2.1. Citra Digital
Citra digital adalah citra yang terdiri dari sinyal-sinyal frekuensi elektromagnetis yang sudah di-sampling sehingga dapat ditentukan ukuran titik gambar tersebut yang pada umumnya disebut pixel.[6] Pengolahan citra digital adalah sebuah disiplin ilmu yang mempelajari hal-hal yang berkaitan dengan perbaikan kualitas gambar (peningkatan kontras, transformasi warna, restorasi citra), transformasi gambar (rotasi, translasi, skala, transformasi geometrik), melakukan pemilihan citra ciri (feature images) yang optimal untuk tujuan analisis, melakukan proses penarikan informasi atau deskripsi objek atau pengenalan objek yang terkandung pada citra, melakukan kompresi atau reduksi data untuk tujuan penyimpanan data, transmisi data, dan waktu proses data. Input dari pengolahan citra adalah citra, sedangkan output-nya adalah citra hasil pengolahan.[9]
2.2. Citra Bitmap (BMP)
Meskipun format BMP tidak bagus dari segi ukuran berkas, namun format BMP memiliki kualitas gambar yang lebih baik dari format JPG maupun GIF. Karena citra dalam format BMP umumnya tidak dimampatkan/dikompresi sehingga tidak ada informasi yang hilang. Bitmap terdiri dari baris dan kolom pada titik image graphics di komputer. Nilai dari titik disimpan dalam satu atau lebih bit. Bit yang umum adalah 8, artinya setiap piksel panjangnya 8 bit. Delapan bit ini merepresentasikan nilai intensitas piksel. Dengan demikian ada sebanyak2 = 256 derajat keabuan mulai dari 0-255.[2]
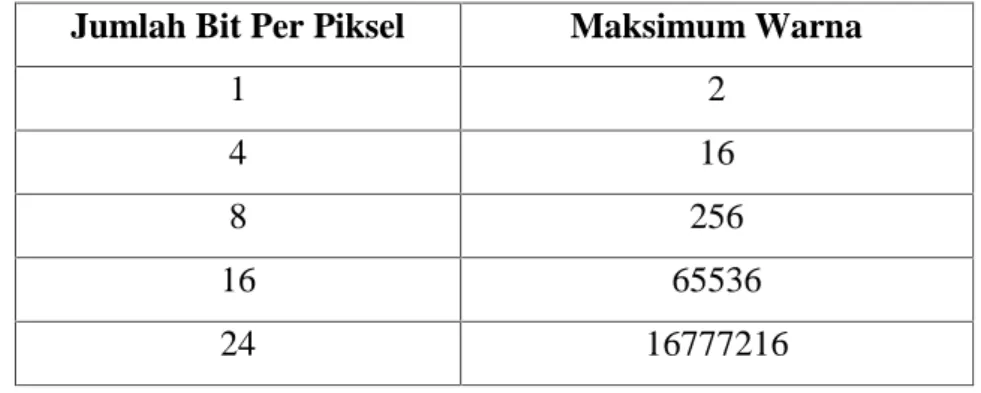
Citra dalam format BMP ada tiga macam : citra biner, citra berwarna, dan citra hitam-putih (grayscale). Citra biner hanya memiliki dua kemungkinan nilai piksel yaitu hitam dan putih. Citra ini hanya membutuhkan 1 bit untuk mewakili nilai setiap piksel dari citra biner. Citra berwarna adalah citra yang lebih umum. Dimana setiap piksel pada citra warna mewakili warna yang merupakan kombinasi dari tiga warna dasar (RGB = Red Green Blue). Setiap warna dasar menggunakan penyimpanan 8 bit = 1 byte, yang berarti setiap warna mempunyai gradasi sebanyak 255 warna. Setiap komponen warna RGB-nya disimpan di dalam tabel RGB yang disebut palet. Setiap komponen panjangnya 8 bit, jadi ada 256 nilai keabuan untuk warna merah, 256 nilai keabuan untuk warna hijau dan 