Steps of an Ideal Research Program in the Empirical Social Sciences: From Context of Discovery to Context of Justification
Erich H. Witte1 Frank Zenker2 University of Hamburg, Germany Lund University, Sweden
Abstract
The current crisis in the social sciences, especially in psychology, is not readily comparable to the usual crisis discourse, because many researchers have now in fact lost confidence in knowledge which is based on empirical results. This paper argues that, in order to make headway, researchers must seek to integrate extant knowledge in a research program, and they must adapt their inference strategy as they go along. This entails moving from the context of discovery to the context of justification. Justification (confirmation) is a comparative notion, however, and therefore possible only when alternative hypotheses are specified. Without such specification no justification can be achieved, and so only a vague and intuitive confidence in our empirical discoveries would remain warranted.
Keywords: confirmation, knowledge accumulation, replicability crisis, research program, significance test
1 Prof. (em.) Dr. Erich H. Witte Social and Economic Psychology University of Hamburg
Von-Melle-Park 5 D-20146 Hamburg
http://www.epb.uni-hamburg.de/de/personen/witte-0
2 Frank Zenker
Department of Philosophy Lund University
Kungshuset, Lundagård 22 222 Lund, Sweden [email protected]
Steps of an Ideal Research Program in the Empirical Social Sciences: From Context of Discovery to Context of Justification
Erich H. Witte3 Frank Zenker4 University of Hamburg, Germany Lund University, Sweden
Abstract: The current crisis in the social sciences, especially in psychology, is not readily comparable to the usual crisis discourse, because many researchers have now in fact lost confidence in knowledge which is based on empirical results. This paper argues that, in order to make headway, researchers must seek to integrate extant knowledge in a research program, and they must adapt their inference strategy as they go along. This entails moving from the context of discovery to the context of justification. Justification (confirmation) is a comparative notion, however, and therefore possible only when alternative hypotheses are specified. Without such specification no justification can be achieved, and so only a vague and intuitive confidence in our empirical discoveries would remain warranted.
Keywords: confirmation, knowledge accumulation, replicability crisis, research program, significance test
3 Prof. (em.) Dr. Erich H. Witte Social and Economic Psychology University of Hamburg
Von-Melle-Park 5 D-20146 Hamburg
http://www.epb.uni-hamburg.de/de/personen/witte-0
4 Frank Zenker
Department of Philosophy Lund University
Kungshuset, Lundagård 22 222 Lund, Sweden [email protected]
1. Introduction
Psychology and other empirical social sciences currently experience a state of crisis. This is not an entirely new claim (Sturm & Mühlberger, 2012); scholars have
diagnosed a crisis of their discipline from 1889 (Willy) to the present day, most recently in Perspectives on Psychological Science (Pashler & Wagenmakers, 2012; Spellman, 2012). Similarly, the special crisis of significance testing is as old as the significance test (Harlow, Mulaik & Steiger, 1997; Witte, 1980). Regardless, we certainly are in a crisis when many of us have lost any confidence as to which among a plethora of published empirical results can be trusted. What do we really know from our results?
Below, we provide a diagnosis of the current crisis (Sect. 2). If we are right, then the predominant use of statistical inference methods is implicated negatively. We by and large seem to employ such methods in underpowered studies which produce theoretically disconnected one-off discoveries. Such results, we argue, are neither stable and replicable discoveries nor justifications of a theoretical hypothesis, something that can only arise in the framework of a cumulative research program. We lay out four steps of such a program (Sect. 3), and go on to argue that our scientific knowledge can only improve by entering the context of justification (Sect. 4). Moreover, we point out critically that many of our best theories currently remain theoretically underdeveloped, because they do not yet predict precise effects (Sect. 5). Unless the community makes significant headway in conducting coordinated long term research endeavors, or so we prophesize, the crisis discourse shall linger on.
2. The status quo
solutions proposed one also finds the intensification of communication and the exchange of data, or the exchange of the design characteristics of experimental studies prior to an experiment (Nosek & Bar-Anan, 2012).
