MODEL KLASIFIKASI NILAI AKHIR MATA KULIAH DATA
MINING BERDASARKAN AKTIVITAS MAHASISWA PADA LMS
MENGGUNAKAN POHON KEPUTUSAN
MUTIARA SANTIKA
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
BOGOR 2017
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA*
Dengan ini saya menyatakan bahwa skripsi berjudul Model Klasifikasi Nilai Akhir Mata Kuliah Data Mining Berdasarkan Aktivitas Mahasiswa pada LMS Menggunakan Pohon Keputusan adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Februari 2017 Mutiara Santika NIM G64144043
ABSTRAK
MUTIARA SANTIKA. Model Klasifikasi Nilai Akhir Mata Kuliah Data Mining Berdasarkan Aktivitas Mahasiswa pada LMS Menggunakan Pohon Keputusan. Dibimbing oleh MAYANDA MEGA SANTONI dan IMAS SUKAESIH SITANGGANG.
Setiap perguruan tinggi selalu melakukan evaluasi dari hasil proses perkuliahan yang telah dilakukan. Prediksi nilai pada suatu mata kuliah berperan sebagai early warning terhadap kondisi performansi akademik studi mahasiswa. Hasil prediksi secara keseluruhan dapat digunakan sebagai acuan dalam mengevaluasi proses pendidikan. Untuk melakukan prediksi nilai dapat dilakukan dengan melihat beberapa aspek, salah satunya yaitu aktivitas mahasiswa pada Learning Management System (LMS). Terdapat berbagai macam metode klasifikasi, salah satu metode dalam data mining untuk klasifikasi adalah pohon keputusan dengan algoritme C50. Penelitian ini bertujuan untuk membentuk model klasifikasi nilai akhir mata kuliah data mining berdasarkan aktivitas pada LMS. Penelitian ini menggunakan data mahasiswa dan data log aktivitas penggunaan LMS mahasiswa Program Studi Ilmu Komputer FMIPA IPB pada mata kuliah data mining tahun ajaran 2015/2016. Pada penelitian ini dilakukan sebanyak 3 kali iterasi. Hasil uji model klasifikasi pada iterasi pertama, didapat akurasi model terbaik menggunakan 10 fold pada percobaan 4 kelas sebesar 64.29%. Pada iterasi kedua sebesar 40.00% dan pada iterasi ketiga dengan melakukan percobaan pada 2 kelas sebesar 85.71%. Kata kunci: C50, data mining, learning management system, pohon keputusan
ABSTRACT
MUTIARA SANTIKA. Classification Model of Data Mining Course Final Score Based on Student Activities in Learning Management System using Decision Tree. Supervised by MAYANDA MEGA SANTONI and IMAS SUKAESIH SITANGGANG.
Every university performs student evaluation from the result of a completed learning process. Prediction of course’s grade can be done as an early warning regarding student’s academic performance. Prediction result can be used as a reference to evaluate the education process. There are several aspects of evaluation, one of which is student activities on learning management system (LMS). This study aims to build a classification model of final score of data mining course based on LMS activity using C50 decision tree algorithm. This study uses students data and log file of LMS activity of data mining course in academic year of 2015/2016 which is enrolled by Computer Science students in IPB. This study uses 3 iteration. The result of the classification model in the first iteration obtained the best model accuracy using 10-fold in 4 experiment class of 64.29%. In the second iteration 40.00% and in the third iteration conducting experiments on two class of 85.71%. Keywords: C50, data mining, decision tree, learning management system.
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer
pada
Departemen Ilmu Komputer
MUTIARA SANTIKA
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
BOGOR 2017
MODEL KLASIFIKASI NILAI AKHIR MATA KULIAH DATA
MINING BERDASARKAN AKTIVITAS MAHASISWA PADA LMS
Penguji:
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah subhanahu wa ta’ala atas segala karunia-Nya sehingga karya ilmiah ini berhasil diselesaikan. Tema yang dipilih dalam penelitian yang dilaksanakan sejak bulan Agustus 2016 ini ialah data mining, dengan judul Model Klasifikasi Nilai Akhir Mata Kuliah Data Mining Berdasarkan Aktivitas Mahasiswa pada LMS Menggunakan Pohon Keputusan.
Penulis menyadari bahwa dalam proses penulisan skripsi ini banyak mengalami kendala dan masalah, namun berkat bantuan, bimbingan, kerjasama dari berbagai pihak dan berkah dari Allah subhanahu wa ta'ala sehingga kendala-kendala yang dihadapi tersebut dapat diatasi. Untuk itu penulis menyampaikan ungkapan terima kasih kepada Bapak Khaerun selaku ayah, Ibu Santi selaku ibu, serta seluruh keluarga atas segala doa dan kasih sayangnya. Serta ucapan terima kasih dan penghargaan kepada Ibu Mayanda Mega Santoni, SKomp MKom dan Ibu Dr Imas Sukaesih Sitanggang, SSi MKom selaku pembimbing yang telah dengan sabar, tekun, tulus dan ikhlas meluangkan waktu, tenaga, dan pikiran memberikan bimbingan, motivasi, arahan, dan saran-saran yang sangat berharga kepada penulis selama menyusun skripsi.
Penulis juga menyampaikan terima kasih kepada:
1 Bapak Muhammad Ashyar Agmalaro, SSi MKom selaku penguji.
2 Bapak Dr Ir Agus Buono, MSi MKom selaku Ketua Departemen Ilmu Komputer IPB.
3 Seluruh dosen, staff tata usaha, dan staf pegawai Departemen Ilmu Komputer IPB.
4 Seluruh teman – teman sebimbingan.
5 Adik-adik tersayang Alfiyawati Santika dan Nabliya Ayu Ramadhani.
6 Teman-teman yang selalu mendukung yaitu Widyah, Amanda, Putri Indo, Jayantika, Septian, Febri, Ghifari, Nano, Agung, Aswin, Arda, Guswandi, Addinul, Jais, Zulfa.
7 Seluruh teman-teman Program S1 Alih Jenis Ilmu Komputer IPB Angkatan 9. Semoga segala bantuan, bimbingan, motivasi, dan dukungan yang telah diberikan kepada penulis senantiasa dibalas oleh Allah subhanahu wa ta’ala. Semoga karya ilmiah ini bermanfaat bagi semua pihak yang membutuhkan.
Bogor, Februari 2017 Mutiara Santika
DAFTAR ISI
DAFTAR TABEL vi DAFTAR GAMBAR vi DAFTAR LAMPIRAN vi PENDAHULUAN 1 Latar Belakang 1 Perumusan Masalah 2 Tujuan Penelitian 2 Manfaat Penelitian 2Ruang Lingkup Penelitian 3
TINJAUAN PUSTAKA 3
Learning Management System 3
Web Mining 4
Pohon Keputusan 5
Algoritme C50 5
K-Fold Cross Validation 7
METODE 7
Data Penelitian 7
Tahapan Penelitian 9
Lingkungan Pengembangan 12
HASIL DAN PEMBAHASAN 13
Iterasi Pertama 14
Iterasi Kedua 20
Iterasi Ketiga 24
Evaluasi dan Analisis Model Klasifikasi 28
SIMPULAN DAN SARAN 28
Simpulan 28
Saran 29
DAFTAR PUSTAKA 29
LAMPIRAN 31
DAFTAR TABEL
1 Atribut data log penggunaan LMS 7
2 Perhitungan precision dan recall dengan confusion matrix 12 3 Potongan jumlah aktivitas pada iterasi pertama 15 4 Interval untuk masing-masing atribut pada iterasi pertama 15 5 Batas bawah dan batas atas yang digunakan pada iterasi pertama 16 6 Rentang nilai untuk masing-masing kategori pada iterasi pertama 16 7 Pemberian kategori untuk masing-masing aktivitas pada iterasi pertama 16 8 Jumlah nilai mutu mata kuliah data mining pada iterasi pertama 17 9 Distribusi jumlah data latih dan data uji pada iterasi pertama 17 10 Confusion matrix yang dihasilkan pada iterasi pertama 19 11 Nilai precision dan recall yang dihasilkan pada iterasi pertama 19 12 Potongan jumlah aktivitas pada iterasi kedua 20 13 Interval untuk masing-masing atribut pada iterasi kedua 21 14 Batas bawah dan batas atas yang diperoleh untuk masing-masing atribut 21 15 Rentang nilai untuk masing-masing kategori pada iterasi kedua 21 16 Pemberian kategori untuk masing-masing aktivitas pada iterasi kedua 22 17 Distribusi jumlah data latih dan data uji pada iterasi kedua 22 18 Confusion matrix yang dihasilkan pada iterasi kedua 24 19 Nilai precision dan recall yang dihasilkan pada iterasi kedua 24 20 Potongan jumlah aktivitas pada iterasi ketiga 25 21 Batas bawah dan batas atas untuk masing-masing atribut 25 22 Rentang nilai untuk masing-masing kategori pada iterasi pertama 25 23 Pemberian kategori untuk dan label kelas pada iterasi ketiga 26 24 Jumlah data untuk masing-masing kelas pada iterasi ketiga 26 25 Distribusi jumlah data latih dan data uji pada iterasi ketiga 26 26 Confusion matrix yang dihasilkan pada iterasi ketiga 28 27 Nilai precision dan recall yang dihasilkan pada iterasi ketiga 28
DAFTAR GAMBAR
1 Halaman home LMS mata kuliah data mining 3
2 Halaman LMS data mining untuk pengumpulan tugas yang diupload 8 3 Halaman LMS untuk melihat tugas mata kuliah data mining 8 4 Halaman LMS untuk melihat mata kuliah data mining 9 5 Halaman LMS untuk melihat modul mata kuliah data mining 9
6 Modul mata kuliah data mining pada LMS 9
7 Tahapan penelitian 10
8 Tahapan praproses data 11
9 Potongan data log pembelajaran sebelum praproses data 14 10 Data log dengan pengguna dosen dan asisten praktikum 14 11 Potongan aktivitas pada data log dengan berbagai macam pengguna 15 12 Potongan kode program untuk membuat model pohon keputusan 18
13 Pohon keputusan untuk iterasi pertama 18
15 Pohon keputusan pada iterasi kedua 23
16 Grafik hasil akurasi pada iterasi kedua 23
17 Pohon keputusan pada iterasi kedua 27
18 Hasil akurasi pada iterasi ketiga 27
DAFTAR LAMPIRAN
1 Aktivitas data log pada LMS 31
2 Jumlah aktivitas pada iterasi pertama 33
3 Aktivitas yang sudah dikategorikan untuk iterasi perama 37
4 Jumlah aktivitas pada iterasi kedua 41
5 Aktivitas yang sudah dikategorikan untuk iterasi kedua 45
6 Data yang digunakan untuk iterasi ketiga 49
7 Kode program cross vold validation 53
8 Pohon keputusan yang dihasilkan pada iterasi pertama 54 9 Pohon keputusan yang dihasilkan pada iterasi kedua 58 10 Pohon keputusan yang dihasilkan pada iterasi ketiga 62
PENDAHULUAN
Latar Belakang
Setiap perguruan tinggi perlu melakukan evaluasi dari hasil proses perkuliahan yang telah dilakukan. Menurut Kuh et al. (2006), terkait prestasi akademik mahasiswa terdapat beberapa faktor yang mempengaruhi keberhasilan belajar yaitu pengalaman sebelum perkuliahan dan karakteristik latar belakang siswa serta pengalaman perkuliahan yang meliputi perilaku siswa (student behaviours), kondisi institusi (institution condition) dan keterlibatan siswa (student engangement). Dari beberapa faktor tersebut, prediksi nilai pada suatu mata kuliah dapat berperan sebagai early warning terhadap kondisi performansi studi mahasiswa. Selanjutnya, hasil prediksi secara keseluruhan dapat digunakan sebagai acuan dalam mengevaluasi proses pendidikan, kurikulum, dan hal lain yang berkaitan dengan penyelenggaraan pendidikan (Fatriandini et al. 2013).
