KLASIFIKASI MUTASI JABATAN STRUKTURAL PEGAWAI NEGERI
SIPIL MENGGUNAKAN METODE DECISION TREE
Yanti, I Ketut Edy Purnama, dan Surya Sumpeno Teknik Elektro,Institut Teknologi Sepuluh Nopember
Alamat: Gedung B, C & AJ Kampus ITS Sukolilo, Surabaya, 60111, Indonesia Email: yanti.cgbmajid@gmail.com
ABSTRAK
Pemberian rekomendasi usulan mutasi jabatan struktural selama ini membutuhkan waktu yang relatif lama karena dilakukan secara manual serta tidak memiliki pola atau belum bisa mengikuti aturan yang berlaku. Untuk mengatasi hal tersebut dibutuhkan sistem klasifikasi agar memiliki pola serta waktu yang relatif singkat dengan teknik klasifikasi data mining
menggunakan metode Decision Tree C4.5, Label data sebanyak 6 kelas, pengujian sistem
menggunakan data testing sebanyak 25% dari data yang ada. Dalam pengklasifikasian
digunakan pemilihan kriteria atribut berdasarkan information gain, gain ratio dan gini indeks
yang akan diperbandingkan untuk mengetahui tingkat akurasinya. Hasil dari penelitian ini menunjukkan bahwa sistem klasifikasi yang dibangun memiliki tingkat akurasi yang berbeda
berdasarkan tabel confusion Matrix yaitu information gain sebesar 87,18%, gini indeks
86,75% dan gain ratio 82,48%, masing-masing membutuhkan waktu 3 (tiga) detik dalam
pembentukan sistem klasifikasi. Melihat tingkat akurasi dari ketiga pemilihan atribut tersebut maka information gain dapat dipergunakan dalam pemberian rekomendasi mutasi jabatan struktural untuk pengambilan keputusan lebih lanjut.
Kata kunci: Mutasi Jabatan Struktural, Data Mining, Decision Tree C4.5, Information Gain, Gain Ratio, Gini Indeks.
PENDAHULUAN
Pemberian rekomendasi mutasi jabatan struktural masih belum berjalan dengan maksimal sesuai dengan aturan yang berlaku atau tidak memiliki pola mutasi jabatan struktural serta waktu yang relatif lama karena dilakukan secara manual. Hal ini menjadi salah satu penyebab penurunan kinerja Pegawai Negeri Sipil (PNS) dalam bekerja atau pun dalam memberikan layanan ke masyarakat sehingga dibutuhkan sistem klasifikasi yang diharapkan mampu memberikan solusi terhadap pelaksanaan mutasi jabatan struktural dengan membuat pola mutasi jabatan struktural dengan waktu yang relatif singkat.
Ada beberapa penelitian sebelumnya yang membahas tentang mutasi jabatan struktural di lingkup pemerintah daerah seperti yang dilakukan oleh (Pramutoko, 2012) dan (Sriyana, 2013) namun belum ada yang penulis temukan penelitian yang membahas tentang pengklasifikasian mutasi jabatan struktural sehingga penulis anggap bahwa hal tersebut layak untuk diteliti dalam rangka membantu dalam pemberian rekomendasi usulan mutasi.
Metode decision tree yang merupakan pengembangan dari algoritme ID3 (Iterative
Dichotomiser 3) dan juga salah satu algoritme pohon keputusan yang terkenal karena memiliki kelebihan antara lain: mudah dimengerti serta menarik karena dapat divisualisasikan dalam bentuk gambar berupa pohon keputusan (Prabowo Pudjo Widodo, 2013) (Bhatt, 2012) .
Metode klasifikasi Decision Tree merupakan metode yang masuk kelas frequency tabel yaitu
fitur/variable, metode lainnya yang masuk kelas tersebut antara lain (Sayad, 2010-2012) : One R, ZeroR dan Naive Bayesian.
