PENGENALAN POLA KLASIFIKASI STATUS REGISTRASI CALON MAHASISWA BARU UNIVERSITAS SANATA DHARMA DENGAN
ALGORITMA REDUCT BASED DECISION TREE (RDT)
Skripsi
Oleh : Nama : A.Tendy NIM : 075314014
PROGRAM STUDI TEKNIK INFORMATIKA JURUSAN TEKNIK INFORMATIKA FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA YOGYAKARTA
2012
PATTERN RECOGNITION FOR CLASSIFICATION SANATA DHARMA UNIVERSITY’S NEW STUDENT REGISTRATION STATE
USING REDUCT BASED DECISION TREE (RDT) ALGORITHM
A Thesis
By :
A.Tendy
Student Number : 07 5314 014
INFORMATICS ENGINEERING STUDY PROGRAM DEPARTMENT OF INFORMATION TECHNOLOGY
SANATA DHARMA UNIVERSITY YOGYAKARTA
2012
HALAMAN PERSEMBAHAN
Road To Microsoft
Skripsi ini saya persembahkan
untuk : Yesus Kristus & Bunda
Maria, Keluarga, Sahabat dan
Teman-Teman
Terimakasih
ABSTRAK
Pendaftaran mahasiswa baru adalah salah satu kegiatan yang dilakukan setiap tahun oleh setiap universitas termasuk Universitas Sanata Dharma. Dalam kegiatan registrasi tersebut, ada banyak kasus dimana tidak semua mahasiswa melakukan registrasi kembali setelah diterima di Universitas Sanata Dharma. Untuk mengenali mengapa kasus tersebut terjadi, perlu dilakukan kajian terhadap pola klasifikasi status daftar ulang calon mahasiswa baru berdasarkan data pendaftaran mahasiswa baru. Kajian tersebut dapat dilakukan dengan menerapkan teknik penambangan data (data mining).
Tujuan penelitian ini adalah melakukan pengenalan pola klasifikasi status daftar ulang calon mahasiswa baru Universitas Sanata Dharma dengan menerapkan algoritma Reduct Based Decision Tree (RDT). Data yang digunakan dalam penelitian adalah data pendaftaran mahasiswa baru tahun 2007-2010 sebanyak 5251 record. Penelitian ini menghasilkan 679 pola klasifikasi. Dari pola yang dihasilkan ternyata letak kabupaten sekolah menentukan status registrasi calon mahasiswa baru. Sistem yang dibangun telah diuji dengan menggunakan teknik 5-fold cross validation dan menghasilkan akurasi sebesar 41, 5159 %.
Kata kunci : Daftar Ulang Mahasiswa, Penambangan data, Reduct Based DecisionTree.
ABSTRACT
Admission is one of the annual activity that was held by every universities,
including Sanata Dharma University. In the process of admission, not all
admitted students resgister as new students after they were accepted in Sanata
Dharma University. To find out about those cases, a study toward the
classification pattern of re-registration status of admitted students, based on the
admission’s data, was needed. The study can be done by applying data mining
technique.
The objective of the study is to indentify the classification pattern of re-
registration status of University Sanata Dharma’s admitted students by applying
Reduct Based Decision Tree (RDT) algorithm. The data that was used in the
research is the admission’s data of 2007-2010 that amounted to 5251 record.
The result from the research is 679 classification patterns. From the pattern that
was resulted, it turns out that the location of school regency determines the
registration status of the admitted students. The system that was constructed has
been tested by using 5-fold cross validation technique the accuracy of the system
is 41, 5159 %.
Key word : University Student Admission, Data Mining, Reduct Based Decision
Tree.
KATA PENGANTAR
Puji dan syukur kehadirat Tuhan Yang Maha Esa, karena pada akhirnya penulis dapat menyelesaikan penelitian tugas akhir ini yang berjudul “Pengenalan Pola Klasifikasi Daftar Ulang Calon Mahasiswa Baru Universitas Sanata Dharma dengan Algoritma Reduct Based Decision Tree (RDT)”.
Penelitian ini tidak akan selesai dengan baik tanpa adanya dukungan, semangat, dan motivasi yang telah diberikan oleh banyak pihak. Untuk itu, penulis ingin mengucapkan terima kasih kepada:
1. Ibu Ridowati Gunawan, S.Kom., M.T. selaku ketua program studi Teknik Informatika.
2. Ibu P.H. Prima Rosa, S.Si., M.Sc. selaku dosen pembimbing atas kesabaran, waktu, dan kebaikan yang telah diberikan.
3. Ibu Sri Hartati Wijono, S.Si., M.Kom. selaku dosen penguji atas kritik dan saran yang telah diberikan.
4. Pihak sekretariat dan laboran Fakultas Sains dan Teknologi yang turut membantu penulis dalam menyelesaikan tugas akhir ini.
5. Kedua orang tua, bapak Thomas Suwarto S.Pak dan ibu Impala Mumpun atas kasih sayang, semangat, dan dukungan yang tak henti-hentinya diberikan kepada penulis.
6. Susteran PI Eduard Michelis, atas beasiswa dan bantuan selama studi penulis di Universitas Sanata Dharma.
7. Arum Citra Dewi A, Terimakasih atas bantuannya yang tak terhingga, sehingga penulis mampu menyelesaikan semua ini. Terimakasih juga atas doa dan dukungannya. Semoga Tuhan Memberkati
8. Maya Endah Megawati, terimakasih telah datang dan mewarnai hari-hari serta merubah segalanya menjadi lebih indah.
9. Teman-teman RPL, M. Vindy, Sinta, Beta, Obi. Terimakasih atas banyak pengalaman yang didapat dalam setiap diskusi
10. Seluruh Teman-teman TI 2007 lainnya atas segala kebersamaan dan dukungan yang selalu diberikan kepada penulis.
11. Rekan Kerja DSSystem, Vika, Kiki, Koco, Wina, Arum dll.
12. Pihak-pihak lain yang turut membantu penulis dalam menyelesaikan tugas akhir ini, yang tidak dapat disebutkan satu per satu.
Penelitian tugas akhir ini masih memiliki banyak kekurangan. Untuk itu, penulis sangat membutuhkan saran dan kritik untuk perbaikan di masa yang akan datang. Semoga penelitian tugas akhir ini dapat membawa manfaat bagi semua pihak.
Yogyakarta, 28 Agustus 2012
Penulis
DAFTAR ISI
HALAMAN JUDUL ...i
HALAMAN JUDUL (INGGRIS) ... ii
HALAMAN PERSETUJUAN ... iii
HALAMAN PENGESAHAN ...iv
HALAMAN PERSEMBAHAN ...v
PERNYATAAN KEASLIAN KARYA ...vi
ABSTRAK ... vii
ABSTRACT ... viii
LEMBAR PERSETUJUAN PUBLIKASI ...ix
KATA PENGANTAR ...x
DAFTAR ISI ... xii
DAFTAR TABEL ...xv
DAFTAR GAMBAR ... xvii
BAB I PENDAHULUAN ...1
1.1 Latar Belakang Masalah ...1
1.2 Rumusan Masalah ...2
1.3 Tujuan Penelitian...3
1.4 Batasan Masalah ...3
1.5 Metodologi Penelitian ...3
1.6 Sistematika Penulisan ...5
BAB II TINJAUAN PUSTAKA ...6
2.1 Penambangan Data ...6
2.1 Proses Penambangan Data...6
2.3 Himpunan dan Himpunan Kasar ...8
2.3.1 Relasi ...8
2.3.2 Relasi Ekivalensi ...8
2.3.3 Kelas Ekivalensi ...9
2.3.4 Pengetahuan Dasar Himpunan Kasar ...10
2.3.5 Ruang Hampiran atau Perkiraan (Set Approximation) ...11
2.4 Reduct dan Core ...13
2.5 Discernibility Matrix dan Boolean Matrix. ...14
2.6 Reduct Based Decision Tree...16
2.6.1 Reduct Computation Algorithm (RCA)...18
2.6.1 Pohon Keputusan (Decision Tree)...18
2.7 Contoh Penerapan Algortima ...21
2.8 Cross Validation...29
BAB III ANALISIS Dan DESAIN...30
3.1 Identifikasi Sistem ...30
3.2 Analisis Sistem ...31
3.2.1 Analisis Data Awal ...31
3.2.2 Pemrosesan Awal ...32
3.2.2.1 Pembersihan Data (Data Cleaning) ...32
3.2.2.2 Integrasi Data (Data Integration) ...32
3.2.2.3 Seleksi Data (Data Selection)...33
3.2.2.4 Transformasi ...33
3.3 Analisis Kebutuhan Sistem ...35
3.3.1 Diagram Use Case ...35
3.3.2 Diagram Konteks ...38
3.4 Perancangan Umum Sistem...38
3.4.1 Masukan Sistem...38
3.4.2 Proses Sistem ...41
3.4.2.1 Proses Transformasi ...43
3.4.2.2 Proses Reduct ...44
3.4.2.3 Proses Reduce Data Pelatihan ...45
3.4.2.4 Proses Pembentukan Aturan ...46
3.4.2.5 Proses Simpan Aturan ...48
3.4.2.6 Proses Prediksi ...48
3.4.2.7 Proses Pengukuran Tingkat Akurasi ...50
3.4.3 Keluaran Sistem...52
3.4.4 Diagram Kelas Analisis ...52
3.4.4.1 Diagram Kelas dan Fungsinya ...55
3.4.5 Perancangan Basis Data ...58
3.4.5.1 Perancangan Konseptual ...58
3.4.5.2 Perancangan Logical ...59
3.4.5.3 Perancangan Fisikal ...59
3.4.6 Perancangan Struktur Data ...62
3.4.7 Perancangan Antarmuka Sistem ...64
3.4.7.1 Halaman Utama ...64
3.4.7.2 Halaman Input Data ...65
3.4.7.3 Hasil Reduct Atribut ...66
3.4.7.4 Lihat Pohon Keputusan ...67
3.4.7.5 Halaman Prediksi ...68
3.4.7.6 Halaman Lihat Jumlah Daftar Ulang ...69
BAB IV IMPLEMENTASI PROGRAM ...70
4.1 Spesifikasi Perangkat Lunak dan Perangkat Keras ...70
4.2 Implementasi Use Case ...70
BAB V ANALISIS SISTEM ...81
5.1 Analisis Hasil Program...81
5.2 Evaluasi Pola Data Pendaftaran Mahasiswa Baru...83
5.3 Presentasi Pengetahuan ...94
DAFTAR TABEL
Tabel 2.1 Contoh tabel kelas ekivalensi ...9
Tabel 2.2 Contoh Database ...14
Tabel 2.3 Discernibility matrix untuk data pada Tabel 2.2...15
Tabel 2.4 Matriks Boolean untuk data pada Tabel 2.3 ...15
Tabel 2.5 Algoritma dan varian RDT ...16
Tabel 2.6 Contoh data tabel T1 ...21
Tabel 2.7 Atribut data diurutkan berdasarkan keputusan ...22
Tabel 2.8 Dircernibility matrix ...22
Tabel 2.9 Boolean matriks dengan maksimal b dan c atribut ...23
Tabel 2.10 Boolean matrix yang nilai atribut b dan c adalah 1 maka dihapus ...23
Tabel 2.11 Boolean matriks hasil penghapusan ...24
Tabel 2.12 Boolean matriks hapus nilai atribut d adalah 1 ...25
Tabel 2.13 Boolean matriks hasil penghapusan dan maksimal nya menjadi 2 ...25
Tabel 2.14 Boolean matriks hapus yang nilai b adalah 1...25
Tabel 3.1 Data Awal ...31
Tabel 3.2 Aturan Transformasi Data Nilai Tes Masuk ...34
Tabel 3.3 Deskripsi Use Case ...36
Tabel 3.4 Atribut Input Sistem...38
Tabel 3.5 Atribut Input Sistem Data Uji ...39
Tabel 3.6 Fungsi kelas dalam program ...55
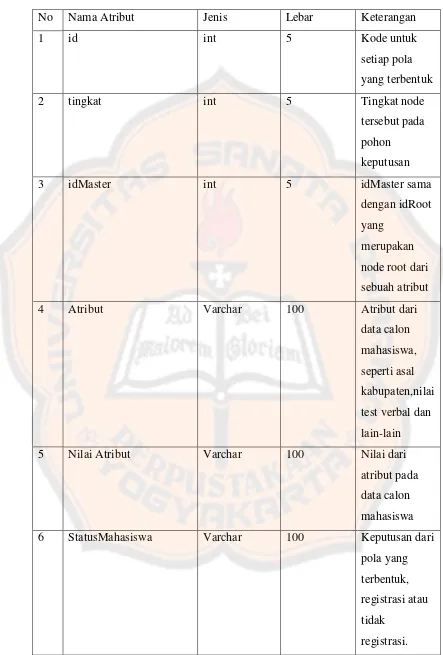
Tabel 3.7 Struktur data tabel pola klasifikasi...59
Tabel 3.8 Struktur data tabel standar deviasi ...61
Tabel 3.9 Bentuk penyimpanan dalam Arraylist ...63
Tabel 5.1 Daftar Pola Tidak Registrasi dengan Jumlah Frekuensi >= 7 ...83
Tabel 5.2 Daftar Pola Registrasi dengan Jumlah Frekuensi >= 7 ...86
Tabel 5.3 Akurasi Pola Per Prodi...92
Tabel 5.4 Hasil Pengukuran Akurasi dengan Menggunakan 5-fold Cross Validation...93
DAFTAR GAMBAR
Gambar 2.1 Proses Penambangan Data ...7
Gambar 2.2 Himpunan kasar A dengan hampiran bawah K ( A) dan hampiran atas K ( A) dalam ruang hampiran K ( X , R) ...13
Gambar 2.3 Pohon Keputusan...19
Gambar 2.4 Contoh Pohon Keputusan ...19
Gambar 2.5 Algoritma C4.5 ...26
Gambar 3.1 Diagram Use Case...35
Gambar 3.2 Diagram Konteks...38
Gambar 3.3 Alur proses pembentukan pola ...42
Gambar 3.4 Alur proses prediksi data ...43
Gambar 3.5 Alur kelas untuk use case input data pelatihan ...52
Gambar 3.6 Alur kelas untuk use case transformasi data ...53
Gambar 3.7 Alur kelas untuk use case reduct ...53
Gambar 3.8 Alur kelas pembentukan pohon keputusan...54
Gambar 3.9 Alur kelas pembentukan pohon keputusan...54
Gambar 3.10 ER Diagram...58
Gambar 3.11 Contoh Pohon Keputusan ...62
Gambar 3.12 Tampilan Halaman Utama ...64
Gambar 3.13 Tampilan Halaman Input Data ...65
Gambar 3.14 Tampilan Halaman Hasil Reduct...66
Gambar 3.15 Tampilan Halaman Lihat Pohon Keputusan...67
Gambar 3.16 Tampilan Halaman Lihat Pohon Keputusan...68
Gambar 3.17 Tampilan halaman lihat alokasi kuota...69
Gambar 4.1 Halaman Utama...71
Gambar 4.2 Konfirmasi keluar dari sistem ...72
Gambar 4.3 Halaman Input Data ...72
Gambar 4.4 File Chooser ...74
Gambar 4.5 Halaman tampilkan data ...75
Gambar 4.6 Data yang sudah ditransformasi ...75
Gambar 4.7 Halaman hasil reduct ...76
Gambar 4.8 Peringatan bahwa pohon sudah terbentuk ...76
Gambar 4.9 Halaman pohon keputusan ...77
Gambar 4.10 Konfirmasi keluar dari sistem ...77
Gambar 4.11 Konfirmasi bahwa aturan berhasil disimpan ...78
Gambar 4.12 Halaman prediksi data ...79
Gambar 4.13 Halaman hasil prediksi ...80
Gambar 4.14 Halaman alokasi kuota ...80
BAB I PENDAHULUAN
1.1 Latar Belakang Masalah
Dalam proses Penerimaan Mahasiswa Baru (PMB) melalui jalur non prestasi, seorang calon mahasiswa harus melakukan serangkaian tes tertulis sebelum mereka dinyatakan diterima sebagai mahasiswa Universitas Sanata Dharma. Selanjutnya setelah mengikuti serangkaian tes dan dinyatakan lulus maka semua data calon mahasiswa yang diterima ini disimpan dalam basisdata tersendiri. Untuk melengkapi persyaratan dan bukti bahwa calon mahasiswa yang dinyatakan lulus tersebut benar-benar terdaftar sebagai mahasiswa Universitas Sanata Dharma, maka para calon mahasiswa diwajibkan melakukan daftar ulang kembali. Setelah melakukan daftar ulang, maka seorang calon mahasiswa telah dinyatakan secara resmi menjadi mahasiswa di Universitas Sanata Dharma.
Pada kenyataannya setiap kali pendaftaran calon mahasiswa baru dilakukan, semua mahasiswa yang diterima belum tentu melakukan daftar ulang kembali. Diduga ada berbagai faktor yang menyebabkan calon mahasiswa baru tidak melakukan daftar ulang. Sehingga masalah yang dihadapi adalah bagaimana mengenali pola klasifikasi status registrasi atau status daftar ulang calon mahasiswa, serta melakukan prediksi untuk mengetahui jumlah mahasiswa yang melakukan registrasi maupun menetapkan kebijakan-kebijakan lain terkait dengan PMB.
Ada berbagai macam cara untuk menyelesaikan permasalahan diatas, salah satunya adalah dengan penambangan data (data mining). Penambangan data adalah teknik untuk mengekstraksi informasi atau menemukan pola yang penting atau pola data unik dari basisdata yang besar. Salah satu pendekatan yang dilakukan adalah menggunakan konsep himpunan kasar seperti yang terdapat dalam algoritma Reduct Based Decision Tree (RDT). Algoritma RDT dapat dipergunakan untuk melakukan eliminasi atribut data yang tidak penting dan mengambil atribut-atribut yang berperan penting untuk pembentukan pola, serta
kemudian membentuk pohon keputusan dengan menggunakan salah satu algoritma pohon keputusan seperti ID3, C4.5, CART, J.48 dan lain-lain.
