PENERAPAN ALGORITMA APRIORI UNTUK MEMPEROLEH
ASSOCIATION RULE ANTAR ITEMSET BERDASARKAN PERIODE
PENJUALAN DALAM SATU TRANSAKSI
Devi Fitrianah, Ade Hodijah
Program Studi Teknik Informatika, Fakultas Ilmu Komputer, Universitas Mercu Buana JL. Raya Meruya Selatan, Kembangan, Jakarta, 11650
Email: [email protected], [email protected] Abstrak
Dalam dunia bisnis yang penuh persaingan menuntut seorang pengambil keputusan untuk melihat peluang-peluang yang dapat meningkatkan penjualan di perusahaannya. Salah satu unsur penting pendukung pengambilan keputusan adalah ketersediaan data transaksi dalam jumlah besar sebagai sumber informasi untuk analisis kecenderungan pola pembelian belanja konsumen. Untuk itu dalam penulisan ini dikembangkan aplikasi analisis association untuk mengekstraksi dan menginterpretasi pola kecenderungan produk-produk yang sering dibeli bersamaan pada periode penjualan tertentu dari data transaksi menggunakan algoritma apriori.
Algoritma apriori ini akan membentuk frequent itemset sebanyak yang telah ditentukan sebelumnya berdasarkan dua parameter, support dan confidence, untuk menemukan aturan asosiasi antara suatu kombinasi item. Proses yang dilakukan diawali dengan persiapan data melalui preprocessing data kemudian ditransformasi ke dalam bentuk yang dapat diolah pada proses selanjutnya yaitu join dan prune hingga pembentukan association rules.
Dari hasil pengujian, aplikasi yang dibangun mampu melakukan penerapan algoritma apriori dengan terbentuknya pola-pola frequent itemset dari data transaksi sebagai bahan analisis pola pembelian belanja konsumen.
Kata Kunci: Apriori, Frequent Itemset, Association rules, Data Transaksi
1. Pendahuluan
Gudang data yang berisi data bisnis merupakan salah satu aset utama yang dimiliki perusahaan. Bagi perusahaan dengan skala kecil, seperti toko-toko kecil, pengolahan data dengan sistem basis data sederhana sudah mencukupi untuk bahan analisa seorang manajer dalam pengambilan keputusan. Tidak demikian dengan perusahaan yang bergerak dengan skala besar, yang memasarkan produk dalam jumlah besar dengan jenis item yang juga sangat banyak dan beragam, misalnya sebuah supermarket, yang setiap bulannya harus menangani ratusan bahkan ribuan transaksi.
Untuk meningkatkan “usability” ketersediaan data transaksi sebagai sumber informasi, misalnya penggunaan computer based method untuk menganalisis, meringkas dan mengekstraksi “knowledge” dari data tersebut, perlu adanya suatu sistem yang dapat mendukung manajer dalam mengambil keputusan secara cepat dan juga tepat. Salah satu cara untuk mendapatkan knowledge adalah dengan melakukan penambangan data. Penambangan data diperlukan untuk memperoleh informasi-informasi yang cukup untuk dianalisa lebih lanjut. Pada supermarket, informasi tersebut dapat berupa produk-produk apa saja yang sering terjual pada periode waktu tertentu dan data produk lain yang dibeli secara bersamaan oleh konsumen. Selanjutnya dapat diambil satu contoh hasil analisis yang diinginkan, seperti jika manajer
pemasaran telah mengetahui produk apa saja yang biasa dibeli bersamaan maka salah satu tindakan konkrit yang dapat dilakukan adalah menata rak-rak barangnya, seperti tata letak barang mana yang harus diletakkan berdekatan sehingga memudahkan konsumen untuk mendapatkan barang atau mengingatkan konsumen jika pada saat itu lupa ingin membeli atau membutuhkan barang tersebut. Selain itu, manajer juga dapat mengambil sikap dengan menyediakan lebih banyak barang tertentu di waktu-waktu tertentu, sehingga nantinya kedua keputusan ini dapat mendatangkan keuntungan yang lebih bagi perusahaan.
