Gambar 8 Langkah-langkah deteksi cluster dengan algoritme DDBC. Performansi Hasil Cluster
Pada tahap ini dilakukan analisis terhadap hasil cluster. Analisis yang digunakan adalah analisis cluster variance. Besarnya variance within cluster (Vw) dan variance between cluster (Vb) akan dihitung untuk mengukur besarnya penyebaran dari data hasil clustering. Visualisasi Clustering
Hasil akhir clustering diimplementasikan dalam bentuk visual berupa map based. Tampilan peta akan menunjukkan hasil pengelompokan wilayah hotspot berdasarkan tingkat kerawanan terjadinya kebakaran hutan. Perbedaan warna pada node menandakan pengelompokkan suatu titik ke dalam cluster yang berbeda.
Implementasi
Pada tahap ini akan diimplementasikan hasil clustering data hotspot beserta visualisasi. Implementasi dilakukan menggunakan bahasa pemrograman PHP. Berikut merupakan perangkat lunak dan perangkat keras yang digunakan untuk mengembangkan sistem adalah sebagai berikut:
Perangkat lunak:
Sistem operasi : Windows 7 Ultimate XAMPP 1.7
DBMS PostgreSQL
Bahasa Pemrograman PHP 4.49
Web browser Mozilla Firefox 4 Notepad++
GeoServer
Adobe Dreamwaver CS3 Perangkat keras:
Prosesor: Intel® Core(TM)2 Duo CPU T6600 @ 2.20 GHz
Memory 2 GB
Monitor dengan resolusi 1024x768 px Mouse dan keyboard
HASIL DAN PEMBAHASAN
Praproses Data
Data yang diperoleh dalam penelitian ini merupakan data hasil analisis kueri yang telah diujikan pada penelitian Kurniawan (2011). Data hotspot yang digunakan adalah titik-titik yang muncul berulang kali di rentang tahun 2002 hingga 2005. Banyaknya data yang diperoleh dari hasil analisis kueri sebanyak 151 data. Kemunculan titik api pada suatu daerah bervariasi. Kemunculan paling banyak yakni tiga kali dalam rentang tahun tersebut, namun terdapat pula titik yang hanya muncul di satu tahun tertentu.
Berdasarkan hasil kueri tersebut, data hotspot yang diperoleh merupakan titik api yang muncul berulang kali di Provinsi Riau, Jambi,
Sumatera Utara, Sumatera Barat, Kalimantan Barat, Kalimantan Tengah, dan Sulawesi Selatan. Tampilan contoh data yang digunakan pada penelitian dapat dilihat secara detail pada Lampiran 1. Keseluruhan data tersebut akan diolah melalui beberapa tahap di dalam algoritme DDBC. Pada proses akhir dari tahap estimasi hubungan antar titik masih digunakan keseluruhan data, namun untuk tahap berikutnya yakni tahap deteksi clustering terjadi proses pencarian ketetanggaan menggunakan konsep RST (Relationship Strength Threshold).
Pada penelitian ini besarnya RST yang digunakan adalah 0.5, sehingga perolehan nilai bobot final dari tahap akhir estimasi hubungan antar titik akan diperiksa apakah bernilai lebih kecil dari RST. Hubungan antar titik yang kuat dinilai lebih besar atau sama dengan besarnya RST. Banyaknya data yang memenuhi konsep hubungan yang kuat tersebut, untuk selanjutnya diolah pada tahap clustering adalah sebanyak 15 titik. Pencocokan kebutuhan data dengan teknik algoritme DDBC membutuhkan penghapusan beberapa atribut dari data hasil analisis kueri. Atribut yang dihapus yaitu Vs, Ve, dan keterangan, selain penghapusan beberapa atribut yang tidak banyak berpengaruh, ditambahkan pula atribut yang penting dalam teknik DDBC yaitu atribut vertex.
