PENGEMBANGAN HIDDEN MARKOV MODELS UNTUK FONEM
BERBAHASA INDONESIA PADA SISTEM KONVERSI SUARA
KE TEKS
SRI DANURIATI
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
BOGOR
2010
PENGEMBANGAN HIDDEN MARKOV MODELS UNTUK FONEM
BERBAHASA INDONESIA PADA SISTEM KONVERSI SUARA
KE TEKS
SRI DANURIATI
Skripsi
Sebagai salah satu syarat untuk memperoleh gelar
Sarjana Komputer pada
Departemen Ilmu Komputer
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
ABSTRACT
SRI DANURIATI. Hidden Markov Models (HMM) development for Indonesian-language phoneme on Speech to text transcription system. Supervised by AGUS BUONO.
Speech to text transcription system is a system used to convert a voice signal from a microphone or a telephone into a single or a set of words. Research on speech to text transcription systems has been widely applied. But these systems tend to be developed based on words, hence they are inefficient when developed for a large vocabulary.
This study uses Baum Welch algorithm for HMM training, Forward algorithm for HMM testing, and Mel-Frequency cepstral coefficient (MFCC) to extract voice features. Data used in this study consist of 5 words in Indonesian language. Phonemes are generated from the segmentation process, and then trained with Baum Welch algorithm to generate the model. This study produced 10 models. The best accuracy obtained is 82% generated by testing the HMM with 2 States and 5 epochs.
Judul Skripsi : Pengembangan Hidden Markov Models untuk fonem berbahasa Indonesia pada sistem konversi suara ke teks
Nama : Sri Danuriati
NRP : G64051452
Menyetujui: Pembimbing,
Dr. Ir. Agus Buono, M.Si., M.Komp.
NIP. 19660702 199302 1 001
Mengetahui:
Ketua Departemen Ilmu Komputer,
Dr. Ir. Sri Nurdiati, M.Sc.
PRAKATA
Alhamdulillahi Robbil a’lamin, segala puji penulis panjatkan kepada Allah SWT yang telah
melimpahkan rahmat dan karunia yang tak terbatas sehingga penulis dapat menyelesaikan tugasu akhir ini. Sholawat serta salam selalu tercurahkan untuk Rasulullah SAW, sahabat, keluarga dan pengikutnya yang tetap istoqomah menjalankan risalah-Nya.
Penulis menyadari bahwa keberhasilan penyelesaian tugas akhir ini tidak terlepas dari pihak-pihak yang telah banyak membantu. Oleh karena itu, penulis sampaikan terima kasih kepada Bapak Dr. Ir. Agus Buono, M. Si., M. Komp. sebagai pembimbing yang selalu sabar dalam memberikan arahan dan saran selama penyelesaian tugas akhir ini, serta Bapak Mushthofa, S. Kom., M. Sc. dan Bapak Ahmad Ridha, S. Kom., M. S. yang telah bersedia menjadi moderator dan penguji dalam seminar dan sidang penulis.
Penulis ucapkan terima kasih kepada seluruh keluarga khususnya orang tua penulis yang tiada henti-hentinya memberikan doa, dukungan, pendidikan dan kepercayaan penuh atas apa yang penulis kerjakan hingga saat ini, juga kepada mas Anto dan Desi yang selalu memberikan keceriaan, semangat, dan dukungan selama ini. Penulis ucapkan terima kasih kepada Ninon, Zissalwa, Karina, Vera dan Yuni yang selalu memberikan semangat dan menjadikan penulis bagian dari kalian, merupakan kebahagiaan dan kebanggaan yang tak terkira telah memiliki kalian dalam hidup ini. Kepada teman-teman Ilkom 42 penulis ucapkan terima kasih karena telah memberikan keceriaan dan persahabatannya, juga kepada Heru dan Prameswari yang telah memberikan semangat dan dukungan selama pengerjaan tugas akhir. Kepada Mutia dan Yohan yang bersedia menjadi pembahas dalam seminar tugas akhir penulis ucapkan terima kasih. Kepada teman-teman di Harmony dan Maharlika yang telah memenuhi hari-hari penulis menjadi lebih berwarna penulis mengucapkan terima kasih kost
especially for reni and icha karena sudah memberikan tempat tinggal dan dukungan selama
mengerjakan tugas akhir. Kemudian penulis sampaikan terima kasih kepada seluruh staf dan karyawan Departemen Ilmu Komputer , teman-teman Ilkom 43 serta seluruh pihak lainnya yang tidak dapat disebutkan satu persatu.
Penulis menyadari bahwa dalam penelitian ini masih terdapat kekurangan, sehingga kritik dan saran yang membangun penulis harapkan dari semua pihak. Semoga penelitian ini dapat bermanfaat. Amin
Bogor, Juli 2010
RIWAYAT HIDUP
Penulis dilahirkan pada tanggal 3 April 1987 di Jakarta. Penulis merupakan anak kedua dari tiga bersaudara pasangan Danuri dan Sri Wahyuni.
Pada tahun 2005 penulis lulus dari SMA Negeri 67 Jakarta dan diterima di Program Studi Ilmu Komputer, Departemen Ilmu Komputer, Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor melalui jalur SPMB (Seleksi Penerimaan Mahasiswa Baru). Selama mengikuti kegiatan perkuliahan penulis aktif dalam kegiatan Himpunan Mahasiswa Ilmu Komputer (HIMALKOM) periode 2006/2007.
DAFTAR PUSTAKA Halaman DAFTAR TABEL ... v DAFTAR GAMBAR ... v DAFTAR PENDAHULUAN ... 1 Latar Belakang ... 1 Tujuan Penelitian ... 1 Ruang Lingkup ... 1 TINJAUAN PUSTAKA ... 1 Speech Recognition ... 1
Pemrosesan Sinyal Suara ... 2
Ekstraksi Sinyal Suara ... 3
Hidden Markov Model (HMM) ... 4
Algoritme Forward ... 5
Algoritme Backward ... 6
Algoritme Baum-Welch ... 6
Longest Common Subsequence (LCS) ... 6
METODE PENELITIAN ... 7
Kerangka Pemikiran ... 7
Studi Pustaka ... 7
Perumusan Masalah ... 7
Pendefinisian Metode Penelitian ... 7
Pengambilan Data... 7 Praproses ... 8 Pemodelan/Inisialisasi ... 8 Pelatihan Model... 9 Pengujian ... 10 Postprocessing ... 10 Penerapan LCS ... 10
Perhitungan Tingkat Akurasi ... 10
HASIL DAN PEMBAHASAN... 10
Hasil Postprocessing ... 11
Hasil Pengujian Model HMM ... 11
Hasil Pengujian Model HMM dengan 2 State ... 11
Hasil Pengujian Model HMM dengan 3 State ... 12
Hasil Pengujian Model HMM dengan 4 State ... 12
Hasil Pengujian Model HMM dengan 5 State ... 12
Hasil Pengujian Kata ... 13
Penggunaan Kata Lain Pada LCS ... 13
Pengujian Kata Lain ... 14
KESIMPULAN DAN SARAN... 14
Kesimpulan ... 14
Saran ... 14
DAFTAR PUSTAKA ... 14
DAFTAR TABEL
Halaman
1 Kata dalam penelitian ... 8
2 Hasil postprocessing ... 11
3 Akurasi maksimum dan minimum setiap kata ... 13
DAFTAR GAMBAR Halaman 1 Tahapan transformasi sinyal suara menjadi informasi ... 3
2 Ilustrasi frame blocking pada sinyal suara ... 3
3 Frame sinyal sebelum proses windowing ... 3
4 Frame sinyal setelah proses windowing ... 3
5 Fonem /a/ dalam domain waktu ... 4
6 Fonem /a/ dalam domain frekuensi ... 4
7 Mel-frequency filter ... 4
8 HMM dalam pengamatan kondisi cuaca ... 5
9 Ilustrasi proses perhitungan algoritme Forward ... 6
10 Proses perhitungan algoritme Backward ... 6
11 Ilustrasi perhitungan algoritme Baum-Welch ... 6
12 Diagram proses konversi suara ke teks ... 7
13 Suara sebelum cutting silent ... 8
14 Overlap antar frame ... 8
15 Ilustrasi penggabungan fonem hasil segmentasi ... 8
16 Grafik akurasi LCS dan pencocokan string ... 11
17 Grafik akurasi HMM setiap State ... 11
18 Grafik akurasi HMM 2 State ... 11
19 Grafik akurasi HMM 3 State ... 12
20 Grafik akurasi HMM 4 State ... 12
21 Grafik akurasi HMM 5 State ... 13
22 Grafik akurasi setiap kata untuk setiap State ... 13
23 Grafik akurasi penerapan LCS dengan 5 kata dan 8 kata... 13
PENDAHULUAN Latar Belakang
Secara umum, dalam berkomunikasi manusia menggunakan bahasa yang disampaikan dalam bentuk ucapan ataupun perkataan. Agar informasi yang ingin disampaikan dapat dipahami, sebuah pesan harus disampaikan dengan baik sehingga tidak terjadi kesalahartian maksud dari pesan tersebut. Bagi manusia, mengenali suara tidaklah sulit untuk dilakukan, namun hal ini bukanlah hal yang mudah dilakukan oleh sebuah komputer. Hal inilah yang mendorong dikembangkannya penelitian di bidang suara, salah satunya adalah penelitian mengenai konversi suara ke teks (speech to text
transcription) yang bertujuan agar suara
manusia dapat diproses dan dikonversi menjadi teks yang kemudian dapat dikenali oleh sistem, dan selanjutnya diharapkan manusia dapat berkomunikasi dengan komputer selayaknya dengan manusia.
