7
KAJIAN PUSTAKA
2.1 Artificial Intelligence
Kecerdasan Buatan (Artificial Intelligence) dapat didefinisikan sebagai teknologi yang mensimulasikan kecerdasan manusia, yaitu bagaimana mendefinisikan dan mencoba menyelesaikan persoalan menggunakan computer dengan meniru bagaimana cara manusia menyelesaikan suatu permasalahan.
Beberapa aplikasi kecerdasan buatan adalah :
• Sistem pakar Æ program komputer yang memperlihatkan derajat keahlian
dalam pemecahan masalah di bidang tertentu sebanding dengan seorang pakar. Keahlian sistem pakar dalam memecahkan suatu masalah diperoleh dengan cara merepresentasikan pengetahuan seorang atau beberapa orang pakar dalam format tertentu dan menyimpannya dalam basis pengetahuan. • Algoritma genetika Æ program komputer yang mensimulasikan proses
evolusi. Dalam hal ini populasi dari kromosom dihasilkan secara random dan memungkinkan untuk berkembang biak sesuai dengan hukum-hukum evolusi dengan harapan akan menghasilkan individu kromosom yang prima. Kromosom ini pada kenyataannya adalah kandidat penyelesaian dari masalah, sehingga bila kromosom yang baik berkembang, solusi yang baik terhadap masalah diharapkan akan dihasilkan.
• Pemrosesan bahasa alami Æ dengan pengolahan bahasa alami, diharapkan
user dapat berkomunikasi dengan komputer dengan menggunakan bahasa sehari-hari.
• Neural network Æ jaringan dari sekelompok unit pemroses kecil yang
dimodelkan berdasarkan jaringan saraf manusia. JST merupakan sistem adaptif yang dapat merubah strukturnya untuk memecahkan masalah berdasarkan informasi eksternal maupun internal yang mengalir melalui jaringan tersebut.
• Robotika
• Computer vision Æ mencoba untuk dapat menginterpretasikan gambar atau
obyek-obyek melalui computer.
• Problem solving Æ komputer memberi solusi pemecahan berdasarkan
pengalaman-pengalaman yang ada. Ide dasarnya adalah bahwa manusia seringkali merujuk kepada pengalaman sebelumnya jika ada suatu masalah.
• Machine learning
2.2 Machine Learning
Machine learning adalah ilmu yang mempelajari cara untuk membuat
komputer/program cerdas. Komputer dapat digunakan untuk menyelesaikan berbagai macam permasalahan, beberapa permasalahan dapat dapat diselesaikan dengan mudah bila menggunakan program yang memang didesain untuk menyelesaikan masalah tersebut. Tetapi ada juga permasalahan yang sulit untuk diselesaikan, permasalahan tersebut dapat dibagi menjadi 4 kategori :
1. Masalah yang tidak mempunyai tenaga ahli.
Contoh : Suatu pabrik manufaktur modern yang melakukan otomatisasi perlu memperkirakan seberapa besar kemungkinan kesalahan dengan menganalisa hasil pembacaan sensor. Masalah muncul ketika pabrik tersebut menggunakan mesin yang baru, dan belum ada tenaga ahli yang mengerti dengan detail bagaimana cara kerja mesin tersebut, sehingga programmer tidak dapat melakukan wawancara dengan tenaga ahli untuk mengetahui pengetahuan yang dibutuhkan dalam pembuatan sistem komputer mesin tersebut. Masalah ini dapat diselesaikan dengan menggunakan machine learning yang akan mempelajari data yang terekam, berbagai kesalahan yang pernah terjadi, dan aturan-aturan yang yang telah diberikan.
2. Masalah yang memiliki tenaga ahli, tetapi mereka tidak dapat menjelaskan kemampuan mereka.
Contoh : Proses pengerjaan speech recognition, hand-writing recognition, dan
natural-language understanding sulit dijelaskan oleh para ahli. Untungnya,
dengan menggunakan machine learning, kita dapat memasukkan input yang telah diketahui labelnya, sehingga mesin dapat belajar untuk memetakan input kepada label yang telah disediakan.
3. Masalah yang parameternya terus menerus berubah dengan cepat.
Contoh : Keadaan pasar saham cepat sekali berubah, sekalipun programmer dapat merancang program prediksi yang bagus, program tersebut perlu diperbarui secara berkala. Machine learning dapat mengurangi beban programmer dengan memodifikasi aturan-aturan prediksi yang telah dipelajari.
4. Aplikasi yang perlu dimodifikasi untuk setiap user yang berbeda.
Contoh : Program untuk menyaring e-mail yang tidak diinginkan memerlukan pengaturan yang berbeda jika digunakan oleh user yang berbeda. Tidak mungkin jika kita meminta setiap user untuk memprogram aturannya sendiri, dan tidak mungkin kita menyediakan software engineer untuk setiap user sehingga mereka dapat terus melakukan update pada progamnya. Machine learning dapat mempelajari e-mail mana yang tidak diperlukan user, dan memasukkannya kedalam aturan penyaringan secara otomatis.
Dalam meneliti suatau permasalahan, machine learning menggunakan pertanyaan yang digunakan pada bidang data mining, statistik, dan psikologi, tetapi dengan penekanan yang berbeda.
Data Mining berbeda dengan database, database adalah sekumpulan informasi yang disusun sedemikian rupa untuk dapat diakses oleh sebuah software tertentu. Database tersusun atas bagian yang disebut field dan record yang tersimpan dalam sebuah file. Sebuah field merupakan kesatuan terkecil dari informasi dalam sebuah database. Sekumpulan field yang saling berkaitan akan membentuk record, sedangkan Data
mining adalah kegiatan untuk menemukan informasi atau pengetahuan yang berguna
secara otomatis dari data yang jumlahnya besar. Data Mining merupakan salah satu proses dari keseluruhan proses yang ada pada Knowledge Discovery in Databases (KDD). KDD sendiri merupakan sekumpulan proses untuk menemukan pengetahuan yang bermanfaat dari data. KDD terdiri dari serangkaian langkah perubahan, termasuk data preprocessing dan juga post processing. Data preprocessing merupakan langkah
untuk mengubah data mentah menjadi format yang sesuai untuk tahap analisis berikutnya. Contoh beberapa aplikasi dari data mining adalah :
• Melihat pola beli pemakai dari waktu ke waktu. Sebagai contoh, ketika seseorang menikah bisa saja dia kemudian memutuskan pindah dari single account ke joint account (rekening bersama) dan kemudian setelah itu pola beli-nya berbeda dengan ketika dia masih bujangan.
• Kita dapat memanfaatkan data mining untuk melihat hubungan antara
penjualan satu produk dengan produk lainnya. Sebagai contoh, kita dapat mencari pola penjualan minuman soda sedemikian rupa sehingga kita dapat mengetahui barang apa sajakah yang harus kita sediakan untuk meningkatkan penjualan minuman soda atau mencari pola penjualan mie sedemikian rupa sehingga kita dapat mengetahui barang apa saja yang juga dibeli oleh pembeli mie. Dengan demikian kita bisa mengetahui dampak jika kita tidak lagi menjual mie.
Data mining berusaha mencari pola pada suatu data. Statistik berpusat pada
bagaimana cara suatu data dapat dihasilkan. Psikologi mempelajari cara manusia untuk mempelajari suatu permasalahan. Berbeda dengan statistik, data-mining, dan psikologi,
machine learning berusaha mencari solusi yang paling akurat, dan efektif. Sebagai
ilustrasi, pada suatu program untuk mengenali percakapan machine learning akan berusaha mencari sistem pengenalan suara yang paling akurat, dan efektif. Statistik, dan psikologi akan mencari solusi dengan menguji berbagai hipotesa mengenai pengenalan suara. Data mining akan berusaha mencari pola pada data percakapan.
