IV. HASIL DAN PEMBAHASAN
4.1 Pengumpulan Data
Tahap awal yang dilakukan adalah mengumpulkan data tweet berbahasa Indonesia dengan pencarian kata kunci “kuliah online” dan “kuliah daring”
menggunakan Twitter API. Terlebih dahulu dilakukan Import Libraries yang disediakan oleh Python. Library yang digunakan dalam pengumpulan data yang digunakan adalah library tweepy yang dapat mengakses API twitter secara langsung di console ataupun script. Library sys adalah library yang digunakan untuk menyediakan akses ke beberapa variabel yang digunakan atau dikelola oleh penerjemah, library matplotlib.pyplot digunakan untuk membuat fungsi visualisasi kedalam bentuk grafik.
Gambar 1. Import Library Python yang dibutuhkan
Untuk dapat mengambil data dari twitter, terlebih dahulu mendaftar di twitter Developer, dilakukan pengisian semua form yang ditampilkan. Setelah selesai proses mendaftar akan diberikan consumer key, consumer secret, acces token dan acces token secret yang digunakan untuk mengakses data pada twitter.
Proses mendaftar aplikasi dapat dilihat pada Gambar 15.
Gambar 2. Mendaftar pada Developer Twitter
Setelah didapatkan Token dari Developer twitter selanjutnya dilakukan authentikasi token dengan code python seperti pada Gambar 16.
Gambar 3. Code Python Aunthentikasi Token
Setelah terkoneksi dengan twitter, program akan meminta data tentang kata kunci maupun hashtag yang dicari, kemudian dimasukkan kedalam variabel keyword dan akan meminta jumlah data tweet yang akan dianalisis. Kemudian dimasukkan kedalam variabel noOfTweet yang berupa integer. Variabel tweet akan melakukan operasi pengambilan data yang telah disimpan pada variabel searchTerm dan noOfSearchTerm. Kata kunci yang digunakan dalam pencarian data adalah “Kuliah Online” dan “Kuliah Daring”. Penggunaan Query tersebut dkarenakan kuliah online dan kuliah daring adalah istilah yang digunakan untuk mendeskripsikan pembelajaran yang tetap berlangsung selama pandemi Covid- 19 dengan sistem perkuliahan menggunakan teknologi dan tidak tatap muka.
Pengambilan data diambil perhari sejak dimulai nya penelitian ini adalah per periode Januari 2021 – Maret 2021. Hal ini dikarena API Twitter yang digunakan tidak mendukung dalam pengambilan data dalam waktu yang lama dikarenakan setiap hari data twitter selalu update dan terperbaharui dengan otomatis.
Gambar 4. Code Python Crawling data
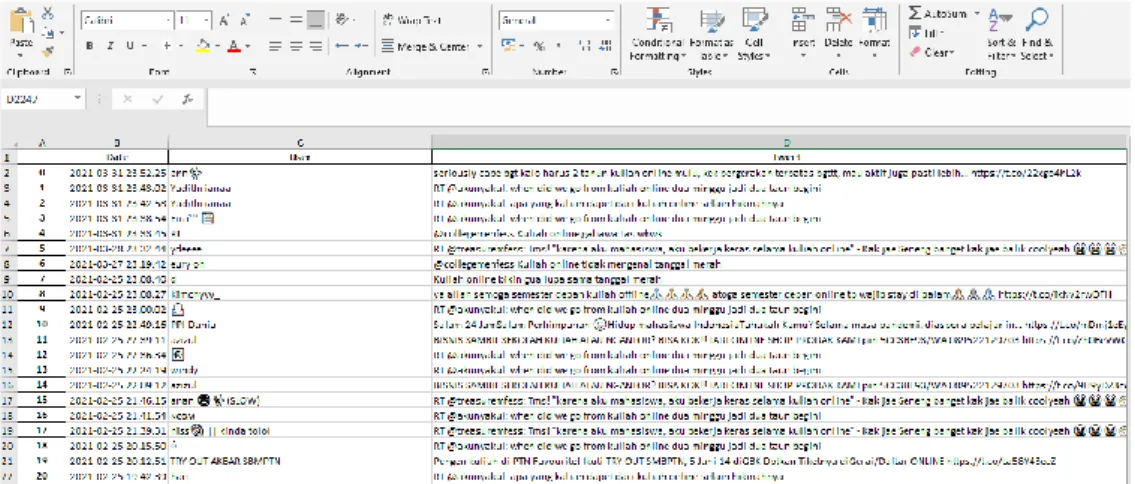
Data yang terkumpul sebanyak 2000 tweet dikumpulkan dan disimpan kedalam file excel dengan format .xlsx. Tidak ada batasan dalam jumlah data yang diambil namun dengan 2000 data diharapkan dapat mewakili hasil opini masyarakat secara umum. Data yang tersimpan terdiri dari tanggal pembuatan tweet, user twitter yang memposting tweet mengenai kuliah daring dan kuliah online serta tweet yang diposting. Data yang terkumpul dalam format excel dapat dilihat pada Gambar 18.