The crisis seems to involve a dilemma between publishing significant results, on the one hand, and increasing the trustworthiness of scientific knowledge, on the other (Nosek, Spies & Motyl, 2012; Bakker, van Dijk & Wicherts, 2012). Generally, a very long path leads from the discovery of a new effect to its theoretical explanation. But the distinction—well-known in the philosophy of science—between a context of discovery and a context of justification (Reichenbach, 1938; Schickore & Steinle, 2006) has been mostly ignored in our fundamental approach to theory testing. Significance tests and Bayes-tests alike —whether with a Cauchy distributed prior or a normally distributed prior (Dienes, 2012; Rouder et al., 2009; Wagenmakers et al., 2012)—do normally not specify alternative explanatory hypotheses. Usually, only the null hypothesis is well-specified, so that a sufficiently large deviation from this parameter can be accepted as a non-random result, which is then taken to translate into a discovery of theoretical interest. But a statistically supported discovery of this kind does emphatically not amount to a justification (confirmation) of a parameter that is derived from a theory.
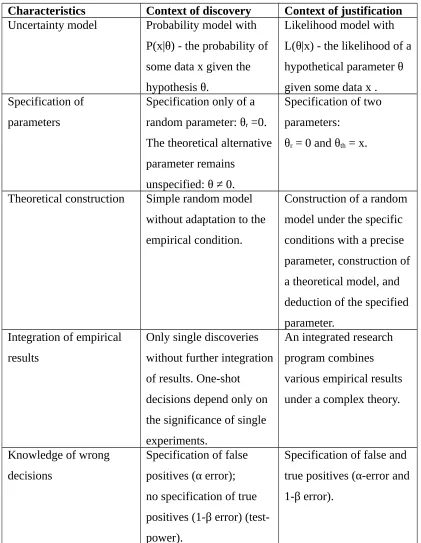
Characteristics Context of discovery Context of justification Uncertainty model Probability model with
P(x|θ) - the probability of some data x given the hypothesis θ.
Likelihood model with L(θ|x) - the likelihood of a hypothetical parameter θ
Theoretical construction Simple random model without adaptation to the
Table 1. Comparison of salient characteristics in the context of discovery and the context of justification
because the results obtained up to this point did lend a degree of support to the null hypothesis that was 6.2 times larger than the degree lent to the alternative
hypothesis, under the knowledge-based prior with a more acceptable distribution of the effects observed (Bem, Utts & Johnson, 2011). Such support is considered “substantial evidence” for the null-hypothesis (Jeffreys, 1961; Wagenmakers et al., 2011).
The method of hypothesis testing that Wagenmakers et al. employed is based on the sequential analysis developed by Wald (1947). As a tool within a research strategy, this method oscillates between the context of discovery and the context of
justification. The method cannot reflect a purely confirmatory strategy, because neither the alpha error (the chance of a false positive result) nor the beta error (the chance of a false negative result) in sequentially testing the two specified hypotheses (p=0.50 against p=0.531 given in Wagenmarkers et al.’s case, based on Bem’s (2011) results) are known if the number of observations varies with the observed results. Without knowledge of these errors, the replicability and the trust in the observed empirical result as a theoretical foundation for a justification is missed. The scientific community needs trustworthy data to test their theories, and such trustworthiness is owed in large part to the knowledge of errors (Mayo, 1996).
The crucial question is whether a given test condition is strong enough to provide for a clear justification of the null-hypothesis. After all, the same sequential testing strategy would result in the acceptance of the alternative hypothesis if only one had stopped testing after about 38 sessions, something to be read off from the curve in figure 2 (see Wagenmakers et al., 2012, 636; Simmons et al., 2011 illustrate the same problem). If we accept an effect size of g=3.1% as a theoretical specification originating from empirical results obtained in the past (see Bem, 2011, 409,
When employing this kind of empirical rigor as a decision criterion, the null hypothesis to be accepted must be 19 times more probable than the alternative hypothesis, given that the selected strength of the experimental condition (0.95/ 0.05) counts as trustworthy enough for a scientifically acceptable decision. In Jeffreys’s (1961) classification for the plausibility of a hypothesis, this is called “strong evidence” for H0. So, how many observations are necessary to support the
null hypothesis in the context of justification? The answer is 2828 (see Cohen, 1977, 169 on calculating the number of observations). If we want to be sure—sure, that is, under specified α- and β-errors—then we incur an extreme number of data points (observations, subjects, sessions, etc.). The main reasons for this tall number are the effect size between the two rivaling hypotheses, which is very small, and the
rigorous control of both errors.
