PROTOTIPE PENGENALAN SUARA SEBAGAI PENGGERAK DINAMO STARTER PADA MOBIL
Rezza Aditya/20405609
Fakultas Teknologi Industri, Jurusan Teknik Mesin Universitas Gunadarma Jl. Margonda Raya No.100, Depok 16424
E-mail : [email protected]
ABSTRAK
Pengolahan sinyal digital telah banyak digunakan dalam berbagai aplikasi, salah satunya adalah teknik pengenalan suara. Penulisan ini bertujuan untuk membuat prototipe sistem yang memanfaatkan teknologi pengenalan suara (speaker recognition) sebagai penggerak dinamo starter pada mobil. Speaker recognition dibagi menjadi 2 bagian, yaitu speaker verification dan speaker identification. Teknologi ini juga menggunakan dua metode, yaitu MFCC (Mel Frequency Cepstrum Coefficients) untuk proses ekstraksi ciri dari sinyal suara dan kedua metode DTW (Dynamic Time Warping) untuk proses pencocokan. Perancangan prototipe pengenalan suara menggunakan modul Parallax Say It, modul mikrokontroller AVR ATMega16, modul LCD 16x2, modul motor driver, Motor dc, baterai 12V. Proses pengolahan sinyal suara dilakukan pada software Matlab untuk mengetahui cara kerja metode MFCC dan DTW. Hasil pengujian memperlihatkan tingkat akurasi paling rendah adalah 80 % dengan nilai threshold 3,5118, sedangkan tingkat akurasi tertinggi yaitu 85 % dengan nilai threshold 5,3.
1. PENDAHULUAN
Dengan adanya kemajuan teknologi dalam bidang pengolahan sinyal digital (Digital Signal Processing) telah membawa dampak positif dalam kehidupan manusia. Pengolahan sinyal digital telah banyak digunakan dalam berbagai aplikasi. Sebagai contoh, aplikasi-aplikasi tersebut meliputi teknik pengenalan suara, kompresi sinyal (data, gambar), dan juga televisi dan telepon digital (Dadang Gunawan dan Filbert Hilman Juwono, 2012).
Teknologi pengenalan suara (speaker recognition) merupakan salah satu teknologi biometrika yang tidak memerlukan biaya besar serta peralatan khusus. Pada dasarnya setiap manusia memiliki sesuatu yang unik/khas yang hanya dimiliki oleh dirinya sendiri. Suara merupakan salah satu dari bagian tubuh manusia yang unik dan dapat dibedakan dengan mudah. Disamping itu, sistem biometrika suara memiliki karakteristik seperti, tidak dapat lupa, tidak mudah hilang dan tidak mudah untuk dipalsukan karena keberadaannya melekat pada diri manusia sehingga keunikannya lebih terjamin.
(http://donupermana.wordpress.com/maka lah/sistem-biometrik-absensi).
Pada tugas akhir ini dibuat sebuah prototipe sistem yang memanfaatkan teknologi pengenalan suara (Speaker Recognition) yang menggunakan modul Parallax Say It sebagai pemroses pengolahan sinyal suara yang diteruskan ke Mikrokontroler ATMega16. Sistem ini diharapkan akan mengenali suara dari pengguna kemudian hasil dari pengenalan suara tersebut digunakan sebagai kata sandi dan perintah untuk menjalankan dinamo starter/motor dc yang kemudian akan menghidupkan mobil.
2. LANDASAN TEORI
2.1 Konsep Dasar Pengenalan Suara
Dalam kehidupan sehari-hari, manusia melakukan berbagai jenis komunikasi dengan sesama manusia, misalnya: body language, berbicara (speech) dan lain-lain. Diantara banyak komunikasi yang dilakukan oleh manusia, berbicara (speech) memberikan paling banyak informasi penting dan paling efektif dalam berkomunikasi. Informasi-informasi tersebut antara lain: gender, keadaan kesehatan, emosi, serta identitas pembicara.
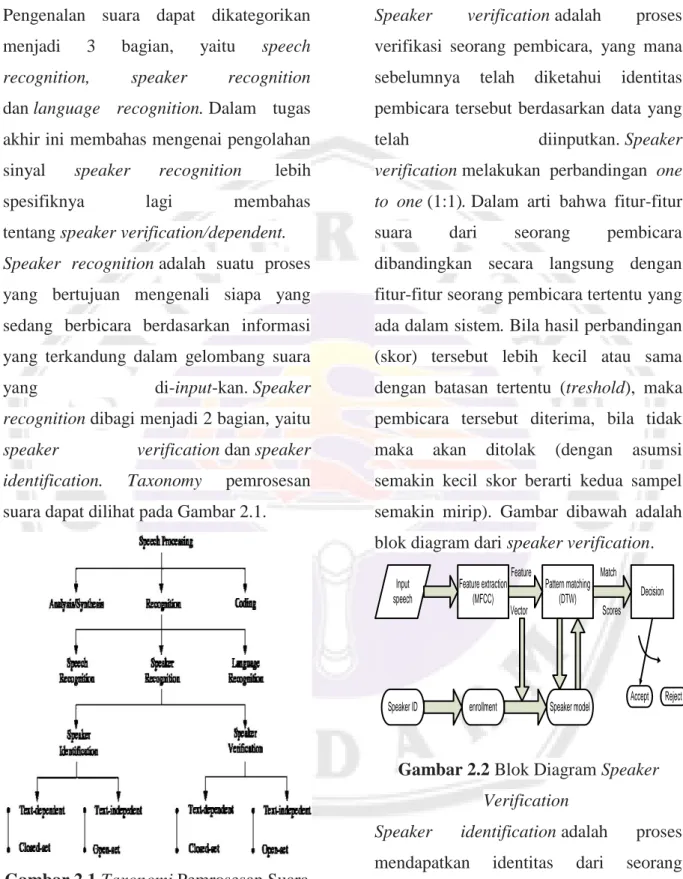
Pengenalan suara dapat dikategorikan menjadi 3 bagian, yaitu speech recognition, speaker recognition dan language recognition. Dalam tugas akhir ini membahas mengenai pengolahan sinyal speaker recognition lebih spesifiknya lagi membahas tentang speaker verification/dependent. Speaker recognition adalah suatu proses yang bertujuan mengenali siapa yang sedang berbicara berdasarkan informasi yang terkandung dalam gelombang suara yang di-input-kan. Speaker recognition dibagi menjadi 2 bagian, yaitu speaker verification dan speaker identification. Taxonomy pemrosesan suara dapat dilihat pada Gambar 2.1.
