Prediksi Keputusan Minat Penjurusan Siswa SMA Yadika 5
Menggunakan Algoritma Naïve Bayes
Detrinal Putra, Arief Wibowo
Program Studi Teknik Informatika, Fakultas Teknologi Informasi
Universitas Budi Luhur
[email protected], [email protected]
Abstrak
Minat belajar adalah hal yang penting dalam proses pembelajaran, karena hal tersebut akan mempermudah siswa dalam memahami pembalajaran di sekolah. Kurikulum 2013 dikembangkan untuk mempersiapkan siswa dalam memilih peminatan dengan tujuan untuk melatih kemapuan dan mengasah perkembangan seorang siswa yang akan melanjutkan pendidikan selanjutnya yaitu Sekolah Menengah Atas (SMA). Penelitian ini menggunakan algoritma Naïve Bayes dengan teknik pengklasifikasi data mining untuk memperkirakan atau memprediksi keputusan minat penjurusan di SMA. Hasil penelitian menunjukkan bahwa dengan menggunakan algoritma Naïve Bayes pada data siswa untuk memprediksi keputusan peminatan jurusan diperoleh tingkat akurasi sebesar 93.75%, tingkat presisi sebesar 83.33%, dan tingkat recall sebesar 100%. Hasil pemodelan dengan algoritma Naïve Bayes dapat diimplementasikan dalam bentuk aplikasi untuk memprediksi keputusan minat penjurusan SMA.
Keywords: Data mining, Naïve Bayes, Peminatan Siswa, Prediksi, Klasifikasi
1. Pendahuluan
Pentingnya minat belajar dalam proses pembelajaran mempengaruhi keputusan dalam penentuan penjurusan bagi siswa SMA. Bila tidak ada minat dari siswa terhadap pembelajaran maka akan muncul kesulitan dalam melakukan pembelajaran yang dilalui. Minat dalam sebuah pembelajaran adalah penerimaan akan suatu hubungan antara diri sendiri dengan sesuatu yang ada diluar diri sendiri semakin besar minat pembelajaran yang akan diambil oleh siswa itu sendiri. Sebagaimana telah ditetapkan oleh Menteri Pendidikan RI bahwa Kurikulum 2013 dikembangkan untuk mempersiapkan siswa/i agar menentukan kemampuan dan mengasah mental seorang siswa/i yang akan melanjutkan ke jenjang Sekolah Menengah Atas (SMA). Pada kurikulum 2013 ini ada proses pemilihan kelompok peminatan, yang merupakan bagian penting untuk perkembangan seorang siswa/i yang akan masuk ke jenjang selanjutnya, serta menjadi pedoman memlilih jurusan untuk masuk ke tahap pendidikan selanjutnya. Peminatan adalah suatu keputusan yang dilakukan peserta didik untuk memilih kelompok matapelajaran sesuai minat, bakat, dan kemampuan selama mengikuti pembelajaran di SMA. Pemilihan peminatan dilakukan atas dasar kebutuhan untuk melanjutkan keperguruan tinggi. Demikian juga struktur kurikulum SMA sebagaimana tercantum dalam Permendikbud nomor 69 tahun 2013, mata pelajaran yang dapat diikuti dan diambil terdiri atas Kelompok mata pelajaran Wajib dan mata pelajaran Pilihan. Mata pelajaran pilihan terdiri atas pilihan akademik untuk Sekolah Menengah Atas. Mata pelajaran pilihan ini memberi corak kepada fungsi satuan pendidikan, dan di dalamnya terdapat pilihan sesuai dengan minat peserta didik. Struktur ini menerapkan prinsip bahwa peserta didik merupakan subjek dalam belajar yang memiliki hak untuk memilih matapelajaran sesuai dengan minatnya [1].
