SKRIPSI
Oleh:
Daniel Rachman
311410065
PROGRAM STUDI TEKNIK INFORMATIKA
SEKOLAH TINGGI TEKNOLOGI PELITA BANGSA
BEKASI
2018
SKRIPSI
Diajukan Sebagai Salah Satu Syarat Untuk Menyelesaikan Program Strata Satu (S1) pada Program Studi Teknik Informatika
Oleh:
Daniel Rachman
311410065
PROGRAM STUDI TEKNIK INFORMATIKA
SEKOLAH TINGGI TEKNOLOGI PELITA BANGSA
BEKASI
2018
iv
KATA PENGANTAR
Puji syukur penulis panjatkan kehadiran Allah SWT. yang telah melimpahkan segala rahmat dan hidayah-Nya, sehingga tersusunlah Skripsi yang berjudul
“KLASIFIKASI PENDUDUK MISKIN PROVINSI NUSA TENGGARA
TIMUR MENGGUNAKAN ALGORITMA NAÏVE BAYES DAN CROSS
VALIDATION”.
Skripsi tersusun dalam rangka melengkapi salah satu persyaratan dalam rangka menempuh ujian akhir untuk memperoleh gelar Sarjana Komputer (S.Kom.) pada Program Studi Teknik Informatika di Sekolah Tinggi Teknologi Pelita Bangsa.
Penulis sungguh sangat menyadari, bahwa penulisan Skripsi ini tidak akan terwujud tanpa adanya dukungan dan bantuan dari berbagai pihak. Sudah selayaknya, dalam kesempatan ini penulis menghaturkan penghargaan dan ucapan terima kasih yang sebesar-besarnya kepada:
a. Bapak Dr. Ir. Suprianto, M.P. selaku Ketua STT Pelita Bangsa
b. Bapak Aswan S. Sunge, S.E., M.Kom. selaku Ketua Program Studi Teknik Informatika STT Pelita Bangsa.
c. Bapak Elkin Rilvani, S.Kom., M.M.. selaku Dosen pembimbing utama yang telah banyak memberikan arahan dan bimbingan kepada penulis dalam penyusunan Skripsi ini.
d. Ir. Tri Ngudi Wiyatno, M.T. selaku Dosen pembimbing kedua yang telah banyak memberikan arahan dan bimbingan kepada Penulis dalam penyusunan Skripsi ini. e. Seluruh Dosen STT Pelita Bangsa yang telah membekali penulis dengan
wawasan dan ilmu di bidang Teknik Informatika.
f. Seluruh staf STT Pelita Bangsa yang telah memberikan pelayanan terbaiknya kepada penulis selama perjalanan studi jenjang Strata 1.
v
g. Rekan-rekan mahasiswa STT Pelita Bangsa, khususnya angkatan 2014, yang telah banyak memberikan inspirasi dan semangat kepada penulis untuk dapat menyelesaikan studi jenjang Strata 1.
h. Ibu dan Ayah tercinta yang senantiasa mendo’akan dan memberikan semangat dalam perjalanan studi Strata 1 maupun dalam kehidupan penulis.
Akhir kata, Penulis mohon maaf atas kekeliruan dan kesalahan yang terdapat dalam Skripsi ini dan berharap semoga Skripsi ini dapat memberikan manfaat bagi khasanah pengetahuan Teknologi Informasi di lingkungan STT Pelita Bangsa khususnya dan Indonesia pada umumnya.
Bekasi, November 2018
vi DAFTAR ISI
Halaman
PERSETUJUAN………... i
PENGESAHAN……… ii
PERNYATAAN KEASLIAN PENELITIAN………. iii
KATA PENGANTAR………... iv DAFTAR ISI………... vi DAFTAR TABEL……… ix DAFTAR GAMBAR………... x DAFTAR LAMPIRAN………... xi ABSTRACT……… xii ABSTRAK……….. xiii BAB I PENDAHULUAN……….. 1 1.1 Latar Belakang……… 1 1.2 Identifikasi Masalah……… 4 1.3 Rumusan Masalah………... 4 1.4 Batasan Masalah………. 4
vii
1.5.1 Tujuan………... 5
1.5.2 Manfaat………... 5
1.6 Sistematika Penulisan………... 5
BAB II TINJAUAN PUSTAKA………... 7
2.1 Tinjauan Studi……… 7
2.2 Kajian Pustaka………... 13
2.2.1 Data Mining ………... 13
2.2.2 Tahap-tahap Data Mining………... 13
2.2.3 Konsep Klasifikasi………... 17
2.2.4 Naïve Bayes………. 18
2.2.5 Cross Validation………... 20
2.3 Tinjauan Organisasi………... 22
2.3.1 Keadaan Geografis dan Administrasi NTT…………... 22
2.3.2 Populasi dan Mata Pencarian Penduduk NTT……… 24
2.4 Kerangka Pemikiran………... 24
2.5 Hipotesis Penelitian………... 25
BAB III METODE PENELITIAN……….. 26
viii
3.2 Teknik Analisis Data………. 26
3.3 Langkah Penelitian……… 30
3.4 Peralatan ………... 31
3.5 Waktu Penelitian……… 32
BAB IV HASIL DAN PEMBAHASAN……….. 34
4.1 Hasil……….. 34
4.1.1 Perhitungan Naïve Bayes………. 34
4.1.2 Implementasi Klasifikasi Naïve Bayes Pada Rapid Minner………….. 46
4.1.3 Akurasi Klasifikasi……… 47
4.2 Pembahasan………. ……. 50
BAB V KESIMPULAN DAN SARAN……… 52
5.1 Kesimpulan……… 52
5.2 Saran……… …….. 52
DAFTAR PUSTAKA……….. 53 LAMPIRAN……….
ix
DAFTAR TABEL
Halaman
Tabel 2.1 Penelitian Sebelumnya Yang Relevan………... 9
Tabel 3.1 Atribut Dataset……… 28
Tabel 3.2 Jadwal Kegiatan Penelitian………. 32
Tabel 4.1 Kriteria Yang Digunakan………. 34
Tabel 4.2 Probolitas Keterangan Penduduk………. 35
Table 4.3 Atribut Kabupaten………. 36
Table 4.4 Atribut Kecamatan………. 37
Table 4.5 Atribut Program………. 38
Tabel 4.6 Atribut Jumlah Penduduk……….. 38
Tabel 4.5 Atribut Belum APBN……… 39
Tabel 4.6 Atribut Belum APBD………. 40
Tabel 4.7 Data Testing……… 41
Tabel 4.8 Perhitungan P (ci)……… 42
x
DAFTAR GAMBAR
Halaman
Gambar 2.1 Tahap-Tahap Data Maning………... 16
Gambar 2.2 Skema 10 Fold……….. 21
Gambar 2.3 Kerangka Pemikiran……….. 25
Gambar 3.1 Pemahaman Bisnis……… 27
Gambar 3.2 Dataset……….. 28
Gambar 4.1 Proses Rapid Miner……….. 46
Gambar 4.2 Hasil Klasifikasi Rapid Miner……….. 47
Gambar 4.3 Model Pengujian……… 47
Gambar 4.4 Sub Proses Cross Validation………. 48
Gambar 4.5 Confusion Matrix Penduduk………. 49
xi
DAFTAR LAMPIRAN
Halaman Lampiran 1 Data Training………..………... Lampiran 2 Data Test………..………...
xii ABSTRACT
Poverty is the condition of a person or group of people, male and female, unable to fulfill their basic rights to maintain and develop a dignified life. East Nusa Tenggara is one of the provinces in Indonesia. Poverty in the province of East Nusa Tenggara in September 2017 reached 1,134.74 thousand people. In this case East Nusa Tenggara is difficult to determine the poor or not poor population. In this study, it is proposed to use data mining techniques to classify the poor population. Data mining techniques to classify based on population. The algorithm used is Naïve Bayes. From this study, Naive Bayes succeeded in classifying the poor population with an accuracy rate of 59%. In the study, the data was 200 people..
xiii ABSTRAK
Kemiskinan adalah kondisi seseorang atau sekelompok orang, laki laki dan perempuan, tidak mampu memenuhi hak dasarnya untuk mempertahankan dan mengembangkan kehidupan yang bermartabat. Nusa Tenggara Timur adalah salah satu provinsi yang berada di Indonesia, Kemiskinan diprovinsi Nusa Tenggara Timur pada bulan September 2017 mencapai 1.134,74 ribu orang. Dalam hal ini Nusa Tenggara Timur sulit menentukan penduduk yang miskin atau tidak miskin Pada penelitian ini diusulkan penggunaan teknik data mining untuk mengklasifikasi penduduk miskin. Teknik data mining untuk mengklasifikasi berdasarkan jumlah penduduk. Algoritma yang digunakan yaitu Naïve Bayes, Dari penelitian ini Naive Bayes ini berhasil mengklasifikasi penduduk miskin dengan persentase keakuratan sebesar 59% .Dalam penelitian menggunakan data sebanyak 200 penduduk.
Kata kunci : Kemiskinan, Nusa Tenggara Timur, Data Mining, Naïve Bayes.
1 BAB I PENDAHULUAN 1.1 Latar Belakang
Kemiskinan adalah kondisi seseorang atau sekelompok orang, laki laki dan perempuan, tidak mampu memenuhi hak dasarnya untuk mempertahankan dan mengembangkan kehidupan yang bermartabat sehingga dalam upaya meningkatkan kesejahteraan tersebut dapat dilakukan melalui program penanggulangan kemiskinan baik berupa bantuan sosial maupun pemberdayaan masyarakat. Banyak penelitian terkait klasifikasi kesejahteraan rumah tangga seringkali menggunakan variabel target/kelas berupa kategori miskin dan tidak miskin.
Indonesia merupakan salah satu Negara berkembang di asia khususnya asia tenggara. Salah satu masalah yang sering dihadapi oleh Negara berkembang adalah kemiskinan. Berdasarkan data yang dikeluarkan oleh Badan Pusat Statistik, angka kemiskinan di Indonesia pada tahun 1999 mencapai 47.97 juta jiwa. Pada tahun 2018 jumlah penduduk miskin menjadi 29.95 juta jiwa. Nusa Tenggara Timur adalah salah satu provinsi yang berada di Indonesia, Kemiskinan diprovinsi Nusa Tenggara Timur pada bulan September 2017 mencapai 1.134,74 ribu orang.
