KLASIFIKASI PEMBELI YANG MELAKUKAN ONLINE SHOPPING MENGGUNAKAN ALGORITME CORRELATED NAIVE BAYES
SKRIPSI
Diajukan Untuk Memenuhi Salah Satu Syarat Memperoleh Gelar Sarjana Komputer
Program Studi Informatika
Oleh:
Aroom Putri Iswari 175314062
PROGRAM STUDI INFORMATIKA FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA YOGYAKARTA
CLASSIFICATION OF BUYER WHO DO ONLINE SHOPPING USING CORRELATED
NAIVE BAYES ALGORITHM
THESIS
Present as Fulfillment of the Requirement to Obtain Sarjana Komputer Degree
in Informatics Study Program
By:
Aroom Putri Iswari 175314062
INFORMATICS STUDY PROGRAM DEPARTMENTS OF INFORMATICS FACULTY OF SCIENCE AND TECHNOLOGY
UNIVERSITAS SANATA DHARMA YOGYAKARTA
i
HALAMAN PERSETUJUAN PEMBIMBING
ONLINE SHOPPING MENGGUNAKAN ALGORITME CORRELATED NAIVE BAYES
Oleh:
Aroom Putri Iswari 175314062
Telah disetujui oleh:
Dosen Pembimbing
ii
HALAMAN PENGESAHAN SKRIPSI
KLASIFIKASI PEMBELI YANG MELAKUKAN ONLINE SHOPPING MENGGUNAKAN ALGORITME CORRELATED NAIVE BAYES
Dipersiapkan dan ditulis oleh:
AROOM PUTRI ISWARI NIM : 175314062
Telah dipertahankan di depan Panitia Penguji Pada tanggal 6 Juli 2021
Dan dinyatakan memenuhi Syarat
Susunan Panita Penguji
Nama Lengkap Tanda Tangan
Ketua : Agnes Maria Polina S.Kom., M.Kom.
Sekertaris : Drs. Hari Suparwito, S.J., M.App.IT Pembimbing : Eko Hari Parmadi S.Si., M.Kom.,
Yogyakarta, 20 Juli 2021 Fakultas Sains dan Teknologi
Universitas Sanata Dharma Dekan
iii
HALAMAN PERSEMBAHAN
“ Reach the goal, enjoy and take every single point in your process. No need to be
worry because good result doesn’t come to smart person, but for the one who want to fight and take the worst to be better. Just make your mom proud of you my
little sister. Ganbatte Kudasai ” (Mas Ireng, 2017)
“ Hidup ini tidak adil, jadi biasakan dirimu ” – Patrick Star
“ Sudah kukatakan aku adalah aku, kau adalah kau. Soal siapa yang lebih hebat itu tidak penting. ” – Nara Shikamaru
Skripsi ini dipersembahkan untuk: “ Diri sendiri ”
“ Orangtua, Keluarga ”
iv
PERNYATAAN KEASLIAN KARYA
Saya menyatakan dengan sesungguhnyaa bahwa skripsi yang saya tulis ini tidak memuat karya tau bagian karya orang lain, kecuali yang tekah disebutkan dalam kutipan daftar pustaka, sebagaimana karya ilmiah.
Yogyakarta, 17 Juli 2021 Penulis
Aroom Putri Iswari
v ABSTRAK
Perdagangan yang awalnya berjalan melalui pertemuan secara langsung antara pedagang dengan konsumen, sekarang dapat dilakukan melalui jaringan internet dan dikenal sebagai perdagangan elektronik. Perdangan elektronik membantu pedagang dan konsumen memiliki kebebasan melakukan transaksi dengan fleksibel dan jangkauannya mencakup seluruh dunia. Bentuk perdagangan elektronik telah merambah ke antarmuka web, dengan munculnya berbagai startup di berbagai belahan dunia. Tersedianya layanan ini dapat mengubah beberapa pola perdagangan dengan sistem transaksi penjual dengan konsumen yang menjalankan kegiatannya melalui jaringan internet. Sistem perdagangan online ini menghasilkan kumpulan data yang memungkinkan adanya penelitian pengolahan data tersebut untuk mendapatkan penilaian terhadap konsumen yang akan melakukan transaksi belanja atau yang hanya melihat-lihat barang tanpa ada niatan untuk membelinya.
Penelitian ini menggunkan metode Correlated Naive Bayes Classifier untuk mengklasifikasikan user yang berpotensi melakukan pembelian barang
online. Proses perangkingan atribut menggunakan Principal Component Analysis
(PCA) dan untuk mengatasi keseimbangan atara data minor dan data mayor digunakan Synthetic Minority Oversampling Technique (SMOTE) dengan variasi
nearest neighbor dan precentage data minor. Dari pengujian data yang telah
dilakukan, atribut Administrative merupakan atribut yang paling berpengaruh dalam klasifikasi pembeli yang melakukan online shopping. Hasil akurasi terbaik diperoleh dengan angka 84.6044%. Hasil tercapai ketika menggunakan menggunakan 10-Fold Cross Validation, tanpa melalui SMOTE.
vi ABSTRACT
Trade that initially ran through face-to-face meetings between traders and consumers, can now be done via the internet and is known as electronic commerce. Electronic commerce helps merchants and consumers have the freedom to make transactions with flexibility and reach worldwide. This form of electronic commerce has penetrated into the web interface, with the emergence of various startups in different parts of the world. The availability of this service can change several trading patterns with a seller-consumer transaction system that runs its activities through the internet network. This online trading system produces a collection of data that allows research into processing the data to get an assessment of consumers who will make shopping transactions or who are just looking at goods without any intention to buy them.
This study use Correlated Naive Bayes Classifier method to classify users who have the potential to purchase goods online. The attribute ranking process uses Principal Component Analysis (PCA) and to overcome the balance between minor and major data, Synthetic Minority Oversampling Technique (SMOTE) used with variations of nearest neighbor and minor data percentage. From the data testing that has been done, the Administrative attribute is the most influential attribute in the classification of buyers who do online shopping. The best accuracy results were obtained with a figure of 84,6044%. Results are achieved when using 10-Fold Cross Validation, without going through SMOTE.
Keywords: e-commerce, data mining, Correlated Naive Bayes, classification
vii
LEMBAR PERNYATAAN PUBLIKASI KARYA ILMIAH UNTUK KEPENTINGAN AKADEMIS
Yang bertanda tangan dibawah ini, saya mahasiswa Universitas Sanata Dharma:
Nama : Aroom Putri Iswari
Nim : 175314062
Demi pengembangan ilmu pengetahuan, saya memberikan kepada Perpustakaan Universitas Sanata Dharma karya ilmiah saya yang berjudul:
KLASIFIKASI PEMBELI YANG MELAKUKAN ONLINE SHOPPING MENGGUNAKAN ALGORITME CORRELATED NAIVE BAYES
Beserta perangkat yang diperlukan (bila ada). Dengan demikian saya memberikan kepada Perpustakaan Universitas Sanata Dharma untuk menyimpan, mengalikan dalam bentuk media lain untuk kepentingan akademis tanpa perlu meminta ijin dari saya maupun royalty kepada saya selama tetap mencantumkan nama saya sebagai penulis.
Demikian pernyataan ini saya buat dengan sebenarnya.
Yogyakarta, 17 Juli 2021
viii
KATA PENGANTAR
Puji syukur pada kehadirat Tuhan Yang Maha Esa, penulis dapat menyelesaikan Skripsi dengan judul Klasifikasi Pembeli Yang Melakukan Online Shopping Menggunakan Algoritme Correlated Naive Bayes. Skripsi ini disusun untuk memenuhi salah satu syarat menyelesaikan Sarjana Informatika pada Fakultas Sains dan Teknologi, Universitas Sanata Dharma Yogyakarta. Berkat bantuan dan bimbingan oleh berbagai pihak yang selalu mendukung untuk meyelesaikan Skripsi. Pada kesempatan ini penulis dengan segenap kerendahan hati mengucapkan terima kasih kepada:
1. Ibu Kusmiyati selaku orang tua yang mendukung, mendorong, memotivasi penulis dan senantiasa memberikan kasih sayang kepada penulis.
2. Dwi Brahma, Ireng Triatmojo dan Sinta Listya selaku kakak penulis yang selalu memberikan dukungan dan motivasi.
3. Kustopo, Sugiyem, Sigit Widyanto, Dharma Setyawan, Galuh Pratiwi, Riyana, Fatma, Anjarina, Kumara Ghani, Bara Atlancea, Suanda Veto, Catalea Elliose beserta keluarga besar simbah Darso Sutrisno yang turut serta memberikan semangat, motivasi dan saran secara langsung maupun tidak langsung kepada penulis.
4. Bapak Sudi Mungkasi, S.Si., M.Math.Sc,. Ph.D selaku Dekan Fakultas Sains dan Teknologi Universitas Sanata Dharma.
5. Bapak Robertus Adi Nugroho, M.Eng selaku Ketua Program Studi Informatika Universitas Sanata Dharma.
6. Bapak Eko Hari Parmadi S.Si., M.Kom selaku dosen pembimbing tugas akhir yang telah memberikan bimbingan, pengajaran dan ilmu-ilmu baru yang penulis dapatkan selama penyusunan skripsi ini. 7. Bapak Drs. Johanes Eka Priyatma M.Sc., Ph.D.selaku dosen
pembimbing akademik yang selalu memberikan bimbingan, nasehat selama masa perkuliahan.
ix
8. Segenap Dosen Fakultas Sains dan Teknologi khususnya Program Studi Informatika Universitas Sanata Dharma yang telah mendidik dan memberikan ilmu pengetahuan selama proses perkuliahan. 9. Teman-teman Informatika Universitas Sanata Dharma angkatan
2017 yang telah berdinamika selama perkuliahan dan saling menyemangati dalam menyelesaikan Skripsi .
10. Teman-teman kelas Basis Data ‘Penak Miring’ yang menciptakan suasana belajar menyenangkan dan saling menemani, menghibur, menyemangati serta memberikan dukungan satu sama lain.
