PENDAHULUAN
Latar BelakangBerbicara merupakan metode komunikasi yang paling alamiah. Begitu nyamannya orang menggunakan suara sebagai media komunikasi sampai menginginkan dapat berkomunikasi dengan komputer melalui media ini dibandingkan menggunakan antarmuka primitif seperti keyboard atau alat penunjuk lainnya.
Teknologi Automatic Speech Recognizer (ASR) merupakan cabang ilmu kecerdasan buatan yang mencakup akuisisi pengetahuan, pemodelan bahasa, pencocokan pola, dan adaptasi. Seperti telah diketahui, Hidden
Markov Model telah banyak diaplikasikan
untuk masalah pengenalan suara beberapa tahun belakangan ini. Jaringan syaraf tiruan banyak digunakan untuk menyelesaikan masalah pengenalan-pengenalan pola, yang memetakan sejumlah input ke sejumlah output. Salah satunya adalah masalah pengenalan suara.
Teknologi ASR, khususnya dalam penerapannya sebagai Continuous Digit
Recognizer (CDR), berkembang seiring
dengan kebutuhan akan interaksi manusia dengan komputer yang semakin meningkat. CDR banyak diaplikasikan dalam berbagai hal contohnya pemasukan data otomatis, voice
dialing telephone, sistem perbankan otomatis,
dan sistem telephone-based lainnya.
Hingga saat ini ilmuwan dari berbagai negara telah dan masih mengembangkan CDR untuk bahasanya masing-masing. Penelitian mengenai CDR sudah banyak berkembang untuk bahasa Inggris. Salah satu contohnya adalah penelitian yang dilakukan oleh Cosi et
al (1997). Penelitian ini menggunakan
basisdata suara yang cukup besar berisi ribuan kalimat. Penelitian ini memberikan akurasi tingkat kata sebesar 96,36% dan 86,82% untuk akurasi tingkat kalimat. Duc et al (2001) juga telah mengembangkan CDR untuk bahasa Vietnam. CDR berbahasa Vietnam ini memiliki akurasi sebesar 90,48% pada tingkat kata dan 73,97% pada tingkat kalimat. CDR juga telah dibuat untuk bahasa Italia oleh Cosi (2000) dengan akurasi mencapai 98,24% untuk akurasi tingkat kata dan 87,89% untuk tingkat kalimat. Penelitian yang disebut di atas dilakukan menggunakan
Centre for Speech and Language Understanding (CSLU) toolkit dari Oregon
Graduate Institute of Science and Technology
(OGI), Amerika Serikat. CSLU toolkit ini
dapat diperoleh di http://cslu.cse.ogi.edu/toolkit secara bebas
untuk penggunaan non komersil. Penelitian mengenai ASR berbahasa Indonesia belum banyak dilakukan dan sejauh pengamatan penulis CDR berbahasa Indonesia belum tersedia sehingga perlu dilakukan penelitian lebih lanjut mengenai hal tersebut.
Tujuan
Penelitian ini bertujuan untuk membandingkan metode pengenalan kata menggunakan data hand-labeled, force
alignment, dan Forward Backward Neural Networks (FBNN) pada pengenalan bilangan
berbahasa Indonesia menggunakan CSLU
toolkit.
Ruang Lingkup
1 Kata yang dapat dikenali dibatasi pada kata dasar bilangan sesuai dengan ejaan bahasa Indonesia yang disempurnakan. 2 Pengenalan kata dilakukan berdasarkan
fonem. Setiap fonem hanya dibagi ke dalam satu bagian saja (independent
part).
3 Analisis kinerja sistem dilakukan berfokus pada akurasi pengenalan sistem yang meliputi insertion, deletion, dan
substitution.
TINJAUAN PUSTAKA
Gelombang SuaraInput ke dalam suatu sistem pengenal suara adalah gelombang suara yang merupakan barisan perubahan udara yang cukup kompleks. Perubahan udara ini disebabkan oleh jalur spesifik yang dilewati udara mulai dari celah suara (glottis) sampai ke rongga mulut atau rongga hidung.
Gelombang suara direpresentasikan dengan memetakan perubahan tekanan udara terhadap waktu. Contoh gelombang suara dapat dilihat pada Gambar 1.
Gambar 1 Gelombang suara sebagai input sistem pengenal suara.
