PERBANDINGAN 3 METODE DALAM DATA MINING
UNTUK PREDIKSI PENERIMA BEASISWA BERDASARKAN PRESTASI DI SMA NEGERI 6 SURAKARTA
Naskah Publikasi Program Studi Informatika Fakultas Komunikasi dan Informatika
Oleh :
Veronica Andriyana
Yusuf Sulistyo Nugroho, S.T., M.Eng
PROGRAM STUDI INFORMATIKA
FEKULTAS KOMUNIKASI DAN INFORMATIKA UNIVERSITAS MUHAMMADIYAH SURAKARTA
PERBANDINGAN 3 METODE DALAM DATA MINING
UNTUK PREDIKSI PENERIMA BEASISWA BERDASARKAN PRESTASI DI SMA NEGERI 6 SURAKARTA
Veronica Andriyana, Yusuf Sulistyo Nugroho
Program Studi Informatika, Fakultas Komunikasi dan Informatika Universitas Muhammadiyah Surakarta
Email : veronica.andriyana8@gmail.com
Abstraksi
Dalam rangka meningkatkan akses dan minat belajar siswa serta mengangkat mutu sekolah, SMA N 6 Surakarta mengalokasikan dana beasiswa dalam bentuk apresiasi untuk siswa berprestasi. Namun masih ada hal yang menjadi permasalahan yang sering muncul, yaitu kurang tepatnya penyaluran beasiswa terhadap siswa. Beasiswa untuk siswa berprestasi bertujuan memotivasi siswa untuk selalu meningkatkan prestasi akademik maupun non akademik dan membantu siswa yang kurang mampu tetapi berprestasi. Untuk mengatasi permasalahan tersebut adalah dengan cara menerapkan proses data mining.
Dalam memprediksi siswa yang menerima beasiswa berdasarkan prestasi menggunakan metode Naive Bayes, Decision Tree Algoritma ID3, dan Regresi Linear. Atribut yang digunakan terdiri dari Nilai rata-rata, Gender, Ekstrakurikuler, Jurusan, Semester, Jumlah Tanggungan Orang Tua, Gaji Orang Tua, dan Beasiswa. Untuk melakukan proses data mining tersebut di perlukan tools pembantu yaitu RapidMiner 5.
Pengimplementasian data mining menggunakan perbandingan 3 metode dapat diketahui bahwa berdasarkan dari jumlah sampel 305 siswa hasil nilai precision metode Decision Tree Algoritma ID3 lebih baik digunakan untuk penelitian ini dibandingkan dengan metode yang lain. Sedangkan berdasarkan nilai recall dan accuracy, Regresi Linear lebih baik digunakan dibandingkan metode lain. Tetapi apabila dilihat dari hasil secara keseluruhan prediksi penerima beasiswa variabel yang paling berpengaruh adalah Nilai rata-rata.
Kata kunci : Algoritma ID3, Data mining, Decision Tree, Naive Bayes, Regresi Linear
PENDAHULUAN
Dalam dunia pendidikan, data yang berlimpah dan berkesinam-bungan mengenai siswa yang dibina dan alumni terus dihasilkan. Menurut Jing (2004) dan Merceron (2005) dalam Nugroho (2014), data yang
Negeri 6 Surakarta mengalokasikan dana beasiswa dalam bentuk apresiasi untuk siswa berprestasi. Namun masih ada permasalahan yang sering muncul, yaitu kurang tepatnya penyaluran beasiswa terhadap siswa, misalnya siswa yang sebenarnya tidak layak mendapatkan beasiswa tetapi mendapatkan beasiswa, sebaliknya siswa yang berhak mendapatkan beasiswa baik itu beasiswa beprestasi maupun beasiswa kurang mampu tetapi tidak mendapatkan beasiswa. Tujuan dari adanya beasiswa untuk siswa berprestasi tersebut yaitu memotivasi siswa untuk selalu meningkatkan prestasi akademik maupun non akademik, membantu siswa yang kurang mampu tetapi berprestasi, dan menumbuhkan rasa percaya diri siswa untuk berkompetitif dalam mengembangkan potensinya.