If so, then it cannot suffice to publish the testing strategy before and a stopping rule after inspection of the data obtained. In comparison, sequential testing is certainly not as problematic as “double-dipping” (Kriegeskorte et al., 2009) in order to inflate the α-error. Nevertheless, sequential testing does necessarily inflate the β-error (under fixed effects), and so increases the chance that a true difference is not detected in the empirical condition used. In the case at hand, the β-error is at least β=0.58 with α=0.05 (one-sided), g=0.05 and n=200 (see Cohen, 1977, 155). Here, the size of the beta error is incompatible with an acceptable empirical condition that can decide between the two specified hypotheses.
Generally, in the context of justification and for the purpose of a (more or less) definite decision between two specified hypotheses, the effect size is known and the α- and β-error can be chosen as tolerable. But doing so effectively fixes the number of necessary observations. Specifically, the smaller the effect size, the larger is the number of necessary observations. Therefore, theories that can only predict small effects must be confronted with a large number of observations, much larger than is normally the case in our empirical studies. Conversely, given the typically small effect sizes of our theories and the typically low number of observations reported in our journals, few published effects can even hope to count as replicable, i.e., as real discoveries.
move on to torture the data. Such statistically significant results are then declared to be scientifically significant observations. This is our main strategy in psychology compared with those employed in biology, physics, and sociology (Witte &
Strohmeier, 2013). Predictably, one finds a huge number of underpowered studies in our journals (Bakker, van Dijk & Wicherts, 2012)—studies which, by their very design, cannot even hope to produce real and replicable discoveries. This problem frequently arises when a significant result is obtained, but the power of the observed effect is nevertheless too low (<.80/<.95) to safely reject the null hypothesis
(Francis, 2012).The high number and frequency of design-insufficient studies points us to a dilemma between the scientist and her field, or between the individual and science as a whole. This relation should be disentangled (Witte, 2005). Merely moving from t-tests to Bayes-factors cannot provide an adequate solution to the crisis (Wetzels et al., 2011). A poignant example of why this is the case is seen in the Bayesian analyses of Bem’s psi hypothesis, several of which come to quite different conclusions (Bem, Utts & Johnson, 2011; Dienes, 2012). After all, in all these cases, only the random model is well-specified, while alternative hypotheses are not. Statistically significant deviations, or comparisons based on a sufficiently great Bayes-factor, between a specified random hypothesis and an unspecified alternative hypothesis are invariably accepted as theoretically significant. Thereby, one has not yet moved from the context of discovery—which is governed by the possibility that something non-random might be observed—to the context of justification—which is governed by some theoretically specified parameter which can be based on an accumulation of antecedent research (see above).
3. The long path of a research program
3.1 The first step: ideas without controlled observation
Invariably, the first step of a research program involves an idea about something, perhaps an intuition. (The intuition itself may be interesting for psychological or sociological reasons, but it is less relevant for the development of a scientific idea.) For this process, C.S. Peirce coined the term retroduction. By definition, an intuition is not based on systematic observation, and yet a scientist must be impressed enough to explore her idea further. She could try to find further hints in subjective
experience, in theoretical observations, or in discussions with colleagues. Convinced her idea is relevant, she will work more systematically, and will move from studying material immediately at hand to thought-experiment, computer simulation,
publishing an idea-paper (without significance tests), etc. Importantly, such activities remain perfectly possible without engaging in any form of systematic empirical data collection.
3.2 The second step: devising an empirical condition to observe a phenomenon
The next step is to establish the idea vis-à-vis a method, so that it may potentially count as the discovery of a phenomenon in reality. To this end, one is required to produce, and then control, an empirical condition under which the phenomenon can be observed. Naturally, empirical observation can be misleading because of random effects (sampling and measurement errors). Therefore, the phenomenon should deviate from a simple random effect.
