IDENTIFIKASI PENCILAN DAN PETA PENCILAN PADA ANALISIS KOMPONEN UTAMA UNTUK DATA MENJULUR
Anna Fauziyah G14080036
Pembimbing: Dr. Ir. Kusman Sadik, M.Si Dr. Ir. I Made Sumertajaya, MS
Abstrak
Analisis Komponen Utama (AKU) merupakan salah satu analisis peubah ganda yang pada dasarnya mentransformasikan secara linier peubah asal menjadi peubah baru yang dinamakan komponen utama. Akan tetapi, AKU yang didasarkan pada matriks ragam peragam ini sangat sensitif terhadap keberadaan pencilan. Sensitifitas terhadap pencilan pada AKU-Klasik dapat diatasi dengan AKU yang kekar (AKU-K) yang bekerja sangat baik pada data yang memiliki sebaran simetrik atau tidak menjulur. Apabila data peubah asal menjulur ma ka banyak titik data yang sebenarnya bukan pencilan dianggap sebagai pencilan. Kemudian dikembangkanlah pendekatan AKU-K yang cocok untuk data menjulur dengan mendefinisikan berbagai kriteria baru untuk menggambarkan pencilan yaitu AKU-KAO. Pada penelitian ini digunakan empat metode yaitu AKU-Klasik, AKU-KMCD, AKU-K, dan AKU-KAO untuk mengetahui perbandingan efektifitas metode dalam mengidentifikasi pencilan pada data menjulur. Keempat metode tersebut dicobakan pada dua set data yang dikontaminasi pencilan dengan proporsi 0%, 5%, 10%, dan 15%. Hasil yang diperoleh dari penelitian ini menunjukkan bahwa metode AKU-KAO mampu mengatasi pengaruh kehadiran pencilan pada data menjulur karena memiliki tingkat kesalahan identifikasi yang paling kecil. Hal tersebut diperkuat dengan adanya peta pencilan yang memberikan gambaran secara visual dalam pengidentifikasian pencilan.
Kata kunci : data menjulur, pencilan, analisis komponen utama kekar, peta pencilan. Disetujui oleh :
Ketua Komisi Pembimbing Anggota Komisi Pembimbing
(Dr. Ir. Kusman Sadik, M.Si) (Dr. Ir. I Made Sumertajaya, MS)
PENDAHULUAN
Latar Balakang
Konsep dasar dari Analisis Komponen Utama (AKU) adalah pereduksian dimensi sekumpulan peubah asal menjadi peubah baru yang berdimensi lebih kecil yang saling bebas dan tetap mempertahankan informasi yang terkandung di dalamnya. Peubah baru tersebut disebut komponen utama. Akan tetapi, AKU yang didasarkan pada matriks ragam peragam ini sangat sensitif terhadap keberadaan pencilan.
Pada tahun 2005 Hubert et al. memperkenalkan pendekatan Robust Principal Component Analysis (ROBPCA) atau Analisis Komponen Utama Kekar (AKU-K) yang menghasilkan komponen utama yang tidak dipengaruhi oleh pencilan. AKU-K menggabungkan konsep Projection Pursuit (PP) dengan Minimum Covariance Determinant
(MCD). PP digunakan untuk inisiasi reduksi dimensi awal sedangkan MCD digunakan sebagai penduga matriks ragam peragam yang kekar.
Tahap awal AKU-K yaitu mereduksi dimensi awal dengan melakukan dekomposisi nilai singular untuk membatasi pengamatan terhadap ruang yang direntangnya. Kemudian menentukan h keterpencilan dengan menggunakan rumus Stahel-Donoho. Setelah itu, dihitung penduga nilai tengah dan matriks ragam peragam MCD untuk h keterpencilan terkecil. Matriks ragam peragam didekomposisi sehingga diperoleh komponen utamanya. Sebanyak k komponen utama pertama dipilih dan semua data diproyeksikan pada subruang �0 berdimensi-k yang direntang oleh k vektor ciri pertama. Untuk setiap pengamatan dihitung jarak ortogonalnya Kemudian diperoleh subruang kekar penduga
peragam semua pengamatan. Tahap terakhir yaitu menghitung kembali penduga nilai tengah dan matriks ragam peragam pada subruang berdimensi-k dengan menggunakan pembobot MCD pada data yang diproyeksikan. Pendugaan ini menggunakan algoritma FAST-MCD yang diadaptasi (Rousseeuw 1999). Komponen utama akhir adalah vektor ciri dari matriks ragam peragam tersebut.
