BAB II
LANDASAN TEORI
2.1. Algoritma
Algoritma adalah logika, metode dan tahapan (urutan) sistematis yang digunakan untuk memecahkan suatu permasalahan (Utami, 2005).Algoritma adalah urutan langkah-langkah logis penyelesaian masalah yang disusun secara sistematis (Munir, 2005). Berdasarkan defenisi tersebut dapat diambilkesimpulan bahwa Algoritma merupakan ilmu yang mempelajari cara menyelesaikan masalah dengan langkah-langkah yang disusun dengan sistematis dan menggunakan bahasa yang logis untuktujuan tertentu.
Sebuah algoritma tidak saja harus benar, tetapi juga harus mangkus (efisien). Algoritma yang bagus adalah algoritma yang mangkus. Kemangkusan algoritma diukur dari berapa jumlah waktu dan ruang (space) memori yang dibutuhkan untuk menjalankannya. Algoritma yang mangkus ialah algoritma yang meminimumkan kebutuhan waktu dan ruang. Kebutuhan waktu dan ruang suatu algoritma bergantung pada ukuran masukan (n), yang menyatakan jumlah data yang diproses. Kemangkusan algoritma dapat digunakan untuk menilai algoritma yang terbaik.
2.2. Notasi Asimptotik
Untuk membandingkan dan menyusun urutan dari pertumbuhan, ilmuwan komputer menggunakan tiga notasi:
Dalam penelitian ini, penulis akan membandingkan Ө ( big theta) dari algoritma Smith dan algoritma Raita
2.2.1 Notasi O
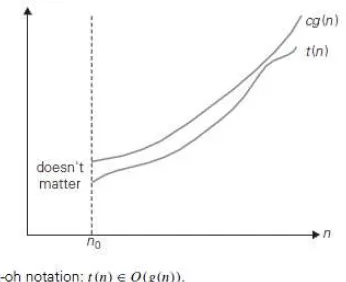
Fungsi t(n) dikatakan berada padaO(g(n)), disimbolkan kan dengan t(n) ϵ O(g(n)), jika t(n) diberi batas atas oleh beberapa pengali konstan dari g(n) untuk semua n bernilai besar, contohnya, jika ada beberapa konstan c bernilai positif dan n0 integer bukan negatif seperti t(n) ≤ cg(n) untuk semua n ≥ n0 (Levitin, 2012).
Adapun grafik dari notasi big-oh seperti pada gambar 2.1 berikut ini.
Gambar 2.1 Notasi Big – oh (Levitin, 2012).
2.2.2 Notasi Ө
Adapun grafik dari notasi big-theta seperti pada gambar 2.2 berikut ini.
Gambar 2.2 Notasi Big – theta (Levitin, 2012). 2.2.3 NotasiΩ
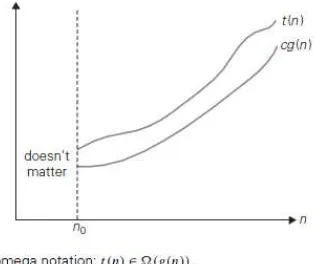
Fungsi t(n) dikatakan berada dalam Ω(g(n)), disimbolkan dengan t(n) ϵ Ω(g(n)), jika t(n) diberi batas bawah oleh beberapa pengali konstan dari g(n) untuk semua n bernilai besar, contohnya, jika ada beberapa konstan c bernilai positif dan n0 integer bukan negatif seperti t(n) ≥ cg(n) untuk semua n ≥ n0 (Levitin, 2012).
Adapun grafik dari notasi big-omega seperti pada gambar 2.3 berikut ini.
Gambar 2.3 Notasi Big – omega (Levitin, 2012).
