PROPOSAL
PENELITIAN PASCASARJANA ITS
DANA ITS TAHUN 2020
JUDUL PENELITIAN
METODE KLASIFIKASI PADA DATA IMBALANCE
MENGGUNAKAN MWMOTE DAN SMOTE+TL
PADA PERILAKU BERISIKO REMAJA DI JAWA TIMUR
Tim Peneliti:
Dr. Dra. Kartika Fithriasari, M.Si.
(Statistika/ Fakultas Sains dan Analitika Data/Institut Teknologi Sepuluh Nopember Dr. Ismaini Zain, M.Si.
(Statistika/Fakultas Sains dan Analitika Data/Institut Teknologi Sepuluh Nopember) Dr. Rr. Iswari Hariastuti, Dra. M. Kes.
(BKKBN – Jawa Timur)
Erma Oktania Permatasari, S.Si., M.Si.
(Statistika/Fakultas Sains dan Analitika Data/Institut Teknologi Sepuluh Nopember)
DIREKTORAT PENELITIAN DAN PENGABDIAN KEPADA MASYARAKAT INSTITUT TEKNOLOGI SEPULUH NOPEMBER
SURABAYA 2020
ii DAFTAR ISI
HALAMAN SAMPUL ... ...i
DAFTAR ISI ... ii DAFTAR TABEL ... iv DAFTAR GAMBAR ... v DAFTAR LAMPIRAN ... vi BAB I ... 7 RINGKASAN ... 7 BAB II ... 8 LATAR BELAKANG ... 8 2.1 Latar Belakang ... 8 2.2 Rumusan Masalah ... 11 2.3 Tujuan Penelitian ... 11
2.4 Urgensi dan Manfaat Penelitian ... 11
BAB III... 13 TINJAUAN PUSTAKA ... 13 3.1 Penelitian terdahulu ... 13 3.2 Klasifikasi ... 14 3.3 Decision Tree ... 14 3.4 CART ... 15 3.5 Random Forest ... 16 3.6 SMOTE+TL ... 17 3.7 MWMOTE ... 18
3.8 Kriteria Evaluasi Kinerja (Performance) ... 18
BAB IV ... 22
METODE ... 22
4.1 Tahapan Penelitian ... 22
4.2 Diagram Alir ... 23
4.3 Luaran ... 23
4.4 Organisasi Tim Peneliti ... 24
BAB V ... 26 JADWAL ... 26 BAB VI ... 27 DAFTAR PUSTAKA ... 27 BAB VII ... 29 LAMPIRAN ... 29
Biodata Tim Peneliti... 30
iii
SURAT PERNYATAAN KESEDIAAN ANGGOTA TIM PENELITIAN ... 40 SURAT PERNYATAAN KESEDIAAN ANGGOTA TIM PENELITIAN ... 41 LAMPIRAN 1 : Justifikasi Anggaran Penelitian ... 42
iv
DAFTAR TABEL
Tabel 3.1 Confusion Matrix ... 18
Tabel 3.2 Kriteria Nilau AUC ... 19
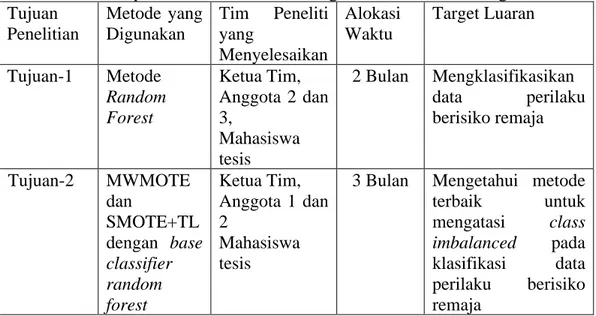
Tabel 4. 1 Tahapan Penelitian, Metode, Tugas Tim, Waktu dan target Luaran ... 22
Tabel 4. 2 Susunan Organisasi Tim Peneliti dan Pembagian Tugas ... 24
Tabel 4.3 Total Biaya ... 25
v
DAFTAR GAMBAR
Gambar 3.1 Ilustrasi Decision Tree ... 15
Gambar 3.2 Ilustrasi CART ... 16
Gambar 3.3 Road Map Penelitian Pusat Penelitian Sains Fundamental ... 20
Gambar 3.4 Road Map Penelitian Laboratorium Statistika Komputasi ... 21
vi
DAFTAR LAMPIRAN
Biodata Tim Peneliti…….……….….……… 30 Surat Pernyataan Kesediaan Anggota Tim Penelitian…...……...………….…………. 39 Surat Pernyataan Kesediaan Anggota Tim Penelitian…………...……...….…………. 40 Surat Pernyataan Kesediaan Anggota Tim Penelitian…………...……...….…………. 41 Rencana Anggaran Biaya….……….. 42
7 BAB I RINGKASAN
Klasifikasi merupakan salah satu metode data mining yang digunakan untuk memprediksi kelas target secara akurat. Salah satu metode klasifikasi yang sering digunakan adalah decision tree. Salah satu algoritma decision tree adalah CART. Algortima CART dapat dikembangkan menjadi metode random forest. Random forest ini merupakan metode klasifikasi yang terbuat dari kumpulan decision tree. Kelebihan random forest adalah memberikan akurasi yang bagus dan dapat mengatasi data yang tidak lengkap dan data dalam jumlah besar. Akan tetapi, jika berhadapan dengan class imbalanced, random forest menghasilkan akurasi yang kurang optimal. Sehingga diperlukan penanganan pada class imbalanced yaitu dengan menerapkan teknik resampling (MWMOTE dan SMOTE+TL) pada metode klasifikasi random forest. Data yang digunakan adalah data perilaku berisiko remaja melakukan hubungan seksual dan perilaku berisiko remaja menggunakan narkoba yang diperoleh dari SKAP BKKBN, dimana kasus perilaku berisiko remaja relatif kecil yang menandakan bahwa ada kasus class imbalanced pada data SKAP BKKBN dan jika diklasifikasikan akan menghasilkan hasil yang kurang optimal. Sehingga untuk mengklasifikasikan data perilaku berisiko remaja akan digunakan metode klasifikasi random sampling dengan MWOTE dan SMOTE+TL untuk menangani class imbalanced pada data perilaku berisiko remaja. Penelitan ini bertujuan untuk mengklasifikasikan data perilaku berisiko remaja dan mengetahui metode mana yang terbaik untuk mengatasi class imbalanced pada klasifikasi perilaku berisiko remaja.
Kata-kata kunci: Klasifikasi, Random Forest, Class Imbalanced, MWMOTE, SMOTE+TL.
8 BAB II
LATAR BELAKANG
2.1 Latar Belakang
Di zaman yang teknologi informasinya semakin pesat, keberagaman data yang tersedia merupakan suatu informasi yang penting, sehingga data mining menjadi sangat dibutuhkan. Terutama karena dengan data mining, bisa didapatkan informasi dan data dalam jumlah yang besar. Pengertian data mining sendiri adalah proses penambangan atau penemuan informasi baru dengan mencari pola atau aturan tertentu dari sejumlah data yang sangat besar. Data mining juga sering disebut sebagai knowledge discovery in database (KDD), yaitu kegiatan yang meliputi pengumpulan, pemakaian data, historis untuk menemukan keteraturan, pola atau hubungan dalam dataset yang berukuran besar [1].
Salah satu metode data mining yang sering digunakan adalah metode klasifikasi. Metode klasifikasi adalah suatu metode supervised yang digunakan untuk mengklasifikasikan setiap item pada dataset kedalam grup atau kelas yang telah ditentukan. Metode klasifikasi digunakan untuk memprediksi variabel dependen kategorik (atribut kelas). Tujuan dari metode klasifikasi ini adalah untuk memprediksi kelas target secara akurat. Contohnya, model klasifikasi dapat digunakan untuk mengidentifikasi pemohon pinjaman sebagai resiko kredit rendah, sedang dan tinggi.
Klasifikasi adalah proses menemukan kumpulan pola data satu dengan yang lainnya untuk dapat digunakan memprediksi data yang belum memiliki kelas data tertentu [2]. Sebagai algoritma klasifikasi yang melibatkan metode dari statistik, kecerdasan buatan dan manajemen database, juga dapat di kategorikan sebagai kunci elemen dalam interpretasi data dan visualisasi data [3].
Decision tree adalah salah satu algoritma yang paling banyak digunakan untuk masalah klasifikasi. Sebuah decision tree terdiri dari beberapa simpul yaitu tree’s root, internal node dan leafs. Klasifikasi menggunakan decision tree dilakukan oleh routing dari simpul akar sampai tiba di simpul. menggunakan decision tree dilakukan oleh routing dari simpul akar sampai tiba di simpul daun. Algoritma decision tree antara lain ID3, C4.5, C5.0, and CART.
9
Dengan menerapkan metode bootstrap aggregating dan random feature selection pada metode classification and regression tree (CART) maka dapat dikembangkan menjadi metode random forest. Random forest adalah model yang dibuat dari kumpulan decision tree. Random forest adalah salah satu metode berbasis klasifikasi dan regresi dimana terdapat proses agregasi pohon keputusan [4].
Kelebihan random forest adalah dapat menghasilkan kesalahan yang lebih rendah, memberikan akurasi yang bagus, dapat mengatasi data dalam jumlah besar secara efisien, efektif untuk mengatasi data yang tidak lengkap dan tidak terdapat pemangkasan variabel seperti pada algoritma pohon klasifikasi tunggal. Random forest dianggap sebagai salah satu teknik pembelajaran umum paling akurat yang ada. Walaupun random forest mempunyai banyak kelebihan, akan tetapi, sama seperti metode klasifikasi lainnya, random forest juga bisa menghasilkan hasil yang kurang optimal pada dataset yang imbalanced.