Dalam proses konversi suara ke teks salah satu hal yang paling penting adalah pengenalan kata (speech recognition). Pada proses pengenalan kata, sistem digunakan untuk membandingkan suara masukan dengan suatu
database suara dan menghasilkan data yang
paling cocok dengan suara tersebut jika ada. Teknologi pengenalan suara memungkinkan manusia berkomunikasi dengan komputer dengan memberikan perintah dalam bahasa sehari-hari yang harus dijalankan oleh komputer, sehingga komunikasi manusia dengan komputer tidak hanya bergantung dengan mouse dan keyboard saja. Dalam beberapa aplikasi, antarmuka yang dikombinasikan dengan suara terbukti lebih efisien daripada antarmuka yang tanpa melibatkan suara, terutama bagi seseorang yang memiliki keterbatasan fisik yang sangat merasakan manfaat dari aplikasi tersebut.
Penelitian mengenai konversi suara ke teks telah banyak dilakukan. Salah satunya adalah penelitian dilakukan oleh Ruvinna tahun 2008. Namun sistem yang dikembangkan cenderung berbasiskan kata, dimana setiap kata yang terdapat dalam kamus kata dimodelkan dengan sebuah Hidden Markov Models (HMM). Hal ini mengakibatkan kurang efisiennya sistem apabila dikembangkan menjadi sistem yang bersifat large vocabulary. Oleh karena itu, pada penelitian ini akan dikembangkan suatu sistem konversi suara ke teks berbasiskan fonem, yang mana untuk semua kata yang terdapat dalam
kamus kata akan dimodelkan ke dalam beberapa model yang banyaknya bergantung pada jumlah fonem yang ada dalam kamus kata tersebut.
Tujuan Penelitian
Tujuan penelitian ini adalah menerapkan Markov model tersembunyi untuk fonem berbahasa Indonesia pada sistem konversi suara ke teks menggunakan algoritme Baum-Welch.
Ruang Lingkup
Penelitian ini terbatas pada pengenalan kata (isolated word), bukan pengenalan kalimat. Kata yang digunakan untuk proses pembentukan model sebanyak lima kata yang mengandung 10 fonem asli dan fonem transisi. Kata yang dapat dikenali berasal dari pembicara yang terlatih (speaker dependent).
TINJAUAN PUSTAKA
Speech Recognition
Pengenalan kata (speech recognition)
merupakan suatu proses dimana komputer dapat mengidentifikasi kata-kata yang diucapkan (Cook 2002, diacu dalam Mandasari 2005). Proses identifikasi dibutuhkan agar sistem dapat mengenali suatu input suara sehingga menghasilkan output yang sesuai dengan tujuan dibuatnya sebuah sistem.
Berdasarkan output yang dihasilkan, terdapat berbagai aplikasi pengenalan suara, diantanya (Campbell, 1997):
1. Speaker recognition a. Speaker verification
Sistem hanya menghasilkan dua output yaitu ‘yes’ atau ‘no’. Aplikasi pada sistem verifikasi pembicara banyak digunakan pada sistem transaksi pelanggan, misalnya untuk mengetahui apakah suara yang diproses merupakan pelanggan atau bukan.
b. Speaker tracking
Sistem memproses input suara dengan mencari suara tersebut apakah ada dalam database atau model. Aplikasi ini biasanya digunakan pada bidang periklanan untuk mengetahui berapa kali suatu iklan muncul dalam waktu tertentu.
c. Speaker identification
Sistem menghasilkan beberapa output sesuai dengan jumlah pembicara yang dikenali sistem. Input berupa suara yang
berasal dari pembicara yang telah dilatih. Sistem akan mengidentifikasi pemilik suara tersebut.
2. Speech to text transcription
Speech to text transcription system (sistem
konversi suara ke teks) merupakan sistem yang berfungsi mengkonversi sebuah sinyal suara yang berasal dari mikropon atau telepon, menjadi satu atau sekumpulan kata (string). Saat ini, sebuah sistem konversi suara hanya dapat mengkonversi sinyal suara yang merupakan hasil pengucapan kata dalam bahasa tertentu. Namun pada akhirnya, diharapkan dapat dikembangkan sebuah sistem konversi suara yang dapat mengidentifikasi suara dalam beragam bahasa dengan berbagai pembicara.
Berbagai sistem pengenalan suara telah banyak dikembangkan, Dalam mengklasifikasikan sistem pengenalan suara, perlu memperhatikan beberapa parameter, seperti (Jurafsky, 2007):
a. Jumlah kosakata
Semakin kecil (sedikit) jumlah kosakata yang diimplementasikan dalam sebuah ASR maka semakin sedikit kata yang harus dikenali oleh sistem, begitu juga sebaliknya. Berdasarkan jumlah katanya, sistem dapat dibagi menjadi 2 macam yaitu sistem yang dapat mengenali small vocabulary (≤1000 kata) dan large vocabulary (>1000 kata).
b. Cara dan gaya bicara
Jika sistem hanya dapat mengenali kata tunggal dalam sekali proses maka disebut dengan isolated word recognition, sedangkan jika sistem dapat mengenali beberapa kata (sebuah kalimat) dalam sekali waktu maka disebut dengan continous speech recognition. Sistem dengan continous speech recognition sangat sulit diimplementasikan, untuk itu perlu dibedakan antara cara bicara antara manusia dengan manusia (conversation speech) dengan cara bicara manusia dengan mesin (read
speech).
c. Media dan noise
Media yang digunakan dalam aplikasi komersial maupun pada laboratorium penelitian merupakan media yang berkualitas, misalnya
head mounted microfones. Dengan mikrofon
tersebut, distorsi dari sinyal suara dapat dihindari, sehingga diharapkan kualitas suara yang dihasilkan juga baik. Selain itu kualitas sinyal suara juga dipengaruhi oleh noise. Jika terdapat noise (misalnya bunyi selain sinyal
suara) ketika proses perekaman, maka kualitas sinyal yang dihasilkan tidak akan baik. Jika keberadaan noise lebih dari 30dB maka suara memiliki low noise, sedangkan jika kurang dari 10 dB maka high noise.
d. Karakteristik pembicara
Lebih mudah mengembangkan sistem yang dapat mengenali dialek standar, atau dengan kata lain suara yang dikenali berasal dari pembicara yang sudah dilatih (speaker
dependent) dari pada sistem yang dapat
mengenali suara yang berasal dari pembicara yang belum dilatih (speaker independent).
Untuk membangun sebuah sistem pengenalan suara diperlukan tahapan yang terdiri dari beberapa proses, di antaranya adalah transformasi sinyal suara analog, ekstraksi ciri suara, dan memodelkan suara menggunakan metode tertentu.
Pemrosesan sinyal suara
Pemrosesan sinyal suara merupakan teknik mentransformasi sinyal suara menjadi informasi yang berarti sesuai dengan yang diinginkan (Buono, 2009). Dalam proses transformasi tersebut, terdapat tahapan-tahapan yang perlu dilakukan di antaranya dijitalisasi sinyal analog, ekstraksi ciri, dan pengenalan pola, seperti yang diilustrasikan pada Gambar 1.
