Advances in Intelligent Systems and Computing
Volume 573
Series editor
About this Series
The series“Advances in Intelligent Systems and Computing”contains publications on theory, applications, and design methods of Intelligent Systems and Intelligent Computing. Virtually all disciplines such as engineering, natural sciences, computer and information science, ICT, economics, business, e-commerce, environment, healthcare, life science are covered. The list of topics spans all the areas of modern intelligent systems and computing.
The publications within“Advances in Intelligent Systems and Computing”are primarily textbooks and proceedings of important conferences, symposia and congresses. They cover significant recent developments in thefield, both of a foundational and applicable character. An important characteristic feature of the series is the short publication time and world-wide distribution. This permits a rapid and broad dissemination of research results.
Advisory Board
Chairman
Nikhil R. Pal, Indian Statistical Institute, Kolkata, India e-mail: [email protected]
Members
Rafael Bello Perez, Universidad Central“Marta Abreu”de Las Villas, Santa Clara, Cuba e-mail: [email protected]
Emilio S. Corchado, University of Salamanca, Salamanca, Spain e-mail: [email protected]
Hani Hagras, University of Essex, Colchester, UK e-mail: [email protected]
LászlóT. Kóczy, Széchenyi István University, Győr, Hungary e-mail: [email protected]
Vladik Kreinovich, University of Texas at El Paso, El Paso, USA e-mail: [email protected]
Chin-Teng Lin, National Chiao Tung University, Hsinchu, Taiwan e-mail: [email protected]
Jie Lu, University of Technology, Sydney, Australia e-mail: [email protected]
Patricia Melin, Tijuana Institute of Technology, Tijuana, Mexico e-mail: [email protected]
Nadia Nedjah, State University of Rio de Janeiro, Rio de Janeiro, Brazil e-mail: [email protected]
Ngoc Thanh Nguyen, Wroclaw University of Technology, Wroclaw, Poland e-mail: [email protected]
Jun Wang, The Chinese University of Hong Kong, Shatin, Hong Kong e-mail: [email protected]
Radek Silhavy
•Roman Senkerik
Zuzana Kominkova Oplatkova
Zdenka Prokopova
•Petr Silhavy
Editors
Arti
fi
cial Intelligence Trends
in Intelligent Systems
Proceedings of the 6th Computer
Science On-line Conference 2017
(CSOC2017), Vol 1
Editors
Radek Silhavy
Faculty of Applied Informatics Tomas Bata University in Zlín Zlin
Czech Republic Roman Senkerik
Faculty of Applied Informatics Tomas Bata University in Zlín Zlin
Czech Republic
Zuzana Kominkova Oplatkova Faculty of Applied Informatics Tomas Bata University in Zlín Zlin
Czech Republic
Zdenka Prokopova
Faculty of Applied Informatics Tomas Bata University in Zlín Zlin
Czech Republic Petr Silhavy
Faculty of Applied Informatics Tomas Bata University in Zlín Zlin
Czech Republic
ISSN 2194-5357 ISSN 2194-5365 (electronic) Advances in Intelligent Systems and Computing
ISBN 978-3-319-57260-4 ISBN 978-3-319-57261-1 (eBook) DOI 10.1007/978-3-319-57261-1
Library of Congress Control Number: 2017937148
©Springer International Publishing AG 2017
This work is subject to copyright. All rights are reserved by the Publisher, whether the whole or part of the material is concerned, specifically the rights of translation, reprinting, reuse of illustrations, recitation, broadcasting, reproduction on microfilms or in any other physical way, and transmission or information storage and retrieval, electronic adaptation, computer software, or by similar or dissimilar methodology now known or hereafter developed.
The use of general descriptive names, registered names, trademarks, service marks, etc. in this publication does not imply, even in the absence of a specific statement, that such names are exempt from the relevant protective laws and regulations and therefore free for general use.
The publisher, the authors and the editors are safe to assume that the advice and information in this book are believed to be true and accurate at the date of publication. Neither the publisher nor the authors or the editors give a warranty, express or implied, with respect to the material contained herein or for any errors or omissions that may have been made. The publisher remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Printed on acid-free paper
This Springer imprint is published by Springer Nature The registered company is Springer International Publishing AG
Preface
This book constitutes the refereed proceedings of the Artificial Intelligence Trends in Intelligent Systems Section of the 6th Computer Science On-line Conference 2017 (CSOC 2017), held in April 2017.
Particular emphasis is laid on modern trends in artificial intelligence and its application to intelligent systems. New algorithms, methods, and applications of optimization algorithm, neural network, and deep learning and hybrid algorithms are also presented.
