II-1
BAB II
LANDASAN TEORI
2.1
Intrusion Detection System
Intrusion Detection System (IDS) adalah komponen penting sistem pertahanan untuk melindungi komputer dan jaringan dari aksi penyalahgunaan. Tujuan dari IDS adalah mengkarakteristikkan gejala atau kejadian yang menunjukkan terjadinya intrusi, sehingga dapat mendeteksi semua intrusi yang ada tanpa adanya kesalahan mendeteksi kejadian normal sebagai intrusi [MCH00]. Motivasi dari penggunaan IDS dapat bervariasi seperti mengumpulkan informasi forensik sehingga mampu mengetahui penyusup, men-triger aksi tertentu untuk melindungi sistem ketika terjadi serangan, atau digunakan sebagai alat untuk mengidentifikasi dan memperbaiki kelemahan yang terdapat pada sistem.
Pendeteksian intrusi merupakan proses pemantauan dan analisis kejadian yang terjadi pada sebuah komputer dan atau jaringan untuk mendeteksi tanda-tanda terjadinya permasalahan security. Umumnya, sebuah IDS memberi notifikasi kepada analis (system administrator) ketika terdapat kemungkinan terjadinya intrusi. Adapun tantangan yang dihadapi oleh IDS [LAZ03] adalah sebagai berikut:
1. Ukuran data yang sangat besar. 2. Data berdimensi tinggi.
3. Data yang berdekatan waktunya umumnya berhubungan.
4. Distribusi kelas yang tidak seimbang (data intrusi umumnya sangat jarang) 5. Memerlukan preprocessing dari data yang dikumpulkan sehingga dapat
dianalisis. Misalnya, untuk mengambil informasi dasar mengani alamat asal tujuan data koneksi yang telah dikumpulkan dengan memeriksa bagian header paket data, sampai memeriksa bagian pesan dari paket data untuk mengatahui informasi lebih lanjut seperti jumlah usaha login yang gagal. 6. High performance computing sangat penting terutama untuk IDS yang online,
2.1.1 Arsitektur
Arsitektur IDS dapat dilihat pada gambar II-1. Terdapat tiga komponen utama dari IDS yaitu:
1. Sensor, berfungsi untuk mengumpulkan data dan meneruskannya kepada analyser. Contoh data yang dikumpulkan adalah paket data pada jaringan, log file, system call trace.
2. Analyser, berfungsi untuk menerima masukan dari satu atau lebih sensor atau dari analyzer yang lain. Analyser selanjutnya akan menganalisis data yang diterima kemudian menentukan apakah telah terjadi intrusi atau tidak.
3. Antarmuka berfungsi untuk memungkinkan pengguna melihat keluaran dari sistem atau mengontrol perilaku sistem.
4.
Gambar II-1 Arsitektur IDS [HAN06] 2.1.2 Intrusi
Intrusi adalah semua aksi yang dapat membahayakan integritas, kerahasiaan dan ketersediaan sebuah resource [MUK02]. Secara umum, ada beberapa cara penyerang dapat melakukan intrusi yaitu pendekatan sosial, eksploitasi kelemahan(bug) pada program, penyalahgunaan fitur sistem, kesalahan konfigurasi, masquerading [KEN99].
Ada banyak jenis dan variasi intrusi pada jaringan komputer. Pada DARPA 98 intrusion detection evaluation data, yang banyak digunakan untuk mengevaluasi sistem pendeteksi intrusi, intrusi dapat dikelompokkan ke dalam 4 kategori utama yaitu Denial of Service, User to Root, Remote to User, dan Probes [KEN99].
1. Denial of Service
Denial of Service (DOS) adalah jenis serangan dimana penyerang mengakibatkan terjadinya komputasi atau penggunaan memori yang menghabiskan resource yang tersedia sehingga sebuah mesin tidak dapat menangani atau menolak request dari pengguna.
Sensor 1 Sensor n Sensor 2 Network Sensor events
Classifier Human analyst Clustering
2. User to Root
User to Root adalah jenis serangan dimana penyerang mulai mengakses sebuah sistem dengan menggunakan user account yang terdapat pada sistem tersebut. User account ini biasanya diperoleh dengan cara sniffing password, serangan kamus, atau social engineering.
3. Remote To User
Remote to User adalah serangan yang terjadi ketika penyerang dapat mengirim paket data ke sebuah mesin lewat jaringan (penyerang tidak memiliki user account pada mesin tersebut), kemudian mengeksploitasi beberapa kelemahan untuk mendapatkan akses lokal sebagai pengguna pada mesin tersebut.
4. Probes
Probes merupakan aksi penyusup untuk memperoleh informasi atau mengetahui kelemahan pada sistem dengan cara men-scan jaringan komputer. Dengan mengetahui pemetaan mesin dan service yang tesedia pada jaringan, maka penyusup dapat menggunakan informasi ini untuk mencari kelemahan pada sistem.
2.1.3 Network-based IDS
Berdasarkan sumber datanya IDS dibedakan menjadi Network-based IDS dan Host-based IDS. Network-Host-based IDS memeriksa data yang ditransmisikan melalui jaringan sehingga dapat memonitor beberapa host secara bersamaan. Akan tetapi, dengan semakin meningkatnya kecepatan transmisi data pada jaringan maka performansi dari Network-based IDS dapat menurun. Meskipun demikian, IDS jenis ini sangat populer karena mudah di-deploy dan dikelola sebagai komponen yang berdiri sendiri dan umumnya hampir tidak memiliki dampak terhadap performansi sistem yang dilindungi. Sebaliknya, Host-based IDS beroperasi pada sistem yang dilindungi dan mendeteksi intrusi dengan cara memeriksa data audit atau data log misalnya system call trace atau log aplikasi. Oleh karena itu, IDS jenis ini mampu mendeteksi intrusi yang spesifik terhadap aplikasi tertentu tetapi menggunakan resource pada host tersebut.