Dengan memanfaatkan data yang berhubungan dengan kepegawaian serta melihat banyak usulan mutasi jabatan struktural struktural dari Satuan Kerja Perangkat Daerah (SKPD) setiap saat dengan jenjang dan jumlah yang relatif bervariasi, diharapkan mampu memberikan sebuah solusi untuk menjawab persolan pola mutasi jabatan struktural yang ada di daerah. Penelitian ini bukan bertujuan untuk membuat sistem pendukung keputusan mutasi jabatan struktural untuk menduduki jabatan tertentu karena keterbatasan data yang dimiliki namun hanya sebatas mendapatkan model pola klasifikasi mutasi jabatan struktural berdasarkan
eselon menggunakan metode decision tree yang lebih cepat dibandingkan dengan cara manual
yang di harapkan bisa dipergunakan untuk pemberian rekomendasi usulan mutasi jabatan struktural ke pengambil kebijakan sebagai pengambil keputusan lebih lanjut jika sistem klasifikasi yang dibangun memiliki akurasi di atas 70%.
METODE
Penelitian yang dilakukan menggunakan teknik klasifikasi data mining dengan algoritme
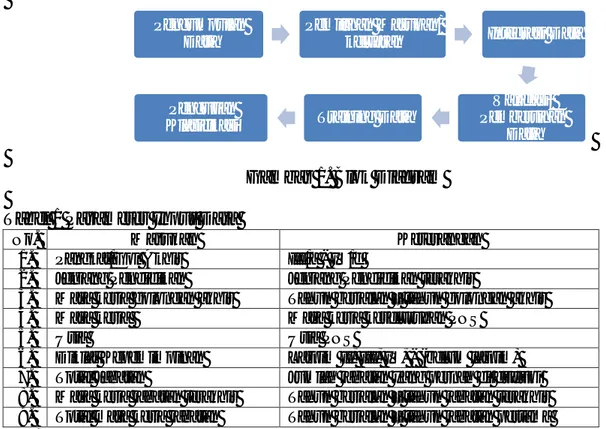
Decision Tree C4.5 denganpemilihan kriteria atribut berdasarkan information gain, gain ratio dan gini indeks sebagai kriteria pemilihan atribut yang terkenal dalam Decision Tree (Santosa, 2007) . Proses penelitian dapat dilihat pada blok diagram Gambar 1.
Berdasarkan Gambar 1, dapat dijelaskan blok diagram tersebut sebagai berikut : Melakukan pengumpulan data dari berbagai file yang berhubungan dengan data kepegawaian yaitu gaji = 4471 data, riwayat pendidikan = 13331 data, Data PNS = 4627 data, riwayat diklat = 221 data, riwayat jabatan = 9772 data, calon latpim 2012 = 121 data, latpim III tahun 2005 = 40 data, latpim IV tahun 2004 = 40 data, calon latpim IV tahun 2004 = 49 data, Lampiran SK ijin/tubel serta bantuan ijin/tubel = 59 sheet.
Tahap selanjutnya adalah menentukan parameter input dan output seperti terlihat pada Tabel 1 sebelum menyatukan dalam satu file baru sebagai database. Atribut total jabatan, masa kerja jabatan akhir, total masa kerja jabatan dan masa kerja keseluruhan tidak terdapat dalam data awal namun penulis melakukan perhitungan sendiri berdasarkan data yang telah
ada. Melakukan pembersihan data untuk mengatasi data yang bermasalah seperti missing
value/tidak lengkap dan noisy (Hermawati, 2013) (Bhatt, 2012) agar didapatkan data dengan kualitas yang baik sesuai kebutuhan. Total data yang didapatkan pada tahap ini adalah sebesar 934 data, masing-masing terdiri atas eselon II.b 28 data, III.a 44 data, III.b 75 data, IV.a 324 data, IV.b 55 data, dan Non eselon 408 data.
Data olah terdiri atas data nominal dan numerik, tidak dilakukan metode untuk
mengkategorikan data karena Decision Tree C4.5 bisa menangani data numerik. Data numerik
secara otomatis akan diubah menjadi kategori dengan 2 rentang nilai tiap kategori.