Jika bekerja pada data imbalanced, hampir semua algoritma klasifikasi akan menghasilkan akurasi yang jauh lebih tinggi untuk kelas mayoritas daripada kelas minoritas [5]. Imbalanced data atau data tidak seimbang sendiri biasanya merujuk pada permasalah klasifikasi di mana kelas-kelas tidak terwakili secara sama dimana jumlah kelas satu lebih besar dibandingkan dengan jumlah kelas lainnya [6].
Sebagian besar dataset pada metode klasifikasi tidak mempunyai jumlah kelas yang sama persis antar satu sama lainya, akan tetapi jika perbedaan jumlah antar kelas hanya sedikit tidak menjadi masalah. Sebagai contoh sebuah dataset yang tidak seimbang memiliki rasio 1:100, dimana 1 merepresentasikan class minoritas (positive) sedangkan 100 merepresentasikan class mayoritas (negative). Sebuah metode klasifikasi yang mencoba untuk memaksimalkan akurasinya, dapat mencapai akurasi 99% hanya menggunakan class negative (mayoritas) tanpa melihat class positive (minoritas).
Model yang dibuat dengan menggunakan data tidak seimbang akan menghasilkan akurasi prediksi pada kelas minoritas yang rendah. Banyaknya informasi yang diperoleh dari kelas mayoritas akan mendominasi kelas minoritas sehingga menyebabkan batas-batas keputusan yang bias dalam sistem klasifikasi [7]. Permasalahan imbalanced yang terjadi pada machine learning, sering mengakibatkan misclassification sehingga berdampak pada nilai akurasi prediksi kelas menurun [8].
10
Salah satu cara untuk mengatasi permasalahan imbalanced adalah dengan menggunakan pendekatan teknik resampling. Teknik resampling adalah salah satu teknik preprocessing dimana distribusi data diseimbangkan kembali untuk mengurangi efek distribusi kelas tidak seimbang dalam proses pembelajaran. Pendekatan resampling dibagi menjadi tiga kategori: metode over-sampling, under-sampling, dan hibrida yang menggabungkan kedua pendekatan sampling [9].
Over-sampling merupakan salah satu cara untuk menangani permasalahan imbalanced yaitu dengan melakukan pendistribusian data yang seimbang dengan cara replikasi instance (data sintetik) minoritas secara acak dengan melakukan iterasi. Tujuan dari oversampling adalah untuk meningkatkan jumlah kelaas minoritas pada dataset untuk mencapai distribusi kelas yang seimbang. Over-sampling memiliki kekurangan dalam membuat data sintetik dengan munculnya overfitting karena mekanisme ini membuat data sintetik kurang tepat [10].
Untuk menangani overfitting pada over-sampling maka dapat digunakan metode Majority Weighted Minority Over-sampling Technique (MWMOTE). Pembuatan data sintetik pada MWMOTE terdapat 3 tahap, yaitu identifikasi sampel kelas minoritas dan kelas mayoritas pada dataset, pembobotan kelas minoritas, dan clustering. Hasil usulan tersebut ternyata mampu menurunkan derajat bias atau noise, serta menghasilkan data sintetik dengan tingkat akurasi lebih baik [11].
Selain metode over-sampling ada juga metode hybrid-sampling salah satunya yaitu SMOTE+TL (Synthetic Minority Over-sampling Method + Tomek Links). SMOTE merupakan salah satu metode yang populer yang digunakan untuk menangani ketidakseimbangan kelas. Teknik ini mensintesis sampel baru dari kelas minoritas untuk menyeimbangkan dataset dengan cara sampling ulang sampel kelas minoritas [12]. Kombinasi antara SMOTE dan Tomek Link ini digunakan sebagai metode pembersihan data. Cara kerja Tomek Link adalah dengan menghapus data minor ataupun mayor yang memiliki kesamaan karakteristik. Untuk setiap data, jika satu tetangga yang paling dekat memiliki kelas label yang berbeda dengan data tersebut maka kedua data akan dihapus karena dianggap sebagai noise atau misclassify [13]. Metode ini memberikan hasil yang sangat baik untuk data yang tidak seimbang.
11
Adapun data yang digunakan pada penelitian ini adalah data perilaku berisiko remaja yang terdiri dari perilaku berisiko remaja melakukan hubungan seksual dan perilaku berisiko remaja menggunakan narkoba yang diperoleh dari SKAP BKKBN Jawa Timur 2018. Pada data yang diperoleh dari SKAP BKKBN ini, jumlah perilaku berisiko remaja menggunakan narkoba dan jumlah perilaku berisiko remaja melakukan hubungan seksual relatif kecil. Hal ini menunjukkan bahwa terdapat perbedaan jumlah antar kelas yang menandakan bahwa ada kasus class imbalanced pada data SKAP BKKBN ini. Sehingga
hasil klasifikasi yang dihasilkan akan kurang optimal. Sehingga untuk
mengklasifikasikan data perilaku berisiko remaja ini diperlukan juga penangan class imbalanced pada data tersebut agar hasil klasifikasi yang diperoleh optimal.
2.2 Rumusan Masalah
Sehingga berdasarkan latar belakang tersebut, maka akan dilakukan penelitian untuk mengklasifikasikan data perilaku berisiko remaja menggunakan narkoba dan melakukan hubungan seksual dengan metode random forest dan mengkombinasikannya dengan algoritma MWMOTE dan SMOTE+TL sebagai penanganan class imbalanced.
2.3 Tujuan Penelitian
Adapun tujuan dari penelitian ini adalah sebagai berikut.
1. Mengklasifikasikan data perilaku berisiko remaja menggunakan narkoba dan melakukan hubungan seksual.
2. Mengetahui metode terbaik dalam mengatasi class imbalanced pada klasifikasi perilaku berisiko remaja di Jawa Timur dengan menggunakan base classifier random forest.
2.4 Urgensi dan Manfaat Penelitian
Perilaku berisiko remaja melakukan hubungan seksual dan menggunakan narkoba semakin tinggi, sehingga perlu dilakukan analisis untuk mengetahui faktor-faktor apa saja yang mempengaruhi perilaku berisiko yang dilakukan remaja. Urgensi dari penelitian ini adalah untuk mengatasi class imbalance dan melakukan klasifikasi pada data perilaku berisiko remaja dimana data tersebut remaja guna mengetahui faktor-faktor yang mempengaruhi perilaku berisiko yang dilakukan remaja.
12
Manfaat dari penelitian ini adalah dapat menambah pengetahuan tentang penerapan metode re-sampling SMOTE+TL dan MWMMOTE untuk mengatasi class imbalanced yang berguna untuk meningkatkan performa dari metode klasifikasi.
13 BAB III
TINJAUAN PUSTAKA
3.1 Penelitian terdahulu
Adapun penelitian terdahulu yang digunakan yang pertama yaitu penelitian dari Sain & Purnami [14] yang membahas tentang metode sampling untuk data imbalanced. Data yang digunakan yaitu data kesehatan yang tidak imbalanced. Metode yang digunakan adalah SVM dengan SMOTE, Tomek Links dan SMOTE+TL. Hasilnya menunjukkan bahwa metode SMOTE+TL mempunyai performa lebih baik dibandingkan hanya dengan menggunakan SMOTE atau Tomek Links saja.
Jatmiko, dkk [15] membahas tentang pengklasifikasian perilaku seks pra-nikah di Indonesia, dimana data tersebut imbalanced. Hasil penelitian menunjukkan bahwa metode random forest tanpa penanganan data imbalanced menghasulkan akurasai yang bias dengan nilai sensitivity 0, sedangkan jika dilakukan penanganan pada data imbalanced tersebut, nilai sensitivity dan presisinya meningkat.
Penelitian dari Untoro dan Buliali [16] yang membahas tentang penanganan data tidak seimbang menggunakan metode Classifier Decision Tree (J48) dengan MWMOTE dan data yang digunakan adalah data laboratorium yang memiliki rasio imbalanced 2:8, dimana 2 merupakan kelas minoritas yaitu penyakit yang jarang dan 8 adalah kelas mayoritas. Hasil dari penelitian ini diketahui bahwa metode dimana metode Classifier Decision Tree (J48) dengan MWOTE dapat meningkatkan akurasi dari data sebesar 3.13% dibandingkan hanya menggunakan Classifier Decision Tree (J48) tanpa penanganan data imbalanced.
Penelitian lainnya adalah dari Santos, dkk [16]. Penelitian ini membandingkan beberapa metode untuk penanganan data imbalanced, dimana data yang digunakan adalah 86 dataset. Dari penelitian ini diperoleh kesimpulan bahwa metode SMOTE+TL dan MWMOTE merupakan metode over-sampling yang terbaik karena mempunyai nilai AUC tertinggi dibanding yang lain.
Maisya, dkk[17] meneliti tentang perilaku berisiko remaja. Hasil penelitian ini menunjukkan bahwa remaja sudah mengkonsumsi rokok dan minuman keras walaupun masih duduk dibangku sekolah menengah dan bahkan ada yang melakukan
seks-14
pranikah. Salah satu faktor yang mempengaruhi perilaku berisiko remaja ini adalah pengaruh teman sebaya. Remaja yang memiliki teman yang berperilaku berisiko juga akan melakukan perilaku berisiko dikarenakan remaja ingin diakui oleh lingkungan pertemanannya dan tidak dianggap ketinggalan jaman. Maharti [18] meneliti tentang faktor-faktor yang berhubungan dengan perilaku berisiko remaja menggunakan narkoba, dimana hasil dari penelitian ini menunjukkan bahwa kemudahan mendapatkan narkoba dan teman sebaya merupakan salah faktor yang menyebabkan terjadinya perilaku beresiko penyalahgunaan narkoba.
