3.1 Waktu dan Tempat
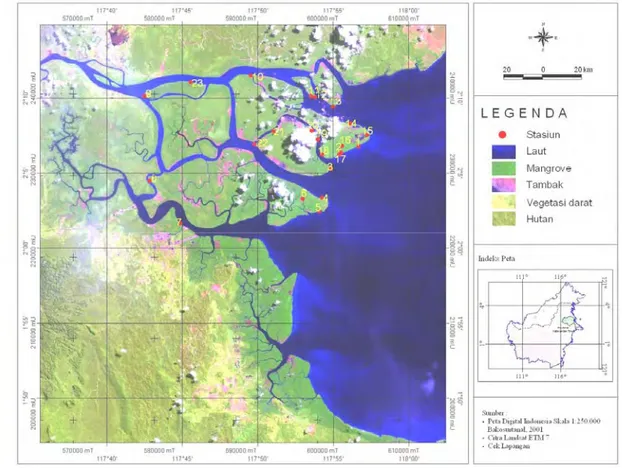
Pemrosesan awal data citra satelit dilakukan pada bulan Februari – Juni 2005. Pengambilan data insitu pada bulan Juli 2005, kemudian dilanjutkan dengan pemrosesan akhir (data hasil survei lapang dan data citra satelit) sampai dengan bulan Desember 2005. Lokasi studi yang dipilih untuk penelitian adalah Berau, Kalimantan Timur yang meliputi kecamatan Sambaliung dan Talisayan. Pemrosesan data dilakukan di Laboratorium Penginderaan Jauh dan Sistem Informasi Geografi Kelautan, Jurusan Ilmu dan Teknologi Kelautan, Fakultas Perikanan dan Ilmu Kelautan, IPB, Bogor. Peta lokasi studi dan posisi stasiun pengambilan data ditampilkan pada Gambar 10.
Gambar 10 Peta lokasi studi dan posisi stasiun pengambilan data
Bahan utama yang dipergunakan pada penelitian ini adalah citra Landsat TM dan ETM+, peta-peta pendukung (peta hasil digitasi yang dilakukan oleh the
nature conservancy/TNC Berau) serta data hasil pengukuran di lapangan.
Dalam survei lapang, ada beberapa peralatan yang digunakan untuk mengukur parameter fisika lingkungan yang membatasi mangrove, yaitu:
(1) Thermometer, digunakan untuk mengukur suhu perairan
(2) Refraktometer, digunakan untuk mengukur salinitas (English et al. 1997) (3) Secchi disk, digunakan untuk mengukur kecerahan (English et al. 1997) (4) Depth gauge, digunakan untuk mengukur kedalaman
(5) Floating drouge dan stop watch, digunakan untuk mengukur kecepatan pergerakan air (arus)
(6) Global positioning system (GPS), digunakan untuk menentukan posisi (7) Kompas, digunakan untuk menentukan arah.
Dalam pengamatan komunitas mangrove, diperlukan: perahu motor, roll meter, kamera, peta citra satelit Landsat-5 TM hasil pengolahan awal.
Dalam pengolahan data, beberapa peralatan yang diperlukan adalah: seperangkat personal computer lengkap dengan printer. Software yang digunakan meliputi ER Mapper 6.4, ERDAS Imagine 8.5, Idrisi Kilimajaro dan Arc View 3.3, serta software untuk analisis statistik SPSS 12.
3.3 Data
Kuantitas data yang diperlukan meliputi:
1) Data Spasial
Data spasial yang dipergunakan adalah citra Landsat-5 TM hasil liputan tanggal 16 Juni 1991 serta Landsat-7 ETM+ hasil liputan tanggal 15 Mei 2000, 27 Februari 2001 dan 21 Mei 2002 (path/row : 116/059).
2) Data Lapangan
Data lapangan yang diperlukan meliputi data tentang parameter lingkungan fisika perairan (suhu, salinitas kecerahan, kedalaman), lingkungan kimia perairan (pH) serta data kerapatan kanopi mangrove. Data ini diperoleh dari pengamatan langsung di lapangan pada tanggal 9-16 Juli 2005. Pengamatan data kerapatan kanopi mangrove dilakukan pada beberapa lokasi yang
berbeda, dengan membuat transek berukuran 30 x 30 meter (sesuai resolusi spasial Landsat TM) pada tiap stasiun. Pada setiap transek diidentifikasi jenis mangrove yang dominan serta diukur persentase penutupan kanopinya. Posisi stasiun pengambilan data lapangan ditampilkan pada Lampiran 1.