Gambar 5. Hasil Pengumpulan data dengan Twitter API 4.2 Praprocessing Data
Tahapan praprocessing data perlu dilakukan karena beberapa kalimat tweet yang didapatkan tidak sepenuhnya menggunakan kata baku dan menggunakan bahasa indonesia yang baik. Preprocessing dilakukan menggunakan bantuan library pada bahasa pemrograman Python. Praprocessing data dilakukan dengan tahap Case Folding, Tokenizing, Filtering, Stemming sehingga menghasilkan data bersih dan siap untuk lanjut pada proses berikutnya
Case Folding
Case Folding adalah proses merubah data tweet menjadi lowercase.
Berikut merupakan contoh data penelitian yang dilakukan proses case folding.
Kode program untuk melakukan tahap case folding dapat dilihat pada Gambar 19 dan hasil tahapan case folding dapat dilihat pada Tabel 7.
Gambar 6. Kode Program tahap Case Folding Tabel 1. Hasil Praprocessing Case Folding
No Tweet Case Folding
1. Sangat mewakili dan yang mau kuliah online aja gamau offline mending keluar kampus aja sekalian daripada ribet🤪
https://t.co/TVrd8vTkHD
sangat mewakili dan yang mau kuliah online aja gamau offline mending kelu ar kampus aja sekalian daripada ribet https://t.co/tvrd8vtkhd
2. @collegemenfess Kuliah gapapa offline kalo udh efektif bgt (but mungkin blm lah ya) tp gue minta
bgt sidang online
https://t.co/ftsoHFgiHR
@collegemenfess Kuliah gapapa offlin e kalo udh efektif bgt (but mungkin bl m lah ya) tp gue minta bgt sidang onli ne https://t.co/ftsoHFgiHR
Sumber : Data diolah, 2021 Tokenizing
Tokenizing dalam penelitian ini merupakan tahapan dalam memecah string atau input terhadap suatu teks yang telah melewati tahap case folding berdasarkan tiap kata yang menyusunnya dan menghilangkan URL, @mention dan hashtag. Tahap tokenization dilakukan dengan menggunakan fungsi nltk_tokenize( ), library pada bahasa pemrograman Python3 yang bernama NLTK.
Dilakukan Import library terlebih dahulu yang dapat dilihat pada Gambar 20.
Gambar 7. Import Library yang dibutuhkan
Library string digunakan untuk memuat satu karakter atau lebih yang ada pada data tweet. Terlebih dahulu diimport library re untuk melakukan tahapan Regular Expression (regex) atau deretan karakter yang digunakan untuk pencarian teks dengan menggunakan pola (pattern). Dengan menggunakan library regex dapat memudahkan dalam mencari string tertentu dari teks yang banyak. Selain itu pada tahap ini juga dilakukan proses removing number, whitespace dan punctuation (tanda baca).
Gambar 8. Code Python Tahap Tokenzining
Tabel 2. Hasil Prapocessing Tokenizing
No Tweet Tokenizing
1. Sangat mewakili dan yang mau kuliah online aja gamau offline mending keluar kampus aja sekalian daripada ribet🤪 https ://t.co/TVrd8vTkHD
sangat, mewakili, dan, yang, mau, kuli ah, online, aja, gamau, offline,mending, keluar, kampus, aja, sekalian,
daripada, ribet
2. @collegemenfess Kuliah gapapa offline kalo udh efektif bgt (but mungkin blm lah ya) tp gue mi nta bgt sidang online https://t.
co/ftsoHFgiHR
kuliah, gapapa, offline, kalo, udh, efekt if, bgt, but, mungkin, blm, lah, ya, tp, g ue, minta, bgt, sidang, online
Sumber : Data diolah, 2021
Pada tahap ini juga dilakukan proses normalization, yaitu mengubah kata yang tidak lengkap, kesalahan dalam pengetikan (typo) kedalam kata yang normal dan dapat dipahami dengan baik. Hasil tahapan normalisasi dapat dilihat pada Tabel 9.
Gambar 9. Code Python Tahap Normalization Tabel 3. Hasil Proses Normalization
No Tweet Normalization
1. kuliah, gapapa, offline, kalo, udh, efektif, mungkin, blm, tp, bgt, sidang, online
Kuliah, tidak, offline, kalau, sudah, efektif, mungkin, belum, tapi, banget, sidang, online
Sumber : Data diolah, 2021 Filtering
Proses membuang kata yang tidak memiliki arti. Proses filtering disebut dengan Stopword Removal. Pada tahap ini menggunakan nltk. NLTK ( Natural Language ToolKit) adalah Library yang disediakan oleh oleh Python untuk membangun program analisis teks. Terlebih dahulu dilakukan proses install library nltk pada anaconda prompt.
