TUGAS AKHIR – SS 141501
DETEKSI DINI PENYAKIT KANKER LEHER RAHIM (SERVIKS) DI KOTA BOGOR MENGUNAKAN REGRESI LOGISTIK BINER DAN SUPPORT VECT OR MACHINE (SVM)
AGIL DARMAWAN NRP 1308 100 084
Dosen Pembimbing
Sant i Wulan Purnami, M. Si. , Ph. D
JURUSAN STATISTIKA
Fakult as Mat emat ika dan Il mu Penget ahuan Alam Inst it ut Teknologi Sepul uh Nopember
TUGAS AKHIR – SS 141501
DETEKSI DINI PENYAKIT KANKER LEHER RAHIM (SERVIKS) DI KOTA BOGOR MENGUNAKAN REGRESI LOGISTIK BINER DAN SUPPORT VECT OR MACHINE (SVM)
AGIL DARMAWAN NRP 1308 100 084
Dosen Pembimbing
Santi Wulan Purnami, M. Si. , Ph. D
JURUSAN STATISTIKA
Fakultas Matematika dan Ilmu Pengetahuan Alam Institut Teknologi Sepuluh Nopember
N JUDUL
FINAL PROJECT – SS141501
EARLY DETECTION OF CERVIXAL CANCER IN BOGOR
USING BINARY LOGISTIC REGRESSION AND SUPPORT
VECTOR MACHINE (SVM)
Agil Darmawan NRP 1308 100 084
Supervisor
Santi Wulan Purnami, M.Si., Ph.D
DEPARTMENT OF STATISTICS
Faculty Of Mathematics And Natural Sciences Institut Teknologi Sepuluh Nopember
v
DETEKSI DINI PENYAKIT KANKER LEHER RAHIM DI KOTA BOGOR MENGUNAKAN REGRESI LOGISTIK
BINER DAN SUPPORT VECTOR MACHINE (SVM)
Nama : Agil Darmawan NRP : 1308 100 084
Jurusan : Statistika FMIPA-ITS Dosen Pembimbing : Santi Wulan P.,M.Si.,Ph.D.
ABSTRAK
Negara-negara berkembang menyumbang 370.000 dari total 466.000 kasus serviks kanker yang diperkirakan terjadi di dunia dalam tahun 2000. Sebagian besar kasus kanker serviks disebabkan oleh infeksi Human Papilloma Virus (HPV). Kanker serviks tidak akan terdiagnosa secara langsung karena ada fase pra-ganas selama beberapa tahun, maka dibutuhkan deteksi dini untuk mencegah munculnya fase ganas pada kanker serviks. Untuk melakukan deteksi dini tersebut digunakan metode klasifikasi Support Vector Machine (SVM) yang akan dibandingkan dengan Regresi Logistik Biner. Selain untuk melihat ketepatan klasifikasi Regresi Logistik Biner juga digunakan untuk mengetahui variabel predictor yang paling berpengaruh terhadap respon. Dalam penelitian ini, data diambil dari Studi Kohort Faktor Risiko Penyakit Tidak Menular di Kota Bogor. Variabel prediktor yang digunakan adalah sebanyak 13 variabel. Faktor resiko yang berpengaruh signifikan pada taraf signifikasi 90% (=0,1) terhadap Kanker Serviks pada Analisis Regresi Logistik Biner adalah Lama penggunaan kontrasepsi, Riwayat Keluarga dan Tes Pap Smear. Performansi klasifikasi menggunakan SVM pada semua kombinasi baik 90:10, 70:30, dam 50:50 adalah sebesar 100%, sedangkan nilai specificity semua 0%. Akurasi klasifikasi menggunakan Logistik Biner tertinggi adalah kombinasi 90:10 sebesar 100%, kombinasi 70:30 sebesar 87,7%, sedangkan kombinasi 50:50 sebesar 55,5%..
vi
vii
EARLY DETECTION OF THE CERVIXAL CANCER IN BOGOR USING BINARY LOGISTIC REGRESSION AND
SUPPORT VECTOR MACHINE (SVM)
Name : Agil Darmawan NRP : 1308 100 084
Department : Statistika FMIPA-ITS Supervisor ;: Santi Wulan P.,M.Si.,Ph.D.
ABSTRAK
Developing countries accounted for 370,000 of the total 466,000 cases of cervical cancer are expected to occur in the world in the year 2000 Most cases of cervical cancer are caused by infection with Human Papilloma Virus (HPV). Cervical cancer will not be diagnosed directly because there is a pre-malignant phase for several years, it is necessary to prevent the emergence of early detection of malignant phase in cervical cancer. For the early detection of the used classification method Support Vector Machine (SVM) which will be compared to Binary Logistic Regression. In addition to seeing the classification accuracy Binary logistic regression was also used to determine the most influential predictor variables on the response. In this study, the data was taken from Cohort Study of Risk Factors of Non-Communicable Diseases in the city of Bogor. Predictor variables used were as many as 13 variables. Risk factors that have a significant effect on the 90% significance level ( = 0.1) against Cervical Cancer in Binary Logistic Regression Analysis is Older contraceptive use, family history and Pap Smear Tests. Performance of classification using SVM on all the good combination of 90:10, 70:30, 50:50 dam is at 100%, while the specificity values of all 0%. Classification accuracy using Binary Logistic highest is 90:10 combination of 100%, 87.7% combination of 70:30, while the combination of 50:50 at 55.5%.
viii
ix
KATA PENGANTAR
Alhamdulillah puji syukur penulis panjatkan kehadirat Allah SWT, yang atas rahmat, taufik, dan hidayah-Nya sehingga penulis mampu menyelesaikan penyusunan Tugas Akhir yang berjudul “Deteksi Dini Penyakit Kanker Leher Rahim (Serviks) di Kota Bogor Mengunakan Regresi Logistik Biner dan Support Vector Machine (SVM)”.
Selama penulisan laporan Tugas akhir ini tentunya penulis tidak lepas dari bantuan dan sokongan dari banyak fihak. Oleh karena itu, dengan penuh kerendahan hati penulis ingin mengucapkan terima kasih kepada semua yang membantu penyelesaian dalam proses Tugas Akhir ini, khususnya kepada : 1. Allah SWT yang karena kasih sayang-Nya penulis mampu
menyelesaikan Tugas Akhir ini.
2. Almarhum Kedua orang tuaku, Ayahanda Masykur Idris, S.H dan Ibunda Siti Khudewi A.Z. yang membuat penulis terus termotivasi. Serta mbak Ana Nur Aida. Mereka adalah keluarga terbaik yang Allah turunkan untuk penulis.
3. Ibu Dr. Santi Wulan Purnami, S.Si.,M.Si. selaku dosen pembimbing atas segala kesabaran dalam memnberi bimbingan, saran, semangat, dan waktu yang diberikan kepada penulis hingga laporan Tugas Akhir ini selesai. 4. Bapak Dr. Suhartono, M.Sc. selaku Ketua Jurusan Statistika
ITS.
5. Bapak Dr. Purhadi, M.Sc dan Ibu Ir. Mutia Salamah, M.Kes, selaku dosen penguji atas kritik dan saran demi sempurnanya Tugas Akhir ini.
6. Bapak Dr. Wahyu Wibowo, S.Si., M.Si. selaku dosen wali, atas masukan dan bimbingannya selama penulis berada di bangku kuliah.
x
8. Fairizi, Ikhsan, Erik, Septian, Zainudin dan Reza yang telah menjadi sahabat baik suka maupun duka. Terimakasih atas semangat, motivasi, uluran waktu, dan doanya.
9. Nur Fain yang dengan segala keikhlasan untuk bersedia meminjamkan laptop sehingga penulis mampu menyelesai-kan Tugas Akhir ini.
10. Penghuni Ma‟had Ukhuwah Islamiyah, Al Faruqi, dan Pondok Hijrah yang membersamai penulis sepanjang masa perkuliahan.
11. Pak Ripan beserta segenap keluarga Litbangkes Kemenkes RI yang membantu penyusunan dna pengiriman data.
12. Keluarga besar JMMI ITS dan Statistika Angkatan 2008 atas kebersamaan yang indah selama ini.
13. Semua pihak yang tidak dapat disebutkan satu-persatu yang telah membantu hingga pelaksanaan Tugas Akhir ini dapat terselesaikan dengan baik.
Dalam Penulisan laporan ini penulis merasa masih banyak kekurangan-kekurangan baik pada teknis penulisan maupun materi, mengingat akan kemampuan yang dimiliki penulis. Untuk itu kritik dan saran dari semua pihak sangat penulis harapkan demi penyempurnaan pembuatan laporan ini.