Dari latar belakang seperti terpapar di atas, dapat dirumuskan permasalahan yaitu bagaimana melakukan penambangan data transaksi penjualan dengan association rule mining menggunakan algoritma apriori untuk mengetahui pola-pola
frequent itemset agar diperoleh hasil analisis
kecenderungan pola pembelian belanja konsumen. Data yang diambil sebagai contoh kasus adalah basis data Northwind yang merupakan database
default saat instalasi SQL Server 2005.
Hasil penulisan ini diharapkan dapat memberikan gambaran langkah-langkah penerapan algoritma apriori dalam menambang data.
2. Teori Penunjang
Topik yang dibahas merupakan topik yang berkaitan dengan analisis yang berkaitan dengan kebiasaan belanja konsumen, maka metode yang
paling tepat digunakan adalah Market Basket
Analysis. Untuk menghasilkan pola asosiasinya,
penulis menggunakan algoritma apriori.
2.1 Data Mining
Data mining atau Knowledge Discovery in
Database adalah proses untuk menemukan interesting knowledge dari sejumlah besar data
yang disimpan baik di dalam transactional
database, data warehouse atau tempat
penyimpanan informasi lainnya[1].
2.2 Association Rule Mining
Association rule mining adalah suatu prosedur
untuk mencari hubungan antar item dalam suatu
data set yang ditentukan[1]. Association Rule Mining meliputi dua tahap:
a. Mencari kombinasi yang paling sering terjadi dari suatu itemset (frequent itemset).
b. Meng-generate Association Rule dari frequent
itemset yang telah dibuat sebelumnya.
Umumnya ada dua ukuran kepercayaan (interestingness measure) yang digunakan dalam menentukan suatu association rule, yaitu Support dan Confidence[3].
2.3 Market basket analysis
Market Basket Analysis merupakan analisis
terhadap kebiasaan konsumen berbelanja pada supermarket dengan cara menemukan asosiasi dan korelasi diantara berbagai macam items yang dimasukkan konsumen di dalam keranjang belanjaannya [5]. Secara lebih spesifik, market
basket analysis bertujuan untuk mengetahui items
apa saja yang sering dibeli bersamaan oleh konsumen. Items di sini diartikan sebagai berbagai macam produk atau barang pada supermarket tersebut.
Fungsi association rules seringkali disebut dengan “market basket analysis”. Fungsi ini paling banyak digunakan untuk menganalisa data dalam rangka keperluan strategi pemasaran, desain catalog, dan proses pembuatan keputusan bisnis. Algoritma paling dasar untuk mencari itemset sering muncul (disebut frequent itemset) adalah algoritma apriori.
2.4 Algoritma Apriori
Algoritma apriori adalah algoritma analisis
keranjang pasar yang digunakan untuk menghasilkan aturan asosiasi, dengan pola
“if-then”. Algoritma apriori menggunakan pendekatan
iteratif yang dikenal dengan level-wise search, dimana k-kelompok produk digunakan untuk mengeksplorasi (k+1)-kelompok produk atau (k+1)-itemset [1].
Beberapa istilah yang digunakan dalam algoritma apriori antara lain:
a. Support (dukungan): probabilitas pelanggan membeli beberapa produk secara bersamaan dari seluruh transaksi. Support untuk aturan “X ⇒ Y” adalah probabilitas atribut atau
kumpulan atribut X dan Y yang terjadi bersamaan.
b. Confidence (tingkat kepercayaan): probabilitas kejadian beberapa produk dibeli bersamaan dimana salah satu produk sudah pasti dibeli. Contoh: jika ada n transaksi dimana X dibeli, dan ada m transaksi dimana X dan Y dibeli bersamaan, maka confidence dari aturan if X
then Y adalah m/n.
