BAB 3
ANALISIS DAN PERANCANGAN SISTEM
3.1 Algoritma Prosedur Klasifikasi
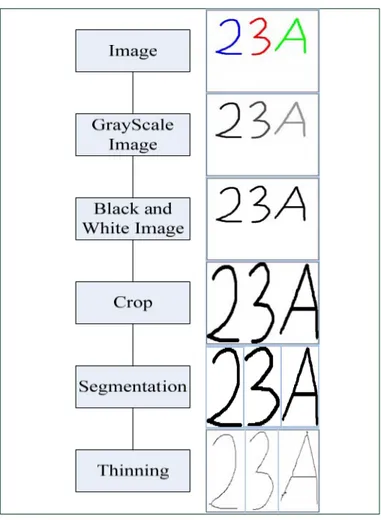
Dalam sistem Pengenalan Tulisan Tangan ini input berupa sebuah citra karakter, yang akan diproses menjadi fitur yang merupakan representasi dari citra karakter tersebut. Fitur tersebut akan menjadi input bagi SVM, yang kemudian akan mengklasifikasinya ke dalam kelas – kelasnya. Umumnya diagram alir untuk sebuah proses klasifikasi terdiri dari preprocessing, ekstraksi fitur, fitur matching, dll.
Gambar 3.1 Diagram Alir Klasifikasi Umum
• Input
Input untuk klasifikasi, bisa berupa citra dijital, suara, dll. • Preprocessing
Proses untuk membersihkan noise dan mengkonsentrasikan input kepada fitur – fitur, untuk input citra, umumnya menggunakan image processing, dll.
• Ekstraksi Fitur
Salah satu proses terpenting di dalam klasifikasi, yaitu proses pengambilan fitur yang adalah ciri khas pola dalam input. Pemilihan ekstraksi fitur sangat penting agar dapat menghasilkan klasifikasi yang baik.
Setelah diekstrak fitur dari inputnya, akan didapatkan fitur dari input. • Database
Berisi rule – rule atau pola dari data hasil pelatihan. • Fitur Database
Fitur yang digunakan untuk melatih database. • Matching
Mencocokkan fitur input dengan fitur dari database. • Hasil
Hasil dapat berupa, kelas, representasi dari kelas, dll.
Sistem ini juga melakukan klasifikasi dengan proses – proses yang sama, tetapi dalam sistem ini posisi Database digantikan sebuah Model SVM yang menyimpan nilai – nilai hasil training dari proses training sebelumnya. Berikut adalah algoritma prosedur klasifikasi SVM.
3.1.1 Inisialisasi
Tahap pertama adalah menginisialisasi objek – objek penting yang akan dipakai dalam seluruh sistem. Objek penting tersebut antara lain adalah Model SVM yang telah di simpan sebelumnya di dalam sebuah file dan seluruh data pelatihan yang pernah dilatih sebelumnya.
PSEUDOCODE
If ada file Model then load Model
Else Create Model
If ada file Data then load Data
3.1.2 Preprocessing
Gambar 3.2 Block Diagram Preprocessing
Preprocessing yang dilakukan meliputi :
3.1.2.1 Citra Grayscale
Citra yang di masukkan akan diproses menjadi citra grayscale, dengan cara, diambil nilai R, G, B dari masing – masing pixel dari citra. Perhitungan untuk mendapatkan nilai grayscale untuk masing – masing pixel adalah : 11 1 59 1 30 1 B G R grayscale= + +
Gambar 3.3 Citra Grayscale
PSEUDOCODE
Inisialisasi Height
Inisialisasi Width
Inisialisasi GrayScaleImg [Height] [Width]
Do i = 0 to Height - 1
Do j = 0 to Width - 1
GrayScaleImg [i] [j] = Image [i] [j].R * 0.30 +
Image [i] [j].G * 0.59 + Image [i] [j].B * 0.11
EndDo
EndDo
3.1.2.2 Mencari nilai threshold yang diperlukan dalam proses selanjutnya dari citra grayscale
Setelah diubah menjadi grayscale proses selanjutnya adalah mengubahnya menjadi citra biner, sebelumnya dicari dulu nilai threshold dari histogram nilai grayscale. Dengan cara mencari dari histogram di nilai
grayscale mana terjadi perubahan intensitas yang cukup signifikan (kontras),
maka diambil nilai tengah dari nilai grayscale tersebut sebagai nilai threshold.
