CHAPTER 20
Relative File Proce ssing
OBJECTIVES
To familiarize you with
1.
How relative files are created, updated, and used for reporting.
2.
Methods used for organizing relative files.
CONTENTS
PROCESSINGRELATIVEDISKFILES
What Is a Relative File? Creating Relative Files
Sequential Reading of Relative Files Random Reading of Relative Files Random Updating of Relative Files Self-Test
CONVERTING AKEYFIELD TO ARELATIVE KEY
END-OF-CHAPTERAIDS
Chapter Summary Key Terms
P
ROCESSINGR
ELATIVED
ISKF
ILESWhat Is a Re lative File ?
We have seen in Chapter 16 how disk files that are organized asI NDEXEDcan be accessed
and updated randomly. The relative method of file organization is another technique used when files are to be accessed randomly.
With indexed files, the key fields of records to be accessed are looked up in an index to find the disk address. With relative files, the key field is converted to an actual disk address so that there is no need for an index or for a search to find the location of a record. We begin with the simplest type of relative file where there is a direct one-to-one correlation between the value of the key and its disk location. That is, the key also serves as a relative record number.
Suppose, for example, an Accounts Receivable file is created with records entered in
sequence by ACCT- NO. If the ACCT- NOs vary from0001 to 9999, then the record with
ACCT- NO 0001can be placed in the first disk location, the record withACCT- NO 0002
can be placed in the next, and so on. Accessing records randomly from such a relative
file is an easy task. To find a record withACCT- NO 9785, the computer goes directly to
the9785th record location on the disk.
When a key field does not have consecutive values, as is the case with many
ACCT-NOs, we can still use the relative method of file organization but we need to convert the
key to a disk address using some type of algorithm or mathematical formula.
Relative file organization is best used where each record contains a kind of built-in relative record number. Files with records that have key fields with fairly consecutive
values are ideal for using relative organization. CUST- NO, PART- NO, and EMP- NOkey
fields are often consecutive or nearly consecutive. Since not all files have records with such key fields, however, relative files are not used as often as indexed files.
One advantage of relative files is that the random access of records is very efficient because there is no need to look up the address of a record in an index; we simply convert the key to a disk address and access the record directly.
The field that supplies the key information, such asACCT- NOabove, can also serve
as a relative record number or RELATIVE KEY. The inputyoutput instructions in the
PROCEDURE DI VI SI ONfor random or sequential processing of relative files are very
similar to those of indexed files. The following is theSELECTstatement used to create
or access a relative file:
WhenACCESSisSEQUENTI AL, as in the sequential reading of the file, theRELATI VE
KEYclause is optional. WhenACCESSisRANDOMorDYNAMI C, the RELATI VE KEYclause
is required. ARELATI VE KEYmust be unique.
If ACCESS I S DYNAMI Cis specified, you can access the file both sequentially and
randomly in the same program, using appropriate inputyoutput statements. Suppose
you wish to update a relative file randomly and, when the update procedure is
com-pleted, you wish to print the file in sequence. UseACCESS I S DYNAMI Cfor this procedure,
because it permits both sequential and random access. Here again, this is very similar to the processing of indexed files.
SELECTfile-name-1ASSI GN TOimplementor-name-1 [ORGANI ZATI ON I S]RELATI VE
ACCESS I S SEQUENTI AL [RELATI VE KEY I Sdata-name-1]
RANDOM
RELATI VE KEY I Sdata-name-1
H
DYNAMI CJ
FI LE STATUS I Sdata-name-2].FI LE STATUSfield that specifies inputyoutput error conditions may be defined in
WORKI NG- STORAGEand used in exactly the same way as with indexed files, discussed in Chapter 16.
TheFDthat defines and describes the relative file is similar to indexed fileFDs except
that the RELATI VE KEYis not part of the record but is a separate WORKI NG- STORAGE
entry:
FI LE SECTI ON.
FD file-name
LABEL RECORDS ARE STANDARD.
01 record.
.. .
WORKI NG- STORAGE SECTI ON. ..
.
05 (relative-key-field) PI C . . . .
Example SELECT REL- FI LE
ORGANI ZATI ON I S RELATI VE ACCESS I S SEQUENTI AL RELATI VE KEY I S R- KEY. .
. . FD REL- FI LE
. . .
WORKI NG- STORAGE SECTI ON.
01 R- KEY PI C 9( 3) .
In some relative files, each record’s key field is the same asR- KEY, its relative key (e.g.,
a record withACCT- NO5832 is found at the 5,832nd disk location). In other relative files,
each record’s key field must be converted toR- KEY, its relative key.
Cre ating Re lative File s
Relative files are created sequentially, and either the computer or the user can supply
the key. When a relative file’sSELECTstatement includesACCESS I S SEQUENTI AL, the
RELATI VE KEYclause can be omitted. If theRELATI VE KEYclause is omitted, the com-puter writes the records with keys designated as 1 to n. That is, the first record is placed
in relative record location 1 (RELATI VE KEY = 1), the second in relative record location
2 (RELATI VE KEY = 2), and so on.
Suppose the programmer designatesCUST- NOas theRELATI VE KEYwhen creating
the file. The record withCUST- NO 001 will be the first record on disk, the record with
CUST- NO 002 will be the second record, and so on. If there is noCUST- NO 003, then a
blank record will automatically be inserted by the computer. Similarly, suppose a
CUST-NOfield that also serves as aRELATI VE KEYis entered in sequence as10,20,30, and so
on; blank records would be inserted in disk locations1 to 9,11to 19,21to 29, . . . .
This allows records to be added later between the records originally created. That is, if aCUST- NOof09is inserted in the file later on, there is space available for it so that it will be in the correct sequence.
The following program excerpt writes 10 records with COBOL assigningRELATI VE
KEYs1 to10to the records being written:
SELECT TRANS- FI LE ASSI GN TO DI SK2. SELECT REL- FI LE ASSI GN TO DI SK1
ORGANI ZATI ON I S RELATI VE
ACCESS I S SEQUENTI AL. kˆˆNoRELATI VE KEYneed be specified
. . .
OPEN I NPUT TRANS- FI LE OUTPUT REL- FI LE. READ TRANS- FI LE
AT END MOVE ’ NO ’ TO ARE- THERE- MORE- RECORDS
PERFORM 200- WRI TE 10 TI MES. .