Berdasarkan permasalahan tersebut dapat diambil solusi dengan cara memanfaatkan teknik data mining dengan membandingkan 3 metode untuk prediksi siswa penerima beasiswa berdasarkan prestasi yaitu Naïve Bayes, Decision Tree Algoritma
ID3, Regresi Linear. Dengan analisis perbandingan tersebut, diharapkan dapat membantu menemukan informasi tentang siswa yang menerima beasiswa berdasarkan prestasi sehingga membantu pihak sekolah dalam mencari solusi dapat mengetahui tingkat prestasi siswa dan lebih meningkatkan lagi mutu pendidikan sekolah dengan adanya siswa-siswa yang berprestasi.
LANDASAN TEORI
1. Prediksi / Peramalan
Menurut susanto dalam Mauriza (2014) Prediksi adalah memperkirakan sesuatu yang akan terjadi pada masa yang mendatang. Prediksi juga dapat digunakan dalam pengklasifi-kasian, tidak hanya untuk memprediksi time series, karena sifatnya yang bisa menghasilkan class berdasarkan atribut yang ada.
2. Data Mining
pemakaian data, historis, untuk menemukan keteraturan, pola atau hubungan dalam set data berukuran besar. (Santoso, 2007) 3. Naive Bayes
Naive Bayes adalah teknik prediksi berbasis probabilitic sederhana yang berdasar pada penerapan Teorema Bayes (aturan Bayes) dengan asumsi independensi
(ketidakketergantungan) yang kuat. (Prasetyo, 2012)
4. Decision Tree Algoritma ID3 Decision Tree adalah metode untuk menemukan fungsi pendekatan yang bernilai diskrit dan tahan terhadap data-data yang memiliki kesalahan (noisy data) serta mampu mempelajari ekspresi-ekspresi disjunctive seperti OR. Iterative Dychotomizer version 3 (ID3) adalah salah satu jenis decision
tree yang umumnya digunakan untuk menemukan aturan yang diharapkan bisa berlaku untuk data-data tidak lengkap atau belum pernah kita ketahui. (Lesmana, 2012)
5. Regresi Linear
Analisis regresi adalah teknik statistik untuk permodelan dan investigasi hubungan dua atau lebih variabel. (Santosa, 2007)
METODE PENELITIAN a. Penentuan Atribut
Tahap yang pertama adalah menganalisis dan menyeleksi data keseluruhan untuk mendapatkan atribut dengan record yang relevan terhadap
keluaran yang diinginkan.
Atribut yang digunakan dalam prediksi penerima beasiswa terdapat dalam tabel 1
Tabel 1 Daftar Atribut
Atribut Variabel
Beasiswa Y
Nilai rata – rata X1
Gender X2