256 nilai keabuan untuk warna biru. Nilai setiap piksel tidak menyatakan derajat keabuan secara langsung, tetapi nilai piksel menyatakan indeks tabel RGB yang memuat nilai keabuan merah (R), nilai keabuan hijau (G), nilai keabuan biru (B) untuk masing-masing piksel bersangkutan. Sedangkan citra hitam putih hanya memiliki satu kanal pada setiap pikselnya, dengan kata lain nilai bagian RED = GREEN = BLUE yang digunakan untuk menunjukkan tingkat intensitas. Format citra ini mendukung citra dengan jumlah bit per piksel sebanyak 1, 4, 8, 16, dan 24 bit per piksel. Berikut ini tabel yang menunjukkan hubungan antara banyaknya bit per piksel dengan jumlah warna maksimum yang dapat disimpan dalam bitmap seperti pada tabel 2.1.[2]
Tabel 2.1. Hubungan bit per piksel dengan maksimum warna pada bitmap Jumlah Bit Per Piksel Maksimum Warna
1 2
4 16
8 256
16 65536
Contoh gambar BMP dapat dilihat seperti pada gambar 2.1.
Gambar 2.1. Contoh Gambar BMP
2.3. Citra Portable Network Graphics ( PNG )
Portable Network Graphic (PNG, dibaca ping) yang diprakarsai oleh Thomas Boutell dari PNG Development Group pada 1 Oktober 1996 dirancang agar menjadi lebih baik daripada format yang terdahulu yang sudah dilegalkan yaitu GIF. PNG mempunyai beberapa persamaan fitur dengan GIF antara lain menggunakan algoritma kompresi tak berugi, mendukung kedalaman warna sampai 8-bit piksel (2 = 256 warna)/citra berindeks (indexed images), mendukung untuk web browser, mendukung transparency, dan mendukung interlacing. Perbedaannya adalah terdapat adanya penambahan fitur-fitur baru antara lain : mendukung kedalaman warna 16-bit (aras keabuan/grayscale) serta citra berwarna 24-bit dan 48-bit (true color images), memiliki alpha channel untuk mengontrol transparency, memiliki gamma storage dan gamma correction (kontrol untuk ketajaman/brightness sebuah citra), memiliki pendeteksi kesalahan (error detection), dan memiliki teknik pencocokan warna yang lebih canggih dan akurat. PNG menggunakan metode kompresi deflate yang merupakan algoritma kompresi tak berugi. Deflate adalah kelanjutan versi dari algoritma kompresi Lempel-Ziv. Sistem kerja deflate sama dengan algoritma LZW yaitu melakukan pemindaian dengan cara garis horisontal.[8] Berikut contoh gambar PNG seperti pada gambar 2.2.
