Bab IV
Pembahasan dan Hasil Penelitian IV.1 Statistika Deskriptif
Pada bab ini akan dibahas mengenai statistik deskriptif dari variabel yang digunakan yaitu IHSG di BEI selama periode 1 April 2011 sampai dengan 30 Maret 2012. Pada periode tersebut terdapat sebanyak 248 hari perdagangan saham. Pada tabel 4.1 di bawah ini dapat lihat hasil statistika deskriptif IHSG selama periode pengamatan :
Tabel 4.1
Statistika Deskriptif IHSG Periode 1 April 2011 – 30 Maret 2012
Descriptive Statistics
N Minimum Maximum Mean Std. Deviation IHSG 248 3269.451 4193.441 3840.65648 159.533054 Valid N (listwise) 248
Sumber : Data diolah
Selama periode pengamatan (lampiran 1), nilai IHSG yang tertinggi yaitu sebesar 4193.441 terjadi pada tanggal 1 Agustus 2011 dan nilai IHSG yang terendah yaitu sebesar 3269.451 pada tanggal 4 Oktober 2011. Selama periode pengamatan ada kecenderungan membentuk pola trend berubah-ubah dapat dikatakan perekonomian cenderung tidak stabil.
Pada periode pengamatan data IHSG memiliki standar deviasi sebesar 159.53 dan mean sebesar 3840.65 sehingga nilai indeks IHSG memiliki variasi dari nilai rata-ratanya yang cukup tinggi. Hal ini berarti menunjukkan bahwa data tersebut tidak stasioner karena nilai rata-rata dan variannya cenderung berubah-ubah dari periode ke periode.
IV.2 Analisis Data
Analisis data yang digunakan pada penelitian ini yaitu menggunakan metode ARIMA. Sebelum dilakukan perhitungan dengan menggunakan metode
ARIMA, penelitian ini melakukan serangkaian uji-uji seperti uji kestasioneran
data, proses differencing, dan pengujian correlogram untuk menentukan koefisien autoregresi.
IV.2.1 Uji Pola Data
Uji pola data merupakan menganalisis pola pergerakan data saham per periode (harian, mingguan, bulan, atau tahun). Pola data menggambarkan karakteristik data dalam suatu periode. Berikut ini merupakan grafik pergerakan harian IHSG selama periode pengamatan penelitian:
Gambar 4.1
Data Harian IHSG Periode 1 April 2011 – 30 Maret 2012
Pada gambar 4.1 terlihat data pergerakan harian IHSG periode mulai 1 April 2011 – 30 Maret 2012 menunjukan terjadi pola trend berubah-ubah dan memiliki variansi yang cukup tinggi. Oleh karena itu, dapat dikatakan bahwa data pada periode penelitian menunjukkan data yang tidak stasioner. Data yang tidak stasioner perlu dilakukan proses differencing agar data menjadi data yang bersifat stasioner, yaitu data yang nilai rata-rata dan variansinya relatif konstan dalam suatu periode.
IV.2.2 Kestasioneran Data
Menurut Aritonang (2002:105), kestasioneran dapat diperiksa dengan analisis otokorelasi dan otokorelasi parsial. Data yang dianalisis dalam ARIMA merupakan data yang bersifat stationer.
Pada data time series dilakukan pengelompokkan pola data dengan menggunakan time lag (selisih waktu) selama 1 hari (time lag lainnya misalnya 2 hari, 3 hari, sampai dengan 36 hari) dalam analisis otokorelasi terhadap data tersebut. Berdasarkan pengujian tiap otokorelasi maka dapat didentifikasi pola datanya. Penentuan lag biasanya ditetapkan dua musim atau secara umum sebanyak 20 periode (DeLurgio, 1998 dalam Aritonang, 2002). Analisis dilakukan dengan menggunakan beberapa time lag dan koefisien otokorelasi yang diuji. Berikut ini merupakan hasil perhitungan fungsi otokorelasi dengan jumlah lag 20 dengan menggunakan program SPSS 20.0 dapat dilihat pada tabel sebagai berikut:
Tabel 4.2
Perhitungan Fungsi Otokorelasi
Sumber : Data diolah
Berdasarkan tabel 4.2 terlihat angka otokorelasi, pada lag 1 sampai 11 yang mempunyai nilai di atas 0.5. Hal ini mengarah pada adanya otokorelasi pada variabel IHSG. Berikut ini merupakan grafik fungsi otokorelasi adalah sebagai berikut:
Gambar 4.2
Grafik Fungsi Otokorelasi
Sumber : Data diolah
Berdasarkan gambar 4.2 autokorelasi terlihat bahwa grafik autokorelasi berbeda secara signifikan dari nol dan mengecil secara perlahan membentuk garis lurus. Hal ini menunjukkan bahwa data belum stasioner terhadap mean. Untuk itu, sebelum diproses lebih jauh dengan ARIMA, maka perlu dilakukan proses differencing.
