i
Universitas Sanata Dharma Yogyakarta
SKRIPSI
Diajukan Untuk Memenuhi Salah Satu Syarat Memperoleh Gelar Sarjana Teknik Program Studi Teknik Informatika
Oleh:
SetiawanWasito
065314065
JURUSAN TEKNIK INFORMATIKA
FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA
YOGYAKARTA
ii
Sanata Dharma University Yogyakarta
A Thesis
Presented as Partial Fullfillment of The Requirements To Obtain The Sarjana Teknik Degree
In Informatics Engineering Study Program
By:
SetiawanWasito
Student Number: 065314065
INFORMATICS ENGINEERING STUDY PROGRAM
FACULTY OF SCIENCE AND TECHNOLOGY
SANATA DHARMA UNIVERSITY
YOGYAKARTA
v
Terang akan lebih berarti di tempat
yang gelap
Keeps trying until the end
vi
kecuali yang telah tercantum dan disebutkan dalam kutipan serta daftar pustaka sebagaimana layaknya karya ilmiah.
Yogyakarta, 20 November 2010 Penulis
vii
berorientasi subyek yang didesain untuk mendukung keputusan sistem pendukung keputusan. Penulis membuat gudang data yang diperuntukkan Dekan Fakultas Sains dan Teknologi guna memantau perkembangan mahasiswa setiap prodi. Data tersebut dibutuhkan untuk pelaporan EPSBED (Evaluasi Program Studi Berbasis Evaluasi Diri) dan pelaporan Penerimaan Mahasiswa Baru. Data yang akan dibuat gudang data adalah mengenai akademik mahasiswa yaitu jumlah SKS, angka_mutu, IPS, IPK, dan nilai test PMB. Data jumlah SKS, angka_mutu, IPS, dan IPK terletak pada Sistem Informasi Akademik dan data-data disimpan di database tiap prodi pada tabel mhs (berisi nomor mahasiswa dan angkatan), tabel
mtk (berisi kode matakuliah, nama matakuliah, dan SKS), tabel tw (berisi matakuliah tawar yang akan ditawarkan pada semester yang bersangkutan), dan tabel kh (menghitung jumlah SKS, angka_mutu, IPS, dan IPK). Sedangkan nilai test PMB terletak pada Sistem Penerimaan Mahasiswa Baru dan data-data disimpan di database pmb pada tabel nf (berisi nilai test PMB).
Gudang data yang akan dibuat adalah menggabungkan database pada Sistem Informasi Akademik dan database pada Sistem Penerimaan Mahasiswa Baru, gudang data yang telah terbentuk selanjutnya akan diproses menjadi database Online Analytical Processing (OLAP) menggunakan Kettle dan Star
Schema. Gudang data yang terbentuk dapat menghitung jumlah SKS tiap
mahasiswa, menghitung angka mutu, nilai IPS dan IPK mahasiswa, dan jumlah nilai test Penerimaan Mahasiswa Baru. Perhitungan yang dilakukan oleh gudang data memberikan informasi hasil yang tepat (hasil sama dengan Sistem Informasi Akademik dam Penerimaan Mahasiswa Baru).
viii
oriented that design to support the decision of decision support system. The writer creates the data warehouse that is design for the Dean of the Faculty of Science and Technology to monitor academic progress of each study program. The data required for reporting EPSBED (Study Program Evaluation Based on Self Evaluation) and reporting Admissions. The data that will be use as data warehouse is student’s academic data that are the sum of SKS, grade quality, IPS, IPK, and PMB test grade. Data of the sum of SKS, grade quality, IPS, and IPK is located in Academic Information System and stored in the database of each study program on the mhs table (contains of student’s quality and force quality), mtk table (contains of course code, course name, and credits), tw table (contains of courses that available in the semester), and kh table (counting the sum of credits, grade quality, IPS, and IPK). The PMB test grade located in Student Admission System and stored in pmb database in the nf table (contains of PMB test grade).
The data warehouse that is going to be made bundles database on the Academic Information System and database on Student Admission System. After that, the formed database will be processed into Online Analytical Processing (OLAP) database using Kettle (Pentaho Data Integration) and Star Schema. The data warehouse can to calculate each student’s sum credits, grade quality, IPS and IPK grade, and the total test grade of Student Admission. The calculation of the data warehouse gives accurate result information (the same result with Academic Information System and Student Admission System).
ix
Yang bertanda tangan di bawah ini, saya mahasiswa Universitas Sanata Dharma : Nama : Setiawan Wasito
NIM : 065314065
Demi pengembangan ilmu pengetahuan, saya memberikan kepada Perpustakaan Universitas Sanata Dharma karya ilmiah saya yang berjudul:
Implementasi Gudang Data Untuk Keprluan Akademik Mahasiswa Studi Kasus Fakultas Sains dan Teknologi Universitas Sanata Dharma Yogyakarta
Beserta perangkat yang diperlukan (bila ada). Dengan demikian saya memberikan kepada Perpustakaan Universitas Sanata Dharma hak untuk menyimpan, mengalihkan dalam bentuk media lain, mengelolanya dalam bentuk pangkalan data, mendistribusikannya secara terbatas, dan mempublikasikannya di internet dan media lain untuk kepentingan akademis tanpa perlu meminta izin dari saya maupun memberikan royalti kepada saya selama tetap mencantumkan nama saya sebagai penulis.
Demikian pernyataan ini saya buat dengan sebenarnya.
Yogyakarta, 20 November 2010 Penulis
x
“IMPLEMENTASI GUDANG DATA UNTUK KEPRLUAN AKADEMIK MAHASISWA STUDI KASUS FAKULTAS SAINS DAN TEKNOLOGI UNIVERITAS SANATA DHARMA YOGYAKARTA”. Skripsi ini disusun untuk memenuhi salah satu syarat tugas akhir memperoleh gelar Sarjana Teknik Universitas Sanata Dharma.
Selama menyelesaikan skripsi ini, penulis telah banyak memperoleh bimbingan, dukungan, dan bantuan dari banyak pihak. Maka kesempatan ini, penulis ingin menghaturkan banyak terima ksaih kepada:
1. Ridowati Gunawan, S.Kom., M.T., selaku dosen pembimbing skripsi, atas kesabarannya dalam membimbing penulis, memberikan waktu, dukungan,serta saran yang sangat membantu penulis.
2. Puspaningtyas Sanjoyo Adi, S.T., M.T., selaku Kaprodi Teknik Informatika selaku dosen penguji.
3. P.H. Prima Rosa, S.Si., M.Sc. dan Bapak Puspaningtyas Sanjoyo Adi, S.T., M.T., selaku dosen penguji.
4. Seluruh staff pengajar Prodi Teknik Informatika Fakultas Sains dan Teknologi Universitas Sanata Dharma.
5. Kedua orang tua penulis dan Bpk/Ibu Sudaryono yang telah begitu sabar dan setia mendampingi serta memberikan semangat yang luar biasa sehingga skripsi ini dapat terselesaikan.
6. Katarina Ika Yuniana S.Pd. yang begitu setia mendampingi penulis, memberikan semangat.
xi
sempurna. Oleh karena itu, penulis dengan senang hati bersedia menerima sumbangan pikiran dan saran maupun kritik untuk menyempurnakan penulisan ini.