Melakukan training data menggunakan pemilihan kriteria atribut information gain, gain
ratio dan gini indeks dalam penentuan simpul akar/cabang. Dilakukan beberapa perubahan parameter agar didapatkan hasil akurasi yang lebih tinggi dengan pre pruning data yaitu mininal jumlah data tiap daun, minimal jumlah data tiap cabang, minimal gain, kedalaman
pohon, konfidensi. Melakukan pengujian sistem klasifikasi menggunakan data testing untuk
mengetahui tingkat akurasi berdasarkan tabel confusion Matrix sebanyak 25% (234 data) data
dengan pemilihan secara stratified. Pemilihan kriteria atribut yang paling akurat yang akan
Gambar 1. Blok Diagram Tabel 1 Parameter Input Data
No. Masukan Keterangan
1. Pangkat/Gol Akhir III/a - IV/d
2. Jenjang Pendidikan Jenjang Pendidikan terakhir
3. Masa kerja golongan akhir Tahun berjalan – tahun golongan akhir 4. Masa kerja Masa kerja keseluruhan PNS
5. Usia Usia PNS
6. Diklat Kepemimpinan Latpim II, III, IV, - (belum latpim) 7. Total Jabatan Jumlah jabatan yang pernah di duduki 8. Masa kerja jabatan terakhir Tahun berjalan – tahun jabatan terakhir 9. Total masa kerja jabatan Tahun berjalan – tahun jabatan pertama
Parameter data keluaran yang dihasilkan adalah penentuan eselon/jabatan yang diberikan kepada PNS tersebut yaitu : Non Eselon, IV.b, IV.a, III.b, III.a, II.b.
Information gain
Merupakan pemilihan atribut dengan mengukur seberapa baik atribut dipisahkan ke
dalam kelas yang ada namun sebelumnya dihitung nilai entropy yang berfungsi mengetahui
bobot suatu atribut dengan formula sebagai berikut (Bhatt, 2012) :
Entropy (S)= �- pi
n
i=1
.log2pi (1) Dimana S adalah himpunan kasus/keputusan, n adalah jumlah partisi S dan Pi adalah
proporsi keputusan terhadap S.
Gain (S,A)=Entropy (S)- �|Si| |S|
n
i=1
*Entropy (Si) (2 ) Dimana : n adalah jumlah partisi atribut A, A adalah semua nilai yang mungkin dari atribut tersebut, |si| adalah bagian/subset nilai S, |s| adalah jumlah kasus dalam S
Gain ratio
Menghitung nilai split information untuk dipergunakan dalam menghitung nilai gain
ratio. Formula untuk split information dan gain ratio adalah sebagai berikut (Bhatt, 2012) :
SplitInformation (S,A)=-�|Si| |S| n i=1 log2|Si| |S| (3)
Gainratio (S,A)= Gain(S,A)
SplitInformation (S,A) (4)
Gini indeks
Pengumpulan Data
Pemilihan Masukan/
keluaran Integrasi Data
Validasi/ Pembersihan Data Training Data Pengujian Klasifikasi
Formula untuk menghitung gini indeks isi setiap atribut adalah sebagai berikut (Hermawati, 2013) : IG(A)=1-�Pn2 n i=1 (5)
Dimana : Pn adalah Rasio observasi dalam kotak A yang masuk kelas i, n adalah jumlah
kelas/variabel dari cabang/kotak A. Langkah selanjunya adalah menghitung gini split sebagai
penentuan simpul akar/cabang dengan formula sebagai berikut (Hermawati, 2013) :
GiniSplit (A)=� |Si|
|S|IG(A)
n
i=1
(6)
Information gain dan gain ratio menggunakna nilai tertinggi untuk menentukan simpuk akar/cabang pohon sedangkan gini indeks berdasarkan nilai terkecil.
Pengujian Klasifikasi
Melakukan testing klasfikasi untuk mengetahui tingkat akurasi berdasarkan tabel
confusion matrix dengan formula sebagai berikut (Sayad, 2010-2012) :
Akurasi= ∑Data Benar
∑Total Data Uji x 100% (7)
HASIL DAN PEMBAHASAN
Hasil Training Pemilihan Kriteria Atribut Berdasarkan Information Gain
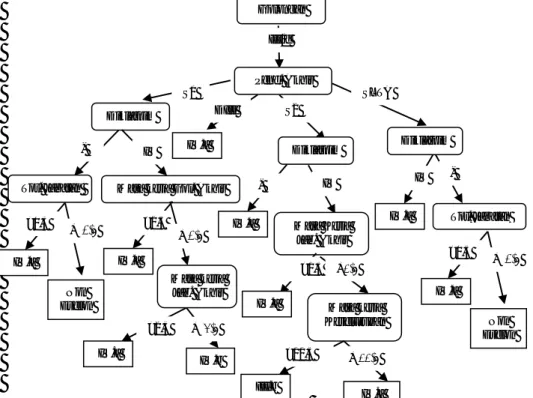
Pada Gambar 2 yang merupakan sebagian dari hasil pohon keputusan yang dibentuk
berdasarkan pemilihan kriteria information gain. Pada Gambar tersebut dapat dilihat bahwa
node yang paling atas adalah Golongan yang menjadi simpul akar karena memiliki nilai
information gain tertinggi dibandingkan atribut yang lain. Golongan terbagi ke dalam 7 split
sesuai jumlah golongan yang ada dalam data, dari III/a sampai dengan IV/c, sebagai contoh
split untuk Gol akhir III/d yang melakukan perulangan untuk menghasilkan kelas data. Untuk melihat urutannnya, bisa dilakukan dengan melihat arah anak panah yang dihasilkan dari suatu simpul dan akhir dari simpul tersebut adalah kelas data dengan lambang berbentuk kotak.