Selain pengamatan grafik dan hasil perhitungan fungsi otokorelasi, pemeriksaan kestasioneran data juga dapat dilakukan berdasarkan hasil perhitungan dan pengujian correlogram fungsi otokorelasi parsial. Berikut ini merupakan hasil perhitungan fungsi otokorelasi adalah sebagai berikut:
Tabel 4.3
Perhitungan Fungsi Otokorelasi Parsial
Sumber : Data diolah
Berdasarkan tabel 4.3, perhitungan autokorelasi parsial terlihat bahwa nilai autokorelasi parsial mendekati nol setelah lag pertama yaitu sebesar 0.015. Hal ini menunjukan bahwa data belum stasioner. Pemeriksaan kestasioneran data juga dapat dilihat berdasarkan grafik fungsi otokorelasi parsial. Berikut ini merupakan grafik fungsi otokorelasi parsial adalah sebagai berikut:
Gambar 4.3
Grafik Fungsi Otokorelasi Parsial
Sumber : Data diolah
Berdasarkan gambar 4.3, grafik autokorelasi parsial terlihat bahwa grafik autokorelasi parsial mendekati nol setelah lag pertama. Hal ini menunjukan bahwa data belum stasioner. Dari analisis grafik autokorelasi dan autokorelasi parsial atau dengan teknik correlogram menunjukan bahwa data bersifat tidak stationer, sedangkan metode ARIMA memerlukan data yang bersifat stasioner. IV.2.3 Proses Differencing (Pembedaan)
Dalam menggunakan metode ARIMA memerlukan data yang bersifat stasioner. Berdasarkan gambar 4.2 dan gambar 4.3 menunjukan data IHSG tidak stasioner. Data IHSG yang tidak stasioner harus dilakukan transformasi agar data menjadi bersifat stasioner dengan melakukan proses differencing. Proses
differencing yaitu data yang asli (Yt) diganti dengan perbedaan pertama data asli tersebut atau dapat dirumuskan sebagai berikut (Aritonang, 2002:107):
Hasil proses pembedaan (differencing) ini dapat digambarkan dalam bentuk grafik sebagai berikut:
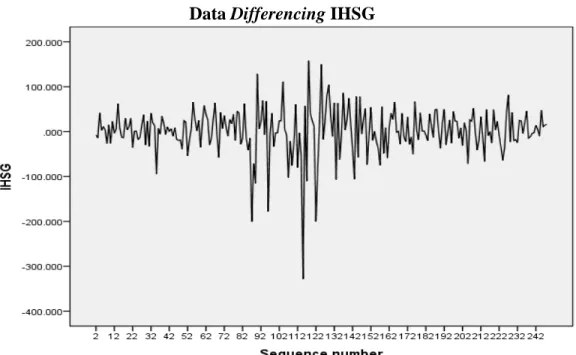
Gambar 4.4 Data Differencing IHSG
Sumber: Data diolah
Pada grafik 4.4 di atas data IHSG telah dilakukan proses differencing sebesar 1. Dari grafik sequence di atas terlihat bahwa grafik tidak menunjukkan tren atau musiman dan bergerak di sekitar rata-rata. Dengan demikian, dapat dikatakan bahwa data tersebut sudah stasioner terhadap mean dan varians.
Data IHSG yang sudah dilakukan proses dilakukan proses differencing sebesar 1 digunakan kembali untuk membuat correlogram (Dyt). Berikut ini merupakan hasil perhitungan fungsi otokorelasi dan fungsi otokorelasi parsial dari data yang sudah stasioner serta grafik correlogram-nya.
Tabel 4.4
Perhitungan Fungsi Otokorelasi setelah differencing
Berdasarkan tabel 4.4 dapat dilihat koefisien otokorelasi secara statistik dengan menggunakan taraf signifikan α = 5% dan jumlah observasi (n = 247) dengan batas intervalnya yaitu 0 ± 1,96 / ( atau 0 ± 0,125 yang melewati batas interval, yaitu pada lag 4 secara statistik sebesar -0.155, lag 7 sebesar 0.198, dan lag 17 -0.212. Dengan demikian koefisien autokorelasi yang melebihi batas interval, atau berbeda secara nyata dengan nol, dapat dikatakan berdasarkan analisis correlogram data IHSG harian dalam periode penelitian dengan
differencing = 1 data sudah stasioner. Berikut ini hasil grafik fungsi otokorelasi
setelah differencing adalah sebagai berikut:
Gambar 4.5
Grafik Fungsi Otokorelasi setelah Differencing
Sumber : Data diolah
Berdasarkan gambar 4.5 terlihat grafik fungsi otokorelasi setelah diffrerencing, koefisien otokorelasi untuk beberapa lag tidak berbeda signifikan dari nol atau berbeda dari nol untuk beberapa lag didepan maka dapat dikatakan bahwa data bersifat stasioner. Serta dengan menggunakan taraf signifikan α = 5% dan jumlah observasi (n = 247) maka batas intervalnya yaitu 0 ± 1,96 / ( atau 0 ± 0,125. Dengan demikian koefisien yang melebihi batas interval yaitu lag 4, lag, 7, dan lag 17.
Kestasioneran data juga dapat dilihat berdasarkan perhitungan dan grafik fungsi otokorelaso parsial. Berikut ini merupakan hasil perhitungan fungsi otokorelasi parsial setelah differencing adala sebagai berikut:
Tabel 4.5
Perhitungan Fungsi Otokorelasi Parsial setelah differencing
Sumber : Data diolah
Berdasarkan tabel 4.5 dapat dilihat koefisien otokorelasi parsial secara statistik dengan menggunakan taraf signifikan α = 5% dan jumlah observasi (n = 247) dengan batas intervalnya yaitu 0 ± 1,96 / ( atau 0 ± 0,125 terjadi pada lag 4 sebesar -0,175, pada lag 7 secara statistik sebesar 0.149 dan pada lag 17 sebesar -0.234. Dengan demikian koefisien autokorelasi yang melebihi batas interval, atau berbeda secara nyata dengan nol dapat dikatakan data IHSG harian dalam periode penelitian setelah melakukan proses differencing = 1 data sudah
stasioner. Berikut ini hasil grafik fungsi otokorelasi parsial setelah differencing adalah sebagai berikut:
Gambar 4.6
Grafik Fungsi Otokorelasi Parsial setelah differencing
Sumber : Data diolah
Berdasarkan gambar di atas terlihat beberapa koefisien yang signifikan. Dengan menggunakan taraf signifikan α = 5% dan jumlah observasi (n = 247) maka batas intervalnya yaitu 0 ± 1,96 / ( atau 0 ± 0,125. Dengan demikian koefisien autokorelasi yang melebihi batas interval, atau berbeda secara nyata dengan nol yaitu pada lag 4, lag 7, dan lag 17, dapat dikatakan berdasarkan analisis correlogram data IHSG harian dalam periode penelitian dengan
IV.2.4 Penentuan Nilai p, d, dan q dalam ARIMA
Pada bagian sebelumnya telah dilakukan penentuan nilai d (differencing) sebesar 1. Proses differencing dilakukan karena data awal yang sebelumnya tidak stasioner sehingga dilakukan proses pembedaan sebesar 1 agar data menjadi stasioner.
Dalam menentukan nilai p dan q dapat ditentukan berdasarkan dari pola fungsi autokorelasi dan otokorelasi parsial (Mulyono, 2000). Dari grafik 4.5 dan grafik 4.6 dapat dilihat koefisien otokorelasi menuju secara bertahap atau gelombang dan otokorelasi parsial menurun secara bertahap / bergelombang maka dapat di identifikasikan bahwa proses tersebut merupakan proses ARIMA (p,d,0).