Data mining merupakan suatu proses eksraksi atau penggalian data yang belum diketahui sebelumnya, setelah melakukan penganalisaan data ternya memiliki pola tertentu. Munculnya data mining dilatarbelakangi dengan adanya data explosion. Dalam data mining, data yang tersimpan semakin banyak atau menumpuk
dengan tidak disertai pemanfaatan atau pengolahan lebih lanjut [2]. Data mining berusaha melakukan, menggali atau mengolah data dengan tujuan menemukan pola-pola tersembunyi. Dengan pola-pola-pola-pola tersebut maka akan menghasilkan informasi atau pengetahuan yang berharga dan bermanfaat. Naïve Bayes merupakan algoritme yang terdapat pada data mining. Naïve Bayes merupakan pengklasifikasian dengan menggunakan Teknik probabilitas dan statistik, untuk melakukan prediksi peluang yang akan terjadi [3]. Berdasarkan latar belakang tersebut maka perlu dilakukan penelitian data mining menggunakan algoritme Naïve Bayes untuk memprediksi peminatan siswa SMA Yadika 5, hasil penelitian diimplementasikan berupa aplikasi prediksi keputusan peminatan yang dapat dimanfaatkan menjadi strategi dalam proses pembelajaran.
2. Metodologi Penelitian
2.1 Tahap Penelitian
Pada penelitian ini data yang didapat berdasarkan data set yang dikumpulkan dari sekolah Yadika 5 angkatan 2016-2018 dengan total sebanyak 306 data siswa. Data dipakai sebagai proses data training dan data testing dengan menggunakan pembagian 80% : 20%. Salah satu pendekatan yang bisa dilakukan adalah dengan mengoptimalkan pemanfaatan data yang sudah ada untuk mengetahui siswa/i yang akan diputuskan masuk peminatan. Langkah-langkah untuk melakukan data mining mengikuti aturan KDD sebagai berikut [4]:
a) Data Seletion
Pemilihan (seleksi) data dari sekumpulan data operasional perlu dilakukan sebelum tahap penggalian informasi dalam KDD dimulai. Data hasil seleksi yang akan digunakan untuk proses data mining, disimpan dalam suatu berkas terpisah dari basis data operasional.
b) Pre-processing/Cleaning
Proses cleaning antara lain membuang duplikasi data, memeriksa data yang tidak konsisten dan memperbaiki kesalahan pada data. Pada proses ini dilakukan juga proses enrichment, yaitu proses memperkaya data yang sudah ada dengan data atau informasi lain yang relevan dan diperlukan untuk KDD.
c) Transformation
Coding adalah proses transformasi pada data yang telah dipilih, sehingga data tersebut sesuai untuk proses data mining.
d) Data Mining
Data Mining adalah proses mencari pola atau informasi menarik dalam data terpilih dengan menggunakan teknik atau metode tertentu.
e) Interpretation/Evaluation
Pola informasi yang dihasilkan dari proses data mining diterjemahkan menjadi bentuk yang lebih mudah dimengerti oleh pihak yang berkepentingan.
2.2 Algoritma Naïve Bayes
Naïve Bayes merupakan salah satu algoritma yang terdapat pada teknik klasifikasi. Naive bayes merupakan pengklasifikasian dengan metode probabilitas dan statistik yang ditemukan oleh ilmuan Inggris Thomas Bayes, yaitu memprediksi peluang dimasa depan bedasarkan pengalaman dimasa sebelumnya sehingga dikenal sebagai Teorema Bayes. Teorema bayes mimiliki persamaan umum [5]:
(1)
Adapaun:
X = Data class yang belum diketahui
P(H|X) = Probabilitas hipotesis H berdasarkan kondisi x(posterioriprobobality) P(H) = Probabilitas hipotesis H (priorprobability)
P(X|H) = Probabilitas X berdasarkan kondisi pada hipotesis H P(X) = Probabilitas X
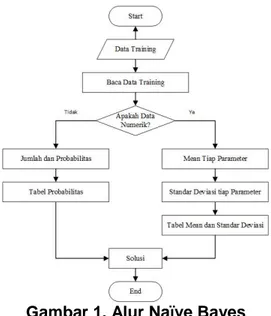
Alur dari metode Naïve Bayes sebagai berikut [6]: a. Baca data training
b. Hitung jumlah data probabilitas, namun apabila data numerik maka:
c. Cari nilai mean dan standar deviasi dari masing-masing parameter yang merupakan data numerik
d. Cari nilai probabilitas dengan cara menghitung jumlah data yang sesuai dari dari kategori yang sama dibagi dengan jumlah data pada kategori tersebut.