. . 200- WRI TE.
WRI TE REL- REC FROM TRANS- REC I NVALI D KEY DI SPLAY ’ ERROR’
END- WRI TE.
* * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * The INVALID KEY clause is executed if there is * * insufficient space to store the record or if records *
* are not in sequence. *
* * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * READ TRANS- FI LE
AT END MOVE ’ NO ’ TO ARE- THERE- MORE- RECORDS
END- READ.
In this case there is no need for aRELATI VE KEYclause in theSELECTstatement because
the computer will assign relative locations to each record.
Often, a transaction file has a field that is to be used as the relative key for the relative
file. The following example shows one way the programmer could supply theRELATI VE
KEYs when creating a relative file:
SELECT TRANS- FI LE ASSI GN TO DI SK2. SELECT REL- FI LE ASSI GN TO DI SK1
ORGANI ZATI ON I S RELATI VE ACCESS I S DYNAMI C
RELATI VE KEY I S WS- ACCT- NO. kˆThis must be aWORKI NG-STORAGEentry
DATA DI VI SI ON. FI LE SECTI ON. FD TRANS- FI LE
LABEL RECORDS ARE STANDARD. 01 TRANS- REC.
05 ACCT- NO PI C 9( 5) . 05 REST- OF- REC PI C X( 95) . FD REL- FI LE
LABEL RECORDS ARE STANDARD.
01 REL- REC PI C X( 100) . WORKI NG- STORAGE SECTI ON.
01 WORK- AREAS.
05 ARE- THERE- MORE- RECORDS PI C X( 3) VALUE ’ YES’ . 88 NO- MORE- RECORDS VALUE ’ NO ’ . 05 WS- ACCT- NO PI C 9( 5) .
PROCEDURE DI VI SI ON. 100- MAI N- MODULE.
OPEN I NPUT TRANS- FI LE OUTPUT REL- FI LE. READ TRANS- FI LE
AT END MOVE ’ NO ’ TO ARE- THERE- MORE- RECORDS
END- READ.
PERFORM 200- WRI TE- RTN UNTI L NO- MORE- RECORDS. CLOSE TRANS- FI LE
REL- FI LE. STOP RUN. 200- WRI TE- RTN.
MOVE ACCT- NO TO WS- ACCT- NO. MOVE TRANS- REC TO REL- REC. WRI TE REL- REC
I NVALI D KEY DI SPLAY ’ WRI TE ERROR’
END- WRI TE.
READ TRANS- FI LE
AT END MOVE ’ NO ’ TO ARE- THERE- MORE- RECORDS
END- READ.
In the preceding, the inputACCT- NOfield also serves as a relative record number or
RELATI VE KEY. Later on, we will see that if theACCT- NOis not generally consecutive
or is too long, we canconvertit to a relative key using different types of procedures or
Se que ntial Re ading o f Re lative File s
The records in relative files may be read sequentially, that is, in the order that they
were created. Because a relative file is created in sequence byRELATI VE KEY, a sequential
READreads the records in ascending relative key order.
There is no need to specify aRELATI VE KEYfor reading from a relative file
sequen-tially. Consider the following example:
SELECT REL- FI LE ASSI GN TO DI SK1 ORGANI ZATI ON I S RELATI VE
ACCESS I S SEQUENTI AL. kˆˆRELATI VE KEYnot needed when sequentially reading from the file
. . .
OPEN I NPUT REL- FI LE OUTPUT PRI NT- FI LE. READ REL- FI LE
AT END MOVE ’ NO ’ TO ARE- THERE- MORE- RECORDS
END- READ.
PERFORM 200- CALC- RTN UNTI L NO- MORE- RECORDS. CLOSE REL- FI LE
PRI NT- FI LE. STOP RUN.
200- CALC- RTN. .
. (process each record in sequence) .
READ REL- FI LE
AT END MOVE ’ NO ’ TO ARE- THERE- MORE- RECORDS
END- READ.
Note, then, that reading from a relative file sequentially is the same as sequentially reading from either an indexed file or a standard sequential file. (An indexed file,
how-ever, must always include theRECORD KEYclause in theSELECTstatement even when
ACCESS I S SEQUENTI AL.)
Rando m Re ading o f Re lative File s
Suppose we wish to find theBAL- DUEfor selected customer records in a relative file.
Suppose, too, that an inquiry file includes the customer numbers of the specific records
sought. These inquiry records are not in sequence by relative keys. Assume that the
customer number was used as a relative record number orRELATI VE KEY. With COBOL
85, we can code:
COBOL SELECT REL- FI LE ASSI GN TO DI SK1
ORGANI ZATI ON I S RELATI VE ACCESS I S RANDOM
RELATI VE KEY I S WS- KEY. kˆˆTheRELATI VE KEYmust be a
WORKI NG- STORAGEentry
SELECT QUERY- FI LE ASSI GN TO DI SK2. DATA DI VI SI ON.
FI LE SECTI ON. FD QUERY- FI LE
LABEL RECORDS ARE STANDARD. 01 QUERY- REC.
05 Q- KEY PI C 9( 5) .
The wordFI LLERmust be included for COBOL 74 but is optional with COBOL 85
05 PI C X( 75) . FD REL- FI LE
LABEL RECORDS ARE STANDARD. 01 REL- REC.
05 CUST- NO PI C 9( 5) . 05 CUST- NAME PI C X( 20) . 05 BAL- DUE PI C 9( 5) . 05 PI C X( 70) . WORKI NG- STORAGE SECTI ON.
01 STORED- AREAS.
05 ARE- THERE- MORE- RECORDS PI C X( 3) VALUE ’ YES’ . 88 NO- MORE- RECORDS VALUE ’ NO ’ . 05 WS- KEY PI C 9( 5) .
100- MAI N- MODULE.
OPEN I NPUT QUERY- FI LE REL- FI LE. READ QUERY- FI LE
AT END MOVE ’ NO ’ TO ARE- THERE- MORE- RECORDS
END- READ.
PERFORM 200- CALC- RTN UNTI L NO- MORE- RECORDS. CLOSE QUERY- FI LE
REL- FI LE. STOP RUN. 200- CALC- RTN.