2.2.1 Tugas Pembelajaran Analisis dan Empiris
Tugas pembelajaran dapat digolongkan kedalam banyak dimensi yang berbeda. Salah satu dimensi yang penting adalah perbedaan antara pembelajaran empiris dan analisis. Pembelajaran empiris adalah pembelajaran yang bergantung pada beberapa bentuk pengalaman eksternal, sedangkan pembelajaran analisis tidak memerlukan input eksternal.
Misalnya, pada pembelajaran masalah bermain tic-tac-toe. Misalkan seorang programmer telah menyediakan aturan-aturan penyandian untuk permainan dalam bentuk fungsi yang menunjukkan apakah gerakan yang diusulkan adalah legal atau ilegal, dan fungsi lain yang menunjukkan menang, kalah, atau seri. Dengan melihat kedua fungsi diatas, tidaklah sulit untuk menulis sebuah program komputer yang akan berulang kali memainkan permainan tic-tac-toe dengan dirinya sendiri.
Anggaplah bahwa program ini mengingat setiap langkah yang pernah dilakukannya. Untuk setiap posisi akhir (yaitu, di mana sudah ditentukan siapa yang menang, kalah, atau seri), ia akan mengingat hasilnya. Seiring dengan makin banyaknya permainan yang dilakukan, program akan mengingat langkah-langkah mana yang menyebabkan dia mengalami kekalahan, dan langkah-langkah mana yang menyebabkan musuh menang. Demikian pula, ia dapat mengingat langkah mana yang menyebabkan dia mengalami kemenangan, dan langkah-langkah mana yang menyebabkan musuh kalah. Setelah memainkan cukup banyak permainan, pada akhirnya program dapat menentukan langkah yang menyebabkan kemenangan atau kekalahan dan bermain tic-tac-toe dengan sempurna. Pembahasan
diatas adalah bentuk pembelajaran analisis karena tidak ada input eksternal yang diperlukan. Program ini mampu meningkatkan performa hanya dengan menganalisis masalah.
Sebaliknya, jika sebuah program harus mempelajari aturan tic-tac-toe. Program akan menentukan langkah mana yang dapat dilakukan dan seorang ahli akan menunjukkan langkah mana yang legal dan yang ilegal serta posisi yang akan menyebabkan kemenangan, kekalahan, atau seri. Program dapat mengingat pengalaman ini. Setelah mencoba setiap posisi yang mungkin dan mencoba segala langkah yang dimungkinkan, program akan memiliki pengetahuan lengkap tentang aturan main. Inilah yang disebut pembelajaran empiris, karena program tidak bisa menyimpulkan aturan permainan secara analisis, program harus berinteraksi dengan seorang ahli untuk memberikan pembelajaran.
Garis pemisah antara pembelajaran analisis, dan empiris dapat menjadi buram. Misalkan suatu program telah mengetahui aturan permainan tic-tac-toe. Namun, jika pada kasus sebelumnya program bermain melawan dirinya sendiri, kali ini program akan melawan manusia. Dengan mempelajari peraturan yang ada, program akan mengingat langkah-langkah yang pernah dilakukan, dan mengetahui langkah yang diperlukan untuk memperoleh kemenangan, kekalahan, atau seri. Kemampuan program untuk bermain tic-tac-toe akan meningkat pesat bila bermain melawan pemain yang berpengetahuan luas (bukan dengan mencoba berbagai posisi acak ketika sedang bermain dengan dirinya sendiri). Jadi, selama proses pembelajaran, program akan menunjukkan performa yang lebih baik. Namun pada kasus ini
program tidak membutuhkan seorang ahli atau input eksternal lainnya, karena dia menyimpulkan langkah-langkah permainan secara analisis.
Pada permasalahan diatas, keseluruhan tugas pembelajaran yang dilakukan oleh program adalah suatu pembelajaran analisis, karena program belajar dengan menganalisa langkah-langkah yang pernah dia lakukan, tetapi program menyelesaikan masalah secara empiris, karena program perlu mengetahui langkah mana yang umumnya digunakan oleh manusia.
Perbedaan pembelajaran analisis dan empiris tidak terlihat terlalu signifikan pada tic-tac-toe. Tetapi pada catur, kedua pembelajaran tersebut akan memberikan hasil yang sangat berbeda.
2.2.2 Supervised Learning
Misalkan kita ingin membuat suatu program komputer yang ketika diberi gambar seseorang, dapat menentukan apakah orang dalam gambar tersebut pria atau wanita. Program yang kita buat tersebut adalah yang disebut sebagai classifier, karena program tersebut berusaha menetapkan kelas (yaitu pria atau wanita) ke sebuah objek (gambar). Tugas supervised learning adalah untuk membangun sebuah classifier dengan memberikan sekumpulan contoh training yang sudah diklasifikasi (pada kasus ini, contohnya adalah gambar yang telah dimasukkan ke kelas yang tepat).
Tantangan utama pada supervised learning adalah generalisasi: Setelah menganalisa beberapa contoh gambar, supervised learning harus menghasilkan suatu classifier yang dapat digunakan dengan baik pada semua gambar.
Pasangan objek, dan kelas yang menunjuk pada objek tersebut adalah suatu contoh yang telah diberi label. Himpunan contoh yang telah diberi label akan menghasilkan suatu algoritma pembelajaran yang disebut training set. Misalkan kita menyediakan suatu training set kepada algoritma pembelajaran, dan algoritma tersebut menghasilkan output yang berupa classifier. Bagaimana cara mengukur kualitas classifier ini? Solusi yang umumnya digunakan adalah dengan menggunakan himpunan contoh berlabel yang lain yang disebut sebagai test set. Kita dapat mengukur persentase contoh yang diklasifikasi dengan benar atau persentase contoh yang mengalami kesalahan klasifikasi.
Pendekatan yang dilakukan untuk menghitung persentase mengasumsikan bahwa setiap klasifikasi adalah independen, dan setiap klasifikasi sama pentingnya. Asumsi ini sering sekali dilupakan.
Asumsi bahwa setiap kelas adalah independen seringkali dilanggar bila ada suatu ketergantungan sementara pada data. Contohnya, seorang dokter pada suatu klinik mengetahui bahwa suatu wabah penyakit sedang terjadi. Oleh karena itu, setelah melihat beberapa pasien yang kesemuanya terserang flu, ada kemungkinan besar kalau dokter akan menganggap pasien berikutnya mengidap penyakit yang sama, walaupun pasien tidak menunjukkan gejala sejelas gejala penyakit pasien sebelumnya.
Asumsi bahwa semua klasifikasi sama pentingnya seringkali dilanggar bila ada perubahan resiko yang berhubungan dengan perbedaan perhitungan kesalahan. Contoh : classifier harus menentukan suatu apakah seorang pasien terserang kanker atau tidak berdasarkan perhitungan laboratorium. Ada dua macam kesalahan. Yang pertama disebut, kesalahan false positive, yaitu kesalahan yang muncul ketika classifier mengklasifikasi orang yang sehat sebagai orang yang mengidap kanker.
False negative muncuk ketika classifier mengklasifikasi orang yang mengidap
kanker sebagai orang yang sehat. Umumnya, false negative lebih sering beresiko daripada false positive, sehingga kita harus menggunakan algoritma pembelajaran yang dapat menimbulkan false negative lebih sedikit, walaupun hasilnya akan menimbulkan lebih banyak false positive.
Supervised learning tidak hanya mempelajari classifier, tetapi juga mempelajari fungsi yang dapat memprediksi suatu nilai numerik. Contoh : ketika diberi foto seseorang, kita ingin memprediksi umur, tinggi, dan berat orang yang ada pada foto tersebut. Tugas ini sering disebut sebagai regresi. Pada kasus ini, setiap contoh training yang terlah diberi label berisi sebuah objek, dan nilai yang dimilikinya. Kualitas dari fungsi prediksi biasanya diukur sebagai kuadrat perbedaan nilai pemprediksi.
Ada banyak algoritma pembelajaran yang dikembangkan dari supervised learning. Algoritma-algoritma tersebut tersebut adalah : decision trees, artificial neural networks, support vector machine.