Berdasarkan peubah waktu, sinyal dapat diklasifikasikan menjadi dua yaitu:
a. Sinyal waktu kontinyu: kuantitas sinyal terdefinisi pada setiap waktu dalam selang kontinyu. Sinyal waktu kontinyu disebut juga sinyal analog.
b. Sinyal waktu diskret: kuantitas sinyal terdefinisi pada waktu diskret tertentu. Dijitalisasi sinyal analog dapat dilakukan melalui dua tahap yaitu sampling dan kuantisasi. Sampling merupakan pengamatan sinyal analog pada waktu tertentu, sehingga diperoleh sinyal waktu diskret. Nilai dari hasil
sampling tersebut dibulatkan ke nilai terdekat
(rounding) sehingga menghasilkan sinyal suara dijital dan proses ini dikenal dengan kuantisasi. Sinyal suara dijital kemudian dilakukan proses pembacaan sinyal per frame dengan lebar frame tertentu yang saling tumpang tindih. Proses ini dikenal dengan proses Frame
blocking. Barisan frame berisi informasi yang
lengkap dari sebuah sinyal suara. Untuk merepresentasikan informasi yang terdapat dalam frame-frame tersebut dilakukan ekstraksi ciri sehingga dihasilkan vektor-vektor yang
3
nantinya digunakan dalam pengenalan pola. Metode ekstraksi ciri untuk sinyal suara yang memiliki kinerja yang baik adalah MFCC
(Mel-Frequency Cepstrum coefficient), sedangkan
metode pengenalan pola yang saat ini sedang
trend adalah Hidden Markov Model (Buono,
2009).
Gambar 1 Tahapan transformasi sinyal suara menjadi informasi (Buono, 2009).
Ekstraksi sinyal suara
Terdapat banyak cara untuk merepresentasikan sinyal yang diucapkan seseorang, salah satunya yaitu MFCC
(Mel-Frequency Cepstral Coefficient). Dibandingkan
teknik lain, dalam mengekstraksi sinyal suara yang bersifat low noise (>30 dB) teknik MFCC relatif lebih baik (Buono, 2009). Hal ini dikarenakan cara kerja MFCC didasarkan pada perbedaan frekuensi yang dapat ditangkap oleh telinga manusia sehingga mampu merepresentasikan sinyal suara sebagaimana manusia merepresentasikan.
Proses MFCC terdiri dari tahapan berikut (Do, 1994):
Frame blocking
Seperti yang telah dijelaskan dalam subbab sebelumnya, dalam proses ini sinyal suara dibagi kedalam frame-frame yang saling
overlap, hal ini dilakukan agar tidak ada
sedikitpun sinyal yang hilang. Proses Frame
blocking pada sinyal suara diilustrasikan dalam
Gambar 2.
Gambar 2 Ilustrasi frame blocking pada sinyal suara.
Windowing
Akibat proses Frame blocking terjadi distorsi (ketidakberlanjutan sinyal) antar frame. Untuk meminimalisasi distorsi tersebut maka dilakukan proses windowing yaitu proses filtering pada tiap frame dengan cara mengalikan setiap frame tersebut dengan fungsi
window tertentu yang ukurannya sama dengan frame. Fungsi window yang dianggap cukup
sederhana sehingga mudah digunakan adalah
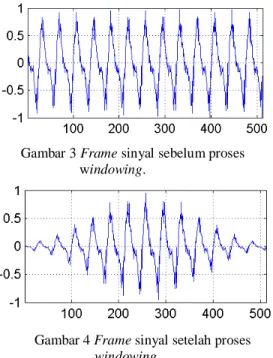
window Hamming. Gambar 3 menunjukkan
contoh frame sinyal yang belum melalui proses
windowing sedangkan hasil dari windowing
ditunjukkan pada Gambar 4.
Gambar 3 Frame sinyal sebelum proses windowing.
Gambar 4 Frame sinyal setelah proses
windowing.
Discrete Transformation Fourier (DCT). DCT merupakan transformasi setiap frame dengan N sample dari domain waktu ke domain frekuensi. Hal ini dilakukan karena pendengaran manusia didasarkan pada analisis frekuensi dan dengan mengunakan analisis
frekuensi dapat mempermudah pemrosesan suara. Algoritme yang digunakan adalah Fast
Fourier Transformation (FFT). Berikut
persamaan yang digunakan pada proses ini:
(1) Hasil dari tahapan ini biasanya disebut dengan
spectrum atau periodogram. Gambar 5 dan 6
dan mengilustrasikan sebuah sinyal suara dalam domain waktu dan frekuensi.
Gambar 5 Fonem /a/ dalam domain waktu.
Gambar 6 Fonem /a/ dalam domain frekuensi. Mel-Frequency Wrapping
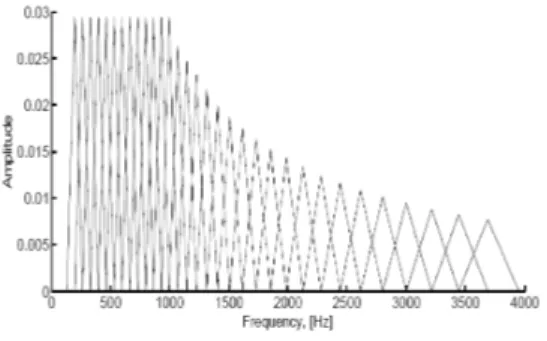
Persepsi sistem pendengaran manusia terhadap frekuensi sinyal suara ternyata tidak hanya bersifat linear. Penerimaan sinyal suara untuk frekuensi rendah (<1000) bersifat linear, sedangkan untuk frekuensi tinggi (>1000) bersifat logaritmik. Skala inilah yang disebut dengan skala mel-frequency yang berupa filter, seperti yang diilustrasikan pada Gambar 7. Persamaan berikut menunjukkan hubungan skala mel dengan frekuensi dalam Hz:
(2) Proses wrapping terhadap sinyal dalam domain frekuensi dilakukan menggunakan persamaan berikut:
(3) dimana i=1,2,3…,M (M adalah jumlah filter segitiga) dan Hi(k) adalah nilai filter segitiga
ke-i untuk frekuensi akustik sebesar k.
Gambar 7 Mel-frequency filter. Transformasi Cosinus
Tahapan ini digunakan untuk memperoleh vektor ciri, dimana ukuran vektor bergantung pada jumlah koefisien yang diinginkan. Berikut adalah persamaan yang digunakan dalam transformasi cosinus:
(4)
dimana j=1,2,3, …, K (K adalah jumlah koefisien yang diinginkan) dan M adalah jumlah filter.
Hidden Markov Model ( HMM )
Sebelum mendefinisikan HMM, perlu dibahas terlebih dulu mengenai Markov chain (rantai Markov). Markov chain merupakan kumpulan state yang transisi antar statenya memiliki nilai peluang yang mengindikasikan kemungkinan jalur state tersebut diambil. Jumlah peluang transisi yang keluar dari suatu
state adalah satu. Markov chain bermanfaat
untuk menghitung peluang urutan kejadian yang dapat diamati. Pada kondisi tertentu tidak semua kejadian dapat diamati secara langsung , namun dapat dievaluasi dari kejadian lain yang dapat diamati secara langsung. Untuk masalah seperti ini diperlukan modifikasi dari rantai Markov yang disebut dengan Hidden Markov
Model.
Dalam HMM kondisi yang tidak dapat diamati secara langsung direpresentasikan dengan hidden state. Setiap hidden state menghasilkan variable yang dapat diamati yang disebut dengan observable state. Observable
state ini berupa vektor dan memiliki distribusi
peluang yang mengikuti hidden state. Gambar 8 mengilustrasikan contoh HMM dalam menggambarkan kondisi cuara dengan media pengamatan kondisi alga.
5
Gambar 8 HMM dalam pengamatan kondisi cuaca.
Berikut ini adalah simbol-simbol yang dipakai dalam HMM (Dudad & Desai, 1996): N adalah jumlah state yang digunakan
dalam HMM. State=(1,2,3…,N). Semua
state dalam model terhubung satu sama lain.
M adalah jumlah kemungkinan kemunculan peubah yang terobservasi/teramati.
T adalah panjang rangkaian observasi. π adalah peluang tahap awal berada di suatu
state. π={i} dengan i=P(q1=i) yaitu
peluang pada tahap awal berada pada state i. Dalam hal ini berlaku persamaan berikut.
(5) A merupakan peluang transisi antar state. A={aij} dimana aij = P{qt+1= j|qt=i},
peluang berada pada state j saat waktu t+1 apabila diketahui bahwa saat waktu t berada pada state i.
