Text Clustering using Frequent Contextual Termset
Tubagus Mohammad Akhriza
School of Communication and Information System Shanghai Jiao Tong University
Shanghai, P.R. China [email protected]
Yinghua MA, Jianhua LI
School of Information Security EngineeringShanghai Jiao Tong University Shanghai, P.R. China
Abstract – We introduce frequent contextual termset (FCT) as an alternative concept of termset construction for text clustering which is produced from the interestingness of documents. Comparing to state-of-art termset, the proposed approach has some advantages: (1) more efficient in termset production (2) more effective in storing the vocabulary amongst documents which express the context amongst documents and (3) more suitable to discover specificity of dataset. To utilize FCT we also introduce frequent contextual termset based hierarchical clustering (FCTHC) which adopts the concept of centroids in K-means with some main differences. The experiment shows that FCT is the correct pattern to perform text clustering and FCTHC provides flexible approach in clusters construction.
Keywords–Frequent Contextual Termset, Frequent Itemset, Text clustering
I. INTRODUCTION
Frequent itemset (FI) has been widely developed and used to perform text clustering in principle that the terms of documents are assumed as the items of transactions. The advantages of this approach compared to distance based clustering such as K-means, agglomerative and divisive approaches have been reported in some papers [2,3,4,5,6] i.e. (1) reduces data dimension (2) provides more understandable cluster description and (3) provides high clustering accuracy.
In FI based text clustering, the construction of termset is done by computing the interestingness between terms in dataset. The termset which satisfies the minimum frequency support (minsupp) is considered as frequent termset. However, the usage of minsupp is dilemmatic particularly in order to discover specificity of dataset. If big minsupp is used then there will be more information lost; if the minsupp
is too small then it will take more time to mine the termset. The other issues which are also considered about the FI approach for text clustering are as follows: (1) Context sensitivity – Because the approach of termset mining in FI is based on terms’ interestingness, then the termset produced seems does not care about the context sensitivity of the terms. For example, the “apple” in document is not always fruit, while in the transaction database practically “apple” has been categorized as fruit. (2) Termset specificity – Rather than to find the popular termset, we consider finding the specific termset in order to discover surprising knowledge in dataset. Specific termset which is expressed in long termset often exist in a small number of documents and is possible discarded if big minimum support is applied in FI mining. Regarding to context sensitivity issue, using the specific
termset is the right way to free the context amongst termsets. For example, saying “Java gamelan programming” and “Java gamelan music instrument” are clearly free the context about “Java gamelan”.
To answer above issues we propose a novel concept about the frequent contextual termset (FCT) which is produced by interestingness of pairs of document. The differences between FCT and FI are briefly described as follows: (1) FCT is produced from interestingness of pairs of document in dataset, while the FI is mined from interestingness of pairs of term in dataset. (2) In FCT production, there is no process of pairing terms and computing the document support of the paired terms. This approach makes the mining of FCT is more efficient than FI
for the same given minsupp.
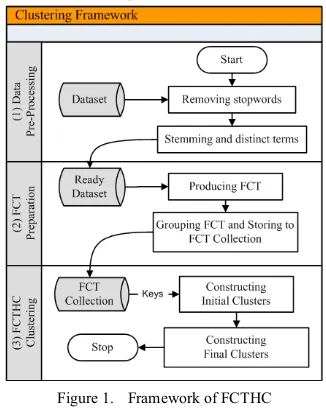
To utilize FCT for text clustering, we introduce FCT based Hierarchical Clustering (FCTHC). The proposed framework is shown as Fig. 1.
Figure 1. Framework of FCTHC
The entire proposed clustering framework contains three stages: (1) Dataset pre-processing “cleans up” the original documents from all classes i.e. by removing stop-words such as numbers, “I”, “and”, “or”, etc.; stemming terms into their root form. The ready dataset is placed in one file which each of line contains one cleaned document. (2) FCT Preparation includes producing FCTs, grouping them and storing them into FCT collection. (3) The clustering process is performed by FCTHC. FCTHC adopts the concept of K-means about the usage of centroids. In our approach “centroid” is called “key” which acts like centroid to construct the initial
2011 International Conference on Information Management, Innovation Management and Industrial Engineering
978-0-7695-4523-3/11 $26.00 © 2011 IEEE DOI
339
2011 International Conference on Information Management, Innovation Management and Industrial Engineering
978-0-7695-4523-3/11 $26.00 © 2011 IEEE DOI 10.1109/ICIII.2011.86
clusters. Keys are taken from FCT collection. The clustering process is divided into two steps: (1) constructing initial clusters (2) constructing final clusters.