Cara mengetahui kemiskinan dengan cara melakukan pendataan kependudukan khususnya masalah kemiskinan yang dilakukan oleh Badan Pusat Statistik setiap 3 tahun sekali. Proses pendataan dilakukan dengan cara door to door, cara ini dianggap kurang efektif dari pekerjaan ini BPS menghasilkan data yang
berlimpah mengenai kemiskinan. Kemiskinan ini harus diperhatikan untuk dapat mengetahui ketepatan jenis/klasifikasi didapat dari pengelolahan data yang ada dan tersimpan dalam basis data (database). Pada data kemiskinan tersebut dari banyak nilai untuk mengetahui miskin atau tidaknya masyarakat, hal ini sesuai dengan bidang keilmuan IT lain yaitu data mining yang bisa diintegrasikan kembali. Data mining adalah proses yang memanfaatkan suatu metode untuk memperoleh informasi baru dengan mencari pola atau aturan tertentu dari sejumlah data yang sangat besar.
Pendekatan yang dapat digunakan untuk menganalisis sekumpulan data adalah klasifikasi. Klasifikasi merupakan salah satu teknik data mining yang digunakan untuk membangun suatu model dari sampel data yang belum terklasifikasi untuk digunakan mengklasifikasi sampel data baru ke dalam kelas-kelas yang sejenis. Klasifikasi termasuk ke dalam supervised learning karena menggunakan sekumpulan data untuk dianalisis terlebih dahulu, kemudian pola dari hasil analisis tersebut digunakan untuk pengklasifikasian data uji.
Salah satu penelitian yang dilakukan oleh Erfan Karyadiputra mengenai analisis algoritma Naïve Bayes untuk klasifikasi status kesejahteraan rumah tangga keluarga binaan sosial. Penelitian dilakukan dengan jumlah data sebanyak 30 data set, hasilnya di dapatkan bahwa nilai akurasi tertinggi diperoleh dengan menggunakan algoritma Naïve Bayes sebesar 85,80%.
Performa pengklasifikasi biasanya diukur dengan ketepatan atau tingkat galat.
Naive Bayes (NB) adalah algoritma klasifikasi probabilitas sederhana yang
independen. Naive Bayes juga merupakan algoritma klasifikasi yang utama pada data
mining dan banyak diterapkan dalam masalah klasifikasi di dunia nyata karena
memiliki performa klasifikasi yang tinggi. Menghitung peluang untuk suatu hipotesis, menghitung peluang dari suatu kelas dari masing-masing kelompok atribut yang ada, dan menentukan kelas mana yang paling optimal.
Dari paparan diatas maka peneliti mengusulkan menggunakan bidang ilmu
Data mining untuk menyelesaikannya dengan metode Klasifikasi untuk menetukan
akurasi data kemiskinan diprovinsi Nusa Tenggara Timur.
Pemilihan algoritma klasifikasi yang tepat untuk mengklasifikasi akurasi adalah hal yang sangat mempengaruhi kepercayaan masyarakat kepada Badan Pusat Statistik oleh karena itu penulis memilih Naive Bayes (NB) untuk peneltian ini NB adalah salah satu algoritma yang paling banyak digunakan dalam masalah klasifikasi karena sederhana dan keefektifannya. Namun Naïve Bayes juga memiliki masalah dalam akurasi perhitungannya, Pada permasalah Naïve Bayes ini akan dibantu Cross
Validation (CV) untuk meningkatkan akurasi perhitungannya
Berdasarkan uraian permasalahan diatas penulis akan mencoba mebuat sebuah penelitian yang berjudul “KLASIFIKASI PENDUDUK MISKIN PROVINSI NUSA TENGGARA TIMUR MENGGUNAKAN ALGORITMA NAÏVE BAYES DAN CROSS VALIDATION”.
1.2 Identifikasi Masalah
Dari latar belakang masalah yang telah jelaskan diatas dapat diketahui permasalahan dalam penelitian kali ini adalah
1. Sulitnya menentukan masyarakat miskin diprovinsi Nusa Tenggara Timur. 2. Menentukan penduduk miskin oleh BPS masih menggunakan cara sensus. 1.3 Rumusan Masalah
Berdasarkan identifikasi masalah diatas adalah bagaimana menerapkan teknik
data mining dengan metode Naïve Bayes untuk menampilkan akurasi kemiskinan
diprovinsi Nusa Tenggara Timur.
Maka pertanyaan penelitian yang timbul adalah bagaimana menentukan penduduk miskin Nusa Tenggara Timur menggunakan algoritma Naïve Bayes dan
cross validation?
1.4 Batasan Masalah
Agar permasalahan lebih terarah, maka perlu adanya batasan masalah. Adapun batasan masalah pada skripsi ini:
1. Pengklasifikasian penduduk miskin didasarkan pada yang ada pada provinsi Nusa Tenggara Timur
2. Klasifikasi penduduk miskin didasarkan pada data di situs data.go.id yang ada pada provinsi Nusa Tenggara Timur.
1.5 Tujuan dan Manfaat 1.5.1 Tujuan
Adapun tujuan dari penelitian yang dilakukan adalah untuk menentukan penyelesaian penduduk miskin menggunakan algoritma Naïve Bayes.
1.5.2 Manfaat
1. Hasil penelitian ini diharapkan dapat digunakan untuk membantu mengidentifikasi kemiskinan diprovinsi Nusa Tenggara Timur.
2. Hasil penelitian ini diharapkan dapat memberikan sumbangan untuk pengembangan teori yang berkaitan metode klasifikasi data mining untuk klasifikasi kemiskinan khususnya metode Naive Bayes.
3. Hasil penelitian ini diharapkan dapat memberikan masukan pada instansi terkait dalam rangka mengambil kebijakan untuk mengevaluasi kebijakan dalam upaya mengentaskan kemiskinan diprovinsi Nusa Tenggara Timur. 1.6 Sistematika Penulisan
Sistematika penulisan dan gambaran umum setiap bab dalam penulisan ini adalah sebagai berikut:
BAB I PENDAHULUAN
Pada bab ini membahas tentang Latar Belakang, Identifikasi Masalah, Rumusan Masalah, Batasan Masalah, Tujuan dan Manfaat Penelitian, dan Sistematika Penulisan.
BAB II TINJAUAN PUSTAKA
Pada bab ini membahas tentang Kajian Pustaka, Tinjauan Studi, Tinjauan Organisasi, Kerangka Berfikir, dan Hipotesis Penelitian.
BAB III METODE PENELITIAN
Pada bab ini membahas tentang Metode Penelitian, Metode Pemilihan Sampel, Metode Pengumpulan Data, Teknik Analisis Data, Langkah Penelitian, Peralatan dan Waktu Penelitian.
BAB IV HASIL DAN PEMBAHASAN
Bab ini akan menjelaskan tentang hasil serta pembahasan dari penelitian yang sudah dilakukan.
BAB V KESIMPULAN DAN SARAN
Bab ini berisikan kesimpulan dan saran dari penelitian yang sudah dilakukan secara keseluruhan serta memberikan beberapa saran sebagai acuan apabila ada yang akan melanjutkan penelitan ataupun ingin mengembangkan penelitian ini.
BAB II
TINJAUAN PUSTAKA
2.1 Tinjauan Studi
Menurut penelitian yang sudah dilakukan oleh (Erfan Karyadiputra et al, 2016) dimana penelitian tersebut menggunakan metode klasifikasi status kesejahteraan rumah tangga menggunakan Naïve Bayes berbasis seleksi atribut chi
squared. Hasilnya pun membuktikan bahwa akurasi untuk algoritma naive bayes
sebesar 85.80% dengan nilai area under cover (AUC) 0.930. Pada eksperimen kedua dengan menggunakan algoritma naive bayes berbasis seleksi atribut chi squared menjadi 86.78% dan nilai AUC 0.944. Pada eksperimen kedua terbukti bahwa dengan penambahan optimasi dapat meningkatkan nilai akurasi.
Penelitian yang lainnya juga pernah dilakukan diantaranya ialah penelitian (Karyadiputra, Kom, 2016) dimana penelitian tersebut menggunakan metode klasifikasi Naive Bayes dalam menentukan status kesejahteraan rumah tangga keluarga binaan sosial. Hasilnya pun membuktikan bahwa akurasi untuk algoritma
naive bayes sebesar 85.80% dengan nilai area under cover (AUC) 0.930.
Hasil lain penelitian yang pernah di lakukan (Nuraeni, 2017) tersebut menggunakan metode klasifikasi Naive Bayes dalam Penentuan Kelayakan Kredit pada Studi Kasus Bank Mayapada Mitra Usaha Cabang PGC. Hasil penelitian untuk nilai akurasi algoritma klasifikasi Naïve Bayes Classifier adalah 89.33%, Sementara
untuk evaluasi menggunakan ROC Curve untuk model klasifikasi Naïve Bayes
Classifier nilai AUC adalah 0.955 dengan tingkat diagnosa Excellent Classification.
Hasil lain penelitian yang pernah di lakukan (Widiastuti, Santosa, & Supriyanto, 2014) penelitian tersebut menggunakan algoritma naïve bayes menggunakan metode optimasi particle swarm optimization (PSO) dalam menentukan deteksi penyakit jantung. Hasilnya pun membuktikan bahwa akurasi untuk algoritma naive bayes sebesar 82.14% dengan nilai area under cover (AUC) 0.686 dengan kategori “poor classification”. Pada eksperimen kedua dengan menggunakan algoritma Naive Bayes berbasis PSO menjadi 92.86% dan nilai AUC 0.839 dengan kategori “good classification”. Pada eksperimen kedua terbukti bahwa dengan penambahan optimasi dapat meningkatkan nilai akurasi.
Hasil lain Penelitian yang pernah di lakukan (Salmu & Solichin, 2017) dimana penelitian tersebut menggunakan Metode klasifikasi Naive Bayes dalam menentukan Prediksi Kelulusan Tepat Waktu. Hasilnya pun membuktikan bahwa akurasi untuk algoritma naive bayes sebesar 80.72%.
