BAB 2
LANDASAN TEORI
2.1 Computer Vision
Computer Vision merupakan salah satu cabang ilmu pengetahuan yang bertujuan untuk membuat suatu keputusan yang berguna mengenai objek fisik nyata dan keadaan berdasarkan sebuah gambar atau citra (Shapiro & Stockman, 2001). Computer vision merupakan kombinasi antara :
a. Pengolahan Citra
Pengolahan Citra (Image Processing) merupakan bidang yang berhubungan dengan proses perubahan pada citra agar mendapatkan kualitas citra yang lebih baik. b. Pengenalan Pola
Pengenalan Pola (Pattern Recognition) merupakan bidang yang berhubungan dengan proses identifikasi objek pada citra atau interpretasi citra, yang bertujuan untuk mengekstrak informasi yang disampaikan oleh citra.
2.2 Pengolahan Citra Digital
Pengolahan citra digital (digital image processing) adalah metode yang digunakan untuk memanipulasi citra digital sehingga menghasilkan kualitas citra yang lebih baik. Pengolahan citra digital berfokus pada dua tugas utama, yaitu peningkatan informasi bergambar untuk interpretasi manusia dan pengolahan data citra untuk penyimpanan, transmisi dan representasi untuk persepsi mesin otonom (Annadurai & Shanmugalakshmi, 2007).
2.2.1 Resizing
ukuran yang sama dan mempercepat proses pengolahan citra ketika ukuran citra diperkecil.
2.2.2 Color Space Conversion
Konversi ruang warna (color space conversion) adalah proses pengubahan suatu ruang warna ke ruang warna lainnya dengan tranformasi matematis. Konversi ruang warna digunakan untuk mendapatkan channel warna yang mengandung informasi tertentu dalam suatu citra.
2.2.2.1 RGB to Grayscale Conversion
Salah satu proses konversi ruang warna yang paling sering dilakukan adalah grayscaling, yaitu proses pengubahan citra warna yang memiliki ruang warna RGB menjadi citra keabuan. Proses ini mengubah 3 channel red, green dan blue menjadi 1 channel gray (keabuan) dengan transformasi matematis seperti persamaan 2.1 (Bradski & Kaehler, 2008).
= 0.299. + 0.587. + 0.114.
Dimana : Y = citra hasil konversi RGB menjadi Grayscale
R = nilai red channel pada piksel G = nilai green channel pada piksel B = nilai blue channel pada piksel
2.2.2.2 Normalized RGB
Normalized RGB sering disebut dengan warna murni. Proses normalisasi RGB merupakan proses pengubahan nilai RGB dalam range 0 sampai 1 yang dibentuk secara independen dari berbagai tingkat pencahayaan. Jumlah dari nilai red, green dan blue channel yang telah dinormalisasi adalah 1. Ketiga channel yang telah dinormalisasi tersebut tidak memiliki informasi yang signifikan dan dapat diabaikan, sehingga dapat mengurangi dimensi ruang. Proses normalisasi RGB dilakukan dengan persamaan 2.2 sampai 2.4 (Ennehar, et al., 2010).
= + + = + + = + +
Dimana : R’ = nilai red channel yang telah dinormalisasi pada piksel G’ = nilai green channel yang telah dinormalisasi pada piksel B’ = nilai blue channel yang telah dinormalisasi pada piksel R = nilai red channel pada piksel
G = nilai green channel pada piksel B = nilai blue channel pada piksel
2.2.2.3 RGB to HSV Conversion
HSV (Hue, Saturation, Value) memiliki karakteristik utama dari warna tersebut, yaitu :
1. Hue, menyatakan warna yang sebenarnya, seperti merah, violet dan kuning, yang digunakan untuk menentukan kemerahan (redness), kehijauan (greeness) dan sebagainya.
2. Saturation, terkadang disebut chroma, mewakili tingkat intensitas warna.
3. Value, merupakan kecerahan dari warna. Nilainya berkisar antara 0-100%. Apabila nilainya 0 maka warnanya akan menjadi hitam. Semakin besar nilai value maka semakin cerah dan muncul variasi-variasi baru dari warna tersebut.