2.2.2.1Decision Tree
Di dalam kehidupan manusia sehari-hari, manusia selalu dihadapkan oleh berbagai macam masalah dari berbagai macam bidang. Masalah-masalah ini yang dihadapi oleh manusia tingkat kesulitan dan kompleksitasnya sangat bervariasi, mulai dari yang teramat sederhana dengan sedikit faktor-faktor/hal-hal berkaitan dengan masalah tersebut dan perlu diperhitungkan sampai dengan yang sangat rumit dengan banyak sekali faktor-faktor/hal-hal yang turut serta berkaitan dengan masalah tersebut dan perlu untuk diperhitungkan.
Untuk menghadapi masalah-masalah ini, manusia mulai mengembangkan sebuah sistem/cara yang dapat membantu manusia agar dapat dengan mudah mampu untuk menyelesaikan masalah-masalah tersebut. Adapun pohon keputusan ini adalah sebuah jawaban akan sebuah sistem / cara yang manusia kembangkan untuk membantu mencari dan membuat keputusan untuk masalah-masalah tersebut dan dengan memperhitungkan berbagai macam faktor yang ada di dalam lingkup masalah tersebut. Dengan pohon keputusan, manusia dapat dengan mudah melihat mengidentifikasi dan melihat hubungan antara faktor-faktor yang mempengaruhi suatu masalah dan dapat mencari penyelesaian terbaik dengan memperhitungkan faktor-faktor tersebut. Pohon keputusan ini juga dapat menganalisa nilai resiko dan nilai suatu informasi yang terdapat dalam suatu alternatif pemecahan masalah.
Peranan pohon keputusan ini sebagai alat bantu dalam mengambil keputusan (decision support tool) telah dikembangkan oleh manusia sejak perkembangan teori pohon yang dilandaskan pada teori graf. Kegunaan pohon keputusan yang sangat
banyak ini membuatnya telah dimanfaatkan oleh manusia dalam berbagai macam sistem pengambilan keputusan.
Skema Pohon keputusan :
a. Struktur Dasar Pohon
Berdasarkan teori graf, definisi pohon adalah “sebuah graf, tak-berarah, terhubung, yang tidak mengandung sirkuit”.
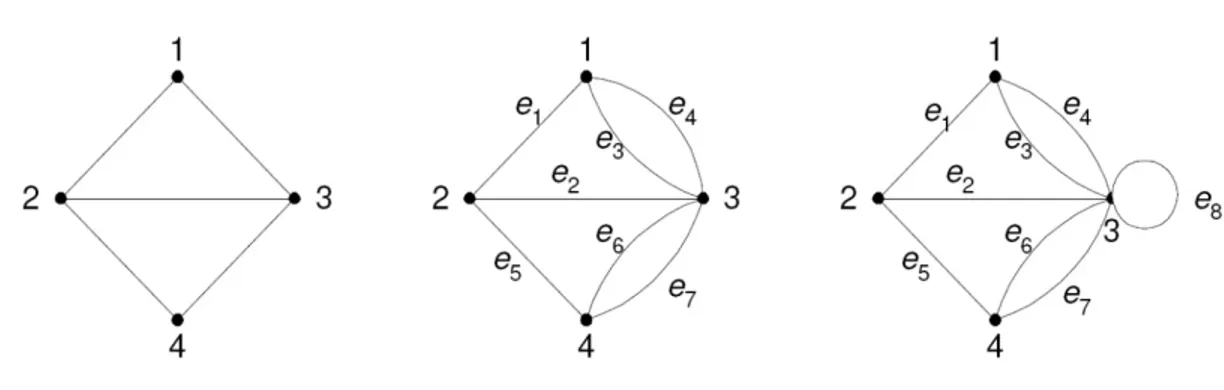
Graf adalah suatu representasi visual dari objek-objek diskrit yang dinyatakan dengan noktah, bulatan, atau titik, serta hubungan yang ada antara objek-objek tersebut. Secara matematis, graf didefinisikan sebagai pasangan himpunan (V,E) yang dalam hal ini :
V = himpunan tidak-kosong dari simpul-simpul (vertices) = { v1 , v2 , ... , vn } E = himpunan sisi (edges) yang menghubungkan sepasang simpul = {e1 , e2 , ... , en }
Gambar 2.1 Beberapa Contoh Graf
Suatu titik (.) juga dapat disebut sebagai graf, graf tersebut disebut sebagai graf trivial, yaitu suatu graf yang terdiri dari sebuah titik tanpa sisi.
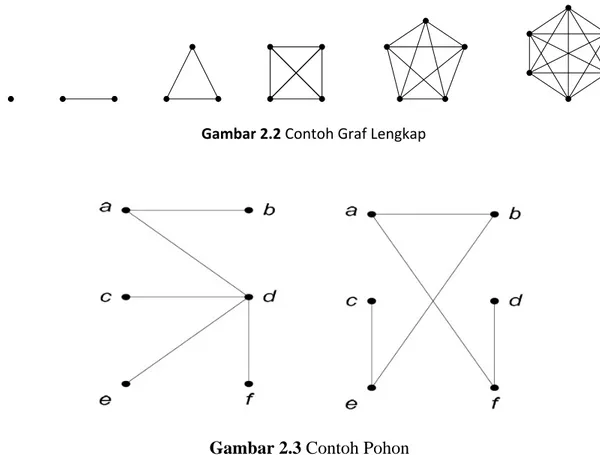
Ada juga beberapa graf khusus, salah satunya adalah graf lengkap (complete graph) yaitu graf sederhana yang setiap simpulnya mempunyai sisi ke semua simpul
lainnya. Graf lengkap dengan n buah simpul dilambangkan dengan Kn. Jumlah sisi
pada graf lengkap yang terdiri dari n buah simpul adalah n(n – 1)/2.
Gambar 2.3 Contoh Pohon
Selain itu, sebuah pohon juga memenuhi salah satu dari pernyataan-pernyataan yang ekuivalen di bawah ini :
Misal G adalah sebuah pohon.
• Setiap pasang simpul di dalam G terhubung dengan lintasan tunggal. • G terhubung dan memiliki m = n – 1 buah sisi.
• G tidak mengandung sirkuit dan memiliki m = n –1 buah sisi.
• G tidak mengandung sirkuit dan penambahan satu sisi pada graf akan membuat
hanya satu sirkuit.
• G terhubung dan semua sisinya adalah jembatan.
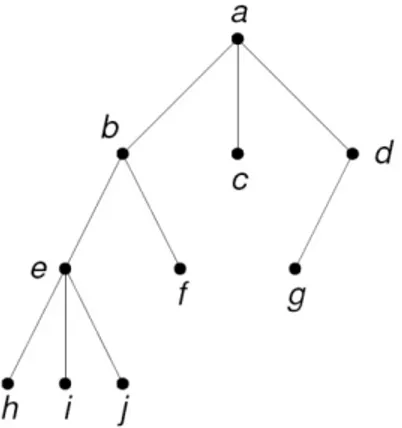
Adapun permodelan pohon yang biasa dipakai dalam pohon keputusan adalah rooted tree (pohon berakar), pohon yang satu buah simpulnya diperlakukan sebagai akar dan sisi-sisinya diberi arah sehingga menjadi graf berarah.
Gambar 2.4 Contoh Pohon Berakar
Beberapa terminologi dalam pohon berakar :
• Anak/Child atau Orangtua/Parent : b,c, dan d adalah anak dari a dan a
adalah orangtua dari b,c, dan d.
• Lintasan/Path : lintasan dari a ke j adalah a,b,e,j. Panjang lintasan dari a
ke j adalah jumlah sisi yang dilalui, yaitu 3.
• Saudara kandung/Sibling : b,c,dan d adalah saudara kandung sebab
mempunyai orangtua yang sama yaitu a.