Penulis
xii
HALAMAN PERSETUJUAN ... iii
HALAMAN PENGESAHAN ... iv
MOTTO ... v
PERNYATAAN KEASLIAN HASIL KARYA ... vi
ABSTRAK ... vii
ABSTRACT ... viii
PERNYATAAN PERSETUJUAN PUBLIKASI KARYA ILMIAH UNTUK KEPERNTINGAN AKADEMIS ... ix
KATA PENGANTAR ... x
DAFTAR ISI ... xii
DAFTAR TABEL ... xvi
DAFTAR GAMBAR ... xvii
xiii
2.5. Multi Dimensional Modelling ... 15
2.5.1. Cube, Dimension, Measure, and Member ... 15
2.5.2. Tabel Fakta dan Dimensi (Fact and Dimension Tables) ... 15
2.5.3. Skema Bintang (Star Schema) ... 16
2.5.4. Surrogate Key ... 17
Bab III. ANALISIS DAN PERANCANGAN SISTEM ... 18
3.1. Analisis Kebutuhan ... 23
3.2. Analisis Sistem ... 23
3.3. Langkah-langkah perancangan gudang data ... 23
3.3.1. Membaca Data Legacy ... 23
3.3.1.1. Sistem Informasi Akademik ... 23
3.3.1.2. Sistem Informasi Penerimaan Mahasiswa Baru ... 30
3.3.2. Menggabungkan Data Dari Sumber Terpisah ... 33
3.3.3. Memindahkan Data Dari Sumber Ke Server Gudang Data .. 34
3.3.4. Memecah Gudang Data Dalam Tabel Fakta Dan Dimensi ... 45
3.3.4.1. Cube khs ... 46
3.3.4.2. Cube ips ... 47
3.3.4.3. Cube ipk ... 48
3.3.4.4. Cube pmb ... 49
Bab IV. IMPLEMENTASI DAN ANALISA SISTEM ... 50
4.1. Membaca Data Legacy ... 52
4.1.1. Tabel mhs Database skripsi_fisika ... 52
4.1.2. Tabel mtk Database skripsi_fisika... 53
4.1.3. Tabel kh Database skripsi_fisika ... 53
4.1.4. Tabel tw Database skripsi_fisika ... 54
4.1.5. Tabel nf Database skripsi_pmb ... 55
xiv
Database skripsi_gabungan ... 58
4.3.1.2.1. Membaca nama tabel... 58
4.3.1.2.1. Set Variabel ... 58
4.3.1.2.3. Memasukkan Variabel ... 59
4.3.1.3. Tabel gabung_mhs_prodi Database skripsi_gabungan ... 59
4.3.2. Tabel gabung_mtk ... 60
4.3.3. Tabel gabung_tw_mtk ... 62
4.3.4. Tabel gabung_khs ... 63
4.3.5. Tabel ips ... 64
4.3.6. Tabel ipk ... 65
4.3.7. Tabel gabung_pmb ... 66
4.4. Memecah gudang data dalam tabel fakta dan tabel dimensi ... 67
4.4.1. Tabel dimensi dim_mhs_prodi ... 67
4.4.2. Tabel dimensi dim_tw_mtk ... 68
4.4.3. Tabel dimensi dim_ambil ... 69
4.4.4. Tabel fakta fact_khs ... 70
4.4.5. Tabel fakta fact_ips ... 71
4.4.6. Tabel fakta fact_ipk ... 72
4.4.7. Tabel fakta fact_pmb ... 73
4.5. Pembentukan Skema Bintang ... 74
4.5.1. Skema Bintang KHS ... 74
4.5.2. Skema Bintang IPS ... 76
4.5.3. Skema Bintang IPK ... 77
4.5.4. Skema Bintang PMB ... 79
Bab V. ANALISIS HASIL ... 81
xv
5.2. Kelebihan Sistem ... 84
5.3. Kekurangan Sistem ... 84
Bab VI. KESIMPULAN ... 85
6.1. Kesimpulan ... 85
6.2. Saran ... 86
Daftar Pustaka ... 87
xvi
Tabel 2.1. Karakteristik Gudang Data ... 7
Tabel 2.2. Komponen Metadata ... 9
Tabel 3.1. mhsprodi ... 23
Tabel 3.2. Contoh data mhsprodi ... 25
Tabel 3.3. mtkprodi ... 27
Tabel 3.4. Contoh data mtkprodi... 28
Tabel 3.5. khprodiangkatan ... 29
Tabel 3.6. Contoh data master khprodiangkatan ... 29
Tabel 3.7. Master twproditahunakademik ... 30
Tabel 3.8. Contoh data master twproditahunakademik ... 30
Tabel 3.9. prd_std ... 30
Tabel 3.10. Contoh data prd_std ... 31
Tabel 3.11. nftahunprodi ... 32
Tabel 3.12. Contoh Data nftahunprodi ... 32
Tabel 3.13. Tabel mhsprodi ... 34
Tabel 3.14. Tabel gabung_mhs ... 34
Tabel 3.15. Tabel gabung_mhs_prodi ... 35
Tabel 3.16. Tabel mtk ... 36
Tabel 3.17. Tabel gabung_mtk... 36
Tabel 3.18. Tabel tw_prodi ... 37
Tabel 3.19. Tabel gabung_tw ... 38
Tabel 3.20. Tabel gabung_tw_mtk... 39
Tabel 3.21. Tabel khprodi ... 40
Tabel 3.22. Tabel gabung_kh ... 41
Tabel 3.23. Tabel ips ... 42
Tabel 3.24. Tabel ipk ... 42
xvii
Gambar 2.1. Arsitektur Data Warehouse ... 10
Gambar 2.2. Sistem Kerja Data Warehouse ... 14
Gambar 2.3. Star Schema dari PHI-Minimart ... 17
Gambar 3.1. Pelaporan EPSED ... 17
Gambar 3.2. Ilustrasi tentang studi kasus yang digunakan dalam penelitian ini... 32
Gambar 3.3. Star Schema dari fact_gabungan ... 45
Gambar 3.4. Star Schema dari fact_khs ... 46
Gambar 3.5. Star Schema dari fact_ips ... 47
Gambar 3.6. Star Schema dari fact_ipk ... 48
Gambar 3.7. Star Schema dari fact_pmb ... 49
Gambar 4.1. Langkah pembentukan tabel pada gudang data ... 51
Gambar 4.2. mhs3214.ktr ... 52
Gambar 4.3. Tabel mhs3214 ... 52
Gambar 4.4. mtk3214.ktr ... 53
Gambar 4.5. Tabel mtk3214... 53
Gambar 4.6. kh32142004.ktr ... 53
Gambar 4.7. Tabel kh32142004 ... 54
Gambar 4.8. tw321420041.ktr ... 54
Gambar 4.9. Tabel tw321420041 ... 54
Gambar 4.10. pmb_fisika.ktr ... 55
Gambar 4.11. Tabel nf20043214 ... 55
Gambar 4.12. Arsitektur Gudang Data ... 56
Gambar 4.13. mhs3214.ktr ... 57
Gambar 4.14. Tabel mhs3214 ... 57
Gambar 4.15. Tabel mhs ... 58
xviii
Gambar 4.21. Tabel gabung_mhs_prodi ... 60
Gambar 4.22. mtk3214.ktr ... 60
Gambar 4.23. Tabel mtk3214... 61
Gambar 4.24. Tabel mtk... 61
Gambar 4.25. Tabel gabung_mtk ... 61
Gambar 4.26. Tabel tw database skripsi_fisika ... 62
Gambar 4.27. Tabel tw3214 ... 62
Gambar 4.28. Tabel tw database skripsi_gabungan ... 62
Gambar 4.29. Tabel gabung_tw ... 63
Gambar 4.30. Gabung tw mtk.ktr ... 63
Gambar 4.31. Tabel gabung_tw_mtk ... 63
Gambar 4.32. Tabel kh database skripsi_fisika ... 63
Gambar 4.33. Tabel kh database skripsi_gabungan ... 64
Gambar 4.34. Tabel gabung_khs ... 64
Gambar 4.35. ips.ktr ... 64
Gambar 4.36. Tabel ips ... 65
Gambar 4.37. ipk.ktr ... 65
Gambar 4.38. Tabel ipk ... 66
Gambar 4.39. Tabel nf database skripsi_pmb ... 66
Gambar 4.40. Tabel gabung_pmb ... 66
Gambar 4.41. dim_mhs_prodi.ktr ... 67
Gambar 4.42. Tabel dim_mhs_pro... 67
Gambar 4.43. dim_tw_mtk.ktr ... 68
Gambar 4.44. Tabel dim_tw_mtk ... 68
Gambar 4.45. dim_ambil.ktr ... 69
Gambar 4.46. Tabel dim_ambil ... 69
xix
Gambar 4.52. Tabel ipk ... 72
Gambar 4.53. fact_pmb.ktr ... 73
Gambar 4.54. Tabel fact_pmb ... 73
Gambar 4.55. SkemaKHS.xml ... 74
Gambar 4.56. Hasil SkemaKHS.xml ... 75
Gambar 4.57. SkemaIPS.xml ... 76
Gambar 4.58. Hasil SkemaIPS.xml... 77
Gambar 4.59. SkemaIPK.xml ... 77
Gambar 4.60. Hasil SkemaIPK.xml ... 78
Gambar 4.61. SkemaPMB.xml ... 79
Gambar 4.62. Hasil SkemaPMB.xml ... 80
Gambar 5.1. Data KHS Prodi pada OLAP ... 81
Gambar 5.2. Data KHS Prodi pada Excel ... 82
Gambar 5.3. Data IPS Prodi pada OLAP ... 82
Gambar 5.4. Data IPK Prodi pada OLAP ... 83
Gambar 5.5. Data Nilai test PMB pada OLAP ... 83
1 1.1. Latar Belakang
Penerimaan Mahasiswa Baru (PMB) di Universitas Sanata Dharma dilakukan dengan menggunakan dengan Sistem Informasi PMB. Semua sudah terkomputerisasi dengan baik, semua informasi disimpan dalam database PMB. Informasi yang disimpan meliputi profil calon mahasiswa,
pendaftaran, nilai test sampai dengan registrasi. Setelah calon mahasiswa itu registrasi maka akan menjadi mahasiswa baru di lingkungan Universitas Sanata Dharma sesuai dengan pilihan program studinya. Semua informasi pada waktu PMB akan dikirim ke Sistem Informasi Akademik. Sistem Informasi Akademik memiliki database yang berbeda, masing-masing berdiri sendiri.
Fakultas Sains dan Teknologi merupakan salah satu Fakultas di Universitas Sanata Dharma. Fakultas ini memiliki 5 buah program studi yaitu Teknik Informatika, Teknik Elektro, Teknik Mesin, Mekatronika, Fisika, dan Matematika. Semua informasi pada kelima prodi tersebut disimpan pada Sistem Informasi Akademik tiap prodi.
1.2. Rumusan Masalah
Berdasarkan latar belakang yang telah diuraikan diatas, permasalahan yang dapat dirumuskan adalah: Bagaimana membuat suatu gudang data dan database Online Analytical Processing (OLAP) akademik mahasiswa untuk Dekan Fakultas Sains dan Teknologi Universitas Sanata Dharma Yogyakarta dalam memantau perkembangan mahasiswa setiap prodi yang digunakan untuk pelaporan EPSBED (Evaluasi Program Studi Berbasis Evaluasi Diri) dan pelaporan nilai test Penerimaan Mahasiswa Baru.
1.3. Tujuan
Membuat database Online Analytical Processing (OLAP) dari gudang data akademik mahasiswa dan PMB, sehingga diperoleh informasi jumlah SKS, angka_mutu, nilai IPS, nilai IPK selama 4 semester, nilai test PMB yang mencakup nilai verbal, numerik, mekanik, ruang, Bahasa Inggris dan jumlah dari kelima nilai tesebut.
1.4. Batasan Masalah
Agar penulisan tugas akhir ini tidak keluar dari inti dan tujuannya serta tidak menjadi luas dan kompleks, maka perlu diberi batasan pada beberapa hal:
1. Nilai test Penerimaan Mahasiwa Baru (PMB), nilai IPS, dan nilai IPK yang diambil dari mahasiswa Fakultas Sains dan Teknologi Universitas Sanata Dharma angkatan 2004, 2005, 2006, dan 2007 selama 4 semester.
2. Implementasi dengan menggunakan Kettle (Pentaho Data Integration).
1.5. Metodologi Penelitian
1. Mencari dokumen teks / Excel dari database yang berbeda. 2. Merubah ke dalam gudang data (data warehouse).
3. Membuat skema bintang.
4. Merubah ke dalam database OLAP.
1.6. Sistematika Penulisan
Sistematika penulisan tugas akhir ini terdiri atas enam bab, yang diuraikan selengkapnya sebagai berikut :
BAB I: PENDAHULUAN
Bab ini berisi latar belakang penulisan tugas akhir, rumusan masalah, batasan masalah, metodologi penelitian, dan sistematika penulisan.