MOVE Q- KEY TO WS- KEY. READ REL- FI LE
I NVALI D KEY DI SPLAY ’ ERROR - NO RECORD FOUND’ NOT I NVALI D KEY DI SPLAY CUST- NAME BAL- DUE
END- READ.
READ QUERY- FI LE
AT END MOVE ’ NO ’ TO ARE- THERE- MORE- RECORDS
END- READ.
TheI NVALI D KEYclause is executed if thekeyon the query file does not match a key on the relative file.
With COBOL 74, we must use an error switch because theNOT I NVALI D KEYclause
is unavailable:
COBOL WORKI NG- STORAGE SECTI ON.
01 STORED- AREAS. .
. .
05 ERR- SWI TCH PI C 9 VALUE 0. 88 ERR- SWI TCH- OFF VALUE 0. .
. .
200- CALC- RTN.
MOVE Q- KEY TO WS- KEY. READ REL- FI LE
I NVALI D KEY
DI SPLAY ’ ERROR - NO RECORD FOUND’ MOVE 1 TO ERR- SWI TCH.
I F ERR- SWI TCH- OFF
DI SPLAY CUST- NAME BAL- DUE ELSE
MOVE 0 TO ERR- SWI TCH. READ QUERY- FI LE
AT END MOVE ’ NO ’ TO ARE- THERE- MORE- RECORDS.
Interactive Processing. Instead of using an inputQUERY- FI LE, we can inquire about each customer’s name and balance due using an interactive program:
COBOL 85
I DENTI FI CATI ON DI VI SI ON. PROGRAM- I D. I NQUI RY. ENVI RONMENT DI VI SI ON. I NPUT- OUTPUT SECTI ON. FI LE- CONTROL.
SELECT REL- FI LE ASSI GN TO DI SK ORGANI ZATI ON I S RELATI VE ACCESS I S RANDOM
RELATI VE KEY I S WS- KEY. DATA DI VI SI ON.
FI LE SECTI ON. FD REL- FI LE
05 CUST- NO PI C 9( 5) . 05 CUST- NAME PI C X( 20) . 05 BAL- DUE PI C 9( 5) . 05 PI C X( 70) . WORKI NG- STORAGE SECTI ON.
01 STORED- AREAS.
05 ARE- THERE- MORE- RECORDS PI C X VALUE ’ Y’ . 05 WS- KEY PI C 9( 5) . PROCEDURE DI VI SI ON.
100- MAI N- MODULE.
OPEN I NPUT REL- FI LE. PERFORM 200- CALC- RTN
UNTI L ARE- THERE- MORE- RECORDS = ’ N’ OR ’n’ . CLOSE REL- FI LE.
STOP RUN. 200- CALC- RTN.
DI SPLAY ’ ENTER CUST NO’ . ACCEPT WS- KEY.
READ REL- FI LE
I NVALI D KEY DI SPLAY ’ ERROR - NO RECORD FOUND’ NOT I NVALI D KEY DI SPLAY CUST- NAME BAL- DUE
END- READ.
DI SPLAY ’ ARE THERE MORE I NQUI RI ES ( Y/ N) ?’ . ACCEPT ARE- THERE- MORE- RECORDS.
In the above, the computer assumes a direct conversion from the file’s key field to
its disk location. That is, the record withCUST- NO 942is the 942nd record in the file.
When the file is accessed randomly, the computer will directly access each record by theCUST- NOrelative key. We can also use a conversion procedure to convert a key field to a relative key, as we will discuss later.
Rando m Updating o f Re lative File s
When updating a relative file, you can access each record to be changed andREWRI TE
it directly. The relative file must be opened asI - O, the required record must be read,
changed, and then rewritten for each update.
Suppose we wish to read a transaction file and add the corresponding transaction amounts to records in a relative master accounts receivable file. With COBOL 85, we could code:
COBOL SELECT TRANS- FI LE ASSI GN TO DI SK2.
SELECT REL- FI LE ASSI GN TO DI SK1 ORGANI ZATI ON I S RELATI VE ACCESS I S RANDOM
RELATI VE KEY I S WS- KEY. DATA DI VI SI ON.
FI LE SECTI ON. FD TRANS- FI LE
LABEL RECORDS ARE STANDARD. 01 TRANS- REC.
05 T- KEY PI C 9( 5) . 05 T- AMT PI C 999V99. FD REL- FI LE
LABEL RECORDS ARE STANDARD. 01 REL- REC.
05 CUST- NO PI C 9( 5) . 05 CUST- NAME PI C X( 20) . 05 BAL- DUE PI C 9( 5) . 05 PI C X( 70) . WORKI NG- STORAGE SECTI ON.
05 ARE- THERE- MORE- RECORDS PI C X( 3) VALUE ’ YES’ . 88 NO- MORE- RECORDS VALUE ’ NO ’ . 05 WS- KEY PI C 9( 5) .
PROCEDURE DI VI SI ON. 100- MAI N- MODULE.
OPEN I NPUT TRANS- FI LE I - O REL- FI LE. READ TRANS- FI LE
AT END MOVE ’ NO ’ TO ARE- THERE- MORE- RECORDS
END- READ.
PERFORM 200- CALC- RTN UNTI L NO- MORE- RECORDS. CLOSE TRANS- FI LE
REL- FI LE. STOP RUN. 200- CALC- RTN.
MOVE T- KEY TO WS- KEY. READ REL- FI LE
I NVALI D KEY DI SPLAY ’ ERROR ’ , WS- KEY NOT I NVALI D KEY PERFORM 300- UPDATE- RTN
END- READ.
READ TRANS- FI LE
AT END MOVE ’ NO ’ TO ARE- THERE- MORE- RECORDS
END- READ.
300- UPDATE- RTN.
ADD T- AMT TO BAL- DUE. REWRI TE REL- REC
I NVALI D KEY DI SPLAY ’ REWRI TE ERROR’
END- REWRI TE.
Using COBOL 74, we must use an error switch and replace200- CALC- RTNwith:
COBOL WORKI NG- STORAGE SECTI ON.
01 STORED- AREAS. .
. .
05 ERR- SWI TCH PI C 9 VALUE 0. 88 ERR- SWI TCH- OFF VALUE 0. .
. .