3.2 Klasifikasi
Klasifikasi adalah proses untuk menemukan model atau fungsi yang menjelaskan atau membedakan konsep atau kelas data, dengan tujuan untuk dapat memperkirakan kelas dari suatu objek yang labelnya tidak diketahui [2].
Proses klasifikasi dapat dibagi menjadi dua fase. Fase pertama adalah fase learning dimana sebagian data yang sudah memiliki label kelas data akan diumpamakan untuk membentuk model perkiraan. Fase kedua yaitu fase testing dimana model yang sudah terbentuk diuji dengan sebagian data lainnya (selain data yang digunakan untuk fase learning) sehingga didapatkan nilai akurasi dari model yang dihasilkan pada fase learning. Setelah didapatkan dan nilai akurasinya telah mencukupi maka model ini dapat dipakai untuk memprediksi kelas data lainnya yang belum diketahui (selain data yang digunakan untuk fase learning dan testing).
3.3 Decision Tree
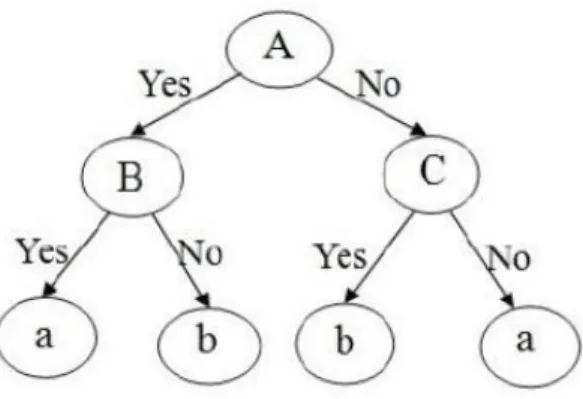
Decision tree adalah algoritma yang paling banyak digunakan untuk masalah klasifikasi. Sebuah decision tree terdiri dari beberapa simpul yaitu tree’s root, internal node dan leafs. Konsep entropi digunakan untuk penentuan pada atribut mana sebuah pohon akan terbagi (split). Dalam pohon keputusan, setiap simpul internal membagi ruang menjadi dua atau lebih sesuai dengan fungsi diskrit dari input atribut nilai. Dalam kasus yang paling sederhana dan paling sering, setiap tes menganggap sebagai atribut tunggal, sehingga ruang dipartisi kosong disesuaikan dengan nilai atribut. rapa simpul yaitu tree’s root, internal node dan leafs. Konsep menggunakan decision tree dilakukan oleh routing dari simpul akar sampai tiba di simpul daun.
15
Gambar 3.1 Ilustrasi Decision Tree
Menurut Saputra [19], decision tree merupakan metode yang paling efisien untuk menyaring sesuatu lewat pohon keputusan apakah suatu data lolos atau tidak terhadap saringan dengan proses yang cukup cepat dengan tahapan dalam membuat sebuah pohon keputusan sebagai berikut:
1. Menyiapkan data training yang sudah dikelompokkan ke dalam kelas tertentu. 2. Menentukan akar dari atribut, dimana akar akan diambil dari atribut yang terpilih
yaitu dengan cara menghitung nilai gain dari masing-masing atribut. Nilai gain yang tertinggi akan menjadi akar pertama. Sebelum menghitung nilai gain dari atribut, hitung nilai entropy.
Adapun rumus untuk menghitung nilai entropy adalah sebagai berikut: 𝐸𝑛𝑡𝑟𝑜𝑝𝑦 (𝑦) = −𝑝1𝑙𝑜𝑔2𝑝1− 𝑝2𝑙𝑜𝑔2𝑝2−. . . −𝑝𝑛𝑙𝑜𝑔2𝑝𝑛 (1) dimana:
𝑝1, 𝑝2, … , 𝑝𝑛: proporsi kelas 1, kelas 2, …, dan kelas n dalam output 3.4 CART
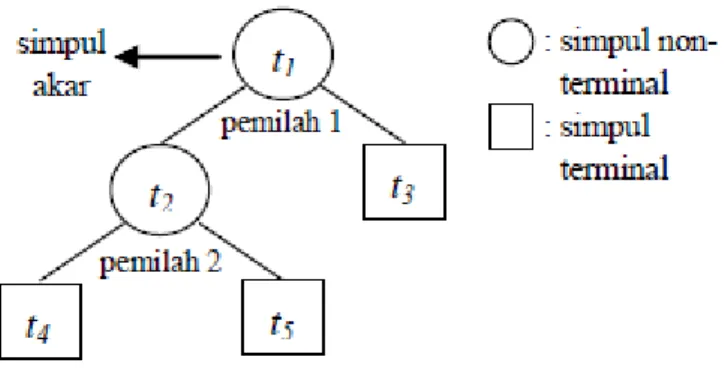
CART (Classification and Regression Tree) merupakan metode eksplorasi data yang didasarkan pada teknik pohon keputusan. Pohon klasifikasi dihasilkan saat peubah respons berupa data kategorik, sedangkan pohon regresi dihasilkan saat peubah respons berupa data numerik [20]. Pohon terbentuk dari proses pemilahan rekursif biner pada suatu gugus data sehingga nilai peubah respons pada setiap gugus data hasil pemilahan akan lebih homogen [20].
16
Gambar 3.2 Ilustrasi CART
Pohon disusun oleh simpul t1, t2, …, t5. Setiap pemilah (split) memilah simpul non-terminal menjadi dua simpul yang saling lepas. Hasil prediksi respons suatu amatan terdapat pada simpul terminal [21].
Pembangunan pohon klasifikasi CART meliputi tiga hal [20], yaitu: 1. Pemilihan pemilah (split)
2. Penentuan simpul terminal 3. Penandaan label kelas 3.5 Random Forest
Random forest merupakan salah satu metode klasifikasi yang terdiri dari kumpulan decision trees. Random Forest adalah pengembangan dari metode CART, yaitu dengan menerapkan metode bootstrap aggregating (bagging) dan random feature selection. Dalam random forest, banyak pohon ditumbuhkan sehingga terbentuk hutan (forest), kemudian analisis dilakukan pada kumpulan pohon tersebut. Pada gugus data yang terdiri atas n amatan dan p peubah penjelas, random forest dilakukan dengan cara:
1. Lakukan bootstrap yaitu mengambil sampel acak berukuran n dengan pengembalian pada tiap dataset.
2. Memilih m dimana m<p peubah penjelas pada setiap simpul, variabel m dipilih secara acak dan m terbaik digunakan untuk membagi simpul. Nilai m konstan selama pertumbuhan forest. Membangun pohon sampai mencapai ukuran maksimum (tanpa pemangkasan) dengan menggunakan sampel bootsrap.
3. Ulangi tahap 1 dan 2 sebanyak k kali, hingga terbentuk sebuah hutan yang terdiri dari k pohon.
17
4. Lakukan pendugaan penggabungan (aggregating) berdasarkan k buah pohon (missal menggunakan majority vote (suara terbanyak) pada kasus klasifikasi atau rata-rata pada kasus regresi).
Error klasifikasi random forest diduga melalui error OOB yang diperoleh dengan cara [22]:
1. Lakukan prediksi terhadap setiap data OOB pada pohon yang bersesuaian. Data OOB (out of bag) adalah data yang tidak termuat dalam contoh bootstrap. 2. Secara rata-rata, setiap amatan gugus data asli akan menjadi data OOB sebanyak
sekitar 36% dari banyak pohon. Oleh karena itu, pada langkah 1, masing-masing amatan gugus data asli mengalami prediksi sebanyak sekitar sepertiga kali dari banyaknya pohon. Jika a adalah sebuah amatan dari gugus data asli, maka hasil prediksi random forest terhadap a adalah gabungan dari hasil prediksi setiap kali a menjadi data OOB.
3. Error OOB dihitung dari proporsi misklasifikasi hasil prediksi random forest dari seluruh amatan gugus data asli.
3.6 SMOTE+TL
Synthetic Minority Oversampling Technique (SMOTE) adalah salah satu metode oversampling untuk mengatasi class imbalanced. SMOTE bekerja dengan menghasilkan data synthetic pada kelas minoritas bukan dengan menggunakan replacement atau randomized sampling techniques (Chawla, 2005). Metode SMOTE bekerja dengan mencari k-nearest neighbors (yaitu ketetanggaan terdekat data sebanyak k) untuk setiap data di kelas minoritas, setelah itu dibuat data sintetis sebanyak presentase duplikasi yang diinginkan antara data minor dan k-nearest neighbors yang dipilih secara acak [12].
SMOTE+TL adalah metode SMOTE yang diterapkan dengan metode Tomek Links setelah data di oversampling dengan menggunakan SMOTE. Tomek Link didefinisikan sebagai pasangan data dari kelas yang berbeda, satu dari kelas minoritas dan yang lainnya dari kelas mayoritas (𝑥𝑖, 𝑥𝑗), yang mempunyai neighbors terdekat antar satu sama lain.
Pada metode ini, pertama adalah mengaplikasikan metode SMOTE untuk oversampling kelas minoritas, kemudian diidentifikasi menggunakan Tomek Links dan kedua pasangan data dari masing-masing pasangan dihapus [16].