3.4 Analisis Data
Analisis digital diproses dengan menggunakan software ER Mapper 6.4, ERDAS Imagine 8.5, Idrisi Kilimajaro dan Arc View 3.3 sedangkan analisis visual dilakukan berdasarkan hasil identifikasi objek. ER Mapper 6.4 digunakan untuk preprocessing, yang meliputi koreksi geometrik dan radiometrik. ERDAS Imagine digunakan untuk melakukan transformasi produk Level 1 (L1) ke spektral radians, pengambilan training area, uji ketelitian keterpisahan yang meliputi transformed divergency dan jeffries-matusita distance, klasifikasi citra serta uji ketelitian matric contingency. Idrisi Kilimajaro digunakan untuk proses transformasi indeks vegetasi, overlay antara citra klasifikasi tahun 1991 dengan tahun 2002 serta overlay antara citra klasifikasi dengan citra indeks vegetasi. Arc View 3.3 digunakan untuk konversi dari data raster ke data vektor serta untuk membuat tampilan akhir (layout). Secara lebih lengkap, proses yang dilakukan terhadap data citra meliputi:
3.4.1 Preprocessing
Pada preprocessing dilakukan koreksi radiometrik dan koreksi geometrik. Koreksi geometrik dilakukan untuk mendapatkan citra yang sesuai dengan posisi yang sebenarnya di bumi. Metode yang digunakan untuk koreksi geometrik adalah polynomial orde 1, eksekusi resampling terhadap data citra menggunakan model nearest neighbour. Koreksi radiometrik dilakukan untuk memperbaiki nilai-nilai pixel yang tidak sesuai dengan nilai pantulan atau pancaran spektral objek yang sebenarnya, teknik/metode koreksi radiometrik yang digunakan adalah penyesuaian histogram (histogram adjustment).
3.4.2 Transformasi produk Level 1 (L1) ke spektral radians
Konversi dari digital number (Qcal) produk Level 1 (L1) pada data
λ λ λ λ Q Q LMIN LMIN LMAX L cal cal + ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ − = max
Persamaan diatas dapat juga didefinisikan sebagai: rescale cal rescale Q B G Lλ = × + ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ − = max cal rescale Q LMIN LMAX G λ λ λ LMIN Brescale = dimana: Lλ = spektral radians (W/(m2.sr.µm))
Qcal = nilai pixel yang dikalibrasi
Qcalmax = nilai pixel minimum yang dikalibrasi (DN=255)
LMINλ = spektral radians minimum (W/(m2.sr.µm))
LMAXλ = spektral radians maksimum (W/(m2.sr.µm))
Berdasarkan NASA 2007, konversi dari digital number (Qcal) produk
Level 1 (L1) Landsat-7 ETM+ ke spektral radians (Lλ) menggunakan persamaan:
(
)
λ λ λ λ Q Q LMIN Q Q LMIN LMAX L cal cal cal cal + − ∗ ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ − − = min min max dimana: Lλ = spectral radians (W/(m2.sr.µm))Qcal = nilai pixel yang dikalibrasi
Qcalmin = nilai pixel minimum yang dikalibrasi (DN=0 untuk NLAPS
products atau 1 untuk LPGS products)
Qcalmax = nilai pixel minimum yang dikalibrasi (DN=255)
LMINλ = spectral radians minimum (W/(m2.sr.µm))
LMAXλ = spectral radians maksimum (W/(m2.sr.µm))
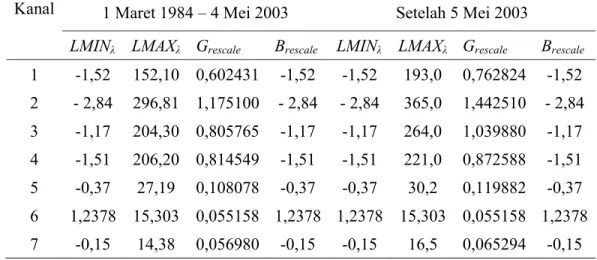
Pada Tabel 2 ditampilkan secara spesifik parameter LMINλ dan LMAXλ
serta nilai Grescale dan Brescale yang digunakan untuk mengubah nilai radians pada
data Landsat-5 TM dengan tanggal akuisisi antara 1 Maret 1984 – 4 Mei 2003 serta setelah 5 Mei 2003. Pada Tabel 3 merupakan parameter yang digunakan untuk mengubah ke nilai radians pada data Landsat-7 ETM+, untuk sistem
pemrosesan produk NLAPS (Qcalmin = 0) maupun produk LPGS (Qcalmin = 1).