Dua karakteristik penting dari sebuah gelombang suara adalah frekuensi dan amplitudo. Frekuensi adalah banyaknya gelombang tersebut berulang (cycles) dalam satu detik. Banyaknya cycles per detik disebut Hertz (Hz). Amplitudo suatu gelombang merupakan jumlah variasi tekanan udara pada suatu titik. Amplitudo yang besar menunjukkan tekanan udara yang lebih besar pada waktu tersebut, nilai nol menandakan tekanan udara normal (atmospheric), sedangkan amplitudo dengan nilai negatif menandakan tekanan udara di bawah normal. Dua sifat yang berhubungan dengan frekuensi dan amplitudo adalah pitch dan loudness.
Pitch berkorelasi positif dengan frekuensi,
sedangkan loudness berkorelasi positif dengan
power, yang merupakan nilai kuadrat dari
amplitudo (Jurafsky & Martin 2000). Spektral, Spektrogram, dan Formant
Jika hanya melalui gelombang suara saja, klasifikasi fonem tidak dapat dilakukan secara rinci. Untuk menghasilkan klasifikasi fonem yang lebih terperinci dibutuhkan representasi gelombang suara dalam bentuk fitur-fitur spektral. Spektrum adalah representasi komponen-komponen gelombang suara dalam frekuensi yang berbeda-beda (Jurafsky & Martin 2000). Spektrum dihasilkan dari proses transformasi fourier yang dapat memisahkan komponen frekuensi sebuah gelombang. Pada gelombang suara, dengan representasi bentuk spektrum terlihat jelas karakteristik yang berbeda dari setiap fonem.
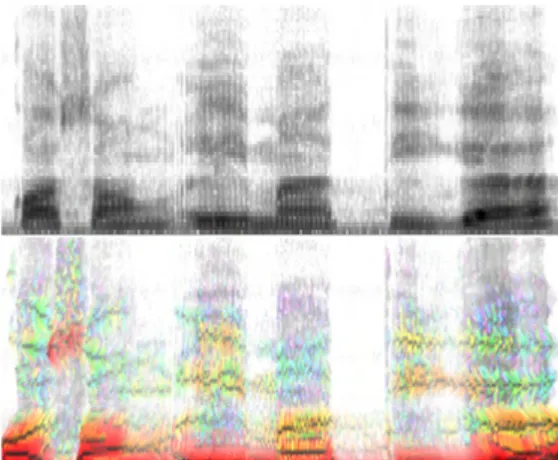
Jika sebuah spektrum menunjukkan komponen frekuensi dari sebuah gelombang pada suatu waktu tertentu, maka spektrogram menggambarkan perubahan frekuensi ini terhadap waktu (Jurafsky & Martin 2000). Sumbu horizontal pada spektrogram menyatakan waktu, sama seperti pada gelombang suara, sedangkan sumbu vertikal menyatakan frekuensi. Contoh spektrogram dapat dilihat pada Gambar 2.
Spektrogram biasanya dihitung dan disimpan di dalam memori komputer dalam bentuk array 2 dimensi. Untuk sebuah spektrogram S, kekuatan energi dari sebuah komponen frekuensi pada waktu t direpresentasikan dengan warna pada titik yang dimaksud S(t, f). Daerah dengan warna yang lebih gelap pada spektrogram menggambarkan amplitudo pada komponen frekuensi tersebut. Bagian berwarna gelap dalam spektrogram merepresentasikan
puncak-puncak spektral disebut formant (Jurafsky & Martin 2000).
Selain ditampilkan dalam bentuk skala keabuan, terdapat pula spektrogram yang digambarkan dengan warna untuk menunjukkan fitur penting dari sebuah spektrogram. Sumbu horizontal dari spektrogram menyatakan waktu sedangkan sumbu horizontal menyatakan frekuensi dalam satuan Hertz. Warna yang berbeda-beda menandakan intensitas energi pada suatu titik tertentu. Warna merah menggambarkan peningkatan energi sepanjang sumbu vertikal, warna biru menggambarkan penurunan energi, warna kuning dan hijau menggambarkan energi maksimum, sedangkan warna putih berarti tidak terdapat energi yang cukup untuk menjadi perhatian.
Gambar 2 Spektrogram skala keabuan dan berwarna dari suatu gelombang suara tertentu.
Representasi spektral dapat memberikan petunjuk yang spesifik pada identifikasi fonem. Hal ini disebabkan karena setiap fonem memiliki formant yang unik.