e. Mendapatkan nilai dalam table mean, standar deviasi dan probabilitas
Gambar 1. Alur Naïve Bayes
2.3 Pengujian dengan Confusion Matrix
Pada tahap ini pengujian model penelitian dilakukan dengan metode Confusion Matrix yang mempresentasikan hasil evaluasi model dengan menggunakan tabel matrik, Jika dataset terdiri dari 2 kelas, kelas pertama dianggap positif dan kelas kedua dianggap negatif. Evaluasi menggunakan confusion matrix menghasilkan nilai Akurasi, Precision, Recall, serta F-Measure. Akurasi dalam klasifikasi merupakan presentasi ketepatan
record data diklasifikasikan secara benar setelah dilakukan pengujian pada hasil klasifikasi. Precision merupakan proposikasi yang diprediksi positif yang juga positif benar pada data sebenarnya. Recall merupakan proporsi kasus positif yang sebenarnya diprediksi positif secara benar.
True Positive (TP) merupakan jumlah record postif dalam dataset yang diklasifikasikan positif. True Negative (TN) merupakan jumlah record negative dalam dataset yang diklasifikasikan positif. False Positive (FP) merupakan jumlah record negatif dalam dataset yang diklasifikasikan positif. False Negative (FN) merupakan jumlah record positif dalam dataset yang diklasifikasikan negatif. Berikut adalah persamaan model Confusion Matrix [7]:
Accuracy adalah jumlah perbandingan data yang benar dengan jumlah keseluruhan data
(2)
Precision digunakan untuk mengukur seberapa besar proporsi dari kelas data positif yang berhasil diprediksi dengan benar dari keseluruhan hasil prediksi kelas positif.
(3)
Recall digunakan untuk menunjukkan presentase kelas data positif yang berhasil diprediksi benar dari keseluruhan data kelas positif
(4)
3. Hasil dan Pembahasan
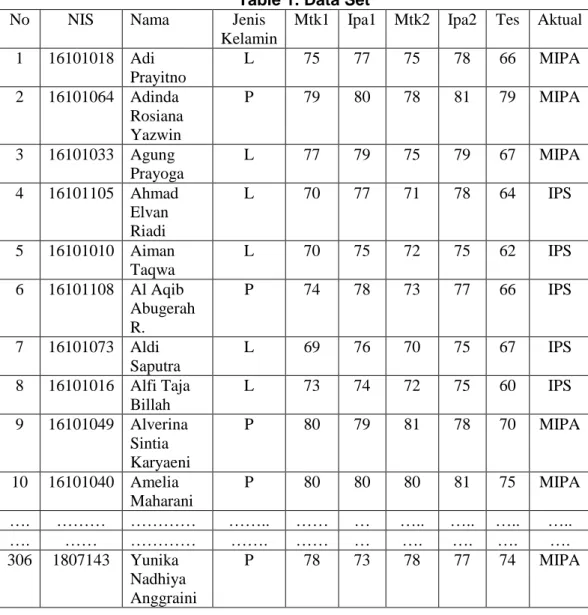
Pada tahap pengumpulan data didapatkan berjumlah 306 data, yang dimana data tersbut dibagi menjadi dua bagian yaitu 245 untuk data training dan 61 data untuk dijadikan testing. Pada pengumpulan data atribut yang didapat sebanyak 9 atribut yaitu, NIS, Nama, Jenis Kelamin, Nilai Mtk semester 1, Nilai Ipa semester 1, Nilai Mtk semester 2, Nilai Ipa semester 2, Nilai Tes, dan juga hasil penentuan dari pihak sekolah yang berfungsi sebagai label atau target. Dari 9 atribut tersebut maka atribut yang akan digunakan untuk perhitungan hanya 5 atribut saja yaitu, Nilai Mtk semester 1, Nilai Ipa semester 1, Nilai Mtk semester 2, Nilai Ipa semester 2, dan Nilai tes. Bentuk data dapat dilihat pada Tabel 1.