Citra yang tertangkap oleh kamera web memiliki warna RGB. Untuk mengurangi efek iluminasi pada sebuah citra, kita dapat mengkonversikan warna citra tersebut ke colour space yang lain. Pada penelitian sebelumnya, Zarit et al. pada tahun 1999 membandingkan performa colour space dan mendapatkan kesimpulan bahwa HSV colour space merupakan colour space terbaik untuk mendeteksi warna kulit. Adapun persamaan yang digunakan untuk mengkonversi warna RGB ke HSV yaitu seperti ditunjukkan pada persamaan 2.5 sampai 2.8 dibawah ini (diambil dari www.docs.opencv.org) :
(2.2)
= max ( , , )
2.2.2.4 RGB to YCbCr Conversion
YCbCr merupakan suatu ruang warna yang sering digunakan pada studio televisi eropa dan untuk kompresi citra. Ruang warna ini memiliki 3 (tiga) channel, yaitu :
1. Y, merupakan komponen single yang menyimpan informasi luminance
2. Cb, merupakan komponen yang menyimpan informasi chrominance dan
merepresentasikan perbedaan antara komponen blue channel dan nilai referensi
3. Cr, merupakan komponen yang menyimpan informasi chrominance dan
merepresentasikan perbedaan antara komponen red channel dan nilai referensi Dalam pendeteksian warna kulit yang bervariasi dan memiliki sensitivitas untuk beberapa faktor seperti kondisi pencahayaan, karakteristik individu, etnis, karakteristik kamera, dan sebagainya, pemilihan ruang warna sangatlah berpengaruh. Pada penelitian sebelumnya, Premal & Vinsley pada tahun 2014 mendeteksi adanya kebakaran hutan menggunakan ruang warna YCbCr dan menyimpulkan bahwa ruang warna ini sangat
(2.7)
baik mendeteksi warna walaupun dalam keadaan pencahayaan yang berubah-ubah, karena ruang warna ini memisahkan antara luminance dan chrominance.
Adapun persamaan yang digunakan untuk mengkonversi warna RGB ke YCbCr yaitu seperti ditunjukkan pada persamaan 2.9 sampai 2.11 dibawah ini (diambil dari www.docs.opencv.org) :
= 0.299. + 0.587. + 0.114. = ( − ). 0.713 +
= ( − ). 0.564 +
dimana
= 32768,128, 8 − 16 −
0.5, floating − point
Keterangan :
Y = nilai luminance channel pada piksel Cr = nilai chrominance red channel pada piksel Cb = nilai chrominance blue channel pada piksel R = nilai red channel pada piksel
G = nilai green channel pada piksel B = nilai blue channel pada piksel
2.2.3 Perbaikan Citra (Image Enhancement)
Tahap perbaikan citra dilakukan untuk meningkatkan kualitas citra agar lebih mudah diproses dan untuk menekankan karakteristik pada citra dengan cara memanipulasi parameter pada citra. Perbaikan citra memungkinkan informasi yang ingin ditampilkan atau diproses dari sebuah citra menjadi lebih baik dan jelas.
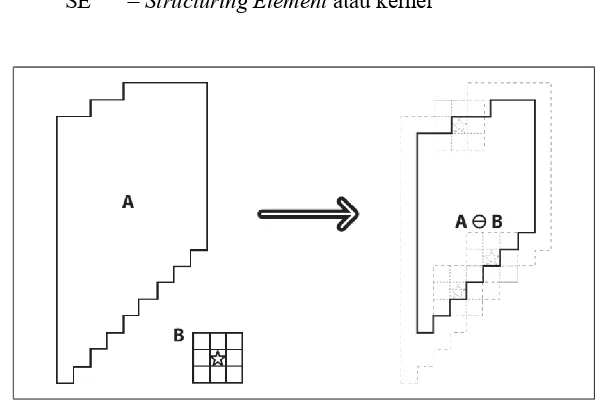
2.2.3.1 Erosion
sebuah citra. Kernel atau structuring element merupakan matriks berukuran m x n yang memiliki titik pusat.
Pada umumnya, proses erosi yang dilakukan pada sebuah citra menghasikan objek yang lebih kecil dan menghilangkan titik-titik objek menjadi bagian dari background berdasarkan kernel yang digunakan. Pada penelitian sebelumnya, Febriani, et al. pada tahun 2014 menggunakan proses erosi untuk menghilangkan objek lain diluar area optic disc dalam pengidentifikasian diabetic retinopathy melalui citra retina. Erosi dilakukan dengan persamaan 2.12 (Moeslund, 2012).