Units spektral radians adalah W/(m2.sr.µm).
Tabel 2 Nilai Spektral Radians, LMINλ dan LMAXλ dalam W/(m2.sr.µm) pada
LANDSAT-5 TM
Kanal 1 Maret 1984 – 4 Mei 2003 Setelah 5 Mei 2003
LMINλ LMAXλ Grescale Brescale LMINλ LMAXλ Grescale Brescale
1 -1,52 152,10 0,602431 -1,52 -1,52 193,0 0,762824 -1,52 2 - 2,84 296,81 1,175100 - 2,84 - 2,84 365,0 1,442510 - 2,84 3 -1,17 204,30 0,805765 -1,17 -1,17 264,0 1,039880 -1,17 4 -1,51 206,20 0,814549 -1,51 -1,51 221,0 0,872588 -1,51 5 -0,37 27,19 0,108078 -0,37 -0,37 30,2 0,119882 -0,37 6 1,2378 15,303 0,055158 1,2378 1,2378 15,303 0,055158 1,2378 7 -0,15 14,38 0,056980 -0,15 -0,15 16,5 0,065294 -0,15
Sumber : Chander and Markham 2003
Tabel 3 Nilai LMINλ dan LMAXλ dalam W/(m2.sr.µm) pada LANDSAT-7 ETM+
Kanal Sebelum 1 Juli 2000 Setelah 1 Juli 2000
Low Gain High Gain Low Gain High Gain
LMINλ LMAXλ LMINλ LMAXλ LMINλ LMAXλ LMINλ LMAXλ
1 -6,2 297,5 -6,2 194,3 -6,2 293,7 -6,2 191,6 2 -6,0 303,4 -6,0 202,4 -6,4 300,9 -6,4 196,5 3 -4,5 235,5 -4,5 158,6 -5,0 234,4 -5,0 152,9 4 -4,5 235,0 -4,5 157,5 -5,1 241,1 -5,1 157,4 5 -1,0 47,70 -1,0 31,76 -1,0 47,57 -1,0 31,06 6 0,0 17,04 3,2 12,65 0,0 17,04 3,2 12,65 7 -0,35 16,60 -0,35 10,932 -0,35 16,54 -0,35 10,80 8 -5,0 244,00 -5,0 158,40 -4,7 243,1 -4,7 158,3 Sumber : NASA 2007
3.4.3 Penajaman citra (image enhancement)
Pada penelitian ini, pemilihan kanal dilakukan dengan menggunakan
index factor (OIF) untuk merangking 20 kombinasi dari tiga kombinasi kanal
yang dibuat dari enam kanal data Landsat TM (tidak termasuk infra merah thermal). Algoritma yang digunakan adalah:
∑
∑
= = = 3 1 ) ( 3 1 j rj k k Abs S OIF dimana:Sk = standar deviasi untuk kanal k
Abs(rj) = nilai absolut koefisien korelasi antara dua dari tiga kanal
OIF terpilih adalah yang memberikan nilai paling tinggi, karena akan menampilkan lebih banyak warna, sehingga memberikan lebih banyak informasi.
3.4.4 Uji ketelitian keterpisahan (separability)
Keterpisahan statistik (statistical separability) merupakan suatu analisis
yang digunakan untuk menguji performansi dari sebuah pengklasifikasi. Pengklasifikasi yang baik memiliki kemungkinan kesalahan yang sangat kecil di dalam membedakan antara kelas yang satu dengan kelas yang lainnya.
(1) Transformed divergency
Metode transformed divergency digunakan dalam penelitian ini untuk mengukur tingkat keterpisahan antar kelas atau signature yang diwakili oleh
training sample (Swain & Davis 1978; Jensen 1986).