Finding no significant deviation from a random effect in one’s results, however, does not immediately lead to an informative state of knowledge. .After all, complicity with a random model is to be expected—and so could be explained— whenan experimental condition is not sensitive enough to detect a given effect although “it is there.” It would thus be naïve to treat the absence of significant deviation from random as evidence for the absence of a given effect. To treat this caveat, one’s logic of decision making must change. Insignificant deviations may signal epistemic value —and so need not be literal “null results,”— whenever the observed p-value is expectable given the high chance of not obtaining a significant deviation from a random model in the experimental condition. This leads to the Neyman-Pearson-test-theory of statistical inference where we also have an estimate of the β-error, i.e., the chance of not detecting a true effect. This theory can thus support (belief in) a discovery also vis-à-vis insignificant results. Such resultsbecome exponentially less informative, however, as the β-error increases. Itshould generally be small enough for a true effect to stand only a small chance of non-detection.
Obviously, the idea that obtaining an insignificant result might depend on the empirical situation is based on our experience of obtaining insignificant results; results are known that could be explained by a random sampling variation or measurement errors. In this epistemic condition, it is clear that several influences can hide the phenomenon under such random effects. Therefore, an empirical test of a theoretical discovery should be optimal in the sense that the empirical evidence not only features a small p-value under the random model, but also the highest
probability for all true deviations from the random effect. In short, it should be the most powerful test to detect the theoretical assumption. The Neyman-Pearson-test-theory generally meets these demands. Furthermore, the test should be unbiased in the sense that one will almost certainly detect a true effect upon sufficiently
increasing the number of observations.
3.3 The third step: replication and meta-analysis
2000; Schoenemann & Scargle, 2008). Should effect sizes be heterogeneous, then the conditions and the size of the effects must be differentiated between various conditions. Exactly this is the purpose of a meta-analysis. However, meta-analyses are heavily based on published articles. These constitute a biased sample of all empirical results, thus leading to an exaggeration of the real effect-sizes (Francis, 2012). Therefore, the simple strategy of inducing over prior findings should be corrected by more theoretical strategies in order to reproduce given empirical results (Witte, 1996; Witte, 2005).
With the so obtained information, however, the relevance of the context of discovery within a progressing research program seems to be exhausted. Any subsequent step must be guided by the specification of the effect size, which is to be justified (confirmed) vis-à-vis new data samples. These data might be retrodictions—data obtained independently from data used in the context of discovery—or classical predictions of new data.
3.4 The fourth step: precisification of effect sizes
A clear indicator for having moved from the context of discovery to the context of justification is the précised effect size to be expected in new data. Such precision arises from an induction over empirical results (via parameter estimation or a combination of published significant results via meta-analysis) or a more constructive (quantitative) reanalysis of convincing results which then has to be “transformed” into a kind of deduction, namely by using the parameter as a
theoretical expectation in new data, and so as a first step of theoretical construction (see e.g. Witte, 1996). Of course, HARKing (Kerr, 1998; Simmons et al., 2011) and double dipping (Kriegeskorte et al., 2009) are illegal forms of justification, because testing whatever is found, here, must lead to a confirmation. But such confirmation has little to do with a test of a hypothesis. If there is a theoretical intuition regarding the effect potentially expectable paired with a confirmation of this intuition, then it is also a theoretical explanation of this amount of influence that should be provided.
itself can thus lead to new discoveries afterwards, rendering the assumption of a linear progress in only one direction as too simple. However, the idea of progress which is based on knowledge of the original phenomenon has to be accepted. Likewise, one should accept the qualitative difference between the context of
discovery, featuring vague ideas regarding the amount of effect-size, and the context of justification, featuring a précised idea of a theoretical model comparable to the precision of the random model.
4. Why we must enter the context of justification
Our research usually remains in the context of discovery, and the publication of meta-analyses about discovered effects is followed by a meta-meta-analysis (Cafri, Kromrey & Brannick, 2010; Schmidt, Oh & Hayes, 2009). But mere iteration, and so ever higher order analysis, is of little help when running a progressing research program (Chan & Arvey, 2012; Mitchell, 2012; Ferguson & Heene, 2012; Stegenga, 2011). Entering the context of justification is necessary. The problems which have been discussed over the last years can be solved not by the leniency of reviewers, not by the disclosure of data collection, not by opening the bottleneck of publication, but only by moving to the context of justification.