Akhir kata, penulis berharap semoga Allah memberikan imbalan yang setimpal pada mereka yang telah memberikan bantuan, dan dapat menjadikan semua bantuan ini sebagai ibadah,
Amiin Yaa Robbal „Alamiin.
Surabaya, 10 April 2016
xi
DAFTAR ISI
Halaman
HALAMAN JUDUL... i
TITLE PAGE ... ii
LEMBAR PENGESAHAN ...iii
ABSTRAK ... v
ABSTRACT ... vii
KATA PENGANTAR ... ix
DAFTAR ISI ... xi
DAFTAR TABEL ...xiii
DAFTAR GAMBAR ... xv
DAFTAR LAMPIRAN ... xvii
BAB I PENDAHULUAN ... 1
1.1 Latar Belakang ... 1
1.2 Rumusan Masalah ... 3
1.3 Tujuan Penelitian ... 4
1.4 Manfaat Penelitian ... 4
BAB II TINJAUAN PUSTAKA ... 5
2.1 Statistika Deskriptif ... 5
2.2 Regresi Logistik Biner ... 5
2.3 Support Vector Machine ... 10
2.4 Kanker Serviks ... 16
BAB III METODOLOGI PENELITIAN ... 19
3.1 Sumber Data ... 19
3.2 Variabel Penelitian ... 19
3.3 Langkah Analisis ... 20
BAB IV ANALISIS DAN PEMBAHASAN ... 23
4.1 Deskripsi Faktor resiko Kanker serviks ... 23
4.2 Analisis dengan Regresi Logistik Biner ... 25
4.3 Klasifikasi Regresi Logistik Biner ... 33
4.3 Analisis menggunakan SVM ... 36
xii
BAB V KESIMPULAN
DAN SARAN
... 39
5.1 Kesimpulan... 39
5.2 Saran ... 39
DAFTAR PUSTAKA ... 41
xiii
DAFTAR TABEL
Halaman
Tabel 2.1 Tabel Ketepatan Klasifikasi ... 9
Tabel 2.2 Fungsi kernel pada SVM ... 15
Tabel 3.2 Variabel Penelitian ... 20
Tabel 4.1 Statistika Deskriptif ... 23
Tabel 4.2 Crosstab variabel skala nominal ... 24
Tabel 4.3 Uji Univariabel ... 25
Tabel 4.4 Uji Serentak ... 27
Tabel 4.5 Uji Parsial dan Estimasi Parameter ... 28
Tabel 4.6 Uji Kebaikan Model ... 31
Tabel 4.7 Hasil uji data training 50% ... 32
Tabel 4.8 Hasil uji data training 70% ... 33
Tabel 4.9 Hasil uji data training 90% ... 33
Tabel 4.10 Hasil klasifikasi 50:50... 34
Tabel 4.11 Hasil klasifikasi 70:30... 34
Tabel 4.12 Hasil klasifikasi 90:10... 35
Tabel 4.13 Perbandingan Hasil klasifikasi ... 35
Tabel 4.14 Penghitungan SVM training 50% ... 36
Tabel 4.15 Penghitungan SVM training 70% ... 37
Tabel 4.16 Penghitungan SVM training 90% ... 37
xiv
xv
DAFTAR GAMBAR
Halaman
Gambar 2.1 Hyperplane SVM ... 11
Gambar 2.2 .Pemisah non Linier SVM ... 13
Gambar 2.2 Transformasi ruang vektor dimensi tinggi ... 14
Gambar 2.3 Kanker serviks pada sistem reproduksi ... 16
xvi
xvii
DAFTAR LAMPIRAN
Halaman
Lampiran 1 Data Studi Kohort PTM 2011 kanker serviks ... 51
Lampiran 2 Uji Univariabel ... 52
Lampiran 3 Uji Kesesuaian Model ... 53
Lampiran 4 Uji Serentak ... 54
Lampiran 5 Uji Parsial dan Estimasi Parameter ... 55
xviii
1
BAB I
PENDAHULUAN
1.1 Latar Belakang
Kanker serviks merupakan suatu problem kesehatan masyarakat bagi perempuan dewasa di negara-negara berkembang di Asia Tenggara, Amerika Tengah dan Selatan, Afrika. Sebagian besar kasus kanker serviks disebabkan oleh infeksi Human Papilloma Virus (HPV), virus menular yang menginfeksi sel dan dapat menyebabkan \kanker invasif. Negara-negara berkembang menyumbang 370.000 dari total 466.000 kasus serviks kanker yang diperkirakan terjadi di dunia dalam tahun 2000. Di seluruh dunia, kanker serviks diklaim menjangkit 231.000 wanita per tahun, lebih dari 80% yang terjadi di negara berkembang (WHO, 2001).
Kanker serviks memiliki tahap pra-ganas yang berlangsung beberapa tahun. Oleh karena itu untuk mendeteksi dini adanya kanker serviks dianjurkan untuk melakukan pemeriksaan Pap Smear (Susanti, 2012).
Data-data ini diperkuat dengan penelitian Yayasan Kanker Indonesia yang memperkirakan, ada sekitar 52 juta perempuan Indonesia memiliki risiko terkena kanker serviks. Semua data tersebut seolah mempertegas asumsi bahwa setiap perempuan berisiko terkena infeksi Human Papilloma Virus (HPV), virus penyebab kanker serviks (kotabogor.go.id). Data dari Yayasan Kanker Indonesia juga (2009), di Kota besar rasio terjangkitnya penyakit ini adalah 90 per 100.000 penduduk. Angka ini 400% lebih tinggi dari Belanda yang hanya 9 per 100.000 penduduk.
Kota Bogor menjadi wilayah yang berinisiatif untuk merealisasikan hal tersebut dengan mengadakan “Layanan
Papsmear dan KB Gratis” dengan menghadirkan 100 Ibu Rumah
2
sel karsinoma penyebab Kanker Leher Rahim. Tes Pap Smear sebaiknya dilakukan satu kali setahun oleh setiap wanita yang sudah melakukan hubungan seksual (kotabogor.go.id). Salah satu faktor yang menjadikan resiko terjangkitnya kanker serviks menjadi besar adalah tidak rutinnya tes Pap Smear tersebut (Mc Cormick, 2011).
Faktor resiko adalah faktor atau variabel yang diduga mampu meningkatkan resiko terkena penyakit. Usia yang rawan terserang penyakit ini adalah perempuan berusia 35-55 tahun, perempuan yang berusia > 65 tahun persentase terserang penyakit adalah 20%. Selain faktor usia, penggunaan kontrasepsi jenis hormonal seperti pil dan suntik juga meningkatkan resiko terserang kanker serviks, terutama untuk penggunaan yang lama . Faktor lain, perempuan yang sering melahirkan anak (paritas) dan ganti-ganti pasangan seksual meningkatkan resiko kanker ini (health.detik.com). Adanya riwayat kanker pada keluarga juga meningkatkan resiko terjangkit kanker serviks (asiacancer.com). Faktor resiko lain adalah merokok, karena rokok dapat mengganggu sistem imun tubuh dalam melawan virus (Mc Cormick, 2011).
3
Jadi variabel penjelas tidak harus memiliki distribusi normal, linier, maupun memiliki varian yang sama dalam setiap group (identik). Selain itu variabel bebas dalam regresi logistik bisa campuran dari variabel kontinyu, diskrit dan dikotomis.
Pada penelitian Intansari (2012) tersebut didapatkan akurasi ketepatan klasifikasi menggunakan Bagging Logistic sebesar 70,74%. Nilai tersebut masih tergolong rendah, sehingga hasil klasifikasi menggunakan Bagging Logistic belum bisa dijadikan referensi. Untuk mengatasi hal tersebut dibutuhkan metode klasifikasi lain yang memiliki ketepatan klasifikasi tinggi, yaitu Support Vector Machine (SVM). SVM adalah metode learning machine yang bekerja atas prinsip Structural Risk Minimization (SRM) dengan tujuan menemukan pemisah (hyperplane) terbaik yang memisahkan dua buah class pada input space. Keunggulan SVM adalah memiliki tingkat akurasi klasifikasi yang tinggi dibanding metode lain seperti Logistic Regression, Neural Netwotk (NN) dan Discriminant Analysis (Nugroho & Handoko, 2003). Pada penelitian Rahman (2012) tentang Kanker Payudara menggunakan Regresi Logistik Ordinal dan SVM, hasil pengukuran klasifikasi kedua metode, akurasi SVM sebesar 98,11 % jauh lebih tinggi dari pada Regresi Logistik Ordinal yang bernilai 56,60%.