( , ) = ( , ) ⊖
Dimana : g(x,y) = citra hasil erosi dengan matriks x,y f(x,y) = citra asal dengan matriks x,y SE = Structuring Element atau kernel
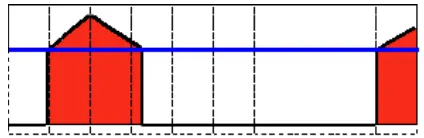
Gambar 2.1. Erosion : Mengambil Nilai Minimum Daerah Kernel B (Bradski & Kaehler, 2008)
Gambar 2.1 menunjukkan bahwa proses erosi menghitung nilai minimum setiap piksel dari citra asal A yang berada di daerah kernel B dan menghasilkan gambar baru dengan cara menggantikan nilai titik pusat kernel dengan nilai minimum yang didapatkan. Perhitungan akan dilakukan pada setiap piksel citra asal A (Bradski & Kaehler, 2008).
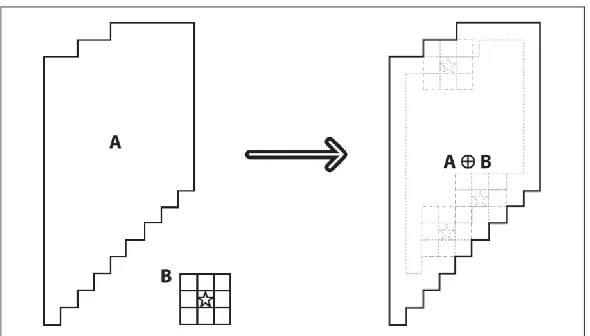
2.2.3.2 Dilation
Dilation merupakan kebalikan dari proses erosi. Dilation atau dilasi merupakan salah satu operasi morfologi citra yang menghitung nilai maksimum lokal berdasarkan area kernel atau structuring element. Pada umumnya, proses dilasi yang dilakukan pada sebuah citra menghasikan objek yang lebih besar dan meleburkan titik-titik objek menjadi bagian dari objek berdasarkan kernel yang digunakan. Dilasi dilakukan dengan persamaan 2.13 dibawah ini (Moeslund, 2012).
( , ) = ( , ) ⊕
Dimana : g(x,y) = citra hasil erosi dengan matriks x,y f(x,y) = citra asal dengan matriks x,y SE = Structuring Element atau kernel
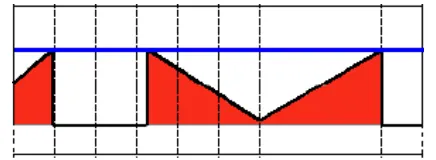
Gambar 2.2. Dilation : Mengambil Nilai Maximum Daerah Kernel B (Bradski & Kaehler, 2008)
Gambar 2.2 menunjukkan bahwa proses dilasi menghitung nilai maksimum setiap piksel dari citra asal A yang berada di daerah kernel B dan menghasilkan gambar baru dengan cara menggantikan nilai titik pusat kernel dengan nilai maksimum yang didapatkan. Perhitungan akan dilakukan pada setiap piksel citra asal A (Bradski & Kaehler, 2008).
2.2.3.3 Gaussian Blur
Blurring (pengaburan), sering juga disebut smoothing, merupakan pemerataan nilai piksel-piksel tetangga yang menghilangkan detail halus dari suatu citra. Pada penelitian ini, teknik blurring yang digunakan adalah Gaussian Blur. Gaussian Blur merupakan teknik pengaburan suatu citra menggunakan fungsi Gaussian, yang digunakan untuk mengurangi noise pada citra dan mengurangi detail (Nayakwadi & Pokale, 2014).
Gaussian blur telah banyak digunakan pada penelitian sebelumnya, seperti pada penelitian yang dilakukan oleh Zhaoxue, et al. pada tahun 2008 yang melakukan segmentasi bentuk hati secara otomatis pada CT (Computerized Tomography) Image berdasarkan Gaussian blurring pada citra biner. Dalam penelitian ini dapat disimpulkan bahwa Gaussian Blur cukup efisien sebagai langkah awal untuk digunakan perfusi hati berdasarkan citra CT abdomen.
Persamaan fungsi Gaussian untuk satu dimensi ditunjukkan pada persamaan 2.14.
( ) =
√Maka untuk citra dua dimensi, persamaan fungsi Gaussian berubah menjadi seperti ditunjukkan pada persamaan 2.15.