• Derajat : derajat adalah jumlah anak yang ada pada simpul tersebut. A
berderajat 3, dan b berderajat 2. Derajat suatu pohon adalah derajat maksimum dari semua simpul yang ada. Pohon pada gambar 3 berderajat 3.
• Daun : daun adalah simpul yang tidak mempunyai anak. c,f,g,h,i,dan j
adalah daun.
• Simpul dalam/Internal nodes : simpul yang mempunyai anak. Simpul a,b,
dan d adalah simpul dalam.
• Tingkat/Level : adalah 1 + panjang lintasan dari simpul teratas ke simpul
tersebut. Simpul teratas mempunyai tingkat = 1.
• Pohon n-ary : pohon yang tiap simpul cabangnya mempunyai banyaknya
n buat anak disebut pohon n-ary. Jika n=2, pohonnya disebut pohon bin-ary(binary/biner).
Gambar 2.5 Pohon Biner
b. Struktur Pohon Keputusan
Secara umum, pohon keputusan dalah suatu gambaran permodelan dari suatu persoalan yang terdiri dari serangkaian keputusan yang mengarah ke solusi. Tiap simpul dalam menyatakan keputusan dan daun menyatakan solusi.
Permodelan pohon keputusan di sini berupa permodelan pohon n-ary, dengan jumlah anak yang dapat berbeda-beda tiap simpulnya.
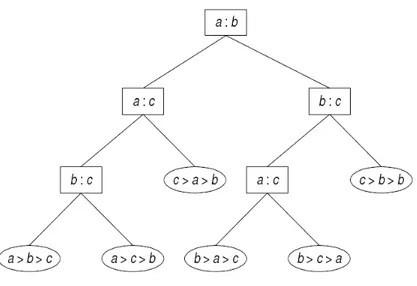
Gambar 2.6 Pohon keputusan untuk mengurutkan 3 buah bilangan a, b, dan c
Pohon keputusan pada gambar 2.5 dibaca dari atas ke bawah. Simpul paling atas pada pohon keputusan ini adalah simpul akar. Simpul yang ditandai dengan tanda kotak di simpul tersebut disebut dengan simpul keputusan. Cabang-cabang yang mengarah ke kanan dan kekiri dari sebuah cabang keputusan merepresentasikan kumpulan dari alternatif keputusan yang bisa diambil. Hanya satu keputusan yang dapat diambil dalam suatu waktu.
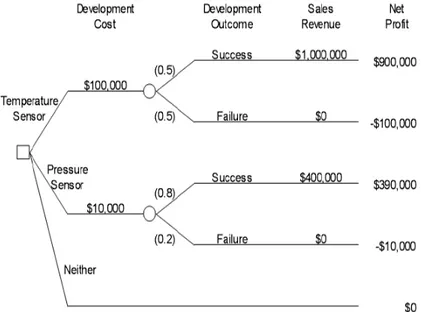
Dalam beberapa pohon keputusan, juga sering disertakan simpul tambahan, yaitu simpul probabilitas. simpul ini biasa ditandai dengan gambar lingkaran kecil yang disertai dengan angka pada cabang-cabang yang mengakar pada simpul probabilitas itu. Angka-angka yang terletak pada cabang-cabang tersebut merupakan probalitas kesempatan akan munculnya keputusan yang ada di cabang tersebut dalam pilihan.
Sebagai sebuah catatan, pohon keputusan tidak hanya dapat ditulis secara vertikal, namun juga dapat secara horizontal. Pada penulisan secara horizontal, pembacaan pohon keputusan dimulai dari kiri ke kanan.
Selain itu, di posisi paling bawah sebuah pohon keputusan juga dapat ditambahkan sebuah titik akhir (endpoint), yang merepresentasikan hasil akhir dari sebuah lintasan dari akar pohon keputusan pohon tersebut sampai ke titik akhir itu.
Gambar 2.7 Pohon keputusan horizontal dan mengandung simpul probabilitas
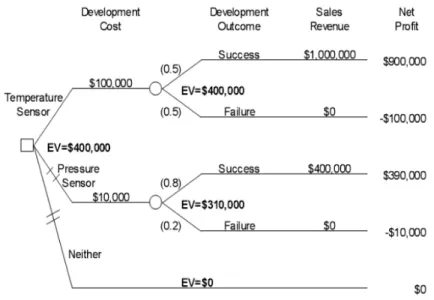
Expected value / hasil estimasi adalah sebuah estimasi hasil dari sebuah
keputusan tertentu. Hasil ini didapatkan dari mengkalikan setiap kemungkinan peluang terjadinya suatu kemungkinan lalu menambahkan hasilnya menhadi suatu jumlah.
Expected value decision criterion / kriteria keputusan hasil estimasi adalah suatu seleksi agar dapat memilih sebuah alternatif keputusan yang mempunyai hasil estimasi yang paling baik / yang paling diinginkan. Dalam situasi bila “more is
better” atau lebih banyak itu lebih baik, maka pilihan keputusan dengan hasil estimasi paling tinggi adalah yang terbaik, sedangkan dalam situasi bila ”less is better”, maka pilihan keputusan dengan hasil estimasi paling rendah adalah yang terbaik.
Gambar 2.8 Pohon keputusan dengan expected value/hasil estimasi
Di dalam pohon keputusan pada gambar 2.7, cabang pohon keputusan yang mengandung alternatif pilihan yang kurang disarankan/kurang baik menurut kriteria hasil estimasi ditandai dengan tanda ‘//’ pada cabang tersebut. Hasil estimasi pada setiap simpul probabilitas ditandai dengan tanda ‘EV’. Hasil estimasi yang terdapat pada simpul keputusan bernilai sama dengan hasil estimasi bila kita mengkuti cabang tersebut sampai mencapai keputusan akhir.
Decision tree rollback adalah suatu teknik untuk menghitung selama suksesif
hasil estimasi yang ada dari simpul keputusan di akhir pohon sampai kembali ke akar pohon keputusan tersebut.
Decision strategy/ strategi pengambilan keputusan adalah semua spesifikasi lengkap dari semua kemungkinan pilihan yang sesuai dengan kriteria hasil dari sebuah pengambilan keputusan suatu masalah secara sekuensial dengan menggunakan sebuah pohon keputusan.
Dalam decision analysis, pohon keputusan dapat diartikan sebagai sebuah alat untuk membuat ide yang secara umum dapat mengacu kepada sebuah graf atau sebuah model dari keputusan-keputusan dan akibat-akibat yang dapat muncul dari keputusan-keputusan tersebut, termasuk peluang terjadinya suatu kejadian, biaya yang dibutuhkan, dan utilitas. Melalui pohon ini strategi terbaik untuk menyelesaikan suatu masalah dapat diketahui. Pohon keputusan juga digunakan untuk mengkalkulasikan peluang kondisi-kondisi yang mungkin akan terjadi desertai dengan analisis-analisis faktor-faktor yang mempengaruhi keputusan yang diambil dengan menggunakan pohon keputusan tersebut.
2.2.2.2Artificial Neural Network
Saat ini bidang kecerdasan buatan dalam usahanya menirukan intelegensi manusia, belum mengadakan pendekatan dalam bentuk fisiknya melainkan dari sisi yang lain. Pertama-tama diadakan studi mengenai teori dasar mekanisme proses terjadinya intelegensi. Bidang ini disebut ‘Cognitive Science’. Dari teori dasar ini dibuatlah suatu model untuk disimulasikan pada komputer, dan dalam perkembangannya yang lebih lanjut dikenal berbagai sistem kecerdasan buatan yang salah satunya adalah jaringan saraf tiruan. Dibandingkan dengan bidang ilmu yang lain, jaringan saraf tiruan relatif masih baru. Sejumlah literatur menganggap bahwa konsep jaringan saraf tiruan bermula pada makalah Waffen McCulloch dan Walter Pitts pada tahun 1943. Dalam makalah
tersebut mereka mencoba untuk memformulasikan model matematis sel-sel otak. Metode yang dikembangkan berdasarkan sistem saraf biologi ini, merupakan suatu langkah maju dalam industri komputer.