Ekstrakurikuler X3
Jurusan X4
Semester X5
Jumlah tanggungan orang tua X6
b. Implementasi Data Mining 1. Naive Bayes
Klaifikasi Bayesian adalah klasifikasi statistik yang bisa memprediksi probabilitas sebuah class. Klasifikasi ini
dihitung berdasarkan Teoema Bayes. (Widiastuti, 2010) Persamaan dari teorema Bayes dirumuskan seperti Persamaan 1 berikut ini :
... (1)
2. Decision Tree Algoritma ID3 Hal yang harus dilakukan dalam metode decision tree
adalah menghitung entrophy dan information gain. (Ranny dkk, 2012)
Persamaan 2 Rumus entrophy :
...(2) Persamaan 3 Rumus Information Gain
...(3)
3. Regresi Linear
Analisis regresi adalah teknik statistik untuk permodelan dan
investigasi hubungan dua atau lebih variabel. (Santosa, 2007) Persamaan 4 Rumus Regresi Linear :
...(4)
HASIL DAN PEMBAHASAN 1. Penentuan Sampel
Untuk mendapatkan sampel yang dapat menggambarkan dan mewakili jumlah populasi, maka dalam penentuan sampel penelitian ini digunakan rumus Slovin (Umar, 2004)
Rumus Slovin dirumuskan seperti Persamaan 5 berikut ini :
... (5) n = 1290 / 1 + 1290 (0,05)2 n = 305,325 siswa
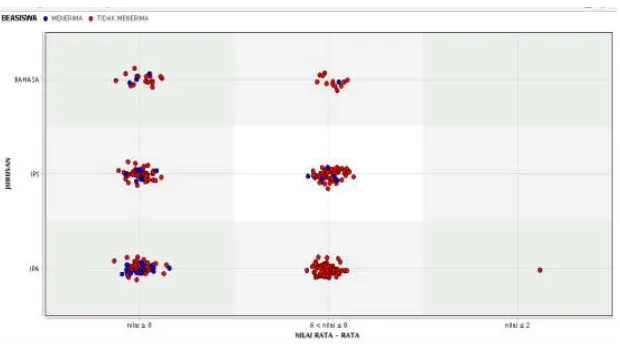
Gambar 1 Scatter Plot NaiveBayes menggunakan data testing 2. Hasil Implementasi Naive
Bayes menggunakan
RapidMiner 5
Berdasarkan scatter plot pada gambar 1 menunjukkan bahwa penerima beasiswa dengan nilai rata-rata nilai≥8 dan jurusan BAHASA sebagian ada yang menerima beasiswa. Sedangkan nilai≥8 dan jurusan IPA hasilnya tidak ada yang menerima beasiswa.
3. Hasil Implementasi Decision
Tree Algortima ID3
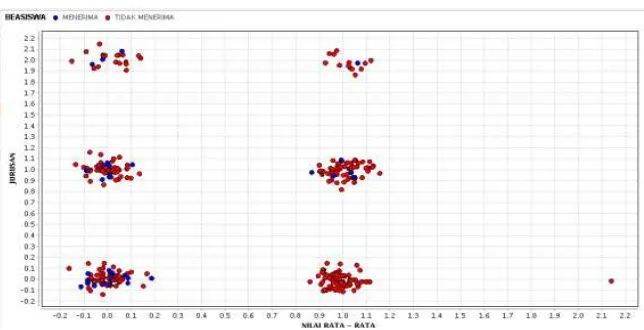
menggunakan RapidMiner 5 Berdasarkan scatter plot dalam gambar 2 menunjukkan bahwa 6<nilai≤8 dan Jurusan IPA hasilnya mayoritas TIDAK MENERIMA.
Sedangkan nilai≥8 dan Jurusan IPS hasilnya mayoritas TIDAK MENERIMA tetapi ada beberapa siswa yang MENERIMA beasiswa tersebut.
4. Hasil Implementasi Regresi
Linear menggunakan
RapidMiner 5
Gambar 2 Tampilan hasil decision tree pada Scatter Plot
Gambar 3 Scatter view Regresi Linear
5. Perhitungan Naive Bayes
Sebagai contoh penulis mengambil salah satu data uji yang memiliki ciri sebagai berikut :
nilai ≥ 8, PEREMPUAN, OLAHRAGA, IPA, semester 5, tanggungan ≤ 4, gaji ≤ 1500000. Apakah siswa tersebut Menerima atau Tidak Menerima beasiswa ?