B adalah peluang kemunculan peubah yang terobservasi pada suatu state. B={bj(k)}
dimana bj(k)=P{vk saat t|qt=j} yaitu peluang
simbol vk saat t jika state yang terjadi adalah
j.
HMM membutuhkan 2 parameter (N dan M), simbol observasi, dan beberapa nilai peluang yaitu A, B, dan π. Secara umum HMM dinotasikan dengan
λ = (A,B, π)
Jika nilai A,B, dan π telah didapatkan, maka HMM dapat digunakan untuk menghasilkan barisan state O = O1O2 …. OT.
Dalam Rabinner 1989, ada 3 masalah mendasar dalam HMM yaitu:
1. Problem 1 (Evaluation):
Jika diberikan barisan observasi O = O1O2…OT, dan sebuah model λ = (A,B,π) ,
bagaimana menghitung P(O|λ) peluang munculnya barisan observasi tersebut. Ada dua algoritme yang bisa digunakan untuk menyelesaikan problem 1 yaitu algoritme
Forward dan Backward, yang akan dijelaskan
pada subbab tersendiri. 2. Problem 2 (Decoding):
Jika diberikan model λ = (A,B,π) dan barisan observasi O = O1O2…OT, bagaimana
memilih barisan state Q = q1q2…Qt terhadap
barisan observasi tersebut yang memiliki peluang terbesar. Ada beberapa solusi yang dapat digunakan, salah satunya adalah dengan algoritme Forward.
3. Problem 3 (Learning):
Masalah ini berkaitan dengan pembelajaran HMM menggunakan data latih, yaitu dengan melakukan pendugaan terhadap parameter HMM yaitu A,B, π untuk memaksimalkan P(O|λ) peluang munculnya barisan observasi.
Untuk melatih HMM dapat digunakan algoritme Baum-Welch yang merupakan kombinasi dari algoritme Forward dan
Backward. Sebenarnya tujuan dari pembelajaran adalah menentukan parameter model HMM dari suatu set data latih, sedemikian sehingga model mampu mengenali objek baru yang mirip dengan data latih.
Algoritme Forward
Variabel Forward didefinisikan dengan αt(i)=P(O1 O2 … Ot, qt=i|λ) yaitu peluang
sebagian barisan observasi O1 O2 … Ot dan
state i pada waktu t, jika diketahui model λ,
dapat diselesaikan dengan (Rabiner, 1989): Inisialisasi: αi(1)=i bi(O1), 1 ≤ i ≤ N. (6) Induksi: (7) Terminasi: (8) Langkah pertama menginisialisasi peluang
Forward sebagai peluang bersama state i dan
O1. Langkah induksi merupakan penghitungan
menunjukkan bagaimana menghitung peluang
state j pada saat t+1 dari semua kemungkinan state i dari N state pada saat t.
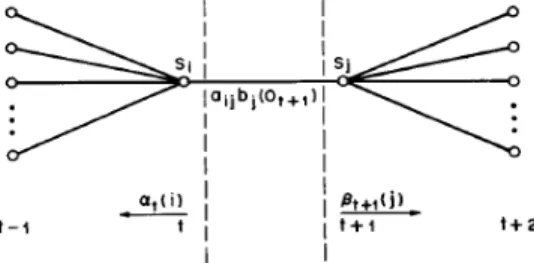
Gambar 9. Ilustrasi proses perhitungan algoritme Forward.
Algoritme Backward
Dengan cara yang sama kita dapat mendefinisikan variabel Backward dengan Βt(i)=P(Ot+1 Ot+2… OT|qt=Si, λ) yaitu peluang sebagian barisan observasi dari t+1 sampai akhir, diketahui state Si pada waktu t dan model λ, dapat diselesaikan dengan (Rabiner, 1989):
Inisialisasi:
βi(T) = 1 , 1 ≤ i ≤ N. (9)
Induksi:
(10) Proses perhitungan algoritme Backward diilustrasikan pada Gambar 10.
Gambar 10 Proses perhitungan algoritme
Backward. Algoritme Baum-Welch
Algoritme Baum-welch digunakan untuk melatih parameter HMM (A,B,) sehingga memaksimumkan peluang barisan observasi. Untuk menggambarkan prosedur reestimasi (update) parameter HMM, diperlukan variable γt(i) yaitu peluang berada di state i pada waktu t
dan ξt(i,j) yaitu peluang berada di state i pada waktu t dan berada di state j pada waktu t+1, yang diformulasikan dengan persamaan berikut (Rabiner, 1989):
(11)
(12) Proses Reestimasi atau meng-update parameter HMM menggunakan persamaan dibawah ini:
(13)
(14)
(15) Sebenarnya solusi ketiga permasalah dalam HMM berhubungan satu sama lain dan saling melengkapi karena algoritme Bum-welch merupakan gabungan dari algoritme Forward dan Backward sebagaimana diilustrasikan Gambar 11.
Gambar 11 Ilustrasi perhitungan algoritme Baum-Welch.
Longest Common Subsequence (LCS)
LCS merupakan permasalah untuk menemukan subsequence atau subbarisan terpanjang yang ada diantara dua buah string. Misalnya diketahui 2 buah string:
X = (A B C B D A B C D) Y = (B A C A D B C A A)
maka Z = ( B C A B C ) adalah subsequence terpanjang dari X dan Y. Banyak metode yang digunakan untuk menyelesaikan masalah LCS,
S1 S2 … SN ai1 ai2 aiN t βt(i) Si t+1 βt+1(j) S1 S2 … SN a1i a2i aNi t αt(i) t+1 αt+1(j) Si
7
salah satunya yaitu dengan dynamic programming.
Algoritme detail dari LCS disajikan pada Lampiran 1.
METODE PENELITIAN Kerangka Pemikiran
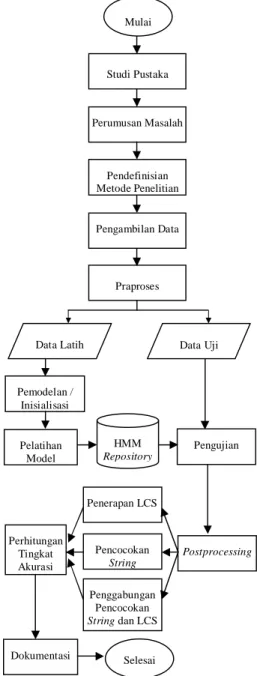
Penelitian ini dilakukan dalam beberapa tahap, di antaranya adalah studi pustaka, pendefinisian metode penelitian, pengambilan data, praproses, pengujian, perhitungan akurasi dan dokumentasi. Gambar 12 mengilustrasikan seluruh tahapan dalam penelitian ini.
Studi Pustaka
Studi pustaka dilakukan untuk mengetahui informasi yang dibutuhkan selama penelitian serta memahami tahapan yang harus dilakukan dalam metode penelitian. Informasi yang harus diketahui antara lain pemrosesan sinyal suara,
speech recognition, Hidden Markov Models
(HMM) dan informasi lain yang dipaparkan dalam bab tinjauan pustaka. Pustaka yang digunakan berasal dari beberapa sumber buku dan penelitian lain yang berhubungan dengan konversi suara ke teks.
Perumusan Masalah
Berdasarkan studi pustaka yang telah dilakukan maka permasalahan yang diteliti adalah bagaimana membuat sistem konversi suara ke teks dengan cara memodelkan fonem yang terdapat dalam kamus kata.
Pendefinisian Metode Penelitian
Penelitian ini menggunakan beberapa metode di antaranya yaitu MFCC yang digunakan pada proses ekstraksi sinyal suara, algoritme Baum-Welch yang digunakan dalam proses pelatihan model yang di dalamnya melibatkan algoritme Forward dan Backward, dan prosedur LCS digunakan untuk memproses hasil pengujian.
Proses ekstraksi sinyal suara menggunakan MFCC karena cara kerja metode ini didasarkan pada gelombang frekuensi yang dapat ditangkap telinga manusia, sehingga dapat memrepresentasikan sinyal suara sebagaimana manusia memrepresentasikan. Sedangkan pada proses pelatihan digunakan algoritme Baum-Welch karena menurut Shu et all.(2003) algoritme ini dapat melatih HMM dengan baik dibandingkan algoritme lain. Disamping itu, algoritme Baum-Welch tidak memerlukan
insialisasi yang cukup baik untuk menghasilkan model yang baik.