Inisialisasi Histogram
Inisialisasi ContrastHistogram
Inisialisasi Height
Inisialisasi Width
Inisialisasi variabel – variabel
Do i = 0 to Height - 1
Do j = 0 to Width - 1
Pengisian Histogram
Cek maksimum kontras
EndDo
EndDo
Do i = 0 to Height - 1
Do j = 0 to Width - 1
Pengisian ContrastHistogram dengan nilai kontras
yang relevan
EndDo
EndDo
Inisialisasi Sum, ContrastSum, ContrastMass, IMass
Do i = 0 to 255
Sum = Sum + i * ContrastHistogram [i]
ContrastMass = ContrastMass + ContrastHistogram [i]
IMass = IMass + Histogram [i]
EndDo
Inisialisasi MassKiri, MassKanan, MidKiri, MidKanan,
Fmax, OtsuValue
Do i = 0 to 255
MassKiri = MassKiri + ContrastHistogram [i]
If MassKiri = 0 then Continue
MassKanan = ContrastMass – MassKiri
If MassKanan = 0 then Break
ContrastMass = ContrastMass + i * ContrastHistogram
MidKiri = ContrastMass / MassKiri
MidKanan = (Sum – ContrastSum) / MassKanan
OtsuValue = MassKiri * MassKanan * (MidKiri -
MidKanan)
If OtsuValue > Fmax then
Fmax = OtsuValue
Threshold = i + 1
EndIf
EndDo
3.1.2.3 Konversi citra menjadi citra biner (Thresholding)
Setelah didapatkan nilai threshold selanjutnya adalah mengubah citra biner dengan kondisi jika nilai grayscale dari pixel dibawah nilai
threshold, maka pixel menjadi pixel hitam, dan jika nilai grayscale dari pixel
diatas atau sama dengan nilai threshold, maka pixel menjadi pixel putih.
Gambar 3.4 Citra Biner
PSEUDOCODE
Inisialisasi BWImage
Inisialisasi Height
Inisialisasi Width
Do i = 0 to Height - 1
Do j = 0 to Width - 1
If Image [i] [j] >= Threshold then
BWImage [i] [j] = 255
ElseIf Image [i] [j] < Threshold then
BWImage [i] [j] = 0
EndIf
EndDo EndDo
3.1.2.4 Cropping citra untuk mengambil informasi yang penting saja dari dalam citra.
Setelah diubah menjadi citra biner, maka dari suatu citra, diambil informasi yang penting saja, dengan cara menghilangkan space kosong (berwarna putih) yang tidak terpakai di dalam citra.
Gambar 3.6 Citra biner setelah di crop
PSEUDOCODE
Inisialisasi CropImage
Inisialisasi X, Y, Width, Height
CropImage = Image.Clone(Rectangle(X, Y, Width, Height))
3.1.2.5 Segmentasi citra untuk membagi setiap karakter dalam citra
Setelah dipastikan informasi pada citra adalah yang benar – benar penting saja, maka akan dilakukan proses segmentasi, untuk memotong dan membagi setiap karakter yang ada di dalam citra. Metode Segmentasi yang dilakukan dengan Histrogram-Based Method (Linda G. Shapiro and George C. Stockman (2001): “Computer Vision”, pp 279-325, New Jersey, Prentice-Hall). Proses segmentasi ini dibagi menjadi 3 tahap :
a. Segmentasi Baris
Segmentasi Baris adalah proses mencari baris kalimat pada sebuah citra. Proses ini akan mencari posisi koordinat y dari suatu baris kalimat pada sebuah citra. Proses ini dilakukan dengan cara, didapatkan histogram horizontal (intensitas pixel hitam dalam tiap baris), lalu dicari dari atas ke bawah, di koordinat manakah terjadi perubahan intensitas pixel dari intensitas 0 (tidak ada pixel hitam
sama sekali dalam 1 baris) menjadi intensitas > 0 (minimal 1 pixel hitam dalam 1 baris), dan intensitas > 0 menjadi intensitas 0. Koordinat dimana terjadi perubahan intensitas dari intensitas 0 menjadi intensitas > 0, akan menjadi koordinat y awal dari suatu baris. Sedangkan koordinat dimana terjadi perubahan intensitas dari intensitas > 0 menjadi intensitas 0, akan menjadi koordinat y akhir dari suatu baris. Koordinat – koordinat tersebut akan disimpan untuk tahap selanjutnya. PSEUDOCODE Inisialisasi HistogramY Inisialisasi Height Inisialisasi Width Do i = 0 to Height Do j = 0 to Width Pengisian HistogramY EndDo EndDo Inisialisasi Flag Do i = 0 to Height - 1
Pencarian titik dimana terjadi perubahan pixel
putih menjadi hitam dan disimpan sebagai
koordinat y awal dari baris
Pencarian titik dimana terjadi perubahan pixel
hitam menjadi putih dan disimpan sebagai
koordinat y akhir dari baris (pencarian
koordinat y awal dilakukan lebih dulu)
EndDo
Segmentasi Karakter adalah proses mencari karakter dalam tiap baris kalimat yang telah dicari dalam tahap sebelumnya. Mirip seperti proses sebelumnya, proses kali ini akan mencari posisi koordinat x dari suatu karakter pada tiap baris dan posisi koordinat y dalam proses ini diasumsikan sama dengan posisi koordinat y barisnya. Proses ini dilakukan dengan cara, didapatkan histogram vertikal (intensitas pixel hitam dalam 1 kolom) dari tiap baris yang telah didapatkan posisinya di tahap sebelumnya, lalu dicari dari kiri ke kanan, di koordinat manakah terjadi perubahan intensitas pixel dari intensitas 0 menjadi intensitas > 0, dan intensitas > 0 menjadi intensitas 0. Koordinat dimana terjadi perubahan intensitas dari intensitas 0 menjadi intensitas > 0 akan menjadi koordinat x awal dari suatu karakter. Dan koordinat dimana terjadi perubahan intensitas dari intensitas > 0 menjadi intensitas 0 akan menjadi koordinat x akhir dari suatu karakter. Koordinat – koordinat ini akan disimpan untuk tahap selanjutnya.