Salah satu contoh penentuan eselon IV.a berdasarkan Golongan III/d adalah sebagai berikut : Jika Golongan = III/d & Diklatpim = IV & Masa kerja jab. Akhir ≤ 3,5 Maka Eselon
IV.a. Total aturan keputusan berdasarkan pemilihan kriteria information gain adalah 24
aturan keputusan yang terbagi ke dalam 6 kelas data.
Hasil Training Pemilihan Kriteria Atribut Berdasarkan Gini Indeks
Pada Gambar 3 yang merupakan sebagian dari hasil pohon keputusan yang dibentuk
berdasarkan pemilihan kriteria gini indeks. Pada Gambar tesebut dapat dilihat bahwa node
yang paling atas adalah Golongan yang menjadi simpul akar karena memiliki nilai gini indeks
terkecil dibandingkan atribut yang lain. Golongan terbagi ke dalam tujuh split sesuai jumlah golongan yang ada dalam data dari III/a sampai dengan IV/c, sebagai contoh split untuk Golongan III/c yang melakukan perulangan untuk menghasilkan kelas data.
Salah satu contoh penentuan eselon III.b berdasarkan Golongan akhir III/c adalah sebagai berikut : Jika Golongan = III/c & Pend. Akhir = S2 & Masa kerja Jab. Akhir = ≤1,5 &
Masa kerja keseluruhan > 11,5 maka Eselon III.b. Total aturan keputusan berdasarkan gini
Gambar 2 Bagian Pohon Keputusan Pemilihan Atribut Information Gain
Gambar 3 Bagian Pohon Keputusan Pemilihan Atribut Gini Indeks Hasil Training Pemilihan Kriteria Atribut Berdasarkan Gain Ratio
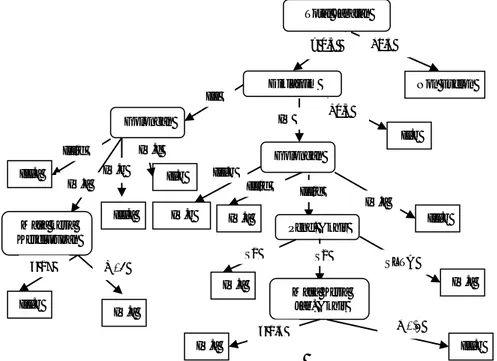
Pada Gambar 4 yang merupakan sebagian dari hasil pohon keputusan yang dibentuk berdasarkan pemilihan kriteria gain rati. Pada gambar tersebut dapat dilihat bahwa node yang
paling atas adalah Total jabatan yang menjadi simpul akar karena memiliki nilai gain ratio
terbesar dibandingkan atribut yang lain. Total jabatan terbagi atas 2 splityaitu >0,5 dan ≤0,5.
Sebagai contoh split untuk >0,5 yang melakukan perulangan untuk menghasilkan kelas data
sedangkan split ≤0,5 langsung menghasilkan kelas data.
Golongan
Diklatpim III/d
Masa Kerja Jab Akhir III.b III IV IV.a - Usia IV.a ≤3,5 ≤43,5 >3,5 IV.a >43,5 Pend. Akhir S1 III.b IV.a S2 Golongan Pend. Akhir Diklatpim IV S2 S1 III/c Masa Kerja Jab. Akhir >1,5 Diklatpim IV -
Masa kerja Gol. Akhir Tot. Jabatan >0,5 IV.a ≤ 0,5 Non Eselon >1,5 IV.a ≤ 0,5 DIII IV.a Masa kerja Jab. Akhir >2,5 IV.a ≤ 2,5 IV.b - IV.a IV.a ≤1,5 Masa kerja Keseluruhan >11,5 III.b ≤ 11,5 IV.a Diklatpim SLTA IV IV.a - Tot. Jabatan >0,5 IV.a ≤ 0,5 Non Eselon
Salah satu contoh penentuan eselon III.b adalah sebagai berikut : Jika Total jabatan > 0,5 & Diklatpim = IV & Golongan = IV/a Maka Eselon III.b. Total aturan keputusan berdasarkan
gain ratio adalah 22 aturan keputusan yang terbagi ke dalam 6 kelas data.