Atribut vertex diperoleh berdasarkan nilai lintang dan bujur yang mewakili suatu titik api. Penambahan atribut vertex bertujuan mempermudah pembentukan relationship graph. Penerapan aspek temporal dimasukkan ke dalam atribut year yang menyimpan komponen tahun kemunculan titik api. Frekuensi kemunculan setiap hotspot berbeda-beda, sebagai contoh terdapat data hotspot yang hanya muncul sekali pada tahun 2002. Namun terdapat pula titik api yang muncul sebanyak tiga kali yaitu pada tahun 2002, tahun 2003, dan tahun 2005. Keseluruhan data hotspot tetap
digunakan untuk perhitungan pada tahap selanjutnya. Tabel 3 merupakan contoh data hotspot yang digunakan pada penelitian. Estimasi Hubungan Titik
Data hotspot yang telah diolah pada tahap praproses selanjutnya akan dicari hubungannya menggunakan fungsi jarak euclid. Secara garis besar proses estimasi hubungan antar titik pada penelitian ini dapat dilihat pada Gambar 9. Perhitungan jarak dilakukan pada titik yang muncul setiap tahunnya. Hasil jarak euclid tersebut selanjutnya diolah dengan menggunakan persamaan influence function. Jenis influence function yang digunakan pada penelitian adalah square wave function. Penggunaan square wave function bertujuan pula sebagai fungsi kernel function yang akan memberikan keluaran berupa nilai Boolean. Nilai jarak antar titik seperti diperoleh pada Gambar 9c diproses menggunakan square wave function yang mempunyai nilai threshold ( sebesar 4.842. Nilai threshold tersebut merupakan hasil standar deviasi dari perolehan jarak euclid dari keseluruhan data (Kang 2008). Besarnya jarak antar titik yang bernilai lebih besar dari threshold diberi nilai 0 yang artinya hubungan antar titik tersebut tidak berpengaruh terhadap keseluruhan data clustering dan hubungan titik tersebut dikatakan lemah.
Hasil akhir dari fungsi kernel tersebut akan memberikan nilai keluaran boolean yaitu 0 dan 1, dapat dilihat pada Gambar 9d. Nilai-nilai hubungan antar titik yang telah diperoleh, maka selanjutnya akan dilakukan perhitungan kekuatan hubungan. Besarnya kekuatan hubungan ( merepresentasikan bobot yang menghubungkan dua buah titik dengan memasukkan nilai boolean yang telah diperoleh sebelumnya ke dalam persamaan strength relationship, maka didapat nilai = 0.25.
Tabel 3 Contoh data hotspot yang digunakan pada penelitian
Lintang Bujur Time Vertex Nama_kab Nama_prop The_geom -1.478 104.035 2002 M Muaro Jambi Jambi 01010000000A -1.478 104.035 2003 M Muaro Jambi Jambi 01010000000A -1.478 104.035 2005 M Muaro Jambi Jambi 01010000000A 0.339 103.058 2002 U Pelalawan Riau 0101000000C1 0.339 103.058 2004 U Pelalawan Riau 0101000000C2 0.339 103.058 2005 U Pelalawan Riau 0101000000C3 1.632 101.746 2002 AS Dumai (Kota) Riau 01010000009A
RST = = 0.5
Gambar 9 Tahapan estimasi hubungan pada data penelitian. Pada penelitian ini, besarnya nilai strength
relationship untuk setiap hubungan antar titik yang berpengaruh memiliki nilai yang sama yaitu 0.25, hal tersebut terjadi berdasarkan perolehan nilai boolean melalui perumusan square wave function adalah sama yakni sebesar 1. Kasus yang lain terjadi pada hubungan antar titik yang menghasilkan nilai 0 dalam perhitungan square wave function, maka hubungan titik tersebut pun akan memperoleh bobot sebesar 0. Gambar 9e memberikan representasi sederhana untuk proses perolehan nilai strength relationship hubungan antar titik setiap tahun kemunculannya.