PSEUDOCODE Inisialisasi HistogramX Inisialisasi JumlahBaris Inisialisasi Width Inisialisasi AwalBaris Inisialisasi AkhirBaris Do i = 0 to JumlahBaris Do j = 0 to Width - 1
Do k = AwalBaris [i] to AkhirBaris [i] – 1
Pengisian HistogramX
EndDo
EndDo
Pencarian titik dimana terjadi perubahan
pixel putih menjadi hitam dan disimpan
sebagai koordinat x awal karakter
Pencarian titik dimana terjadi perubahan
pixel hitam menjadi putih dan disimpan
sebagai koordinat x akhir karakter (pencarian
koordinat x awal dilakukan dulu)
EndIf
EndDo EndDo
c. Segmentasi Tinggi Karakter
Segmentasi Tinggi Karakter adalah proses menghilangkan pixel yang tidak penting di dalam tiap segmen karakter yang telah didapatkan dari proses sebelumnya. Proses ini akan mencari posisi koordinat y dari tiap segmen karakter, koordinat y yang dicari adalah posisi dimana terdapat intensitas pixel hitam > 0. Proses ini dilakukan dengan cara, menggunakan histogram horizontal (intensitas pixel hitam dalam 1 baris) dari tiap karakter yang telah didapatkan posisinya di tahap sebelumnya, lalu dicari dari atas ke bawah, di koordinat manakah pertama kali dan terakhir kalinya intensitasnya > 0. Koordinat pertama kali terdeteksi intensitas > 0 akan menjadi koordinat y awal dari suatu karakter. Dan koordinat terakhir kali terdeteksi intensitas > 0 akan menjadi koordinat y akhir dari suatu karakter. Setelah proses ini, telah didapatkan posisi x, y, panjang dan lebar dari tiap karakter, dari info tersebut akan dilakukan cropping untuk tiap karakter, dan setiap hasil crop akan disimpan.
Inisialisasi XawalKarakter Inisialisasi XakhirKarakter Inisialisasi YawalKarakter Inisialisasi YakhirKarakter Inisialisasi HistogramY Do i = 0 to XawalKarakter.Length – 1
Do j = XawalKarakter [i] to XakhirKarakter [i]
– 1
Do k = YawalKarakter [i] to YakhirKarakter
[i] – 1
Pengisian HistogramY
EndDo
EndDo
Do j = YawalBaris [i] to YakhirBaris [i] – 1
Pencarian koordinat y dimana pixel hitam
pertama kali muncul dan disimpan sebagai
koordinat y awal dari karakter
Pencarian koordinat y dimana pixel hitam
terakhir muncul dan disimpan sebagai
koordinat y akhir dari karakter (pencarian
koordinat y awal dilakukan lebih dulu)
EndDo EndDo