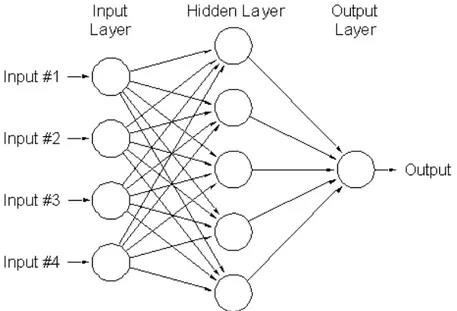
Pemodelan dengan algoritma jaringan syaraf tiruan, dapat diguinakan untuk menyelesaikan persoalan-persoalan yang sering kita jumpai dalam kehidupan. Jaringan Syaraf Tiruan adalah suatu sistem pengolahan informasi yang cara kerjanya menirukan cara kerja jaringan syaraf manusia. Aplikasi yang dapat diselesaikan dengan jaringan syaraf tiruan cukup banyak, antara lain : pengenalan suara, pengenalan pola, system control, diagnosa suatu penyakit dalam bidang kedokteran, segmentasi dan pengolahan citra.
Jaringan syaraf tiruan tersusun atas beberapa element pemproses, yaitu : neuron, unit, sel atau node, yang saling terhubung dalam bentuk directed graph melalui jalur sinyal searah yang disebut dengan koneksi. Dalam jaringan syaraf, struktur pengolahan informasi akan mengikuti bentuk grafik terarah dengan beberapa definisi sebagai berikut:
• Node pada graph disebut dengan elemen pemroses (processing element). • Link pada graph disebut denga koneksi.
• Setiap elemen pemroses dapat menerima sejumlah input. • Setiap elemen pemroses dapat memiliki beberapa output. • Setiap elemen pemroses memiliki memori lokal.
• Setiap elemen pemroses memiliki fungsi transfer (transfer function) yang dapat
menggunakan dan mengubah isi memori local, memakai sinyal output dari processing element.
• Sinyal dari input dari luar system saraf tiruan yang menuju system tersebuut
datang dari hubungan-hubungan yang berasal dari dunia luar system.
Gambar 2.9 Contoh Jaringan Syaraf Tiruan
2.2.2.3 Support Vector Machine
Support Vector Machine atau lebih dikenal sebagai SVM dikembangkan oleh
Vapnik. Tidak seperti kebanyakan model neural network yang mengimplementasikan prinsip empirical risk minimization, SVM mengimplemantasikan prinsip structural
risk minimization yang bertujuan untuk meminimalisasi sebuah hubungan dari
kesalahan umum (upper bound of generalization error) daripada meminimalisasi kesalahan pelatihan (training error). Prinsip ini mengacu pada fakta bahwa generalization error terjadi karena beberapa training error dan sebuah interval kepercayaan yang bergantung pada dimensi Vapnik-Chervonenkis. Oleh karena itu, SVM mendapatkan sebuah struktur jaringan yang optimum dengan menemukan
sebuah keseimbangan yang tepat diantara kesalahan empiris (empirical error) dan interval kepercayaan Vapnik-Chervonenkis (VC-confidence interval).
Keuntungan lain dari SVM adalah hasil pelatihan dari SVM dapat menyelesaikan sebuah linearly constrained quadratic programming. Artinya, solusi yang diberikan SVM unik dan optimal. Sebenarnya SVM dikembangkan untuk masalah pengenalan pola atau pengklasifikasian (pattern recognition problem), akan tetapi dengan pengenalan ε-insensitive loss function, SVM mampu menyelesaikan masalah estimasi regresi non-linear (non-linear regression estimation problem).
Untuk menyelesaikan masalah linear, SVM menggunakan fungsi
Dimana Y adalah hasil, yi adalah nilai kelas dari pelatihan vektor xi. Vektor
x=(x1,x2,…,xn) adalah sebuah input dan vektor xi adalah vektor pendukung. Untuk kasus non-linear, SVM menggunakan fungsi
Fungsi dari adalah untuk mendefinisikan fungsi kernel (kernel function) untuk meng-generate hasil sementara untuk membentuk mesin dengan tipe-tipe yang berbeda pada kasus non-linear. untuk membentuk aturan keputusan (decision rules), ada tiga tipe SVM yang sering digunakan yaitu :
• Sebuah mesin polinomial (a polynomial machine)
• Sebuah mesin fungsi radial basis (a radial basis function machine)
Dimana adalah bandwidth dari basis radial fungsi kernel
• Sebuah mesin jaringan saraf tiruan dua layer (a two-layer neural network machine)
dimana v dan c adalah parameter dari fungsi sigmoid
Proses pembelajaran untuk menghasilkan fungsi keputusan (decision function) pada SVM direpresentasikan oleh struktur dua layer yang mirip dengan Back
Propagation Network (BPN). Akan tetapi, algoritmanya berbeda, pada SVM
berdasarkan teori optimalisasi (optimization theory) yang meminimalisasi kesalahan klasifikasi yang terjadi karena teori pembelajaran statistik (statistical learning theory).
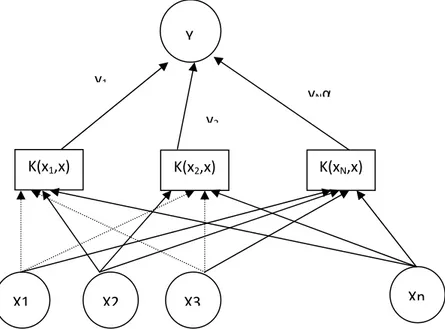
Skema dari SVM tampak pada gambar di bawah ini:
Gambar 2.10 Skema Support Vector Machine K(x1,x) K(x2,x) K(xN,x) y1 y2 yNα Y X1 X2 X3 Xn
Melakukan perbandingan dengan keterbatasan BPN, keuntungan utama dari SVM adalah : pertama, SVM hanya memiliki dua parameter bebas yang dinamakan upper bound dan kernel parameter. Kedua, SVM menghasilkan solusi yang unik dan optimal. Ketiga, SVM mengimplementasikan prinsip structural risk minimization (SRM) yang dikenal memiliki sebuah performa atau kinerja general yang baik dimana SRM meminimalisasi sebuah upper bound dari kesalahan general (generalization error) daripada meminimalisasi kesalahan training (training error).
2.2.3 Unsupervised Learning
Unsupervised learning adalah teknik machine learning yang digunakan untuk
mendapatkan pengetahuan dengan meneliti data-data yang tidak diketahui output-nya. Sistem akan diberi pola input, dan akan diperintahkan untuk mencari keteraturan pola. Deep Belief Networks (DBNs), dan sparse coding adalah model dari unsupervised learning yang sering digunakan. Sesuai dengan perkembangan algoritma, model-model tersebut telah diaplikasikan pada sejumlah aplikasi machine learning, termasuk computer vision, text modelling, dan collaborative filetering. Model ini cocok digunakan pada masalah yang mempunya dimensi tinggi. Ketika diaplikasikan kepada gambar, model tersebut dapat menghasilkan jutaan parameter, parameter tersebut dapat diproses dengan menggunakan jutaan contoh training yang belum diberi label sebagai input. Sayangnya, dengan algoritma yang ada saat ini,
parameter learning dapat memakan waktu yang sangat lama, bahkan bisa
meneliti DBNs, dan sparse coding, kita harus menggunakan input yang memiliki sedikit parameter, atau dengan membagi-bagi parameter yang ada.
