4. PENGUJIAN DAN ANALISA
Pengujian dilakukan langsung di Laboratorium Telematika gedung I lantai 4 Universitas Kristen Petra Surabaya. Pengujian yang dilakukan adalah sebagai berikut:
Pengujian pengiriman spam dan ham setelah algoritma yang terpasang di setiap e-mail server sudah dilatih. Tujuan dilakukan hal ini adalah menguji peforma setiap algoritma dalam memisahkan spam dan ham dengan berbagai kondisi.
Pengujian kemampuan setiap algoritma dalam memisahkan spam dan ham dengan bahasa selain bahasa Inggris. Pengujian ini dilakukan untuk mengukur kemampuan algoritma dalam mendeteksi spam dengan bahasa asing lain.
Bahasa yang digunakan adalah bahasa Spanyol dan Prancis.
Pengujian kemampuan algoritma ketika membaca hanya bagian header atau body. Hasil dari pengujian ini akan menentukan algoritma mana yang digunakan pada pengujian selanjutnya, penggabungan algoritma untuk membaca bagian dari e-mail.
Pengujian dengan merubah konfigurasi dari program yang menjalankan algoritma. Pengujian ini akan mengeksplorasi opsi-opsi yang ditawarkan untuk meningkatkan akurasi algoritma ataupun menyesuaikannya dengan kebutuhan.
Analisa dan solusi untuk mengatasi spam yang didasari dari hasil analisa pengujian-pengujian yang sudah dilakukan.
Peralatan-peralatan yang digunakan dalam pengujian adalah sebagai berikut:
Ubuntu Server versi 12.10 yang digunakan sebagai e-mail server.
PuTTY Release 0.61 sebagai media akses milik client.
Oracle VM Virtualbox 4.2.16 sebagai media tempat e-mail server berjalan.
SpamAssassin versi 3.3.2 untuk menerima e-mail sekaligus sebagai filter yang menggunakan Naive Bayes Classifier.
crm114-20090807-BlameThorstenAndJenny sebagai filter yang menggunakan k-NN Algorithm dan Support Vector Machine.
Postfix 2.9.3 sebagai program Mail Transfer Agent (MTA)
FileZilla 3.7.3 sebagai program FTP untuk mengirimkan dataset pelatihan ataupun pengujian ke e-mail server.
Program buatan sendiri untuk mengirimkan e-mail pengujian.
Sesuai dengan skenario simulasi yang terdapat pada bab 3.5.4., Proses pengujian akan menggunakan tahapan-tahapan simulasi ini untuk menghasilkan data hasil pengujian. Tahap-tahap simulasi untuk pengujian ini adalah:
1. Menyalakan mesin-mesin e-mail server yang digunakan untuk pengujian.
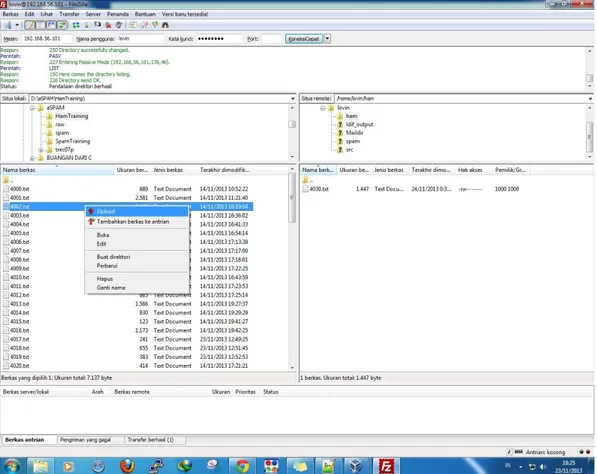
2. Menambahkan data pelatihan jika pengujian yang dilakukan memerlukannya. Data pelatihan akan ditempatkan di sebuah folder pada tiap-tiap mesin. Proses pelatihan diesekusi sesuai dengan program yang digunakan algoritma tiap server.
Gambar 4.1. Upload File Untuk Pelatihan Algoritma
3. E-mail yang digunakan untuk pengujian diletakkan pada satu folder sesuai dengan sampel yang akan diujikan menggunakan program FTP. Setiap sampel memiliki sebuah folder untuk menempatkan data pengujian agar data pengujian tidak tercampur satu sama lain.
Gambar 4.2. Folder Terpisah Untuk Setiap Sampel
4. Program pengirim e-mail dikonfigurasi untuk mengakses folder yang berisi e-mail pengujian dan mengirimkan e-mail ke alamat yang dituju.
5. Program pengirim e-mail dijalankan.
Gambar 4.3. Program Pengirim E-mail Sedang Berjalan
6. Menunggu program mengirimkan semua e-mail ke alamat yang dituju dan diproses oleh algoritma yang bekerja.
7. Mencatat hasil kerja dari filter yang sedang diuji yang terlihat menggunakan program FTP dengan mengakses folder inbox. Parameter yang dilihat disini adalah jumlah e-mail yang masuk, dilihat dari jumlah berkas yang ada di pojok kiri bawah layar.
Gambar 4.4. Inbox
8. Menghapus semua e-mail yang berada di dalam inbox setelah data dicatat agar data antar pengujian tidak tercampur satu sama lain.
Gambar 4.5. Penghapusan E-mail Setelah Pengujian.