c. Minimum support: parameter yang digunakan sebagai batasan frekuensi kejadian atau
support count yang harus dipenuhi suatu
kelompok data untuk dapat dijadikan aturan. d. Minimum confidence: parameter yang
mendefinisikan minimum level dari confidence yang harus dipenuhi oleh aturan yang berkualitas.
e Itemset: kelompok produk
f. Support count: frekuensi kejadian untuk sebuah kelompok produk atau itemset dari seluruh transaksi.
g. Kandidat itemset (C
k): itemset-itemset yang
akan dihitung support count-nya. h. Frequent itemset (F
k): itemset yang sering
terjadi, atau itemset-itemset yang sudah melewati batas minimum support yang telah ditentukan.
Ada dua proses utama yang dilakukan algoritma apriori, yaitu:
1. Join (penggabungan): untuk menemukan F
k,
C
k dibangkitkan dengan melakukan proses join
F
k-1 dengan dirinya sendiri, Ck=Fk-1*Fk-1, lalu
anggota C
k diambil hanya yang terdapat
didalam F
k-1.
2. Prune (pemangkasan): menghilangkan anggota C
k yang memiliki support count lebih kecil
dari minimum support agar tidak dimasukkan ke dalam F
k.
Metodologi dasar algoritma apriori untuk membangkitkan frequent itemset terbagi menjadi dua tahap:
a. Analisa pola frekuensi tinggi
1. Menelusuri seluruh record di basis data transaksi dan menghitung support count dari tiap item. Ini adalah kandidat 1-itemset, C
1.
Nilai support menggunakan rumus [2]: Total transaksi A berisi transaksi Jumlah A Support _ _ _ _ ) ( = transaksi Total B A berisi transaksi Jumlah B A Support _ _ _ _ ) , ( = ∩ 2. Frequent 1-itemset F 1 dibangun dengan menyaring C
besar sama dengan minimum support untuk dimasukkan kedalam F
1.
3. Untuk membangun F
2, algoritma apriori
menggunakan proses join untuk menghasilkan C
2.
4. Dari C
2, 2-itemset yang memiliki support count
yang lebih besar sama dengan minimum
support akan disimpan ke dalam L
2.
5. Proses ini diulang sampai tidak ada lagi kemungkinan k-itemset.
Contoh tahapan pembangkitan C
1, F1, C2, F2, C3, F3
terlihat pada Gambar 1.
b. Pembentukan aturan asosiatif
Dari beberapa frequent itemset yang telah ditemukan, dapat dibangkitkan aturan-aturan
asosiasi yang berkualitas. Syarat aturan asosiasi yang adalah harus memenuhi minimum support dan
minimum confidence yang telah ditentukan. Confidence dari setiap aturan yang dibangkitkan
dapat dihitung dengan menggunakan rumus [2]: ) ( _ sup ) ( _ sup ) ( A count port B A count port B A Confidence ⇒ = ∩
Berdasarkan rumusan diatas, aturan asosiasi dapat dibangkitkan dengan langkah:
1. Untuk setiap itemset l, bangkitkan seluruh subset
l yang tidak kosong.