1.2 Perumusan Masalah
Permasalahan yang akan dibahas pada penelitian ini berdasarkan latar belakang di atas adalah sebagai berikut.
1. Apa saja faktor-faktor yang mempengaruhi terjangkitnya penyakit kanker serviks di Kota Bogor menggunakan Regresi Logistik Biner?
2. Bagaimana klasifikasi penyakit kanker servik berdasarkan faktor-faktor yang mempengaruhi menggunakan Regresi Logistik Biner dan Support Vector Machine (SVM)?
4
1.3 Tujuan
Berdasarkan permasalahan di atas, maka tujuan dari penelitian ini adalah sebagai berikut.
1. Untuk mendapatkan faktor-faktor yang mempengaruhi ter-jangkitnya penyakit kanker serviks di Kota Bogor menggu-nakan Regresi Logistik Biner.
2...Untuk mendapatkan model klasifikasi penyakit kanker serviks berdasarkan faktor-faktor yang mempengaruhi menggunakan Regresi Logistik Biner dan Support Vector Machine (SVM). 3...Untuk mendapatkan model terbaik dari perbandingan
ketepatan klasifikasi metode Regresi Logistik Biner dan Support Vector Machine (SVM).
1.4 Manfaat
Manfaat yang diharapkan dari penelitian ini antara lain. 1. .Menambah khazanah penerapan ilmu Statistika dalam bidang
kesehatan.
2...Dengan mengetahui faktor – faktor yang mempengaruhi penyakit kanker serviks bisa memberikan masukan kepada instansi kesehatan untuk rutin memberikan penyuluhan dan fasilitas kesehatan terkait kanker serviks kepada masyarakat. 3...Dengan mengetahui model deteksi kanker serviks, bisa
5 BAB II
TINJAUAN PUSTAKA
2.1. Statistika Deskriptif
Statistika deskriptif adalah metode yang digunakan untuk mendeskripsikan atau menggambarkan data, meliputi pengumpu-lan, pengorganisasian, serta penyajian data dengan menggunakan ukuran pemusatan, ukuran keragaman, ukuran bentuk, dan ukuran relatif sehingga dapat memberikan informasi yang jelas, berguna, dan mudah dimengerti. (Walpole, 1995). Penelitian ini meng-gunakan data kategorik sehingga menmeng-gunakan tabulasi silang (crosstab).
Ciri penggunaan crosstab adalah data input yang berskala nominal atau ordinal, seperti tabulasi antara gender seseorang dengan tingkat pendidikan orang tersebut, pekerjaan seseorang dengan sikap orang tersebut dengan suatu produk tertentu, dan lainnya. Pembuatan crosstab dapat juga disertai dengan penghitu-ngan tingkat hubupenghitu-ngan (asosiasi) antar variabel.
2.2 Regresi Logistik Biner
Analisis Regresi adalah suatu metode yang mendiskripsi-kan antara variabel respon dan satu atau lebih variabel penjelas atau prediktor (Hosmer dan Lemeshow, 2000). Regresi Logistik Biner adalah metode regresi yang mampu menyelesaikan kasus di mana variabel respon berupa dichotomous, ya-tidak, sukses-gagal, normal-cacat, hidup-mati, benar-salah, laki-laki-perempu-an, dan sebagainya. Variabel respon adalah data kategorik (Agresti, 2002).
Outcome variabel y yang terdiri dari 2 kategori, yaitu “sukses” dan “gagal” dinotasikan dengan y = 1 (sukses) dan y = 0 (gagal). Variabel y tersebut mengikuti distribusi Bernaulli untuk setiap observasi tunggal. Fungsi probabilitas untuk setiap obser-vasi adalah :
y y
y
6
Di mana jika y = 0 maka f(y) = 1 – π dan jika y = 1 maka f(y) = π. Fungsi regresi logistiknya dapat ditulis sebagai berikut :
z menunjukkan bahwa model Logistik sebetulnya menggambarkan probabilitas atau resiko dari suatu objek. Model regresi logistik-nya adalah sebagai berikut :
Untuk mempermudah pendugaan parameter regresi maka persamaan (2.3) di atas dapat diuraikan menggunakan transforma-si logit dari π (x) sebagai berikut :
model tersebut merupakan fungsi linear dari parameter – parame-ternya.
2.2.1 Estimasi Parameter
Estimasi parameter pada regresi Logistik menggunakan Maximum Likelihood. Metode ini menduga parameter β dengan cara memaksimumkan fungsi likelihood dan mensyaratkan data harus mengikuti suatu distribusi tertentu. Pada regresi Logistik biner, setiap percobaan mengikuti distribusi Bernaulli sehingga dapat ditentukan fungsi likelihoodnya.
7
lainnya, i = 1, 2, …, n maka fungsi probabilitas untuk setiap pasangan adalah sebagai berikut :
i
Fungsi likelihood tersebut lebih mudah dimaksimumkan dalam bentuk log l(β) dan dinyatakan dalam L(
). hasilnya disamadengankan 0.
8
Berikutnya adalah melakukan pengujian secara serentak untuk mengetahui keberartian koefisien β secara serentak terha-dap respon.
H0 : β1 = β2 = … = βp = 0
H1 : minimal ada satu βj ≠ 0 j = 1, 2, …, p
Statistik uji :
dengan v derajat bebas banyaknya parameter dalam model tanpaβ0.
Kemudian dilakukan pengujian keberartian terhadap koe-fisien β secara univariat terhadap variabel respon yaitu dengan membandingkan parameter hasil maksimum likelihood, dugaan β dengan standard error parameter tersebut.
H0 : βi = 0
diperoleh melalui persamaan berikut :
2
Statistik uji tersebut mengikuti distribusi chi square sehingga tolak H0 jika W2 > 2(1) dengan v derajat bebas
9
Uji berikutnya adalah Uji Kesesuaian Model. Ini dimak-sudkan untuk mendapatkan informasi apakah terdapat perbedaan antara hasil pengamatan dengan kemungkinan hasil prediksi model.
: rata-rata taksiran peluang g : jumlah grup'
k
n : banyak observasi grup ke - k
Daerah penolakannya adalah, tolak H0 jika 2 < 2(p-1,)
2.2.2 Evaluasi Performansi Model
Performansi dalam melakukan klasifikasi kanker serviks diuji ketepatannya menggunakan data testing. Pengukuran ketepatan klasifikasi menggunakan sensitivitas, spesivisitas, dan akurasi berdasarkan model yang terbentuk.
Tabel 2.1 Ketepatan klasifikasi Observasi Prediksi
Gagal Sukses
Gagal n11 n12
Sukses n21 n22
n11: kategori gagal yang diprediksi gagal
n12: kategori gagal yang diprediksi sukses
n21: kategori sukses diprediksi gagal
n22: kategori sukses diprediksi sukses
10
Specificity :
Sensitifity :
2.3 Support Vector Machine (SVM)
Metode klasifikasi modern Support Vector Machine (SVM) pertama kali diperkenalkan oleh Vapnik pada tahun 1992, dipre-sentasikan di Annual Workshop on Computational Learning Theory. SVM adalah metode learning machine yang bekerja atas prinsip Structural Risk Minimization (SRM) dengan tujuan me-nemukan pemisah (hyperplane) terbaik yang memisahkan dua buah class pada input space (Nugroho dan Handoko, 2003).
Metode SVM berbeda dengan klasifikasi neural network yang mencari hyperplane antar class, namun SVM berusaha me-nemukan hyperplane paling tepat pada input space. Prinsip dasar SVM adalah linear classifier, dan selanjutnya dikembangkan agar dapat digunakan untuk kasus non-linear dengan memasukkan konsep Kernel. Dengan begitu, ada suatu jaminan bahwa klasi-fikasi menggunakan SVM akan menghasilkan pemetaan yang sangat akurat (Lin, 2003).
2.3.1 Konsep Support Vector
11
Gambar 2.1 SVM mendapatkan hyperplane terbaik yang memisahkan class–1 dan +1
Alternatif garis pemisah (discrimination boundaries) di-tunjukkan pada gambar (1a). Pemisah terbaik antara kedua class dapat ditemukan dengan mengukur margin hyperplane tersebut. dan mencari titik maksimalnya. Margin adalah jarak antara hyper-plane tersebut dengan pattern terdekat dari masing-masing class. Garis solid pada gambar (1b) menunjukkan hyperplane yang terbaik, yaitu yang terletak tepat pada tengah-tengah kedua class, sedangkan titik merah dan kuning yang berada dalam lingkaran hitam adalah support vector.