BAB II: LANDASAN TEORI
Bab ini membahas sekilas tentang gudang data dan juga teori-teori lain yang mendukung dalam penulisan tugas akhir ini. BAB III: ANALISIS DAN PERANCANGAN SISTEM
Bab ini berisi analisa dan perancangan gudang data. BAB IV: IMPLEMENTASI DAN ANALISA SISTEM
Bab ini berisi pembuatan gudang data. BAB V : ANALISIS HASIL
Bab ini berisi laporan dan hasil pembangunan gudang data. BAB VI : KESIMPULAN DAN SARAN
4 2.1. Online Transaction Processing (OLTP)
Database OLTP berisi informasi sehari-hari yang dibutuhkan oleh
sebuah organisasi untuk menjalankan bisnisnya. Sebuah database OLTP biasanya mengandung data-data yang spesifik terhadap suatu proses bisnis. Beban kerja sistem informasi OLTP difokuskan pada perekaman, perubahan, dan penghapusan data secara real time. Dengan demikian sistem dan database OLTP sangat mission critical artinya tidak boleh ada gangguan
dalam sistem ini atau operasional tidak bisa berjalan baik. Sistem informasi yang bisa dikategorikan OLTP adalah [1]:
• Enterprise Resource Planning (ERP) dengan contoh produk seperti SAP, Compiere/ Adempiere, Microsoft Dynamics, dan lain-lain.
• Human Resource Management (HRM) dengan contoh produk seperti
OrangeHRM, PeopleSoft, dan lain-lain.
2.2. Gudang Data
Gudang data mengintegrasikan data yang telah disimpan dalam periode waktu tertentu dan sering digunakan untuk menambah informasi. Menurut Inmon (1992) gudang data didefinisikan sebagai sekumpulan data yang terintegrasi, basis data berorientasi subyek yang didesain untuk mendukung fungsi sistem pengambilan keputusan, dimana setiap unit dari data adalah non-volatile dan relevan untuk waktu tertentu [2]. Gudang data lebih besar dari beberapa jenis basis data, ukurannya mencapai gigabyte bahkan sampai dengan terabyte.
diakses. Gudang data juga melakukan transformasi dari data operasional ke dalam bentuk relasional, akan tetapi tidak seluruh data yang ditransformasikan hanya data yang dibutuhkan untuk pengambilan keputusan saja. Dalam sebuah organisasi dimungkinkan untuk membuat gudang data lebih dari satu. Gudang data merupakan salah satu solusi untuk masalah akses data.
Keuntungan dari gudang data adalah sebagai berikut [2]: a. Meningkatkan produktifitas pengetahuan para pekerja.
b. Mendukung seluruh data yang diperlukan oleh pengambil keputusan. c. Menyediakan data yang siap diakses untuk data yang penting
d. Melindungi operasi basis data dari proses ad hoc.
e. Menyediakan ringkasan informasi untuk level tingkat tinggi.
f. Menyediakan kemampuan untuk penelusuran informasi lebih dalam.
Hasil yang dapat diperoleh dari gudang data adalah sebagai berikut: a. Meningkatkan pengetahuan bisnis.
b. Mampu melakukan persaingan bisnis bahkan menjadi pemimpin bisnis. c. Mempertinggi service dan kepuasan pelanggan.
d. Memberikan fasilitas pembuatan keputusan. e. Membantu mempersingkat proses bisnis.
Ada 2 asumsi yang dibuat terhadap gudang data yaitu [2]:
a. Gudang data secara fisik terpisah dari seluruh sistem operasional. b. Gudang data menggabungkan data dan data transaksi untuk manajemen
dan memisahkan mereka dari yang digunakan untuk transaksi on-line.
Tidak seluruh organisasi memerlukan gudang data, gudang data sebaiknya digunakan untuk organisasi yang [2]:
a. Datanya disimpan dalam sistem yang berbeda.
informasi.
c. Data besar dengan bermacam-macam jenis pengguna.
d. Memiliki data yang sama dengan representasi berbeda dalam sistem yang berbeda.
e. Format data yang tidak beraturan.
2.2.1. Komponen Gudang Data
Ada banyak komponen yang terdapat dalam gudang data, diantaranya [2]: 1. Penyimpan data
Penyimpan data operasional adalah komponen yang paling umum dalam gudang data. Setiap hari organisasi akan melakukan penyimpanan data operasional dimana data yang disimpan adalah tunggal untuk suatu aplikasi tertentu. Fungsi dari penyimpanan data operasioanal dalam gudang data adalah sebagai sumber aliran data mentah. Organisasi dalam penyimpanan data ini pada umumnya berorientasi subyek, dan berfokus pada pelanggan, produk, order, kebijakan hal lain diseputarnya. Penyimpanan data ini sering juga disebut sebagai gudang data secara fisik.
2. Data pasar (mart data)
Data pasar adalah bagian dari gudang data dimana hanya data yang relevan saja yang dipelihara. Data pasar sering dilihat sebagai cara untuk meningkatkan masukan ke dalam bidang dari gudang data dan membuat seluruh kesalahan menjadi kecil. Data pasarnya biasanya digunakan oleh firma untuk memperkecil biaya dan memperkecil skala.
3. Metadata
Metadata merupakan salah satu contoh dari gudang data secara logikal. Yang digunakan untuk memperoleh informasi dan mengakses data secara aktual. Sistem legacy pada umumnya tidak menyimpan record tentang karakteristik dari data, seperti berapa item data yang
data dapat diakses. Metadata adalah data sederhana tentang data yaitu lebih memperhatikan informasi yang disimpan tentang gudang dari pada informasi yang disediakan oleh gudang.
4. Sistem pendukung keputusan dan sistem informasi eksekutif. Keduanaya bukanlah bagian dari gudang data akan tetapi aplikasi-aplikasinya digunakan untuk gudang data.
2.2.2. Karakteristik Gudang Data
Karakteristik utama dari gudang data dalam dilihat pada table 2.1:
Tabel 2.1 : Karakteristik Gudang Data [2]
Karakteristik Deskripsi Subject Orientation Data diorganisir sesuai dengan kebutuhan user.
Integrated Menghilangkan kerancuan dalam hal penamaan dan
kekacauan informasi. Data harus “clean”.
Nonvolatile Data hanya dapat dibaca, tidak dapat diubah oleh
user
Time-series Data dalam rangkaian waktu, bukan hanya status
saat ini.
Summarized Data operasioanl dikumpulkan (diringkas), untuk
mendukung keputusan.
Larger Memelihara data dari waktu ke waktu selama
diperlukan.
Not Normalized Data dapat redundant.
Metadata Data mengenai data untuk user dan personil gudang
data.
Input Data operasioanal ditambah data eksternal yang
2.2.3. Metadata
Metadata adalah data mengenai data. Ini adalah informasi tentang gudang data bukan informasi yang disediakan oleh gudang. Metadata menghasilkan 2 hal essensial yaitu staf dan user dari gudang data. Setiap grup membutuhkan informasi yang berbeda. Untuk staf gudang data, metadata mengandung [2]:
a. Sebuah direktori tentang apakah isi dari gudang data. Direktori menginformasikan dimana data disimpan. Ini adalah sebuah index yang digunakan ketika sebuah query diajukan untuk menemukan informasi yang benar.
b. Sebuah petunjuk untuk memetakan data dari bentuk operasional ke bentuk gudang. Ketika data dipindahkan ke gudang, data harus dalam format standar dan harus harus mengikuti ketentuan yang berlaku pada gudang yaitu harus bersih. Petunjuk harus menyediakan instruksi bagaimana setiap kelompok data ditransformasikan sehingga menjadi bentuk yang benar.
c. Aturan yang digunakan untuk membuat ringkasan.
Bagi pengguna gudang data, metadata mengandung:
a. Istilah bisnis yang digunakan untuk menggambarkan data.
b. Nama-nama teknis yang sesuai dengan istilah bisnis yang dapat digunakan untuk akses data.
c. Sumber data, aturan yang digunakan untuk mengambil data dan kapan data dibangun.
Tabel 2.2 : Komponen Metadata
Komponen Isi Pengguna
Direktori Teknis Informasi tentang data Data warehouse administrator.
Direktori Bisnis Perspektif pengguna terhadap data.
End user
Petunjuk Informasi Akses ke direktori bisnis dan gudang data
End user
2.2.4. Format Data
Konsep normalisasi data dalam sistem transaksi, mempunyai popularitas yang panjang dalam database relational, namun tidak dapat dipakai dalam gudang data. Dalam sistem transaksi perhatian utama adalah untuk mengeliminasi redundansi. Prinsipnya, space penyimpanan itu mahal dan tidak seharusnya diboroskan.
Filosofi dalam gudang data adalah mengatur data sehingga mudah digunakana dan dapat diperoleh kembali dengan cepat. Redundansi sangat dibenarkan.
2.2.5. Arsitektur Gudang Data
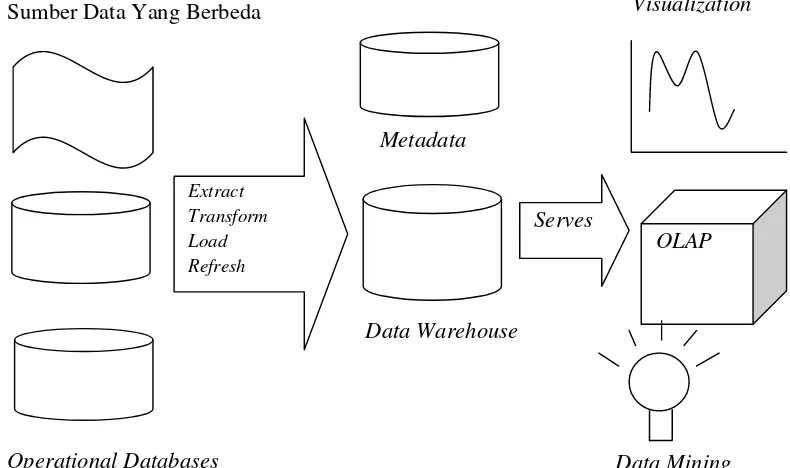
Gambar 2.1 : Arsitektur Data Warehouse
Setiap hari organisasi melakukan kegiatan dan melakukan perubahan terhadap basis data operasional. Data dari basis data operasioanl dan sumber data eksternal lainnya disimpulkan dengan menggunakan gateway atau standar eksternal penghubung yang lain yang mendukung DBMS seperti Open Database Connectivity (ODBC). ODBC adalah program aplikasi yang menghubungkan antara program client untuk menghasilkan pernyataan SQL agar dapat dilakukan eksekusi oleh server.