Menurut Hadi (2012:92) Jika proses uji pola data, didapatkan bahwa
differencing 1 dan data sudah stasioner maka langkah selanjutnya adalah
melakukan estimasi model untuk peramalan harga saham. Model yang digunakan adalah ARIMA (p,d,q)
di mana :
p = ordo dari model AR,
d = differencing yang dilakukan agar data stasioner, q = ordo dari MA.
Pada penelitian ini, dapat diidentifikasi bahwa:
p = 17, terlihat berdasarkan grafik 4.5 grafik autokorelasi untuk data
differencing 1, ada satu koefisien yang signifikan, yaitu pada lag 17
q = 1, proses differencing yang dilakukan agar data menjadi stasioner adalah differencing 1
q = 17, terlihat berdasarkan grafik 4.6 grafik autokorelasi parsial untuk data differencing 1, ada satu koefisien yang signifikan, yaitu pada lag 17.
Berdasarkan identifikasi data tersebut, dapat dilakukan pendugaan terhadap model prediksi, yaitu ARIMA (17,1,0), ARIMA (0,1,17), ARIMA (17,1,17) dan
Expert Modeler. Expert Modeler merupakan pilihan secara automatically model
yang di pilih dari menu forecasting SPSS 20.0. Berdasarkan Expert Modeler terpilih model Expert Modeler ARIMA (0,1,17). Sebelum dilakukan peramalan atau prediksi maka dilakukan prose diagnostic checking terlebih dahulu untuk menentukan model telah dispesifikasi secara benar.
IV.2.5 Diagnostic Checking
Setelah pembentukan model ARIMA diperoleh untuk prediksi IHSG mendatang, maka dilakukan tahap diagnostic checking, yaitu memerika atau menguji apakah model telah dispesifikasi secara benar atau apakah telah dipilih p, d, dan q dengan benar. Ada beberapa cara untuk memeriksa model ARIMA, yaitu sebagai berikut:
1. Pengukuran Residual
Pengukuran residual dilakukan untuk menentukan apakah Model ARIMA dispesifikasi dengan benar. Jika model ARIMA dispesikasi benar, kesalahannya harus random atau antar-eror tidak berhubungan, sehingga fungsi otokorelasi dari kesalahan tidak berbeda dengan nol. Jika tidak demikian, spesifikasi model yang lain perlu diduga dan diperiksa (Mulyono, 2000:132).
Berdasarkan model ARIMA tersebut, dilakukan pengukuran terhadap model prediksi, yaitu ARIMA (17,1,0), ARIMA (0,1,17) , ARIMA (17,1,17) dan Expert
A. Model ARIMA (17,1,0)
Model ARIMA (17,1,0) yang telah dilakukan pengukuran residual dengan gambar ACF residual dan PACF residual adalah sebagai berikut:
Gambar 4.7
Grafik ACF dan PACF Residual ARIMA (17,1,0)
Sumber : Data diolah
Pada gambar 4.7 menunjukan bahwa kedua grafik mempunyai kesamaan, yakni tidak ada satupun bar yang melampaui garis batas; atau dapat dikatakan bahwa residu dari model ARIMA (17,1,0) bersifat random atau antar-error tidak berhubungan. Dengan demikian, dapat disimpulkan model
B. Model ARIMA (0,1,17)
Model ARIMA (0,1,17) yang telah dilakukan pengukuran residual dengan gambar ACF residual dan PACF residual adalah sebagai berikut:
Gambar 4.8
Grafik ACF dan PACF Residual ARIMA (0,1,17)
Sumber : Data diolah
Pada gambar 4.8 menunjukan bahwa kedua grafik mempunyai kesamaan, yakni tidak ada satupun bar yang melampaui garis batas; atau dapat dikatakan bahwa residu dari model ARIMA (0,1,17) bersifat random atau antar-error tidak berhubungan. Dengan demikian, dapat disimpulkan model
C. Model ARIMA (17,1,17)
Model ARIMA (17,1,17) yang telah dilakukan pengukuran residual dengan gambar ACF residual dan PACF residual adalah sebagai berikut:
Gambar 4.9
Grafik ACF dan PACF Residual ARIMA (17,1,17)
Sumber : Data diolah
Pada gambar 4.9 menunjukan bahwa kedua grafik mempunyai kesamaan, yakni tidak ada satupun bar yang melampaui garis batas; atau dapat dikatakan bahwa residu dari model ARIMA (17,1,17) bersifat random atau antar-error tidak berhubungan. Dengan demikian, dapat disimpulkan model
D. Expert Modeler ARIMA (0,1,17)
Expert Modeler ARIMA (0,1,17) yang telah dilakukan pengukuran residual
dengan gambar ACF residual dan PACF residual adalah sebagai berikut: Gambar 4.10
Grafik ACF dan PACF Residual Expert Modeler ARIMA (0,1,17)
Sumber : Data diolah
Pada gambar 4.10 menunjukan bahwa kedua grafik mempunyai kesamaan, yakni ada satu bar yang melampaui garis batas tetapi dapat dikatakan dikatakan bahwa residu dari model ARIMA (0,1,17) bersifat random atau antar-error tidak berhubungan karena jumlah lag yang signifikan tidak melebihi dua. Dengan demikian, dapat disimpulkan model ARIMA (0,1,17) sudah dispesifikasi dengan benar.
2. Modifted Box-Pierce (Ljung-Box) Q Statistic
Modifted Box-Pierce (Ljung-Box) Q Statistic digunakan untuk menguji
apakah apakah fungsi autokorelasi kesalahan semuanya tidak berbeda dari nol. Jika statistik Q lebih kecil dari nilai kritis chi-square (lampiran 4.2), maka semua koefisien autokorelasi dianggap tidak berbeda dari nol atau model telah dispesifikasi dengan benar (mulyono, 2000:132).
Berdasarkan hasil diagnostic checking dari pengukuran residual semua model sudah dispesifikasi dengan benar maka dilakukan pengujian Modifted
Box-Pierce (Ljung-Box) Q Statistic. Hasil pengukuran Modifted Box-Pierce
(Ljung-Box) Q Statistic beerdasarkan hasil SPSS 20.0 pada model ARIMA (17,1,0), ARIMA (0,1,17), ARIMA (17,1,17), dan Expert Modeler ARIMA
(0,1,17) adalah sebagai berikut:
A.Model ARIMA (17,1,0)
Model ARIMA (17,1,0) yang telah dilakukan pengukuran Modifted
Box-Pierce (Ljung-Box) Q Statistic adalah sebagai berikut:
Tabel 4.6
Modifted Box-Pierce (Ljung-Box) ARIMA (17,1,0)
Sumber : Data diolah
Pada Tabel 4.6 menunjukan nilai statistik Ljung-Box sebesar 3.873 yang diartikan jika dibandingkan dengan nilai distribusi chi-square (X²) dengan df sebesar 1 pada α = 5 %, yaitu 3.84146 (lampiran 2). Dengan demikian, dapat disimpulkan nilai statistik Hitung Ljung-Box sebesar 3.873 > dari nilai
distribusi chi-square tabel sebesar 3.84146, bahwa model ARIMA (17,1,0) tidak dapat dispesifikasi dengan benar.