( , ) =
Dimana : G(x) = citra hasil Gaussian Blur
2.2.4 Thresholding
Thresholding merupakan teknik binerisasi yang digunakan untuk mengubah citra keabuan menjadi citra biner. Thresholding dapat digunakan dalam proses segmentasi citra untuk mengidentifikasi dan memisahkan objek yang diinginkan dari background berdasarkan distribusi tingkat keabuan atau tekstur citra (Liao, et al.,
(2.14)
2001). Proses thresholding menggunakan nilai batas (threshold) untuk mengubah nilai piksel pada grayscale image menjadi hitam atau putih.
Teknik thresholding telah banyak dilakukan pada penelitian sebelumnya, seperti penelitian yang dilakukan oleh Du & Chang pada tahun 2002 yang melakukan proses thresholding pada video untuk mendeteksi teks. Pada penelitian ini disimpulkan bahwa teknik thresholding sudah umum digunakan untuk mendeteksi dokumen dan dapat mengatasi background yang kompleks pada citra keabuan. Adapun beberapa tipe thresholding yang dapat diimplementasikan pada sebuah citra keabuan, yaitu :
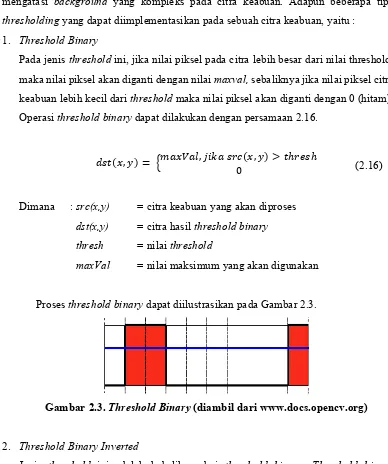
1. Threshold Binary
Pada jenis threshold ini, jika nilai piksel pada citra lebih besar dari nilai threshold, maka nilai piksel akan diganti dengan nilai maxval, sebaliknya jika nilai piksel citra keabuan lebih kecil dari threshold maka nilai piksel akan diganti dengan 0 (hitam). Operasi threshold binary dapat dilakukan dengan persamaan 2.16.
( , ) = , 0( , ) > ℎ ℎ
Dimana : src(x,y) = citra keabuan yang akan diproses dst(x,y) = citra hasil threshold binary thresh = nilai threshold
maxVal = nilai maksimum yang akan digunakan
Proses threshold binary dapat diilustrasikan pada Gambar 2.3.
Gambar 2.3. Threshold Binary (diambil dari www.docs.opencv.org)
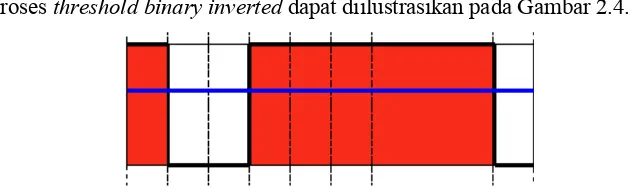
2. Threshold Binary Inverted
Jenis threshold ini adalah kebalikan dari threshold binary. Threshold binary inverted akan mengganti nilai piksel menjadi nilai 0 jika nilai piksel citra keabuan lebih kecil dari threshold, sebaliknya jika nilai piksel pada citra keabuan lebih besar
dari nilai threshold maka nilai piksel akan diganti dengan nilai maxval. Operasi threshold binary inverted dapat dilakukan dengan persamaan 2.17.
( , ) = 0, ( , ) > ℎ ℎ
Dimana : src(x,y) = citra keabuan yang akan diproses dst(x,y) = citra hasil threshold binary inverted thresh = nilai threshold
maxVal = nilai maksimum yang akan digunakan
Proses threshold binary inverted dapat diilustrasikan pada Gambar 2.4.
Gambar 2.4. Threshold Binary Inverted (diambil dari www.docs.opencv.org)
3. Threshold Truncate
Pada jenis threshold ini, nilai maksimum pada piksel adalah nilai threshold. Jika nilai piksel pada citra keabuan lebih besar, maka nilai tersebut akan dipotong. Operasi threshold truncate dapat dilakukan dengan persamaan 2.18.
( , ) = ℎ ℎ , ( , )( , ) > ℎ ℎ
Dimana : src(x,y) = citra keabuan yang akan diproses dst(x,y) = citra hasil threshold binary inverted thresh = nilai threshold
Proses threshold binary truncate dapat diilustrasikan pada Gambar 2.5 .