200- CALC- RTN.
MOVE T- KEY TO WS- KEY. READ REL- FI LE
I NVALI D KEY DI SPLAY ’ ERROR ’ , WS- KEY MOVE 1 TO ERR- SWI TCH. I F ERR- SWI TCH- OFF
PERFORM 300- UPDATE- RTN ELSE
MOVE 0 TO ERR- SWI TCH. READ TRANS- FI LE
AT END MOVE ’ NO ’ TO ARE- THERE- MORE- RECORDS.
TheI NVALI D KEYclause of theREADstatement is executed if the record in the transaction file did not match a corresponding record in the relative file.
Interactive Processing. We can randomly update a relative file interactively as well:
COBOL 85
I DENTI FI CATI ON DI VI SI ON. PROGRAM- I D. RUPDATE. ENVI RONMENT DI VI SI ON. I NPUT- OUTPUT SECTI ON. FI LE- CONTROL.
SELECT REL- FI LE ASSI GN TO DI SK ’ DI SK1’ ORGANI ZATI ON I S RELATI VE
RELATI VE KEY I S WS- KEY. DATA DI VI SI ON.
FI LE SECTI ON. FD REL- FI LE
LABEL RECORDS ARE STANDARD. 01 REL- REC.
05 CUST- NO PI C 9( 5) . 05 CUST- NAME PI C X( 20) . 05 BAL- DUE PI C 9( 5) . 05 PI C X( 70) . WORKI NG- STORAGE SECTI ON.
01 STORED- AREAS.
05 ARE- THERE- MORE- RECORDS PI C X VALUE ’ Y’ . 05 WS- KEY PI C 9( 5) . 05 T- AMT PI C 9( 5) . PROCEDURE DI VI SI ON.
100- MAI N- MODULE. OPEN I - O REL- FI LE. PERFORM 200- CALC- RTN
UNTI L ARE- THERE- MORE- RECORDS = ’ N’ OR ’n’ . CLOSE REL- FI LE.
STOP RUN. 200- CALC- RTN.
DI SPLAY ’ ENTER CUST NO’ . ACCEPT WS- KEY.
READ REL- FI LE
I NVALI D KEY DI SPLAY ’ ERROR ’ , WS- KEY NOT I NVALI D KEY PERFORM 300- UPDATE- RTN
END- READ.
DI SPLAY ’ ARE THERE MORE RECORDS ( Y/ N) ?’ . ACCEPT ARE- THERE- MORE- RECORDS.
300- UPDATE- RTN.
DI SPLAY ’ ENTER TRANSACTI ON AMT’ . ACCEPT T- AMT.
ADD T- AMT TO BAL- DUE. REWRI TE REL- REC
I NVALI D KEY DI SPLAY ’ REWRI TE ERROR’
END- REWRI TE.
TheI NVALI D KEYclause of theREWRI TEstatement is executed if the key inWS- KEY
is outside the file’s range. TheI NVALI D KEYclause is required when reading, writing,
or rewriting records unless theUSE AFTER EXCEPTI ONprocedure is coded for performing
inputyoutput error functions. The FI LE STATUSspecification can also be used in the
SELECTstatement for determining which specific inputyoutput error occurred when an
I NVALI D KEYcondition is met.
To delete relative records from a file, use theDELETEverb as we did with indexed
files:
MOVE relative-record-number TO working-storage-key.
DELETE file-name RECORD
I NVALI D KEY imperative-statement
END- DELETE.
Once deleted, the record is removed from the file and cannot be read again.
SELF-TEST 1. When creating a relative file,ACCESS I S . When using a relative file as input,
ACCESS I Seither or .
2. RELATI VE KEYis optional when reading or writing a relative file (sequentially, randomly). 3. (T or F) IfACCT- NOis used to calculate a disk address when writing records on a relative file,
thenACCT- NOmust be moved to aWORKI NG- STORAGEentry designated as theRELATI VE KEY
before aWRI TEis executed.
This is a rather simplified example, but such a direct conversion from key to disk address can be made. In this way, there is no need to establish an index, and records may be accessed directly, simply by including a formula for the conversion of a key field to a relative key in the program.
The algorithm or conversion procedure, then, is coded:
1. When creating the relative file. Each record’s key field is used to calculate the
RELATI VE KEYfor positioning or writing each record.
2. When accessing the relative file randomly. Again, the inquiry or transaction
record’s key will need to be converted to aRELATI VE KEYbefore reading from
the relative file randomly.
This type of relative processing requires more programming than when processing indexed files because a conversion procedure is necessary and the hashing technique is sometimes complex. But the random access of relative files is faster than the random
5. (T or F) Relative file organization is the most popular method for organizing a disk file that may be accessed randomly.
Solutions 1. SEQUENTI AL;SEQUENTI AL;RANDOM(orDYNAMI C) 2. sequentially
3. T
4. F—125 must be moved to aWORKI NG- STORAGEentryspecified in theRELATI VE KEYclause of theSELECTstatement or converted to theWORKI NG- STORAGE RELATI VE KEY, as described in the next section.
5. F—Indexed file organization is still the most popular.
C
ONVERTING AK
EYF
IELD TO ARELATIVE KEY
As noted, a key field such asCUST- NOorPART- NOcan often serve as a relative record
number orRELATI VE KEY. Sometimes, however, it is impractical to use a key field as a
RELATI VE KEY.
Suppose a file has Social Security number as its key or identifying field for each record. It would not be feasible to also use this field as a relative record number or
RELATI VE KEY. It would not be practical to place a record with a Social Security number of 977326322 in relative record location 977,326,322. Most files do not have that much space allotted to them, and, even if they did, Social Security numbers as relative record locations would result in more blank areas than areas actually used for records.
Similarly, suppose we have a five-digitTRANS- NOthat serves as a key field for records
in a transaction file. AlthoughTRANS- NOcould vary from 00001 to 99999, suppose there
are only approximately 1000 actual transaction numbers. To useTRANS- NOitself as a
RELATI VE KEYwould be wasteful since it would mean allocating 99999 record locations for a file with only 1000 records.
In such instances, the key field can be converted into aRELATI VE KEY. Methods used
to convert or transform a key field into a relative record number are calledhashing.