Data yang ditransmisikan melalui jaringan dikirim sebagai kumpulan potongan pesan yang disebut paket. Oleh karena itu, Network-based IDS memonitor paket-paket ini untuk mendeteksi adanya intrusi. Untuk mengumpulkan data yang ditransmisikan melalui jaringan pada UNIX dapat digunakan kakas TCPdump atau variannya Windump untuk sistem operasi Windows. Dengan menggunakan kakas ini, dapat diset data apa saja yang ingin dikumpulkan. Selain itu, untuk membatasi volume data yang terkumpul, biasanya hanya bagian header dari datagram yang dikumpulkan dengan ukuran default. Bagian header ini dapat dilihat pada gambar II-2 dan umumnya memiliki ukuran 68 byte, sedangkan contoh output dari TCPdump dapat dilihat pada gambar II-3.
Gambar II-2 Contoh packet
Gambar II-3 Contoh output TCPdump
09:32:43:910000 merupakan timestamp dalam format (jam:menit:detik:bagian dari detik). nmap.edu adalah host asal dan 1173 adalah nomor port asal. Tanda > menunjukkan arah aliran data dari asal ke tujuan. dns.net menunjukkan host tujuan dan 21 adalah nomor port tujuan. S adalah TCP flag (SYN flag). 62697789:62697789(0) merupakan [initial TCP sequence number : ending TCP sequence number(jumlah data dlm byte)], sedangkan win 512 adalah ukuran buffer pada nmap.edu untuk koneksi ini. Ada beberapa protokol yang digunakan untuk transmisi paket melalui jaringan yaitu TCP (Transport Control protocol), UDP(User Datagram Protocol) dan ICMP (Internet Control Message Protocol). Pada data DARPA 98, terdapat data-data koneksi yang menggunakan ketiga protokol ini.
2.1.4 Pendeteksian Intrusi dengan Data Mining
Pendeteksian intrusi dengan data mining dilakukan melalui outlier analysis. Pada dataset, sering kali terdapat data yang tidak sesuai dengan general behaviour atau
model data. Data seperti ini berbeda dan tidak konsisten dengan data yang lain dan disebut dengan outlier. Outlier mining dapat dipandang dalam dua bagian permasalahan yaitu mendefinisikan data yang dapat dianggap tidak konsisten dan bagaimana cara yang efisien untuk mining outlier yang sudah didefenisikan. Oleh karena itu pendeteksian intrusi sering juga dipandang sebagai pendeteksian outlier. Menurut [HAN06], terdapat beberapa alasan mengapa data mining dapat digunakan untuk mendeteksi intrusi yaitu:
1. Data mining menerapkan algoritma tertentu untuk mengekstrak pattern dari data 2. Aktivitas normal maupun intrusi meninggalkan jejak (evidence) pada data yang
diaudit.
3. Dari sudut pandang data, pendeteksian intrusi merupakan proses analisis data. 4. Data mining sudah berhasil diaplikasikan pada domain aplikasi terkait seperti
fraud detection dan fault/alarm management
5. Proses pembelajaran dapat dilakukan terhadap data traffic. Dengan pendekatan supervised learning melalui pembelajaran dapat dibangun model dari data intrusi yang sudah pernah terjadi. Dengan pendekatan unsupervised learning proses pembelajaran dapat mengidentifikasi aktivitas-aktivitas yang mencurigakan.
6. Data mining dapat digunakan untuk mengubah atau me-maintain model terhadap data yang bersifat dinamis.
Contoh data yang akan di-mining untuk pendeteksian intrusi dapat dilihat pada gambar II-4. Data yang digunakan umumnya merupakan data koneksi jaringan dalam bentuk TCPDump. Data ini merupakan data mentah yang masih harus dipreprocess terlebih dahulu menjadi connection records. Untuk dapat memperoleh atribut-atribut koneksi data ke jaringan dapat digunakan perangkat lunak TCPtrace seperti yang digunakan pada [LAZ03].
Teknik data mining yang dapat diterapkan dalam pendeteksian intrusi dapat berupa supervised learning maupun unsupervised learning. Teknik supervised learning memerlukan dataset yang diberi label data normal atau data intrusi sesuai dengan jenisnya. Namun, dataset yang memiliki label cukup sulit untuk diperoleh dalam aplikasi yang sebenarnya. Selain itu, sulit untuk memastikan apakah semua label yang telah diberikan mewakili semua jenis intrusi. Oleh karena itu, unsupervised learning
juga banyak digunakan, tetapi pada teknik ini intrusi yang dideteksi tidak diketahui jenisnya seperti pada supervised learning.
Gambar II-4 Pemrosesan data koneksi jaringan dengan data mining [HAN06]
Berdasarkan metode yang digunakan, pendeteksian intrusi dapat dibagi menjadi dua kategori yaitu misuse detection (signature-based) dan anomaly detection (noise characterization). Kedua metode ini memiliki kelebihan dan kekurangan. Dalam pendekatan misuse detection yang menggunakan teknik data mining, pendeteksian intrusi dilakukan dengan cara membuat model data intrusi dari data set yang sudah diberi label intrusi. Hal ini berbeda dengan pendekatan misuse detection yang menggunakan basis data untuk menyimpan signature dari intrusi yang diketahui secara manual. Perbedaannya, dengan data mining, model signature (pattern) dari intrusi dibangun secara otomatis lewat pelatihan. Selanjutnya, model dari hasil pelatihan dapat digunakan untuk mendeteksi intrusi. Jadi teknik klasifikasi dalam pendeteksian intrusi merupakan pendekatan misuse detection. Kelebihan utama dari pendekatan ini adalah mampu mendeteksi intrusi yang sudah diketahui secara akurat, tetapi tidak dapat mendeteksi jenis intrusi yang belum diketahui (benar-benar baru dan belum pernah dilihat sebelumnya).