Gambar 2.2. Contoh Gambar PNG
2.4. Kompresi Data
Kompresi data merupakan cabang ilmu komputer yang bersumber dari teori informasi. Teori informasi sendiri dipelopori oleh Claude Shannon sekitar tahun 1940-an. Teori ini mendefenisikan jumlah informasi di dalam pesan sebagai jumlah minimum bit yang dibutuhkan yang dikenal sebagai entropy. Teori ini juga memfokuskan pada berbagai metode tentang informasi termasuk tentang redundancy (informasi tak berguna) pada suatu pesan dimana semakin banyak redundancy maka semakin besar pula ukuran pesan, upaya mengurangi redundancy inilah yang akhirnya melahirkan subjek ilmu tentang kompresi data.[10] Kompresi citra adalah proses pemampatan citra yang bertujuan untuk mengurangi duplikasi data pada citra sehingga memory yang digunakan untuk merepresentasikan citra menjadi lebih sedikit daripada representasi citra semula.[7]
Salomon Dan Motta (2010) menyatakan “Data compression is the process of converting an input data stream (the source stream or the original raw data) into another data stream (the output, the bitstream, or the compressed stream) that has a smaller size. A stream can be a file, a buffer in memory, or individual bits sent on a communications channel.”[5]
Kompresi data merupakan suatu teknik untuk memperkecil jumlah ukuran data dari data aslinya. Kompresi data sangat menguntungkan apabila terdapat suatu data yang berukuran sangat besar dan di dalamnya banyak mengandung pengulangan
Gambar 2.2. Contoh Gambar PNG
2.4. Kompresi Data
Kompresi data merupakan cabang ilmu komputer yang bersumber dari teori informasi. Teori informasi sendiri dipelopori oleh Claude Shannon sekitar tahun 1940-an. Teori ini mendefenisikan jumlah informasi di dalam pesan sebagai jumlah minimum bit yang dibutuhkan yang dikenal sebagai entropy. Teori ini juga memfokuskan pada berbagai metode tentang informasi termasuk tentang redundancy (informasi tak berguna) pada suatu pesan dimana semakin banyak redundancy maka semakin besar pula ukuran pesan, upaya mengurangi redundancy inilah yang akhirnya melahirkan subjek ilmu tentang kompresi data.[10] Kompresi citra adalah proses pemampatan citra yang bertujuan untuk mengurangi duplikasi data pada citra sehingga memory yang digunakan untuk merepresentasikan citra menjadi lebih sedikit daripada representasi citra semula.[7]
Salomon Dan Motta (2010) menyatakan “Data compression is the process of converting an input data stream (the source stream or the original raw data) into another data stream (the output, the bitstream, or the compressed stream) that has a smaller size. A stream can be a file, a buffer in memory, or individual bits sent on a communications channel.”[5]
Kompresi data merupakan suatu teknik untuk memperkecil jumlah ukuran data dari data aslinya. Kompresi data sangat menguntungkan apabila terdapat suatu data yang berukuran sangat besar dan di dalamnya banyak mengandung pengulangan
Gambar 2.2. Contoh Gambar PNG
2.4. Kompresi Data
Kompresi data merupakan cabang ilmu komputer yang bersumber dari teori informasi. Teori informasi sendiri dipelopori oleh Claude Shannon sekitar tahun 1940-an. Teori ini mendefenisikan jumlah informasi di dalam pesan sebagai jumlah minimum bit yang dibutuhkan yang dikenal sebagai entropy. Teori ini juga memfokuskan pada berbagai metode tentang informasi termasuk tentang redundancy (informasi tak berguna) pada suatu pesan dimana semakin banyak redundancy maka semakin besar pula ukuran pesan, upaya mengurangi redundancy inilah yang akhirnya melahirkan subjek ilmu tentang kompresi data.[10] Kompresi citra adalah proses pemampatan citra yang bertujuan untuk mengurangi duplikasi data pada citra sehingga memory yang digunakan untuk merepresentasikan citra menjadi lebih sedikit daripada representasi citra semula.[7]