Berikut ini adalah tugas-tugas yang dapat diselesaikan unsupervised learning :
a. Pemahaman dan Visualisasi
Kebanyakan algoritma unsupervised learning menciptakan pengaturan hirarki yang sama. Tugas dari hierarchical clustering adalah mengatur sekumpulan objek menjadi sebuah hirarki sehingga objek yang memiliki kesamaan dapat dijadikan satu kelompok. Secara umum, hal ini dilakukan dengan menentukan ukuran kesamaan antara dua objek dan kemudian mencari kumpulan benda-benda yang lebih mirip satu sama lain daripada mereka ke objek dalam kelompok lain. Non-hierarchical clustering berusaha untuk mempartisi data kedalama beberapa cluster yang telah diuraikan
Pendekatan lain dalam pemahaman dan visualisasi data adalah mengatur benda-benda di dimensi ruang yang rendah (misalkan, pada bidang dua dimensi) sehingga objek yang serupa menjadi saling berdekatan. Misalkan, suatu benda diwakili oleh lima nilai real dengan attribut : tinggi, lebar, panjang, berat, warna, dan kepadatan. Kita dapat mengukur kemiripan dua objek dengan melihat jarak Euclidean (jarak dua titik yang dapat dihitung dengan alat ukur, dan rumus phytagoras) mereka pada bidang lima dimensi. Setiap objek diberikan dua dimensi baru (x dan y) sehingga jaka
Euclidean antar objek pada bidang dua dimensi menjadi proporsional dengan jarak
Euclidean pada bidang lima dimensi. Kita dapat meletakkan tiap objek sebagai
b. Deteksi Keanehan
Tugas kedua unsupervised learning adalah mendeteksi adanya keanehan. Contoh : untuk mendeteksi kecurangan penggunaan kartu kredit, terlebih dahulu kita harus mengumpulkan berbagai transaksi kartu kredit yang legal, dan menentukan nilai P(t) untuk transaksi t. Kemudian, diberikan tranksai baru bernama t’, jika nilai P(t’) sangat kecil, maka dapat disimpulkan kalau t’ adalah transaksi yang tidak biasa, dan harus dilaporkan kepada yang berwajib. Pada pabrik manufaktur, salah satu prosedur pengendalian kualitas adalah memberikan peringatan setiap kali suatu objek yang tidak biasa dihasilkan oleh proses perakitan.
c. Penyelesaian Objek
Manusia memiliki kemampuan yang luar biasa dalam memberikan deskripsi fragmentis suatu objek atau situasi. Sebagai contoh, hanya dengan melihat bagian belakang suatu mobil, kita dapat mentukan dengan akurat, seperti apa mobil tersebut. Penyelesaian objek bertujuan untuk memprediksi bagian yang hilang dari suatu objek dengan menggunakan deskripsi parsial dari objek tersebut.
d. Perolehan Informasi
Tugas keempat unsupervised learning adalah memperoleh objek yang relevan (dokumen, gambar, sidik jari) dari sekumpulan/kelompok objek. Perolehan informasi biasanya dilakukan dengan pemberian deskripsi parsial suatu objek, kemudian menggunakannya untuk menentukan objek pada suatu kelompok mana yang memiliki kemiripan dengan deskripsi yang telah diberikan.
e. Kompresi Data
Pada situasi tertentu kita tidak ingin menyimpan atau mengirim suatu objek yang penuh dengan rincian. Contohnya : Gambar yang diambil oleh suatu kamera memerlukan ruang sebesar 3 megabytes. Dengan menggunakan kompresi data, gambar tersebut dapat direduksi menjadi 50 kilobytes (60 kali lebih kecil) tanpa mengurangi kualitas gambar. Kompresi data melibatkan pengenalan, dan penghapusan aspek-aspek yang tidak relevan pada suatu data (atau mengenali, dan mengambil aspek-aspek yang penting pada data). Sebagian besar metode kompresi data bekerja dengan cara mengidentifikasi subimage, dan substring yang sering muncul, dan memasukkannya pada suatu “kamus”. Setiap subimage, dan substring dapat digantikan dengan referensi berukuran jauh lebih kecil yang terdapat pada “kamus”.
2.3 Pasar Modal
Dalam dunia pasar modal, pergerakan saham merupakan hal esensial untuk diperhatikan para investor dan analis. Untuk mendapatkan keuntungan dari investasi yang ditanamkan, para investor harus mempunyai kemampuan dalam menganalisa pergerakan harga saham di masa mendatang. Sebelum kita membahas lebih lanjut mengenai pergerakan saham, ada baiknya kita memahami terlebih dahulu pengertian pasar modal.
Menurut Darmadji dan Fakhruddin (2001), “ Pasar modal (capital market) merupakan pasar untuk berbagai instrument keuangan jangka panjang yang bisa
diperjualbelikan, baik dalam bentuk utang ataupun modal sendiri”. Pasar modal di Indonesia dikeloloa oleh Bapepam di bawah pengendalian menteri keuangan Republik Indonesia.
Pasar modal memiliki peran besar bagi perekonomian suatu Negara karena pasar modal menjalankan dua fungsi sekaligus, yaitu fungsi ekonomi dan fungsi keuangan. Pasar modal dikatakan memiliki funsi ekonomi karena pasar modal menyediakan fasilitas yang mempertemukan dua kepentingan yaitu pihak yang memiliki kelebihan dana (investor) dan pihak yang memerlukan dana (issuer). Pasar modal dikatakan memiliki fungsi keuangan karena pasar modal memberikan kemungkinan dan kesempatan memperoleh imbalan (return) bagi pemilik dana.
Pasar modal di Indonesia untuk saat ini ada dua, yaitu Bursa Efek Jakarta (BEJ) dan Bursa Efek Surabaya (BES). Darmaji dan Fakhruddin juga menjelaskan “Bursa efek adalah lembaga atau perusahaan yang menyelenggarakan atau menyediakan fasilitas sistem (pasar) untuk mempertemukan penawaran jual dan beli efek antar berbagai perusahaan atau perorangan yang terlibat dengan tujuan memperdagangkan efek perusahaan-perusahaan yang tercatat di bursa efek”.
2.3.1 Saham
Saham adalah tanda penyertaan atau kepemilikan seseorang atau badan, dalam suatu perusahaan yang akan memberikan keuntungan dalam bentuk dividen dan
capital gain. Artinya jika seseorang membeli selembar saham, maka dia telah
menjadi salah satu pemilik perusahaan sekian persen yang tertulis di dalam kertas saham tersebut.
Saham biasa adalah jenis saham yang paling mudah ditemukan dalam pasar modal. Pemegang saham biasa memiliki hak voting dalam dalam pengambilan keputusan perusahaan. Saham biasa atau common stock antara lain :
• Blue Chip-Stock (Saham Unggulan)
Adalah saham dengan tingkat imbal investasi paling stabil dan memiliki reputasi yang baik dan dalam sejarahnya mampu membayar deviden secara konsisten. Biasanya perusahaan tersebut merupakan leader dari perusahaan sejenis dan industrinya memiliki stabilitas usaha yang tinggi dan merupakan standar untuk mengukur perusahaan lain.
• Growth Stock
Adalah saham dengan tingkat imbal investasinya yang lebih tinggi dari saham sejenis.
• Defensive Stock
Adalah saham yang penurunan imbal investasinya tidak sebesar penurunan imbal investasi pasar secara keseluruhan. Saham jenis ini memiliki systematic risk yang rendah. Contoh defensive company adalah perusahaan penyedia kebutuhan pokok (misal distributor makanan pokok seperti beras atau gula).
• Cyclical Stock
Adalah saham yang memiliki tingkat imbal investasi yang berfluktuatif dibandingkan dengan imbal investasi pasar secara keseluruhan. Saham ini memiliki systematic risk yang tinggi. Contoh cyclical company adalah perusahaan property.
• Seasonal Stock
Adalah saham yang memiliki tingkat imbal investasi yang sangat fluktuatif sesuai dengan periode (musim) tertentu. Contoh seasonal company adalah perusahaan kartu ucapan.
• Speculative Stock
Adalah saham yang memiliki tingkat imbal investasi yang rendah atau negative dan memiliki kemungkinan kecil untuk memberikan imbal investasi yang normal atau tinggi. Contoh speculative stock adalah saham pengeboran minyak.