9. Mengakhiri simulasi.
Ada batasan-batasan yang diterapkan pada pengujian ini. Batasan-batasan tersebut adalah:
Pelatihan:
- E-mail yang digunakan untuk pelatihan antar mesin sama persis.
- E-mail yang digunakan untuk pelatihan berbeda dengan e-mail yang digunakan untuk pengujian.
- Pemilihan e-mail yang digunakan untuk pelatihan diambil secara acak.
- Pada pengujian yang menambahkan e-mail pelatihan, setiap mesin mendapatkan e-mail yang sama persis satu sama lain.
- Sistem auto-learning setiap algoritma dalam posisi mati.
Sampel:
- Sampel spam didapatkan dari gabungan corpora TREC dan pengumpulan sendiri dari layanan e-mail umum Google Mail dan Yahoo Mail.
- Semua sampel spam dan ham menggunakan bahasa Inggris.
- Sampel dengan bahasa Prancis dan Spanyol ditranslasikan langsung dengan bantuan layanan Google Translate ( translate.google.com ).
Pengujian:
- Mesin lovinta4.com bertugas sebagai pengirim e-mail ke mesin lovinta.com, lovinta2.com, dan lovinta3.com.
- E-mail yang akan dikirim diletakkan dalam satu direktori.
- Semua e-mail yang sedang diujikan akan dikirimkan secara bersamaan ke tiga mesin yang sedang menjalankan algoritma mail filter menggunakan program yang sudah dibuat.
- Tidak ada mesin lain yang mengirim e-mail kecuali lovinta4.com.
- Sistem pengecekan spam melalui internet milik SpamAssassin dalam kondisi mati.
- Setiap kali e-mail sudah diterima dan perhitungan selesai, isi dari kotak masuk tiap mesin dihapus.
Skor:
- Perhitungan yang dilakukan adalah tingkat akurasi algoritma membaca spam dan tingkat false positive yang terjadi.
- Sensitivitas algoritma yang digunakan adalah 1.5 (satu koma lima).
- Perhitungan akurasi algoritma dalam mendeteksi spam didapatkan dengan cara:
Dimana nilai spam yang berhasil dideteksi adalah = Spam yang dikirimkan - Spam yang masuk ke inbox.
- Perhitungan jumlah kejadian false positive didapatkan dengan cara:
Dimana nilai ham yang salah dideteksi adalah:
Ham yang dikirimkan - Ham yang masuk ke inbox.
- Nilai total merupakan penggabungan dari kedua nilai yaitu nilai akurasi spam dan false positive. Kegunaan nilai total adalah untuk mengetahui rata-rata peforma sebuah algoritma. Rumus yang digunakan adalah :
Nilai Total = (AS*0.4) + ( (100-FP) *0.6) Dimana :
AS = Nilai akurasi spam FP = Nilai false positive
Nilai maksimal yang dapat dimiliki oleh sebuah algoritma adalah 100.
Hasil ini akan didapatkan jika sebuah algoritma dapat memblokir semua spam dan membiarkan semua ham untuk masuk ke dalam inbox. Nilai false positive mendapatkan porsi yang lebih besar karena parameter ini dianggap lebih penting untuk mencegah hilangnya data penting di dalam sebuah e-mail.
4.1. Pengujian Secara Umum
Pengujian secara umum disini memiliki maksud adalah menguji algoritma menggunakan sampel utama yang didapatkan untuk mengukur kemampuan setiap algoritma. Pengujian yang akan dilakukan pada bagian ini adalah:
- Pengujian pengiriman spam dan ham dengan sampel pelatihan minimum.
- Pengujian pengiriman spam dan ham dengan jumlah sampel pelatihan yang ditambah secara bertahap.
- Pengujian pengiriman spam dan ham dengan jumlah sampel pengujian minimum.
- Pengujian untuk mengukur waktu yang dibutuhkan untuk melatih sebuah algoritma.
4.1.1. Pengujian Algoritma Dengan Sampel Pelatihan Minimum
Pengujian ini dilakukan untuk mengetahui kemampuan algoritma- algoritma ketika dalam kondisi paling dasar. Data yang digunakan untuk pengujian adalah sebagai berikut:
Jumlah spam yang diujikan = 1600
Jumlah ham yang diujikan = 400
Jumlah spam yang digunakan untuk pelatihan = 200
Jumlah ham yang digunakan untuk pelatihan = 200 Hasil dari pengujian ini adalah:
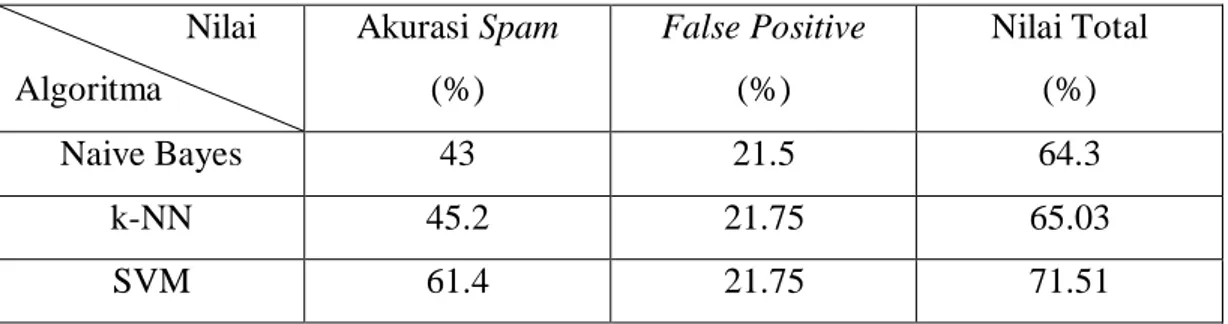
Tabel 4.1. Hasil Pengujian Awal Algoritma Nilai
Algoritma
Akurasi Spam (%)
False Positive (%)
Nilai Total (%)
Naive Bayes 43 21.5 64.3
k-NN 45.2 21.75 65.03
SVM 61.4 21.75 71.51
Dari hasil pengujian tampak bahwa algoritma-algoritma yang diuji masih belum dapat memisahkan spam dan ham dengan baik. Naive Bayes dan k-NN mencetak hasil yang nyaris sama sedangkan SVM memiliki skor yang cukup baik dibandingkan yang lain.