Salomon Dan Motta (2010) menyatakan “Data compression is the process of converting an input data stream (the source stream or the original raw data) into another data stream (the output, the bitstream, or the compressed stream) that has a smaller size. A stream can be a file, a buffer in memory, or individual bits sent on a communications channel.”[5]
Kompresi data merupakan suatu teknik untuk memperkecil jumlah ukuran data dari data aslinya. Kompresi data sangat menguntungkan apabila terdapat suatu data yang berukuran sangat besar dan di dalamnya banyak mengandung pengulangan
karakter. Kompresi data umumnya diterapkan pada komputer, karena setiap simbol yang muncul pada komputer memiliki nilai bit-bit yang berbeda. Misal pada ASCII setiap simbol yang dimunculkan memiliki panjang 8 bit, misal kode A pada ASCII mempunyai nilai desimal = 65, jika diubah dalam bilangan biner menjadi 010000001. Kompresi data digunakan untuk mengurangkan jumlah bit- bit yang dihasilkan dari setiap simbol yang muncul.[3]
Jika data hasil kompresi tersebut akan ditransmisikan maka pihak pengirim dan pihak penerima harus memiliki teknik algoritma kompresi yang sama. Sehingga data tersebut dapat dibaca oleh pihak penerima. Kompresi dalam hal ini sangat membantu, karena selain memperkecil ukuran data, dengan kompresi maka kebutuhan bandwidth akan lebih kecil dan data yang dikirimkan lebih cepat sampai pada penerima.[3]
2.5. Dekompresi Data
Sebuah data yang sudah dikompres tentunya harus dapat dikembalikan lagi kebentuk aslinya, prinsip ini dinamakan dekompresi. Untuk dapat merubah data yang terkompresi diperlukan cara yang berbeda seperti pada waktu proses kompresi dilaksanakan. Jadi pada saat dekompresi catatan header yang berupa byte-byte tersebut terdapat catatan isi mengenai isi dari file tersebut . Catatan header akan menuliskan kembali mengenai isi dari file tersebut, jadi isi dari file sudah tertulis oleh catatan header sehingga hanya tinggal menuliskan kembali pada saat proses dekompres. Proses dekompresi sempurna (kembali kebentuk aslinya). Secara umum proses kompresi dan dekompresi dapat dilihat seperti pada Gambar 3.[4]
Kompresi
Dekompresi
Gambar 2.3. Alur Kompresi Dekompresi Lossless File Input
(.bmp/.png)
File Output (.erl)
Metode kompresi data dapat dikelompokkan dalam dua kelompok besar yaitu metode lossless dan metode lossy yaitu:
1. Metode Lossless
Pada teknik ini tidak ada kehilangan data atau informasi. Jika data dikompres secara lossless, data asli dapat direkonstruksi kembali sama persis dari data yang telah dikompresi, dengan kata lain data asli tetap sama sebelum dan sesudah kompresi. Secara umum teknik lossless digunakan untuk penerapan yang tidak bisa mentoleransi setiap perbedaan antara data asli dan data yang telah direkonstruksi. Data berbentuk tulisan misalnya file teks, harus dikompresi menggunakan teknik lossless, karena kehilangan sebuah karakter saja dapat mengakibatkan kesalahpahaman. Lossless compression disebut juga dengan reversible compression karena data asli bisa dikembalikan dengan sempurna. Akan tetapi rasio kompresinya sangat rendah, misalnya pada data teks, gambar seperti GIF dan PNG. Contoh metode ini adalah Shannon-Fano Coding, Run Length Encoding, Arithmetic Coding dan lain sebagainya.[4]
2. Metode Lossy
Pada teknik ini akan terjadi kehilangan sebagian informasi atau data. Data yang telah dikompresi dengan teknik ini secara umum tidak bisa direkonstruksi sama persis dari data aslinya. Di dalam banyak penerapan, rekonstruksi yang tepat bukan suatu masalah. Sebagai contoh, ketika sebuah sample suara ditransmisikan, nilai Universitas Sumatera Utara eksak dari setiap sample suara belum tentu diperlukan. Tergantung pada yang memerlukan kualitas suara yang direkonstruksi, sehingga banyaknya jumlah informasi yang hilang di sekitar nilai dari setiap sample dapat ditoleransi. Umumnya teknik kompresi lossy membuang bagian-bagian data yang sebenarnya tidak berguna seperti data yang tidak dapat dilihat maupun didengar oleh manusia. Contoh metode ini adalah transform Coding, Wavelet dan lain-lain. Lossy