2. Untuk setiap subset s dari l yang tidak kosong, buat aturan ‘s => (l- s)’ jika
confidence imum s count port l count port _ min ) ( _ sup ) ( _ sup ≥
Gambar 1. Pencarian candidate itemsets dan frequent itemset dengan minimum support = 2 [Sumber: Han, Jiawei, and Micheline Kamber, Data Mining: Concepts and Techniques,
Morgan Kaufmann, 2001, p. 233 (telah diolah kembali).] Algoritma aprirori dapat dilihat sebagai berikut [1]:
L1 = find_frequent_1_itemset(D);
For (k=2; Lk-1≠∅; k++)
{ Ck = apriori_gen(Lk-1,min_sup);
For each transaction t ∈ D //scan D for counts
For each candidate c ∈ Ct { c.count ++; } } Lk = { c ∈ Ck | c.count ≥ min_sup } } return L = UkLk;
Procedure apriori_gen(Lk-1:frequent(k-1)-itemsets; min_sup:min_sup_threshold)
For each itemset l1 ∈ Lk-1
{ For each l2 ∈ Lk-1
{ If ( (l1[1]= l2[1]) ∧ (l1[2]= l2[2]) ∧…∧
(l1[k-2]= l2[k-2]) ∧ (l1[k-1] < l2[k-1]) )then
{ c = l1ZY l2; //join step: generate candidates
If (has_infrequent_subset(c,Lk-1)) then
{ delete c; //prune step: remove unfruitful candidate }Else { add c to Ck; }
} }
}
return Ck;
Procedure has_infrequent_subset(c:candidate_k-itemset; Lk-1:frequent_(k-1)-itemsets) //use prior
knowledge
For each (k-1)-subset s of c { If s ∉ Lk-1 then
{ return TRUE; }
}
return FALSE; 3. Desain Sistem
3.1 Analisa Kebutuhan Sistem
Dalam mengimplementasikan algoritma apriori untuk mencari aturan asosiasi, penulis menggunakan basis data Northwind, dimana dalam basis data tersebut terdapat diantaranya 3 tabel, yaitu tabel “Orders” menyimpan transaksi yang terjadi dalam suatu perusahaan, tabel “OrderDetails“ menjelaskan barang apa saja yang terbeli dalam masing-masing transaksi pada tabel “Orders“, sedangkan tabel “Products“ menyimpan detail data barang yang terbeli untuk setiap transaksi pada tabel “OrderDetails“.
Atribut-atribut yang dipilih, yaitu atribut ”OrderDate” sebagai representasi waktu, ”Quantity” sebagai representasi stok, ”ProductName” sebagai representasi jenis barang yang dibeli oleh konsumen. Data yang dapat diterima oleh algoritma apriori adalah hanya data yang bersifat numerik, sehingga diperlukan proses transformasi data terlebih dahulu. Proses transformasi data teks atau kategorial menjadi numerik adalah dengan cara memberikan nilai integer kepada setiap data yang berbeda secara kontinyu. Data yang bernilai sama maka akan mempunyai nilai integer yang sama.
Atribut-atribut yang belum bertipe numerik, yakni atribut “ProductName” dan “OrderDate”, maka pada atribut-atribut tersebut harus dilakukan numerisasi terlebih dahulu. Sedangkan atribut “Quantity” telah bertipe numerik, sehingga tidak perlu lagi dilakukan proses numerisasi.
Pada atribut “ProductName” kategori yang ada hanya berupa “Dibeli” dan “Tidak dibeli”, maka setelah dilakukan proses numerisasi, data “Dibeli” akan ditransformasi menjadi 1 dan data “Tidak dibeli” menjadi 0.
Selanjutnya numerisasi pada atribut “OrderDate” ini difokuskan pada data tanggal transaksi dengan rentang waktu per-3 kali dalam sebulan, yakni tanggal (1-10) adalah “Periode awal bulan” akan ditransformasi menjadi 1, (11-20) adalah “Periode tengah bulan” akan ditransformasi menjadi 2, dan (21-tanggal akhir per bulan) adalah “Periode akhir bulan” akan ditransformasi menjadi 3.
Langkah dalam pembuatan aplikasi association
rule mining menggunakan algoritma apriori
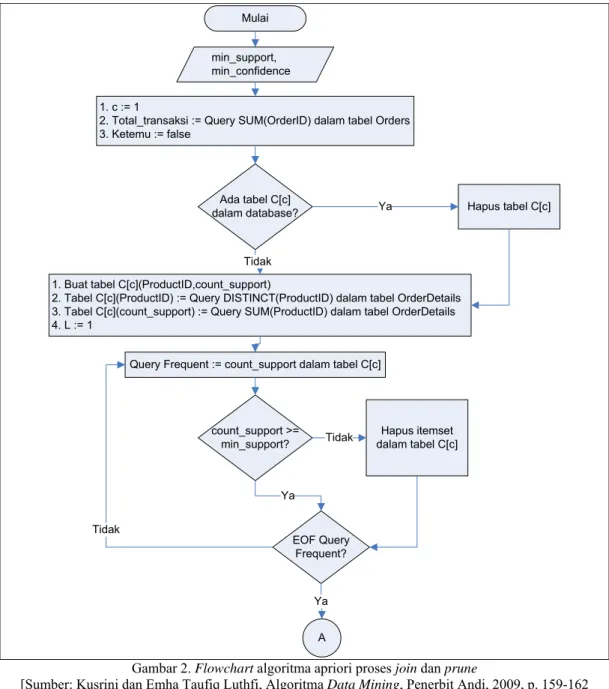
dijelaskan dalam flowchart yang tampak pada Gambar 2, Gambar 3, dan Gambar 4 berikut.