Gambar 10. Code Python Install NLTK
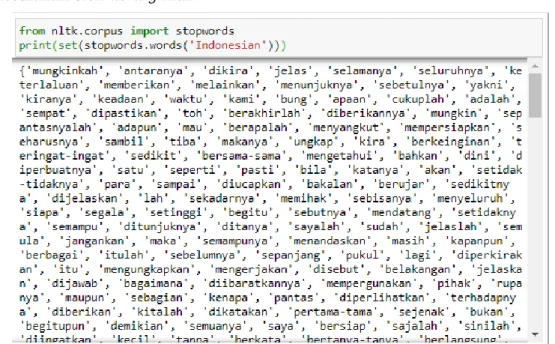
Setelah library diinstal selanjutnya dilakukan proses download stopword yang ada dan menggunakan stopword bahasa indonesia. Hasilnya tweet yang didapatkan dan menggunakan kata yang ada dalam list stopword indonesia akan dibersihkan.
Gambar 11. Code Python Import nltk
Gambar 25 menunjukkan kalimat stopword bahasa indonesia yang disediakan oleh library nltk .
Gambar 12. List Stopword Indonesia
Selain list stopword Indonesia yang disediakan oleh library nltk, ditambahkan list kata yang tidak dibutuhkan dalam analisis sentimen dengan cara menambahkan secara langsung kata pada list_stopword.extends agar dapat dihapus oleh sistem. Hasil tahapan Filtering dapat dilihat pada Tabel 10.
Gambar 13. Code Python Tahap Filtering Tabel 4. Hasil Praprocessing Filtering.
No Tweet Filtering
1.
Kuliah, tidak, offline, kalau,
sudah,efektif, mungkin, belum, tapi , banget, sidang, online
Kuliah, offline, kalau, efektif, mung kin, belum, sidang, online
Sumber : Data diolah,2021 Stemming
Stemming adalah tahap mencari root (dasar) kata dari tiap kata hasil filtering dengan menghapus kata imbuhan di depan maupun imbuhan di belakang kata. Tahap stemming dilakukan dengan menggunakan bantuan library pada bahasa pemrograman Python3 yang bernama Sastrawi. Dalam hal ini, dilakukan instalasi library menggunakan perintah pip install sastrawi seperti pada Gambar 27
Gambar 14. Perintah Instalasi Library Sastrawi
Setelah library telah berhasil diinstall, selanjutnya adalah mengimport kelas StemmerFactory dari library Sastrawi.
Gambar 15. Import kelas Sastrawi
Gambar 16. Code Python Tahapan Stemming
Hasil proses stemming akan menghapus kata yang memiliki imbuhan pada awalan, akhiran maupun sisipan kata menjadi bentuk kata dasar.
Tabel 5. Hasil Tahapan Stemming
Kata Imbuhan Kata Dasar
mewakili tergantung paginya perkuliahan berharap punggungku tertekan maksudnya penjualnya dikampus memakai bersekolah mengerjakan berbicara
wakil gantung pagi kuliah harap punggung tekan maksud jual kampus pakai sekolah kerja bicara
4.3 Pelabelan Data
Pelabelan data hasil crawling dan telah melalui tahapan preprocessing dilakukan secara manual dengan menggunakan textbob dengan melihat polarity,subjectivity yang dimiliki oleh teks tweet yang telah dikumpulkan.
Textblob adalah salah satu library yang disediakan oleh Python untuk pemrosesan dibidang Natural Language Processing yang dapat memberikan tag kata, ekstraksi kata, sentiment analysis. Saat ini textblob hanya tersedia dalam bahasa inggris oleh sebab itu pada penelitian ini yang menggunakan bahasa Indonesia dilakukan translate ke dalam bahasa inggris terlebih dahulu. Penentuan kelas positif, netral dan negatif didasari oleh nilai polaritas. Nilai polaritas pada analisis sentimen berada pada rentang 1 sampai -1. Teks tweet dengan nilai polaritas mengarah ke nilai 1 menunjukan sentimen kelas positif, nilai polaritas mengarah ke nilai -1 menunjukan kelas sentimen negatif dan nilai polaritas berkisar pada nilai 0 masuk kedalam kelas netral. Hasil pelabelan dengan textblob dapat dlihat pada Gambar 30.
Gambar 17. Hasil pelabelan tweet dengan TextBlob
Selanjutnya data akan dibagi dengan 80% data latih dan 20% data uji.
Sentimen pada data training sejumlah 1600 dibagi secara manual sesuai kelasnya. 400 data lainnya akan digunakan sebagai data uji. Untuk klasifikasi data training dapat dilihat pada Tabel 12.