Formulasi transformed divergency dapat dituliskan dengan rumus:
(
)
(
)
(
)
(
(
)
(
)(
)
T)
j i j i j i j i j i ij tr C C C C tr C C D = − −1− −1 + −1− −1 μ −μ μ −μ 2 1 2 1 ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ − − = 8 exp 1 2000 ij ij D TD dimana:i,j = pasangan kelas/signature ke i dan j
D = nilai divergensi
µ = rataan kelas ukuran N x 1
tr,-1,T = operasi trace, inverse dan transpose matriks
TD = transformed divergency
Transformed divergency memiliki nilai maksimum sebesar 2000 dimana
diperoleh kemungkinan kesalahan 0%. Melalui harga TD ini dapat ditentukan apakah sebuah pasangan kelas memiliki keterpisahan yang baik atau kurang baik, yaitu:
a) Jika TDij = 2000, keterpisahan kelas i dan j baik
b) Jika Tdij << 2000, keterpisahan kelas i dan j kurang baik
Jika seluruh kombinasi pasangan kelas mempunyai harga TDij = 2000,
maka diperoleh suatu pengklasifikasi dengan kemungkinan kebenaran yang tinggi.
(2) Jeffries-matusita distance (JM)
Formula yang digunakan dalam jeffries-matusita distance (JM) adalah:
⎟ ⎟ ⎟ ⎠ ⎞ ⎜ ⎜ ⎜ ⎝ ⎛ × + + − ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ + − = − j i j i j i j i T j i C C C C C C ( ) 2 ln 2 1 ) ( 2 ) ( 8 1 μ μ 1 μ μ α
(
− −α)
= e JMij 21 dimana:i,j : pasangan kelas/signature ke i dan j
C : matrik kovarian kelas ukuran N x N (N = jumlah kanal
kombinasi)
µ : rataan kelas ukuran N x 1
ln : fungsi natural logarithm
TD : determinan pada Ci
Jeffries-Matusita Distance (JM) telah memenuhi dalam pemisahan kelas
seperti transformed divergency, tapi dalam komputasinya tidak seefisien
transformed divergency.
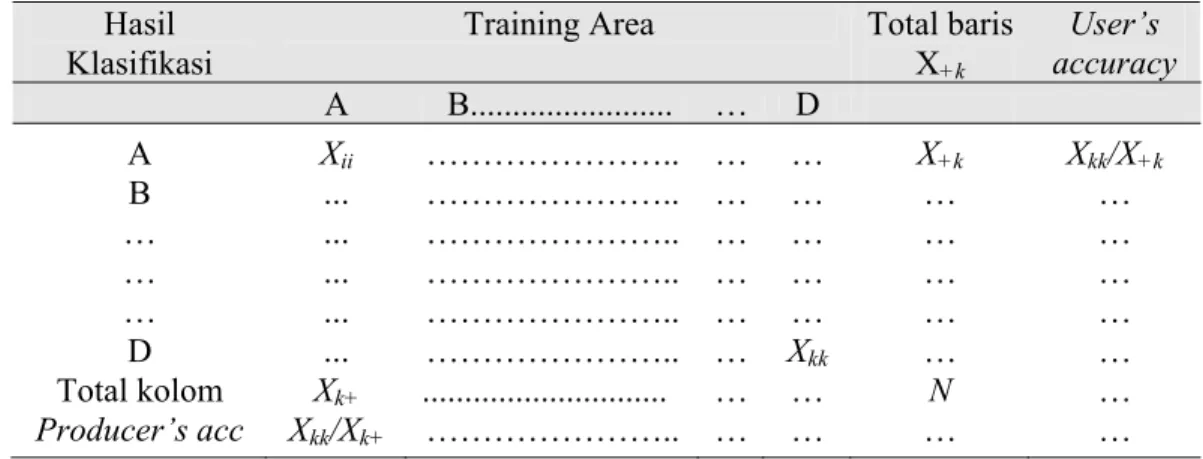
3.4.5 Uji ketelitian matric contingency
Akurasi klasifikasi dapat diuji dengan menggunakan matric contingency (Richards 1995; Jaya 1996). Uji ketelitian matric contingency atau lebih sering
disebut matrik kesalahan (confussion matrix), persentase ketelitian suatu kelas diperoleh dari perbandingan jumlah pixel yang benar masuk pada training area dengan jumlah pixel pada training area suatu kelas dalam matrik kontingensi antar kelas. Persentase ketelitian klasifikasi secara keseluruhan dihitung dari perbandingan antara jumlah pixel yang benar setiap kelas dengan total jumlah
pixel training area keseluruhan (Tabel 4).