Fig.2 shows how FCTs are produced from documents. One document is possible containing more than one topic and the other documents are needed to extract those topics. The information about “programming language” is extracted from D1 by D2. And the “database” is extracted from D1 by D3. The “programming language” and “database” are FCTs.
Figure 2. FCT Production
In the clustering process, FCTs are grouped according to the similarity computed amongst them. Fig. 3 shows the cluster constructed from both “programming language” and “database”.
Figure 3. Clusters of Produced FCT.
Fig. 3 shows an important note that the overlap clusters in frequent termset based clustering is a natural phenomenon. The circles below the clusters are the documents set which support the cluster construction. It is shown that even each cluster’s topic is different but possible they contain the same document which in this illustration is D1.
II. FREQUENT TERMSET BASED CLUSTERING
A new criterion for clustering transactions using frequent itemsets is introduced by Wang et al [1] and the attempt to use frequent itemsets to cluster documents is firstly proposed by Beil et al [2] in principle that this method can also be applied to text clustering by treating terms of a document as items of a transaction. In [2] is described that the key idea is not to cluster the high-dimensional vector space, but to consider only the low-dimensional frequent term sets as cluster candidates. A well-selected subset of the set of all frequent term sets can be considered as a clustering. Beil et al propose Frequent Termset based Clustering (FTC) which is flat clustering and HFTC as the hierarchical FTC. Both of them naturally construct the number of cluster.
Many approaches have been proposed to utilize FI for text clustering. Fung et al [3] propose FIHC to improve FCT/HFCT in disjointing the clusters. Yu et al [4] propose TDC by using frequent closed itemset (FCI) instead of using entire frequent itemset to construct the topic directory. Malik and Kender [5] propose frequent closed interestingness itemset (FCII) by utilizing some interestingness measurements to construct the termsets. Su et al. [6] propose a text clustering based on maximal frequent itemset (MFI).
III. THE FREQUENT CONTEXTUAL TERMSET
A. FCT and FI comparison
Compared to mining the termset by pairing terms in FI, producing termset by pairing document has some advantages: (1) More efficient because we bypass the process of pairing term and the process of finding the support of each termset. The termset produced by our approach must be the interesting termset. (2) More effective and suitable for documents clustering, with the reason that we directly keep the vocabularies between documents. (3) More effective to find specific termset by means that the specificity of terms is not depended on the number of supporting documents but on the specificity coefficient given between documents.
B. More Detail about Frequent Contextual Termset
This section explains more detail about FCT. We believe that a document which has interestingness with the others will posses same termset in some degree of specificity. Supposed D is a document set and Di (i=1,..,n) are the documents of D. Ti is the terms set of Di∈ D. For each pair Di,Dj ∈D, production function P is defined as equation (1)
(
i j)
ji D T D D
D
P: × → ∈ ∩ (1)
× is binary operator which is defined as interestingness of a pair of document Di and Dj as definition 1:
1) Definition 1. A pair of document Di, Dj ∈ D is interesting if satisfies specificity coefficient α such as equation (2) ,(3).
0 , ≥ ≥ ∩ =
× j i j α α
i D D D
D (2)
In equation (2) α is the number of term shared by Di and Dj. The product of P is T ∈ (Di Dj) i.e. the termset which is named as the Contextual Termset (CT). Term “contextual” is given to distinguish the main idea with state-of-art termset i.e. capturing the context of documents.
We argue that the specificity coefficient α can be utilized to free the context amongst documents. For example, supposed that D1=“information retrieval system” and D2=“business information system”. Using equation (2) and different α we have following results:
• If α=1 then |D1D2|≥ 1, T={information, system}, D1 and D2 are considered have three possible contexts i.e. “information”, ”system” or “information system”.
• If α=2 then |D1D2|≥ 2, T={information system}, D1 and D2 have the same context only about “information system”
To record the number of document producing the CT, we propose the Production Support PSupp as follows
2) Definition 2. The Production Support (PSupp) of contextual termset is determined by the number of document produce the termset using definition 1. Supposed DP is a set of Documents which produce a CT, then Psupp is defined as equation (3)
Psupp(CT) = |DP| (3)
340
As a comparison, in FI mining we compute supp(T) i.e. the number of documents which contain termset T.
3) Definition 3. Frequent Contextual Termset (FCT) is contextual termset which PSupp satisfies given minimum support Minsupp.
Psupp(CT) ≥ Minsupp (4)
Minsupp could be a fraction or a number of documents producing the CT.
C. Producing FCT
The algorithm of FCT production using equation (2) is shown in Algorithm 1.