Pembobotan akan bertambah terhadap suatu hubungan titik apabila hubungannya muncul berulang di tahun berikutnya. Perulangan pembobotan tersebut diinisialisasi menggunakan nilai awal sebesar 0.25 pada tahun 2002. Hubungan titik yang muncul kembali di tahun berikutnya akan bertambah menjadi 0.5, sedangkan hubungan titik yang tidak muncul di tahun berikutnya berkurang menjadi 0. Banyaknya perulangan dilakukan hingga tahun 2005 dan selanjutnya akan diperoleh bobot final dari relationship graph. Modifikasi Ketetanggan
Bobot yang merepresentasikan kekuatan hubungan antar titik kembali diolah guna kebutuhan clustering. Teknik DDBC menggunakan konsep RST neighborhood, besarnya nilai RST dapat dihitung melalui
persamaan yang telah diberikan sebelumnya. Gambar 10 berikut menjelaskan perhitungan nilai RST yang digunakan di dalam penelitian.
Gambar 10 Perhitungan nilai RST. Penggunaan nilai f adalah sebesar 1 yakni merepresentasikan waktu kemunculan suatu objek sebagai ketetanggaan dari objek lain yang merupakan bagian cluster. Kemunculan objek tersebut sebagai tetangga objek cluster adalah paling banyak satu kali dalam rentang empat tahun berdasarkan penggunaan data.
Besarnya history window (h) yang digunakan adalah 4. Penggunaan nilai history window tersebut merujuk berdasarkan time stamp yang digunakan pada penelitian yaitu disimpan di dalam atribut year. Atribut year yang digunakan yaitu tahun 2002, 2003, 2004, dan 2005. Penggunaan nilai p sebesar 3 yakni merepresentasikan waktu kemunculan objek yang merupakan bagian cluster sebagai ketetanggaan dari objek lain di cluster tersebut.
Titik-titik yang memiliki bobot bernilai kurang dari RST tidak akan disertakan pada
01 functionExpandCluster($SetofPoint, $Point,$clID, $Min){ 02 global $classified; 03 global $cluster_NOISE; 04 global $cluster; 05 $seeds = $SetofPoint[$Point]; 06 07 if(count($seeds) < $Min){ 08 array_push($cluster_NOISE, $Point); 09 return 0; } 10 else{ 11 12 foreach($seeds as $point_seed => $value_seed){ 13 $result_currentP = $SetofPoint[$point_seed];}
tahap clustering berikutnya karena hubungan vertex tersebut didefinisikan lemah. Titik yang bernilai lebih dari RST digunakan dalam konsep RST Neighborhood dan akan diproses selanjutnya dalam tahap clustering.
Deteksi Cluster
Banyaknya jumlah titik yang memenuhi RST Neighborhood sebanyak 15 titik. Tampilan data untuk daerah-daerah yang memenuhi syarat hubungan ketetanggan yang dinilai kuat dapat dilihat pada Lampiran 2. Hubungan titik tersebut memiliki nilai strength relationship yang lebih besar dari RST. Berdasarkan data yang diperoleh titik-titik tersebut merepresentasikan daerah yang berada pada Provinsi Riau dan Sumatera Utara. Titik tersebut selanjutnya dikelompokkan sesuai dengan konsep clustering pada konsep DBSCAN.
Banyaknya titik yang berada dalam ketetanggaan RST harus memenuhi salah satu syarat DBSCAN yaitu mempunyai titik tetangga yang lebih besar jumlahnya dari jumlah titik minimum (minPts). Besarnya nilai minPts yang digunakan pada penelitian ini adalah 4. Ukuran standar besarnya nilai minPts sebesar 4 telah cukup mewakili jumlah ketetanggan suatu point (Ester et al. 1996). Berdasarkan penggunaan nilai minPts yang berubah-ubah pada penelitian dapat disimpulkan adanya hubungan antara minPts dan pembentukan cluster. Semakin kecil nilai minPts, maka semakin kecil kemunculan noise, dan sebaliknya semakin besar minPts, maka semakin sedikit jumlah cluster yang terbentuk.
