IV-1
Bab IV
Eksperimen
4.1
Dataset
Eksperimen dilakukan dengan menggunakan 28 buah dataset yang diambil dari UCI
dataset repository. LAMPIRAN B berisi mengenai properti dari 28 buah dataset yang
digunakan dalam eksperimen. Properti-properti tersebut adalah jumlah instance, jumlah kelas, jumlah atribut nominal, jumlah atribut numerik, serta jumlah missing
values.
4.2
Kakas
Kakas yang digunakan untuk melakukan eksperimen adalah aplikasi yang dibangun dengan menggunakan NetBeans 5.0, JDK 1.5.0, dan WEKA 3.5.3. Aplikasi ini dibangun dengan menggunakan library dari WEKA ditambah dengan implementasi
delegating classifiers. Library yang berasal dari WEKA adalah sebagai berikut:
1. weka.classifiers.trees.J48 2. weka.classifiers.meta.AdaBoostM1 3. weka.classifieris.meta.Bagging 4. weka.classifiers.evaluation 5. weka.attributeSelection 6. weka.core 7. weka.estimators 8. weka.filters
Aplikasi menerima masukan berupa arsip data latih, jenis classifier yang ingin dibentuk beserta parameter-parameter sesuai dengan jenis classifier-nya, dan nilai
k-fold cross validation. Aplikasi akan memberikan keluaran berupa model dari classifier yang terbentuk dan hasil dari k-fold cross validation.
4.3
Skenario Eksperimen
Masing-masing dari 28 buah dataset digunakan untuk membangun single classifier,
multi-classifiers dengan menggunakan bagging dengan jumlah base classifier 10 dan
20 buah, multi-classifiers dengan menggunakan boosting dengan jumlah base
classifier 10 dan 20 buah, serta delegating classifiers 1% dengan jumlah base classifier 20 buah dan delegating classifiers 2% dengan jumlah base classifier 10
buah. Dengan demikian, dari 28 buah dataset tersebut akan dihasilkan 196 buah
classifier.
Masing-masing dari 196 buah classifier yang dihasilkan akan diukur performansinya dengan cara menghitung rata-rata nilai AUC (Area Under ROC Curve) dari 20x5-
folds cross validation yang dilakukan. ROC (Receiver Operating Curve) merupakan
sebuah teknik yang digunakan untuk memvisualisasikan performansi dan memilih
classifier berdasarkan performansinya. ROC merupakan sebuah grafik dua dimensi
dimana nilai true positive menjadi sumbu Y dan nilai false positive menjadi sumbu X. ROC menggambarkan trade-off relatif antara true positive dan false positive. AUC merupakan daerah di bawah kurva ROC. Nilai AUC ekuivalen dengan probabilitas sebuah classifer akan memilih instance positif secara acak lebih tinggi daripada memilih instance negatif secara acak. Semakin besar area di bawah kurva ROC yang dimiliki oleh suatu classifier maka nilai AUC yang dimilikinya pun semakin besar dan performansinya pun semakin baik. [FAW04]
Setiap 5- folds Cross Validation yang dilakukan akan menghasilkan nilai AUC untuk setiap kelas yang ada pada dataset. Rata-rata dari nilai AUC untuk setiap kelas akan menjadi nilai AUC sebuah 5- folds cross validation. Karena 5- folds cross validation dilakukan sebanyak 20 kali maka rata-rata nilai AUC dari 20 kali 5- folds cross
validation inilah yang digunakan sebagai nilai akurasi dari sebuah classifier.
Pengukuran nilai efisiensi didapat dari waktu yang dibutuhkan untuk melakukan pembelajaran dan 20x5-folds cross validation dari setiap classifier.