Hashing techniques can be fairly complex. We will illustrate a relatively simple one
here. We use the following hashing technique to compute aRELATI VE KEYfor the
pre-cedingTRANS- NOexample:
DI VI DE TRANS- NO BY 1009 REMAI NDER REL- KEY.
TheREMAI NDERfrom this division will be a number from 0 to 1008 that is a sufficiently
large relative record number orRELATI VE KEY. If we add 1 to thisREMAI NDER, we get
Figure 20.1 Program that creates a relative file.
access of indexed files because there is no need to look up a record’s address from an index.
When creating a relative file, then, it may be necessary to include a routine or
al-gorithm for calculating the disk record’s location orRELATI VE KEY. See Figure 20.1 for
an illustration of a program that creates a relative file using a hashing algorithm called thedivision algorithm method, which is similar to the one described previously.
I DENTI FI CATI ON DI VI SI ON. PROGRAM- I D. CREATE.
* * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * THI S PROGRAM CREATES A RELATI VE FI LE * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * *
ENVI RONMENT DI VI SI ON. I NPUT- OUTPUT SECTI ON. FI LE- CONTROL.
SELECT TRANS- I N ASSI GN TO DI SK1. SELECT RELATI VE- FI LE ASSI GN TO DI SK2
ORGANI ZATI ON I S RELATI VE ACCESS I S SEQUENTI AL
RELATI VE KEY I S RELATI VE- KEY- STORE. *
DATA DI VI SI ON. FI LE SECTI ON. FD TRANS- I N
LABEL RECORDS ARE STANDARD. 01 I N- REC.
05 TRANS- NO PI C 9( 5) . 05 QTY- ON- HAND PI C 9( 4) . 05 TOTAL- PRI CE PI C 9( 5) V99. 05 PI C X( 64) . FD RELATI VE- FI LE
LABEL RECORDS ARE STANDARD. 01 DI SK- REC- OUT.
05 DI SK- REC- DATA.
10 D- PART- NO PI C 9( 5) . 10 D- QTY- ON- HAND PI C 9( 4) . 10 D- TOTAL- PRI CE PI C 9( 5) V99. 10 PI C X( 64) . WORKI NG- STORAGE SECTI ON.
01 WORK- AREAS.
05 ARE- THERE- MORE- RECORDS PI C X( 3) VALUE ’ YES’ . 88 NO- MORE- RECORDS VALUE ’ NO ’ . 05 STORE1 PI C S9( 8) .
01 RELATI VE- KEY- STORE PI C 9( 5) . *
PROCEDURE DI VI SI ON. 100- MAI N- MODULE.
OPEN I NPUT TRANS- I N OUTPUT RELATI VE- FI LE. READ TRANS- I N
AT END MOVE ’ NO ’ TO ARE- THERE- MORE- RECORDS
END- READ.
PERFORM 200- WRI TE- RTN UNTI L NO- MORE- RECORDS. CLOSE TRANS- I N
RELATI VE- FI LE. STOP RUN.
200- WRI TE- RTN.
MOVE I N- REC TO DI SK- REC- DATA.
* * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * THE FOLLOWI NG I S ONE METHOD FOR CALCULATI NG * * * * * * A RELATI VE RECORD NO. * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * *
WRI TE DI SK- REC- OUT
I NVALI D KEY PERFORM 300- COLLI SI ON
END- WRI TE.
READ TRANS- I N
AT END MOVE ’ NO ’ TO ARE- THERE- MORE- RECORDS
END- READ.
300- COLLI SI ON.
DI SPLAY ’ WRI TE ERROR ’ , I N- REC.
The same hashing technique or routine is needed for the program that creates the relative file, for the program that updates the file, and for programs that report from it. Since this hashing technique will be used in several programs, it is often written in an independent program or subprogram and called in as needed.
Collisions
Acollisionoccurs when two or more relative keys are transformed by therandomizing algorithminto the same record address. The possibility of a collision always exists when creating or accessing relative files in which the key field needs to be converted into a
relative record number orRELATI VE KEY.
In Figure 20.1,TRANS- NOs of 2019 and 4037 would both produce remainders of 1,
which convert to relative keys of 2. In fact, the only way a collision would be avoided
entirely in this program is if the TRANS- NOs were consecutive (e.g., 4037–5036,
5045 –6044, etc.: 4037/1009 has a remainder of 1, 4038/1009 has a remainder of 2, etc.). One solution to the collision problem is to create a file where colliding records are
placed in anoverflow area. This overflow area would be in a part of the file beyond the
highest possible address for records placed using the randomizing algorithm. This over-flow area must be large enough to handle the anticipated number of collisions and would use a second algorithm for storing colliding records. This second algorithm
would be executed if anI NVALI D KEYcondition were met.
Another method for dealing with collisions is to add 1 to the relative key and attempt to write the record in the next disk location. Continue attempting to write in the next disk location until space is actually found. If you get to the end of the allotted file space without finding a blank area, return to the beginning of the file and continue searching until blank space is found.
To handle collisions using the division algorithm method, we would substitute the
following for300- COLLI SI ONabove. Note that aFI LE STATUScode of22means that
a duplicate primary key appeared during an attempted write (e.g., theWRI TEcould not
be executed because a record with the same primary key is already on the disk).
300- COLLI SI ON.
I F WS- FI LE- STATUS = 22
ADD 1 TO RELATI VE- KEY- STORE PERFORM 400- SEARCH- FOR- SPACE
UNTI L WS- FI LE- STATUS = 00 ELSE
DI SPLAY ’ WRI TE ERROR’
END- I F.
400- SEARCH- FOR- SPACE.
I F FI LE- STATUS = 22 AND RELATI VE KEY > 1010
MOVE 1 TO RELATI VE- KEY- STORE
END- I F.
WRI TE DI SK- REC- OUT I NVALI D KEY
ADD 1 TO RELATI VE- KEY- STORE
END- WRI TE.
This assumes space on disk for 1010 records. TheSELECTstatement forRELATI
VE-FI LEwould have ACCESS I S RANDOMand FI LE STATUS I S WS- FI LE- STATUS, with
WS- FI LE- STATUSdefined inWORKI NG- STORAGE.