A seemingly insurmountable canyon appears to separate the context of discovery from the context of justification. The critiques of statistical research methods arise in the context of justification and are directed at the context of discovery. If an effect seems to be truly discovered by a meta-analysis, then the scientific community has to turn around, and it will seek to justify (confirm) a précised effect, i.e., a concrete selection of the formerly vague deviations from random. Such research clearly differs from parameter-estimation based on data from a sample. This turnaround will also help bury “undead theories,” something not possible given the methods
available in the context of discovery (Ferguson & Heene, 2012).
The present crisis of replication and of statistical inference in general can only be solved by embarking onto the long path of a research program, by moving from the context of discovery to the context of justification, and by ever adapting the
If there is a concrete effect to be tested against a random model, then a study can be planned with fixed and known α- and β-error. The Neyman-Pearson-theory is the most efficient tool to plan this empirical condition with the least number of observations under specified α- and β-errors, and two précised hypotheses. In this specified condition, the likelihood-ratio can serve as the crucial criterion for the acceptance of a theoretically predicted parameter or model. The acceptance-criterion is given by the likelihood-ratio of the power (1-β) divided by the error of the first kind (α) for a justification of the alternative hypothesis; for the justification of the random (null) hypothesis, it is the ratio of (1-α) / β (Wald, 1947; Witte, 1980). Only if the likelihood-ratio of the empirical results surpasses this criterion (which
normally takes the value 19 for α=β=0.05, or the value 99 for α=β=0.01) could we be convinced that the theoretical prediction is justified under a tolerable error-range.
As a decision criterion, the likelihood-ratio of the error terms from the Neyman-Pearson-theory is comparable to the classification scheme proposed by Jeffreys (1961), if the errors are taken into consideration equally seriously (α=β), with α=0.05 meaning log (19) (“strong evidence”) or α=0.01 meaning log (99) (“very strong evidence,” nearly “extreme evidence”).
Our statistical methods are always only tools to detect phenomena or to confirm (justify) theoretical assumptions. But these tools are not the machinery that produces knowledge, insofar as knowledge is based on theory, and theory in the empirical social sciences must be justified by data. In a nutshell, a loose discovery cannot be firmly justified. If we understand what we know from our publications so far, and if it is our aim to reach an improved state of knowledge, then we must enter the context of justification with all its consequences and demands (Ioannidis, 2012).
5. Precise theoretical constructs, anyone?
edition on small group behavior (Witte & Davis, 1996), 11 theories in the first volume are sufficiently specified to yield a precise prediction of the quantitative results; the 10 theories in the second volume still remain in the context of discovery, featuring vague predictions. Obviously, precise theoretical constructions are
possible, but they appear to be very rare, nevertheless.
A related critique originates in the context of discovery and is directed at the context of justification: If the theoretical assumptions are never proven in reality vis-à-vis data, and if the assumed phenomenon is never discovered in a specific context, then such results indicate that one does not deal with a developing research program in the empirical social sciences. Rather than increase knowledge, we do arm-chair psychology. Yet, not the methods, nor the publisher and the individual author are primarily responsible for the replicability crisis and for the lack of trust in
“knowledge” communicated in publications. We may largely account for this as a consequence of our wide-spread ignorance of fruitfully combining the context of discovery with the context of justification in the framework of a research program that improves our knowledge through data. The implications for the training of our young scientist are obvious.
6. Conclusion
Psychologists may have no choice but to dare a courageous leap across that canyon which separates the context of discovery from the context of justification.
Otherwise, we may have to watch our field tumble down into the canyon.
According to our diagnosis, the replicability crisis is in large part owed to our tradition of making separate “one-off discoveries” of effects that deviate
significantly from a chance model, as well as the related tradition of publishing such results as scientifically relevant discoveries—rather than as the parameter
estimations that they are. As most of the so-conducted research has in fact “discovered” only small effects, the respective studies too often remain
underpowered in the sense of comprising too few data-points (Maxwell, 2004), and so remain in the context of discovery where vague effect sizes are the norm and the published discoveries themselves—when viewed as theoretically relevant
A clear indicator for having moved to the context of justification is the testing of a précised effect size to be expected in new data against a précised random effect or a précised alternative hypothesis. This requires a diachronic notion of the research process, i.e., a research program (rather than a series of disconnected one-off underpowered discoveries), where the adaptation of one’s methods of statistical inference to prior knowledge has become normal. Schematically, one starts with simple p-values (Fisher), moves on to the best test against a random-model
Fig. 1 Schematic representation of salient steps of the research process in the context of justification
Of course, a specified effect size should be deduced from a theory as a prediction. The quantitative specification without a theoretical explanation might be a first step in the context of justification. A progressing research program, however, deduces the specified prediction from a theoretical model and provides an explanation of its amount.