11. Semua pihak yang telah ikut membantu dan tidak dapat disebutkan satu persatu disini.
Penulis menyadari masih banyak kekurangan pada Skripsi karena pengalaman dan pengetahun yang masih terbatas. Oleh karena itu, kritik dan saran diharapkan untuk membangun Skripsi ini. Akhir kata, penulis berhatap Skripsi ini dapat berguna dan bermanfaat bagi berbagai pihak.
Penulis
x DAFTAR ISI
HALAMAN PERSETUJUAN PEMBIMBING ... i
HALAMAN PENGESAHAN ... ii
HALAMAN PERSEMBAHAN ... iii
PERNYATAAN KEASLIAN KARYA ... iv
ABSTRAK ... v
ABSTRACT ... vi
LEMBAR PERNYATAAN PUBLIKASI KARYA ILMIAH ... vii
KATA PENGANTAR ... viii
DAFTAR ISI ... x
DAFTAR GAMBAR ... xiii
BAB I PENDAHULUAN ... 1 1.1. Latar Belakang ... 1 1.2. Rumusan Masalah ... 2 1.3. Tujuan ... 2 1.4. Manfaat ... 3 1.5. Batasan Masalah ... 3 1.6. Sistematika Penulisan ... 3
BAB II LANDASAN TEORI ... 5
2.1. Tinjauan Pustaka ... 5
2.2. Perdagangan Elektronik ... 6
2.3. Knowledge Discovey in Database (KDD) ... 7
2.4. Data Mining ... 9
2.5. Naive Bayes Classifiers ... 11
2.5.1. Correlated Naive Bayes Classifiers ... 12
2.6. Synthethic Minority Oversampling Technique (SMOTE)... 13
2.7. Principal Component Analysis (PCA) ... 14
2.8. K-fold Cross Validation ... 14
2.9. Confusion Matrix ... 16
BAB III METODOLOGI PENELITIAN ... 18
3.1. Gambaran Umum Sistem ... 18
xi
3.3. Pembersihan Data ... 21
3.4. Seleksi Data ... 21
3.5. Transformasi Data ... 22
3.6. Modelling Correlated Naive Bayes ... 27
3.7. Akurasi ... 32 3.8. Desain Antarmuka ... 33 3.9. Spesifikasi Sistem ... 33 BAB IV IMPLEMENTASI ... 34 4.1. Input Data ... 34 4.2. Transformasi Data ... 34
4.3. Correlated Naive Bayes ... 35
BAB V ANALISA HASIL DAN PEMBAHASAN ... 37
5.1. Uji Data Kelompok ... 37
5.1.1. Dataset tanpa melalui SMOTE... 38
5.1.2. Fold 3, SMOTE Precentage 100% ... 39
5.1.3. Fold 3, SMOTE Precentage 200% ... 40
5.1.4. Fold 3, SMOTE Precentage 300% ... 41
5.1.5. Fold 3, SMOTE Precentage 400% ... 42
5.1.6. Fold 5, SMOTE Precentage 100% ... 43
5.1.7. Fold 5, SMOTE Precentage 200% ... 44
5.1.8. Fold 5, SMOTE Precentage 300% ... 45
5.1.9. Fold 5, SMOTE Precentage 400% ... 46
5.1.10. Fold 7, SMOTE Precentage 100% ... 47
5.1.11. Fold 7, SMOTE Precentage 200% ... 48
5.1.12. Fold 7, SMOTE Precentage 300% ... 49
5.1.13. Fold 7, SMOTE Precentage 400% ... 50
5.1.14. Fold 10, SMOTE Precentage 100% ... 51
5.1.15. Fold 10, SMOTE Precentage 200% ... 52
5.1.16. Fold 10, SMOTE Precentage 300% ... 53
5.1.17. Fold 10, SMOTE Precentage 400% ... 54
5.2. Uji Data Tunggal ... 55
5.3. Pembahasan ... 56
5.4. Uji Validasi ... 56
xii
6.1. KESIMPULAN ... 59 6.2. SARAN ... 59 DAFTAR PUSTAKA ... 60
xiii
DAFTAR GAMBAR
Gambar 2.1 Proses KDD (Jiawei dan Micheline, 2006) ... 7
Gambar 2.2 Model 3-fold cross validation ... 15
Gambar 2.3 5-fold Cross Validation (Bramer, 2016) ... 15
Gambar 3.1 Gambaran Umum Sistem ... 18
Gambar 3.2 Desain Antarmuka ... 33
Gambar 4.1 Implementasi Program Input Data ... 34
Gambar 4.2 Implementasi Program Transformasi ... 35
Gambar 4.3 Implementasi Program Atribut dikali Kelas ... 35
Gambar 4.4 Implementasi Program Perhitungan nilai R ... 35
Gambar 4.5 Implementasi Program Probabilitas kemunculan kelas ... 35
Gambar 4.6 Implementasi Program Probabilitas independen kelas Y dari semua fitur kelas X ... 36
Gambar 4.7 Implementasi Program Peluang Kelas ... 36
Gambar 4.8 Implementasi Program Nilai Akurasi ... 36
Gambar 5.1 Hasil dataset tanpa melalui SMOTE, Correlated Naive Bayes ... 38
Gambar 5.2 Hasil dataset tanpa melalui SMOTE, Naive Bayes ... 39
Gambar 5.3 Hasil Fold 3, SMOTE Precentage 100%, Correlated Naive Bayes .. 39
Gambar 5.4 Hasil Fold 3, SMOTE Precentage 100%, Naive Bayes ... 40
Gambar 5.5 Hasil Fold 3, SMOTE Precentage 200%, Correlated Naive Bayes .. 40
Gambar 5.6 Hasil Fold 3, SMOTE Precentage 200%, Naive Bayes ... 41
Gambar 5.7 Hasil Fold 3, SMOTE Precentage 300%, Correlated Naive Bayes .. 41
Gambar 5.8 Hasil Fold 3, SMOTE Precentage 300%, Naive Bayes ... 42
Gambar 5.9 Hasil Fold 3, SMOTE Precentage 400%, Correlated Naive Bayes .. 42
Gambar 5.10 Hasil Fold 3, SMOTE Precentage 400%, Naive Bayes ... 43
Gambar 5.11 Hasil Fold 5, SMOTE Precentage 100%, Correlated Naive Bayes 43 Gambar 5.12 Hasil Fold 5, SMOTE Precentage 100%, Naive Bayes ... 44
Gambar 5.13 Hasil Fold 5, SMOTE Precentage 200%, Correlated Naive Bayes 44 Gambar 5.14 Hasil Fold 5, SMOTE Precentage 200%, Naive Bayes ... 45
Gambar 5.15 Hasil Fold 5, SMOTE Precentage 300%, Correlated Naive Bayes 45 Gambar 5.16 Hasil Fold 5, SMOTE Precentage 300%, Naive Bayes ... 46
xiv
Gambar 5.17 Hasil Fold 5, SMOTE Precentage 400%, Correlated Naive Bayes 46
Gambar 5.18 Hasil Fold 5, SMOTE Precentage 400%, Naive Bayes ... 47
Gambar 5.19 Hasil Fold 7, SMOTE Precentage 100%, Correlated Naive Bayes 47 Gambar 5.20 Hasil Fold 7, SMOTE Precentage 100%, Naive Bayes ... 48
Gambar 5.21 Hasil Fold 7, SMOTE Precentage 200%, Correlated Naive Bayes 48 Gambar 5.22 Hasil Fold 7, SMOTE Precentage 200%, Naive Bayes ... 49
Gambar 5.23 Hasil Fold 7, SMOTE Precentage 300%, Correlated Naive Bayes 49 Gambar 5.24 Hasil Fold 7, SMOTE Precentage 300%, Naive Bayes ... 50
Gambar 5.25 Hasil Fold 7, SMOTE Precentage 400%, Correlated Naive Bayes ...50
Gambar 5.26 Hasil Fold 7, SMOTE Precentage 400%, Correlated Naive Bayes ...51
Gambar 5.27 Hasil Fold 10, SMOTE Precentage 100%, Correlated Naive Bayes ...51
Gambar 5.28 Hasil Fold 10, SMOTE Precentage 100%, Naive Bayes ...52
Gambar 5.29 Hasil Fold 10, SMOTE Precentage 200%, Correlated Naive Bayes ...52
Gambar 5.30 Hasil Fold 10, SMOTE Precentage 200%, Naive Bayes ...53
Gambar 5.31 Hasil Fold 10, SMOTE Precentage 300%, Correlated Naive Bayes ...53
Gambar 5.32 Hasil Fold 10, SMOTE Precentage 300%, Naive Bayes ...54
Gambar 5.33 Hasil Fold 10, SMOTE Precentage 400%, Correlated Naive Bayes ...54
Gambar 5.34 Hasil Fold 10, SMOTE Precentage 400%, Naive Bayes ... 55
Gambar 5.35 Uji Data Tunggal ... 55
Gambar 5.36 Hasil Uji Data Tunggal ... 55
Gambar 5.37 Nilai Probabilitas Kelas pada MATLAB ... 57
Gambar 5.38 Nilai Probabilitas Kelas pada Microsoft Excel ... 57
Gambar 5.39 Hasil perkalian atribut dengan kelas pada MATLAB ... 57
Gambar 5.40 Hasil perkalian atribut dengan kelas pada Microsoft Excel ... 58
Gambar 5.41 Nilai r pada MATLAB ... 58
Gambar 5.42 Nilai R pada MATLAB ... 58
Gambar 5.43 Nilai R pada Microsoft Excel ... 58
xv
DAFTAR TABEL
Tabel 2.1 Tabel Koefisien Korelasi ... 13
Tabel 2.2 Confusion Matrix ... 16
Tabel 3.1 Keterangan Atribut ... 18
Tabel 3.2 Contoh Data dari dataset Online Shoppers Purchasing Intention ... 20
Tabel 3.3 Pemeringkatan atribut menggunakan aplikasi Weka ... 21
Tabel 3.4 Tranformasi Atribut Month ... 22
Tabel 3.5 Transformasi Atribut Visitor Type ... 23
Tabel 3.6 Tabel Kolom Pertama ( Administrative ) ... 23
Tabel 3.7 Hasil Normalisasi Kolom Pertama ... 25
Tabel 3.8 Hasil tranformasi pada contoh data dari dataset Online Shoppers Purchasing Intention ... 26
Tabel 3.9 Data Atribut Product Related Duration ... 27
Tabel 3.10 Hasil perhitungan nilai R-Square ... 28
Tabel 3. 11 Perhitungan Prior Probability... 29
Tabel 3.12 Confusion Matrix ... 33
Gambar 5.1 Hasil dataset tanpa melalui SMOTE, Correlated Naive Bayes ... 38
Gambar 5.2 Hasil dataset tanpa melalui SMOTE, Naive Bayes ... 39
Gambar 5.3 Hasil Fold 3, SMOTE Precentage 100%, Correlated Naive Bayes .. 39
Gambar 5.4 Hasil Fold 3, SMOTE Precentage 100%, Naive Bayes ... 40