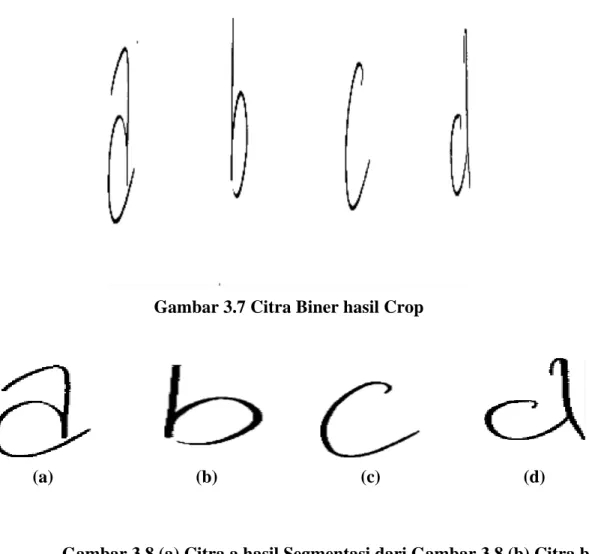
Gambar 3.7 Citra Biner hasil Crop
(a) (b) (c) (d)
Gambar 3.8 (a) Citra a hasil Segmentasi dari Gambar 3.8 (b) Citra b hasil Segmentasi (c) Citra c hasil Segmentasi (d) Citra d hasil Segmentasi
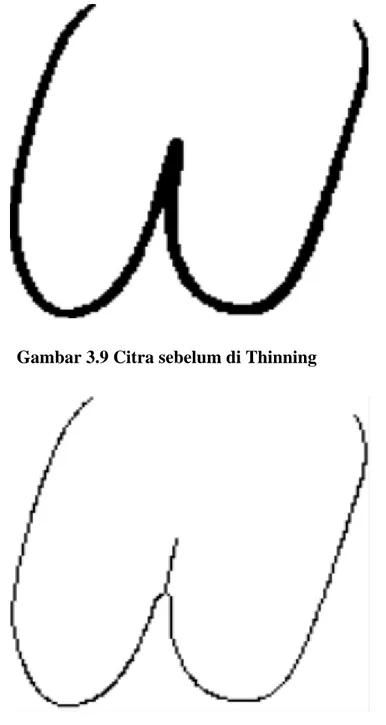
3.1.2.6 Thinning untuk menghilangkan ketebalan dalam setiap karakter
Setelah setiap karakter dibagi – bagi menjadi suatu citra sendiri, maka proses selanjutnya adalah proses Thinning. Proses Thinning adalah proses mengecilkan garis pada suatu karakter. Proses ini penting karena proporsi ketebalan garis pada tiap karakter bisa jadi berbeda, untuk memastikan konsistensi proporsi ketebalan garis, maka dilakukan thinning.
Ada beberapa metode untuk proses Thinning, diantaranya ada metode Stentiford atau Zhang-Suen, kedua metode ini sama – sama
Template-Based Mark-and-Delete Thinning Algorithm, dari kedua metode ini, Zhang-Suen lebih cepat dan mudah untuk diimplementasikan, dan juga metode Zhang-Suen lebih baik dalam mengekstraksi garis lurus dalam raster, jadi hasil lebih berupa garis lurus (Martin and Tosunoglu, 2000) .
Algoritma yang dipakai didalam proses Thinning di sistem ini adalah Algoritma Zhang-Suen. Algoritma ini adalah method yang paralel, itu berarti nilai yang baru diambil hanya bergantung pada nilai iterasi sebelumnya. Algoritma ini terbuat dari 2 sub-iterasi. Pertama, sebuah piksel I (i,j) terhapus jika syarat-syarat berikut dipenuhi [1]:
a) Nilai konektifitasnya satu.
b)Mempunyai sedikitnya 2 piksel tetangga yang hitam dan tidak lebih dari enam.
c) Sedikitnya salah satu dari I(i,j+1), I(i-1,j), and I(i,j-1) adalah putih. d)Sedikitnya salah satu dari I(i-1,j), I(i+1,j), and I(i,j-1) adalah putih.
Pada sub-iterasi kedua [2] kondisi pada langkah c dan d berubah. a) Nilai konektifitasnya satu.
b)Mempunyai sedikitnya 2 piksel tetangga yang hitam dan tidak lebih dari enam.
c) Sedikitnya salah satu dari I(i-1,j), I(i,j+1), and I(i+1,j) adalah putih. d)Sedikitnya salah satu dari I(i,j+1), I(i+1,j), and I(i,j-1) adalah putih.
Pada akhirnya, piksel-piksel yang memenuhi syarat-syarat di atas, akan dihapus. Jika diakhir salah satu sub-iterasi tidak ada piksel yang dihapus, maka algoritmanya berhenti.