Selain AKU-K, terdapat AKU Kekar MCD (AKU-KMCD) yang merupakan analisis dimana akar ciri kekar saling berkorespondensi dengan vektor ciri kekar dari matriks ragam peragam dari h pengamatan yang memiliki keterpencilan terkecil. Hal tersebut menghasilkan subruang AKU yang sama dengan AKU-K tetapi tidak dengan nilai dari akar ciri dan vektor cirinya.
Sensitifitas terhadap pencilan pada AKU-Klasik dapat diatasi dengan AKU-K yang bekerja sangat baik pada data yang memiliki sebaran simetrik atau tidak menjulur. Apabila data peubah asal menjulur maka banyak titik data yang sebenarnya bukan pencilan dianggap sebagai pencilan. Pada tahun 2009 Hubert et al. mengembangkan pendekatan AKU-K yang cocok untuk data menjulur dengan mendefinisikan berbagai kriteria baru untuk menggambarkan pencilan. Pendekatan ini terdiri dari langkah-langkah yang sama dengan AKU-K sebelumnya akan tetapi pada pendekatan baru ini dilakukan beberapa modifikasi. Perbedaan mendasar dari pendekatan AKU-K baru ini dengan pendekatan AKU-K sebelumnya yaitu terletak pada penggantian perhitungan keterpencilan pada AKU-K yang menggunakan rumus Stahel-Donoho (AKU-K) dengan menggunakan rumus perhitungan keterpencilan baru yaitu adjusted outlyingness (AKU-KAO).
Tujuan Penelitian ini bertujuan untuk:
1. Mengetahui perbandingan efektifitas metode AKU-Klasik, AKU-KMCD, AKU-K, dan AKU-KAO dalam mengidentifikasi pencilan pada data menjulur yang memiliki berbagai proporsi pencilan
2. Mengetahui penerapan peta pencilan (outlier map) pada data menjulur
3. Mengetahui penerapan AKU-Klasik dan AKU-KAO pada data menjulur.
METODOLOGI
Data
Data yang digunakan dalam penelitian ini diperoleh dari data simulasi. Data simulasi yang digunakan merupakan data menjulur dari hasil pembangkitan bilangan acak normal inverse
gaussian (NIG) dengan kontaminasi berbagai proporsi pencilan.
Metode
Penelitian ini dilakukan dengan langkah-langkah sebagai berikut:
1. Membangkitkan data menjulur yaitu data yang menyebar NIG(γ,δ,µ,σ). Dimana µ adalah parameter lokasi, σ adalah parameter skala, dan γ dan δ adalah parameter bentuk yang menentukan kemenjuluran dan panjang ekor. Jumlah peubah yang dibangkitkan sebanyak 10 peubah dengan n1=500 dan n2=100. Kemudian memberikan beberapa proporsi pencilan. Proporsi pencilan yang diberikan adalah 0% (tanpa pencilan), 5%, 10% dan 15%. Pembangkitan pencilan dilakukan dengan cara pengekstriman data pengamatan biasa pada h peubah dari p peubah pada setiap pengamatan yang terpilih
2. Melakukan identifikasi pencilan dengan menggunakan metode Klasik, AKU-KMCD, AKU-K, dan AKU-KAO untuk setiap data pada langkah 1. Kemudian membandingkan hasil dari keempat metode tersebut. Hal yang dibandingkan adalah jumlah pencilan yang teridentifikasi pada setiap metode
3. Membandingkan peta pencilan yang dihasilkan oleh metode Klasik, AKU-KMCD, AKU-K, dan AKU-KAO
4. Melakukan penerapan Klasik dan AKU-KAO pada data menjulur dengan proporsi pencilan 5%
5. Melakukan penerapan AKU-Klasik pada data menjulur dengan proporsi pencilan 5% tetapi pencilan yang teridentifikasi dihilangkan 6. Membandingkan hasil Klasik dan
AKU-KAO pada langkah 4 dan 5. Hal yang dibandingkan adalah akar ciri dan proporsi kumulatif komponen utama pertama.
