1
KLASIFIKASI KEBUTUHAN NON-FUNGSIONAL MENGGUNAKAN FSKNN
DENGAN PENGEMBANGAN SINONIM DAN HIPERNIM BERBASIS ISO/IEC 9126
Denni Aldi Ramadhani1, Siti Rochimah2, Umi Laili Yuhana3
Teknik Informatika, Fakultas Teknologi Informasi, Institut Teknologi Sepuluh Nopember 1dennialdi@gmail.com, 2siti@its-sby.edu; 3yuhana@if.its.ac.id
Abstrak
Kebutuhan non-fungsional merupakan salah satu faktor penting yang berperan dalam kesuksesan pengembangan perangkat lunak yang sering kali dilupakan oleh pengembang sehingga menimbulkan efek yang merugikan. Untuk mendapatkan kebutuhan non-fungsional dibutuhkan suatu sistem otomatisasi identifikasi kebutuhan non fungsional. Dalam penelitian ini diusulkan suatu sistem otomatisasi identifikasi kebutuhan non fungsional dari kalimat kebutuhan berbasis algoritma klasifikasi FSKNN dengan pengembangan term pada data latih menggunakan sinonim dan gabungan hipernim dan sinonim berbasis ISO/IEC 9126. Dalam pengujiannya dataset kalimat kebutuhan yang digunakan adalah 1342 kalimat dari 6 dataset yang berbeda. Hasil dari penelitian ini adalah pengembangan term dengan menggunakan gabungan hipernim dan sinonim dapat memperbaiki kinerja accuracy sebesar 8.1%, precision sebesar 13% dan recall sebesar 4.9%.
Kata Kunci: kebutuhan non-fungsional, klasifikasi multi-label, Fuzzy Similarity based K-Nearest Neighbour.
Abstract
Non-functional requirements is one of the important factors that play a role in the success of software development that is often forgotten by the developer, causing adverse effects. To obtain the non-functional requirements needed an automation system identification non-functional requirements. In this study proposed an an automation system of identification of non-functional requirements from the requirement sentences based classification algorithms FSKNN with term enrichment on training data using synonyms and combined hypernym and synonyms based on ISO / IEC 9126. In the testing phase the dataset of requirement sentence used was 1342 sentences from six different datasets Results of this research is the term enrichment by using a combination hypernym and synonyms can improve performance accuracy by 8.1%, precision by 13% and a recall by 4.9%.
Keywords: Non-Functional Requirement, multi-label classification, Fuzzy Similarity based K-Nearest Neighbour.
I. PENDAHULUAN
Mengetahui kebutuhan non fungsional yang berkaitan erat dengan aspek kualitas perangkat lunak merupakan sesuatu yang penting karena aspek kualitas dalam kebutuhan non fungsional merupakan salah satu faktor yang berperan dalam kesuksesan mengembangkan sebuah sistem. Dunia industri dalam prakteknya juga terlalu fokus pada faktor kebutuhan fungsional dan sering melupakan faktor kebutuhan non fungsional hingga mencapai pada tahap desain dan pengembangan [1]. Pada kenyataannya jika aspek kualitas kebutuhan non fungsional tidak dipertimbangkan dan tidak diketahui maka menimbulkan efek yang merugikan, baik untuk kesuksesan pengembangan sistem perangkat lunak tersebut dan juga bagi para pemangku kepentingan.
Masalah yang timbul karena kurang diperhatikannya identifikasi kebutuhan non-fungsional dalam pengembangan perangkat lunak adalah kegagalan
kinerja ketika perangkat lunak telah disebarkan (deployment) ke lingkungan masyarakat [2] [3]. Efek merugikan juga dapat berdampak untuk para pemangku kepentingan, biasanya karena para pemangku kepentingan telah mengeluarkan dana besar untuk suatu proyek pengembangan perangkat lunak yang pada akhirnya perangkat lunak tersebut tidak berguna secara maksimal [4].
Banyak penelitian yang telah dilakukan untuk mengidentifikasi perangkat lunak, salah satu penelitian seperti yang dilakukan oleh Slankas dan Williams mengajukan sebuah sistem yang disebut dengan NFR Locator. Sistem ini terdiri dari dua proses yaitu pada proses pertama melakukan parsing dokumen kebutuhan menjadi kalimat – kalimat yang tersusun dalam bentuk directed graph, proses parsing ini menggunakan Stanford Natural Language Parser. Proses kedua melakukan klasifikasi terhadap kalimat hasil proses pertama dengan menggunakan pendekatan pembelajaran diawasi berbasis algoritma KNN dan
Information Technology Journal. Vol 1 No 1 January 2015, 2 - 6
memanfaatkan fungsi distance metric Levenshtein untuk mengukur jarak data uji dengan data tetangga terdekatnya [5].