2.3.2 Support Vector Classification
Data yang ada dinotasikan sebagai sedangkan
untuk respon/target masing-masing dinotasikan sebagai ………, yang mana l adalah banyaknya data.
Diketahui bahwa X memiliki pola tertentu, yaitu apabila …..termasuk ke dalam class maka diberikan label (target)yi1 dan yi 1. Diasumsikan +1 dan –1 dapat terpisah secara sempurna oleh hyperplane berdimen-i d, yang didefinisikan :
w
.
x
b
0
(2.16) (1b)(1a)
i lyi 1,1, 1,2,...,
d i
x
i
12
Pattern
x
i
yang termasuk class –1 (sampel negatif) dapat dirumuskan sebagai pattern yang memenuhi pertidaksamaan se-bagai berikut :
w
.
x
b
1
(2.17)Pattern
x
i
yang masuk class +1(sampel positif) dapat dirumuskan sebagai pattern yang memenuhi pertidaksama-an :
w
.
x
b
1
(2.18) Margin terbesar dapat ditemukan dengan memaksimalkan nilai jarak antara hyperplane dan titik terdekatnya, yaitu 1/ w . Hal ini dapat dirumuskan sebagai Quadratic Programming (QP) problem, yaitu mencari titik minimal persamaan (2.19), dengan memperhatikan constraint persamaan (2.20).
2 Problem ini dapat diselesaikan dengan teknik metode Lagrange Multiplier.
bahwa pada titik optimal gradient L = 0, persamaan (2.21) dapat dimodifikasi sebagai maksimalisasi problem yang hanya mengandung saja i, sebagaimana persamaan (2.22) di bawah.
13
Dari hasil dari perhitungan ini diperoleh i yang
kebanya-kan bernilai positif. Data yang berkorelasi dengan i yang positif
inilah yang disebut sebagai support vector.
2.3.3 Soft Margin
Teorema di atas berjalan atas asumsi bahwa kedua class dapat terpisah secara sempurna oleh hyperplane. Namun umum-nya dua buah class pada input space tidak dapat terpisah secara sempurna. Hal ini menyebabkan constraint pada persamaan (2.20) tidak terpenuhi, sehingga optimisasi tidak dapat dilakukan.
Gambar 2.2 Pemisah non Linier SVM
Untuk mengatasi masalah ini, SVM dirumuskan ulang dengan memperkenalkan teknik soft margin. Dalam soft margin, persamaan (2.20) dimodifikasi dengan memasukkan slack variabel , dengan ( > 0).
y
i
w
.
x
i
b
1
i
(2.24)
Sehingga persamaan (2.19) diubah menjadi :
14
2.3.4 Fungsi Kernel pada SVM
Pada hakikatnya masalah dalam domain dunia nyata jarang yang bersifat linear separable. Kebanyakan dari kasus tersebut bersifat non linear. Untuk menyelesaikan problem non linear, SVM dimodifikasi dengan memasukkan Fungsi Kernel.
Dalam non linear SVM, pertama-tama data x dipetakan oleh fungsi Φ(x) ke ruang vektor yang berdimensi lebih tinggi. Pada ruang vektor yang baru ini, hyperplane yang memisahkan kedua class tersebut dapat dikonstruksikan. Hal ini sejalan dengan teori Cover yang menyatakan “Jika suatu transformasi bersifat non linear dan dimensi dari feature space cukup tinggi, maka data pada input space dapat dipetakan ke feature space yang baru, dimana pattern-pattern tersebut pada probabilitas tinggi dapat dipisahkan secara linear” (Nugroho dan Handoko, 2003).
Pada gambar 2.2 (kiri) diperlihatkan data pada class kuning dan data pada class merah yang berada pada input space berdimensi dua tidak dapat dipisahkan secara linear. Selanjutnya gambar 2 (kanan) menunjukkan bahwa fungsi Φ memetakan tiap data pada input space tersebut ke ruang vektor baru yang berdimensi lebih tinggi (dimensi 3), dimana kedua class dapat dipisahkan secara linear oleh sebuah hyperplane. Notasi matematika dari mapping ini adalah :
:
d
q d < q (2.26)Input space X Feature Space Φ(X)
15
Pemetaan ini dilakukan dengan menjaga topologi data, dalam artian dua data yang berjarak dekat pada input space akan berjarak dekat juga pada feature space, sebaliknya dua data yang berjarak jauh pada input space akan juga berjarak jauh pada feature space. Selanjutnya proses pembelajaran pada SVM dalam menemukan titik-titik support vector, hanya bergantung pada dot product dari data yang sudah ditransformasikan pada ruang baru yang berdimensi lebih tinggi, yaitu Φ(
x
i
).Φ(xj
).
Disebabkan transformasi Φ ini tidak diketahui dan sangat sulit untuk difahami, maka perhitungan dot product tersebut sesuai teori Mercer dapat digantikan dengan Fungsi Kernel
) , (xi xj
K yang mendefinisikan secara implisit transformasi Φ.
Fungsi Kernel dirumuskan sebagai berikut (Gunn, 1998) : K(xi,xj)
Fungsi Kernel memberikan berbagai kemudahan, karena dalam proses pembelajaran SVM, untuk menentukan support vector, kita hanya cukup mengetahui Fungsi Kernel yang dipakai, dan tidak perlu mengetahui wujud dari fungsi non linear Φ. Berbagai jenis Fungsi Kernel dikenal sebagaimana dirangkumkan pada Tabel 2.2.
Tabel 2.2 Fungsi Kernel yang umum pada SVM Jenis Kernel Fungsi
Polynomial K(xi,xj)
xi,xj
1
p Basis Function(RBF) persamaan berikut :
16 training set yang terpilih sebagai support vector, dengan kata lain data
x
i yang berkorespondensi pada i ≥ 0.2.4 Kanker Serviks
Leher rahim (serviks) adalah bagian dari sistem reproduk-si perempuan yang terletak di bagian bawah yang sempit dari rahim (uterus atau womb) (www.kankerleherrahim.com). Kanker ini merupakan kanker ganas yang terbentuk dalam jaringan ser-viks (organ yang menghubungkan uterus dengan vagina). Ada beberapa tipe kanker serviks. Tipe yang paling umum dikenal adalah squamous cell carcinoma (SCC), yang merupakan 80 hingga 85 persen dari seluruh jenis kanker serviks. Infeksi Hu-man Papilloma Virus (HPV) merupakan salah satu faktor utama tumbuhnya kanker jenis ini (www.parkwaycancercentre.com).
Gambar 2.4 Kanker Serviks pada Sistem Reproduksi Wanita Faktor Resiko Kanker Serviks
ter-17
kena penyakit kanker serviks menjadi lebih besar. Berbagai studi telah menemukan faktor-faktor yang bisa meningkatkan resiko terjangkitnya kanker serviks. Faktor resiko tersebut adalah :
1. Human Papploma Virus (HPV)
Virus ini adalah faktor utama terjangkitnya kanker ser-viks dan bisa ditularkan kepada orang lain melalui hubungan seksual (Mc Cormick, 2011). Upaya preventif adalah melalui tes Pap Smear untuk melihat kondisi kenormalan sel – sel leher ra-him.
2. Tidak adanya tes Pap Smear
Umumnya kanker serviks terjadi pada perempuan yang tidak melakukan uji Pap Smear secara teratur. Tes pap ini adalah upaya menemukan sel – sel sebelum bersifat kanker (precance-rous cells) (Mc Cormick, 2011). Tes Pap sebaiknya dilakukan rentang waktu 10-20 hari pasca periode menstruasi. 3. Menikah dini
Menikah dini juga menjadi faktor risiko kanker serviks. Karena menikah muda, yakni ketika dilakukan di usia belasan tahun, umumnya diikuti kegiatan seksual di usia muda juga (Rouzeau, 2012). Padahal pada saat seseorang masih muda terjadi perubahan sel yang sangat agresif.
4. Usia
Kanker serviks paling sering terjadi pada perempuan yang berusia lebih dari 40 tahun. Namun tidak menutup kemung-kinan terjadi pula pada usia produktif 25-40 tahun. Perempuan yang berusia di atas 65 tahun, angka kejadiannya sekitar 20% (www.parkwaycancercentre.com).
5. Hubungan seksual
18
6. Merokok
Perempuan perokok yang terinfeksi HPV mempunyai resiko yang lebih tinggi karena rokok dapat melemahkan sistem imun. (Mc Cormick, 2011).
7. Penggunaan kontrasepsi
Penggunaan pil-pil pengontrol kehamilan untuk jangka waktu lama beresiko terjangkit kanker serviks. Jenis yang bere-siko adalah kontrasepsi hormonal, seperti pil, suntik, implant, dan IUD (Rouzeau, 2012).