Gambar 12 Diagram proses konversi suara ke teks.
Pengambilan Data
Pengambilan data suara dilakukan dengan frekuensi sampe (Fs) 11 KHz untuk setiap kata. Data berasal dari satu pembicara yang mengucapkan 5 kata, dimana masing-masing kata diulang sebanyak 50 kali. Kata yang digunakan dalam penelitian ini dapat dilihat pada Tabel 1. Data Latih Mulai HMM Repository Pendefinisian Metode Penelitian Studi Pustaka Perumusan Masalah Pengambilan Data Praproses Data Uji Pelatihan Model Pengujian Pemodelan / Inisialisasi Dokumentasi Perhitungan Tingkat Akurasi Postprocessing Selesai Penerapan LCS Pencocokan String Penggabungan Pencocokan String dan LCS
Overlap
50%
Frame 30 ms
Tabel 1 Kata dalam penelitian
Kata
Fonem Fonem
asli Fonem transisi
Alam /a/,/l/,/m/ /al/,/la/,/am/ Aman /a/,/m/,/n/ /am/,/ma/,/an/ Malam /a/,/l/,/m/ /ma/,/al/,/la/,/am/ Mana /a/,/m/,/n/ /ma/,/an/,/na/ Nama /a/,/m/,/n/ /na/,/am/,/ma/
Berdasarkan Tabel 1 dapat dilihat bahwa fonem yang digunakan untuk menghasilkan model sebanyak 10 fonem yang terdiri dari fonem asli dan fonem transisi.
Praproses
Data yang dihasilkan merupakan data kotor karena mengandung blank atau jeda yang terdapat pada awal dan akhir suara seperti pada Gambar 13. Data tersebut selanjutnya dibersihkan dari blank dan proses ini disebut pembersihan data (cutting silent).
Gambar 13 Suara sebelum cutting silent. Tahap praproses berikutnya adalah ekstraksi ciri sinyal suara menggunakan metode MFCC. Tujuan ekstraksi ciri adalah mentransformasi gelombang sinyal ke dalam vektor-vektor ciri akustik, dimana setiap vektornya merepresentasikan informasi yang terdapat pada beberapa frame. MFCC yang diimplementasikan dalam sistem ini merupakan fungsi yang dikembangkan oleh Stanley pada tahun 1998. Dalam penggunaannya, fungsi ini memerlukan beberapa parameter yaitu:
1. Input, merupakan sinyal suara yang akan diekstrak. Sinyal suara yang digunakan adalah hasil dari proses pembersihan data. 2. Sampling rate yaitu banyaknya data yang
akan diambil dalam satu detik. Sampling
rate yang digunakan dalam penelitian ini
adalah 11000 Hz.
3. Time frame adalah lamanya waktu yang diinginkan dalam satu frame dalam milisekon. Time frame yang digunakan adalah sebesar 30 ms.
4. Overlap yaitu overlapping yang diinginkan antara satu frame dengan frame selanjutnya.
Overlap yang digunakan adalah sebesar
50%, yang diilustrasikan pada Gambar 14.
Gambar 14 Overlap Antar Frame. 5. Cepstral coefficient yaitu banyaknya
koefisien cepstral yang diinginkan sebagai
output. Cepstral coeffisient yangdigunakan
dalam penelitian ini adalah 13, jadi masing-masing frame akan menghasilkan vektor ciri Ot yang terdiri dari 13 koefisien cesptral.
Setelah didapatkan hasil ekstraksi, langkah berikutnya adalah mensegmentasi vektor ciri sesuai dengan fonem yang terdapat dalam setiap data. Kemudian menggabungkan vektor-vektor tersebut berdasarkan fonemnya seperti pada Gambar 15.
Gambar 15 Ilustrasi penggabungan fonem hasil segmentasi.
Segmentasi menghasilkan kumpulan data berdasarkan fonem sehingga dihasilkan 10 data fonem yaitu data /a/, /l/, /m/, /n/, /al/, /la/, /am/, /ma/, /an/, dan /na/.
Pemodelan/Inisialisasi
Proses inisialisasi HMM dimulai dengan mengelompokkan (clustering) setiap data fonem, dimana jumlah cluster menunjukkan jumlah state yang digunakan dalam model HMM. Proses ini diperlukan untuk mendapatkan nilai awal parameter (A, , B) yang dibutuhkan dalam membangun sebuah model HMM. Nilai B terdiri dari 2 variabel yaitu µ dan ∑, dimana µ adalah rata-rata nilai silent suara ALAM AMAN MALAM MANA NAMA A1A2…AT1 L1L2…LT2 NA1NA2…NAT10
9
observasi setiap state untuk setiap koefisien dan ∑ adalah ragam nilai observasi untuk setiap
state. Nilai A dan didapat dari formula
berikut.
Pada penelitian ini menggunakan 10 data fonem, sehingga proses inisialisasi menghasilkan 10 macam HMM(A, µ, B).
Pelatihan Model
Pelatihan HMM dilakukan dengan menggunakan algoritme Baum-Welch karena banyak studi yang telah membuktikan bahwa algoritme ini mampu melatih HMM lebih baik dari pada algoritme Viterbi (Shu, 2003).
Algoritme Baum-Welch merupakan penggabungan 2 buah algoritme yaitu algoritme
Forward dan Backward. Nilai variable α dan β
yang dihasilkan oleh kedua algoritme tersebut, digunakan untuk menghasilkan variable γ dan ξ yang kemudian akan digunakan untuk
meng-update nilai parameter HMM (A, µ, B). Karena
vektor ciri suara memiliki multi koefisien (d=13) maka dalam menentukan nilai B menggunakan gaussian multivariate:
(16) Hasil perhitungan algoritme Baum-Welch sering kali menghasilkan nilai yang sangat kecil hingga mendekati 0. Misalnya pada persamaan 14. Ketika nilai ( ) = 0, maka menjadi tidak terdefinisi. Untuk mengatasi hal tersebut perlu digunakan fungsi scaling untuk mentransformasi nilai α dan β agar tetap berada range sehingga dapat dihitung. Berikut adalah fungsi scaling untuk menghasilkan koefisien C,
(17) Tahapan dalam melatih HMM adalah sebagai berikut:
1. Menghitung nilai α dan β dengan menyertakan fungsi scaling.
a. Algoritme Forward Inisialisasi: (18.a) (18.b) Induksi: (19.a) (19.b) Terminasi: (20) b. Algoritme Backward Inisialisasi: ( ) = 1 (21.a) ( ) = ( ). (21.b) Induksi: ( ) = ∑ ( ) ( + 1) (22.a) ( ) = ( ) (22.b) 2. Menghitung nilai γ dan ξ.
(23)
( 24) 3. Mengupdate nilai (A, , B).
(25)
(26)
(27) 4. Ketiga proses di atas terus dilakukan hingga
Pengujian
Pengujian dilakukan menggunakan algoritme Forward dengan menghitung peluang data uji terhadap model HMM. Setiap vektor pada sebuah data uji dihitung nilai peluangnya terhadap setiap model fonem HMM. Vektor tersebut diklasifikasikan ke dalam fonem yang menghasilkan nilai peluang terbesar, sehingga menghasilkan barisan representasi fonem yang merupakan hasil klasifikasi vektor data uji tersebut. Pengujian dilakukan untuk semua data latih dan data uji.
Postprocessing
Postprocessing dilakukan untuk meningkatkan akurasi sistem dengan cara menghilangkan redundansi representasi fonem pada barisan yang dihasilkan dari proses pengujian. Selanjutnya representasi fonem tersebut diubah menjadi karakter yang mewakili masing-masing fonem. Kemudian dilakukan kembali penghilangan redundansi karakter antara fonem asli dengan fonem transisinya.
Teknik postprocessing yang digunakan dalam penelitian ini belum mempertimbangkan seluruh fonem falid yang ada dalam kata berbahasa Indonesia, sehingga tidak dapat diterapkan pada kata yang mengandung fonem yang berulang, misalnya kata ‘maaf’, ‘koordinasi’, dan sebagainya.
Penerapan LCS
Penerapan LCS dilakukan agar sistem menghasilkan kata yang sesuai dengan kamus kata. Hal ini dilakukan dengan mencari
subsequence antara string hasil postprocessing
dengan setiap kata dalam kamus. Kata dengan
subsequence terpanjang diidentifikasi sebagai output sistem. Pada sistem ini diasumsikan
bahwa jika hasil LCS dari beberapa kata memiliki panjang subsequence yang sama, maka output yang dihasilkan akan dipilih secara acak. Dalam implementasi LCS pada penelitian ini, menggunakan program yang dibuat oleh Roger Jang.
