From Concrete to Abstract: Multilayer Neural
Networks for Disaster Victims Detection
Indra Adji Sulistijono
Graduate School of Engineering Technology Politeknik Elektronika Negeri Surabaya (PENS)
Kampus PENS, Surabaya, Indonesia Email: [email protected]
Anhar Risnumawan
Mechatronics Engineering Division Politeknik Elektronika Negeri Surabaya (PENS)Kampus PENS, Surabaya, Indonesia Email: [email protected]
Abstract—Search-and-rescue (SAR) team main objective is to quickly locate victims in post-disaster scenario. In such disaster scenario, images are usually complex containing highly cluttered background such as debris, soil, gravel, ruined building, and clothes, which are difficult to distinguish from the victims. Previ-ous methods which only work on nearly uniform background taken from either indoor or yard are not suitable and can deteriorate the detection system. In this paper, we demonstrate the feasibility of multilayer neural network for disaster victims detection on highly cluttered background. Theoretical justifica-tion from which deep learning learns from concrete to object abstraction is established. In order to build a more discriminative system, this theoretical justification then leads us to perform pre-training using data-rich datasheet followed by finetuning only on the last layers using data-specific datasheet while keeping the other layers fixed. A new Indonesian disaster victims datasheet is also provided. Experimental results show the efficiency of the method for disaster victims detection in highly cluttered background.
I. INTRODUCTION
Disasters always happen in people lives and can never be predicted. Every disaster is almost always the case fatalities. In most cases of disasters, most victims occur because of delay in handling the victims, which can be due to late location and the number of victims information. Primary objective of any search and rescue (SAR) operation is to quickly locate human victims after disaster. While employing ground robot for a SAR application has been highly developed, yet most of these robots have a disadvantage of mobility exploration of disaster area. Today, with the widely available and low-cost of unmanned aerial vehicles (UAVs), quickly exploring a disaster area from air to identify human victims is highly feasible [1]–[3]. Moreover, employing vision based UAVs leads to a reduction in the number and weight of on-board sensors and thus can result in smaller and cheaper UAVs.
State-of-the-art works for vision-based human victims de-tection have been proposed by [4]–[6], using images either from indoor or yard. However, differing from the nearly uni-form background of victims detection of those works, victim detection on a disaster site is interestingly more challenging. Images taken from a disaster site tend to have highly clut-tered background such as debris, soil, gravel, ruined building, clothes, etc, which are difficult to distinguish from victims, as shown in Fig. 1. Moreover, state-of-the-art methods often use many hand-crafted features followed by cascaded classifiers.
Fig. 1. Nearly uniform background of human victims detection from previous works (Top-row). Highly cluttered background of disaster victims detection and several results from our detection (middle and bottom rows). It can be observed that the background is highly cluttered and complex as compared to previous human victims detection works.
Those methods are however prone to errors due to many manual designs.
automatically learned from CNNs can be transferred also to specific tasks. The features are typically generic and can be intertwined with simple classifiers.
To the best of our knowledge, we are the first who mainly study deep learning or multilayer neural networks for disaster victims detection on highly cluttered background. Our contributions are then three folds; First, we demonstrate the feasibility of multilayer neural networks for disaster victim detection on highly cluttered background. Second, theoretical justification of concrete-to-abstract mechanism using entropy is established. It has been known that deep learning learns from concrete to object abstraction by visualizing its kernel filter empirically [7], [11]–[13], which had been shown by experimental results. This mechanism is however difficult to understand theoretically. Interestingly, in order to build a more discriminative system, this theoretical justification thus leads us to perform pre-training on data-rich datasheet such as ImageNet and then finetuning only on the last two fully connected layers using data-specific datasheet, while keeping the other layers fixed. Third, we provide a new Indonesian Disaster Vistims datasheet called IDV-50 and its baseline performance for evaluation.
The rest of this paper is organized as follows. Section II describes related works. In Section III explains the method-ology and it consists of III-A the theoretical justification of concrete-to-abstract mechanism, III-B describes the possibility of finetuning, III-C describes a new IDV-50 datasheet, and III-D explains the training procedure. IV and V describe experiments and conclusion, respectively.