Berikut ini adalah daftar tabel penelitian sebelumnya yang menjadi bahan acuan Penulis sebagai literatur penelitian :
Tabel 2.1 Penelitian Sebelumnya yang Relevan
No Nama Penulis Judul Jurnal Tahun Atribut Metode Hasil
1 Nur Aeni Widiastuti, et al Algoritma Klasifikasi Data Mining Naïve Bayes Berbasis Particle Swarm Optimization Untuk Dateksi Penyakit Jantung 2014 Usia, Jenis kelamin, Hasil darah, Thorax, Hasil rekam jantung, Cepat capek, Merokok, Hipertensi dan Tekanan darah. Metode Kalsifika si Naïve Bayes Hasil dari algoritma naïve bayes mendapatkan akurasi 82.14% dan nilai (AUC) 0.686, PSO mendapatkan akurasi 92.86% dan nilai (AUC) 0.839 2 Erfan Karyadiputra, et al Klasifikasi Status Kesejahteraan Rumah Tangga Keluarga Binaan Sosial Menggunakn Algoritma Naïve Bayes Berbasis Seleksi Atribut 2016 Jenis kelamin KRT, Umur KRT, Pendidikan KRT, Lapangan usaha KRT, Skp KRT, Spt KRT, Jenis atap, Kualitas atap, Kualitas dinding, Jenis lantai, Sumber Metode Kalsifika si Naïve Bayes, Seleksi Atribut Chi Squared Hasil dari algoritma naïve bayes mendapatkan akurasi 85.80% dan nilai (AUC) 0.930, Algoritma naïve bayes berbasis seleksi atribut chi squared
Chi Squared penerangan, Bahan bakar memasak dan Jumlah individu. mendapatkan akurasi 86.78% dan nilai (AUC) 0.944 3 Erfan Karyadiputra Analisis Algoritma Naïve Bayes Untuk Klasifikasi Status Kesejahteraan Rumah Tangga Keluarga Binaan Sosial 2016 Jenis kelamin, Umur KRT, Pendidikan KRT, Lapangan usaha KRT, Skp KRT, Spt KRT, Jenis atap, Kualitas atap, Jenis dinding, Kualitas dinding, Jenis lantai, Sumber air minum, Bahan bakar memasak, Sumber penerangan, Jumlah keluarga, Jumlah individu. Metode Kalsifika si Naïve Bayes Hasil dari algoritma naïve bayes mendapatkan akurasi 85.80% dan nilai (AUC) 0.930.
4 Nia Nuraeni Penentuan Kelayakan Kredit Dengan Algoritma Naïve Bayes Classifier: studi kasus Bank mayapada Mitra Usaha Cabang PGC 2017 Jenis usaha, Status tempat usaha, Lama usaha, Sistem penjualan, Sistem pembelian, Omset, Gross profit margin, Repayment capacity dan Fasilitas. Metode Kalsifika si Naïve Bayes Hasil dari algoritma naïve bayes Classifier mendapatkan akurasi 89.33% dan nilai (AUC) 0.955 5 Supardi Salmu, et al Prediksi Tingkat Kelulusan Mahasiswa Tepat Waktu Menggunakan Naive Bayes: Studi Kasus UIN Syarif Hidayatullah Jakarta 2017 Jenis kelamin, Jenis seleksi, Pendapatan ayah, Pendidikan ibu, IP semester 1, IP semester 2, IP semester 3, IP semester 4, SKS semester 1, SKS semester 2, SKS semester 3 dan SKS semester 4. Metode Kalsifika si Naïve Bayes Hasil dari algoritma naïve bayes mendapatkan akurasi 80.72%
Berdasarkan tabel 2.1 dari banyaknya penelitian yang ada algoritma naïve
bayes masih efektif dalam menklasifikasi dan menentukan akurasi. Oleh karna itu
untuk meningkatkan performansi algoritma Naïve Bayes perlu adanya penelitian dengan menerapkan suatu parameter yang sama untuk menangani beberapa dataset yang memiliki karateristik berbeda sehingga dapat diketahui secara detail tingkat Klasifikasian.
Penulis memilih Cross Validation sebagai metode statistik untuk meningkatkan performansi algoritma Naïve Bayes dalam mengklasifikasi data karena algoritma Naïve Bayes dan Cross Validation dinilai mampu serta efektif di beberapa penelitian sebelumnya.
Penelitian yang dilakukan oleh (Septiani, Studi, & Informatika, 2017) Dari metode. Cross Validation sebagai metode statistik hasil penelitian yang telah dilakukan pada data pasien penderita penyakit hepatitis maka dapat disimpulkan bahwa metode klasifikasi data mining Algoritma Naive Bayes menghasilkan akurasi 83,71% dan nilai AUC 0,812. Dengan demikian dapat disimpulkan bahwa metode
Cross Validation sebagai metode statistik ini akurat dalam melakukan prediksi untuk
2.2 Kajian Pustaka
2.2.1 Data Mining
Data mining, sering juga disebut knowledge discovery in database (KDD),
adalah kegiatan yang meliputi pengumpulan, pemakaian data historis untuk menentukan pola keteraturan, pola hubungan dalam set data berukuran besar (Septiani, 2017).
Data mining merupakan sebuah teknik untuk menggali informasi tersembunyi untuk memperoleh manfaat lebih dari data yang ada (Iskandar & Suprapto, 2013).
Data mining merupakan proses yang menggunakan teknik statistik,
matematika, kecerdasan buatan, dan machine learning untuk mengekstraksi dan mengidenfikasi informasi yang bermanfaat dan pengetahuan yang terakit dari berbagai database besar/Data Warehouse (Tampubolon et al., 2013).
2.2.2 Tahap-Tahap Data Mining
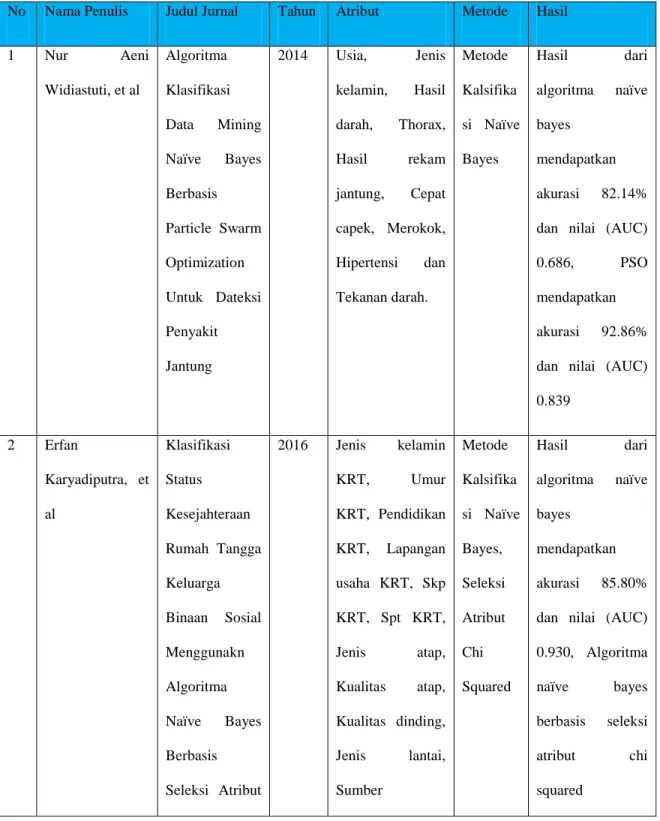
Rangkaian proses, Data Mining dapat dibagi menjadi beberapa tahap proses. Tahap- tahap tersebut bersifat interaktif, pemakai terlibat langsung atau dengan perantaraan knowledge base. Tahap-tahap Data Mining adalah sebagai berikut: Tahap-tahap data mining ada 7 yaitu :(Asriningtias et al., 2014)
a. Pembersihan data (data cleaning)
Pembersihan data merupakan proses menghilangkan noise dan data yang tidak relevan. Pada umumnya data yang diperoleh, baik dari database memiliki isian-isian yang tidak sempurna seperti data yang hilang, data yang tidak valid
atau juga hanya sekedar salah ketik. Data- data yang tidak relevan itu juga lebih baik dibuang. Pembersihan data juga akan mempengaruhi performasi dari teknik data mining karena data yang ditangani akan berkurang jumlah dan kompleksitasnya.
b. Integrasi data (Data integration)
Integrasi data merupakan penggabungan data dari berbagai database ke dalam satu database baru. Integrasi data perlu dilakukan secara cermat karena kesalahan pada integrasi data bisa menghasilkan hasil yang menyimpang dan bahkan menyesatkan pengambilan aksi nantinya.
c. Seleksi Data (Data Selection)
Data yang ada pada database sering kali tidak semuanya dipakai, oleh karena itu hanya data yang sesuai untuk dianalisis yang akan diambil dari database. d. Transformasi data (Data Transformation)
Data diubah atau digabung ke dalam format yang sesuai untuk diproses. Sebagai contoh beberapa metode standar seperti analisis asosiasi dan clustering hanya bisa menerima input data kategorikal. Karenanya data berupa angka numerik yang berlanjut perlu dibagi-bagi menjadi beberapa interval. Proses ini sering disebut transformasi data.
e. Proses mining
Merupakan suatu proses utama saat metode diterapkan untuk menemukan pengetahuan berharga dan tersembunyi dari data.
Untuk mengidentifikasi pola-pola menarik kedalam knowledge based yang ditemukan. Dalam tahap ini hasilnya berupa pola-pola yang khas maupun model prediksi dievaluasi untuk menilai apakah hipotesa yang ada memang tercapai.
g. Presentasi pengetahuan (knowledge presentation)
Merupakan visualisasi dan penyajian pengetahuan mengenai metode yang digunakan untuk memperoleh pengetahuan yang diperoleh pengguna.Tahap terakhir adalah bagaimana memformulasikan keputusan atau aksi dari hasil analisis yang didapat. Karenanya presentasi dalam bentuk pengetahuan yang bisa dipahami semua orang adalah satu tahapan yang diperlukan.Dalam presentasi ini, visualisasi juga bisa membantu mengkomunikasikan hasil data mining (Han, 2006).
Pada gambar 2.1 menggambarkan tahapan – tahapan yang ada pada data mining.
Gambar 2. 1 Tahap-tahap Data Mining
Sumber : ((jiawei han, micheline kamber, n.d.)
Pengelompokan Data Mining dibagi menjadi beberapa kelompok yaitu : (Fajrin, Maulana, Informatika, Batam, & Soeprapto, 2018)
a. Deskripsi
Deskripsi merupakan cara untuk menggambarkan pola dan kecenderungan yang terdapat dalam data yang dimiliki.
b. Estimasi
Estimasi hampir sama dengan klasifikasi, kecuali variable target estimasi lebih ke arah numerik daripada ke arah kategori. Model yang dibangun menggunakan record lengkap yang menyediakan nilai variable target sebagai nilai prediksi.
c. Prediksi
Prediksi menerka sebuah nilai yang belum diketahui dan juga memperkirakan nilai untuk masa mendatang.
d. Klasifikasi
Dalam klasifikasi terdapat target variable kategori, misal penggolongan pendapatan dapat dipisahkan dalam tiga kategori, yaitu tinggi, sedang, dan rendah.
e. Pengklasteran
Merupakan pengelompokan record, pengamatan, atau memperhatikan dan membentuk kelas objek-objek yang memiliki kemiripan.
f. Asosiasi
Asosiasi bertugas menemukan atribut yang muncul dalam satu waktu. Dalam dunia bisnis lebih umum disebut analisis keranjang belanja.