Gambar 2.1 Taxonomi Pemrosesan Suara
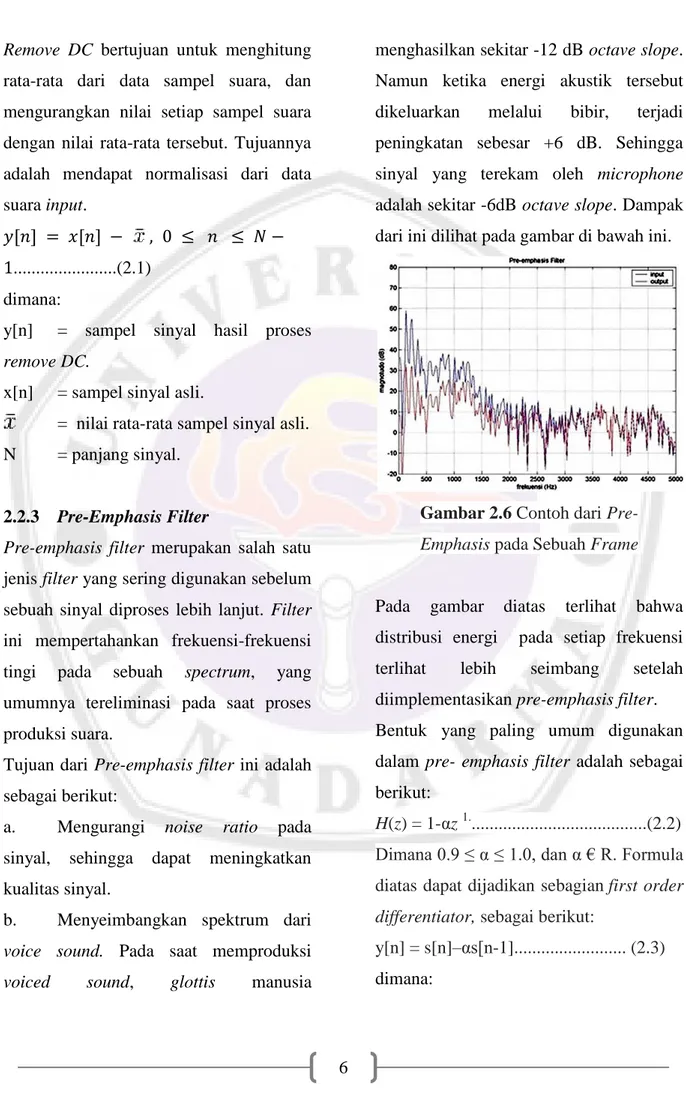
Speaker verification adalah proses verifikasi seorang pembicara, yang mana sebelumnya telah diketahui identitas pembicara tersebut berdasarkan data yang
telah diinputkan. Speaker
verification melakukan perbandingan one to one (1:1). Dalam arti bahwa fitur-fitur suara dari seorang pembicara dibandingkan secara langsung dengan fitur-fitur seorang pembicara tertentu yang ada dalam sistem. Bila hasil perbandingan (skor) tersebut lebih kecil atau sama dengan batasan tertentu (treshold), maka pembicara tersebut diterima, bila tidak maka akan ditolak (dengan asumsi semakin kecil skor berarti kedua sampel semakin mirip). Gambar dibawah adalah blok diagram dari speaker verification.
Input speech Feature extraction (MFCC) Pattern matching (DTW) Decision
Speaker ID enrollment Speaker model Accept Reject
Feature Vector
Match Scores
Gambar 2.2 Blok Diagram Speaker
Verification
Speaker identification adalah proses mendapatkan identitas dari seorang pembicara dengan membandingkan fitur-fitur suara yang diinputkan dengan semua
dalam database. Berbeda dengan pada speaker verification, proses ini melakukan perbandingan one to many (1:N).
2.2 MFCC (Mel Frequency Cepstrum
Coefficients)
MFCC (Mel Frequency Cepstrum Coefficients) merupakan salah satu metode yang banyak digunakan dalam bidang speech technology, baik speaker recognition maupun speech
recognition. Metode ini digunakan untuk melakukan feature extraction, sebuah proses yang mengkonversikan sinyal suara menjadi beberapa parameter. Beberapa keunggulan dari metode ini adalah sebagai berikut:
a. Mampu untuk menangkap karakteristik suara yang sangat penting bagi pengenalan suara, atau dengan kata lain dapat menangkap informasi-informasi
penting yang terkandung
dalam sinyal suara.
b. Menghasilkan data seminimal mungkin, tanpa menghilangkan informasi-informasi penting yang dikandungnya. c. Mereplikasi organ pendengaran manusia dalam melakukan persepsi terhadap sinyal suara.
Gambar 2.3 Contoh Sinyal Suara
Contoh dari sinyal suara dapat dilihat pada gambar di atas. Pengujian yang dilakukan untuk periode waktu yang cukup pendek (sekitar 10 sampai 30 milidetik) akan menunjukkan karakteristik sinyal suara yang stationary.Tetapi bila dilakukan dalam periode waktu yang lebih panjang karakteristik signal suara akan terus berubah sesuai dengan kata yang diucapkan.
MFCC feature extraction sebenarnya merupakan adaptasi dari sistem pendengaran manusia, dimana signal suara akan di-filter secara linear untuk frekuensi rendah (dibawah 1000 Hz) dan secara logaritmik untuk frekuensi tinggi (diatas 1000 Hz). Gambar dibawah ini merupakan block diagram untuk MFCC.
Remove DC Pre-emphasis Decision Continuous speech Discrete cosine trnsform Mel frequency warping Fast fourier transform Windowing Cepstral liftering Spectrums Mel spectrums Mel cepstrums Feature extraction Frame
Gambar 2.4 Blok Diagram untuk MFCC
2.2.1 Konversi Analog menjadi Digital
Sinyal–sinyal yang natural pada umumnya seperti sinyal suara merupakan signal continue dimana memiliki nilai yang tidak terbatas. Sedangkan pada komputer, semua sinyal yang dapat diproses oleh komputer hanyalah signal discrete atau sering dikenal sebagai istilah digital signal. Agar sinyal natural dapat diproses oleh komputer, maka harus diubah terlebih dahulu dari data signal continue menjadi discrete. Hal itu dapat dilakukan melalui 3 proses, diantaranya adalah proses sampling data, proses kuantisasi dan proses pengkodean.