II. RELATEDWORK
There have been quite a lot number of literatures on people detection using other sensors. Since many mobile robotic are equipped with laser range scanners, a lot of effort have been dedicated to using them for people detection and tracking [14]–[18]. The combination between visual and laser based detectors has been mainly explored in [19], where a laser range scanner is employed for extracting regions of interest in camera images and improving the confidence of an AdaBoost-based visual detector. Thermal images have also been used for people detection using either the method [20], [21] or by directly applying methods originally designed for detection of people in bright-day images [22].
Combined information from different types of sensors have been recently proposed for autonomous victim detection [23], [24] applications. The work by [23] comes particularly similar with this work from which victim detection is taken from UAVs. The authors proposed to utilize a thermal camera to pre-filter promising image locations and subsequently verify them using a visual object detector. While in [23] people lying on the ground are assumed to be in ideal and nearly uniform background, in our paper we address the significantly more complex problem of detecting people in highly cluttered background. Note that the results of our work can still be used in combination with thermal camera images, which similarly to [23] can be used to restrict the search to image locations likely to contain people or to prune false positives, which contain no thermal evidence.
The combination of multiple sensors for people detection is encouragingly beneficial in many scenarios, however it comes at the cost especially for unmanned aerial vehicles of an increased payload for the additional sensors. This paper there-fore aims to evaluate and disaster victim detection in highly cluttered background and to minimize sensor requirements as well.
III. METHODOLOGY
Previous works require features and model parameters to be manually designed and optimized through a tedious job of trial-and-error cycle including re-adjusting the features and re-learning the classifiers. In this work, CNN is employed instead to learn the features representation, jointly optimizing the features as well as the classifiers.
Overall system of this work is shown in Fig. 2. It is assumed that the robots able to continuously send images to a server for processing and thus we mainly focus on the algorithm. Conventionally, in order to classify a box region
u whether it is victim or background, a set of features Q(u) = (Q1(u), Q2(u), . . . , QN(u)) are manually extracted. Then a binary classifier kl for each labell is learned, which is a separate block from the features extraction. The objective is then to maximize to recognize the labels l contained in box region u such that l∗ =
argmaxl∈LP(l|u), where labels L ={victim,background} and a posterior probability distri-bution P(l|u) =kl(Q(u))over labels given the inputs.
CNN comprises of multiple layers of features which are stacked together. A layer consisted ofN linear filters followed by a non-linear activation functionhis called a convolutional layer. A feature map fm(x, y)is an input to a convolutional layer, where (x, y) ∈ Sm are spatial coordinates on layer m. The feature map fm(x, y) ∈ RC contains C channels
fmc(x, y) to indicatec-th channel feature map. The output of
convolutional layer is a new feature map fmn+1 such that,
fmn+1=hm(gmn), wheregnm=Wmn ∗fm+bnm (1) gnm,Wmn, and bnm denote the n-th net input, filter kernel, and
bias on layer m, respectively. An activation layerhm such as the Rectified Linear Unit (ReLU)hm(f) = max{0, f}is used in this work. In order to build translation invariance in local neighborhoods, convolutional layers are usually intertwined with normalization, subsampling, and pooling layers. Pooling layer is obtained by taking maximum or averaging over local neighborhood contained in c-th channel of feature maps. The process starts with f1 equal to the resized box region u, performs convolution layer by layer, and ends by connecting the last feature map to a logistic regressor for classification to get the correct label output probability. All the models parameters are jointly learned from the training data. This is achieved by minimizing the classification loss over a training data using commonly Stochastic Gradient Descent (SGD) and back-propagation.
A. From Concrete to Abstract
Fig. 2. Overall block diagram of disaster victims detection. Multiple UAV robots are spread around disaster area and sending images data to a GPU-based server. Our method which is installed in the server then processes each image from which the output is analyzed and provides a command for the robots. It is note that the method is implemented in the server for high computation.
on the beginning layers it learns from pixel, to motif, to part, and then object consecutively with the increasing number of layers, this is shown in Fig. 3. This kind of mechanism is however relatively difficult to understand theoretically.