Ada 3 jenis gudang data yaitu:
1. Gudang data virtual: membiarkan pemakai untuk melakukan akses secara langsung ke dalam data operasional. Disini gudang data bersifat virtual, tidak real. Gudang data virtual biasanya digunakan untuk memperkecil biaya operasional dan biasanya untuk mengetahui data apa yang sebenarnya dicari oleh pemakai.
2. Gudang data terpusat adalah sebuah penyimpanan fisik basis data tunggal yang berisi seluruh data untuk suatu area tertentu, departemen
Extract Transform Load Refresh
Serves
OLAP Metadata
Data Warehouse Sumber Data Yang Berbeda
Operational Databases
Visualization
atau divisi. Gudang data terpusat ini biasanya dipilih jika ada data yang dibutuhkan secara umum dan ada sejumlah pemakai yang telah siap terhubung melalui jaringan komputer. Gudang data ini real yang berarti data yang disimpan dalam gudang data ada secara fisik dan diakses dari suatu tempat dan harus selalu dipelihara.
3. Gudang data terdistribusi. Sesuai dengan namanya, komponen-komponen dari gudang data terdistribusi melalui sejumlah penyimpanan fisik basis data.
2.2.6. Langkah Pembuatan Gudang Data 1. Membaca data legacy
Memperhatikan bagian-bagian data yang perlu untuk dibersihkan 2. Menggabungkan data dari berbagai sumber terpisah
Setiap jenis informasi yang diinginkan mungkin berasal dari beberapa file yang harus digabungkan untuk digunakan pada gudang data.
3. Memindahkan data dari sumber ke server gudang data
Membuat standarisasi format dan copy-kan data dari sumber sekaligus data dibuat bersih (clean).
4. Memecah gudang data dalam tabel fakta dan tabel dimensi Tabel fakta dan tabel dimensi disusun menurut kebutuhan subyek.
2.2.7. Data Staging
2.2.8. Implementasi Gudang Data
Ada banyak cara untuk membuat dan memelihara sebuah gudang data yang besar. Basis data dengan skema yang baik harus didesain agar mudah melakukan integrasi dengan sekumpulan data yang sumbernya terpisah. Permasalahan yang terjadi pada saat membuat gudang data adalah masalah “integrasi semantik”. Bila sumber data berasal dari sumber yang berbeda tentunya semantiknya berbeda pula. Gudang data harus dapat melakukan proses pembersihan terhadap data. Data dengan maksud yang sama seharusnya dipandang sama. Perbedaan-perbedaan harus dihilangkan dalam gudang data.
Hal yang penting dalam gudang data adalah bagaimana memelihara data itu sendiri dalam gudang data. Sistem yang akan dilakukan adalah dengan menggunakan sistem katalog. Informasi tentang data yang disimpan berada pada sistem ini. Jadi gudang data harus dihubungkan dengan sistem katalog dan hal ini biasanya disimpan dalam basis data yang terpisah yang dikenal dengan nama metadata repository (data tentang gudang). Seperti yang telah dikemukakan sebelumnya, yang lebih diperhatikan disini adalah data tentang gudang data dan bukan isi dari gudang data.
Gudang data iniliah kemudian dimanfaatkan oleh bermacam-macam peralatan seperti termasuk didalamnya OLAP, algoritma data mining, peralatan untuk visualisasi informasi, paket statistik, dan penghasil laporan.
Denis Kozar (1997), wakil pimpinan dari Enterprise Information Architecture dari Chase Manhattan Bank mengemukakan ‘tujuh kesalahan
fatal’ dalam menerapkan gudang data yaitu:
dibangun dengan harapan akan ada orang yang memanfaatkannya. 2. Kesalahan dalam membuat kerangka arsitektur gudang data. Hal yang
penting adalah bagaimana membangun kerangka arsitektur gudang data. Kerangka inilah yang merupakan blue print untuk membangun dan menggunakan berbagai komponen gudang data. Sehingga kesalahan pada pembuatan kerangka ini akanlah berakibat sangat fatal.
3. Ketidakmampuan menyusun asumsi
Asumsi dan data potensial harus dimasukkan ke dalam kerangka gudang data. Asumsi yang harus dipersiapkan antara lain:
a.Berapa banyak data yang akan dimasukkan ke dalam gudang data? b.Berapa sering data harus diperbaharui?
c.Dimanakah gudang data akan diterapkan?
Jawaban tepat atas pertanyaan diatas akan sangat membantu dalam pembuatan gudang data.
4. Kesalahan dalam menentukan peralatan yang akan digunakan untuk menyelesaikan tugas. Dalam memilih peralatan untuk membangun gudang data haruslah tepat. Peralatan gudang data tidaklah sama dengan peralatan yang digunakan untuk membangun sistem operasional.
5. Kesalahan dalam siklus hidup gudang data. Siklus hidup gudang data berbeda dengan System Development Life Cycle (SDLC). Walaupun memiliki kesamaan, akan tetapi ada perbedaan mendasar yaitu bahwa siklus hidup gudang data tidak pernah berakhir, selalu berlanjut sehingga perlu selalu diperbaharui. Hal ini heruslah perlu disadari. 6. Cenderung membatalkan data yang mengandung perbedaan. Perlu
dilakukan penyesuaian terhadap data yang berbeda dan buka menghilangkan data.
7. Menggagalkan dokumen yang ada kesalahan.
IT
2.3. Extract, Transform, dan Load (ETL)
Untuk melakukan data warehousing maka diperlukan utilitas yang dirancang khusus untuk hal tersebut. Utilitas tersebut harus memiliki kemampuan [1]:
1. Membaca dari dan mengirim data ke berbagai sumber (file teks, excel, database relational, dan sebagainya)
2. Mampu meyesuaikan / transformasi data
3. Memiliki informasi metadata pada setiap perjalanan transformasi. 4. Memiliki audit log yang baik.
5. Dapat ditingkatkan performanya dengan scale up dan scale out. 6. Mudah diimplementasikan
Secara singkat proses tersebut dibagi dalam 3 proses besar yaitu Extract (mengambil), Transform (transformasi), dan Load (menyimpan) atau disingkat ETL dapat dilihat pada gambar 2.2.
Gambar 2.2 : Sistem Kerja Data Warehouse Dokumen
Text / Excel
Database
Database
OLAP Data Warehouse
SKEMA Bintang Mapping Data
2.4. Online Analytical Processing (OLAP)
Database OLAP dirancang dan difokuskan pada kecepatan
pembacaan data terutama dari volume data yang besar. Umumnya database OLAP tidak mengantisipasi perubahan data yang dilakukan oleh pengguna.
Tetapi sebaliknya, isi dari database dipopulasi dengan suatu proses batch dan biasanya dilakukan dalam periode tertentu. Proses batch ini biasanya juga melibatkan pembacaan bukan hanya satu tapi juga dari berbagai sumber data OLTP untuk diintegrasikan dan ditranformasikan. Proses inilah yang umumnya disebut dengan data warehousing [1].
2.5. Multi Dimensional Modelling
2.5.1. Cube, Dimension, Measure, and Member
Teknologi OLAP menganut multi dimensional modeling, artinya kita dapat melihat analisis pengukuran dengan pandangan berbagai dimensi. Di dalam konsep ini kita perlu mengenal berbagai istilah yang berkaitan dengan OLAP [1]:
1. Cube: adalah struktur multi dimensional konseptual, terdiri dari dimension dan measure dan biasanya mencakup pandangan bisnis
tertentu.
2. Dimension / dimensi: adalah struktur view / sudut pandang yang
menyusun cube. Dimensi dapat terdiri dari berbagai level. 3. Measure: nilai pengukuran itu sendiri.
4. Member: isi / anggota dari suatu dimension / measure tertentu.
2.5.2. Tabel Fakta dan Dimensi (Fact and Dimension Tables)
Tabel fakta (fact table) yaitu tabel yang berisi fakta numerik, jika semua data disimpan pada tabel fakta tunggal, maka hasilnya adalah tabel yang besar sekali. Tabel dimensi (dimension table) yaitu tabel yang berisi petunjuk (pointer) ke tabel fakta, digunakan untuk menunjukkan darimana data dapat ditemukan dan tabel terpisah dibutuhkan untuk setiap dimensi.
Di dalam model multi dimensional, database terdiri dari beberapa tabel fakta dan tabel dimensi saling terkait. Suatu tabel fakta berisi berbagai nilai agregasi yang menjadi dasar pengukuran (measure) serta beberapa key yang terkait ke tabel dimensi yang akan menjadi sudut pandang dari measure tersebut.
Dalam perkembangannya, susunan fact table dan dimension table ini memiliki standar perancangan atau schema karena terbukti meningkatkan performa dan kemudahan dalam penerjemahan ke sistem OLAP.
Schema inilah yang menjadi dasar untuk melakukan data
warehousing. Dua schema yang paling umum digunakan oleh berbagai
OLAP engine adalah skema bintang (star schema) dan skema butir salju
(snowflake schema) [1]
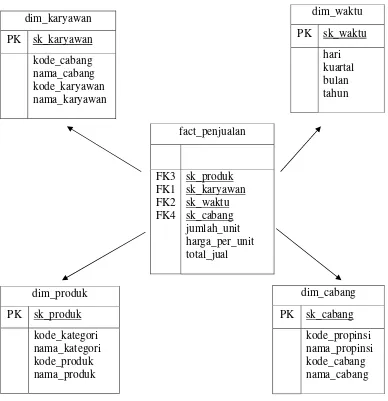
2.5.3. Skema Bintang (Star Schema)
dim_karyawan
Gambar 2.3 : Star Schema dari PHI-Minimart
2.5.4. Surrogate Key
Surrogate key adalah key / kolom data di tabel dimensi yang
18 3.1. Analisis Kebutuhan
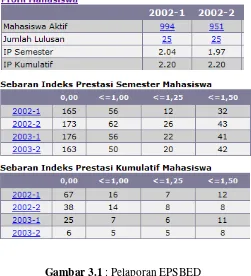
Dekan Fakultas Sains dan Teknolgi Universitas Sanata Dharma ingin mengetahui perkembangan kemajuan akademik mahasiswa pada tiap program studi. Data tersebut dibutuhkan untuk pelaporan EPSBED yaitu IPS, IPK, sebaran IPS, dan sebaran IPK seperti pada gambar 3.1 tiap semester yang meliputi nilai IPS dan IPK dan pelaporan PMB tiap tahun yang meliputi nilai test PMB.