Pada penelitian lainnya juga mengajukan sebuah cara untuk menyelesaikan permasalahan identifikasi aspek kualitas kebutuhan non fungsioanl dengan pendekatan pembelajaran semi-diawasi (semi-supervised learning) berbasis algoritma Naive Bayes. Algoritma Naive Bayes digunakan untuk proses pelatihan yang digabungkan dengan metode Expectation Maximization (EM) yang bertujuan untuk mengurangi jumlah data latih. Proses pertama yaitu dengan melakukan praproses terhadap dokumen kebutuhan untuk mendapatkan term kunci dari dokumen, dan proses kedua adalah melakukan klasifikasi dengan metode gabungan tersebut. Dokumen yang tidak terlabeli dianggap memiliki kehilangan data karena kurangnya label kelas [6].
Beberapa penelitian diatas tidak mempertimbangkan pengembangan pada fitur atau term yang digunakan untuk melakukan proses klasifikasi. Fitur atau term pada data latih dapat dikembangkan dengan menggunakan sinonim dan hipernim dengan memanfaatkan dictionary Wordnet, sehingga fitur atau term yang akan digunakan pada data latih dapat berkembang maknanya secara lebih luas.
Pada penelitian ini akan mengusulkan sebuah sistem otomatisasi indentifikasi kalimat kebutuhan dengan menerapkan metode klasifikasi multi-label berbasis algoritma FSKNN dengan menambahkan pengembangan term dalam data latih berdasarkan hubungan gabungan hipernim dan sinonim berbasis Wordnet Kategori aspek kualitas yang digunakan berbasis model kualitas standar internasional ISO/IEC 9126.
II. METODE
Metode penelitian ini terdiri atas 3 tahap utama yaitu : otomatisasi pelabelan data latih dengan pengembangan term sinonim dan gabungan hipernim sinonim, tahap pelatihan FSKNN yang terdiri dari subproses pengelompokan pola pelatihan dan penghitungan prior probability dan nilai likelihoods, dan tahap klasifikasi FSKNN.
2.1 Tahap Otomatisasi Pelabelan Data Pelatihan Pada fase data pelatihan otomatisasi label terdiri dari empat tahap: preprocessing, pengembangan term dalam data pelatihan berdasarkan hubungan gabungan antara hipernim dan sinonim, pembobotan tf-idf, dan pengukuran nilai kemiripan. Semua tahapan otomatisasi data training pelabelan didasarkan pada penelitian yang telah dilakukan oleh Suharso dan Rochimah [7]. Kecuali pada fase kedua adalah kontribusi dari penelitian ini yaitu mengembangkan term pada data pelatihan menggunakan sinonim dan
gabungan pola hipernim dan sinonim seperti pada Gambar 1 dan Gambar 2.
2.2 Tahap Pelatihan FSKNN
Tahap pelatihan Semantic-FSKNN terdiri dari dua tahap yaitu pengelompokan pola pelatihan dan penghitungan prior probability [8].
1. Pengelompokan Pola Pelatihan
Pengelompokan dokumen pelatihan !", !$, … , !& ke
dalam p kluster berbasis pada fuzzy similarity measure. Diberikan !' '(, )* dan !! '(, )* yang merupakan distribusi term '( pada kategori )*, yang didefinisikan
sebagai berikut: !' '(, )* = -./01/ 2 /34 -./ 2 /34 (1) !! '(, )* = 2/34567(-./)01/ 0./ 2 /34 (2)
Untuk 1 ≤ i ≤ m dan 1 ≤ j ≤ p, dimana :
:;<(=) = 1, ?@AB = > 0 0, ?@AB = = 0 (3) Sehingga tentunya akan didapatkan 0 ≤ !' '(, )* dan
!! '(, )* ≤ 1. Tahapan selanjutnya menghitung
derajat keanggotaan '( terhadap kategori )*, pada
proses penghitungan derajat keanggotaan '( terhadap
kategori )* diberikan suatu penambahan formula baru agar nilai yang didapatkan dari proses pengukuran keterkaitan semantik dapat ikut diperhitungkan.
