2. DASAR TEORI
Pada bab ini dibahas dasar teori yang mendukung pengerjaan skripsi ini.
Dasar teori yang dibahas adalah Knowledge Management System, algoritma Vector Space Model, algoritma Stemming Porter dan web programming.
2.1 Knowledge Management System
Knowledge Management System merupakan mekanisme dan proses yang terpadu dalam pengolahan informasi yang berhubungan dengan penciptaan berbagai informasi menjadi aset intelektual organisasi yang permanen.
Pengolahan informasi berupa penyimpanan, pemeliharaan dan pengorganisasian informasi.
Menurut Tobing (2007), knowledge management didefinisikan sebagai pendekatan-pendekatan sistemik yang membantu pengolahan informasi dan knowledge. Tujuan dari knowledge management adalah menyebarkan informasi dan knowledge kepada orang yang tepat pada saat yang tepat.
2.1.1 Jenis-jenis Knowledge Management System
Knowledge dibedakan menjadi dua jenis, yaitu tacit knowledge dan explicit knowledge. Tacit knowledge adalah knowledge yang terletak di mind atau di dalam diri seseorang yang diperoleh melalui pengalaman dan pekerjaannya.
Sedangkan explicit knowledge adalah segala bentuk knowledge yang sudah direkam dan didokumentasikan sehingga lebih mudah didistribusikan dan dikelola. Bentuk-bentuk umum dari explicit knowledge dapat berupa dokumen- dokumen, prosedur-prosedur, dan petunjuk-petunjuk (Tobing, 2007).
2.1.2 Prinsip Knowledge Management System
Menurut Davenport (2000), ada lima prinsip dalam knowledge management yang dapat membantu menyatukan kerja menjadi lebih efektif, yaitu:
1. Knowledge management mengembangkan kesadaran akan nilai pengetahuan yang dicari dan keinginan untuk berinvestasi dalam proses mengembangkannya.
2. Knowledge management mengidentifikasi knowledge worker yang mendukung knowledge management system.
3. Knowledge management mempertegas potensi yang kreatif dalam ide-ide yang kompleks dan berbeda-beda, memandang perbedaan itu sebagai hal yang positif daripada sebagai sumber permasalahan, dan menghindari jawaban sederhana untuk pertanyaan yang kompleks.
4. Knowledge management memperjelas kebutuhan akan knowledge sehingga dapat mendukung, menghargai dan mengarahkan pada sebuah tujuan umum.
5. Knowledge management memperkenalkan tolak ukur dan titik sukses yang mencerminkan nilai sebenarnya dari knowledge.
2.1.3 Peran dalam Pengelolaan Knowledge
Dalam bukunya, Tobing (2007) mengutarakan ada tiga pilihan peran yang dapat muncul dalam pengelolaan knowledge, yaitu: pengelolaan knowledge sebagai produk, knowledge management diarahkan untuk mempertemukan orang yang memiliki knowledge dan orang yang membutuhkan knowledge, dan mengkombinasikan kedua pilihan sebelumnya. Pada pilihan peran yang pertama, knowledge management diarahkan pada proses kodifikasi knowledge dan menempatkannya dalam repository knowledge yang dapat diakses oleh user sesuai otoritasnya. Sedangkan pada pilihan peran kedua, knowledge management lebih diutamakan pada media yang digunakan untuk memfasilitasi pertemuan antara orang yang memiliki knowledge dan orang yang membutuhkan knowledge.
Pilihan ketiga merupakan kombinasi antara dua pilihan yang lain yang membutuhkan sumber daya yang lebih besar.
2.1.4 Proses-Proses Knowledge Management
Proses knowledge management dibagi menjadi tiga proses utama, yaitu:
knowledge acquisition, knowledge sharing, dan knowledge utilization. Knowledge acquisition melibatkan komponen sistem distribusi dan storage serta knowledge worker. Akusisi knowledge terjadi ketika proses interaksi antara pengguna knowledge dengan knowledge source berlangsung dengan efektif yang ditandai dengan mengalirnya knowledge dari knowledge source ke pengguna knowledge.
Knowledge sharing melibatkan komponen knowledge worker dan aplikasi
distribusi dan kolaborasi. Sedangkan dalam knowledge utilization, pemanfaatan dari knowledge yang tersedia akan membantu meningkatkan pengalaman intektual karyawan dalam suatu perusahaan yang menerapkan knowledge management.