Relative files can be accessed either sequentially or randomly. Sequential access of a relative file means that the records are read and processed in order by key field as with sequential files that are sorted into key field sequence. This is rarely done with relative files because records with sequential key fields do not necessarily follow one another if a hashing technique is used for determining relative keys. When we randomly access a relative file, either (1) another input file (typically a transaction or query file) or (2) transactions entered interactively will indicate which disk records are to be accessed. ThusACCESS I S RANDOMis the usual method for reading and updating relative files.
Suppose that a master payroll file has been created with Social Security number used
to calculate theRELATI VE KEY. To access any payroll record on this file, we read in a
transaction field calledI N- SSNO, perform the calculations necessary for convertingI
N-SSNOto a disk address, and store that address in aWORKI NG- STORAGEfield called
SSNO-CONVERTED. Note that theRELATI VE KEYwould also be defined asSSNO- CONVERTED.
When the appropriate value has been moved toSSNO- CONVERTED, we can then execute
the following:READ RELATI VE- FI LE I NVALI D KEY. . . . TheREADinstruction will move
into storage the record with a relative record number specified inSSNO- CONVERTED.
Many of the inputyoutput instructions that apply to indexed files apply to all relative
files, even those in which theRELATI VE KEYmust be converted to a disk location.
CLAUSES USED TO UPDATE RANDOM-ACCESS FILES
OPEN I - O Used when a relative file is being updated.
REWRI TE Writes back onto a relative file (you can only useREWRI TEwhen
the file is opened as I - Oand a record has already been read
from it).
I NVALI D KEY Is required with relative (and indexed) files for a randomREAD
and anyWRI TE,DELETE, andREWRI TEunless aUSE AFTER
STAN-DARD EXCEPTI ONdeclarative has been specified. The computer
will perform the statements following the I NVALI D KEYif the
record cannot be found or if theRELATI VE KEYis blank or not
numeric. A NOT I NVALI D KEY clause may also be used with
COBOL 85.
DELETE Eliminates records from the file.
START Positions the file at some point other than the beginning, for subsequent sequential retrieval of records.
AFI LE STATUSclause can be used in theSELECTstatement with all relative files as
well as with indexed files. Note, however, thatonly one keymay be used with relative
files; there is no provision forALTERNATE RECORD KEYs as with indexed files.
Several otherrandomizingor hashingalgorithmsfor calculating relative file disk
ad-dresses are as follows:
RANDOMIZING OR HASHING ALGORITHMS
For transforming a numeric key field to a relative record number:
Algorithm Explanation Examples Folding Split the key into two or
more parts, add the parts, truncate if there are more digits than needed (de-pending on file size)
1. AnACCT NOkey40125
a. Split and add each part: 01 `
254RELATI VE KEYof 26. b. The record would be placed in
the 26th disk location.
2. AnACCT NOkey42341
Split and add: 23`414RELATI VE
Algorithm Explanation Examples Digit
Extraction
Extract a digit in a fixed digit position—try to
ana-lyze digit distribution
before selecting the digit position
1. An ACCT NOkey 40125; we may
make theRELATI VE KEY15 if we
as-sume that the second and fourth numbers are the most evenly dis-tributed.
2. ARELATI VE KEYof 31 may be
ex-tracted from anACCT NOof 2341.
Square value truncation
Square the key value and truncate to the number of digits needed
AnACCT NOkey40125
a. Square the key giving a value of 15625.
b. Truncate to three positions; 625
be-comes theRELATI VE KEY.
Here, again, if a collision occurs, theI NVALI D KEYclause of a randomREADor any
WRI TEwould be executed. Separate routines would then be necessary to handle these collisions.
In summary, one main difference between a relative file and an indexed file is that relative files may require a calculation for computing the actual address of the disk record. Relative files do not, however, use an index for looking up addresses of disk records.
In general, it isnot efficientto process relative files sequentially when aRELATI VE KEY
is computed using a randomizing algorithm. This is because the records that are
phys-ically adjacent to one another do not necessarily have their key fields such asACCT- NO
orPART- NOin sequence. Hence, relative file organization is primarily used for random access only. Note, too, that algorithms for transforming key fields into relative record numbers sometimes place records on a disk in a somewhat haphazard way so that increased disk space is required. Thus, although relative files can be processed rapidly, they do not usually make the most efficient use of disk space.
CHAPTER SUMMARY A. What is a Relative File?
1. Relative files, like indexed files, can be accessed randomly.
2. With a relative file, there is no index. Instead, a record’s key field such asACCT- NOis converted to a relative record number orRELATI VE KEY. The conversion can be one-to-one (RELATI VE KEY4record key), or a randomizing algorithm may be used to calculate a relative record number from a record’s key field.
3. The random accessing of a relative file is very fast because there is no need to look up a disk address from an index.
4. Sequential access of a relative file may be slow because records adjacent to one another in the file do not necessarily have key fields in sequence.
B. Processing Relative Files 1. SELECTstatement.
a. CodeORGANI ZATI ON I S RELATI VE
b. RELATI VE KEYclause Uses
(1) For randomly accessing the file.
(2) For sequential reads and writes if a conversion is necessary from a record’s key field to aRELATI VE KEY.
(3) The data-name used as the relative record number orRELATI VE KEYis defined in
WORKI NG- STORAGE.
2. Processing routines. a. Creating a relative file:
(1) ACCESS I S SEQUENTI ALin theSELECTstatement.
(2) Move the input record’s key field to theRELATI VE KEY, which is inWORKI NG- STOR-AGE(or convert the input key to aWORKI NG- STORAGErelative key) andWRI TE . . . I NVALI D KEY . . ..
b. Accessing a relative file randomly:
(1) ACCESS I S RANDOMin theSELECTstatement.
(2) Move the transaction record’s key field to theRELATI VE KEY, which is inWORKI NG-STORAGE(or convert) andREAD . . . I NVALI D KEY . . ..
c. When updating a relative file, open it asI - O,ACCESS I S RANDOM, and useREAD,WRI TE,
REWRI TE, orDELETEwithI NVALI D KEYclauses.
KEY TERMS Digit extraction Division algorithm
method
Folding Hashing
Randomizing algorithm
RELATI VE KEY
Square value truncation
CHAPTER SELF-TEST 1. SupposePART- NOin an inventory file is to be used as theRELATI VE KEY. Write theSELECT
statement for the relative file. Include aRELATI VE KEYclause.