Saham Preferen memiliki prioritas utama dibanding saham biasa dalam pembagian deviden dan asset. Jika perusahaan dilikuidasi, pemegang saham jenis ini diutamakan. Pemegang saham preferen tidak memiliki hak voting dalam pengambilan keputusan perusahaan, walaupun ada juga saham preferen yang memiliki hak voting untuk hal-hal tertentu seperti pemilihan direktur.
Saham perusahaan diperdagangkan di bursa saham atau disebut bursa efek. Penjualan saham ke masyarakat pada awalnya melalui proses penawaran saham (pasar perdana) atau sering disebut IPO (Initial Public Offering). “High risk high
return” istilah ini sering kita dengar dalam dunia investasi saham. Memang bila
dibandingkan dengan deposito, resiko saham jauh lebih tinggi, namun saham juga memiliki potensi keuntungan lebih besar.
Dalam dunia investasi saham dikenal dua jenis resiko, yaitu resiko sistematik (systematic risk) dan resiko tidak sistematik (unsystematic risk). Resiko sistematik mengacu pada resiko pasar yaitu ketidakpastian hasil perolehan investasi yang
dipengaruhi faktor inflasi, pertumbuhan ekonomi, perubahan tingkat suku bunga, kondisi sosial politik. Resiko sistematik ini mempengaruhi perusahaan secara keseluruhan. Contoh resiko sistematik terjadi pada saat kondisi perekonomian terkena resesi atau faktor keamanan terganggu, pada keadaan ini bisa saja sejumlah saham yang secara fundamental kondisinya baik, namun harganya turun drastis.
Sedangkan resiko tidak sistematik mengacu pada resiko yang unik pada setiap perusahaan. Contohnya, mogok kerja yang terjadi di suatu perusahaan selama jangka waktu tertentu akan mengurangi atau menghentikan proses produksi perusahaan tersebut. Hal ini akan menyebabkan berkurangnya pendapatan dan laba perusahaan tersebut. Resiko tidak sistematik ini dapat dikurangi dengan melakukan diversifikasi investasi di sejumlah perusahaan yang tidak berasal dari sektor sejenis.
Resiko-resiko di atas dapat menimbulkan kerugian investasi yang biasa disebut capital loss. Capital loss terjadi bila harga beli suatu saham lebih tinggi dari harga jual saham tersebut. Sebaliknya keuntungan saham dapat diperoleh dari capital gain dan dividen. Capital gain terjadi jika harga jual lebih tinggi dibandingkan harga belinya. Dividen adalah pembagian bagian keuntungan perusahaan kepada para pemegang saham. Besarnya dividen yang dibagikan perusahaan ditentukan oleh para pemegang saham pada saat berlangsungnya RUPS (Rapat Umum Pemegang Saham)
2.3.2 Index Saham
Index saham adalah kumpulan dari saham-saham dan merupakan indikator pasar untuk mengukur dan mencatat rata-rata tingkat perubahan harga saham baik sebagian maupun keseluruhan harga saham biasa yang ditransaksikan di bursa.
Fluktuasi harga saham selayaknya ekonomi biasa ditentukan oleh banyaknya permintaan dan penawaran. Penawaran yang tinggi akan menyebabkan penurunan harga saham dan permintaan yang tinggi akan menyebabkan kenaikan harga saham. Penawaran dan permintaan dipicu oleh berbagai faktor baik secara langsung maupun tidak langsung. Berbagai faktor tersebut dapat dijadikan indikator apakah harga saham naik atau turun. Untuk menganalisa faktor-faktor tersebut digunakan metode analisa fundamental dan analisa teknikal.
2.3.3 Analisa Fundamental
Analisa fundamental adalah studi tentang ekonomi, industry, dan kondisi perusahaan untuk memperhitungkan nilai dari saham perusahaan. Analisa fundamental menitikberatkan pada data-data kunci dalam laporan keuangan perusahaan untuk memperhitungkan apakah harga saham sudah diapresiasi secara akurat.
Secara umum untuk menganalisa perusahaan dengan menggunakan analisa fundamental terdiri dari empat langkah yaitu:
1. Menghitung kondisi ekonomi secara keseluruhan
Kondisi ekonomi dipelajari untuk memperhitungkan jika kondisi ekonomi secara keseluruhan baik untuk pasar saham. Apakah tingkat inflasi tinggi atau rendah? Apakah suku bunga naik atau turun? Apakah konsumen yakin atau ragu-ragu dalam mengeluarkan uang? Apakah neraca perdagangan untung atau rugi? Apakah supply uang naik atau turun? ini adalah sebagian pertanyaan seorang fundamental analis untuk
memperhitungkan jika kondisi ekonomi secare keseluruhan baik untuk pasar.
2. Menghitung kondisi industri secara keseluruhan
Industri perusahaan dimana secara langsung mempengaruhi masa depan perusahaan tersebut. Bahkan saham yang paling baik pun dapat menghasilkan imbal (return) yang minim jika keadaan industri sedang sulit. Biasanya saham yang lemah dalam industri yang kuat lebih disukai daripada saham yang kuat dalam industri yang lemah.
3. Menghitung kondisi perusahaan
Setelah melihat dari sisi ekonomi dan industri, kita perlu memperhitungkan kesehatan keuangan sebuah perusahaan. Jika sebuah perusahaan yang telah kita analisa secara ekonomi dan industri baik tetapi kita tidak memperhatikan kondisi perusahaan tersebut, maka akan sia-sia semua analisa fundamental yang kita lakukan. Karena pasar saham adalah pasar ekspektasi dimana pemegang saham mengharapkan perusahaannya selalu menghasilkan laba yang pada akhirnya laba ini akan dibagikan kepada pemegang saham yang kita kenal dengan istilah deviden. Namun, tidak semua pemegang saham mengharapkan pembagian deviden karena pada dasarnya keuntungan yang diperoleh dari permainan saham bukan hanya berupa deviden tetapi ada juga yang disebut capital gain yaitu keuntungan yang diperoleh dari fluktuasi harga saham yang biasanya diharapkan oelh investor yang memilki time horizon yang pendek.
4. Menghitung kondisi perusahaan biasanya dilakukan dengan menggunakan rasio-rasio keuangan.
Rasio secara garis besar dibagi dalam lima kategori utama, antara lain : profitability (keuntungan), price (harga), liquidity (likuiditas), leverage (dukungan), dan efficiency (efisiensi).
Setelah memperhitungkan kondisi ekonomi, industri, dan perusahaan. Seorang fundamental analis dapat mulai memperhitungkan apakah saham suatu perusahaan overvalued, undervalued, atau pas harganya. Beberapa model penilaian telah disusun untuk membantu kita menghitung nilai saham. Model penilaian tersebut menyertakan model deviden yang menitikberatkan pada nilai dari pendapatan yang diharapkan, dan model aset yang menitikberatkan pada nilai dari aset perusahaan.
2.3.4 Analisa Teknikal
Analisa teknikal merupakan sebuah metode paling dasar dalam investasi di dunia pasar modal. Prinsipnya adalah kombinasi antara studi harga seperti : pembukaan (opening), harga tertinggi (high), harga terendah (low), dan penutupan (closing) dengan menggunakan grafik-grafik (charts) yang terbentuk dari studi harga tersebut sebagai peta utama untuk menentukan langkah berikutnya.
Analisa teknikal pertama kali diperkenalkan oleh Charles Dow, perhatiannya pada dasar-dasar gerakan harga menciptakan metode yang betul-betul baru dalam
menganalisa pasar. Tiga buah prinsip yang digunakan sebagai dasar dalam melakukan analisa teknikal, yaitu :
1) Market Price Discounts Everything
Yaitu segala kejadian-kejadian yang dapat mengakibatkan gejolak pada bursa saham secara keseluruhan atau harga saham suatu perusahaan, seperti : faktor ekonomi, politik fundamental dan termasuk juga kejadian-kejadian yang tidak dapat diprediksikan sebelumnya seperti adanya peperangan, gempa bumi dan lain sebagainya akan tercermin pada harga pasar.