Dengan tingginya tingkat ketersediaan knowledge, maka upaya dan waktu yang dikerahkan untuk mencari knowledge dapat dikurangi (Tobing, 2007).
2.2 Algoritma Vector Space Model
Salah satu metode yang sering digunakan untuk mengukur relevansi pada suatu information retrieval adalah vector space model. Vector Space Model adalah model aljabar untuk menghitung relevansi dengan mendefinisikan sebuah vektor yang mewakili setiap dokumen dan vektor yang mewakili query (Grossman, 2004).
Dalam Vector Space Model, dokumen dan query dapat didefinisikan seperti berikut:
( )
( ) (2.1) Setiap dimensi yang membentuk vektor dokumen ataupun query ditentukan oleh term yang ada. Jika word dianggap sebagai term maka jumlah dimensi suatu dokumen adalah jumlah word yang ada pada dokumen tersebut. Suatu dokumen yang memiliki term maka dokumen tersebut pasti memiliki nilai vektor tidak sama dengan 0.
Weighting merupakan perhitungan bobot dari tiap dimensi. Salah satu cara weighting paling terkenal adalah TF-IDF. TF-IDF adalah metode untuk memberikan bobot hubungan suatu kata terhadap dokumen. Metode ini menggabungkan 2 konsep perhitungan bobot yaitu, frekuensi kemunculan sebuah kata di dalam sebuah dokumen tertentu dan inverse frekuensi dokumen yang mengandung kata tersebut.
Proses pembobotan dari term yang ada menggunakan rumus berikut:
|* | +|| | (2.2) Keterangan rumus:
: frekuensi term t pada dokumen d | |
|* | +| : Inverse Document Frequency (IDF)
| | : banyaknya dokumen
|* | +| : banyaknya dokumen yang memiliki term t
Similarity antar query dan dokumen dilihat dari besar sudut cosinus yang dimiliki oleh vektor query dan vektor dokumen yang akan dibandingkan. Jika kedua vektor tersebut memiliki similarity yang tinggi, maka query dan dokumen tersebut dianggap memiliki hubungan (Grossman, 2004). Rumus untuk pencarian similarity sebagai berikut:
( ) ∑
√∑ ( ) ∑ ( )
(2.3)
Keterangan rumus:
Q : vektor query
: vektor dokumen ke-i
: dimensi ke-j pada vektor query
: dimensi ke-j pada vektor dokumen ke-i t : banyaknya dimensi
Berikut ini adalah contoh perhitungan similarity dengan menggunakan algoritma vector space model:
Terdapat 3 dokumen:
D1: "Shipment of gold damaged in a fire"
D2: "Delivery of silver arrived in a silver truck"
D3: "Shipment of gold arrived in a truck"
Query yang akan dicari adalah “gold silver truck”.
Dari dokumen-dokumen dan query yang ada dilakukan perhitungan TF-IDF.
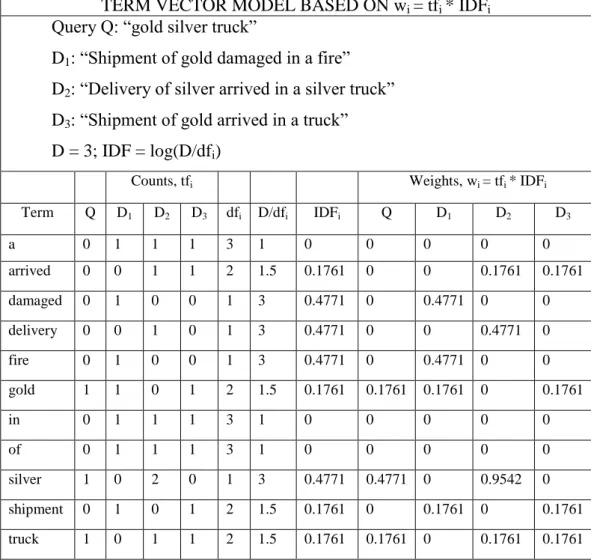
Hasil perhitungan TF-IDF ditunjukkan pada Tabel 2.1.