2. If a record is written on a relative file withPART- NO 12and a second record withPART- NO 12is to be written, an error (will, will not) occur.
3. The field used to specify aFI LE STATUScode could be tested to determine if two records on a relative file have the same .
4. The field specified with theRELATI VE KEYclause must be defined in .
5. It is generally faster to access a relative file randomly than an indexed file because .
6. Write a procedure to accept an inputT- PART- NOfrom a terminal and use it to look up the corresponding relative record and print its QTY- ON- HAND. Assume thatT- PART- NOcan be used as theRELATI VE KEY.
7. Modify the procedure in Question 6 to enable the operator at the terminal to change the QTY-ON- HAND.
8. Suppose we want to print theQTY- ON- HANDfor records withPART- NO100 through 300. We use the statement to position the file at the correct point.
9. For Question 8, the file must be accessed as either or .
10. A RELATI VE KEY clause is not required in a program that reads from a relative file if .
Solutions 1. SELECT I NV- FI LE
ORGANI ZATI ON I S RELATI VE ACCESS I S SEQUENTI AL RELATI VE KEY I S WS- PART- NO.
2. will
3. RELATI VEkey 4. WORKI NG- STORAGE
5. there is no need to look up the address of the record from an index 6. For COBOL 85, we could code:
ACCEPT T- PART- NO.
MOVE T- PART- NO TO WS- PART- NO. READ I NV- FI LE
I NVALI D KEY DI SPLAY ’ ERROR’
NOT I NVALI D KEY DI SPLAY QTY- ON- HAND
Sample
OUT-FILE
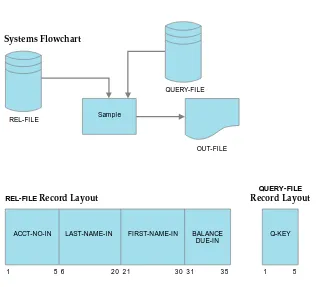
Systems Flowchart
REL-FILE
1 56 20 21 3031 35
ACCT-NO-IN
REL-FILERecord Layout
QUERY-FILE
LAST-NAME-IN FIRST-NAME-IN BALANCE DUE-IN
1 5
Q-KEY
QUERY-FILE
Record Layout Figure 20.2
Problem definition for the Practice Program.
For COBOL 74, we would code:
ACCEPT T- PART- NO.
MOVE T- PART- NO TO WS- PART- NO. READ I NV- FI LE
I NVALI D KEY DI SPLAY ’ ERROR’
MOVE ’ YES’ TO ERR- CODE. I F ERR- CODE = ’ NO ’
DI SPLAY QTY- ON- HAND ELSE
MOVE ’ NO ’ TO ERR- CODE.
7. DI SPLAY ’ CHANGE QTY- ON- HAND ( Y/ N) ?’ . ACCEPT ANS.
I F ANS = ’ Y’
ACCEPT QTY- ON- HAND REWRI TE I NV- REC
I NVALI D KEY DI SPLAY ’ ERROR’
END- REWRI TE END- I F.
Note:Both Questions 6 and 7 need to be put into the context of a structured program if the
procedures are to be repeated. 8. START
9. SEQUENTI AL;DYNAMI C
10. the file is accessed sequentially and the first record is to be placed in the first relative record area, the second in the second relative record area, and so on.
PRACTICE PROGRAM
1 2 3 4 5 6 7 8 9
OUT-FILE Printer Spacing Chart
9 9 9 9 9
a. TheQUERY- FI LEcontains theACCT- NOs of all records that are to print, with their corresponding
BALANCE- DUE.
b. TheRELATI VE KEYis aWORKI NG- STORAGEentry calledWS- KEY. It is the same as theACCT- NO
in the relative file.
The pseudocode, hierarchy chart, and program are in Figure 20.3.
Structured Pseudocode
MAIN-MODULE
START
Open the Files
Read a Record from the Query File
PERFORM Calc-Rtn UNTIL no more Query Records End-of-Job Operations
STOP
CALC-RTN
Read a corresponding Relative Record IF a match is found
THEN
Move Relative Data to Output Area Write Output Record
ENDIF
Read a Record from the Query File
Hierarchy Chart
Program
I DENTI FI CATI ON DI VI SI ON. PROGRAM- I D. SAMPLE. AUTHOR. NANCY STERN.
* * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * THI S PROGRAM TAKES AN ACCOUNT NUMBER FROM THE QUERY FI LE & READS THE* * MASTER FI LE FOR THAT ACCOUNT NUMBER. I F A MATCH I S FOUND THE ACCOUNT* * NUMBER, NAME, AND BALANCE ARE PRI NTED OUT. I F NO MATCH I S FOUND THE* * RECORD I S DI SREGARDED & THE NEXT RECORD I S READ FROM THE QUERY FI LE. * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * *
ENVI RONMENT DI VI SI ON. I NPUT- OUTPUT SECTI ON. FI LE- CONTROL.
SELECT REL- FI LE ASSI GN TO RELMDAT3 ORGANI ZATI ON I S RELATI VE ACCESS I S RANDOM
RELATI VE KEY I S WS- KEY.
LABEL RECORDS ARE STANDARD. 01 REL- REC.
05 ACCT- I N PI C 9( 5) . 05 LAST- NAME PI C X( 15) . 05 FI RST- NAME PI C X( 10) . 05 BALANCE- DUE PI C 999V99. 05 PI C X( 45) . FD QUERY- FI LE
LABEL RECORDS ARE STANDARD. 01 QUERY- REC.
05 Q- KEY PI C 9( 5) . 05 PI C X( 75) . FD OUT- FI LE
LABEL RECORDS ARE OMI TTED.
