Data dibagi menjadi dua kategori:
1. Data simulasi yang dibangkitkan mengikuti dua sebaran yang tercantum pada Tabel 1, sebaran tersebut dipilih karena secara umum resiko operasional mengikuti sebaran tersebut (Cruz 2002). Sebaran tersebut juga cenderung memiliki kemencengan yang positif yang berarti bahwa sebaran tersebut menjulur ke kanan. Selain itu, menurut Vose (2008) sebaran Ekponensial dan Lognormal bersifat leptokurtis ditandai dengan nilai kurtosisnya yang besar (jika dibandingkan dengan sebaran normal yang kurtosisnya bernilai 3). Kedua sebaran tersebut juga bernilai 0 pada saat x < 0.
Tabel 1 Sebaran yang digunakan dalam simulasi
Sebaran fX x pada x ≥ 0 Kemencengan Kurtosis
Eksponensial(2) fX x = 2e – 2x 2 9
Lognormal(0,1) fX x = 1
y 2 exp
ln(y)2
2 5 50
2. Data aktual, data Welfare Reform Inggris Raya oleh Christina Beatty. Data menggambarkan kerugian finansial per individu usia produktif per tahun yang dikaji berdasarkan delapan faktor kerugian (dapat dilihat pada Tabel 2) dan diukur dalam pound sterling. Data memiliki 379 amatan setiap faktornya. Makna ‘faktor’ dalam kajian ini adalah suatu kerugian operasional, bukan ‘faktor’ dalam arti peubah bebas.
Tabel 2 Faktor- faktor kerugian pada data Welfare Reform
Faktor Kerugian finansial per individu usia produktif per tahun (diukur dalam pound sterling) yang diakibatkan oleh Faktor A Housing Benefit: Local housing Allowance
Faktor B Housing Benefit:Under occupation ('bedroom tax')
Faktor C Non-dependent deduction
Faktor D Household benefit cap
Faktor E Disability living allowance
Faktor F Incapacity benefits
Faktor G Child benefit
Faktor H 1 per cent uprating
Metode Penelitian
Gambar 1 Tahapan penelitian yang akan dilakukan
Tahapan penelitian
1. Membangkitkan data sesuai dengan kombinasi sebaran dan ukuran contoh yang diinginkan, kemudian dilakukan uji apakah contoh tersebut menyebar sesuai dengan sebaran yang diinginkan atau tidak dengan menggunakan uji Kolmogorov-Smirnov,
K = max F x – G(x)
Di mana F x adalah fungsi sebaran kumulatif (fsk) empiris dari data contoh, sedangkan G(x) adalah fsk dari sebaran yang diinginkan untuk masing- masing
Diu lang 100 ka li Data simu lasi Eksponensial(2) Lognormal(0,1) n = 100 n = 500 Kernel TKN TKCM GPD E k,Xq E TKN,Xq E TKCM,Xq E GP D,Xq
Dibandingkan M etode terbaik Data Aktual
Bias & KTG Bias & KTG Bias & KTG Bias & KTG
nilai amatan. Hipotesis nol adalah contoh menyebar sesuai dengan sebaran yang diinginkan, dan hipotesis nol tidak ditolak jika nilai-p (diambil dari tabel Kolmogorov-Smirnov) lebih dari 0.05. Langkah ini dilakukan hingga didapat kesimpulan hipotesis nol tidak ditolak.
2. Dari keempat sebaran fk,X x , fkn,X x , fkc,X x , dan fGPD,X x masing- masing
ditentukan fsk-nya, dan dari masing- masing fsk ditentukan fungsi kebalikan sebaran kumulatif (fksk)-nya. Di mana fksk adalah k,Xq = Fk,X
– 1 (q),
kn,X
q
= Fkn,X – 1 (q), kc,Xq = F – 1kc,X(q), dan GPD,Xq = FGPD,X – 1 q – 0.9 10 yang tidak
lain merupakan fungsi kuantil. Masing- masing fksk dicari nilainya pada kuantil 0.90, 0.91, …, 0.99.
3. Mengulangi langkah 1 dan 2 sebanyak 100 ulangan.
4. Mencari nilai harapan untuk masing metode pendugaan pada masing-masing kuantil dari seluruh hasil ulangan, dan didapat E k,Xq , E kn,Xq , E kc,Xq , dan E GPD,Xq .
5. Mencari nilai bias untuk masing metode pendugaan pada masing-masing kuantil, biasq,metode - j = E j,Xq – q, di mana q merupakan nilai kuantil populasi pada kuantil q. Dan mencari nilai dugaan kuadrat tengah galat (KTG) masing- masing metode pendugaan pada masing- masing kuantil,
KTGq,metode - j = metode - j,X,ulangan - i
q
– q 2
100
i=1
100 .