Algorithm 1: FCT Production
1. Load dataset containing doc
2. Input alpha Å minimum specificity coefficient
3. Input PSupp Å desired minimum PSupp
4. For i= 0 to dataset.size-1
FCTs are saved into FCT Collection in alphabetical order, grouped by FCT, and summarized by the document identifier i and j which produced them. On line 5.e, the CTs which do not satisfy α (alpha) are saved as isolated CT. In proposed FCTHC algorithm, they are utilized in process of constructing the final clusters.
IV.FCT BASED HIERARCHICAL CLUSTERING
The overall proposed clustering approach is divided by two steps: (1) Constructing initial clusters (2) Constructing final clusters. We introduce FCT based Hierarchical Clustering (FCTHC) to utilize FCT for performing text clustering. The concept of K-means [7] is adopted i.e. using centroids to construct the clusters but with some important difference approaches as follows:
1) In our approach, we call the “centroid” as the “key” and acts as the initial point of cluster construction. Each key computes its similarity with the rest of available FCT and will take the FCT as its member if satisfies the similarity threshold S.
2) The key is utilized in different ways compare to K-means as follows:
a. Keys can be chosen with desired length L.
b. The first key is taken randomly from FCT collection.
c. The next keys are chosen sequentially from the rest of FCT. We consider choosing the key which doesn’t share same term with previous selected keys. The idea is to provide clusters with different topic although it is still possible that the member of cluster shares the same term with the others cluster.
d. The FCTs which have been taken as a cluster’s member can not be used to other clusters construction.
e. The combination usage of key length L and similarity threshold S can be utilized to construct the hierarchy.
3) FCTHC naturally doesn’t accept the number of clusters as input but it provides clusters merging to achieve the N number of final clusters. While K-means accepts desired number of clusters K as the main feature.
The overall algorithm of initial clusters construction is shown in algorithm 2. The FCTCollection loaded on line 3 is FCT collection which is produced from algorithm 1. The
Cluster(key) on line 9 is a variable for the cluster which is constructed from key.
Algorithm 2: Initial Clusters Construction
1. Input L Å key length
2. Input S Å minimum similarity threshold between key and FCTs
3. Load FCTcollection
4. theRestFCT Å FCTcollection
5. Key Å select randomly the first key with length=L
6. Do
7. For each fct in theRestFCT
8. if similarity(key,fct) satisfies S then
9. Cluster(key) += fct
10. theRestFCT –= fct
11. Next
12. Key Å select next key with length=L
13. Loop to step 6 until no key available in theRestFCT
14. Clusters = ∪{Cluster(Key)}
15. ClusteredFCT = fct ∈ Clusters
16. UnclusteredFCT = FCTcollection – ClusteredFCT
Algorithm 2 uses equation (5) as similarity measurement:
j
After the initial clusters are constructed, the next step is constructing the final clusters. To construct the final clusters, we adopt the approach proposed in [6] i.e. (1) merging the clusters i.e. by merging the DS(C), document set of cluster C (2) placing documents of un-clustered FCTs and documents of CTs which are isolated when producing FCT into existing clusters. We propose following algorithm to merge the clusters which actually follows the FCTHC algorithm.
Algorithm 3: Clusters Merging
1. Input N Å a fixed number for final cluster number
2. Input OTH Å overlapping threshold
3. Select N number of DS(C) as keys which each chosen DS(C)
has big size but low overlap amongst keys with respect to OTH. This to distinguish the keys as far as possible.
4. Assign each of the rest of DS(C) into a selected key which
returns highest overlapping score
Algorithm 3 uses equation (5) as overlap function by assuming DS(Ci) and DS(Cj) as Di and Dj respectively.
After merging process finished, the next process is to place documents of the un-clustered FCT and documents of CTs which are isolated during FCT production into existing clusters. The document is placed into the cluster which returns highest similarity. Equation (5) is also used as similarity measurement for this process.
341
V. EXPERIMENTAL RESULT
A. Dataset
The dataset used to examine FCT and FCTHC quality is the same as the dataset used in [2, 3] i.e. Classic4 by involving all 4 classes with 7095 documents i.e. class Med, CISI, CRAN and CACM with 1033, 1460, 1398, 3204 documents respectively.
B. Quality Measurement and Analysis
We use F-measure formula as has been reported in [7]. For each class i and cluster j, first we compute the Recall(i,j) and Precision(i,j) to get F(i,j) as follows:
R(i,j) = Recall(i,j) = nij/ni (6)
P(i,j) = Precision(i,j) = nij/nj (7)
F(i,j) = (2*R(i,j)*P(i,j)) / (P(i,j)+R(i,j)) (8)
nij is the number of member class i in cluster j. ni is number of member of class i, nj is number of member of cluster j.