Penyebab utama dari rendahnya tingkat akurasi ini sudah jelas adalah kurangnya sampel pelatihan. Banyak spam yang masuk ke dalam inbox berupa iklan dan tawaran bisnis yang sekilas terlihat menggiurkan. Spam tipe ini masih cukup sulit dibedakan karena ada juga beberapa ham yang dapat menawarkan bisnis yang sah, berbeda dengan spam yang sudah terlihat jelas seperti iklan obat kuat yang sangat terkenal sebagai salah satu bentuk paling umum dari spam.
4.1.2. Pengujian Algoritma Dengan Penambahan Jumlah Sampel Latihan Secara Bertahap.
Pengujian ini bertujuan untuk menguji apakah dengan penambahan jumlah sampel yang digunakan untuk pelatihan, meningkatkan peforma setiap algoritma secara signifikan. Data yang digunakan adalah sebagai berikut:
Jumlah spam yang diujikan = 1600
Jumlah ham yang diujikan = 400
Jumlah spam yang digunakan untuk pelatihan = +100/pengujian
Jumlah ham yang digunakan untuk pelatihan = +100/pengujian
Dilakukan pengulangan sebanyak 5(lima) kali.
Hasil dari pengujian ini adalah:
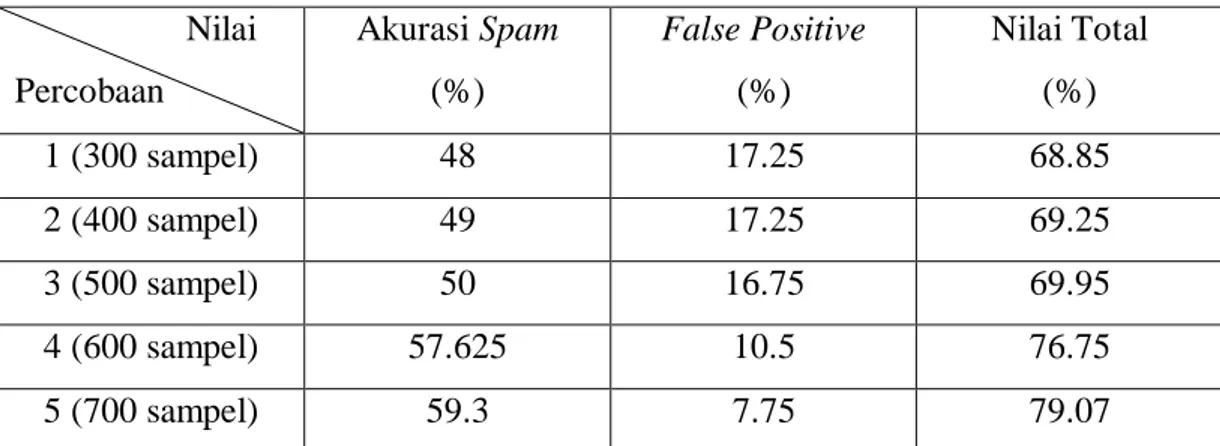
Tabel 4.2.Hasil Pengujian Penambahan Sampel Untuk Naive Bayes Nilai
Percobaan
Akurasi Spam (%)
False Positive (%)
Nilai Total (%)
1 (300 sampel) 48 17.25 68.85
2 (400 sampel) 49 17.25 69.25
3 (500 sampel) 50 16.75 69.95
4 (600 sampel) 57.625 10.5 76.75
5 (700 sampel) 59.3 7.75 79.07
Tabel 4.3. Hasil Pengujian Penambahan Sampel Untuk k-NN Nilai
Percobaan
Akurasi Spam (%)
False Positive (%)
Nilai Total (%)
1 (300 sampel) 45.8 18.25 67.37
2 (400 sampel) 46.1 18 67.64
3 (500 sampel) 46.4 15.75 69.11
4 (600 sampel) 51.9 13.75 72.51
5 (700 sampel) 57.9 11.75 76.11
Tabel 4.4. Hasil Pengujian Penambahan Sampel Untuk SVM Nilai
Percobaan
Akurasi Spam (%)
False Positive (%)
Nilai Total (%)
1 (300 sampel) 61.8 17.5 74.22
2 (400 sampel) 62.3 17 74.72
3 (500 sampel) 62.8 15.25 75.97
4 (600 sampel) 66.9 13.5 78.66
5 (700 sampel) 70.8 11.5 81.42
Dari pengujian ini dapat dilihat bahwa peningkatan akurasi meningkat cukup dratis, terutama pada penambahan 600 dan 700 sampel latihan. Hal ini menandakan penambahan jumlah sampel membuat algoritma-algoritma mendapatkan banyak contoh kata di dalam database mereka dan proses penentuan
keputusan apakah sebuah e-mail tergolong dalam kategori spam menjadi lebih mudah untuk dilakukan.