Pengolahan data dilakukan dengan menggunakan perangkat lunak MATLAB 7.7.0(R2008b) dan Microsoft Excel 2007.
HASIL DAN PEMBAHASAN
Karakteristik Data
Tabel 1 Nilai Medcouple tiap peubah
Tabel 1 menunjukkan besarnya kemenjuluran data pada setiap peubah. Nilai medcouple melebihi nilai 0 sehingga data dapat dikatakan menjulur. Nilai medcouple berkisar antara -1 sampai 1. Jika nilainya 0 maka sebarannya tidak menjulur (simetrik). Simulasi dilakukan dengan menggunakan metode AKU-Klasik, AKU-KMCD, AKU-K, dan AKU-KAO. Karena semua simulasi dilakukan pada set data yang mengandung pencilan sebesar 0%, 5%, 10%, dan 15%, maka α yang digunakan untuk setiap metode adalah sebesar 85%.
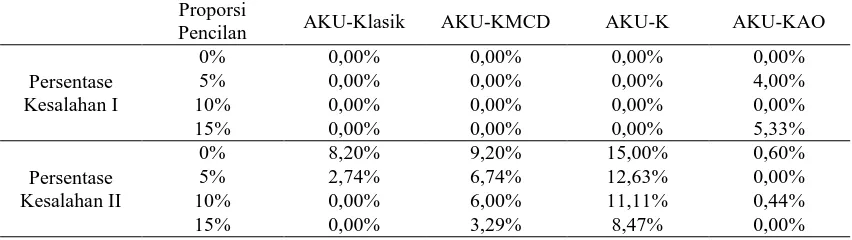
Identifikasi Pencilan pada n1=500 Tabel 2 menunjukkan kesalahan identifikasi pencilan pada data menjulur yang dibangkitkan dari NIG(1,0.8,0,1) dengan n1=500 data, p=10 dimensi dan rank k=2 (k adalah banyaknya komponen utama yang diambil) dikontaminasi dengan data yang diekstrimkan. Kesalahan I merupakan kesalahan dimana pencilan teridentifikasi sebagai data bukan pencilan. Sedangkan, Kesalahan II merupakan kesalahan dimana data bukan pencilan teridentifikasi sebagai pencilan. Metode yang baik adalah metode yang mengidentifikasi data secara tepat.
Pada data tanpa pencilan (proporsi pencilan 0%) dan data dengan proporsi pencilan 10% tidak terdapat Kesalahan I untuk keempat metode (Gambar 1). Artinya, keempat metode tersebut mengidentifikasi pencilan secara tepat. Pada
proporsi pencilan 5%, AKU-KAO memiliki persentase Kesalahan I sebesar 4%. Artinya, AKU-KAO mengidentifikasi pencilan sebagai data bukan pencilan sebanyak 1 pencilan dari 25 pencilan yang dikontaminasikan. Sedangkan, pada data dengan proporsi pencilan 15%, AKU-KAO memiliki persentase Kesalahan I sebesar 5.33%.