Layer 1
Layer 2
Layer 3 Layer 4
Layer 5
Fig. 3. Filters visualization (bottom-row on each layer) with the corre-sponding image patches (top-row on each layer) of CNN trained on ImageNet datasheet using deconvolution technique of [11]. CNN structure consisting of 5 layers is used, as suggested by [7]. Note that the pattern of filters are shown from motif, to part, and object consecutively with the increasing number of layers. Best viewed in color.
In order to provide theoretical justification of those mech-anism, entropy of the neural network is measured. Entropy is similar to information as defined by Shannon [25] and provides a basis for measuring information as well. A low value of this entropy indicates that the network layer is highly class selective, while a large value indicates that it generalizes to many classes. The entropy computation however requires explicit knowledge of the output probability density, while the probability in neural network is not available since the net-works solely learn from empirical data samples. We can solve this by using probabilistic model on neural network nodesso that the output probability density is explicitly available.
Binarization of networks filters leads to an insignificant
performance drop for both classification and detection [13]. For simplicity as well, binarization is applied to the network filters. Without loss of generality, assume that the network performs feed-forward of input data from first toM layers. Each layer contains single node. The net input g is a scalar α > 0 if binary random variable of feature map F is present, and−α
otherwise (weights and bias can be adjusted so as to make this true) and additive Gaussian noise of standard deviation σ is embedded on the net input, so that the distribution of g is an even mixture of the two Gaussian densities,
G+(gm), 1
σ√2πexp
−(gm−α)2/2σ2
G−
(gm), 1
σ√2πexp
−(gm+α)2/2σ2
(2)
Bayes’ rule is then applied to find the posterior probability of F giveng on layermwith unit uniform prior,
P(F|g)m=
P(gm|Fm)P(Fm)
Qm
p=1P(gp|Fp)P(Fp) +P(gp|¬Fp)P(¬Fp)
= G
+(gm)
Qm
p=1G+(gp) +G−(gp)
= C1·exp
gm/σ2
Qm
p=1expgp/σ
2+ exp−gp/σ2
=
1
1 + exp−2gm/σ2
C1
Qm−1
p=1 expgp/σ
2+ exp−gp/σ2 (3)
where the constant C1 = (m−1)σ
√
2π. The entropy of a binary random variable F as a function of P(F|g) = f is given by,
H(F) =−P(F|g) logP(F|g)−(1−P(F|g)) log(1−P(F|g))
(4)
A well-known quadratic approximation is,
˜
H(F) = 8
expP(F|g)(1−P(F|g))≈H(F) (5)
By binarizing its weights W ∈ {0,1}, the output of
of (5) can be ignored. Thus, by substituting (3) to (5) such
where the constant C= 8
exp(m−1)σ
√
2π.
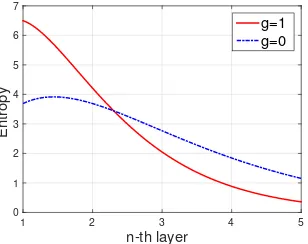
The entropy of formula (6) is plotted and shown in Fig. 4. Interestingly, this theoretical justification clearly shows that network learns from concrete to abstract, from less to higher selective to a class since the entropy values is decreasing with the increasing layer number. This is inline with the empirical result of [13].
Note that with the increasing layer number, the network becomes more and more selective to a class, as the entropy value is decreasing.
B. Possibility of Finetuning
Overfitting on empirical data samples is often encountered when a large networks is trained on a small datasheet. To solve this, Fig. 4 theoretically shows that the beginning layers can be trained using a large data-rich datasheet, such as ImageNet, then the last layers can be trained using a more data-specific datasheet, in this case disaster victims datasheet, this process is called finetune. The reason is because the beginning layers tend to generalize quite well for many classes (indicated by higher entropy values), thus can be used for many tasks, while the last layers tend to be highly specific class (indicated by lower entropy values).
This motivate us to perform finetuning on the last layers. More specifically, the networks are trained using a large data-rich ImageNet, then the last two layers are trained again using a data-specific disaster victims datasheet while keeping the other layers fixed. The last two layers are used for finetuning as suggested by [13].