18 3.7 MWMOTE
MWMOTE merupakan metode yang di usulkan oleh Barua, Islam, Yao & Murase [11] untuk mengatasi masalah class imbalanced secara efisien. Cara kerja MWMOTE adalah dengan menghasilkan sampel synthetic pada data minoritas. MWMOTE dimulai dengan mengindentidikasi data minoritas (Simin), dan diberikan bobot tertentu (Sw),
berdasarkan jarak ke data terdekat pada kelas mayoritas. Bobot ini kemudian dikonversi ke probabilitas terpilih Sp dan akan digunakan pada tahap oversampling.
Untuk menghasilkan sampel synthetic yang baru, seluruh data pada kelas minoritas Smin di kelompokkan ke grup M. Kemudian data minoritas x dari Simin dipilih berdasarkan probabilitas terpilih Sp dan data minoritas acak lain pada Smin yang masuk ke dalam kelompok yang sama dengan x digunakan untuk menghasilkan sampel synthetic yang baru dengan cara yang sama dengan SMOTE. Pendekatan ini dilakukan sebanyak yang sebanyak N yang diperlukan dari sampel synthetic.
3.8 Kriteria Evaluasi Kinerja (Performance)
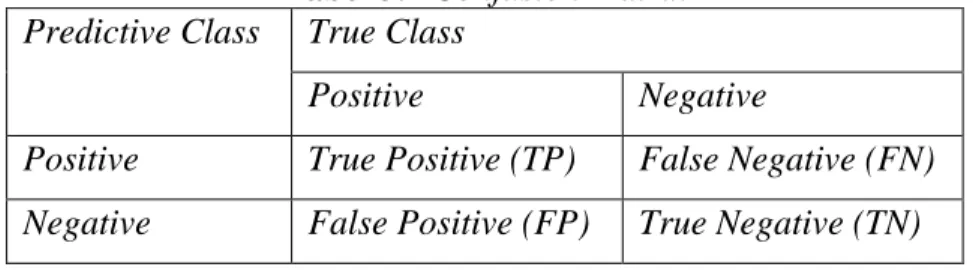
Dalam klasifikasi, hamper tidak mungkin ntuk membuat klasifikasi yang sempurna untuk mengklasifikasikan semua objek. Untuk data tidak seimbang, akurasi lebih didominasi oleh ketepatan pada data kelas minoritas, maka matriks yang tepat adalah AUC (Area Under the ROC Curve), F-Measure, G-mean, Apparent Error Rate (APER), Total Accuracy Rate (1-APER), dan akurasi kelas minoritas (Zhang & Wang, 2011). Confusion matrix merupakan metode yang menggunakan table matriks seperti pada Tabel 3.1, jika data set hanya terdiri dari dua kelas, kelas yang satu dianggap sebagai positif dan yang lainnya negatif [23].
Tabel 3.1 Confusion Matrix Predictive Class True Class
Positive Negative
Positive True Positive (TP) False Negative (FN) Negative False Positive (FP) True Negative (TN)
Untuk menghitung digunakan persamaan di bawah ini [23]
1. Accuracy digunakan untuk menghitung akurasi hasil klasifikasi. 𝐴𝑐𝑐𝑢𝑟𝑎𝑐𝑦 = 𝑇𝑃+𝑇𝑁
19
2. Sensitivity (Recall) atau TPrate yaitu proporsi dari hasil klasifikasi yang bernilai True Positive.
𝑅𝑒𝑐𝑎𝑙𝑙 = 𝑇𝑃
𝐹𝑁+𝑇𝑃 (3)
3. Specificity atau TNrate yaitu proporsi dari hasil klasifikasi yang bernilai True Positive.
𝑆𝑝𝑒𝑐𝑖𝑓𝑖𝑐𝑖𝑡𝑦 = 𝑇𝑁
𝐹𝑃+𝑇𝑁 (4)
4. Precision yaitu bagian dari predicted yang bernilai positive.
𝑃𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 = 𝑇𝑃
𝑇𝑃+𝐹𝑃 (5)
5. F-Measure merupakan rata-ratatertimbang antara precision dan recall dimana jika nilai F-Measure tinggi maka nilai precision dan recall juga tinggi.
𝐹 − 𝑀𝑒𝑎𝑠𝑢𝑟𝑒 = 2 ×𝑅𝑒𝑐𝑎𝑙𝑙×𝑃𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛
𝑅𝑒𝑐𝑎𝑙𝑙+𝑃𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 (6)
6. Area Under Curve (AUC) digunakan sebagai ukuran evaluasi untuk dataset tidak seimbang,
𝐴𝑈𝐶 =𝑠𝑒𝑛𝑠𝑖𝑡𝑖𝑣𝑖𝑡𝑦+𝑆𝑝𝑒𝑐𝑖𝑓𝑖𝑐𝑖𝑡𝑦
2 (7)
Adapun interval ketepatan klasifikasi yang baik dengan perhitungan AUC adalah sebagai berikut [24]:
Tabel 3.2 Kriteria Nilau AUC
Nilai AUC Keterangan
0.5-0.6 Kurang 0.6-0.7 Cukup 0.7-0.8 Baik 0.8-0.9 Sangat Baik 0.9-1.0 Sempurna 3.9 Remaja
Remaja adalah mereka yang mengalami masa transisi (peralihan) dari masa kanak-kanak menuju masa dewasa, yaitu antara usia 12-13 tahun hingga usia 20-an, perubahan yang terjadi termasuk drastis pada semua aspek perkembangannya yaitu meliputi perkembangan fisik, kognitif, kepribadian dan sosial [25]. masa remaja adalah peralihan dari masa anak dengan masa dewasa yang mengalami perkembangan semua aspek/ fungsi untuk memasuki masa dewasa [26]. Secara global masa remaja berlangsung antara 12 –
20
21 tahun, dengan pembagian 12 – 15 tahun: masa remaja awal, 15 – 18 tahun: masa remaja pertengahan, 18 – 21 tahun masa remaja akhir [27].
3.10 Perilaku Berisiko
Perilaku beresiko ini adalah perilaku yang memiliki akibat yang serius. Perilaku yang berisiko adalah perilaku yang dapat menyebabkan kematian atau dapat menimbulkan penyakit pada remaja, yaitu merokok, perilaku yang menyebabkan cedera dan kekerasan, alkohol dan obat terlarang, diet yang dapat menyebabkan kematian, gaya hidup bebas, serta perilaku seksual yang dapat meyababkan kehamilan dan kematian. Beberapa masalah kesehatan yang terjadi pada remaja berkaitan dengan perilaku berisiko yaitu merokok, minum minuman, beralkohol, penyalahgunaan narkoba, dan melakukan hubungan seksual pranikah [28].
3.11 Road Map Penelitian
Penelitian ini relevan dengan Penelitian pada Pusat Studi Sains Fundamental sebagaimana dapat dilihat pada Gambar 3.3.
Gambar 3.3 Road Map Penelitian Pusat Penelitian Sains Fundamental
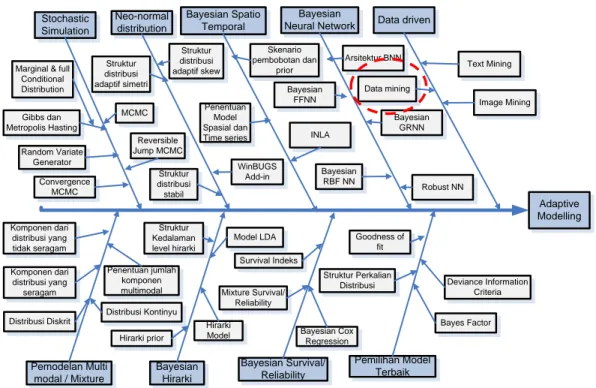
Penelitian ini juga relevan dengan salah satu topik penelitian yang dikembangkan oleh ketua peneliti di Laboratorium Statistika Komputasi yang ada di Departemen Statistika ITS sebagaimana Gambar 3.4.
21 Stochastic Simulation Adaptive Modelling Neo-normal distribution Pemodelan Multi modal / Mixture Bayesian Hirarki Pemilihan Model Terbaik Convergence MCMC Gibbs dan Metropolis Hasting Reversible Jump MCMC Random Variate Generator Marginal & full Conditional Distribution MCMC Struktur Perkalian Distribusi Bayes Factor Deviance Information Criteria Hirarki prior Hirarki Model Goodness of fit Distribusi Diskrit Komponen dari distribusi yang tidak seragam Struktur Kedalaman level hirarki Penentuan jumlah komponen multimodal Bayesian Survival/ Reliability Mixture Survival/ Reliability Bayesian Cox Regression Survival Indeks Bayesian Neural Network Struktur distribusi adaptif simetri Struktur distribusi adaptif skew Struktur distribusi stabil WinBUGS Add-in Text Mining Bayesian RBF NN Bayesian Spatio Temporal Skenario pembobotan dan prior Arsitektur BNN Data driven Bayesian FFNN Robust NN Bayesian GRNN Data mining Image Mining Penentuan Model Spasial dan
Time series INLA
Komponen dari distribusi yang seragam
Distribusi Kontinyu
Model LDA
22 BAB IV METODE
4.1 Tahapan Penelitian
Adapun tahapan-tahapan kegiatan untuk penelitian yaitu sebagaimana Tabel 4.1. Tabel 4. 1 Tahapan Penelitian, Metode, Tugas Tim, Waktu dan target Luaran Tujuan Penelitian Metode yang Digunakan Tim Peneliti yang Menyelesaikan Alokasi Waktu Target Luaran Tujuan-1 Metode Random Forest Ketua Tim, Anggota 2 dan 3, Mahasiswa tesis 2 Bulan Mengklasifikasikan data perilaku berisiko remaja Tujuan-2 MWMOTE dan SMOTE+TL dengan base classifier random forest Ketua Tim, Anggota 1 dan 2 Mahasiswa tesis
3 Bulan Mengetahui metode
terbaik untuk mengatasi class imbalanced pada klasifikasi data perilaku berisiko remaja
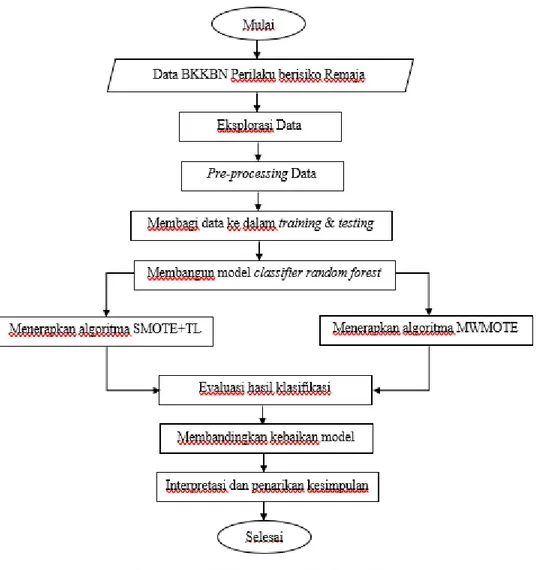
Adapun langkah-langkah analisis pada penelitian ini adalah sebagai berikut. 1. Melakukan eksplorasi pada data dependen dan independen.
2. Melakukan pre-processing data.
3. Membagi data menjadi data training dan data testing.
4. Menerapkan algoritma random forest pada data perilaku berisiko remaja.
a. Mengambil m jumlah variabel prediktor secara acak dan menentukan k pohon yang akan dibentuk.
b. Membentuk tree model dari dataset testing dengan kombinasi m variabel prediktor yang diambil secara acak dan k buah ukuran pohon.
5. Menerapkan algoritma MWMOTE dan SMOTE+TL pada data perilaku berisiko remaja dengan random forest sebagad base classifier.
6. Menglasifikasikan data dan melakukan pengujian akurasi.
7. Membandingkan rata-rata akurasi dan AUC dari hasil klasifikasi dengan menggunakan berbagai metode imbalanced.
23
8. Menginterpretasikan hasil klasifikasi yang mempunyai performa terbaik dan menarik kesimpulan dan saran.
4.2 Diagram Alir
Adapun diagram alir dari penelitian ini adalah sebagai berikut:
Gambar 4.1 Diagram Alir Penelitian 4.3 Luaran
Luaran yang akan dicapai dari penelitian ini adalah sebagai berikut.
1. Publikasi 1 makalah atau paper pada jurnal internasional terindeks scopus berkategori Q2. Rencana di Songklanakarin Journal of Science and Technology (SJST).
2. Satu makalah hasil Conference hasil riset yang telah dilakukan pada seminar nasional maupun internasional.
24 4.4 Organisasi Tim Peneliti
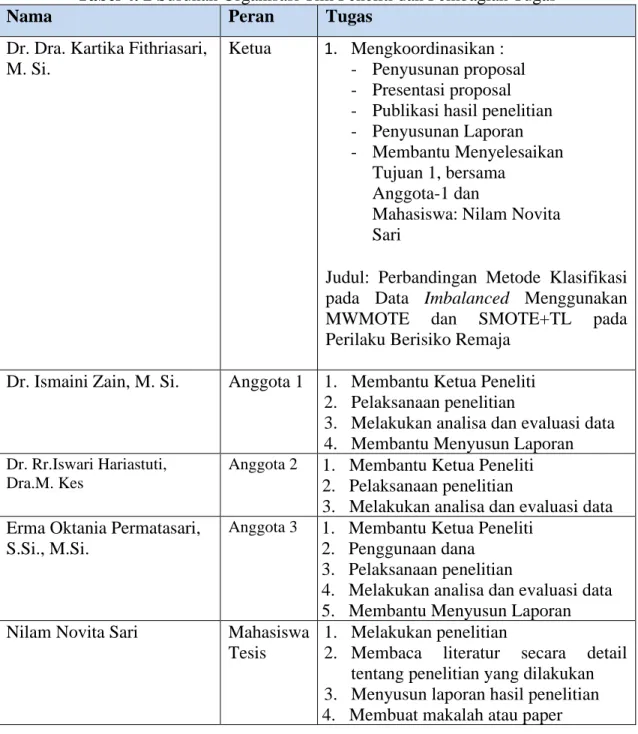
Tabel 4. 2 Susunan Organisasi Tim Peneliti dan Pembagian Tugas
Nama Peran Tugas
Dr. Dra. Kartika Fithriasari, M. Si.
Ketua 1. Mengkoordinasikan :
- Penyusunan proposal - Presentasi proposal - Publikasi hasil penelitian - Penyusunan Laporan - Membantu Menyelesaikan
Tujuan 1, bersama Anggota-1 dan
Mahasiswa: Nilam Novita Sari
Judul: Perbandingan Metode Klasifikasi pada Data Imbalanced Menggunakan
MWMOTE dan SMOTE+TL pada
Perilaku Berisiko Remaja
Dr. Ismaini Zain, M. Si. Anggota 1 1. Membantu Ketua Peneliti
2. Pelaksanaan penelitian
3. Melakukan analisa dan evaluasi data 4. Membantu Menyusun Laporan Dr. Rr.Iswari Hariastuti,
Dra.M. Kes
Anggota 2 1. Membantu Ketua Peneliti 2. Pelaksanaan penelitian
3. Melakukan analisa dan evaluasi data Erma Oktania Permatasari,
S.Si., M.Si.
Anggota 3 1. Membantu Ketua Peneliti 2. Penggunaan dana
3. Pelaksanaan penelitian
4. Melakukan analisa dan evaluasi data 5. Membantu Menyusun Laporan
Nilam Novita Sari Mahasiswa
Tesis
1. Melakukan penelitian
2. Membaca literatur secara detail
tentang penelitian yang dilakukan 3. Menyusun laporan hasil penelitian 4. Membuat makalah atau paper
4.5 Rencana Anggaran Biaya
25
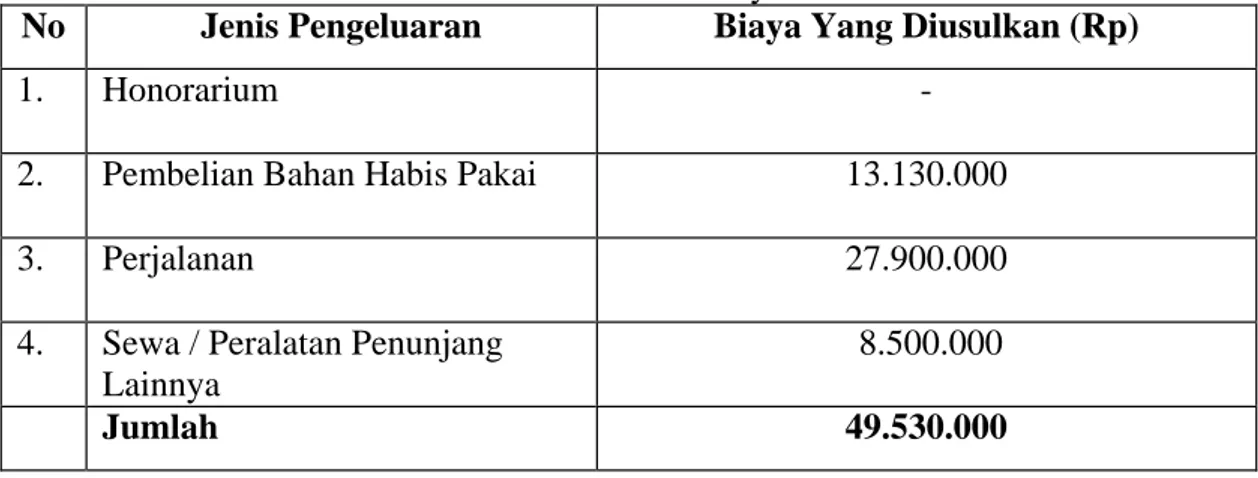
Tabel 4.3 Total Biaya
No Jenis Pengeluaran Biaya Yang Diusulkan (Rp)
1. Honorarium -
2. Pembelian Bahan Habis Pakai 13.130.000
3. Perjalanan 27.900.000
4. Sewa / Peralatan Penunjang
Lainnya
8.500.000
Jumlah 49.530.000
Terbilang: Empat Puluh Sembilan Juta Lima Ratus Tiga Puluh Ribu Rupiah. Uraian secara detail tentang biaya penelitian diberikan pada Lampiran-1.
26 BAB V JADWAL
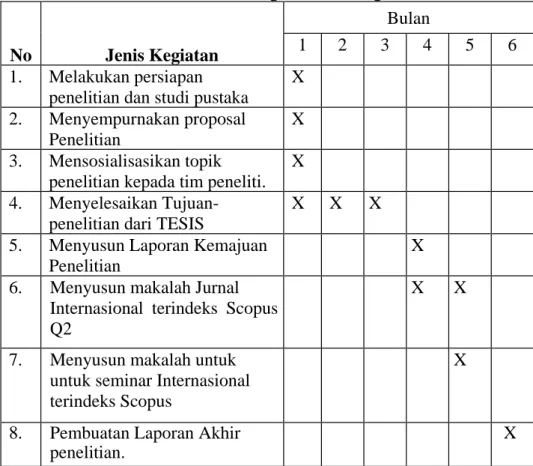
Penelitian ini direncanakan selama 8 bulan dengan jadwal penelitian sebagai mana Tabel 5.1.
Tabel 5.1 Rencana Kegiatan dan Target Penelitian
No Jenis Kegiatan
Bulan
1 2 3 4 5 6
1. Melakukan persiapan
penelitian dan studi pustaka
X
2. Menyempurnakan proposal
Penelitian
X
3. Mensosialisasikan topik
penelitian kepada tim peneliti.
X
4. Menyelesaikan
Tujuan-penelitian dari TESIS
X X X
5. Menyusun Laporan Kemajuan
Penelitian
X
6. Menyusun makalah Jurnal
Internasional terindeks Scopus Q2
X X
7. Menyusun makalah untuk
untuk seminar Internasional terindeks Scopus
X
8. Pembuatan Laporan Akhir
penelitian.
27 BAB VI
DAFTAR PUSTAKA
[1] Santosa, B. 2007. Data Mining Teknik Pemanfaatan Data untuk Keperluan Bisnis. Yogyakarta: Graha Ilmu.
[2] Han, J., Kamber & M., Pei, J. 2011. Data Mining Concepts and Techniques 3rd Edition. Waltham: Elsevier Inc.
[3] Berry, M. J. & Linoff, G. S. 2004. Data Mining Techniques for marketing, sale, customer relationship management. Indianapolis: Wiley Publishing, Inc.
[4] Dhawangkhara, M. & Riksakomara, E. 2017. “Prediksi Intensitas Hujan Kota Surabaya dengan Matlab Menggunakan Teknik Random Forest dan CART (Studi Kasus Kota Surabaya)”. Jurnal Teknik ITS, 6(1): 94-99.
[5] Gu, Q., Wang, X. M., Wu, Z., Ning, B. & Xin, C. S. 2016. ”Improved SMOTE Algorithm Based on Genetic Algorithm for Imbalanced Data Classification”. Journal of Digital Information Management, Vol. 14, No. 2.
[6] Pangastuti, S.S., Fithriasari, K., Iriawan, N. & Suryaningtyas, W. 2019. “Classification
Boosting in Imbalanced Data”. Malaysian Journal of Science, Vol. 38, No. Sp2, p. 36-45.
[7] Jian, C., Gao, J. & Ao, Y. 2017. “Imbalanced Defect Classification for Mobile Phone Screen Glass Using Multifractal Features and a New Sampling Method”. Journal of Springer Science and Business Media.
[8] Guo, S., Guo, D., Chen, L. & Jiang, Q. 2016. “A centroid-based gene selection method for microarray data classification”. Journal of Theoretical Biology, 400(2016), 32-41. [9] Jian, C., Gao, J. & Ao, Y. 2016. “A New Sampling Method for Classifying Imbalanced
Data Based on Support Vector machine Ensemble”. Neurocomputing, 193, 115-122. [10] Untoro, M. C. & Buliali, J. L. 2018. “Penanganan Imbalanced Class Data Laboratorium
Kesehatan dengan Majority Weighted Minority Oversampling Technique”. Jurnal Ilmiah Teknologi Sistem Informasi.
[11] Barua, S., Islam, M. M., yao, X. & Murase, K. 2014. “MWMOTE-Majority Weighted Minority Oversampling Technique for Imbalanced Data Set Learning”. IEEE Trans. Knowl. Data Eng., 26 (2), 405-425 .
[12] Iriawan, N., Fithriasari, K., Ulama, B.S.S., Suryaningtyas, W., Pangastuti, S.S., Cahyani, N. & Qadrini, L. 2018. “On The Comparison: Random Forest, SMOTE-Bagging, and Bernoulli Mixture to Classify Bidikmisi Dataset in East Java”. 2018 International Conference on Computer Engineering, Network and Intelligent Multimedia (CENIM),
Surabaya, Indonesia, 2018, pp. 137-141.
[13] Sastrawan, A. S., Baizal, ZK. A. & Bijaksana, M. A. 2010. “Analisis Pengaruh Metode Combine Sampling dalam Churn Prediction untuk Perusahaan Telekomunikasi”. [14] Sain, H. & Purnami, S. W. 2015. “Combine Sampling Support Vector Machine for
Imbalanced Data Classification”. Procedia Computer Science, 72, 59-66.
[15] Jatmiko, Y. A., Padmadisastra, S. & Chadidjah, A. 2019. “Analisis Perbandingan Kinerja Cart Konvemmsional, Bagging dan Random Forest pada Klasifikasi Objek: Hasil dari Dua Simulasi”. Media Statistika, 12(2): 1-12.
[16] Santos, M. S., Soares, J. P., Abreu, P. H., Araujo, H. & Santos, J. 2018. “Cross-Validation for Imbalanced Data”. IEEE Computational Intelligence Magazine, 13(4), p:59-76.
28
[17] Maisya, I. B., Susilowati, A. & Rachmalina, R. 2013. “Gambaran Perilaku Berisiko Remja di kelurahan Kebon Kelapa Kecamatan Bogor Tengah Kota Bogor Tahun 2013 (Studi Kualitatif)”. Jurnal Kesehatan Reproduksi, Vol. 4 No 3, p:123-130.
[18] Maharti, V. I. 2015. “Faktor-faktor yang Berhubungan dengan Perilaku Penyalahgunaan Narkoba pada Remaja Usia 15-19 Tahun di Kecamatan Semarang Utara Kota Semarang”. Jurnal Kesehatan Masyarakat, Vol. 3, No. 3.
[19] Saputra, R. A. 2014. “Komparasi Algoritma Klasifikasi Data Mining untuk Memprediksi Penyakit Tuberculosis (TB): Studi Kasus Puskesmas Karawang Sukabumi”. Seminar Nasional Inovasi dan Tren (SNIT).
[20] Breiman, Leo. Friedman, J., Olshen, R. and Stone, C. 1984. Classification and Regression Trees. New York: Chapman & Hall.
[21] Dewi, N. K., Syafitri, U. D. & Mulyadi, S. Y. 2011. “Penerapan Metode Random Forest dalam Driver Analysis”. Forum Statistika dan Komputasi, p: 35-43.
[22] Liaw. A. & Wiener, M. Des 2002. “Classification and Regression by Random Forest”. Rnews, Vol. 2/3:18-22
[23] Olson, D. & Yong, Shi. 2008. Pengantar Ilmu Pengalian Data Bisnis. Jakarta: Salemba Empat.
[24] Bekkar, M., Djemaa, H. K. & Alitouche, T. A., 2013. “Evaluation Measure for Models Assessment over Imbalanced Data Sets”. Journal of Information Engineering and Aplications.
[25] Gunarsa, S. 2006. Psikologi Perkembangan Anak dan Dewasa. Jakarta: Gunung Mulia. [26] Rumini, S. & Sundari, S. 2004. Perkembangan Anak dan Remaja. Jakarta: PT. Asdi
Mahasatya.
[27] Monks, F.J., Knoers, A.M.P. & Haditono, S.R. 2002. Psikologi Perkembangan: Pengantar dalam Berbagai Bagiannya. Yogyakarta: Gadjah Mada University Press. [28] Bart, Smet. (1994). Psikologi Kesehatan. PT. Gramedia Widiasarna Indonesia : Jakarta.
29 BAB VII LAMPIRAN
30
Biodata Tim Peneliti
1. Ketua
a. Nama Lengkap : Dr. Dra. Kartika Fithriasari, M.Si.