Untuk melakukan prediksi nilai dapat dilakukan dengan melihat beberapa aspek, salah satunya yaitu aktivitas mahasiswa pada Learning Management System (LMS). Aktivitas belajar melalui LMS dapat memberikan nilai positif terhadap keberhasilan tujuan belajar. Prediksi nilai suatu mata kuliah dapat dilakukan dengan berbagai cara, salah satunya dapat dilakukan dengan menggunakan pendekatan teknik data mining. Menurut Han et al. (2012), data mining merupakan proses menemukan pengetahuan dan pola yang menarik dari data yang berjumlah besar. Klasifikasi merupakan salah satu metode dalam data mining untuk mengetahui label kelas dari suatu record dalam data. Banyak metode klasifikasi yang digunakan saat ini seperti Support Vector Machine, Bayesian Method, Neural Networks, K-neighbouor Method dan Decison Tree (pohon keputusan). Dari metode klasifikasi tersebut pohon keputusan menunjukkan kinerja aplikasi yang lebih baik. Daerah pengambilan keputusan yang sebelumnya kompleks dapat diubah menjadi lebih sederhana dan spesifik, sehingga proses pengambilan keputusan lebih menginterpretasikan solusi dari permasalahan.
Beberapa penelitian telah dilakukan dalam memprediksi nilai akhir melalui aktivitas pada LMS. Romero et al. (2010) melakukan penelitian untuk memprediksi nilai akhir mahasiswa menggunakan Moodle courses. Penelitian ini menggunakan 10 atribut yaitu course, n_assignment, n_quiz_a, n_quiz_s, n_posts, n_read, total_time_assignment, total_time_quiz, total_time_forum, dan mark. Pada penelitian ini dihasilkan salah satu algoritme terbaik untuk memprediksi nilai akhir yaitu algoritme pohon keputusan. Algoritme tersebut merupakan algoritme yang mudah untuk dipahami dan memungkinkan interpretasi dari model yang diperoleh serta dapat digunakan dalam proses pembuatan keputusan. Ackapinar et al. (2015) melakukan penelitian dengan memodelkan performansi akademik mahasiswa berdasarkan interaksi dalam pembelajaran online. Penelitian ini dilakukan dengan menggunakan 11 atribut yaitu n_login, d_usage, n_post, n_tag, n_postnav, n_postass, n_answer, n_dissnav, n_answernav, n_questionAss, dan f_grades. Penelitian ini dilakukan dengan membandingkan akurasi yang dihasilkan dari beberapa metode salah satunya adalah Classification Tree. Delgado et al. (2006) melakukan penelitian dengan memprediksi nilai akhir mahasiswa menggunakan Moodle logs dengan neural network. Pada penelitian ini data yang digunakan yaitu
2
IP address, date and hour of the access, complete name, action (resource view, course view, user view, user update, upload, resource updates, resource add, forum view), dan information (marks, user profile). Penelitian ini menghasilkan sebesar 80% dapat memprediksi nilai dengan metode neural network.
Oleh karena itu, pada penelitian ini akan membuat model klasifikasi nilai akhir pada mata kuliah data mining di Departemen Ilmu Komputer FMIPA IPB berdasarkan aktivitas LMS. Alasannya, karena mata kuliah data mining dapat mewakili mata kuliah yang ditawarkan pada mayor Ilmu Komputer FMIPA IPB dan aktivitas penggunaan LMS pada mata kuliah ini dilakukan secara rutin. Penelitian ini dilakukan dengan menggunakan metode pohon keputusan yaitu algoritme C50, sehingga dapat digunakan sebagai acuan untuk meningkatkan mutu pendidikan di IPB khususnya pada penyelenggaraan mata kuliah data mining di Program Studi S1 Ilmu Komputer.
Perumusan Masalah
Berdasarkan latar belakang, perumusan masalah dalam penelitian ini adalah:
1 Bagaimana mengklasifikasikan nilai akhir mahasiswa mata kuliah data mining berdasarkan aktivitas pada log LMS dengan menggunakan algoritme pohon keputusan C50?
2 Bagaimana mendapatkan aktivitas penting pada LMS yang mempengaruhi nilai mata kuliah data mining yang ditawarkan Program Studi S1 Ilmu Komputer FMIPA IPB?
Tujuan Penelitian
Tujuan penelitian ini adalah:
1 Membuat model klasifikasi untuk memprediksi nilai akhir mata kuliah data mining yang ditawarkan Program Studi S1 Ilmu Komputer FMIPA IPB berdasarkan aktivitas pada LMS.
2 Menentukan aktivitas pada LMS yang mempengaruhi performa mahasiswa berdasarkan hasil klasifikasi menggunakan pohon keputusan algoritme C50.
Manfaat Penelitian
Penelitian ini diharapkan dapat membentuk model klasifikasi untuk memudahkan dalam memprediksi nilai akhir mata kuliah data mining, berdasarkan aktivitas pada LMS dengan memanfaatkan data log penggunaan LMS. Sehingga dapat dijadikan sebagai acuan untuk meningkatkan mutu pendidikan di IPB khususnya pada penyelenggaraan mata kuliah data mining di Program Studi S1 Ilmu Komputer. Selain itu, untuk mendapatkan informasi mengenai aktivitas penting pada LMS yang mempengaruhi performa mahasiswa, agar kedepannya dapat meningkatkan penggunaan LMS dan pengembangan LMS.
3
Ruang Lingkup Penelitian
Ruang lingkup penelitian ini ialah:
1 Penelitian ini dibatasi pada penggunaan LMS untuk mahasiswa reguler dan alih jenis Program Studi S1 Ilmu Komputer FMIPA IPB.
2 Data yang digunakan yaitu data mahasiswa regular dan alih jenis S1 Ilmu Komputer IPB berupa nim dan nilai akhir mata kuliah data mining, serta data log penggunaan LMS pada mata kuliah data mining tahun ajaran 2015/2016. 3 Penelitian ini menerapkan algoritme C50 yang terdapat pada package C50
dalam aplikasi R.
TINJAUAN PUSTAKA
Learning Management System
LMS atau yang juga dikenal sebagai Virtual Learning Environtment (VLE) adalah media pembelajaran berbasis web yang bisa menjadi solusi untuk digunakan dalam proses pembelajaran. Beberapa alasan menggunakan media pembelajaran ini adalah terjadi peningkatan efektivitas pembelajaran dan prestasi akademik siswa, menambah kenyamanan, menarik lebih banyak perhatian siswa kepada materi yang disampaikan dalam pembelajaran, dapat diterapkan dengan berbagai tingkat dan model pembelajaran, serta dapat menambah waktu pembelajaran dengan memanfaatkan teknologi internet (Kim dan Won 2007).
Tujuan adanya LMS di IPB yaitu sebagai fasilitator untuk mendukung dalam kegiatan pembelajaran dan dapat memantau dalam proses evaluasi pembelajaran. Tampilan LMS untuk mata kuliah data mining di IPB dapat dilihat pada Gambar 1. Gambar 1 menampilkan halaman home LMS mata kuliah data mining.
4
Web Mining
Menurut Srivastava et al. (2003) web mining merupakan aplikasi teknik data mining untuk mengekstrak pengetahuan (knowledge) dari data web. Ada dua pendekatan yang digunakan untuk mendefinisiskan web mining, yaitu pendekatan berbasis proses dan pendekatan berbasis data. Pendekatan berbasis proses yaitu web mining sebagai kumpulan suatu aktivitas sedangkan pendekatan berbasis data yaitu web mining sebagai terminologi tipe data web yang digunakan untuk proses data mining. Web mining dapat dibagi dalam tiga kategori berdasarkan jenis data yang diekstrak yaitu Web content mining (WCM), Web structure mining (WSM), dan Web Usage Mining (WUM). WCM merupakan penemuan informasi terhadap content web yang terdiri dari teks, gambar, audio, video, metadata, dan hyperlinks. WSM merupakan penemuan model yang berkaitan dengan struktur hubungan web yang meliputi intrapage structure dan interpage structure. WUM merupakan proses untuk mengaplikasikan teknik data mining dalam melakukan penemuan pengetahuan berupa pola penggunaan dari web.
Pada penelitian sebelumnya Romero et al. (2014) telah berhasil memprediksi nilai akhir mahasiswa menggunakan Moodle courses. Data yang digunakan pada penelitian tersebut sebanyak 438 data mahasiswa dari Universitas Cordoba di Spanyol, dengan 7 mata kuliah dan 10 atribut. Tujuh mata kuliah tersebut yaitu Security and Hygiene in The Work, Projects, Engineering Firm, Programming for Enginnering, Computer Science Basis, Applied Computer Science, dan Scientific Programming. Sepuluh atribut yang digunakan yaitu Course, n_assignment, n_quiz_a, n_quiz_s, n_posts, n_read, total_time_assignment, total_time_quiz, total_time_forum, dan Mark. Penelitian dilakukan dengan membandingkan 5 metode klasifikasi yaitu Klasifikasi Statistik, Pohon Keputusan, Rule Induction, Fuzzy, dan Neural Networks. Pada penelitian ini dihasilkan algoritme terbaik yaitu algoritme Pohon Keputusan, Rule Induction dan Fuzzy Rule, karena ketiga algoritme tersebut merupakan algoritme yang mudah untuk dipahami, diinterpretasi dan dapat digunakan dalam proses pembuatan keputusan.
Ackapinar et al. (2015) memodelkan performansi akademik mahasiswa berdasarkan interaksi dalam pembelajaran online. Data yang digunakan yaitu data log selama 14 minggu penggunaan online learning, 76 mahasiswa dengan 3803 logins, 4130 posts, 3937 tags, dan lebih dari 100,000 page view. Sebelas atribut yang digunakan yaitu n_login, d_usage, n_post, n_tag, n_postnav, n_postass, n_answer, n_dissnav, n_answernav, n_questionAss, dan f_grades. Atribut nilai akhir diperoleh dari mata kuliah Computer Hardware. Penelitian dilakukan dengan membandingkan 3 metode Naïve Bayes, Classification Tree dan CN2 Rules. Hasil penelitian menunjukkan bahwa algoritme Naïve Bayes lebih baik daripada algoritme klasifikasi lain. Algoritme Naïve Bayes mengklasifikasikan 75.4% dari mahasiswa sesuai dengan kelasnya yaitu (Fail, Pass/Good). Selain itu, model klasifikasi juga memprediksi mahasiswa yang gagal sebesar 81.5% dan mahasiswa lulus sebesar 91.8%.