4.4 Hasil Eksperimen
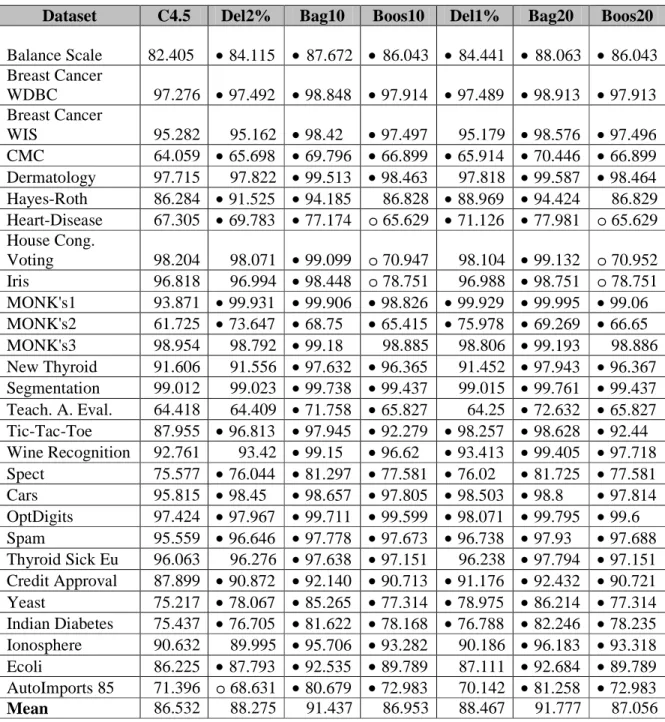
Tabel IV-1 Nilai rata-rata AUC untuk setiap classifier yang dihasilkan
Dataset C4.5 Del2% Bag10 Boos10 Del1% Bag20 Boos20
Balance Scale 82.405 • 84.115 • 87.672 • 86.043 • 84.441 • 88.063 • 86.043 Breast Cancer WDBC 97.276 • 97.492 •98.848 •97.914 • 97.489 •98.913 •97.913 Breast Cancer WIS 95.282 95.162 •98.42 •97.497 95.179 •98.576 •97.496 CMC 64.059 • 65.698 •69.796 •66.899 • 65.914 •70.446 •66.899 Dermatology 97.715 97.822 •99.513 •98.463 97.818 •99.587 •98.464 Hayes-Roth 86.284 • 91.525 •94.185 86.828 • 88.969 •94.424 86.829 Heart-Disease 67.305 • 69.783 •77.174 o65.629 • 71.126 •77.981 o65.629 House Cong. Voting 98.204 98.071 •99.099 o70.947 98.104 •99.132 o70.952 Iris 96.818 96.994 •98.448 o78.751 96.988 •98.751 o78.751 MONK's1 93.871 • 99.931 •99.906 •98.826 • 99.929 •99.995 •99.06 MONK's2 61.725 • 73.647 •68.75 •65.415 • 75.978 •69.269 •66.65 MONK's3 98.954 98.792 •99.18 98.885 98.806 •99.193 98.886 New Thyroid 91.606 91.556 •97.632 •96.365 91.452 •97.943 •96.367 Segmentation 99.012 99.023 •99.738 •99.437 99.015 •99.761 •99.437 Teach. A. Eval. 64.418 64.409 •71.758 •65.827 64.25 •72.632 •65.827 Tic-Tac-Toe 87.955 • 96.813 •97.945 •92.279 • 98.257 •98.628 •92.44 Wine Recognition 92.761 93.42 •99.15 •96.62 • 93.413 •99.405 •97.718 Spect 75.577 • 76.044 •81.297 •77.581 • 76.02 •81.725 •77.581 Cars 95.815 • 98.45 •98.657 •97.805 • 98.503 •98.8 •97.814 OptDigits 97.424 • 97.967 •99.711 •99.599 • 98.071 •99.795 •99.6 Spam 95.559 • 96.646 •97.778 •97.673 • 96.738 •97.93 •97.688 Thyroid Sick Eu 96.063 96.276 •97.638 •97.151 96.238 •97.794 •97.151 Credit Approval 87.899 • 90.872 •92.140 •90.713 • 91.176 •92.432 •90.721 Yeast 75.217 • 78.067 •85.265 •77.314 • 78.975 •86.214 •77.314 Indian Diabetes 75.437 • 76.705 •81.622 •78.168 • 76.788 •82.246 •78.235 Ionosphere 90.632 89.995 •95.706 •93.282 90.186 •96.183 •93.318 Ecoli 86.225 • 87.793 •92.535 •89.789 87.111 •92.684 •89.789 AutoImports 85 71.396 o68.631 •80.679 •72.983 70.142 •81.258 •72.983 Mean 86.532 88.275 91.437 86.953 88.467 91.777 87.056
Tabel IV-1 berisi nilai akurasi yang merupakan nilai AUC dari setiap classifier yang dihasilkan untuk masing-masing dataset. Kolom pertama berisi nama-nama dari
dataset yang digunakan. Kolom kedua berisi nilai AUC untuk single classifier, kolom
ketiga berisi nilai AUC untuk delegating classifiers 2% dengan 10 buah base
classifier, kolom kelima berisi nilai AUC untuk boosting dengan 10 base classifier,
kolom keenam berisi nilai AUC untuk delegating classifiers 1% dengan 10 buah base
classifier, kolom ketujuh berisi nilai AUC untuk bagging dengan 20 base classifier,
kolom kedelapan berisi nilai AUC untuk boosting dengan 20 base classifier.