Gambar 3.9 Citra sebelum di Thinning
Gambar 3.10 Citra sesudah di Thinning
PSEUDOCODE
Inisialisasi ThinBitmap
Inisialisasi Height
Inisialisasi Field [Width] [Height]
Inisialisasi Mark [Width] [Height]
Change = 0
Do
Change = 0
Do i = 0 to Height – 1
Do j = 0 to Width – 1
If Field [i] [j] = 1 then
Tandai Posisi i, j kedalam Mark jika
memenuhi syarat [1] EndIf EndDo EndDo Do i = 0 to Height – 1 Do j = 0 to Width – 1
If Mark [i] [j] = 1 then
Change = 1 Field [i] [j] = 0 Else Field [i] [j] = 1 EndIf EndDo EndDo Do i = 0 to Height – 1 Do j = 0 to Width – 1
If Field [i] [j] = 1 then
Tandai Posisi i, j kedalam Mark jika
memenuhi syarat [2]
EndIf
EndDo
EndDo
Do j = 0 to Width – 1
If Mark [i] [j] = 1 then
Change = 1 Field [i] [j] = 0 Else Field [i] [j] = 1 EndIf EndDo EndDo While Change = 1
3.1.3 Ekstraksi Fitur (Feature Extraction)
Setelah melalui tahap preprocessing maka data citra akan masuk dalam proses feature extraction, yang menggunakan metode zoning. Dalam proses zoning feature dibagi per segmen menjadi 100 segmen, yang masing – masing segmen besarnya M/10 x N/10 pixel (M adalah panjang citra, N adalah lebar citra), seperti berikut :
Dari setiap segmen itu akan didapatkan jumlah pixel hitam yang akan dibagi jumlah pixel di dalam segmen ( (M/10) * (N/10) ), nilai ini akan menjadi salah satu nilai untuk input vector. Jika nilai dari semua segmen dikumpulkan, maka akan didapatkan sebuah input vector [1, 100]. Hasil dari proses feature extraction ini adalah sebuah feature vector yang siap untuk dijadikan input ke dalam proses SVM.
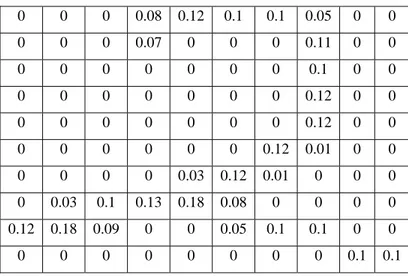
Berikut adalah contoh nilai feature vector dari sebuah citra yang telah melewati proses feature extraction, citra tersebut adalah karakter ‘2’.
Gambar 3.12 Citra karakter ‘2’
Table 3.1 Tabel Nilai Feature Vector untuk objek karakter ‘2’
0 0 0 0.08 0.12 0.1 0.1 0.05 0 0 0 0 0 0.07 0 0 0 0.11 0 0 0 0 0 0 0 0 0 0.1 0 0 0 0 0 0 0 0 0 0.12 0 0 0 0 0 0 0 0 0 0.12 0 0 0 0 0 0 0 0 0.12 0.01 0 0 0 0 0 0 0.03 0.12 0.01 0 0 0 0 0.03 0.1 0.13 0.18 0.08 0 0 0 0 0.12 0.18 0.09 0 0 0.05 0.1 0.1 0 0 0 0 0 0 0 0 0 0 0.1 0.1 PSEUDOCODE
Inisialisasi ListNode [101]
Inisialisasi Height
Inisialisasi Width
Do Index = 0 to 99
Inisialisasi SumBlackPixel
Inisialisasi SegmentHeight = Height / 10
Inisialisasi SegmentWidth = Width / 10;
Inisialisasi i, j
Do i = 0 to SegmentHeight – 1
Do j = 0 to SegmentWidth – 1
Jumlahkan pixel hitam di dalam segmen
EndDo
Jika masih terdapat pixel walau segment width telah
selesai ditelusuri, telusuri pixel sisa dan jumlahkan
pixel hitamnya
EndDo
Jika masih terdapat pixel walau segment height telah
selesai ditelusuri, telusuri pixel sisa dan jumlahkan pixel
hitamnya
ListNode [index] = SumBlackPixel / (SegmentWidth *
SegmentHeight)
EndDo
ListNode [index + 1] = Width / Height
3.1.4 Klasifikasi SVM
3.1.5.1 Proses inisialisasi objek Parameter dan Problem (class untuk data training)
Sebelum membuat objek model, terlebih dahulu harus ada objek dari class Problem dan objek dari class Parameter.
Objek Problem berisi semua nilai X dan Y yang telah terkumpul sebagai database yang berisi data training.
X adalah matriks input dari citra – citra hasil pembelajaran yang sudah melalui proses training. Matriks X berukuran [N x D] dimana N adalah jumlah dimensi dari input vector dan D adalah banyaknya citra pembelajaran yang telah dimasukkan.