Penelitian serupa juga pernah dilakukan oleh penulis lain dalam skripsi (Haryanto,2006) . Studi kasus yang digunakan oleh penulis tersebut adalah data pendaftaran Universitas Sanata Dharma tahun 2005-2006 sebanyak 1400 record, dan tingkat akurasi presdiksinya mencapai 61,64%. Beberapa saran yang menjadi masukan dari penelitian sebelumnya adalah :
a. Proses pembentukan pohon yang sangat lama, dan aturan yang diperoleh tidak disimpan kedalam bentuk file atau basisdata. Sehingga setiap melakukan prediksi harus mengulangi dari tahap pembentukan pohon. b. Pemilihan atribut dilakukan secara manual, tanpa algoritma tertentu.
c. Program belum mampu menangani data bertipe numerik secara langsung, tetapi data harus dikonversi menjadi bertipe string. Sehingga disarankan untuk menggunakan algoritma C4.5 yang bisa menangani data bertipe numerik secara langsung.
Dalam penelitian ini akan digunakan semua saran diatas untuk pengembangan program, baik dari performansi, efektifitas dan tingkat keakurasian. Terutama pada saran nomor dua, pemilihan atribut dalam penelitian ini tidak lagi dilakukan secara intuitif tetapi dipilih menggunakan proses reduct dalam algoritma Reduct Based Decision Tree (RDT). Pohon keputusan akan dibangun menggunakan algoritma C4.5.
Dengan menggunakan penambangan data ini, maka diharapkan pola klasifikasi status daftar ulang mahasiswa dapat dikenali sehingga dan digunakan untuk proses penentuan kuota maupun pengambilan keputusan-keputusan lain terkait PMB.
1.2 Rumusan Masalah
menggunakan algoritma Reduct Based Decision Tree (RDT) pada basisdata Penerimaan Mahasiswa Baru (PMB). Kedua, bagaimana melakukan prediksi status registrasi calon mahasiswa yang telah diterima dan menghitung jumlah calon mahasiswa yang diprediksi akan mendaftar ulang.
1.3 Tujuan Penelitian
Tujuan dari penelitian ini adalah mengenali pola klasifikasi status daftar ulang mahasiswa, sehingga dapat dimanfaatkan untuk prediksi status registrasi calon mahasiswa yang telah diterima dan menghitung jumlah calon mahasiswa yang diprediksi akan mendaftar ulang.
1.4 Batasan Masalah
Agar penelitian ini terfokus ke inti permalasahan berdasarkan rumusan masalah diatas, maka penulis memberi batasan-batasan sebagai berikut:
a. Pendekatan yang digunakan adalah dengan menggunakan algorima RDT b. Pohon keputusan dibentuk dengan algoritma C45
c. Data mahasiswa yang digunakan adalah data mahasiswa dengan status telah diterima melalui jalur test.
d. Input adalah data PMB yang diperoleh Biro Administrasi dan Perencanaan Sistem Informasi (BAPSI) Universitas Sanat Dharma Yogyakarta tahun 2007-2010 dengan atribut gelombang, pilihan1, pilihan2, pilihan3, jenis kelamin, kabupaten asal, kabupaten sekolah, jenis SMU, nilai penalaran verbal, nilai kemampuan numerik, kemampuan nilai mekanik, nilai hubungan ruang, nilai bahasa inggris dan status registrasi mahasiswa. e. Penelitian ini tidak menerapkan teknik pruning dalam pembentukan pohon
keputusan.
1.5 Metodologi Penelitian
Metodologi yang digunakan dalam penelitian ini adalah A. Studi Pustaka
C. Knowledge discovery in database (KDD) yang terdiri dari : a. Pembersihan Data (Data Cleaning)
Pembersihan data merupakan proses menghilangkan noise dan data yang tidak konsisten atau data yang tidak relevan.
b. Integrasi Data (Data Integration)
Integrasi data merupakan proses penggabungan data dari berbagai sumber.
c. Seleksi Data (Data Selection)
Seleksi data merupakan proses menyeleksi data dimana data yang relevan diambil dari database.
d. Transformasi Data (Data Transformation)
Data diubah atau digabung ke dalam format yang sesuai untuk diproses dalam penambangan data.
e. Penambangan Data (Data Mining)
Penambangan data merupakan suatu proses utama saat metode diterapkan untuk menemukan pengetahuan berharga dan tersembunyi dari data. Dalam penelitian ini algoritma yang digunakan adalah Reduct Based Decision Tree (RDT).
f. Evaluasi Pola (Pattern Evaluation)
Untuk mengidentifikasi pola-pola menarik kedalam knowledge based yang ditemukan.
g. Presentasi Pengetahuan (Knowledge Presentation)
Merupakan visualisasi dan teknik representasi pengetahuan untuk menyajikan pengetahuan yang ditambang kepada pengguna.
1.6 Sistematika Penulisan
Sistematika penulisan tugas akhir ini adalah sebagai berikut :
BAB I : PENDAHULUAN
Bab ini berisi latar belakang masalah, rumusan masalah, tujuan penelitian, batasan masalah, metodologi penelitian, dan sistematika penulisan.
BAB II : TINJAUAN PUSTAKA
Bab ini berisi dasar-dasar teori yang digunakan dalam penyusunan tugas akhir meliputi penambangan data, himpunan kasar, RDT, pohon keputusan dan algoritma C4.5
BAB III : ANALISIS DAN DISAIN
Bab ini berisi tentang analisis serta perancangan aplikasi penambangan data.
BAB IV : IMPLEMENTASI PROGRAM
Bab ini berisi implementasi penerapan teknik penambangan data dalam aplikasi.
BAB V : ANALISIS HASIL
Bab Analisis berisi tentang hasil analisis dari hasil output yang diperoleh
BAB VI : PENUTUP
BAB II
TINJAUAN PUSTAKA
2.1 Penambangan Data
Pengertian penambangan data (data mining) sangat beragam, beberapa penulis diantaranya mendefinisikan sebagai berikut :
1. Ekstraksi atau penambangan pengetahuan dari sejumlah besar data (Han dan Kamber ,2006)
2. Data mining adalah kegiatan yang meliputi pengumpulan, pemakaian data historis untuk menemukan keteraturan, pola dan hubungan dalam set data berukuran besar (Santosa , 2007)
3. Data mining adalah metode yang digunakan untuk mengektraksi informasi prediktif tersembunyi dalam database (Lee dan Santana, 2010)
Jadi dapat diambil kesimpulan bahwa, data mining atau penambangan data adalah proses atau kegiatan mengektraksi data untuk mencari pola, keteraturan dan informasi yang tersembunyi dalam data yang besar atau basis data. Dengan diperolehnya informasi-informasi yang berguna dari data-data yang ada, hubungan antara item dalam transaksi, maupun informasi-informasi yang potensial, selanjutnya dapat diekstrak dan dianalisa serta diteliti lebih lanjut dari berbagai sudut pandang. Informasi yang ditemukan ini selanjutnya dapat diaplikasikan untuk aplikasi manajemen, melakukan pengambilan keputusan dan lain sebagainya. Dengan semakin berkembangnya kebutuhan akan informasi- informasi, semakin banyak pula bidang-bidang yang rnenerapkan konsep data mining.
2.2 Proses Penambangan Data
Data mining juga dikenal dengan istilah lain Knowledge Discovery in Database (KDD), dimana tahapan-tahapan untuk memperoleh knowledge tersebut dibagi menjadi beberapa tahap seperti diilustrasikan dalam gambar 2.1
Gambar 2.1 Langkah-langkah dalam Penambangan Data
Sumber : Han & Kamber (2006)
Berikut ini adalah penjelasan tahapan-tahapan KDD dari gambar 2.1 diatas :
a. Pembersihan dan Penggabungan Data (Data Cleaning and Integration) Pada tahap ini data-data yang tidak konsisten dan tidak sempurna seperti salah ketik, duplikasi data ataupun atribut-atribut yang tidak relevan dibersihkan (dibuang), karena data yang tidak relevan tersebut akan mengurangi akurasi data yang akan di-mining nantinya. Kemudian setelah itu data-data dari database di integrasikan (digabungkan) yang bertujuan untuk mendapatkan data yang lebih banyak lagi dan hasil yang lebih akurat.
b. Pemilihan dan Transformasi Data (Selection and Transformation)
diubah bentuk sesuai dengan jenis dan data yang akan dicari dalam database. Tranformasi data juga akan berpengaruh untuk menentukan kualitas data mining.
c. Penambangan Data (Data Mining)
Penambangan data merupakan suatu proses utama saat metode diterapkan untuk menemukan pengetahuan berharga dan tersembunyi dari data.
d. Evaluasi dan Presentasi Pola (Evaluation and Presentation)
Untuk mengidentifikasi pola-pola menarik kedalam knowledge based yang ditemukan. Dan presentasi merupakan visualisasi dan penyajian pengetahuan mengenai metode yang digunakan untuk memperoleh pengetahuan yang diperoleh pengguna.
2.3 Himpunan dan Himpunan Kasar 2.3.1 Relasi
Relasi atau hubungan antara himpunan A dan B adalah pemasangan anggota-anggota himpunan A dengan anggota-anggota himpunan B dengan aturan tertentu (Liu,1995).
2.3.2 Relasi Ekivalensi
Dikatakan juga oleh Liu (1995), suatu relasi R pada himpunan S dikatakan ekuivalen jika memenuhi ketiga hal berikut ini :
1. Refleksif , xRx
2. Simetri, jika xRy maka yRx
3. Transitif, Jika xRy dan yRz maka xRz
3. Transitif. Diketaui xRy dan yRz yang artinya x– y = 4n dan y– z = 4m Diperoleh x – ( z + 4m ) = 4n kemudian x – z = 4n + 4m = 4( n + m ). Itu artinya xRz. Maka terbukti bahwa R Transitive.