B.Model ARIMA (0,1,17)
Model ARIMA (0,1,17) yang telah dilakukan pengukuran Modifted
Box-Pierce (Ljung-Box) Q Statistic adalah sebagai berikut:
Tabel 4.7
Modifted Box-Pierce (Ljung-Box) ARIMA (0,1,17)
Sumber : Data diolah
Pada Tabel 4.7 menunjukan nilai statistik Ljung-Box sebesar 3.450 yang diartikan jika dibandingkan dengan nilai distribusi chi-square (X²) dengan df sebesar 1 pada α = 5 %, yaitu 3.84146 (lampiran 2). Dengan demikian, dapat disimpulkan nilai statistik Hitung Ljung-Box sebesar 3.450 < dari nilai distribusi chi-square tabel sebesar 3.84146, bahwa model ARIMA (0,1,17) dapat dispesifikasi dengan benar.
C.Model ARIMA (17,1,17)
Model ARIMA (17,1,17) yang telah dilakukan pengukuran Modifted
Box-Pierce (Ljung-Box) Q Statistic adalah sebagai berikut:
Tabel 4.8
Modifted Box-Pierce (Ljung-Box) ARIMA (17,1,17)
Pada Tabel 4.8 menunjukan nilai statistik Ljung-Box sebesar 0 yang diartikan jika dibandingkan dengan nilai distribusi chi-square (X²) dengan df sebesar 0 pada α = 5 %, yaitu 0. Dengan demikian, dapat disimpulkan bahwa model ARIMA (17,1,17) dapat dispesifikasi dengan benar karena nilainya sama dengan 0.
D.Expert Modeler ARIMA (0,1,17)
Expert Modeler ARIMA (0,1,17) yang telah dilakukan pengukuran Modifted
Box-Pierce (Ljung-Box) Q Statistic adalah sebagai berikut:
Tabel 4.9
Modifted Box-Pierce (Ljung-Box) EM ARIMA (0,1,17)
Sumber : Data diolah
Pada Tabel 4.9 menunjukan nilai statistik Ljung-Box sebesar 3.450 yang diartikan jika dibandingkan dengan nilai distribusi chi-square (X²) dengan df sebesar 1 pada α = 5 %, yaitu 3.84146 (lampiran 2). Dengan demikian, dapat disimpulkan nilai statistik Hitung Ljung-Box sebesar 3.450 < dari nilai distribusi chi-square tabel sebesar 3.84146, bahwa Expert Modeler ARIMA (0,1,17) dapat dispesifikasi dengan benar.
3. Mean Square Error (MSE)
Jika terdapat banyak spesifikasi model yang lolos dalam diagnostic
checking, maka yang dipilih adalah model yang memberikan MSE terkecil. MSE
yang lebih kecil menunjukkan bahwa model lebih cocok dengan data. Jika MSE diantara model-model itu tidak menunjjukkan perbedaan menonjol, semua model
terpilih dipertahankan dan seleksi didasarkan pada hasil ex post forecasts (Muyono, 2000:133).
Berdasarkan diagnostic checking sebelumnya menggunakan Modifted
Box-Pierce (Ljung-Box) Q Statistic model ARIMA yang tidak dapat dispesifikasi
dengan benar yaitu, model ARIMA (17,1,0). Dengan demikian, dapat disimpulkan model ARIMA yang dilakukan pengukuran MSE terkecil, yaitu model ARIMA (0,1,17), model ARIMA (17,1,17), dan Expert Modeler (0,1,7) sebagai berikut:
A.Model ARIMA (0,1,17)
Model ARIMA (0,1,17) yang telah dilakukan pengukuran MSE adalah sebagai berikut:
Tabel 4.10
Tabel Goodness of Fit dari model ARIMA (0,1,17)
Sumber : Data diolah
Berdasarkan tabel 4.10 didapatkan bahwa Nilai kesalahan RMSE = 49.566,
MAPE = 0.900 dan MAE = 34.069. Serta, nilai kecocokan model dengan data
adalah sebesar R2 = 0.910 artinya bahwa 91% model sudah sesuai dengan data yang sebenarnya.
B.Model ARIMA (17,1,17)
Model ARIMA (17,1,17) yang telah dilakukan pengukuran MSE adalah sebagai berikut:
Tabel 4.11
Tabel Goodness of Fit dari model ARIMA (17,1,17)
Sumber : Data diolah
Berdasarkan tabel 4.11 didapatkan bahwa Nilai kesalahan RMSE = 47.772,
MAPE = 0.837 dan MAE = 31.799. Serta, nilai kecocokan model dengan data
adalah sebesar R2 = 0.923 artinya bahwa 92.3% model sudah sesuai dengan data yang sebenarnya.
C.Expert Modeler ARIMA (0,1,17)
Model ARIMA (0,1,17) yang telah dilakukan pengukuran MSE adalah sebagai berikut:
Tabel 4.12
Tabel Goodness of Fit dari Expert Modeler ARIMA (0,1,17)
Berdasarkan tabel 4.12 didapatkan bahwa Nilai kesalahan RMSE = 46.924,
MAPE = 0.934 dan MAE = 35.316. Serta, nilai kecocokan model dengan data
adalah sebesar R2 = 0.87 artinya bahwa 92.3% model sudah sesuai dengan data yang sebenarnya.
IV.2.6 Peramalan
Peramalan atau prediksi dilakukan dengan menggunakan model yang terbaik dari hasil diagnostic checking. Berdasarkan hasil diagnostic checking dari pengukuran residual menunjukan semua model ARIMA telah dispesifikasi dengan benar karena residu dari semua model ARIMA bersifat random atau antar-error tidak berhubungan. Sedangkan, berdasarkan diagnostic checking menggunakan Modifted Box-Pierce (Ljung-Box) Q Statistic model ARIMA yang tidak dapat dispesifikasi dengan benar yaitu, model ARIMA (17,1,0). Serta menggunakan pengukuran MSE, diantara model-model ARIMA tidak menunjukkan perbedaan menonjol maka semua model terpilih dipertahankan dan diseleksi didasar hasil permalan.