Berdasarkan nilai yang didapatkan di setiap pengujian, posisi algoritma terbaik dipegang oleh SVM, kemudian diikuti oleh Naive Bayes dan k-NN yang nilainya tidak terpaut jauh. Selama pengujian, SVM juga terlihat memiliki peforma yang stabil.
Jika dilihat dari nilai akurasi spam dan false positive, algoritma terbaik masih dipegang oleh SVM, sedangkan performa terbaik dalam mencegah false positive dimiliki oleh algoritma Naïve Bayes.
4.1.3. Pengujian Algoritma Dengan Sampel Pengujian Minimum
Pengujian ini dilakukan untuk mengetahui kemampuan algoritma- algoritma ketika dalam kondisi sudah menerima sampel pelatihan dengan banyak dan diuji menggunakan sampel pengujian sedikit. Data yang digunakan untuk pengujian adalah sebagai berikut:
Jumlah spam yang diujikan = 200
Jumlah ham yang diujikan = 200
Jumlah spam yang digunakan untuk pelatihan = 1000
Jumlah ham yang digunakan untuk pelatihan = 1000 Hasil dari pengujian ini adalah:
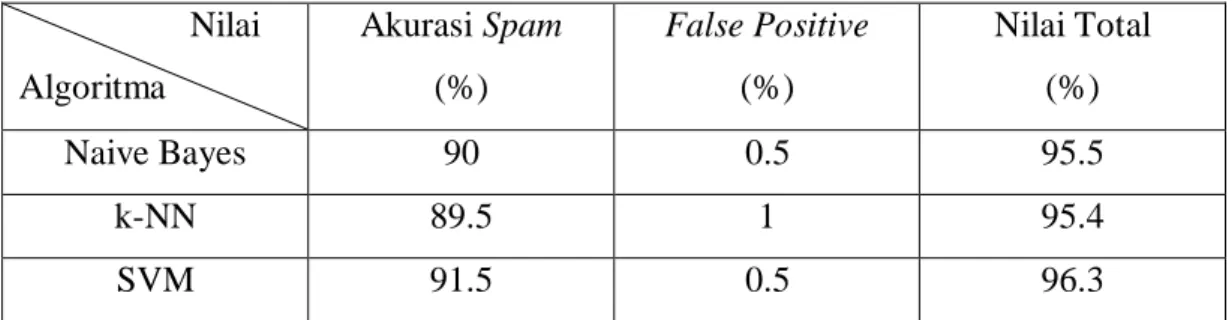
Tabel 4.5. Hasil Pengujian Algoritma Dengan Sampel Pengujian Minimum Nilai
Algoritma
Akurasi Spam (%)
False Positive (%)
Nilai Total (%)
Naive Bayes 90 0.5 95.5
k-NN 89.5 1 95.4
SVM 91.5 0.5 96.3
Dari hasil pengujian tampak bahwa algoritma-algoritma yang diuji sudah menunjukkan hasil yang cukup baik. Nilai false positive sudah nyaris mencapai hasil sempurna, dengan kesalahan tertinggi pada algoritma K-NN dengan nilai 1 persen dari total pengujian. Naive Bayes dan SVM mencetak nilai yang sama di
false positive, tetapi untuk akurasi spam, SVM masih lebih unggul dengan margin 2 persen.
Dari hasil pengujian ini dan juga dari pengujian 4.1.2, bisa ditarik kesimpulan bahwa performa algoritma akan meningkat dan berbanding lurus dengan jumlah sampel pelatihan yang diberikan. Baik tingkat akurasi spam maupun false positive mendapatkan hasil yang positif dari proses ini.
4.1.4. Pengujian Waktu yang Dibutuhkan Untuk Pelatihan Algoritma
Pengujian ini dilakukan untuk mengukur waktu yang dibutuhkan program yang menjalankan algoritma untuk mempelajari sampel-sampel spam dan ham yang digunakan untuk pelatihan Data yang digunakan adalah sebagai berikut:
Jumlah spam yang digunakan untuk pelatihan = 1000
Jumlah ham yang digunakan untuk pelatihan = 1000
Pengukuran akan dilakukan sebanyak 10 kali percobaan dengan penambahan 100 sampel secara bertahap.
Sampel spam dan ham yang dilatihkan sama-sama ditambahkan 100 dalam setiap tahap, membuat total sampel yang dilatihkan sebanyak 200 setiap tahap.
Proses pengujian dilakukan dengan cara:
Melakukan reset database yang digunakan setiap program algoritma.
Menjalankan program untuk melatih algoritma sesuai dengan program yang digunakan algoritma tersebut.
Mencatat waktu yang diperlukan dari mulai program berjalan sampai proses pelatihan selesai.
Me-reset database untuk melakukan pengujian selanjutnya.