Gambar 1 Persentase Kesalahan I pada n1=500 Pada Tabel 2 terlihat bahwa keempat metode yaitu AKU-Klasik, AKU-KMCD, AKU-K, dan AKU-KAO memiliki persentasi Kesalahan II yang beragam. Pada proporsi pencilan 0%, AKU-Klasik memiliki Kesalahan II sebesar 8.20%. Artinya, AKU-Klasik mengidentifikasi data bukan pencilan sebagai pencilan sebanyak 41 pencilan dari 500 data bukan pencilan (data pengamatan biasa). Pada AKU-KMCD terdapat Kesalahan II sebesar 9.20%. Artinya, AKU-KMCD mengidentifikasi data bukan pencilan sebagai pencilan sebanyak 46 pencilan dari 500 data bukan pencilan. Sedangkan pada AKU-K terdapat Kesalahan II yang relatif tinggi yaitu sebesar 15%. Artinya, AKU-K mengidentifikasi data bukan pencilan sebagai pencilan sebanyak 75 pencilan dari 500 data bukan pencilan. Berbeda dengan AKU-KAO yang memiliki Kesalahan II yang cukup kecil dibandingkan dengan ketiga metode yang lainnya yaitu sebesar 0.6%. Artinya, AKU-KAO mengidentifikasi data bukan pencilan sebagai pencilan sebanyak 3 pencilan dari 500 data bukan pencilan. Pada data dengan proporsi pencilan 5%, tidak terdapat Kesalahan II untuk AKU-KAO. Sedangkan pada ketiga metode lainnya yaitu AKU-Klasik, AKU-KMCD, dan Tabel 2 Persentase kesalahan identifikasi pencilan pada data menjulur n1=500, p=10 dan k=2
Proporsi
Pencilan AKU-Klasik AKU-KMCD AKU-K AKU-KAO
Tabel 3 Persentase kesalahan identifikasi pencilan pada data menjulur n2=100, p=10 dan k=2 Proporsi
Pencilan AKU-Klasik AKU-KMCD AKU-K AKU-KAO
Persentase Kesalahan I
0% 0,00% 0,00% 0,00% 0,00%
5% 0,00% 0,00% 0,00% 0,00%
10% 0,00% 0,00% 0,00% 0,00%
15% 6,67% 0,00% 0,00% 6,67%
Persentase Kesalahan II
0% 8,00% 14,00% 18,00% 3,00%
5% 4,21% 10,53% 15,79% 2,11%
10% 7,78% 10,00% 15,56% 0,00%
15% 0,00% 3,53% 8,24% 0,00%
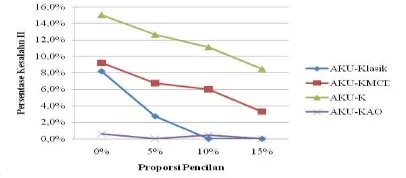
AKU-K memiliki Kesalahan II masing-masing sebesar 2.74%, 6.74%, dan 12,63%. Ketika proporsi pencilan ditambahkan menjadi 10% dan 15%, AKU-Klasik tidak mencatat Kesalahan II. Artinya, AKU-Klasik mengidentifikasi secara tepat data bukan pencilan. Pada AKU-KMCD terdapat Kesalahan II sebesar 6% ketika proporsi pencilan meningkat menjadi 10%. Pada AKU-K terdapat Kesalahan II sebesar 11.11%. Sedangkan pada AKU-KAO terdapat sedikit Kesalahan II yaitu sebesar 0.44%. Pada proporsi pencilan 15% AKU-KMCD dan AKU-K memiliki Kesalahan II masing-masing sebesar 3.29% dan 8.47%. Secara keseluruhan AKU-K memiliki Kesalahan II yang paling tinggi yaitu diatas 8% diikuti oleh AKU-KMCD dan AKU-Klasik. Sedangkan AKU-KAO memiliki Kesalahan II yang relatif kecil yaitu dibawah 1% (Gambar 2). Kesalahan I dan Kesalahan II dapat dilihat lebih rinci pada Lampiran 2.
Gambar 2 Persentase Kesalahan II pada n1=500 Identifikasi Pencilan pada n2=100 Pada Tabel 3 menunjukkan set data menjulur dengan n2=100, p=10 dan k=2. Pada data dengan proporsi pencilan sebanyak 0%, 5%, dan 10% memberikan hasil bahwa tidak terdapat Kesalahan I ketika menggunakan metode AKU-Klasik, AKU-KMCD, AKU-K, dan AKU-KAO. Artinya, keempat metode tersebut mengidentifikasi pencilan secara tepat pada proporsi pencilan 0%, 5%, dan 10%. Akan tetapi, AKU-Klasik mencatat Kesalahan I sebesar 6.67% pada proporsi pencilan sebanyak 15%. Artinya, AKU-Klasik mengidentifikasi pencilan sebagai data bukan
pencilan sebanyak 1 pencilan dari 15 pencilan yang dikontaminasikan. Sama seperti AKU-Klasik, AKU-KAO juga memiliki Kesalahan I sebesar 6.67%.