Proses sampling adalah suatu proses untuk mengambil data signal continue untuk setiap periode tertentu. Dalam melakukan proses sampling data, berlaku aturan Nyquist, yaitu bahwa frekuensi sampling (sampling rate)
minimal harus 2 kali lebih tinggi dari frekuensi maksimum yang akan di-sampling. Jika signal sampling kurang
dari 2 kali frekuensi
maksimum sinyal yang akan di-sampling, maka akan timbul efek aliasing. Aliasing adalah suatu efek dimana sinyal yang dihasilkan memiliki frekuensi yang berbeda dengan sinyal aslinya. Proses kuantisasi adalah proses untuk membulatkan nilai data ke dalam bilangan-bilangan tertentu yang telah ditentukan terlebih dahulu. Semakin banyak level yang dipakai maka semakin akurat pula data sinyal yang disimpan tetapi akan menghasilkan ukuran data besar dan proses yang lama.
Proses pengkodean adalah proses pemberian kode untuk tiap-tiap data sinyal yang telah terkuantisasi berdasarkan level yang ditempati.
Gambar 2.5 Proses
Pembentukan Sinyal Digital 2.2.2 Remove DC
Remove DC bertujuan untuk menghitung rata-rata dari data sampel suara, dan mengurangkan nilai setiap sampel suara dengan nilai rata-rata tersebut. Tujuannya adalah mendapat normalisasi dari data suara input.
...(2.1)
dimana:
y[n] = sampel sinyal hasil proses remove DC.
x[n] = sampel sinyal asli.
= nilai rata-rata sampel sinyal asli. N = panjang sinyal.
2.2.3 Pre-Emphasis Filter
Pre-emphasis filter merupakan salah satu jenis filter yang sering digunakan sebelum sebuah sinyal diproses lebih lanjut. Filter ini mempertahankan frekuensi-frekuensi tingi pada sebuah spectrum, yang umumnya tereliminasi pada saat proses produksi suara.
Tujuan dari Pre-emphasis filter ini adalah sebagai berikut:
a. Mengurangi noise ratio pada sinyal, sehingga dapat meningkatkan kualitas sinyal.
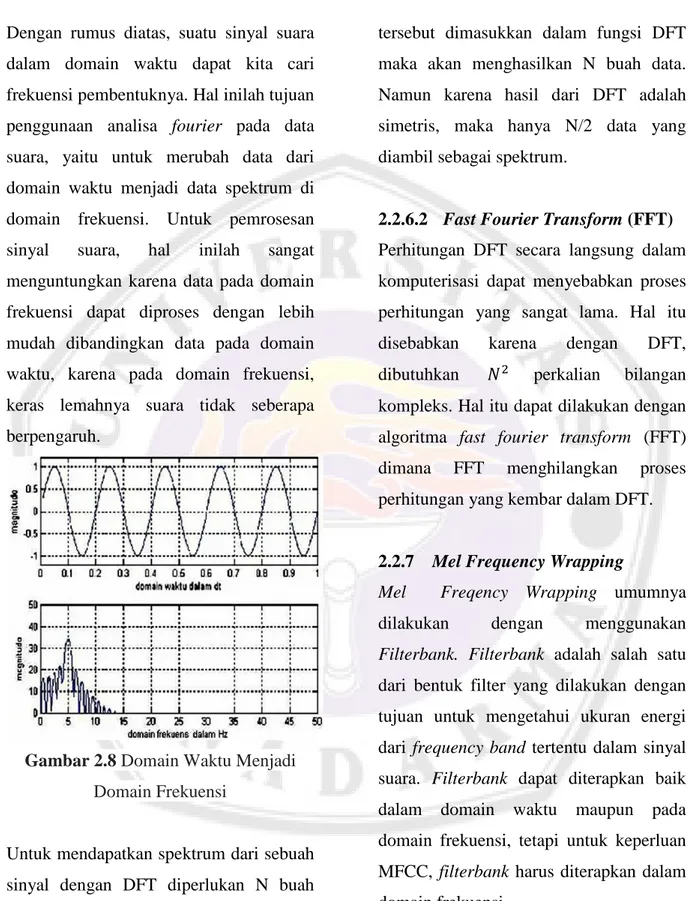
b. Menyeimbangkan spektrum dari voice sound. Pada saat memproduksi voiced sound, glottis manusia
menghasilkan sekitar -12 dB octave slope. Namun ketika energi akustik tersebut dikeluarkan melalui bibir, terjadi peningkatan sebesar +6 dB. Sehingga sinyal yang terekam oleh microphone adalah sekitar -6dB octave slope. Dampak dari ini dilihat pada gambar di bawah ini.
Gambar 2.6 Contoh dari
Pre-Emphasis pada Sebuah Frame
Pada gambar diatas terlihat bahwa distribusi energi pada setiap frekuensi terlihat lebih seimbang setelah diimplementasikan pre-emphasis filter. Bentuk yang paling umum digunakan dalam pre- emphasis filter adalah sebagai berikut:
H(z) = 1-αz 1...(2.2) Dimana 0.9 ≤ α ≤ 1.0, dan α € R. Formula diatas dapat dijadikan sebagian first order differentiator, sebagai berikut:
y[n] = s[n]–αs[n-1]... (2.3) dimana:
y[n] = sinyal hasil pre-emphasis filter. s[n] = sinyal sebelum pre-emphasis filter.
2.2.4 Frame Blocking
Karena sinyal suara terus mengalami perubahan akibat adanya pergeseran artikulasi dari organ produksi vokal , sinyal harus diproses secara short segments (short frame). Panjang frame yang biasa digunakan untuk pemrosesan sinyal adalah antara 10-30 milidetik. Panjang frame yang digunakan sangat mempengaruhi keberhasilan dalam analisa spektral. Di satu sisi, ukuran dari frame harus sepanjang mungkin untuk dapat menunjukkan frekuensi yang baik. Tetapi di lain sisi, ukuran frame juga harus cukup pendek untuk dapat menunjukkan resolusi waktu yang baik.
Gambar 2.7 Bentuk Sinyal yang di Frame Blocking
Proses frame ini dilakukan terus sampai seluruh sinyal dapat diproses. Selain itu, proses ini umumnya dilakukan secara overlapping untuk setiap frame- nya. Panjang daerah overlap yang umum digunakan adalah kurang lebih 30% sampai 50% dari panjang frame. Overlapping dilakukan untuk menghindari hilangnya ciri atau karakteristik suara pada perbatasan perpotongan setiap frame.