2.2.3 Konsep Klasifikasi
Klasifikasi adalah penempatan objek-objek ke salah satu dari beberapa kategori yang telah ditetapkan sebelumnya. Klasifiksi banyak digunakan untuk memprediksi kelas pada suatu label tertentu, yaitu dengan mengklasifikasi data
(membangun model) berdasarkan training set dan nilai-nilai (label kelas) dalam mengklasifikasikan atribut tertentu dan menggunakannya dalam mengklasifikasikan data yang baru (Meilina, 2015).
Klasifikasi adalah salah satu pembelajaran yang paling umum di data mining. Klasifikasi didefinisikan sebagai bentuk analisis data untuk mengekstrak model yang akan digunakan untuk memprediksi label kelas (Sartika, Sensuse, Indo, Mandiri, & Komputer, 2017).
Klasifikasi adalah proses untuk menemukan model atau fungsi yang menjelaskan atau membedakan konsep atau kelas data, dengan tujuan untuk dapat memperkirakan kelas dari suatu objek yang labelnya tidak diketahui (Bustami, 2014). 2.2.4 Naive Bayes
Naive bayes merupakan perhitungan teorema bayes yang paling
sederhana,karena mampu mengurangi kompleksitas komputasi menjadi multiplikasi sederhana dari probabilitas (Sartika et al., 2017).
Naive Bayes merupakan pengklasifikasian dengan metode probabilitas dan
statistik yang dikemukan oleh ilmuwan Inggris Thomas Bayes, yaitu memprediksi peluang di masa depan berdasarkan pengalaman dimasa sebelumnya sehingga dikenal sebagai Teorema Bayes (Bustami, 2014)
Rumus dari theorem bayes:
Keterangan :
X = Data dengan class yang belum diketahui
H = Hipotesis data X merupakan suatu class spesifik
P(H|X) = Probabilitas hipotesis H berdasarkan kondisi X (posteriori prob) P(H) = Probabilitas hipotesis H (prior prob)
P(X|H) = Probabilitas X berdasarkan kondisi tersebut P(X) = Probabilitas dari X
Naive bayes merupakan teknik prediksi berbasis probabilitas sederhana yang
berdasar pada penerapan aturan bayes dengan asumsi ketidaktergantungan yang kuat. Selain itu naive bayes juga dapat menganalisa variabel-variabel yang paling mempengaruhinya dalam bentuk peluang (Listiana, Sudjalwo, & Gunawan, 2015)
Navie Bayes merupakan algoritma klasifikasi yang sederhana dimana setiap
atribut bersifat independent dan memungkinkan berkontribusi terhadap keputusan akhir (Hasan, 2017)
Naive Bayes merupakan teknik prediksi berbasis probabilistik sederhana
independensi (ketidaktergantungan) yang kuat (Supriyanti, Kusrini, & Amborowati, 2016)
2.2.5 Cross Validation
Pendekatan alternatif untuk 'training dan testing' yang sering diadopsi ketika sejumlah contoh kecil (dan yang banyak yang memilih menggunakan terlepas dari ukuran) dikenal sebagai k kali lipat cross-validasi. Jika dataset terdiri kasus N, ini dibagi menjadi bagian-bagian k sama, k biasanya menjadi sejumlah kecil seperti 5 atau 10 (Jika N tidak tepat habis dibagi oleh k, bagian akhir akan memiliki kasus lebih sedikit dari k lain – 1 bagian) Serangkaian berjalan k kini dilakukan. Setiap bagian k pada gilirannya digunakan sebagai ujian menetapkan dan k lainnya - 1 bagian digunakan sebagai training set (Bramer, 2007).(Kadek Wibowo, Sfenrianto, 2015)
Statistik atau penambangan data, tugas umumnya adalah mempelajari model dari data yang tersedia. Model semacam itu mungkin merupakan model regresi atau penggolong. Masalah dengan mengevaluasi model tersebut adalah bahwa hal itu dapat menunjukkan kemampuan prediksi yang memadai pada data pelatihan, tetapi mungkin gagal untuk memprediksi data tak terlihat di masa depan. Cross validation adalah prosedur untuk memperkirakan kinerja generalisasi dalam konteks ini. Ide untuk Cross validation berasal dari tahun 1930. Di kertas satu sampel digunakan untuk regresi dan yang kedua untuk prediksi. Mosteller dan Turki, dan berbagai orang lain mengembangkan gagasan ini lebih lanjut. Pernyataan cross validation yang jelas, yang mirip dengan versi k-fold cross validation saat ini, pertama kali muncul di. Pada
tahun 1970, baik Stone dan Geisser menggunakan Cross validation sebagai sarana untuk memilih parameter model yang tepat, sebagai lawan menggunakan Cross
validation murni untuk memperkirakan kinerja model. Saat ini, Cross validation
diterima secara luas di komunitas penambangan data dan pembelajaran mesin, dan berfungsi sebagai prosedur standar untuk estimasi kinerja dan pemilihan model (Payam Refaeilzadeh, Lei Tang, n.d.).
Cross-validation (CV) adalah metode statistik yang dapat digunakan untuk
mengevaluasi kinerja model atau algoritma dimana data dipisahkan menjadi dua subset yaitu data proses pembelajaran dan data validasi / evaluasi. Model atau algoritma dilatih oleh subset pembelajaran dan divalidasi oleh subset validasi. Selanjutnya pemilihan jenis CV dapat didasarkan pada ukuran dataset. Biasanya CV
K-fold digunakan karena dapat mengurangi waktu komputasi dengan tetap menjaga
keakuratan estimasi.
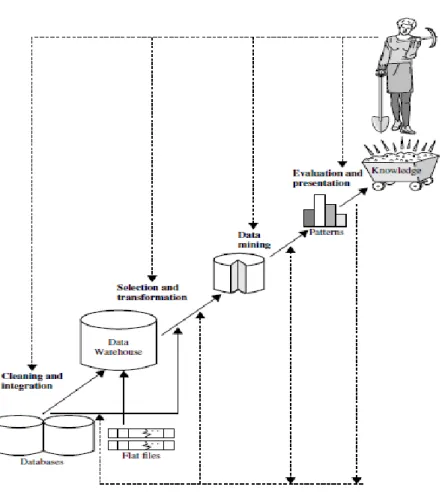
Gambar 2. 2 Skema 10 Fold CV Sumber : ((Indrayanti, Devi Sugianti, 2017)
10 fold CV adalah salah satu K fold CV yang direkomendasikan untuk pemilihan model terbaik karena cenderung memberikan estimasi akurasi yang kurang bias dibandingkan dengan CV biasa, leave-one-out CV dan bootstrap. Dalam 10 fold CV, data dibagi menjadi 10 fold berukuran kira-kira sama, sehingga kita memiliki 10 subset data untuk mengevaluasi kinerja model atau algoritma. Untuk masing-masing dari 10 subset data tersebut, CV akan menggunakan 9 fold untuk pelatihan dan 1 fold untuk pengujian seperti diilustrasikan.
Fold ke-1 adalah ketika bagian ke-1 menjadi data uji (testing data) dan sisanya
menjadi data latih (training data). Selanjutnya, hitung akurasi berdasarkan porsi data tersebut. Perhitungan akurasi tersebut dengan menggunakan persamaan sebagai berikut.
Keterangan : Data Uji benar Klasifikasi : Jumlah data uji
Total Data Uji : Jumlah total dataset testing
2.3 Tinjauan Organisasi
2.3.1 Keadaan Geografis dan Administratif Provinsi NTT
Provinsi Nusa Tenggara Timur (NTT) terdiri dari pulau-pulau yang memiliki penduduk yang beraneka ragam, dengan latar belakang yang berbeda-beda. Provinsi NTT sebelumnya lazim disebut dengan “Flobamora” (Flores, Sumba, Timor dan Alor). Sebelum kemerdekaan RI, Flobamora bersama Kepulauan Bali, Lombok dan
Sumbawa disebut Kepulauan Sunda Kecil. Namun setelah proklamasi kemerdekaan beralih nama menjadi “Kepulauan Nusa Tenggara”, sampai dengan tahun 1957 Kepulauan Nusa Tenggara merupakan daerah Swatantra Tingkat I (statusnya sama dengan Provinsi sekarang ini). Selanjutnya tahun 1958 berdasarkan Undang-Undang Nomor 64 tahun 1958 Daerah Swatantra Tingkat I Nusa Tenggara dikembangkan menjadi 3 Provinsi yaitu Provinsi Bali, Provinsi Nusa Tenggara Barat dan Provinsi Nusa Tenggara Timur. Dengan demikian Provinsi Nusa Tenggara Timur keberadaannya adalah sejak tahun 1958 sampai sekarang.
Berdasarkan Peraturan Menteri Dalam Negeri No. 6 Tahun 2008 tanggal 31 Januari 2008, luas daerah Provinsi NTT adalah 48.718,10 kilometer persegi atau sebesar 2,55 persen dari total luas daerah wilayah Indonesia (BPS, 2009). Provinsi NTT terletak antara 80-1200 Lintang Selatan dan 1180-1250 Bujur Timur dan memiliki 1.192 pulau (42 pulau dihuni dan 1.150 pulau tidak dihuni). Sebagian besar wilayahnya bergunung dan berbukit, hanya sedikit dataran rendah. Memiliki sebanyak 40 sungai dengan panjang antara 25-118 kilometer (BPS, 2010). Sebagai bagian dari negara maritim, Provinsi NTT dikelilingi oleh perairan maupun daratan. Provinsi NTT di sebelah utara berbatasan dengan Laut Flores, di sebelah selatan berbatasan dengan Samudera Indonesia, sebelah barat berbatasan dengan pulau Sumbawa dan Provinsi NTB, dan di sebelah timur berbatasan dengan negara Timor Leste.
Secara administratif, berdasarkan Peraturan Menteri Dalam Negeri No. 6 Tahun 2008, Provinsi NTT terdiri dari 20 kabupaten, 1 kota, 254 kecamatan, 297 kelurahan dan 2.387 desa.
2.3.2 Populasi dan Mata Pencaharian Penduduk NTT
Jumlah penduduk di provinsi ini adalah 4.683.827 jiwa dengan laju pertumbuhan penduduk sebesar 2,07%. Jumlah penduduk laki-laki sebanyak 2.326.487 jiwa dan penduduk perempuan sebanyak 2.357.340 jiwa (2010). Kepadatan penduduk di Nusa Tenggara Timur sebesar 96 jiwa/km2, dengan presentasi penduduk yang tinggal di perkotaan kurang lebih 20%, dan sisanya sebesar 80% mendiami kawasan pedesaan. Sebagian besar penduduk beragama Kristen dengan rincian persentase kurang lebih sebagai Katolik 46,43% Protestan 45,34%, Islam 6,38% , Hindu 0,11% Buddha 0,01% dan sebanyak 1,73% menganut agama dan kepercayaan lainnya.
pertanian masih menjadi lapangan pekerjaan utama bagi penduduk Nusa Tenggara Timur (NTT). Kondisi ini terlihat dari 64,70 persen atau 71,27 persen dari 2.061.229 orang angkatan kerja di NTT hidup sebagai petani.