Fakta menunjukkan :
P( Y =MENERIMA)= 31 / 305 = 0,10164
P( Y =TIDAK MENERIMA)= 274 / 305 = 0,89836
Fakta :
P (X1= nilai≥ 8 |Y=
P (X1= nilai≥ 8 |Y= TIDAK MENERIMA)= 125 / 274 = 0,45620
P (X2= PEREMPUAN |Y= MENERIMA)= 19 / 31 = 0,61290
P (X2= PEREMPUAN |Y= TIDAK MENERIMA)= 90 / 274 = 0,32847
P (X3= OLAHRAGA |Y= MENERIMA)= 3 / 31 = 0,09677 P (X3= OLAHRAGA |Y= TIDAK MENERIMA)= 22 / 274 = 0,08029
P (X4= IPA |Y= MENERIMA)= 2 / 31 = 0,06452
P (X4= IPA |Y= TIDAK MENERIMA)= 7 / 274 = 0,02555
P (X5= 5 |Y= MENERIMA)= 1 / 31 = 0,03226
P (X5= 5 |Y=TIDAK MENERIMA)= 4 / 274 = 0,01460
P (X6= tanggungan≤ 4 |Y= MENERIMA)= 1 / 31 = 0,03226 P (X6= tanggungan≤ 4 |Y= TIDAK MENERIMA)= 2 / 274 = 0,00730
P (X7= gaji ≤ 1500000 |Y= MENERIMA)= 1 / 31 = 0,03226
P (X7= gaji ≤ 1500000|Y= TIDAK MENERIMA)= 1 / 274 = 0,00365
HMAP dari keadaan ini dapat dihitung dengan :
P(X1= nilai ≥ 8, X2=
PEREMPUAN, X3=
OLAHRAGA, X4= IPA, X5= 5, X6= tanggungan≤ 4, X7 = gaji ≤ 1500000 | Y = MENERIMA)
= 0,00105287
P(X1= nilai ≥ 8, X2= PEREMPUAN, X3= OLAHRAGA, X4= IPA, X5= 5, X6= tanggungan≤ 4, X7= gaji ≤ 1500000 | Y = TIDAK
MENERIMA) = 0,0000107389 KEPUTUSAN PREDIKSI BEASISWA = MENERIMA.
a) Menentukan Root Node
Root Node adalah atribut yang memiliki nilai information gain paling tinggi.
Tabel 2 Information gain tertinggi
Atribut Nilai gain
Gender 0,001
Nilai rata - rata 0,035 Ekstrakurikuler 0,028
Jurusan 0,000
Semester 0,015
Tanggungan orang tua
0,002
Gaji orang tua 0,009
b) Menentukan Internal Node pertama
Menentukan internal node pada Nilai rata-rata 6 < nilai ≤ 8 didapatkan nilai information gain seperti pada tabel 3.
Tabel 3 Nilai Information gain Atribut Nilai Gain
rata-rata 6 < nilai ≤ 8
Gender 0,005
Ekstrakurikuler 0,017
Jurusan 0,039
Semester 0,033
Tanggungan orang tua
0,001
Gaji orang tua 0,018
c) Menentukan Internal Node kedua Menentukan internal node pada Nilai rata-rata 6 < nilai ≤ 8 dan jurusan BAHASA didapatkan
nilai information gain seperti pada tabel 4.
Tabel 4 Nilai Information gain Atribut Nilai Gain
6 < nilai ≤ 8 BAHASA
Gender 0,061
Ekstrakurikuler 0,075
Semester 0,026
Tanggungan orang tua
0,075
Gaji orang tua 0,048
d) Menentukan Leaf Node
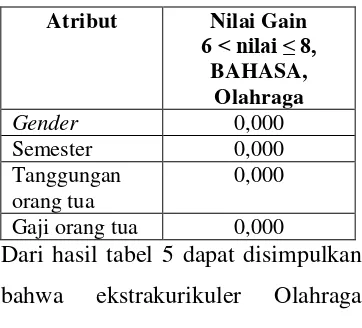
Menentukan leaf node pada Nilai rata-rata 6 < nilai ≤ 8, jurusan BAHASA dengan ekstrakurikuler Olahraga didapatkan nilai information gain seperti pada tabel 5.
Tabel 5 Nilai Information gain Atribut Nilai Gain
6 < nilai ≤ 8, BAHASA,
Olahraga
Gender 0,000
Semester 0,000
Tanggungan orang tua
0,000
Gaji orang tua 0,000
Dari hasil tabel 5 dapat disimpulkan bahwa ekstrakurikuler Olahraga menghasilkan leaf node, karena hasil dari information gain bernilai 0.