Fonem Bahasa Indonesia dan Karakteristik Formant-nya
Para ahli bahasa mengelompokkan bunyi yang digunakan dalam sebuah bahasa ke dalam sejumlah kategori abstrak yang disebut fonem. Fonem juga dapat diartikan sebagai unit bunyi terkecil yang membedakan arti. Di dalam bahasa Indonesia dikenal 31 simbol fonem yaitu [PPPBDEPDIKBUD 1996]: Fonem vokal (6 buah): /a/, /i/, /u/, /e/, /ə/,
dan /o/
Fonem konsonan (18 buah): /p/, /t/, /c/, /k/, /b/, /d/, /j/, /g/, /m/, /n/, /ñ/, /ŋ/, /s/, /h/, /r/, /l/, /w/, /y/
Fonem serapan (4 buah): /f/, /z/, /ſ/, /x/ Fonem diftong (3 buah): /aw/, /ay/, /oy/.
Kata-kata yang akan dikenali pada penelitian kali ini hanya terbatas pada kata dasar bilangan saja, maka tidak semua fonem di atas digunakan dalam penelitian ini, beberapa yang digunakan adalah sebagai berikut:
/a/, /i/, /u/, /e/, /o/, /p/, /t/, /k/, /b/, /d/, /j/, /g/, /m/, /n/, /ŋ/, /s/, /h/, dan /l/.
Setiap fonem memiliki karakteristik
formant yang unik yang dapat membedakan
satu dengan lainnya. Untuk fonem vokal (/a/, /i/, /u/, /e/, /o/), formant yang dihasilkan relatif stabil, kuat, dan tidak berubah-ubah. Pada spektrogram fonem dari kategori ini mudah diidentifikasi.
Hal ini berbeda pada kategori huruf nasal (/m/, /n/, /ŋ/). Kategori ini memiliki energi yang jauh lebih sedikit dibandingkan dengan kategori fonem vokal. Penyebabnya adalah terhalangnya hampir seluruh rongga sehingga suara keluar melalui rongga hidung.
Kategori berikutnya adalah plosive yang terdiri dari fonem /p/, /t/, /k/, /b/, /d/, /g/.
Formant kategori plosive ditandai dengan
ledakan energi akustik yang diikuti oleh jeda yang singkat. Selain itu kategori ini juga ditandai oleh perubahan yang cepat dari energi akustik yang kecil atau sama sekali tidak ada sampai ledakan singkat berenergi tinggi pada pita frekuensi yang luas.
Kategori fonem fricative juga merupakan kategori fonem yang mudah dikenali. Fonem /s/ termasuk dalam kategori ini. Keberadaan fonem ini pada spektrogram ditandai pada daerah dengan frekuensi tinggi dengan distribusi energiyang bersifat random.
Fonem /l/ termasuk ke dalam kategori
approximant. Penanda kategori ini adalah
energi yang labih lemah dibandingkan dengan kategori fonem. Hal ini disebabkan adanya sedikit penghalang pada jalur vocal tract.
Kategori fonem lainnya adalah affricate, contohnya adalah fonem /j/. Kategori ini merupakan gabungan dari plosive dan
fricative (Carmell et al 1997).
Jaringan Syaraf Tiruan (JST)
Studi mengenai JST terinspirasi oleh bidang ilmu neurobiologi. Menurut Fausett (1994), JST adalah suatu pemrosesan
informasi yang memiliki karakteristik sebagai berikut
1 Arsitektur jaringan, yaitu pola hubungan antar neuron.
2 Algoritma pelatihan atau pembelajaran, merupakan metode penentuan bobot pada hubungan antar neuron.
3 Fungsi aktivasi yang dijalankan pada masing-masing neuron pada input untuk menentukan output.
JST mampu belajar membentuk asosiasi antara input dan output, menyimpan data pelatihan serta mempelajari polanya. Hal ini penting pada proses pengenalan suara mengingat pola akustik yang tidak pernah sama. JST juga mampu menghitung fungsi-fungsi non-linear dan non-parametrik dari input sehingga dapat mentransformasi data secara lebih kompleks.
Arsitektur JST meliputi pengaturan neuron dalam suatu lapisan dan pola hubungan dalam lapisan dan di antara lapisan. Dalam JST, neuron diatur dalam sebuah lapisan (layer). Ada 3 tipe lapisan, yaitu lapisan input, lapisan tersembunyi, dan lapisan output. Berdasarkan lapisannya JST dikelompokkan sebagai jaringan lapis tunggal (single layer), jaringan lapis banyak (multi
layer), dan jaringan lapis kompetitif
(competitive layer). Jaringan lapis tunggal memiliki satu lapis hubungan bobot. Jaringan lapis banyak memiliki satu atau lebih lapisan tersembunyi antara lapisan input dan output. Sedangkan jaringan dengan lapis kompetitif membentuk suatu bagian dari sejumlah besar jaringan-jaringan syaraf. Gambar 3 merupakan contoh sederhana dari sebuah JST.