Gambar 3.1 : Pelaporan EPSBED
3.2. Analisis Sistem
masalah yaitu dengan membuat gudang data untuk Dekan Fakultas Sains dan Teknologi Universitas Sanata Dharma Yogyakarta, yaitu menggabungkan database tiap prodi pada Sistem Informasi Akademik Mahasiswa dengan
database PMB pada Sistem Informasi Penerimaan Mahasiswa Baru menjadi
sebuah gudang data. Guna membuat gudang data untuk keperluan akademik mahasiswa maka diperlukan:
1. Bahan berupa data Excel yaitu:
A. Kartu Hasil Studi (KHS) mahasiswa angkatan 2004, 2005, 2006, dan 2007 selama 4 semester. Meliputi:
a) Angkatan
B. Data Penerimaan Mahasiswa Baru (PMB) angkatan 2004, 2005, 2006, dan 2007
3.3. Langkah-langkah perancangan gudang data 1. Membaca data legacy
Memperhatikan bagian-bagian data yang perlu untuk dibersihkan 2. Menggabungkan data dari berbagai sumber terpisah
Setiap jenis informasi yang diinginkan mungkin berasal dari beberapa file yang harus digabungkan untuk digunakan pada gudang data.
3. Memindahkan data dari sumber ke server gudang data
Membuat standarisasi format dan copy-kan data dari sumber sekaligus data dibuat bersih (clean).
4. Memecah gudang data dalam tabel fakta dan tabel dimensi Tabel fakta dan tabel dimensi disusun menurut kebutuhan subyek.
3.3.1. Membaca data legacy
Data legacy tersebar dalam sistem terpisah dengan struktur data sebagai berikut:
3.3.1.1. SISTEM INFORMASI AKADEMIK
Pada Sistem Informasi Akademik ini memiliki beberapa table di database.
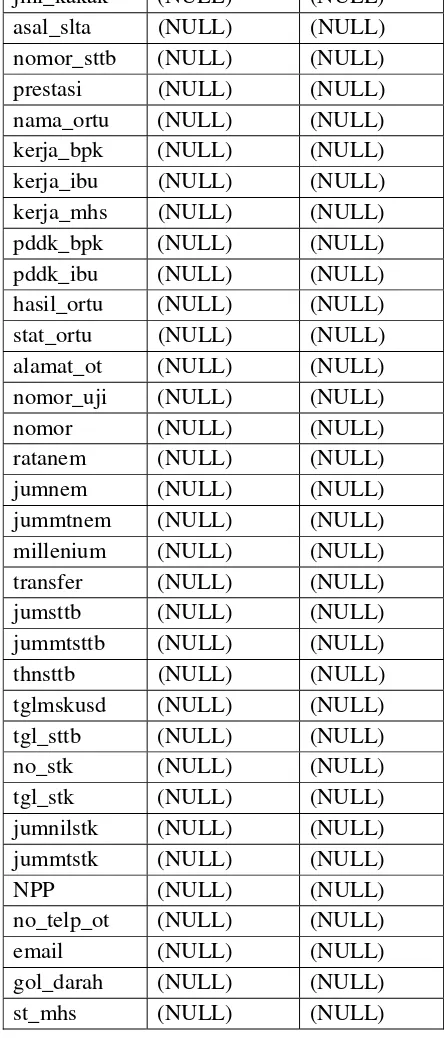
Tabel 3.1 : mhsprodi
mhsprodi Tabel mahasiswa pada tiap prodi PK nomor_mhs NIM mahasiswa sebagai primary key nirm Berisi kota lahir mahasiswa Berisi tempat lahir mahasiwa Berisi tanggal lahir mahasiwa Berisi kode agama
Berisi kode kawin Berisi kode sex. Berisi kode gereja.
Berisi kode kabupaten tempat tinggal sekarang Berisi kode pos tempat tinggal sekarang Berisi alamat asal dari mahasiswa
Berisi kode kabupaten tempat tinggal sekarang Berisi kode pos tempat tinggal sekarang Berisi NIM mahsiswa
Berisi kode warganegara (WNI / WNA) Berisi hobi dari mahsiswa
Berisi jumlah adik kandung Berisi jumlah kakak kandung Berisi asal SLTA
Berisi nomor STTB
Berisi nama orang tua mahasiswa Berisi pekerjaan bapak
Berisi pekerjaan ibu
Berisi pekerjaan mahasiswa Berisi pendidikan bapak Berisi pendidikan ibu Berisi penghasilan orang tua Berisi alamat tinggal orang tua. Berisi nomor ujian
Berisi nomor pendaftaran Berisi rata-rata NEM Berisi jumlah NEM
Berisi jumlah mata pelajaran pada NEM
Berisi jumlah STTB Berisi tahun STTB
Berisi tanggal masuk ke USD Berisi tanggal STTB
Berisi nomor STK Berisi tanggal STK Berisi jumlah nilai STK
Berisi jumlah mata pelajaran pada STK Berisi no telp orang tua
Berisi email
Tabel 3.1 merupakan tabel mahasiswa pada tiap prodi (mhsprodi) contoh mhs3214. mhs merupakan mahasiswa, 3214 merupakan kode prodi. Tabel ini memuat beberapa field yang ada pada setiap program studi. Field nomor_mhs sebagai primary key dari tabel mhsprodi. Terdapat pula beberapa field yaitu nama_mhs, kota_lahir, nirm, tempat_lahir, tgl_lahir, kd_agama,
kd_kawin, kd_sex, kd_gereja, alamat_skr, kd_kab_skr, kd_pos_skr, alamat_asal, kd_kab_asal, kd_pos_asal, nomor_mhs1, kd_warga, hobi, smb_biaya, jml_adik, jml_kakak, asal_slta, nomor_sttb, prestasi, nama_ortu, kerja_bpk, kerja_ibu, kerja_mhs, pddk_bpk, pddk_ibu, hasil_ortu, stat_ortu, alamat_ot,nomor_uji, nomor, ratanem, jumnem, jummtnem, millennium, transfer, jumsttb, thnsttb, tglmskusd, tgl_sttb, no_stk, tgl_stk, jumnilstk, jummtstk, NPP, no_telp_ot, email, gol_darah, st_mhs.
Tabel 3.2 : Contoh data mhsprodi:
nomor_mhs 9058 23049
nirm (NULL) (NULL)
nama_mhs (NULL) (NULL)
kota_lahir (NULL) (NULL)
tempat_lahir (NULL) (NULL) tgl_lahir (NULL) (NULL)
kd_agama (NULL) (NULL)
kd_kawin (NULL) (NULL)
kd_sex (NULL) (NULL)
kd_gereja (NULL) (NULL)
alamat_skr (NULL) (NULL)
kd_kab_skr (NULL) (NULL)
kd_pos_skr (NULL) (NULL)
alamat_asal (NULL) (NULL)
kd_kab_asal (NULL) (NULL)
kd_pos_asal (NULL) (NULL)
nomor_mhs1 (NULL) (NULL)
kd_warga (NULL) (NULL)
hobi (NULL) (NULL)
smb_biaya (NULL) (NULL)
jml_kakak (NULL) (NULL) asal_slta (NULL) (NULL)
nomor_sttb (NULL) (NULL)
prestasi (NULL) (NULL)
nama_ortu (NULL) (NULL)
kerja_bpk (NULL) (NULL)
kerja_ibu (NULL) (NULL)
kerja_mhs (NULL) (NULL)
pddk_bpk (NULL) (NULL)
pddk_ibu (NULL) (NULL)
hasil_ortu (NULL) (NULL)
stat_ortu (NULL) (NULL)
alamat_ot (NULL) (NULL)
nomor_uji (NULL) (NULL)
nomor (NULL) (NULL) ratanem (NULL) (NULL) jumnem (NULL) (NULL)
jummtnem (NULL) (NULL)
millenium (NULL) (NULL)
transfer (NULL) (NULL) jumsttb (NULL) (NULL)
jummtsttb (NULL) (NULL)
thnsttb (NULL) (NULL)
tglmskusd (NULL) (NULL)
tgl_sttb (NULL) (NULL) no_stk (NULL) (NULL) tgl_stk (NULL) (NULL) jumnilstk (NULL) (NULL) jummtstk (NULL) (NULL)
NPP (NULL) (NULL)
no_telp_ot (NULL) (NULL)
email (NULL) (NULL)
gol_darah (NULL) (NULL)
st_mhs (NULL) (NULL)
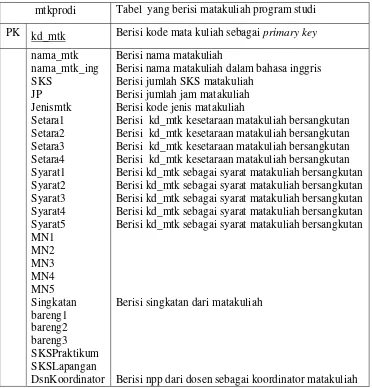
Tabel 3.3 : mtkprodi
Tabel 3.3 merupakan tabel matakuliah prodi (mtkprodi) contoh: mtk3214. mtk merupakan matakuliah, 3214 merupakan kode prodi. Tabel ini memuat beberapa field yang ada pada setiap program studi. Field kd_mtk sebagai primary key dari tabel mhsprodi. Terdapat pula beberapa field yaitu nama_mtk, nama_mtk_ing, SKS, JP, Jenismtk, Setara1, Setara2, Setara3, Setara4, Syarat1, Syarat2, Syarat3, Syarat4, Syarat5, MN1, MN2, MN3, MN4, MN5, Singkatan, bareng1, bareng2,bareng3,SKSPraktikum, SKSLapangan,dan DsnKoordinator.