6. Mengulangi tahapan 1-5 untuk kombinasi simulasi lainnya.
7. Mengevaluasi nilai bias dan nilai dugaan KTG yang dihasilkan masing- masing metode pada masing- masing kombinasi simulasi. Dari hasil evaluasi tersebut diambil metode terbaik.
8. Metode terbaik selanjutnya diterapkan dalam menduga VaR pada data Welfare
Reform untuk masing- masing faktor. Guna keperluan evaluasi hasil pendugaan
maka data akan dibagi menjadi dua bagian yaitu data pelatihan yang digunakan untuk keperluan pendugaan VaR dan data validasi yang digunakan untuk keperluan evaluasi dengan menggunakan back testing. Proporsi data pelatihan dan data validasi yang digunakan adalah 50:50, setengah bagian data adalah data pelatihan dan setengah bagian lainnya adalah data validasi. Data tersebut dibagi secara acak.
Perangkat lunak yang digunakan dalam penelitian ini adalah MATLAB® R2009b, dan Microsoft Office.
HASIL DAN PEMBAHASAN
Eksplorasi Data
Data yang digunakan dalam penelitian ini terdiri dari dua kategori. Kategori pertama yaitu data simulasi secara visual ditampilkan pada Lampiran 1, dapat dilihat bahwa contoh histogram cenderung menjulur ke kanan begitu juga dengan sebarannya yang terlihat bersifat ekor gemuk pada ekor kanan. Kategori kedua
yaitu data Welfare Reform, masing- masing faktor ditampilkan secara visual pada Lampiran 2, dapat dilihat bahwa secara umum histogram cenderung menjulur ke kanan yang terlihat bersifat ekor gemuk pada ekor kanan. Pengecualian pada Faktor G dan Faktor H, pada faktor tersebut histogram cenderung mendekati simetri dan normal.
Pada umumnya sebaran kerugian resiko operasional tidak mengikuti sebaran Normal dan cenderung memiliki karakteristik tersendiri seperti yang dijelaskan pada Bab Pendahuluan. Sifatnya yang tidak mengikuti sebaran Normal tersebut mengakibatkan hasil analisis tidak akan memberikan hasil yang baik apabila analisis dilakukan dengan mengasumsikan data menyebar Normal seperti analisis-analisis statistika pada umumnya. Setelah diuji dengan menggunakan uji kenormalan Kolmogorov-Smirnov, dapat dilihat pada Tabel 3 bahwa seluruh faktor tidak menyebar normal. Data kategori pertama dan kedua memiliki persamaan sifat yaitu sama-sama menjulur pada salah satu sisi dan sebarannya sama-sama cenderung bersifat ekor gemuk.
Tabel 3 Hasil eksplorasi data pada masing- masing faktor data Welfare Reform Faktor Kemencengan Kurtosis Nilai-pa Keterangana
A 5.879 59.609 < 0.010 Tidak menyebar normal B 1.110 3.748 < 0.010 Tidak menyebar normal
C 0.382 2.604 0.017 Tidak menyebar normal
D 4.575 29.282 < 0.010 Tidak menyebar normal E 0.704 3.149 < 0.010 Tidak menyebar normal F 0.872 3.414 < 0.010 Tidak menyebar normal G 0.413 3.560 < 0.010 Tidak menyebar normal H 0.296 2.629 < 0.010 Tidak menyebar normal a
Berdasarkan hasil uji kenormalan Kolmogorov-Smirnov
Penerapan Beberapa Metode Pendugaan Sebaran dalam Menduga VaR pada Data Simulasi yang Bersifat Ekor Gemuk
Simulasi dilakukan guna melihat sifat bias dari masing- masing metode pendugaan. Dari keseluruhan metode, transformasi penduga kepekatan kernel merupakan yang paling rumit. Transformasi penduga kepekatan kernel merupakan gabungan dari metode non-parametrik dan metode parametrik dengan menggabungkan kelebihan masing- masing metode, sehingga sebagian menyebutnya sebagai metode semi-parametrik.
Secara garis besar transformasi penduga kepekatan kernel dilakukan seperti pada Gambar 2. Data ditransformasi sehingga nilainya berkisar antara 0 sampai 1 dan data menyebar mendekati sebaran Seragam(0,1), transformasi dilakukan dengan menggunakan fungsi sebaran kumulatif dari sebaran tertentu. Setelah data ditransformasi, dilakukan penduga kepekatan kernel biasa pada data tersebut kemudian dilakukan transformasi balik. Meskipun fungsi kernel dan kriteria lebar jendela yang digunakan sama dengan penduga kepekatan kernel bia sa, sebaran hasil transformasi penduga kepekatan kernel lebih mendekati sebaran sebenarnya dibandingkan dengan sebaran hasil penduga kepekatan kernel biasa. Transformasi