C. Disaster Victim Datasheet
We collect 50 images from internet and real disaster area taken by camera, this is called Indonesian Disaster Victims 50 (IDV-50) datasheet. The datasheet can be downloaded from the following site, http://anhar.lecturer.pens.ac.id/files/
Publications/IDV 2016IES.tar.gz. This datasheet contains 19 images for testing and the rest for training. Differing from victim detection of [4]–[6], which tend to have uniform back-ground such as fully covered by grass, street, and road, our datasheet is more challenging, images background are com-plex containing highly cluttered background, such as debris, soil, gravel, ruined building, clothes, etc, which are not so distinguishable from victims.
D. Training
We build the CNN structure based upon Krizhevsky et al. [7], [9]. More specifically, 227x227 RGB regions are subtracted by its mean values. Features are then computed by forward propagating the mean-subtracted regions through five convolutional layers and two fully-connected layers. This eventually produces a 4096 feature vector from each box region using the Caffe [26] implementation of the CNN. We employ selective-search algorithm [27] to generate region boxes proposals. These proposals are then resized to 227x227 to match the first convolutional layer input size. We perform two steps of pre-training and finetuning as follows:
Data-rich driven pre-training. We discriminatively pre-trained the whole CNN layers on a large data-rich ImageNet using the open source Caffe CNN library [26].
Data-specific driven finetuning. In order to adapt the CNN parameters with the disaster victim detection task, we set the CNN parameters from first to fifth layers fixed, letting the last two fully connected layers parameters changed from the data-specific datasheet. The datasheet contains a quite large number of images from mixed IDV-50 and VOC [28] training data, thus can prevent from overfitting. We continue SGD training with a learning rate of 0.001 (1/10th of the initial pre-training rate) allowing finetuning to make progress while not severely damaging the initialization.
IV. EXPERIMENTS
For experiments, a standard PC core-i5 8Gb RAM running GPU 1Gb memory is used. The publicly available CNN ImageNet model [26] is used as pre-trained model. Then the last two fully-connected layers are trained again using the data-specific datasheet. The training roughly takes about one week.
truth for not less than a threshold th= 0.5 and 0 otherwise, with no multiple scoring from the same ground truth. From the formula (7), the precision shows the number of correctly predicted bounding boxes compared to the number of predicted bounding boxes, and the recall shows the number of correctly predicted bounding boxes compared to the number of ground truth bounding boxes. Thus predicting with many bounding boxes would likely produce lower precision and high recall, while predicting with less bounding boxes would produce high precision and lower recall. A good method should have high balanced score between precision and recall.
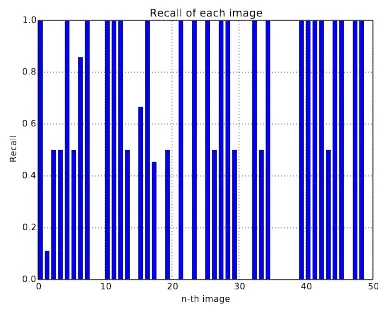
Due to unavailable datasheets from [4]–[6] and its imple-mentation, the performance of our method is tested on IDV-50 and provide a baseline measurement for others to evaluate. The performance is shown in Fig. 5 and Fig. 6. It can be seen that our method shows relatively well for detecting victims on highly cluttered background, it shows quite high precision while not degrading much the recall. For some images however our method could not detect any victims, which are shown in Fig. 7. This could be attributed to the victim’s visual features which are not so obvious for the detection. The training data could be added more with the fail-case images in order to solve this problem. We will investigate this case for future works.
0 10 20 30 40 50
n-th image 0.0
0.2 0.4 0.6 0.8 1.0
Precision
Precision of each image
Fig. 5. Precision result for each image. Note that for several images our method able to detect the victims precisely, which are indicated by the maximum precision value.
Qualitative results are shown in Fig. 8. It is interesting to note that for even small victims in highly cluttered background, our method still shows fairly well to detect the victims. This could be because our model likely deep enough to discrimi-natively detect the victims.