Mulai min_support, min_confidence 1. c := 1
2. Total_transaksi := Query SUM(OrderID) dalam tabel Orders 3. Ketemu := false
Ada tabel C[c]
dalam database? Hapus tabel C[c]
1. Buat tabel C[c](ProductID,count_support)
2. Tabel C[c](ProductID) := Query DISTINCT(ProductID) dalam tabel OrderDetails 3. Tabel C[c](count_support) := Query SUM(ProductID) dalam tabel OrderDetails 4. L := 1
Ya
Tidak
Query Frequent := count_support dalam tabel C[c]
count_support >= min_support? Hapus itemset dalam tabel C[c] Tidak EOF Query Frequent? Ya Tidak Ya A
Gambar 2. Flowchart algoritma apriori proses join dan prune
[Sumber: Kusrini dan Emha Taufiq Luthfi, Algoritma Data Mining, Penerbit Andi, 2009, p. 159-162 (telah diolah kembali).]
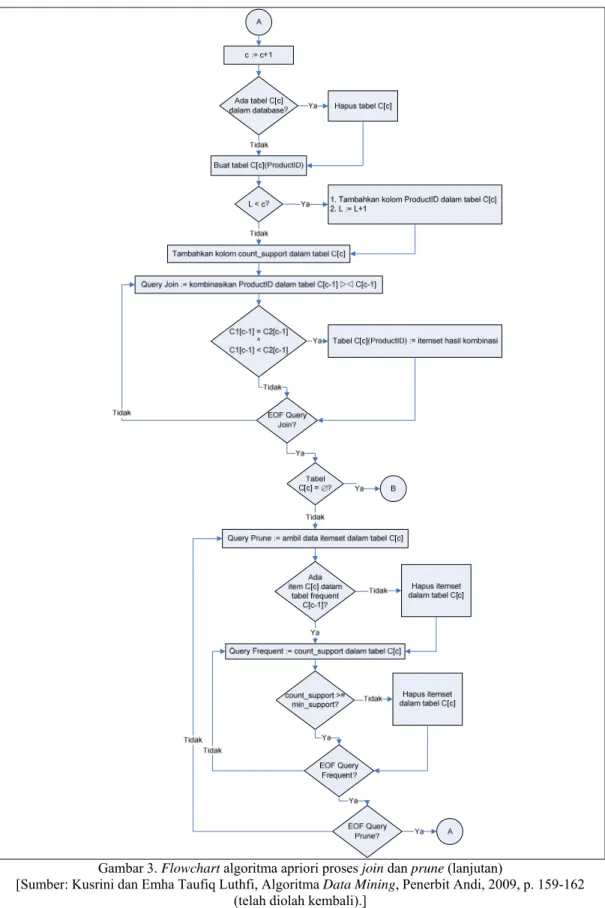
Gambar 3. Flowchart algoritma apriori proses join dan prune (lanjutan)
[Sumber: Kusrini dan Emha Taufiq Luthfi, Algoritma Data Mining, Penerbit Andi, 2009, p. 159-162 (telah diolah kembali).]