Dalam pendekatan yang kedua yaitu anomaly detection, deteksi intrusi dilakukan dengan cara membuat model dari data normal, kemudian mendeteksi deviasi antara
model normal dengan data yang diobservasi. Kelebihan dari anomaly detection adalah dapat mendeteksi intrusi jenis baru sebagai deviasi dari data normal. Akan tetapi, intrusi yang dideteksi dengan metode ini tidak dapat diketahui jenisnya seperti pada misuse detection dan cenderung menghasilkan false positive yang tinggi.
Anomaly detection dapat diimplementasikan dalam bentuk supervised anomaly detection atau unsupervised anomaly detection. Dalam pendekatan yang pertama, digunakan data pelatihan yang hanya mengandung data normal, sedangkan pada pendekatan kedua tidak diketahui informasi apapun dari data pelatihan. Pendekatan kedua juga banyak diteliti karena jika data pelatihan sangat besar maka akan sulit memastikan semua data tersebut adalah data normal.
2.2
Support Vector Machine
Support Vector Machine (SVM) adalah sistem pembelajaran yang menggunakan ruang hipotesis berupa fungsi-fungsi linier dalam sebuah ruang fitur (feature space) berdimensi tinggi, dilatih dengan algoritma pembelajaran yang didasarkan pada teori optimasi dengan mengimplementasikan inductive bias yang berasal dari teori pembelajaran statistik [CHR00]. Teori yang mendasari SVM sendiri sudah berkembang sejak 1960-an, tetapi baru diperkenalkan oleh Vapnik, Boser dan Guyon pada tahun 1992 dan sejak itu SVM berkembang dengan pesat. SVM adalah salah satu teknik yang relatif baru dibandingkan dengan teknik lain, tetapi memiliki performansi yang lebih baik di berbagai bidang aplikasi seperti bioinformatics, pengenalan tulisan tangan, klasifikasi teks dan lain sebagainya [CHR01].
Proses pembelajaran pada SVM bertujuan untuk mendapatkan hipotesis berupa bidang pemisah terbaik yang tidak hanya meminimalkan empirical risk yaitu rata-rata error pada data pelatihan, tetapi juga memiliki generalisasi yang baik. Generalisasi adalah kemampuan sebuah hipotesis untuk mengklasifikasikan data yang tidak terdapat dalam data pelatihan dengan benar. Untuk menjamin generalisasi ini, SVM bekerja berdasarkan prinsip Structural Risk Minimization (SRM). Penjelasan lebih lanjut mengenai SRM dapat dilihat pada lampiran B.
2.2.1 SVM pada Linearly SeparableData
Linearly separable data merupakan data yang dapat dipisahkan secara linier. Misalkan
{
x1,...,xn}
adalah dataset dan yi∈{
+1,−1}
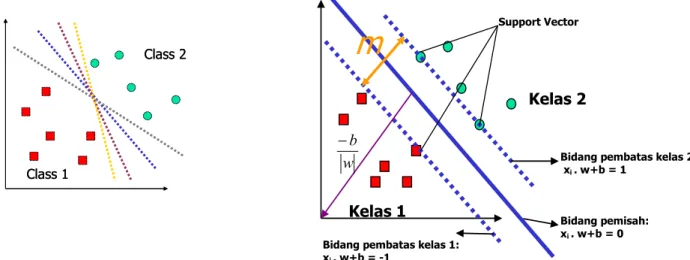
adalah label kelas dari data xi.. Pada gambar II-5 dapat dilihat berbagai alternatif bidang pemisah yang dapat memisahkan semua data set sesuai dengan kelasnya. Namun, bidang pemisah terbaik tidak hanya dapat memisahkan data tetapi juga memiliki margin paling besar.Gambar II-5 Alternatif bidang pemisah (kiri) dan bidang pemisah terbaik dengan margin (m) terbesar (kanan)
Adapun data yang berada pada bidang pembatas ini disebut support vector. Dalam contoh di atas, dua kelas dapat dipisahkan oleh sepasang bidang pembatas yang sejajar. Bidang pembatas pertama membatasi kelas pertama sedangkan bidang pembatas kedua membatasi kelas kedua, sehingga diperoleh:
1 1 . 1 1 . − = − ≤ + + = + ≥ + i i i i y for b w x y for b w x (2.1)
w adalah normal bidang dan b adalah posisi bidang relatif terhadap pusat koordinat. Nilai margin (jarak) antara bidang pembatas (berdasarkan rumus jarak garis ke titik pusat) adalah w w b b ( 1 ) 2 1 = − − − −
. Nilai margin ini dimaksimalkan dengan tetap memenuhi (2.1). Dengan mengalikan b dan w dengan sebuah konstanta, akan dihasilkan nilai margin yang dikalikan dengan konstanta yang sama. Oleh karena itu, konstrain (2.1) merupakan scaling constraint yang dapat dipenuhi dengan rescaling b dan w. Selain itu, karena Memaksimalkan
w 1 sama dengan Class 1 Class 2 Class 1 Class 2
Bidang pembatas kelas 2: xi . w+b = 1 Kelas 1 Kelas 2
m
Support Vector Bidang pemisah: xi . w+b = 0Bidang pembatas kelas 1: xi . w+b = -1
w b
meminimumkan w2dan jika kedua bidang pembatas pada (2.1) direpresentasikan dalam pertidaksamaan (2.2),
(
x.w+b)
−1≥0yi i (2.2)
maka pencarian bidang pemisah terbaik dengan nilai margin terbesar dapat dirumuskan menjadi masalah optimasi konstrain, yaitu
(
.)