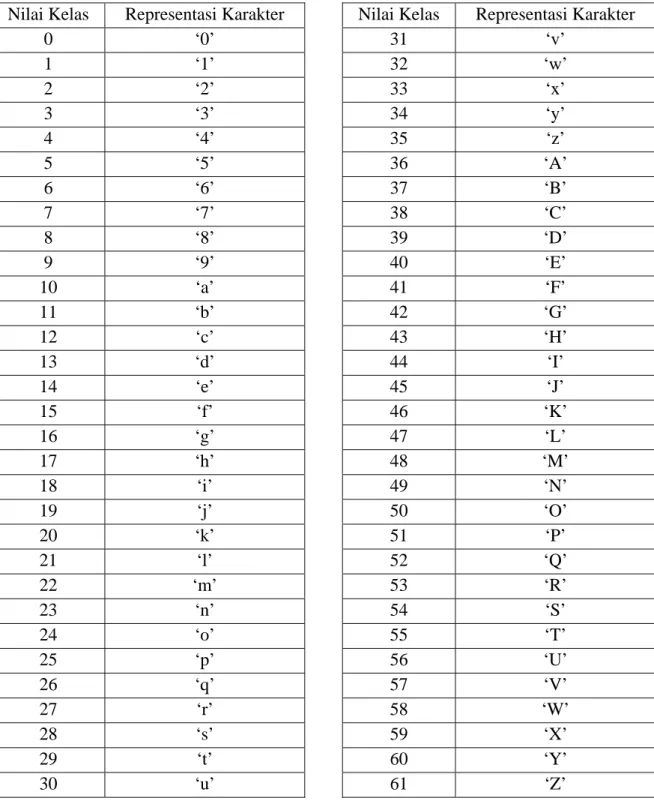
Y adalah matriks output yang berisikan kelas – kelas output yang diharapkan dari sistem. Matriks Y berukuran [N x 1] adapun nilai – nilai dari kelas – kelas output ini :
Table 3.2 Tabel Kelas / Kategori
Nilai Kelas Representasi Karakter
0 ‘0’ 1 ‘1’ 2 ‘2’ 3 ‘3’ 4 ‘4’ 5 ‘5’ 6 ‘6’ 7 ‘7’ 8 ‘8’ 9 ‘9’ 10 ‘a’ 11 ‘b’ 12 ‘c’ 13 ‘d’ 14 ‘e’ 15 ‘f’ 16 ‘g’ 17 ‘h’ 18 ‘i’ 19 ‘j’ 20 ‘k’ 21 ‘l’ 22 ‘m’ 23 ‘n’ 24 ‘o’ 25 ‘p’ 26 ‘q’ 27 ‘r’ 28 ‘s’ 29 ‘t’ 30 ‘u’
Nilai Kelas Representasi Karakter
31 ‘v’ 32 ‘w’ 33 ‘x’ 34 ‘y’ 35 ‘z’ 36 ‘A’ 37 ‘B’ 38 ‘C’ 39 ‘D’ 40 ‘E’ 41 ‘F’ 42 ‘G’ 43 ‘H’ 44 ‘I’ 45 ‘J’ 46 ‘K’ 47 ‘L’ 48 ‘M’ 49 ‘N’ 50 ‘O’ 51 ‘P’ 52 ‘Q’ 53 ‘R’ 54 ‘S’ 55 ‘T’ 56 ‘U’ 57 ‘V’ 58 ‘W’ 59 ‘X’ 60 ‘Y’ 61 ‘Z’
Objek Parameter berisi parameter – parameter yang diperlukan dalam pembuatan objek, misalnya tipe SVM, tipe kernel, nilai C, nilai Gamma, nilai Nu, dsb. Setelah ada kedua objek tersebut maka objek model dapat dibuat. Objek Model inilah yang menjadi inti dari sistem, “otak” dari sistem pengenalan ini.
PSEUDOCODE
Inisialisasi objek Problem (berisi data yang akan
dilatih)
Inisialisasi objek Parameter
Masukkan parameter – parameter pilihan user ke dalam objek Parameter
3.1.5.2 Proses Training dan buat Model
Dengan objek dari class Problem dan objek dari class Parameter, maka objek Model dapat dibuat dengan cara langsung menggunakan fungsi static Training.train() dengan parameter objek Problem dan objek Parameter. Model inilah yang akan dipakai untuk proses pengenalan. Proses training akan menghasilkan Model yang lebih terlatih. Parameter – parameter untuk proses training diantaranya tipe SVM, tipe Kernel, nilai Gamma, nilai Nu dan nilai C dapat diubah. Parameter Tipe SVM mempengaruhi parameter nilai Nu dan nilai C, jika Tipe SVM yg dipilih adalah Nu-SVC maka parameter yang dapat diisi adalah nilai Nu, jika Tipe SVM yg dipilih adalah C-SVC maka parameter yang dapat diisi adalah nilai C. Untuk sistem ini, kernel yang digunakan defaultnya adalah RBF, karena kernel yang baik digunakan untuk permulaan adalah RBF (Chih, Jen-Lin; 2008), tapi kernel dapat dipilih sesuai keinginan. Gamma adalah parameter untuk kernel, jika kernel yang digunakan adalah linear, Gamma menjadi tidak terpakai. Nilai Nu dan C adalah parameter untuk SVM, nilai Nu dan C adalah konstanta yang dipakai dalam proses optimasi SVM.