Gambar 5.5 Hasil Fold 3, SMOTE Precentage 200%, Correlated Naive Bayes .. 40
Gambar 5.6 Hasil Fold 3, SMOTE Precentage 200%, Naive Bayes ... 41
Gambar 5.7 Hasil Fold 3, SMOTE Precentage 300%, Correlated Naive Bayes .. 41
Gambar 5.8 Hasil Fold 3, SMOTE Precentage 300%, Naive Bayes ... 42
Gambar 5.9 Hasil Fold 3, SMOTE Precentage 400%, Correlated Naive Bayes .. 42
Gambar 5.10 Hasil Fold 3, SMOTE Precentage 400%, Naive Bayes ... 43
Gambar 5.11 Hasil Fold 5, SMOTE Precentage 100%, Correlated Naive Bayes 43 Gambar 5.12 Hasil Fold 5, SMOTE Precentage 100%, Naive Bayes ... 44
Gambar 5.13 Hasil Fold 5, SMOTE Precentage 200%, Correlated Naive Bayes 44 Gambar 5.14 Hasil Fold 5, SMOTE Precentage 200%, Naive Bayes ... 45 Gambar 5.15 Hasil Fold 5, SMOTE Precentage 300%, Correlated Naive Bayes 45
xvi
Gambar 5.16 Hasil Fold 5, SMOTE Precentage 300%, Naive Bayes ... 46
Gambar 5.17 Hasil Fold 5, SMOTE Precentage 400%, Correlated Naive Bayes 46 Gambar 5.18 Hasil Fold 5, SMOTE Precentage 400%, Naive Bayes ... 47
Gambar 5.19 Hasil Fold 7, SMOTE Precentage 100%, Correlated Naive Bayes 47 Gambar 5.20 Hasil Fold 7, SMOTE Precentage 100%, Naive Bayes ... 48
Gambar 5.21 Hasil Fold 7, SMOTE Precentage 200%, Correlated Naive Bayes 48 Gambar 5.22 Hasil Fold 7, SMOTE Precentage 200%, Naive Bayes ... 49
Gambar 5.23 Hasil Fold 7, SMOTE Precentage 300%, Correlated Naive Bayes 49 Gambar 5.24 Hasil Fold 7, SMOTE Precentage 300%, Naive Bayes ... 50
Gambar 5.25 Hasil Fold 7, SMOTE Precentage 400%, Correlated Naive Bayes 50 Gambar 5.26 Hasil Fold 7, SMOTE Precentage 400%, Correlated Naive Bayes 51 Gambar 5.27 Hasil Fold 10, SMOTE Precentage 100%, Correlated Naive Bayes ...51
Gambar 5.28 Hasil Fold 10, SMOTE Precentage 100%, Naive Bayes ...52
Gambar 5.29 Hasil Fold 10, SMOTE Precentage 200%, Correlated Naive Bayes ...52
Gambar 5.30 Hasil Fold 10, SMOTE Precentage 200%, Naive Bayes ...53
Gambar 5.31 Hasil Fold 10, SMOTE Precentage 300%, Correlated Naive Bayes ...53
Gambar 5.32 Hasil Fold 10, SMOTE Precentage 300%, Naive Bayes ...54
Gambar 5.33 Hasil Fold 10, SMOTE Precentage 400%, Correlated Naive Bayes ...54
Gambar 5.34 Hasil Fold 10, SMOTE Precentage 400%, Naive Bayes ...55
Gambar 5.35 Uji Data Tunggal ... 55
Gambar 5.36 Hasil Uji Data Tunggal ... 55
Gambar 5.37 Nilai Probabilitas Kelas pada MATLAB ... 57
Gambar 5.38 Nilai Probabilitas Kelas pada Microsoft Excel ... 57
Gambar 5.39 Hasil perkalian atribut dengan kelas pada MATLAB ... 57
Gambar 5.40 Hasil perkalian atribut dengan kelas pada Microsoft Excel ... 58
Gambar 5.41 Nilai r pada MATLAB ... 58
Gambar 5.42 Nilai R pada MATLAB ... 58
Gambar 5.43 Nilai R pada Microsoft Excel ... 58
1 BAB I PENDAHULUAN 1.1. Latar Belakang
Perkembangan teknologi yang terjadi dalam berbagai bidang kehidupan telah mengubah pola yang sudah ada, perdagangan merupakan salah satu bidang yang mengalami perubahan pola sebagai dampak dari perkembangan teknologi. Perdagangan yang awalnya berjalan melalui pertemuan secara langsung antara pedagang dengan konsumen, sekarang dapat dilakukan melalui jaringan internet dan dikenal sebagai perdagangan elektronik. Perdangan elektronik membantu pedagang dan konsumen memiliki kebebasan melakukan transaksi dengan fleksibel dan jangkauannya mencakup seluruh dunia.
Berdasarkan data Internet sales as a percentage of total retail sales (ratio
%) (2019) yang himpun oleh Office for National Statistics pada website
https://www.ons.gov.uk/, dijabarkan data sejak tahun 2007 hingga tahun 2019, memiliki presentase data yang mengalami kenaikan tiap tahunnya. Kenaikan data
internet sales ini, peran konsumen dapat diklasifikasikan dengan memperhatikan
laku konsumen, dalam hal ini konsumen memiliki kemungkinan apakah akan melakukan transaksi belanja atau hanya melakukan window shopping. Perubahan tingkah laku konsumen ini perlu dibaca oleh penjual dalam proses bertransaksi, dengan membaca tingkah laku konsumen, dapat dilakukan penyusunan strategi pemasaran yang akan membantu penjual melakukan sistem perdagangan elektronik yang lebih efektif.
Sistem perdagangan online yang menghasilkan kumpulan data, memungkinkan adanya kemampuan untuk melakukan pengolahan data untuk mendapatkan penilaian terhadap konsumen yang akan melakukan transaksi belanja atau yang hanya melihat barang tanpa ada niatan untuk membelinya. Kemampuan ini dapat diterapkan dengan menggunakan algoritme machine learning tertentu.
Terdapat penelitian mengenai intensi konsumen online seperti penelitian
Real-Time Prediction of Online Shoppers’ Purchasing Intention Using Random Forest (Baati dan Mohsil, 2020) menghasilkan nilai akurasi sebesar 86.78% dengan
metode Naive Bayes.. Penelitian dengan dataset yang sama dilakukan untuk melakukan studi komparatif algoritme data mining dengan teknik oversampling yang berbeda dalam memprediksi perilaku pembeli online (Obiedat, 2020), penelitian menggunakan model Random Forest, MLP dan Decision Tree. Random Forest menjadi model pengklasifikasi terbaik dalam akurasi, F1-score dan presisi dengan 89.1%, 60.7% dan 69%. Penelitian perbandingan model algoritme machine
learning dengan menggunakan WEKA dan Sci-Kit Learn dalam mengklasifikasikan niat pembelanja menghasilkan nilai akurasi untuk metode
Naive Bayes dengan menggunakan WEKA sebesar 80.886% dan Sci-Kit Learn
sebesar 83.427%. Penelitian yang dilakukan oleh (Senduk, 2020) dengan analisis user dalam pembelian barang online dengan metode K-Nearest Neighbor (KNN) dengan hasil akurasi 86.2028%.
Berdasarkan uraian di atas, penelitian ini mencoba membangun sistem untuk melihat konsumen yang berpotensi melakukan pembelian barang secara
online menggunakan metode Correlated Naive Bayes. Implementasi metode ini
juga akan menghitung akurasi dari algoritme Correlated Naive Bayes dalam melakukan klasifikasi terhadap konsumen yang berpotensi melakukan barang
online berdasarkan data online shoppers purchasing intention.
1.2. Rumusan Masalah
Rumusan masalah yang diperoleh dari latar belakang adalah sebagai berikut: 1. Tidak diketahuinya atribut yang mempengaruhi klasifikasi pembeli yang
melakukan online shopping menggunakan dataset online shoppers
purchasing intention.
2. Tidak diketahuinya nilai akurasi yang diperoleh dari klasifikasi pengunjung yang berpotensi melakukan pembelian barang online berdasarkan data
online shoppers purchasing intention menggunakan algoritme Correlated Naive Bayes.
1.3. Tujuan
Tujuan yang hendak dicapai dalam penelitian ini adalah sebagai berikut: 1. Mengetahui atribut yang mempengaruhi hasil klasifikasi data online
2. Mengetahui tingkat akurasi dalam melakukan klasifikasi pengunjung yang berpotensi melakukan pembelian barang online berdasarkan data online
shoppers purchasing intention dengan metode Correlated Naive Bayes.
1.4. Manfaat
Manfaat dari penelitian ini adalah:
1. Membantu pelaku usaha perdagangan online dalam melakukan identifikasi konsumen yang berpotensi melakukan transaksi agar dapat membuat sistem bisnis dan pemasaran yang lebih efektif.
2. Hasil dari penelitian ini dapat dijadikan bahan kajian bagi semua ilmu yang berkaitan dengan algoritme Correlated Naive Bayes.
1.5. Batasan Masalah
Batasan masalah yang ditetapkan dalam penelitian ini adalah:
1. Data Online Shoppers Purchasing Intention Dataset merupakan sebuah data publik dan diperoleh dari UCI Repository Machine Learning.