2.3.3 Kelas Ekivalensi
Dalam relasi ekuivalensi pasti terdapat kelas ekivalensi. Misalkan diberikan R relasi ekuivalen pada S maka untuk semua a S terdapat suatu himpunan yang berisikan semua anggota S yang berelasi ke a , dinotasikan [ a ] = { a S | a R x}. Tabel 2.1 berikut ini merupakan contoh sebuah tabel dengan objeknya adalah kelas ekivalensi. Tabel dibawah ini adalah contoh data dari 18 pasien penderita kanker berdasarkan lokasi asal tumor, lung (L), colon (L). Empat atribut yang dicatat dari pasien-pasien tersebut adalah level ekspresi atau perubahan bentuk dari ketiga gen dalam metastatic tumor dan dibandingkan dengan kesehatan penderita. (0: unchanged, ↓down-regulated, ↑ up-regulated) serta dilihat penderita smoking yes or no.
Tabel 2.1 Contoh tabel kelas ekivalensi
2.3.4 Pengetahuan Dasar Himpunan Kasar
Himpunan kasar (rough sets) pertama kali diperkenalkan oleh Zdzislaw Pawlak dari Warsaw University of Technology di Polandia pada tahun 1982 sebagai suatu metode matematis untuk mendeskripsikan himpunan tidak tegas, dalam arti bahwa elemen-elemen tertentu dalam semestanya tidak dapat ditentukan secara tegas apakah merupakan anggota himpunan itu atau tidak, karena elemen-elemen itu tidak dapat dibedakan satu sama lain akibat keterbatasan atau ketidaklengkapan pengetahuan atau informasi yang tersedia mengenai elemen-elemen itu (Susilo, 2006) . Pada awalnya himpunan kasar dikembangkan untuk menangani ketidakpastian dan ketidaktegasan (Pawlak, 2003) dalam bidang analisis data. Dasar pengembangan teori himpunan kasar adalah asumsi bahwa setiap elemen dalam semesta wacananya terkait dengan informasi mengenai elemen itu, dan bahwa elemen-elemen dengan informasi yang sama adalah elemen-elemen yang takterbedakan (Indiscernibility). Pada dasarnya pendekatan terhadap himpunan kasar adalah suatu hampiran terhadap himpunan taktegas itu dengan menggunakan sepasang himpunan tegas yang dikonstruksikan berdasarkan suatu partisi pada semesta himpunan itu. Sebagai partisi bisaanya diambil partisi yang terimbas oleh relasi ekivalensi “takterbedakan” antara elemen-elemen dalam semesta itu. Dengan demikian kelas-kelas ekivalensi dalam partisi itu memuat elemen-elemen semesta yang takterbedakan satu sama lain. Relasi ekivalensi adalah model matematik paling sederhana yang dapat dipergunakan untuk merepresentasikan keadaan di mana elemen-elemen tertentu dalam suatu semesta tidak dapat dibedakan satu sama lain, dengan mengingat bahwa relasi “takterbedakan” itu pada dasarnya adalah suatu relasi ekivalensi, yaitu bersifat refleksif, simetrik, dan transitif. Konsep himpunan kasar adalah perampatan konsep himpunan tegas, dalam arti bahwa himpunan tegas adalah kejadian khusus dari himpunan kasar.
lain bisa disebutkan bahwa Rough Set dibagi atau direpresentasikan kedalam dua bentuk yaitu :
2.3.5 Ruang Hampiran atau Perkiraan (Set Approximation)
Menurut Pawlak (1821) , Misalkan X adalah suatu semesta yang takkosong, R adalah suatu relasi ekivalensi pada X, [x]R {y X | (x, y) R}
atas dari A dalam K (upper approximation atau negative region), dengan lambang
K ( A), adalah
K ( A) {[x]R X / R | [ x]R A }
xX
{x X | [ x]R A } ……….. 2.2
yaitu gabungan semua himpunan elementer yang beririsan dengan A. Hampiran bawah dari A menyajikan himpunan elemen-elemen semesta yang pasti merupakan anggota himpunan A, sedangkan hampiran atas dari A menyajikan himpunan elemen-elemen semesta yang mungkin merupakan anggota himpunan A. Perhatikan bahwa K ( A) A K ( A). Elemen-elemen semesta yang tidak berada dalam hampiran atas dari A adalah elemen-elemen yang pasti tidak merupakan anggota A.
Selisih hampiran atas dan hampiran bawah dari himpunan A dalam K, yaitu BK ( A) K ( A) K ( A), disebut daerah batas (boundary) dari himpunan A
dalam K. Jika BK ( A) , yaitu K ( A) K ( A) A , maka A merupakan gabungan himpunan elementer dalam K dan disebut himpunan yang dapat dideskripsikan secara tepat dalam K (atau himpunan tegas dalam K). Jika BK ( A) , maka A
tidak dapat dideskripsikan secara tepat dalam K dan disebut himpunan kasar dalam K. Dengan perkataan lain, himpunan kasar adalah himpunan bagian dari semesta yang mempunyai daerah batas yang takkosong.
K(A)
Kualitas hampiran dalam suatu ruang hampiran dinyatakan dengan suatu ukuran ketepatan. Bila K ( X , R) adalah suatu ruang hampiran dan A suatu himpunan bagian dari X, maka banyaknya atom dalam K ( A) dan K ( A), yang
disajikan dengan ( A) dan ( A), berturut-turut disebut ukuran dalam dan ukuran luar dari A dalam K. Jika ( A) ( A), maka A dikatakan terukur dalam K. Ketepatan hampiran dari A dalam K didefinisikan sebagai bilangan real
K ( A) ( A)
informasi. Bisa disimpulkan core adalah atribut yang paling berpengaruh dan penting dalam pembentukan pola.
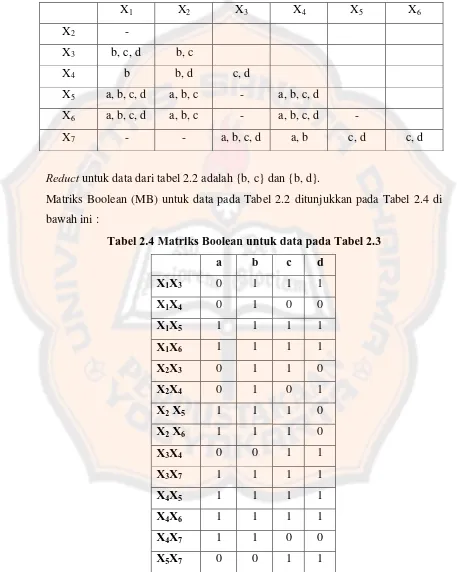
2.5 Discernibility Matrix dan Boolean Matrix.
Jika atribut dari dua pasang objek berbeda, yang akan menjadi masukan matrik dari pasangan objek tersebut adalah atribut-atribut mereka yang berbeda saja (Yellasiri, 2008). Jadi Discernibility matrix merupakan sekumpulan matrik yang berbeda atributnya antara objek (i) dengan objek (j). Boolean Matrix (BM) atau disebut juga dengan matriks boolean (MB) adalah penyajian discernibility matriks dalam bentuk matriks dua dimensi dengan nilai boolean, yakni 1 atau 0. Matriks bernilai satu jika nilai dari pasangan objek (i) dan (j) berbeda dan sebaliknya.
Contoh 2.1 :
Discernibility matrix yang sesuai dengan contoh database ditunjukkan pada Tabel 2.2 dengan U = {X1, X2, …, X7}, C = {a, b, c, d}, D = {E}. M(X1,X3) = {b, c, d}.
U = Semua elemen, responden atau record dari sampel data C = Semua atribut kondisi dari sistem informasi / table D = Atribut keputusan dari table
M = Pasangan dari setiap responden U yang D-nya berbeda
Discernibility matrix untuk data pada Tabel 2.2 ditunjukkan pada Tabel 2.3, untuk atribut dengan nilai keputusan sama diberi tanda “-“ :
Tabel 2.3 Discernibility matrix untuk data pada Tabel 2.2
X1 X2 X3 X4 X5 X6
Matriks Boolean (MB) untuk data pada Tabel 2.2 ditunjukkan pada Tabel 2.4 di bawah ini :
Tabel 2.4 Matriks Boolean untuk data pada Tabel 2.3
X6X7 0 0 1 1
2.6 Reduct Based Decision Tree
Algoritma RDT adalah algoritma yang lahir dengan memanfaatkan kelebihan-kelebihan dari teori himpunan kasar dan algoritma pohon keputusan yang seudah ada sebelumnya, maka akan meningkatkan efisiensi, kesederhanaan dan kemampuan generalisasi dari kedua algoritma tersebut (Yellasiri, 2008). Algoritma Reduct Based Decision Tree (RDT) sebagian besar memiliki dua langkah penting, yaitu Reduct Computation dan pembentukan pohon DT Construction atau pembentukan pohon keputusan.
RDT juga memiliki banyak jenis-jenis nya, yang merupakan pengembangan lebih lanjut dari RDT itu sendiri, dan letak pengembangan adalah dengan memodifikasi salah satu langkah dalam proses reduct nya (Adhiguru, Minz and Jain, 2006) . Perbedaan dan deskripsi dari masing-masing algoritma tersebut bisa dilihat dalam tabel 2.5 berikut, data diambil dari hasil pengujian pada sebuah dataset nutrisi (Jain,2006) :
Tabel 2.5 Algoritma dan varian RDT
reduct pada data set tetapi tidak sampai kepada proses klasifikasi dan prediksi (Jain, 2011), sehingga digunakan pohon keputusan untuk melakukan pencarian pola dan keputusannya. Bisa dilihat bahwa RDT ini benar-benar menggabungkan antara kelebihan Rough Set dengan reduct-nya dan pohon keputusan untuk pencarian polanya. Sehingga atribut-atribut yang sangat berperan penting dalam pencarian pola data bisa diperoleh dari proses reduct atribut dalam konsep rough set ini. Kemudian dibentuk pola dengan algoritma pohon keputusan berdasarkan atribut hasil reduct tersebut.
Namun, yang menjadi masalah utama atau problem mendasar untuk banyak praktek aplikasi yang menggunakan Rough Set ini, adalah mendefinisikan metode (method) mana yang efisien, untuk pemilihan atribut yang penting dalam klasifikasi objek suatu universe (Yellasiri, 2008). Dalam software Rosetta (Rough Set Toolkit), algoritma yang digunakan untuk me-reduct data adalah Johnson Algorithm dan Genetic Algorithm. Oleh karena itu, Ramadevi Yellasiri mengusulkan algoritma RDT yang berbeda untuk reduct atribut data yang lebih sederhana dibandingkan dengan Johnson Algorithm dan Genetic Algorithm. Algoritma yang digunakan oleh Yellasiri adalah Reduct Computation Algorithm (RCA). Walaupun sederhana, dari pengujian dengan Kappa Statistic, untuk membandingkan dengan teknik klasifikasi yang satu dengan yang lain, algoritma RDT Yellsiri ini cukup menunjukkan tingkat akurasi yang lebih baik dibandingkan yang lain.
2.6.1 Reduct Computation Algorithm (RCA)
Dalam algoritma ini, tabel keputusan digunakan sebagai input dan atribut- atribut utama yang diperoleh disebut reduct adalah outputnya (Yellasiri, C.R.RAO, Ramakhrisna, Prathima,2008). Atribut-atribut yang menjadi output tersebut disebut SPA (Set of Predominant Attribute) atau Himpunan Atribut Dominan (HAP). Adapun algoritma RCA tersebut adalah sebagai berikut :
a. Baca tabel keputusan T1
b. Urutkan baris secara ascending order pada atribut keputusannya c. Inisialisasikan himpunan atribut-atribut utama SPA ke null
d. Buat sebuah matrik boolean seperti yang dijelaskan pada langkah 5, dengan membuat sebuah baris untuk setiap pasangan baris (responden) yang memiliki perbedaan pada atribut keputusannya.
e. Buat sebuat baris dengan nilai „1‟ dan „0‟. Tandai a „1‟ ke elemen jika dari pasangan baris (responden) memiliki nilai atribut berbeda, selain itu tandai dengan „0‟
f. Ulangi langkah „7‟ dan „8‟ sampai jumlah baris dalam Matriks Boolean bernilai „0‟ atau matriknya menjadi null.
g. Ambil atribut „a‟ yang memiliki hasil penjumlahan maksimum dari baris-baris, dan tambahkan ke SPA
h. Hapus semua baris dari matrik boolean yang mempunyani nilai elemen
„1‟ dari atribut „a‟ tersebut
i. Jika matrik boolean tidak null, tampilkan “SPA secara kasar menjelaskan tentang atribut keputusan”.
j. Tetapkan SPA sebagai hasil reduct
2.6.2 Pohon Keputusan (Decision Tree)
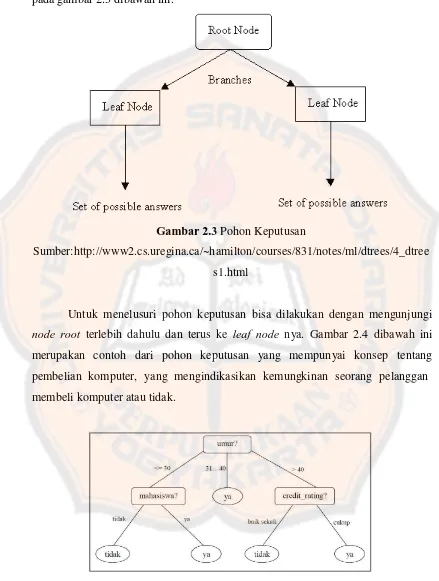
(leaf node / terminal node) menggambarkan kelas-kelas atau objek yang kita cari. Node yang paling atas disebut akar (root node) . Untuk lebih jelasnya bisa dilihat pada gambar 2.3 dibawah ini.
Gambar 2.3 Pohon Keputusan
Sumber:http://www2.cs.uregina.ca/~hamilton/courses/831/notes/ml/dtrees/4_dtree s1.html
Untuk menelusuri pohon keputusan bisa dilakukan dengan mengunjungi node root terlebih dahulu dan terus ke leaf node nya. Gambar 2.4 dibawah ini merupakan contoh dari pohon keputusan yang mempunyai konsep tentang pembelian komputer, yang mengindikasikan kemungkinan seorang pelanggan membeli komputer atau tidak.
Gambar 2.4 Contoh Pohon Keputusan
Walaupun banyak variasi model pohon keputusan dengan tingkat kemampuan dan syarat yang berbeda, pada umumnya beberapa ciri kasus berikut cocok untuk diterapkan dengan pohon keputusan:
a. Data / example dinyatakan dengan pasangan atribut dan nilainya. b. Label / output data bisaanya bernilai diskrit.
c. Data mempunyai missing value.
Kelebihan dari metode pohon keputusan adalah :
a. Daerah pengambilan keputusan yang sebelumnya kompleks dan sangat global, dapat diubah menjadi lebih simpel dan spesifik.
b. Eliminasi perhitungan-perhitungan yang tidak diperlukan, karena ketika menggunakan metode pohon keputusan maka sample diuji hanya berdasarkan kriteria atau kelas tertentu.
c. Fleksibel untuk memilih fitur dari node internal yang berbeda, fitur yang terpilih akan membedakan suatu kriteria dibandingkan kriteria yang lain dalam node yang sama. Kefleksibelan metode pohon keputusan ini meningkatkan kualitas keputusan yang dihasilkan jika dibandingkan ketika menggunakan metode penghitungan satu tahap yang lebih konvensional d. Dalam analisis multivariat, dengan kriteria dan kelas yang jumlahnya
sangat banyak, seorang penguji bisaanya perlu untuk mengestimasikan baik itu distribusi dimensi tinggi ataupun parameter tertentu dari distribusi kelas tersebut. Metode pohon keputusan dapat menghindari munculnya permasalahan ini dengan menggunakan kriteria yang jumlahnya lebih sedikit pada setiap node internal tanpa banyak mengurangi kualitas keputusan yang dihasilkan.
Kekurangan dari metode pohon keputusan adalah:
meningkatnya waktu pengambilan keputusan dan jumlah memori yang diperlukan.
b. Pengakumulasian jumlah eror dari setiap tingkat dalam sebuah pohon keputusan yang besar.
c. Kesulitan dalam mendesain pohon keputusan yang optimal.
d. Hasil kualitas keputusan yang didapatkan dari metode pohon keputusan sangat tergantung pada bagaimana pohon tersebut didesain.
2.7 Contoh Penerapan Algoritma
a. Baca tabel keputusan T1
Pada langkah yang pertama ini seperti yang ditunjukkan pada tabel 2.6, data awal dengan atribut keputusannya digunakan sebagai data input.
Tabel 2.6 Contoh data tabel T1
ID a b c d E
X1 1 0 2 1 1
X2 1 0 2 0 1
X3 1 2 0 0 2
X4 1 2 2 1 0
X5 2 1 0 0 2
X6 2 1 1 0 2
X7 2 1 2 1 1
b. Urutkan data secara ascending berdasarkan atribut keputusan
Selanjutnya data diurutkan secara urut dari keputusan yang paling rendah sampai ke yang keputusannya paling tinggi seperti pada table 2.7, fungsi pengurutan ini adalah untuk meningkatkan efisiensi setiap
Tabel 2.7 Atribut data diurutkan berdasarkan keputusan
ID a b c d E
X4 1 2 2 1 0
X1 1 0 2 1 1
X2 1 0 2 0 1
X7 2 1 2 1 1
X3 1 2 0 0 2
X5 2 1 0 0 2
X6 2 1 1 0 2
Setelah data diurutkan, maka dibentuk menjadi discernibility matrix , setiap atribut antar objek yang berbeda dimasukkan kedalam table discernibility matrix seperti pada gambar 2.8 dibawah ini
Tabel 2.8 Dircernibility matrix
X4 X1 X2 X7 X3 X5
X1 b
X2 b, d -
X7 a, b -
X3 c,d b, c, d b, c a, b, c, d
X5 a, b, c, d a, b, c, d a, b, c c,d -
X6 a, b, c, d a, b, c, d a, b, c c,d - -
Tabel 2.9 Boolean matriks dengan maksimal b dan c atribut
a b c d
X4 X1 0 1 0 0
X4 X2 0 1 0 1
X4 X7 1 1 0 0
X4 X3 0 0 1 1
X4 X5 1 1 1 1
X4 X6 1 1 1 1
X1 X3 0 1 1 1
X1 X5 1 1 1 1
X1 X6 1 1 1 1
X2 X3 0 1 1 0
X2 X5 1 1 1 0
X2 X6 1 1 1 0
X7 X3 1 1 1 1
X7 X5 0 0 1 1
X7 X6 0 0 1 1
SUM 8 12 12 10
{b, c}
Selanjutnya setiap atribut „b‟ dan „c‟ yang bernila satu akan dihapus, sehingga hasilnya menjadi seperti tabel 2.10 dan 2.11 dibawah ini.
Tabel 2.10 Boolean matrix yang nilai atribut b dan c adalah 1 dihapus
a b c d
X4 X1 0 1 0 0
X4 X2 0 1 0 1
X4 X7 1 1 0 0
X4 X5 1 1 1 1 x
X4 X6 1 1 1 1 x
X1 X3 0 1 1 1 x
X1 X5 1 1 1 1 x
X1 X6 1 1 1 1 x
X2 X3 0 1 1 0 x
X2 X5 1 1 1 0 x
X2 X6 1 1 1 0 x
X7 X3 1 1 1 1 x
X7 X5 0 0 1 1
X7 X6 0 0 1 1
Mencari lagi atribut yang paling maksimal untuk ditambahkan kedalam SPA nya.
Tabel 2.11 Boolean matriks hasil penghapusan
a b c d
X4 X1 0 1 0 0
X4 X2 0 1 0 1
X4 X7 1 1 0 0
X4 X3 0 0 1 1
X7 X5 0 0 1 1
X7 X6 0 0 1 1
SUM 1 3 3 4
{d}
Lakukan lagi penghapusan, pada atribut maksimal yang nilainya adalah
Pada table 2.12 dibawah ini, hapus matrik Boolean yang nilai atribut “d” nya adalah satu. Baris yang harus dihapus adalah pasangan objek X4X2,X4X3,X7X5 dan X7X6. Hasil penghapusan baris ini bias dilihat pada table 2.13.
Tabel 2.12 Boolean matriks hapus nilai atribut d adalah 1
a b c d
X4 X1 0 1 0 0
X4 X2 0 1 0 1 x
X4 X7 1 1 0 0
X4 X3 0 0 1 1 x
X7 X5 0 0 1 1 x
X7 X6 0 0 1 1 x
Tabel 2.13 Boolean matriks hasil penghapusan dan maksimal nya menjadi 2
a b c d
X4 X1 0 1 0 0
X4 X7 1 1 0 0
SUM 1 2 0 0
{b}
Masih pada table 2.13, setelah baris dihapus pada table 2.12, hitung kembali nilai maksimal dari matrik boolean.
Tabel 2.14 Boolean matriks hapus yang nilai b adalah 1
a b c d
X4 X1 0 1 0 0 x
X4 X7 1 1 0 0 x
Reduct : {b,c}, {d}, {b}
Ada beberapa algoritmanpohon keputusan, salah satunya adalah C4.5. C4.5 merupakan pengembangan dari dari algoritma ID3 (Iterative Dichotomiser 3), oleh karena itu C4.5 membuat pohon keputusan mempunyai langkah-langkah yang sama seperti pada ID3. ID3 sendiri dikembangkan oleh J. Ross Quinlan. Sedangkan pada perangkat lunak open source WEKA mempunyai versi sendiri yang dikenal sebagai J48.
Gambar 2.5 Algoritma C4.5
Sumber : Said, 2006
Untuk memilih atribut sebagai akar, dipilih atribut yang menghasilkan simpul yang paling “purest” (paling bersih). Kalau dalam satu cabang anggotanya berasal dari satu kelas maka cabang ini disebut pure. Semakin pure suatu cabang semakin baik. Ukuran purity dinyatakan dengan tingkat impurity. Salah satu criteria impurity adalah information gain. Jadi dalam memilih atribut untuk untuk memecah obyek dalam beberapa kelas harus dipilih atibut yang menghasilkan information gain paling besar.
dan diskret. Split untuk atribut numerik yaitu mengurutkan contoh berdasarkan atribut kontiyu A, kemudian membentuk ambang batas (threshold) M dari contoh- contoh yang ada dari kelas mayoritas pada setiap partisi yang bersebelahan, lalu menggabungkan partisi-partisi yang bersebelahan tersebut dengan kelas mayoritas yang sama. Split untuk atribut diskret A mempunyai bentuk value (A) εX, dimana X ⊂domain(A).
Untuk melakukan pemisahan obyek (split) dilakukan tes terhadap atribut dengan mengukur tingkat ketidakmurnian pada sebuah simpul (node). Pada algoritma C4.5 digunakan rasio perolehan (gain ratio). Sebelum menghitung rasio perolehan, perlu menghitung dulu nilai informasi dalam satuan bits dari suatu kumpulan objek. Cara menghitungnya dilakukan dengan menggunakan konsep entropi.
…………(2.3)
S : ruang (data) sampel yang digunakan untuk pelatihan
p+ : jumlah yang bersolusi positif (mendukung pada data sampel untuk kriteria
tertentu)
p- : jumlah yang bersolusi negatif (tidak mendukung pada data sampel untuk
kriteria tertentu). Catatan :
1. Entropi(S) = 0, jika semua contoh pada S berada dalam kelas yang sama.
2. Entropi(S) = 1, jika jumlah contoh positif dan negatif dalam S adalah sama.
3. 0 < Entropi(S) < 1, jika jumlah contoh positif dan negatif dalam S tidak sama.
…………(2.4)
Kemudian menghitung perolehan informasi dari output data atau variabel dependent y yang dikelompokkan berdasarkan atribut A, dinotasikan dengan gain (y,A). Perolehan informasi, gain (y,A), dari atribut A relatif terhadap output data y adalah:
…(2.5)
Nilai (A) adalah semua nilai yang mungkin dari atribut A, dan yc adalah subset dari y dimana A mempunyai nilai c. Term pertama dalam persamaan di atas adalah entropi total y dan term kedua adalah entropi sesudah dilakukan pemisahan data berdasarkan atribut A.
Untuk menghitung rasio perolehan perlu diketahui suatu term baru yang disebut pemisahan informasi (Split Info). Pemisahan informasi dihitung dengan cara :
…(2.6) bahwa S1 sampai Sc adalah c subset yang dihasilkan dari pemecahan S dengan menggunakan atribut A yang mempunyai sebanyak c nilai. Selanjutnya rasio perolehan (gain ratio) dihitung dengan cara :
2.8 Cross Validation
Dalam k-fold Cross Validation, data akan dipartisi secara acak ke dalam k subset yang saling eksklusif satu sama lain atau disebut “folds,” D1, D2, …Dk,
setiap folds mempunyai jumlah yang sama. Pelatihan dan pengujian dilakukan sebanyak k kali. Pada iterasi ke – i partisi Di digunakan sebagai data uji,
sedangkan sisa partisi lainnya digunakan sebagai data pelatihan. Maka dari itu pada iterasi pertama, D1 digunakan sebagai data uji dan D2, D3, ….Dk digunakan
sebagai data pelatihan. Pada iterasi kedua, D2 digunakan sebagai data uji,
sedangakan D1, D3, ….Dk digunakan sebagai data pelatihan. Pada iterasi ketiga,D3
digunakan sebagai data uji, sedangkan D1, D2, …Dk digunakan sebagai data
BAB III
ANALISIS DAN DESAIN
3.1 Identifikasi Sistem
Setiap pergantian tahun akademik baru, Universitas Sanata Dharma selalu melakukan Penerimaan Mahasiswa baru (PMB). Setiap calon mahasiswa baru ini yang bukan melewati jalur prestasi harus melakukan serangkaian test tertulis terlebih dahulu. Calon mahasiswa yang diterima belum tentu semuanya melakukan daftar ulang. Untuk kasus seperti itulah Ketua Program Studi perlu mengenali pola status registrasi calon mahasiswa dan melakukan prediksi status registrasi calon mahasiswa yang telah diterima dan menghitung jumlah calon mahasiswa yang diprediksi akan mendaftar ulang. Masalah tersebut dapat diatasi dengan menggunakan metode penambangan data, karena dengan penambangan data bisa dikenali karakteristik mahasiswa yang tidak melakukan daftar ulang.
Sistem yang akan dibangun dalam penelitian ini adalah sistem yang mampu mengenali karakteristik status registrasi atau daftar ulang calon mahasiswa dari data yang tersedia. Data-data mahasiswa diambil dari data pendaftaran mahasiswa baru mulai dari angkatan tahun 2007 sampai dengan 2010. Data masukan berupa file dengan format .csv, yang nantinya akan disimpan di database. Selanjutnya sistem akan memproses masukan tersebut dengan menggunakan algoritma RDT yang nantinya akan menghasilkan suatu pola klasifikasi. Dengan ditemukannya pola tersebut, maka sistem akan mampu melakukan prediksi dari masukan data mahasiswa baru, mahasiswa mana yang mungkin tidak melakukan daftar ulang sehingga bisa menjadi pertimbangan bagi kaprodi.