8. Hamil muda
Usia pertama melahirkan yang terlalu dini juga menjadi factor resiko kanker serviks (Rouzeau, 2012).
9. Banyak anak
Pada saat kehamilan, sel-sel mulut rahim kondisinya ber-beda, menjadi tidak tahan kalau seandainya terpapar berulang ka-li, sehingga HPV mudah masuk. Kalau makin berulang kali hamil maka makin berulang risiko masuknya infeksi HPV (Rouzeau, 2012).
10.Riwayat Keluarga
19 BAB III
METODOLOGI PENELITIAN
3.1 Sumber Data
Data yang digunakan merupakan data sekunder mengenai Kanker Leher Rahim yang didapatkan dari Studi Kohort Faktor Resiko Penyakit Tidak Menular di Kota Bogor 2011 oleh Kemen-kes RI dengan banyak data 729 responden. Unit penelitian adalah perempuan usia 25-65 tahun di Bogor. Data awal sebanyak 1032 responden, peneliti mengurangi jumlah responden karena adanya missing data.
3.2 Variabel Penelitian
Tabel 3.1 Variabel Penelitian
Kode Variabel Definisi
Y Diagnosa kanker serviks 1: Terjangkit
2: Tidak terjangkit
X1 Usia Usia responden saat survey
X2 Status Pernikahan 1: Iya 2: Tidak
X3 Jumlah pasangan seksual 1: 1 pasangan 2: > 1 pasangan
X4 Pendarahan saat menstruasi 1: Iya 2: Tidak
X5 Usia pertama melahirkan
Usia saat melahirkan anak pertama
X6 Banyak anak Jumlah anak yang dilahirkan
X7 Jenis kontrasepsi 1: Hormonal 2: Tidak hormonal
X8 Waktu kontrasepsi Lama penggunaan kontrasepsi
X9
Riwayat kangker pada keluarga
1: Ada 2: Tidak
X10 Vaksinasi HPV
1: Pernah 2: Tidak pernah
X11 Usia menikah Usia pertama menikah
X12 Uji Pap Smear 1: Pernah 2: Tidak
20
Penelitian ini menggunakan variabel respon (Y) biner, yaitu Terjangkit Kanker Serviks (y=1) ada sebanyak 4 responden dan Tidak Terjangkit Kanker Serviks (y=2) sebanyak 725 responden. Pada variabel Status Pernikahan (X2) dalam Kuesioner Kohort
terdapat empat pilihan jawaban : 1: Belum Menikah [dikoding 2] 2: Menikah [dikoding 1] 3: Cerai hidup [dikoding 1] 4: Cerai mati [dikoding 1],
untuk pilihan 3 dan 4 peneliti memasukkan ke pilihan Menikah karena pada dasarnya yang telah bercerai telah menikah sebelumnya. Variable Pendarahan [X4] saat Menstruasi
dihilangkan observasi yang memiliki nilai 0.
Variabel Banyak anak yang dilahirkan (X6) pada Kuesioner
Kohort terdapat pilihan pengisian : 1: Lahir Hidup
2: Lahir Mati,
dalam penelitian ini dua pilihan tersebut digabungkan, karena sama-sama memiliki informasi yang dibutuhkan, yaitu jumlah anak yang telah lahir.
Variabel Penggunaan Kontrasepsi [X7] dihapus karena
semua responden menggunakan kontrasepsi, atau semua observasi bernilai X7=1.
Variabel Usia pertama menikah (X12) pada Kuesioner
diwakili oleh pertanyaan “umur pertama kali berhubungan intim” pada kode Gc.04.
3.3 Langkah Analisis Data
Langkah-langkah analisis data yang digunakan dalam penelitian ini adalah :
1. Melakukan pengumpulan data sekunder dari penelitian Kohort Litbangkes 2011.
21
3. Mendapatkan faktor-faktor yang mempengaruhi terjangkitnya penyakit kanker serviks di Kota Bogor menggunakan Regresi Logistik Biner, dengan langkah analisis:
a. Seleksi kandidat dengan Uji Univariabel b. Estimasi Parameter βj
c. Melakukan Pengujian Parameter d. Uji Kesesuaian Model
4. Membuat model klasifikasi penyakit kanker serviks menggunakan Regresi Logistik Biner, dengan kombinasi : a. Training-testing 90:10
b. Training-testing 70:30 c. Training-testing 50:50
5. Menghitung performansi klasifikasi Regresi Logistik Biner dengan pengukuran Accuracy, Specificity, dan Sensitifity. 6. Membuat model klasifikasi penyakit kanker serviks
menggunakan Support Vector Machine (SVM). Dengan langkah analisis :
a. Menentukan data training-testing dengan 3 kombinasi; I. Training-testing 90:10
II. Training-testing 70:30 III. Training-testing 50:50
b. Menentukan Fungsi Kernel yang dipakai, dalam penelitian kali ini menggunakan Gaussian Radial Basis Function (RBF).
c. Menentukan parameter C=10 dan σ=2.
7. Menghitung klasifikasi beserta ketepatan akurasinya dengan pengukuran Accuracy, Specificity, dan Sensitifity..
8. Membandingkan performansi antara ketepatan klasifikasi Regresi Logistik Biner dengan Support Vector Machine (SVM).
22
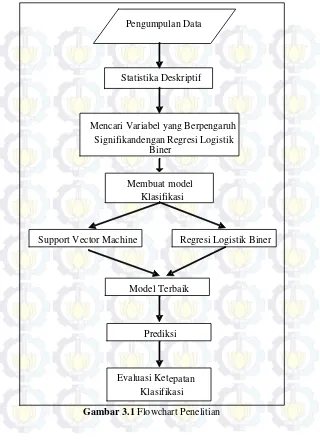
Gambar 3.1 Flowchart Penelitian Statistika Deskriptif
Mencari Variabel yang Berpengaruh Signifikan dengan Regresi Logistik
Biner
Membuat model Klasifikasi
Regresi Logistik Biner Support Vector Machine
Model Terbaik Pengumpulan Data
Prediksi
23 BAB IV
ANALISIS DAN PEMBAHASAN
4.1 Deskripsi Faktor Resiko Kanker Serviks
Pada analisis ini didapatkan gambaran umum mengenai karakteristik faktor resiko penyakit kanker serviks di kota Bogor menggunakan Statistika Deskriptif dan tabulasi silang (crosstab). Statistika deskriptif digunakan untuk variabel yang berskala interval/rasio, sedangkan tabulasi silang digunakan untuk variabel berskala nominal/ordinal.
Tabel 4.1 Statistika Deskriptif variabel berskala rasio Variabel Diagnosa Mean Stdev Min Max Usia saat menikah
(tahun) [X12]
Terjangkit 23 3,37 18 25 Tidak
24
terjangkit adalah 4 anak, sedangkan yang tidak terjangkit 3 anak.
Dari responden yang terjangkit, usia pertama melahirkan yang paling muda adalah 19 tahun, sedangkan paling tua berusia 26 tahun. Dari responden yang tidak terjangkit, usia pertama melahirkan yang paling muda adalah 13 tahun, sedangkan paling tua berusia 40 tahun. Dari respon-den yang terjangkit, usia saat menikah yang paling muda adalah 18 tahun, sedangkan paling tua berusia 25 tahun. Responden yang tidak terjangkit, usia saat menikah yang paling muda adalah 12 tahun, yang paling tua 88 tahun.
Berikut ini hasil tabulasi silang variabel independen yang berskala kategorikal terhadap Diagnosa Penyakit Kanker Serviks.
Tabel 4.2 Tabulasi silang variabel kategorik
Variabel
Diagnosa Terjangkit Tidak
terjangkit
Jenis kontrasepsi (X7)
25
Tabel tersebut memperlihatkan karakteristik hubungan antara variabel faktor resiko dengan diagnosa penyakit kanker serviks. Responden yang terjangkit kanker serviks 0,549% belum pernah vaksinasi HPV. Terlihat pula bahwa responden perokok yang tidak pernah mengalami pendarahan saat menstruasi terjangkit kanker serviks sebesar 0,274%. Respon-den yang tidak terjangkit kanker serviks 92,87% belum pernah uji Pap Smear dan 95,5% tidak memiliki riwayat kanker pada keluarga.