compression disebut juga irreversible compression karena data asli mustahil untuk dikembalikan seperti semula. Kelebihan teknik ini adalah rasio kompresi yang tinggi dibanding metode lossless. Keuntungan dari metode lossy atas lossless adalah dalam beberapa kasus metode lossy menghasilkan file kompresi yang lebih kecil dibandingkan dengan metode lossless. Metode lossy sering digunakan untuk mengkompresi suara, gambar dan video karena data tersebut dimaksudkan kepada human interpretation dimana pikiran dapat dengan mudah “mengisi bagian-bagian yang kosong” atau melihat kesalahan yang sangat kecil atau inkonsistensi. Sedangkan lossless digunakan untuk mengkompresi data untuk diterima ditujuan dalam kondisi asli seperti dokumen teks. Lossy akan mengalami generation loss pada data sedangkan pada lossless tidak terjadi karena data yang hasil dekompresi sama dengan data asli.[4]
2.6. Lempel-Ziv-Markov Chain Algorithm (LZMA)
LZMA merupakan algoritma yang telah dikembangkan sejak 1998. Pertama kali diperkenalkan dan digunakan oleh software kompresi terpopuler yaitu 7z atau 7-zip yang diciptakan oleh Igor Pavlov. Prinsip dasar dari algoritma LZMA sama dengan LZ77, hanya saja LZMA telah mengalami perkembangan pada beberapa fitur, diantaranya adalah ditingkatkannya rasio kompresi, semakin besarnya ukuran dari dictionary yang digunakan pada proses kompresi. LZMA juga dikembangkan kedalam bentuk modul berbasis Python. Modul tersebut bernama pylzma. Pylzma dapat dijalankan pada OS Windows, Linux, dan OSX.[3]
LZMA adalah algoritma yang digunakan untuk kompresi data dengan menggunakan sebuah skema dictionary compression, yang hampir sama dengan LZ77, dan mampu menghasilkan rasio kompresi yang sangat baik. Pada kompresi LZMA, stream kompresi yang dihasilkan adalah stream dari bit yang di-encode menggunakan adaptive binary range encode. Stream dibagi kedalam paket. Setiap paket menjelaskan sebuah byte tunggal, atau sebuah urutan LZ77 dimana length dan distance-nya secara implisit atau eksplisit dikodekan.[1]
Contoh Proses Encoding dan Decoding menggunakan LZMA adalah sebagai berikut:
Misal kita memiliki string:
ABAABAAABBBAABBABBBBAB
Kita mulai dari string paling kiri yaitu A
A | BAABAAABBBAABBABBBBAB
Selanjutnya kita melihat frasa berikutnya yang belum ditemukan. Sebelumnya A. Maka selanjutnya B
A | B | AABAAABBBAABBABBBBAB
Frasa selanjutnya yang belum ditemukan adalah AA maka string yang kita miliki menjadi :
A | B | AA | BAAABBBAABBABBBBAB
Frasa selanjutnya yang belum ditemukan adalah BA maka string yang kita miliki menjadi :
A | B | AA | BA | AABBBAABBABBBBAB
Frasa selanjutnya yang belum ditemukan adalah AAB maka string yang kita miliki menjadi :
A | B | AA | BA | AAB | BBAABBABBBBAB
Frasa selanjutnya yang belum ditemukan adalah BB maka string yang kita miliki menjadi :
A | B | AA | BA | AAB | BB | AABBABBBBAB
Frasa selanjutnya yang belum ditemukan adalah AABB maka string yang kita miliki menjadi :
A | B | AA | BA | AAB | BB | AABB | ABBBBAB
Frasa selanjutnya yang belum ditemukan adalah AB maka string yang kita miliki menjadi :
A | B | AA | BA | AAB | BB | AABB | AB | BBBAB
Frasa selanjutnya yang belum ditemukan adalah BBB maka string yang kita miliki menjadi :
A | B | AA | BA | AAB | BB | AABB | AB | BBB | AB Frasa terakhir dan telah berulang adalah AB maka string yang kita miliki menjadi :
A | B | AA | BA | AAB | BB | AABB | AB | BBB | AB
Karena semua huruf sudah habis maka frasa terakhir akan berulang, yaitu AB yang sebelumnya kita sudah temukan dan tidak menjadi masalah.