Data-data yang dipergunakan dalam penelitian ini adalah data-data calon mahasiswa baru dari angkatan tahun 2007 sampai dengan angkatan tahun 2010. Data ini mencakup seluruh program studi yang ada di Universitas Sanata Dharma, yang diperoleh dari Biro Administrasi dan Perencanaan Sistem Informasi (BAPSI) Universitas Sanata Dharma Yogyakarta.
3.2 Analisis Sistem 3.2.1 Analisis Data Awal
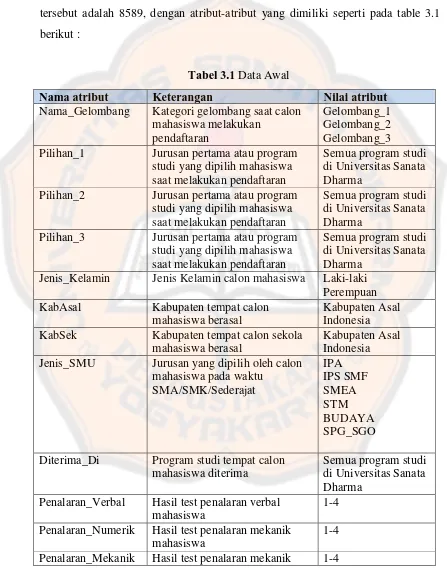
Data pendaftaran calon mahasiswa yang diperoleh dari BAPSI terdiri dari empat data file dengan eksistensi .xml. Jumlah record dari keseluruhan data tersebut adalah 8589, dengan atribut-atribut yang dimiliki seperti pada table 3.1 berikut :
Tabel 3.1 Data Awal
Nama atribut Keterangan Nilai atribut
Nama_Gelombang Kategori gelombang saat calon mahasiswa melakukan
pendaftaran
Gelombang_1 Gelombang_2 Gelombang_3 Pilihan_1 Jurusan pertama atau program
studi yang dipilih mahasiswa saat melakukan pendaftaran
Semua program studi di Universitas Sanata Dharma
Pilihan_2 Jurusan pertama atau program studi yang dipilih mahasiswa saat melakukan pendaftaran
Semua program studi di Universitas Sanata Dharma
Pilihan_3 Jurusan pertama atau program studi yang dipilih mahasiswa saat melakukan pendaftaran
Semua program studi di Universitas Sanata Dharma
Jenis_Kelamin Jenis Kelamin calon mahasiswa Laki-laki Perempuan
KabAsal Kabupaten tempat calon
mahasiswa berasal
Kabupaten Asal Indonesia KabSek Kabupaten tempat calon sekola
mahasiswa berasal
Kabupaten Asal Indonesia Jenis_SMU Jurusan yang dipilih oleh calon
mahasiswa pada waktu
Diterima_Di Program studi tempat calon mahasiswa diterima
Semua program studi di Universitas Sanata Dharma
Penalaran_Verbal Hasil test penalaran verbal mahasiswa
1-4
Penalaran_Numerik Hasil test penalaran mekanik mahasiswa
1-4
mahasiswa
Penalaran_Ruang Hasil test penalaran ruang mahasiswa
1-4
NilaiBahasa_Inggris Hasil test kemampuan bahasa Inggris mahasiswa
1-4
3.2.2 Pemrosesan Awal
Sebelum data digunakan untuk proses penambangan data, data mentah yang diperoleh harus melewati pemrosesan awal terlebih dahulu. Langkah- langkah yang digunakan dalam pemrosesan awal sesuai dengan empat tahapan awal dalam Knowledge discovery in databases (KDD) yaitu pembersihan data, integrasi data, seleksi data dan transpormasi data.
3.2.2.1 Pembersihan Data (Data Cleaning)
Pembersihan data (Data Cleaning) merupakan tahap awal dalam proses KDD. Pada data mentah terdapat beberapa record yang tidak relevan. Dalam proses pembersihan data ini data-data yang tidak relevan tersebut dibuang.
Atribut-atribut lain yang dilakukan cleaning antara lain Pilihan_1, Pilihan_2 dan Pilihan_3, kabupaten sekolah, kabupaten asal. Untuk atribut Pilihan_2, jika ada kolom atribut Pilihan_2 kosong, maka akan diisikan dengan nilai “Kosong”. Demikian juga dengan Pilihan_3, jika ditemukan kolom dari atribut Pilihan_3 yang kosong, maka akan diisikan dengan nilai Kosong. Untuk kabupaten asal dan kabupaten sekolah juga diisikan dengan nilai “kosong” apabila ditemukan field yang kosong.
3.2.2.2 Integrasi Data (Data Integration)
α
3.2.2.3 Seleksi Data (Data Selection)
Pada tahap ini dilakukan tahap pembuangan atribut-atribut yang tidak diperlukan atau tidak dibutuhkan dalam penelitian. Dalam penelitian ini, semua atribut seperti pada tabel 3.1 digunakan, dan tidak ada yang dibuang.
3.2.2.4 Transformasi
Pada tahap ini dilakukan peringkasan atau perubahan bentuk data mentah agar mudah dikelola untuk proses penambangan data, tanpa mengurangi esensi dari data tersebut. Dari data yang diperoleh, beberapa diantaranya merupakan data yang berupa angka yang sifatnya beragam, sehingga diperlukan pengelompokan data dengan rentang jangkauan tertentu. Sedangkan untuk data yang bukan numerik, tidak dilakukan transformasi data. Dalam penelitian ini, transformasi data dilakukan terhadap atribut-atribut nilai test seperti nilai verbal, nilai numerik, nilai mekanik, nilai ruang dan nilai bahasa inggris, yang pada awalnya berkisar antara nilai 1-10 ditranformasikan menjadi nilai interval dan menjadi nilai diskrit (discretization) 1,2,3 dan 4. Dalam penelitian data nilai terdistribusi normal, sehingga diterapkan aturan transformasi menggunakan teknik statistic, yaitu dengan rumus perkiraan interval untuk rata – rata (Supranto, Johanes,1992) :sebagai berikut :
Dalam penelitian ini diasumsikan selang kepercayaannya adalah 95% jadi didapatkan untuk nilai adalah 5% (didapatkan dari : 100% - selang kepercayaan). Jadi didapatkan nilai Z α
2
adalah 1,96. Nilai tersebut
didapatkan dari tabel normal Z (negative z). Setelah nilai galat standar didapatkan maka dapat dibentuk aturan 4 interval seperti pada table 3.2 berikut :
Tabel 3.2 Aturan Transformasi Data Nilai Tes Masuk
Nilai_baru Rumus
1 x > = X + 1.96 * σ / n 2 X <= x < X + 1.96 * σ / n
3 X - 1.96 * σ / n <= x < X
3.3 Analisis Kebutuhan Sistem 3.3.1 Diagram Use Case
Interaksi yang terjadi antara pengguna dan sistem digambarkan seperti pada gambar 3.1 dibawah ini
Input data Pendaftaran
<<depends on>>
Transformasi Data
<<depends on>>
Reduct atribut
Pengguna
<<depends on>>
Bentuk Pohon Keputusan
<<extends>>
Simpan Aturan
Prediksi
Gambar 3.1 Diagram Use Case
Tabel 3.3 Deskripsi Use Case
No. Nama Use Case Deskripsi Singkat
1 Input data pendaftaran mahasiswa Use case ini
menggambarkan proses angka ke nilai diskret dengan interval tertentu
3 Reduct atribut Use Case ini
menyimpan aturan pohon keputusan yang terbentuk dari proses penambangan data dalam bentuk tabel kedalam basisdata.