The volume Artificial Intelligence Trends in Intelligent Systems brings and presents new approaches and methods to real-world problems and exploratory research that describes novel approaches in the definedfields.
CSOC 2017 has received (all sections) 296 submissions, in which 148 of them were accepted for publication. More than 61% of accepted submissions were received from Europe, 34% from Asia, 3% from Africa, and 2% from America. Researches from 27 countries participated in CSOC 2017 conference.
CSOC 2017 conference intends to provide an international forum for the dis-cussion of the latest high-quality research results in all areas related to computer science. The addressed topics are the theoretical aspects and applications of com-puter science, artificial intelligences, cybernetics, automation control theory, and software engineering.
Computer Science On-line Conference is held online, and modern communi-cation technology which is broadly used improves the traditional concept of sci-entific conferences. It brings equal opportunity to participate to all researchers around the world.
The editors believe that readers willfind the following proceedings interesting and useful for their own research work.
March 2017 Radek Silhavy
Petr Silhavy Zdenka Prokopova Roman Senkerik Zuzana Kominkova Oplatkova
Organization
Program Committee
Program Committee Chairs
Zdenka Prokopova, Ph.D., Associate Professor, Tomas Bata University in Zlin, Faculty of Applied Informatics, email: [email protected]
Zuzana Kominkova Oplatkova, Ph.D., Associate Professor, Tomas Bata University in Zlin, Faculty of Applied Informatics, email: [email protected]
Roman Senkerik, Ph.D., Associate Professor, Tomas Bata University in Zlin, Faculty of Applied Informatics, email: [email protected]
Petr Silhavy, Ph.D., Senior Lecturer, Tomas Bata University in Zlin, Faculty of Applied Informatics, email: [email protected]
Radek Silhavy, Ph.D., Senior Lecturer, Tomas Bata University in Zlin, Faculty of Applied Informatics, email: [email protected]
Roman Prokop, Ph.D., Professor, Tomas Bata University in Zlin, Faculty of Applied Informatics, email: [email protected]
Prof. Viacheslav Zelentsov, Doctor of Engineering Sciences, Chief Researcher of St. Petersburg Institute for Informatics and Automation of Russian Academy of Sciences (SPIIRAS).
Program Committee Members
Boguslaw Cyganek, Ph.D., DSc, Department of Computer Science, University of Science and Technology, Krakow, Poland.
Krzysztof Okarma, Ph.D., DSc, Faculty of Electrical Engineering, West Pomeranian University of Technology, Szczecin, Poland.
Monika Bakosova, Ph.D., Associate Professor, Institute of Information Engineering, Automation and Mathematics, Slovak University of Technology, Bratislava, Slovak Republic.
Pavel Vaclavek, Ph.D., Associate Professor, Faculty of Electrical Engineering and Communication, Brno University of Technology, Brno, Czech Republic.
Miroslaw Ochodek, Ph.D., Faculty of Computing, Poznan University of Technology, Poznan, Poland.
Olga Brovkina, Ph.D., Global Change Research Centre Academy of Science of the Czech Republic, Brno, Czech Republic & Mendel University of Brno, Czech Republic.
Elarbi Badidi, Ph.D., College of Information Technology, United Arab Emirates University, Al Ain, United Arab Emirates.
Luis Alberto Morales Rosales, Head of the Master Program in Computer Science, Superior Technological Institute of Misantla, Mexico.
Mariana Lobato Baes, M.Sc., Research-Professor, Superior Technological of Libres, Mexico.
Abdessattar Chaâri, Professor, Laboratory of Sciences and Techniques of Automatic control & Computer engineering, University of Sfax, Tunisian Republic. Gopal Sakarkar, Shri. Ramdeobaba College of Engineering and Management, Republic of India.
V.V. Krishna Maddinala, Assistant Professor, GD Rungta College of Engineering & Technology, Republic of India.
Anand N. Khobragade, Scientist, Maharashtra Remote Sensing Applications Centre, Republic of India.
Roman Senkerik Petr Silhavy Radek Silhavy Jiri Vojtesek Eva Volna Janez Brest Ales Zamuda Roman Prokop Boguslaw Cyganek Krzysztof Okarma Monika Bakosova Pavel Vaclavek Olga Brovkina Elarbi Badidi
Organizing Committee Chair
Radek Silhavy, Ph.D., Tomas Bata University in Zlin, Faculty of Applied Informatics, email: [email protected]
Conference Organizer (Production)
OpenPublish.eu s.r.o.
Web:http://www.openpublish.eu Email: [email protected]
Conference Website, Call for Papers
http://www.openpublish.eu
Contents
A Genetic Algorithm to Improve Lifetime of Wireless Sensor
Networks by Load Balancing. . . 1 Nazila Karkooki, Mohammad Khalily-Dermany, and Pouria Polouk
Proposal of a Fuzzy Control System for Heat Transfer Using PLC. . . .. . . . 11 Martin Nesticky, Tomas Skulavik, and Jaroslav Znamenak
The Study of Improved Particle Filtering Target Tracking Algorithm
Based on Multi-features Fusion. . . 20 Hongxia Chu, Zhongyu Xie, Du Juan, Rongyi Zhang, and Fanming Liu
Reflecting on Imbalance Data Issue When Teaching
Performance Measures. . . 33 PavelŠkrabánek and Filip Majerík
Ontology Based Knowledge Representation for Cognitive Decision
Making in Teaching Electrical Motor Concepts. . . 43 Atul Prakash Prajapati and D.K. Chaturvedi
Parametric Optimization Based on Bacterial Foraging
Optimization. . . 54 Daria Zaruba, Dmitry Zaporozhets, and Elmar Kuliev
Hybrid Approach for Graph Partitioning. . . 64 Vladimir Kureichik, Daria Zaruba, and Vladimir Kureichik Jr.
The Combined Method of Semantic Similarity Estimation of Problem
Oriented Knowledge on the Basis of Evolutionary Procedures. . . 74 V.V. Bova, E.V. Nuzhnov, and V.V. Kureichik
The Development of Genetic Algorithm for Semantic Similarity
Estimation in Terms of Knowledge Management Problems. . . 84 Yury Kravchenko, Ilona Kursitys, and Victoria Bova
Scheme Partitioning by Means of Evolutional Procedures
Using Symbolic Solution Representation. . . 94 Oleg B. Lebedev, Svetlana V. Kirilchik, and Eugeniy Y. Kosenko
Application of Ontological Approach for Learning
Paths Formation. . . 105 Boris K. Lebedev, Oleg B. Lebedev, and Tatiana Y. Kudryakova
Empirical Evaluation of the Cycle Reservoir with Regular Jumps
for Time Series Forecasting: A Comparison Study . . . 115 Mais Haj Qasem, Hossam Faris, Ali Rodan, and Alaa Sheta
Forecasting of Convective Precipitation Through NWP Models
and Algorithm of Storms Prediction. . . 125 DavidŠaur
Novel Decision-Based Modeling of Minimizing Usage Cost
of Electricity in Smart Grid. . . 137 A. Abdul Khadar, Javed Ahamed Khan, and M.S. Nagaraj
Integrated Algorithm of the Domain Ontology Development. . . 146 Viktor Kureichik and Irina Safronenkova
Formal Models of the Structural Errors in the Knowledge Bases
of Intellectual Decision Making Systems. . . 156 Olga Dolinina and Natalya Suchkova
Hybrid Particle Swarm Optimization and Backpropagation Neural
Network for Organic and Inorganic Waste Recognition . . . 168 Christ R.A. Djaya, Novi Sucianti, Randy, and Lili A. Wulandhari
Calibration of Low-Cost Three Axis Accelerometer
with Differential Evolution. . . 178 Ales Kuncar, Martin Sysel, and Tomas Urbanek
Hierarchical Rough Fuzzy Self Organizing Map
for Weblog Prediction. . . 188 Arindam Chaudhuri and Soumya K. Ghosh
Approach to the Minimum Cost Flow Determining in Fuzzy
Terms Considering Vitality Degree. . . 200 Victor Kureichik and Evgeniya Gerasimenko
Query Focused Multi document Summarization Based
on the Multi facility Location Problem. . . 210 Ercan Canhasi
Query Focused Multi-document Summarization Based
on Five-Layered Graph and Universal Paraphrastic Embeddings . . . 220 Ercan Canhasi
Prediction of Diseases Using Hadoop in Big Data
-A Modified Approach. . . 229 D. Jayalatchumy and P. Thambidurai
Building an Intelligent Call Distributor. . . 239 Thien Khai Tran, Dung Minh Pham, and Binh Van Huynh
A Fuzzy Logic Based Recommendation System for Classified
Advertisement Websites. . . 249 Umar Sharif, Md. Rafik Kamal, and Rashedur M. Rahman
Potential Risk Factor Analysis and Risk Prediction System
for Stroke Using Fuzzy Logic. . . 262 Farzana Islam, Sarah Binta Alam Shoilee, Mithi Shams,
and Rashedur M. Rahman
Weighted Similarity: A New Similarity Measure for Document
Ranking Features. . . 273 Mehrnoush Barani Shirzad and Mohammad Reza Keyvanpour
Face Identification and Face Classification Using Computer
Vision and Machine Learning Algorithm. . . 281 Suhas Athani and C.H. Tejeshwar
DEMST-KNN: A Novel Classification Framework to Solve
Imbalanced Multi-class Problem. . . 291 Ying Xia, Yini Peng, Xu Zhang, and HaeYoung Bae
Combined Method for Integration of Heterogeneous Ontology