V. CONCLUSION
In this paper, we have demonstrated the feasibility of deep learning for disaster victims detection on highly cluttered background tested using the new IDV-50 datasheet. Compared to the previous works, all the parameters from our method are jointly optimize as an end-to-end system, it is fully feed-forward and can be computed efficiently. Theoretical justi-fication from which deep learning learns from concrete to object abstraction consecutively with the increasing number of layers is provided. In order to build a more discriminative system, this theoretical justification then leads us to perform
0 10 20 30 40 50
n-th image 0.0
0.2 0.4 0.6 0.8 1.0
Recall
Recall of each image
Fig. 6. Recall result for each image. Note that for many images our method able to fully detect the victims correctly, which are indicated by the maximum recall value.
Fig. 7. Failure cases when the victims are covered with clothes.
pre-training using data-rich datasheet followed by finetuning only on the last two fully connected layers using data-specific datasheet while keeping other layers fixed. The experiments show encouraging results that it would be beneficial for SAR teams to quickly locate the victims.
REFERENCES
[1] J. Cooper and M. A. Goodrich, “Towards combining uav and sensor operator roles in uav-enabled visual search,” inHuman-Robot
Interac-tion (HRI), 2008 3rd ACM/IEEE InternaInterac-tional Conference on. IEEE,
2008, pp. 351–358.
[2] W. E. Green, K. W. Sevcik, and P. Y. Oh, “A competition to identify key challenges for unmanned aerial robots in near-earth environments,”
inICAR’05. Proceedings., 12th International Conference on Advanced
Robotics, 2005. IEEE, 2005, pp. 309–315.
[3] K. Nordberg, P. Doherty, G. Farneb¨ack, P.-E. Forss´en, G. Granlund, A. Moe, and J. Wiklund, “Vision for a uav helicopter,” inInternational Conference on Intelligent Robots and Systems (IROS), workshop on
aerial robotics. Lausanne, Switzerland, 2002, pp. 29–34.
[4] M. Andriluka, P. Schnitzspan, J. Meyer, S. Kohlbrecher, K. Petersen, O. Von Stryk, S. Roth, and B. Schiele, “Vision based victim detection from unmanned aerial vehicles,” in Intelligent Robots and Systems
(IROS), 2010 IEEE/RSJ International Conference on. IEEE, 2010,
pp. 1740–1747.
[5] P. Blondel, A. Potelle, C. P´egard, and R. Lozano, “Fast and viewpoint robust human detection for sar operations,” in Safety, Security, and
Rescue Robotics (SSRR), 2014 IEEE International Symposium on.
0.885
0.722
0.986
0.983
0.899
0.926
0.703
0.841 0.710
0.591
0.989
0.851 0.822
0.955
0.947
0.992
0.814 0.568
0.891
0.8220.584
0.963
Fig. 8. Several results of our disaster victims detection on highly cluttered background. The detected victims are shown with its probability values. Best viewed in color.
[6] P. Blondel, A. Potelle, C. Pgard, and R. Lozano, “Human detection in uncluttered environments: From ground to uav view,” in Control Automation Robotics Vision (ICARCV), 2014 13th International
Con-ference on, Dec 2014, pp. 76–81.
[7] A. Krizhevsky, I. Sutskever, and G. E. Hinton, “Imagenet classification with deep convolutional neural networks,” in Advances in neural
information processing systems, 2012, pp. 1097–1105.
[8] K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,”arXiv preprint arXiv:1409.1556, 2014. [9] R. Girshick, J. Donahue, T. Darrell, and J. Malik, “Rich feature hierarchies for accurate object detection and semantic segmentation,”
inProceedings of the IEEE conference on computer vision and pattern
recognition, 2014, pp. 580–587.
[10] R. B. Girshick, “Fast R-CNN,” CoRR, vol. abs/1504.08083, 2015. [Online]. Available: http://arxiv.org/abs/1504.08083
[11] M. D. Zeiler and R. Fergus, “Visualizing and understanding convolu-tional networks,” inComputer vision–ECCV 2014. Springer, 2014, pp. 818–833.
[12] A. Risnumawan, I. A. Sulistijono, J. Abawajy, and Y. Saadi, “Text detection in low resolution scene images using convolutional neural network,” inSCDM, 2016, to be published.