Pencocokan String
Pencocokan string dilakukan pada hasil
postprocessing dengan setiap kata dalam kamus
menggunakan fungsi di Matlab yaitu strmatch. Fungsi ini akan mencari string awal pada hasil
postprocessing yang cocok dengan sebuah kata.
Misalnya strmatch(‘alam’,’alamlam’) akan bernilai 1.
Penggabungan Pencocokan String dan LCS
Proses ini dilakukan dengan menerapkan kedua teknik di atas yaitu pencocokan string dan penerapan LCS pada hasil postprocessing. Langkah pertama yaitu dengan melakukan pencocokan string terhadap hasil
postprocessing. Jika langkah tersebut tidak
menghasilkan string yang cocok, maka dilakukan penerapan LCS. Dengan penggabungan kedua teknik tersebut diharapkan dapat meningkatkan akurasi sistem.
Perhitungan Tingkat Akurasi
Perhitungan tingkat akurasi dilakukan dengan membandingkan jumlah output yang benar yang dihasilkan sistem dengan jumlah seluruh data. Persentase tingkat akurasi dihitung dengan fungsi berikut.
% =∑
∑
HASIL DAN PEMBAHASAN
Data suara yang dihasilkan seluruhnya berjumlah 250 data suara yang meliputi 5 kata seperti pada Tabel 1 dan masing-masing kata memiliki 50 data suara. Data tersebut masih berupa data suara kotor karena masih terdapat
silent, sehingga perlu dibersihkan dengan
menghilangkan silent. Kemudian data diekstraksi menggunakan MFCC yang dimplementasi menggunakan fungsi yang sudah tersedia yang dikembangkan oleh Stanley pada tahun 1998. Seperti yang telah dijelaskan sebelumnya, frame yang digunakan sebesar 30 ms, dimana terjadi overlap antar frame sebesar 50%, dan cepstral coefficient yang digunakan sebesar 13 untuk setiap frame. Setiap data hasil ekstraksi kemudian disegmentasi berdasarkan fonem asli dan fonem transisi sehingga menghasilkan data fonem. Proses segmentasi dilakukan secara manual karena sampai saat ini belum ada metode yang dapat melakukannya secara otomatis, sehingga membutuhkan waktu yang cukup lama. Data fonem yang dihasilkan dari segmentasi kemudian ditetapkan 70% sebagai data latih dan 30% sebagai data uji.
Pelatihan setiap model HMM dilakukan dengan algoritme Baum-Welch hingga didapatkan model yang menghasilkan akurasi yang baik. Pelatihan dilakukan dengan beberapa frekuensi pelatihan yaitu 5, 10, dan 15 epoh dengan jumlah state 2, 3, 4, dan 5.
11 Hasil postprocessing
Seperti yang telah dijelaskan pada bab sebelumnya, output dari sistem konversi ini tidak hanya dihasilkan dengan pelatihan HMM, tetapi model juga melalui proses
postprocessing, penerapan LCS, pencocokan string, dan penggabungan pencocokan string
dan LCS. Hal ini dilakukan untuk meningkatkan akurasi sistem. Hasil proses
postprocessing merupakan barisan fonem yang
belum sesuai dengan kata yang sebenarnya. Tabel 2 menunjukkan variasi hasil
postprocessing pada masing-masing kata.
Tabel 2 Hasil postprocessing
Kata
Alam Aman Malam Mana Nama
ALAM AMAN MNMALA
M MANA NAMAN
ALAMN AMANL MALALA
MN MAN NAMAM N ALALA M AMAMA N MALAMA LA MANAN NAMNM AN ALALM N AMALA N MAMALA LAM MANLA N NALAMA M ALALA MN AMAML AN MAMLAM ALA MAMAN AN NANAMN MA
Hasil Pengujian Model HMM
Hasil pengujian setiap data uji terhadap model merupakan hasil dari penerapan LCS, pencocokan string dan penggabungan keduanya. Setiap model HMM dilatih dengan beberapa iterasi pelatihan, yaitu 5, 10, dan 15 epoh dengan 2, 3, 4, dan 5 state.
Dari beberapa percobaan, akurasi terbaik dihasilkan melalui penerapan gabungan pencocokan string dan LCS. Gambar 16 menunjukkan akurasi rata-rata dari penerapan LCS, pencocokan string dan gabungan keduanya. Dari Gambar 16 dapat diketahui bahwa akurasi tertinggi didapat dari penerapan gabungan LCS dan pencocokan string, sehingga teknik tersebut digunakan dalam pengujian seluruh model HMM.
Gambar 16 Grafik akurasi LCS dan pencocokan
string.
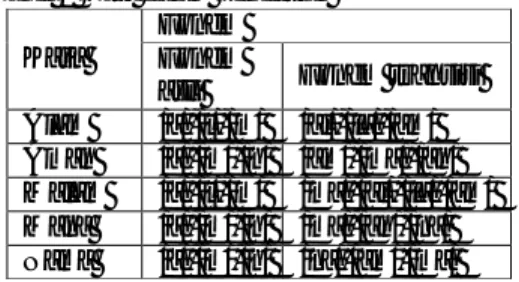
Akurasi dihasilkan HMM setiap state dapat dilihat pada Gambar 17. Akurasi yang dihasilkan oleh HMM 2 state dengan 5 epoh merupakan akurasi tertinggi yaitu sebesar 82%, sedangkan akurasi terendah yaitu 50% dihasilkan oleh HMM 5 state dengan 10 epoh. Dari Gambar 17 dapat diketahui bahwa kenaikan jumlah state HMM tidak diiringi dengan peningkatan akurasi, begitu juga dengan jumlah iterasi pelatihan. Dari hal tersebut dapat disimpulkan bahwa jumlah state dan jumlah epoh tidak mempengaruhi kinerja HMM.
Gambar 17 Grafik akurasi HMM setiap state.
Hasil pengujian Model HMM dengan 2 State
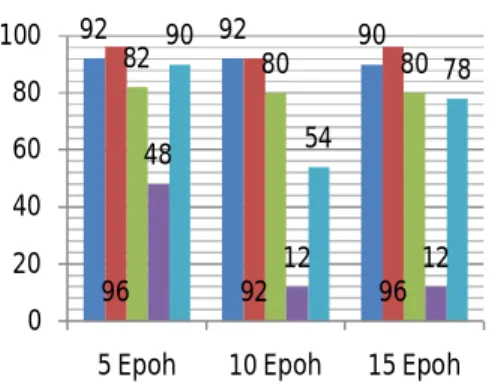
Hasil pengujian model HMM merupakan hasil dari penerapan gabungan LCS dan pencocokan string. Gambar 18 menunjukkan akurasi HMM 2 state untuk setiap epoh. Akurasi rata-rata tertinggi dihasilkan oleh HMM 2 state dengan 5 epoh yaitu sebesar 81,6%. Kata dapat dikenali paling baik oleh HMM 2 state adalah kata ALAM dengan akurasi rata-rata sebesar 91%.
Gambar 18 Grafik akurasi HMM 2 state. Pengujian HMM dengan 5 kali pelatihan secara umum menghasilkan akurasi sebesar 81,6%. Akurasi tertinggi sebesar 96% dihasilkan melalui pengujian kata AMAN,
50 45.5 69 0 50 100 LCS Match Match+LCS 82 68 64 63 64 65 80 50 65 66 60 62 0 50 100
2 State 3 State 4 State 5 State 5 Epoh 10 Epoh 15 Epoh
92 92 90 96 92 96 82 80 80 48 12 12 90 54 78 0 20 40 60 80 100
5 Epoh 10 Epoh 15 Epoh
sedangkan akurasi terendah yaitu 48% dihasilkan oleh kata MANA.
Secara umum HMM dengan 10 epoh menghasilkan akurasi sebesar 64%. Kata yang dapat dikenali paling baik adalah kata ALAM dan AMAN yaitu 92%, sedangkan dalam mengenali kata MANA, HMM hanya menghasilkan akurasi 12% yang merupakan akurasi terendah dari pengujian HMM 10 epoh.
HMM yang dilatih 15 kali, secara umum menghasilkan akurasi sebesar 64,8%. Akurasi terbesar dimiliki oleh kata AMAN yaitu 96%, sedangkan akurasi terendah yaitu sebesar 12% dihasilkan dari pengujian kata MANA.