1 0 . 2 1 min 2 ≥ − +b w x y t s w i i (2.3)Persoalan ini akan lebih mudah diselesaikan jika diubah ke dalam formula lagrangian yang menggunakan lagrange multiplier. Dengan demikian permasalahan optimasi konstrain dapat diubah menjadi:
∑ ∑ = = + + − ≡ n i i i i n i i p b w b w x y w b w L 1 1 2 , ) . ( 2 1 ) , , ( min α α α (2.4)
dengan tambahan konstrain, αi ≥0( nilai dari koefisien lagrange). Dengan meminimumkan Lp terhadap w dan b, maka dari ( , , )=0
∂ ∂ α b w L b p diperoleh (2.5) dan dari ( , , )=0 ∂ ∂ α b w L w p diperoleh (2.6). 0 1 =
∑
= i n i iy α (2.5) n i i i iyx w∑
= = 1 α (2.6)Vektor w sering kali bernilai besar (mungkin tak terhingga), tetapi nilai αi terhingga. Untuk itu, formula lagrangian Lp (primal problem) diubah kedalam dual problem LD. Dengan mensubsitusikan persamaan (2.6) ke LP diperoleh dual problem LD dengan konstrain berbeda. j i j i n j i j i n i i D y y x x L . 2 1 ) ( 1 , 1 1
∑
∑
= = = − ≡ α αα α (2.7) D p b w L L max min , α= . Jadi persoalan pencarian bidang pemisah terbaik dapat dirumuskan
sebagai berikut: 0 , 0 . . . 2 1 1 1 , 1 1
max
≥ = − ≡∑
∑
∑
= = = = i i n i i j i j i n j i j i n i i D y t s x x y y L α α α α α α (2.8)Dengan demikian, dapat diperoleh nilai αi yang nantinya digunakan untuk menemukan w. Terdapat nilai αi untuk setiap data pelatihan. Data pelatihan yang memiliki nilai αi >0adalah support vector sedangkan sisanya memiliki nilai αi =0 . Dengan demikian fungsi keputusan yang dihasilkan hanya dipengaruhi oleh support vector.
Formula pencarian bidang pemisah terbaik ini adalah pemasalahan quadratic programming, sehingga nilai maksimum global dari αi selalu dapat ditemukan. Setelah solusi pemasalahan quadratic programming ditemukan (nilai αi), maka kelas dari data pengujian x dapat ditentukan berdasarkan nilai dari fungsi keputusan:
b x x y x f i i d ns i i d =
∑
+ = . ) ( 1 α , (2.9) ix adalah support vector, ns = jumlah support vector dan xd adalah data yang akan diklasifikasikan.
2.2.2 SVM pada Nonlinearly Separable Data
Untuk mengklasifikasikan data yang tidak dapat dipisahkan secara linier formula SVM harus dimodifikasi karena tidak akan ada solusi yang ditemukan. Oleh karena itu, kedua bidang pembatas (2.1) harus diubah sehingga lebih fleksibel (untuk kondisi tertentu) dengan penambahan variabel ξi (ξi ≥0,∀i : ξi =0 jika xi diklasifikasikan dengan benar) menjadi xi.w+b≥1-ξi untuk kelas 1 dan xi.w+b≤−1+ξi untuk kelas 2. Pencarian bidang pemisah terbaik dengan dengan penambahan variabel ξi sering juga disebut soft margin hyperplane. Dengan demikian formula pencarian bidang pemisah terbaik berubah menjadi:
0 1 ) . ( . . 2 1 min 1 2 ≥ − ≥ + ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ +
∑
= i i i i n i i b x w y t s C w ξ ξ ξ (2.10)C adalah parameter yang menentukan besar penalti akibat kesalahan dalam klasifikasi data dan nilainya ditentukan oleh pengguna. Bentuk persoalan (2.10) memenuhi prinsip SRM, dimana meminimumkan 2
2 1
dimensi VC dan meminimumkan ⎟ ⎠ ⎞ ⎜ ⎝ ⎛
∑
= n i i C 1ξ berarti meminimumkan error pada data pelatihan [OSU97].
Gambar II-6 Soft margin hyperplane
Selanjutnya, bentuk primal problem sebelumnya berubah menjadi:
{
}
i n i i n i i i i i n i i p b w b w x y C w b w L α∑
ξ∑
α ξ∑
μξ = = = − + − + − ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ + ≡ 1 1 1 2 , 1 ) . ( 2 1 ) , , (min
(2.11)Pengubahan Lp ke dalam dual problem, menghasilkan formula yang sama dengan persamaan (2.6) sehingga pencarian bidang pemisah terbaik dilakukan dengan cara yang hampir sama dengan kasus dimana data dapat dipisahkan secara linier, tetapi rentang nilai αi adalah 0≥αi ≥C. Instance yang memiliki nilai αi =C disebut bounded support vector.