Dengan demikian, dapat disimpulkan model yang terbaik ARIMA yang lolos diagnostic checking atau telah dispesifikasi dengan benar, yaitu model
ARIMA (0,1,17), model ARIMA (17,1,17), dan Expert Modeler (0,1,7). Jika
model terbaik telah ditetapkan, model tersebut dapat dilakukan peramalan atau prediksi IHSG pada harian mendatang. Model ARIMA dan Hasil prediksi IHSG pada harian mendatang yang telah dispesifikasi dengan benar adalah sebagai berikut:
A.Model ARIMA (0,1,17)
Berdasarkan pembentukan model prediksi ARIMA (0,1,17), didapatkan hasil prediksi IHSG mendatang dan grafik adalah sebagai berikut:
Hasil Prediksi:
Tabel 4.13
Hasil Prediksi IHSG Periode Mendatang ARIMA (0,1,17)
Sumber : Data diolah
Berdasarkan hasil analisa model ARIMA (0,1,17) maka didapatkan hasil prediksi IHSG periode harian mendatang selama 7 hari ke depan seperti pada tabel 4.13.
Gambar 4.11
Grafik Prediksi IHSG Periode Harian Mendatang ARIMA (0,1,17) Model Description
Model Type Model ID IHSG Model_1 ARIMA(0,1,17)
Sumber : Data diolah
Pada gambar 4.11 menunjukkan bahwa fit value dalam data penelitian hampir mendekati dengan data sebenarnya dan terlihat bahwa kurvanya hampir berimpit dengan kurva data sebenarnya. Serta, hasil perdiksi IHSG periode harian mendatang selama 7 hari ke depan menunjukkan tren yang berubah pada pada prediksi ke-249 sampai dengan prediksi ke-255.
B.Model ARIMA (17,1,17)
Berdasarkan pembentukan model prediksi ARIMA (17,1,17), didapatkan hasil prediksi IHSG mendatang dan grafik adalah sebagai berikut:
Model Description
Model Type Model ID IHSG Model_1 ARIMA(17,1,17) Hasil Prediksi:
Tabel 4.14
Hasil Prediksi IHSG Periode Harian Mendatang ARIMA (17,1,17)
Sumber : Data diolah
Berdasarkan hasil analisa model ARIMA (17,1,17) maka didapatkan hasil prediksi IHSG periode harian mendatang selama 7 hari ke depan seperti pada tabel 4.14.
Gambar 4.12
Grafik Prediksi IHSG Periode Harian Mendatang ARIMA (17,1,17)
Sumber : Data diolah
Pada gambar 4.12 menunjukkan bahwa fit value dalam data penelitian hampir mendekati dengan data sebenarnya dan terlihat bahwa kurvanya hampir berimpit dengan kurva data sebenarnya. Serta, hasil perdiksi IHSG periode harian mendatang selama 7 hari ke depan menunjukkan tren yang berubah pada pada prediksi ke-249 sampai dengan prediksi ke-255.
C.Expert Modeler
Dalam SPSS 20.0 terdapat satu pilihan dalam memodelkan data time series, yaitu menggunakan metode expert model. Pembentukan model prediksi ARIMA dilakukan secara automatically model akan dipilikan hasil prediksi IHSG mendatang dan grafik adalah sebagai berikut:
Model Description
Model Type Model ID IHSG Model_1 EM ARIMA(0,1,17) Hasil Prediksi:
Tabel 4.15
Hasil Prediksi IHSG Periode Mendatang Expert Modeler (0,1,17)
Sumber : Data diolah
Berdasarkan hasil analisa model ARIMA (17,1,17) maka didapatkan hasil prediksi IHSG periode harian mendatang selama 7 hari ke depan seperti pada tabel 4.15.
Gambar 4.13
Grafik Prediksi IHSG Periode Harian Mendatang Expert Modeler (0,1,17)
Sumber : Data diolah
Pada Gambar 4.13 menunjukkan bahwa fit value dalam data penelitian hampir mendekati dengan data sebenarnya dan terlihat bahwa kurvanya hampir berimpit dengan kurva data sebenarnya. Serta, hasil perdiksi IHSG periode harian mendatang selama 7 hari ke depan menunjukkan tren yang menaik pada pada prediksi ke-249 sampai dengan prediksi ke-255.
IV.2.7 Pengukuran Kesalahan Peramalan
Dalam suatu peramalan harus dilakukan pengukuran kesalahan yang disebabkan oleh suatu teknik peramalan tertentu. Semua model prediksi memiliki perbedaan nilai sebenarnya (actual) dengan nilai peramalan yang biasa disebut sebagai residual.
Menurut Arsyad (2001:58) terdapat beberapa teknik untuk menghitung kesalahan atau residual dari setiap tahap peramalan:
1. Mean Absolute Deviation (MAD) atau simpangan absolut rata-rata
2. Mean Squared Error (MSE) atau kesalahan rata-rata kuadrat
3. Mean Absolute Percentage Error (MAPE) atau persentase kesalahan absolute
rata-rata
4. Mean Percentage Error (MPE) atau persentase kesalahan rata-rata
Ada empat cara untuk mengukur akurasi dari hasil peramalan. Dalam mengukur akurasi hasil peramalan dilakukan dengan cara membandingkan hasil prediksi dengan data yang sebenarnya. Berikut ini hasil perhitungan pengukuran kesalahan Peramalan model ARIMA, adalah sebgai berikut:
A. Model ARIMA (0,1,17)
Tabel 4.16
Perhitungan Evaluasi Hasil Prediksi ARIMA (0,1,17)
t IHSG (Yt) Ramalan (Y) Error (Et) I Et I Et² I Et I / Yt % Et/Yt % 02/04/2012 4166,07 4115,96 50,11 50,11 2511,41 1,20 1,20 03/04/2012 4251,44 4108,07 143,38 143,38 20557,25 3,37 3,37 04/04/2012 4134,04 4095,02 39,01 39,01 1521,94 0,94 0,94 05/04/2012 4166,37 4095,91 70,47 70,47 4965,46 1,69 1,69 06/04/2012 4154,07 4098,27 55,80 55,80 3113,53 1,34 1,34 09/04/2012 4149,80 4092,55 57,25 57,25 3277,10 1,38 1,38 10/04/2012 4130,01 4103,41 26,60 26,60 707,72 0,64 0,64 Jumlah 29151,81 442,62 442,62 36654,41 10,58 10,58 n 7 7 7 7 7 7 Mean 4164,54 63,23 63,23 5236,34 1,51 1,51
MAD MAE MSE MAPE MPE
Sumber: Data diolah
Berdasarkan tabel 4.16 terlihat bahwa MAD menunjukkan bahwa setiap prediksi terdeviasi secara rata-rata sebesar 63.23, MSE sebesar 5236.34, dan MAPE sebesar 1,51 %. Nilai MPE sebesar 1.511 % menunjukkan bahwa model tersebut tidak bias karena nilainya mendekati nol, maka perhitungan dari teknik tidak terlalu tinggi atau terlalu rendah dalam meramalkan IHSG yang mendatang.