Proses Encoding LZMA adalah sebagai berikut:
Untuk melakukan encoding terhadap string diatas, setiap frase yang kita temukan kita jadikan dictionary. Jadi untuk frasa selanjutnya kita tidak perlu menuliskan semua frasa tapi cukup dengan menuliskan nomor dari dictionary-nya.
Seperti berikut ini :
1 2 3 4 5 6 7 8 9 10 Nomor Dictionary A B AA BA AAB BB AABB AB BBB AB Proses Decoding 0A 0B 1A 2A 3B 2B 5B 1B 6B 8 Hasil Encoding Baris ketiga merupakan hasil encoding dari string diatasnya. Bisa kita lihat bahwa untuk meng-encoding frasa ke 7 (AABB) kita cukup dengan menuliskan 5B. Nilai 0 merupakan frasa ke 0 yang akan di encoding sebagai 0.
Ukuran Sebelum Kompresi = 22 String Ukuran Setelah Kompresi = 10 String
Rasio Pemampatan = 100% − x 100% = 100% - 45,455% = 54,545%, artinya 54,455% dari string semula telah dimampatkan.
2.7. Run Length Encoding
Algoritma Run Length Encoding adalah melakukan kompresi dengan memindahkan pengulangan byte yang sama berturut-turut atau secara terus menerus. Algoritma ini digunakan untuk mengompresi citra yang memiliki kelompok-kelompok piksel yang berderajat keabuan yang sama. Pada metode ini dilakukan pembuatan rangkaian pasangan nilai (P,Q) untuk setiap baris piksel, dimana nilai P menyatakan nilai derajat keabuan, sedangkan nilai Q menyatakan jumlah piksel berurutan yang memiliki derajat keabuan tersebut.[4]
Berbeda dengan teknik-teknik sebelumnya yang bekerja berdasarkan karakter per karakter, teknik run length ini bekerja berdasarkan sederetan karakter yang berurutan. Run Length Encoding adalah suatu algoritma kompresi data yang bersifat lossless. Algoritma ini mungkin merupakan algoritma yang paling mudah untuk dipahami dan diterapkan.[6]
Sebagai contoh sebuah citra dengan nilai piksel ”120, 120, 120, 120, 150, 200, 200, 200, 200, 150, 150, 150, 150, 120, 150, 150, 150, 150”, nilai piksel pertama 120, kedua 120, karakter ketiga 120, karakter keempat 120, dan karakter kelima 150, dikarenakan pada nilai piksel kelima tidak sama dengan sebelumnya, sehingga 4 nilai piksel pertama yang mengalami perulangan akan dijumlahkan semuanya dan nilai yang dijumlahkan adalah banyaknya nilai piksel yang akan diulang, sehingga