Delgado et al. (2006) memprediksi nilai akhir mahasiswa menggunakan Moodle logs menggunakan neural network models. Penelitian ini dilakukan kepada 240 mahasiswa Universitas Cordoba di Spanyol pada mata kuliah Methodology and Programming Technology. Pada penelitian ini data yang digunakan yaitu IP
5 address, date and hour of the access, complete name, action (resource view, course view, user view, user update, upload, resource updates, resource add, forum view), dan information (marks, user profile). Penelitian ini menghasilkan sebesar 80% dapat memprediksi nilai menggunakan metode neural network.
Pohon Keputusan
Pohon keputusan merupakan salah satu metode klasifikasi yang menggunakan representasi struktur pohon. Setiap node pada pohon keputusan merepresentasikan atribut, cabangnya merepresentasikan nilai dari atribut dan daun merepresentasikan kelas. Node paling atas dari pohon keputusan disebut sebagai node akar atau root (Han et al 2012).
Pembentukan pohon keputusan terdiri atas tahap-tahap berikut (Han et al 2012): 1 Konstruksi tree, yaitu membuat tree yang diawali dengan pembentukan bagian
akar, kemudian data terbagi berdasarkan atribut-atribut yang cocok untuk dijadikan node akar.
2 Pemangkasan tree (pruning), yaitu mengidentifikasi dan membuang cabang yang tidak diperlukan pada tree yang telah terbentuk.
3 Pembentukan aturan keputusan, yaitu membuat aturan keputusan dari tree yang telah dibentuk.
Algoritme C50
Algoritme C50 adalah perluasan dari algoritme C4.5 dan Iterative Dichotomizer 3 (ID3) (Patil et al. 2012). C50 adalah algoritme klasifikasi yang dapat menangani kumpulan data besar. C50 lebih baik daripada C4.5 dalam hal kecepatan, memori dan efisiensi. Model C50 dapat membagi sampel berdasarkan nilai information gain terbesar. Atribut yang memiliki information gain terbesar akan dipilih sebagai parent atau untuk node selanjutnya (Han et al. 2012).
Algoritme C50 memiliki tiga parameter input yaitu D, attribute_list, dan attribute_selection_method. D merupakan data latih dengan label kelas yang terkait. Attribute list menggambarkan suatu tuple himpunan dari kandidat atribut dan attribute selection method menentukan prosedur untuk memilih atribut yang mengolah tuple menurut kelasnya (Han et al. 2012).
Algoritme generate decision tree sebagai parameter input adalah sebagai berikut (Han et al. 2012):
1 D, data latih yang telah ditentukan label kelasnya.
2 Attribute_list, himpunan yang terdiri dari kandidat atribut.
3 Attribute_selection_method, prosedur untuk memilih atribut yang mengolah tuple menurut kelasnya.
Algoritme klasifikasi pohon keputusan adalah sebagai berikut (Han et al. 2012): 1 Buat simpul N.
2 Jika semua tuple di D memiliki kelas yang sama yaitu C maka jadikan N sebagai simpul daun dan beri label C.
6
jadikan simpul N sebagai simpul daun dan diberi label dengan kelas yang terbanyak.
4 Terapkan attribute selection method (D, attribute list) untuk mendapatkan atribut uji terbaik.
5 Beri label simpul N dengan atribut data uji.
6 Jika atribut bernilai diskret dan dapat dipisahkan, maka: Attribute_list <- attribute_list – atribut uji
7 Untuk setiap nilai j dari atribut uji yaitu:
Buat Dj menjadi kumpulan data tuple untuk memenuhi hasil j.
Jika Dj kosong, maka tambahkan simpul daun dengan label dari kelas yang terbanyak.
Selainnya, tambah cabang baru dengan memanggil fungsi Generate_decision_tree (Dj, attribute_list) ke simpul N.
8 Kembali ke N.
Model klasifikasi yang digunakan yaitu tree dan rule-based. Tree dimulai sebagai node tunggal, N mewakili tuple D. Tree memiliki struktur pohon seperti flowchart yang masing-masing simpul internal non leaf node menunjukkan pengujian pada atribut. Masing-masing cabang mewakili hasil dari pengujian dan masing-masing simpul daun merupakan label kelas. Root merupakan simpul paling atas pada struktur tree, sedangkan rule-based merupakan cara yang baik untuk mewakili informasi atau pengetahuan. Aturan klasifikasi menggunakan aturan IF (kondisi) – THEN (kesimpulan) untuk klasifikasi. IF merupakan bagian (or left side) dari aturan ini dikenal sebagai aturan prasyarat, sedangkan THEN (or right side) merupakan bagian konsekuen (Han et al. 2012).
Penelitian ini menggunakan nilai information gain sebagai ukuran pemilihan atribut. Atribut dengan information gain terbesar ditentukan sebagai atribut pemisah untuk simpul N. Ukuran pemilihan atribut didefinisikan pada persamaan 1 (Han et.al 2012).
Info(D) = −∑𝑚𝑖=1𝑝𝑖𝑙𝑜𝑔₂ (𝑝𝑖) (1)
Dengan info (D) merupakan informasi yang dibutuhkan untuk mengklasifikasi label kelas sebuah tuple di D. 𝑝𝑖 adalah jumlah sample untuk kelas 𝑖. Fungsi log menggunakan basis 2, karena informasi yang dikodekan dalam bit. Info(D) juga dikenal sebagai entropy.
Partisi tuple di D pada beberapa atribut A memiliki nilai v yang berbeda {a1,a2, …, av} dari data latih. Atribut A digunakan untuk memisahkan D ke dalam 𝑣 partisi atau sub himpunan {D1, D2, …, D𝑣 }. |Dj|/|D| merupakan bobot partisi ke-j. Nilai entropy yang dihasilkan untuk mengklasifikasi tuple dari D berdasarkan partisi oleh A dapat dilihat pada persamaan 2 (Han et al. 2012):
InfoA(D) = −∑𝑣 𝐷𝑗×
𝑗=1 Info (Dj) (2)
D
Untuk mendapatkan nilai gain yang diperoleh pada atribut A dapat dilihat pada persamaan 3 sebagai berikut:
7 Gain (A) = Info(D) – InfoA(D) (3) Gain (A) menyatakan berapa banyak cabang yang akan diperoleh pada A. Atribut A dengan information gain tertinggi. Information gain (A), dipilih sebagai atribut pada node N (Han et al. 2012).
K-Fold Cross Validation
Menurut Refaeilzadeh et al. (2008) K-Fold Cross Validation adalah sebuah metode yang membagi himpunan contoh secara acak menjadi k himpunan bagian (subset). Pada metode ini dilakukan pengulangan sebanyak k kali untuk data pelatihan dan pengujian. Pada setiap pengulangan, satu subset digunakan untuk pengujian, sedangkan subset sisanya digunakan untuk pelatihan. Kelebihan dari metode ini adalah tidak adanya masalah dalam pembagian data. Setiap data akan menjadi test set sebanyak satu kali dan akan menjadi training set sebanyak k-1 kali. Kekurangan dari metode ini adalah algoritme pembelajaran harus dilakukan sebanyak k kali yang berarti menggunakan k kali waktu komputasi
METODE
Data Penelitian
Data yang digunakan pada penelitian ini adalah data mahasiswa reguler dan alih jenis Program Studi S1 Ilmu Komputer FMIPA IPB tahun ajaran 2015/2016. Selain itu digunakan data log penggunaan LMS untuk mata kuliah data mining tahun ajaran 2015/2016. Atribut pada data log penggunaan LMS diacu dari penelitian yang dilakukan oleh Romero et al. (2010) dan Akcapinar et al. (2015). Aktivitas pada data log penggunaan LMS merupakan atribut yang akan digunakan pada penelitian ini. Atribut data log penggunaan LMS pada mata kuliah data mining dapat dilihat pada Tabel 1.
Tabel 1 Atribut data log penggunaan LMS
No Nama Atribut Kode Keterangan
1 n_assigment V1 Jumlah tugas yang di-upload
2 n_view_assigment V2 Jumlah view tugas mata kuliah data mining
3 n_course_view V3 Jumlah view mata kuliah data mining 4 n_course_module_view V4 Jumlah view modul
5 Nilai akhir V5 Nilai akhir
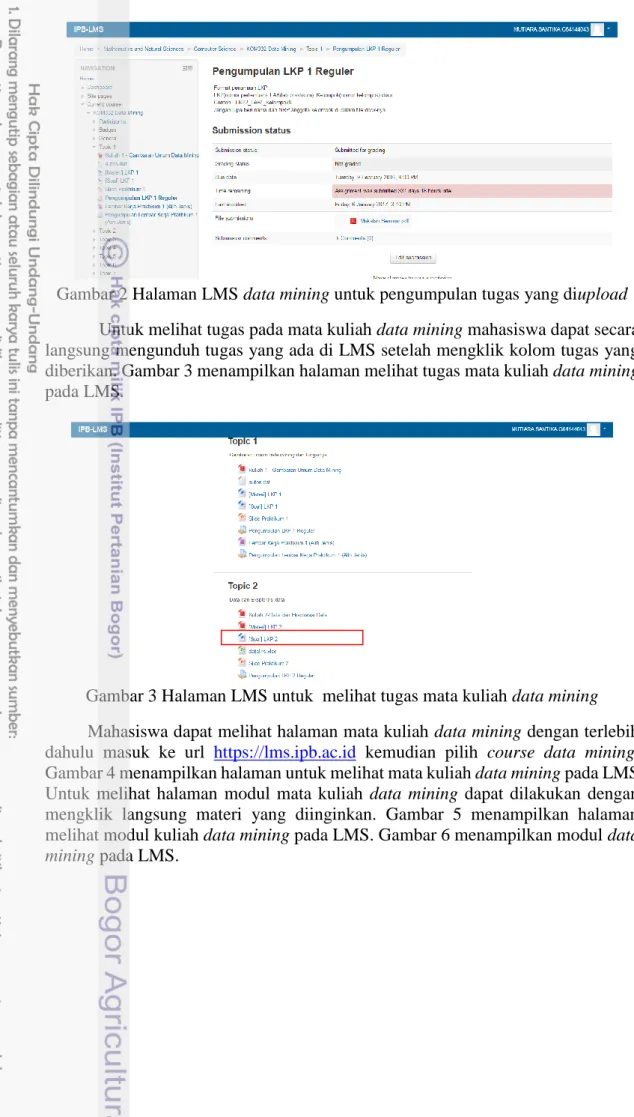
Halaman aktivitas pengumpulan tugas yang diupload menampilkan submission status yang tediri dari grading status, due date, time remaining, last modified, file submission, dan submission comment. Halaman aktivitas pengumpulan tugas yang diupload dapat dilihat pada Gambar 2.