(2.17)
Gambar 2.5. Threshold Truncate (diambil dari www.docs.opencv.org)
4. Threshold to Zero
Threshold to zero akan menggantikan nilai piksel menjadi 0 (hitam) jika nilai piksel pada citra keabuan lebih kecil daripada nilai threshold. Operasi threshold to zero dapat dilakukan dengan persamaan 2.19.
( , ) = ( , ), 0( , ) > ℎ ℎ
Dimana : src(x,y) = citra keabuan yang akan diproses dst(x,y) = citra hasil threshold binary inverted thresh = nilai threshold
Proses threshold binary truncate dapat diilustrasikan pada Gambar 2.6.
Gambar 2.6. Threshold to Zero (diambil dari www.docs.opencv.org)
5. Threshold to Zero Inverted
Jenis threshold ini merupakan kebalikan dari threshold to zero. Threshold to zero inverted akan menggantikan nilai piksel menjadi 0 (hitam) jika nilai piksel pada citra keabuan lebih besar daripada nilai threshold. Operasi threshold to zero dapat dilakukan dengan persamaan 2.20.
( , ) = 0, ( , ) > ℎ( , ) ℎ
(2.19)
Dimana : src(x,y) = citra keabuan yang akan diproses dst(x,y) = citra hasil threshold binary inverted thresh = nilai threshold
Proses threshold binary truncate dapat diilustrasikan pada Gambar 2.7.
Gambar 2.7. Threshold to Zero Inverted (diambil dari www.docs.opencv.org)
2.2.5 Inversi
Inversi merupakan proses negatif pada citra, dimana setiap nilai piksel pada citra dibalik dengan acuan threshold yang diberikan (Febriani, 2014). Pada umumnya, proses inversi yang dilakukan pada sebuah citra untuk memperjelas warna putih atau abu-abu pada bagian gelap. Pada penelitian sebelumnya, Febriani, et al. pada tahun 2014 menggunakan proses inversi untuk melakukan proses perkalian citra dengan citra hasil proses contrast stretching agar menghasilkan citra optic disc yang tereliminasi dalam pengidentifikasian diabetic retinopathy melalui citra retina. Untuk citra 8 bit, proses inversi dilakukan dengan persamaan 2.21.
( , ) = 255 − ( , )
Dimana : src(x,y) = nilai piksel pada citra input
dst(x,y) = nilai piksel pada citra setelah proses inversi
2.3 Average Background
Metode average background pada dasarnya menghitung nilai rata-rata dan standard deviasi dari setiap piksel yang didefinisikan sebagai model background. Metode ini merupakan salah satu cara yang dapat mengatasi kelemahan pada proses background subtraction (Bradski & Kaehler, 2008). Average background telah digunakan sebelumnya pada penelitian sebelumnya, seperti pada tahun 2015, Goswami, et al.
melakukan penelitian untuk mendeteksi kejadian yang tidak biasa terjadi di sekitar mesin ATM, guna untuk meningkatkan keamanan ATM. Pada penelitian ini disimpulkan bahwa metode ini dapat membantu mempercepat performa sistem pendeteksi walaupun hanya menggunakan kamera yang memiliki resolusi yang rendah. Ada empat tahap yang dilakukan pada metode ini yaitu :
1. Mengakumulasikan atau mengumpulkan frame-frame video dengan jarak waktu tertentu
2. Melakukan proses frame differencing pada frame-frame video yang telah diakumulasikan, lalu mencari nilai rata-rata piksel yang berbeda diantara frame 3. Segmentasi citra background dengan proses thresholding
4. Inversi citra hasil thresholding
Seperti yang telah dijabarkan diatas, terdapat proses frame differencing dan background subtraction pada metode average background. Berikut ini adalah penjelasan tentang kedua teknik tersebut.
2.3.1 Background Subtraction
Background subtraction merupakan proses untuk mendeteksi pergerakan atau perbedaan signifikan yang terjadi pada frame video ketika dibandingkan dengan citra referensi. Tujuan dari background subtraction yaitu untuk memisahkan objek dan background sehingga gerakan dari sebuah objek dapat terdeteksi.
Teknik ini mendefinisikan frame video pertama sebagai background lalu mendeteksi perbedaan yang terjadi pada frame-frame selanjutnya, sehingga dapat didefinisikan sebagai pergerakan objek. Proses background subtraction dilakukan dengan persamaan 2.22 dan 2.23 dibawah ini (Alex & Wahi, 2014).