mtkprodi Tabel yang berisi matakuliah program studi PK kd_mtk Berisi kode mata kuliah sebagai primary key nama_mtk
Berisi nama matakuliah dalam bahasa inggris Berisi jumlah SKS matakuliah
Berisi jumlah jam matakuliah Berisi kode jenis matakuliah
Berisi kd_mtk kesetaraan matakuliah bersangkutan Berisi kd_mtk kesetaraan matakuliah bersangkutan Berisi kd_mtk kesetaraan matakuliah bersangkutan Berisi kd_mtk kesetaraan matakuliah bersangkutan Berisi kd_mtk sebagai syarat matakuliah bersangkutan Berisi kd_mtk sebagai syarat matakuliah bersangkutan Berisi kd_mtk sebagai syarat matakuliah bersangkutan Berisi kd_mtk sebagai syarat matakuliah bersangkutan Berisi kd_mtk sebagai syarat matakuliah bersangkutan
Berisi singkatan dari matakuliah
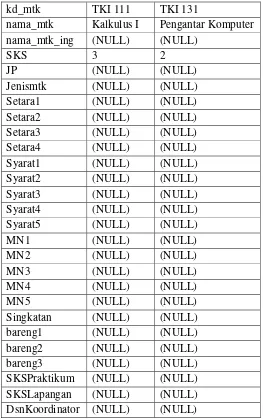
Tabel 3.4 : Contoh data master mtkprodi:
Tabel 3.4 merupakan contoh data tabel mtkprodi. Data yang diperoleh adalah kd_mtk, nama_mtk, dan SKS.
kd_mtk TKI 111 TKI 131
nama_mtk Kalkulus I Pengantar Komputer nama_mtk_ing (NULL) (NULL)
SKS 3 2
JP (NULL) (NULL)
Jenismtk (NULL) (NULL)
Setara1 (NULL) (NULL)
Setara2 (NULL) (NULL)
Setara3 (NULL) (NULL)
Setara4 (NULL) (NULL)
Syarat1 (NULL) (NULL)
Syarat2 (NULL) (NULL)
Syarat3 (NULL) (NULL)
Syarat4 (NULL) (NULL)
Syarat5 (NULL) (NULL)
MN1 (NULL) (NULL)
MN2 (NULL) (NULL)
MN3 (NULL) (NULL)
MN4 (NULL) (NULL)
MN5 (NULL) (NULL)
Singkatan (NULL) (NULL)
bareng1 (NULL) (NULL)
bareng2 (NULL) (NULL)
bareng3 (NULL) (NULL)
Tabel 3.5 : khprodiangkatan
Tabel 3.5 merupakan tabel KHS (Kartu Hasil Studi) prodi tiap angkatan (khprodiangkatan) contoh: kh32142004. kh merupakan KHS (Kartu Hasil Studi), 3214 merupakan kode prodi, 2004 merupakan angkatan pada mahasiswa. Tabel ini memuat beberpa field yang ada pada setiap program studi. Field Nomor_mhs sebagai primary key, terdapat pula beberapa field yaitu kd_mtk, Nama_mtk, SKS, Nilai, dan ambil.
Tabel 3.6 : Contoh data master khprodiangkatan
Tabel 3.6 merupakan contoh data tabel khprodiangkatan. Data yang diperoleh adalah Nomor_mhs, kd_mtk, nama_mtk, SKS, Nilai, dan ambil
khprodiangkatan Tabel kartu hasil studi prodi angkatan PK Nomor_mhs NIM mahasiswa sebagai primary key kd_mtk
Berisi jumlah sistem kredit semester matakuliah bersangkutan
Berisi hasil nilai yang telah dicapai oleh mahasiswa pada matakuliah bersangkutan
Berisi tahun akademik matakuliah yang bersangkutan yang diambil oleh mahasiswa.
Nomor_mhs 8999068 9058
kd_mtk MAB 114 MAB 115
Nama_mtk Kimia Biologi SKS 2 2 Nilai C D
Tabel 3.7 : Master twproditahunakademik
Tabel 3.7 merupakan tabel tawar matakuliah program studi tiap tahun akademik (twproditahunakademik) contoh: tw321420041. tw merupakan tawar, 3214 merupakan kode prodi, 20041 merupakan tahun akademik.
Tabel 3.8 : Contoh data master twproditahunakademik
Tabel 3.8 merupakan contoh data tabel twproditahunakademik. Data yang diperoleh adalah kd_mtk.
3.3.1.2. SISTEM INFORMASI PENERIMAAN MAHASISWA BARU
Tabel 3.9 : prd_std
twproditahunakademik Tabel tawar matakuliah prodi tahun akademik PK kd_mtk Kode matakuliah sebagai primary key
Hrpsks
kd_mtk MAB 114 MAB 115
Hrpsks (NULL) (NULL)
prd_std Tabel program studi
PK Kd_prg Berisi kode program studi sebagai primary key Kd_prd
Berisi kode prodram studi Berisi kode jurusan Berisi kode fakultas Berisi nama program studi Berisi kode akreditasi
Berisi nama kepala program studi Berisi tanggal berdiri program studi Berisi nomor SK berdiri program studi Berisi singkatan program studi
Tabel 3.9 merupakan tabel program studi yang memuat kode program studi dank kode-kode yang lain. Terdapat field Kd_prg sebagai primary key berisi kode program studi. Terdapat beberapa field yaitu Kd_prd, Kd_jur_Kd_fak, Nama_prg, Kd_akre, Tgl_diri, SK_diri, Singkatp, Bank, ID, Jenjang, Kd_kamp, Almt_mail, Ekst_telp, Url, nama_prg_ing, server, dan isAktif.
Nama_prg PEND. SEJARAH TEKNIK INFORMATIKA
Kd_akre 3 1
Kaprodi Drs. Johanes Rasul Sutarjo Puspaningtyas Sanjoyo Adi, S.T.,M.T.
Tgl_diri 0000-00-00 0000-00-00
SK_diri
Almt_mail [email protected] [email protected]
Ekst_telp Url nama_prg_ing
server 172.21.200.5 172.21.200.5
isAktif Y Y
Tabel 3.10 merupakan contoh data tabel prd_std. Data yang diperoleh adalah Kd_prd, Kd_jur_Kd_fak, Nama_prg, Kd_akre, Tgl_diri, Singkatp, Bank, ID, Jenjang, Kd_kamp, Almt_mail, server, dan isAktif.
Url
nama_prg_ing server
isAktif
Berisi alamat internet program studi
Berisi nama program studi dalam bahasa inggris Berisi IP server program studi
Tabel 3.11 : nftahunprodi
Tabel 3.11 merupakan tabel nilai pada tahun dan prodi tertentu contoh nf20043214. nf merupakan nilai, 2004 menunjukkan tahun, dan 3214 merupakan kode prodi. Terdapat field nomor sebagai primary key dari calon mahasiswa, nil11, nil12, nil13, nil14, nil15, final, kep, ket, keputusan, dan pesan.
Tabel 3.12 : Contoh data nftahunprodi nomor 050004049 050004061
nil11 7.00 5.00
Tabel 3.12 merupakan contoh data tabel nftahunprodi. Data yang diperoleh adalah nomor, nil11, nil12, nil13,nil14, dan nil15.
nftahunprodi Tabel nilai tahun prodi
PK nomor Berisi nomor pendaftaran calon mahasiswa sebagai primary key
Berisi nilai Bahasa Inggris
3.3.2. Menggabungkan data dari sumber terpisah
Seperti sudah dijelaskan pada landasan teori bahwa sumber data dari suatu gudang data bisa muncul dari sistem yang berbeda dengan format bahasa yang mungkin berbeda pula. Pada studi kasus yang digunakan dalam penelitian ini yaitu Fakultas Sains dan Teknologi Universitas Sanata Dharma Yogyakarta, kebetulan semua data dibangun dengan bahasa pemrograman yang sama, namun mengandung perbedaan format dan istilah pada beberapa atribut
Gambar 3.2 : Ilustrasi tentang studi kasus yang digunakan dalam penelitian ini.
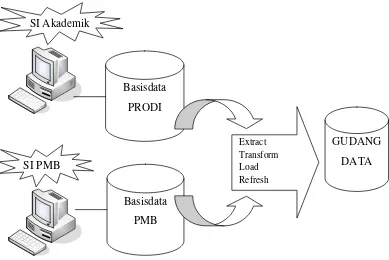
Gambar 3.1 mengilustrasikan bahwa gudang data yang akan divisualisasikan berasal dari 2 basis data dengan 2 program aplikasi yang mengaksesnya. Kedua program aplikasi tersebut adalah:
1. SI Akademik: program aplikasi untuk menangani akademik mahasiswa yaitu berupa, KRS, KHS, data mahasiswa.
SI Akademik
Basisdata PRODI
Basisdata PMB SI PMB
GUDANG DATA
Tabel 3.13 : Tabel mhsprodi
Database prodi Database gudang data
Database gudang data Database gudang data
Tabel 3.14 : Tabel gabung_mhs
2. SI PMB: program aplikasi untuk menangani pendaftaran sampai dengan mahasiswa registrasi dan mendapatkan NIM.
3.3.3. Memindahkan data dari sumber ke server gudang data
Sebelum data dipindahkan ke server gudang data, harus dilakukan penyusunan tabel gudang data dengan memperhatikan hasil dari langkah-langkah sebelumnya. Bentuk gudang data untuk studi kasus di Fakultas Sains dan Teknologi Universitas Sanata Dharma Yogyakarta adalah: a. Tabel mhs
Tabel mhsprodi pada database prodi akan dipindahkan ke dalam database gudang data dapat dilihat pada tabel 3.13. Pada database gudang
data akan terbentuk tabel mhsprodi. Tabel mhsprodi akan digabungkan menjadi satu dengan cara data staging dapat dilihat pada tabel 3.14
Tabel 3.15 : Tabel gabung_mhs_prodi
Database gudang data
Database pmb
Database gudang data
TABEL HAL-HAL PENTING
mhs3214 mhs3114 mhs5013 mhs5114 mhs5314
• Menggabungkan tabel mhs3214, mhs3114, mhs5013, mhs5114, dan mhs5314 ke dalam sebuah tabel yang bernama gabung_mhs
• Ada tambahan field Angkatan dan field asalDatabase
Tabel gabung_mhs pada database gudang data telah terbentuk. Field asalDatabase masih terdapat kode seperti mhs3214. Kode-kode
Tabel 3.16 : Tabel mtk
Database prodi Database gudang data
Database gudang data Database gudang data
Tabel 3.17 : Tabel gabung_mtk b. Tabel mtk
Tabel mtkprodi pada database prodi akan dipindahkan ke dalam database gudang data dapat dilihat pada tabel 3.16. Pada database gudang
data akan terbentuk tabel mtkprodi. Tabel mtkprodi akan digabungkan menjadi satu dengan cara data staging dapat dilihat pada tabel 3.17.