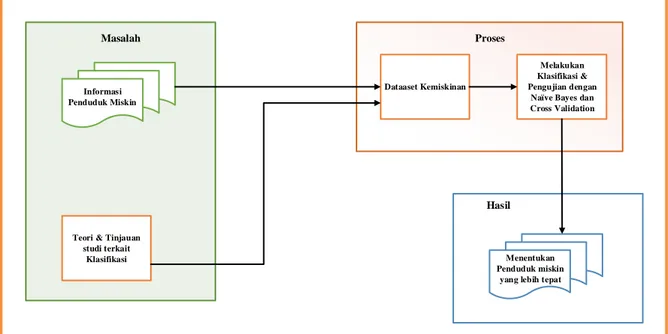
2.4 Kerangka Pemikiran
Agar lebih terfokus untuk menyelesaikan permasalahan yang ada maka disusunlah kerangka pemikiran sebagai gambaran global dalam penelitian ini sebagai berikut :
Dataaset Kemiskinan
Melakukan Klasifikasi & Pengujian dengan
Naïve Bayes dan Cross Validation Informasi
Penduduk Miskin
Teori & Tinjauan studi terkait
Klasifikasi Menentukan
Penduduk miskin yang lebih tepat
Masalah Proses
Hasil
Gambar 2.3 Kerangka Pemikiran
2.5 Hipotesis Penelitian
Hipotesis merupakan jawaban sementara dari pertanyaan penelitian. Hipotesis berfungsi untuk menentukan ke arah pembuktian, artinya hipotesis merupakan pernyataan yang harus dibuktikan.Maka hipotesis penelitian ini adalah “Diduga untuk klasifikasi penduduk miskin dengan menggunakan Naïve Bayes dan
26 BAB III
METODE PENELITIAN
3.1 Metode Pengumpulan Data
Pengumpulan data merupakan bagian paling penting dalam sebuah penelitian. Ketersediaan data akan sangat menentukan dalam proses pengolahan dan analisa selanjutnya. Karenanya, dalam pengumpulan data harus dilakukan teknik yang menjamin bahwa data diperoleh itu benar, akurat dan bisa dipertanggung jawabkan sehingga hasil pengolahan dan analisa data tidak biasa. Pengumpulan data bersifat teoritis yang berhubungan dengan penelitian ini. Pengambilan data tersebut dilakukan dengan cara mempelajari literatur-literatur, jurnal-jurnal penelitian, bahan kuliah dan sumber-sumber lain yang ada hubungannya dengan permasalahan yang dibahas. Pengumpulan data dalam penelitian ini adalah sebagai berikut :
1. Pengumpulan data sekunder
Data sekunder merupakan data yang diperoleh dari bentuk yang telah menjadi informasi seperti dataset pada database. Pada penelitian ini data sekunder didapatkan dari website Data.go.id.
3.2 Teknik Analisis Data
Penelitian ini menggunakan model CRISP-DM (Cross Standart Industries for
Data Mining), yang memiliki siklus hidup terdiri dari 6 tahap. Adapun
1. Pemahaman Bisnis (Business Understanding)
Pada tahapan pertama penulis mencoba untuk memahami permasalahan yang ada dalam mengklasifikasi kemiskinan pada provinsi nusa tenggara timur. Sehingga dapat menentukan tujuan dan pola yang akan didapatkan dengan data mining.
Faktor dalam penentuan penduduk miskin bisanya terdapat pada salah satu atribut yang mempunyai faktor terbesar dalam menentukan kemiskinan, dimana atribut berperan terhadap kemiskinan.
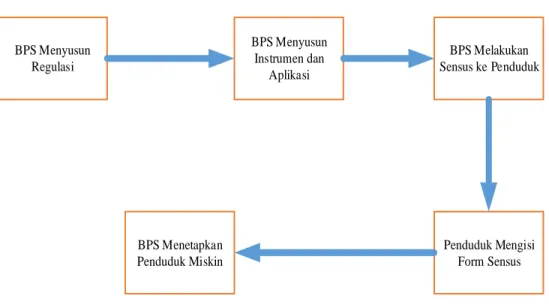
BPS Menyusun Regulasi BPS Menyusun Instrumen dan Aplikasi BPS Melakukan Sensus ke Penduduk Penduduk Mengisi Form Sensus BPS Menetapkan Penduduk Miskin
Gambar 3.1 Pemahaman Bisnis 2. Data Understanding Phase (Fase Pemahaman Data)
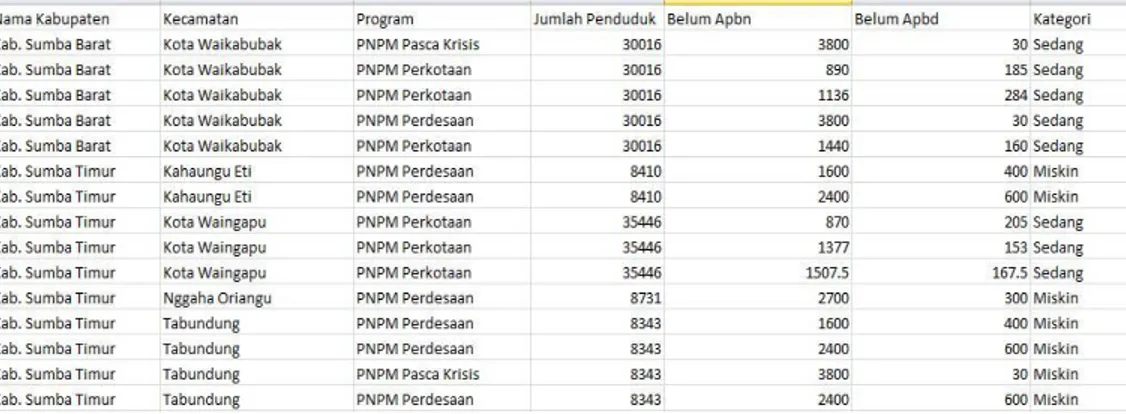
Pada kegiatan pencatatan data Bisnis Proses untuk menentukan penduduk miskin ke database menggunakan attribute sebagai berikut : Nama Kabupaten, Kecamatan, Tahun, Program, Jumlah Penduduk, Belum APBN, Belum APBD dan
Kategori, Dari attribute diatas maka sebagian data akan digunakan untuk Klasifikasi penduduk miskin dalam proses data mining.
Gambar 3.2 Dataset 3. Data Preparation Phase (Fase Pengolahan Data)
Pada proses pembersihan data adalah proses untuk membersihkan data yang dihasilkan pada tahapan mengvaluasi data. Pada tahap pembersihan data ini melakukan pembersihan data sebagai berikut :
a. Nilai attribute yang bersifat tidak standar akan tetap diproses, untuk melakukan klasifikasi penduduk miskin maka dilakukan transformasi data agar mudah dalam melakukan proses klasifikasi.
Tabel 3.1 Atribut Dataset
NO Atribut Type Keterangan
1 Nama Kabupaten Binominal Digunakan
3 Tahun Numeric Tidak Digunakan
4 Program Binominal Digunakan
5 Jumlah Penduduk Numeric Digunakan
6 Belum Apbn Numeric Digunakan
7 Belum Apbd Numeric Digunakan
8 Kategori Binominal Digunakan
b. Dari data penduduk miskin tidak terdapat missing value, untuk mencegah terjadinya missing value maka setiap nilai yang kosong akan diganti dengan nilai 0.
4. Modeling Phase (Fase Pemodelan)
Tujuan dari pemodelan data mining adalah untuk mencari hasil dari berbagai situasi yang ada. Alat perangkat lunak untuk data mining seperti visualisasi (mensplit data dan membangun hubungan) dan analisis metode data mining (untuk mengidentifikasikan variable berjalan dengan baik secara bersamaan) dapat berguna untuk analisis awal model yang akan digunakan. Pembagian data ke dalam set pelatihan dan pengujian juga diperlukan untuk pemodelan. Model yang akan diuji yaitu algoritma Naïve Bayes dan Cross-Validation.
5. Evaluation Phase (Fase Evaluasi)
Melakukan pengujian terhadap model-model yang bertujuan untuk mendapatkan model yang paling akurat. Evaluasi dan validasi dilakukan dengan menggunakan metode Confusion Matrix dan kurva ROC (Receiver Operating
Characteristic).
6. Deployment Phase (Fase Penyebaran)
Pembentukan model selanjutnya melakukan analisa dan pengukuran pada tahap sebelumnya, pada tahap ini diterapkan model atau rule yang paling akurat dan selanjutnya dapat digunakan untuk mengevaluasi data baru.
3.3 Langkah Penelitian
Langkah penelitian untuk menyelesaikan permasalah penelitian yang ada dengan langkah-langkah sebagai berikut :
1. Langkah awal yang dilakukan yaitu melakukan identifikasi masalah yang ada dalam suatu perusahaan
2. Melakukan pengumpulan data yang didapat dari perusahaan. 3. Analisis data lalu pembersihan data dan pemilihan atribut
4. Mempersiapan untuk melakukan analisis data dengan menerapkan Naive Baiyes
Classifier dan Cross-validation untuk klasifikasi penduduk miskin.