2. Sistem dibuat dengan Matlab.
3. Jumlah K-Fold Cross Validation yang digunakan dalam penelitian ini adalah 3,5,7 dan 10 K-Fold Cross Validation.
1.6. Sistematika Penulisan
Membagikan gambaran dan kerangka pada setiap bab, maka dibutukan model sistematika penulisan. Berikut merupakan gambaran dari sistematika penulisan pada masing-masing bab:
1. Bab I Pendahuluan
Bab ini berisi latar belakang, rumusan masalah, tujuan penelitian, manfaat penelitian, batasan penelitian dan sistematika penulisan.
2. Bab II Landasan Teori
Bab ini menjelaskan mengenai algoritme Naive Bayes beserta teori-teori mengenai penambangan data, klasifikasi dan perdagangan online untuk memecahkan masalah yang diteliti.
Bab ini menjelaskan mengenai gambaran umum, tahap-tahap penelitian, data, perhitungan Correlated Naive Bayes, peralatan penelitian dan desain
user interface.
4. Bab IV Implementasi
Bab ini bersisi tentang implementasi ke dalam program berdasarkan hasil perancangan.
5. BAB VAnalisa Hasil dan Pembahasan
Bab ini berisi tentang hasil dari percobaan yang diimplementasikan ke dalam program komputer berdasarkan hasil perancangan.
6. Bab VI Penutup
5 BAB II
LANDASAN TEORI 2.1. Tinjauan Pustaka
Berbagai penelitian telah dilakukan untuk mengklasifikasikan niat pembelanja online, salah satunya adalah prediksi intensi pembelanja online menggunakan algoritme Random Forest yang menghasilkan nilai akurasi sebesar 86.78% untuk algoritme Random Forest, 86.66% untuk algoritme Naive Bayes dan 86.59 untuk algoritme C4.5 (Baati dan Mohsil, 2020). Penelitian lain menggunakan berbagai algoritme data mining untuk memprediksi niat pembelanja online (Obiedat, 2020) menghasilkan algoritme Random Forest sebagai pengklasifikasi dengan akurasi tertinggi dengan nilai sebesar 89.1%.
Penelitian lain yang dilakukan oleh Christian (2019) menggunakan perbandingan model algoritme machine learning dengan menggunakan WEKA dan
Sci-Kit Learn dalam mengklasifikasikan niat pembelanja menghasilkan nilai
akurasi untuk metode Naive Bayes tertinggi menggunakan Sci-Kit Learn dengan akurasi sebesar 83.427% dan akurasi tertinggi yang didapatkan dengan algoritme Random Forest menggunakan WEKA dengan akurasi sebesar 90.133%. Penelitian yang dilakukan oleh Senduk (2020) dengan analisis user dalam pembelian barang
online dengan metode K-Nearest Neighbor (KNN) dengan hasil akurasi 86.2028%.
Penelitian tersebut menggunakan dataset yang sama, besumber dari data publik UCI
Repository Machine Learning yaitu data mengenai Online Shoppers Purchasing Intention Dataset.
Penelitian mengenai algoritme Correlated Naive Bayes dapat dilihat pada penelitian mengenai kombinasi Metode Correlated Naive Bayes dan Metode Seleksi Fitur Wrapper untuk Klasifikasi Data Kesehatan yang dilakukan oleh Hairani dan Innuddin (2019) mengolah dataset Pima Indian Diabetes dan Thyroid. Hasil akurasi tertinggi dari dataset Pima Indian Diabetes untuk algoritme
Correlated Naive Bayes dengan pemilihan fitur sebesar 71.40% dan untuk
algoritme Naive Bayes didapatkan hasil dengan pemilihan fitur sebesar 69.79%. Untuk dataset Thyroid didapatkan hasil akurasi tertinggi untuk metode Correlated
Naive Bayes dengan pemilihan fitur sebesar 79.38% untuk Naive Bayes dengan
pemilihan fitur sebesar 68.83%.
Penelitian komparasi akurasi algoritme Correlated Naive Bayes Classifer dan
Naive Bayes Classifer untuk diagnosis penyakit diabetes menggunakan dataset pima indian diabetes menghasilkan nilai rata-rata akurasi untuk metode Correlated Naive Bayes Classifer sebesar 67.15% dan untuk algoritme Naive Bayes Classifer
sebesar 64.33% (Hairani dkk, 2018). Penelitian yang dilakukan oleh Muktamar, Setiawan dan Adji (2015) yang melakukan analisis perbandingan akurasi algoritme
Correlated Naive Bayes Classifier dengan Naive Bayes Classifier menunjukkan
hasil tingkat akurasi algoritme Correlated Naive Bayes Classifier lebih besar dibanding algoritme Naive Bayes Classifier. Perbedaan nilai akurasi sebesar 2.443% untuk dataset iris, 28.666% untuk dataset balance-scale, 14.889% untuk
dataset haberman dan nilai akurasi sebesar 7.1116667% untuk dataset servo.
Berdasarkan penelitian yang telah dilakukan, maka akan dilakukan sebuah penelitian untuk melakukan klasifikasi pembeli yang melakukan online shopping berdasarkan data online shoppers purchasing intention dan menggunakan algoritme
Correlated Naive Bayes. Dengan data yang digunakan adalah data publik dari UCI Repository Mahine Learning yaitu Online Shoppers Purchasing Intention Dataset.
2.2. Perdagangan Elektronik
Perdagangan elektronik adalah suatu bentuk perdagangan yang memiliki karakteristik tersendiri, dimana perdagangan tidak dibatasi oleh lingkup nasional, transaksi tidak saling bertemu secara pribadi, dan menggunakan internet sebagai media yang digunakan (Sunusi, 2013). Bentuk e-commerce telah merambah ke antarmuka web, dengan munculnya berbagai startup dalam bidang perdagangan elektronik di seluruh berbagai belahan dunia. Amazon, Ebay, Alibaba, Shopee dan Tokopedia merupakan contoh dari berbagai startup e-commerce yang dapat diakses melalui antarmuka web. Tersedianya layanan ini akan mengubah beberapa pola perdagangan dengan sistem transaksi penjual dengan konsumen yang menjalankan kegiatannya melalui jaringan internet. Sistem perdagangan online ini akan
menghasilkan kumpulan data, yang memungkinkan adanya penelitian pengolahan data tersebut untuk mendapatkan penilaian terhadap konsumen yang akan melakukan transaksi belanja atau yang hanya melihat-lihat barang tanpa ada niatan untuk membelinya.
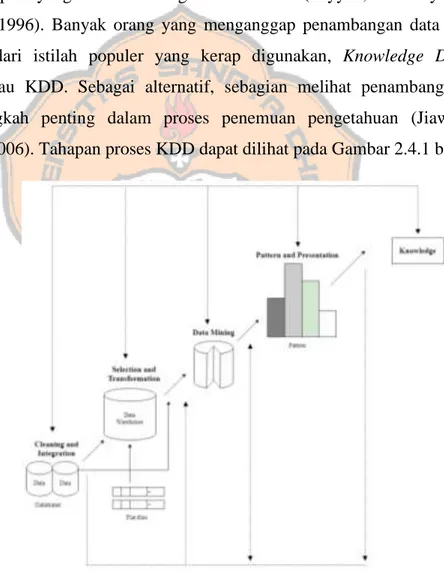
2.3. Knowledge Discovey in Database (KDD)
KDD didefinisikan sebagai proses yang rumit untuk mengidentifikasi kebenaran identifikasi, hal baru, berpotensi berguna dan akhirnya dapat menemukan pola yang mudah dimengerti dalam data (Fayyad, Piatetsky-Shapiro dan Smyth, 1996). Banyak orang yang menganggap penambangan data sebagai persamaan dari istilah populer yang kerap digunakan, Knowledge Discovey
Database atau KDD. Sebagai alternatif, sebagian melihat penambangan data
sebagai langkah penting dalam proses penemuan pengetahuan (Jiawei dan Micheline, 2006). Tahapan proses KDD dapat dilihat pada Gambar 2.4.1 berikut:
Gambar 2.1 Proses KDD (Jiawei dan Micheline, 2006)
Proses Knowledge Discovery in Database (KDD) dijabarkan sebagai berikut :
1. Data Cleaning (Pembersihan Data)
Data cleaning merupakan tahap untuk melakukan pembersihan
terhadap noise, data yang tidak konsisten dan pada tahapan ini pula akan dilakukan pembersihan terhadap missing values. Dataset yang digunakan pada penelitian ini tidak ditemukan adanya missing values.
2. Data Integration (Integrasi Data)
Data integration dilakukan untuk menggabungkan data yang berasal
dari berbagai sumber data yang ada. Data yang berasal dari berbagai macam sumber atau tempat penyimpanan data akan digabungkan ke suatu tempat penyimpanan yang saling berkaitan.
3. Data Selection (Seleksi Data)
Data selection dilakukan untuk menganalisis hubungan dan
menganalisis atribut. Pemeriksaan kepada atribut-atribut untuk menetukan relevan atau tidaknya atribut tersebut untuk dilakukan penambangan data. Atribut yang tidak relevan akan disingkirkan dari proses penambangan data. 4. Data Transformation (Transformasi Data)
Data transformation dilakukan untuk mengubah atau dikonsolidasikan ke dalam bentuk yang sesuai dengan penambangan data. Penelitian ini akan merubah data pada atribut yang memiliki bentuk data nominal menjadi data yang memiliki bentuk data numerik. Metode transformasi yang akan digunakan dalam penelitian kali ini adalah metode
min-max. Persamaan 2.4 (Jiawei, Micheline dan Jian, 2012) berikut ini
akan digunakan untuk meghitung normalisasi dengan metode min-max: 𝑣1′ = 𝑣1−𝑚𝑖𝑛𝐴
𝑚𝑎𝑥𝐴−𝑚𝑖𝑛𝐴 (𝑛𝑒𝑤_𝑚𝑎𝑥𝐴 − 𝑛𝑒𝑤_𝑚𝑖𝑛𝐴) + 𝑛𝑒𝑤𝑚𝑖𝑛𝐴 (2.1)
Persamaan tersebut dapat diubah melalui persamaan matematika menjadi persamaan (2.2) sebagai berikut:
𝑣1′ = (𝑣1−𝑚𝑖𝑛𝐴)(𝑛𝑒𝑤_𝑚𝑎𝑥𝐴−𝑛𝑒𝑤_𝑚𝑖𝑛𝐴)
𝑚𝑎𝑥𝐴−𝑚𝑖𝑛𝐴 + 𝑛𝑒𝑤_𝑚𝑖𝑛𝐴 (2.2)
Keterangan:
𝑣1′ : Hasil nomalisasi min-max.