TABEL HAL-HAL PENTING
mtk3214 mtk3114 mtk5013 mtk5114 mtk5314
Database prodi
Database gudang data Tabel 3.18 : Tabel twprodi
c. Tabel tw
TABEL HAL-HAL PENTING
tw321420041
• Menggabungkan tabel tw321420041,
tw321420042, tw321420051, tw321420052, tw321420061, tw321420062, tw321420071, tw321420072, tw321420081 dan tw321420082 ke dalam sebuah tabel yang bernama tw3214
• Ada tambahan field asalTabel
tw311420041
• Menggabungkan tabel tw311420041,
tw311420042, tw311420051, tw311420052, tw311420061, tw311420062, tw311420071, tw311420072, tw311420081 dan tw311420082 ke dalam sebuah tabel yang bernama tw3114
• Ada tambahan field asalTabel
tw501320041
• Menggabungkan tabel tw501320041,
tw501320042, tw501320051, tw501320052, tw501320061, tw501320062, tw501320071, tw501320072, tw501320081 dan tw501320082 ke dalam sebuah tabel yang bernama tw5013
• Ada tambahan field asalTabel twproditahunakademik
PK kd_mtk
twprodi PK kd_mtk
Database gudang data Database gudang data Tabel 3.19 : Tabel gabung_tw
tw501320081
• Menggabungkan tabel tw511420041,
tw511420042, tw511420051, tw511420052, tw511420061, tw511420062, tw511420071, tw511420072, tw511420081 dan tw511420082 ke dalam sebuah tabel yang bernama tw5114
• Ada tambahan field asalTabel
tw531420041
• Menggabungkan tabel tw531420041,
tw531420042, tw531420051, tw531420052, tw531420061, tw531420062, tw531420071, tw531420072, tw531420081 dan tw531420082 ke dalam sebuah tabel yang bernama tw5314
• Ada tambahan field asalTabel
Tabel twproditahunakademik pada database prodi akan dipindahkan ke dalam database gudang data dengan proses data staging dapat dilihat pada tabel 3.18. Pada database gudang data akan terbentuk tabel twprodi. Tabel twprodi akan digabungkan menjadi satu dengan cara data staging dapat dilihat pada tabel 3.19.
Tabel 3.20 : Tabel gabung_tw_mtk
Database gudang data
Database gudang data
Database gudang data TABEL HAL-HAL PENTING
tw3214 tw3114 tw5013 tw5114 tw5314
• Menggabungkan tabel tw3214, tw3114, tw5013, tw5114, dan tw5314 ke dalam sebuah tabel yang bernama gabung_tw.
Tabel 3.19 tabel gabung_tw merupakan tabel penggabungan dari twprodi. Field pada asalTabel masih berisi kode-kode seperti tw311420041. Sehingga harus diubah menjadi field baru dengan nama TahunAkd. Selanjutnya tabel gabung_tw dan gabung_mtk digabung menjadi sebuah tabel dangan nama gabung_tw_mtk seperti pada tabel 3.20
gabung_ tw PK kd_mtk
asalTabel gabung_ tw_mtk
Tabel 3.21 : Tabel khprodi
Database prodi Database gudang data
d. Tabel kh
TABEL HAL-HAL PENTING
kh32142004 kh32142005 kh32142006 kh32142007
• Menggabungkan tabel kh32142004, kh32142005, kh32142006, dan kh32142007 ke dalam sebuah tabel yang bernama kh3214
kh31142004 kh31142005 kh31142006 kh31142007
• Menggabungkan tabel kh31142004, kh31142005, kh31142006, dan kh31142007 ke dalam sebuah tabel yang bernama kh3114
kh50132004 kh50132005 kh50132006 kh50132007
• Menggabungkan tabel kh50132004, kh50132005, kh50132006, dan kh50132007 ke dalam sebuah tabel yang bernama kh5013
kh51142004 kh51142005 kh51142006 kh51142007
• Menggabungkan tabel kh51142004, kh51142005, kh51142006, dan kh51142007 ke dalam sebuah tabel yang bernama kh5114
kh53142004 kh53142005 kh53142006 kh53142007
• Menggabungkan tabel kh53142004, kh53142005, kh53142006, dan kh53142007 ke dalam sebuah tabel yang bernama kh5314
Tabel krproditahunakademik pada database prodi akan dipindahkan ke dalam database gudang data dengan proses data staging dapat dilihat pada tabel 3.21. Pada database gudang data akan terbentuk tabel krprodi. Selanjutnya tabel krprodi akan digabungkan menjadi tabel gabung_khs seperti pada gambar 3.22
Tabel 3.22 : Tabel gabung_kh
Database gudang data
Database gudang data
Database gudang data
TABEL HAL-HAL PENTING kh3214
kh3114 kh5013 kh5114 kh5314
• Menggabungkan tabel kh3214, kh3114, kh5013, kh5114, dan kh5314 ke dalam sebuah tabel yang bernama gabung_khs.
• Ada perubahan field yaitu Nilai char(1) menjadi Angka_mutu int(11).
Tabel 3.22 tabel gabung_khs merupakan tabel penggabungan dari khprodi. Pada tabel khprodi terdapat field Nilai diubah dari char menjadi Angka_mutu yang bertipe int sehingga dapat dilakukan perhitungan. Field Angka_mutu diperoleh memalui tabel nilai.
Tabel 3.23 : Tabel ips
Database gudang data Database gudang data
Tabel 3.24 : Tabel ipk
Database gudang data
Database gudang data e. Tabel ips
Tabel 3.23 merupakan pembentukan tabel ips yang dilakukan dengan mengambil dari tabel gabung_khs. Perhitungan dilakukan dengan mengurutkan field nomor_mhs dan ambil yang bertujuan untuk melakukan perhitungan pada tiap ambil. Perhitungan yang dilakukan adalah field angka_mutu dikalikan dengan SKS, yang akan menghasilkan field baru bernama mutu. Mutu dan SKS akan dijumlah tiap ambil dan tiap nomor_mhs. Jumlah dari mutu dan SKS kemudian dibagi dan menghasilkan field baru bernama ips.
f. Tabel ipk
Tabel 3.24 merupakan pembentukan tabel ipk yang dilakukan dengan mengambil dari tabel gabung_khs. Perhitungan dilakukan dengan
Tabel 3.25 : Tabel gabung_pmb
Database pmb
Database gudang data mengurutkan field nomor_mhs dan kd_mtk dengan ketentuan angka_mutu diurutkan paling besar. Hal ini bertujuan untuk mencari nilai paling tinggi jika mahasiswa yang bersangkutan mengulang suatu matakuliah. Perhitungan yang dilakukan adalah field angka_mutu dikalikan dengan SKS, yang akan menghasilkan field baru bernama mutu. Mutu dan SKS akan dijumlah tiap nomor_mhs. Jumlah dari mutu dan SKS kemudian dibagi dan menghasilkan field baru bernama ipk.
g. Tabel nf
TABEL HAL-HAL PENTING
nf20043114
• Menggabungkan tabel nf20043114, nf20043214, nf20045013, nf20045114, nf20045314, nf20053114, nf20053214, nf20055013, nf20055114, nf20055314, nf20063114, nf20063214, nf20065013, nf20065114, nf20065314, nf20073114, nf20073214, nf20075013, nf20075114, nf20075314ke dalam sebuah tabel yang bernama gabung_pmb.
nf20065114 nf20065314 nf20073114 nf20073214 nf20075013 nf20075114 nf20075314
3.3.4. Memecah gudang data dalam tabel fakta dan tabel dimensi.
Gambar 3.3 : Star Schema fact_gabungan
Karena pembacaan data dari tabel fact_gabungan sangat besar, maka tabel fact_gabungan dapat dipecah menjadi beberapa tabel fakta dengan asumsi nilai informasi yang didapat tidak berubah.
3.3.4.1 Cube khs
Cube khs dengan star schema fact_khs seperti pada gambar 3.3. Star schema fact_khs memiliki tabel fakta yaitu fact_khs dan tabel
dimensi yaitu tabel dim_mhs_prodi dan dim_tw_mtk. Nilai pengukuran dalam cube khs adalah SKS dan angka_mutu.
Gambar 3.4 : Star Schema fact_khs dim_mhs_prodi
PK sk_mhs_prodi Angkatan
nomor_mhs Nama_prg
dim_tw_mtk PK sk_tw_mtk kd_mtk
nama_mtk SKS TahunAkd
fact_khs
FK1 FK2
sk_mhs_prodi sk_tw_mtk SKS
3.3.4.2. Cube ips
Cube ips dengan star schema fact_ips seperti pada gambar 3.4.
Star schema fact_ips memiliki tabel fakta yaitu fact_ips dan tabel
dimensi yaitu tabel dim_mhs_prodi dan dim_ambil. Nilai pengukuran dalam cube ips adalah SKS dan ips.
Gambar 3.5 : Star Schema fact_ips dim_mhs_prodi
PK sk_mhs_prodi Angkatan
nomor_mhs Nama_prg
dim_ambil PK sk_ambil
ambil
fact_ips
FK1 FK2
3.3.4.3. Cube ipk
Cube ipk dengan star schema fact_ipk seperti pada gambar 3.5.
Star schema fact_ipk memiliki tabel fakta yaitu fact_ipk dan tabel
dimensi yaitu tabel dim_mhs_prodi. Nilai pengukuran dalam cube ipk adalah SKS dan ipk.
Gambar 3.6 : Star Schema fact_ipk dim_mhs_prodi
PK sk_mhs_prodi Angkatan
nomor_mhs Nama_prg
fact_ipk
FK1 sk_mhs_prodi SKS
3.3.4.4. Cube pmb
Cube pmb dengan star schema fact_pmb seperti pada gambar 3.6.