Hasil dari pengujian ini adalah:
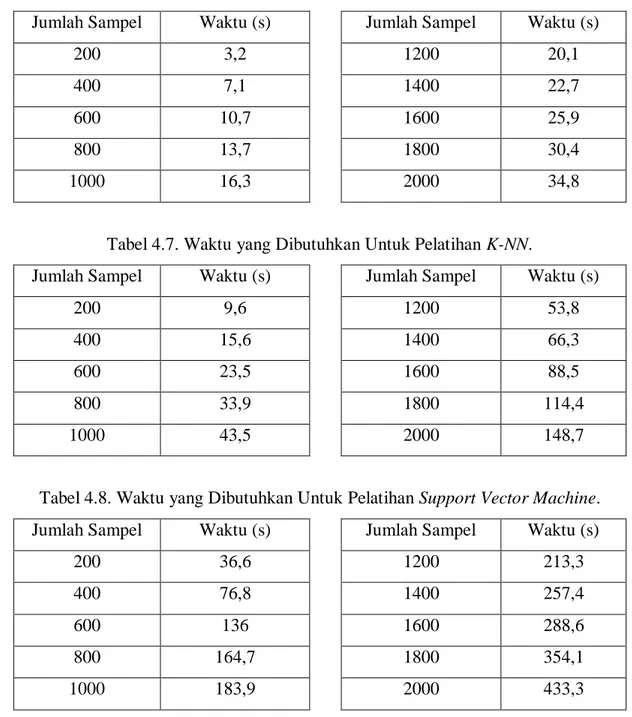
Tabel 4.6. Waktu yang Dibutuhkan Untuk Pelatihan Naive Bayes Classifier.
Jumlah Sampel Waktu (s) Jumlah Sampel Waktu (s)
200 3,2 1200 20,1
400 7,1 1400 22,7
600 10,7 1600 25,9
800 13,7 1800 30,4
1000 16,3 2000 34,8
Tabel 4.7. Waktu yang Dibutuhkan Untuk Pelatihan K-NN.
Jumlah Sampel Waktu (s) Jumlah Sampel Waktu (s)
200 9,6 1200 53,8
400 15,6 1400 66,3
600 23,5 1600 88,5
800 33,9 1800 114,4
1000 43,5 2000 148,7
Tabel 4.8. Waktu yang Dibutuhkan Untuk Pelatihan Support Vector Machine.
Jumlah Sampel Waktu (s) Jumlah Sampel Waktu (s)
200 36,6 1200 213,3
400 76,8 1400 257,4
600 136 1600 288,6
800 164,7 1800 354,1
1000 183,9 2000 433,3
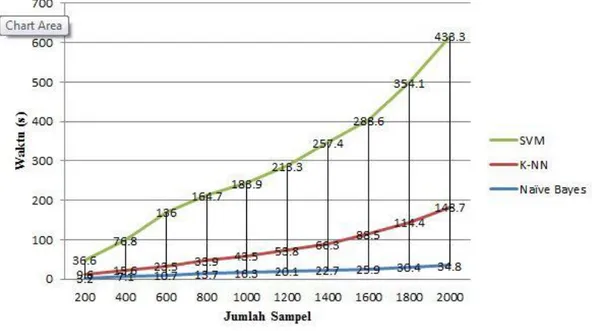
Dari hasil pengujian tampak bahwa waktu yang dibutuhkan untuk menyelesaikan proses pelatihan cukup bervariasi. Naïve Bayes memerlukan waktu paling singkat untuk menyelesaikan pelatihannya sedangkan SVM memerlukan waktu paling lama. Penambahan waktu yang terjadi antar jumlah sampel yang diberikan hampir seragam, tetapi semakin banyak jumlah sampel yang diberikan maka waktu yang diperlukan bertambah cukup banyak dan melebihi interval yang ada. Hal ini dapat dilihat di gambar 4.6.
Gambar 4.6. Grafik waktu yang diperlukan setiap algoritma.
Lamanya waktu yang diperlukan kemungkinan besar dikarenakan kompleksnya algoritma dan model database yang digunakan oleh algoritma tersebut. Kemungkinan lain adalah efektivitas program yang menjalankan algoritma. SVM dan K-NN yang bertumpu pada crm114 dan Mailtrainer, Naïve Bayes menggunakan SpamAssassin dan modul sa-learn bawaan SpamAssassin.
Berbeda dengan Mailtrainer yang masih merupakan program uji coba, sa-learn milik SpamAssassin sudah tidak dalam tahap pengembangan lagi.
4.2. Pengujian Menggunakan Bahasa Asing
Pengujian ini bertujuan untuk menguji kemampuan algoritma dalam membaca e-mail yang menggunakan bahasa asing diluar bahasa Inggris. Bahasa yang digunakan dalam pengujian ini adalah bahasa Prancis dan bahasa Spanyol.
Data yang digunakan adalah sebagai berikut:
Jumlah spam yang diujikan = 400 setiap bahasa
Jumlah ham yang diujikan = 200 setiap bahasa
Jumlah spam yang digunakan untuk pelatihan = 200 setiap bahasa
Jumlah ham yang digunakan untuk pelatihan = 200 setiap bahasa
Spam dan ham kedua bahasa ini dikirimkan secara bersamaan.