2.3Pencocokan String (String Matching)
Masalah string matching, yaitu menemukan semua kejadian dari satu string
sebagai substring dari satu sama lain, merupakan masalah mendasar dalam ilmu
komputer.(Nebel, 2006).Pencocokan string adalah masalah mendasar yang
stringadalah proses menemukan jumlah kejadian dari P pola panjang m di T teks
panjang n, di mana dalam prakteknya m jauh lebih kecil dari n.(Abdulrakeeb &
Hassan, 2017).Pencocokan string (string matching) merupakan proses pencarian semua kemunculan query yang selanjutnya disebut pola (pattern) ke dalam string yang lebih panjang (teks). Patterndisimbolkan dengan x=x[0...m-1] dan panjangnya adalah m. Teks disimbolkan dengan y=y[0...n-1] dan panjangnya adalah n. Kedua string terdiri dari sekumpulan karakter yang disebut alfabet disimbolkan dengan Σ dan mempunyai ukuran σ (Sarmo, 2012).
Algoritma pencocokan stringatau string matching algorithm adalah algoritma untukmelakukan pencarian semua kemunculan string pendek P[0..n-1] yang disebut pattern di string yang lebih panjang T[0..m-P[0..n-1] yang disebut teks. (Kumara, 2008).
Persoalan dalam pencarian string dirumuskan sebagai berikut. 1. Diberikan teks, yaitu string yang panjangnya n karakter
2. Diberikan pattern, yaitu string dengan panjang m karakter (m<n) yang akan dicari di dalam teks
Setelah itu,dicari lokasi pertama pada teks yang bersesuaian dengan pattern. Contoh :
Teks : Pattern :
Algoritma pencocokan stringdiklasifikasikan menjadi dua, yaitu :
1. Inexact string matching atau Fuzzy string matching, adalah pencocokan string secara samar, yaitu pencocokan string dimana string yang dicocokkan memiliki kemiripan namun keduanya memiliki susunan karakter yang berbeda (mungkin jumlah atau urutannya) tetapi string tersebut memiliki kemiripan, baik kemiripan tekstual/penulisan atau kemiripan ucapan (Rochmawati, 2015). Sebuah tantangan signifikan di similarity join adalah untuk mengimplementasikan sebuah efektif fuzzy (samar) pada operasi
pencocokan untuk menemukan semua pasangan string sejenis yang mungkin
tidak sama persis. (Wang, Li, & Fe, 2011). Misalnya, pattern‘MULIA’ akan
2. Exact string matching, merupakan pencocokan stringsecara tepat dengan
susunan karakter dalam string yang dicocokkan memiliki jumlah maupun urutan karakter dalam string yang sama (Syaroni, 2005). algoritma exact string matching yang merupakan kelas penting dari algoritma
pencarianstring yang mencoba untuk menemukan semua kejadian yang
mungkin dari pola P ukuran m dari T teks string ukuran n. Misalnya,
pattern‘MUTIA’ hanya akan menunjukkan kecocokan dengan string ‘MUTIA’ pada teks ‘ZARIANI MUTIA SYARA’.Algoritma Smith dan Raita adalah algoritma yang tergolong dalam exact string matching. Kedua algoritma tersebut lah yang akan dibahas pada penelitian ini.
2.4. Algoritma Smith
Algoritma Smith diperkenalkan oleh P. D. Smith pada tahun 1991. Smith memperhatikan bahwa dengan menghitung pergeseran dengan karakter teks persis di samping karakter jendela teks paling kanan terkadang memberikan pergeseran yang lebih pendek daripada menggunakan karakter jendela teks paling kanan. Lalu ia menganjurkan untuk mengambil maksimum antara kedua nilai. (Charras &Lecroq, 2004).
Kebanyakan algoritma pencocokan string terdiri dari fase preprocessing dan
fase pencarian. Tahap preprocessing menganalisis karakter dalam pola untuk
menggunakan informasi ini untuk menentukan pergeseran pola dalam kasus
ketidakcocokan atau seluruh pencocokan, dengan tujuan mengurangi jumlah
perbandingan karakter, sedangkan fase pencarian mendefinisikan urutan
perbandingan karakter dalam setiap upaya antara pola dan teks.(Klaib&Osborne,
2009).