Tabel 2.1. Hasil Analisa TF-IDF
TERM VECTOR MODEL BASED ON wi = tfi * IDFi Query Q: “gold silver truck”
D1: “Shipment of gold damaged in a fire”
D2: “Delivery of silver arrived in a silver truck”
D3: “Shipment of gold arrived in a truck”
D = 3; IDF = log(D/dfi)
Counts, tfi Weights, wi = tfi * IDFi
Term Q D1 D2 D3 dfi D/dfi IDFi Q D1 D2 D3
a 0 1 1 1 3 1 0 0 0 0 0
arrived 0 0 1 1 2 1.5 0.1761 0 0 0.1761 0.1761
damaged 0 1 0 0 1 3 0.4771 0 0.4771 0 0
delivery 0 0 1 0 1 3 0.4771 0 0 0.4771 0
fire 0 1 0 0 1 3 0.4771 0 0.4771 0 0
gold 1 1 0 1 2 1.5 0.1761 0.1761 0.1761 0 0.1761
in 0 1 1 1 3 1 0 0 0 0 0
of 0 1 1 1 3 1 0 0 0 0 0
silver 1 0 2 0 1 3 0.4771 0.4771 0 0.9542 0
shipment 0 1 0 1 2 1.5 0.1761 0 0.1761 0 0.1761
truck 1 0 1 1 2 1.5 0.1761 0.1761 0 0.1761 0.1761
Nilai-nilai dalam kolom weights pada Tabel 2.1 akan digunakan untuk menghitung vektor setiap dokumen dan query. Perhitungan vektor-vektor setiap dokumen adalah sebagai berikut:
| | √∑ (2.4)
| | √ √
| | √ √
| | √ √
Sedangkan perhitungan vektor query adalah sebagai berikut:
| | √∑ (2.5)
| | √ √
Selanjutnya hasil perhitungan vektor-vektor dokumen dan query yang ada akan digunakan dalam perhitungan dot product seperti yang ditunjukan dalam perhitungan berikut ini:
∑ (2.6)
Setelah nilai dari dot product diperoleh, langkah terakhir yang dilakukan adalah menghitung similarity value. Berikut ini adalah contoh perhitungan similarity value:
( ) (2.7)
| | | |
| | | |
| | | |
Hasil yang diperoleh dalam perhitungan similarity value digunakan untuk menentukan peringkat untuk semua dokumen dimulai dari dokumen yang paling sesuai dengan query yang ada. Berdasarkan hasil yang telah diperoleh, maka peringkat dokumen adalah sebagai berikut:
Peringkat 1:
Peringkat 2:
Peringkat 3:
2.3 Algoritma Stemming Porter
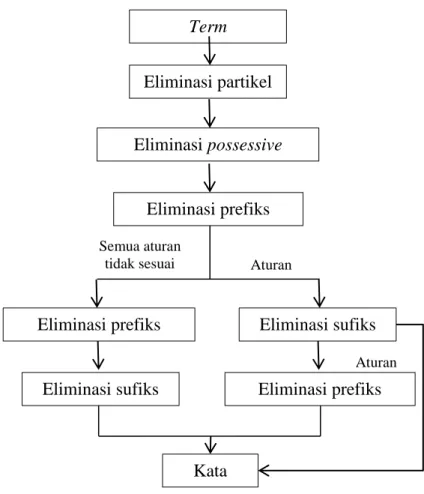
Stemming merupakan proses untuk mendapatkan kata dasar dari sebuah term dengan menghilangkan segala kata imbuhan yang terdapat dalam term tersebut (Tala, Fadillah Z., n.d.). Pada proses stemming untuk bahasa Indonesia dilakukan proses menghilangkan sufiks, prefiks, partikel kata dan possessive pronouns. Proses stemming dengan menggunakan algoritma Stemming Porter dapat dilihat pada Gambar 2.1.
Gambar 2.1. Algoritma Porter
Menurut Tala (n.d.), ada beberapa kondisi yang digunakan pada setiap aturan yang ada. Salah satu kondisi yang digunakan yaitu measure. Measure yang digunakan dalam bahasa Indonesia adalah jumlah suku kata yang ada pada sebuah kata. Perhitungan suku kata sebagai measure dilakukan pada sebuah kata tanpa imbuhan, contoh kata “bekerja” maka hanya bagian kata ”kerja” yang dihitung jumlah suku katanya. Kondisi lain untuk sebuah aturan yaitu pengecekan huruf pertama berupa huruf vokal atau konsonan dan beberapa kondisi lainnya.