Hasil dari pengujian ini adalah:
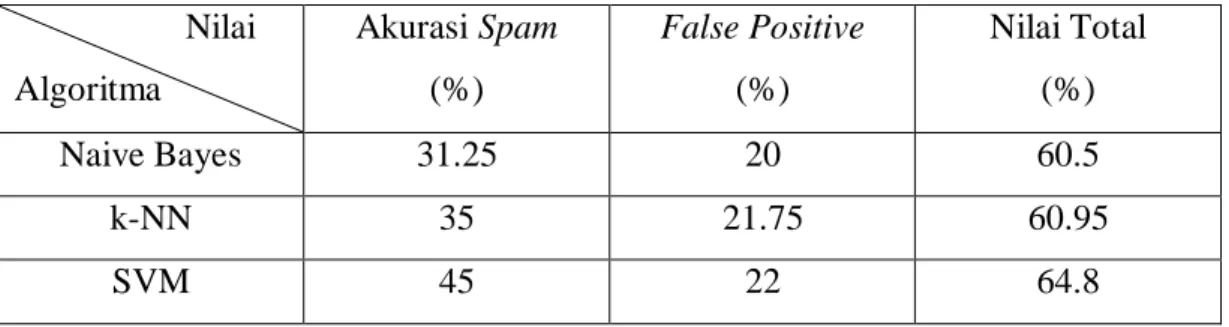
Tabel 4.9. Hasil Pengujian Dengan Bahasa Asing.
Nilai Algoritma
Akurasi Spam (%)
False Positive (%)
Nilai Total (%)
Naive Bayes 31.25 20 60.5
k-NN 35 21.75 60.95
SVM 45 22 64.8
Nilai akurasi menurun cukup jauh. Kali ini, selain faktor jumlah sampel untuk pelatihan sedikit, kata-kata yang asing bagi setiap algoritma membuat proses pelatihan perlu dilakukan lebih sering dengan jumlah data yang jauh lebih banyak. Selain itu adanya beberapa karakter asing yang digunakan seperti “ ¿ ” di bahasa Spanyol serta penggunaan acute, grave, dan sebagainya pada huruf di bahasa Prancis (sebagai contoh, “ é ” dan “ è “) mempersulit algoritma untuk membaca e-mail.
Ada juga cara lain yaitu menggunakan sistem rules dari SpamAssassin, hanya saja perlu dicari tahu terlebih dahulu kata-kata apa yang sangat sering muncul sebagai acuan untuk mencari spam. Terlepas dari itu, setiap algoritma yang digunakan memiliki potensi untuk membaca bahasa asing, hanya saja diperlukan jumlah data yang tidak sedikit seperti disebutkan diatas.
4.3. Pengujian Penggabungan Algoritma 4.3.1. Pengujian Awal
Pengujian ini memanfaatkan e-mail yang didapatkan dari dataset corpus TREC yang digunakan dalam pengujian ini. Dataset TREC ikut menyertakan bagian header dari e-mail yang berada dalam dataset-nya. Bagian header ini akan dianalisis secara terpisah dengan dianggap menjadi bagian “body” dari e-mail.
Pengujian ini akan menganalisa dua bagian utama dari e-mail, header dan body secara terpisah kemudian menentukan algoritma mana yang lebih optimal untuk membaca suatu bagian dari e-mail dibandingkan dengan algoritma lainnya.
Gambar 4.7. Contoh e-mail yang digunakan dalam pengujian
Data yang digunakan pada pengujian ini adalah:
Jumlah spam yang diujikan = 600
Jumlah ham yang diujikan = 400
Jumlah spam yang digunakan untuk pelatihan = sama dengan kondisi setelah pelatihan terakhir 4.1.2 + 200 header
Jumlah ham yang digunakan untuk pelatihan = sama dengan kondisi setelah pelatihan terakhir 4.1.2 + 200 header
Pengujian pertama : header saja.
Pengujian kedua : body saja.
Pengujian ketiga : header dan body.
Hasil dari pengujian ini adalah:
Tabel 4.10. Hasil Pengujian Bagian Header Saja.
Nilai Algoritma
Akurasi Spam (%)
False Positive (%)
Nilai Total (%)
Naive Bayes 40.1 2.33 74.6
k-NN 28.5 1.33 70.602
SVM 43.5 0 77.4
Bagian header memiliki banyak informasi seperti nama pengirim, nama penerima, dan lain sebagainya, hanya saja untuk menebak apakah header tersebut merupakan bagian dari spam atau tidak di dalam sebuah sistem tertutup cukup sulit. Hal ini dikarenakan untuk memanfaatkan informasi yang ada di header, analisa dengan bantuan internet dirasa lebih bermanfaat karena informasi pada bagian header mayoritas berisi rincian bagaimana e-mail ini sampai ke tangan penerima, termasuk alamat pengirim dan penerima. Jika analisa dengan internet diaktifkan, e-mail server dapat mengecek apakah alamat e-mail pengirim merupakan sebuah e-mail yang sah atau tidak.
Tingkat False Positive rendah karena sedikit sekali faktor yang dapat membuat sebuah ham salah dideteksi sebagai spam melalui bagian header saja.
Faktor paling besar yang membuat hal ini terjadi adalah pada bagian subject, dimana jika subject sebuah e-mail tidak mengandung kata-kata yang mengandung kata kunci spam, kemungkinan besar header tersebut dianggap sebagai ham, yang juga menyebabkan tingkat akurasi spam menurun. Selain itu, mayoritas pengirim spam juga berusaha agar subject yang dimiliki spam yang mereka kirimkan tidak terlihat seperti spam pada umumnya, terutama bagi para pengirim scam dan phising.