Pada Tabel 3 terlihat bahwa keempat metode yaitu AKU-Klasik, AKU-KMCD, AKU-K, dan AKU-KAO memiliki persentasi Kesalahan II yang beragam sama seperti pada data n1=500. Pada proporsi pencilan 0%, AKU-Klasik memiliki Kesalahan II sebesar 8%. Artinya, AKU-Klasik mengidentifikasi data bukan pencilan sebagai pencilan sebanyak 8 pencilan dari 100 data bukan pencilan. Pada AKU-KMCD terdapat Kesalahan II sebesar 14.00%. Sedangkan pada AKU-K terdapat Kesalahan II yang relatif tinggi yaitu sebesar 18%. Artinya, AKU-K mengidentifikasi data bukan pencilan sebagai pencilan sebanyak 18 pencilan dari 100 data bukan pencilan. Berbeda dengan AKU-KAO yang memiliki Kesalahan II yang cukup kecil dibandingkan dengan ketiga metode yang lainnya yaitu sebesar 3%. Artinya, AKU-KAO mengidentifikasi data bukan pencilan sebagai pencilan sebanyak 3 pencilan dari 100 data bukan pencilan.
AKU-Klasik yang tidak mencatat Kesalahan II ketika proporsi pencilan meningkat menjadi 15%. Pada proporsi pencilan 10%, AKU-Klasik memiliki Kesalahan II sebesar 7.78%. Pada AKU-KMCD terdapat kesalahan sebesar 10%. Sedangkan pada AKU-K terdapat Kesalahan II yaitu sebesar 15.56%. pada proporsi pencilan 15% AKU-KMCD dan AKU-K memiliki Kesalahan II masing-masing sebesar 3.53% dan 8.24%.
Gambar 4 Persentase Kesalahan II pada n2=100 Secara keseluruhan AKU-K memiliki Kesalahan II yang paling tinggi yaitu diatas 8% tidak berbeda jauh dengan hasil pada n1=500. Kemudian diikuti oleh KMCD dan AKU-Klasik. Sedangkan AKU-KAO memiliki Kesalahan II yang relatif kecil yaitu dibawah 4% (Gambar 4). Kesalahan I dan Kesalahan II pada data n2=100 dapat dilihat lebih rinci pada Lampiran 3.
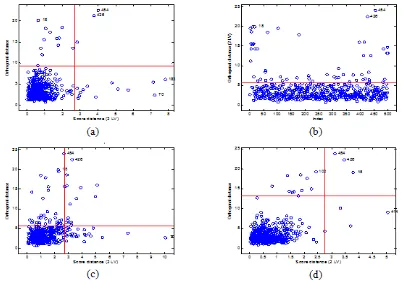
Peta pencilan (Outlier Map)
Peta pencilan merupakan peta yang memplotkan jarak ortogonal dengan score distance. Peta ini membedakan pencilan menjadi tiga jenis yaitu amatan berpengaruh baik, pencilan ortogonal, dan amatan berpengaruh buruk. Gambar 5 menunjukkan peta pencilan pada saat proporsi pencilan 5% pada n1=500 dengan k=2 dimensi. Gambar 5(a) merupakan peta pencilan untuk AKU-Klasik. Peta tersebut menggambarkan 13 amatan berpengaruh baik, pencilan ortogonal sebanyak 12 pencilan, dan 3 amatan berpengaruh buruk. Peta pencilan AKU- KMCD pada Gambar 5(b) hanya memplotkan jarak ortogonal dengan urutan pengamatannya dan hanya menggambarkan pencilan ortogonal. Peta tersebut menggambarkan sebanyak 57 pencilan ortogonal. Gambar 5(c) merupakan peta pencilan AKU-K. Peta ini menggambarkan 33 amatan berpengaruh baik, pencilan ortogonal sebanyak 36 pencilan, dan 16 amatan berpengaruh buruk. Peta pencilan AKU-KAO pada Gambar 5(d) menggambarkan 4 amatan berpengaruh baik, pencilan ortogonal sebanyak 12 pencilan, dan 16 amatan berpengaruh buruk.