Gambar 3 Arsitektur JST dengan sebuah lapisan tersembunyi.
Berdasarkan skema interkoneksinya, jaringan dapat dibagi menjadi jaringan feed
X1 X2 X3 Y Z2 Z1 w1 w2 w3 y1 y2
forward dan recurrent. Koneksinya dapat
dibagi ke dalam koneksi simetrik dan asimetrik. Pada jaringan feed forward semua koneksinya satu arah berasal dari lapisan input menuju lapisan output. Sedangkan pada jaringan recurrent terdapat loop atau koneksi
feedback. Sebuah jaringan dikatakan memiliki
koneksi yang simetrik apabila terdapat koneksi dari node i ke node j, begitu juga sebaliknya. Kedua koneksi itu memiliki bobot yang sama. Jika koneksi antar node tidak simetrik seperti disebutkan di atas, maka koneksinya disebut koneksi asimetrik (Fu 1994).
Sebelum JST digunakan untuk mengklasifikasikan pola, terlebih dahulu dilakukan proses pembelajaran untuk menentukan struktur jaringan, terutama dalam penentuan nilai bobot. Ada dua tipe pembelajaran, yaitu pembelajaran dengan pengarahan (supervised learning) dan tanpa pengarahan (unsupervised learning). Beberapa metode pembelajaran yang digunakan antara lain metode Hebb, Perceptron, Adaline, Madaline, Backpropagation, Self Organizing
Map (SOM), dan Learning Vector Quantization (LVQ). Arsitektur jaringan yang
digunakan pada penelitian ini adalah multi
layer perceptron (MLP) karena MLP dapat
digunakan untuk menyelesaikan masalah klasifikasi nonlinear karena dapat membentuk daerah keputusan yang lebih kompleks (Fu 1994). MLP merupakan jaringan syaraf tiruan
feed forward dengan paling tidak satu lapis
tersembunyi layer. MLP biasa dilatih menggunakan algoritma pembelajaran
backpropagation. Pelatihan menggunakan
algoritma backpropagation terdiri dari tiga fase yaitu fase feed forward pola input pembelajaran, fase kalkulasi dan propagasi balik error yang didapat dan fase penyesuaian bobot.
Fungsi aktivasi merupakan fungsi yang menentukan level aktivasi, yaitu keadaan internal sebuah neuron dalam JST. Keluaran aktivasi ini biasanya dikirim sebagai sinyal ke neuron lainnya. Fungsi aktivasi yang umum digunakan adalah (Fausett 1994):
Fungsi identitas
( )
x xf = untuk setiap x Fungsi tangga biner
( )
⎩
⎨
⎧
< ≥ = θ θ x jika x jika x f 0 1 Fungsi sigmoid biner
) exp( 1 1 ) ( x x f − + =
Fungsi sigmoid bipolar
) exp( 1 ) exp( 1 ) ( x x x f − + − − = Ekstraksi Ciri
Ekstraksi ciri mempunyai input sinyal suara analog dan sebagai outputnya adalah
feature vector untuk setiap frame (time slice).
Untuk dapat menghasilkan feature vector terdapat beberapa langkah yang dilalui. Tahap pertama adalah melakukan digitasi terhadap sinyal suara analog. Proses ini terdiri dari
sampling dan kuantisasi (Jurafsky & Martin
2000).
Sampling artinya mengukur amplitudo
sinyal pada suatu indeks waktu tertentu. Dalam hal ini dikenal istilah sampling rate, yaitu banyaknya sampling yang dilakukan setiap detik. Sampling rate yang umum digunakan adalah 8000 Hz dan 16000 Hz. Jumlah sample minimum untuk sebuah cycle adalah sebanyak dua sample, satu sample untuk mengukur bagian positif dan sisanya mengukur bagian negatif gelombang. Jumlah
sample yang melebihi ketentuan di atas dapat
meningkatkan akurasi penghitungan amplitudo, sedangkan sebaliknya, jika jumlah
sample tidak memenuhi akan mengakibatkan
hilangnya frekuensi gelombang suara. Sehingga frekuensi maksimum yang dapat diukur adalah setengah dari sampling rate.