Dari perhitungan implementasi Regresi Linear menggunakan RapidMiner menghasilkan sebuah persamaan sebagai berikut : Y = (0,136 × NILAI RATA – RATA) – ( 0,078 × SEMESTER)
+ (0,021 × JUMLAH
TANGGUNGAN ORANG TUA) + 0,858
Dari persamaan tersebut dibuktikan dengan perhitungan manual dengan mengambil beberapa sampel data seperti di bawah ini :
Pengujian penghitungan siswa yang MENERIMA BEASISWA : Y = (0,136 × 4) – (0,078 × 2) + (0,021 × 0) + (0,015 × 0) + 0,858 = 1,246
Karena hasilnya mendekati 1 maka hasilnya MENERIMA.
KESIMPULAN
Berdasarkan penjelasan dan analisis yang telah diuraikan, maka dapat ditarik kesimpulan bahwa :
1. Variabel yang paling mempengaruhi dari hasil perhitungan 3 metode (Naive Bayes, Decision Tree Algoritma
ID3, dan Regresi Linear) adalah nilai rata – rata.
2. Berdasarkan dari nilai precision, metode Decision Tree Algoritma ID3 lebih baik digunakan dalam penelitian ini karena memiliki nilai lebih baik dari pada algoritma yang lainnya.
3. Berdasarkan nilai recall dan accuracy, Regresi Linear lebih
baik digunakan dalam penelitian ini karena memiliki nilai lebih baik dari metode yang lain.
4. Hasil dari nilai precision, recall, dan accuracy nya adalah sebagai berikut:
a. Naive Bayes hasil precision 89,90% , recall 99,64%, dan accuracy 89,51%.
b. Decision Tree Algoritma ID3 hasil precision 90,04% , recall 82,48%, dan accuracy 76,07%. c. Regresi Linear hasil precision
DAFTAR PUSTAKA
Lesmana, Dody Putu. 2012. ‘Perbandingan Kinerja Decision Tree J48 dan ID3 Dalam Pengklasifikasian Diagnosis Penyakit Diabetes Mellitus’. Jurnal Teknologi dan Informatika, Vol. 2, no. 2.
Mauriza, Ahmad Fikri. 2014. ‘Implementasi Data Mining Untuk Memprediksi Kelulusan Mahasiswa Fakultas Komunikasi dan Informatika UMS Menggunakan Metode Naïve Bayes’, Skripsi.Fakultas Komunikasi Dan Informatika, Universitas Muhammadiyah Surakarta.
Nugroho, Yusuf Sulistyo. 2014. ‘Klasifikasidan Prediksi Masa Studi dan Prestasi Mahasiswa Fakultas Komunikasi dan Informatika Universitas Muhammadiyah Surakarta’, Jurnal KomuniTI, Vol VI, No 1, Maret 2014.
Prasetyo, Eko. 2012. Data Mining konsep dan aplikasi menggunakan matlab. Yogyakarta: Andi.
Ranny dkk. 2012. ‘Pemilihan Diet Nutrien bagi Penderita Hipertensi Menggunakan Metode Klasifikasi Decision Tree’, Jurnal Teknik ITS, Vol. 1, No.1.
Santosa, Budi. 2007. Data Mining Terapan dengan Matlab. Yogyakarta: Graha Ilmu.
Santoso, Budi. 2007. Data Mining Teknik Pemanfaatan Data untuk Keperluan Bisnis. Yogyakarta: GrahaIlmu.
Umar, Husein (2014). Metode Penelitian Untuk Skripsi Dan Tesis Bisnis. Cetakanke – 6.Jakarta : PT Raja GrafindoPersada.
BIODATA PENULIS
Nama : Veronica Andriyana
NIM : L200110086
Tempat Lahir : Surakarta
Tanggal Lahir : 8 Februari 1993
Jenis Kelamin : Perempuan
Agama : Islam
Pendidikan : S1
Fakultas : Jurusan Informatika/Fakultas Komunikasi dan Informatika
Universitas : Universitas Muhammadiyah Surakarta
Alamat : Jl. Tarumanegara Utara II, Tempel RT 5 RW 7, Banyuanyar, Banjarsari, Surakarta
Nomor Telepon : 085799480482