Perancangan SVM dibantu dengan menggunakan pustaka LibSVM, LibSVM menawarkan fungsi untuk membuat Model SVM dengan berbagai macam formulasi, tipe kernel.
a) Formulasi
Formulasi – formulasi yang ada didalam LibSVM, diantaranya : o C-Support Vector Classifier (C-SVC)
o v-Support Vector Classifier (v-SVC) o Distribution Estimation (One-Class SVM) o ε-Support Vector Regression (ε-SVR) o v-Support Vector Regression (v-SVR) b) Kernel
Pilihan Kernel yang ada didalam LibSVM, diantaranya : o Linear
o Polynomial o RBF o Sigmoid o Precomputed
LibSVM juga menawarkan fungsi untuk melakukan skala pada fitur dengan menggunakan Class Scaling.
Dalam formulasi SVM ada 2 parameter yang penting, yaitu C dan γ. LibSVM menawarkan fungsi untuk melakukan optimasi terhadap 2 parameter ini dengan menggunakan Class PrecomputedKernel.
PSEUDOCODE
Inisialisasi Model
3.1.5.3 Proses Simulasi Klasifikasi
Dalam proses pengenalan (klasifikasi), user akan memasukkan citra yang ingin dikenali ke dalam program, lalu dilakukan juga preprocess terhadap citra tersebut lalu dibagi per segmen dan didapatkan input vector. Input vector tersebut akan dimasukkan ke dalam model SVM sebagai input di dalam proses pengenalan yang akan menghasilkan output berupa integer yang merepresentasikan suatu class output. Proses pengenalan ini dilakukan dengan menggunakan fungsi static Prediction.Predict() dengan parameter objek Model dan array dari Node input yang akan dimasukkan ke Model SVM. Di dalam sistem ini juga disediakan fitur untuk menyimpan output dari proses ini ke dalam text file.
PSEUDOCODE
Inisialisasi SegmentasiCitra
Inisialisasi Output
Inisialisasi Karakter yang berisi karakter dari 0-9 dan
a-z dan A-Z
Do i = 0 to SegmentasiCitra.Length – 1
Panggil fungsi ekstraksi fitur masukkan ke variabel
Test
kelas = Prediction.Predict(Model, Test)
Output = Output & Karakter [kelas]
EndDo
Tampilkan variabel Output pada Textbox
3.2 Perancangan Sistem
Pada perancangan sistem terdapat arsitektur sistem, diagram hierarki, state transition diagram, dan layout sistem.
3.2.1 Arsitektur Sistem
Gambar 3.13 Flowchart Sistem Pengenalan Karakter Tulis Tangan Online
Arsitektur sistem ini dimulai dengan inisialisasi sistem yaitu menetapkan variabel – variabel awal dalam program, di sini juga dilakukan load model SVM yang pernah disimpan sebelumnya.
Setelah itu sistem menunggu inputan berupa citra digital, inputan dapat ditulis langsung di tempat yang sudah disediakan atau dimasukkan dari file – file yang sudah ada.
Setelah citra digital telah siap, citra akan di preprocessing, untuk menghilangkan noise, preprocessing terdiri dari :
• Grayscaling • Thresholding • Cropping • Segmentation • Thinning
Preprocessing akan menghasilkan citra yang telah bersih dari noise, setelah itu diproses dalam proses ekstraksi fitur, proses ini mengambil fitur – fitur yang merupakan representasi dari sebuah citra yaitu feature vector.
Setelah didapatkan fitur, maka selanjutnya adalah proses SVM, dari fitur tersebut bisa langsung di test apakah dikenali atau tidak dengan proses recognize, atau dimasukkan sebagai objek yang akan dilatih dalam proses training. Proses
training akan menghasilkan sebuah model SVM, model ini merupakan representasi
dari seluruh metode SVM. Model ini juga dapat disimpan ke dalam file untuk dipakai lagi. Proses recognize menggunakan model SVM yang sudah ada, input dimasukkan ke dalam model SVM untuk diketahui kelasnya. Selanjutnya proses validasi juga termasuk di dalam simulasi, validasi sama seperti proses recognize memasukkan input baru ke dalam model SVM untuk diketahui kelasnya, tetapi dalam validasi, kelasnya sudah diketahui, maka dilakukan perbandingan hasil yang dikeluarkan SVM dengan kelas yang diharapkan.