Models for Big Data Processing and Analysis. . . 302 Viktor Kureychik and Alexandra Semenova
Enhancing Extraction Method for Aggregating Strength Relation
Between Social Actors. . . 312 Mahyuddin K.M. Nasution and Opim Salim Sitompul
A Case Study on Flat Rate Estimation Based on Fuzzy Logic . . . 322 Kazi Kowshin Raihana, Fayezah Anjum, Abu Saleh Mohammed Shoaib,
Md. Abdullah Ibne Hossain, M. Alimuzzaman, and Rashedur M. Rahman SA-Optimization Based Decision Support Model for Determining
Fast-Food Restaurant Location . . . 333 Ditdit Nugeraha Utama, Muhammad Ryanda Putra, Mawaddatus Su’udah, Zulfah Melinda, Nur Cholis, and Abdul Piqri
Bayesian Regularization-Based Classification for Proposed Textural
and Geometrical Features in Brain MRI. . . 343 V. Kiran Raj and Amit Majumder
The Comparison of Effects of Relevant-Feature Selection Algorithms
on Certain Social-Network Text-Mining Viewpoints . . . 354 JanŽižka and František Dařena
An Improved Speaker Identification System Using Automatic Split-Merge Incremental Learning (A-SMILE) of Gaussian
Mixture Models. . . 364 Ayoub Bouziane, Jamal Kharroubi, and Arsalane Zarghili
Sarcasm Identification on Twitter: A Machine Learning Approach. . . .. . . . 374 AytuğOnan
The Problem of Critical Events’Combinations
in Air Transportation Systems. . . 384 Leonid Filimonyuk
Using Text Mining Methods for Analysis of Production Data
in Automotive Industry. . . 393 Lukas Hrcka, Veronika Simoncicova, Ondrej Tadanai, Pavol Tanuska,
and Pavel Vazan
Entropy Based Surface Quality Assessment of 3D Prints. . . 404 Jarosław Fastowicz and Krzysztof Okarma
Dim Line Tracking Using Deep Learning for Autonomous
Line Following Robot. . . 414 Grzegorz Matczak and Przemysław Mazurek
Properties of Genetic Algorithms for Automated
Algebras Generation. . . 424 Hashim Habiballa, Matej Hires, and Radek Jendryscik
An Application of a Discrete Firefly Algorithm in the Context
of Smart Mobility. . . 434 Ezzeddine Fatnassi, Noor Guesmi, and Tesnime Touil
Hybrid Fuzzy Algorithm for Solving Operational Production
Planning Problems . . . 444 L.A. Gladkov, N.V. Gladkova, and S.A. Gromov
Synthesis Production Schedules Based on Ant Colony
Optimization Method . . . 456 Yuriy Skobtsov, Olga Chengar, Vadim Skobtsov,
and Alexander N. Pavlov
The Use of Deep Learning for Segmentation of Bone Marrow
Histological Images. . . 466 Dorota Oszutowska–Mazurek and Oktawian Knap
Innovative Intelligent Interaction Systems of Loader Cranes
and Their Human Operators. . . 474 Maciej Majewski and Wojciech Kacalak
Smart Control of Lifting Devices Using Patterns and Antipatterns . . . .. . . . 486 Maciej Majewski and Wojciech Kacalak
Application of Clustering Techniques for Video Summarization–
An Empirical Study . . . 494 Alvina Anna John, Binoy B. Nair, and P.N. Kumar
Survey on Various Traffic Monitoring and Reasoning Techniques. . . 507 H. Haritha and T. Senthil Kumar
The Influence of Archive Size to SHADE. . . 517 Adam Viktorin, Roman Senkerik, Michal Pluhacek, and Tomas Kadavy
Comparing Border Strategies for Roaming Particles on Single
and Multi-swarm PSO . . . 528 Tomas Kadavy, Michal Pluhacek, Adam Viktorin, and Roman Senkerik
On the Randomization of Indices Selection
for Differential Evolution. . . 537 Roman Senkerik, Michal Pluhacek, Adam Viktorin, and Tomas Kadavy
Author Index. . . 549
Enhancing Extraction Method for Aggregating
Strength Relation Between Social Actors
Mahyuddin K.M. Nasution(B)and Opim Salim Sitompul
Information Technology Department, Fakultas Ilmu Komputer Dan Teknologi Informasi (Fasilkom-TI), and Information System Centre,
Universitas Sumatera Utara, 1500 USU, Medan, Sumatera Utara, Indonesia [email protected]
Abstract. There are differences in the resultant of extracting the rela-tions between social actors based on two streams of approaches in prin-ciple. However, one of the methods like the superficial methods can upgraded to make the information extraction by using the principles of the other methods, and this needs proof systematically. This paper serves to reveal some formulations have the function for resolving this issue. Based on the results of experiments conducted the expanded method is the adequate.
Keywords: Search engine
·
Search term·
Query·
Social actor·
Singleton·
Doubleton1
Introduction
Extracting social network from Web has carried out with a variety of approaches ranging from simple to complex [1]. Unsupervised method or superficial method generally more concise and low cost, but only generates the strength relations between social actors from heterogeneous and unstructured sources such as the Web [2]. Instead, supervised methods are generally more complicated and high cost and it produces labels of relationship between social actors, but it came from sources, homogeneous and semi-structured like corpuses [3,4]. However, to generate social networks that enable to express semantically meaning is not easy [5]. This requires a method to represent their privilege of both methods: An approach is not only produces a relationship but re-interpret the relationship based on the aggregation principle. This paper aimed to enhance the superficial method for extracting social network from Web.
2
Problem Definition
The initial concept semantically of the extraction of social network from Web is to explore a series of names through co-occurrence using search engine [6,7]. Then, the extraction of social network made possible by involving the occurrence. Formally, the following we stated extracting social networks [8,9].
c
Springer International Publishing AG 2017
R. Silhavy et al. (eds.),Artificial Intelligence Trends in Intelligent Systems,
Enhancing Extraction Method for Aggregating Strength Relation 313
Occurrence and co-occurrence individually are a query (q) representing a social actor and a query representing a pair of social actors. On the occurrence, qcontains a name of social actor, for exampleq=”Mahyuddin K. M. Nasution”. While on the co-occurrence,q contains two names of social actors, for example q =”Mahyuddin K. M. Nasution”, ”Shahrul Azman Noah” [2]. Therefore, names of social actors are the search terms, and we define it formally as follows
Definition 2. A search term tk consists of words or phrase, i.e.tk ={wk|k=
1, . . . , o}.
We use the well query to pry information from the Web by submitting it to search engine. A search engine works on a collection of documents or web pages, or more precisely as follows [10].
Definition 3. Ωis a set of web pages indexed search engine, if there are a table
relation of(ti, ωj)such thatΩ={(t, ω)ij}, whereti is search terms andωj is a
Proposition 1. Iftx∈ S,S is a set of singleton search terms of search engine,
then there are vector spaceΩx⊆Ω for generating hit count|Ωx|.
Proof. For tx ∈ S, it means that tx ∈ ω and ω ∈ Ω, or S ∈ Ω, every web page that is indexed by search engine contains at least one occurrence of tx, where based on Definition3 Ωx = {(tx, ωx)ij}. Thus for all web pages be in force {Ωx(tx) = 1} so thatΩx⊆Ω be the singleton search engine event of web pages that contain an occurrence oftx∈ωx, and based on Definition4, we have
314 M.K.M. Nasution and O.S. Sitompul
As information of any social actor, the singleton is the basic of search engine property that statistically related to the social actor. In this case, the singleton be the necessary condition for gaining the information of social actor from Web although it contains connatural trait (bias and ambiguity), and naturally it becomes the social dynamic of human beings [2]. Hit count is main information for a social actor based on Web, and validation of this information can obtained by crawling one after one the snippets list returned by the search engine [11].
Definition 5. Let tx is a search term. A snippet is a set of words, i.e. sx =
{wi|i = 1, . . . ,±50}. A list of snippets is Lx ={sj|j = 1, . . . , J}x,m ≤ |Ωx|, then size of snippet|sx|=±50words andLx is a matrixMjk that consists ofj rows and kcolumns where each column refers to one token of word w∈sj.
Lemma 1. If wis a token inL, thenwstatistically has the character.
Proof. It is known that w ∈ sx, sx ∈ L, we havew as one token inL. Based proved thatwhas the character, i.e. the relative probability ofw
p(w) = |w|
Proof. Similar to Proposition1, and based on Definitions3 and 6, we have the hit count of doubleton as follows
|Ωx∩Ωy|=
Ω
Enhancing Extraction Method for Aggregating Strength Relation 315
Lemma 2. If wis a token inLD as list of snippets based on doubleton, thenw
statistically has the character in the doubleton.