( , ) = ( , ) − ( , )
( , ) = 1 ∶0 ∶ ( , ) ≤ ( , ) >
Dimana : Rk (x,y) = citra hasil perbedaan frame
fk (x,y) = citra frame
B (x,y) = citra background T = nilai threshold
(2.22)
Background subtraction memiliki kelebihan yaitu mudah untuk diimplementasi dan cepat, namun juga memiliki kekurangan ketika terjadi perubahan iluminasi atau pencahayaan pada video karena juga akan terdefinisi sebagai perbedaan piksel (Bradski & Kaehler, 2008). Teknik background subtraction telah digunakan pada penelitian sebelumnya, seperti penelitian yang dilakukan oleh Intachak & Kaewapichai pada tahun 2011, yang menggunakan teknik tersebut untuk video traffic monitoring.
2.3.2 Frame Differencing
Frame differencing adalah suatu teknik sederhana yang yang digunakan untuk mendeteksi perbedaan piksel antara dua frame video. Teknik ini biasanya digunakan untuk mendeteksi pergerakan objek berdasarkan perbedaan piksel yang terjadi pada dua frame video dengan interval waktu yang singkat. Untuk mengetahui perbedaan frame video yang terjadi dilakukan perhitungan matematis dengan persamaan 2.24 sampai 2.26 (Alex & Wahi, 2014).
Differential :
= − , ( − 0 ) > 0
Negative Differential :
= | − | , 0 ( − ) > 0
Fully Differential :
= | − |
Dimana : Dk = hasil citra frame differencing
fk = citra frame
fk-1 = citra frame sebelumnya dengan interval waktu
Teknik frame differencing juga telah digunakan dalam penelitian sebelumnya seperti penelitian yang dilakukan oleh Kang & Hayes pada tahun 2015. Pada penelitian ini, teknik frame differencing digunakan dalam pengenalan wajah untuk personalisasi kendaraan.
(2.24)
(2.25)
2.4 Ekstraksi Fitur
Ekstraksi fitur merupakan proses yang menonjolkan ciri atau karakteristik pada suatu citra yang mengandung informasi penting untuk proses pengklasifikasian ataupun analisa data citra. Tujuan dari proses ekstraksi fitur adalah untuk meningkatkan efektivitas dan efisiensi dari proses analisa ataupun pengklasifikasian. Salah satu teknik computer vision untuk mengekstraksi fitur adalah dengan teknik pendeteksian contour, convex-hull dan convexity defects.
Pada penelitian sebelumnya, Youssef, et al. pada tahun 2010 menggunakan teknik tersebut untuk mengekstraksi fitur yang terdapat pada citra yang tertangkap oleh kamera dalam pengenalan aktifitas manusia yang dapat digunakan untuk pengawasan ataupun analisa medis. Berikut ini adalah penjelasan tentang ekstraksi fitur menggunakan contour, convex-hull dan convexity defects.
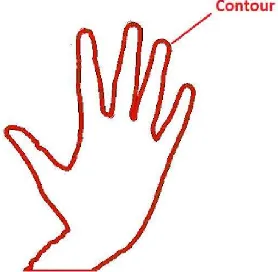
2.4.1 Contour
Kontur (contour) dapat didefinisikan sebagai suatu keadaan yang terjadi karena adanya perubahan intensitas pada piksel-piksel yang bertetangga. Dengan adanya perubahan intensitas ini, maka titik-titik tepi (edge) pada citra dapat terdeteksi. Kontur juga dapat didefinisikan sebagai urutan titik yang dapat menguraikan bentuk atau region (Williamson, A, 2014). Gambaran contour dapat dilihat pada Gambar 2.8.
Gambar 2.8. Contour (Dhawan & Honrao, 2013)
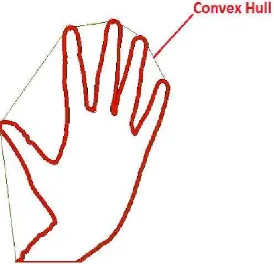
2.4.2 Convex-Hull
Gambar 2.9. Convex-Hull (Dhawan & Honrao, 2013)
2.4.3 Convexity Defects
Convexity defects merupakan titik atau vector yang diperoleh dari titik contour dan garis convex-hull. Convexity defects direpresentasikan dengan 4 (empat) elemen titik atau vector, yaitu :
1. Start_index, yaitu titik kontur yang mendefinisikan permulaan dari defects 2. End_index, yaitu titik kontur yang mendefinisikan akhir dari defects 3. Farthest_index, yaitu titik terjauh dari garis convex-hull ke titik kontur 4. Fix_depth, yaitu perkiraan fixed-point dari jarak antara titik terjauh dari garis
convex-hull ke titik kontur.