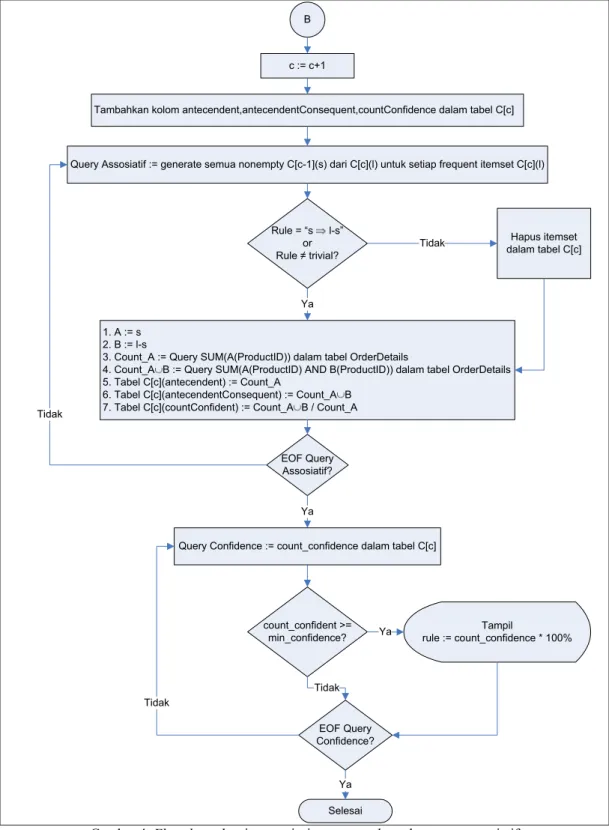
B
Tambahkan kolom antecendent,antecendentConsequent,countConfidence dalam tabel C[c]
Query Assosiatif := generate semua nonempty C[c-1](s) dari C[c](l) untuk setiap frequent itemset C[c](l)
count_confident >= min_confidence? EOF Query Confidence? Ya Tidak Tampil rule := count_confidence * 100% c := c+1 Rule = “s l-s” or Rule ≠ trivial? Hapus itemset dalam tabel C[c] Tidak 1. A := s 2. B := l-s
3. Count_A := Query SUM(A(ProductID)) dalam tabel OrderDetails
4. Count_A B := Query SUM(A(ProductID) AND B(ProductID)) dalam tabel OrderDetails 5. Tabel C[c](antecendent) := Count_A
6. Tabel C[c](antecendentConsequent) := Count_A B 7. Tabel C[c](countConfident) := Count_A B / Count_A
Ya
EOF Query Assosiatif?
Query Confidence := count_confidence dalam tabel C[c] Ya
Tidak
Selesai Ya Tidak
Gambar 4. Flowchart algoritma apriori proses pembentukan aturan asosiatif
[Sumber: Kusrini dan Emha Taufiq Luthfi, Algoritma Data Mining, Penerbit Andi, 2009, p. 159-162 (telah diolah kembali).]
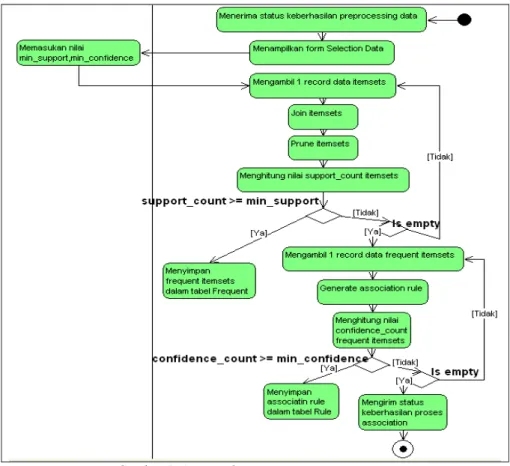
Gambar 5. Activity diagram use case association
3.2 Tahap Proses Association
Desain dari proses ini dapat dilihat pada
Gambar 5. Tahap proses Association adalah aplikasi berbasis Windows XP dan dibangun menggunakan software kompilasi PHP serta
database engine MySQL.