Tabel 6. Sentimen Data Twitter
Positif Netral Negatif Jumlah
401
20,05% 1368
68,40% 231
11,55% 2000
100%
Sumber : Data diolah, 2021
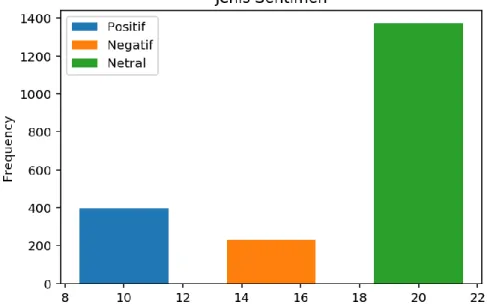
Didapatkan hasil akhir dari pelabelan sebanyak 2000 data tweet adalah sebanyak 401 tweet yang masuk dalam kelas positif, 1368 tweet kelas netral dan 231 tweet kelas negatif. Persentase labeling data dapat dilihat pada Gambar 31.
Gambar 18. Hasil persentase labelling data tweet
4.4 Ekstraksi Fitur
Setelah data tweet melalui proses praprocessing, data selanjutnya kan dibentuk menjadi sebuah model klasifikasi. Sebelum membuat model ada beberapa tahapan yang perlu dilakukan agar dapat menghasilkan model yang baik.
Dalam tahapan ekstraksi fitur, tahap awal yang dilakukan adalah mengubah dataset penelitian ke dalam representasi vector. Python memiliki Library yang bernama Scikit Learn yang dapat digunakan dalam Machine Learning. Pada library ini terdapat algoritma CountVectorizer yang dapat mengubah fitur teks menjadi sebuah representasi vector. Hasil representasi vector didapatkan 2000 angka yang mempunyai 4092 Kata. Hasil representasi dapat dilihat pada Gambar 32
Gambar 19. Code Python CountVectorizer
Gambar 20. Data Word Vector
Setelah merubah data teks menjadi word vector, selanjutnya dilakukan penjelajahan beberapa kata yang sering dgunakan atau kata mana yang muncul secara bersamaan. Digunakan model probabilistik N-gram yang digunakan untuk memprediksi kata berikutnya. Penerapan N-gram dapat dilakukan dalam membuat Bigram dan Trigram. Bigram adalah N-gram yang terdiri dari 2 item atau kata dari sebuat kalimat. Trigram adalah N-gram yang terdiri dari 3 item atau kata dari sebuah kalimat. Code Python untuk menjalankan perintah bigram dan hasil bigram dapat dilihat pada Gambar 34.
Gambar 21. Hasil tahapan Bigram
Gambar 22. Hasil Tahapan Trigram 4.5 Implementasi Klasifikasi Naive Bayes
Setelah melalui praprocessing data dan vectorizer selanjutnya dibuat model yang akan digunakan untuk melakukan klasifikasi pada data uji. Proses ini dilakukan dengan menggunakan bantuan library pada bahasa pemograman Python3 yang bernama scikit-learn untuk proses klasifikasi. Pada proses klasifikasi digunakan data uji sebanyak 20% dari data keseluruhan. Pembagian data dapat dilihat pada gambar 36.
Gambar 23. Pembagian Data Tes dan Uji
Didapatkan hasil dari x_train_shape, x_test_shape, y_train_shape dan y_test_shape seperti pada Gambar 37.
Gambar 24.Hasil dari pembagian data
Langkah selanjutnya adalah melakukan klasifikasi digunakan library Multinomial Naive Bayes. Adapun implementasi proses klasifikasi dapat dilihat pada Gambar 38.
Gambar 25. Script Python Klasifikasi Naive Bayes
Proses klasifikasi dilakukan dengan perhitungan probabilitas antar kalimat terhadap setiap kelas agar dapat menghasilkan dengan jelas prediksi data yang dimasukan. Data uji yang digunakan sebesar 400 data akan digunakan untuk menguji model klasifikasi yang dibuat dengan menggunakan algoritma Naive Bayes.
4.6 Pengujian Model Klasifikasi Naive Bayes
Untuk mengetahui performa dari Algoritma Naive Bayes, maka dilakukan pengujian terhadap model yang telah dibuat. Hasil klasifikasi akan divisualisasi dalam bentuk confusion matrix. Confusion matrix merupakan salah satu metode yang dapat digunakan untuk mengukur kinerja suatu metode klasifikasi. Pada dasarnya confusion matrix mengandung informasi yang membandingkan hasil klasifikasi yang dilakukan oleh sistem dengan hasil klasifikasi yang seharusnya.
Berikut adalah pengujian model klasifikasi dengan menggunakan library python sklearn.metric yang didalamnya memiliki confusion_matrix dan divisualisasi dalam dengan menggunakan seaborn yang merupakan pustaka visualisasi dengan sumber terbuka dibangun diatas pustaka matplotlib.