[13] P. Agrawal, R. Girshick, and J. Malik, “Analyzing the performance of multilayer neural networks for object recognition,” inComputer Vision–
ECCV 2014. Springer, 2014, pp. 329–344.
[14] K. O. Arras, S. Grzonka, M. Luber, and W. Burgard, “Efficient people tracking in laser range data using a multi-hypothesis leg-tracker with adaptive occlusion probabilities,” in Robotics and Automation, 2008.
ICRA 2008. IEEE International Conference on. IEEE, 2008, pp. 1710–
1715.
[15] K. O. Arras, O. M. Mozos, and W. Burgard, “Using boosted features for the detection of people in 2d range data,” inProceedings 2007 IEEE
International Conference on Robotics and Automation. IEEE, 2007,
pp. 3402–3407.
[16] A. Carballo, A. Ohya, and S. Yuta, “Multiple people detection from a mobile robot using double layered laser range finders,” in ICRA
Workshop, 2009.
[17] A. Fod, A. Howard, and M. Mataric, “A laser-based people tracker,” in
Robotics and Automation, 2002. Proceedings. ICRA’02. IEEE
Interna-tional Conference on, vol. 3. IEEE, 2002, pp. 3024–3029.
[18] D. Schulz, W. Burgard, D. Fox, and A. B. Cremers, “People tracking with mobile robots using sample-based joint probabilistic data associ-ation filters,”The International Journal of Robotics Research, vol. 22, no. 2, pp. 99–116, 2003.
[19] G. Gate, A. Breheret, and F. Nashashibi, “Centralized fusion for fast people detection in dense environment,” in Robotics and Automation,
2009. ICRA’09. IEEE International Conference on. IEEE, 2009, pp.
76–81.
[20] J. W. Davis and V. Sharma, “Robust detection of people in thermal imagery,” inPattern Recognition, 2004. ICPR 2004. Proceedings of the
17th International Conference on, vol. 4. IEEE, 2004, pp. 713–716.
[21] Q.-C. Pham, L. Gond, J. Begard, N. Allezard, and P. Sayd, “Real-time posture analysis in a crowd using thermal imaging,” in2007 IEEE
Conference on Computer Vision and Pattern Recognition. IEEE, 2007,
pp. 1–8.
[22] F. Suard, A. Rakotomamonjy, A. Bensrhair, and A. Broggi, “Pedestrian detection using infrared images and histograms of oriented gradients,”
in2006 IEEE Intelligent Vehicles Symposium. IEEE, 2006, pp. 206–
212.
[23] P. Doherty and P. Rudol, “A uav search and rescue scenario with human body detection and geolocalization,” inAustralasian Joint Conference
on Artificial Intelligence. Springer, 2007, pp. 1–13.
[24] A. Kleiner and R. Kummerle, “Genetic mrf model optimization for real-time victim detection in search and rescue,” in 2007 IEEE/RSJ
International Conference on Intelligent Robots and Systems. IEEE,
2007, pp. 3025–3030.
[25] C. E. Shannon, “A mathematical theory of communication,” ACM
SIGMOBILE Mobile Computing and Communications Review, vol. 5,
no. 1, pp. 3–55, 2001.
[26] Y. Jia, E. Shelhamer, J. Donahue, S. Karayev, J. Long, R. Girshick, S. Guadarrama, and T. Darrell, “Caffe: Convolutional architecture for fast feature embedding,”arXiv preprint arXiv:1408.5093, 2014. [27] J. R. Uijlings, K. E. van de Sande, T. Gevers, and A. W. Smeulders,
“Selective search for object recognition,”International journal of
com-puter vision, vol. 104, no. 2, pp. 154–171, 2013.
[28] M. Everingham, L. Van Gool, C. K. I. Williams, J. Winn, and A. Zisser-man, “The pascal visual object classes (voc) challenge,”International

![Fig. 3.Filters visualization (bottom-row on each layer) with the corre-sponding image patches (top-row on each layer) of CNN trained on ImageNetdatasheet using deconvolution technique of [11]](https://thumb-ap.123doks.com/thumbv2/123dok/2363273.1637750/3.612.80.270.267.514/filters-visualization-sponding-patches-trained-imagenetdatasheet-deconvolution-technique.webp)