Pada tahap ini dilakukan proses association rule
mining terhadap data transaksi Northwind yang
telah tersimpan dalam tabel TabularTransaksi. Implementasi dilakukan menggunakan algoritma apriori dengan melakukan proses analisa pola frekuensi tinggi (proses join dan prune) kemudian proses pembentukan aturan asosiatif (proses
generate association rule).
3.3 Desain Database
Basis data yang dikembangkan terdiri dari tabel yang bersifat referensi, input, dan output.
Tabel yang bersifat referensi ini terdiri dari 3 tabel, yaitu tabel “Orders”, “OrderDetails”, dan
“Products”. Tabel ini merupakan tabel dari basis data transaksi penjualan, yaitu Northwind, yang diperoleh saat instalasi SQL Server 2000, database
default. Relasi tabel relasi ini dapat dilihat pada
gambar 7
Tabel yang bersifat input adalah tabel “Transaksi”, yakni tabel tabel yang menyimpan data sebagai input ke proses association. Seluruh data yang berada dalam tabel ini telah bersifat numerik. Terakhir adalah tabel yang bersifat
output, tabel yang akan menyimpan data hasil association. Tabel ini terdiri dari 2 tabel. Pertama,
tabel “Frequent”, yakni tabel yang menyimpan data
frequent itemsets, hasil proses join dan prune.
Kedua, tabel “Rule”, yakni tabel yang menyimpan data association rule, hasil proses pembentukan aturan asosiatif. Susunan tabel input dan tabel
output dapat dilihat pada gambar 8.
IDFREQUENT = IDFRE QUE NT
ORDERID = ORDE RID
TRANSAKSI ORDERID integer PRODUCTID integer QUANTITY integer ORDERDATE integer FREQUENT IDFREQUENT integer ORDERID integer PRODUCTID integer SUPPORT_COUNT integer BASEORDERIDFREQ integer RULE IDRULE integer IDFREQUENT integer ANTECENDENT integer CONSEQUENT integer COUNT_SUPPORT integer COUNT_CONFIDENCE integer BASEORDERIDRL integer
Gambar 7. Rancangan basis data dari aplikasi yang akan dibangun
4. Pengujian Sistem
Pengujian dilakukan menggunakan spesfikasi
hardware dan software berikut:
Processor : Intel Dual-Core 1.2 GHz
Memory : 1 GB
Operating System : Ms. Windows XP SP2
Database : MySQL
Berikut adalah skenario pengujian yang dilakukan: 1. Apakah sistem dapat melakukan proses
association rule mining dengan jumlah atribut data berbeda sesuai dengan pilihan pengguna?
2. Apakah sistem dapat melakukan pra pemrosesan data (transformasi atribut)?
3. Apakah sistem dapat melakukan proses asosiasi termasuk proses join dan prune? 4. Apakah sistem dapat menampilkan hasil
asosiasi?
5. Apakah sistem dapat menyimpan hasil asosiasi?
Hasil implementasi dapat dilihat dari gambar 8 sampai gambar 11. Hasil pengujian lengkap terdapat pada table hasil pengujian.