Gambar 26. Code Python Confusion Matrix
Gambar 40 menunjukkan hasil visualisasi Confusion Matrix. Setelah diketahui Confusion Matrix dari model yang dibuat selanjutnya dilakukan perhitungan nilai akurasi dari model klasifikasi Naive Bayes yang telah dibuat menggunakan sklearn.metrics dengan mengimport accuracy score yang disediakan oleh library scikit.learn. Didapatkan hasil dari perhitungan matrix dengan Code Python yaitu sebesar 0,8275
Gambar 28. Code Python Perhitungan Akurasi Model 4.7 Evaluasi Model
Setelah pengujian model selesai dilakukan langkah selanjutnya yang dilakukan adalah melakukan evaluasi model. Evaluasi model bertujuan untuk menghasilkan confusion matrix dengan ukuran 3 x 3. Confusion Matrix memberikan informasi perbandingan hasil klasifikasi yang dilakukan oleh model klasifikasi dengan hasil klasifikasi sebenarnya. Hasil evaluasi model dengan confusion matrix dilihat pada Tabel 13.
Gambar 27. Visualisasi Confusion Matrix
Tabel 7. Hasil Confusion Matrix
Predict Class
Positif Netral Negatif
Actual Class
Positif Netral Negatif
27 19 3
13 238
10
6 18 66 Sumber : Data diolah, 2021
Tabel 13 memperlihatkan Confusion Matrix berupa matrixs dengan ukuran 3 x 3 yang mewakili setiap kelas klasifikasi positif, netral dan negatif. Dari confusion matrix dapat dijelaskan bahwa model mengklasifikasikan secara benar sebesar 27 data sebagai positif, 238 data sebagai netral dan 66 sebagai data negatif. Selain itu model salah dalam memprediksi 6 data ke dalam kelas negatif yang seharusnya positif (False Positf), serta salah dalam memprediksi 3 data ke dalam kelas positif yang seharusnya negatif (False Negatif).
Berdasarkan hasil pada pengujian model klasifikasi Naive Bayes sebelumnya nilai akurasi pada keseluruhan sistem dapat dihitung sebesar 82,75%. Untuk menghitung nilai akurasi dapat dilihat pada Gambar 42.
Gambar 29. Kode Python Perhitungan Akurasi
Perhitungan akurasi manual dari perhitungan matriks diatas adalah sebagai berikut.
Akurasi = True Positif + True Netral + True Negatif
𝑇𝑜𝑡𝑎𝑙 𝐷𝑎𝑡𝑎 𝑦𝑎𝑛𝑔 𝑑𝑖 𝑈𝑗𝑖
x 100 %
=
331400 x 100 % = 82,75 %
Akurasi menggambarkan seberapa besar tingkat akurat model yang telah dibuat dapat mengklasifikasi data dengan benar. Akurasi didapatkan dari perhitungan rasio prediksi benar dengan keseluruhan data. Dengan mengetahui besarnya nilai akurasi pada kinerja keseluruhan sistem dapat dinyatakan tingkat kemampuan sistem dalam mencari ketepatan antara informasi yang diinginkan penguna dengan jawaban yang diberikan sistem. Tingkat keberhasilan sistem dalam menemukan sebuah informasi dalam penelitian ini sebesar 82,75 %.
Selanjutnya untuk melihat performa klasifikasi dari setiap kelas dapat diketahui melalui nilai presisi, recall dan f1 score pada setiap kelas klasifikasi.
Presisi menggambarkan tingkat keakuratan data yang diminta dengan hasil yang diberikan oleh model. Presisi didapatkan dari perhitungan rasio prediksi benar dibandingkan dengan keseluruhan hasil yang diprediksi positif. Recall menggambarkan keberhasilan model dalam menemukan kembali informasi yang dimasukkan dalam pengujian. Recall didapatkan dari hasil perhitungan rasio prediksi benar positif dibandingkan dengan keseluruhan data yang benar positif.
F1-Score merupakan parameter tunggal ukuran keberhasilan retrieval yang menggabungkan recall dan precision.
Hasil nilai presisi, recall, dan f1-score memiliki nilai sebesar 0-1. Semakin tinggi nilai maka semakin baik hasil model yang dibuat.
Nilai akurasi yang tinggi didapat ketika banyak data yang berhasil diklasifikasi dengan benar sesuai kelas sentimennya. Dapat diketahui juga nilai Precision dan Recall. Nilai Precision mengikuti nilai akurasi, semakin tinggi nilai akurasi maka akan diikuti nilai Precision yang tinggi juga, begitu sebaliknya. Nilai Precision adalah jumlah data positif yang benar diklasifikasi sebagai data positif dibagi total data yang diklasifikasi sebagai data positif. Sedangkan Nilai recall adalah jumlah data positif yang benar diklasifikasi sebagai data positif dibagi jumlah data positif sebenarnya. Pada confusion matrix sebelumnya, dapat diketahui nilai true positif dan true negatif. True positif adalah nilai data positif yang diklasifikasi dengan benar sesuai kelas sentimennya, yaitu positif. True negatif adalah nilai data sentimen yang diklasifikasi dengan benar sesuai kelas sentimennya, yaitu negatif. Perbandingan nilai presisi,recall dan F1-Score dapat dilihat pada Tabel 14.