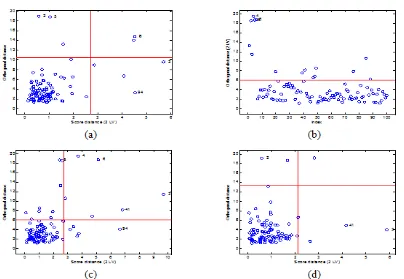
Gambar 6 merupakan peta pencilan pada saat proporsi pencilan 5% pada n2=100 dengan k=2 dimensi. Peta pencilan AKU-Klasik pada Gambar 6(a) menggambarkan 4 amatan berpengaruh baik,
pencilan ortogonal sebanyak 3 pencilan, dan 2 amatan berpengaruh buruk. Gambar 6(b) merupakan peta pencilan AKU-KMCD yang hanya memplotkan pencilan ortogonal jarak ortogonal dengan urutan pengamatannya dan hanya menggambarkan pencilan ortogonal. Peta tersebut menggambarkan sebanyak 15 pencilan ortogonal. Gambar 6(c) merupakan peta pencilan AKU-K yang menggambarkan 5 amatan berpengaruh baik, pencilan ortogonal sebanyak 9 pencilan, dan 6 amatan berpengaruh buruk. Peta pencilan AKU-KAO pada Gambar 6(d) menggambarkan 3 amatan berpengaruh baik, pencilan ortogonal sebanyak 2 pencilan, dan 2 amatan berpengaruh buruk. Secara keseluruhan peta pencilan AKU-Klasik, AKU- KMCD, dan AKU-K pada n1=500 dan n2=100 hampir sama karena pada peta pencilan ketiga metodetersebut terlalu banyak menggambarkan pengamatan biasa sebagai pencilan. Sedangkan pada peta pencilan AKU-KAO, pencilan yang digambarkan cukup sesuai dengan proporsi pencilan yang dikontaminasikan.
Penerapan AKU-Klasik dan AKU-KAO AKU-Klasik dan AKU-K merupakan analisis yang digunakan pada data yang simetrik. Oleh karena itu, data peubah asal harus memiliki sebaran yang simetrik. Jika datanya tidak simetrik maka akan banyak titik data yang sebenarnya
bukan pencilan dianggap sebagai pencilan. Pada penelitian ini dilakukan penerapan AKU-Klasik pada data menjulur dengan n=500, p=10 dan proporsi pencilan sebesar 5%. Kemudian analisis tersebut juga diterapkan pada data ketika pencilan yang teridentifikasi dihilangkan. Pencilan yang dihilangkan yaitu sebanyak 38 pencilan (lihat Lampiran 2). Selain itu dilakukan pula penerapan analisis komponen utama kekar untuk data menjulur (AKU-KAO) pada n=500, p=10 dan proporsi pencilan sebesar 5%.
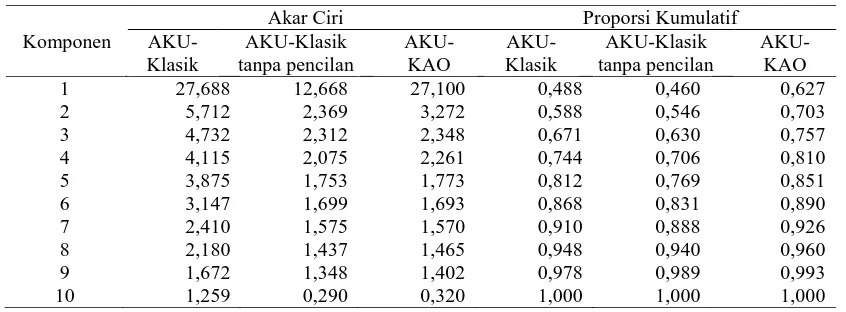
Tabel 4 menunjukkan ringkasan hasil analisis komponen utama pada AKU-Klasik, AKU-Klasik tanpa pencilan, dan AKU-KAO. Hal yang dibandingkan yaitu akar ciri dan proporsi kumulatif komponen utama pertama. AKU-Klasik menghasilkan akar ciri pertama sebesar 27.688 dan mampu menerangkan keragaman data sebesar 0.488 atau 48.8%. Ketika pencilan yang teridentifikasi dihilangkan, AKU-Klasik menghasilkan akar ciri pertama yang nilainya lebih kecil yaitu sebesar 12.668 dan mampu menerangkan keragaman data sebesar 0.460 atau 46%.