Gambar 1. Pola Pengembangan Term dengan Sinonim
Gambar 2. Pola Pengembangan Term dengan Gabungan Hipernim dan Sinonim
3 EF '(, )* = !' '(, )* GHI "JKJG,"JLJM!'('K, )L) × GHI!! '(, )* "JKJG,"JLJM!!('K, )L) (4) Untuk 1 ≤ i ≤ m dan 1 ≤ j ≤ p. Tahapan selanjutnya adalah menentukan fuzzy similarity dari setiap dokumen d, d =O", O$, … , OG , terhadap kategori )*
sebagai berikut : :@P !, )* = EQ'@,)? ⨂ E!('@) S .34 EQ'@,)? ⨁ E!('@) S .34 (5)
Dimana ⨂ dan ⨁ merupakan fuzzy norm dan
t-conorm yang secara berurutan didefinisikan sebagai
berikut : = ⨂ U = =×U (6) = ⨁ U = = + U − =×U (7) Dan
E
X'
(=
-. SYZ 4[/[S-/ (8)E
X'
( merupakan derajat keanggotaan dari term '(terhadap d. Tahapan terakhir adalah mendefinisikan derajat keanggotaan dari dokumen d terhadap kategori )* sebagai berikut :
E\1 ! =
5(G X,\1
SYZ
4[/[]5(G X,\/ (9) Untuk 1 ≤ j ≤ p. Untuk setiap dokumen pelatihan !(,
1 ≤ i ≤ l, akan dilakukan perhitungan E\1 !(
,
1 ≤ j ≤p, dengan menggunakan persamaan 15. Untuk
mendefinisikan p kluster, ^", ^$, … , ^M, adalah sebagai
berikut :
^L= {!KE\/(!K) ≥ a, 1 ≤ c ≤ d (10)
Untuk 1 ≤ v ≤ p, dimana α adalah threshold yang didefinisikan oleh user untuk digunakan dalam proses pelatihan.
Untuk setiap !(, 1 ≤ i ≤ l, didefinisikan search set e(
untuk setiap ^L⊆ e( jika dan hanya jika !(∈ ^L, 1 ≤
v ≤ p. Proses berikutnya akan dijelaskan pada pseudo-code yang ditunjukkan pada Gambar 3, dengan catatan
pada mulanya ^L= ∅, 1 ≤ v ≤ p, dan eK= ∅, 1 ≤ u ≤ l.
Keluaran yang berupa search set e", e$, … , e&
selanjutnya akan digunakan untuk menentukan data tetangga terdekat yang dapat membantu melakukan perhitungan nilai prior probability dan nilai likelihood pada tahapan berikutnya.
2. Penghitungan Prior Probability
Diberikan i j* yang merupakan prior probability
yang harus diketahui nilainya terlebih dahulu sebelum melanjutkan ke dalam setiap observasi, sedangkan i k j* merupakan suatu kelas likelihood dan
merupakan sebuah conditional probability bahwa j*
memiliki keterkaitan dengan observasi E. Perhitungan probabilitas ini dilakukan dari pola pelatihan yang didapatkan sebelumnya, sebagai berikut :
i j*= 1 =
5l 2.3401.
$5l& (11)
i j*= 0 = 1 − i j* = 1 (12)
Dimana s merupakan nilai smoothing constant, yang biasanya bernilai real positif kecil. Tahapan berikutnya melakukan perhitungan kelas likelihood i k j* . E
dapat bernilai 0,1, ... , atau k. Untuk setiap dokumen pelatihan !(, 1 ≤ i ≤ l, dimana m( = !
L", !L$, … , !Ln
merupakan k-nearest neighbor yang diambil dari
search set e( dan <(= <"(, <$(, … , <M( , yang
merupakan vektor jumlah label yang didefinisikan : <*(= LoqLp 4U*o (13) Untuk 1 ≤ j ≤ p. Tahap selanjutnya didefinisikan :
r s, ? = &(q"U*(tu((?) (14) r s, ? = &(q"U*(tu((?) (15) Dimana U*(= 1 − U*( dan tu( ? = 1, ?@AB s = <*( 0, ?@AB s ≠ <*( (16)
Kemudian didefinisikan likelihoods, sebagai berikut :
Gambar 3. Pseudo-code proses pengelompokan dan proses pendefinisian search set Gi [8]
Information Technology Journal. Vol 1 No 1 January 2015, 4 - 6
i k = s j*= 1 = nl" 5l5lw(u,*)p w(L,*) /3x (17) i k = s j*= 0 = nl" 5l5lw(u,*)p w(L,*)
/3x (18) Untuk setiap e = 0, 1, ... , k dan j = 1, 2, ... , p, karena ukuran dari e(, 1 ≤ i ≤ l selalu lebih kecil daripada
jumlah pola pelatihan awal, menghitung likelihoods dapat dilakukan secara efisien.