SVM mendapatkan posisi pertama di semua faktor penilaian, oleh karena itu dapat disimpulkan bahwa algoritma terbaik dari ketiga algoritma yang
digunakan untuk mendeteksi bagian header saja adalah algoritma SVM.
Tabel 4.11. Hasil Pengujian Bagian Body Saja.
Nilai Algoritma
Akurasi Spam (%)
False Positive (%)
Nilai Total (%)
Naive Bayes 56.3 8.75 77.27
k-NN 57.9 11.75 76.11
SVM 69.8 10.5 81.62
Pengujian pada bagian body saja menunjukkan bahwa secara rata-rata, algoritma terbaik adalah SVM. Jika dilihat secara terpisah, algoritma terbaik untuk mencegah false positive adalah Naïve Bayes dan algoritma dengan akurasi spam terbaik adalah SVM. Hasil ini nantinya akan digunakan untuk pengujian 4.3.2.
4.3.2. Pengujian Penggabungan Algoritma Dari Hasil Awal
Percobaan ini menggunakan dasar dari pengujian 4.3.1 untuk menentukan algoritma mana saja yang dicoba untuk digabungkan. Dari hasil pengujian, didapati bahwa performa terbaik untuk bagian header saja menjadi milik SVM, sedangkan untuk bagian body terbagi menjadi dua. Akurasi spam tertinggi dimiliki oleh SVM, sedangkan untuk false positive terendah dimiliki oleh Naïve Bayes. Dari hasil ini, akan diuji penggabungan antara algoritma SVM dengan Naïve Bayes serta SVM dengan SVM.
Tabel 4.12. Hasil Pengujian Penggabungan Algoritma.
Nilai Algoritma
Akurasi Spam (%)
False Positive (%)
Nilai Total (%)
SVM + Naive Bayes 46.5 9 73.2
SVM + SVM 47.5 10.5 72.7
Penurunan akurasi yang disebabkan oleh bagian header ikut terbawa ketika pengujian dilakukan untuk kedua bagian secara bersamaan. Hal ini dikarenakan terbatasnya jumlah sampel pelatihan header yang tersedia sehingga algoritma tidak dapat menggunakan informasi yang terdapat pada bagian header secara maksimal.
Penggabungan algoritma terbukti dapat membawa hasil positif dalam meningkatkan akurasi. Dapat dilihat disini bahwa ketika algoritma SVM pada bagian header digabungkan dengan Naïve Bayes pada bagian body, tingkat false positive yang rendah milik Naïve Bayes membantu mengurangi jumlah false positive yang dialami ketika SVM diterapkan di kedua bagian e-mail. Sayangnya, tingkat akurasi spam yang lebih rendah dari SVM membuat kombinasi SVM + SVM masih memiliki nilai tertinggi untuk nilai akurasi spam.
4.4. Pengujian Dengan Konfigurasi yang Diubah
Program yang digunakan untuk menjalankan algoritma memiliki konfigurasi yang dapat diatur sehingga algoritma yang berjalan bisa disesuaikan sesuai dengan keperluan penggunanya. Konfigurasi yang diubah disini adalah nilai sensitivitas.
Nilai sensitivitas adalah sebuah batasan berupa nilai untuk menentukan apakah sebuah e-mail masuk ke dalam kategori spam atau ham. Sebuah e-mail akan ditentukan menjadi sebuah spam jika hasil analisa menghasilkan nilai yang sama atau melebihi batasan nilai yang ditetapkan. Semakin rendah nilai sensitivitas, semakin sensitif algoritma dalam mendeteksi spam.
Data yang digunakan untuk pengujian adalah sebagai berikut:
Jumlah spam yang diujikan = 200
Jumlah ham yang diujikan = 200
Jumlah spam yang digunakan untuk pelatihan = 1000
Jumlah ham yang digunakan untuk pelatihan = 1000
Sensitivitas yang diuji adalah 1 (tinggi), 1,5 (sedang), dan 2 (rendah).
Hasil dari pengujian ini adalah :
Tabel 4.13. Hasil Pengujian Algoritma Dengan Sensitivitas Tinggi Nilai
Algoritma
Akurasi Spam (%)
False Positive (%)
Nilai Total (%)
Naive Bayes 93 2.5 95.7
k-NN 92 3 95
SVM 94.5 2.5 96.3
Tabel 4.14. Hasil Pengujian Algoritma Dengan Sensitivitas Sedang Nilai
Algoritma
Akurasi Spam (%)
False Positive (%)
Nilai Total (%)
Naive Bayes 90 0.5 95.5
k-NN 89.5 1 95.4
SVM 91.5 0.5 96.3
Tabel 4.15. Hasil Pengujian Algoritma Dengan Sensitivitas Rendah Nilai
Algoritma
Akurasi Spam (%)
False Positive (%)
Nilai Total (%)
Naive Bayes 89.5 0 95.8
k-NN 88 1 94.6
SVM 90 0.5 95.7
Dapat dilihat pada tabel 4.13, peningkatan sensitivitas meningkatkan akurasi spam semua algoritma sebanyak 3-4% dibandingkan dengan tingkat sensitivitas sedang. Peningkatan sensitivitas bukan tanpa celah karena tingkat false positive juga meningkat lantaran rendahnya skor yang dibutuhkan agar sebuah e-mail tidak dikategorikan sebagai spam.
Berbanding terbalik dengan peningkatan sensitivitas, ketika sensitivitas diturunkan, nilai false positive mendapatkan penurunan dan sebagai timbal baliknya, nilai akurasi spam juga menurun.