B.Model ARIMA (17,1,17)
Tabel 4.17
Perhitungan Evaluasi Hasil Prediksi ARIMA (17,1,17)
t IHSG (Yt) Ramala n (Y) Error (Et) I Et I Et² I Et I / Yt % Et/Yt % 02/04/2012 4166,07 4098,86 67,21 67,21 4517,45 1,61 1,61 03/04/2012 4251,44 4091,59 159,85 159,85 25553,30 3,76 3,76 04/04/2012 4134,04 4084,64 49,40 49,40 2440,46 1,19 1,19 05/04/2012 4166,37 4076,98 89,39 89,39 7990,93 2,15 2,15 06/04/2012 4154,07 4076,57 77,49 77,49 6005,32 1,87 1,87 09/04/2012 4149,80 4089,08 60,72 60,72 3687,16 1,46 1,46 10/04/2012 4130,01 4123,13 6,879 6,88 47,32 0,17 0,17 jumlah 29151,81 510,95 510,95 50241,94 12,21 12,21 n 7 7 7 7 7 7 Mean 4164,54 72,99 72,99 7177,42 1,74 1,74
MAD MAE MSE MAPE MPE
Sumber: Data diolah
Berdasarkan tabel 4.17 terlihat bahwa MAD menunjukkan bahwa setiap prediksi terdeviasi secara rata-rata sebesar 72.99, MSE sebesar 7177.42, dan MAPE sebesar 1.74 %. Nilai MPE sebesar 1.74 % menunjukkan bahwa model tersebut tidak bias karena nilainya mendekati nol, maka perhitungan dari teknik tidak terlalu tinggi atau terlalu rendah dalam meramalkan IHSG yang mendatang.
C. Expert Modeler
Tabel 4.18
Perhitungan Evaluasi Hasil Prediksi Expert Modeler (0,1,17)
t IHSG (Yt) Ramalan (Y) Error (Et) I Et I Et² I Et I / Yt % Et/Yt % 02/04/2012 4166,072 4126,21 39,86 39,86 1588,66 0,96 0,96 03/04/2012 4251,444 4125,72 125,72 125,72 15806,02 2,96 2,96 04/04/2012 4134,036 4121,83 12,21 12,21 148,99 0,30 0,30 05/04/2012 4166,374 4131,55 34,82 34,82 1212,78 0,84 0,84 06/04/2012 4154,067 4135,36 18,71 18,71 350,03 0,45 0,45 09/04/2012 4149,80 4128,24 21,56 21,56 465,01 0,52 0,52 10/04/2012 4130,013 4133,23 -3,21 3,21 10,33 0,08 -0,08 jumlah 29151,81 249,67 256,10 19581,81 6,09 5,94 n 7 7 7 7 7 7 Mean 4164,54 35,67 36,59 2797,40 0,87 0,85
MAD MAE MSE MAPE MPE
Sumber: Data diolah
Berdasarkan tabel 4.18 terlihat bahwa MAD menunjukkan bahwa setiap prediksi terdeviasi secara rata-rata sebesar 35.67, MSE sebesar 2797.40, dan MAPE sebesar 0.87 %. Nilai MPE sebesar 0.85 % menunjukkan bahwa model tersebut tidak bias karena nilainya mendekati nol, maka perhitungan dari teknik tidak terlalu tinggi atau terlalu rendah dalam meramalkan IHSG yang mendatang. IV.2.8 Pemilihan Model Terbaik
Model prediksi ARIMA (p,d,q) akan memberikan hasil peramalan yang berbeda-beda maka harus dipilih salah satu model yang terbaik, yaitu model yang menunjukkan tingkat akurasi yang baik. Ada beberapa kriteria untuk pemilihan model terbaik, yaitu dengan menggunakan data sebenarnya dengan nilai peramalannya (forecasting-nya) di mana perbedaan ini disebut dengan residual (Hadi, 2012:92).
Dalam penelitian ini telah dilakukan beberapa model prediksi ARIMA. Hasil model prediksi didapatkan nilai penyimpangan hasil prediksi dengan nilai data sesungguhnya. Berikut ini kriteria penyimpangan antara prediksi dan data asli adalah sebagai berikut:
Tabel 4.19
Ukuran Kebaikan Model ARIMA
Model MAD MAE MSE MAPE MPE
ARIMA (0.1,17) 63.231 63.231 5236.344 1.511 1.511 ARIMA (17,1,17) 72.993 72.993 7177.421 1.744 1.744
EM ARIMA (0,1,17) 35.667 36.585 2797.402 0.870 0.848
Sumber: Data diolah
Berdasarkan tabel 4.19 Dapat dilihat bahwa dari ketiga model ARIMA, ada satu nilai model ARIMA yang memberikan nilai penyimpangan terkecil yaitu model Expert Modeler ARIMA (0,1,17) sebesar MAD 35.667, MAE 36.585, MSE 2797.402, MAPE 0.870, dan MPE 0.848. maka model Expert Modeler
ARIMA (0,1,17) merupakan model yang terbaik untuk melakukan prediksi IHSG
pada harian yang mendatang. IV.3 Pengujian Hipotesis
Pendekatan Autokorelasi Dasar pengambilan keputusan:
Ho : rk = 0, ada lag (nilai IHSG terdahulu) tertentu, yaitu Yt-1, Yt-2, …, Yt-n berpengaruh tidak signifikan positif dalam meramal Yt (nilai IHSG periode harian pada waktu t)
H1 : rk = 0, ada lag (nilai IHSG terdahulu) tertentu, yaitu Yt-1, Yt-2, …, Yt-n berpengaruh signifikan positif dalam meramal Yt (nilai IHSG periode harian pada waktu t)
Hasil keputusan:
Berdasarkan pengujian correlogram ada tiga koefisien otokorelasi dan otokorelasi parsial yang signifikan dalam pembentukan model ARIMA yaitu pada lag 4 (nilai 4 hari sebelumnya), lag 7 (nilai 7 hari sebelumnya) lag 17 (nilai 17 hari sebelumnya). Dengan menggunakan α = 5 % maka batas intervalnya adalah 0 ± 0,124. Dari tabel 4.4 terlihat koefisien otokorelasi pada lag 4, lag 7, dan lag 17 secara statistik berbeda dari nol atau melebihi confidence limit, yaitu rk lag 4 = -0.155, rk lag 7 = 0.198 dan rk lag 17 = -0.212 dan dari tabel 4.5 terlihat koefisien otokorelasi parsial pada lag 4, lag 7, dan lag 17 secara statitik berbeda dari nol atau melebihi confidence limit, yaitu rk lag 4 = -0.175, rk lag 7 = 0.149 dan rk lag 17 = -0.234.