Tabel 8. Nilai Presisi, Recall, dan F1-Score Evaluasi Model Jenis Klasifikasi Presisi Recall F1-Score
Positif 0,59 0,55 0,57
Netral 0,87 0,91 0,89
Negatif 0,84 0,73 0,78
Sumber : Data diolah, 2021
Hasil dari evaluasi model dapat dilihat bahwa nilai presisi dan recall disetiap kelas dapat dikatakan memiliki tingkat kemampuan yang tinggi dalam mencari ketepatan antara informasi yang diminta oleh pengguna. Nilai presisi untuk kelas positif sebesar 59%, untuk kelas netral sebesar 87%, untuk kelas negatif sebesar 84%. Angka ini dapat diartikan bahwa proporsi label yang diprediksi dengan benar dari total prediksi cukup tinggi untuk kelas netral dan positif. Sedangkan tingkat keberhasilan sistem dalam menemukan kembali sebuah informasi untuk kelas positif sebesar 55%, untuk kelas netral sebesar
91% dan kelas negatif sebesar 73%. Hal ini berarti kinerja keberhasilan sistem dalam menemukan kembali informasi yang bernilai positif dalam dokumen rendah dibandingkan dengan menemukan informasi kembali yang bernilai negatif dan netral. Didapatkan rata rata nilai precision sebesar 82%, nilai recall sebesar 83% dan nilai F1-Score sebesar 82%.
4.8 Hasil dan Visualisasi Klasifikasi Sentimen Visualisasi Menggunakan Python 3
Setelah dilakukan proses pembersihan data dan klasifikasi selanjutnya didapatkan hasil sentimen. Wordcloud adalah bentuk visualisasi dari data teks yang menggambarkan kumpulan kata yang banyak terdapat dalam sebuah analisis teks. Wordcloud dibuat dengan menggunakan library Wordcloud dan PIL (Python Imaging Library) yaitu pustaka tambahan gratis dan sumber terbuka untuk bahasa pemrograman Python yang menambahkan dukungan untuk membuka, memanipulasi, dan menyimpan banyak format file gambar yang berbeda. Script Python untuk membuat wordcloud dapat dilihat pada Gambar .
Gambar 30. Script Python Membuat wordcloud
Gambar 44 menunjukkan tampilan wordcloud yang terdiri dari kata yang banyak muncul dalam data penelitian.
Gambar 31. Wordcloud dalam data penelitian
Klasifikasi Kelas Sentimen
Untuk dapat mengetahui secara umum hasil klasifikasi sentimen, dilakukan proses mencetak data teks yang memiliki kelas sentimen positif, netral dan negatif. Gambar 45 menunjukkan script python yang digunakan untuk menampilkan data sesuai dengan kelas.
Gambar 32. Script Python Menampilkan data perkelas Hasil data klasifikasi teks sentimen kelas positif
1. sudah nyaman sama kuliah online
2. Dulu ingin cepat kuliah offline tapi sekarang nyaman online 3. Untung kuliah online jadi waktu bisa fleksibel
Hasil data klasifikasi teks sentimen kelas netral 1. Nyaman kuliah offline dan online
2. Kuliah online bagus dan offline bagus 3. Offline dan online sama, sama belajar
Hasil data klasifikasi teks sentimen kelas negatif 1. Stress kuliah online tugas banyak
2. Makin kesini rasa kuliah online tidak jelas 3. Internet mati tidak bisa ikut kuliah
Visualisasi Hasil Klasifikasi Menggunakan NVIVO 10
Setelah proses klasifikasi dengan menggunakan metode Naive Bayes selesai dilakukan selanjutnya digunakan aplikasi Nvivo untuk menampilkan hasil visualisasi. Terlebih dahulu hasil dataset yang telah siap digunakan diimpor ke dalam software QSR NVivo 10, selanjutnya melakukan koding terhadap data tersebut. Richard (dalam Bandur, 2016) mengartikan koding sebagai proses penemuan ide utama yang terdapat dalam transkrip serta menemukan topik- topik yang bersumber dari pencarian ide utama tersebut. Koding merupakan proses mereduksi data untuk menjelaskan karakteristik atau atribut partisipan.
Bandur (2016) mengartikan koding sebagai suatu proses iteratif, yaitu kegiatan peneliti kualitatif secara kontinu dalam analisis data. Dalam proses tersebut dibentuk kategorisasi data berdasarkan konsep-konsep yang muncul dalam data, membandingkan konsep-konsep dan/atau kategori-kategori data serta menyatukan kembali semua konsep dan kategori data yang berhubungan satu
dengan lainnya. Pada akhirnya, proses ini akan berhenti ketika tidak lagi ditemukan konsep-konsep baru dalam data. Tujuan koding adalah untuk mendalami masalah penelitian berdasarkan penjelasan-penjelasan dan pola-pola yang terdapat dalam data penelitian. Koding juga bertujuan mengumpulkan semua informasi yang relevan dari berbagai sumber berkaitan dengan suatu kasus tertentu. Kategori tema yang dianalisis peneliti selama proses koding disimpan dalam nodes, sehingga nodes berperan sangat penting dalam manajemen dan analisis data kualitatif dengan NVivo.