2.2.5 Windowing
Proses framing dapat menyebabkan terjadinya kebocoran spektral (spectral leakage) atau aliasing. Aliasing adalah sinyal baru dimana memiliki frekuensi yang berbeda dengan sinyal aslinya. Efek ini dapat terjadi karena rendahnya jumlah sampling rate, ataupun karena proses frame blocking dimana menyebabkan sinyal menjadi discontinue. Utuk mengurangi kemungkinan terjadinya kebocoran spektral, maka hasil dari proses framing harus melewati proses window. Sebuah fungsi window yang baik harus menyempit pada bagian main lobe dan melebar pada bagian side lobe-nya.
Berikut adalah representasi dari fungsi window terhadap sinyal suara yang diinputkan.
...(2.4)
dimana:
= nilai sampel sinyal hasil windowing
= nilai sampel dari frame sinyal ke i
= fungsi window
N = frame size, merupakan kelipatan 2
Ada banyak fungsi window, namun yang paling sering digunakan dalam aplikasi speaker recognition adalah hamming window. Fungsi window ini menghasilkan sidelobe level yang tidak terlalu tinggi (kurang lebih -43 dB), selain itu noise yang dihasilkan pun tidak terlalu besar . Fungsi Hamming window adalah sebagai berikut: ...(2.5) dimana: n = 0,1,...,M-1 M = panjang frame 2.2.6 Analisis Fourier
Analisis fourier adalah sebuah metode yang memungkinkan untuk melakukan analisa terhadap spectral properties dari sinyal yang diinputkan. Representasi dari
spectral properties sering disebut sebagai spectrogram.
Dalam spectrogram terdapat hubungan yang sangat erat antara waktu dan frekuensi. Hubungan antara frekuensi dan waktu adalah hubungan berbanding terbalik. Bila resolusi waktu yang digunakan tinggi, maka resolusi frekuensi yang dihasilkan akan semakin rendah.
2.2.6.1 Discrete Fourier Transform
(DFT)
DFT merupakan perluasan dari transformasi fourier yang berlaku untuk sinyal-sinyal diskrit dengan panjang yang terhingga. Semua sinyal periodik terbentuk dari gabungan sinyal-sinyal sinusoidal yang menjadi satu yang dapat dirumuskan sebagai berikut:
...(2.6) dimana:
N = jumlah sampel yang akan diproses
= nilai sampel sinyal
k = variabel frekuensi diskrit, dimana akan bernilai ( .
Dengan rumus diatas, suatu sinyal suara dalam domain waktu dapat kita cari frekuensi pembentuknya. Hal inilah tujuan penggunaan analisa fourier pada data suara, yaitu untuk merubah data dari domain waktu menjadi data spektrum di domain frekuensi. Untuk pemrosesan sinyal suara, hal inilah sangat menguntungkan karena data pada domain frekuensi dapat diproses dengan lebih mudah dibandingkan data pada domain waktu, karena pada domain frekuensi, keras lemahnya suara tidak seberapa berpengaruh.
Gambar 2.8 Domain Waktu Menjadi
Domain Frekuensi
Untuk mendapatkan spektrum dari sebuah sinyal dengan DFT diperlukan N buah sampel data berurutan pada domain waktu, yaitu x[m] sampai x[m+N-1]. Data
tersebut dimasukkan dalam fungsi DFT maka akan menghasilkan N buah data. Namun karena hasil dari DFT adalah simetris, maka hanya N/2 data yang diambil sebagai spektrum.
2.2.6.2 Fast Fourier Transform (FFT) Perhitungan DFT secara langsung dalam komputerisasi dapat menyebabkan proses perhitungan yang sangat lama. Hal itu disebabkan karena dengan DFT, dibutuhkan perkalian bilangan kompleks. Hal itu dapat dilakukan dengan algoritma fast fourier transform (FFT) dimana FFT menghilangkan proses perhitungan yang kembar dalam DFT.
2.2.7 Mel Frequency Wrapping
Mel Freqency Wrapping umumnya dilakukan dengan menggunakan Filterbank. Filterbank adalah salah satu dari bentuk filter yang dilakukan dengan tujuan untuk mengetahui ukuran energi dari frequency band tertentu dalam sinyal suara. Filterbank dapat diterapkan baik dalam domain waktu maupun pada domain frekuensi, tetapi untuk keperluan MFCC, filterbank harus diterapkan dalam domain frekuensi.
Gambar 2.9
Magnitude dari Rectangular dan Triangul ar Filterbank
Filterbank menggunakan representasi konvolusi dalam melakukan filter terhadap sinyal. Konvolusi dapat dilakukan dengan melakukan multiplikasi antara spektrum sinyal dengan koefisien filterbank. Berikut ini adalah rumus yang digunakan dalam filterbanks.
...(2.7)
dimana:
N = jumlah magnitude spectrum
S[j] = magnitude spectrum pada frekuensi j.
= koefisien filterbank pada frekuensi j (1 ≤ i ≤ M).
M = jumlah channel dalam filterbank.
Presepsi manusia terhadap frekuensi dari sinyal suara tidak mengikuti linier scale. Frekuensi yang sebenarnya (dalam Hz) dalam sebuah sinyal akan diukur manusia secara subyektif dengan menggunakan mel scale. Mel frequency scale adalah linier frekuensi scale pada frekuensi dibawah 1000 Hz dan merupakan logarithmic scale pada frekuensi diatas 1000 Hz.
2.2.8 Discrete Cosine Transform
(DCT)
DCT merupakan langkah terakhir dari proses utama MFCC feature extraction. Konsep dasar dari DCT adalah mendekorelasikan mel spectrum sehingga menghasilkan representasi yang baik dari properti spektral lokal. Pada dasarnya konsep DCT sama dengan inverse fourier transform. Namun hasil dari DCT mendekati PCA (principle component analysis). PCA adalah metode statik klasik yang digunakan secara luas dalam analisa data dan kompresi. Hal inilah yang menyebabkan seringkali DCT menggantikan inverse fourier transform dalam proses MFCC feature extraction. Berikut adalah formula yang digunakan untuk menghitung DCT.
...(2.8)
dimana:
= keluar dari proses filterbank pada index k.