8
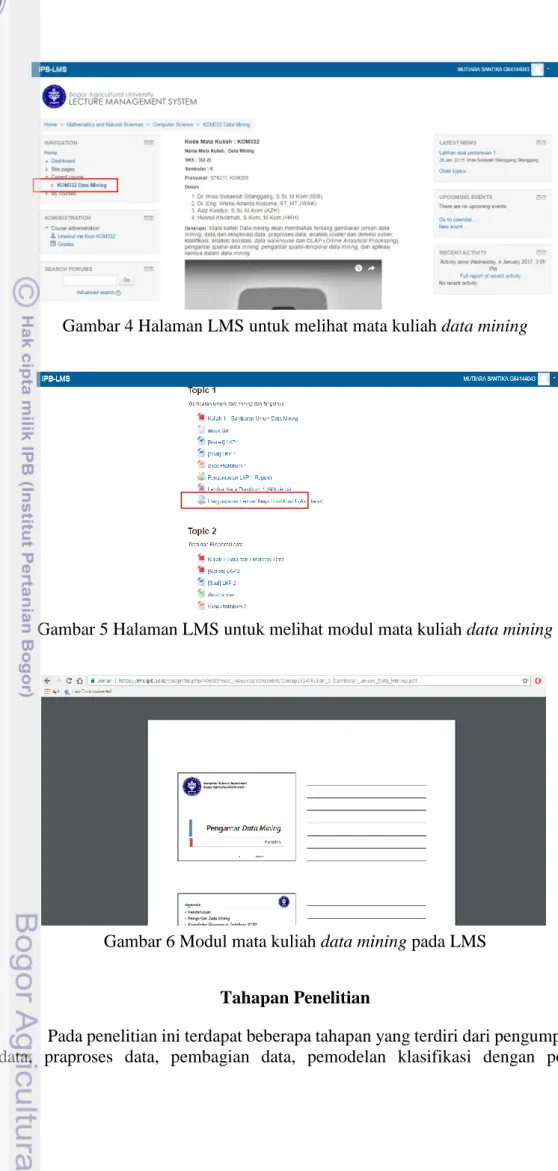
Gambar 2 Halaman LMS data mining untuk pengumpulan tugas yang diupload Untuk melihat tugas pada mata kuliah data mining mahasiswa dapat secara langsung mengunduh tugas yang ada di LMS setelah mengklik kolom tugas yang diberikan. Gambar 3 menampilkan halaman melihat tugas mata kuliah data mining pada LMS.
Gambar 3 Halaman LMS untuk melihat tugas mata kuliah data mining Mahasiswa dapat melihat halaman mata kuliah data mining dengan terlebih dahulu masuk ke url https://lms.ipb.ac.id kemudian pilih course data mining. Gambar 4 menampilkan halaman untuk melihat mata kuliah data mining pada LMS. Untuk melihat halaman modul mata kuliah data mining dapat dilakukan dengan mengklik langsung materi yang diinginkan. Gambar 5 menampilkan halaman melihat modul kuliah data mining pada LMS. Gambar 6 menampilkan modul data mining pada LMS.
9
Gambar 4 Halaman LMS untuk melihat mata kuliah data mining
Gambar 5 Halaman LMS untuk melihat modul mata kuliah data mining
Gambar 6 Modul mata kuliah data mining pada LMS
Tahapan Penelitian
Pada penelitian ini terdapat beberapa tahapan yang terdiri dari pengumpulan data, praproses data, pembagian data, pemodelan klasifikasi dengan pohon
10
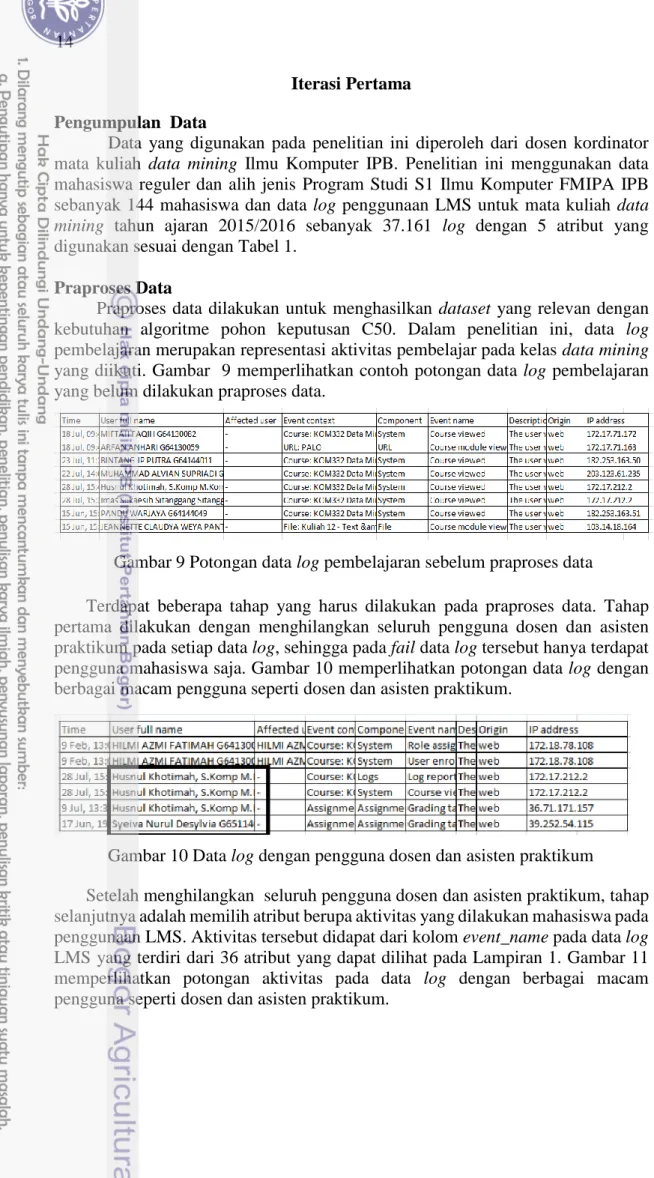
keputusan, model klasifikasi aktivitas mahasiswa, pengujian model klasifikasi, evaluasi dan analisis model klasifikasi, dan analisis aktivitas pada LMS yang mempengaruhi nilai mata kuliah data mining. Keseluruhan tahapan pada penelitian ini dapat dilihat pada Gambar 7.
Gambar 7 Tahapan penelitian
Pengumpulan data
Penelitian ini menggunakan data mahasiswa reguler dan alih jenis Program Studi S1 Ilmu Komputer FMIPA IPB sebanyak 144 mahasiswa dan data log penggunaan LMS untuk mata kuliah data mining tahun ajaran 2015/2016 sebanyak 37.161 log. Data diperoleh dari dosen kordinator mata kuliah data mining Ilmu Komputer IPB.
Praproses Data
Praproses dilakukan untuk meningkatkan kualitas data sehingga menghasilkan akurasi dan efisiensi data yang meningkat. Pada tahapan ini, data yang dikumpulkan dibersihkan dan dilakukan analisis untuk menentukan pemilihan atribut pengguna mahasiswa.
Setelah memilih aktivitas dengan pengguna mahasiswa, tahap yang selanjutnya yaitu memilih atribut berupa aktivitas yang dilakukan mahasiswa pada penggunaan LMS. Aktivitas tersebut didapat dari kolom event_name pada data log LMS yang terdiri dari view mata kuliah, view modul mata kuliah, jumlah view tugas, jumlah upload tugas dan nilai akhir sebagai kelas keputusan.
Tahap selanjutnya yaitu menghitung jumlah setiap aktivitas pada data log LMS. Setiap aktivitas akan dikelompokkan menjadi 4 grup yaitu tinggi (3), sedang (2), rendah (1), dan tidak ada informasi (0). Pengelompokkan 4 grup diperoleh dengan menentukan kategori untuk masing-masing aktivitas.
Langkah selanjutnya yaitu memberikan label kelas untuk setiap data log pengguna LMS. Secara umum pemberian label kelas ini akan dibagi menjadi dua percobaan. Percobaan pertama yaitu mengelompokkan data sesuai dengan nilai
11 akhir masing-masing mahasiswa, yakni nilai mutu A, AB, B, dan BC. Percobaan kedua yaitu mengelompokkan data menjadi dua kategori kelas, yakni kelas K1 yang terdiri dari nilai mutu A dan AB, serta kelas K2 yang terdiri dari nilai mutu B dan BC. Gambar 8 menjelaskan urutan yang dilakukan saat praproses data.
Pembagian Data
Untuk melakukan klasifikasi data dibagi menjadi data latih dan data uji. Data latih digunakan untuk membangun model pohon keputusan, sedangkan data uji digunakan untuk menguji model pohon keputusan. Pembagian data menggunakan metode k-cross fold validation. K-cross fold validation adalah sebuah metode yang membagi himpunan contoh secara acak menjadi k himpunan bagian (subset) Refaeilzadeh et al. (2008).
Pemodelan Klasifikasi Pohon Keputusan
Pada tahap ini dibangun model klasifikasi untuk membentuk pohon keputusan. Pembentukan pohon keputusan ini menggunakan algoritme C50. Algoritme ini menggunakan nilai information gain dalam membuat pohon keputusan. Model klasifikasi dibuat dengan menggunakan bahasa pemograman R dengan package yang telah tersedia yaitu C50.
Pengujian Model Klasifikasi
Pada tahap pengujian model klasifikasi dilakukan dengan perhitungan akurasi serta menghitung nilai precision dan recall. Pada tahap ini akurasi dihitung dari model klasifikasi. Akurasi berfungsi untuk menunjukkan tingkat kebenaran pengklasifikasian data terhadap kelas yang sebenarnya. Tingkat akurasi yang baik adalah tingkat akurasi yang mendekati 100%. Semakin tinggi tingkat akurasi maka semakin rendah kesalahan klasifikasi. Dalam penelitian ini, apabila akurasi dari model terbaik lebih kecil 70% akan dilakukan praproses data kembali. Metode yang digunakan dalam proses perhitungan akurasi adalah metode 10-cross fold validation. Akurasi diperoleh dari data uji dengan menggunakan rumus pada Persamaan 4.
𝐴𝑘𝑢𝑟𝑎𝑠𝑖 =∑ 𝑑𝑎𝑡𝑎 𝑢𝑗𝑖 𝑦𝑎𝑛𝑔 𝑑𝑖𝑘𝑙𝑎𝑠𝑖𝑓𝑖𝑘𝑎𝑠𝑖𝑘𝑎𝑛 𝑏𝑒𝑛𝑎𝑟
∑ 𝑑𝑎𝑡𝑎 𝑢𝑗𝑖 ×100% (4)
Menurut Amin et al (2012) precision adalah bagian data yang di ambil sesuai dengan informasi yang dibutuhkan sedangkan recall adalah pengambilan
12
data yang berhasil dilakukan terhadap bagian data yang relevan dengan query. Tabel 2 menunjukkan bentuk precision dan recall dari confusion matrix. Persamaan 5 menunjukkan perhitungan precision dan Persamaan 6 menunjukkan perhitungan recall.