3.2.2 Diagram Hierarki
Gambar 3.14 Diagram Hierarki Aplikasi Pengenalan Karakter Tulis Tangan
Aplikasi pengenalan karakter tulis tangan dimulai dengan Menu yang terdiri dari 3, yaitu File, Input dan Output. File terdiri dari tiga Menu, yaitu Load Image,
Save SVM, dan Exit. Load Image berfungsi untuk memasukkan citra dari file, Save
SVM untuk menyimpan SVM yang telah dibuat ke dalam file, Exit untuk keluar dari aplikasi. Input terdiri dari satu Menu, yaitu Pen Mode yang berfungsi untuk memperbesar Canvas Original Image. Output terdiri dari satu Menu, yaitu Save
Output to File yang berfungsi untuk menyimpan hasil dari Textbox Result ke dalam
Citra karakter dapat langsung dibuat di dalam Canvas Original Image, atau dimasukkan dari file dengan menu Load Image. Setelah ada citra, maka
Preprocessing dapat dilakukan, hasil dari Preprocessing akan muncul di Picturebox
Image Input. Setelah Image Input terisi, Segmentation dapat dilakukan,
Segmentation akan membagi citra di dalam Image Input menjadi beberapa citra.
Setelah Segmentation, selanjutnya bisa dipilih Menu untuk melakukan
Validasi, Recognize, atau Training. Ketiga menu tersebut akan menghasilkan output
di dalam Text Result.
3.2.3 State Transition Diagram
3.2.3.1State Transition Diagram untuk proses Training
Di dalam Main Menu terdapat File, Input, Output. Dari File, menu yang tersedia adalah Load Image, Save SVM, dan Exit. Dari Input, menu yang tersedia adalah Pen Mode, dari situ Main Menu dapat dipilih kembali. Menu Output, juga terdiri dari satu menu yaitu Save Output to File.. Citra dapat digambar langsung di dalam aplikasi, cara lain untuk memasukkan citra adalah dengan menu Load Image, setelah citra siap, maka menu
Preprocessing dapat dilakukan, setelah Preprocessing, baru menu
Segmentation dapat dijalankan. Untuk melakukan Training, Expected Output
harus diisi terlebih dulu, setelah dilakukan Training, hasilnya akan tampil dalam Result. Dari menu Preprocessing, Segmentation dan pengisian
Expected Output, bisa langsung memilih kembali ke Main Menu.
3.2.3.2 State Transition Diagram untuk proses Simulasi
Modul Simulasi dan Training tidak jauh berbeda, yang berbeda adalah setelah dilakukan Segmentation, yang dilakukan selanjutnya adalah Recognize
3.2.3.3State Transition Diagram untuk proses Validasi
Gambar 3.17 STD untuk modul Validasi
Pada modul validasi, langkah – langkah sampai menu Segmentation masih sama dengan modul Training atau Simulasi. Setelah Segmentation,
Expected Output diharuskan untuk diisi, lalu setelah Validate dilakukan, maka hasilnya akan keluar di Result, dan di Validate Output.
3.2.4 Layout Sistem
Gambar 3.18 Layout Perancangan Sistem Pengenalan Karakter Tulis Tangan
Pengguna akan diminta untuk memasukkan inputan. Salah satu caranya adalah dengan memilih file citra pada menu Load Image (nomor 1) yang selanjutnya akan menampilkan citra tersebut pada box Original Image. Box ini juga dapat langsung digambar dengan menggunakan pointer, dengan begitu inputan dapat langsung dibuat di dalam aplikasi. Tahap selanjutnya adalah dilakukan
Preprocessing (nomor 4) yang akan menghasilkan gambar yang sudah di
Preprocessing. Setelah dilakukan Preprocessing baru di Segmentation (nomor 5),
Segmentation adalah pembagian gambar pada citra yang telah di Preprocessing,
akan tampil pada bagian box Images,. Jika citra segmentasi yang akan dikenali terlalu banyak, layar hanya akan menampilkan lima citra segmentasi, button Prev (nomor 6) dan Next (nomor 7) sebagai tombol navigasi untuk mengatur citra mana yang akan ditampilkan. Tidak semua citra setelah di segmentation akan bersih dari noise, maka disediakan tombol Remove (nomor 9) untuk menghapus citra segmentasi tersebut jika pengguna tidak membutuhkan citra tersebut. Jika ingin menghapus seluruhnya disediakan tombol Clear (nomor 8). Sebelum di Training diharuskan mengisi box Training (nomor 13) yang berisi parameter yang akan digunakan untuk proses pelatihan. Button Recognize (nomor 10) digunakan untuk mengenali huruf yang sudah diproses sehingga keluar hasil output di Textbox
Result (nomor 14). Validate (nomor 11) berfungsi untuk membandingkan data yang
sudah di Recognize dengan Expected Output sehingga akan diketahui berapa error yang terjadi. Training (nomor 12) berfungsi untuk melatih data.