= jumlah koefisien yang diharapkan.
Koefisien ke nol dari DCT pada umumnya akan dihilangkan, walaupun sebenarnya mengindikasikan energi dari frame sinyal tersebut. Hal dilakukan karena, berdasarkan penelitian-penelitian yang pernah dilakukan, koefisien ke nol ini tidak reliable terhadap speaker recognition.
2.2.9 Cepstral Liftering
Hasil dari proses utama MFCC feature extraction memiliki beberapa kelemahan. Low order dari cepstral coefficients sangat sensitif terhadap spectral slope, sedangkan bagian high order-nya sangat sensitif terhadap noise. Oleh karena itu, cepstral liftering menjadi salah satu standar teknik yang diterapkan untuk meminimalisasi sensitifitas tersebut.
Cepstral liftering dapat dilakukan dengan mengimplementasikan fungsi window terhadap cepstral features.
...(2.9) dimana:
L = jumlah cepstral coefficients. N= index dari cepstral coefficients.
Cepstral liftering menghaluskan spektrum hasil dari main processor sehingga dapat digunakan lebih baik untuk pattern matching.
2.3 Pencocokan dengan Metode DTW (Dynamic Time Warping)
Satu masalah yang cukup rumit dalam pengenalan wicara adalah poses perekaman yang terjadi seringkali berbeda durasinya, biarpun kata atau kalimat yang diucapkan sama. Bahkan untuk satu suku kata yang sama atau vokal yang sama seringkali proses perekaman terjadi dalam durasi yang berbeda. Sebagai akibatnya proses matching antara sinyal uji dengan sinyal referensi (template) seringkali tidak menghasilkan nilai yang optimal.
Sebuah teknik yang cukup populer di awal perkembangan teknologi pengolahan sinyal wicara adalah dengan memanfaatkan sebuah teknik dynamic-programming yang juga lebih dikenal sebagai Dynamic Time Warping (DTW). Teknik ini ditujukan untuk mengakomodasi perbedaan waktu antara proses perekaman saat pengujian dengan yang tersedia pada template sinyal referensi. Prinsip dasarnya adalah dengan memberikan sebuah rentang „steps‟ dalam ruang (dalam hal ini sebuah frame-frame waktu dalam sample, frame-frame waktu dalam template) dan digunakan untuk mempertemukan lintasan yang menunjukkan local match terbesar (kemiripan) antara time frame yang lurus. Total similarity cost yang diperoleh dengan algorithm ini merupakan sebuah indikasi seberapa bagus sample dan template ini memiliki kesamaan, yang selanjutnya akan dipilih best-matching template.
DTW (Dynamic Time Warping) adalah metode untuk menghitung jarak antara dua data time series. Keunggulan DTW dari metode jarak yang lainnya adalah mampu menghitung jarak dari dua vektor data dengan panjang berbeda.
Jarak DTW diantara dua vektor dihitung dari jalur pembengkokkan optimal (optimal warping path) dari dua vektor tersebut. Ilustrasi pencocokan dengan metode DTW ditunjukkan pada gambar dibawah ini.
Gambar 2.10 Pencocokan Sequence (a)
Alignment Asli dari 2 Sequence (b) Alignment dengan DTW
Dari beberapa teknik yang digunakan untuk menghitung DTW, salah satu yang paling handal adalah dengan metode pemrograman dinamis. Jarak DTW dapat dihitung dengan rumus:
...(2.10)
Kolom dengan nilai dinamakan matriks jarak terjumlahkan. Berikut ini adalah contoh matriks jarak terjumlahkan.
Gambar 2.11 Ilustrasi Matriks Jarak
Terjumlahkan (Cumulative Distance Matrix) antara 2 Vektor
3.
PERANCANGAN
3.1 Perancangan Alat
Perancangan suatu alat yang akan dibuat merupakan suatu tahapan yang sangat penting dalam membuat suatu program ataupun melanjutkan ke langkah selanjutnya, karena dengan perencanaan tersebut diharapkan mendapatkan hasil yang baik dan maksimal, dalam perancangan sistem yang penulis buat adalah pengendalian suatu alat pengenalan suara untuk menghidupkan mobil.
Pembuatan alat pengenalan suara ini membutuhkan beberapa modul yang dilampirkan pada tabel 3.1
Tabel 3.1 Daftar alat/modul
No. Alat/modul Jumlah
1 Parallax say it 1 2 Mikrokontroller 1 AVR ATmega16 3 LCD 16x2 1 4 Motor driver 1 5 Motor dc 1 6 Baterai 12 V 1
Semua komponen dipasang sesuai dengan rangkaian yang digunakan. Kemudian rangkaian tersebut diuji coba dengan menggunakan multimeter, untuk mengetahui apakah rangkaian tersebut sudah terhubung dengan benar. Diagram blok dari prototipe alat pengenalan suara ini adalah sebagai berikut:
Mikrokontroler PC4 PB0(RX) PB1(TX) PB2 PA0 PA1 PA2 PA4 PA5 PA6 PA7 P5(Input1) P7(Input2) P2(Output1) P3(Output2) P4(Vs) P9(Vss) P8(GND) PC5 Motor Driver L298 ATmega16 TX RX VDC GND Led Parallax Say It RS R/W E DB4 DB5 DB6 DB7 LCD 16x2 P10(VCC) P11(GND) VDD VSS (+) (-) Baterai 12V (-) (+) Dinamo Starter 7805 (+) (+) (-) +5V +12V Saklar Regulator
Gambar 3.1 Blok diagram sistem
Dan untuk konsep desain seperti gambar dibawah ini:
Dinamo Starter Modul LCD 2x16 Karakter Baterai 12V Modul Parallax Say It Motor Driver Suara Manusia ATmega16
Gambar 3.2 Konsep desain
Dalam Gambar 3.3 adalah berisi prinsip kerja secara keseluruhan dari rangkaian yang dibuat. Sehingga keseluruhan blok dari alat dapat membentuk suatu sistem yang dapat bekerja atau difungsikan sesuai dengan perancangan.
3.1.1 Rangkaian Modul Mikrokontroler
Rangkaian mikrokontroler merupakan blok kendali dari alat, karena seluruh proses input dan output-nya dilakukan pada blok rangkaian ini. Pada penelitian ini digunakan mikrokontroler berbasis AVR 8-bit ATMega16 dengan kemasan 40 pin DIP (Dual Inline Package) seperti yang ditunjukkan pada Gambar 3.4.