Proof. Similar to Lemma1, and based on Definitions5 and6, we have the char-acter of win the doubleton as follows
pD(w) =
|w| |Ωx∩Ωy|
∈[0,1], (4) where |w| ≤ |Ωx∩Ωy| and|Ωx∩Ωy| = 0.
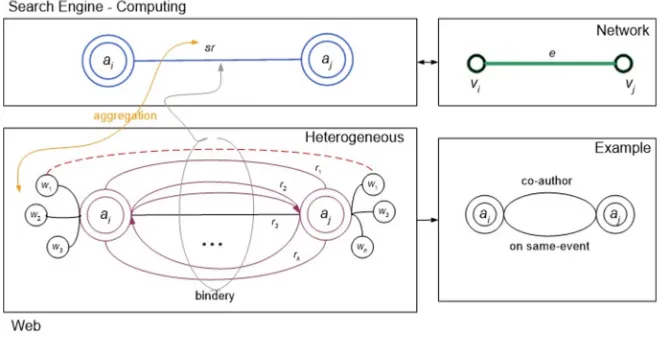
Fig. 1.Type of snippets based on co-occurrence (Google search engine)
316 M.K.M. Nasution and O.S. Sitompul
of three (triple) dots between two names of social actors. Triple dots naturally is a word in text. The direct relations represented by direct co-occurrences like co-author, but the indirect relations represented by indirect co-occurrences such as citation or present on same event.
3
The Proposed Approach
The method of extracting information from Web recognized as the superficial method, categorized in unsupervised stream, involving a search engine to obtain the information like the hit counts used in computation [12]. Generally, for gen-erating relation between actors applied the similarity measurement [13].
Definition 7. rs∈Ris the strength relation between two social actorsa, b∈A
if it meets the comparison among the different information of two actors (aand
b)and the common information of them (a∩b)in the similarity measurement. Orsr=sim(a,b,a∩b)in [0,1],a∩b≤a anda∩b≤b.
Suppose we use Jaccard coefficient, we possesssrbased on hit counts
sr= |Ωa∩Ωb|
|Ωa|+|Ωb| − |Ωa∩Ωb|
∈[0,1], (5) where|Ωa∩Ωb| ≤ |Ωa| and|Ωa∩Ωb| ≤ |Ωb|.
Lemma 3. If ir is a indirect relation between two social actors a, b∈A, then
ir statistically has the character in the doubleton.
Proof. Suppose the indirect relationsircan be recognized in each snippet based on doubleton, we have number of the indirect relations in the snippets list based on doubleton or |ir|, |ir| = number of snippets contain triple dots. Therefore, we generate the character ofiras follows
p(ir) = |ir|
|Ωa∩Ωb|
∈[0,1], (6) where|ir| ≤ |Ωa∩Ωb|and|Ωa∩Ωb| = 0.
Proposition 3. If sr is a strength relation between two social actorsa, b∈A,
then the aggregation ofsr consists of three binderies.
Proof. Suppose p(ir) ∈ [0,1] (Eq. (6)) as probability of the indirect relation based on doubleton, then probability of the direct relation (dr) based on dou-bleton is as follows
p(dr) = |dr|
|Ωa∩Ωb|
∈[0,1], (7) where|dr| ≤ |Ωa∩Ωb|and|Ωa∩Ωb| = 0.
Enhancing Extraction Method for Aggregating Strength Relation 317
characteristics arep(ir) andp(dr), respectively. However, 1−p(ir)−p(dr)≥0, ifp(ir) +p(dr)−1= 0, we obtain
p(ur) = 1−(p(ir) +p(dr)) (8) i.e. the character of relation has not be determined with certainty through the co-occurrence. Becausep(ir),p(dr) andp(ur) can be considered as the percentage values, the multiplication of a characteristic with the strength relation regarded as bindery based on type of relations. Therefore, we have three bindings of the strength relations as follows
J1 A bindery of strength relations based on the direct relations,
srdr=sr∗p(dr)∈[0,1] (9) J2 A bindery of strength relations based on the indirect relations,
srir=sr∗p(ir)∈[0,1] (10) J3 A bindery of strength relations based on the unclear relations,
srur=sr∗p(ur)∈[0,1] (11)
Fig. 2.Type of relations based the social network extraction
Proposition 4. If sr is a strength relation between two social actors a, b∈A,
then the aggregation ofsr consists of sheets.
Proof. Based on Proposition 3and by applying Eq. (4) to the strength relation sr, we can generate the aggregations based on words and we call it as the sheets of relationssh, i.e.