Tabel 2 Perhitungan precision dan recall dengan confusion matrix Klasifikasi Positif Klasifikasi Negatif
Aktual Positif TP FN Aktual Negatif FP TN 𝑃𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 = TP TP+FP (5) 𝑅𝑒𝑐𝑎𝑙𝑙 = TP TP+FN (6)
Evaluasi dan Analisis Model Klasifikasi
Pada tahap ini digunakan nilai akurasi terbaik dari pengujian model klasifikasi. Akurasi terbaik digunakan untuk menganalisis aktivitas LMS yang paling berpengaruh pada mata kuliah data mining. Dalam penelitian ini, proses evaluasi dan analisis model klasifikasi akan dilakukan jika memenuhi syarat model dengan akurasi terbaik lebih besar sama dengan 70%. Analisis tersebut direpresentasikan ke dalam pohon keputusan.
Lingkungan Pengembangan
Spesifikasi perangkat keras dan perangkat lunak yang digunakan untuk penelitian ini adalah sebagai berikut:
1 Perangkat keras yang digunakan berupa komputer personal dengan spesifikasi:
Intel® Core™ i3 CPU @2.20 GHz
RAM 2 GB
Harddisk Internal 512 GB 2 Perangkat lunak yang digunakan:
Sistem Operasi Windows 7 32-bit
Bahasa pemrograman R versi 3.3.1 untuk menjalankan RStudio
RStudio versi 0.98.1102 untuk proses klasifikasi
13
HASIL DAN PEMBAHASAN
Berdasarkan tahapan penelitian pada Gambar 7 yang telah dijelaskan sebelumnya bahwa proses evaluasi dan analisis model klasifikasi akan dilakukan jika memenuhi syarat akurasi model terbaik lebih besar sama dengan 70%. Pada penelitian ini terdapat 3 kali iterasi.
Iterasi pertama dimulai dari proses pengumpulan data, praproses data, pembagian data menjadi data latih dan data uji, pemodelan klasifikasi pohon keputusan yang menghasilkan model klasifikasi aktivitas mahasiswa. Kemudian dilanjutkan tahap pengujian model klasifikasi. Pada tahap pengujian model klasifikasi, akurasi yang diperoleh dipastikan apakah sudah memenuhi syarat lebih besar sama dengan 70%. Pada iterasi pertama setiap atribut dihitung berdasarkan jumlah keseluruhan aktivitas yang dilakukan mahasiswa. Setelah menghitung jumlah keseluruhan aktivitas, tahap selanjutnya yaitu menentukan kategori pada masing-masing atribut yang kemudian dilanjutkan dengan proses klasifikasi. Dari proses klasifikasi yang dilakukan, model dengan akurasi terbaik pada iterasi pertama sebesar 64.29%. Akurasi tersebut lebih kecil sama dengan 70% sehingga dilakukan praproses data kembali dan dilakukan iterasi kedua.
Pada iterasi kedua tahapan yang dilakukan sama dengan iterasi pertama. Namun yang membedakan adalah pada tahap praproses data (Gambar 8) yaitu menghitung jumlah aktivitas pada LMS. Perubahan terjadi pada atribut V3 dan V4 sedangkan untuk V1 dan V2 tetap. Jumlah aktivitas pada atribut V3 dan V4 dihitung per hari dimana semua kejadian yang terjadi dalam 1 hari dihitung sebagai 1 aktivitas. Berbeda dengan perhitungan aktivitas pada iterasi pertama dimana setiap kejadian dihitung satu aktivitas. Tahap selanjutnya yaitu menentukan kategori pada masing-masing atribut yang kemudian dilanjutkan dengan proses klasifikasi. Dari proses klasifikasi yang dilakukan, model dengan akurasi terbaik pada iterasi kedua menghasilkan akurasi lebih kecil sama dengan 70% yaitu sebesar 40.00% sehingga dilakukan praproses data kembali dan dilakukan iterasi ketiga.
Pada iterasi ketiga tahapan yang dilakukan sama dengan iterasi pertama dan kedua namun pada salah satu tahap praproses data yaitu pemberian label kelas berubah. Sebelumnya pada iterasi pertama dan kedua percobaan dilakukan dengan 4 kelas yaitu kelas dengan nilai mutu A, AB, B dan BC. Namun pada iterasi ketiga percobaan dilakukan untuk 2 kelas yaitu K1 yang terdiri dari kelas dengan nilai mutu A dan AB serta K2 yang terdiri dari kelas dengan nilai mutu B dan BC. Pada iterasi ketiga menghasilkan model dengan akurasi terbaik lebih besar sama dengan 70% yaitu sebesar 85.71%. Karena pada iterasi ketiga pengujian model klasifikasi sudah memenuhi syarat untuk model dengan akurasi terbaik lebih besar sama dengan 70.00%, sehingga dapat dilakukan tahap selanjutnya yaitu evaluasi dan analisis model klasifikasi. Pada tahap evaluasi dan analisis model klasifikasi akan diperoleh aktivitas pada LMS yang mempengaruhi nilai mata kuliah data mining. Penjelasan lebih jelas untuk setiap iterasi dapat dilihat dibawah ini.
14
Gambar 9 Potongan data log pembelajaran sebelum praproses data
Iterasi Pertama
Pengumpulan Data
Data yang digunakan pada penelitian ini diperoleh dari dosen kordinator mata kuliah data mining Ilmu Komputer IPB. Penelitian ini menggunakan data mahasiswa reguler dan alih jenis Program Studi S1 Ilmu Komputer FMIPA IPB sebanyak 144 mahasiswa dan data log penggunaan LMS untuk mata kuliah data mining tahun ajaran 2015/2016 sebanyak 37.161 log dengan 5 atribut yang digunakan sesuai dengan Tabel 1.
Praproses Data
Praproses data dilakukan untuk menghasilkan dataset yang relevan dengan kebutuhan algoritme pohon keputusan C50. Dalam penelitian ini, data log pembelajaran merupakan representasi aktivitas pembelajar pada kelas data mining yang diikuti. Gambar 9 memperlihatkan contoh potongan data log pembelajaran yang belum dilakukan praproses data.
Terdapat beberapa tahap yang harus dilakukan pada praproses data. Tahap pertama dilakukan dengan menghilangkan seluruh pengguna dosen dan asisten praktikum pada setiap data log, sehingga pada fail data log tersebut hanya terdapat pengguna mahasiswa saja. Gambar 10 memperlihatkan potongan data log dengan berbagai macam pengguna seperti dosen dan asisten praktikum.
Setelah menghilangkan seluruh pengguna dosen dan asisten praktikum, tahap selanjutnya adalah memilih atribut berupa aktivitas yang dilakukan mahasiswa pada penggunaan LMS. Aktivitas tersebut didapat dari kolom event_name pada data log LMS yang terdiri dari 36 atribut yang dapat dilihat pada Lampiran 1. Gambar 11 memperlihatkan potongan aktivitas pada data log dengan berbagai macam pengguna seperti dosen dan asisten praktikum.
15
Dari 36 aktivitas pada data log dipilih 4 aktivitas yang dijadikan sebagai atribut yang dilakukan oleh mahasiswa disesuaikan dengan penelitian yang dilakukan oleh Romero et al. (2010) dan Akcapinar et al. (2015) yaitu a submission has been submitted yang diinisialisasi dengan n_assignment (V1), The status of the submission has been viewed diinisialisasi dengan n_view assignment (V2), n_course_view (V3), dan n_course_module_view (V4). Kemudian dari data mahasiswa digunakan nilai mutu mata kuliah data mining sebagai kelas keputusan. Tahap selanjutnya yaitu menghitung jumlah aktivitas. Pada iterasi pertama setiap atribut dihitung berdasarkan jumlah keseluruhan aktivitas yang dilakukan mahasiswa. Tabel 3 memperlihatkan potongan jumlah aktivitas pada data log untuk masing-masing aktivitas. Jumlah keseluruhan aktivitas dapat dilihat pada Lampiran 2.
Tabel 3 Potongan jumlah aktivitas pada iterasi pertama
Pengguna V1 V2 V3 V4
Mahasiswa 1 5 30 51 60
Mahasiswa 2 4 12 137 50
Mahasiswa 3 7 26 33 55
Mahasiswa 4 5 27 48 61
Dari hasil jumlah aktivitas yang didapat untuk masing-masing mahasiswa, selanjutnya dihitung interval atau rentang nilai untuk masing-masing atribut. Perhitungan rentang nilai dibagi menjadi 4 grup yaitu tinggi yang dikodekan dengan (3), sedang dikodekan dengan (2), rendah dikodekan dengan (1) dan tidak ada informasi dikodekan dengan (0). Perhitungan rentang nilai dapat dilihat pada Persamaan 7. Setelah dilakukan perhitungan, diperoleh hasil interval seperti pada Tabel 4.