Gambar 3.3 Pin-pin ATMega16 kemasan 40 pin
Pada mikrontroler AVR ATMega16, pin PD0 dan PD1 digunakan untuk komunikasi serial menggunakan antarmuka UART (Universal Asynchronous Receiver/Transmitter) yang berfungsi untuk melakukan pertukaran data atau komunikasi dua arah. Konfigurasi komunikasi serial kedua modul adalah 9600 baud, 8 bit data, No parity, 1 bit stop. PD0 (RXD) berfungsi untuk menerima data dari modul Parallax Say It, dan PD1 (TXD) berfungsi untuk mengirim data ke modul Parallax Say It. Berikut adalah diagram blok koneksi modul parallax say it dengan mikrokontroler ATMega16:
VCC GND 3.3V – 5V GND ERX ETX TX(PIND.1) RX(PIND.0)
Parallax Say It ATmega16
LED PIND.2
Gambar 3.4 Koneksi modul Parallax Say It dengan modul ATMega16
Protokol komunikasi hanya menggunakan karakter ASCII (American Standard Code for Information Interchange) yang dibagi dalam dua kelompok utama:
Perintah dan status karakter, masing-masing di jalur TX dan RX, dipilih diantara huruf kecil.
Perintah argumen atau rincian status, pada jalur TX dan RX, yang mencakup berbagai huruf kapital.
Setiap perintah yang dikirim pada jalur TX, dengan nol atau lebih byte argumen tambahan, menerima jawaban pada jalur RX dalam bentuk byte status yang diikuti oleh nol atau argumen lebih.
Ada penundaan minimum sebelum setiap byte yang dikirim dari modul parallax say it ke mikrokontroler pada jalur RX(PIND.0), pengaturan awalnya 20 ms dan dapat dirubah dalam rentang 0-9 ms, 10-90 ms, 100 ms-1 s. Pengaturan penundaan tergantung pada jenis
mikrokontroler yang dipakai apakah lambat atau cepat.
Gambar 3.5 Skematik Modul Mikrokontroler
3.1.2 Rangkaian Modul Driver Motor DC
Sebuah rangkaian driver motor dc terdiri atas komponen-komponen sebagai berikut, yaitu sebuah ic h-bridge motor driver L298, dua buah resistor 10 ohm sebagai r-sense, delapan buah dioda 1N4002, dan dua buah kapasitor 100 nF. Semua komponen tersebut kemudian dirangkai menjadi sebuah rangkaian driver motor yang akan mengendalikan pergerakan motor dc pada mobil.
Gerak motor dc akan ditentukan dari input yang diberikan pada L298.Terdapat enam jalur input pada L298 yang terdiri atas input data arah pergerakan motor dan
input untuk PWM (Pulse Width Modulation). Kecepatan motor akan diatur melalui variasi lebar pulsa yang diberikan oleh mikrokontroler sebagai input PWM. Dibawah ini adalah gambar rangkaian modul driver motor dc.
Gambar 3.6 Skematik Modul Motor Driver
3.1.3 Rangkaian Modul LCD
Untuk penampil perintah suara, maka digunakan LCD 16x2 sebagai penampil karakter angka dan huruf. Pemrograman pada LCD ini menggunakan mode 4-bit. Jadi bentuk pengukuran yang dilakukan dapat ditampilkan dengan LCD 16x2 ini dan memerlukan program khusus pada IC Mikrokontroler untuk dapat memerintah LCD 16x2 menampilkan karakter-karakter tersebut. Jenis LCD yang perancang gunakan adalah modul LCD dot matrik dengan konsumsi daya yang rendah, namun mempunyai tampilan yang lebar dengan kontras yang tinggi sehingga dapat
dilihat dengan jelas. Dibawah ini adalah gambar rangkaian modul LCD.
Gambar 3.7 Skematik modul LCD
3.1.4 Rangkaian Modul Pengenalan Suara
Parallax Say It merupakan modul voice recognition multi-fungsi. Modul ini mendukung hingga 32 custom Speaker Dependet (SD) trigger atau perintah, bahkan dapat digunakan pada bahasa apapun. Komunikasi dengan perangkat lain menggunakan komunikasi serial antar muka UART (Universal Asynchronous Receiver/Transmitter). Modul ini juga dapat dihubungkan dengan komputer melalui USB menggunakan software GUI (Graphical User Interface) yang mudah digunakan. Protokol komunikasi menggunakan karakter ASCII. Dibawah ini adalah gambar skema rangkaian modul Parallax Say It.
Gambar 3.8 Skematik modul Parallax Say It
3.3 Hasil Perancangan
Gambar 3.9 Hasil perancangan prototipe pengenalan suara sebagai penggerak
dinamo starter pada mobil
4.
PEMBAHASAN
4.1 Pengolahan Sinyal Suara
Tujuan dari proses pengolahan suara adalah untuk mendapatkan ciri atau
parameter dari sinyal suara. Proses pengolahan sinyal suara dilakukan pada software Matlab. Pada penelitian ini, proses MFCC diimplementasikan dengan menggunakan toolbox yang telah tersedia, yaitu speech and audio processing toolbox yang dikembangkan oleh Roger Jang pada tahun 1996. Adapun tahapan-tahapan proses MFCC yang dilakukan adalah: voice recording, remove silent, remove dc, pre-emphasis, frame blocking, windowing, fast fourier transform, filterbank, discrete consine transform dan cepstral liftering.
4.1.1 Voice Recording
Pengambilan data suara dilakukan dengan perekaman suara pada frekuensi sampel (Fs) 16 KHz selama dua detik. Gambar 4.1 merupakan sinyal suara kata “jitu‟.
Gambar 4.1 Sinyal Suara Asli Kata “Jitu”
Tempat yang digunakan untuk proses pengambilan suara dilakukan pada kondisi
ruangan dengan tingkat kebisingan yang rendah, karena bila noise yang terdapat pada ruangan terlalu besar dapat menyulitkan saat proses pembersihan data suara.
4.1.2 Remove Silent
Langkah ini tidak termasuk dalam proses utama MFCC. Namun berdasarkan penelitian yang telah dilakukan, silent yang terdapat dalam data suara sangat mempengaruhi tingkat keberhasilan sistem dalam melakukan pengenalan. Maka dari itu proses remove silent diperlukan untuk menghilangkan frame-frame yang mengandung silent seperti pada Gambar 4.2. Proses yang dilakukan adalah mendeteksi mulai sinyal suara awal dan berakhir ketika sudah tidak diucapkan. Hasil data suara dari proses remove silent dapat dlihat pada Gambar 4.3.