Berdasarkan koefisien otokorelasi parsial pada lag 4, lag 7, dan lag 17 secara statistik berbeda dari nol atau melebihi confidence limit dapat digunakan untuk menjawab hipotesis yang diajukan karena nilai IHSG terdahulu yaitu pada pada lag 4, lag 7, dan lag 17 berpengaruh signifikan dalam peramalan model
ARIMA. Sedangkan nilai terdahulu selain pada lag 4, lag 7, dan lag 17 tidak
mempunyai pengaruh yang signifikan terhadap prediksi IHSG yang mendatang dengan model ARIMA. Berikut ini merupakan lebih jelas pengujian hipotesisnya adalah sebagai berikut:
IHSG pada waktu 4 hari sebelum t (Yt-4) mempunyai nilai koefisien otokorelasi parsial melebihi confidence limit (rk = -0,175 < -0,125), berarti IHSG Yt-17 mempunyai pengaruh yang signifikan dalam prediksi Yt.
IHSG pada waktu 7 hari sebelum t (Yt-7) mempunyai nilai koefisien otokorelasi parsial melebihi confidence limit (rk = 0.149 > 0,125), berarti IHSG Yt-17 mempunyai pengaruh yang signifikan dalam prediksi Yt
IHSG pada waktu 17 hari sebelum t (Yt-17) mempunyai nilai koefisien otokorelasi parsial melebihi confidence limit (rk = -0,234 < -0,125), berarti IHSG Yt-17 mempunyai pengaruh yang signifikan dalam prediksi Yt
IHSG pada waktu selain Yt-4, Yt-7, dan Yt-17 mempunyai nilai koefisien otokorelasi parsial didalam interval confidence limit (0 ± 0,125) berarti IHSG Y t-17 mempunyai pengaruh yang tidak signifikan dalam prediksi Yt
Jadi dapat disimpulkan bahwa ada nilai IHSG yang terdahulu yang berpengaruh signifikan terhadap prediksi menggunakan metode ARIMA yaitu pada saat Yt-4, Yt-7, dan Yt-17 sedangkan nilai IHSG terdahulu lainnya tidak berpengaruh secara signifikan dalam prediksi nilai Yt (IHSG periode harian pada waktu t)
Pendekatan Regresi Linier Sederhana Korelasi
Hasil penelitian mengunakan hasil SPSS 20.0 dapat ditunjukan pada tabel 4.20 adalah sebagai berikut:
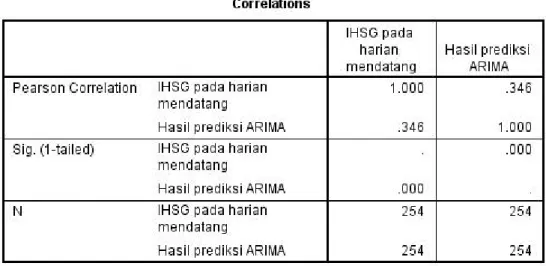
Tabel 4.20
Correlations
Sumber : Data diolah
Hasil tabel 4.20 menunjukkan hubungan hasil prediksi menggunakan metode
ARIMA terhadap IHSG pada harian mendatang sebesar 0.346. Angka ini
menunjukkan hubungan korelasi yang rendah antara hasil prediksi menggunakan metode ARIMA dengan hasil IHSG pada harian Mendatang. Sig (1-tailed) = 0,000 menunjukkan hubungan yang signifikan karena 0,000, dimana 0,05 merupakan taraf signifikannya.
Koefisien Determinasi (R2 )
Hasil penelitian mengunakan hasil SPSS 20.0 dapat ditunjukan pada tabel 4.21 adalah sebagai berikut:
Tabel 4.21 Koefisien Determinasi
Sumber : Data diolah
Berdasarkan tabel 4.21 model summary menunjukkan bahwa R Square sebesar 0.120 berarti pengaruh hasil prediksi dengan menggunakan ARIMA hanya 12% ( 0.120 x 100%) sedangkan 88 % (100%-12%) oleh Faktor lainnya. Standar Error
of Estimate (SEE) yang ditunjukan pada tabel diatas sebsar 156.254545 dalam
arti semakin kecil nilai SEE makan model regresi semakin tepat dalam memprediksi nilai IHSG pada harian Mendatang
Uji Signifikansi Simultan (Uji Statistik F)
Hasil penelitian mengunakan hasil SPSS 20.0 dapat ditunjukan pada tabel 4.22 adalah sebagai berikut:
Tabel 4.22 Uji Statistik F
Hipotesis
Ho : b1 = 0, Analisis prediksi IHSG dengan menggunakan metode ARIMA tidak berpengaruh signifikan terhadap IHSG pada harian mendatang di BEI
Ha : b1 ≠ 0, Analisis prediksi IHSG dengan menggunakan metode ARIMA berpengaruh signifikan terhadap IHSG periode harian mendatang di BEI
Dasar pengambilan keputusan:
Bila F hitung > F tabel, maka Ho dinyatakan ditolak
Kriteria untuk mengetahui signifikansi atau tidaknya pengeruh tersebut yaitu:
p > 0,05 dinyatakan tidak signifikan
Berdasarkan tabel 4.22 dari Uji ANOVA atau F test menunjukkan hasil uji signifikan ANOVA menunjukkan bahwa F hitung (34.304) > F Tabel (3,84) maka Ho ditolak (ha diterima) serta dengan nilai Sig. sebesar 0.000. Jika dibandingkan dengan α = 0.05, nilai sig (0.000 < 0.05). Artinya Ho ditolak (Ha diterima). Dengan demikian, hal ini menunjukkan Analisis prediksi IHSG dengan menggunakan metode ARIMA berpengaruh signifikan terhadap IHSG periode harian mendatang di BEI.