Table 1. Data Set
No NIS Nama Jenis
Kelamin
Mtk1 Ipa1 Mtk2 Ipa2 Tes Aktual 1 16101018 Adi Prayitno L 75 77 75 78 66 MIPA 2 16101064 Adinda Rosiana Yazwin P 79 80 78 81 79 MIPA 3 16101033 Agung Prayoga L 77 79 75 79 67 MIPA 4 16101105 Ahmad Elvan Riadi L 70 77 71 78 64 IPS 5 16101010 Aiman Taqwa L 70 75 72 75 62 IPS 6 16101108 Al Aqib Abugerah R. P 74 78 73 77 66 IPS 7 16101073 Aldi Saputra L 69 76 70 75 67 IPS 8 16101016 Alfi Taja Billah L 73 74 72 75 60 IPS 9 16101049 Alverina Sintia Karyaeni P 80 79 81 78 70 MIPA 10 16101040 Amelia Maharani P 80 80 80 81 75 MIPA …. ……… ………… …….. …… … ….. ….. ….. ….. …. …… ………… ……. …… … …. …. …. …. 306 1807143 Yunika Nadhiya Anggraini P 78 73 78 77 74 MIPA
Pada Tabel 1 terlihat bahwa total data ada 306 baris, dan data yang disajikan tersebut akan dijadikan sebagai data training maupuan data testing. Data tersebut selanjutnya akan melewati proses perhitungan untuk menentukan nilai dari setiap atribut yang sudah kita dapatkan, antara lain mean dan standar deviasi.
a) Menghitung mean dan standart deviasi
Nilai mean dan standart deviasi diambil dari masing – masing atribut yang ada pada table di atas, antara lain Mtk1, Ipa1, Mtk2, Ipa2, dan tes pada setiap kategori. Hasil proses yang menunjukan nilai mean dan standart deviasi terlihat pada Tabel 2.
Tabel 2. Hasil Perhitungan Mean
Kelas Mtk1 Ipa1 Mtk2 Ipa2 Tes
Mipa 78.789 77.872 78.413 78.294 68.174 Ips 74.886 75.241 74.976 75 60.157
Pada Tabel 2 memperlihatkan hasil perhitungan mean dari data training yang sudah di sediakan.
Tabel 3. Hasil Perhitungan Standar Deviasi
Kelas Mtk1 Ipa1 Mtk2 Ipa2 Tes Mipa 4.032 3.44 3.462 3.066 5.326 Ips 4.643 3.662 3.815 3.492 7.225
Pada Tabel 3 memperlihatkan hasil standar deviasi dari data training yang sudah disiapkan sebelumnya.
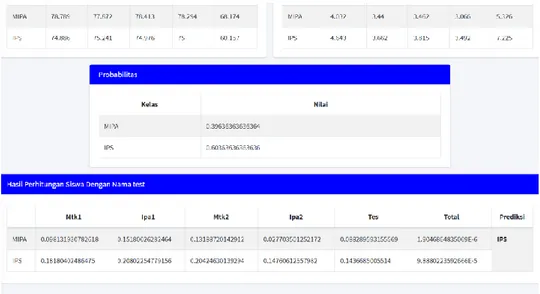
Tabel 4. Probabilitas
Kelas Nilai
MIPA 0.39636363636364 IPS 0.60363636363636
Pada Tabel 4 memperlihatkan hasil nilai probabilitas dari data training yang sudah ditentukan.