Nilai akurasi yang ditandai dengan (●) menunjukkan bahwa akurasi classifier tersebut terjadi peningkatan yang signifikan secara statistik, sedangkan nilai akurasi yang ditandai dengan (○) menunjukkan bahwa akurasi classifier tersebut terjadi penurunan yang signifikan secara statistik. Perbandingan nilai akurasi ini dilakukan terhadap akurasi C4.5 (single classifier) dengan menggunakan t-test 99% significance. Masing-masing nilai AUC yang dihasilkan pada setiap iterasi 5-folds cross validation dapat dilihat pada LAMPIRAN C.
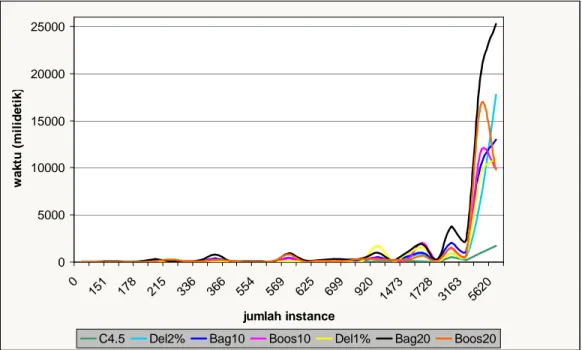
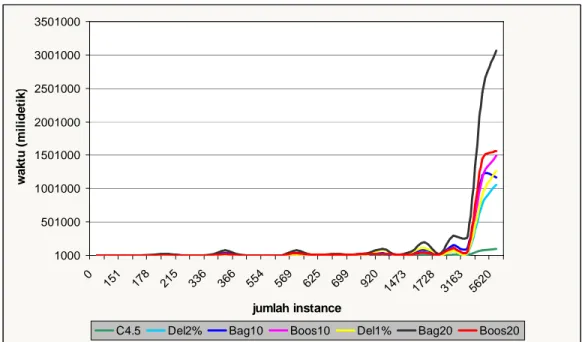
Gambar IV-1 merupakan grafik yang menunjukkan waktu untuk melakukan pembelajaran guna membentuk classifier. Sedangkan Gambar IV-2 merupakan grafik yang menunjukkan waktu yang dibutuhkan bagi masing-masing classifier untuk melakukan pengetesan yaitu melakukan 20x5-folds cross validation.
0 5000 10000 15000 20000 25000 0 151 178 215 336 366 554 569 625 699 920 1473 1728 3163 5620 jumlah instance w a k tu ( m il id e ti k )
C4.5 Del2% Bag10 Boos10 Del1% Bag20 Boos20
1000 501000 1001000 1501000 2001000 2501000 3001000 3501000 0 151 178 215 336 366 554 569 625 699 920 1473 1728 3163 5620 jumlah instance w a k tu ( m il id e ti k )
C4.5 Del2% Bag10 Boos10 Del1% Bag20 Boos20
Gambar IV-2 Grafik waktu 20x5-folds cross validation
Waktu untuk melakukan pembelajaran dan 20x5-folds cross validation yang dibutuhkan oleh masing-masing dataset untuk setiap classifier dapat dilihat pada LAMPIRAN D.