Gambar 9. Form Association
Gambar 10. Form association rules mining Persentase
Aturan asosiasi yang diperoleh pada gambar 10 sebagai berikut:
1. JIKA membeli Asparagus dan Squash, MAKA akan membeli Beans dengan nilai support 28.6% dan confidence 80%
2. JIKA membeli Asparagus dan Beans, MAKA akan membeli Squash dengan nilai support 28.6% dan confidence 80%
Aturan asosiasi yang diperoleh pada gambar 11 sebagai berikut:
1. JIKA membeli Asparagus dan Squash, MAKA akan membeli Beans dengan nilai support 28.6% dan confidence 80%
Detail periode: • Asparagus
- Periode awal bulan: 1 - Periode tengah bulan: 0 - Periode akhir bulan: 1 • Squash
- Periode awal bulan: 1 - Periode tengah bulan: 0 - Periode akhir bulan: • Beans
- Periode awal bulan: 1 - Periode tengah bulan: 0 - Periode akhir bulan: 0
2. JIKA membeli Asparagus dan Beans, MAKA akan membeli Squash dengan nilai support 28.6% dan confidence 80%
• Asparagus
- Periode awal bulan: 1 - Periode tengah bulan: 0 - Periode akhir bulan: 1 • Beans
- Periode awal bulan: 1 - Periode tengah bulan: 0 - Periode akhir bulan: 1 • Squash
- Periode awal bulan: 1 - Periode tengah bulan: 0 - Periode akhir bulan: 1
Tabel 1 Hasil Pengujian Implementasi
No Kebutuhan Terpen uhi Keterangan Y a T i d a k 1
Sistem dapat melakukan proses
association rule mining dengan
jumlah atribut data berbeda sesuai pilihan pengguna. √
Pengguna dapat menginputkan data sesuai yang diinginkan sebagai input ke proses association. Pemenuhan kebutuhan ini terhadap sistem terdapat pada menu “Selection Data”.
2
Sistem mampu melakukan pra pemrosesan data (transformasi atribut).
√
Sistem berhasil melakukan transformasi menggunakan pengukuran variabel biner untuk atribut “ProductName” dan pengukuran kategorial untuk atribut “OrderDate”. Pemenuhan kebutuhan ini terhadap sistem terdapat pada menu “Association”.
3
Sistem dapat melakukan proses algoritma association, dalam hal ini algoritma apriori, termasuk dilakukannya proses join dan
prune.
√
Sistem telah mengimplementasikan algoritma apriori. Pemenuhan kebutuhan ini terhadap sistem terdapat pada menu “Association”.
4
Sistem dapat menampilkan hasil
association, sehingga data-data
yang memiliki kecenderungan pembelian bersama dapat diketahui. Informasi pengelompokkan data barang ini berdasarkan persentase dan periode penjualan.
√
Pengguna dapat melihat data hasil
association dan melihat hasilnya dalam
format tabel dan grafi. Pemenuhan kebutuhan ini terhadap sistem terdapat pada menu “Interpretasi Persentase dan Periode”.
5
Sistem dapat menyimpan hasil
association
√
Hasil proses association yang terakhir dilakukan dapat dilihat pengguna walau aplikasi telah dimatikan. Pemenuhan kebutuhan ini terhadap sistem terdapat pada menu “View the last association”.
4. KESIMPULAN
Dari hasil pembahasan dapat disimpulkan bahwa penulisan telah berhasil untuk:
¾ Semakin tinggi batasan minimum support
count yang ditentukan maka association rules yang dihasilkan semakin sedikit.
Sehingga menurunkan data barang yang dihasilkan namun lebih meningkatkan asosiasi diantara user’s threshold dengan pengelompokkan data barang.
¾ Bila di-input-kan nilai threshold yang tidak sesuai dengan jumlah maksimum
support_count dan confidence berdasarkan
jumlah kemunculan itemset pada database, maka hasil pencarian association rule akan menghasilkan daftar yang “null”. Hal ini dikarenakan nilai threshold tidak memenuhi minimal persayaratan frequent 2-itemset.
5. DAFTAR PUSTAKA
[1] Han, Jiawei and Micheline Kamber, “Data
Mining Concepts and Techniques”, Morgan
Kaufmann, California, 2001.
[2] Kusrini, Emha Taufiq Luthfi, 2009, Algoritma
Data Mining, Penerbit Andi, Yogyakarta.
[3] Larose, D. T., 2005, Discovering Knowledge in
data: An Introduction to Data Mining, A John
Wiley and sons, Inc., Publication, New Jersey. [4] Santosa, Budi. 2007. Data Mining-Teknik
Pemanfaatan Data Untuk Keperluan Bisnis. Graha Ilmu. Yogyakarta.
[5]Olson, David dan Yong Shi. 2006. Introduction
to Business Data Mining. New York: