PEGAWAI DENGAN MENGGUNAKAN ALGORITMA
LEVENSHTEIN DISTANCE
SKRIPSI
Oleh :
HAQIQI AGUS D.F.
0834010166
PROGRAM STUDI TEKNIK INFORMATIKA
FAKULTAS TEKNOLOGI INDUSTRI
UNIVERSITAS PEMBANGUNAN NASIONAL
Puji syukur ke hadirat Allah SWT yang telah memberikan rahmat dan karunia-Nya, sehingga dapat terselesaikannya Tugas Akhir ini.
Dengan selesainya tugas akhir ini tidak terlepas dari bantuan banyak pihak yang telah memberikan masukan-masukan. Untuk itu penyusun mengucapkan terima kasih sebagai perwujudan rasa syukur atas terselesaikannya tugas akhir ini dengan lancar. Ucapan terima kasih ini saya tujukan kepada :
1. Bapak Prof. Dr. Ir. Teguh Soedarto, MP selaku Rektor Universitas Pembangunan Nasional “Veteran” Jawa Timur.
2. Bapak Sutiyono, MT selaku Dekan Fakultas Teknologi Industri UPN “Veteran” Jawa Timur.
3. Dr. Ir. Ni Ketut Sari, MT. selaku Ketua Jurusan Teknik Informatika UPN “Veteran” Jawa Timur.
4. Intan Yuniar Purbasari, S.Kom., M.Cs. selaku dosen pembimbing I pada Tugas Akhir ini, yang telah banyak memberikan petunjuk, masukan, bimbingan, dorongan serta kritik yang bermanfaat sejak awal hingga terselesainya Tugas Akhir ini.
5. Wahyu S.J. Saputra, S.Kom.M.Kom. selaku dosen pembimbing II yang telah banyak memberikan petunjuk, masukan serta kritik yang bermanfaat hingga terselesainya Skripsi ini.
7. Terima kasih untuk seseorang yang tidak saya sebut namanya, yang selama ini memberikan support, dukungan dan do’a sehingga saya mampu untuk menyelesaikan Tugas Akhir ini. Untuk keluarganya terimakasih om Wahib, Tante Ayu, Mbak Evi, Mas Heru, Mas Fendin, terimakasih atas dukungannya selama ini.
8. Terimakasih buat teman seperjuanganku Ekshadi, Kiki Oktaria, Rizky Firmansyah, Slamet Soendoro, Min Umami, Eva Yulia, Maysita, Eva Yulia, Eca, Dudi Harianto, Eka Adi Saputra, Andre Istighfarianto, Eng, yang telah memberi semangat dan banyak membantu selama ini.
9. Terimakasih buat teman bermain dan teman fitnesku, Om Mayoon, Mas Emil, Mas David, Mas Ari, Mas Freedy, John Key trimakasih yang banyak karena kalian sudah ajak aku refresing disaat otak ini lagi butek..
10.Serta orang-orang yang tidak dapat saya sebutkan satu persatu namanya. Terimakasih atas bantuannya semoga Allah SWT yang membalas semua kebaikan dan bantuan tersebut
Surabaya, 2012
ii
Syukur Alhamdulillaahi rabbil ‘alamin terucap ke hadirat Allah SWT atas segala limpahan Rahmat-Nya sehingga dengan segala keterbatasan waktu, tenaga, pikiran dan keberuntungan yang dimiliki, akhirnya peneliti dapat menyelesaikan Tugas Akhir yang berjudul “PERANCANGAN SISTEM PENILAIAN TES KETELITIAN ENTRY DATA UNTUK PEREKRUTAN PEGAWAI DENGAN MENGGUNAKAN ALGORITMA LEVENSHTEIN DISTANCE”
tepat waktu.
Tugas Akhir ini disusun guna diajukan sebagai salah satu syarat untuk menyelesaikan program Strata Satu (S1) pada jurusan Teknik Informatika,
Fakultas Teknologi Industri, UPN ”VETERAN” Jawa Timur.
Dalam penyusunan Tugas akhir ini, Peneliti berusaha untuk menerapkan ilmu yang telah didapat selama menjalani perkuliahan dengan tidak terlepas dari petunjuk, bimbingan, bantuan, dan dukungan berbagai pihak.
Dengan tidak lupa akan kodratnya sebagai manusia, Peneliti menyadari bahwa dalam karya tugas akhir ini masih mengandung kekurangan sehingga dengan segala kerendahan hati, Peneliti masih akan tetap terus mengharapkan saran serta kritik yang membangun dari rekan-rekan pembaca.
Surabaya, 2012
v
2.2 Metode Pendeteksi Plagiarisme ... 8
2.9 Levenshtein Distance ... 15
2.10 Pengertian dan Sejarah Netbeans ... 17
2.11 Platform Netbeans ... 18
2.12 Netbeans IDE (Integrated Development Environment) ... 19
2.13 Paket-Paket Tambahan Netbeans IDE ………. 20
2.14 Unified Modelling Languange (UML) ... . 24
2.15 Use Case Diagram ... . 25
2.16 Class Diagram ... . 27
2.17 Activity Diagram ... . 30
2.18 Sequence Diagram ... 31
2.19 Cardinality Ratio ... . 32
BAB III ANALISIS DAN PERANCANGAN SISTEM ... 34
3.1 Analisis Kebutuhan Sistem ... 34
3.2 Perancangan Sistem ... 35
3.2.1 Algoritma Levenshtein Distance ... 35
3.2.2 Kemiripan Sintatik dan Semantik ... 37
3.2.3 Tokenizing ... 38
3.2.4 Implementasi Penilaian Menggunakan SynSemSim ... 39
3.2.5 Alir Sistem ... 40
3.2.6 Use Case Diagram ... 40
3.2.7 Activity Diagram ... 42
3.2.8 Sequence Diagram ... . 44
3.2.9 Class Diagram ... . 48
3.3 Perancangan Awal User Interface Levenshtein Test ... 49
BAB IV IMPLEMENTASI ... 51
4.1 Spesifikasi Sistem ... 51
4.2 Implementasi User Interface ... 51
4.2.1 Tampilan Login Peserta ... 52
4.2.3 Halaman Login Administrator ... . 57
4.2.4 Halaman Admin-Data Peserta ... 58
4.2.5 Halaman Admin-Data Artikel Test ... . 59
4.2.6 Halaman Admin-Trial Lavenshtein Test ... . 60
4.2.7 Halaman Admin-Setting Login Admin ... . 61
BAB V UJI COBA DAN EVALUASI ... 62
5.1.4 Uji CobaSistem Pada Halaman Trai Test Dengan Inputan Kata Yang Masih Kurang. ... . 65
5.1.5 Uji Coba Pada Sistem Pada Halaman Trial Test Dengan Inputan Kata Yang Melebihi Banyak Kata Yang di Ujikan. ... . 66
5.1.6 UJi Coba Sistem Pada Halaman Trial Test Dimana Peran “.” Ataupun “,” Masih diperhitungkan. ... 66
5.2. Evaluasi Terhadap User Dengan Sistem ... 67
5.2.1. Evaluasi Perbandingan Perhitungan Manual Dengan Sistem .... 69
BAB VI PENUTUP ... 71
6.1. Kesimpulan ... 71
DOSEN PEMBIMBING II : WAHYU S.J. SAPUTRA, S.Kom.,M.Kom. PENYUSUN : HAQIQI AGUS DIAN FIRMANSYAH
i
ABSTRAK
Di era globalisasi ini perkembangan teknologi berkembang begitu pesat seiring dengan kemajuan pola pikir sumber daya manusia yang semakin maju. Keinginan untuk selalu menciptakan suatu hasil karya mengalami perubahan secara bertahap yang bersifat kompetitif agar dapat menciptakan kemudahan bagi manusia. Perencanaan dan usaha pemenuhan kebutuhan sumber daya manusia, yang dilakukan dalam seleksi, bila dikelola secara professional akan sangat menentukan mutu dan kesuksesan perusahaan. Dengan kata lain seleksi pegawai yang di bagian entry data kebanyakan tes penguasaan pada Microsoft Excel, tes semacam ini masih kurang efektif, dikarenakan tidak dapat diketahuinya seberapa tingkat ketelitian, oleh karena itu dalam kasus ini akan merancang sebuah system penilaian tes ketelitian, dimana pihak manajemen dalam proses seleksi pegawai, khususnya pada proses penilaian hasil tes ketelitian entry data untuk perekrutan pegawai.
Mendukung pembuatan aplikasi tersebut maka perlu adanya metode yang dipakai dalam skripsi ini akan menggunakan algoritma Levenshtein Distance, Algoritma Levenshtein Distance adalah suatu pengukuran (metrik) yang dihasilkan melalui perhitungan jumlah perbedaan ("jarak") yang terdapat diantara dua untaian karakter (string). Teknik menghitung kemiripan antar kalimat adalah menghitung kemiripan arti tiap kata dengan seluruh kata pada kalimat lain,dimana pada algoritma ini dapat dilihat seberapa tepat ketelitian yang di miliki oleh seseorang dan aplikasi ini akan di buat dengan menggunakan bahasa pemrograman java.
Tes ketelitian entry data secara secara umum akan menunjukkan seberapa tinggi tingkat ketelitian seseorang yang harus dilakukan secara berhati-hati dan dengan algoritma yang tepat, tes seperti ini akan memperoleh sumber daya yang baik untuk jangka waktu yang lebih panjang. Dalam aplikasi ini penguji menentukan data apa saja yang dipakai,dari hasil evaluasi perbandingan perhitungan manual dengan perhitungan dengan system didapatkan kesamaan pada perhitungan penilain akhir.
Kata Kunci: Sistem Pendukung Keputusan, AlgoritmaLevenshtein Distance, Tes
1 1.1. Latar Belakang
Di era globalisasi ini perkembangan teknologi berkembang begitu pesat seiring dengan kemajuan pola pikir sumber daya manusia yang semakin maju. Keinginan untuk selalu menciptakan suatu hasil karya mengalami perubahan bertahap yang bersifat kompetitif agar dapat menciptakan kemudahan bagi manusianya sendiri yang di dukung dengan perangkat - perangkat canggih. Kondisi tersebut menginspirasi peneliti selaku mahasiswa untuk menciptakan produk yang bersifat ekonomis dan efisien dengan hasil yang bersifat kualitatif.
Dunia kerja, khususnya pada kantor perpajakan, kantor perpajakan sering membutuhkan pegawai yang cepat dan teliti dalam memasukan data-data perusahan yang sangat penting, pegawai tersebut bertugas memasukan data-data penting perusahan yang menyangkut perpajakan, tetapi sering terjadi kasus kesalahan dalam memasukkan data di karenakan kurang tingginya ketelitian pegawai, hal ini sangatlah berdampak buruk pada kantor perpajakan.
Menilai tingkat ketelitian calon pegawai, maka perlu di buatkanlah aplikasi pada desktop yang berupa system penilaian ketelitian entry data untuk perekrutan calon pegawai, menambahkan cara lama yang masi kurang efektif, karena tes nya hanya pada Microsoft Excel saja, tanpa dapat mengetahui tingkat ketelitian entry data, sehingga perlu di buatlah system ini agar kantor perpajakan atau perusahaan benar-benar mendapatkan pegawai yang diharapkan.
1.2. Perumusan Masalah
Berdasarkan latar belakang masalah yang telah diuraikan di atas, maka dapat ditarik suatu rumusan masalah sebagai berikut :
a. Bagaimana merancang suatu sistem untuk penilaian ketelitian entry data untuk perekrutan pegawai?
b. Bagaimana hasil nilai similarity menggunakan algoritma Levenshtein
Distance?
c. Bagaimana mengetahui tingkat kecepatan pengetikan / input data.
1.3. Batasan Masalah
diberikan pembatasan atau ruang lingkup pembahasan. Adapun batasan - batasan masalah adalah sebagai berikut :
a. Sistem menguji kemiripan ejaan kalimat, symbol, dan angka. b. Hanya digunakan bagi peserta yang mengikuti tes.
c. Digunkan di perusahaan untuk mencari pegawai yang mempunyai ketelitian dan kecepatan dalam hal pengetikan dan input data
d. Sistem tidak untuk di online kan.
1.4. Tujuan
Tujuan yang ingin dicapai dalam tugas akhir ini adalah merancang system penilaian tes ketelitian entry data untuk perekrutan pegawai dengan menggunakan algoritma levenshtein distance.
1.5. Manfaat
Adapun manfaat yang akan diperoleh dalam pembuatan system ini adalah sebagai berikut:
a. Sistem dapat menentukan persentase kemiripan (similarity) antara dokumen yang diujikan dengan dokumen inputan calon karyawan .
b. Sistem dapat melakukan timer pada saat proses tes pengetikan berlangsung, sehingga nantinya dapat diketahui berapa lama waktu dalam proses input atau pengetikan data berlangsung.
c. Sistem dapat melakukan penilaian atau scoring dengan waktu yang singkat. d. Mempermudah pihak HRD melakukan tes ketelitian dan kecepatan entry
1.6. Metodologi
Sebelum menganalisis lebih jauh terhadap penilaian ketelitian entry data, maka disusun metodologi yang dijabarkan dalam langkah-langkah sebagai berikut:
1. Studi Literatur
Mempelajari tentang sistem informasi retrieval dan metode pencocokan string melalui berbagai macam media, antara lain melalui internet, jurnal-jurnal dan buku yang berhubungan dengan text processing.
2. Perancangan Sistem
Melakukan perancangan sistem dengan menguji algoritma yang digunakan terhadap data-data yang ada, yang sudah di persiapkan untuk mengetahui algoritma tersebut baik atau cocok di gunakan.
3. Implementasi
Pembuatan aplikasi penilaian ketelitian berdasarkan perancangan yang telah dibuat sebelumnya ke dalam program komputer.
4. Uji coba produk dan evaluasi.
Melakukan uji coba program yang telah dibuat. Kemudian melakukan evaluasi terhadap kekurangan program dan memperbaikinya, sehingga menjadikan sebuah system yang benar-benar mempunyai tinggi kegunaan dan kemudahan dalam menjalankan system tersebut.
5. Penulisan Buku Tugas Akhir
1.7 Sistematika Penulisan
Dalam dokumentasi laporan tugas akhir ini, pembahasan disajikan dalam enam bab dengan sitematika pembahasan sebagai berikut :
a. BAB I PENDAHULUAN
Bab ini berisikan tentang latar belakang masalah, perumusan masalah,
batasan masalah, tujuan, manfaat, dan sistematika penulisan pembuatan tugas akhir ini.
b. BAB II LANDASAN TEORI
Pada bab ini menjelaskan tentang teori-teori pemecahan masalah yang berhubungan dan digunakan untuk mendukung dalam pembuatan tugas akhir
ini.
c. BAB III ANALISIS DAN PERANCANGAN SISTEM
Bab ini dijelaskan tentang tata cara perancangan sistem yang digunakan untuk
mengolah sumber data yang dibutuhkan sistem antara lain : Perancangan perangkat keras, perancangan perangkat lunak, seperti pada Flowchart , Use Case, dan perancangan server data
d. BAB IV IMPLEMENTASI SISTEM
Pada bab ini menjelaskan implementasi dari program yang telah dibuat
e. BAB V UJI COBA DAN EVALUASI
Pada bab ini menjelaskan tentang pelaksanaan uji coba dan evaluasi dari pelaksanaan uji coba dari program yang dibuat.
f. BAB VI PENUTUP
Bab ini berisi kesimpulan dan saran dari penulis untuk pengembangan sistem
g. DAFTAR PUSTAKA
7 2.1. Kemiripan Sintatik dan Semantik
Teknik menghitung kemiripan kata secara sintaktik pada penelitian menggunakan algoritma Levenshtein Distance. Algoritma ini menghitung kemiripan antar kata berdasarkan total biaya terkecil dari transformasi salah satu kata menjadi kata yang lain dengan menggunakan edit-rules, yaitu penambahan karakter (insertion), penggantian karakter (subtituion), dan penghapusan karakter(deletion) [6]. Algoritma Levenshtein Distance dimulai dari elemen pojok kiri atas sebuah larik (array) dua dimensi dengan indeks baris adalah karakter sumber dan indeks kolom adalah karakter target yang dibandingkan dengan kata sumber. Tiap cell[i,j] merepresentasikan biaya terkecil dari transformasi karakter ke-i dari kata sumber ke karakter ke-j dari kata target. Biaya edit-distance adalah nilai dari cell[n,m]. Untuk biaya edit-distance adalah pada cell[n,m] yaitu 2. Setelah mendapatkan biaya edit-distance maka untuk menghitung nilai Levenshtein dilakukan perhitungan seperti yang terdapat pada gambar seperti di bawah ini.
Lavenshtein Distance menggunakan Persamaan :
Nilai kemiripan (similarity score) diasumsikan pada rentang 0 (nol) hingga 1 (satu), yang artinya nilai 1 adalah nilai maksimum yang menunjukan bahwa dua kata adalah sama identik [7]. Pendekatan yang digunakan oleh penelitian ini mampu mengukur nilai kemiripan antar dua string berdasarkan pada susunan karakter.
2.2. Metode Pendeteksi Plagiarisme
Metode pendeteksi plagiarisme dibagi menjadi tiga bagian yaitu metode perbandingan teks lengkap, metode dokumen fingerprinting, dan metode kesamaan kata kunci. Berikut ini penjelasan dari masing-masing metode dan algoritma pendeteksi plagiarisme :
a. Perbandingan Teks Lengkap. Metode ini diterapkan dengan membandingkan semua isi dokumen. Dapat diterapkan untuk dokumen yang besar. Pendekatan ini membutuhkan waktu yang lama tetapi cukup efektif, karena kumpulan dokumen yang diperbandingkan adalah dokumen yang disimpan pada penyimpanan lokal.
Metode perbandingan teks lengkap tidak dapat diterapkan untuk kumpulan dokumen yang tidak terdapat pada dokumen lokal. Algoritma yang digunakan pada metode ini adalah algoritma Brute-Force , algoritma edit distance, algoritma Boyer Moore dan algoritma lavenshtein distance
baik semua teks yang terdapat di dalam dokumen atau hanya sebagian teks saja. Prinsip kerja dari metode dokumen fingerprinting ini adalah dengan menggunakan teknik hashing. Teknik hashing adalah sebuah fungsi yang mengkonversi setiap 9 string menjadi bilangan. Misalnya Rabin-Karp, Winnowing dan Manber
c. Kesamaan Kata Kunci. Prinsip dari metode ini adalah mengekstrak kata kunci dari dokumen dan kemudian dibandingkan dengan kata kunci pada dokumen yang lain. Pendekatan yang digunakan pada metode ini adalah teknik dot.
2.3. Teks Mining
mining. Dapat pula dikatakan bahwa teks mining merupakan salah satu bentuk aplikasi kecerdasan buatan (artificial intelligence / AI).
Teks mining mencoba memecahkan masalah information overload dengan menggunakan teknik-teknik dari bidang ilmu yang terkait. Teks mining dapat dipandang sebagai suatu perluasan dari data mining atau knowledge-discovery in database (KDD), yang mencoba untuk menemukan pola-pola menarik dari basis data berskala besar. Namun teks mining memiliki potensi komersil yang lebih tinggi dibandingkan dengan data mining, karena kebanyakan format alami dari penyimpanan informasi adalah berupa teks. Teks mining menggunakan informasi teks tak terstruktur dan mengujinya dalam upaya mengungkap dalam teks. Perbedaan mendasar antara teks mining dan data mining terletak pada sumber data yang digunakan. Pada data mining, pola-pola diekstrak dari basis data yang terstruktur, sedangkan di teks mining, pola-pola diekstrak dari data tekstual (natural language ). Secara umum, basis data didesain untuk program dengan tujuan melakukan pemrosesan secara otomatis, sedangkan teks ditulis untuk dibaca langsung oleh manusia.
2.4. Ruang Lingkup Teks Mining
transformasi teks (text transformation), pemilihan fitur (feature selection), dan penemuan pola (pattern discovery).[3]
a. Text Preprocessing
Tahap ini melakukan analisis semantik (kebenaran arti) dan sintaktik (kebenaran susunan) terhadap teks. Tujuan dari pemrosesan awal adalah untuk mempersiapkan teks menjadi data yang akan mengalami pengolahan lebih lanjut.
b. Text Transformation
Transformasi teks atau pembentukan atribut mengacu pada proses untuk mendapatkan representasi dokumen yang diharapkan. Pendekatan representasi dokumen yang lazim. Transformasi teks sekaligus juga melakukan pengubahan kata-kata ke bentuk dasarnya dan pengurangan dimensi kata di dalam dokumen. Tindakan ini diwujudkan dengan menerapkan stemming dan menghapus
stopwords. c. Feature Selection
terlalu banyak. Algoritma yang digunakan pada teks mining, biasanya tidak hanya melakukan perhitungan pada dokumen saja, tetapi juga pada feature . Empat macam feature yang sering digunakan:
Character , merupakan komponan individual, bisa huruf, angka,
karakter spesial dan spasi, merupakan block pembangun pada level paling tinggi pembentuk semantik feature , seperti kata, term dan concept . Pada umumnya, representasi character-based ini jarang digunakan pada beberapa teknik pemrosesan teks.
Words.
Terms merupakan single word dan multiword phrase yang terpilih
secara langsung dari corpus. Representasi term-based dari dokumen tersusun dari subset term dalam dokumen.
Concept, merupakan feature yang di-generate dari sebuah dokumen
secara manual, rule-based, atau metodologi lain. d. Pattern Discovery
Pattern discovery merupakan tahap penting untuk menemukan pola
iterasi ke satu atau beberapa tahap sebelumnya. Sebaliknya, hasil interpretasi merupakan tahap akhir dari proses teks mining dan akan disajikan ke pengguna dalam bentuk visual.
2.5. Ektraksi Dokumen
Teks yang akan dilakukan proses teks mining, pada umumnya memiliki beberapa karakteristik diantaranya adalah memiliki dimensi yang tinggi, terdapat noise pada data, dan terdapat struktur teks yang tidak baik. Cara yang digunakan dalam mempelajari suatu data teks, adalah dengan terlebih dahulu menentukan fitur-fitur yang mewakili setiap kata untuk setiap fitur yang ada pada dokumen. Sebelum menentukan fitur-fitur yang mewakili, diperlukan tahap preprocessing yang dilakukan secara umum dalam teks mining pada dokumen, yaitu case
folding, tokenizing, filtering, stemming, tagging dan analyzing.
2.6. Case Folding dan Tokenizing
Case folding adalah mengubah semua huruf dalam dokumen menjadi huruf kecil, hanya huruf „a‟ sampai dengan „z‟ yang diterima. Karakter selain huruf
dihilangkan dan dianggap delimiter . Tahap tokenizing / parsing adalah tahap pemotongan string input berdasarkan tiap kata yang menyusunnya.
2.7. Filtering
Filtering adalah tahap mengambil kata-kata penting dari hasil token. Bisa menggunakan algoritma stoplist (membuang kata yang kurang penting) atau wordlist (menyimpan kata penting). Stoplist / stopword adalah kata-kata yang tidak deskriptif yang dapat dibuang dalam pendekatan bag-of-words. Contohnya adalah „yang‟, „di‟, „dan‟, „dari‟, dan seterusnya.
Gambar 2.3 Filtering
2.8. Stemming
Gambar 2.4 Stemming
2.9. Levenshtein Distance
Levenshtein Distance atau sering disebut juga edit distance adalah suatu
pengukuran (metrik) yang dihasilkan melalui perhitungan jumlah perbedaan ("jarak") yang terdapat diantara dua untaian karakter (string). Perbedaan yang diukur adalah jumlah minimal operasi penambahan (insert), penghapusan (delete) dan penggantian karakter (substitute) yang dibutuhkan untuk meniadakan perbedaan diantara keduanya. Teknik menghitung kemiripan antar kalimat adalah menghitung kemiripan arti tiap kata dengan seluruh kata pada kalimat lain. Sebagai contoh:
Kalimat 1: “John eats apple”. Kalimat 2: “Apple eats John”.
Proses tokenizing dari kedua kalimat tersebut menghasilkan token: Tokens 1 = {“John”, “eats”, “apple”}.
Tokens 2 = {“Apple”, “eats”, ”John”}.
Hubungan Antar Kata :
Gambar 2.5 Hubungan Antar Kata
Rancangan dan Arsitektur Sistem Penilaian Ketelitian Otomatis :
Gambar 2.6 Rancangan dan Arsitektur
2.10. Pengertian dan Sejarah Netbeans
NetBeans adalah Integrated Development Environment (IDE) berbasiskan Java dari Sun Microsystems yang berjalan di atas Swing. Swing sebuah teknologi Java untuk pengembangan aplikasi Desktop yang dapat bejalan di berbagai macam platforms seperti Windows, Linux, Mac OS X and Solaris.
Suatu IDE adalah lingkup pemrograman yang diintegrasikan kedalam suatu aplikasi perangkat lunak yang menyediakan pembangun. Graphic User
Interface (GUI), suatu text atau kode editor, suatu compiler atau interpreter dan
suatu debugger. Netbeans merupakan software development yang Open Source, dengan kata lain software ini di bawah pengembangan bersama dan juga bebas biaya.
NetBeans merupakan sebuah proyek kode terbuka yang sukses dengan
pengguna yang sangat luas, komunitas yang terus tumbuh, dan memiliki hampir 100 mitra. Sun Microsystems mendirikan proyek kode terbuka NetBeans pada bulan Juni 2000 dan terus menjadi sponsor utama.
Mengacu pada dua hal, yakni platform untuk pengembangan aplikasi desktop java, dan sebuah Integrated Development Environment (IDE) yang dibangun menggunakan platform NetBeans. Platform NetBeans memungkinkan aplikasi dibangun dari sekumpulan komponen perangkat lunak moduler yang disebut „modul‟. Sebuah modul adalah suatu arsip Java (Java archive) yang memuat kelas-kelas Java untuk berinteraksi dengan NetBeans Open API dan file
manifestasi yang mengidentifikasinya sebagai modul. Aplikasi yang dibangun
baru. Karena modul dapat dikembangkan secara independen, aplikasi berbasis platform NetBeans dapat dengan mudah dikembangkan oleh pihak ketiga secara mudah dan powerful.
Pengembangan NetBeans diawali dari Xelfi, sebuah proyek mahasiswa tahun 1997 di bawah bimbingan Fakultas Matematika dan Fisika Universitas Charles, Praha. Sebuah perusahaan kemudian dibentuk untuk proyek tersebut dan menghasilkan versi komersial NetBeans IDE hingga kemudian dibeli oleh Sun Microsystem pada tahun 1999. Sun kemudian menjadikan NetBeans open source pada bulan Juni tahun 2000. Sejak itu komunitas NetBeans terus berkembang.
2.11. Platform Netbeans
Platform NetBeans adalah framework yang dapat digunakan kembali
(reusable) untuk menyederhanakan pengembangan aplikasi desktop. Ketika aplikasi berbasis platform NetBeans dijalankan, kelas Main dari platform dieksekusi. Modul-modul yang tersedia ditempatkan di sebuah registry di dalam memori, dan tugas startup modul dijalankan. Secara umum, kode modul dimuatkan ke dalam memori hanya ketika ia diperlukan.
Aplikasi dapat menginstal modul secara dinamis. Aplikasi dapat memasukkan modul Update Center untuk mengijinkan pengguna aplikasi men-download digitally-signed upgrade dan fitur-fitur baru secara langsung ke dalam aplikasi yang berjalan. Penginstalan kembali sebuah upgrade atau rilis baru tidak memaksa pengguna untuk men-download keseluruhan aplikasi lagi.
Platform NetBeans menawarkan layanan-layanan yang umum bagi aplikasi
aplikasi. Fitur-fitur yang disediakan oleh platform NetBeans:
a. Manajemen antarmuka (misal: menu & toolbar). b. Manajemen pengaturan pengguna.
c. Manajemen penyimpanan (menyimpan dan membuka berbagai macam data).
d. Manajemen jendela.
e. Wizard framework (mendukung dialog langkah demi langkah).
2.12. Netbeans IDE (Integrated Development Environment)
NetBeans IDE adalah IDE open source yang ditulis sepenuhnya dengan
bahasa pemrograman Java menggunakan platform NetBeans. NetBeans IDE mendukung pengembangan semua tipe aplikasi Java (J2SE, web, EJB, dan aplikasi mobile). Fitur lainnya adalah sistem proyek berbasis Ant, kontrol versi, dan refactoring.
Versi terbaru setelah itu adalah NetBeans IDE 5.5.1 yang dirilis Mei 2007 mengembangkan fitur-fitur Java EE yang sudah ada (termasuk Java Persistence support, EJB-3 dan JAX-WS). Sementara paket tambahannya, NetBeans Enterprise Pack mendukung pengembangan aplikasi perusahaan Java EE 5, meliputi alat desain visual SOA, skema XML, web service dan pemodelan UML.
NetBeans C/C++ Pack mendukung proyek C/C++.
semua modul yang diperlukan dalam pengembangan Java dalam sekali download, memungkinkan pengguna untuk mulai bekerja sesegera mungkin. Modul-modul juga mengijinkan NetBeans untuk bisa dikembangkan. Fitur-fitur baru, seperti dukungan untuk bahasa pemrograman lain, dapat ditambahkan dengan menginstal modul tambahan. Sebagai contoh, Sun Studio, Sun Java Studio Enterprise, dan Sun Java Studio Creator dari Sun Microsystem semuanya berbasis NetBeans IDE.
2.13. Paket – Paket Tambahan Netbeans IDE
Sejak Juli 2006, NetBeans IDE di lisensikan di bawah Common
Development and Distribution License (CDDL), yaitu lisensi yang berbasis
Mozilla Public License (MPL).
Paket-Paket Tambahan NetBeans IDE :
a. NetBeans Mobility Pack
NetBeans Mobility Pack adalah alat untuk mengembangkan aplikasi
yang berjalan pada perangkat bergerak (mobile), umumnya telepon seluler, tetapi juga mencakup PDA, dan lain-lain.
NetBeans Mobility Pack dapat digunakan untuk menulis, menguji,
dan debugging aplikasi untuk perangkat bergerak yang menggunakan teknologi berplatform Java Micro Edition (platform Java ME). Paket ini mengintegrasikan dukungan terhadap Mobile
Information Device Profile (MIDP) 2.0, Connected Limited Device Configuration (CLDC) 1.1, dan Connected Device Configuration
Mobility Pack saat ini tersedia dalam dua klaster yang berbeda, yang
satu memuat CDC dan yang lainnya CLDC.
b. NetBeans Profiler
NetBeans Profiler adalah alat untuk mengoptimalkan aplikasi Java,
membantu menemukan kebocoran memori dan mengoptimalkan kecepatan. Profiler ini berdasarkan sebuah proyek riset Sun
Laboratories yang dahulu bernama Jfluid. Riset tersebut
mengungkap teknik tertentu yang dapat digunakan untuk menurunkan overhead proses profiling aplikasi Java. Salah satu dari teknik tersebut adalah instrumentas i kode byte dinamis, yang berguna untuk profiling aplikasi Java yang besar. Dengan menggunakan instrumentasi kode byte dinamis dan algoritma-algoritma tambahan, Netbeans Profiler mampu mendapatkan informasi runtime aplikasi yang terlalu besar atau kompleks bagi profiler lain. NetBeans IDE 6.0 akan mendukung Profiling Point yang memungkinkan kita memprofilkan titik yang tepat dari eksekusi dan mengukur waktu eksekusi.
c. NetBeans C/C++ Pack
NetBeans C/C++ Pack menambahkan dukungan terhadap pengembang C/C++ ke NetBeans IDE 5.5. Paket ini memperbolehkan pengembang menggunakan sekumpulan kompiler dan alat sendiri bersama dengan NetBeans IDE untuk membangun
aplikasi native untuk MS Windows, Linux, dan Solaris. Paket ini
template, browser kelas yang dinamis, dukungan pembuatan file dan fungsionalitas debugger. Para pengembang juga dapat mengembangkan paket tersebut dengan fungsionalitas tambahan mereka sendiri.
d. NetBeans Enterprise Pack
NetBeans Enterprise Pack memperluas dukungan terhadap
pengembangan aplikasi perusahaan dan web service di NetBeans IDE 5.5.
Enterprise Pack ini mengembangkan kemampuan untuk menulis,
menguji, dan debug aplikasi dengan arsitektur berorientasi layanan (Service-Oriented Architecture) menggunakan XML, BPEL, dan
Java web service. Paket ini menambahkan alat desain visual untuk
pemodelan UML, skema XML, dan web service orchestration, juga dukungan untuk web service dengan menggunakan identitas yang aman. Paket ini juga menginstal dan mengkonfigurasi runtime yang diperlukan, termasuk mesin BPEL dan server manajemen identitas yang terintegrasi dengan Sun Java System Application Server.
e. NetBeans Ruby Pack
Versi NetBeans 6.0 mendatang akan mengijinkan pengembangan IDE menggunakan Ruby dan Jruby, sebagaimana Rails untuk dua implementasi Ruby yang lain. Preview NetBeans Ruby Pack tersedia sejak rilis Milestone 7 NetBeans 6.
Ruby Pack memasukkan fungsionalitas editor seperti:
- Pewarnaan sintaks untuk Ruby - Pelengkapan kode
- Occurence highlighting
- Pop-up dokumentasi yang terintegrasi untuk pemanggilan Ruby API
- Analisis semantik dengan highlighting parameter dan variabel lokal yang tidak terpakai
f. NetBeans JavaScript Editor
NetBeans JavaScript Editor menyediakan perluasan dukungan
terhadap JavaScript dan CSS. Fitur-fiturnya antara lain: a) Editor JavaScript :
- Syntax highlighting
- Pelengkapan kode untuk objek dan fungsi native - Semua fitur dalam editor NetBeans
- Pembuatan kerangka kelas JavaScript secara otomatis - Pembuatan pemanggilan AJAX dari template
b) Ekstensi editor CSS
- Pelengkapan kode untuk nama-nama style - Navigasi cepat melalui panel navigator
- Penampilan deklarasi aturan CSS di List View - Penampilan struktur file di Tree View
- Mengurutkan outline view berdasarkan nama, tipe, atau urutan deklarasi (List & Tree)
- Pemfaktoran kembali sebagian nama rule (hanya Tree)
2.14. Unified Modelling Language (UML)
Unified Modelling Language (UML) adalah sebuah "bahasa" yang telah
menjadi standar dalam industri untuk visualisasi, merancang dan mendokumentasikan sistem piranti lunak. UML menawarkan sebuah standar untuk merancang model sebuah sistem. Dengan menggunakan UML dapat membuat model untuk semua jenis aplikasi piranti lunak, dimana aplikasi tersebut dapat berjalan pada piranti keras, sistem operasi dan jaringan apapun, serta ditulis dalam bahasa pemrograman apapun. Tetapi karena UML juga menggunakan class dan operation dalam konsep dasarnya, maka ia lebih cocok untuk penulisan piranti lunak dalam bahasa-bahasa berorientasi objek seperti C++, Java, C# atau VB.NET. Walaupun demikian, UML tetap dapat digunakan untuk modeling aplikasi prosedural dalam VB atau C.
Seperti bahasa-bahasa lainnya, UML mendefinisikan notasi dan
syntax/semantik. Notasi UML merupakan sekumpulan bentuk khusus untuk
bermunculan di dunia. Diantaranya adalah: metodologi booch [1], metodologi coad [2], metodologi OOSE [3], metodologi OMT [4], metodologi shlaer-mellor [5], metodologi wirfs-brock [6], dsb. Masa itu terkenal dengan masa perang metodologi (method war) dalam pendesainan berorientasi objek. Masing-masing metodologi membawa notasi sendiri-sendiri, yang mengakibatkan timbul masalah baru apabila kita bekerjasama dengan group/perusahaan lain yang menggunakan metodologi yang berlainan.
Seperti juga tercantum pada gambar diatas UML mendefinisikan diagram-diagram sebagai berikut:
a. use case diagram b. class diagram c. statechart diagram d. activity diagram e. sequence diagram f. collaboration diagram
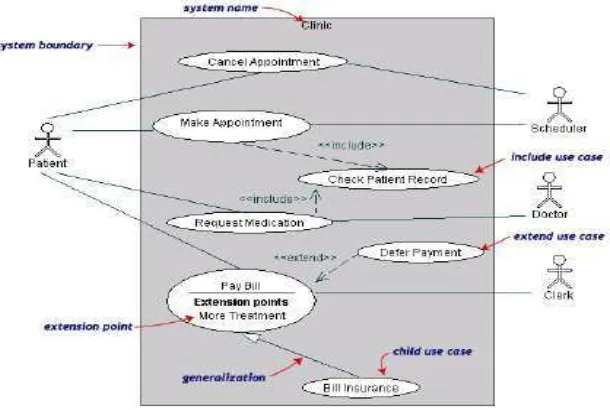
2.15.Use Case Diagram
Use case diagram menggambarkan fungsionalitas yang diharapkan dari
sebuah sistem. Yang ditekankan adalah “apa” yang diperbuat sistem, dan bukan
melakukan pekerjaan-pekerjaan tertentu.
Use case diagram dapat sangat membantu bila kita sedang menyusun requirement sebuah sistem, mengkomunikasikan rancangan dengan klien, dan merancang test case untuk semua feature yang ada pada sistem.
Sebuah use case dapat meng-include fungsionalitas use case lain sebagai bagian dari proses dalam dirinya. Secara umum diasumsikan bahwa use case yang di-include akan dipanggil setiap kali use case yang meng-include dieksekusi secara normal. Sebuah use case dapat di-include oleh lebih dari satu use case lain, sehingga duplikasi fungsionalitas dapat dihindari dengan cara menarik keluar fungsionalitas yang common.
Sebuah use case juga dapat meng-extend use case lain dengan behaviour-nya sendiri. Sementara hubungan generalisasi antar use case menunjukkan bahwa use case yang satu merupakan spesialisasi dari yang lain. Contoh Use Case Diagram bisa dilihat pada Gambar 2.7
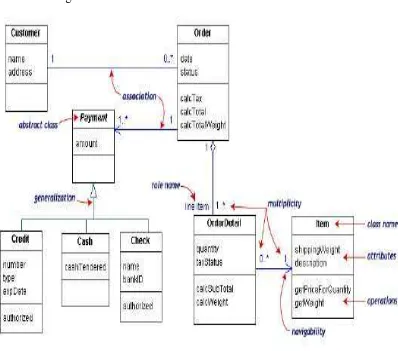
2.16.Class Diagram
Class adalah sebuah spesifikasi yang jika diinstansiasi akan menghasilkan sebuah objek dan merupakan inti dari pengembangan dan desain berorientasi objek. Class menggambarkan keadaan (atribut/properti) suatu sistem, sekaligus menawarkan layanan untuk memanipulasi keadaan tersebut (metoda/fungsi).
Class diagram menggambarkan struktur dan deskripsi class, package dan objek beserta hubungan satu sama lain seperti containment, pewarisan, asosiasi, dan lain-lain.Class memiliki tiga area pokok :
a. Nama (dan stereotype) b. Atribut
c. Metoda
Atribut dan metoda dapat memiliki salah satu sifat berikut :
a. Private, tidak dapat dipanggil dari luar class yang bersangkutan b. Protected, hanya dapat dipanggil oleh class yang bersangkutan dan
anak-anak yang mewarisinya.
c. Public, dapat dipanggil oleh siapa saja
Class dapat merupakan implementasi dari sebuah interface, yaitu class abstrak yang hanya memiliki metoda. Interface tidak dapat langsung diinstansiasikan, tetapi harus diimplementasikan dahulu menjadi sebuah class. Dengan demikian interface mendukung resolusi metoda pada saat run-time.
Gambar 2.9 Contoh Class Abstrak
Sesuai dengan perkembangan class model, class dapat dikelompokkan menjadi package. Kita juga dapat membuat diagram yang terdiri atas package.
Gambar 2.10 Contoh Package
Hubungan Antar Class
b. Agregasi, yaitu hubungan yang menyatakan bagian (“terdiri atas..”). c. Pewarisan, yaitu hubungan hirarkis antar class. Class dapat
diturunkan dari class lain dan mewarisi semua atribut dan metoda class asalnya dan menambahkan fungsionalitas baru, sehingga ia disebut anak dari class yang diwarisinya. Kebalikan dari pewarisan adalah generalisasi.
d. Hubungan dinamis, yaitu rangkaian pesan (message) yang di-passing dari satu class kepada class lain. Hubungan dinamis dapat digambarkan dengan menggunakan sequence diagram yang akan
dijelaskan kemudian. Contoh class diagram :
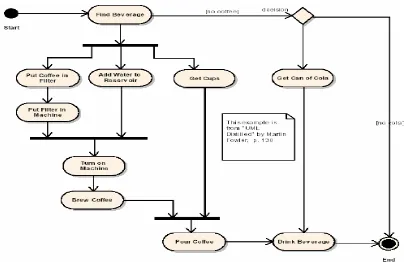
2.17.Activity Diagram
Activity diagram menggambarkan berbagai alir aktivitas dalam sistem
yang sedang dirancang, bagaimana masing-masing alir berawal, decision yang mungkin terjadi, dan bagaimana mereka berakhir. Activity diagram juga dapat menggambarkan proses paralel yang mungkin terjadi pada beberapa eksekusi.
Activity diagram merupakan state diagram khusus, di mana sebagian besar state
adalah action dan sebagian besar transisi di-trigger oleh selesainya state sebelumnya (internal processing). Oleh karena itu activity diagram tidak menggambarkan behaviour internal sebuah sistem (dan interaksi antar subsistem) secara eksak, tetapi lebih menggambarkan proses-proses dan jalur-jalur aktivitas dari level atas secara umum.
Sebuah aktivitas dapat direalisasikan oleh satu use case atau lebih. Aktivitas menggambarkan proses yang berjalan, sementara use case menggambarkan bagaimana aktor menggunakan sistem untuk melakukan aktivitas. Sama seperti state, standar UML menggunakan segi empat dengan sudut membulat untuk menggambarkan aktivitas. Decision digunakan untuk menggambarkan behaviour pada kondisi tertentu. Untuk mengilustrasikan proses-proses paralel (fork dan join) digunakan titik sinkronisasi yang dapat berupa titik, garis horizontal atau vertikal.
Activity diagram dapat dibagi menjadi beberapa object swimlane untuk
Gambar 2.12 Contoh Activity Diagram
2.18.Sequence Diagram
Sequence diagram menggambarkan interaksi antar objek di dalam dan di
Activation bar menunjukkan lamanya eksekusi sebuah proses, biasanya diawali
dengan diterimanya sebuah message. Untuk objek-objek yang memiliki sifat khusus, UML mendefinisikan icon khusus untuk objek-objek boundary, controller dan persistent entity. Contoh sequence diagram:
Gambar 2.13 Contoh Sequence Diagram
2.19.Cardinality Ratio
Dalam penggambaran ER-diagram juga diperlukan cardinality rasio yaitu notasi yang menunjukan banyaknya relasi yang terjadi antar enitas. Cardinality rasio juga untuk membantu gambaran relasi secara lengkap.Terdapat tiga macam relasi dalam hubungan atribut dalam satu file, relasi dari data dapat berupa:
b. Hubungan satu ke banyak (one to many), dimana satu anggota entitas berhubungan lebih dari satu dengan anggota entitas yang lain.
c. Hubungan banyak ke banyak (many to many), dimana satu anggota entitas berhubungan lebih dari satu dengan anggota entitas yang lain serta sebaliknya.
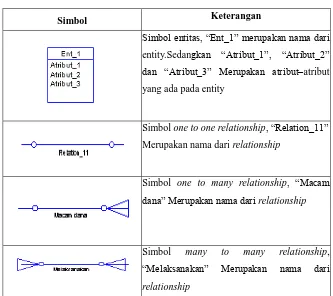
Pada tools PowerDesigner yang digunakan penulis dalam perancangan dan pembuatan sistem, simbol–simbol yang digunakan pada ER diagram konvensional berbeda dengan simbol–simbol yang digunakan oleh tools PowerDesigner. Pada tabel dibawah ini merupakan simbol–simbol ER diagram yang digunakan oleh penulis dalam pembuatan sistem dengan menggunakan tools PowerDesigner.
Tabel 2.2 Simbol ER Diagram (PowerDesigner)
Simbol Keterangan
Simbol entitas, “Ent_1” merupakan nama dari
entity.Sedangkan “Atribut_1”, “Atribut_2”
dan “Atribut_3” Merupakan atribut–atribut yang ada pada entity
Simbol one to one relationship, “Relation_11”
Merupakan nama dari relationship
Simbol one to many relationship, “Macam
dana” Merupakan nama dari relationship
Simbol many to many relationship,
“Melaksanakan” Merupakan nama dari
34
ANALISIS DAN PERANCANGAN SISTEM
3.1. Analisis Kebutuhan Sistem
System penilaian ketelitian entry data ini dikembangkan dalam bentuk dekstop dengan memanfaatkan penggunaan IDE netbeans dengan menggunakan
Bahasa Pemrograman Java. Dimana hasil akhir dari pembuatan aplikasi ini dapat mempermudah pihak perusahaan, khususnya HRD dalam memilih karyawan yang mempunyai ketelitian dan kecepatan dalam pengetikan dan entry data.