Gambar 4.2 Proses Remove Silent
Gambar 4.3 Data Suara setelah Proses Remove Silent
Apabila noise yang terdapat pada suara terlalu besar, maka proses pembersihan data ini tidak dapat berjalan dengan optimal seperti yang terlihat pada Gambar 4.4. Hal ini disebabkan sistem tidak mampu membedakan lagi antara gelombang suara dengan noise dari lingkungan. Noise juga dapat disebabkan dari gangguan distorsi pada gelombang sinyal listrik AC (Alternate Current) yang masuk melalui power battery atau device lain.
Gambar 4.4 Data Suara dengan Remove Silent yang Tidak Optimal
4.1.3 Remove DC
Proses remove DC bertujuan untuk melakukan normalisasi terhadap data sampel suara yang dimasukkan. Hasil data suara dari proses remove DC dapat dlihat pada Gambar 4.5.
Gambar 4.5 Data Suara setelah Proses Remove DC
4.1.4 Pre-Emphasis Filtering
Setelah melewati proses remove dc, selanjutnya data sampel suara akan memasuki proses utama MFCC yaitu pre-emphasis filtering. Gambar dibawah merupakan hasil dari proses pre-emphasis filtering untuk kata “jitu”.
Gambar 4.6 Data Suara setelah Proses Pre-Emphasis Filtering
4.1.5 Frame Blocking
Pada penelitian ini sinyal suara dipotong sepanjang 256 Hz pada setiap pergeseran 128 Hz dengan frekuensi sampling sebesar 8737 Hz. Setiap potongan tersebut dinamakan frame. Jadi setiap satu frame terdapat 256 sampel dari 8737 sampel yang ada. Berikut adalah hasil dari proses frame blocking untuk kata “jitu”.
Gambar 4.7 Data Suara setelah Proses Frame Blocking
Gambar 4.8 Data Suara setelah Proses Frame Blocking (Frame Pertama)
4.1.6 Windowing
Proses windowing dilakukan untuk mengurangi efek diskontinuitas dari proses frame blocking terutama pada
ujung-ujung frame. Gambar dibawah ini adalah hasil dari proses windowing untuk kata “jitu”.
Gambar 4.9 Data Suara setelah Proses Windowing (Frame Pertama)
4.1.7 FFT (Fast Fourier Transform) Dalam penilitian ini proses FFT akan mengubah sinyal suara ke dalam domain frekuensi dengan 256 titik. Gambar dibawah merupakan hasil dari proses FFT untuk kata “jitu”.
Gambar 4.10 Data Suara setelah Proses FFT (frame pertama)
4.1.8 Filterbank
Konsep pendengaran telinga manusia terhadap suara atau bunyi adalah dalam
skala linear pada frekuensi kurang dari 1 KHz dan logaritmik diatas frekuensi 1 KHz. Skala frekuensi filterbank adalah sama dengan konsep pendengaran manusia sehingga skala frekuensi sering dijadikan parameter ekstraksi dalam pengolahan sinyal suara. Dalam penelitian ini panjang dari filterbank adalah 20 setiap frame. Gambar dibawah ini adalah hasil dari proses filterbank untuk kata “jitu”.
Gambar 4.11 Data Suara setelah Proses Filterbank (Frame Pertama)
4.1.9 DCT (Discrete Cosine Transform)
Proses DCT merupakan langkah terakhir dari proses utama MFCC. Hasil dari proses ini adalah mel frekuensi cepstrum koefisien yang merupakan hasil dari proses MFCC. Panjang berikut adalah data koefisien MFCC untuk kata “jitu” dengan jumlah koefisien MFCC sebanyak 13 koefisien untuk masing-masing frame. Gambar dibawah ini adalah hasil dari proses DCT untuk kata “jitu”.
Gambar 4.12 Data Suara setelah Proses DCT (Frame Pertama)
4.1.10 Cepstral Liftering
Cepstral liftering berfungsi untuk menghaluskan spektrum hasil dari proses MFCC sehingga diharapkan dapat meningkatkan akurasi program dalam melakukan pengenalan. Gambar dibawah ini adalah hasil dari proses cepstral liftering untuk kata “jitu”.
Gambar 4.13 Data suara setelah proses cepstral liftering (frame pertama) Gambar dibawah ini adalah hasil keseluruhan ekstraksi ciri pada 67 frame ucapan kata “jitu”.
Gambar 4.14 Hasil Ekstrasi Ciri Ucapan “Jitu” Metode MFCC
4.2 Pengenalan Sinyal Suara dengan DTW (Dynamic Time Warping)
Pengujian terhadap sistem verifikasi suara yang dibuat dalam penelitian ini dilakukan menggunakan metode DTW dengan melakukan proses perhitungan jarak dengan membandingkan dua buah sampel yang diperoleh dari proses ekstraksi ciri. Jarak yang dihitung adalah jarak antara nilai koefisien cepstral MFCC yang ada di template referensi dan menghitung jarak template referensi dengan nilai koefisien cepstral MFCC dari suara uji yang masuk. Dari proses DTW ini akan diperoleh suatu nilai atau skor hasil perbandingan antara dua buah sampel.
4.3 Pengujian
Pengujian ini dilakukan dengan menggunakan data sampel dari 5 orang. Dengan komposisi 1 orang laki-laki
sebagai pengguna, 3 orang laki-laki dan 1 orang perempuan. Masing-masing orang mengucapkan satu buah kata “jitu”. Pengguna diambil data sebanyak 12 data sampel dengan 2 data sampel sebagai template referensi dan 10 data sampel sebagai data uji. Untuk bukan pengguna setiap orang diambil data sebanyak 10 data sampel sebagai data uji, sehingga jumlah sampel yang ada 2+10+(4x10) = 52 data sampel. Dibawah ini adalah tabel skor hasil pencocokan data uji dengan template referensi menggunakan metode DTW.
Tabel 4.1 Skor Pencocokan Data Uji
dengan Template Referensi
Dibawah ini adalah grafik distribusi probabilitas skor pengguna (pengguna sah dan pengguna tidak sah).