5. Untuk melakukan evaluasi dan validasi data mining digunakan Confusion Matrix.
6. Menghasilakan sebuah hasil klasifikasi dengan akurasi yang optimal.
3.4 Peralatan
Penelitian ini memerlukan beberapa perlengakapan penelitian untuk mendukung pelaksanaan penelitian. Berikut ini beberapa perlengkapan yang dibutuhkan untuk menunjang penelitian berupa piranti lunak (Software) maupun piranti keras (Hardware) antara lain :
1. Kebutuhan piranti lunak (Software)
a. Berikut ini beberapa piranti lunak yang dibutuhkan dalam peneletian ini : Sistem Operasi Windows 7, 64 Bit
b. Mendeley Desktop Version 1.19.1 c. RapidMiner Studio Educational 8.2 d. Microsoft Office Word & Excel 2010 e. Microsoft Visio 2013
2. Kebutuhan piranti keras (Hardware)
a. Berikut ini beberapa piranti keras yang dibutuhkan dalam peneletian ini : Laptop Intel i3-2348M @2.30 GHz, Ram 4 GB, HDD 1TB
b. Hardisk External 1 TB c. Printer
3.5 Waktu Penelitian
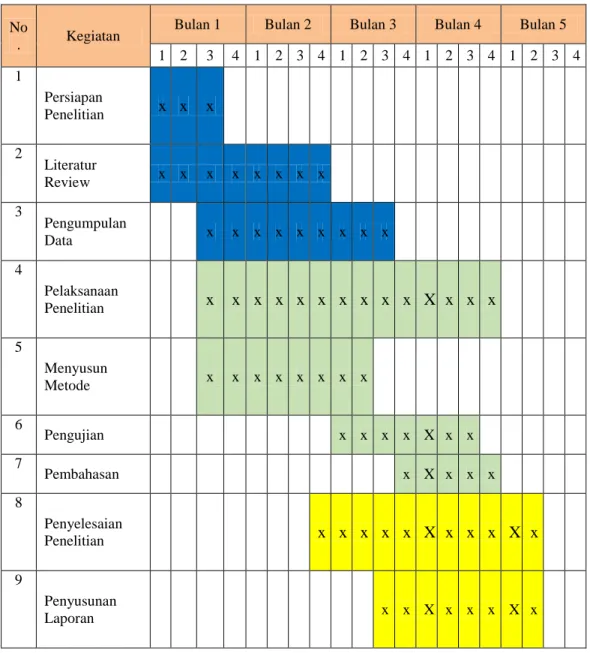
Penelitian ini direncanakan mengikuti jadwal penelitian seperti yang terlihat pada tebel berikut:
Tabel 3.2 Jadwal Kegiatan Penelitian
No
. Kegiatan
Bulan 1 Bulan 2 Bulan 3 Bulan 4 Bulan 5 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 Persiapan Penelitian x x x 2 Literatur Review x x x x x x x x 3 Pengumpulan Data x x x x x x x x x 4 Pelaksanaan Penelitian x x x x x x x x x x X x x x 5 Menyusun Metode x x x x x x x x 6 Pengujian x x x x X x x 7 Pembahasan x X x x x 8 Penyelesaian Penelitian x x x x x X x x x X x 9 Penyusunan Laporan x x X x x x X x
10 Penulisan Skripsi x x x x x X x x x 11 Finalisasi Skripsi x X x X 12 Penyerahan Skripsi X
34 BAB IV
HASIL DAN PEMBAHASAN
4.1 Hasil
Hasil algoritma naïve bayes untuk perhitungan Naive Bayes, implementasi klasifikasi naïve bayes dan akurasi klasifikasi.
4.1.1 Perhitungan Naive Bayes
Perhitungan naive bayes dilakukan dengan menghitung menggunakan data yang diambil dari website data.go.id yang membahas kemiskinan di provinsi Nusa Tenggara Timur sebanyak 7 atribut dan 200 data. Kriteria yang digunakan adalah sebagai berikut :
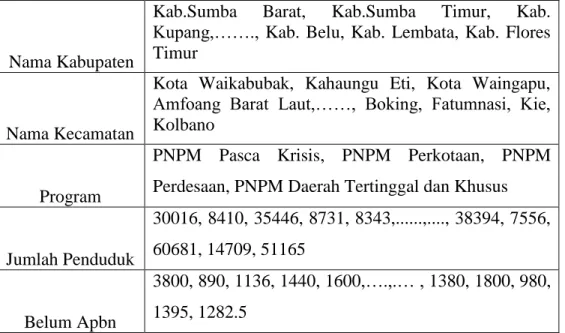
Tabel 4.1 Kriteria yang digunakan
Nama Kabupaten
Kab.Sumba Barat, Kab.Sumba Timur, Kab. Kupang,……., Kab. Belu, Kab. Lembata, Kab. Flores Timur
Nama Kecamatan
Kota Waikabubak, Kahaungu Eti, Kota Waingapu, Amfoang Barat Laut,……, Boking, Fatumnasi, Kie, Kolbano
Program
PNPM Pasca Krisis, PNPM Perkotaan, PNPM Perdesaan, PNPM Daerah Tertinggal dan Khusus
Jumlah Penduduk 30016, 8410, 35446, 8731, 8343,...,...., 38394, 7556, 60681, 14709, 51165 Belum Apbn 3800, 890, 1136, 1440, 1600,….,.… , 1380, 1800, 980, 1395, 1282.5
Belum Apbd
30, 185, 284, 160, 400, 600, 205, 153, 167.5, 300, 350, 150, 120, 790, 345, 380, 145, 155, 142.5
Keterangan
MISKIN dan TIDAK MISKIN
Tabel 4.1 Kriteria Data penduduk miskin yang telah memasuki tahap pengolahan data kemudian akan dilakukan perhitungan dengan menggunakan algoritma naïve bayes sebagai berikut :
1. Menghitung Probabilitas Penduduk
Perhitungan ini untuk menentukan keputusan dengan metode naïve bayes untuk mencari probabilitas dari masing-masing kelas. dalam menentukan keputusan akan ditentukan kelas “Miskin” dan “Tidak Miskin”. Perhitungannya dimana mencari berapa jumlah data Miskin dan Tidak Miskin dari total keseluruhan data training dan membaginya dengan total keseluruhan data.
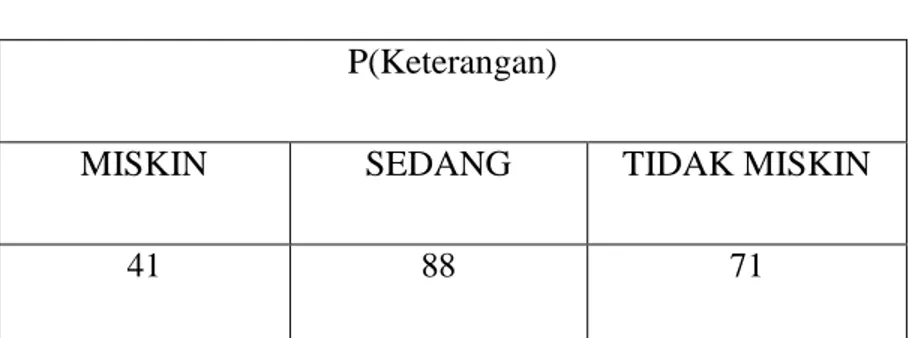
Tabel 4.2 Probabilitas Keterangan Penduduk
P(Keterangan)
MISKIN SEDANG TIDAK MISKIN
2. Menghitung Probabilitas Masing-Masing Atribut
Mencari probabilitas suatu atribut dengan membandingkan atribut dari data testing dengan atribut dari data training. Jumlah atribut dari Penduduk ”Miskin” yang ada pada data training, kemudian dibagikan dengan probabilitas Penduduk “Miskin”. Begitu juga mencari probabilitas untuk Penduduk “Sedang”, “Tidak Miskin”.
a. Nama Kabupaten
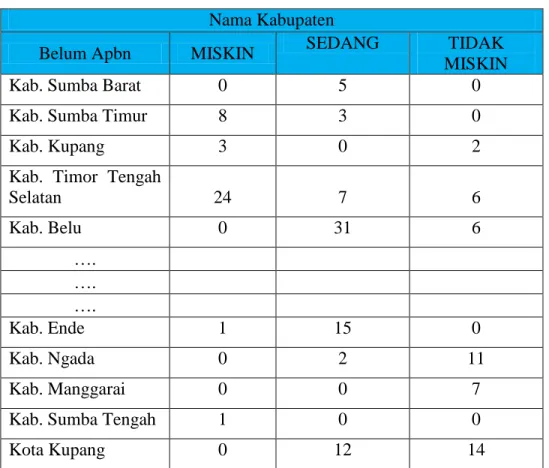
Tabel 4.3 Atribut Kabupaten
Nama Kabupaten
Belum Apbn MISKIN SEDANG TIDAK
MISKIN
Kab. Sumba Barat 0 5 0
Kab. Sumba Timur 8 3 0
Kab. Kupang 3 0 2
Kab. Timor Tengah
Selatan 24 7 6 Kab. Belu 0 31 6 …. …. …. Kab. Ende 1 15 0 Kab. Ngada 0 2 11 Kab. Manggarai 0 0 7
Kab. Sumba Tengah 1 0 0
b. Nama Kecamatan
Tabel 4.4 Atribut Kecamatan
Nama Kecamatan
Belum Apbn MISKIN SEDANG TIDAK
MISKIN Kota Waikabubak 0 5 0 Kahaungu Eti 2 0 0 Kota Waingapu 0 4 0 Nggaha Oriangu 1 0 0 Tabundung 4 0 0 …. …. …. Kelapa Lima 0 0 6 Kota Lama 0 0 1 Kota Raja 0 0 1 Maulafa 0 6 0 Oebobo 0 0 6
c. Program
Tabel 4.5 Atribut Program
Program
(Program) MISKIN SEDANG TIDAK MISKIN
PNPM Pasca Krisis 1 4 0
PNPM Perkotaan 0 27 46
PNPM Perdesaan 23 38 12
PNPM Daerah
Tertinggal dan Khusus 16 20 13
d. Jumlah Penduduk
Tabel 4.6 Atribut Jumlah Penduduk
Jumlah Penduduk
Belum Apbn MISKIN SEDANG TIDAK
MISKIN 30016 0 5 0 8410 2 0 0 35446 0 3 0 8731 1 0 0 8343 4 0 0 …. …. …. 61411 0 0 6 30196 0 0 1
47878 0 0 1
65852 0 6 0
79675 0 0 6
e. Belum Apbn
Tabel 4.7 Atribut Belum Apbn
Belum Apbn
Belum Apbn MISKIN SEDANG TIDAK
MISKIN 51 0 1 0 63 0 0 1 45.3 1 0 0 47.9 2 0 0 60.7 1 0 0 …. …. …. 1282.5 0 1 1 3000 0 1 0 2800 0 2 0 1690 0 1 0 1710 0 1 0
f. Belum Apbd
Tabel 4.8 Atribut Belum Apbd
Belum Apbd
Belum Apbd MISKIN SEDANG TIDAK
MISKIN 30 18 29 18 35 0 0 1 37.5 0 1 3 40 0 1 0 42.5 0 0 1 …. …. …. 900 0 1 0 790 0 0 1 1010 0 0 1 1100 0 0 1 1200 1 0 0
3. Menghitung Probabilitas akhir
Menghitung probabilitas akhir pada setiap kelas, perlu menggunakan data training yang terdapat pada tabel 4.1 dan mengubahnya menjadi nilai yang sudah ditentukan pada perhitungan probabilitas masing-masing atribut, dari masing masing atribut dan nilai probabilitas kelas dikalikan. dari hasil yang sudah ditentukan, jika penduduk “Miskin” bernilai lebih besar maka hasilnya “Miskin”. Begitu pula sebaliknya.