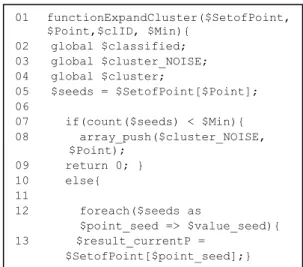
Teknik DDBC yang diterapkan untuk mengelompokan titik-titik api menggunakan konsep yang sama seperti pada DBSCAN, yaitu penggunaan konsep reachable, density-connectivity, dan cluster. Titik yang mempunyai ketetanggaan dengan jumlah yang lebih dari minPts akan diproses untuk dikelompokkan menggunakan fungsi ExpandCluster. Berikut diberikan potongan fungsi ExpandCluster menggunakan bahasa pemrograman PHP pada Gambar 11.
Fungsi ExpandCluster seperti yang dapat dilihat pada Gambar 11 akan memberikan hasil akhir berupa clusters dan noise. Apabila suatu titik tidak mempunyai jumlah tetangga yang lebih besar dari nilai minPts sebesar 4, maka titik tersebut akan dikelompokkan ke dalam noise.
Gambar 11 Potongan fungsi ExpandCluster pada proses clustering.
Berdasarkan penggunaan data yang akan dikelompokkan yakni sebanyak 15 titik, data yang berhasil dideteksi dalam cluster adalah sebanyak 8 titik. Hasil clustering yang diperoleh dari algoritme DDBC yakni sebanyak 3 cluster dan banyaknya noise adalah 3 titik. Pembagian cluster yang dihasilkan berikut dapat dilihat pada Tabel 4, selain itu daerah yang dikelompokkan ke dalam noise adalah Kabupaten Dumai dan Indragiri Hilir.
Tabel 4 Hasil clustering dari algoritme DDBC sebanyak 3 cluster
Clusters Vertex
Cluster 0
Tapanuli Selatan,
Pelalawan, Dumai (Kota), Bengkalis
Cluster 1 Pelalawan Cluster 2 Bengkalis
Pada cluster 0 terdapat 4 kabupaten, cluster 1 dan cluster 2 hanya memiliki masing-masing satu kabupaten. Kabupaten Pelalawan yang dikelompokkan ke dalam cluster 1 dapat didefinisikan sebagai pencilan (outlier), hal yang sama pun berlaku pada daerah Bengkalis yang dikelompokkan dalam cluster 2. Hal ini disebabkan persebaran pola dari kedua titik tersebut tidak mengikuti sebaran yang terbentuk, selain itu berdasarkan hasil clustering dapat dilihat bahwa kedua kabupaten yaitu Pelalawan dan Bengkalis telah dikelompokkan sebelumnya ke dalam cluster 0.
Daerah Pelalawan yang dikelompokkan ke dalam cluster 0 merupakan daerah yang mempunyai nilai lintang dan bujur yang berbeda dengan daerah Pelalawan pada cluster
1, dikarenakan pada penelitian ini informasi yang disimpan oleh suatu daerah hanya terbatas pada level Kabupaten.
Penggunaan dari data awal sebanyak 15 titik terdapat 4 titik yang tidak terdeteksi ke dalam cluster maupun noise yaitu Kabupaten Muaro Jambi, Mandailing Natal, dan Rokan Hulu. Pada penerapan algoritme DDBC ini, hal tersebut dapat terjadi disebabkan daerah-daerah tersebut tidak pernah muncul sebagai tetangga dari titik lain dan jumlah tetangga yang dimiliki daerah tersebut tidak memenuhi banyaknya jumlah titik minimum ketetanggaan (minPts). Evaluasi Hasil Cluster
Hasil clustering yang telah diperoleh pada Tabel 4 akan dilihat nilai persebarannya menggunakan analisis varian. Suatu cluster dikatakan baik apabila anggota di dalam cluster mempunyai tingkat kemiripan yang tinggi antar satu dengan lainnya (internal homogeneity) dan sama sekali berbeda terhadap anggota cluster lainnya (external homogeneity).
Hasil perhitungan nilai cluster variance untuk cluster yang telah terbentuk disajikan dalam Tabel 5. Besarnya cluster variance ( ) pada cluster 1 dan cluster 2 yang masing-masing hanya memiliki satu anggota cluster akan bernilai lebih besar jika dibandingkan dengan cluster variance dari cluster 0.