Proporsi kumulatif data yang diterangkan AKU-Klasik menurun ketika pencilan yang teridentifikasi dihilangkan karena adanya penurunan nilai akar ciri dari komponen utama yang dihasilkan. Hal tersebut terjadi karena data dengan pencilan memiliki keragaman lebih tinggi Gambar 6 Peta pencilan data menjulur n2=100, p=10 dan k=2 dengan proporsi pencilan 5% pada
Tabel 4 Ringkasan hasil komponen utama pada berbagai metode
Komponen
Akar Ciri Proporsi Kumulatif
AKU-daripada data tanpa pencilan. Sedangkan AKU- KAO menghasilkan akar ciri pertama sebesar 27.100 dan proporsi kumulatif data yang diterangkannya yaitu sebesar 0,627 atau 62.7%. Nilai akar ciri pertama komponen utama pada AKU-KAO mampu menerangkan keragaman data yang lebih besar bila dibandingkan dengan nilai akar ciri pertama komponen utama pada AKU- Klasik dan AKU-Klasik tanpa pencilan.
Menurut Johnson (2007) salah satu kriteria penentuan banyaknya jumlah komponen utama yang digunakan adalah dengan mengambil sejumlah komponen utama yang mampu menjelaskan 80% total keragaman dari data. Peubah yang digunakan yaitu sebanyak 10 buah. Pada AKU-Klasik diperlukan sebanyak 5 komponen utama. Pada AKU-Klasik tanpa pencilan diperlukan sebanyak 6 komponen utama. Sedangkan pada AKU-KAO hanya diperlukan sebanyak 4 komponen utama.
KESIMPULAN DAN SARAN
Kesimpulan
Analisis komponen utama kekar untuk data menjulur (AKU-KAO) menunjukkan hasil yang lebih baik dalam mengidentifikasi pencilan pada data menjulur daripada AKU-Klasik, AKU-K, dan AKU-KMCD. AKU-KAO mengidentifikasi pencilan secara tepat dan konsisten dibandingkan dengan ketiga metode lainnya yang menganggap titik data pencilan sebagai pencilan (Kesalahan I) dan titik data bukan pencilan sebagai pencilan (Kesalahan II). AKU-Klasik, AKU-K, dan AKU-KMCD didesain untuk data simetrik sehingga kurang tepat jika digunakan pada data menjulur. AKU-KAO mampu mengatasi pengaruh kehadiran pencilan pada data menjulur dengan n1=500 maupun pada data dengan n2=100. Hal tersebut diperkuat dengan adanya peta pencilan yang memberikan gambaran secara visual dalam pendeteksian pencilan.
Saran
Penetapan α yang digunakan untuk setiap metode perlu ditetapkan secara tepat agar terdapat keseimbangan antara kekekaran dan efisiensi dalam komputasi karena semakin kecil α semakin kekar AKU-K tetapi semakin tidak akurat.
DAFTAR PUSTAKA
Brys G. Hubert M. Struyf A. 2004. A Robust Measure of Skewness. Journal of Computational and Graphical Statistics. 13: 996-1017.
Draper NR. Smith H. 1992. Analisis Regresi Terapan Edisi Kedua. Sumantri B. penerjemah. Jakarta: Gramedia Pustaka Utama. Terjemahan dari: Applied Regression Analysis.
Hubert M. Rousseeuw PJ. Vanden-Branden K. 2005. ROBPCA: A New Approach to Robust Principal Component Analysis. Technometrics. 47: 64-79.
Hubert M. Rousseeuw PJ. Verdonck T. 2009. Robust PCA for Skewed Data and Its Outlier Map. Computational Statistics & Data Analysis. 53: 2264-2274.
Hubert M. Van der Veeken S. 2008. Outlier Detection for Skewed Data. Journal of Chemometrics. 22: 235-246.
Johnson RA. Wichern DW. 2007. Applied Multivariate Statistical Analysis. Ed ke-6. New Jersey : Prentice Hall. Inc.
Jolliffe IT. 2002. Principal Component Analysis. Ed ke-2. New York: Springer-Verlag. Inc. Montgomery DC. Peck EA. 1992. Introduction to
Linear Regression Analysis. Ed ke-2. New York: John Wiley & Sons. Inc.