Berikutnya adalah kuantisasi, yaitu menyimpan nilai amplitudo ini ke dalam nilai integer, yang dalam hal ini memakai representasi 8 bit atau 16 bit.
Setelah sinyal didigitisasi, berikutnya adalah menyekatnya dalam bagian-bagian kecil penyusun sinyal suara dengan ukuran waktu yang tetap, misalnya 10 ms. Bagian-bagian kecil ini disebut frame. Langkah berikutnya adalah merepresentasikannya dalam domain spektral menjadi feature vector yang merupakan input bagi tahap berikutnya. Beberapa fitur yang sering digunakan adalah
linear predictive coding (LPC), koefisien cepstral, atau perceptual linear prediction
(PLP).
Koefisien cepstral merupakan representasi fitur yang paling populer saat ini.
Penelitian ini menggunakan fitur yang berasal dari Mel Frequency Cepstral Coefficient (MFCC) beserta turunannya yaitu MFCC delta. MFCC ditambah fitur energinya menghasilkan 13 koefisien demikian pula MFCC delta dengan fitur energinya juga menghasilkan 13 koefisien. Secara keseluruhan dihasilkan 26 koefisien untuk sebuah frame.
MFCC didasarkan pada variasi dari frekuensi kritis telinga manusia. Filter diletakkan secara linear pada frekuensi rendah dan logaritmik pada frekuensi tinggi untuk mendapatkan karakteristik suara yang penting dari fonem. Gambar 4 merupakan blok diagram yang menjelaskan secara umum proses untuk mendapatkan mel cepstrum.
Gambar 4 Blok diagram MFCC. Berikut adalah penjelasan dari blok diagram di atas (Do 1994)
1 Frame Blocking. Pada tahap ini gelombang suara dipecah ke dalam frame yang terdiri dari N sampel. Penelitian ini membagi gelombang suara menjadi
frame-frame berukuran 10 msec dengan
80 sampel.
2 Windowing. Proses windowing ini dilakukan untuk setiap frame, dengan tujuan untuk meminimalisasi diskontinuitas sinyal pada awal dan akhir
frame. Konsepnya adalah memperhalus
distorsi spektral hingga mendekati nol pada awal dan akhir setiap frame. Beberapa window yang biasa digunakan
antara lain adalah rectangle, gaussian,
hamming, atau hanning window. Jika
didefinisikan window sebagai w(n) dengan 0≤n≤ N−1, dimana N adalah banyaknya sampel dalam tiap frame, maka sinyal hasil proses windowing dapat dinyatakan sebagai berikut:
yl(n)=xl(n)w(n) 0≤n≤ N−1 3 Fast Fourier Transform (FFT). Tahap ini
mengkonversi tiap frame dengan N sampel dari domain waktu ke domain frekuensi. FFT, algoritma implementasi
Discrete Fourier Transform (DFT),
didefinisikan pada himpunan N sampel
{xn} sebagai berikut N jkn e N k xk n X 1 2 / 0 π − ∑− = = n=0, 1, 2,…, N-1.
Nilai j pada persamaan di atas merupakan unit imajiner yaitu j= −1. Secara umum Xn merupakan bilangan kompleks. Hasil dari langkah ini disebut spektrum sinyal atau periodogram.
4 Mel frequency (MF) wrapping. Studi psikofisik menunjukkan bahwa persepsi manusia mengenai frekuensi sebuah sinyal suara tidak berupa skala linear sehingga untuk tiap suara dengan frekuensi f, pitch subjektifnya diukur dengan skala “mel”. Skala MF merupakan selang frekuensi linear untuk frekuensi dibawah 1000 Hz, dan selang frekuensi logaritmik untuk frekuensi di atas 1000 Hz. Persamaan berikut digunakan untuk menghitung MF jika diberikan suatu frekuensi f
) 700 1 ( 10 log * 2595 ) (f = + mel
5 Cepstrum. Pada langkah terakhir ini dikonversikan kembali log mel spectrum ke domain waktu, hasilnya disebut MFCC. Representesi cepstral dari spektrum suara memberikan representasi yang baik tentang local spectral
properties dari sinyal yang diberikan.
Karena hasil dari mel spectrum coeffients dan logaritmanya (dari hasil 4) adalah bilangan real, maka dapat dikonversikan ke domain waktu menggunakan Discrete
Cosine Transform (DCT).