2) Price Moves in Trend
Yaitu harga suatu saham akan tetap bergerak dalam suatu trend. Harga mulai bergerak ke satu arah, turun atau naik. Trend ini akan berkelanjutan sampai pergerakan harga melambat dan memberikan peringatan sebelum berbalik dan bergerak ke arah yang berlawanan.
3) History Repeats Itself
Karena analisa teknikal juga menggambarkan faktor psikologis para pelaku pasar, maka pergerakan historis dapat dijadikan acuan untuk memprediksi pergerakan harga pasar di masa yang akan datang. Pola historis ini dapat terlihat dari waktu ke waktu di grafik. Pola-pola ini mempunyai makna yang dapat diintepretasikan untuk memprediksi pergerakan harga saham.
a) Supply and Demand
Pasar modal sebenarnya adalah perwujudan dari tawar-menawar, hanya saja barang yang diperjualbelikan adalah surat-surat berharga berupa saham, obligasi, waran, right dan lain sebagainya.
Karena banyaknya pembeli dan penjual serta tingginya varisai ekspektasi antara investor satu dengan yang lainnya, maka mekanisme pasar modal diatur dengan menggunakan model lelang. Model lelang disusun berdasarkan logika penjual dan pembeli. Penjual sebagai pemilik barang jelas akan berupaya mendapatkan harga sebesar-besarnya, sedangkan pembeli ingin mendapatkan barang dengan harga semurah-murahnya.
Untuk mengatur terjadinya transaksi atas penawaran-penawaran tersebut, maka dibuat suatu model lelang dengan cara mempertemukan harga penawaran yang terbaik untuk membeli maupun menjual.
Asumsi dasar dalam analisa teknikal adalah bahwa harga sangat ditentukan oleh keseimbangan antara supply dan demand. Dimana jika terjadi ekses supply (kelebihan supply atas demand), maka harga akan jatuh dan demikian sebaliknya, jika terjadi ekses demand, maka harga akan naik.
b) Trend
Trend atau kecenderungan pergerakan dalam suatu arah harga adalah
salah satu terminologi terpenting dalam melakukan analisa teknikal, karena pada dasarnya analisa teknikal itu sendiri dikembangkan atas sebuah asumsi dasar, yaitu harga bergerak dalam sebuah kecenderungan (trend) itu sendiri.
Karena itu indikator-indikator yang terdapat dalam analisa teknikal modern atau yang sering disebut candlestick sebenarnya hanyalah merupakan alat untuk mendapatkan indikasi apakah trend harga itu akan muncul, berakhir, berlanjut, atau berubah. Setelah menemukan indikasi awal mengenai arah pergerakan trend harga, investor dapat mengambil keputusan apakah akan melakukan aksi buy, sell, atau hold.
Garis trend akan tetap berlaku selama tidak terjadi penetrasi atau penembusan oleh pergerakan harga. Dalam hal ini, garis trend akan memiliki perilaku yang sama dengan garis support dan resistance. Secara garis besar, garis trend dapat dibagi menjadi tiga, yaitu:
• Trend meningkat (uptrend)
Adalah garis yang memiliki kemiringan positif. Dibentuk dari minimal dua titik harga terendah. Dengan catatan titik harga terendah kedua harus berada di atas titik terendah pertama. Kenaikan harga yang didukung oleh suatu pertumbuhan demand, menunjukkan uptrend yang terjadi. Uptrend akan tetap valid selama harga yang terbentuk di pasar tetap berada di atas atau setara dengan uptrend line itu sendiri. Jika harga yang dibentuk di pasar mulai menembus uptrend line, maka dikatakan bahwa trend itu akan berakhir.
• Trend menurun (downtrend)
Kebalikan dari uptrend, downtrend dibentuk dengan cara menghubungkan minimal dua titik harga tertinggi dan memiliki kemiringan negative.
• Trend mendatar (horizontal trend)
Dalam analisa teknikal garis uptrend berlaku sama seperti garis support dan garis downtrend berlaku seperti garis resistance, sedangkan garis horizontal trend akan berlaku sebagai garis support dan resistance sekaligus.
c) Support and Resistance
Adalah sebuah titik batas atas (resistance) dan batas bawah (support) dari pergerakan harga. Titik support adalah sebuah level (titik/tingkat/range) dimana pada level harga tersebut akan timbul minat beli yang lebih kuat dari minat jual. Kondisi ini akan mengakibatkan terjadinya ekses demand yang akan meningkatkan harga di pasar, sehingga menghentikan trend penurunan harga. Sebaliknya titik resistance adalah sebuah level (titik/tingkat/range) dimana akan timbul penguatan minat jual yang lebih besar dibandingkan minta beli, yang secara otomatis akan mengakibatkan timbulnya ekses supply, sehingga mengakibatkan turunnya harga saham.
Contoh dalam satu bulan terakhir harga terendah (titik support) suatu saham adalah Rp 500 perlembar saham, maka jika batas harga terendah ini
tertembus, missal menjadi Rp 400, maka level Rp 500 akan menjadi batas atas pergerakan saham (resistance). Jika dalam satu bulan terakhir tingkat resistance (batas atas pergerakan harga) berada di level Rp 1.500 per saham, maka jika pergerakan harga saham menembus batas atas tersebut (contoh Rp 1.600 per saham), maka level harga Rp 1.500 itu akan menjadi garis support bagi pergerakan harga saham yang baru. Biasanya garis support dan resistance dibentuk dari batasan tertinggi dan terendah dari range transaksi selama satu tahun terakhir, karena dianggap mempunyai tingkat validasi yang tinggi.
d) Overbought and Oversold
Secara harfiah, overbought dapat diartikan sebagai kondisi jenuh beli, sedangkan oversold dapat dikatakan sebagai kondisi jenuh jual. Kondisi jenuh beli muncul setelah terjadinya aksi beli selama beberapa waktu, sementara aksi jenuh jual terjadi setelah terjadinya aksi jual selama beberapa waktu.
Di pasar para pembeli memiliki batas harga tertinggi yang akan mereka bayar untuk memperoleh sebuah barang atau jasa, sedangkan penjual memiliki batas harga minimal yang mereka akan terima untuk menjual barang atau jasa mereka.
Mekanisme overbought dan oversold juga bekerja dengan cara yang sama. Titik overbought adalah titik dimana harga telah mencapai level tertinggi yang dapat diterima oleh pembeli, karena itu untuk melakukan transaksi berikutnya mau tidak mau penjual harus menurunkan harga jualnya.
Pembentukan titik harga tertinggi yang dapat diterima oleh pembeli ini dapat didasarkan atas berbagai macam pertimbangan, yaitu dapat berupa target
keuntungan maksimum jangka pendek, atau dapat pula berupa batas harga teoritis maksimum yang biasanya didasarkan atas beberapa variabel, seperti: Price per Earning Ration, Growth Rate, PBV, dan lain-lain.
Setelah harga mencapai harga maksimum yang dapat diterima oleh pembeli, maka kenaikan harga akan berhenti dan kemungkinan besar akan mengalami perubahan arah (trend reversal). Penurunan harga ini sebagian besar diakibatkan oleh aksi jual yang dilakukan oleh investor guna mendapatkan keuntungan.
Kondisi oversold dapat pula diterangkan dengan menggunakan kurva
demand dan supply yang cukup sederhana. Apabila pemunculan kondisi
overbought diawali dengan aksi beli selama beberapa waktu, maka kondisi
oversold akan didahului dengan aksi jual yang terjadi selama beberapa waktu. Kondisi oversold terjadi jika harga telah menyentuh level harga terendah yang dapat diterima oleh penjual, oleh karena itu untuk setiap unit tambahan yang diinginkan oleh pembeli, maka pembeli harus membayar lebih mahal.