6 Prediksi Use case ini
3.3.2 Diagram Konteks
Berikut ini merupakan aliran data dalam proses yang input dan output yang terjadi antara pengguna dan sistem secara garis besar digambarkan melalui diagram konteks di bawah ini:
Pengguna
Data pelatihan, data tes
Pola yang terbentuk, hasil transformasi, hasil reduct hasil prediksi
Pengenalan Pola Klasifikasi Status Registrasi Calon Mahasiswa Baru Universitas Sanata Dharma Dengan Algoritma Reduct Based Decision Tree (RDT)
Gambar 3.2 Diagram Konteks
3.4 Perancangan Umum Sistem 3.4.1 Masukan Sistem
Masukan sistem yang akan digunakan dalam penelitian ini adalah himpunan data pelatihan (data training) dan data uji. Data pelatihan tediri dari 15 atribut, atribut-atribut tersebut dijabarkan seperti pada tabel 3.4 dibawah ini :
Tabel 3.4 Atribut Input Sistem
Nama atribut Keterangan Nilai atribut
Nama_Gelombang Kategori gelombang saat calon mahasiswa melakukan
pendaftaran
Gelombang_1 Gelombang_2 Gelombang_3 Pilihan_1 Jurusan pertama atau program
studi yang dipilih mahasiswa saat melakukan pendaftaran
Semua program studi di Universitas Sanata Dharma
Pilihan_2 Jurusan pertama atau program studi yang dipilih mahasiswa saat melakukan pendaftaran
Semua program studi di Universitas Sanata Dharma
Pilihan_3 Jurusan pertama atau program studi yang dipilih mahasiswa
saat melakukan pendaftaran Dharma Jenis_Kelamin Jenis Kelamin calon mahasiswa Laki-laki
Perempuan
KabAsal Kabupaten tempat calon
mahasiswa berasal
Kabupaten Asal Indonesia KabSek Kabupaten tempat calon sekola
mahasiswa berasal
Kabupaten Asal Indonesia Jenis_SMU Jurusan yang dipilih oleh calon
mahasiswa pada waktu
Diterima_Di Program studi tempat calon mahasiswa diterima
Semua program studi di Universitas Sanata Dharma
Penalaran_Verbal Hasil test penalaran verbal mahasiswa
1-4
Penalaran_Numerik Hasil test penalaran mekanik mahasiswa
1-4
Penalaran_Mekanik Hasil test penalaran mekanik mahasiswa
1-4
Penalaran_Ruang Hasil test penalaran ruang mahasiswa
1-4
NilaiBahasa_Inggris Hasil test kemampuan bahasa Inggris mahasiswa
1-4
Sedangkan data masukan untuk data uji hampir sama dengan data pelatihan, tetapi dikurangi atribut keputusan, yaitu status registrasi mahasiswa. Masukan untuk data uji dijabarkan seperti pada tabel 3.5 dibawah ini :
Tabel 3.5 Atribut Input Sistem Data Uji
Nama atribut Keterangan Nilai atribut
Nama_Gelombang Kategori gelombang saat calon mahasiswa melakukan
pendaftaran
Gelombang_1 Gelombang_2 Gelombang_3 Pilihan_1 Jurusan pertama atau program
studi yang dipilih mahasiswa saat melakukan pendaftaran
Semua program studi di Universitas Sanata Dharma
Pilihan_2 Jurusan pertama atau program studi yang dipilih mahasiswa saat melakukan pendaftaran
Semua program studi di Universitas Sanata Dharma
Pilihan_3 Jurusan pertama atau program studi yang dipilih mahasiswa
saat melakukan pendaftaran Dharma Jenis_Kelamin Jenis Kelamin calon mahasiswa Laki-laki
Perempuan
KabAsal Kabupaten tempat calon
mahasiswa berasal
Kabupaten Asal Indonesia KabSek Kabupaten tempat calon sekola
mahasiswa berasal
Kabupaten Asal Indonesia Jenis_SMU Jurusan yang dipilih oleh calon
mahasiswa pada waktu
Diterima_Di Program studi tempat calon mahasiswa diterima
Semua program studi di Universitas Sanata Dharma
Penalaran_Verbal Hasil test penalaran verbal mahasiswa
1-4
Penalaran_Numerik Hasil test penalaran mekanik mahasiswa
1-4
Penalaran_Mekanik Hasil test penalaran mekanik mahasiswa
1-4
Penalaran_Ruang Hasil test penalaran ruang mahasiswa
1-4
NilaiBahasa_Inggris Hasil test kemampuan bahasa Inggris mahasiswa
1-4
Dalam penelitian ini perhitungan akurasi dilakukan dengan menggunakan 5-fold cross validation. Jumlah data dalam penelitian ini tergantung dari jumlah record yang akan dimasukkan sebagai data pelatihan misalkan n data dengan keputusan “daftar ulang” sebanyak „i‟ dan keputusan “tidak daftar ulang” sebanyak „j‟, maka pembagian data untuk setiap fold-nya adalah sebagai berikut :
a. Kelompokkan data dengan keputusan „i‟
b. Tempatkan setiap satu objek mahasiswa dengan keputusan i kesetiap fold, sampai seluruh mahasiswa dengan keputusan „i‟ habis
c. Lanjutkan dengan mahasiswa dengan keputusan „j‟
a. Iterasi pertama
Data pada fold 1 akan menjadi data uji sedangkan untuk data pada fold 2-5 akan menjadi data pelatihan.
b. Iterasi kedua
Data pada fold 2 akan menjadi data uji sedangkan untuk data pada fold 1 dan fold 3-5 akan menjadi data pelatihan.
c. Iterasi ketiga
Data pada fold 3 akan menjadi data uji sedangkan untuk data pada fold 1, 2 dan fold 4-5 akan menjadi data pelatihan.
d. Iterasi keempat
Data pada fold 4 akan menjadi data uji sedangkan untuk data pada fold 1-3 dan fold 5 akan menjadi data pelatihan.
e. Iterasi kelima
Data pada fold 5 akan menjadi data uji sedangkan untuk data pada fold 1-4 akan menjadi data pelatihan.
.. 3.3
Pengukuran keakurasian dilakukan dengan menghitung rata-rata akurasi untuk setiap data uji di setiap akurasi.
3.4.2 Proses Sistem
Mulai
Masukkan Data Pelatihan
Proses Transformasi Data
Tampilkan Hasil Transformasi
Proses Reduct
Tampilkan Hasil Reduct
Reduce Data Pelatihan
Tampilkan Tabel Hasil
Reduce
Proses Pembentuka Aturan
Tampilkan Aturan
Simpan Aturan
Selesai
Gambar 3.3 Alur proses pembentukan pola
Mulai
Masukkan Data Uji
Proses Prediksi
Tampilkan Hasil Prediksi
dan Alokasi Kuota
Selesai
Gambar 3.4 Alur proses prediksi data
Algoritma dari setiap proses-proses diatas diuraikan seperti dibawah ini :
3.4.2.1 Proses Transformasi
1. Masukkan Data
2. Cari nilai rata-rata untuk setiap kolom yang akan ditransformasi pada data 3. Cari nilai Standar Deviasi untuk setiap kolom yang akan ditransformasi pada
data
3.4.2.2 Proses Reduct
1. Baca Tabel input .csv T1
2. Simpan Tabel dalam bentuk matriks array 2 dimensi T1 [ ][ ] 3. Urutkan baris secara ASC berdasarkan atribut keputusan
4. Buat Array SPA[ ] // untuk menyimpan set predominan attribute 5. Buat Array untuk menyimpan semua atribut tabel, ArrDataAttribut [ ] 6. Buat Boolean Matriks BM [ ] [ ]
for (int i = 0; i < T1.length; i++) {
for (int j = 1; j < T1.length - i; j++) { int w = i + j;
int lengthh = attribut.length - 1;
if (!T1[ I ][attribut.length - 1].equalsIgnoreCase(T1[ w ] [attribut.length - 1] )) {
construct = construct + 1;
for (int k = 0; k < attribut.length - 1; k++) {
// Jika keputusannya sama, Lanjut }
}
7. Buat array untuk menampung jumlah setiap kolom pada BM, ArrJmlBM [ ] 8. Menghitung jumlah BM dari setiap atribut dan dimasukkan kedalam
ArrJmlBM [ ]
9. Int counter,temp,terbesar; 10. Counter = 0;
for (i=0; i<BM.column.count; i++) { for (j=0 ; j<BM.rows.count; j++) {
temp = BM[j][i];
terbesar = terbesar + temp; }
ArrJmlBM [counter] = terbesar Counter +=1;
Terbesar =0; }
Counter =0;
12. Buat Array untuk menampung proses penyimpanan index attribute SPA, ArrTemp[ ]
13. Cari A, data nilai terbesar dari array ArrJmlBM [ ]
14. Bandingkan nilai A dengan setiap nilai pada ArrJmlBM [ ], jika sama dengan nilai A, maka simpan index nya, dan masukkan kedalam array ArrTemp[ ] 15. Membandingkan setiap nilai data pada array ArrTemp[ ], dan bandingkan
nilai tersebut dengan index pada ArrDataAttribut [ ], dapatkan isinya ArrDataAttribut [ ], dan masukkan ke array SPA[ ], sebagai atribut predominan
16. Hapus nilai data BM[][] yang nilainya 1 untu setiap barisnya yang kolomnya seperti pada setiap nilai pada ArrTemp[ ]
17. Kosongkan ArrTemp[ ] 18. Kosongkan ArrJmlBM[ ]
19. Ulangi langkah 8 – 19 sampai isi BM[ ][ ] habis
3.4.2.3 Proses Reduce Data Pelatihan
a. Baca data pelatihan
3.4.2.4 Proses Pembentukan Aturan
a. Ambil atribut-atribut dari proses reduct dari SPA b. Mengubah bentuk data menjadi bentuk pohon
a. Menentukan node awal
Langkah yang dilakukan untuk menentukan node awal adalah menghitung nilai gain tiap atribut kecuali atribut keputusan.
Berikut merupakan langkah-langkah penghitungannya : a) Hitung jumlah baris pada sampel data
b) Hitung entropi atribut keputusan dengan rumus 2.3 c) Cari atribut-atribut dan hitung jumlah atribut yang akan
dihitung nilai gainnya
d) Hitung jumlah kejadian untuk atribut ke-i e) Untuk atribut ke-i, kejadian ke-j
Hitung jumlah sampel yang memenuhi syarat kejadian dengan atribut ke-i = kejadian ke-j dan status = Daftar Ulang
Hitung jumlah sampel yang memenuhi syarat kejadian dengan atribut ke-i = kejadian ke-j dan status = tidak DU.
f) Kemudian hitung nilai entropi pada kejadian ke-j dengan rumus 2.4 g) Lakukan langkah e dan f untuk keseluruhan atribut ke-i
h) Hitung rata-rata terbobot entropi atribut ke-i dengan rumus 2.5 i) Hitung nilai gain atribut ke-i dengan mengurangkan entropi atribut
keputusan dengan rata-rata terbobot entropi atribut ke-i. j) Cari Split dengan rumus 2.6
j) Cari Gain Ratio dengan rumus 2.7
j) Cari nilai gain ratio atribut paling besar. Atribut inilah yang akan menjadi node awal.
b. Menyusun pohon