b. NIP/NIDN : 19691212 199303 2 002
c. Fungsional/Pangkat/Gol : Lektor
d. Bidang Keahlian : Statistik Komputasi
e. Departemen/Fakultas : Statistika/Sains dan Analitika data
f. Alamat Rumah dan No. Telp. : Perum ITS Jl. Teknik Komputer V Blok U-178
Surabaya / 0818396410
g. Riwayat penelitian/pengabdian :
Penelitian
No Judul Penelitian Peran Tahun
1 Analisis Twitter Untuk Evaluasi
Pembangunan Kota Surabaya
Dengan Pendekatan Model
Bayesian Hirarki dan Machine Learning
Ketua 2019
2 Pemodelan dan Pemetaan
Big-Data Program Bidikmisi Sebagai Early Warning System dalam Rangka Mempersiapkan SDM di Era MEA dengan
Pendekatan Hierarchical
Bayesian
Anggota 2018
3 Pengembangan Model Detektor
Ketepatan Penentuan ROI pada citra MRI Tumor Otak dengan
pendekatan Bayesian Skew
Normal Mixture Model
Anggota 2018
4 Analisis Twitter untuk Evaluasi
Pembangunan Kota Surabaya
Dengan Pendekatan Model
Bayesian Hirarki Dan Machine Learning
Ketua 2018
5 Pendekatan Binary Logit
Model-Bayesian Network Hybrid Untuk Analisis Pencemaran Bakteri Salmonella
Sp Pada Udang Vaname
(Litopenaeus Vannamei)
Anggota 2017
6 Pemodelan dan Pemetaan
Big-Data Program Bidikmisi
Sebagai Early Warning System
31 dalam Rangka Mempersiapkan SDM di Era MEA dengan
Pendekatan Hierarchical
Bayesian
Pengabdian
No Judul Penelitian Peran Tahun
1 Analisis dan Survey Tingkat Pemahaman Budaya Surabaya 2018 (Bappeko Surabaya)
Ketua 2018
2 Analisis dan Survey Tingkat
Kepedulian Masyarakat Dalam
Kegiatan Yang Mendorong
Nilai-Nilai Kebangsaan di
Surabaya 2018 (Bappeko
Surabaya)
Ketua 2018
3 Analisis dan Survey Tingkat
persepsi Masyarakat atas
pelaksanaan pembangunan kota 2018 (Bappeko Surabaya)
Ketua 2018
4 Pelatihan Pengolahan Data
Statistik Sektoral untuk
Perangkat Daerah Pemerintah Provinsi Jawa Timur
Anggota 2019
h. Publikasi :
No Judul Penelitian Peran Tahun
1 Classification Boosting in Imbalanced Data
2019 2 Linking Twitter Sentiment
Knowledge with Infrastructure Development
2018
3 On the Comparison of Deep Learning Neural Network and Binary Logistic Regression for Classifying the Acceptance Status of Bidikmisi Scholarship Applicants in East Java
2018
4 On The Markov Chain Monte Carlo Convergence Diagnostic of Bayesian Finite Mixture Model for Income Distribution
2018
5 Bayesian Network Inference In Binary Logistic Regression: A Case Study Of Salmonella Sp
32 Bacterial Contamination On Vannamei Shrimp
6 Clustering the Stationary And Non Stationary Time Series Based On Autocorrelation Distance Of Hierarchical And K-Means Algorithm
2017
7 On The Value At Risk Using Bayesian Mixture Laplace Autoregressive Approach For Modelling The Islamic Stock Risk Investment
2017
i. Paten : -
j. Tugas akhir, Tesis, dan Disertasi yang selesai dibimbing:
No Judul Penelitian Tahun
1 Model Hierarchical Survival
pada Kasus Kejadian Demam Berdarah Dengue (DBD) di Kota Surabaya
Tesis 2019
2 Klastering Data Twitter dengan
Menggunakan Metode Laten Dirichlet Allocation (LDA) dan Laten Semantic Analysis (LSA)
Tesis 2019
3 Pengaruh Long Memory
Terhadap Pengujian Asimetris dan Aplikasinya pada Data Indeks Harga Saham Gabungan
Tesis 2019
4 Analisis Perilaku Remaja
Melakukan Seks Pra-Nikah di
Jawa Timur Menggunakan
CART dengan
SMOTE-N-ENN dan Adasyn
Skripsi 2020
5 Klasifikasi Sentimen data
Ulassan Wisatawan Candi
Borobudur di Situs Tripadvisor Menggunakan SVM dan K-NN
Skripsi 2019
6 Text Clustering untuk Pengelompokkan Topik Aduan
Masyarakat Kepala
Pemerintahan Kota Surabaya dengan K-Means dan Self Organizing Maps
Skripsi 2019
7 Identifikasi Wajah
Menggunakan Multi Layer
Perceptron dan Convolutional Neural Network
33
8 Analisis Rekomendasi Film
Menggunakan Kombinasi
Single Linkage Clustering dan K-Means Clustering dengan
Pendekatan User-Based
Collaborative Filtering
Skripsi 2019
9 Analisis Klasifikasi Black
Campaign Tweets pada Periode Kampanye Pemilihan Presiden 2019
Skripsi 2019
10 Text Analysis pada Maskapai
Penerbangan Indonesia di
Twitter Menggunakan Metode K-Means dan Support Vector Machine
Skripsi 2019
11 Perbandingan Metode K-Means dan Fuzzy C-Means untuk Pengelompokkan Tweet yang ditujukan Kepada PT. Kereta
Api Indonesia (@Kai121)
dengan Menggunakan N-Gram
Skripsi 2019
2. Anggota
a. Nama Lengkap : Dr. Ismaini Zain, M.Si.
NIP/NIDN : 19600525 198803 2 001
b. Fungsional/Pangkat/Gol : Lektor
c. Bidang Keahlian : Studi Demografi, Analisis data Kategorik,
Teknik Sampling, Statistika Sosial
d. Departemen/Fakultas : Statistika/Sains dan Analitika data
e. Alamat Rumah dan No. Telp. : Deltasari Indah AB/9, Sidoarjo / 08123036678
f. Riwayat penelitian/pengabdian :
Penelitian
No Judul Penelitian Peran Tahun
1 Estimasi Kurva Regresi
Semiparametrik Multivariabel
Menggunakan Pendekatan
Estimator Campuran Spline dan Kernel.
Anggota 2018
2 Pengelompokkan
Kabupaten/Kota Berdasarkan
Indikator Sanitasi Lingkungan
Sebagai Dasar Evaluasi
Pencapaian Tujuan SDGs Di Provinsi Jawa Timur
34
3 Analisis Faktor-Faktor yang
Mempengaruhi Angka
Kematian Bayi (AKB)
Berdasarkan Indikator Sanitasi dan Kesehatan Sebagai Dasar Evaluasi Pencapaian Target SDGs di Provinsi Sulawesi Utara
Anggota 2019
4 Pengelompokan Dan
Pemodelan Kualitas Proses
Pendidikan Perguruan Tinggi Negeri Di Indonesia Menurut
Jalur Masuk Dengan
Pendekatan Metode Ensemble Rock (Robust Clustering Using Links) Dan Similarity Weight And Filter Method (Swfm) Serta Quantile Regression
Ketua 2017
5 Pemodelan Konsumsi Air
Bersih dengan Pendekatan
Model Tobit Double Hurdle Berbasis Analisis Gender pada Rumah tangga Miskin.
Ketua 2017
Pengabdian
No Judul Penelitian Peran Tahun
1 Program Terapan Bidang
Teknologi lnformasi dan
Komunikasi (PRODISTIK)
Madrasah Aliyah Zainul Hasan I Genggong
2017
2 Kampung Literasi Dolly Jilid Ii:
Penguatan Potensi Menulis
Bagi Remaja Di Kawasan Budaya Kelurahan Putat Jaya. Abdimas Reguler ITS Tahun 2018
2017
3 Pelatihan Tata Cara
Penyusunan Proposal Penelitian Dana Ristek Dikti Untuk Dosen Undar Jombang. SK Abdimas Reguler Its.
2018
4 Pelatihan Metodelogi Penelitian
Untuk Dosen Stikom –
Surabaya. Sk Abdimas Reguler Its
2019
5 Penguatan Kampung Literasi
ITS: Meningkatkan
35 Profesionalisme Petugas Taman Baca Masyarakat (TBM) Di Wilayah Kota Surabaya Melalui Program Mentoring Literasi
Berimbang (Balanced
Literacy). ABDIMAS
BERBASIS PENELITIAN ITS tahun 2019:
g. Publikasi :
No Judul Penelitian Peran Tahun
1 Censored Hurdle Negative Binomial Regression (Case Study: Neonatorum Tetanus Case in Indonesia) Provinsi Sumatera Utara, Jurnal Sains dan Seni ITS
2017
h. Paten : -
k. Tugas akhir, Tesis, dan Disertasi yang selesai dibimbing
No Judul Tahun
1 Pemodelan pada data
Penerimaan Calon Mahasiswa Baru melalui Jalur Ujian Tulis Bidang Saintek Tahun 2018
menggunakan Bernoulli
Mixture Model
Tesis 2019
2 Estimasi Kurva Regresi
Semiparametrik untuk data
Longitudinal menggunakan
Estimator Campuran Spline Truncated dan Deret Fourier
Tesis 2019
3 Pengelompokkan Perguruan
Tinggi Negeri (PTN) di
Indonesia Berdasarkan
Keketatan dalam Seleksi
Bersama Masuk Perguruan
Tinggi Negeri (SBMPTN)
Tahun 2018
36 3. Anggota
a. Nama Lengkap : Dr. Rr. Iswari Hariastuti, Dra.M. Kes
b. NIP/NIDN : 19661111 199203 2 008
c. Fungsional/Pangkat/Gol : Peneliti BKKBN
d. Bidang Keahlian : Studi Demografi, Analisis data Kategorik,
Teknik Sampling, Statistika Sosial
e. Departemen/Fakultas : Statistika/Sains dan Analitika data
f. Alamat Rumah dan No. Telp. : Jl Kalibokor Timur 1, Surabaya / 0811312384
g. Riwayat penelitian/pengabdian :
Penelitian
No Judul Penelitian Peran Tahun
1 Keterpajanan Informasi
Tentang Metode Keluarga
Berencana dengan Penggunaan Kontrasepsi di Jawa Timur (Bunga Rampai Analisis Lanjut SDKI 2017)
2019
2 Pola Rencana Penggunaan
Kontrasepsi Pada Wanita Usia Subur di Jawa Timur (Bunga Rampai Analisis Lanjut SDKI 2017)
2019
3 Bunga Rampai: ANALISIS
LANJUT SDKI 2017, Provinsi Jawa Timur
2019
4 Analisis Supply dan Demand
Pengguna Kontrasepsi di
Provinsi Jawa Timur (Bunga Rampai Analisis Lanjut SDKI 2017)
2019
h. Publikasi :
No Judul Penelitian Peran Tahun
1 Biblio-Journaling Therapy
Sebagai Optimalisasi Ayah
1000 Hari Pertama Kehidupan Menurunkan Stunting
2019
2 Analisis Faktor Rendahnya
Penggunaan Kontrasepsi Inta Uterine Device (IUD) di Jawa Timur
37
3 Faktor Sosial-Demografi,
Media Massa Dan Usiapertama Melakukan Hubungan Seksual Pada Remaja Putri Di Indonesia
2019
4 Qualitative Study of Family
Plnnning (KB) Village
Program's Implementation in East Java Province-Indonesia
2019
5 The Effect of Given Information, Knowledge and Community Participation on Farnilty Planing Village Programs in East Java Province-lndonesia
2019
6 Analisa Kontribusi Program
Kampung KB Dalam Upaya Peningkatan Program KKBPK Di Kab. Jombang, Provinsi Jawa Timur
2019
7 Pemahaman Remaja Tentang
Kesehatan Reproduksi
(Pernikahan Dini Dan Perilaku Beresiko) Di Sampang Madura
2017
i. Paten : -
l. Tugas akhir, Tesis, dan Disertasi yang selesai dibimbing
No Judul Tahun
1 Analisis Perilaku Remaja
Melakukan Seks Pra-Nikah di
Jawa Timur Menggunakan
CART dengan SMOTE-N-ENN dan Adasyn
Skripsi 2020
2
4. Anggota
a. Nama Lengkap : Erma Oktania Permatasari, S.Si., M.Si.