Algoritma Viterbi
Algoritma ini ingin menemukan barisan state yang optimum, Q={ q1, q2, q3, …, qT}, jika diberikan barisan observasi O={O1, O2, O3, …, OT}. Pada algoritma ini didefinisikan
Frame Blocking
Windowing
Fast Fourier Transform (FFT)
Mel frequency Wrapping
Cepstrum frame Gelombang suara spectrum Mel spectrum Mel cepstrum
peubah baru, δt(i), sebagai skor terbaik (peluang tertinggi) yang dihitung pada path dari state periode pertama hingga state Si pada periode t. ) | ,..., 2 , 1 , ,..., 2 , 1 ( 1 ,..., 2 , 1 ) ( max λ δ Pq q qt iO O Ot t q q q i t = − =
Prosedur lengkap algoritma Viterbi adalah : 1. Inisialisasi, untuk 1≤i≤N :
0 ) ( 1 ) 1 ( ) ( 1 = = i O i b i i ψ π δ 2. Proses rekursi :
[
1()]
( ) 1max ) ( t iaij bj Ot N i j t = ≤≤ δ− ⋅ δ untuk 2≤t≤T dan 1≤j≤N]
)
(
[
max
arg
)
(
1 1i N t ij tj
−i
a
≤ ≤=
δ
ψ
untuk 2≤t≤T dan 1≤j≤N 3. Terminasi :)
(
max
1 *i
P
T N i≤δ
≤=
dan)
(
max
arg
1 *i
q
T N i Tδ
≤ ≤=
4. Backtracking :)
(
* 1 1 * + +=
t t tq
q
ψ
untuk t=T-1, T-2, …, 1. Algoritma Forward BackwardPada sebuah model Markov tersembunyi peluang observasi barisan O didefinisikan sebagai
P
T(
O
|
S
,
π
)
:)
(
)
(
)
(
)
,
|
(
s1 1 s2 2 sT T TO
S
b
O
b
O
b
O
P
π
=
K
Peluang dari barisan state didefinisikan sebagai sT sT s s s s T
S
a
a
a
P
(
|
π
)
=
1 2 2 3K
−1Sedangkan peluang
P
T(
O
|
π
)
adalah∑
=
S semua T T TO
P
O
S
P
S
P
(
|
π
)
(
|
,
π
)
(
|
π
)
∑ ∏
= −=
S semua T t t s s sb
O
a
t t t 1)
(
1Peluang forward didefinisikan sebagai berikut
)
|
,
,
,
,
(
)
(
1 2π
α
ti
=
P
TO
O
K
O
tS
t=
i
∑
−=
i t j ij t 1(
i
)
a
b
(
O
)
α
Peluang backward adalah
)
,
|
,
,
,
(
)
(
1 2π
β
ti
=
P
TO
t+O
t+K
O
TS
t=
i
∑
+ +=
i ji i t ti
O
b
(
1)
β
1(
)
α
Jadi peluang posterior dari suatu transisi dari
state i ke state j, λij , diberikan peluang observasi dan model Markov tersembunyinya adalah sebagai berikut
)
,
|
,
(
)
(
1π
λ
ijt
=
P
Ts
t=
i
s
t+=
j
O
)
|
(
)
(
)
(
)
(
1 1π
β
α
O
P
j
O
b
a
i
T t t j ij t + +=
∑
∈ + +=
S k T t t j ij tk
j
O
b
a
i
)
(
)
(
)
(
)
(
1 1α
β
α
Peluang posterior berada pada state i pada waktu t dapat dihitung dari persamaan berikut
)
,
|
(
)
(
π
λ
it
=
P
Ts
t=
i
O
∑
∈=
S k T t tk
i
i
)
(
)
(
)
(
α
β
α
Dan transisi antara state pada sebuah model Markov tersembunyi dapat diestimasi menggunakan persamaan berikut (Yan et al 1997).
∑ ∑
∑
− = − ==
1 1 1 1)
(
)
(
)
(
T t k ik T t ij ijt
t
t
a
λ
λ
∑
∑
− = − ==
1 1 1 1)
(
)
(
T t i T t ijt
t
λ
λ
METODOLOGI
Sistem CDR berbahasa Indonesia dalam penelitian ini dikembangkan dengan langkah-langkah pada Gambar 5.
Data
Data suara yang digunakan pada percobaan ini dikumpulkan dari rekaman suara 8 orang speaker dengan lingkungan perekaman dan rentang umur yang sama. Umur speaker berkisar antara 22-25 tahun. Sampel suara yang digunakan berasal dari suara 4 orang pria dan 4 orang wanita. Proporsi data yang digunakan dibagi menjadi tiga bagian, data untuk pelatihan, data untuk