Untuk menguji data yang sudah didapat, diperlukan proses pengujian data untuk menentukan prediksi peminatan siswa dapat dilakukan dengan menggunakan data sebagaimana dijelaskan pada Tabel 5.
Table 5. Data Hitung Manual
Nama Mtk1 Ipa1 Mtk2 Ipa2 Tes Prediksi
Herwan Prastio 74 75 75 72 62 ………
Pada data di Tabel 5 akan dilakukan pengujian manual terhadap nilai yang sudah di miliki. Tahap pertama adalah menghitung Probabilitas mtk1 untuk atribut kelas.
√ √ Menghitung Probabilitas ipa1 untuk atribut kelas
√ √ Menghitung Probabilitas mtk2 untuk atribut kelas
√ √ Menghitung Probabilitas ipa2 untuk atribut kelas
√ √ Menghitung Probabilitas tas untuk atribut kelas
√ √
Mengkalikan semua hasil sesuai dengan data testing untuk mencara kelas
Dengan hasil perhitungan data di atas dapat diprediksi bahwa siswa yang memiliki nilai atribut tersebut memiliki hasil Prediksi=IPS.
3.2 Implementasi System
Setelah melakukan perhitungan data mining dan didapatkan sebuah hasil, maka perhitungan tersebut dapat di uji dengan menggunakan aplikasi yang dibuat. Berikut adalah tampilan dari prediksi peminatan siswa menggunakan algoritma Naïve Bayes. Mulai dari data training, data testing, data baru, perhitungan hasil prediksi dan akurasi.
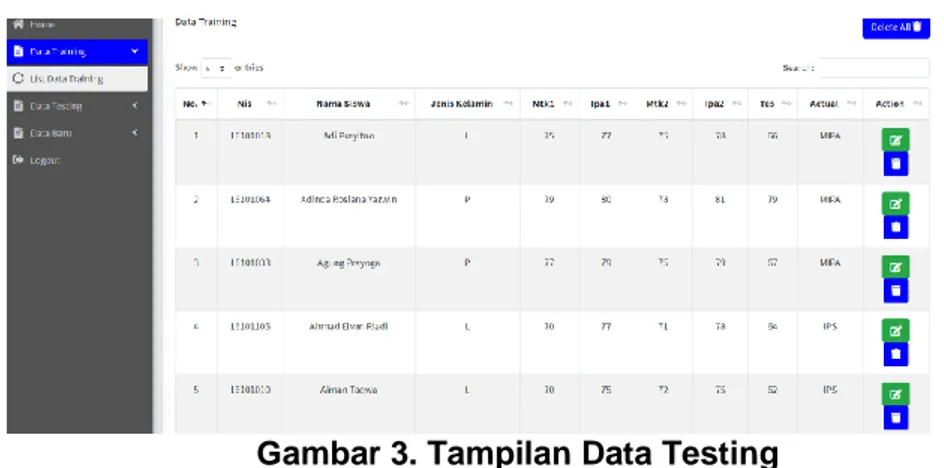
Gambar 2. Tampilan Data Training
Pada gambar 2, merupakan tampilan dari data training dimana terdapat fungsi untuk menambah data atau pun mengimport data training, yang dimana data training tersebut nanti nya akan diproses untuk perhitungan Naïve Bayes.
Gambar 3. Tampilan Data Testing
Pada gambar 3 merupakan tampilan dari data training dimana fungsi yang terdapat didalam tampilan data training ini hampir sama dengan gambar 2. Data testing ini nantinya akan digunakan untuk menentukan hasil prediksi yang tepat dengan menggunakan algoritma Naïve Bayes pada aplikasi yang dikembangkan.
Pada gambar 4 merupakan proses hasil perhitungan prediksi menggunakan algoritma Naïve Bayes berdasarkan data training yang sudah di import. Setelah proses perhitungan selesai maka akan terlihat hasil prediksi tersebut.