Pada algoritma Smith terbagi atas 2 fase, yaitu : 1. Fase Preprocessing
2.4.1. Fase Preprocessing
Fase preprocessingpada algoritma Smith adalah perpaduandari perhitungan fungsi pergeseran bad-character dari algoritma Quick Search dengan fungsi pergeseran bad-character dari algoritma Boyer Moore. Bad-character merupakan kumpulan karakter yang mewakili pola (pattern). Fungsi pergeseran bad-character dari algoritma Boyer Moore disimpan pada tabel bmBc, sementara fungsi pergeseran bad-character dari algoritma Quick Search disimpan pada tabel qsBc. Kedua fungsi tersebut digunakan pada fase preprocessing algoritma Smith.
Contoh perhitungan tabel pergeseran bmBc untuk patternMUTIApada teks ZARIANI MUTIA SYARA.
Pattern :
i 0 1 2 3 4
x[i] M U T I A
Langkah 1 :
Diambil setiap perwakilan karakter dari pattern dan sebuah karakter pembantu “*” untuk mewakilkan karakter yang belum ada.
c M U T I A *
bmBc[c]
Langkah 2 :
Nilai bmBc [x[i]] diisi dengan nilai dari panjang pattern (m). Pada contoh ini karena Pattern memiliki panjang 5, maka nilai bmBc [x[i]] adalah 5.
c M U T I A *
bmBc[c] 5
Langkah 3 :
Dilakukan perhitungan nilai bmBc [x[i]] untuk i=0 sampai i=m-2.(dalam contoh ini i=0 sampai i=3) dengan rumus untuk menghitung bmBc[x[i]] yaitu:
m-i-bmBc [x[i]] = m-i-1 = 5-0-1 = 4
Dikarenakan i sudah bernilai 3, maka proses perhitungan nilai bmBc di hentikan dan nilai A adalah 5 sesuai dengan panjang pola, karena abjad yang tidak ada pada tabel maka diinisialisasikan dengan tanda (*) kemudian nilainya sesuai dengan panjang pola.
Maka, untuk perhitungan tabel BmBc adalah sebagai berikut: Tabel 2.1 Nilai bmBc[c] untuk pattern MUTIA
C M U T I A *
bmBc[c] 4 3 2 1 5 5
Contoh perhitungan tabel pergeseran qsBc untuk patternMUTIApada teks ZARIANI MUTIA SYARA.
Pattern :
I 0 1 2 3 4
x[i] M U T I A
Langkah 1 :
Diambil setiap perwakilan karakter dari pattern dan sebuah karakter pembantu “*” untuk mewakilkan karakter yang belum ada.
C M U T I A *
qsBc[c] Langkah 2 :
Nilai qsBc [x[i]] diisi dengan nilai dari panjang pattern (m+1). Pada contoh ini karena Pattern memiliki panjang 5, maka nilai bmBc [x[i]] adalah 6.
C M U T I A *
qsBc[c] 6
Dilakukan perhitungan nilai qsBc [x[i]] untuk i=0 sampai i=m-1.(dalam contoh ini i=0 sampai i=4) dengan rumus untuk menghitung qsBc [x[i]] yaitu:
Untuk i =0 ; mewakili karakter M pada pattern MUTIA qsBc [x[i]] = m-i = 5-0 = 5
Untuk i =1 ;
qsBc [x[i]] = m-i = 5-1 = 4 Untuk i =2 ;
qsBc [x[i]] = m-i = 5-2 = 3 Untuk i =3 ;
qsBc [x[i]] = m-i = 5-3 = 2 Untuk i =4 ;
qsBc [x[i]] = m-i = 5-4 = 1
Maka, untuk perhitungan tabel qsBc adalah sebagai berikut: Tabel 2.2 Nilai qsBc[c] untuk pattern MUTIA
C M U T I A *
qsBc[c] 5 4 3 2 1 6
2.4.2. Fase Pencarian
Contoh proses pencarian pattern MUTIA pada teks ZARIANI MUTIA SYARA. Dengan nilai bmBc[c] dan qsBc[c] untuk pattern MUTIA dapat dilihat dari tabel 2.3 dibawah ini.