Star schema fact_pmb memiliki tabel fakta yaitu fact_pmb dan tabel
dimensi yaitu tabel dim_mhs_prodi. Nilai pengukuran dalam cube pmb adalah nil11, nil12, nil13, nil14, nil15 dan jumlah.
Gambar 3.7 : Star Schema fact_pmb dim_mhs_prodi
PK sk_mhs_prodi Angkatan
nomor_mhs Nama_prg
fact_pmb
FK1 sk_mhs_prodi nil11
50
mhs3214 mhs3214
mtk3214 mtk3214
database skripsi_fisika database skripsi_gabungan
database skripsi_fisika database skripsi_gabungan
tw321420041
database skripsi_gabungan database skripsi_gabungan
database skripsi_gabungan
B. Tabel mtk dan Tabel tw
4.1. Membaca Data Legacy
4.1.1. Tabel mhs Database skripsi_fisika
Gambar 4.2 : mhs3214.ktr
Gambar 4.2 merupakan rangkaian pembentukan tabel mhs3214 yang bertujuan untuk mengambil data dari Excel kemudian diletakkan ke dalam database dengan langkah:
1. Ambil data dari Excel
2. Mengurutkan data (mengurutkan data dari yang terendah)
3. Menggabungkan data (data yang sama akan digabungkan menjadi satu) 4. Memilih data (data yang akan dipakai)
5. Memasukkan data yang telah diolah ke dalam tabel mhs3214 pada database skripsi_fisika
6. Script SQL untuk pembentukan tabel mhs3214.
Gambar 4.3 : Tabel mhs3214
4.1.2. Tabel mtk Database skripsi_fisika
Gambar 4.4 : mtk3214.ktr
Gambar 4.4 merupakan rangkaian pembentukan tabel mtk3214 yang bertujuan untuk mengambil data dari Excel kemudian diletakkan ke dalam database skripsi_fisika. diawali oleh ambil data dari Excel, memilih data, mengurutkan data, menggabungkan data, memasukkan data ke dalam tabel mtk3214, dan terdapat script SQL untuk pembentukan tabel mtk3214.
Gambar 4.5 : Tabel mtk3214
Gambar 4.5 merupakan hasil dari tabel mtk3214. Terdapat field kd_mtk, nama_mtk dan SKS, sedangkan field lainnya bernilai NULL karena tidak mempunyai data.
4.1.3. Tabel kh Database skripsi_fisika
Gambar 4.6 merupakan pembentukan tabel kh32142004, diawali oleh ambil data dari Excel, memilih baris, memilih data, memasukkan data ke dalam tabel, dan script SQL tabel.
Gambar 4.7 : Tabel kh32142004
Gambar 4.7 merupakan hasil dari tabel kh32142004. Terdapat field nomor_mhs, kd_mtk, Nama_mtk, SKS, Nilai, dan ambil.
4.1.4. Tabel tw Database skripsi_fisika
Gambar 4.8 : tw321420041.ktr
Gambar 4.8 merupakan rangkaian pembentukan tabel tw321420041yang bertujuan untuk memasukkan data pada tabel mtk3214 database skripsi_fisika diawali oleh ambil data dari Excel, pemilihan baris,
memilih data, mengurutkan data, menggabungkan data memasukkan data ke dalam tabel tw321420041, dan script SQL tabel tw321420041.
Gambar 4.9 : Tabel tw321420041
Gambar 4.9 merupakan hasil dari tabel tw321420041. Terdapat field kd_mtk sedangkan field Hrpsks bernilai NULL karena tidak
4.1.5. Tabel nf Database skripsi_pmb
Gambar 4.10 : pmb_fisika.ktr
Gambar 4.10 merupakan pembentukan tabel nf32142004 yang bertujuan mengubah format Excel ke dalam database diawali dengan proses ambil data dari Excel, memilih data, dan memasukkan data ke dalam tabel.
Gambar 4.11 : Tabel nf20043214
Gambar 4.11 merupakan hasil dari tabel nf20043214. Terdapat field nomor, nil11. nil12, nil13, nil14, dan nil15. Field yang lain bernilai
4.2. Menggabungkan data dari sumber terpisah
Gambar 4.12 : Arsitektur Gudang Data
Gambar 4.12 merupakan arsitektur gudang data. Ada 5 database dengan sistem informasi yang sama yaitu skripsi_fisika, skripsi_mat, skripsi_meka, skripsi_te dan skripsi_ti yang memiliki tabel-tabel yang berbeda namanya, akan tetapi strukturnya sama, sedangkan skripsi_pmb memiliki struktur yang berbeda karena sistem informasi juga berbeda. Keenam database selanjutnya akan dilakukan proses ETL menjadi gudang data. Gudang data yang terbentuk akan dijalankan dengan bantuan OLAP.
ETL Serves
OLAP
Data Warehouse Sumber Data Yang Berbeda
4.3. Memindahkan data dari sumber ke server gudang data
4.3.1. Tabel gabung_mhs_prodi
4.3.1.1. Tabel mhs Database skripsi_gabungan
Gambar 4.13 : mhs3214.ktr
Gambar 4.13 merupakan rangkaian pembentukan gudang data mhs3214 yang bertujuan untuk memasukkan tabel mhs3214 pada database skripsi_fisika ke dalam database skripsi_gabungan. Pada
tabel mhs3214 data nomor_mhs tidak memiliki kode tahun, sebagai contoh pada data yang sebenarnya 033214001, 03 mewakili angkatan mahasiswa yaitu 2003, 3214 mewakili prodi, dan 001 adalah nomor urut mahasiswa. Penulis mendapatkan data nomor mahasiswa secara acak. Oleh karena itu data yang ada pada tabel mhs3214, harus disamakan dengan data pada Excel, karena pada Excel terdapat field nomor_mhs dan angkatan.
Gambar 4.14 : Tabel mhs3214
4.3.1.2. Tabel gabung_mhs Database skripsi_gabungan
Gambar 4.15 : Tabel mhs
Gambar 4.15 merupakan 5 tabel mhs (mhs3114, mhs3214, mhs5013, mhs5114, dan mhs5314) pada database skripsi_gabungan, kemudian tabel-tabel mhs akan disatukan dengan proses data staging. Langkah-langkahnya sebagai berikut:
4.3.1.2.1. Membaca nama tabel
Gambar 4.16 : baca nama tabel.ktr
Gambar 4.16 merupakan pembacaan nama tabel. Nama tabel yang banyak kita ketikkan pada notepad, kemudian semua nama pada tabel yang sudah diketikkan dimasukkan ke dalam variabel.
4.3.1.2.2. Set Variabel
Gambar 4.17 merupakan pengambilan variabel yang telah tersimpan pada gambar 4.16. Varibel tersebut akan dijadikan sebuah virtual mesin yang akan dijalankan. Variabel yang sudah dibuat lalu akan dijadikan baris baru untuk proses looping.
4.3.1.2.3. Memasukkan Variabel
Gambar 4.18 : masukkan variabel.ktr
Gambar 4.18 merupakan pemasukkan variabel nama tabel ke dalam tabel yang baru yang bernama gabung_mhs.
Gambar 4.19 : Tabel gabung_mhs
Gambar 4.19 merupakan hasil dari tabel gabung_mhs. Terdapat field Angkatan, nomor_mhs, dan asalDatabase yang masih berupa kode yaitu mhs3114. Untuk mengubah kode tersebut maka akan diolah sehingga dapat dibaca.
4.3.1.3. Tabel gabung_mhs_prodi Database skripsi_gabungan
Gambar 4.20 merupakan pembentukan tabel gabung_mhs_prodi yang bertujuan untuk mengubah kode pada tabel gabung_mhs menjadi keterangan yang dapat dibaca. Terdapat masukan tabel prg_std, masukkan tabel gabung_mhs, menyamakan data antara field Kd_prg dari tabel prg_std dengan field asalDatabase dari tabel gabung_mhs yang telah diubah menjadi prg_std, memilih data, memasukkan data ke tabel gabung_mhs_prodi, dan script SQL pada tabel gabung_mhs_prodi.
Gambar 4.21 : Tabel gabung_mhs_prodi
Gambar 4.21 merupakan hasil dari tabel gabung_mhs_prodi. Terdapat field Angkatan, nomor_mhs, dan Nama_prg.
4.3.2. Tabel gabung_mtk
Gambar 4.22 : mtk3214.ktr
Gambar 4.23 : Tabel mtk3214
Gambar 4.23 merupakan hasil dari tabel mtk3214. Terdapat field kd_mtk, nama_mtk. dan SKS.
Gambar 4.24 : Tabel mtk
Gambar 4.24 merupakan 5 tabel mtk (mtk3114, mtk3214, mtk5013, mtk5114, dan mtk5314) pada database skripsi_gabungan, tabel-tabel mtk akan disatukan dengan proses data staging.
Gambar 4.25 : Tabel gabung_mtk
4.3.3. Tabel gabung_tw_mtk
Gambar 4.26 : Tabel tw database skripsi_fisika
Gambar 4.26 merupakan tabel-tabel tw pada database skripsi_fisika, maka tabel-tabel tw yang ada akan simpan ke dalam database skripsi_gabungan yaitu dengan data staging yang bertujuan
untuk menggabungkan data dari berbagai tabel tw menjadi sebuah tabel seperti pada gambar 4.27.
Gambar 4.27 : Tabel tw3214
Gambar 4.28 : Tabel tw database skripsi_gabungan
Gambar 4.29 : Tabel gabung_tw
Pada tabel gabung_mtk terdapat field kd_mtk, sedangkan pada tabel gabung_tw juga terdapat field yang sama. Oleh karenanya akan digabungkan tabel gabung_mtk dan tabel gabung_tw menjadi satu tabel dengan nama gabung_tw_mtk seperti pada gambar 4.30.
Gambar 4.30 : Gabung tw mtk.ktr
Gambar 4.31 : Tabel gabung_tw_mtk
Gambar 4.31 merupakan hasil dari tabel gabung_tw_mtk. Terdapat field kd_mtk, nama_mtk, SKS, dan TahunAkd.
4.3.4. Tabel gabung_khs