4.2 Analisis Faktor Resiko Kanker Serviks dengan Regresi Logistik Biner
Pada penelitian ini peneliti menggunakan 729 data untuk uji univariabel dan uji signifikasi parameter model. Untuk klasifikasi menggunakan data training sebagai pemben-tukan model dan data testing untuk mengukur ketepatan klasi-fikasi Logistik Biner. Kombinasi data training-testing adalah 90-10, 70-30, dan 50-50. Dengan total 729 responden maka kombinasi 90-10 membagi 656 data training dan 73 data testing. Kombinasi 70-30 membagi 510 data training dan 219 data testing. Kombinasi 50-50 membagi 365 data training dan 364 data testing. Pada pengujian Regresi Logistik Biner kali ini menggunakan = 0,2 dan = 0,1.
4.2.1 Uji Univariabel
Langkah pertama adalah dilakukan seleksi kandidat dengan metode Stepwise manual untuk variabel yang akan dimasukkan model Logisitk Biner dengan Uji Variabel. Hipotesis yang digunakan adalah :
H0 : βi=0 (Variabel indepependen ke-i tidak mempengaruhi
..variabel dependen)
H1 : Minimal satu βi≠0 (Variabel indepependen ke-i
26
Tabel 4.3 Hasil Uji Univariabel
Variabel B df P-value
Jumlah.pasangan.seks 1,031 1 ,374
Constant 4,344 1 0,000
Y dengan X4
Pendarahan.mens 16,070 1 0,998
Constant 5,133 1 0,000
Y dengan X5
Usia.melahirkan1 -0,068 1 0,557
Constant 6,761 1 0,015
Riwayat.keluarga -2,079 1 0,076
27
Dari tabel di atas terlihat bahwa variabel yang signifikan pada taraf nyata 80% ( = 0,2) dalam Uji Univariabel adalah Lama Pemakaian Kontrasepsi (X8), Riwayat Kanker pada
Keluarga (X9), dan Tes Pap Smear (X12). Ketiga variabel yang
signi-fikan tersebut akan dimasukkan dalam model dan diuji secara serentak dan parsial.
4.2.2 Uji Serentak
Pada Uji Parameter baik serentak maupun individu peneliti menggunakan taraf signifikasi 90% (=0,1).
Tabel 4.4 Nilai Overall test
Chi-square df P-value
Step 10,057 3 0,018
Block 10,057 3 0,018
Model 10,057 3 0,018
Hipotesis yang digunakan adalah :
H0 : β8=β9=β12=0 (Variabel independen tidak mempengaruhi H0. Jadi ketiga prediktor secara bersama-sama berpengaruh
28
4.2.3 Uji Parsial dan Estimasi Parameter
Berikut ini akan dilakukan uji segnifikasi secara individu dari tiga prediktor yang lulus uji univariabel. Pengujian ini menggunakan taraf signifikasi 90% (=0,1).
Tabel 4.5 Hasil Uji Individu dan estimasi parameter
Variabel Β Wald P-value Exp (B)
Lama kontrasepsi 0,035 2,826 0,093 1,036 Riwayat keluarga -2,354 3,668 0,055 0,095
Tes PapSmear -2,218 3,253 0,071 0,109
Constant 4,265 29,737 0,000 71,170
Terlihat dari Tabel 4.5 nilai koefisien parameter (βi) adalah :
̃T
: [β0, β8, β9, β12]
: [4.265, 0.035, -2.354, -2.218]
Setiap penambahan satu satuan waktu Lama kontrasepsi akan menambah peluang terjangkitnya kanker serviks sebesar 0,035. Seorang wanita yang tidak memiliki riwayat kanker pada keluarga kemungkinan terserang kanker serviks adalah 10,5 kali (lebih besar) dari pada yang memiliki riwayat keluarga. Seorang wanita yang tidak rutin tes Pap Smear kemungkinan terserang kanker serviks adalah 9,2 kali (lebih besar) dari pada yang pernah tes Pap Smear.
Dari nilai tabel di atas juga terlihat bahwa seluruh variabel memiliki nilai P-value < =0,1. Jadi semua variabel
yang lolos Uji Univariabel, yaitu Lama Kontrasepsi, Riwayat Keluarga, dan Tes Pap Smear, berpengaruh signifikan terhadap diagnosa kanker serviks.
4.2.3.1 Hipotesis variabel X8
H0 : β8 = 0 (Lama kontrasepsi tidak berpengaruh terhadap kanker serviks)
H1 : β8 ≠ 0 (Lama kontrasepsi berpengaruh terhadap kanker
29
ngaruh signifikan terhadap kanker serviks.
4.2.3.2 Hipotesis variabel X9
H0 : β9 = 0 (Riwayat keluarga tidak berpengaruh terhadap
berpengaruh signifikan terhadap kanker serviks.
4.2.3.3 Hipotesis variabel X12
H0 : β12 = 0 (Tes Pap Smear tidak berpengaruh terhadap
30
4.2.4 Uji Kebaikan Model
Langkah berikutnya adalah uji kelayakan model dengan Hosmer and Lemeshow Test. Untuk mengetahui apakah model sudah sesuai kenyataan.
Tabel 4.6 Uji Goodness of fit
Chi-square df P-value
2,639 8 ,955
Hipotesis yang digunakan adalah :
H0: Model telah sesuai (tidak ada perbedaan signifikan antara
hasil pengamatan dengan kemungkinan nilai prediksi) H1: Model tidak sesuai (ada perbedaan signifikan antara hasil
pengamatan dengan kemungkinan nilai prediksi)
Daerah penolakan; tolak H0 jika
2
Statistik Uji:
keputusannya adalah gagal tolak H0. Jadi pada keyakinan 90%
model yang terbentuk telah sesuai, atau model tersebut mampu menjelaskan data dan (tidak ada perbedaan signifikan antara hasil pengamatan dengan kemungkinan nilai prediksi.
4.2.5 Model Regresi Logistik Biner
Variabel yang dimasukkan sebagai model akhir Regresi Logistik Biner adalah parameter yang signifikan pada Uji Parsial, yaitu konstanta, X8,X9 dan X12. Model yang terbentuk
adalah : Model Logit :
31
Model Regresi Logistiknya sebagai berikut :
̂
( )
=
e4 265 0 035 8(1 -2,354 9(1 -2,218 12(11 e4 265 0 035 8(1 -2,354 9(1 -2,218 12(1 , ˆ0(x)1ˆ1(x)
Berikut adalah contoh interpretasi model terbaik yang didapatkan dari variabel X8, X9, dan X12 :
ˆ1(1,1,1)0,432, ˆ0(1,1,1)0,568Peluang seorang perempuan yang lama menggunakan kontrasepsi, mempunyai riwayat kanker pada keluarga, dan tes PapSmear, untuk terjangkit kanker serviks sebesar 0,43. Sedangkan peluang untuk tidak terserang sebesar 0,57.
ˆ1(0,0,0)0,987, ˆ0(0,0,0)0,013
Peluang seorang perempuan yang tidak lama menggunakan kontrasepsi, tidak mempunyai riwayat kanker pada keluarga, dan tidak tes PapSmear, untuk terjangkit kanker serviks sebesar 0,987. Sedangkan peluang untuk tidak terserang sebesar 0,013.
ˆ1(1,1,0)0,875,
ˆ0(1,1,0)0,124Peluang seorang perempuan yang lama menggunakan kontrasepsi, mempunyai riwayat kanker pada keluarga, dan tidak tes PapSmear, untuk terjangkit kanker serviks sebesar 0,88. Sedangkan peluang tidak terserang sebesar 0,12.
ˆ1(0,0,1)0,886,
ˆ0(0,0,1)0,114Peluang seorang perempuan yang tidak lama menggunakan kontrasepsi, tidak mempunyai riwayat kanker pada kel-uarga, dan tes PapSmear, untuk terjangkit kanker serviks sebesar 0,43. Sedangkan peluang untuk tidak terserang sebesar 0,57.
Uji Kelayakan Model tiap kombinasi
32
B df Sig. Overall
Test
Hosmer-Lemeshow
Test Lama Kontrasepsi -0,006 1 0,861
0,085 1,000 Riwayat Keluarga -3,183 1 0,053
Tes Pap Smear -2,988 1 0,076 Constant 6,759 1 0,000
Dari Tabel 4.7 terlihat bahwa dengan data training 50% ketiga variabel secara serentak berpengaruh terhadap respon. Secara individu yang berpengaruh signifikan adalah Riwayat Keluarga dan Tes Pap Smear. Diketahui juga bahwa model yang terbentuk telah dianggap baik/layak.