Since many of our currently best theories merely allow for vague predictions, it will not surprise that we cannot learn very much from repeating another such study. The current crisis is one of failed theory development; the related crisis of replicability is owed to the lack of power in our studies. The loss of confidence in our laboratory results is perhaps more obvious for small and medium effect sizes, but is likewise owed to the lack of power (Mitchell, 2012) and the missing integration into theoretical concepts which are able to grasp complex situations in the field.
Making headway takes researchers who join forces and resources, who coordinate their research under a long term perspective, and who adapt their methods to prior knowledge. It is only in the integrated long run that our knowledge will improve, provided our scientific statements are based on powerful empirical studies with précised hypotheses in a context of justification. Such theoretical developments based on empirical data should be appreciated and should be published as
Acknowledgements
We thank Peter Killeen and Moritz Heene for useful comments on an earlier draft.
References
Bakker, M., van Dijk, A. & Wicherts, J.M. (2012). The rules of the game called psychological science. Perspectives on Psychological Science, 7, 543-554.
Bem, D.J. (2011). Feeling the future: Experimental evidence for anomalous retroactive influences on cognition and affect. Journal of Personality and Social Psychology, 100, 407-425.
Bem, D.J., Utts, J. & Johnson, W.O. (2011). Reply. Must psychologists change the way they analyze their data? Journal of Personality and Social Psychology, 101, 716-719.
Cafri, G., Kromrey, J.D. & Brannick, M.T. ( 2010). A Meta-Meta-Analysis: Empirical review of statistical power, type I error rates, effect sizes, and model selection of meta-analyses published in psychology. Multivariate Behavioral Research, 45, 239-270.
Chan, M.-L, E., Arvey, R.D. (2012). Meta-analysis and the development of knowledge. Perspectives on Psychological Science, 7, 79-92.
Cohen, J. (1977, rev. ed). Statistical power analysis for the behavioral sciences. London: Academic Press.
Dienes, Z. (2012). Bayesian versus orthodox statistics: Which side are you on? Perspectives on Psychological Science, 6, 274-290.
Ferguson, C.J. & Heene, M. (2012). A vast graveyard of undead theories:
Publication bias and psychological science´s aversion to the null. Perspectives on Psychological Science, 7, 555-561.
Fuchs, H.M., Jenny, M. & Fiedler, S.(2012). Psychologists are open to change, yet wary of rules. Perspectives on Psychological Science, 7, 639-642.
Gigerenzer, G. (2010). Personal reflections on theory and psychology. Theory & Psychology, 20, 733-743.
Harlow, L.L., Mulaik, S.A. & Steiger, J.H. (Eds.) (1997). What if there were no significance tests? Mahwah: Erlbaum.
Ioannidis, J.P.A. (2012). Why science is not necessarily self-correcting. Perspectives on Psychological Science, 7, 645-654.
Jeffreys, H. (19613). The theory of probability. Oxford: Oxford University Press.
Kerr, N.L. (1998). HARKing: Hypothesizing after the results are known. Personality and Social Psychology Review, 2, 196-217.
Kriegeskorte, N., Simmons, W.K., Bellgowan, P.S.F. & Baker, C. I. (2009). Circular analysis in systems neuroscience: The dangers of double dipping. Nature
Neuroscience, 12, 535-540.
Lakatos, I. (1978). The Methodology of Scientific Research Programs. Cambridge: Cambridge University Press.
Maxwell, S.E. (2004). The Persistence of Underpowered Studies in Psychological Research: Causes, Consequences, and Remedies. Psychological Methods, 9(2), 147– 163.
Mayo, D. (1996). Error and the growth of experimental knowledge. Chicago: University of Chicago Press.
Mitchell, G. (2012). Revisiting truth or triviality: The external validity of research in the psychological laboratory. Perspectives on Psychological Science, 7, 109-117.