b. NIP : 198810072014042002
c. Fungsional/Pangkat/Gol : Asisten Ahli
d. Bidang Keahlian : -
e. Departemen/Fakultas : Statistika/Sains dan Analitika data
f. Alamat Rumah dan No. Telp. : Jl. Sumedi No.11, Surabaya / 085648143518
38 Penelitian
No Judul Penelitian Peran Tahun
1 Pendekatan Multivariate
Adaptive Regression Spline (MARS) untuk klasifikasi status
terinfeksi penyakit Infeksi
Menular Seksual (IMS) pada Pekerja Seks Komersial (PSK)
di Lokalisasi Moroseneng
Surabaya
2014
2 Pendekatan Multivariate
Adaptive Regression Spline (MARS) untuk pemodelan bayi yang mendapat ASI di Indonesia
2014
Pengabdian
No Judul Penelitian Peran Tahun
1 Pembinaan dan pemetaan
keterampilan kelompok anak jalanan binaan di Surabaya
2014
h. Publikasi :
No Judul Penelitian Peran Tahun
1 Multivariate Adaptive
Regression Spline (MARS) Approach For Classification of Sexually Transmitted Infections (IMS) Diseases On Commercial
Sex Workers (PSK) In
Moroseneng Localization
2015
i. Paten : -
39
SURAT PERNYATAAN KESEDIAAN ANGGOTA TIM PENELITIAN
Yang bertanda tangan dibawah ini kami:
Nama : Dr. Ismaini Zain, M.Si.
NIP : 19600525 198803 2 001
Jurusan/Fakultas : Statistika/Sains dan Analitika data
menyatakan bersedia untuk melaksanakan tanggung jawab sebagai anggota tim penelitian:
Judul Penelitian : Perbandingan Metode Klasifikai pada Data Imbalanced
Menggunakan MWMOTE dan SMOTE+TL pada Perilaku Berisiko Remaja
Ketua Tim Peneliti : Dr. Dra. Kartika Fithriasari, M.Si.
dengan tugas:
- Membantu Ketua Peneliti - Penggunaan dana
- Pelaksanaan penelitian
- Melakukan analisa dan evaluasi data - Membantu Menyusun Laporan
Surat pernyataan ini kami buat dengan sebenarnya untuk digunakan seperlunya.
Surabaya, 08 Maret 2020
Mengetahui, anggota tim peneliti
40
SURAT PERNYATAAN KESEDIAAN ANGGOTA TIM PENELITIAN
Yang bertanda tangan dibawah ini kami:
Nama : Dr. Rr. Iswari Hariastuti, Dra.M. Kes
NIM : 19661111 199203 2 008
Jurusan/Fakultas : -
menyatakan bersedia untuk melaksanakan tanggung jawab sebagai anggota tim penelitian:
Judul Penelitian : Perbandingan Metode Klasifikai pada Data Imbalanced
Menggunakan MWMOTE dan SMOTE+TL pada Perilaku Berisiko Remaja
Ketua Tim Peneliti : Dr. Dra. Kartika Fithriasari, M.Si.
dengan tugas:
- Membantu Ketua Peneliti - Pelaksanaan penelitian
- Melakukan analisa dan evaluasi data - Membantu Menyusun Laporan
Surat pernyataan ini kami buat dengan sebenarnya untuk digunakan seperlunya.
Surabaya, 08 Maret 2020
Mengetahui, anggota tim peneliti
41
SURAT PERNYATAAN KESEDIAAN ANGGOTA TIM PENELITIAN
Yang bertanda tangan dibawah ini kami:
Nama : Erma Oktania Permatasari, S.Si., M.Si.
NIP : 19600525 198803 2 001
Jurusan/Fakultas : Statistika/Sains dan Analitika data
menyatakan bersedia untuk melaksanakan tanggung jawab sebagai anggota tim penelitian:
Judul Penelitian : Perbandingan Metode Klasifikai pada Data Imbalanced
Menggunakan MWMOTE dan SMOTE+TL pada Perilaku Berisiko Remaja
Ketua Tim Peneliti : Dr. Dra. Kartika Fithriasari, M.Si.
dengan tugas:
- Membantu Ketua Peneliti - Penggunaan dana
- Pelaksanaan penelitian
- Melakukan analisa dan evaluasi data - Membantu Menyusun Laporan
Surat pernyataan ini kami buat dengan sebenarnya untuk digunakan seperlunya.
Surabaya, 08 Maret 2020
Mengetahui, anggota tim peneliti
42
LAMPIRAN 1 : Justifikasi Anggaran Penelitian
1. Honorarium
Honor Honor /Jam (Rp) Waktu (Jam/minggu) Minggu Honor Ketua Tim - - Anggota-1 - - Anggota-2 - - Anggota-3 - - Mahasiswa TESIS - - Sub Total (Rp) - 2. Pembelian Habis Pakai
Material Justifikasi Pembelian
Kuantitas Harga Satuan (Rp)
Harga Habis Pakai
Kertas 15 rim 50.000 750.000
Tinta printer 4 buah 250.000 1.000.000
Flash Disk 5 buah 150.000 750.000
Alat-alat tulis 1 Paket 500.000 500.000
Eksternal Hardisk 1 buah 750.000 750.000
Pembelian buku pustaka : 4 buku 750.000 3.000.000
Pembelian Jurnal 4 Jurnal 500.000 2.000.000
Biaya pengambilan data ke BKKBN 1 Paket 1.500.000 1.500.000
Konsumsi Rapat : 4 x 4org x 6bln 96 kali 30.000 2.880.000
43 3. Perjalanan Material Justifikasi Perjalanan Kuantitas Harga Satuan (Rp) Perjalanan
Perjalanan ikut Seminar Internasional Tranportasi Tiket (PP) 4 orang 4 1.250.000 5.000.000 - Hotel 2 Kmr x 2 hari 4 550.000 2.200.000 - Taxi 2 kali (PP) 2 250.000 500.000
- International Conference 1 orang 4 4.250.000 17.000.000
- Conference Proceeding 1 buah 4 buah 800.000 3.200.000
Sub Total Tahun ke-1 (Rp) 27.900.000 4. Sewa / Peralatan Penunjang Lainnya
Material Justifikasi Sewa Kuantitas Harga Satuan (Rp) Sewa Publikasi Jurnal Internasional 1 jurnal 1 Jurnal 7.500.000 7.500.000 Laporan Kemajuan Penelitian 1 Bendel 1 Bendel 500.000 500.000 Laporan Akhir Penelitian 1 Bendel 1 Bendel 500.000 500.000
Sub Total Biaya 8.500.000 Total Biaya 49.530.000
DATA USULAN DAN PENGESAHAN PROPOSAL DANA LOKAL ITS 2020
1. Judul Penelitian
METODE KLASIFIKASI PADA DATA IMBALANCE MENGGUNAKAN
MWMOTE DAN SMOTE+TL PADA PERILAKU BERISIKO REMAJA DI JAWA TIMUR
Skema : PENELITIAN PASCASARJANA
Bidang Penelitian : Sains Fundamental Topik Penelitian : Probability and Statistics 2. Identitas Pengusul
Ketua Tim
Nama : Dr. Dra Kartika Fithriasari M.Si
NIP : 196912121993032002
No Telp/HP : 0818396410
Laboratorium : Laboratorium Statistika Komputasi
Departemen/Unit : Departemen Statistika
Fakultas : Fakultas Sains dan Analitika Data
Anggota Tim
No Nama Lengkap Asal Laboratorium Departemen/Unit Perguruan
Tinggi/Instansi
1 Dr. Dra Kartika
Fithriasari M.Si
Laboratorium
Statistika Komputasi Departemen Statistika ITS
2 Dr. Dra. Ismaini Zain M.Si
Laboratorium Statistika Sosial dan
Kependudukan
Departemen Statistika ITS
3
Erma Oktania Permatasari S.Si,
M.Si
Laboratorium Statistika Sosial dan
Kependudukan
Departemen Statistika ITS
3. Jumlah Mahasiswa terlibat : 1
4. Sumber dan jumlah dana penelitian yang diusulkan
a. Dana Lokal ITS 2020 :
b. Sumber Lain :
49.530.000,-Tanggal Persetujuan Nama Pimpinan Pemberi Persetujuan Jabatan Pemberi Persetujuan Nama Unit Pemberi Persetujuan QR-Code 09 Maret 2020 Prof. Dr. Drs Agus Rubiyanto M.Eng.Sc. Kepala Pusat Penelitian/Kajian/Unggulan Iptek Sains Fundamental 09 Maret 2020 Agus Muhamad Hatta , ST, MSi, Ph.D Direktur Direktorat Riset dan Pengabdian Kepada Masyarakat