Gambaran convexity defects dapat dilihat pada Gambar 2.10.
2.4.4 Moment
Moment merupakan karakteristik dari titik kontur yang dihitung dengan mengintegrasikan seluruh piksel dari titik kontur. Momen biasanya digunakan untuk memandingkan dua titik kontur. Pada umumnya, moment dari sebuah titik kontur didefinisikan sebagai persamaan 2.27 sebagai berikut (Bradski & Kaehler, 2008).
,
= ∑
( , )
Dimana : m = moment
p = x-order
q = y-order
n = batas kontur
I(x,y) = citra hasil ekstraksi fitur
2.4.5 Center of Gravity
Center of Gravity (CoG) adalah titik tengah dari sebuah objek yang terdeteksi dari citra hasil ekstraksi fitur. Pada penelitian sebelumnya, Ling, et al. pada tahun 2013 memanfaatkan informasi dari titik center of gravity untuk menilai kemampuan keseimbangan tubuh manusia pada postur statis dan disimpulkan bahwa titik center of gravity pada tubuh manusia sangat baik dalam memberikan informasi tentang keseimbangan tubuh.
Titik CoG dapat diperoleh dari momen setiap titik kontur yang terdeteksi. Untuk menghitung titik center of gravity dapat dilakukan dengan persamaan 2.28 sebagai berikut (diambil dari www.docs.opencv.org) :
=
,
=
Dimana : x = koordinat x titik center of gravity y = koordinat y titik center of gravity m10 = moment dengan x-order 1 dan y-order 0
m01 = moment dengan x-order 0 dan y-order 1
m00 = panjang piksel dari kontur
(2.27)
2.5 OpenCV
OpenCV (Open Source Computer Vision Library) adalah sebuah API (Application Programming Interface) library yang menyediakan struktur data dan algoritma yang cepat dan efisien serta dapat digunakan untuk pengolahan citra dan real-time computer vision (Bradski & Kaehler, 2008).
Adapun 5 library yang terdapat pada OpenCV, yaitu :
1. CV, merupakan komponen yang berisikan algoritma dasar pengolahan citra digital dan computer vision yang lebih tinggi.
2. ML, merupakan komponen yang berisikan pustaka dari machine learning untuk pengklasifikasian statistical dan clustering tools yang mencakup algoritma seperti berikut :
a. Naïve Bayes Classifier
b. K-nearest Neighbor Algortithm c. Support Vector Machine d. Decision Tree
e. Boosting f. Random Forest
g. Expectation Maximization h. Neural Network
3. HighGUI, berisi fungsi-fungsi I/O untuk penyimpanan dan pembacaan video atau gambar.
4. CXCORE, berisi struktur data, support XML dan fungsi-fungsi grafis. 5. CvAux, berisi both defunct areas dan algoritma eksperimental.
2.6 Penelitian Terdahulu
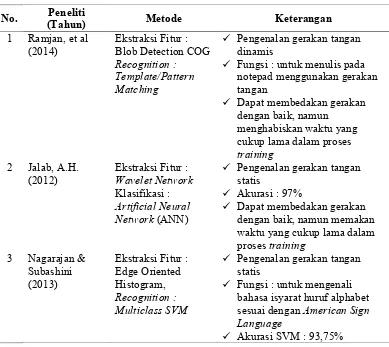
Penelitian tentang pengenalan gerakan tangan (hand gesture recognition) dalam interaksi manusia-komputer telah banyak dilakukan dengan beberapa metode. Pada umumnya pengenalan gerakan tangan ini diimplementasikan untuk bahasa isyarat (sign language), robotik, virtual reality, permainan, dan lain-lain. Seperti yang telah dijelaskan sebelumnya, pengenalan gerakan tangan terbagi atas dua jenis yaitu pengenalan gerakan tangan statis dan pengenalan gerakan tangan dinamis.