Tabel 5 Hasil perhitungan cluster variance
Cluster Cluster variances ( )
Cluster 0 1.676
Cluster 1 10622.094
Cluster 2 10292.851
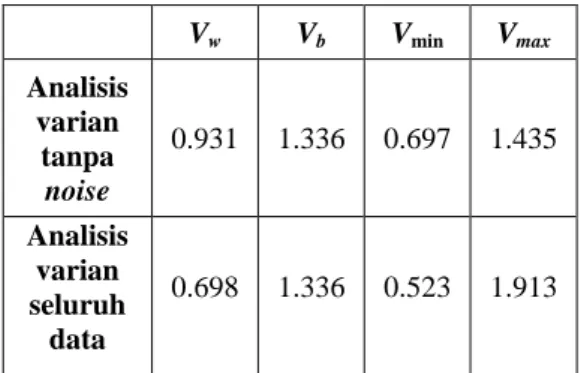
Analisis varian yang digunakan pada penelitian ini menggunakan dua perhitungan yakni analisis cluster seluruh data dan analisis cluster tanpa penggunaan noise. Jumlah seluruh data yang akan dikelompokkan sebanyak 15 titik. Hasil perhitungan analisis varian tersebut disajikan dalam Tabel 6.
Hasil perhitungan analisis varian seluruh data termasuk data noise menghasilkan nilai Vw yang kecil apabila dibandingkan dengan nilai Vw dari perhitungan analisis varian tanpa menyertakan noise. Hal tersebut terjadi pada penelitian dikarenakan pada perhitungan variances within cluster tersebut mengikutsertakan kabupaten yang dikenali sebagai unclassified. Berdasarkan hasil tersebut, maka dapat disimpulkan bahwa besarnya
keragaman dari hasil clustering tanpa noise memiliki kesamaan internal di dalam cluster yang lebih kecil dibandingkan hubungan antar cluster yang sama sekali berbeda. Secara umum hasil perhitungan dengan noise maupun dengan keseluruhan data menghasilkan analisis varian terhadap seluruh cluster telah mampu memenuhi kriteria cluster yang baik.
Tabel 6 Hasil perhitungan keseluruhan analisis varian Vw Vb Vmin Vmax Analisis varian tanpa noise 0.931 1.336 0.697 1.435 Analisis varian seluruh data 0.698 1.336 0.523 1.913
Clustering menggunakan teknik DDBC telah mengelompokan titik api ke dalam tiga cluster yaitu kabupaten yang dikelompokkan ke dalam cluster 0 yaitu Tapanuli Selatan, Pelalawan, Dumai, dan Bengkalis Pada cluster 1 yaitu daerah Pelalawan dan pada cluster 2 yaitu daerah Bengkalis. Daerah-daerah yang dikelompokkan ke dalam cluster 0 menjelaskan bahwa kabupaten tersebut seringkali muncul dalam rentang tahun 2002 sampai 2005, sehingga daerah tersebut akan lebih sering muncul sebagai ketetanggaan suatu daerah lain. Kabupaten yang terdapat dalam cluster 0 termasuk ke dalam kelompok titip api yang berpotensi tinggi terhadap terjadinya kebakaran hutan. Kabupaten yang dikelompokkan ke dalam cluster 1 dan 2 dikenali sebagai outlier, sedangkan Kabupaten Dumai dan Indragiri Hilir pada penelitian ini dideteksi sebagai noise. Daerah-daerah tersebut memiliki jumlah tetangga yang kurang dari titik minimum ketetanggaan yakni sebanyak 4 daerah.
Berdasarkan hal tersebut, maka pengguna dalam hal ini yakni pihak yang berwenang terkait penanggulangan kebakaran hutan dapat mengetahui daerah-daerah yang memiliki potensi tinggi terhadap terjadinya kebakaran hutan dilihat dari besarnya frekuensi kemunculan daerah terkait pada rentang tahun tertentu. Hasil visualisasi hasil clustering pada data kebakaran hutan ditampilkan pada Gambar 12 di bawah ini. Daerah yang dikelompokkan ke dalam cluster 0 ditandai dengan node berwarna merah, daerah yang termasuk cluster 1 ditandai dengan node berwarna biru, dan