Tabel 4 Interval untuk masing-masing atribut pada iterasi pertama Kategori Batas atas Batas bawah Interval
V1 14 1 5
V2 56 1 19
V3 293 8 95
V4 185 8 59
Setiap atribut pada data log yang sudah dijumlahkan aktivitasnya mempunyai batas bawah dan batas atas yang digunakan untuk menentukan rentang nilai. Tabel Gambar 11 Potongan aktivitas pada data log dengan berbagai macam pengguna
16
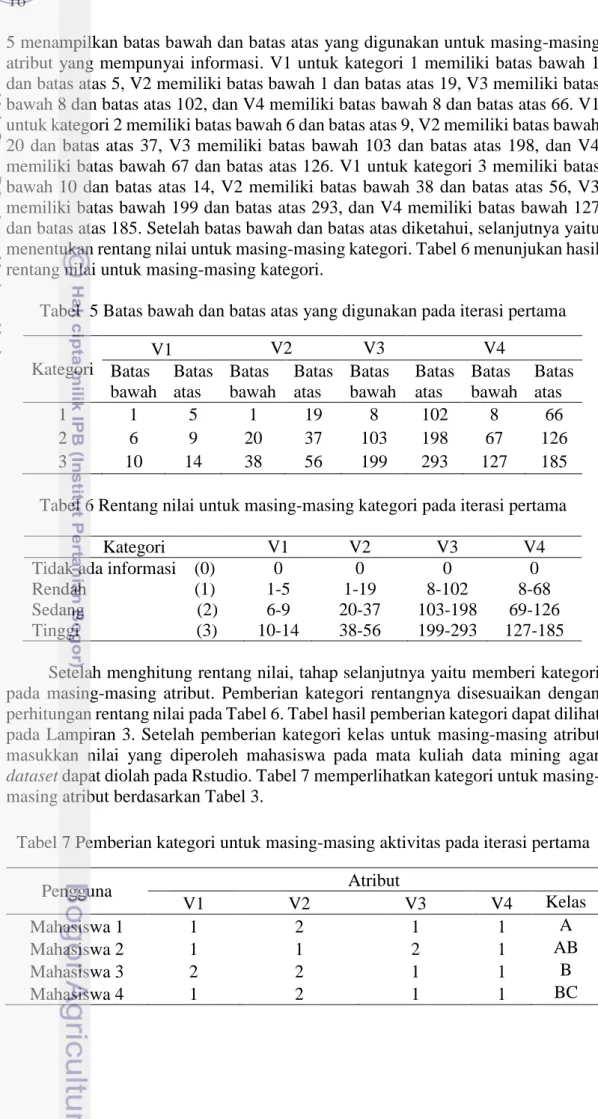
5 menampilkan batas bawah dan batas atas yang digunakan untuk masing-masing atribut yang mempunyai informasi. V1 untuk kategori 1 memiliki batas bawah 1 dan batas atas 5, V2 memiliki batas bawah 1 dan batas atas 19, V3 memiliki batas bawah 8 dan batas atas 102, dan V4 memiliki batas bawah 8 dan batas atas 66. V1 untuk kategori 2 memiliki batas bawah 6 dan batas atas 9, V2 memiliki batas bawah 20 dan batas atas 37, V3 memiliki batas bawah 103 dan batas atas 198, dan V4 memiliki batas bawah 67 dan batas atas 126. V1 untuk kategori 3 memiliki batas bawah 10 dan batas atas 14, V2 memiliki batas bawah 38 dan batas atas 56, V3 memiliki batas bawah 199 dan batas atas 293, dan V4 memiliki batas bawah 127 dan batas atas 185. Setelah batas bawah dan batas atas diketahui, selanjutnya yaitu menentukan rentang nilai untuk masing-masing kategori. Tabel 6 menunjukan hasil rentang nilai untuk masing-masing kategori.
Tabel 5 Batas bawah dan batas atas yang digunakan pada iterasi pertama
Tabel 6 Rentang nilai untuk masing-masing kategori pada iterasi pertama
Setelah menghitung rentang nilai, tahap selanjutnya yaitu memberi kategori pada masing-masing atribut. Pemberian kategori rentangnya disesuaikan dengan perhitungan rentang nilai pada Tabel 6. Tabel hasil pemberian kategori dapat dilihat pada Lampiran 3. Setelah pemberian kategori kelas untuk masing-masing atribut masukkan nilai yang diperoleh mahasiswa pada mata kuliah data mining agar dataset dapat diolah pada Rstudio. Tabel 7 memperlihatkan kategori untuk masing-masing atribut berdasarkan Tabel 3.
Tabel 7 Pemberian kategori untuk masing-masing aktivitas pada iterasi pertama
Pengguna Atribut V1 V2 V3 V4 Kelas Mahasiswa 1 1 2 1 1 A Mahasiswa 2 1 1 2 1 AB Mahasiswa 3 2 2 1 1 B Mahasiswa 4 1 2 1 1 BC Kategori V1 V2 V3 V4 Batas bawah Batas atas Batas bawah Batas atas Batas bawah Batas atas Batas bawah Batas atas 1 1 5 1 19 8 102 8 66 2 6 9 20 37 103 198 67 126 3 10 14 38 56 199 293 127 185 Kategori V1 V2 V3 V4
Tidak ada informasi (0) 0 0 0 0
Rendah (1) 1-5 1-19 8-102 8-68 Sedang (2) 6-9 20-37 103-198 69-126 Tinggi (3) 10-14 38-56 199-293 127-185
17
Pembagian Data
Pada iterasi pertama untuk melakukan klasifikasi data dibagi menjadi data latih dan data uji. Data latih digunakan untuk membangun model pohon keputusan, sedangkan data uji digunakan untuk menguji model pohon keputusan. Pembagian data dilakuan menggunakan 10 cross fold validation. Jumlah data untuk masing-masing kelas pada iterasi pertama dapat dilihat pada Tabel
Tabel 8 Jumlah nilai mutu mata kuliah data mining pada iterasi pertama Huruf mutu Jumlah Mahasiswa
A 37
AB 26
B 53
BC 28
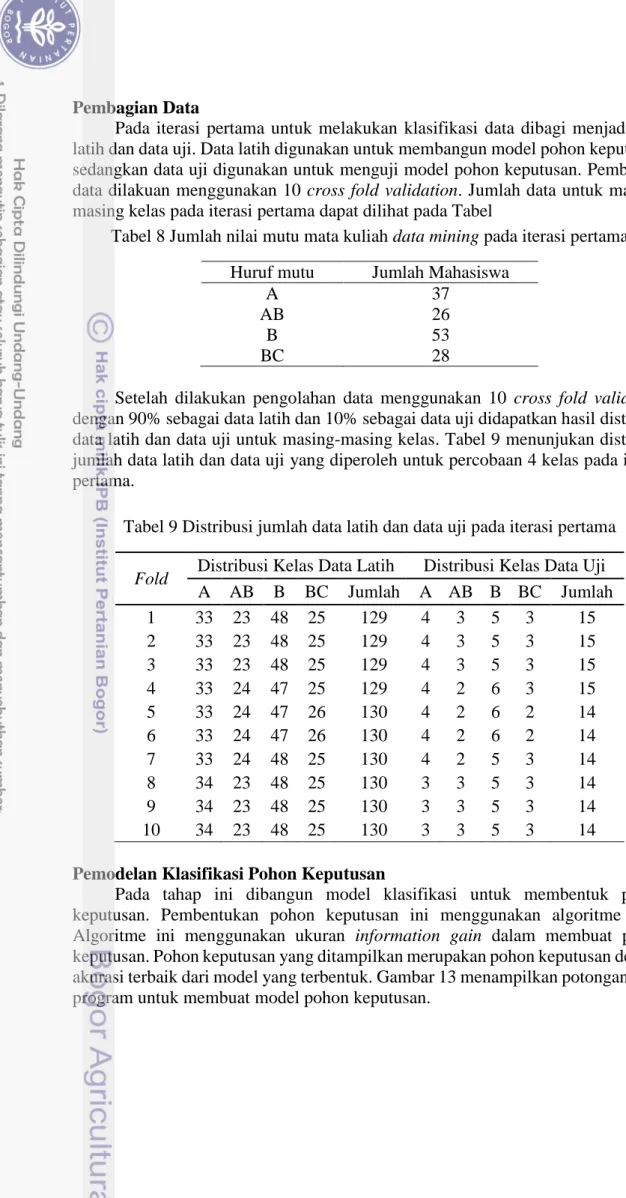
Setelah dilakukan pengolahan data menggunakan 10 cross fold validation dengan 90% sebagai data latih dan 10% sebagai data uji didapatkan hasil distribusi data latih dan data uji untuk masing-masing kelas. Tabel 9 menunjukan distribusi jumlah data latih dan data uji yang diperoleh untuk percobaan 4 kelas pada iterasi pertama.
Tabel 9 Distribusi jumlah data latih dan data uji pada iterasi pertama Fold Distribusi Kelas Data Latih Distribusi Kelas Data Uji
A AB B BC Jumlah A AB B BC Jumlah 1 33 23 48 25 129 4 3 5 3 15 2 33 23 48 25 129 4 3 5 3 15 3 33 23 48 25 129 4 3 5 3 15 4 33 24 47 25 129 4 2 6 3 15 5 33 24 47 26 130 4 2 6 2 14 6 33 24 47 26 130 4 2 6 2 14 7 33 24 48 25 130 4 2 5 3 14 8 34 23 48 25 130 3 3 5 3 14 9 34 23 48 25 130 3 3 5 3 14 10 34 23 48 25 130 3 3 5 3 14
Pemodelan Klasifikasi Pohon Keputusan
Pada tahap ini dibangun model klasifikasi untuk membentuk pohon keputusan. Pembentukan pohon keputusan ini menggunakan algoritme C50. Algoritme ini menggunakan ukuran information gain dalam membuat pohon keputusan. Pohon keputusan yang ditampilkan merupakan pohon keputusan dengan akurasi terbaik dari model yang terbentuk. Gambar 13 menampilkan potongan kode program untuk membuat model pohon keputusan.
18
Potongan program pada Gambar 12 merupakan kode program dari fungsi algoritme pohon keputusan C50 untuk membuat model. Baris 1 menjelaskan list data yang diinisialisai dengan model_all. Baris 2 dan 3 menjelaskan variabel yang menyimpan label atau kelas untuk data latih dan data untuk data latih sedangkan baris 4 dan 5 menjelaskan variabel yang menyimpan data untuk data uji dan label atau kelas untuk data uji. Baris 7 sampai 15 merupakan kode program untuk proses 10 fold cross validation yaitu 9 kali digunakan sebagai data latih dan 1 sebagai data uji. Baris 16 dan 17 untuk menampilkan model secara keseluruhan sedangkan baris 18 digunakan untuk menampilkan pohon keputusan yang terbentuk dari masing-masing model.
Pohon keputusan yang dihasilkan pada iterasi pertama dengan percobaan 4 kelas, diperoleh dari model ke 5 sebagai model terbaik. Pohon keputusan tersebut menampilkan V4 yaitu atribut n_course_module_view sebagai atribut yang memperoleh nilai gain tertinggi atau root dengan jumlah data ≤ 1 sebanyak 84 data terklasifikasi sebagai kelas B. Jika V4 > 1 sebanyak 46 data terklasifikasi sebagai kelas A. Gambar 13 menampilkan pohon keputusan yang dihasilkan pada iterasi pertama. 1 model_all <- list() 2 trainX_all <- list() 3 trainY_all <- list() 4 testX_all <- list() 5 testY_all <- list() 6 # actual cross validation 7 for(k in 1:nrFolds) { 8 # actual split of the data 9 fold <- which(folds == k) 10 data.train <- data[-fold,] 11 data.test <- data[fold,] 12 trainX <- data.train[,1:4] 13 testX <- data.test[,1:4] 14 trainY <-data.train[,5] 15 testY <- data.test[,5]
16 model <- C5.0( trainX, trainY ) 17 model_all[[k]] <- model
18 plot(model_all[[k]])
Gambar 13 Pohon keputusan untuk iterasi pertama
19
Pengujian Model Klasifikasi
Pada tahap ini dilakukan perhitungan akurasi. Tingkat akurasi yang baik adalah tingkat akurasi yang mendekati 100%. Semakin tinggi tingkat akurasi maka semakin rendah kesalahan klasifikasi. Pada tahap pengujian model klasifikasi, percobaan dengan iterasi pertama dipastikan apakah hasil akurasi dari model terbaik yang diperoleh lebih besar sama dengan 70%. Dalam penelitian ini, pada iterasi pertama dihasilkan akurasi dari model terbaik lebih kecil sama dengan 70% yaitu sebesar 64.29% yang diperoleh pada model ke 5. Hasil akurasi pada iterasi pertama dapat dilihat pada Gambar 14.