𝑚𝑖𝑛𝐴 : Nilai minimum data.
𝑚𝑎𝑥𝐴 : Nilai maksimum data.
𝑛𝑒𝑤_𝑚𝑖𝑛𝐴 : Skala minimum yang ditentukan.
𝑛𝑒𝑤_𝑚𝑎𝑥𝐴 : Skala maksimum yang ditentukan. 5. Data Mining (Penambangan Data)
Data mining adalah proses penggunaan teknik, metode ataupun
algoritme tertentu untuk pencarian pola atau informasi di dalam data yang terpilih untuk mencapai tujuan tertentu.
6. Pattern Evaluation (Evaluasi Pola)
Pattern evaluation adalah proses evaluasi dari hasil atau keluaran
teknik data mining berupa pola tertentu untuk dilakukan penilaian tercapainya suatu hipotesa atau tidak.
7. Knowledge Presentation (Presentasi Pengetahuan)
Knowledge presentation dilakukan untuk memvisualisasikan
informasi yang sudah melalui proses data mining kepada pengguna. Langkah 1 sampai dengan 4 merupakan langkah preprocessing, langkah dimana akan dilakukan persiapan data sebelum dilakukannya proses data
mining.
2.4. Data Mining
Menurut Fayyad, Piatetsky-Shapiro dan Smyth (1996) data mining adalah bagian dari proses KDD yang terdiri dari penerapan analisis data dan algoritme yang menghasilkan pola atau model tertentu dengan data yang digunakan. Dua tujuan utama dari data mining dalam pelaksanaanya lebih mengarah ke prediksi dan deskripsi. Prediksi akan mengartikan pada penggunaan beberapa variabel atau bidang di dalam database untuk melakukan prediksi terhadap variabel lain yang tidak diketahui atau yang akan datang sementara deskripsi akan berfokus pada menemukan pola yang dapat dijelaskan kepada manusia yang mendeskripsikan data.
Menurut Daniel (2005) ada beberapa tugas utama yang harus diselesaikan dengan menggunakan data mining. Berikut merupakan tugas data mining yang paling umum:
1. Description (Deskripsi)
Dalam rentang waktu tertentu, peneliti dan analis melakukan percobaan untuk dapat melakukan deskripsi maupun kecenderungan yang terdapat di dalam data. Deskripsi pola dan kecenderungan kerap menampilkan kemungkinan penjelasan dari pola dan kecenderungan yang didapatkan tersebut.
2. Estimation (Estimasi)
Estimasi dapat dikatakan menyerupai klasifikasi kecuali dengan perbedaan variabel target yang berupa numerik daripada kategoris. Model Estimasi dibuat dengan rekaman komplit, yang memberikan nilai variabel target serta nilai prediktor. Berdasarkan nilai-nilai prediktor ini akan dibuat perkiraan nilai target untuk pengamatan baru.
3. Prediction (Prediksi)
Pediksi dapat dikatan menyerupai klasifikasi maupun estimasi, hanya saja untuh hasil keluaran dari prediksi akan berada di jangka waktu lebih depan. Keadaan yang sesuai dapat membuat metode yang digunakan dalam klasifikasi maupun estimasi juga dapat dipakai untuk prediksi. 4. Classification (Klasifikasi)
Klasifikasi sendiri terdapat variabel kategori sasaran, misalnya kelompok penghasilan yang akan dibagi menjadi tiga kelas penghasilan: tinggi, menangah dan rendah ataupun melakukan dengan menggolongkan berdasarkan karakteristik lain yang terkait dengan orang tersebut.
5. Clustering (Pengelompokan)
Clustering mengacu pada pengelompokan data ke dalam objek
serupa. Cluster adalah kumpulan record yang mirip satu sama lain dan berbeda dengan record di cluster lain. Clustering akan berusaha mengelompokkan dataset menjadi kelompok-kelompok yang memiliki
catatan dalam cluster dimaksimalkan sementara catatan luar cluster diminimalkan.
6. Association (Asosiasi)
Asosiasi dalam data mining bertugas untuk menemukan atribut yang bisa berjalan bersama. Asosiasi juga digunakan dalam dunia bisnis, biasa dikenal sebagai analisi keranjang pasar, asosiasi akan digunakan untuk mengungkap aturan demi mengukur hubungan diantara dua atau lebih atribut.
2.5. Naive Bayes Classifiers
Bayesian classifires merupakan salah satu klasifikasi statistik, klasifikasi
ini dapat melakukan prediksi peluang keanggotaan kelas. Bayesian Classification didasari dengan teorema bayes, sebuah teorema yang ditemukan oleh Thomas Bayes pada tahun 1700-an. Studi yang dilakukan dalam membandingkan algoritme klasifikasi menemukan jika simple bayesian classifer atau yang lebih dikenal sebagai Naive Bayesian Classifers memiliki akurasi dan kecepatan yang tinggi ketika diaplikasikan dalam database yang besar (Jiawei dan Micheline, 2006). Metode Naive Cayesian Classification merupakan salah satu metode yang menggunakan model statistik dengan konsep probabilitas. Metode ini diterapkan dengan semua teribut akan memberikan kontibusi dalam pengambilan keputusan, bobot atribut akan sama dan setiap atribut saling bebas satu dengan yang lainnya (Kusumadewi, 2009).
Secara umum, teorema bayes dapat dituliskan dalam bentuk persamaan 2.3. berikut :
𝑃(𝐻|𝑋) = 𝑃(𝑋|𝐻)𝑃(𝐻)
𝑃(𝑋) (2.3)
Keterangan:
X : Data dengan class yang belum diketahui.
H : Hipotesis data merupakan suatu class spesifik.
P(H|X) : Probabilitas hipotesis H berdasarkan kondisi X. P(X|H) : Probabilitas berdasarkan kondisi pada hipotesis.
P(C) : Probabilitas X
Salah satu hal yang dapat berpotensi untuk manambah nilai akurasi dari
Naive Bayes Classifier adalah dengan nilai korelasi atribut terhadap kelas.
Perhitungan korelasi nilai atribut terhadap kelas, akan menjadi dasar ketepatan dari klasifikasi yang tidak hanya probabilitas namun juga seberapa besar korelasi atribut dengan kelas.
2.5.1. Correlated Naive Bayes Classifiers
Correlated Naive Bayes merupakan mutasi dan pengembangan dari
algoritme Naive Bayes Classifier. Metode klasifikasi ini menggunakan algoritme
Naive Bayes Classifier yang berdasar pada nilai probabilitas atribut dari suatu data
yang belum diketahui kelasnya. Sehingga teknik dasar pada algoritme ini berdasarkan pada frekuensi kemunculan data pada dataset, Corelated Naive Bayes
Classifer juga menyertakan perhitungan terhadap nilai korelasi masing-masing
atribut terhadap kelas (Muktamar, Setiawan dan Adji, 2015). Metode Correlated
Naive Bayes Classifier memperhitungkan nilai korelasi (R-Square) antara variabel
bebas (X) terhadap variabel terikat (Y) Penambahan paramater korelasi digunakan untuk mengukur tinggi rendahnya derajat hubungan antara variabel bebas (X) terhadap variabel terikat (Y) (Hairani dkk, 2018).
Persamaan metode Correlated Naive Bayes Classifier klasifikasi ditunjukkan pada persamaan (2.4), metode ini diikuti dengan perhitungan R-Square.
𝑃(𝑌|𝑋) = 𝑃(𝑌)Π𝑖=1 𝑞
𝑃(𝑋𝑖|𝑌)𝜏.𝑅(𝑋𝑖|𝑌)
𝑃(𝑋) (2.4)
Keterangan :
X : Data dengan kelas yang belum diketahui.
Y : Hipotesis data X merupakan suatu kelas spesifik.
P(X|Y) : Probabilitas hipotesis Y berdasarkan kondisi Y. P(Y) : Probabilitas hipotesis Y (prior probabily)
P(X) : Probabilitas dari X.
Π𝑖=1𝑞 (𝑋𝑖|𝑌) : Probabilitas setiap atribut dari data X berdasarkan kondisi hipotesis Y.
𝑅(𝑋𝑖|𝑌) : R-Square setiap atribut dari data X berdasarkan kondisi hipotesis Y.
𝜏 : Bilangan laplacian.
Berikut merupakan persamaan untuk menentukan perhitungan korelasi atribut:
𝑟 = 𝑛.(Σ𝑋𝑌)−(Σ𝑋).(Σ𝑌)
√(𝑛.Σ𝑋2−(Σ𝑋)2)√𝑛.Σ𝑌2−(Σ𝑌)2 (2.5)
𝑅 = 𝑟2 (2.6)
R : R-Square fitur antar kelas.
r : Nilai korelasi antar fitur kelas.
n : Total data pada dataset.
Σ𝑋𝑌 : Total perkalian variabel X denganvariabel Y.
Σ𝑋 : Total variabel X.
Σ𝑌 : Total variabel Y.
Σ𝑋2 : Total variabel X yang dikuadratkan.
Σ𝑌2 : Total variabel Y yang dikuadratkan.
(Σ𝑋)2 : Kuadrat dari total variabel X.
(Σ𝑌)2 : Kuadrat dari total variabel Y.