Tabel 4 Matrik kesalahan (confussion matrix) Hasil
Klasifikasi
Training Area Total baris
X+k User’s accuracy A B... … D A Xii ……….. … … X+k Xkk/X+k B … ……….. … … … … … … ……….. … … … … … … ……….. … … … … … … ……….. … … … … D … ……….. … Xkk … … Total kolom Xk+ ... … … N … Producer’s acc Xkk/Xk+ ……….. … … … …
Uji ketelitian yang dapat dihitung adalah overall accuracy, producer’s
accuracy, user’s accuracy dan kappa accuracy. Overall accuracy adalah
persentase dari pixel-pixel yang terkelaskan dengan tepat, sedang producer’s
accuracy adalah peluang rata-rata (%) suatu pixel yang menunjukkan sebaran dari
masing-masing kelas yang telah diklasifikasi di lapangan dan user’s accuracy adalah peluang rata-rata (%) suatu pixel secara aktual yang mewakili kelas-kelas tersebut. Secara matematis ukuran akurasi tersebut diformulasikan sebagai berikut: % 100 X X = accuracy s Producer' + k kk × % 100 X X = accuracy s Users' k + kk × % 100 N X = accuracy Overall
∑
kk×∑
∑
∑
+ − − r k k + k 2 r k k + + k r k kk X X N X X X N = accuracy Kappa3.4.6 Klasifikasi citra (image classification)
Klasifikasi data digital ini berangkat dari asumsi bahwa variasi pola peubah ganda (multivariate) dari digital number pada suatu areal mempunyai hubungan yang sangat erat dengan kondisi penutupan tanahnya. Diasumsikan juga bahwa penutupan lahan yang sama akan mempunyai sifat-sifat reflektansi (nilai digital number) yang sama pula.
Klasifikasi neural network menggunakan algoritma back propagation, yang terdiri dari input layer, hidden layer dan output layer. Input layer yang digunakan sejumlah 6 (kanal 1, 2, 3, 4, 5 dan 7) dan 5 output layer, yaitu meliputi: perairan, mangrove primer, mangrove sekunder, tambak, lainnya, awan. Hal ini diilustrasikan pada Gambar 11.
Gambar 11 Ilustrasi klasifikasi neural network back propagation.
Tahap-tahap dalam klasifikasi neural network back propagation, yaitu:
Perairan Mangrove Primer Mangrove Sekunder Tambak Lainnya h1 h2 hn b2 n Kanal 1 Kanal 2 Kanal 3 Kanal 4 Kanal 5 Kanal 7 Awan
1) Memilih pixel training untuk tiap kelas dan menetapkan output yang diinginkan vector dm = 0,9 (m = k) dan dm = 0,1(m ≠ k)
Ada nilai target yang ANN coba dihasilkan
2) Bobot awal sebagai jumlah random antara 0 dan 1
3) Set frekuensi untuk updating bobot
(a) setelah tiap pixel training (sequential) (b) setelah semua pixel training tiap kelas
(c) setelah semua pixel training seluruh kelas (batch)
4) Batch training umumnya digunakan untuk meminimalkan frekuensi
peng-update-an bobot
5) Propagasi data training maju melalui network
6) Setelah tiap pixel training dipropagasi kedepan melalui network,
penghitungan output o dan mengakumulasi total error relatif ke output d
∑
∑
− = = k k k P P o d 2 1 2 ) ( 2 1 2ε
Ulangi semua pola training P (pixel) untuk batch training
7) Setelah semua pixel yang ditraining digunakan, penyesuaian bobot wkj
dengan: kj kj w LR w ∂ ∂ = Δ
ε
j S P P k k dS f S h d o d LR k∑
= − = 1 ) ( ) (dimana LR adalah parameter learning rate yang digunakan untuk mengontrol kecepatan convergency
8) Menyesuaikan bobot wij, dengan:
∑
∑
= ⎭⎬ ⎫ ⎩ ⎨ ⎧ ⎥⎦ ⎤ ⎢⎣ ⎡ − = Δ P P i k kj s k k S kj dS f S w p d o d S f dS d LR w k j 1 ) ( ) ( ) (9) Ulangi langkah 4 sampai 7 sehingga ε < threshold
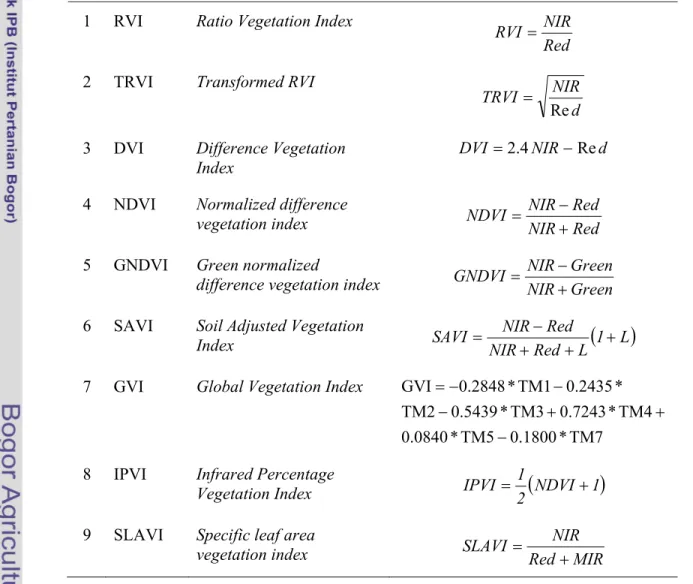
Tingkat kerapatan kanopi mangrove diketahui melalui analisis indeks vegetasi yang didasarkan pada adanya respon objek penginderaan jauh pada kisaran spektrum radiasi merah dengan inframerah dekat. Indeks vegetasi yang diperoleh merupakan nilai-nilai yang memberikan gambaran tentang tingkat kehijauan vegetasi. Untuk mencari hubungan matematis terbaik antara penutupan kanopi dengan algoritma indeks vegetasi digunakan analisis regresi. Formula indeks vegetasi yang diuji pada penelitian ini ditampilkan pada Tabel 5.
Tabel 5 Beberapa formula indeks vegetasi yang dipergunakan pada penelitian
No Formula Tipe Indeks Vegetasi Rumus
1 RVI Ratio Vegetation Index
Red NIR RVI =
2 TRVI Transformed RVI
d NIR TRVI
Re =
3 DVI Difference Vegetation
Index
d NIR DVI =2.4 −Re 4 NDVI Normalized difference
vegetation index NDVI = NIRNIR+−RedRed
5 GNDVI Green normalized
difference vegetation index NIR Green
Green NIR GNDVI + − =
6 SAVI Soil Adjusted Vegetation
Index SAVI = NIRNIR+Red−Red+L
(
1+L)
7 GVI Global Vegetation Index
TM7 * 0.1800 TM5 * 0.0840 TM4 * 0.7243 TM3 * 0.5439 TM2 * 0.2435 TM1 * 0.2848 GVI − + + − − − =
8 IPVI Infrared Percentage
Vegetation Index IPVI = 21
(
NDVI+1)
9 SLAVI Specific leaf area
Dalam analisis regresi dicobakan beberapa model persamaan sebagai berikut: 1) Linear
( )
b t b Y = 0+ 1 2) Logarithmic( )
t b b Y = 0+ 1ln 3) Inverse( )
b t b Y = 0+ 1 4) Quadratic 2 2 1 0 b t b t b Y = + + 5) Cubic 3 2 3 2 1 0 b t b t b t b Y = + + + 6) Power( )
1 0 tb b Y = + atau ln( )
Y =ln( )
b0 +(
b1ln( )
t)
7) Compound( )
b t b Y = 0+ 1 atau ln( )
Y =ln( )
b0 +(
tln( )
b1)
8) S-curve(
b b t)
Y =exp 0+ 1 atau ln( )
Y =b0+( )
b1t 9) Logistic( )
(
b b t)
u Y 1 0 1 1 + = atau ln(
1 1)
ln( )
b0 tln( )
b1 u y− = + 10) Growth(
b b t)
Y =exp 0+ 1 atau ln( )
Y =b0+b1t 11) Exponential( )
b t b Y = 0exp 1 atau ln( )
Y =ln( )
b0 +b1t dimana :Y = persen penutupan kanopi
b = konstanta
t = hasil formula indeks vegetasi
Pemilihan model terbaik ditentukan dari nilai R2 (koefisien determinasi). Pengujian hipotesis melalui analisis ragam, hal ini dimaksudkan untuk menunjukkan apakah persen penutupan kanopi (Y) dengan hasil formula indeks vegetasi (t) memiliki hubungan yang berarti. Hipotesis yang diuji adalah:
H0 : bi = 0
H1 : bi ≠ 0
Kriteria uji adalah jika Fhit > Ftabel maka terima H1, sebaliknya jika Fhit <
Ftabel maka terima H0.