output keempat nilai piksel yang pertama setelah dikompresi adalah hanya sebuah nilai piksel dan diikuti dengan nilai perulangan yaitu ”120,4”, setelah dilakukan kompresi 4 piksel pertama akan dilanjutkan ke nilai berikutnya yaitu nilai kelima 150, kemudian nilai keenam 200, dikarenakan nilai piksel keenam tidak sama dengan nilai piksel kelima, dan nilai piksel kelima tidak mengalami perulangan sehingga nilai piksel yang tidak
mengalami perulangan akan ditambahkan kepada nilai piksel ”120,4”, sehingga menjadi ”120,4150”, dan seterusnya sehingga nilai piksel citra ” 120, 120, 120, 120, 150, 200, 200, 200, 200, 150, 150, 150, 150, 120, 150, 150, 150, 150” setelah dikompresi akan menjadi ”(120,4) (150,1) (200,4) (150,4) (120,1) (150,4)”. Dapat diperhatikan bahwa nilai piksel ” 120, 120, 120, 120, 150, 200, 200, 200, 200, 150, 150, 150, 150, 120, 150, 150, 150, 150” yang berukuran 18 byte / nilai piksel.[4]
Contoh:
Citra Grayscale 3 bit berukuran 10 x 10 piksel akan di-encode dengan algoritma RLE
Gambar 2.4. Citra 3 bit 10 X 10 Piksel Hasil Kompresi (3,3) (5,5) (2,2) (5,2) (6,3) (2,3) (1,2) (7,3) (5,7) (4,3) (5,4) (6,3) (0,8) (1,2) (1,4) (2,3) (5,3) (1,2) (2,5) (3,3) (3,5) (4,2) (1,3) (2,2) (0,2) (3,2) (0,4) (1,3) (0,3) (2,4) 3 3 3 5 5 5 5 5 2 2 5 5 6 6 6 2 2 2 1 1 7 7 7 5 5 5 5 5 5 5 4 4 4 5 5 5 5 6 6 6 0 0 0 0 0 0 0 0 1 1 1 1 1 1 2 2 2 5 5 5 1 1 2 2 2 2 2 3 3 3 3 3 3 3 3 4 4 1 1 1 2 2 0 0 3 3 0 0 0 0 1 1 1 0 0 0 2 2 2 2
Hasil Pengkodean:
3 3 5 5 2 2 5 2 6 3 2 3 1 2 7 3 5 7 4 3 5 4 6 3 0 8 1 2 1 4 2 3 5 3 1 2 2 5 3 3 3 5 4 2 1 3 2 2 0 2 3 2 0 4 1 3 0 3 2 4
Semuanya = 60 Piksel
Ukuran citra sebelum dikompres = 10 x 10 x 3 bit = 300 bit Ukuran citra setelah dikompres = 60 x 3 bit = 180 bit
Rasio pemampatan = 100% − x 100% = 40%, artinya 40% dari citra semula telah dimampatkan.
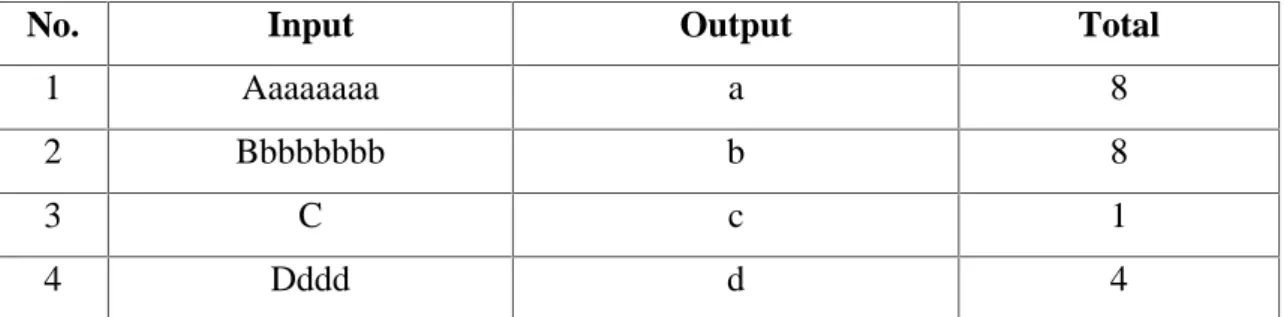
Contoh Proses Kompresi dengan RLE dapat dilihat seperti pada tabel:
Tabel 2.2. Kompresi dengan RLE
No. Input Output Total
1 Aaaaaaaa a 8
2 Bbbbbbbb b 8
3 C c 1
4 Dddd d 4
Contoh Proses Dekompresi dengan RLE dapat dilihat seperti pada tabel:
Tabel 2.3. Dekompresi dengan RLE
No. Input Total Output
1 a 8 aaaaaaaa
2 b 8 bbbbbbbb
3 c 1 C