Gambar 4.15 Grafik Hasil Skor
Pengguna Asli dan Palsu
4.3.1 Hasil Pengujian
Setiap hasil pengujian akan ditampilkan grafik unjuk kerja sistem (FRR dan FAR) atau disebut juga grafik ROC. Hasil pengujian akan disajikan dalam bentuk tabel ataupun grafik untuk mempermudah analisa.
Ada dua pengujian ucapan kata “jitu” yang dilakukan dalam penelitian ini, diantaranya adalah:
Menentukan nilai threshold menggunakan grafik unjuk kerja sistem (FRR dan FAR).
Menentukan nilai threshold menggunakan persamaan 2.13.
4.3.1.1 Menentukan Nilai Threshold
Menggunakan Grafik Unjuk Kerja Sistem (FRR dan FAR)
Pengujian ini bertujuan untuk mengetahui nilai threshold yang akan digunakan untuk sistem dalam melakukan verifikasi. Hasil
pengujian dengan melihat titik pertemuan antara FRR dan FAR. Dibawah ini adalah hasil grafik unjuk kerja sistem (FRR dan FAR).
Gambar 4.16 Kurva Karakterisitik
Kinerja Sistem (FRR dan FAR)
Dalam pengujian ini nilai threshold yang didapat adalah 5.3 dengan tingkat kesalahan 7%.
4.3.1.2 Menentukan Nilai Threshold
Menggunakan Persamaan 2.13
Dalam penilitian ini menemukan bahwa hasil terbaik untuk menentukan nilai threshold menggunakan persamaan 2.13, diperoleh ketika dua ucapan yang sama (“jitu”) digunakan untuk template referensi sistem untuk setiap pengguna. Dari dua ucapan yang sama tersebut dilakukan proses pencocokan menggunakan metode DTW. Skor hasil pencocokan adalah 2.3412.
Untuk menentukan nilai threshold skor hasil pencocokan template referensi di kali 1.5. Jadi nilai threshold-nya adalah 3.5118. Ini berarti bahwa jika skor data uji ≤ 3.5118 maka pengguna dinyatakan sah, bila tidak, maka pengguna dinyatakan tidak sah.
4.4 Analisa Hasil
Dari hasil penelitian dengan menentukan nilai threshold pencocokan, maka akan didapatkan False Aceptance Rate (FAR) dan False Reject Rate (FRR). Nilai FAR akan naik apabila threshold dinaikkan, sedangkan nilai FRR akan turun. Dibawah adalah tabel nilai FRR, FAR, GAR dan akurasi sistem dari hasil threshold yang digunakan pada penelitian ini.
Tabel 4.2 Nilai FRR, FAR, GAR dan Akurasi Sistem
5. PENUTUP
5.1 KesimpulanBerdasarkan hasil penelitian, dapat ditarik beberapa kesimpulan:
1. Hasil pengujian prototipe Threshold FRR (%) FAR (%) GAR (%) Akurasi Sistem (%) 3,5118 20 0 85 80 5,3 10 5 100 85
dinamo starter pada mobil menunjukkan bahwa alat telah bekerja dengan baik dan bergerak sesuai dengan perintah yang diharapkan.
2. Metode Mel Frequency Ceptrums Coefficients adalah metode yang baik untuk ekstraksi fitur dalam pengenalan suara karena mampu untuk menangkap karakteristik suara yang sangat penting bagi pengenalan suara, menghasilkan data seminimal mungkin dan mereplikasi organ pendengaran manusia dalam melakukan persepsi terhadap sinyal suara
3. Proses pengenalan suara sensitif terhadap kebisingan karena dapat mempengaruhi proses ekstraksi fitur sinyal suara.
4. Metode Dynamic Time Warping dapat digunakan untuk membandingkan dua buah fitur suara hasil dari proses MFCC.
5. Tingkat keberhasilan sistem verifikasi tergantung nilai threshold yang digunakan.
5.2 Saran
Dari penelitian ini ada beberapa saran yang
dapat digunakan untuk penelitian
selanjutnya, antara lain adalah sebagai berikut :
1. Pengiriman data ke mikrokontroler dapat dikembangkan dengan menggunakan wireless, sehingga diperoleh sistem pengendalian yang lebih efisien.
2. Penambahan perintah pengenalan suara untuk mengontrol perangkat lain pada mobil seperti lampu, wiper, dan sebagainya.
DAFTAR PUSTAKA
1. Dadang Gunawan dan Juwono, Filbert Hilman, Pengolahan Sinyal Digital Dengan Pemrograman Matlab, Graha Ilmu, Yogyakarta, 2012.
2. Putra, Darma, Sistem Biometrika, Andi, Yogyakarta, 2009.
3. Rangkuti, Syahban,
Mikrokontroller Atmel AVR: Simulasi dan Praktek Menggunakan ISIS Proteus dan CodeVisionAVR, Informatika, Bandung, 2011.
4. Willa, Lukas, Teknnik Digital Mikroprosesor dan Mikrokomputer, Informatika, Bandung, 2010.
5. http://dewey.petra.ac.id/jiunkpe_d g_2834.html. Diakses tanggal: 3 April 2012.
6. http://www4.gu.edu.au:8080/adt-
root/uploads/approved/adt-QGU20040831.115646/public/02Whole.p df. Diakses tanggal: 3 April 2012.
7. ftp://ftp.cs.uef.fi/pub/PhLic/2004_ PhLic_Kinnunen_Tomi.pdf. Diakses tanggal: 3 April 2012.
8. http://icwww.epfl.ch/~hunkeler/ds p/minipro2.pdf. Diakses tanggal: 4 April 2012. 9. http://neural.cs.nthu.edu.tw/jang/b ooks/audioSignalProcessing/. Diakses tanggal: 4 April 2012. 10. http://repo.eepis-its.edu/1445/1/[E- D303-3]_pp.241-248_Pengkodean_Warna_Iris_Mata.pdf. Diakses tanggal: 5 April 2012.
11. http://www.sensoryinc.com/suppor t/docs/80-0206-W.pdf. Diakses tanggal: 12. http://www.atmel.com/Images/doc 2466.pdf. Diakses tanggal: 5 April 2012. 13. http://www.parallax.com/Portals/0/ Downloads/docs/prod/comm/30080-SayItModule-v1.1.pdf. Diakses tanggal: 5 April 2012.
14. http://plaza.ufl.edu/daisyfan/. Diakses tanggal: 8 April 2012.
15. http://hme.ee.itb.ac.id/elektron/?p= 32. Diakses tanggal: 9 April 2012.