Eliminasi partikel Term
Eliminasi possessive
Eliminasi prefiks
Eliminasi prefiks Eliminasi sufiks
Aturan dijalankan
Eliminasi sufiks Eliminasi prefiks
Semua aturan
tidak sesuai Aturan
Semua aturan tidak sesuai
Kata
Ada lima kelompok aturan pada algoritma porter untuk bahasa Indonesia (Tala, n.d.), yaitu:
1. Aturan untuk eliminasi partikel kata
Ada tiga partikel kata yang biasanya terdapat dalam sebuah term, yaitu kah, lah dan pun. Tabel 2.2. Aturan Untuk Eliminasi Partikel Kata menunjukkan daftar aturan yang digunakan untuk menghilangkan partikel kata. Kondisi, jumlah suku kata dan aturan pengganti ketiga aturan tersebut sama. NULL pada kolom aturan pengganti berarti sufiks yang dibuang tidak diganti dengan karakter atau kata lain. Sedangkan NULL pada kolom kondisi berarti tidak ada kondisi lain yang perlu diperiksa selain jumlah suku kata yaitu sebanyak 2 suku kata.
Tabel 2.2. Aturan Untuk Eliminasi Partikel Kata Akhiran Pengganti Suku Kata Kondisi Contoh
-kah NULL 2 NULL diakah → dia
-lah NULL 2 NULL pergilah → pergi
-pun NULL 2 NULL sayapun → saya
2. Aturan untuk eliminasi possessive pronouns
Ada tiga aturan yang digunakan pada proses ini dimana semua aturan pengganti, jumlah suku kata, dan kondisi memiliki aturan yang sama. Tabel 2.3 menunjukkan aturan yang digunakan untuk eliminasi possessive pronouns pada term yang ada.
Tabel 2.3. Aturan Untuk Eliminasi Possessive Pronouns Akhiran Pengganti Suku Kata Kondisi Contoh
-ku NULL 2 NULL bukuku → buku
-mu NULL 2 NULL bukumu → buku
-nya NULL 2 NULL bukunya → buku
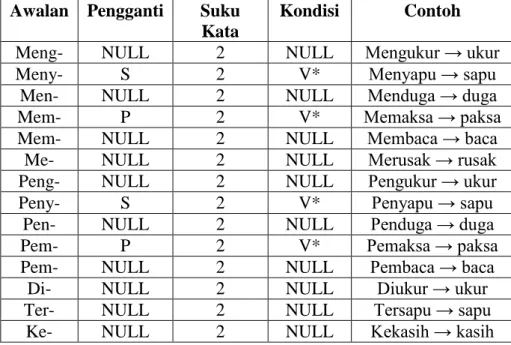
3. Aturan untuk eliminasi prefiks pertama
Tabel 2.4 menunjukkan daftar aturan yang digunakan untuk membuang prefiks pertama. Jika aturan pengganti tidak bernilai NULL berarti kata yang dihasilkan akan ditambah dengan karakter pada rule pengganti. Simbol “V”
sebagai symbol huruf vokal dan symbol “K” untuk huruf konsonan. Simbol
“V*” menunjukkan semua kata yang berawalan dengan huruf vokal. Semua aturan yang ada dicek secara berurutan, jika aturan pertama tidak sesuai maka dicoba aturan kedua, dan seterusnya. Jika semua aturan yang ada tidak sesuai maka term tersebut dianggap tidak memiliki prefiks pertama dan proses eliminasi berikutnya dilakukan.