Menurut Muktamar, Setiawan dan Adji (2015) nilai (r) memiliki kententuan dari nilai koefisien korelasi yakni -1 <= r <= 1. interprestasi koefisien korelasi nilai (r) ditunjukkan pada Tabel 2.1 berikut:
Tabel 2.1 Tabel Koefisien Korelasi
Interval Koefisien Korelasi (r) Tingkat Hubungan
0 – 0.199 Sangat Rendah
0.20 – 0.299 Rendah
0.30 – 0.599 Cukup
0.6 – 0.799 Kuat
0.8 – 1 Sangat Kuat
2.6. Synthethic Minority Oversampling Technique (SMOTE)
Synthetic Minority Oversampling Technique (SMOTE) merupakan teknik
diperkenalkan oleh Chawla, Bowyer dan Hall (2002). SMOTE merupakan suatu teknik baru dengan cara menerapkan duplikat data untuk kelas minoritas yang ada pada dataset dengan sampel sintesis. Metode ini bekerja dengan mencari k-nearest
neighbors (kedekatan tetangga data sebanyak k) untuk masing-masing data pada
kelas minoritas. Data sintesis akan dibuat sebanyak prosentase duplikasi yang dikehendaki antara data minor dan k-nearest neighbors yang dipilih (Siringoringo, 2018).
2.7. Principal Component Analysis (PCA)
Principal Component Analysis (PCA) pada dasarnya adalah untuk
mengurangi dimensi dataset yang berisi sejumlah atribut yang saling terikat, sambil mempertahankan sebanyak mungkin variasi yang ada di dalam dataset. Pengurangan ini dicapai dengan mentransformasi ke dalam kumpulan atribut baru, komponen utama, yang tidak berkorelasi dan pengurutan atribut sehingga beberapa atribut mempertahankan sebagian besar variasi yang ada di semua atribut asli (Jolliffe, 2002). Proses perangkingan data atribut dilakukan dengan menggunakan aplikasi Weka 3.8.5, proses ini akan menghasilkan kombinasi-kombinasi data beserta prosentase urutan dari kombinasi data yang digunakan.
2.8. K-fold Cross Validation
K-fold Cross Validation merupakan sebuah pendekatan alternatif untuk
melatih dan menguji data. Sebuah dataset terdiri dari N buah data, dan akan dibagi menjadi k bagian yang sama. Serangkaian k-runs akan dilakukan, setiap bagian k secara bergantian akan digunakan sebagai data testing dan bagian k-1 lainnya akan dijadikan sebagai data training (Bramer, 2016).
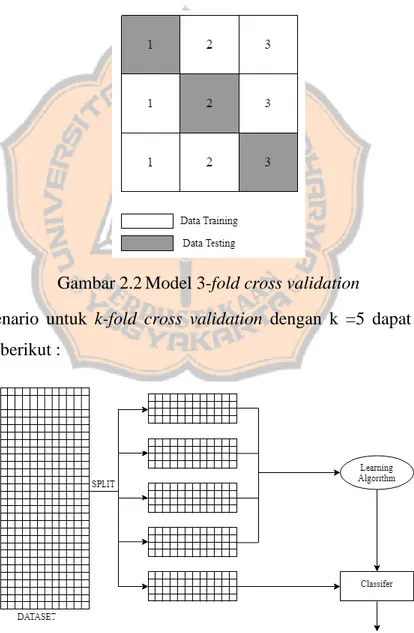
Permodelan K-fold Cross Validation dapat digambarkan menjadi 3-fold
cross validation. Menurut Tempola, Muhammad dan Khairan (2018) proses 3-fold cross validation ini akan menempatkan data untuk dieksekusi sebanyak 3 kali dan
setiap subset data akan memiliki kesempatan untuk menjadi data testing maupun data training. Model pengujian dapat dideskripsikan sebagai berikut dengan asumsi nama data pada pembagian data adalah A1, A2 dan A3:
1. Percobaan pertama menempatkan data A1 sebagai data testing dan data A2 dan A3 sebagai data training.
2. Percobaan pertama menempatkan data A2 sebagai data testing dan data A1 dan A3 sebagai data training.
3. Percobaan pertama menempatkan data A3 sebagai data testing dan data A1 dan A2 sebagai data training.
Sebagai gambaran mengenai proses berjalannya 3-fold cross validation, dapat dilihat pada Gambar 2.3 sebagai berikut:
Gambar 2.2Model 3-fold cross validation
Skenario untuk k-fold cross validation dengan k =5 dapat dilihat pada Gambar 2.7 berikut :
2.9. Confusion Matrix
Untuk mengukur kinerja dari suatu model dapat menggunakan confusion
matrix. Confusion matrix merupakan salah satu metode yang dipakai untuk
melakukan perhitungan nilai akurasi pada konsep data mining (Rosandy, 2016). Hasil dari confusion matrix menggunakan empat penentu untuk menemukan akurasi yang dapat dilihat pada Tabel 2.2 berikut ini:
Tabel 2.2 Confusion Matrix
Aktual Diklasifikasikan sebagai
+ -
+ True positives (TP) False negatives (FN)
- False positives (FP) True negatives (TN)
Perhitungan akurasi dengan tabel confusion matrix dapat dilihat dalam persamaan (2.8) berikut:
𝐴𝑘𝑢𝑟𝑎𝑠𝑖 = 𝑇𝑃+𝑇𝑁
𝑇𝑃+𝑇𝑁+𝐹𝑃+𝐹𝑁 100% (2.7)
Keterangan:
TP : True positive, merupakan jumlah data dengan kelas aktual positif yang dilkasifikasikan menjadi positive.
FP : False positive, merupakan jumlah data dengan kelas aktual positif yang dilkasifikasikan menjadi positive.
FN : False negative, merupakan jumlah data dengan kelas aktual negatif yang dilkasifikasikan menjadi negative.
TN : True negative , merupakan jumlah data dengan kelas aktual negatif yang dilkasifikasikan menjadi negative.
18 BAB III
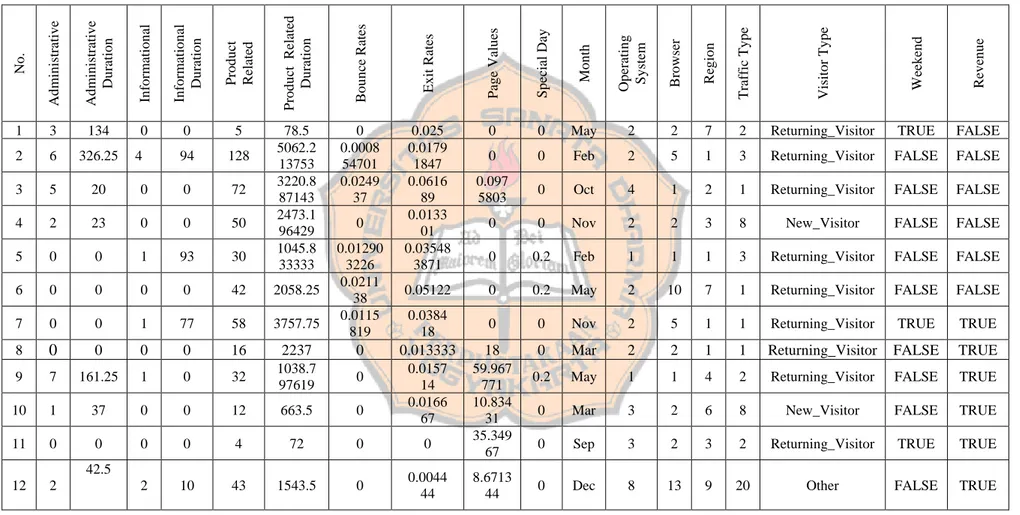
METODOLOGI PENELITIAN 3.1. Gambaran Umum Sistem
Tahap ini akan digambarkan secara umum bagaimana proses pengolahan data untuk klasifikasi dengan metode Correlated Naive Bayes dan Naive Bayes perhitungan nilai akurasi. Alur proses klasifikasi digambarkan secara umum pada Gambar 3.1 berikut:
Gambar 3.1 Gambaran Umum Sistem 3.2. Data
Data yang akan digunakan adalah data Online Shoppers Purchasing
Intention Dataset yang diperoleh dari situs UCI Repository Machine Learning. Data
ini berisi 17 atribut dan 1 kelas dengan 12330 record data. Penjelasan mengenai rincian atribut dapat dilihat pada Tabel 3.1 dan contoh acak dari dataset dapat dilihat ada Tabel 3.2 sebagai berikut ini:
Tabel 3.1 Keterangan Atribut
No. Atribut Keterangan Tipe
1 Administrative Jumlah halaman Adminstrative yang
dikunjungi pengguna (Misal: profile page atau account management).
Numerik
2 Administrative
Duration
Jumlah waktu (dalam detik) yang dihabiskan oleh pengguna pada halaman Administrative.
Numerik
3 Informational Jumlah kunjungan pengguna ke halaman
Informational. (Misal: contact page, about us page).
4 Informational Duration
Jumlah waktu (dalam detik) yang dihabiskan oleh pengguna pada halaman Informational.
Numerik
5 Product
Related
Jumlah halaman Product Related yang dikunjungi pengguna. (Misal: browsing roduk atau halaman produk individual).
Numerik
6 Product
Related Duration
Jumlah waktu (dalam detik) yang dihabiskan oleh pengguna pada halaman Product
Related.
Numerik
7 Bounce Rates Merupakan google analytics metrics.
Mengacu pada presentase pengguna yang masuk ke situs web namun pergi tanpa melakukan interaksi apapun dengan situs web.
Numerik
8 Exit Rates Merupakan google analytics metrics.
Presentase tampilan halaman dari halaman spesifik sebuah web yang diikuti dengan pengunjung yang meninggalkan website.
Numerik
9 Page Values Merupakan google analytics metrics. Nilai
rata-rata untuk halaman web yang dikunjungi pengguna sebelum menyelesaikan transaksi.
Numerik
10 Special Day Merupakan google analytics metrics. Jarak
waktu pengguna mengunjungi situs web pada hari khusus. (Misal hari valentine atau hari natal).
Numerik
11 Month Bulan kunjungan dilakukan oleh pengguna. Kategori
12 Operating
Systems
Sistem operasi yang digunakan saat
mengakses situs web oleh pengguna.
Kategori
13 Browser Jenis browser yang digunakan saat
mengakses situs web oleh pengguna.
Kategori
14 Region Wilayah atau area yang digunakan oleh
pengguna saat mengakses situs web.
Kategori
15 Traffic Type Sumber user mengakses website (Misal
Google, iklan, Facebook, Instagram dll.)