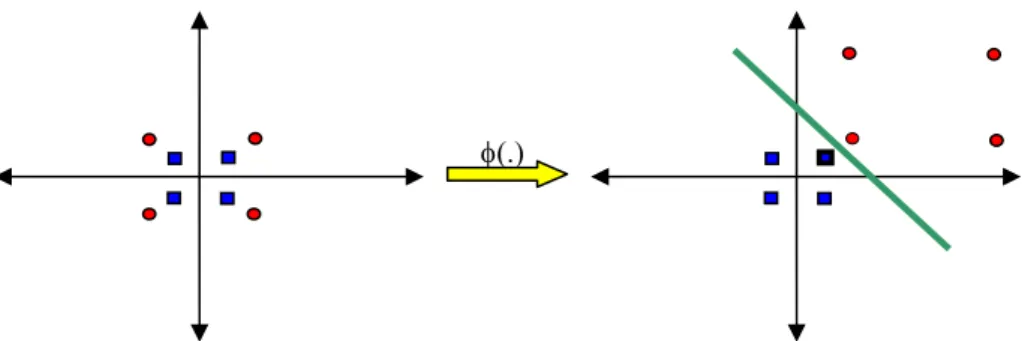
Metode lain untuk mengklasifikasikan data yang tidak dapat dipisahkan secara linier adalah dengan mentransformasikan data ke dalam dimensi ruang fitur (feature space) sehingga dapat dipisahkan secara linier pada feature space.
φ( ) φ( ) φ( ) φ( ) φ( ) φ( )φ( ) φ( )
φ
(.)
φ( ) φ( ) φ( ) φ( ) φ( ) φ( ) φ( ) φ( ) φ( )φ( ) Feature space Input space φ( ) φ( ) φ( ) φ( ) φ( ) φ( ) φ( ) φ( ) φ( ) φ( ) φ( ) φ( )φφ( )( ) φ( ) φ( )φ
(.)
φφ( )( ) φφ( )( ) φ( ) φ( ) φ( ) φ( ) φ( ) φ( ) φ( ) φ( ) φ( ) φ( ) φ( ) φ( ) φ( ) φ( )φφ( )( ) Feature space Input spaceGambar II-7 Transformasi dari vektor input ke feature space
Kelas 1
Kelas 2
xi . w+b = 1
xi . w+b = 0
Caranya, data dipetakan dengan menggunakan fungsi pemetaan (transformasi) )
( k
k x
x →φ ke dalam feature space sehingga terdapat bidang pemisah yang dapat memisahkan data sesuai dengan kelasnya (gambar II-7). Misalkan terdapat data set yang datanya memiliki dua atribut dan dua kelas yaitu kelas positif dan negatif. Data yang memiliki kelas positif adalah
{
( ) (
2,2, 2,−2) (
, −2,2) (
, −2,−2)
}
, dan data yang memiliki kelas negatif{
( ) (
1,1,1,−1) (
, −1,1) (
, −1,−1)
}
. Apabila data ini digambarkan dalam ruang dua dimensi (gambar II-4) dapat dilihat data ini tidak dapat dipisahkan secara linier. Oleh karena itu, digunakan fungsi transformasi berikut:(
)
(
)
(
)
⎪⎭ ⎪ ⎬ ⎫ ⎪⎩ ⎪ ⎨ ⎧ → ≤ + − + − − + − → > + = 2 1 2 2 2 1 2 1 1 2 1 2 2 2 2 1 2 1 , 2 4 , 4 2 , x x x x x x x x x x x x x x φ (2.12)Data sesudah transformasi adalah
{
( ) ( ) ( ) ( )
2,2, 6,2, 6,6, 2,6}
untuk kelas negatif, dan( ) (
) (
) (
)
{
1,1, 1,−1, −1,1, −1,−1}
untuk kelas positif. Selanjutnya pencarian bidang pemisah terbaik dilakukan pada data ini.Gambar II-8 Contoh transformasi untuk data yang tidak dapat dipisahkan secara linier
Dengan menggunakan fungsi transformasi xk →φ(xk), maka nilai ns i
( )
i i iy x w∑
α φ = = 1 dan fungsi hasil pembelajaran yang dihasilkan adalah( )
x y( ) ( )
x x b f ns i i d i i d =∑
+ = φ φ α 1 (2.13) Feature space dalam prakteknya biasanya memiliki dimensi yang lebih tinggi dari vektor input (input space). Hal ini mengakibatkan komputasi pada feature space mungkin sangat besar, karena ada kemungkinan feature space dapat memiliki jumlah feature yang tidak terhingga. Selain itu, sulit mengetahui fungsi transformasi yang tepat. Untuk mengatasi masalah ini, pada SVM digunakan ”kernel trick”. Dari persamaan (2.11) dapat dilihat terdapat dot productφ( ) ( )
xi φ xd . Jika terdapat sebuahfungsi kernel K sehingga K
(
xi,xd) ( ) ( )
=φ xi .φ xd , maka fungsi transformasi φ(xk) tidak perlu diketahui secara persis. Dengan demikian fungsi yang dihasilkan dari pelatihan adalah(
x x)
b K y x f ns i i d i i d =∑
+ = , ) ( 1 α (xi= support vector). (2.14) Syarat sebuah fungsi untuk menjadi fungsi kernel adalah memenuhi teorema Mercer yang menyatakan bahwa matriks kernel yang dihasilkan harus bersifat positive semi-definite. Fungsi kernel yang umum digunakan adalah sebagai berikut:a. Kernel Linier
(
x x)
x x K T i, = i (2.15) b. Polynomial kernel(
,)
=(
γ
. T +)
p,γ
>0 i i x x x r x K (2.16)c. Radial Basis Function (RBF)
(
x
,
x
)
=
exp
(
−
γ
x
−
x
2)
,
γ
>
0
K
i i (2.17) d. Sigmoid kernel(
x
x
)
(
x
x
r
)
K
T i i,
=
tanh
γ
+
(2.18)Menurut tutorial pada [HSU04] fungsi kernel yang direkomendasikan untuk diuji pertama kali adalah fungsi kernel RBF karena memiliki performansi yang sama dengan kernel linier pada parameter tertentu, memiliki perilaku seperti fungsi kenel sigmoid dengan parameter tentu dan rentang nilainya kecil [0,1].