Tabel 4.8 Hasil uji data Training set 70%
Training set 50 B df Sig. Overall Test Lemeshow Test Hosmer-Lama Kontrasepsi 0,024 1 0,287
0,085 0,076 Riwayat Keluarga -2,774 1 0,035
Tes Pap Smear -2,619 1 0,048 Constant 5,085 1 0,000
Dari tabel 4.8 terlihat bahwa dengan data training 70% ketiga variabel secara serentak berpengaruh terhadap respon. Secara individu yang berpengaruh signifikan adalah Riwayat Keluarga dan Tes Pap Smear. Diketahui juga bahwa model yang terbentuk telah dianggap baik/layak.
Tabel 4.9 Hasil uji data Training set 90% Training set 50 B df Sig. Overall
Test
Hosmer-Lemeshow Test Lama Kontrasepsi 0,027 1 0,166
0,046 0,987 Riwayat Keluarga -2,777 1 0,035
Tes Pap Smear -2,627 1 0,048 Constant 5,007 1 0,000
33
Dari tabel 4.9 terlihat bahwa dengan data training 90% ketiga variabel secara serentak berpengaruh terhadap respon. Secara individu yang berpengaruh signifikan adalah Riwayat Keluarga dan Tes Pap Smear. Diketahui juga bahwa model yang terbentuk telah dianggap baik/layak.
4.3 Performansi Klasifikasi Logistik Biner
Mengevaluasi hasil Klasifikasi untuk mengetahui ketepatan hasil klasifikasi pada penelitian ini ada beberapa cara, yaitu dengan sensitivity, specificity, dan accuracy. Testing prediksi menggunakan model yang telah terbentuk. Hasil prediksi Logistik Biner kombinasi 50:50 adalah sebagai berikut :
Tabel 4.10 Hasil Prediksi data testing 50% Observasi
Prediksi
Total Terjangkit Tidak
Terjangkit
Terjangkit 2 0 2
Tidak
Terjangkit 162 200 362
Total 364
Accuracy : n n11 n22 11 n12 n21 n22=
202
364=0,555=55,5
Specivicity : nn11 11 n12=
2
2=1=100%
Sensitivity : n n22 21 n22=
200
362=0,552=55,2
34
Tabel 4.11 Hasil Prediksi data testing 30% Observasi
Prediksi
Total Terjangkit Tidak
Terjangkit
Hasil prediksi Logistik Biner kombinasi 90:10 adalah sebagai berikut :
Tabel 4.12 Hasil Prediksi data testing 10% Observasi
Prediksi
Total Terjangkit Terjangkit Tidak
35
4.3.1 Evaluasi Performansi Klasifikasi Tiap Kombinasi Untuk mengetahui kombinasi mana yang menghasilkan ketepatan klasifikasi paling tinggi perlu dibandingkan ketiga kombinasi tersebut.
Tabel 4.13 Perbandingan ketepatan klasifikasi Kombinasi Akurasi Specivicity Sensitivity
50-50 55,5% 100% 55,2%
70-30 87,7% 100% 87,6%
90-10 100% 100% 100%
Dari tabel di atas terlihat bahwa tingkat akurasi klasifikasi paling tinggi dihasilkan kombinasi traning:testing 90:10 yaitu sebesar 100%. Kombinasi 70:30 menghasilkan akurasi sebesar 87,7%. Sedangkan untuk kombinasi 90:10 menghasilkan akurasi 55,5%. Nilai specificity semua 100%. Dari hasil perhitungan di atas ada indikasi bahwa semakin banyak data training maka akan menghasilkan performansi klasifikasi yang lebih tinggi.
4.4 Klasifikasi menggunakan Support Vector Machine
(SVM)
Analisis SVM pada penelitian ini menggunakan fungsi kernel Gaussian Radial Basis Function (RBF) dengan parameter =2. Parameter SVM sebagai titik penalti dengan C=10. Agar bisa dibandingkan dengan ketepatan klasifikasi Regresi Logistik Biner, maka analisis SVM ini juga menggunakan kombinasi data training-testing 50:50, 70:30, dan 90:10.
Pada fungsi pengalih Lagrange Multiplier
yang bernilai positif. Nilai optimal persamaan tersebut adalah dengan memaksimalkan L terhadap i. Nilai parameter i pada
36
Hasil prediksi SVM kombinasi 50:50 adalah sebagai berikut :
Tabel 4.14 Hasil Prediksi kombinasi 50:50 Observasi
Prediksi
Total Terjangkit Tidak
Terjangkit
Hasil prediksi SVM kombinasi 70:30 adalah sebagai berikut :
Tabel 4.15 Hasil Prediksi kombinasi 70:30 Observasi
Prediksi
Total Terjangkit Terjangkit Tidak
Terjangkit 0 0 0
37
Tabel 4.16 Hasil Prediksi kombinasi 90:10 Observasi
Prediksi
Total Terjangkit Tidak
Terjangkit
Terjangkit 0 0 0
Tidak
Terjangkit 0 73 73
Total 73
Accuracy : n n11 n22 11 n12 n21 n22=
73
73=1=100
Specivicity : nn11 11 n12=
0
0=0=0
Sensitivity : n n22 21 n22=
73
73=1=100
Ketepatan klasifikasi dengan metode Support Vector Machine adalah sebagai berikut :
Tabel 4.17 Ketepatan Klasifikasi SVM Kombinasi Akurasi Specivicity Sensitivity
50-50 100% 0% 100%
70-30 100% 0% 100%
90-10 100% 0% 100%
Dari tabel tersebut terlihat bahwa tingkat akurasi klasifikasi semua kombinasi training-testing adalah sama yaitu sebesar 100%. Nilai Specificity sebesar 0% karena tidak ada observasi Terjangkit yang diprediksi Terjangkit. Semua observasi (pada data testing) dan prediksi menunjuk pada kategori Tidak Terjangkit.
4.5 Perbandingan Performansi Regresi Logistik Biner dengan Support Vector Machine (SVM)
38
Dari tabel 4.13 dan 4.17 terlihat bahwa pada penelitian kali ini tingkat akurasi Support Vector Machine mempunyai nilai akurasi yang sangat tinggi jika dibandingkan Logistik Biner, baik proporsi 90:10, 70:30, maupun 50:50. Hal ini terjadi overfitting karena proporsi kategori respon yang tidak seimbang. Dari total 729 responden, hanya 4 orang yang terjangkit. Selebihnya 725 responden tidak terjangkit kanker serviks.
Data dengan proporsi respon yang tidak seimbang ini menyebabkan prediksi secara keseluruhan mengarah kepada prediksi ”tidak terjangkit” , atau prediksi bahwa responden tidak terjangkit kanker serviks. Karena tidak ada prediksi ke
39
BAB V
KESIMPULAN DAN SARAN
5.1 Kesimpulan
Berdasarkan tujuan penelitian serta hasil analisis dan pembahasan, maka diperoleh kesimpulan sebagai berikut : 1. Faktor resiko yang berpengaruh signifikan pada taraf
signifikasi 90% terhadap Kanker Serviks pada Analisis Regresi Logistik Biner adalah Lama penggunaan kontrasepsi, Riwayat Keluarga dan Tes Pap Smear. Model Logit yang terbentuk dengan memodelkan respon dengan prediktor yang signifikan dalam uji univariabel (Riwayat Keluarga, Tes Pap Smear, dan Merokok) adalah ̂( ) - - . Dari
Mo-del Logit tersebut didapatkan moMo-del Logistik yang menggambarkan proba-bilitas atau resiko dari suatu objek. 2. Akurasi klasifikasi menggunakan Logistik Biner tertinggi
40
5.2 Saran
Saran untuk penelitian selanjutnya adalah :
1. Jika terdapat kasus dengan kategori respon yang tidak seimbang, maka untuk mendapatkan hasil yang lebih baik dan tidak terjadi over fitting perlu digunakan metode pengembangan SVM untuk inballanced data.
41
DAFTAR PUSTAKA
Agresti, Alan. (2002), Categorical Data Analysis Second Edition. New York: John Wiley & Son’s, Inc.
Canhope. (2014). Apa itu Kanker Serviks?. Retrieved March, 2014, from Web Site: http://www.parkwaycancercentre .com
Evennet, Karen. (2003). Pap Smear, Apa yang Perlu Anda Ke-tahui. Jakarta : Arcan Publisher
Gunn, Steve. (1998). Support Vector Machine for Classification and Regression. Taiwan : National Taiwan University Hosmer, D.,W., Lemeshow, S. (2000). Applied Regression
Logis-tic, Second Edition. Canada: John Wiley & Son’s, Inc. Hsu, C.W., Chang, C.C., Lin, C.J. (2003). A Practical Guide to
Support Vector Classification. England : University of
Southampton
Intansari, I.A.S. (2012). Klasifikasi Pasien Hasil pap Smear Test sebagai Pendeteksi Awal Upaya Penanganan Dini pada
Penyakit Kanker Serviks di RS “X” Surabaya dengan
metode Bagging Logistc Regression. Surabaya: Institut Teknologi Sepuluh Nopember.