2.3 Tahap Klasifikasi FSKNN
Proses testing dalam algoritma FSKNN dilakukan dengan menggunakan estimasi maximum a posteriori (MAP). Dimisalkan m(= {!
L", !L$, … , !Ln}
merupakan satu set k-nearest neighbors untuk dokumen testing !z , dan <z= <
" z, < $ z, … , < M z
merupakan vektor jumlah label untuk !z (persamaan
2.15), untuk menentukan kategori mana yang memiliki hubungan dengan !z yaitu dengan cara menghitung
vektor label Uz= U
"z, U$z, … , UMz dari dokumen !z
dengan menggunakan estimasi maximum a posteriori (MAP) sebagai berikut :
U*z
1, ?@AB i j*= 1 k = <*z > i j*= 0 k = <*z 0, ?@AB i j*= 0 k = <*z > i j*= 1 k = <*z Q 0,1 , {'ℎs}O@:s
(19)
Untuk 1 ≤ j ≤ p, dimana j* adalah variabel acak untuk
mengetahui masuk ke dalam kategori )* atau tidak
(j*= 1 untuk iya, dan j*= 0 untuk tidak), E
merupakan variabel untuk jumlah dokumen dalam mz
yang berhubungan dengan kategori )*, dan R[0,1]
mengindikasikan 0 atau 1 dipilih secara acak. Dengan menggunakan Bayes Rule didapatkan :
i j*= ~ k = <*z =
Ä1qÅi k=71Çj?=~
(Éq71Ç) (20) Untuk b = 0, 1. Oleh karena itu persamaan 19 akan berubah menjadi : U*z 1, ?@AB i j*= 1 i k = <*zj*= 1 > i j*= 0 i k = <*zj*= 0 0, ?@AB i j*= 0 i k = <*zj*= 0 > i j*= 1 i k = <*zj*= 1 Q 0,1 , {'ℎs}O@:s (21) Untuk 1 ≤ j ≤ p. Tentunya untuk menghitung U*z harus
ditemukan mz, dan menghitung i j
* (Persamaan 11
dan 12) dan juga i k j* (Persamaan 17 dan 18). Perhitungan yang tidak tergantung pada !z dapat
dilakukan pada proses pelatihan dan sisanya dilakukan ketika proses klasifikasi. Berikut tahapan selama proses klasifikasi tersebut :
1. Hitung E\1 !z , 1 ≤ j ≤ p dengan Persamaan 9
menggunakan informasi atau hasil perhitungan yang dilakukan dengan Persamaan 4, 5 dan 8.
2. Periksa jika E\1 !z ≥ a untuk 1 ≤ j ≤ p, maka
akan didapatkan search set untuk !z yaitu ez=
^*"∪ ^*$∪ … ∪ ^*Ö.
3. Temukan set mz dari k-nearest neighbors terhadap
!z dari ez, dan dapatkan vektor jumlah label <z.
4. Hitung U*z, 1 ≤ j ≤ p menggunakan Persamaan 21
dengan menggunakan informasi yang telah dihitung dalam proses pelatihan dengan Persamaan 11, 12, 17 dan 18.
5. Jika U*z yang didapatkan bernilai 1, maka !z
termasuk ke dalam kategori )*, jika sebaliknya maka !z tidak termasuk ke dalam )
*.
III. HASILDANPEMBAHASAN
Pada bab ini akan dibahas tentang dataset uji coba, skenario uji coba dan analisis dari hasil uji coba. 3.1 Dataset
Dalam pengujian yang akan dilakukan pada penelitian ini menggunakan dataset dari Promise [9], Itrust, CCHIT, World Vista US Veterans Health Care System Documentation, Online Project Marking System SRS, Mars Express Aspera-3 Processing and Archiving Facility SRS dengan total keseluruhan jumlah kalimat kebutuhan mencapai 1342 kalimat. Dimana 60% (805 kalimat) akan digunakan sebagai data latih dan 40% (537 kalimat) akan digunakan sebagai data uji. Hasil klasifikasi dari data uji nantinya akan dievaluasi kinerjanya berdasarkan accuration, precision, recall,
and hamming loss [10].