4.5 Analisa Hasil Eksperimen
Tabel IV-2 Jumlah classifier yang terjadi peningkatan akurasi yang signifikan berdasarkan t-test 99% significance
C4.5 Del2% Bag10 Boos10 Del1% Bag20 Boos20
C4.5 - 16 28 23 16 28 23 Del2% 1 - 26 13 9 27 15 Bag10 0 1 - 0 2 27 0 Boos10 3 9 28 - 9 28 5 Del1% 0 5 24 16 - 27 16 Bag20 0 1 1 0 1 - 0 Boos20 3 9 27 0 10 28 -
Tabel IV-2 berisi jumlah classifier yang terdapat pada baris terjadi peningkatan akurasi yang signifikan berdasarkan t-test 99% significance dari classifier yang terdapat pada kolom. Dari tabel Tabel IV-2 dapat dilihat bahwa :
1. 16 dari 28 delegating classifiers terjadi peningkatan akurasi yang signifikan berdasarkan t-test 99% significance dari nilai akurasi single classifier.
2. Seluruh 28 multi-classifiers yang menggunakan bagging terjadi peningkatan akurasi yang signifikan berdasarkan t-test 99% significance dari nilai akurasi
single classifier.
3. 23 dari 28 multi-classifiers yang menggunakan boosting dengan 10 dan 20 base
classifier terjadi peningkatan akurasi yang signifikan berdasarkan t-test 99% significance dari nilai akurasi single classifier.
4. Hanya 9 dari 28 delegating classifiers 2% terjadi peningkatan akurasi yang signifikan berdasarkan t-test 99% significance dari nilai akurasi multi-classifiers yang menggunakan boosting.
5. Seluruh 28 multi-classifiers yang menggunakan bagging dengan 20 buah base
classifier terjadi peningkatan akurasi yang signifikan berdasarkan t-test 99% significance dari nilai akurasi multi-classifiers yang menggunakan boosting.
6. Hanya 3 dari 28 buah single classifier terjadi peningkatan akurasi yang signifikan berdasarkan t-test 99% significance dari nilai akurasi multi-classifiers yang menggunakan boosting.
7. Hanya 1 dari 28 buah single classifier terjadi peningkatan akurasi yang signifikan berdasarkan t-test 99% significance dari nilai akurasi dari delegating classifiers 2%.
8. 26 dari 28 buah multi-classifiers yang menggunakan bagging dengan 10 buah
base classifier terjadi peningkatan akurasi yang signifikan berdasarkan t-test 99% significance dari nilai akurasi delegating classifiers 2%.
9. 24 dari 28 buah multi-classifiers yang menggunakan bagging dengan 10 buah
base classifier terjadi peningkatan akurasi yang signifikan berdasarkan t-test 99% significance dari nilai akurasi delegating classifiers 1%.
10.27 dari 28 buah multi-classifiers yang menggunakan bagging dengan 20 buah
base classifier terjadi peningkatan akurasi yang signifikan berdasarkan t-test 99% significance dari nilai akurasi delegating classifiers.
11.16 dari 28 buah multi-classifiers yang menggunakan boosting terjadi peningkatan akurasi yang signifikan berdasarkan t-test 99% significance dari nilai akurasi
delegating classifiers 1%.
12.13 dari 28 buah multi-classifiers yang menggunakan boosting dengan 10 buah
base classifier terjadi peningkatan akurasi yang signifikan berdasarkan t-test 99% significance dari nilai akurasi delegating classifiers 2%.
13.15 dari 28 buah multi-classifiers yang menggunakan boosting dengan 20 buah
base classifier terjadi peningkatan akurasi yang signifikan berdasarkan t-test 99% significance dari nilai akurasi delegating classifiers 2%.
14.Seluruh 28 multi-classifiers yang menggunakan bagging dengan 10 buah base
classifier terjadi peningkatan akurasi yang signifikan berdasarkan t-test 99% significance dari nilai akurasi multi-classifier yang menggunakan boosting dengan
10 buah base classifier.
15.Seluruh 27 multi-classifiers yang menggunakan bagging dengan 20 buah base
classifier terjadi peningkatan akurasi yang signifikan berdasarkan t-test 99% significance dari nilai akurasi multi-classifier yang menggunakan boosting dengan