Kategori 16 Visitor Type Tipe pengunjung baru, lama (sudah pernah
berkunjung) atau tidak teridentifikasi .
Kategori
17 Weekend Nilai boolean (TRUE atau FALSE) apakah
pengunjung mengunjungi situs web pada akhir pekan.
Kategori
18 Revenue Nilai boolean untuk pengunjung yang
membeli barang di situs web dengan nilai TRUE dan pengunjung yang tidak membeli barang di situs web dengan nilai FALSE.
Tabel 3.2 Contoh Data dari dataset Online Shoppers Purchasing Intention No . Ad m in is tr ativ e Ad m in is tr ativ e Du ratio n In fo rm atio n al In fo rm atio n al Du ratio n Pro d u ct R elated Pro d u ct R elated Du ratio n B o u n ce R ates E x it R ates Pag e Valu es Sp ecial Day Mo n th Op er atin g Sy stem B ro wser R eg io n T raf fic Ty p e Vis ito r T y p e W eek en d R ev en u e
1 3 134 0 0 5 78.5 0 0.025 0 0 May 2 2 7 2 Returning_Visitor TRUE FALSE 2 6 326.25 4 94 128 5062.2
13753
0.0008 54701
0.0179
1847 0 0 Feb 2 5 1 3 Returning_Visitor FALSE FALSE 3 5 20 0 0 72 3220.8 87143 0.0249 37 0.0616 89 0.097
5803 0 Oct 4 1 2 1 Returning_Visitor FALSE FALSE 4 2 23 0 0 50 2473.1
96429 0
0.0133
01 0 0 Nov 2 2 3 8 New_Visitor FALSE FALSE 5 0 0 1 93 30 1045.8
33333
0.01290 3226
0.03548
3871 0 0.2 Feb 1 1 1 3 Returning_Visitor FALSE FALSE 6 0 0 0 0 42 2058.25 0.0211
38 0.05122 0 0.2 May 2 10 7 1 Returning_Visitor FALSE FALSE 7 0 0 1 77 58 3757.75 0.0115
819
0.0384
18 0 0 Nov 2 5 1 1 Returning_Visitor TRUE TRUE 8 0 0 0 0 16 2237 0 0.013333 18 0 Mar 2 2 1 1 Returning_Visitor FALSE TRUE 9 7 161.25 1 0 32 1038.7
97619 0
0.0157 14
59.967
771 0.2 May 1 1 4 2 Returning_Visitor FALSE TRUE 10 1 37 0 0 12 663.5 0 0.0166
67
10.834
31 0 Mar 3 2 6 8 New_Visitor FALSE TRUE
11 0 0 0 0 4 72 0 0 35.349
67 0 Sep 3 2 3 2 Returning_Visitor TRUE TRUE 12 2
42.5
2 10 43 1543.5 0 0.0044 44
8.6713
3.3. Pembersihan Data
Tahap pembersihan data akan dilakukan dengan mencari missing value dan mencari data outlier. Pencarian missing value dilakukan dengan menggunakan
Microsoft Excel, setiap data pada masing-masing atribut akan dilakukan pengurutan
dari data terkecil hingga data terbesar. Jika pada urutan data ditemukan nilai kosong, maka data tersebuat akan diganti. Hasil pencarian ini tidak menemukan adanya missing value pada dataset. Dalam pencarian data outlier, digunakan pula bantuan Microsoft Excel untuk melakukan perhitungan data. Pencarian ini menemukan data yang memiliki outlier, sehingga data tersebut perlu dihapus untuk menghindari biasnya penelitian. Jumlah data sebelum ditemukannya outlier adalah 12330 record data, setelah ditemukan outlier dan data tersebut dihapus maka data yang dapat dinyatakan sudah bersih adalah 6937 data.
3.4. Seleksi Data
Tahap ini akan dilakukan penyeleksian data untuk menyesuaikan data untuk proses klasifikasi dan mempertahankan atribut yang dibutuhkan serta menghilangkan atribut yang kurang relevan untuk penelitian. Data yang akan digunakan dalam tahap ini sejumlah 6937 data, data ini akan dilakukan pemeringkatan dengan metode Principal Component Analysis (PCA) pada fitur aplikasi Weka. Hasil dari pemeringkatan atribut dapat dilihat pada tabel 3.3 berikut ini:
Tabel 3.3 Pemeringkatan atribut menggunakan aplikasi Weka
No. Rangking Atribut Skor
1 1 Administrative 0.431
2 2 Administrative Duration 0.42
3 6 Informational 0.308
4 7 Informational Duration 0.249
5 3 Product Related 0.389
6 4 Product Related Duration 0.365
7 10 Bounce Rates 0.114
8 5 Exit Rates 0.359
9 8 Page Values 0.143
11 9 Month 0.119 12 17 Operating System 0.003 13 14 Browser 0.036 14 15 Region 0.017 15 16 Traffic Type 0.004 16 12 Visitor Type 0.068 17 13 Weekend 0.037 3.5. Transformasi Data
Tahap ini akan dilakukan perubahan tipe data pada data yang melekat pada atribut, untuk mempermudah proses penambangan data. Atribut month, weekend,
revenue dan visitor type akan diubah ke dalam bentuk tipe data numerik. Kemudian,
atribut pada kolom 1-11 akan dilakukan normalisasi dengan metode min-max untuk memperkecil jarak data yang terlalu jauh. Berikut merupakan proses dari
transformasi data yang berjalan:
3.5.1. Transformasi Atribut Month
Perubahan ini akan membuat nama bulan menjadi numerik, dimana masing-masing bulan akan diberikan nilai atribut sama dengan nomor masing-masing bulan. Perubahan data dapat dilihat pada Tabel 3.4 berikut:
Tabel 3.4 Tranformasi Atribut Month
Month Transform Month
Jan 1 Feb 2 Mar 3 Apr 4 May 5 June 6 Jul 7 Aug 8 Sep 9 Oct 10 Nov 11 Dec 12
3.5.2. Transformasi Atribut Weekend dan Revenue
Pada bagian ini akan merubah nilai dari true-false ke dalam bentuk numerik.
1. Data true akan ditransfomasi menjadi 1. 2. Data false akan ditranformasi menjadi 2. 3.5.3. Tranformasi Atribut Visitor Type
Pada atribut ini terdapat 3 jenis pengunjung, setiap jenisnya akan diubah menjadi bentuk tipe data numerik. Perubahan data dapat dilihat pada Tabel 3.5 berikut:
Tabel 3.5 Transformasi Atribut Visitor Type
Visitor Type Transform Visitor Type
Returning_Visitor 1
New_Visitor 2
Other 3
3.5.4. Transformasi pada atribut kolom 1-10
Atribut pada kolom 1-11 akan dilakukan proses normalisasi dengan metode min-max dengan rantang nilai min adalah 0 dan nilai max adalah 1. Digunakan data kolom pertama pada Tabel 3.2 yakni pada atribut Administratiive sebagai contoh perhitungan, akan dilakukan proses normalisasi sebagai berikut:
1. Menentukan nilai minimum (nmin) = 0 dan nilai maksimum (nmax) = 1.
2. Melakukan pencarian dari nilai minimum dan maksimum dapat dilihat pada Tabel 3.6 berikut ini:
Tabel 3.6 Tabel Kolom Pertama ( Administrative )
No. Data Administrative 1 3 2 6 3 5 4 2 5 0
6 0 7 0 8 0 9 7 10 1 11 0 12 2
Berdasarkan data pada Tabel 3.6 didapatkan data minimum = 0 dan data maksimum = 7.
3. Melakukan perhitungan normalisasi pada setiap data pada kolom pertama. perhitungan nilai normalisasi min-max dapat dihitung dengan persamaan (2.3) Proses perhitungan data dapat dilihat sebagai berikut:
a. Untuk data ke 5,6,7,8.11 dengan nilai data 0 𝑣5,12′ = (0 − 0)(1 − 0)
(7 − 0) + 0
= 0
b. Untuk data ke 10 dengan nilai data 1 𝑣4′ = (1 − 0)(1 − 0)
(7 − 0) + 0
= 0.1428571428571429 c. Untuk data ke 4,12 dengan nilai data 2
𝑣2,8,9,11′ = (2 − 0)(1 − 0)
(7 − 0) + 0
= 0.2857142857142857 d. Untuk data ke 1 dengan nilai data 3 𝑣6′ = (3 − 0)(1 − 0)
(7 − 0) + 0
= 0.4285714285714286 e. Untuk data ke 3 dengan nilai 5
𝑣3′ = (5 − 0)(1 − 0)
= 0,7142857142857143 f. Untuk data ke 2 dengan nilai data 6
𝑣3′ = (6 − 0)(1 − 0)
(7 − 0) + 0
= 0,8571428571428571 g. Untuk data ke 9 dengan nilai data 7
𝑣7′ = (7 − 0)(1 − 0)
(7 − 0) + 0
= 1
4. Hasil normalisasi untuk kolom pertama dapat dilihat pada Tabel 3.7 berikut:
Tabel 3.7 Hasil Normalisasi Kolom Pertama
No. Administrative Data Nilai 1 3 0.4285714285714286 2 6 0.8571428571428571 3 5 0,7142857142857143 4 2 0.2857142857142857 5 0 0 6 0 0 7 0 0 8 0 0 9 7 1 10 1 0.1428571428571429 11 0 0 12 2 0.2857142857142857
Selanjutnya akan dilakukan perhitungan min-max untuk atribut yang ada pada kolom lainnya.