Nosek, B.A. & Bar-Anan, Y. (2012). Scientific utopia: I. Opening scientific communication. Psychological Inquiry, 23, 217-243.
Pashler, H. & Wagenmakers, E.-J. (2012). Editors’ introduction to the special section on replicability in psychological science: A crisis of confidence? Perspectives on Psychological Science, 7, 528-530.
Reichenbach, H. (1938). Experience and prediction. Chicago: The University of Chicago Press.
Rouder, J.N., Speckman,P.L., Sun, D., Morey, R.D. & Iverson, G. (2009). Baysian t-tests for accepting and rejecting the null hypothesis. Psychonomic Bulletin & Review, 16, 225-237.
Schmidt, F.L., Oh, I. & Hayes, T.L. (2009). Fixed versus random-effect models in meta-analysis: Model properties and an empirical comparison of differences in results. British Journal of Mathematical and Statistical Psychology, 62, 97-128.
Schickore, J. & Steinle, F. (2006). (Eds.) Revisiting Discovery and Justification: Historical and Philosophical Perspectives on the Contest Distinction. Dordrecht: Springer.
Scargle, J. D. (2000). Publication Bias: The “File-Drawer” Problem in Scientific Inference. Journal of Scientific Exploration, 14, 91–106.
Schonemann, P. H., & Scargle, J. D. (2008). A Generalized Publication Bias Model. Chinese Journal of Psychology, 50, 21–29.
Simmons, J. P., Nelson, L. D., & Simonsohn, U. (2011). False-Positive Psychology. Psychological Science, 22(11), 1359-1366.Spellman, B. A. (2012). Introduction to the Special Section on Research Practices. Perspectives on Psychological Science, 7, 655-656.
Stegenga, J. (2011). Is meta-analysis the platinum standard of evidence? Studies in History and Philosophy of Biological Sciences, 42, 497-507.
Sturm, Th. & Mühlberger, A. (2012). Crisis discussions in psychology - New historical and philosophical perspectives. Studies in History and Philosophy of Biological Sciences, 43, 425-433.
Wagenmakers, E.-J., Wetzels, R., Borsboom, D. & van der Maas, H.L.J (2011). Why psychologists must change the way they analyze their data: The psi case: Comment on Bem (2011). Journal of Personality and Social Psychology, 100, 426-432.
Wagenmakers, E.-J., Wetzels, R., Borsboom, D., van der Maas, H.L.J. & Kievit, R.A. (2012). An Agenda for purely confirmatory research. Perspectives on Psychological Science, 7, 632-638.
Wald, A. (1947). Sequential Analysis. New York: Wiley.
Wetzels, R., Matzke, D., Lee,M.D., Rouder, J.N., Iverson, G.J. & Wagenmakers, E.-J. (2011). Statistical evidence in experimental psychology: An empirical comparison using 855 t tests. Perspectives on Psychological Science, 6,291-298.
Willy, R. (1889). Die Krisis in der Psychologie. Leipzig: Reisland.
Witte, E.H. (1980). Signifikanztest und statistische Inferenz. Analysen, Probleme, Alternativen. [Significance test and statistical inference. Analyses, problems, alternatives]. Stuttgart: Enke.
Witte, E. H. (1996). The extended group situation theory (EGST): Explaining the amount of change. In: E.H. Witte & J.H. Davis (Eds.). Understanding group behavior (Vol.1) (pp. 253-291). Mahwah: Erlbaum.
Witte, E.H. (2005). Theorienentwicklung und -konstruktion in der Sozialpsychologie.[Theory development and theory construction in social
psychology]. In: E.H. Witte (Ed.) Entwicklungsperspektiven der Sozialpsychologie [Perspectives of development of Social Psychology] (pp. 172-188). Lengerich: Pabst.
Witte, E. H. & Davis, J. H. (Eds.) (1996). Understanding group behavior (Vol.1 +2). Mahwah: Erlbaum.
Witte, E.H. & Kaufman, J. (1997).The stepwise hybrid statistical inference strategy : FOSTIS. HAFOS, 18. retrieved at 8/22/2013 from:
http://psydok.sulb.uni-saarland.de/frontdoor.php?source_opus=2286&la=de