Hasil pengujian Model HMM dengan 3 State
Gambar 19 menunjukkan akurasi HMM 3
state untuk setiap epoh. Akurasi rata-rata
tertinggi dihasilkan oleh HMM 3 state dengan 5 epoh yaitu sebesar 67,6%. Kata yang dapat dikenali paling baik oleh HMM dengan 3 state adalah kata MALAM dengan akurasi rata-rata sebesar 98%.
Gambar 19 Grafik akurasi HMM 3 state. Secara umum HMM dengan 5 epoh menghasilkan akurasi sebesar 67,6%. Kata yang dapat dikenali paling baik adalah kata MALAM yaitu 98%, sedangkan dalam mengenali kata MANA, HMM hanya menghasilkan akurasi 6% yang merupakan akurasi terendah dari pengujian HMM 5 epoh.
Akurasi yang dihasilkan oleh HMM dengan 10 kali pelatihan sebesar 64,8%. Akurasi tertinggi dihasilkan melalui pengujian kata MALAM 96%, sedangkan akurasi terendah dihasilkan melalui pengujian kata MANA yaitu 6%.
Pengujian HMM dengan 15 kali pelatihan secara umum menghasilkan akurasi sebesar 66%. Akurasi tertinggi sebesar 100% dihasilkan
melalui pengujian kata MALAM, sedangkan akurasi terendah yaitu 12% dihasilkan oleh kata MANA.
Hasil pengujian Model HMM dengan 4 State
Gambar 20 menunjukkan akurasi HMM 4
state untuk setiap epoh. Akurasi rata-rata
tertinggi dihasilkan oleh HMM 4 state dengan 10 epoh yaitu sebesar 80,4%. Kata dapat dikenali paling baik oleh HMM 4 state adalah kata MALAM dengan akurasi rata-rata sebesar 89%.
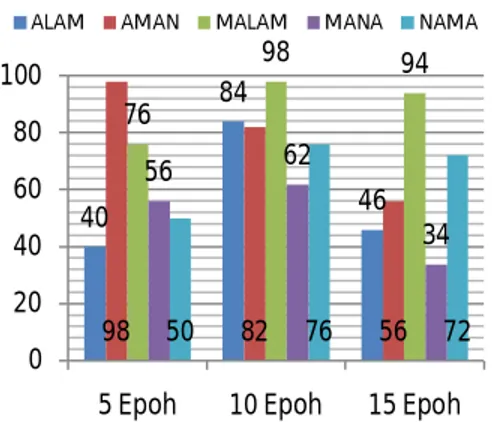
Gambar 20 Grafik akurasi HMM 4 state. Pengujian HMM dengan 5 kali pelatihan secara umum menghasilkan akurasi sebesar 64%. Akurasi tertinggi sebesar 98% dihasilkan melalui pengujian kata AMAN, sedangkan akurasi terendah yaitu 40% dihasilkan oleh kata ALAM.
Secara umum HMM dengan 10 epoh menghasilkan akurasi sebesar 80,4%. Kata yang dapat dikenali paling baik adalah kata MALAM yaitu 98%, sedangkan dalam mengenali kata MANA, HMM hanya menghasilkan akurasi 62% yang merupakan akurasi terendah dari pengujian HMM 10 epoh.
HMM yang dilatih 15 kali, secara umum menghasilkan akurasi sebesar 60,4%. Akurasi terbesar dimiliki oleh kata MALAM yaitu 94%, sedangkan akurasi terendah yaitu sebesar 34% dihasilkan dari pengujian kata MANA.
Hasil pengujian Model HMM dengan 5 State
Akurasi HMM 5 state untuk setiap epoh dapat dilihat pada Gambar 21. Akurasi rata-rata tertinggi yaitu sebesar 63,2% dihasilkan oleh HMM 5 state dengan 5epoh. Kata yang dapat dikenali paling baik oleh HMM dengan 5 state adalah kata MALAM dengan akurasi rata-rata sebesar 82%. 78 84 84 86 78 72 98 96 100 6 6 12 70 60 62 0 20 40 60 80 100
5 Epoh 10 Epoh 15 Epoh
ALAM AMAN MALAM MANA NAMA
40 84 46 98 82 56 76 98 94 56 62 34 50 76 72 0 20 40 60 80 100
5 Epoh 10 Epoh 15 Epoh
13
Gambar 21 Grafik akurasi HMM 5 state. Secara umum HMM dengan 5 epoh menghasilkan akurasi sebesar 63,2%. Kata yang dapat dikenali paling baik adalah kata AMAN yaitu 88%, sedangkan dalam mengenali kata MANA, HMM hanya menghasilkan akurasi 8% yang merupakan akurasi terendah dari pengujian HMM 5 epoh.
Akurasi yang dihasilkan oleh HMM dengan 10 kali pelatihan sebesar 50,4%. Akurasi tertinggi dihasilkan melalui pengujian kata MALAM 78%, sedangkan akurasi terendah dihasilkan melalui pengujian kata MANA yaitu 12%.
Pengujian HMM dengan 15 kali pelatihan secara umum menghasilkan akurasi sebesar 61,6%. Akurasi tertinggi sebesar 82% dihasilkan melalui pengujian kata AMAN dan MALAM, sedangkan akurasi terendah yaitu 24% dihasilkan oleh kata MANA.
Hasil Pengujian Kata
Gambar 22 Grafik akurasi setiap kata untuk setiap state.
Secara umum, kata yang paling baik dikenali oleh semua HMM adalah kata MALAM dengan akurasi rata-rata sebesar 87%, sedangkan kata MANA memiliki akurasi
rata-rata terendah yaitu 25%. Gambar 22 menunjukkan akurasi setiap kata melalui pengujian HMM setiap state, sedangkan Tabel 3 menunjukkan akurasi terendah dan tertinggi untuk masing-masing kata.
Tabel 3 Akurasi maksimum dan minimum setiap kata Fonem Akurasi Min & Max Model HMM ∑State ∑Epoh ALAM 40% 4 5 92% 2 5,10 AMAN 56% 4 15 98% 4 5 MALAM 76% 4 5 100% 3 15 MANA 6% 3 5,10 62% 4 10 NAMA 54% 2 10 90% 3 15
Penggunaan Kata Lain Pada LCS
Kata yang digunakan dalam LCS pada percobaan di atas adalah kata yang terdapat dalam kamus, yaitu ALAM, AMAN, MALAM, MANA, dan MALAM. Untuk mengetahui kestabilan kinerja sistem, penerapan LCS tidak hanya menggunakan kelima kata tersebut, tetapi juga melibatkan kata lain namun mengandung fonem yang sama yaitu AMAL, LAMA, dan MAMA. Gambar 23 menunjukkan perbandingan akurasi penerapan LCS menggunakan kata lain dan tanpa kata lain pada HMM dengan 5 epoh. Berdasarkan Gambar 23 dapat diketahui bahwa penambahan kata lain pada LCS dapat menurunkan tingkat akurasi sistem.
Gambar 23 Grafik akurasi penerapan LCS dengan 5 kata dan 8 kata. Penurunan akurasi yang paling signifikan terjadi pada kata MALAM. Hal ini dikarenakan hasil penerapan gabungan pencocokan string 82 46 60 88 68 82 86 78 82 8 12 24 52 48 60 0 20 40 60 80 100
5 Epoh 10 Epoh 15 Epoh
ALAM AMAN MALAM MANA NAMA
91 95 80 24 60 82 79 98 8 64 57 79 89 50 66 63 79 82 15 53 0 20 40 60 80 100
ALAM AMAN MALAM MANA NAMA
2 State 3 State 4 State 5 State
73 92 85 29 65 72 85 56 21 61 0 20 40 60 80 100
ALAM AMAN MALAM MANA NAMA
dan LCS untuk kata MALAM sebagian besar mengandung karakter awal ‘mama’ misalnya, ‘mamalam’, sehingga banyak yang diidentifikasi sebagai kata MAMA.
Pengujian Kata Lain
Seperti yang telah dijelaskan dalam latar belakang bahwa penelitian ini dilakukan untuk mengatasi ketidakefisienan dari teknik pemodelan berbasiskan kata (Ruvinna, 2008) dimana setiap kata dimodelkan dalam sebuah HMM sehingga tidak mungkin diterapkan pada sistem large vocabulary. Dengan adanya teknik pemodelan berbasiskan fonem dimana setiap fonem dimodelkan dalah sebuah HMM, maka diharapkan sistem yang bersifat large vocabulary dapat dikembangkan. Untuk
mengetahui efektifitas teknik tersebut, maka perlu dilakukan pengujian model HMM terhadap kata lain yang tidak terdapat dalam kamus kata namun mengandung fonem yang sama.