Analisis terhadap pembuatan program aplikasi ini dimaksudkan untuk mengetahui proses pembuatan system penilaian ketelitian entry data untuk perektutan pegawai dengan menggunakan algoritma levenshteinDistance yang siap digunakan pada perusahaan, yang nantinya sangat membantu kelancaran dan kemudahan untuk memilah dan memilih pegawai yang benar-benar sesuai harapan, yaitu pegawai yang cepat dan teliti dalam pengetikan dan input data-data yang banyak.
Dalam perancangan system penilaian ketelitian entry data ini, adapun langkah-langkah yang dilakukan adalah:
a. Mempelajari konsep algoritma Levenshtein distance yang digunakan dalam mendeteksi kesamaan kata.
b. Menganalisis dan merancang sistem untuk mendeteksi Kesamaan kata /
similarity
c. Melakukan implementasi sistem berdasarkan analisis dan perancangan yang telah dilakukan sebelumnya.
d. Melakukan uji coba terhadap sistem yang telah dibuat dengan menganalisis hasil daripada sistem. Hasil yang dikeluarkan oleh sistem berupa persentase kemiripan (similarity) yang dikeluarkan menjadi score atas kemiripan dengan bahan yang di ujikan, dan memberikan timer pada saat proses tes entry data,sehingga dapat diketahui lama pengetikan / entry data.
3.2.1. Algoritma Levenshtein distance
Levenshtein Distance atau sering disebut juga edit distance adalah suatu
pengukuran (metrik) yang dihasilkan melalui perhitungan jumlah perbedaan ("jarak") yang terdapat diantara dua untaian karakter (string).
tiap kata dengan seluruh kata pada kalimat lain. Sebagai contoh: Kalimat 1: “John eats apple”.
Kalimat 2: “Apple eats John”.
Proses tokenizing dari kedua kalimat tersebut menghasilkan token: Tokens 1 = {“John”, “eats”, “apple”}.
Tokens 2 = {“Apple”, “eats”, ”John”}.
Matrix Similarity Kemiripan Semantik :
Tabel 3.1 Kemiripan Semantik
Hubungan Antar Kata :
Gambar 3.2 Rancangan dan arsitektur system
Proses kemiripan semantik dengan menggunakan thesaurus WordNet menghasilkan matrix similarity seperti yang ditunjukkan dalam Tabel 3.1. Setelah matrix similarity didapatkan, maka dilanjutkan proses fast heuristic dan Matching
Average dengan hasil nilai kemiripan kedua kalimat adalah yang artinya adalah
sama identik secara semantik.
3.2.2. Kemiripan Sintatik dan Semantik
Teknik menghitung kemiripan kata secara sintaktik pada penelitian menggunakan algoritma Levenshtein Distance. Algoritma ini menghitung kemiripan antar kata berdasarkan total biaya terkecil dari transformasi salah satu kata menjadi kata yang lain dengan menggunakan edit-rules, yaitu penambahan karakter (insertion), penggantian karakter (subtituion), dan penghapusan karakter(deletion).
Table key artikel Table
sebuah larik (array) dua dimensi dengan indeks baris adalah karakter sumber dan indeks kolom adalah karakter target yang dibandingkan dengan kata sumber. Tiap cell[i,j] merepresentasikan biaya terkecil dari transformasi karakter ke-i dari kata sumber ke karakter ke-j dari kata target. Biaya edit-distance adalah nilai dari cell[n,m]. Untuk biaya edit-distance adalah pada cell[n,m] yaitu 2. Setelah mendapatkan biaya edit-distance maka untuk menghitung nilai Levenshtein dilakukan perhitungan seperti yang terdapat pada gambar seperti di bawah ini.
Lavenshtein Distance menggunakan Persamaan :
Gambar 3.3 Menghitung Nilai Lavenshtein
Nilai kemiripan (similarity score) diasumsikan pada rentang 0 (nol) hingga 1 (satu), yang artinya nilai 1 adalah nilai maksimum yang menunjukan bahwa dua kata adalah sama identik. Pendekatan yang digunakan oleh penelitian ini mampu mengukur nilai kemiripan antar dua string berdasarkan pada susunan karakter.
3.2.3. Tokenizing
Tokenizing adalah proses pemotongan string input berdasarkan kata yang
memegang peranan penting pada tahan tokenizing. Karakter spasi digunakan sebagai delimeter untuk memecah kalimat menjadi kumpulan kata-kata, sedangkan karakter titik digunakan sebagai delimeter untuk memotong paragraf menjadi bentuk kalimat-kalimat. Contoh proses tokenizing :
Gambar 3.4 Tokenizing
3.2.4. Implementasi Penilaian Menggunakan SynSemSim
Implementasi sistem penilaian otomatis menggunakan metode
syntactic-semantic similarity (SynSemSim) terdiri dari beberapa bagian yaitu tokenizing
(memecah kalimat menjadi beberapa token), POS tagging dan parsing (mengidentifikasi struktur kalimat),measuring similarity (menghitung kemiripan kalimat dengan menggunakan metode SynSemSim menghasilkan matrix similarity), scoring (menghitung nilai akhir dari matrix similarity menggunakan metode fast heuristic dan matching average). Pada contoh Kalimat “John eats apple” dan Kalimat 2 “Apple eats John”, proses tokenizing:
Setelah mendapatkan tokens, maka proses POS tagging dan Parsing menghasilkan struktur kalimat seperti yang ditunjukkan pada Gambar 2.2. Dari proses ini didapatkan matrix similarity seperti yang ditunjukan pada Gambar 2.2. Proses fast heuristic masing-masing matrix:
a. Matrix 1 menghasilkan nilai 0,4 + 0,4 = 0,8 b. Matrix 2 menghasilkan nilai 1,0 + 1,0 = 2 c. Matrix 3 menghasilkan nilai 0,4 + 0,4 = 0,8 d. Matrix 4 menghasilkan nilai 1,0 + 1,0 = 2 Maka nilai kemiripan adalah :
3.2.5. Alir Sistem
Perancangan system ini dirancangan dengan menggunakan Unified
Modeling Language (UML), adapun tahapan dalam pembuatannya adalah:
3.2.6. Use Case Diagram
requirement sebuah sistem, mengkomunikasikan rancangan dengan klien, dan
merancang test case untuk semua feature yang ada pada sistem.
Sebuah use case dapat meng-include fungsionalitas use case lain sebagai bagian dari proses dalam dirinya. Secara umum diasumsikan bahwa use case yang di-include akan dipanggil setiap kali use case yang meng-include dieksekusi secara normal. Sebuah use case dapat di-include oleh lebih dari satu use case lain, sehingga duplikasi fungsionalitas dapat dihindari.
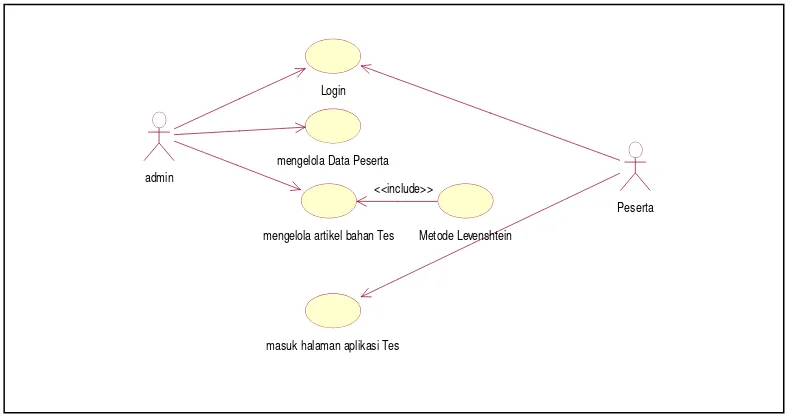
Gambar 3.5 Use Case Diagram
Dalam system ini mempunyai 2 aktor yaitu user dan admin, dimana user melakukan login menginputkan nomer dan nama peserta,lalu masuk halaman aplikasi tes dan mulai mengerjakan.