Menurut Bazeley dan Jackson (2013), nodes merupakan ‘containers’ tempat peneliti menyimpan tema-tema, partisipan, setting penelitian, dan organisasi penelitian. Dengan melihat nodes yang dibuat berdasarkan kategori dan sub- kategori unit analisis, peneliti dapat melihat pola hubungan antar tema konsep yang dihasilkan berdasarkan data. Teknik pembuatan nodes dapat dilakukan secara deduktif tetapi juga dapat dilakukan secara induktif.
Berdasarkan hasil pencarian dengan fitur Word Frequency Query software QSR NVivo 10 dari berbagai sumber data yang telah diimpor, kata ‘kuliah’
merupakan kata dengan frekuensinya paling banyak muncul yaitu 11,50% dari seluruh sumber data penelitian, diikuti dengan kata ‘daring’ dan ‘offline’ yaitu 1,19 % dan 1,14% dari seluruh sumber data penelitian. Gambar 47 menunjukkan Word Cloud dari 50 kata terdominan yang digunakan dalam sumber data penelitian ini
Gambar 33. Word Cloud Kata Dominan Pada Data Penelitian
Untuk memahami penggunaan kata-kata tersebut dari berbagai sumber data penelitian, dapat dilihat melalui fitur Text Search Query. Pada penelitian ini, dapat dipahami bahwa penggunaan kata ‘jaringan’ yang merupakan kata terdominan dari berbagai sumber data penelitian yang telah dikumpulkan. Hasil
pencarian tersebut disajikan dalam Word Tree. Word Tree adalah visualisasi berbasis grafik hasil dari fitur Text Search Query menyampaikan pemahaman yang lebih baik tentang bagaimana kata yang dicari dan kaitan dengan topik tertentu. Word Tree dengan penggunaan kata jaringan dapat dilihat pada Gambar 47.
Gambar 34. Word Tree penggunaan Kata 'jaringan' dalam data penelitian Kata ‘Jaringan’ adalah kata yang paling sering muncul dalam data penelitian. Kata Jaringan memiliki lebih banyak sentimen negatif. Jaringan yang tidak stabil dan sinyal yang susah dapat membuat kegiatan perkuliahan menjadi tidak efektif. Ini biasa dirasakan oleh mahasiswa yang tinggal jauh dari kota atau tinggal di tempat terpencil yang sulit menemukan koneksi internet yang bagus.
Saat kegiatan perkuliahan dimulai niat untuk belajar sudah terkumpul namun akhirnya niat untuk belajar menurun akibat jaringan yang tidak mendukung.
Mahasiswa menjadi malas dan tidak bersemangat lagi memerhatikan penjelasan dosen dikarenakan sudah ketinggalan materi. Bukan hanya mahasiswa yang bisa mengalami gangguan jaringan, faktanya dapat juga ditemui dosen yang memiliki koneksi internet tidak bagus yang membuat penyampaian materi menjadi tidak jelas dan membuat mahasiswa tidak paham. Ditambah lagi waktu menjadi tidak efisien dan terbuang sia-sia saat menunggu koneksi stabil. Koneksi internet yang tidak stabiil juga menimbulkan rasa malas pada seorang mahasiswa.
Gambar 35. Word Tree Penggunaan kata 'Tugas' dalam Data Penelitian Word Tree dengan penggunaan kata tugas dapat dilihat pada Gambar 48.
Permasalahan lainnya adalah banyaknya tugas yang diberikan oleh dosen, namun mereka tidak mengerti dengan apa yang dipelajari dan bagaimana menyelesaikan tugas tersebut. Dampaknya mahasiswa akan merasa stres dan pesimis. Dibutuhkan rasa percaya diri yang tertanam pada mahasiswa.
Kepercayaan diri merupakan bentuk keyakinan terhadap kemampuan yang dimiliki untuk menampilkan sebuah perilaku dalam mencapai suatu tujuan (Saputri et al., 2020). Efikasi diri atau rasa percaya diri atau keyakinan
mahasiswa mengenai kemampuannya menyelesaikan tugas terbilang rendah.
Afnan (2020) menyatakan bahwa efikasi diri dan rasa stres memiliki hubungan variabel yang negatif. Artinya, semakin tinggi efikasi diri mahasiswa maka semakian rendah tingkat stresnya. Sebaliknya, semakin rendah efikasi diri maka semakin tinggi tingkat stresnya.
Gambar 36. Word Tree penggunaan kata 'teknologi' dalam Data Penelitian Gambar 49 menunjukan kata teknologi yang ada dalam data penelitian.
Penerapan kuliah online juga harus sejalan dengan perkembangan teknologi.