Gambar 14 Hasil akurasi pada iterasi pertama
Dari percobaan yang dilakukan pada iterasi pertama, dengan melakukan pengujian pada 4 kelas menghasilkan confusion matrix yang terbentuk dari data uji untuk model terbaik dapat dilihat pada Tabel 10. Dari confusion matrix tersebut dihasilkan kelas AB dan BC bernilai 0. Kelas AB sebanyak 1 terklasifikasi sebagai kelas A dan kelas BC sebanyak 2 terklasifikasi sebagai kelas B. Selain itu nilai precision dan recall yang diperoleh untuk masing-masing kelas dari confusion matrix yang dihasilkan pada tabel 10 dapat dilihat pada Tabel 11.
Tabel 10 Confusion matrix yang dihasilkan pada iterasi pertama
Tabel 11 Nilai precision dan recall yang dihasilkan pada iterasi pertama
Kelas Precision Recall
A 75.00% 75.00% AB 0 0 B 60.00% 100.00% BC 0 0 10.00% 20.00% 30.00% 40.00% 50.00% 60.00% 70.00% 80.00% 90.00% 100.00%
Hasil Akurasi pada Iterasi Pertama
A AB B BC
A 3 0 1 0
AB 1 0 1 0
B 0 0 6 0
20
Iterasi Kedua
Pengumpulan Data
Data yang digunakan pada iterasi kedua sama dengan iterasi pertama yaitu data mahasiswa sebanyak 144 mahasiswa reguler dan alih jenis S1 Ilmu Komputer FMIPA IPB dan data log penggunaan LMS untuk mata kuliah data mining tahun ajaran 2015/2016 sebanyak 37.161 log dengan 5 atribut yang digunakan sesuai dengan Tabel 1.
Praproses Data
Pada tahap praproses data, tahap pemilihan atribut pengguna LMS dan pemilian atribut berupa aktivitas LMS sama dengan yang dilakukan pada iterasi pertama. Namun yang membedakan yaitu perhitungan jumlah aktivitas pada LMS. Perubahan terjadi pada atribut V3 dan V4 sedangkan untuk V1 dan V2 tetap. Jumlah aktivitas pada atribut V3 dan V4 dihitung per hari dimana semua kejadian yang terjadi dalam 1 hari dihitung sebagai 1 aktivitas. Berbeda dengan perhitungan aktivitas pada iterasi pertama dimana setiap kejadian dihitung satu aktivitas. Tabel 12 memperlihatkan potongan jumlah aktivitas pada data log untuk masing-masing atribut. Jumlah keseluruhan aktivitas untuk iterasi kedua dapat dilihat pada Lampiran 4.
Tabel 12 Potongan jumlah aktivitas pada iterasi kedua
Pengguna V1 V2 V3 V4
Mahasiswa 1 5 30 18 13
Mahasiswa 2 4 12 13 11
Mahasiswa 3 7 26 7 13
Mahasiswa 4 5 27 14 11
Seperti yang terlihat pada Tabel 12, jumlah aktivitas pada atribut V3 dan V4 berbeda dari jumlah aktivitas yang diperoleh pada iterasi pertama. Pada iterasi kedua, mahasiswa 2 memiliki jumlah aktivitas sebanyak 13 sedangkan sebelumnya pada iterasi pertama sebanyak 137. Hal ini juga mempengaruhi untuk tahap selanjutnya yaitu pemberian kategori untuk masing-masing mahasiswa.
Sebelum melakukan tahapan pemberian kategori, terlebih dahulu dihitung interval atau rentang nilai untuk masing-masing atribut. Perhitungan rentang nilai sama dengan iterasi pertama yaitu membagi menjadi 4 grup yaitu tinggi yang dikodekan (3), sedang dikodekan (2), rendah dikodekan (1) dan tidak ada informasi (0). Untuk aktivitas V1 dan V2 rentangnya disesuaikan dengan iterasi pertama karena pada iterasi kedua hanya merubah jumlah aktivitas V3 dan V4. Perhitungan rentang nilai untuk masing-masing atribut menggunakan Persamaan 7. Hasil yang diperoleh dapat dilihat pada Tabel 13.
21 Tabel 13 Interval untuk masing-masing atribut pada iterasi kedua
Kategori Batas atas Batas bawah Interval
V1 14 1 5
V2 56 1 19
V3 34 1 11
V4 25 4 7
Setiap atribut pada data log yang sudah dijumlahkan aktivitasnya mempunyai batas bawah dan batas atas yang digunakan untuk menentukan rentang nilai. Tabel 14 menampilkan batas bawah dan batas atas yang digunakan untuk masing-masing atribut yang mempunyai informasi.
Tabel 14 Batas bawah dan batas atas yang diperoleh untuk masing-masing atribut
V1 untuk kategori 1 memiliki batas bawah 1 dan batas atas 5, V2 memiliki batas bawah 1 dan batas atas 19, V3 memiliki batas bawah 1 dan batas atas 11, dan V4 memiliki batas bawah 4 dan batas atas 10. V1 untuk kategori 2 memiliki batas bawah 6 dan batas atas 9, V2 memiliki batas bawah 20 dan batas atas 37, V3 memiliki batas bawah 12 dan batas atas 23, dan V4 memiliki batas bawah 11 dan batas atas 18. V1 untuk kategori 3 memiliki batas bawah 10 dan batas atas 14, V2 memiliki batas bawah 38 dan batas atas 56, V3 memiliki batas bawah 24 dan batas atas 34, dan V4 memiliki batas bawah 19 dan batas atas 25. Setelah batas bawah dan batas atas diketahui, selanjutnya yaitu menentukan rentang nilai untuk masing-masing kategori. Tabel 15 menunjukan hasil rentang nilai untuk masing-masing-masing-masing kategori.
Tabel 15 Rentang nilai untuk masing-masing kategori pada iterasi kedua
Setelah menghitung rentang nilai dari masing-masing atribut tahap selanjutnya yaitu pemberian kategori untuk setiap mahasiswa. Pemberian kategori rentangnya disesuaikan dengan Tabel 15. Tabel hasil pemberian kategori untuk iterasi kedua dapat dilihat pada Lampiran 5. Setelah pemberian kategori kelas untuk masing-masing atribut masukkan nilai yang diperoleh mahasiswa pada mata kuliah
Kategori V1 V2 V3 V4 Batas bawah Batas atas Batas bawah Batas atas Batas bawah Batas atas Batas bawah Batas atas 1 1 5 1 19 1 11 4 10 2 6 9 20 37 12 23 11 18 3 10 14 38 56 24 34 19 25 Kategori V1 V2 V3 V4
Tidak ada informasi (0) 0 0 0 0
Rendah (1) 1-5 1-19 1-11 4-10 Sedang (2) 6-9 20-37 12-23 11-18 Tinggi (3) 10-14 38-56 24-34 19-25
22
data mining agar dataset dapat diolah pada Rstudio. Tabel 16 memperlihatkan kategori untuk masing-masing atribut berdasarkan Tabel 12.
Tabel 16 Pemberian kategori untuk masing-masing aktivitas pada iterasi kedua
Pengguna Atribut V1 V2 V3 V4 Kelas Mahasiswa 1 1 2 2 2 A Mahasiswa 2 1 1 2 2 AB Mahasiswa 3 2 2 1 2 B Mahasiswa 4 1 2 2 2 BC Pembagian Data
Pada iterasi kedua pembagian data dilakukan seperti pada iterasi pertama. Data dibagi menjadi data latih dan data uji. Pembagian data dilakuan menggunakan 10 cross fold validation dengan 90% sebagai data latih dan 10% sebagai data uji. Jumlah data untuk masing-masing kelas pada iterasi kedua dapat dilihat pada Tabel 7. Setelah dilakukan pengolahan didapatkan hasil distribusi data latih dan data uji untuk masing-masing kelas. Tabel 17 menunjukan distribusi jumlah data latih dan data uji yang diperoleh pada iterasi kedua.
Tabel 17 Distribusi jumlah data latih dan data uji pada iterasi kedua Fold Distribusi Data Latih Distribusi Data Uji
A AB B BC Jumlah A AB B BC Jumlah 1 33 23 48 25 129 4 3 5 3 15 2 33 23 48 25 129 4 3 5 3 15 3 33 23 48 25 129 4 3 5 3 15 4 33 24 47 25 129 4 2 6 3 15 5 33 24 47 26 130 4 2 6 2 14 6 33 24 47 26 130 4 2 6 2 14 7 33 24 48 25 130 4 2 5 3 14 8 34 23 48 25 130 3 3 5 3 14 9 34 23 48 25 130 3 3 5 3 14 10 34 23 48 25 130 3 3 5 3 14
Pemodelan Klasifikasi Pohon Keputusan
Pada tahap ini pemodelan klasifikasi pohon keputusan untuk iterasi kedua sama dengan iterasi pertama. Pembentukan pohon keputusan ini menggunakan algoritme C50, dengan menggunakan nilai information gain dalam membuat pohon keputusan. Pohon keputusan yang ditampilkan merupakan pohon keputusan dari model dengan akurasi terbaik yang terbentuk. Gambar 15 menampilkan pohon keputusan yang terbentuk pada iterasi kedua.
23
Pohon keputusan yang dihasilkan pada iterasi kedua dengan percobaan 4 kelas diperoleh dari model ke 4 sebagai model terbaik. Pohon keputusan tersebut menampilkan V4 yaitu atribut course_module_view sebagai atribut yang memperoleh nilai gain tertinggi atau root. Apabila V4 ≤ 1 masuk ke V1 yaitu n_assignment sebagai internal node. Jika V1 ≤ 0 sebanyak 14 data terklasifikasi sebagai kelas B. Jika V1 > 0 sebanyak 20 data terklasifikasi sebagai kelas BC. Apabila V4 > 1 sebanyak 96 data terklasifikasi sebagai kelas B.
Pengujian Model Klasifikasi
Pada tahap pengujian model klasifikasi, percobaan dengan iterasi kedua dilakukan untuk memastikan hasil akurasi dari model terbaik yang diperoleh lebih besar sama dengan 70%. Dalam penelitian ini, pada iterasi kedua dihasilkan akurasi dari model terbaik lebih kecil sama dengan 70% yaitu sebesar 40.00% yang diperoleh pada model ke 4. Hasil akurasi pada iterasi kedua dapat dilihat pada Gambar 16.
Gambar 16 Grafik hasil akurasi pada iterasi kedua 26.67% 20.00% 26.67% 40.00% 35.71% 28.57% 28.57% 35.71% 35.71% 21.43% 29.90% 0.00% 20.00% 40.00% 60.00% 80.00% 100.00%
Hasil Akurasi pada Iterasi Kedua
24
Dari percobaan yang dilakukan confusion matrix yang terbentuk dari data uji untuk model terbaik pada iterasi kedua dapat dilihat pada Tabel 18. Selain itu nilai precision dan recall yang diperoleh untuk masing-masing kelas dari confusion matrix yang dihasilkan pada tabel 18 dapat dilihat pada Tabel 19.