Activity diagram menggambarkan berbagai alir aktivitas dalam sistem
yang sedang dirancang, bagaimana masing-masing alir berawal, decision yang mungkin terjadi, dan bagaimana mereka berakhir. Activity diagram juga dapat menggambarkan proses paralel yang mungkin terjadi pada beberapa eksekusi. a. Activity diagram login
Menggambarkan alir aktivitas login admin dan peserta dalam sistem yang sedang dirancang, yang di mulai dari input login dan validasi user dan password untuk admin. Contoh activity diagram login :
Start
Gambar 3.6 Activity Diagram Login
b. Activity Diagram Masuk Halaman Tes
masuk Aplikasi Tes ketelitian dan Memulai Pengerjaan
kemudian melakukan tes yang sesuai di ujikan, setelah selesai melakukan tes, hasil di simpan di dalam data base.
c. Activity Diagram mengelola artikel bahan tes
input artikel baru
Gambar 3.8 Activity Diagram Mengelola Artikel Bahan Tes
Pada Gambar 3.8 menjelaskan admin memasukkan bahan tes dan menyimpannya pada data base, dan dapat mengecek dan mencoba artikel atau bahan tes yang akan di ujikan pada peserta tes.
d. Activity Diagram Metode Levenshtein
peserta membuka
levenshtein tersebut melakukan eksekusi data.
e. Activity Mengelola Data Peserta
start
Gambar 3.10 Activity Diagram Mengelola Data Peserata
Gambar 3.10 menjelaskan alur kerja admin dimana admin dapat melihat data peserta yang sudah melakuksn tes yang telah tersimpan di dalam data base.
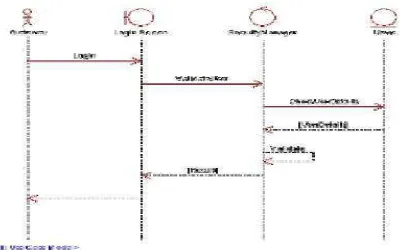
3.2.8. Sequence Diagram
peserta : admin Form Login Control Login Database View form Admin atau Peserta ( )
Gambar 3.11 Sequence Diagram Login
Gambar sequence login diatas dijelaskan peserta/ aktor melakukan login dan apabila ada kolom yang tidak terisi akan ada pesan yang muncul, begitu juga dengan login admin, akan dilakukan pencocokan nama dan password yang sudah di setting dan di simpan di dalam data base yang harus diisi pada kolom nama dan
password, jika salah satu tidak diisikan, maka akan keluar pesan atau petunjuk.
b. Sequence Diagram Masuk Halaman Aplikasi Tes
: Peserta Form Tes
Gambar 3.12 Sequence Diagram Masuk Halaman Tes Validasi Login ( )
menginputkan sesuai bahan tes, setelah itu klik simpan jika sudah penginputan selesai, maka hasil akan tersimpan di dalam
data base.
c. Sequence Diagram Mengelola Artikel Bahan Tes
Pada gambar di bawah terlihat admin dapat menambahkan artikel bahan tes dan menyimpannya, dan dapat menghapus artikel bahan tes yang tidak di butuhkan. Dan semua artikel bahan tes yang ada pada aplikasi, tersimpan di dalam data base, dengan begitu pihak HRD perusahaan tidak susah payah setiap melakukan tes harus membuat lagi bahan tes, sehingga mempermudah dan mempercepat jalannya proses pemilihan calon pegawai.
: admin Form Artikel Control Artikel Database
Form Artikel ( ) input Artikel ( )
get Control ( )
simpan ( )
Validasi Simpan ( )
view data ( )
Pada Gambar 3.14 menjelaskan bagaimana proses kerja system pada metode levenshtein, sampai didapatkan scoring dan penyimpanan data-data peserta
: Peserta Form Tes System Database
Ketelitian
Form Artikel ()
Mengetik Kata Dari Artikel ()
Tokenizing
Get Control () Post tagging & Parsing ()
Get Control ()
Measuring Syntactic & Semantic Symilarity ()
Get Control ()
Scoring ()
Gambar 3.14 Sequence Diagram Metode levenshtein
e. Sequence Mengelola Data Peserta
: admin Form Kelola Data peserta
control data peserta
Database
view form ( ) input kelola data peserta ( )
get control ( )
simpan ( )
validasi simpan ( )
view form kelola data peserta ( )
Gambar 3.15 Sequence Mengelola Data Peserta
3.2.9. Class Diagram
Diagram Class memberikan pandangan secara luas dari suatu sistem dengan menunjukan kelas-kelasnya dan hubungan mereka. Diagram Class bersifat statis; menggambarkan hubungan apa yang terjadi bukan apa yang terjadi jika mereka berhubungan.
Gambar 3.17 Class Diagram User
3.3. Perancangan Awal User Interface Levenshtein Test
Pada gambar di bawah ini merupakan rancangan untuk login peserta dan jika
login untuk admin,pilih menu administrator
Gambar 3.18 Perancangan Login
Pada gambar 3.13 di bawah ini merupakan rancangan system untuk form peserta, tugas peserta melakukan input data ulang dari bahan artikel, ke dalam form input ulang artikel. Di dalam form peserta juga terdapat timer, start, dan simpan. Peserta klik menu start jika siap melakukan input ulang, dan otomatis
Levenshtein Test
No. Peserta :
Nama Peserta :
simpan, dan otomatis timer berhenti.
Gambar 3.19 Perancangan Form Peserta
Untuk gambar di bawah ini adalah rancangan bagi admin, di dalam form tersebut terdapat beberapa menu, yaitu : beranda, data artikel, data peserta, seting, keluar. Menu data artikel adalah tempat untuk menyimpan dan menambah artikel. Menu data peserta adalah tempat data-data peserta yang sudah melakukan tes. Menu seting adalah menu yang digunakan untuk mengganti nama dan password admin. Menu keluar berguna untuk keluar dari aplikasi.
Gambar 3.20 Perancangan Form Admin Levenshtein Test Form Peserta
Timer Timer Timer
Form Input Ulang Artikel Bahan Artikel
Timer START Simpan
Form Admin
Beranda Data
Artikel
51
Pada bab ini akan membahas mengenai implementasi dari rancangan
system aplikasi yang telah dibuat pada bab sebelumnya. Bab ini menjelaskan cara
implementasi proses, dan implementasi antarmuka dari program yang telah dibuat.
4.1. Spesifikasi Sistem
Spesifikasi sistem merupakan sistem yang digunakan untuk memproses semua kegiatan yang terdiri atas masing- masing kegiatan yang saling berkaitan, misalnya dari proses persiapan tes, penginputan data, dan pelaksanaan tes serta sistem ini juga mempunyai admisnitrator yang digunakan untuk mengolah sistem serta database yang berguna untuk menyimpan data.
4.2. Implementasi User Interface
peserta serta materi tes yang harus dikerjakan oleh peserta. Berikut adalah tampilan awal dari aplikasi ini.
Gambar 4.1 Tampilan Awal Sistem
4.2.1. Tampilan Login Peserta
Pada tampilan awal ini terdapat menu input bagi peserta. Dimana pada login ini juga digunakan untuk login admin, sehingga tidak terlalu banyak tampilan login yang dibuat.
Gambar 4.2 Tampilan Login Peserta
Pada Gambar 4.2 adalah tampilan login bagi peserta yang akan melakukan tes ketelitian. Peserta menginputkan nomor peserta dan nama setelah itu peserta akan menuju ke menu selanjutnya untuk melakukan tes.
4.2.2. Tampilan Tes Ketelitian
Pada bagian ini peseta yang mengikuti tes akan dihadapkan pada suatu aplikasi tes ketelitian, dimana pada aplikasi ini peserta tes dituntut untuk menirukan atau mengetik ulang artikel yang telah disediakan oleh system. Artikel yang disediakan oleh system akan berbeda-beda bagi setiap peserta tes.
Gambar 4.3 Tampilan Tes Ketelitian
waktu serta ketepatan menulis ulang artikel tersebut telah sesuai dengan apa yang telah diperintahkan atau tidak.
Berikut adalah potongan code dalam aplikasi ini yang digunakan untuk mengatur dan menghitung ketepatan pengetikan dengan menggunakan algoritma Levenshtein.
private static int cost(char s, char t) { return s==t?0:1;
}
private static int[][] matriks(int s, int t) { int[][] matrix = new int[s + 1][t + 1];
public static int hitungLevenshtein(final String s, final String t) {
char[] s_arr = s.toCharArray(); char[] t_arr = t.toCharArray();
if(s.equals(t)) { return 0; }
if (s_arr.length == 0) { return t_arr.length;} if (t_arr.length == 0) { return s_arr.length;}
int matrix[][] = matriks(s_arr.length,
for (int i = 0; i < s_arr.length; i++) {
for (int j = 1; j <= t_arr.length; j++) { matrix[i+1][j] = minimum(matrix[i][j] + 1,
Gambar 4.4 Potongan Source Code Algoritma Levenshtein
Seperti pada penjelasan metode levenshtein sendiri dimana metode tersebut merupakan pengukuran (matrik) yang dihasilkan melalui perhitungan jumlah perbedaan (jarak) yang terdapat diantara dua untaian karakter (string). Pada code diatas dapat dilihat adanya matriks pada class levenshtein. Seperti pada potongan code “int [ ] [ ] matriks (int s, int t)”, “int [] [] matrix = new int [s + 1] [t + 1];”. Dan perhitungan tersebut didasasrkan pada perhitungan jarak dan dan karakter (string) seperti di tunjukkan pada potongan code :
char [ ] s_arr = s.toCharArray();
char [ ] t_arr = t.toCharArray();
if (s.equals(t)) { return 0; }
if (s_arr.length == 0) { return t_arr.length; }
int matrix [ ] [ ] = matriks(s_arr.length, t_arr.length); dan seterusnya. Pada potongan code dapat dilihat perhitungan yang dilakukan atau implementasi dari metode levenshtein yang diterapkan pada code editor bahasa pemrograman java.