01 OUT- REC PI C X( 132) . WORKI NG- STORAGE SECTI ON.
01 WORK- AREAS.
05 ARE- THERE- MORE- RECORDS PI C X( 3) VALUE ’ YES’ . 88 NO- MORE- RECORDS VALUE ’ NO ’ . 05 WS- KEY PI C 9( 5) .
01 DETAI L- LI NE.
05 PI C X( 19) VALUE SPACES. 05 ACCT- OUT PI C 9( 5) .
05 PI C X( 10) VALUE SPACES. 05 LAST- OUT PI C X( 15) .
05 PI C X( 5) VALUE SPACES. 05 FI RST- OUT PI C X( 10) .
05 PI C X( 10) VALUE SPACES. 05 BALANCE- OUT PI C ZZ9. 99.
05 PI C X( 52) VALUE SPACES. *
PROCEDURE DI VI SI ON. 100- MAI N- MODULE.
OPEN I NPUT REL- FI LE QUERY- FI LE OUTPUT OUT- FI LE. READ QUERY- FI LE
AT END MOVE ’ NO ’ TO ARE- THERE- MORE- RECORDS
END- READ.
PERFORM 200- CALC- RTN UNTI L NO- MORE- RECORDS. CLOSE REL- FI LE
OUT- FI LE QUERY- FI LE. STOP RUN.
200- CALC- RTN.
MOVE Q- KEY TO WS- KEY. READ REL- FI LE
I NVALI D KEY DI SPLAY ’ READ ERROR ’ , WS- KEY NOT I NVALI D KEY
MOVE Q- KEY TO ACCT- OUT MOVE LAST- NAME TO LAST- OUT MOVE FI RST- NAME TO FI RST- OUT MOVE BALANCE- DUE TO BALANCE- OUT WRI TE OUT- REC FROM DETAI L- LI NE
AFTER ADVANCI NG 2 LI NES
END- READ.
READ QUERY- FI LE
AT END MOVE ’ NO ’ TO ARE- THERE- MORE- RECORDS
END- READ.
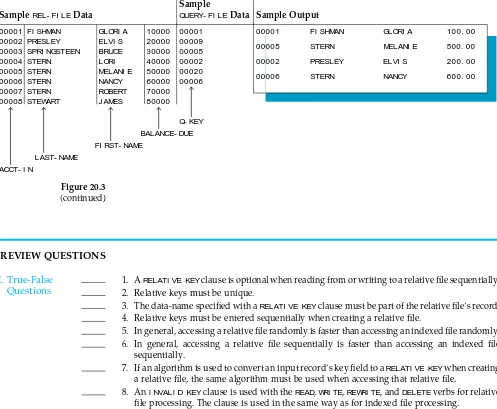
Figure 20.3 (continued) SampleREL- FI LEData
Sample
QUERY- FI LEData Sample Output
00001 FI SHMAN GLORI A 10000 00002 PRESLEY ELVI S 20000 00003 SPRI NGSTEEN BRUCE 30000 00004 STERN LORI 40000 00005 STERN MELANI E 50000 00006 STERN NANCY 60000 00007 STERN ROBERT 70000 00008 STEWART J AMES 80000
Q- KEY BALANCE- DUE FI RST- NAME
LAST- NAME ACCT- I N
00001 00009 00005 00002 00020 00006
00001 FI SHMAN GLORI A 100. 00 00005 STERN MELANI E 500. 00 00002 PRESLEY ELVI S 200. 00 00006 STERN NANCY 600. 00
REVIEW QUESTIONS
I. True-False Questions
1. ARELATI VE KEYclause is optional when reading from or writing to a relative file sequentially. 2. Relative keys must be unique.
3. The data-name specified with aRELATI VE KEYclause must be part of the relative file’s record. 4. Relative keys must be entered sequentially when creating a relative file.
5. In general, accessing a relative file randomly is faster than accessing an indexed file randomly. 6. In general, accessing a relative file sequentially is faster than accessing an indexed file
sequentially.
7. If an algorithm is used to convert an input record’s key field to aRELATI VE KEYwhen creating a relative file, the same algorithm must be used when accessing that relative file.
8. AnI NVALI D KEYclause is used with theREAD,WRI TE,REWRI TE, andDELETEverbs for relative file processing. The clause is used in the same way as for indexed file processing.
9. If a disk file is to be accessed only sequentially, then the method of organization should be sequential,notrelative or indexed.
10. A relative file can be accessed only randomly.
II. Validating Data Modify the Practice Program so that it includes appropriate coding (1) to test for all errors and (2) to print a control listing of totals (records processed, errors encountered, batch totals).
DEBUGGING EXERCISES
Consider the following program excerpt:
SELECT RELATI VE- FI LE ASSI GN TO DI SK1
ORGANI ZATI ON I S RELATI VE ACCESS I S RANDOM
RELATI VE KEY I S R- ACCT- NO. DATA DI VI SI ON.
FI LE SECTI ON FD RELATI VE- FI LE
01 RELATI VE- REC.
05 R- ACCT- NO PI C 9( 5) . 05 R- BAL- DUE PI C 9( 5) V99. 05 PI C X( 88) . WORKI NG- STORAGE SECTI ON.
01 ARE- THERE- MORE- RECORDS PI C X( 3) VALUE ’ YES’ . PROCEDURE DI VI SI ON.
100- MAI N- MODULE.
OPEN I NPUT RELATI VE- FI LE. DI SPLAY ’ ENTER ACCT NO: ’ . ACCEPT R- ACCT- NO.
PERFORM 200- UPDATE- RTN UNTI L R- ACCT- NO = 99999. CLOSE RELATI VE- FI LE.
STOP RUN. 200- UPDATE- RTN.
READ RELATI VE- FI LE
AT END MOVE ’ NO ’ TO ARE- THERE- MORE- RECORDS
END- READ.
DI SPLAY ’ ENTER NEW BAL DUE: ’ . ACCEPT R- BAL- DUE.
WRI TE RELATI VE- RECORD. ACCEPT R- ACCT- NO.
1. Indicate what the program, in general, is intended to accomplish.
2. A syntax error occurs on each line whereR- ACCT- NOis specified. Indicate why and make the necessary corrections.
3. TheOPENstatement is incorrect. Indicate why and make the necessary corrections.
4. TheREADstatement produces a syntax error. Indicate why and make the necessary corrections. 5. TheWRI TEstatement hastwoerrors. Indicate what they are and make the necessary corrections.
PROGRAMMING ASSIGNMENTS
Redo Programming Assignments 1 through 3 in Chapter 16, assuming that the master file is a relative file instead of an indexed file.