Tabel 2.4. Aturan Untuk Eliminasi Prefiks Pertama Awalan Pengganti Suku
Kata
Kondisi Contoh
Meng- NULL 2 NULL Mengukur → ukur
Meny- S 2 V* Menyapu → sapu
Men- NULL 2 NULL Menduga → duga
Mem- P 2 V* Memaksa → paksa
Mem- NULL 2 NULL Membaca → baca
Me- NULL 2 NULL Merusak → rusak
Peng- NULL 2 NULL Pengukur → ukur
Peny- S 2 V* Penyapu → sapu
Pen- NULL 2 NULL Penduga → duga
Pem- P 2 V* Pemaksa → paksa
Pem- NULL 2 NULL Pembaca → baca
Di- NULL 2 NULL Diukur → ukur
Ter- NULL 2 NULL Tersapu → sapu
Ke- NULL 2 NULL Kekasih → kasih
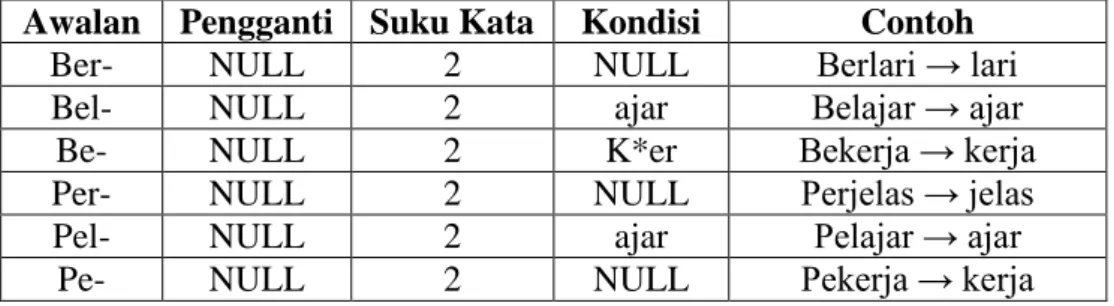
4. Aturan untuk eliminasi prefiks kedua
Tabel 2.5 merupakan daftar aturan yang digunakan untuk menghilangkan prefiks kedua. Seperti yang ditunjukkan dalam Gambar 2.1, proses eliminasi prefiks kedua hanya dilakukan jika pada eliminasi prefiks pertama tidak ditemukan prefiks pertama pada term. Jika term tersebut memiliki prefiks pertama maka proses ini dilakukan setelah eliminasi sufiks. Kondisi seperti
“K*er” berarti kata yang berawalan dengan huruf konsonan dan diakhiri dengan “er” saja yang dianggap memenuhi kondisi.
Tabel 2.5. Aturan Untuk Eliminasi Prefiks Kedua Awalan Pengganti Suku Kata Kondisi Contoh
Ber- NULL 2 NULL Berlari → lari
Bel- NULL 2 ajar Belajar → ajar
Be- NULL 2 K*er Bekerja → kerja
Per- NULL 2 NULL Perjelas → jelas
Pel- NULL 2 ajar Pelajar → ajar
Pe- NULL 2 NULL Pekerja → kerja
5. Aturan untuk eliminasi sufiks
Aturan yang digunakan untuk mengeliminasi sufiks ditunjukkan pada Tabel 2.6. Kondisi yang menjadi syarat pada eliminasi sufiks agak berbeda dengan eliminasi prefiks. Kondisi pada aturan eliminasi sufiks “kan” berarti aturan tersebut dijalankan jika term yang bersangkutan tidak memiliki prefiks berupa ke dan peng. Begitu pula dengan kondisi pada aturan eliminasi sufiks yang lain.
Tabel 2.6. Aturan Untuk Eliminasi Sufiks Akhiran Pengganti Suku
Kata
Kondisi Contoh
-kan NULL 2 Prefix bukan anggota {ke, peng}
Tarikkan → tarik, Mengambilkan →
ambil -an NULL 2 Prefix bukan anggota
{di, meng, ter}
Makanan → makan, Pertemuan → temu -i NULL 2 Prefix bukan anggota
{ber, ke, peng}
Tandai → tanda, Mendapati → dapat
2.4 Web Programming
Suprianto (2008) mendefenisikan web sebagai fasilitas hiperteks untuk menampilkan data berupa teks, gambar, suara, animasi, dan data multimedia lainnya. Situs/web dapat dikategorikan menjadi dua, yaitu web statis dan web dinamis. Web statis adalah web yang berisi/menampilkan informasi-informasi yang sifatnya statis (tetap). Sedangkan web dinamis adalah web yang menampilkan informasi serta dapat berinteraksi dengan pengguna. Web yang dinamis memungkinkan pengguna untuk berinteraksi menggunakan form
sehingga dapat mengolah informasi yang ditampilkan. Web dinamis bersifat interaktif, tidak kaku, dan terlihat lebih indah.
Pemrograman web dibagi menjadi dua kategori, yaitu pemrograman server side dan client side. Pada pemrograman server side, perintah-perintah program (script) dijalankan di server web, kemudian hasil dikirimkan ke browser dalam bentuk HTML biasa. Adapun pada client side, perintah program dijalankan pada web browser sehingga ketika klien meminta dokumen script maka script dapat di- download dari server kemudian dijalankan pada browser yang bersangkutan.