Gambar 4 Bagian Pohon Keputusan Pemilihan Atribut Gain Ratio
Hasil Akurasi Berdasarkan Tabel Confusion Matrix
Berdasarkan Tabel 2, Tabel 3 dan Tabel 4 dapat dilihat tingkat akurasi data berdasarkan data testing sebanyak 234 data dari masing-masing pemilihan atribut. Tingkat akurasi dihitung
berdasarkan formula (7) dengan hasil yang berbeda-beda yaitu berdasarkan information gain
sebesar 87,18%, gini indeks 86,75% dan gain ratio 82,48%. Area yang memiliki latar
berwarna abu-abu merupakan nilai dari data yang di klasifikasikan secara benar.
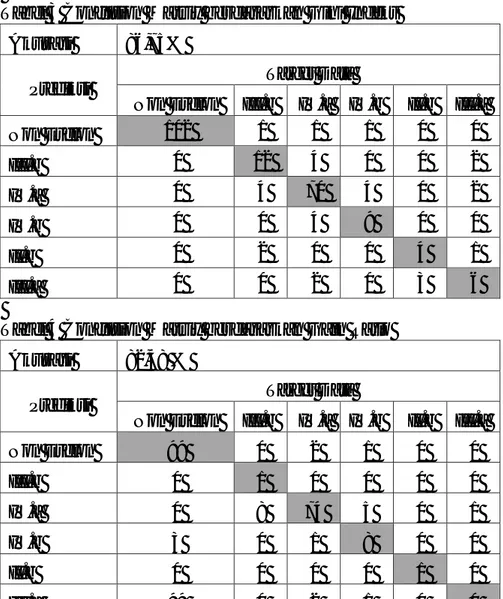
Tabel 2 Confusion Matrix berdasarkan Information Gain Akurasi 87,18%
Prediksi Target Data
Non Eselon III.b IV.a IV.b II.b III.a
Non Eselon 102 0 1 0 0 0 III.b 0 7 1 0 0 1 IV.a 0 9 75 6 0 2 IV.b 0 0 1 8 0 0 II.b 0 1 0 0 4 0 III.a 0 2 3 0 3 8 Total Jabatan Diklatpim III > 0,5 Non Eselon ≤0,5 II.b ≤0,5 IV Golongan II.b IV.c III.b IV.a III/c Pend. Akhir IV.a SLTA S2 Masa Kerja Jab. Akhir III.b ≤ 1,5 > 1,5 IV.a III/d IV.a III.b IV.b S1 IV.a Golongan III.a IV.b III/d III.a IV.a Masa kerja Keseluruhan IV.a ≤ 17 > 17 III.b
Tabel 3 Confusion Matrix berdasarkan Gini Indeks Akurasi 86,75%
Prediksi Target Data
Non Eselon III.b IV.a IV.b II.b III.a
Non Eselon 102 1 1 1 0 0 III.b 0 12 4 0 0 2 IV.a 0 4 70 4 0 2 IV.b 0 0 4 9 0 0 II.b 0 2 0 0 4 1 III.a 0 0 2 0 3 6
Tabel 4 Confusion Matrix berdasarkanGain Ratio Akurasi 82,48 %
Prediksi Target Data
Non Eselon III.b IV.a IV.b II.b III.a
Non Eselon 99 0 2 1 0 0 III.b 0 1 0 0 0 0 IV.a 0 8 74 5 0 1 IV.b 3 0 1 8 0 0 II.b 0 0 0 0 1 0 III.a 99 0 2 1 0 0
Sebagai contoh pada Tabel 2 antara prediksi kelas Non Eselon dengan target data dapat dilihat bahwa yang benar/sesuai antara prediksi dan target data adalah sebanyak 102 data, sementara terdapat kesalahan klasifikasi dimana Eselon yang sebenarnya adalah IV.a namun di prediksikan salah dan masuk ke Non Eselon sebanyak 1 data, namun tidak ada kesalahan prediksi untuk target Non Eselon.