Tabel 2.3 Nilai bmBc[c] dan qsBc[c] untuk pattern MUTIA
C M U T I A *
bmBc[c] 4 3 2 1 5 5
qsBc[c] 5 4 3 2 1 6
Pada fase pencarian, jumlah pergeseran berdasarkan perbandingan terbesar nilai bmBc dari karakter yang paling kanan dari jendela teks yang bersesuaian dengan panjang patterndengan nilai qsBc dari karakter yang
disebelahnya.Algoritma ini akan tetap mencari dengan bergerak kekanan hingga karakter pada teks berakhir. Tetapi, Jika sebelum teks berakhir pattern yang dicari sudah ditemukan, maka jumlah pergeseran pencarian selanjutnya berubah menjadi nilai qsBc dari karakter yang disebelah kanan karakter yang paling kanan dari jendela teks yang bersesuaian dengan panjangpattern. hingga teks berakhir.
Tahap 1 :
Z A R I A N I M U T I A S Y A R A
1
M U T I A
Bergeser sejauh 6 (bmBc[A] = qsBc[N]) Tahap 2 :
Z A R I A N I M U T I A S Y A R A 1
M U T I A
Bergeser sejauh 2 (bmBc[T] = qsBc[I] Tahap 3 :
Z A R I A N I M U T I A S Y A R A 1 2 3 4 5
M U T I A Pada percobaan ketiga, pattern sudah sesuai dengan karakter pada teks. Pada contoh ini teks belum berakhir, maka pencarian akan dilanjutkan dengan nilai pergesaran berubah menjadi qsBc.
Bergeser sejauh 6 (qsBc [SPASI (*)]) Tahap 4 :
Z A R I A N I M U T I A S Y A R A 1
M U T I A
2.5 Algoritma Raita
Algoritma Raita dirancang untuk membandingkan karakter terakhir dari jendela teks dengan pattern yang bersesuaian, jika cocok kemudian karakter pertama,jika cocok juga maka dilanjutkan ke karakter tengah.
Akhirnya,jika mereka benar-benar cocok, maka selanjutnya algoritma akan membandingkan karakter lain mulai dari karakter kedua hingga ke karakter kedua terakhir, dan mungkin membandingkan dengan karakter tengah lagi.
Kebanyakan algoritma pencocokan string terdiri dari fase preprocessing dan
fase pencarian. Tahap preprocessing menganalisis karakter dalam pola untuk
menggunakan informasi ini untuk menentukan pergeseran pola dalam kasus
ketidakcocokan atau seluruh pencocokan, dengan tujuan mengurangi jumlah
perbandingan karakter, sedangkan fase pencarian mendefinisikan urutan
perbandingan karakter dalam setiap upaya antara pola dan teks.(Klaib&Osborne,
2009).
Pada algoritma Raita terbagi atas 2 fase, yaitu : 1. Fase Preprocessing
2. Fase Pencarian
2.5.2 Fase Preprocessing
Fase preprocessingpada algoritma Raitaterdiri dari penghitungan fungsi pergeseran bad-characterdari algoritma Boyer Moore.Bad-character merupakan kumpulan karakter yang mewakili pola (pattern). Fungsi pergeseran bad-character dari algoritma Boyer Moore ini disimpan pada tabel bmBc.
Pattern :
i 0 1 2 3 4
x[i] M U T I A
Langkah 1 :
Diambil setiap perwakilan karakter dari pattern dan sebuah karakter pembantu “*” untuk mewakilkan karakter yang belum ada.
c M U T I A *
bmBc[c] Langkah 2 :
Nilai bmBc [x[i]] diisi dengan nilai dari panjang pattern (m). Pada contoh ini karena Pattern memiliki panjang 5, maka nilai bmBc [x[i]] adalah 5.