318 M.K.M. Nasution and O.S. Sitompul
Generally, this concept is considered to be an approach to the concept of latent semantic analysis [14] that have been put forward and produce labels on the social networks based on the supervised stream or the generative probabilistic model (PGM) [4,15]. This approach as enhancing for superficial method [16,17].
Theorem 1. sris the strength relation between two actors a, b∈Aif and only
if there are aggregation.
Proof. This is a direct consequence of Propositions3 and 4 as the necessary conditions, and Lemmas1,2 and3as the sufficient conditions, see Fig.2.
generate (keyword) INPUT : A set of actors
OUTPUT : aggregation of the strength relations STEPS :
1. |Ωa| ←ta query and search engine. 2. |Ωb| ←tb query and search engine.
3. |Ωa∩Ωa| ←ta∧tb query and search engine.A={w1, w2, . . . , wn} ←Collect words-(terms) per a pair of actors from snippets based on doubleton. 4. |dr| ←List of snippets based on doubleton.
5. |ir| ←List of snippets based on doubleton. 6. sr∗p(dr) andsr∗p(ir)
7. Aggregating sr∗p(dr) andsr∗p(ir) based on the summation of sheets per domain.
8. Measuring recall and precision of relations.
4
Experiment
In this experiment, we implicate n = 469 social actors or n(n−1) = 219,492 potential relations. There are 30,044 strength relations between 469 actors or 14% of potential relations, among them (a) 4,422 direct relations (2%), (b) 21,462 indirect relations (10%), and (c) 4,160 direct and indirect relations (2%). There-fore, there are 21,462 lists of snippets of doubleton (LD) contain the triple dots
in all snippets, or there are 4,422 lists of snippets of doubleton (LD) have no
dots in all snippets.
Suppose we define the ontology domain and taxonomically we interpret in a set of words as follows
1. Direct relations:
(a) author-relationship ={activity, article, author, authors, award, journal, journals, paper, patent, presentation, proceedings, publication, theme, poster,. . .}.
(b) academic rule ={supervisor, cosupervisor, editor, editors, graduate, lec-turer, professor, prof, researcher, reviewer, student,. . .}.
Enhancing Extraction Method for Aggregating Strength Relation 319
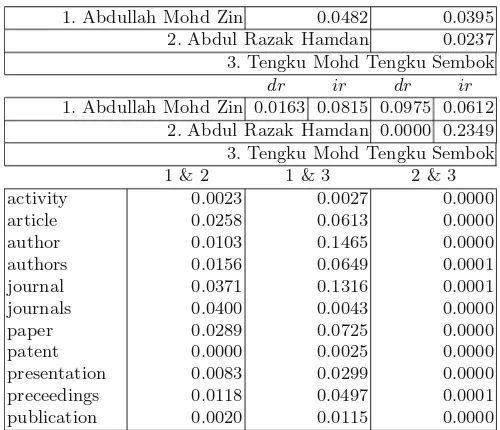
Table 1.The strength relation, direct and indirect relations, and author-relationship
sr
1. Abdullah Mohd Zin 0.0482 0.0395
2. Abdul Razak Hamdan 0.0237
3. Tengku Mohd Tengku Sembok
dr ir dr ir
1. Abdullah Mohd Zin 0.0163 0.0815 0.0975 0.0612 2. Abdul Razak Hamdan 0.0000 0.2349 3. Tengku Mohd Tengku Sembok
(a) scientific event = {chair, conference, conferences, meeting, programme, schedule, seminar, session, sponsor, symposium, track, workshop,. . .}. (b) citation ={reference, references, bibliography,. . .}
With the concept of aggregation starting from the bindery, each bindery consists of chapters (domains), and each chapter contains the sheets (words).
For example, hit counts (|Ωa|) of “Abdullah Mohd Zin”, “Abdul Razak Hamdan”, and “Tengku Mohd Tengku Sembok” are 7,740, 8,280, and 3,860, respectively. While|Ωa∩Ωb|between “Abdullah Mohd Zin” and “Abdul Razak Hamdan” is 736,|Ωa∩Ωc|between “Abdullah Mohd Zin” and “Tengku Mohd Tengku Sembok” is 441, and|Ωb∩Ωc|between “Abdullah Razak Hamdan” and “Tengku Mohd Tengku Sembok” is 281. Therefore, based on Eq. (5) we have three strength relations srlike Table1. From 100 snippets based on doubleton, we have:
1. 60 snippets contain the indirect relations and 12 snippets contain the direct relations for “Abdullah Mohd Zin” and “Abdul Razak Hamdan”,
2. 27 snippets contain the indirect relations and 43 snippets contain the direct relations for “Abdullah Mohd Zin” and “Tengku Mohd Tengku Sembok”, and 3. 66 snippets contain the indirect relations for “Abdul Razak Hamdan” and
320 M.K.M. Nasution and O.S. Sitompul
In this case,p(dr) andp(ir) for a pair of actors there are in Table1. While 100 snippets for each pair of actors are calculatedpD(w) for each word and its value
is directly transferred to the sheets in the appropriate domain, such as Table1.