Gambar 5. Hasil Perhitungan
Pada Gambar 5 terlihat hasil perhitungan dari data baru yang sebelumnya tidak memiliki kelas peminatan. Setelah dilakukan pemprosesan maka akan menampilkan hasil dari prediksi yang dilakukan.
Gambar 6. Tampilan Uji Akurasi
Pada gambar 6 memperlihatkan hasil dari pengolahan data testing maka akan diperoleh hasil pengujian menggunakan metode Confusion Matrix untuk melihat nilai dari akurasi, precision, dan recall.
3.3 Uji Akurasi
Setelah selasai melakukan pengolahan terhadap data training maka akan diperoleh akurasi pada pelatihan data. Untuk perhitungan akurasi menggunakan Confusion Matrix
dilakukan dengan cara menjumlah nilai True Positive dengan True Negative kemudian dibagi dengan total keseluruhan data yang ada. Perhitungan tersebut menghasilkan nilai-nilai berikut:
membagi True Positive dengan total penjumlah dati False Positive dan True Positive dari data yang ada menjadi
. Nilai recall didapat dengan cara
menghitung nilai True Positive yang dibagi dengan total data yang dijumlahkan antara
False Negative dengan True Positive dari data, yaitu sebesar
.
4. Kesimpulan
Berdasarkan hasil dan pembahasan di atas dapat diambil kesimpulan bahwa prediksi penentuan peminatan jurusan dapat dilakukan dengan menggunakan algoritma Naïve Bayes pada data siswa. Dari hasil pemrosesan data siswa, diperoleh nilai akurasi model Naïve Bayes sebesar 93.75%, precision sebesar 83.33%, dan recall sebesar 100%. Model yang diperoleh dapat diimplementasikan dalam bentuk aplikasi yang dibangun untuk digunakan pihak sekolah dalam menentukan strategi pembelajaran dan penentuan keputusan peminatan siswa.
DAFTAR PUSTAKA
[1] Yusuf Ali Kusnindar, “Pengertian Peminatan, Lintas Minat, dan Pendalaman Minat,” blogspot.com, 2014.
http://bezoes.blogspot.com/2014/05/pengertian-peminatan-lintas-minat-dan.html#:~:text=Peminatan adalah suatu keputusan yang,kebutuhan untuk melanjutkan keperguruan tinggi.
[2] R. Wijayatun and Y. Sulistyo, “Prediksi Rating Film Menggunakan Metode Naive Bayes,” J. Tek.
Elektro, vol. 8, no. 2, pp. 60–63, 2016.
[3] H. Naparin, “Klasifikasi Peminatan Siswa SMA Menggunakan Metode Naive Bayes,” Syst. Inf. Syst.
Informatics J., vol. 2, no. 1, pp. 25–32, 2016, doi: 10.29080/systemic.v2i1.104.
[4] D. Nofriansyah, K. Erwansyah, and M. Ramadhan, “Penerapan Data Mining dengan Algoritma Naive Bayes Clasifier untuk Mengetahui Minat Beli Pelanggan terhadap Kartu Internet XL ( Studi Kasus di CV. Sumber Utama Telekomunikasi),” J. Saintikom, vol. 15, no. 2, pp. 81–92, 2016. [5] R. A. Saputra and S. Ayuningtias, “Penerapan Algoritma Naive Bayes Untuk Penentuan Calon
Penerima Beasiswa Pada Smk Pasim Plus Sukabumi,” Swabumi, vol. IV, no. 2, pp. 114–120, 2016. [6] Bustami, “Penerapan Algoritma Naive Bayes,” J. Inform., vol. 8, no. 1, pp. 884–898, 2014. [7] M. F. Rifai, H. Jatnika, and B. Valentino, “Penerapan Algoritma Naïve Bayes Pada Sistem Prediksi
Tingkat Kelulusan Peserta Sertifikasi Microsoft Office Specialist (MOS),” Petir, vol. 12, no. 2, pp. 131–144, 2019, doi: 10.33322/petir.v12i2.471.