Tabel 18 confusion matrix yang dihasilkan pada iterasi kedua
Table 19 Nilai precision dan recall yang dihasilkan pada iterasi kedua
Kelas Precision Recall
A 0 0 AB 0 0 B 38.46% 83.33% BC 50.00% 50.00% Iterasi Ketiga Pengumpulan Data
Data yang digunakan pada iterasi ketiga sama dengan iterasi pertama dan kedua yaitu data mahasiswa reguler dan alih jenis S1 Ilmu Komputer FMIPA IPB sebanyak 144 mahasiswa dan data log penggunaan LMS sebanyak 37.161 log pada mata kuliah data mining tahun ajaran 2015/2016.
Praproses Data
Pada tahap praproses data untuk iterasi ketiga, pemilihan atribut pengguna dan pemilian aktivitas LMS sama dengan yang dilakukan pada iterasi pertama dan kedua. Tahap praproses data pada iterasi ketiga menggunakan jumlah aktivitas pada iterasi pertama. Iterasi pertama digunakan kembali karena pada saat pengujian iterasi pertama dan kedua, menunjukan hasil bahwa iterasi pertama memiliki model dengan akurasi terbaik lebih besar dari pada iterasi kedua.
Pada iterasi ketiga yang membedakan adalah tahap pemberian label kelas. Sebelumnya pada iterasi pertama dan kedua percobaan dilakukan dengan 4 kelas yaitu kelas dengan nilai mutu A, AB, B dan BC. Namun pada iterasi ketiga percobaan dilakukan untuk 2 kelas yaitu K1 yang terdiri dari kelas dengan nilai mutu A dan AB serta K2 yang terdiri dari kelas dengan nilai mutu B dan BC. Percobaan ini dilakukan karena dari model yang terbentuk pada iterasi pertama kelas AB dan BC bernilai 0. Hal ini dikarenakan kelas AB terklasifikasi ke dalam kelas A dan kelas BC terklasifikasi kedalam kelas B. Tabel 20 memperlihatkan potongan jumlah aktivitas pada data log untuk masing-masing atribut
A AB B BC
A 0 0 4 0
AB 0 0 2 0
B 0 0 5 1
25 Tabel 20 Potongan jumlah aktivitas pada iterasi ketiga
Pengguna V1 V2 V3 V4
Mahasiswa 1 5 30 51 60
Mahasiswa 2 4 12 137 50
Mahasiswa 3 7 26 33 55
Mahasiswa 4 5 27 48 61
Dari hasil jumlah aktivitas yang didapat untuk masing-masing mahasiswa, selanjutnya dihitung rentang nilai untuk masing-masing atribut. Perhitungan rentang nilai pada iterasi ketiga sama seperti iterasi pertama dan kedua dengan membagi menjadi 4 grup yaitu tinggi yang dikodekan dengan (3), sedang dikodekan dengan (2), rendah dikodekan dengan (1) dan tidak ada informasi dikodekan dengan (0). Perhitungan rentang nilai dapat dilihat pada Persamaan 7. Tabel 21 menunjukan batas bawah dan batas atas yang diperoleh. dan Tabel 22 menunjukan rentang nilai untuk masing-masing atribut.
Tabel 21 Batas bawah dan batas atas untuk masing-masing atribut
Table 22 Rentang nilai untuk masing-masing kategori pada iterasi pertama
Setelah menghitung rentang nilai, tahap selanjutnya yaitu memberi kategori pada masing-masing atribut. Pemberian kategori rentangnya disesuaikan dengan perhitungan rentang nilai pada Tabel 20. Setelah tahap pemberian kategori untuk masing-masing atribut masukkan nilai yang diperoleh mahasiswa pada mata kuliah data mining sebagai kelas keputusan. Pada iterasi ketiga pemberian label untuk kelas dengan nilai mutu A dan AB dirubah menjadi K1 dan kelas dengan nilai mutu B dan BC menjadi K2. Perubahan ini dilakukan karena pada iterasi pertama confusion matrix dari model terbaik menghasilkan kelas BC terklasifikasi sebagai kelas B sehingga dilakukan percobaan dengan 2 kelas. Tabel 23 memperlihatkan kategori untuk masing-masing atribut dan pemberian label kelas pada iterasi ketiga berdasarkan Tabel 20. Pemberian label kelas untuk keseluruhan data pada iterasi ketiga dapat dilihat pada Lampiran 6.
Kategori V1 V2 V3 V4 Batas bawah Batas atas Batas bawah Batas atas Batas bawah Batas atas Batas bawah Batas atas 1 1 5 1 19 8 102 8 66 2 6 9 20 37 103 198 67 126 3 10 14 38 56 199 293 127 185 Kategori V1 V2 V3 V4
Tidak ada informasi (0) 0 0 0 0
Rendah (1) 1-5 1-19 8-102 8-68 Sedang (2) 6-9 20-37 103-198 69-126 Tinggi (3) 10-14 38-56 199-293 127-185
26
Tabel 23 Pemberian kategori untuk dan label kelas pada iterasi ketiga
Pembagian Data
Pada iterasi ketiga pembagian data dibagi menjadi data latih dan data uji. Pembagian data dilakuan menggunakan 10 cross fold validation. Jumlah data untuk masing-masing kelas pada iterasi ketiga dapat dilihat pada Tabel 24.
Tabel 24 Jumlah data untuk masing-masing kelas pada iterasi ketiga Huruf mutu Jumlah Mahasiswa
K1 63
K2 81
Setelah dilakukan pengolahan data menggunakan 10 cross fold validation dengan 90% sebagai data latih dan 10% sebagai data uji didapatkan hasil distribusi data latih dan data uji untuk masing-masing kelas. Tabel 25 menunjukan distribusi jumlah data latih dan data uji yang diperoleh pada iterasi ketiga.
Tabel 25 Distribusi jumlah data latih dan data uji pada iterasi ketiga Fold Distribusi Data Latih Distribusi Data Uji
K1 K2 Jumlah K1 K2 Jumlah 1 56 73 129 7 8 15 2 56 73 129 7 8 15 3 56 73 129 7 8 15 4 57 72 129 6 9 15 5 57 73 130 6 8 14 6 57 73 130 6 8 14 7 57 73 130 6 8 14 8 57 73 130 6 8 14 9 57 73 130 6 8 14 10 57 73 130 6 8 14
Pemodelan Klasifikasi Pohon Keputusan
Pada tahap ini pembentukan pohon keputusan menggunakan algoritme C50. Algoritme ini menggunakan ukuran information gain dalam membuat pohon keputusan. Pohon keputusan yang ditampilkan merupakan pohon keputusan dengan
Pengguna Atribut V1 V2 V3 V4 Kelas Mahasiswa 1 1 2 1 1 K1 Mahasiswa 2 1 1 2 1 K1 Mahasiswa 3 2 2 1 1 K2 Mahasiswa 4 1 2 1 1 K2
27 akurasi terbaik dari model yang terbentuk. Gambar 17 menampilkan pohon keputusan yang terbentuk pada iterasi ketiga.
Pohon keputusan yang dihasilkan pada iterasi ketiga dengan percobaan 2 kelas diperoleh model terbaik yaitu model ke 5 Pohon keputusan tersebut menampilkan V4 yaitu atribut course_module_view sebagai atribut yang memperoleh nilai gain tertinggi atau root. Apabila V4 ≤ 1 sebanyak 84 data terklasifikasi sebagai kelas K2, sedangkan jika V4 > 1 sebanyak 46 data terklasifikasi sebagai kelas K1
Pengujian Model Klasifikasi
Pada tahap pengujian model klasifikasi, percobaan dengan iterasi ketiga dilakukan untuk memastikan hasil akurasi dari model terbaik yang diperoleh lebih besar sama dengan 70%. Dalam penelitian ini, pada iterasi ketiga dihasilkan akurasi dari model terbaik sebesar 85.71% dan sudah memenuhi syarat akurasi. Hasil akurasi pada iterasi ketiga dapat dilihat pada Gambar 18.
Gambar 18 Hasil akurasi pada iterasi ketiga
Dari percobaan yang dilakukan pada iterasi ketiga confusion matrix yang dihasilkan dari data uji dapat dilihat pada Tabel 27.
60.00% 73.33% 60.00% 60.00% 85.71% 71.43% 71.43% 57.14% 64.29%78.57%68.19% 0.00% 20.00% 40.00% 60.00% 80.00% 100.00%
Hasil Akurasi Iterasi Ketiga
28
Tabel 26 Confusion matrix yang dihasilkan pada iterasi ketiga
Selain itu nilai precision dan recall yang diperoleh untuk masing-masing kelas dari confusion matrix yang dihasilkan pada tabel 27 dapat dilihat pada Tabel 28.
Tabel 27 Nilai precision dan recall pada iterasi ketiga
Kelas Precision Recall
K1 100.00% 66.67%
K2 80.00% 100.00%
Evaluasi dan Analisis Model Klasifikasi
Dari percobaan yang dilakukan pada iterasi pertama hingga ketiga diperoleh 3 model terbaik yang dihasilkan untuk masing-masing iterasi. Dari setiap model tersebut dianalisis bahwa pada setiap model pohon keputusan, atribut yang menjadi root yaitu V4 (course_module_ view). Pada iterasi pertama diketahui dari Gambar 13 , iterasi kedua dari Gambar 15 dan iterasi ketiga dari Gambar 17.
Pada iterasi pertama dan kedua pengujian model klasifikasi dilakukan pada perobaan 4 kelas, sedangkan pada iterasi ketiga pengujian model klasifikasi dilakukan pada 2 kelas. Pada tahap pengujian model klasifikasi untuk iterasi pertama setiap atribut dihitung berdasarkan jumlah keseluruhan aktivitas yang dilakukan mahasiswa. Pada iterasi kedua terjadi perubahan pada atribut V3 dan V4 sedangkan untuk V1 dan V2 tetap. Jumlah aktivitas pada atribut V3 dan V4 dihitung per hari dimana semua kejadian yang terjadi dalam 1 hari dihitung sebagai 1 aktivitas. Berbeda dengan perhitungan aktivitas pada iterasi pertama dimana setiap kejadian dihitung satu aktivitas. Oleh karena itu setelah dilakukan percobaan dari iterasi pertama hingga ketiga, menghasilkan aktivitas yang paling mempengaruhi nilai pada mata kuliah data mining yaitu V4 (course_module_view) .
SIMPULAN DAN SARAN
Simpulan
Pada penelitian ini berhasil melakukan klasifikasi nilai akhir mahasiswa mata kuliah data mining berdasarkan aktivitas pada log LMS dengan menggunakan algoritme pohon keputusan C50. Data yang diperoleh menghasilkan klasifikasi sebanyak 3 kali iterasi. Iterasi pertama dan kedua dilakukan percobaan dengan 4 kelas dan iterasi ketiga dilakukan percobaan dengan 2 kelas menggunakan pohon
K1 K2
K1 4 2