4.2.3. Halaman Login Admin
Pada halaman login admin yang berhak untuk masuk dan mengelola data didalamnya adalah seorang admin yang telah memiliki username serta password admin. Admin disini bertugas untuk mengelola dan mengetahui hasil tes dari peserta tes ketelitian.
Gambar 4.5 Halaman Login Admin
4.2.4. Halaman Admin- Data Peserta
Pada menu data peserta ini, admin dapat mengetahui hasil tes dari para peserta, dimana terdapat kecepatan atau waktu pengerjaan serta ketepatan penulisan yang telah dilakukan oleh peserta tes, sehingga hasil dari tes yang telah dilakukan hanya akan diketahui oleh administrator. Tampilan dari menu peserta tersebut dapat dilihat pada Gambar 4.6.
Gambar 4.6. Halaman Menu Peserta
Pada Gambar 4.6 terdapat menu cari dan juga export data ke excel, pada menu cari ini berfungsi untuk mencari data peserta dengan 3 cara pencarian yaitu berdasar nomer tes, nama dan tanggal tes. Selain itu juga terdapat menu export
excel yang berfungsi untuk meng-eksport data ke excel sehingga data dapat di print dan dapat ditempel sebagai pengumuman hasil tes ke para peserta tes, selain
peserta tes. Caranya dengan memilih salah satu nama peserta setelah itu pilih menu pilihan hapus data.
4.2.5. Halaman Admin- Data Artikel Test
Pada admin dalam sistem ini juga terdapat menu data artikel tes, sehingga dalam menu ini administrator dapat memasukkan artikel yang nantinya sebagai bahan tes bagi peserta.
Gambar 4.7 Halaman Data Artikel Tes
terdapat menu ubah data dan hapus data, apabila admin ingin mengelola data yang sudah ada disediakan oleh sistem ini, apabila ingin menghapus data juga bisa langsung di hapus oleh admin, sehingga data artikel yang sudah tidak digunakan dapat dihapus.
4.2.6. Halaman Admin- Trial Lavenshtein Test
Pada menu ini admin dapat melakukan trial atau uji coba terhadap aplikasi ini, sehingga admin dapat mengetahui jalannya sistem ini sebelum digunakan oleh peserta tes.
Gambar 4.8 Halaman Trial
Pada Gambar 4.8 merupakan gambar halaman trial aplikasi ini, pada menu
trial ini terdapat tampilan yang hampir mirip dengan halaman tes peserta, yaitu
selain itu juga sudah terdapat timer untuk menghitung kecepatan pengetikan serta juga terdapat nilai ketepatan dan ketelitian, setelah selesai mencoba mengetik artikel yang disediakan pada menu trial ini juga langsung dapat melihat hasil uji coba sistem.
4.2.7. Halaman Admin- Setting Login Admin
Pada sistem ini juga terdapat menu setting, pada menu setting ini berguna untuk mengatur data admin yang akan login dalam menu administrator.
Gambar 4.9 Halaman Setting Login
62 BAB V
UJI COBA DAN EVALUASI
Bab ini akan membahas mengenai uji coba terhadap aplikasi tes ketelitian yang telah dibuat dan selanjutnya akan dibuat evaluasi dari hasil uji coba tersebut. Uji coba dilaksanakan untuk mengetahui apakah sistem aplikasi dapat berjalan dengan baik sesuai perancangan yang dibuat. Evaluasi dilakukan untuk menentukan tingkat keberhasilan dari sistem yang dibuat.
Aplikasi ini digunakan oleh sebuah perusahaan yang ingin mencari pegawai peng-input data. Sehingga diciptakannya aplikasi ini. Sehingga pada saat perekrutan karyawan atau pegawai aplikasi ini digunakan untuk menge-test seberapa cepat dan tepat seorang dalam melakukan input suatu data.
5.1. Uji Coba Sistem
Untuk memastikan bahwa sistem ini berjalan dengan lancar, maka akan dilakukan uji coba pada aplikasi ini sehingga aplikasi akan layak untuk digunakan sebagai tes ketelitian suatu perusahaan untuk merekrut karyawan peng-input data.
5.1.1. Uji Coba Sistem Pada Halaman Trial Test Dengan Inputan Sesuai Bahan Uji Coba
Gambar 5.1. Inputan Yang Tidak Ada Kesalahan
5.1.2. Uji Coba Sistem Pada Halaman Trial Test Dengan Inputan Kata yang Sama Tetapi Huruf Besar di Rubah ke Huruf Kecil, dan Sebaliknya.
Pada Gambar 5.2. dapat dilihat, dari hasil inputan tersebut mendapatkan
nilai “0”, dikarenakan pada sistem penilaian ini peserta harus benar-benar melihat
apakah kata tersebut memakai huruf besar atau kecil, meskipun kata yang dituliskannya sama, tetapi tidak menghiraukan pakah itu huruf besar atau kecil, sistem akan menilai yang anda inputkan adalah SALAH, dikarenakan sistem ini menuntut kebenaran inputan.
5.1.3. Uji Coba Sistem Pada Halaman Trial Test Dengan Inputan Jumlah KataYang Sama Tetapi Ada Kesalahan Pada Pengetikkannya.
Pada Gambar 5.3. didapatkan nilai “91”, dikarenakan terdapat sedikit
kesalahan pada pengetikan ysng terletak pada kata AMINNN, kesalhannya adalah kelebihan dua huruf “N”, sehingga sistem memberikan nilai tersebut.
5.1.4. Uji Coba Sistem Pada Halaman Trial Test Dengan Inputan Kata Yang Masih Kurang.
Pada contoh Gambar 5.4. didapatkan nilai “75”, yang dikarenakan pada tes
tersebut inputannya masih kurang satu kata, sehingga menurut perhitungannya pada algoritma Levenshtein Distance, didapatkan nilai sebesar “75”
5.1.5. Uji Coba Sistem Pada Halaman Trial Test Dengan Inputan Kata Yang Melebihi Bnayak Kata Yang di Ujikan
Pada Gambar 5.5 didapatkan nilai “0”, dikarenakan sistem tidak
melakukan perhitungan apabila jumlah kata inputan user melebihi jumlah kata bahan tes yang di ujikan. Sistem masih melakukan scoring apabila jumlah HURUF yang lebih, bukan KATA.
Gambar 5.5. Inputan Yang Melebihi Jumlah Kata Yang di Ujikan
5.1.6. Uji Coba Sistem Pada Halaman Trial Test Dimana Peran “.” Atau “,” Masih diperhitungkan.
Peranan karakter baik itu “.” ataupun “,” masih diperhitungkan pada penilaian, meskipun karakter-karakter yang lainnya seperti “#@*&^%$ dan lain -lain ”. Pada percobaan didapatkan nilai “94” yang meskipun kata-kata yang diketikkan sama,melainkan kurang pada penambahan “.” Berpengaruh pada
Gambar 5.6. Peranan “.” Ataupun “,”
5.2. Evaluasi Terhadap User Dengan Sistem.
Analisis terhadap hasil uji coba sistem, dari sepuluh orang telah didapatkan rata-rata nilai ketepatan pengetikan yang paling baik di dapat tiga orang, dan rata-rata waktu dalam pengetikan memakan waktu 6 menit dalam 123
kata. Bisa di lihat seperti pada Gambar 5.7.
Dari sepuluh orang tersebut, didapatkan nilai akhir yang paling bagus, yaitu dengan cara membagi nilai mreka dengan waktu pengerjaan tes mereka, maka didapatkan nilai akhir yang paling baik dan yang nantinya layak untuk direkrut menjadi pegawai, yang diberi warna kuning merekalah nama-nama yang layak direkrut, berikut lebih jelasnya bias di lihat pada Gambar 5.8.
Gambar 5.8. Peserta Dengan Nilai Terbaik
Dari Gambar 5.18 bisa dilihat,
Dari data-data dan penjelasan tersebut, bahwa sistem ini mampu mendapatkan calon pegawai yang sesuai diharapkan, yaitu pegawai yang cepat dan teliti untuk di pekerjakan pada bagian penginputan data.
5.2.1. Evaluasi Perbandingan Perhitungan Manual Dengan Sistem.
Sebagai contoh kita buat kaliamat terlebih dahulu, seperti contoh kalimat yang akan di ujikan adalah Tokens 1( John eat apple.).
Tokens 2( John eat apple.).
Tokens 2 diperumpamakan sebagai kalimat inputan User, dan Tokens 1 diperumpamakan sebagai bahan uji tes. Kita hitung melalu tabel kemiripan semantic.
Tabel 5.1. Perhitungan Kemiripan
Kolom 1 Kolom 2 Kolom 3
John Eat Apple
Baris 1 John 1 0 0
Baris 2 Eat 0 1 0
Baris 3 Apple 0 0 1
Kemudian akan dilakukan perhitungan dengan rumus : Levenshtein Distence(str1,str2)= 1- edit distance
maxlenght(str1, str2)