3.4.8 Analisis komponen utama
Dalam mencari hubungan matematis terbaik antara respon spektral mangrove dengan persentase penutupan kanopi adalah dengan menggunakan analisis komponen utama.
Peubah bebas yang digunakan terdiri dari; x1 (kanal 2), x2 (kanal 3), x3
(kanal 4) serta x4 (kanal 5). Kanal 2 untuk mengukur nilai pantul hijau pucuk
tumbuhan. Kanal 3 untuk pemisahan vegetasi, yaitu memperkuat kontras antara vegetasi dan non vegetasi. Kanal 4 membantu identifikasi tanaman dan memperkuat kontras antara tanaman dengan tanah dan lahan dengan air. Kanal 5 untuk penentuan jenis tanaman, kandungan air pada tanaman dan kondisi kelembaban tanah.
Tahap-tahap yang dilakukan, yaitu:
(1) Menentukan peubah Z hasil dari pembakuan peubah X (2) Menentukan nilai akar ciri (λi) dari persamaan |R-λI| = 0
(3) Menentukan nilai vektor ciri (ai) untuk setiap akar ciri dengan persamaan
(R-λI) ai = 0
(4) Menentukan komponen utama Kj melalui seleksi akar ciri
Metode yang digunakan dalam menentukan banyaknya komponen utama adalah berdasarkan nilai eigen.
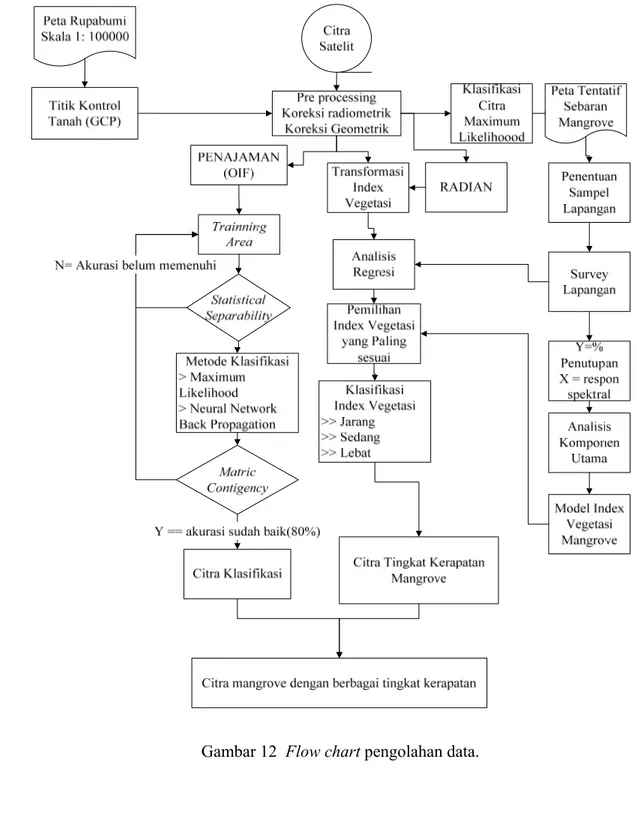
Keseluruhan proses pengolahan data yang dilakukan pada citra Landsat TM dan ETM+ pada penelitian ini ditampilkan pada Gambar 12.