3.2 Skenario Uji Coba
Tahap uji coba pada penelitian ini akan dilakukan dengan dua skenario yang berbeda yaitu uji coba klasifikasi FSKNN menggunakan data latih yang dikembangkan dengan sinonim dan skenario kedua yaitu uji coba klasifikasi FSKNN menggunakan data latih yang dikembangkan dengan gabungan hipernim dan sinonim. Masing – masing skenario akan diuji dengan jumlah tetangga terdekat (k) antara 10 hingga 55 dan setiap k diuji dengan nilai ambang batas antara 0.1 hingga 0.9. Skenario pengujian ini ditujukan untuk mengetahui pola pengembangan term data latih terbaik antara sinonim dan gabungan hipernim dan sinonim. 3.3 Hasil Uji Coba dan Analisis
Dari hasil uji coba pada kedua skenario diketahui bahwa jumlah tetangga terdekat terbaik berada pada k = 30. Dengan hasil evaluasi accuration, precision,
recall, and hamming loss seperti yang ditunjukkan pada
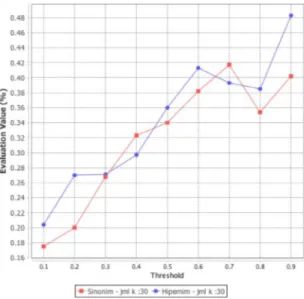
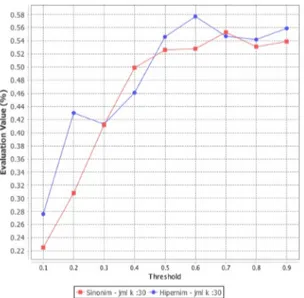
Tabel 1 dan perbandingan masing – masing kinerja dapat dilihat pada Gambar 4, 5, 6 dan 7.
5
Pada Gambar 4 diatas dapat diketahui bahwa kinerja hamming loss (tingkat kesalahan) pada klasifikasi
FSKNN dengan data latih yang dikembangkan menggunakan sinonim lebih rendah dibandingkan klasifikasi FSKNN dengan data latih pengembangan gabungan hipernim dan sinonim. Dari grafik pada Gambar 4 diatas dapat diketahui bahwa pengembangan dengan menggunakan gabungan hipernim dan sinonim tidak efektif untuk kinerja hammingloss karena dapat memicu tingkat kesalahan yang lebih tinggi. Tingkat kesalahan yang lebih tinggi dikarenakan pengembangan dengan menggunakan gabungan hipernim dan sinonim dapat mencakup makna term atau fitur yang lebih luas dibandingkan hanya dengan menggunakan sinonim saja.
Pada Gambar 5 dapat diketahui bahwa secara mayoritas kinerja accuracy pada klasifikasi FSKNN dengan menggunakan pengembangan data latih gabungan hipernim dan sinonim lebih tinggi dibandingkan klasifikasi FSKNN dengan menggunakan pengembangan data latih dari sinonim saja. Titik optimum terletak pada ambang batas 0.9 dengan nilai 48.3% dan dapat diketahui kenaikan nilainya sebesar 8.1% dari nilai FSKNN dengan pengembangan sinonim pada ambang batas yang sama.
Pada Gambar 6 dibawah dapat diketahui kinerja
precision untuk klasifikasi FSKNN dengan pengembangan gabungan hipernim dan sinonim lebih tinggi secara mayoritas dengan titik optimum terletak pada ambang batas 0.9 dengan nilai 79.2% dan kenaikan nilainya sebesar 13% dari nilai FSKNN dengan pengembangan sinonim pada ambang batas yang sama.
Pada Gambar 7 dibawah dapat diketahui kinerja recall untuk klasifikasi FSKNN dengan pengembangan gabungan hipernim dan sinonim lebih tinggi secara mayoritas dengan titik optimum terletak pada ambang batas 0.6 dengan nilai 57.7% dan kenaikan nilainya sebesar 4.9% dari nilai kinerja recall FSKNN dengan pengembangan sinonim pada ambang batas yang sama.