2.2.3 Multi Class SVM
SVM saat pertama kali diperkenalkan oleh Vapnik, SVM hanya dapat mengklasifikasikan data ke dalam dua kelas (klasifikasi biner). Namun, penelitian lebih lanjut untuk mengembangkan SVM sehingga bisa mengklasifikasi data yang memiliki lebih dari dua kelas, terus dilakukan. Ada dua pilihan untuk mengimplementasikan multi class SVM yaitu dengan menggabungkan beberapa SVM biner atau menggabungkan semua data yang terdiri dari beberapa kelas ke dalam sebuah bentuk permasalah optimasi. Namun, pada pendekatan yang kedua permasalahan optimasi yang harus diselesaikan jauh lebih rumit. Metode yang umum digunakan untuk mengimplementasikan multi class SVM adalah One-Against-One, One-Against-All dan DAG SVM. Penjelasan detailnya dapat dilihat pada lampiran C.
2.2.4 One Class SVM
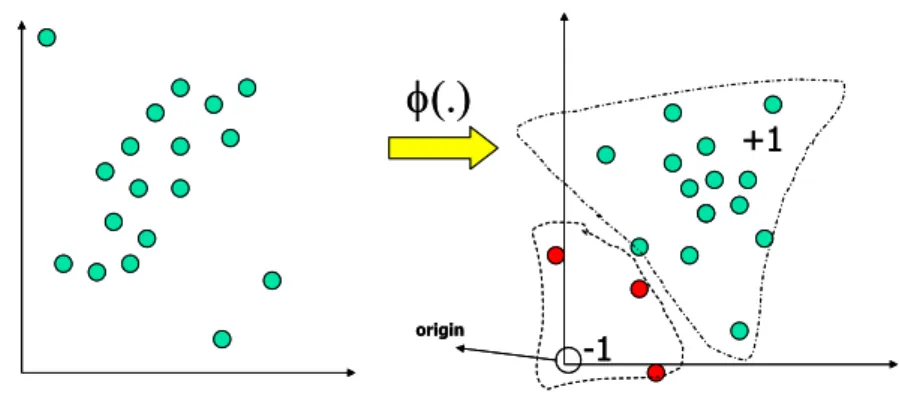
One Class SVM adalah pengembangan dari SVM yang diusulkan oleh [SCH01], untuk permasalahan density estimation. Dengan menggunakan teknik ini, SVM dapat digunakan pada dataset yang tidak memiliki label. Teknik One Class SVM mengidentifikasi outlier diantara contoh data positif dan menggunakannya sebagai contoh data negatif.
Persoalan One Class SVM ini dapat dirumuskan sebagai berikut: misalkan terdapat dataset yang memiliki probability distribution P dalam feature space dan kita ingin mengestimasi subset S pada feature space sehingga probabilitas sebuah data pengujian yang diambil dari P terletak di luar S, dibatasi oleh sebuah nilai v. Solusi dari permasalahan ini diperoleh dengan mengestimasi sebuah fungsi yang bernilai positif pada S dan negatif pada komplemen S. Dengan kata lain fungsi tersebut bernilai +1 pada sebuah area ”kecil” yang memuat hampir semua data dan bernilai -1 jika berada di luar area tersebut.
( )
⎪⎩ ⎪ ⎨ ⎧ ∉ − ∈ + = S x if S x if x f , 1 , 1 (2.19)Prinsip dari teknik ini adalah mentransformasikan vektor input ke dalam feature space dengan menggunakan fungsi kernel, origin dianggap sebagai satu-satunya data negatif. Kemudian, dengan menggunakan ”relaxation parameter”, data yang bukan outlier dipisahkan dari origin. Selanjutnya prinsip kerja algoritma ini sama saja dengan klasifikasi biner pada SVM dengan tujuan mencari bidang pemisah terbaik yang memisahkan data dari origin dengan margin terbesar.
Gambar II-9 Transformasi ke feature space
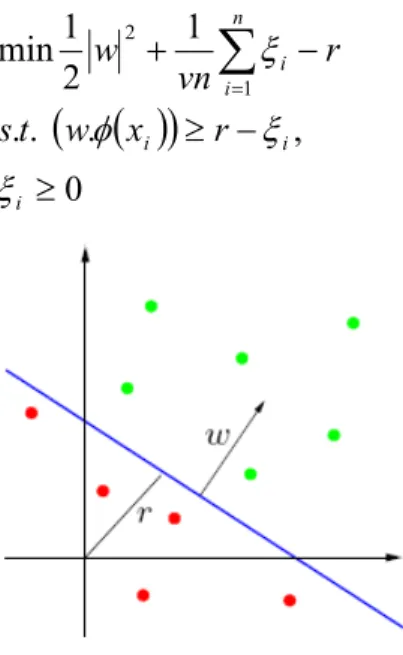
Persoalan pencarian bidang pemisah ini secara matematis adalah persamaan (2.20), dimana ξi adalah penalti terhadap data anomali yang terletak pada sisi bidang pemisah yang salah (sisi tempat data normal) dan v adalah parameter yang mengatur
+1 -1 origin
φ
(.)
+1 -1 originφ
(.)
trade off antara memaksimalkan margin dari origin dan mencakup sebagian besar data pada daerah yang dibuat bidang pemisah dengan rasio outlier yang terdapat pada data pelatihan (seperti parameter C pada SVM untuk klasifikasi).