Berdasarkan Tabel 5, dapat dilihat bahwa semua pemilihan kriteria atribut menghasilkan akurasi di atas 70% dan sudah melebihi dari target sebelumnya yaitu sebesar 70%, sehingga
dianggap layak untuk dijadikan rekomendasi usulan mutasi jabatan struktural. Information
gain memiliki tingkat akurasi tertinggi dibandingkan yang lainnya, Golongan sebagai faktor yang paling berpengaruh dengan menjadi penentu awal klasifikasi, jumlah aturan keputusan
sebanyak 24. Gini indeks juga menjadikan golongansebagai penentu awal klasifikasi, namun
memiliki akurasi yang lebih rendah serta jumlah aturan keputusan yang terbanyak, dengan
aturan keputusan yang lebih banyak akan membuat pengambilan keputusan lebih rumit. Gain
ratio memiliki jumlah aturan keputusan dan pemakaian atribut paling sedikit namun memiliki tingkat akurasi terendah, menjadikan total jabatan sebagai atribut yang paling berpengaruh,
berdasarkan split yang ada, maka sudah bisa di pastikan bahwa ketika seorang PNS belum
pernah menduduki jabatan maka tidak akan pernah bisa menduduki jabatan tertentu, berbeda dengan pemilihan kriteria atribut lainnya yang memungkinkan terjadi promosi jabatan untuk PNS yang belum pernah menjabat sebelumnya.
Tabel 5 Perbandingan Algoritme Pemilihan Kriteria Atribut Decision Tree C4.5 No. Algoritme Jumlah Atribut Simpul Akar Jumlah Aturan
Keputusan Akurasi (%) 1 Information gain 9 Golongan 24 87,16
2 Gini Indeks 9 Golongan 54 86,75
3 Gain Ratio 7 Total Jabatan 22 82,48
KESIMPULAN DAN SARAN
Penelitian ini menghasilkan penentuan klasifikasi mutasi jabatan struktural menggunakan metode Decision Tree C4.5, pemilihan kriteria atribut information gain berdasarkan eselon yaitu Non Eselon, II.b, III.a, III.b, IV.a, IV.b. Hasil penelitian ini, mampu menjawab persoalan mutasi jabatan struktural dalam hal waktu yang relatif lama dengan pola mutasi yang sebelumnya tidak ada.
Dalam penentuan klasifikasi mutasi tersebut, atribut yang menjadi faktor utama sebagai penentu awal adalah Golongan PNS. Penentuan atribut tersebut lebih baik dibandingkan dengan pemilihan kriteria atribut lainnya. Hal tersebut juga sesuai dengan aturan, dimana faktor golongan adalah bagian yang sangat penting/utama dalam menentukan eselon PNS.
Dalam penelitian ini diketahui bahwa jumlah aturan keputusan yang ada masih relatif banyak dengan melibatkan semua atribut yang ada, sehingga pemberian rekomendasi usulan mutasi untuk pengambilan keputusan lebih lanjut agak rumit. Diharapkan dalam penelitian selanjutnya supaya aturan keputusan yang dibuat lebih sederhana agar membantu dalam mempercepat proses pemberian rekomendasi tanpa harus meneliti semua atribut yang selama ini dianggap berpengaruh.
DAFTAR PUSTAKA
Bhatt, A. S. (2012). Comparative Analysis of Attribute Selection Measures Used for
Attribute. International Conference on Radar, Communication and Computing
(ICRCC), (pp. 230-234). Tiruvannamalai, TN, India.
Hermawati, F. A. (2013). Data Mining. Yogyakarta: Penerbit Andi.
Prabowo Pudjo Widodo, D. (2013). Penerapan Data Mining Dengan Matlab. Bandung:
Penerbit Rekayasa Sains.
Pramutoko, B. (2012). Pemahaman Elit Politik Terhadap Kebijakan Mutasi Pegawai di
Lingkungan Pemerintah Kota Kediri. Hal. 1-29(2012).
Santosa, B. (2007). Data Mining - Teknik Pemanfaatan Data untuk Keperluan Bisnis.
Surabaya Indonesia: Graha Ilmu.
Sayad, D. S. (2010-2012). An Introduction to Data Mining. Retrieved Juni 07, 2014, from
http://www.saedsayad.com/
Sriyana. (2013). Pelaksanaan Mutasi Pejabat Struktural pada Kantor Badan Kepegawaian