Apabila sudah menguasai teknologi maka tidak akan sulit untuk dapat beradaptasi dengan teknik pembelajaran daring. Tidak ada masalah mengenai pembelajaran daring yang diterapkan karena mereka sudah terbiasa menggunakan teknologi. Selain itu, bagi mahasiswa yang mengamati penjelasan dosen dari awal hingga akhir akan bisa memahami materi baik banyak maupun sedikit. Point terpenting adalah memusatkan perhatian pada materi yang disampaikan, bertanya jika ada yang kurang dimengerti, dan mengulang materi pembelajaran di waktu luang. Salah satu keuntungan kuliah online ialah kegiatan pembelajarannya dapat direkam sehingga penjelasan dosen bisa diulang kembali di waktu lain. Permasalahan yang timbul selama penerapan kuliah online adalah dosen senior yang tidak begitu mengerti mengenai cara penggunaan teknologi sebagai media pembelajaran. Ketidaktahuan terhadap teknologi menyebabkan proses pembelajaran kuliah online tidak efektif. Aplikasi yang mendukung pembelajaran online tidak sepenuhnya digunakan sehingga proses pembelajaran bersifat monoton dan tidak ada interaksi yang memadai antara mahasiswa dan dosen. Dibutuhkan pelatihan terhadap dosen mengenai penggunaan aplikasi dan teknologi yang mendukung pembelajaran selama kuliah online berlangsung.
Setelah mendapatkan Query yang paling sering muncul dalam data penelitian, disajikan peta nodes penelitian berdasarkan tahapan koding melalui project map yang dapat dilihat pada Gambar 50. Project map adalah representasi grafis dari item yang berbeda dalam proyek. Project map dibuat mengacu pada tema hasil koding yang dapat digunakan untuk mengeksplorasi dan menyajikan koneksi data.
Gambar 37. Project Map Keluhan selama kuliah online
Project map dapat divisualisasikan dalam bentuk diagram hirarkis. Diagram hirarkis memiliki dua tipe yaitu tree maps and sunbursts. Diagram hirarkis adalah diagram yang menunjukkan data hirarkis sebagai satu set empat persegi panjang bertingkat berbagai ukuran. Ukuran menunjukkan jumlah, misalnya, jumlah koding pada node atau jumlah referensi dari koding. Diagram hirarkis memiliki skala terbaik sesuai dengan ruang yang tersedia sehingga ukuran persegi panjang harus dipertimbangkan dalam hubungan satu sama lain, bukan sebagai angka absolut. Wilayah terluas ditampilkan di bagian kiri atas grafik, sedangkan wilayah terkecil ditampilkan di bagian kanan bawah grafik. Pada penelitian ini, digunakan diagram hirarkis karena ingin melihat dominasi kata yang sering banyak muncul dalam data penelitian berdasarkan banyaknya koding terhadap sumber data
Setelah mengetahui tahapan masalah apa saja yang di alami mahasiswa selama penerapan kuliah online maka akan didapatkan keselarasan maupun kekonsistenan dari permasalahan tersebut. Untuk melakukan analisis pada kasus ini, dilakukan analisis kluster (cluster analysis) berbantuan software QSR NVivo berdasarkan kesamaan kata, artinya kata-kata yang terkandung dalam sumber data atau node yang dipilih akan dibandingkan. Sumber data atau node
yang memiliki tingkat yang lebih tinggi dari kesamaan berdasarkan kemunculannya dan frekuensi kata-kata akan ditampilkan mengelompok.
Sumber data atau node yang memiliki tingkat lebih rendah dari kesamaan berdasarkan kemunculannya dan frekuensi kata-kata akan ditampilkan jauh terpisah.
Gambar 38. Pengelompokan Node Berdasarkan Kemiripan Kata
Berdasarkan analisis tersebut yang divisualisasikan dalam Horizontal Dendrogram pada Gambar 51, diperoleh informasi bahwa terdapat empat pasang node yang memiliki kemiripan pada kalimat jaringan dan tugas. Hasil ini didukung oleh korelasi-korelasi yang termasuk kategori sedang hingga cukup tinggi. Informasi ini mengindikasikan bahwa: a) Mahasiswa memiliki kesulitan dalam hal jaringan internet sehingga proses pembelajaran selama kuliah online menjadi terganggu. b) Timbulnya masalah psikologis pada mahasiswa dikarena tugas yang semakin banyak dan kurangnya interaksi terhadap sesama mahasiswa menyebabkan ketidakstabilan emosi dan memicu rasa stress, c) Penggunaan perangkat teknologi secara terus-menerus membuat teknologi yang digunakan seperti laptop dan handphone semakin cepat mengalami kerusakan d) Minimnya pengetahuan dosen mengenai teknologi yang digunakan selama pembelajaran online menyebabkan proses perkuliahan sedikit terhambat e) Penyampaian materi yang susah untuk dipahami oleh mahasiswa jika tidak bertatap muka secara langsung,namun pemberian tugas yang semakin banyak membuat mahasiswa menjadi tidak sanggup untuk tetap menjalankan kuliah online.
25