¦
=
i
i F i j
n n
F max{ (, )} (9)
The Overall-F is shown in Equation (9). The max F is taken over all clusters at all levels and n is the number of data points.
The results of HFTC, FIHC and Bi K-means which are reported in [3] are directly used and compared to FCTHC because we use the same dataset. We run the algorithm using keys with length L=5 and L=10 (abbreviated as L5 and L10 respectively). The similarity threshold S is set to 1 which means that the key will take FCT as its member if they have similar term at least 1 term.
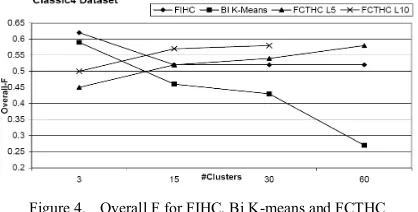
The comparison result of HFTC and FCTHC is separated with others since naturally, both of them do not accept cluster number as input. The overall F of HFTC i.e. 0.61 shows better performance than FCTHC L5 and L10 i.e. 0.54 and 0.55 respectively.
For determined cluster’s number, the comparison of overall F for FIHC, Bi K-means and FCTHC are presented on Fig. 4 and shows that FCTHC performs better than FIHC and BI K-means for bigger number of clusters. This result is important for text clustering particularly for the user who wants to explore more detail the topic or context of dataset.
Figure 4. Overall F for FIHC, Bi K-means and FCTHC
TDC [4] implements the FCI. HCCI [5] and MFTS [6] also implement FCII and MFI which are the condensed representation of FI [8] and have the itemset number less
than entire FI. Accordingly, they show the better performance particularly for the runtime process. We note that the development of the condensed representation of FCTs is important for our future work.
VI. CONCLUSION AND FUTURE WORK
A. Conclusion
Compared to state-of-art frequent termset, FCT has some advantages which have been explained in section 3.A with respect to the dataset used. We have also introduced a novel text clustering based on FCT i.e. FCTHC which in FI based text clustering is also a novel approach. It provides flexible approach to perform text clustering by utilize the keys as starting point for cluster construction. By setting up the parameters the user is able to get the cluster with desired specificity level. It is shown that the pattern found in the form of FCT is comparable with state-of-art approaches to perform text clustering with respect to overall F.
B. Future Work
Further investigation of FCT for the other datasets is our next work. The development of condensed representation of FCT collection will be also an important future work in order to improve clustering quality. FCTHC will be improved particularly in keys selection, constructing the final clusters particularly the merging and after-merging process.
ACKNOWLEDGMENT
This work is funded by the National Natural Science Foundation of China under grant No.60803089, and partly funded by the 973 Project under grant No. 2010CB731403/2010CB731406.
REFERENCES
[1] K. Wang, C. Xu, and B. Liu. “Clustering transactions using large items”. In Proc.CIKM’99, pages 483–490, 1999.
[2] F. Beil, M. Ester and X.W. Xu. “Frequent term-based text clustering”. Proceedings of ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. 2002:436-442.
[3] B.C.M. Fung, K. Wang and M. Ester. “Hierarchical text clustering using frequent itemsets”. Proceedings of SIAM International Conference on Data Mining”. 2003:59-69.
[4] H. Yu, D. Searsmith, X. Li and J. Han, "Scalable Construction of Topic Directory with Nonparametric Closed Termset Mining", In Proc. Fourth IEEE International Conference on Data Mining (ICDM'04), 2004, pp. 563-566.
[5] H.H.Malik and J.R. Kender, "High quality efficient hierarchical text clustering using closed interesting itemsets". In Proceedings of the IEEE International Conference on Data Mining (ICDM 2006), Hong Kong.
[6] Chong Su, Qingcai Chen, Xiaolong Wang, Xianjun Men. “Text Clustering Approach Based on Maximal Frequent Term Sets”. Proceedings of the 2009 IEEE International Conference on Systems, Man, and Cybernetics San Antonio, TX, USA - October 2009. [7] M. Steinbach, G. Karypis, V. Kumar. “A comparison of text
clustering techniques”.Technical Report, University of Minnesota, 2000: 00-34.
[8] Taneli Mielikainen. “Transaction Databases, Frequent Itemsets, and Their Condensed Representations”. 2006. Citeseerx. Vol. 31. pp. 139 – 164. doi: 10.1.1.106.969.
342