-5 0 5 10 15 20 0
50 100 150 200 250 300 350
-2 0 2 4 6 8 10 12 14 16
0 10 20 30 40 50 60 70
Lampiran 1 Histogram data hasil pembangkitan
Histogram data n1=500 dengan p=10 Histogram data n2=100 dengan p=10 Lampiran 2 Kesalahan identifikasi pencilan pada data menjulur n1=500, p=10, dan k=2
Proporsi
pencilan Metode Data
Hasil Deteksi Total Kesalahan I
Kesalahan II Pencilan
Bukan Pencilan
0%
AKU-Klasik Pencilan 0 0
Bukan Pencilan 41 459 500 0,00% 8,20%
AKU-KMCD Pencilan 0 0 0
Bukan Pencilan 46 454 500 0,00% 9,20%
AKU-K Pencilan 0 0 0
Bukan Pencilan 75 425 500 0,00% 15,00%
AKU-KAO Pencilan 0 0 0
Bukan Pencilan 3 497 500 0,00% 0,60%
5%
AKU-Klasik Pencilan 25 0 25
Bukan Pencilan 13 462 475 0,00% 2,74%
AKU-KMCD Pencilan 25 0 25
Bukan Pencilan 32 443 475 0,00% 6,74%
AKU-K Pencilan 25 0 25
Bukan Pencilan 60 415 475 0,00% 12,63%
AKU-KAO Pencilan 24 1 25 4,00% 0,00%
Bukan Pencilan 0 475 475
10%
AKU-Klasik Pencilan 50 0 50 0,00% 0,00%
Bukan Pencilan 0 450 450
AKU-KMCD Pencilan 50 0 50
Bukan Pencilan 27 423 450 0,00% 6,00%
AKU-K Pencilan 50 0 50
Bukan Pencilan 50 400 450 0,00% 11,11%
AKU-KAO Pencilan 50 0 50
Bukan Pencilan 2 448 450 0,00% 0,44%
15%
AKU-Klasik Pencilan 75 0 75 0,00% 0,00%
Bukan Pencilan 0 425 425
AKU-KMCD Pencilan 75 0 75
Bukan Pencilan 14 411 425 0,00% 3,29%
AKU-K Pencilan 75 0 75
Bukan Pencilan 36 389 425 0,00% 8,47%
AKU-KAO Pencilan 71 4 75 5,33% 0,00%
Bukan Pencilan 0 425 425
Frekuensi Frekuensi
Lampiran 3 Kesalahan identifikasi pencilan pada data menjulur n2=100, p=10, dan k=2 Proporsi
pencilan Metode Data
Hasil Deteksi
Total Kesalahan I
Kesalahan II Pencilan
Bukan Pencilan
0%
AKU-Klasik Pencilan 0 0 0
Bukan Pencilan 8 92 100 0,00% 8,00%
AKU-KMCD Pencilan 0 0 0
Bukan Pencilan 14 86 100 0,00% 14,00%
AKU-K Pencilan 0 0 0
Bukan Pencilan 18 82 100 0,00% 18,00%
AKU-KAO Pencilan 0 0 0
Bukan Pencilan 3 97 100 0,00% 3,00%
5%
AKU-Klasik Pencilan 5 0 5
Bukan Pencilan 4 91 95 0,00% 4,21%
AKU-KMCD Pencilan 5 0 5
Bukan Pencilan 10 85 95 0,00% 10,53%
AKU-K Pencilan 5 0 5
Bukan Pencilan 15 80 95 0,00% 15,79%
AKU-KAO Pencilan 5 0 5
Bukan Pencilan 2 93 95 0,00% 2,11%
10%
AKU-Klasik Pencilan 10 0 10
Bukan Pencilan 7 83 90 0,00% 7,78%
AKU-KMCD Pencilan 10 0 10
Bukan Pencilan 9 81 90 0,00% 10,00%
AKU-K Pencilan 10 0 10
Bukan Pencilan 14 76 90 0,00% 15,56%
AKU-KAO Pencilan 10 0 10
Bukan Pencilan 0 90 90 0,00% 0,00%
15%
AKU-Klasik Pencilan 14 1 15 6,67% 0,00%
Bukan Pencilan 0 85 85
AKU-KMCD Pencilan 15 0 15
Bukan Pencilan 3 82 85 0,00% 3,53%
AKU-K Pencilan 15 0 15
Bukan Pencilan 7 78 85 0,00% 8,24%
AKU-KAO Pencilan 14 1 15 6,67% 0,00%