4. Kasus perhitungan Naïve Bayes
Dalam memudahkan pemahaman perhitungan naïve bayes , secara manual akan di buat studi kasus sebagai berikut dan rulenya berupa data training (Lampiran1):
Tabel 4.9 Data Testing
No Kabupaten
Kecamata n
Program Jumlah
Penduduk Belum Apbn Belum Apbd Keterangan
1 Kab. Belu Ende
PNPM
Perdesaan 21396 2700 300 ?
2 Kab. Belu Ende
PNPM Perdesaan 21396 750 30 ? 3 Kab. Kupang Sasita Mean PNPM Perkotaan 18460 2400 600 ? 4 Kab. Kupang Sasita Mean PNPM Perkotaan 18460 2700 300 ?
5 Kab. Belu Ende
PNPM
Perdesaan 21396 1750 30 ?
… … … …
… … … …
96 Kab. Sikka Kelapa Lima
PNPM Daerah Tertinggal dan Khusus
13944 2850 150 ?
97 Kab. Sikka Kelapa Lima
PNPM Daerah Tertinggal dan Khusus
13944 3500 30 ?
98 Kab. Sikka Kelapa Lima PNPM
Daerah Tertinggal
11640 2650 150
dan Khusus
99 Kab. Sikka Kota Soe
PNPM Daerah Tertinggal dan Khusus
11640 1920 480 ?
100 Kab. Sikka Kota Soe
PNPM Daerah Tertinggal dan Khusus
33009 1070 200 ?
Menghitung jumlah Penduduk :
Tabel 4.10 Perhitungan P(H)
Keterangan P(H)
P(Miskin) P(Sedang) P(Tidak Miskin)
Miskin 41/200 Sedang 88/200 Tidak Miskin 71/200 Miskin 0.20 Sedang 0.44 Tidak Miskin 0.35
Tabel 4.11 Menghitung jumlah kelas atau klasifikasi No P(H) P(H/ X) P(X| C1) P(X| C2) P(X| C3) P(X| C4) P(X| C5) P(X| C6) P(X| H) P(X|H )*P(H) Keteran gan 1 41 0.20 0 0 0.56 0 0.07 0.09 0 0 Sedang 88 0.44 0.35 0.04 0.43 0.04 0.04 0.07 1.13 5.0 71 0.35 0.08 0 0.16 0 0 0 0 0 2 41 0.20 0 0 0.56 0 0.14 0.43 0 0 Sedang 88 0.44 0.35 0.04 0.43 0.04 0.07 0.32 8.23 3.62 71 0.35 0.08 0 0.16 0 0.02 0.25 0 0 3 41 0.20 0 0 0 0 0.24 0.21 0 0 Sedang 88 0.44 0.13 0.04 0.30 0.04 0.15 0.15 2.18 9.62 71 0.35 0.19 0 0.64 0 0.01 0.04 0 0 4 41 0.20 0 0 0 0 0.07 0.09 0 0 Sedang 88 0.44 0.13 0.04 0.30 0.04 0.04 0.07 3.12 1.37 71 0.35 0.19 0 0.64 0 0 0 0 0 5 41 0.20 0 0 0.56 0 0 0.43 0 0 Sedang 88 0.44 0.35 0.04 0.43 0.04 0.02 0.32 2.35 1.03 71 0.35 0.08 0 0.16 0 0.01 0.25 0 0 .. .. .. .. .. .. .. .. .. .. .. .. 96 41 0.20 0.07 0 0.39 0 0 0 0 0 Tidak Miskin 88 0.44 0.02 0 0.22 0 0.01 0.02 0 0 71 0.35 0.09 0.08 0.18 0.05 0.01 0.04 5.11 1.81 97 41 0.20 0.07 0 0.39 0 0 0.43 0 0 Tidak
88 0.44 0.02 0 0.22 0 0.01 0.32 0 0 Miskin 71 0.35 0.09 0.08 0.18 0.05 0.04 0.25 9.20 3.26 98 41 0.20 0.07 0 0.39 0 0 0 0 0 Tidak Miskin 88 0.44 0.02 0 0.22 0 0 0.02 0 0 71 0.35 0.09 0.08 0.18 0.04 0.01 0.04 3.83 1.36 99 41 0.20 0.07 0 0.39 0 0 0 0 0 Tidak Miskin 88 0.44 0.02 0 0.22 0 0 0 0 0 71 0.35 0.09 0.08 0.18 0.04 0.01 0.01 1.27 4.53 100 41 0.20 0.07 0 0.39 0 0 0 0 0 Tidak Miskin 88 0.44 0.02 0 0.22 0 0 0 0 0 71 0.35 0.09 0.08 0.18 0.09 0.01 0.01 2.98 1.05
Tabel 4.11 menghitung jumlah penduduk dimana :
a. Nilai P(H) keseluruhan keterangan label “Miskin”, “Sedang” dan “Tidak Miskin”
b. Nilai P(H|X) adalah Hasil dimana label “Miskin”, “Sedang” dan “Tidak Miskin” dibagi dengan keseluruhan data
c. Nilai P(X|C1) adalah Nama Kabupaten yang sudah dihitung dari keseluruhan nilai Miskin dibagi kesluruhan data Miskin, Sedang dan sebaliknya nilai tidak Miskin
d. Nilai P(X|C1) adalah Nama Kecamatan yang sudah dihitung dari keseluruhan nilai Miskin dibagi kesluruhan data Miskin, Sedang dan sebaliknya nilai tidak Miskin
e. Nilai P(X|C3) adalah Program yang sudah dihitung dari keseluruhan nilai Miskin dibagi kesluruhan data Miskin, Sedang dan sebaliknya nilai tidak Miskin
f. Nilai P(X|C4) adalah Jumlah Penduduk yang sudah dihitung dari keseluruhan nilai Miskin dibagi kesluruhan data Miskin, Sedang dan sebaliknya nilai tidak Miskin
g. Nilai P(X|C5) adalah Belum Apbn yang sudah dihitung dari keseluruhan nilai Miskin dibagi kesluruhan data Miskin, Sedang dan sebaliknya nilai tidak Miskin
h. Nilai P(X|C6) adalah Belum Apbd yang sudah dihitung dari keseluruhan nilai Miskin dibagi kesluruhan data Miskin, Sedang dan sebaliknya nilai tidak Miskin
i. Hasil P(X|H) adalah perhitungan dari P(X|C1) sampai P(X|C6) yang sudah dikalikan
j. Hasil P(X|H)*P(H) adalah perhitungan P(X|H) dikalikan Hasil perhitungan P(H)
4.1.2 Implementasi Klasifikasi Naïve Bayes pada RapidMiner
Perhitungan yang telah dilakukan diatas sesuai untuk menentukan kelulusan dengan metode Naïve Bayes. Setelah melakukan perhitungan manual terhadap data training dan data testing, langkah selanjutnya pembuktian dengan menggunakan RapidMiner. Pembuktian perhitungan manual naive bayes terhadap data training dan data testing, akan dilakukan perhitungan menggunakan RapidMiner. RapidMiner yang digunakan adalah versi 8.1.
Gambar 4.1 Proses RapidMiner
Gambar 4.1 Proses RapidMiner pengujian data traning terhadap data testing dalam menentukan Klasifikasi.
Gambar 4.2 Hasil Klasifikasi RapidMiner
Gambar 4. 2 Hasil Prediksi dimana data testing menggunakan sample acak awal dan akhir data yang digunakan dalam penelitian ini.
4.1.3 Akurasi Klasifikasi
Gambar 4.3 menggambarkan rangkaian model pengujian dimana pada dataset source nantinya akan disesuaikan dengan dataset nilai siswa. Kemudian untuk memvalidasi model dari algoritma naïve bayes digunakan metode cross validation. Dimana didalamnya terdapat performance dengan menggunakan confussion matrix sebagai model evaluasi dari kinerja algoritma naïve bayes. Untuk lebih jelasnya dapat dilihat pada gambar 4.4 berikut :
Gambar 4.4 Sub Proses Cross Validation
Dalam sub proses cross validation terdapat dua bagian dimana ada training seperti pada di gambar 4.4 dimana pada bagian training terdapat algoritma naïve
bayes hal tersebut dimaksudkan agar dataset dibuat modelnya menggunakan
algoritma naïve bayes dimana pada cross validation dengan nilai k = 10 folds. Kemudian pada data testing terdapat dua fitur yakni Apply model yang digunakan untuk menerapkan model data yang sudah dilatih sebelumnya dengan data test.
Terakhir dibagian testing terdapat fitur performance dimana fitur tersebut digunakan untuk mengevaluasi hasil kinerja algoritma naïve bayes dengan parameter pengukuran confussion matrix (accuracy,recall,precision).
Pengujian dengan metode Naïve Bayes menggunakan dataset Kemiskinan. Hasil yang didapatkan pengujian ini mendapatkan hasil akurasi sebesar 96,50% dengan nilai presisi serta recall masing-masing kelas dapat dilihat pada gambar 4.5 berikut ini :
Gambar 4. 5 Confusion Matrix Penduduk
Hasil analisa data training pada rapidminer dapat dilihat pada lampiran 1. Untuk menghitung akurasi sebagai berikut:
Diketehui :
Jumlah data yang diuji : 200 Jumlah data yang diprediksi benar : 193
Jumlah data yang diprediksi salah : 10
Hitungan Hasil Akurasi
Hasil = 96.50%
4.2 Pembahasan
Penelitian dilakukan sebanyak dengan menggunakan algoritma Naïve Bayes untuk menentukan klasifikasi penduduk miskin. Teknik preprocessing menggunakan teknik cleaning, integration dan transformation data. Berdasarkan hasil yang sudah didapatkan secara keseluruhan maka dapat dilihat hasil akurasi secara keseluruhan pada tabel 4.6 berikut :
Gambar 4.6 Hasil Pengukuran accuracy
Hasil dari tingkat akurasi klasifikasi Naive Bayes pada Gambar 4.6 menunjukan bahwa tingkat akurasi mencapai 96,50%. Maka dapat disimpulkan hasil akurasi Klasifikasi Naive Bayes dalam penelitian ini, metode Naive bayes merupakan metode yang cukup baik dalam penelitian ini.
52 BAB V
KESIMPULAN DAN SARAN
5.1 Kesimpulan
Berdasarkan data Penduduk yang diperoleh, proses Data Mining membantu dalam penerapan metode Naive Bayes dalam mendapatkan informasi dari hasil Klasifikasi penduduk miskin pada provinsi Nusa tenggara timur yang dijadikan data training, Sehingga dengan demikian metode Naive Bayes ini berhasil mengklasifikasi penduduk miskin dengan persentase accuracy sebesar 96,50% dan recall miskin sebesar 95,15%, sedang sebesar 98,86%, dan tidak miskin sebesar 94,37%. Dalam penelitian menggunakan data sebanyak 200 penduduk.