Threshold
FSKNN - Sinonim FSKNN - Gabungan Hipernim - Sinonim
k=30 k=30
Hammingloss Accuracy Precision Recall Hammingloss Accuracy Precision Recall 0,1 0,292 0,175 0,396 0,225 0,324 0,204 0,435 0,276 0,2 0,303 0,2 0,411 0,308 0,342 0,27 0,426 0,43 0,3 0,286 0,268 0,447 0,412 0,325 0,271 0,453 0,413 0,4 0,255 0,323 0,503 0,499 0,317 0,297 0,462 0,461 0,5 0,254 0,34 0,501 0,526 0,275 0,36 0,53 0,546 0,6 0,217 0,382 0,581 0,528 0,24 0,413 0,621 0,577 0,7 0,199 0,417 0,659 0,553 0,249 0,393 0,616 0,547 0,8 0,236 0,354 0,537 0,531 0,26 0,385 0,604 0,542 0,9 0,2 0,402 0,662 0,539 0,187 0,483 0,792 0,559
Gambar 4. Perbandingan kinerja Hammingloss antara pengembangan Sinonim dan Gabungan Hipernim Sinonim
Gambar 5. Perbandingan kinerja Accuracy antara pengembangan Sinonim dan Gabungan Hipernim Sinonim
Information Technology Journal. Vol 1 No 1 January 2015, 6 - 6
IV. KESIMPULAN
Dari hasil uji coba pada penelitian ini dapat disimpulkan bahwa pengembangan term atau fitur pada data latih dengan menggunakan gabungan hipernim dan sinonim terbukti dapat meningkatkan kinerja accuracy, precision, dan recall dibandingkan dengan pengembangan term atau fitur menggunakan sinonim saja, tetapi pengembangan term atau fitur dengan menggunakan data latih juga memberikan kinerja hamming loss yang lebih tinggi dibandingkan pada pengembangan term menggunakan sinonim.
DAFTAR PUSTAKA
[1] S. Ullah, M. Iqbal and A. M. Khan, "A Survey on Issues in Non-Functional Requirements Elicitation," in 2011 International Conference on Computer Networks and Information Technology (ICCNIT), Peshawar, Pakistan, 2011.
[2] Finkelstein and J. Dowel, "A Comedy of Errors: the London Ambulance Service case study," in Proceedings of the 8th International Workshop on Software Specification and Design, 1996. [3] J. Bertman and N. Skolnik, "EHRs Get a Failing
Grade on Usability," Internal Medicine News, vol. 43, p. 50, 2010.
[4] Hoskinson, "Politico," News, 29 Juni 2011.
[Online]. Available:
http://www.politico.com/news/stories/0611/5805 1.html. [Accessed 20 Oktober 2014].
[5] J. Slankas and L. Williams, "Automated Extraction of Non-Functional Requirements in Available Documentation," in 2013 1st International Workshop on Natural Language Analysis in Software Engineering (NaturaLiSE), San Francisco, CA, USA, 2013.
[6] Casamayor, D. Godoy and M. Campo, "Identification of non-functional requirements in textual specifications : A semi-supervised learning approach," Information and Software Technology, vol. 52, pp. 436-445, 2010. [7] W. Suharso and S. Rochimah, SIstem Deteksi dan
Klasifikasi Otomatis Kebutuhan Non Fungsional Berbasis ISO/IEC 9126, Surabaya: Institut Teknologi Sepuluh November, 2013.
[8] J.-Y. Jiang, S.-C. Tsai and S.-J. Lee, "FSKNN: Multi-label text categorization based on fuzzy similarity and k nearest neighbors," Expert Systems with Applications, vol. 39, pp. 2813-2821, 2012.
[9] PROMISE, "tera-PROMISE," 1 April 2010. [Online].Available:http://openscience.us/repo/re quirements/other-requirements/nfr.html. [Accessed 20 Januari 2015].
[10] P. Prajapati, A. Thakkar and A. Ganatra, "A Survey and Current Research Challenges in Multi-Label Classification Methods," International Journal of Soft Computing and Engineering (IJSCE), vol. 2, no. 1, pp. 248-252, 2012.
Gambar 6. Perbandingan kinerja Precision antara pengembangan Sinonim dan Gabungan Hipernim Sinonim
Gambar 7. Perbandingan kinerja Precision antara pengembangan Sinonim dan Gabungan Hipernim Sinonim
![Gambar 3. Pseudo-code proses pengelompokan dan proses pendefinisian search set G i [8]](https://thumb-ap.123doks.com/thumbv2/123dok/4666280.3422249/3.892.489.808.71.360/gambar-pseudo-code-proses-pengelompokan-proses-pendefinisian-search.webp)