Dari pengujian yang dilakukan, dapat ditarik kesimpulan bahwa sensitivitas lebih baik diatur sesuai dengan preferensi pengguna e-mail server.
Jika cukup banyak spam yang masih masuk ke dalam inbox, sensitivitas bisa diatur agar lebih tinggi. Jika terjadi hal sebaliknya yaitu banyak ham yang tidak masuk ke dalam inbox, nilai sensitivitas bisa direndahkan agar ham tersebut dapat masuk ke dalam inbox. Semua algoritma mendapatkan efek yang sama dari pengaturan sensitivitas ini.
4.4. Solusi Untuk Meningkatkan Kinerja Algoritma
4.4.1. Pemilihan Sampel Pelatihan
Hasil pengujian menunjukkan bahwa sampel yang digunakan untuk pelatihan ham dan spam berdampak besar pada performa algoritma yang berjalan.
Dengan pemilihan sampel yang baik, performa dari algoritma akan meningkat lebih cepat dibandingkan dengan pemilihan sampel yang asal-asalan.
Sampel spam dan ham yang digunakan hendaklah dipilih dengan metode manual dan sesuai dengan lokasi e-mail server ini berjalan. Sampel spam dan ham yang diambil secara sembarangan bukan hanya tidak berdampak pada performa algoritma, tetapi juga memenuhi database yang digunakan dengan kata-kata yang nantinya tidak digunakan.
Sebagai contoh, e-mail server yang berjalan di sebuah universitas lebih baik dilatih dengan sampel yang menitik-beratkan pada spam yang mencoba untuk menipu dengan penawaran beasiswa atau bisnis. Sebuah perusahaan obat atau rumah sakit juga harus melatih e-mail server yang digunakan dengan lebih banyak sampel e-mail yang memiliki kata-kata yang berhubungan dengan dunia medis.
Selain itu, porsi pelatihan haruslah seimbang, atau bahkan jumlah sampel ham haruslah lebih banyak. Hal ini dikarenakan ham lebih sulit untuk diklasifikasikan dibandingkan dengan spam. Spam, meskipun sering diterima oleh e-mail server, memiliki sebuah pola yang dapat dengan mudah dibaca jika sampel pelatihan mencukupi. Lain halnya dengan ham yang dikirimkan oleh seorang individu dengan gaya bahasa serta tata tulis yang sangat bervariasi, jauh lebih bervariasi dibandingkan dengan spam.
Spam yang digunakan untuk sampel pelatihan, selain dipilih secara manual sesuai dengan lokasi e-mail server, juga dapat menggunakan spam yang diterima oleh para user di e-mail tersebut. Spam dari proses ini sangat berguna karena tidak jarang spam dengan tipe yang sama dikirimkan berkali-kali ke seorang user.
Dengan menggunakan spam ini sebagai bahan pelatihan dapat membantu algoritma yang berjalan mencegah spam dengan tipe yang sama masuk kembali ke akun user atau ke user lain di mesin yang sama.
4.5.2. Penggunaan Whitelist, Blacklist, dan Graylist
Metode kedua adalah penggunaan daftar whitelist, blacklist, dan graylist.
Sesuai dengan namanya, istilah ini mengacu pada sebuah daftar alamat e-mail yang akan digunakan sebagai referensi sekaligus elemen yang dicari pada bagian header sebuah e-mail, lebih tepatnya pada bagian pengirim atau sender.
Whitelist merupakan daftar alamat e-mail yang “terpercaya” atau dipercaya oleh user bahwa alamat e-mail yang berada di dalam daftar ini tidak akan mengirimkan spam. E-mail yang dikirimkan oleh semua alamat yang berada di dalam daftar ini akan langsung dianggap sebagai ham dan akan diteruskan ke inbox user.
Blacklist merupakan kebalikan dari whitelist. Blacklist merupakan daftar alamat e-mail yang terkenal sering mengirimkan spam. Semua e-mail yang dikirimkan oleh alamat yang terdapat dalam daftar ini langsung dikategorikan oleh algoritma sebagai spam dan tidak dimasukkan ke dalam inbox user.
Penggunaan whitelist dan blacklist awalnya dirasa cukup, tetapi hal ini tidak akan mengatasi persoalan dimana seorang spammer berhasil mendapatkan sebuah alamat e-mail yang digunakan oleh seseorang yang tidak bersalah. Ketika orang ini tidak mengetahui bahwa akun e-mail yang dimilikinya mengirimkan spam, bisa jadi orang tersebut masuk ke dalam blacklist beberapa e-mail server tanpa sepengetahuan pihak pemilik akun.
Masalah diatas dapat diatasi dengan daftar ketiga yaitu graylist. Graylist berperan pada pertengahan antara whitelist dan blacklist. Jika ada sebuah akun yang tidak pernah mengirimkan spam tiba-tiba mengirimkan spam ke sebuah e- mail server, akun tersebut tidak akan langsung masuk ke dalam blacklist melainkan masuk dulu ke dalam graylist. Jika akun tersebut tidak mengirimkan spam dalam rentang waktu beberapa minggu, akun tersebut akan dihilangkan dari daftar graylist. Tetapi jika aku tersebut mengirimkan spam ketika masih dalam graylist, aku tersebut akan langsung dipindahkan ke dalam blacklist.