5.2 Saran
Berdasarkan pada hasil penelitian yang telah dilakukan Penulis memiliki beberapa saran yang dapat digunakan pada penelitian kedepanya sebagai berikut :
1. Pada penelitian selanjutnya dapat mencoba Menggunakan metode optimasi lain dalam upaya mencari metode optimasi terbaik yang mampu meningkatkan akurasi algoritma naïve bayes secara maksimal.
2. Pada penelitian selanjutnya dapat mencoba menggunakan data yang berbeda dan dengan jumlah data yang lebih besar lagi sehingga menghasilkan tingkat akurasi yang lebih tinggi.
53
DAFTAR PUSTAKA
Asriningtias, Y., Mardhiyah, R., Studi, P., Informatika, T., Bisnis, F., Informasi, T., & Yogyakarta, U. T. (2014). APLIKASI DATA MINING UNTUK MENAMPILKAN INFORMASI, 8(1), 837–848.
Bustami. (2014). Penerapan Algoritma Naive Bayes. Jurnal Informatika, 8(1), 884– 898.
Fajrin, A. A., Maulana, A., Informatika, T., Batam, U. P., & Soeprapto, J. R. (2018). PENERAPAN DATA MINING UNTUK ANALISIS POLA PEMBELIAN KONSUMEN DENGAN ALGORITMA FP- GROWTH PADA DATA TRANSAKSI PENJUALAN, 5(1), 27–36.
Hasan, M. (2017). Menggunakan Algoritma Naive Bayes Berbasis, 9, 317–324. Indrayanti, Devi Sugianti, M. A. A. K. (2017). Fakultas Teknik – Universitas Muria
Kudus 823, 823–829.
Iskandar, D., & Suprapto, Y. K. (2013). Perbandingan akurasi klasifikasi tingkat kemiskinan antara algoritma C4 . 5 dan Naïve Bayes Clasifier, 11(1), 14–17. jiawei han, micheline kamber, jian pei. (n.d.). Data Mining Concepts and
Techniques, Third Edition.
Kadek Wibowo, Sfenrianto, kaman nainggolan. (2015). MENGGUNAKAN NAIVE BAYES SERTA OPTIMASI, 1(1), 1–10.
Karyadiputra, E., Kom, S., & Kom, M. (2016). ANALISIS ALGORITMA NAIVE BAYES UNTUK KLASIFIKASI STATUS KESEJAHTERAAN RUMAH TANGGA KELUARGA BINAAN SOSIAL, 7(4), 199–208.
Listiana, M., Sudjalwo, & Gunawan, D. (2015). Perbandingan Algoritma Decision Tree (C4.5) Dan Naïve Bayes Pada Data Mining Untuk Identifikasi Tumbuh Kembang Anak Balita (Studi Kasus Puskesmas Kartasura). Informatika, 1(1), 18.
Meilina, P. (2015). PENERAPAN DATA MINING DENGAN METODE KALSIFIKASI, 7(1).
Nuraeni, N. (2017). Penentuan Kelayakan Kredit Dengan Algoritma Naïve Bayes Classifier : Studi Kasus Bank Mayapada Mitra Usaha Cabang PGC, III(1), 9–15. Payam Refaeilzadeh, Lei Tang, H. L. A. (n.d.). Cross Validation.
Riyan Eko Putri, Suparti, R. R. (2014). PERBANDINGAN METODE KLASIFIKASI NAÏVE BAYES DAN K-NEAREST NEIGHBOR PADA ANALISIS DATA STATUS KERJA DI KABUPATEN DEMAK TAHUN 2012, 3, 831–838.
Salmu, S., & Solichin, A. (2017). Prediksi Tingkat Kelulusan Mahasiswa Tepat Waktu Menggunakan Naïve Bayes : Studi Kasus UIN Syarif Hidayatullah Jakarta Prediction of Timeliness Graduation of Students Using Naïve Bayes : A Case Study at Islamic State University Syarif Hidayatullah Jakarta, (April), 701– 709.
Sarjana, P., Informatika, T., & Dian, U. (2016). KLASIFIKASI STATUS KESEJAHTERAAN RUMAH TANGGA, 12, 116–122.
Sartika, D., Sensuse, D. I., Indo, U., Mandiri, G., & Komputer, F. I. (2017). Perbandingan Algoritma Klasifikasi Naive Bayes , Nearest Neighbour , dan Decision Tree pada Studi Kasus Pengambilan Keputusan Pemilihan Pola Pakaian. Jurnal Teknik Informatika Dan Sistem Informasi (JATISI), 1(2), 151– 161.
Septiani, W. D. (2017). Komparasi Metode Klasifikasi Data Mining Algoritma C4.5 Dan Naive Bayes Untuk Prediksi Penyakit Hepatitis. Pilar Nusa Mandiri, 13(1), 76–84.
Septiani, W. D., Studi, P., & Informatika, M. (2017). DAN NAIVE BAYES UNTUK PREDIKSI PENYAKIT HEPATITIS, 13(1), 76–84.
Supriyanti, W., Kusrini, & Amborowati, A. (2016). Perbandingan kinerja algoritma c4.5 dan naive bayes untuk ketepatan pemilihan konsentrasi mahasiswa.
Informa, 1(2012), 46–52.
Tampubolon, K., Saragih, H., Reza, B., Epicentrum, K., Asosiasi, A., & Apriori, A. (2013). Implementasi Data Mining Algoritma Apriori Pada Sistem Persediaan Alat-Alat Kesehatan. Informasi Dan Teknologi Ilmiah, 93–106. https://doi.org/2339-210X
Widiastuti, N. A., Santosa, S., & Supriyanto, C. (2014). Algoritma Klasifikasi Data Mining Naïve Bayes Berbasis Particle Swarm Optimization Untuk Deteksi Penyakit Jantung. Jurnal Pseudocode, 1(1), 2355–5920. Retrieved from www.jurnal.unib.ac.id
LAMPIRAN Lampiran 1 Data Training No Nama Kabupaten Kecamata n Program Jumlah Penduduk Belum Apbn Belum Apbd Keateg ori 1 Kab. Sumba Barat Kota Waikabub ak PNPM Pasca Krisis 30016 3800 30 Sedang 2 Kab. Sumba Barat Kota Waikabub ak PNPM Perkotaan 30016 890 185 Sedang 3 Kab. Sumba Barat Kota Waikabub ak PNPM Perkotaan 30016 1136 284 Sedang 4 Kab. Sumba Barat Kota Waikabub ak PNPM Perdesaan 30016 3800 30 Sedang 5 Kab. Sumba Barat Kota Waikabub ak PNPM Perkotaan 30016 1440 160 Sedang 6 Kab. Sumba Timur Kahaungu Eti PNPM Perdesaan 8410 1600 400 Miskin 7 Kab. Sumba Timur Kahaungu Eti PNPM Perdesaan 8410 2400 600 Miskin 8 Kab. Sumba Timur Kota Waingapu PNPM Perkotaan 35446 870 205 Sedang 9 Kab. Sumba Timur Kota Waingapu PNPM Perkotaan 35446 1377 153 Sedang 10 Kab. Sumba Kota Waingapu PNPM Perkotaan 35446 1507.5 167.5 Sedang
Timur 11 Kab. Sumba Timur Nggaha Oriangu PNPM Perdesaan 8731 2700 300 Miskin 12 Kab. Sumba Timur Tabundun g PNPM Perdesaan 8343 1600 400 Miskin 13 Kab. Sumba Timur Tabundun g PNPM Perdesaan 8343 2400 600 Miskin 14 Kab. Sumba Timur Tabundun g PNPM Pasca Krisis 8343 3800 30 Miskin 15 Kab. Sumba Timur Tabundun g PNPM Perdesaan 8343 2400 600 Miskin 16 Kab. Sumba Timur Wula Waijelu PNPM Perdesaan 7023 1400 350 Miskin 17 Kab. Kupang Amfoang Barat Laut PNPM Perdesaan 9196 2400 600 Miskin 18 Kab. Kupang Amfoang Selatan PNPM Perdesaan 8900 1600 400 Miskin 19 Kab. Kupang Amfoang Timur PNPM Perdesaan 7218 1600 400 Miskin 20 Kab. Kupang Kupang Barat PNPM Perdesaan 14813 2850 150 Tidak Miskin 21 Kab. Kupang Nekamese PNPM Perdesaan 9873 2400 600 Tidak Miskin 22 Kab. Timor Tengah Selatan Amanatun Selatan PNPM Perdesaan 19203 2700 300 Miskin 23 Kab. Timor Tengah Amanuba n Barat PNPM Perdesaan 21844 2400 600 Miskin
Selatan 24 Kab. Timor Tengah Selatan Amanuba n Selatan PNPM Perdesaan 25138 2400 600 Miskin 25 Kab. Timor Tengah Selatan Amanuba n Timur PNPM Perdesaan 16781 480 120 Miskin 26 Kab. Timor Tengah
Selatan Batu Putih
PNPM Perdesaan 12219 2400 600 Miskin 27 Kab. Timor Tengah Selatan Boking PNPM Daerah Tertingga l dan Khusus 11412 750 30 Miskin 28 Kab. Timor Tengah Selatan Boking PNPM Daerah Tertingga l dan Khusus 11412 71.5 30 Miskin 29 Kab. Timor Tengah Selatan Fatumnasi PNPM Daerah Tertingga l dan Khusus 6861 500 30 Miskin 30 Kab. Timor Tengah Selatan Fatumnasi PNPM Daerah Tertingga l dan Khusus 6861 750 30 Miskin 31 Kab. Timor Tengah Selatan Fatumnasi PNPM Daerah Tertingga l dan Khusus 6861 500 30 Miskin
32 Kab. Timor Tengah Selatan Kie PNPM Perdesaan 24239 2400 600 Miskin 33 Kab. Timor Tengah Selatan Kie PNPM Perdesaan 24239 2700 300 Miskin 34 Kab. Timor Tengah Selatan Kolbano PNPM Daerah Tertingga l dan Khusus 18460 500 30 Sedang 35 Kab. Timor Tengah Selatan Kolbano PNPM Daerah Tertingga l dan Khusus 18460 51 30 Sedang 36 Kab. Timor Tengah Selatan Kolbano PNPM Perdesaan 18460 2400 600 Sedang 37 Kab. Timor Tengah Selatan Kolbano PNPM Perdesaan 18460 2700 300 Sedang 38 Kab. Timor Tengah Selatan Kot'Olin PNPM Daerah Tertingga l dan Khusus 11173 750 30 Miskin 39 Kab. Timor Tengah Selatan Kot'Olin PNPM Daerah Tertingga l dan Khusus 11173 1000 30 Miskin 40 Kab. Timor Tengah Kot'Olin PNPM Daerah Tertingga 11173 750 30 Miskin