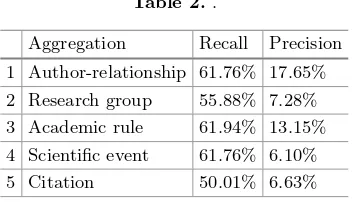
Table 2..
We conduct an experiment using 65 social actors that have direct and indirect relations between them, orn(n−1) = 4,160 potential relations. Based on survey we obtain the relevant relation and this is a comparison of the results obtained through extraction from Web. Based on Table2, the recall and the precision give the impression that the activation of each aggregation of the strength relation as adequate.
5
Conclusion and Future Work
By studying the principle of methods for extraction the relation between social actors, we have an enhanced method for aggregation the relations to interpret more rich about social. Thus, this new method still needs further verification. Future work we study about combination between sheets and domain based on ontology.
References
1. Adamic, L.A., Adar, A.: Friends and neighbours on the web. Soc. Netw.25, 211– 230 (2003)
2. Nasution, M.K.M., Noah, S.A.: Superficial method for extracting social network for academics using web snippets. In: Yu, J., Greco, S., Lingras, P., Wang, G., Skowron, A. (eds.) RSKT 2010. LNCS (LNAI), vol. 6401, pp. 483–490. Springer, Heidelberg (2010). doi:10.1007/978-3-642-16248-0 68
3. Cullota, A., Bekkerman, R., McCallum, A.: Extracting social networks and contact information from email and the Web. In: Proceedings of the 1st Conference on Email and Anti-Spam (CEAS) (2004)
Enhancing Extraction Method for Aggregating Strength Relation 321
5. Heras, S., Atkinson, K., Botti, V., Grasso, F., Juli´an, V., McBurney, P.: Research opportunities for argumentation in social networks. Artif. Intell. Rev.39, 39–62 (2013)
6. Kautz, H., Selman, B., Shah, M.: ReferralWeb: combining social networks and collaborative filtering. Commun. ACM40(3), 63–65 (1997)
7. Finin, T., Ding, L., Zhou, L., Joshi, A.: Social networking on the semantic web. Learn. Organ.12(5), 418–435 (2005)
8. Nasution, M.K.M., Sitompul, O.S., Sinulingga, E.P., Noah, S.A.: An extracted social network mining. In: SAI Computing Conference. IEEE (2016)
9. Nasution, M.K.M.: Social network mining (SNM): a definition of relation between the resources and SNA. Int. J. Adv. Sci. Eng. Inf. Technol.6(6), 975–981 (2016) 10. Nasution, M.K.M.: Modelling and simulation of search engine. In: International
Conference on Computing and Applied Informatics (ICCAI). IOP (2016)
11. Nasution, M.K.M.: New method for extracting keyword for the social actor. In: Nguyen, N.T., Attachoo, B., Trawi´nski, B., Somboonviwat, K. (eds.) ACIIDS 2014. LNCS (LNAI), vol. 8397, pp. 83–92. Springer, Cham (2014). doi:10.1007/ 978-3-319-05476-6 9
12. Matsuo, Y., Mori, J., Hamasaki, M., Nishimura, T., Takeda, T., Hasida, K., Ishizuka, M.: POLYPHONET: an advanced social networks extraction system from the web. J. Web Semant. Sci. Serv. Agents World Wide Web5, 262–278 (2007) 13. Nasution, M.K.M.: New similarity. In: Annual Applied Science and Engineering
Conference (AASEC). IOP (2016)
14. Blei, D.M., Ng, A.Y., Jordan, M.J.: Latent Dirichlet allocation. J. Mach. Learn. Res.3, 993–1022 (2003)
15. McCallum, A., Corrada-Emmanual, A., Wang, X.: Topic and role discovery in social networks. In: Proceedings of the 19th International Joint Conference on Artificial Intelligence, pp. 786–791 (2005)
16. Nasution, M.K.M., Mohd Noah, S.A.: Extraction of academic social network from online database. In: Mohd Noah, S.A. et al. (eds.) Proceeding of 2011 International Conference on Semantic Technology and Information Retrieval (STAIRS 2011), pp. 64–69. IEEE, Putrajaya (2011)