c M U T I A *
bmBc[c] 5
Langkah 3 :
Dilakukan perhitungan nilai bmBc [x[i]] untuk i=0 sampai i=m-2. (dalam contoh ini i=0 sampai i=3) dengan rumus untuk menghitung bmBc[x[i]] yaitu:
Untuk i =0 ; mewakili karakter M pada pattern MUTIA bmBc [x[i]] = m-i-1 = 5-0-1 = 4
Dikarenakan i sudah bernilai 3, maka proses perhitungan nilai bmBc di hentikan dan nilai A adalah 5 sesuai dengan panjang pola, karena abjad yang tidak ada pada tabel maka diinisialisasikan dengan tanda (*) kemudian nilainya sesuai dengan panjang pola.
Maka, untuk perhitungan tabel BmBc adalah sebagai berikut: Tabel 2.4 Nilai bmBc[c] untuk pattern MUTIA
C M U T I A *
bmBc[c] 4 3 2 1 5 5
2.5.3 Fase Pencarian
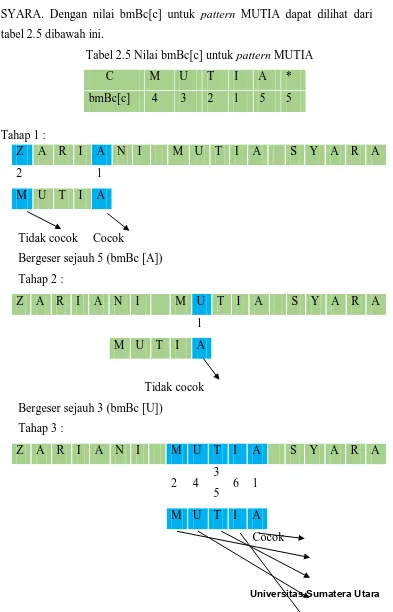
Contoh proses pencarian pattern MUTIA pada teks ZARIANI MUTIA SYARA. Dengan nilai bmBc[c] untuk pattern MUTIA dapat dilihat dari tabel 2.5 dibawah ini.
Tabel 2.5 Nilai bmBc[c] untuk pattern MUTIA
C M U T I A *
bmBc[c] 4 3 2 1 5 5
Tahap 1 :
Z A R I A N I M U T I A S Y A R A
2 1
M U T I A
Tidak cocok Cocok
Bergeser sejauh 5 (bmBc [A]) Tahap 2 :
Z A R I A N I M U T I A S Y A R A
1
M U T I A
Tidak cocok Bergeser sejauh 3 (bmBc [U])
Tahap 3 :
Z A R I A N I M U T I A S Y A R A
2 4 3
5 6 1
M U T I A
Cocok Cocok Cocok Cocok Pada tahap ini dilihat bahwa :
Karakter terakhir pattern cocok . Setelah itu karakter pertama pattern cocok Lalu karakter tengah pattern cocok . Jika akhir, pertama, dan tengah pattern telah cocok maka pencocokan dilanjutkan. Pada karakter kanan dari awal (kedua) patterndan terus bergerak kekanan hingga ke karakter sebelah kiri dari karakter terakhir pattern. jika cocok maka karakter teks dengan karakter pattern dikatakan cocok dan berhasil ditemukan.
2.6 Penelitian yang Relevan
1. Pada penelitian terdahulu yang dilakukan oleh (Nasution, 2016) tentang “Implementasi Algoritma Raita Dalam Kamus Bahasa Indonesia-Mandailing Berbasis Android”, menyimpulkan bahwa pada algoritma Raita digunakan karakter pola sebagai field untuk mencari kaa pada database. 2. Pada penelitian terdahulu yang dilakukan oleh (Hutagalung, 2016) tentang
“Studi PerbandinganKinerja Teoretis dan Riil Algoritma Exact StringMatchingApostolico-Crochemore dan Smith”, menyimpulkan
bahwaSecara teoretis, pada fase pencarian algoritma Smith lebih efektif untuk patternyang sangat pendek, sementara algoritma Apostolico-Crochemore lebih efektif untuk pattern yang panjang.