Junita. (2014). Faktor Resiko Kanker Rahim. Retrieved March, 2014, from Web Site: www.health.detik.com
Kota Bogor. (2011). Seminar Kesehatan "Peduli Perempuan: Cintai Diri, Cegah, Dan Deteksi Kanker Serviks Sejak Dini". Retrieved March, 2014, from Web Site: http://www.kotabogor.go.id
Mc Cormick, C.,C., Giuntoli, R., L. (2011). Patient’s Guide to Cervical Cancer. Baltimore : The John Hopkins Health Corporation
42
Nugroho, A.S., Handoko, D., Witarto, A.B. (2003). Support Vector Machine – Teori dan Aplikasinya dalam Bioinformatika. BPPT
Rouzeau, Vanessa. (2012). Cervical Cancer : A Review. Florida : Herzing University
Rahman, Farizi. (2012). Klasifikasi Tingkat Keganasan Breast Cancer Dengan Menggunakan Regresi Logistik Ordinal Dan Support Vector Machine. Surabaya: Institut Teknologi Sepuluh Nopember.
Susanti, Desi. (2012). Pemeriksaan Pap Smear. Riau : STIKES Tuanku Tambusai Bakinang
Walpole, R. E. (1995). Pengantar Statistika Edisi ke-3(Sumantri, Bambang). Jakarta: PT Gramedia Pustaka Utama
55
LAMPIRAN
Lampiran 1 : Data Studi Kohort PTM 2011 kanker serviks
Y X1 X2 X3 X4 X5 X6 X7 X8 X9 X10 X11 X12 X13
1 52 1 1 2 26 7 1 0 2 2 25 2 2
2 27 1 1 2 20 2 1 0 2 2 19 2 2
2 50 1 1 2 23 4 2 0 2 2 22 2 2
2 45 1 1 2 25 2 2 0 2 2 22 2 2
2 36 1 1 2 28 3 2 0 2 2 24 2 2
1 26 1 1 2 19 3 1 1 2 2 18 2 2
2 50 1 1 2 19 4 1 1 2 2 18 2 2
2 28 1 1 2 20 3 1 1 2 2 19 2 1
2 60 1 1 2 21 5 1 1 2 2 20 2 2
2 48 1 1 2 22 4 1 1 2 2 20 2 1
2 46 1 1 2 22 2 1 1 2 2 21 2 2
2 45 1 1 2 23 3 1 1 2 2 22 2 2
2 31 1 1 2 24 2 1 1 2 2 88 2 2
2 31 1 1 2 25 1 1 1 2 2 23 2 2
2 32 1 1 2 27 2 1 1 2 2 25 2 2
2 46 1 1 2 28 2 1 1 2 2 17 2 2
2 30 1 1 2 28 1 1 1 2 2 27 2 2
2 29 1 1 1 29 1 1 1 2 2 28 2 2
2 31 1 1 2 31 1 2 1 2 2 27 2 2
2 31 1 1 2 20 3 1 2 2 2 20 2 2
2 40 1 1 2 21 2 1 2 2 2 20 2 2
2 51 1 2 1 19 7 1 3 2 2 14 2 2
2 35 1 1 2 19 5 1 3 2 2 18 2 2
2 37 1 1 2 19 4 2 3 2 2 18 2 2
44
Lampiran 2 : Uji Univariabel (seleksi kandidat variabel yang masuk model)
Variables in the Equation
B S.E. Wald
45
Variables in the Equation
B S.E. Wald a. Variable(s) entered on step 1: Status.nikah.
Variables in the Equation
B S.E. Wald
d
f Sig. Exp(B)
Step 1a Jumlah.pasan gan.seks(1) a. Variable(s) entered on step 1: Jumlah.pasangan.seks.
Variables in the Equation
B S.E. Wald
a. Variable(s) entered on step 1: Pendarahan.mens.
Variables in the Equation
46
Variables in the Equation
B S.E. Wald
d
f Sig. Exp(B)
Step 1a Banyak.ana k
,137 ,287 ,230 1 ,632 1,147
Constant 4,509 ,818 30,366 1 ,000 90,84 1 Step 2a Constant 4,852 ,502 93,439 1 ,000 128,0 a. Variable(s) entered on step 1: Banyak.anak.
Variables in the Equation
B S.E. Wald
Constant 4,890 1,00 4
23,737 1 ,000 133,000
Step 2a Constant 4,852 ,502 93,439 1 ,000 128,000 a. Variable(s) entered on step 1: Kontrsepsi.
Variables in the Equation
B S.E.
a. Variable(s) entered on step 1: Jenis.kont.
Variables in the Equation
B S.E.
47
Variables in the Equation
B S.E. Wald
d
f Sig. Exp(B) Step 1a Riwayat.kel
uarga(1) a. Variable(s) entered on step 1: Riwayat.keluarga.
Variables in the Equation
B S.E. Wald
d
f Sig. Exp(B) Step 1a Vaksin.HPV
(1) a. Variable(s) entered on step 1: Vaksin.HPV.
Variables in the Equation
B S.E. Wald
d
f Sig. Exp(B) Step 1a
Usia.nikah ,004 ,053 ,006 1 ,939 1,004
Constant 4,766 1,21 5
15,390 1 ,000 117,46 2 Step 2a Constant 4,852 ,502 93,439 1 ,000 128,00 a. Variable(s) entered on step 1: Usia.nikah.
Variables in the Equation
B S.E. Wald
48
Variables in the Equation
B S.E.
a. Variable(s) entered on step 1: Merokok.
Lampiran 3 : Uji Kesesuaian Model
Hosmer and Lemeshow Test
Step Chi-square df Sig.
1 ,716 2 ,699
Lampiran 4 : Uji Serentak (Overall Test)
Omnibus Tests of Model Coefficients
Chi-square df Sig.
Step 1
Step 6,576 3 ,087
Block 6,576 3 ,087
Model 6,576 3 ,087
Lampiran 5: Uji Individu & Estimasi Parameter
Variables in the Equation
B S.E. Wald df Sig. Exp(B)
49
Lampiran 6 : Syntax dan output SVM pembentukan model
[nsv, alpha, b0] = svc(xtr,ytr,'poly',2,10)
predictedY = svcoutput(xtr,ytr,xts,'poly',1,alpha,b0,1)
Support Vector Classification #50:50 _____________________________ Constructing ...
Optimising ...
Execution time: 70.7 seconds Status : OPTIMAL_SOLUTION |w0|^2 : 0.000006
Margin : 837.463831 Sum alpha : 5119.999984 Support Vectors : 512 (99.2%)
nsv =
50
Support Vector Classification #70:30 _____________________________ Constructing ...
Optimising ...
Execution time: 176.9 seconds Status : OPTIMAL_SOLUTION |w0|^2 : 0.000009
Margin : 679.357193 Sum alpha : 7159.999978 Support Vectors : 716 (99.2%)
nsv =
716
Support Vector Classification #90:10 _____________________________ Constructing ...
Optimising ...
Execution time: 381.1 seconds Status : OPTIMAL_SOLUTION |w0|^2 : 0.000011
Margin : 610.366601 Sum alpha : 9229.999971 Support Vectors : 923 (99.4%)
nsv =
BIODATA DIRI
AGIL DARMAWAN, lahir di Kabupaten Kediri pada tanggal 20 Februari 1990. Penulis adalah anak bungsu dari pasangan Masykur Idris, S.H dan Siti Khudewi Azzah Zuhriah, S.Pd. Penulis memulai pendidikan formalnya dari SDI Al Huda Kediri, MTs N 2 Kediri, MAN 3 Kediri, dan akhirnya diterima sebagai mahasiswa S1 Statistika ITS pada tahun 2008 melalui jalur SNMPTN. Pada tahun 2014 penulis berhasil menyelesaikan
Tugas Akhir dengan judul “Deteksi Dini Penyakit Kanker Leher Rahim (Serviks) di Kota Bogor Mengunakan Support Vector Machine (SVM)”. Selama kuliah penulis aktif di beberapa organisasi kemahasiswaan antara lain sebagai staf PPSDM Forum Studi Islam Statistika (FORSIS) ITS, staf PSDM Himpunan Mahasiswa Statistika (HIMASTA) ITS, staf Professional Statistics (PST), serta organisasi terbesar di ITS
yaitu Jama’ah Masjid Manarul Ilmi (JMMI) ITS.