( )
(
)
0 , . . . 1 2 1 min 1 2 ≥ − ≥ − +∑
= i i i n i i r x w t s r vn w ξ ξ φ ξ (2.20)Gambar II-10 One Class SVM
Dengan menggunakan lagrange multiplier dan fungsi kernel maka persoalan di atas dapat dirumuskan sebagai berikut:
(
)
vn t s x x K i n i i j i j n j i i 1 0 , 1 . . , min 1 1 , 1 ≤ ≤ =∑
∑
= = = α α α α (2.21)Dari hasil pelatihan, akan diperoleh nilai parameter αi, kemudian nilai r dapat dihitung dari persamaan (2.22). Hasil dari proses pembelajaran adalah sebuah fungsi (2.23).
(
i j)
n j jK x x r , 1∑
= = α (2.22)(
x x)
r K x f ns i d i i d =∑
− = , ) ( 1 α , xi=support vector (2.23) 2.2.5 Algoritma Pelatihan SVMPelatihan pada SVM bertujuan untuk mencari solusi permasalahan optimasi konstain yang telah dijelaskan diatas (2.7, 2.10, 2.16, 2.17, 2.20). Untuk jumlah data yang sangat sedikit persoalan ini dapat diselesaikan dengan mudah. Misalkan x1 =0,x2 =1
dengan kelas y∈−1,1 . Dengan mensubstitusi nilai x dan y ke persamaan (2.7) diperoleh: ) ( 2 1 2 1 2 1 α α α − + ⎥ ⎦ ⎤ ⎢ ⎣ ⎡ − ⎥ ⎦ ⎤ ⎢ ⎣ ⎡ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎣ ⎡ = 2 1 2 1 2 1 [11] 0 0 0 0 ] [ 2 1 α α α α α
α (Dalam notasi matriks)
dengan konstrain: α1 −α2 =0,α1 ≥0,α2 ≥0, maka: 0 2 2 1 1 2 1 − α = α , diperoleh α1 =α2 =2.
Bagaimana jika jumlah data yang diproses sangat besar? Berbagai teknik optimasi telah banyak dikembangkan, yang pada dasarnya secara iteratif mencari solusi maksimum dari fungsi objektif. Akan tetapi, teknik-teknik ini memerlukan data disimpan pada memori dalam bentuk matriks kernel [CHR00]. Hal ini akan mengakibatkan kompleksitas data pelatihan meningkat dengan bertambahnya ukuran matriks sehingga penggunaan teknik ini dibatasi oleh jumlah data yang dapat diproses. Untuk dataset yang lebih besar digunakan teknik yang didasarkan pada metode ’working set’. Metode yang banyak digunakan pada SVM saat ini adalah decomposition (misalnya Sequential Minimal Optimization (SMO), LibSVM, SVMLight) [LIN05]. Penjelasan mengenai metode ini dapat dilihat pada lampiran D.
2.2.6 Estimasi Parameter Terbaik
Akurasi model yang akan dihasikan dari proses pelatihan dengan SVM sangat bergantung pada fungsi kernal serta parameter yang digunakan. Oleh karena itu performansinya dapat dioptimasi dengan mencari (mengestimasi) parameter terbaik. Ada beberapa cara yang dapat dilakukan antara lain cross validation (mudah digunakan), leave-one-out (akurat tetapi membutuhkan biaya komputasi yang tinggi) , dan
ξα
-estimator [QUA02]. Cara yang ketiga merupakan modifikasi cara kedua yang diusulkan oleh Joachim [QUA02].K-folds crossalidation dapat digunakan untuk menentukan nilai parameter C dan parameter kernel yang tidak overfit data pelatihan [HSU04]. Dengan metode ini, data yang diambil secara acak kemudian dibagi menjadi k buah partisi dengan ukuran yang
sama. Selanjutnya, dilakukan iterasi sebanyak k. Pada setiap iterasi digunakan sebuah partisi sebagai data pengujian, sedangkan k-1 partisi sisanya digunakan sebagai data pelatihan. Jadi akan dicoba berbagai nilai parameter dan parameter terbaik ditentukan melalui k-folds crossalidation.
Pada tutorial [HSU04] dianjurkan supaya pada setiap iterasi digunakan penambahan parameter secara exponensial. Contohnya untuk kernel RBF nilai parameter yang digunakan pada setiap iterasi adalah
C
=
2
−5,
2
−3,...,
2
15,
γ
=
2
−15,
2
−13,...,
2
3. Kemudian ditemukan nilai parameter terbaik misalnyaC
=
2
3,
γ
=
2
−5. Selanjutnya dilakukan pencarian parameter pada rentang nilai yang lebih kecil sehingga dapat parameter yang baikC
=
2
3,25,
γ
=
2
−5,−25. Setelah nilai parameter terbaik ditemukan pelatihan dilakukan dengan menggunakan keseluruhan data. Pencarian nilai parameter ini disebut juga grid search.2.2.7 SVM pada Imbalanced Dataset
Imbalanced dataset adalah dataset yang memiliki contoh kelas negatif (kelas mayoritas) jauh lebih banyak daripada contoh kelas positif (kelas minoritas) misalnya pada aplikasi fraud detection rasio imbalance dapat mencapai 100:1 dan bahkan bisa mencapai 100000:1 pada aplikasi lain. Banyak teknik klasifikasi yang akurasinya menurun ketika diterapkan pada dataset dengan imbalance ratio yang tinggi karena umumnya teknik tersebut didesain untuk mengeneralisasi data pelatihan dan menghasilkan hipotesis paling sederhana yang sesuai dengan data tersebut [AKB04]. Akan tetapi, hipotesis yang dihasilkan sering kali memprediksi hampir semua instance sebagai kelas yang menjadi mayoritas dalam data pelatihan. Selain itu data dari kelas minoritas mungkin dianggap noise sehingga mungkin saja diabaikan oleh teknik klasifikasi [AKB04].