Pada tahun 2014, Ramjan, et al. menggunakan algoritma Blob Detection COG untuk ekstraksi fitur dan Template/Pattern Matching untuk mengenali gerakan tangan dinamis. Penelitian ini diimplementasikan untuk menulis pada notepad menggunakan gerakan tangan dengan fasilitas ekstra dengan berbagai bahasa seperti bahasa Jepang, Gujarati, Tamil, Kanada, dsb.
Pada penelitian lainnya juga telah dilakukan untuk pengenalan gerakan tangan statis. Jalab, A. H. pada tahun 2012 menggunakan jaringan saraf tiruan untuk mengenali gerakan tangan secara statis. Metode ekstraksi fitur yang digunakan adalah algoritma Wavelet Network dan Artificial Neural Network (ANN). Dalam tahap uji coba, dilakukan pengujian 60 citra gerakan tangan dengan jumlah noise Gaussian yang berbeda-beda dan dibagi menjadi 6 kelas. Adapun tingkat akurasi hasil uji coba tersebut yaitu 97%. Selanjutnya pada tahun 2013, Nagarajan & Subashini melakukan penelitian untuk mengenali bahasa isyarat huruf alphabet sesuai dengan American Sign Language dengan menggunakan metode Edge Oriented Histogram untuk ekstraksi fitur dan menggunakan algoritma Multiclass SVM untuk mengenali gerakan tangan statis. Pada penelitian ini didapat kesimpulan bahwa algoritma Multiclass SVM dapat memberikan akurasi yang baik sebesar 93.75% dalam mengklasifikasikan gerakan tangan statis.
tersebut dapat disimpulkan bahwa teknik computer vision sangat mudah dan cepat untuk diimplementasi dalam pengenalan gerakan tangan.
Yesugade, et al. pada tahun 2014 juga meneliti tentang pengenalan gerakan tangan dengan menggunakan metode sederhana yaitu Blob Detection untuk ekstraksi fitur untuk pengenalan gerakan tangan. Penelitian ini berfokus pada pemanfaatan pengenalan gerakan tangan dalam berbagai fungsionalitas seperti mouse control, kalibrasi single-pointer, kalibrasi multi-pointer, winamp control dan gaming control. Namun pada penelitian ini terdapat batasan dalam keadaan background dan kondisi pencahayaan.
Penelitian terkait lainnya dilakukan oleh Yi & Liangzhong pada tahun 2010, yaitu mendeteksi objek yang bergerak dengan menggunakan metode average background. Pada penelitian ini disimpulkan bahwa metode tersebut dapat mendeteksi background dengan tingkat kompleksitas dalam komputasi yang rendah. Rangkuman dari penelitian terdahulu dapat dilihat pada Tabel 2.1.
Tabel 2.1 Penelitian Terdahulu
No. (Tahun) Peneliti Metode Keterangan
1 Ramjan, et al
(2014) Ekstraksi Fitur : Blob Detection COG Recognition :
Template/Pattern Matching
Pengenalan gerakan tangan dinamis
Fungsi : untuk menulis pada notepad menggunakan gerakan waktu yang cukup lama dalam proses training
Fungsi : untuk mengenali bahasa isyarat huruf alphabet sesuai dengan American Sign Language
Tabel 2.1 Penelitian Terdahulu (lanjutan)
No. (Tahun) Peneliti Metode Keterangan
Semakin besar tingkat pembelajaran SVM, semakin besar pula tingkat akurasi yang dihasilkan. Namun hal ini
dan convexity defects Pengenalan gerakan tangan statis Fingertips Counting merupakan
metode yang sederhana, cepat dan mudah untuk
diimplementasi 5 Yesugade, et al
(2014) Blob Detection statisPengenalan gerakan tangan
Berfokus pada pemanfaatan
Average Background Pendeteksian background
Berfokus pada penggunaan
metode yang memiliki
kompleksitas dalam komputasi yang rendah
Perbedaan penelitian yang dilakukan dengan penelitian terdahulu adalah penelitian ini berfokus pada kesederhanaan metode dan kemudahan pengguna dalam kebebasan penggunaan. Berikut ini adalah metode beserta alasan penggunaan metode yang akan diterapkan pada penelitian ini.
Menggunakan kombinasi ruang warna HSV dan YCbCr, yaitu HSCbCr untuk
mendeteksi warna kulit, sehingga pengguna tidak perlu menggunakan alat seperti Kinect ataupun data glove.
Menggunakan metode average background untuk menangani kondisi
background yang tidak diperlukan, sehingga dapat mempercepat proses pengenalan gerakan tangan.