Transformasi data yang dilakukan meliputi perubahan data kategorial menjadi numerik dan menggunakan fungsi min-max untuk memperkecil rentang data antar atribut. Hasil transformasi yang dilakukan pada data yang berada di Tabel 3.2 dapat dilihat hasilnya pada tabel 3.8 berikut:
Adminis trative Adminis trative Duratio n Informa tional Informa tional Duratio n Produ ct Relat ed Product Related Duratio n Bounce Rates Exit Rates Page Value s Spe cial Day Mo nth Oper ating Syste m Bro wser Reg ion Tra ffic Typ e Vis itor Typ e Wee kend Reve nue 0.4285 71429 0.4107 27969 0 0 0.03 9063 0.0208 9016 0 0.40 5259 0 0 0.2 5 2 2 7 2 1 1 2 0.8571 42857 1 1 1 1 0.1347 13958 0.0404 34336 0.29 0465 0 0 0.2 5 2 2 8 6 1 1 2 0.7142 85714 0.0613 02682 0 0 0.56 25 0.8571 31832 1.1797 2372 1 0.00 1627 0 0.8 75 4 1 2 1 1 0 2 0.2857 14286 0.0704 98084 0 0 0.39 0625 0.6581 58853 0 0.21 5614 0 0 1 2 2 3 8 2 0 2 0 0 0.25 0.9893 61702 0.23 4375 0.2783 13707 0.6104 2795 0.57 5206 0 1 0.2 5 1 1 3 3 1 1 2 0 0 0 0 0.32 8125 0.5477 34682 1 0.83 0294 0 1 0.2 5 2 10 7 1 1 0 2 0 0 0.25 0.8191 48936 0.45 3125 1 0.5479 18441 0.62 2769 0 0 1 2 5 1 1 1 1 1 0 0 0 0 0.12 5 0.5953 0304 0 0.21 6138 0.29 6204 0 0 2 2 1 2 1 0 1 1 0.4942 52874 0.25 0 0.25 0.2764 41386 0 0.25 4729 1 1 0.2 5 1 1 4 2 1 0 1 0.1428 57143 0.1134 09962 0 0 0.09 375 0.1765 68425 0 0.27 0178 0.18 0669 0 0 3 2 6 8 2 0 1 0 0 0 0 0.03 125 0.0191 60402 0 0 0.58 9478 0 0.7 5 3 2 3 2 1 1 1 0.2857 14286 0.1302 68199 0.5 0.1063 82979 0.33 5938 0.4107 51114 0 0.07 2039 0.14 46 0 1 8 13 9 20 3 0 1
3.6.Modelling Correlated Naive Bayes
Tahap permodelan algoritme Correlated Naive Bayes dilakukan pada data yang telah dilakukan preprocessing dan dibentuk modelnya terlebih dahulu dengan aloritma. Sebelum masuk ke dalam tahap perhitungan, data akan dibagi menjadi beberapa bagian menggunakan K-fold cross validation. Data akan dibagi menjadi
K bagian kemudian data akan dijadikan data training dan data testing . Data yang
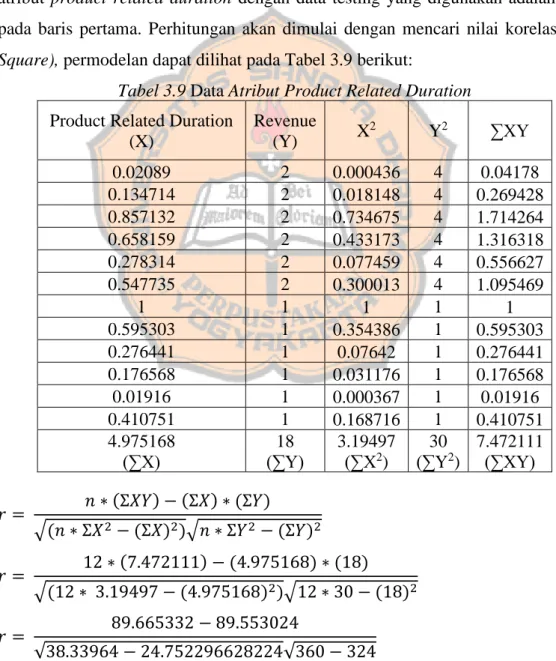
akan digunakan dalam modelling merupakan data yang terdapat pada Tabel 3.8. Untuk permodelan metode Correlated Naive Bayes akan digunakan data pada atribut product related duration dengan data testing yang digunakan adalah data pada baris pertama. Perhitungan akan dimulai dengan mencari nilai korelasi
(R-Square), permodelan dapat dilihat pada Tabel 3.9 berikut:
Tabel 3.9 Data Atribut Product Related Duration
Product Related Duration (X) Revenue (Y) X 2 Y2 ∑XY 0.02089 2 0.000436 4 0.04178 0.134714 2 0.018148 4 0.269428 0.857132 2 0.734675 4 1.714264 0.658159 2 0.433173 4 1.316318 0.278314 2 0.077459 4 0.556627 0.547735 2 0.300013 4 1.095469 1 1 1 1 1 0.595303 1 0.354386 1 0.595303 0.276441 1 0.07642 1 0.276441 0.176568 1 0.031176 1 0.176568 0.01916 1 0.000367 1 0.01916 0.410751 1 0.168716 1 0.410751 4.975168 (∑X) 18 (∑Y) 3.19497 (∑X2) 30 (∑Y2) 7.472111 (∑XY) 𝑟 = 𝑛 ∗ (Σ𝑋𝑌) − (Σ𝑋) ∗ (Σ𝑌) √(𝑛 ∗ Σ𝑋2− (Σ𝑋)2)√𝑛 ∗ Σ𝑌2− (Σ𝑌)2 𝑟 = 12 ∗ (7.472111) − (4.975168) ∗ (18) √(12 ∗ 3.19497 − (4.975168)2)√12 ∗ 30 − (18)2 𝑟 = 89.665332 − 89.553024 √38.33964 − 24.752296628224√360 − 324
𝑟 = 0.112308 √13.587343371776√36 𝑟 = 0.112308 3.686101378390996 ∗ 6 𝑟 = 0.112308 22.11660827034598
𝑟 (Product Related Duration) = 0.005077993814747 𝑅 = 𝑟2
𝑅 = 0.0050779938147472
𝑅(Product Related Duration) = 0.000025
Nilai korelasi R-Square untuk atribut product related duration sudah diperoleh, untuk atribut yang lain nilai tersebut dapat dilihat pada Tabel 3.10 berikut:
Tabel 3.10 Hasil perhitungan nilai R-Square
Atribut R Administrative 0.04186 Administrative Duration 0.052985 Informational 0.005128 Informational Duration 0.048288 Product Related 0.165206
Product Related Duration 0.000025
Bounce Rates 0.205299 Exit Rates 0.291739 Page Values 0.376345 Special Day 0.037037 Month 0.000738 Operating System 0.077586 Browser 0.024463 Region 0.035294 Traffic Type 0.049395 Visitor Type 0.071429 Weekend 0.028571
Tahap selanjutnya akan dilakukan perhitungan terhadap nilai prior
probability, probabilitas independen kelas Y dari semua fitur dalam vektor X,
probabilitas akhir yang diperoleh. Perhitungan nilai prior probability dapat dilihat pada Tabel 3.11 berikut:
Tabel 3. 11 Perhitungan Prior Probability Prior Probability
(Kelas) Jumlah Kelas N
P(X | Kelas ) (𝐾𝑒𝑙𝑎𝑠
𝑁 )
True 6 12 0.5
False 6 12 0.5
Tahap ini akan dilakukan perhitungan terhadap nilai probabilitas independen kelas Y dari semua fitur kelas X dengan acuan data yang terdapat pada Tabel 3.8 dengan baris pertama dijadikan sebagai data testing.
P ( True | Administrative = 0.428571429 ) = 0+1
6 = 0.1666666666666667
P ( False | Administrative = 0.428571429 ) = 1+1
6 = 0.3333333333333333
P ( True | Administrative Duration = 0.410727969) = 0+1
6 = 0.1666666666666667
P ( False | Administrative Duration = 0.410727969) = 1+1
6 = 0.3333333333333333
P ( True | Informational = 0) = 3 +1
6 = 0.6666666666666667
P ( False | Informational = 0) = 4 +1
6 = 0.8333333333333333
P ( True | Informational Duration = 0) = 4+1
6 = 0.8333333333333333
P ( False | Informational Duration = 0 ) = 4+1
6 = 0.8333333333333333
P ( True | Product Related = 0.039063) = 0+1
6 = 0.1666666666666667
P ( False | Product Related = 0.039063 ) = 0+1
6 = 0.1666666666666667
P ( True | Product Related Duration = 0.02089016) = 0+1
6 = 0.1666666666666667
P ( False | Product Related Duration = 0.02089016) = 0+1
6 = 0.1666666666666667
P ( True | Bounce Rates = 0) = 5+1
6 = 1
P ( False | Bounce Rates = 0) = 2+1
6 = 0.5
P ( True | Exit Rates = 0.405259) = 0+1
6 = 0.1666666666666667
P ( False | Exit Rates = 0.405259) = 0+1
P ( True | Page Values = 0) = 5+1
6 = 1
P ( False | Page Values = 0) = 5+1
6 = 1
P ( True | Special Day = 0) = 5 +1
6 = 1
P ( False | Special Day = 0) = 4+1
6 = 0.8333333333333333
P ( True | Month = 5) = 1+1
6 = 0.3333333333333333
P ( False | Month = 5) = 4+1
6 = 0.8333333333333333
P ( True | Operating Systems = 2) = 3+1
6 = 0.6666666666666667
P ( False | Operating Systems = 2) =4+1
6 = 0.8333333333333333 P ( True | Browser = 2) = 3+1 6 = 0.6666666666666667 P ( False | Browser = 2) = 3+1 6 = 0.6666666666666667 P ( True | Region = 7) = 0+1 6 = 0.1666666666666667 P ( False | Region = 7) = 2+1 6 = 0.5
P ( True | Traffic Type = 2) = 3+1
6 = 0.6666666666666667
P ( False | Traffic Type = 2) = 1+1
6 = 0.3333333333333333
P ( True | Visitor Type = 1) = 4+1
6 = 0.8333333333333333
P ( False | Visitor Type = 1) = 5+1
6 = 1
P ( True | Weekend = 1) = 2+1
6 = 0.5
P ( False | Weekend = 1) = 2+1
6 = 0.5
Tahap ini akan dilakukan perkalian antara hasil perhitungan probabilitas independen kelas Y dari semua fitur kelas X akan dengan hasil dari perhitungan R-Square, perhitungan akan dilakukan untuk semua atribut. Hasil dari perhitungan tersebut akan dikalikan dengan perhitungan prior probability untuk masing-masing kelas.
P ( True | X ) = ((P ( True | Administrative = 0.428571429 ) * R ( True |