SVM sendiri merupakan salah satu teknik yang tidak terlalu sensitif terhadap imbalanced dataset karena hipotesis yang dihasilkan hanya dipengaruhi oleh sebagian data yaitu data yang menjadi support vector. Ada beberapa alasan mengapa performansi SVM mungkin menurun jika diterapkan pada imbalanced dataset yaitu data dari kelas minoritas terletak jauh dari bidang pemisah yang ideal, kelemahan pada soft-margin hyperplane (jika nilai parameter C kecil maka SVM cenderung
mengklasifikasikan data sebagai kelas mayoritas), dan rasio support vector yang tidak seimbang [AKB04].
Pendekatan yang populer untuk mengatasi masalah ini adalah memberikan bias kepada teknik klasifikasi sehingga lebih memperhatikan instance dari kelas minoritas. Hal ini dapat dilakukan melalui pemberian penalti yang lebih besar jika terjadi kesalahan dalam mengklasifikasikan kelas minoritas, dibandingkan jika salah mengklasifikasikan kelas mayoritas. Dengan demikian formula SVM diubah menjadi:
(
)
n i b wx y t s C C w i i i i y i y i b w i i ,..., 1 , 0 , 1 . . 2 1 min 1 1 2 , , = ≥ − ≥ + + +∑
∑
− = − = + ξ ξ ξ ξ ξ (3.1)Implementasi modifikasi ini pada prinsipnya sama dengan implementasi SVM sebelumnya, penggunaan C+ atau C−hanyalah kasus khusus bergantung pada kelas instance data. Adapun perubahan utama terdapat pada pengubahan nilai lagrange mulplier selama pelatihan [CHA01]. Selain modifikasi pada teknik klasifikasi, dapat juga dilakukan pendekatan pada level data seperti melakukan oversampling kelas minoritas atau undersampling kelas mayoritas sehingga dihasilkan balanced dataset [AKB04].
2.2.8 Pemilihan Atribut penting (feature selection)
Pada pelatihan dengan menggunakan SVM tidak terdapat mekanisme untuk mengetahui atribut yang penting atau yang kurang penting. Atribut yang kurang penting umumnya tidak mempengaruhi efektifitas teknik klasifikasi. Oleh karena itu, jika atribut yang kurang penting ini dibuang maka efisiensi teknik klasifikasi akan meningkat. Efektifitas teknik klasifikasi juga dapat meningkat jika atribut yang kurang penting ini ternyata menjadi noise.
Pada SVM salah satu cara yang sederhana untuk mengetahui atribut yang penting adalah seperti yang dilakukan pada [MUK02B]. Pemilihan atribut penting dilakukan dengan mengevaluasi efektifitas dan efisiensi teknik klasifikasi setelah sebuah fitur dihilangkan. Dari hasil pengujian setelah fitur ini dihilangkan dapat diketahui sebuah fitur penting atau tidak dari perbedaan efisiensi dan efektifitas. Cara yang lain adalah dengan menggunakan f-score seperti pada [CHE03]. F-score adalah teknik sederhana
untuk mengukur tingkat diskriminasi dua buah vektor bilangan desimal. Jika terdapat vektor data pelatihan xk,k =1,...,m. Jika jumah data kelas positif adalah n+dan n−
adalah jumlah data kelas negatif. Maka F-score atribut ke i adalah :
(3.2) dimana adalah rata-rata dari nilai atribut keseluruhan data, data positif dan data negatif. adalah fitur ke-i dari data kelas positif ke-k dan sebaliknya adalah fitur ke-i dari date kelas negatif ke-k. Semakin besar nilai F(i), maka atribut ini dapat dianggap lebih diskriminatif (lebih penting).
2.2.9 Incremental Training dengan SVM
Pada SVM hanya support vector (data yang berada di perbatasan antar kelas) yang mempengaruhi fungsi keputusan hasil pelatihan. Karakteristik ini, dapat menyelesaikan masalah utama SVM yang menjadi lambat ketika dilatih dengan menggunakan data dalam jumlah yang sangat besar. Dengan demikian, kita dapat memilih kandidat support vector sebelum pelatihan, sehingga mengurangi jumlah data pelatihan dan pada akhirnya mengurangi kebutuhan penggunaan memori [KAT06]. Algoritma incremental training pada SVM dapat dilihat pada lampiran D.
2.2.10 Pendeteksian Intrusi dengan Support Vector Machine
Pada penelitian [MUK02,LAS04,LAS05] digunakan data yang sama dengan dengan data pada penelitian yaitu data KDD CUP 99 yang berasal 94% datanya berasal dari data DARPA 98 dan sisanya dari data DARPA 99. Adapun ringkasan hasil penelitian [MUK02, LAS04, LAS05] dapat dilihat pada lampiran E.
![Gambar II-1 Arsitektur IDS [HAN06]](https://thumb-ap.123doks.com/thumbv2/123dok/2304998.2732810/2.892.132.771.431.578/gambar-ii-arsitektur-ids-han.webp)

![Gambar II-4 Pemrosesan data koneksi jaringan dengan data mining [HAN06]](https://thumb-ap.123doks.com/thumbv2/123dok/2304998.2732810/6.892.248.721.200.567/gambar-pemrosesan-data-koneksi-jaringan-data-mining-han.webp)