Pengujian dilakukan pada suara yang merupakan hasil dari pengucapan kata AMAL, LAMA, dan MAMA, dimana setiap kata dilakukan 10 kali ulangan. Dari pengujian tersebut didapat beberapa akurasi di antaranya 40% untuk AMAL, 0% untuk LAMA dan 50% untuk MAMA.
Seluruh pengujian di atas dilakukan dengan aplikasi sederhana yaitu sitem konversi suara ke teks yang telah dikembangkan dengan Matlab 7.0.1. Antarmuka sistem tersebut dapat dilihat pada Gambar 24.
Gambar 24 Antarmuka sistem konversi suara ke teks.
KESIMPULAN DAN SARAN Kesimpulan
Penelitian ini menghasilkan beberapa model HMM yang merepresentasikan sinyal suara berbahasa indonesia menjadi rangkaian fonem
yang akan membentuk suatu kata. Dari beberapa percobaan, akurasi terbaik dihasilkan melalui penerapan gabungan pencocokan string dan LCS. Akurasi tertinggi yaitu 82% dihasilkan oleh HMM dengan 2 state dan 5 kali pelatihan, sedangkan kata yang paling baik dikenali model adalah kata MALAM dengan akurasi sebesar 87%.
Teknik postprocessing yang digunakan dalam penelitian ini belum mempertimbangkan seluruh fonem falid dalam bahasa Indonesia, sehingga tidak dapat diterapkan pada kata yang mengandung fonem yang sama secara berurutan.
Model terbaik mampu mengenali beberapa kata lain yang mengandung fonem yang sama namun akurasi yang dihasilkan cukup rendah. Percobaan di atas juga menunjukkan bahwa kenaikan jumlah state dan iterasi pelatihan tidak mempengaruhi kinerja pemodelan HMM berbasiskan fonem.
Saran
Penelitian mengenai konversi suara ke teks berdasarkan fonem ini masih sangat memungkinkan untuk dikembangkan lebih lanjut. Teknik postprocessing yang mempertimbangkan seluruh fonem falid dalam bahasa Indonesia diperlukan untuk pengembangan sistem selanjutnya. Jumlah kata yang digunakan dalam penelitian ini membuat sistem yang dihasilkan belum memungkinkan untuk langsung digunakan dalam kondisi nyata. Selain itu perlu dicobakan pengembangan dengan menggunakan jumlah pembicara yang lebih banyak sehingga menghasilkan sistem yang bersifat speaker independent.
DAFTAR PUSTAKA
Buono, A. 2009. Representasi Nilai HOS dan Model MFCC sebagai Ekstraksi Ciri pada Sistem Indentifikasi Pembicara di Lingkungan Ber-noise Menggunakan HMM. [Disertasi]. Depok: Program Studi Ilmu Komputer, Universitas Indonesia.
Campbell, J. P. Speaker Recognition: A Tutorial. IEEE 1997; 85: 1437-1441. Do, MN. 1994. DSP Mini-Project: An
Automatic Speaker Recognition System.
Dudad, R. dan Desai, U. B. 1996. A Tutorial in
Hidden Markov Models. Indian Institut of
Technology, India.
Jurafsky, D. dan Martin, JH. 2007. Speech and
15 Natural Language Processing,
Computational Linguistic, and Speech Recognition. New Jersey: Prentice Hall.
Mandasari, Y. 2005. Pengembangan Model Markov Tersembunyi untuk Pengenalan Kata Berbahasa Indonesia. [Skripsi]. Bogor: Departemen Ilmu Komputer, Institut Pertanian Bogor.
Rabiner, L. R. A Tutorial on Hidden Markov Models and Selected Applications in Speech Recognition. IEEE 1989; 77: 257-258. Resmiwati, N. U. E. 2009. Pengenalan Kata
Berbahasa Indonesia dengan Menggunakan Hidden Markov Models Berbasiskan Fonem.[Skripsi]. Bogor: Departemen Ilmu Komputer, Institut Pertanian Bogor.
Ruvinna. 2008. Pengenalan Kata Berbahasa Indonesia dengan Hidden Markov Models Menggunakan Algoritme Baum-Welch. [Skripsi]. Bogor: Departemen Ilmu Komputer, Institut Pertanian Bogor.
Shu, H., et al. 2003. Baum-Welch Training for
Segment-Based Speech Recognition.
Massachussets Institute of Technology, USA.
17
Lampiran 1 List program LCSfunction [lcscount, lcs_path, lcs_str, lcstable] = lcs(a, b) %LCS Longest (maximum) common subsequence
% Usage:
% [count, lcs_path, lcs_str, lcstable] = lcsm(a, b) % a: input string 1
% b: input string 2 % count: count of LCS
% lcs_path: optimal path of dynamical programming through the lcs table
% lcs_str: LCS string
% lcstable: LCS table for applying dynamic programming %
% Type "lcsm" for a self-demo.
% Roger Jang, 981226 % Roger Jang, 990409
if nargin == 0, selfdemo; return; end a = a(:).'; b = b(:).'; m = length(a); n = length(b); lcstable = zeros(m+1, n+1); prevx = zeros(m+1, n+1); prevy = zeros(m+1, n+1);
% Find LCS using dynamic programming for i=1:m, for j = 1:n, if a(i)==b(j), lcstable(i+1,j+1) = lcstable(i,j)+1; prevx(i+1,j+1) = i; prevy(i+1,j+1) = j;
elseif lcstable(i,j+1) > lcstable(i+1,j), lcstable(i+1,j+1) = lcstable(i,j+1); prevx(i+1,j+1) = i; prevy(i+1,j+1) = j+1; else lcstable(i+1,j+1) = lcstable(i+1,j); prevx(i+1,j+1) = i+1; prevy(i+1,j+1) = j; end end end
% Get rid of initial conditions lcstable = lcstable(2:end, 2:end); prevx = prevx(2:end, 2:end)-1; prevy = prevy(2:end, 2:end)-1;
% ====== Return length of LCS string lcscount = lcstable(m, n);
% ====== Return the optimal path of the dynamical programming if nargout > 1,
now = [m, n];
prev = [prevx(now(1), now(2)), prevy(now(1), now(2))]; lcs_path = now;
while all(prev>0), now = prev;
prev = [prevx(now(1), now(2)), prevy(now(1), now(2))]; lcs_path = [lcs_path; now];
end
lcs_path = flipud(lcs_path); end
% ====== Return the LCS string if nargout > 2, % return LCS string
temp = lcstable((lcs_path(:,2)-1)*m+lcs_path(:,1)); % LCS count along the path
temp = [0; temp]; index = find(diff(temp)); lcs_str = a(lcs_path(index,1)); end % ====== Self demo function selfdemo str1 = 'abxjhbscdrasngssfd'; str2 = 'sdkjtanhsfljskge'; m = length(str1); n = length(str2); figure; %[xx, yy] = meshgrid(1:m, 1:n); %plot(xx(:), yy(:), '.'); axis([0 m+1 0 n+1]); box on; set(gca, 'xtick', 1:m); set(gca, 'ytick', 1:n);
set(gca, 'xticklabel', char(double(str1)')); set(gca, 'yticklabel', char(double(str2)'));
% ====== invoke LCS
[count, lcs_path, lcs_str, lcstable] = feval(mfilename, str1, str2); xlabel(['String1 = ', str1]);
ylabel(['String2 = ', str2]);
title(['LCS table and LCS path; with LCS = ', lcs_str]);
% ====== Plot LCS table for i = 1:m,
for j = 1:n,
text(i, j, int2str(lcstable(i,j)), 'hori', 'center'); end end % ====== Plot LCS path for i = 1:size(lcs_path,1)-1, line(lcs_path(i:i+1, 1), lcs_path(i:i+1, 2));
19
end
% ====== Circle matched elements
temp = lcstable((lcs_path(:,2)-1)*m+lcs_path(:,1)); % LCS count along the path
temp = [0; temp];
index = find(diff(temp));
match_point = lcs_path(index, :);
line(match_point(:,1), match_point(:, 2), ...
'marker', 'o', 'markersize', 15, 'color', 'r', 'linestyle', 'none');