Uji Signifikansi Parameter Individual (Uji Statistik t)
Hasil penelitian mengunakan hasil SPSS 20.0 dapat ditunjukan pada tabel 4.23 adalah sebagai berikut:
Tabel 4.23 Uji Statistik t
Sumber : Data diolah Hipotesis
Ho : b1 = 0, Analisis prediksi IHSG dengan menggunakan metode ARIMA tidak berpengaruh signifikan terhadap IHSG pada harian mendatang di BEI
Ha : b1 ≠ 0, Analisis prediksi IHSG dengan menggunakan metode ARIMA berpengaruh signifikan terhadap IHSG periode harian mendatang di BEI
Dasar pengambilan keputusan:
• Jika t0 > tα atau t0 < -tα, maka H0 ditolak (Ha diterima), artinya Analisis prediksi IHSG dengan menggunakan metode ARIMA berpengaruh signifikan terhadap IHSG periode harian mendatang di BEI.
• Jika -tα ≤ t0 ≤ tα, maka H0 diterima (Ha ditolak), artinya Analisis prediksi IHSG dengan menggunakan metode ARIMA tidak berpengaruh signifikan terhadap IHSG pada harian mendatang di BEI.
Berdasarkan tabel 4.22 Hasil uji t menunjukkan hasil uji signifikan menunjukkan bahwa t hitung (5.857) > t tabel (1.65) maka Ho ditolak (ha diterima) serta dengan nilai Sig. sebesar 0.000. Jika dibandingkan dengan α = 0.05, nilai sig (0.000 < 0.05). Artinya Ho ditolak (Ha diterima). Dengan demikian, hal ini menunjukkan
Analisis prediksi IHSG dengan menggunakan metode ARIMA berpengaruh signifikan terhadap IHSG periode harian mendatang di BEI.
Persamaan Regresi Sederhana Y = a + bx
Y = 3644.716 + 0.057 x
• a = konstanta dari koefisien sebesar 3644.716, menyatakan bahwa jika prediksi IHSG tidak menggunakan metode ARIMA maka transaksi di BEI tetap berjalan sebesar 3644.716.
• b = angka koefisien regresi hasil prediksi menggunakan metode ARIMA sebesar 0.057, yang mempunyai arti setiap satu nilai prediksi yang dihasilkan ARIMA maka transaksi IHSG pada harian mendatang akan naik sebesar 0.057.
IV.4 Hasil Penelitian
Setelah dilakukan pengujian hipotesis dengan SPSS 20.0 hasil analisis dapat disimpulkan sebagai berikut :
1. Hasil analisis teknikal prediksi IHSG dengan menggunakan ARIMA berdasarkan tabel 4.18 dihasilkan model prediksi yang terbaik adalah
Expert Modeler ARIMA (0,1,17) dengan MAD 35.67, MAE 36.59, MSE
2797.40, MAPE 0.87, dan MPE 0.85 atau dapat dikatakan model Expert
Modeler ARIMA (0,1,17) model terbaik digunakan untuk memprediksi
IHSG 7 harian mendatang.
2. Berdasarkan pengujian autokorelasi, dapat dilihat ada nilai IHSG terdahulu berpengaruh terhadap peramalan nilai IHSG menggunakan
metode ARIMA yaitu pada saat Yt-4, Yt-7, danYt-17 sedangkan nilai IHSG terdahulu lainnya tidak berpengaruh secara signifikan dalam peramalan nilai Yt (IHSG periode harian pada waktu t).
3. Hasil model Expert Modeler ARIMA (0,1,17) dalam memprediksi nilai IHSG selama 7 harian mendatang terbukti akurat dengan tingkat kesalahan peramalan rata-rata dengan sebesar 0.87% dari MAPE yang dapat dilihat pada tabel 4.18.
4. Berdasarkan pengujian regresi sederhana, pengaruh hasil prediksi harga saham dengan metode ARIMA berpengaruh signifikan terhadap IHSG periode harian mendatang di BEI dengan nilai konstanta dari koefisien sebesar 3644.716, yang mempunyai arti jika prediksi IHSG tidak menggunakan metode ARIMA maka transaksi di BEI tetap berjalan sebesar 3644.716. dan angka koefisien regresi sebesar 0.057, yang mempunyai arti setiap satu nilai prediksi yang dihasilkan ARIMA maka transaksi IHSG pada harian mendatang akan naik sebesar 0.057.
IV.5 Implikasi
Menurut pada penelitian Sadeq (2008) yang melakukan peramalan IHSG dengan metode ARIMA untuk periode 2 Januari 2006 sampai dengan 28 Desember 2006. Hasil penelitian menunjukkan bahwa metode ARIMA terbukti akurat dengan tingkat persentase kesalahan absolute rata-rata peramalan sebesar 4.13%. Dan dibandingkan dengan hasil penelitian ini pada periode 1 April 2011 sampai dengan 30 Maret 2011 tingkat persentase kesalahan absolute rata-rata peramalan sebesar 0.87 % . Dengan demikian hasil penelitian ini lebih akurat dibandingkan dengan penelitian Sadeq (2008) dan penelitian ini mendukung dari
hasil Sadeq (2008) dan Yani (2004) yang menyebutkan bahwa metode ARIMA dapat digunakan untuk meramal IHSG jangka pendek. Perbedaan nilai tingkat persentase kesalahan absolute rata-rata disebabkan perbedaan antara tingkat fluktuasi nilai IHSG antara periode penelitian. Pada periode peneltiaian yang dilakukan Sadeq terjadi fluktuasi yang berubah-ubah sedangkan fluktuasi nilai IHSG yang diteliti penelitian terjadi fluktuasi nilai IHSG yang tajam pada bulan oktober 2011.